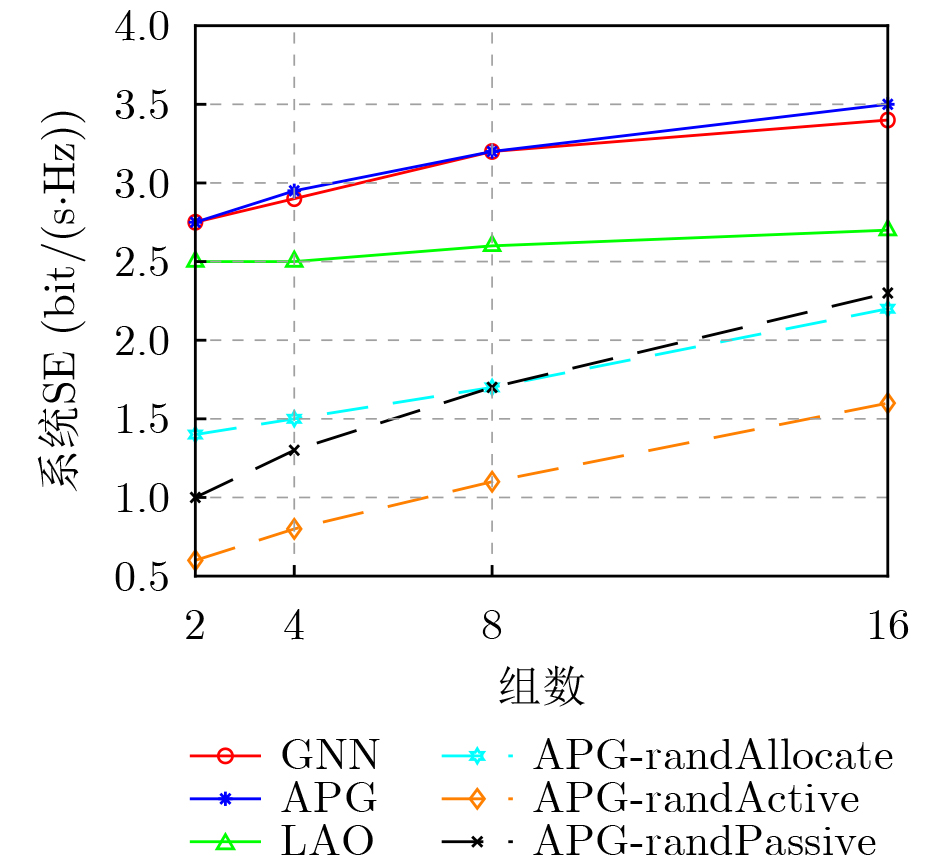
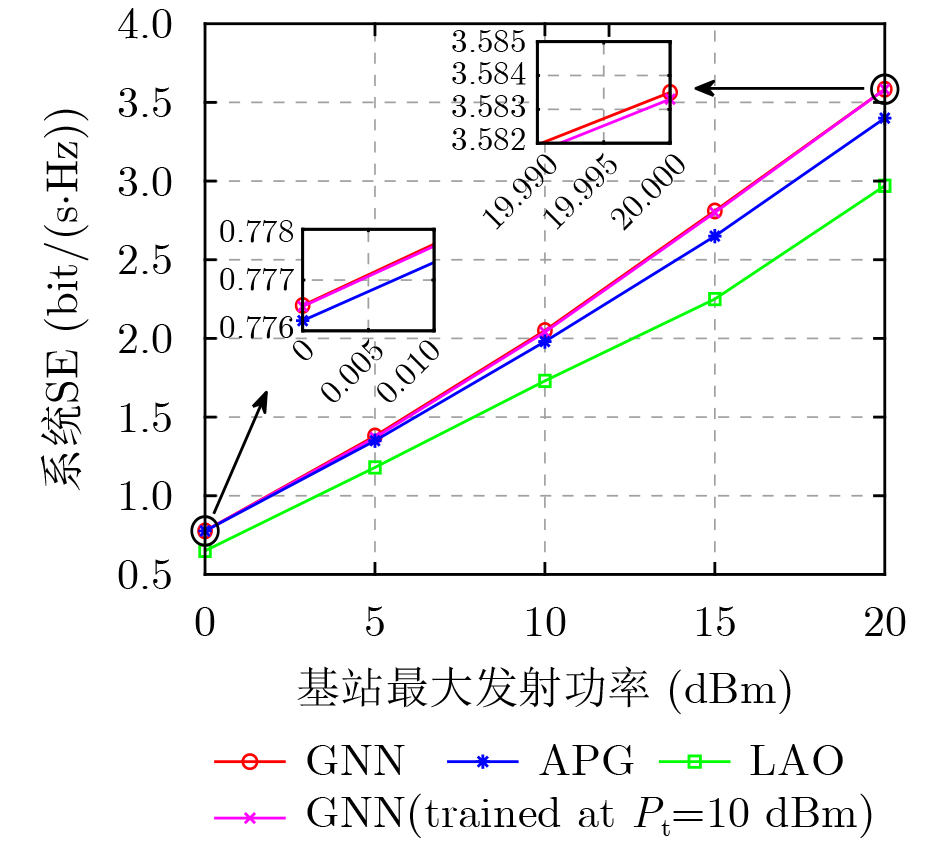
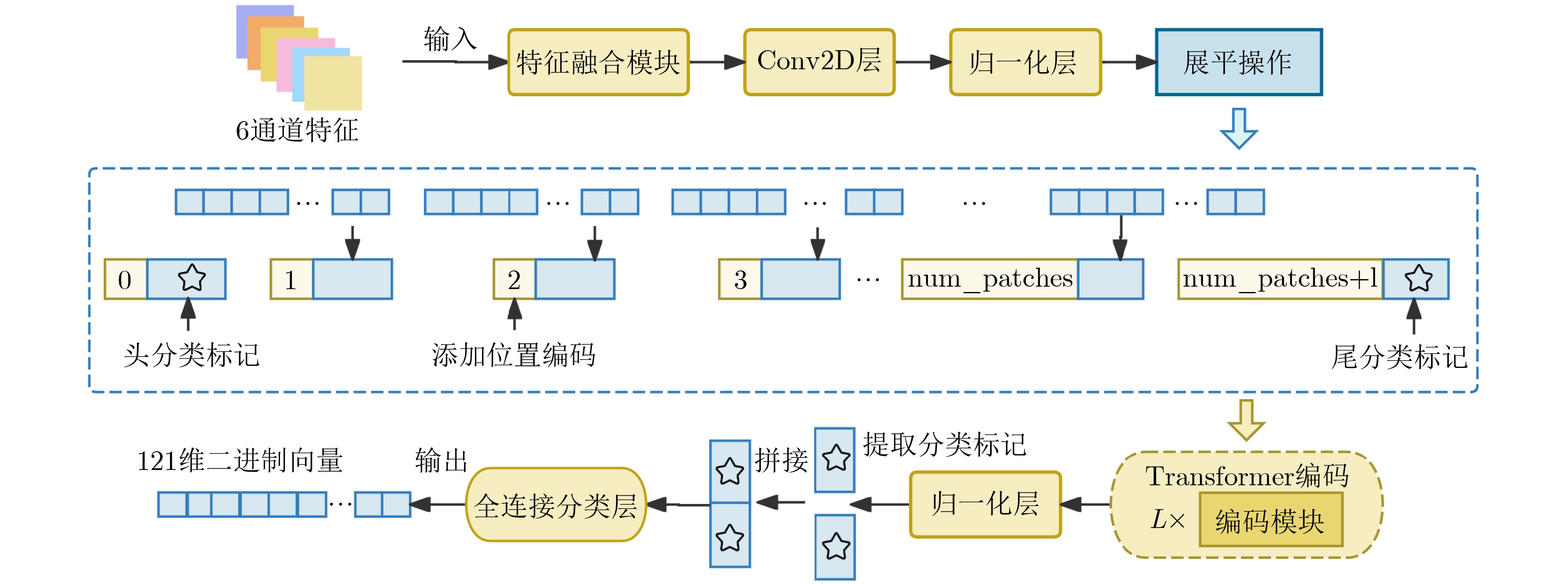
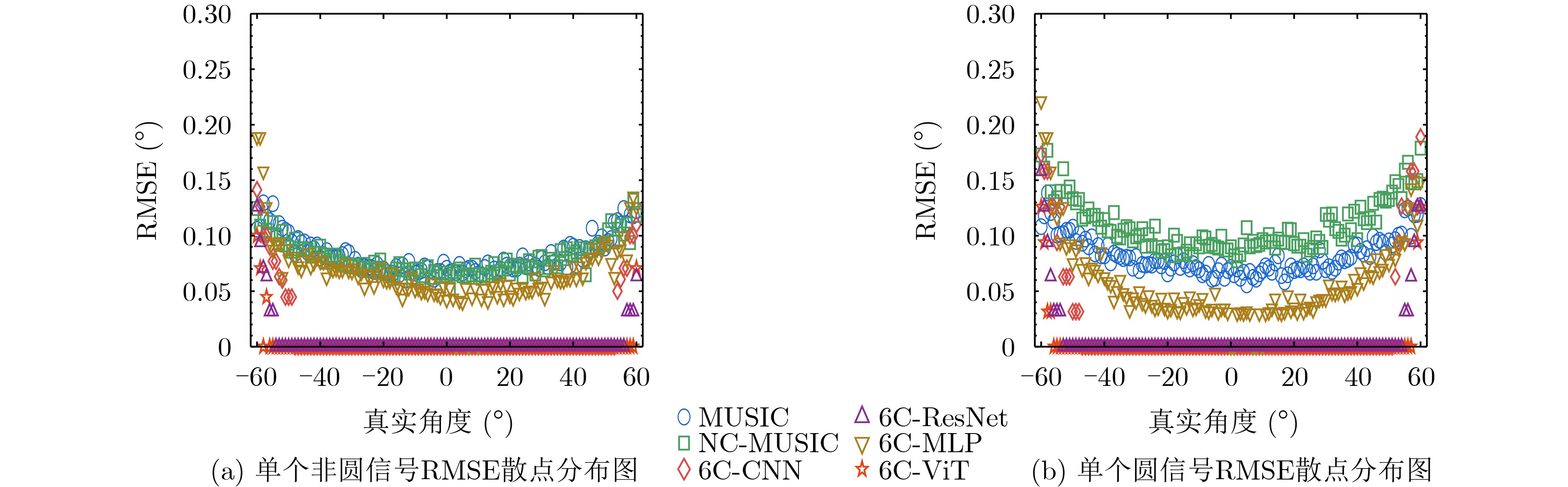
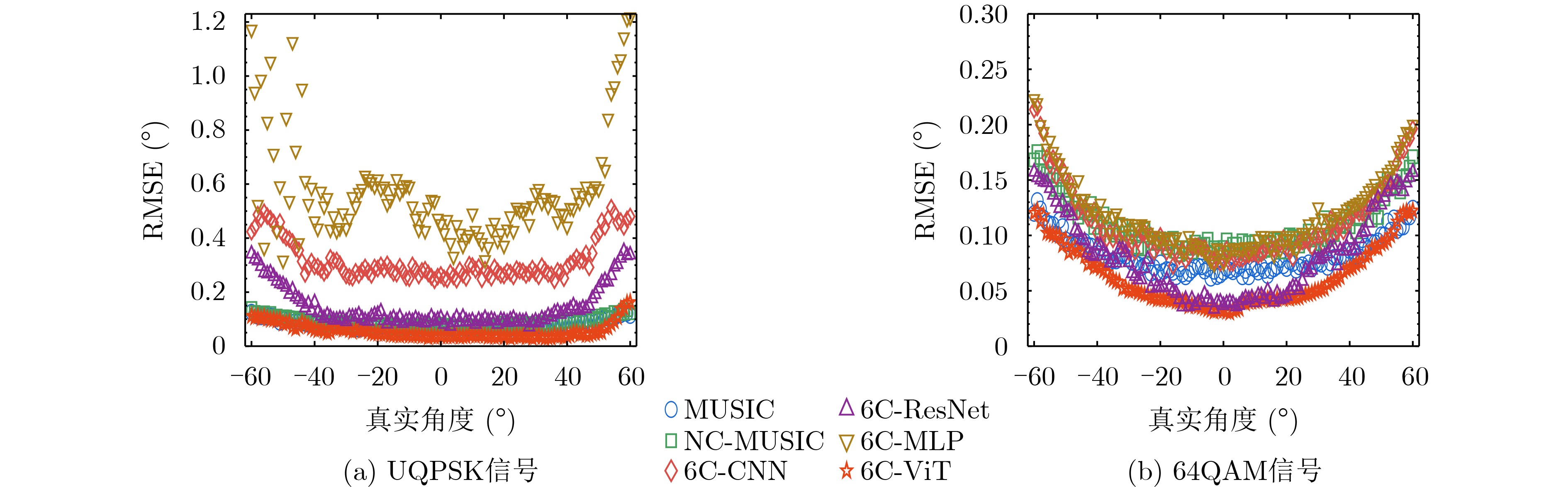
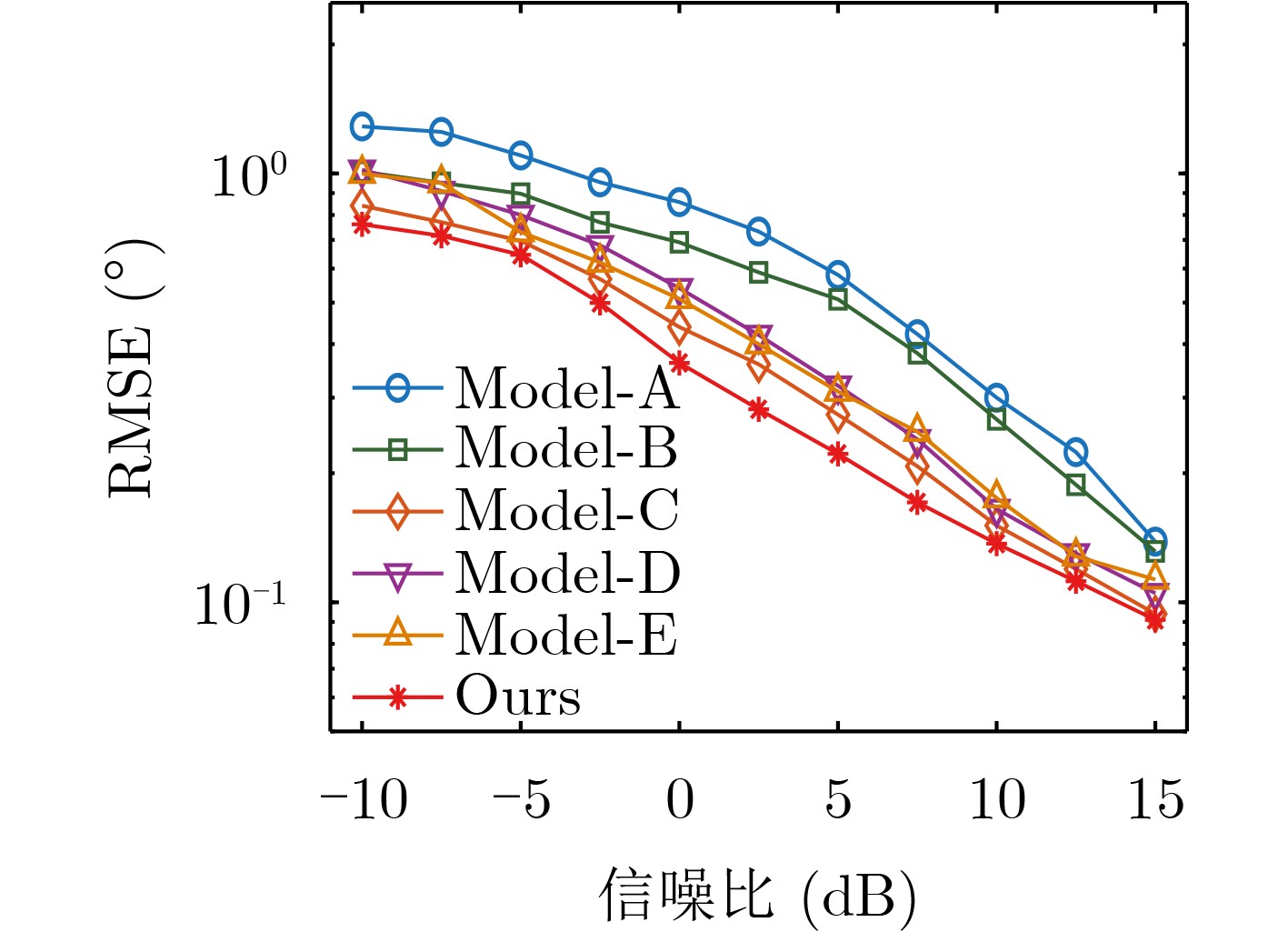
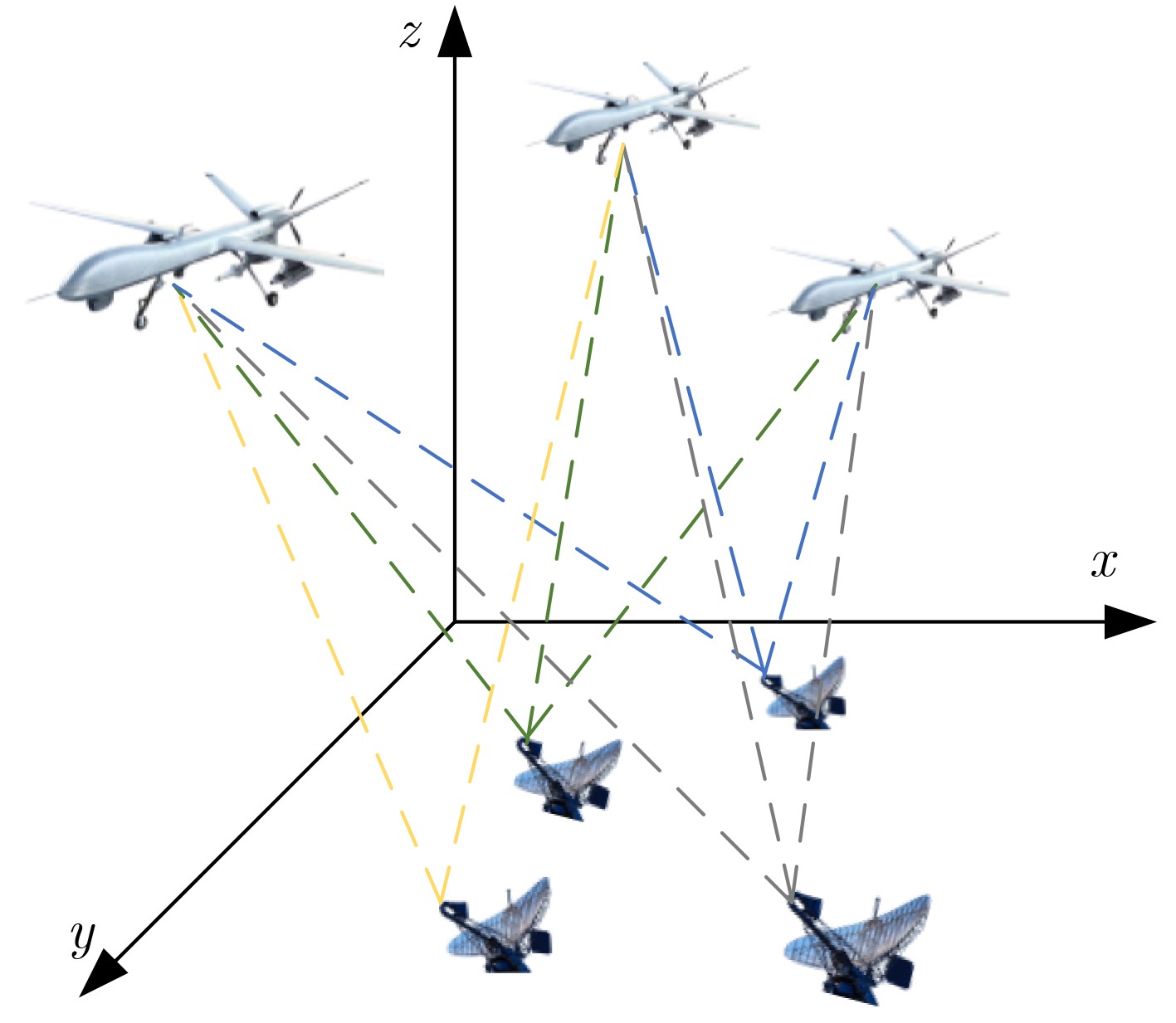
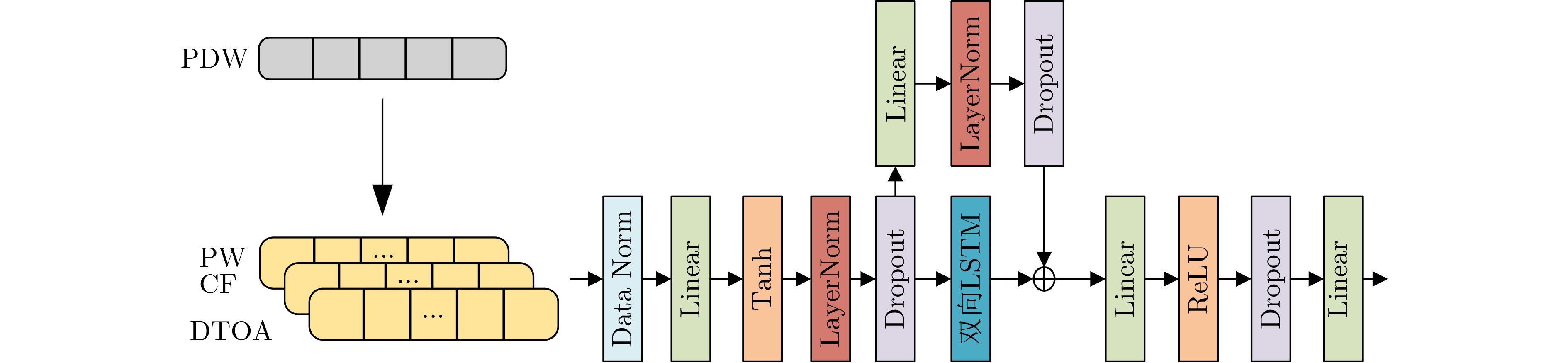
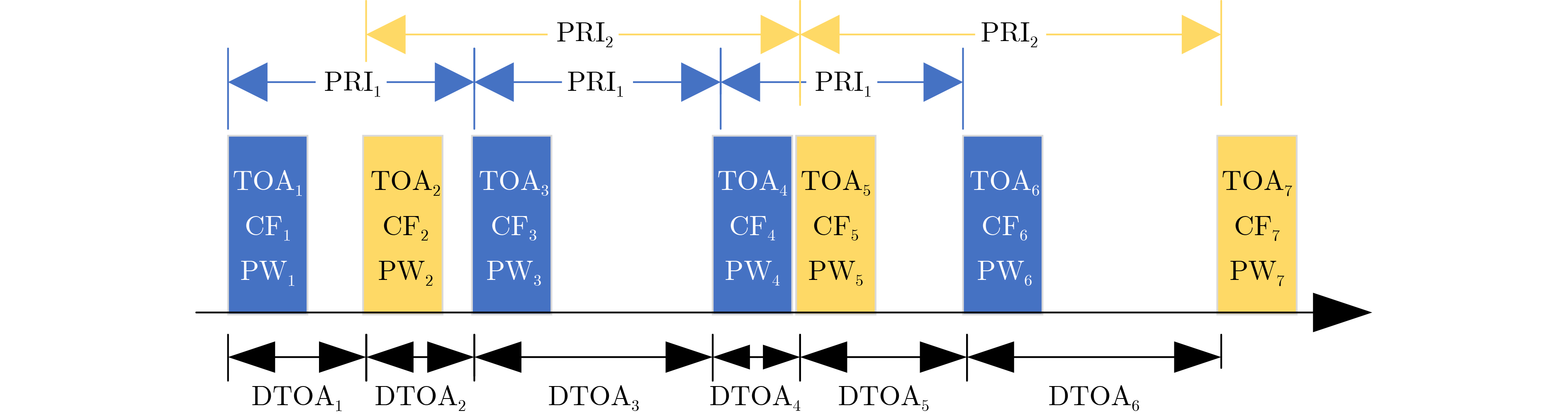
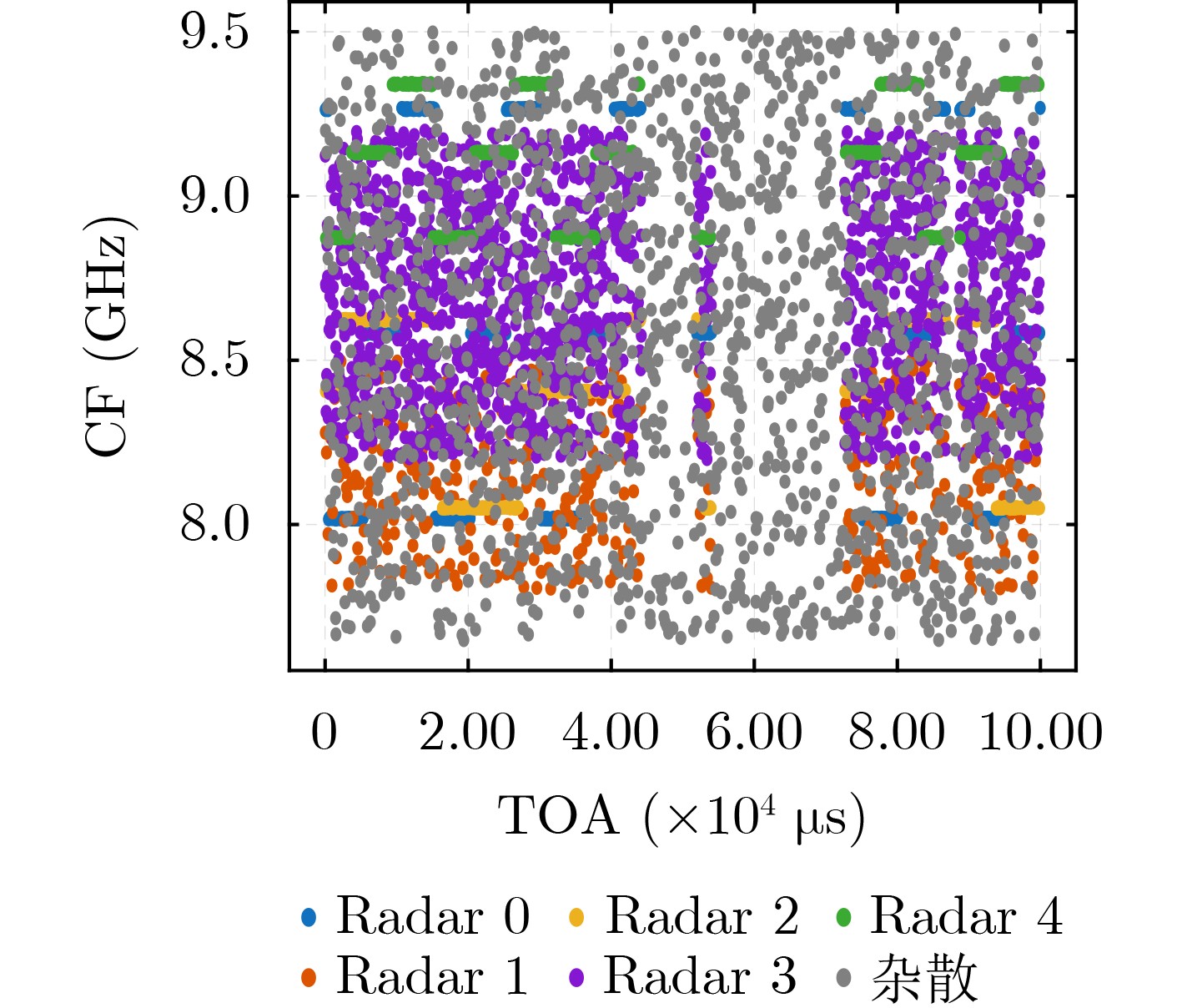
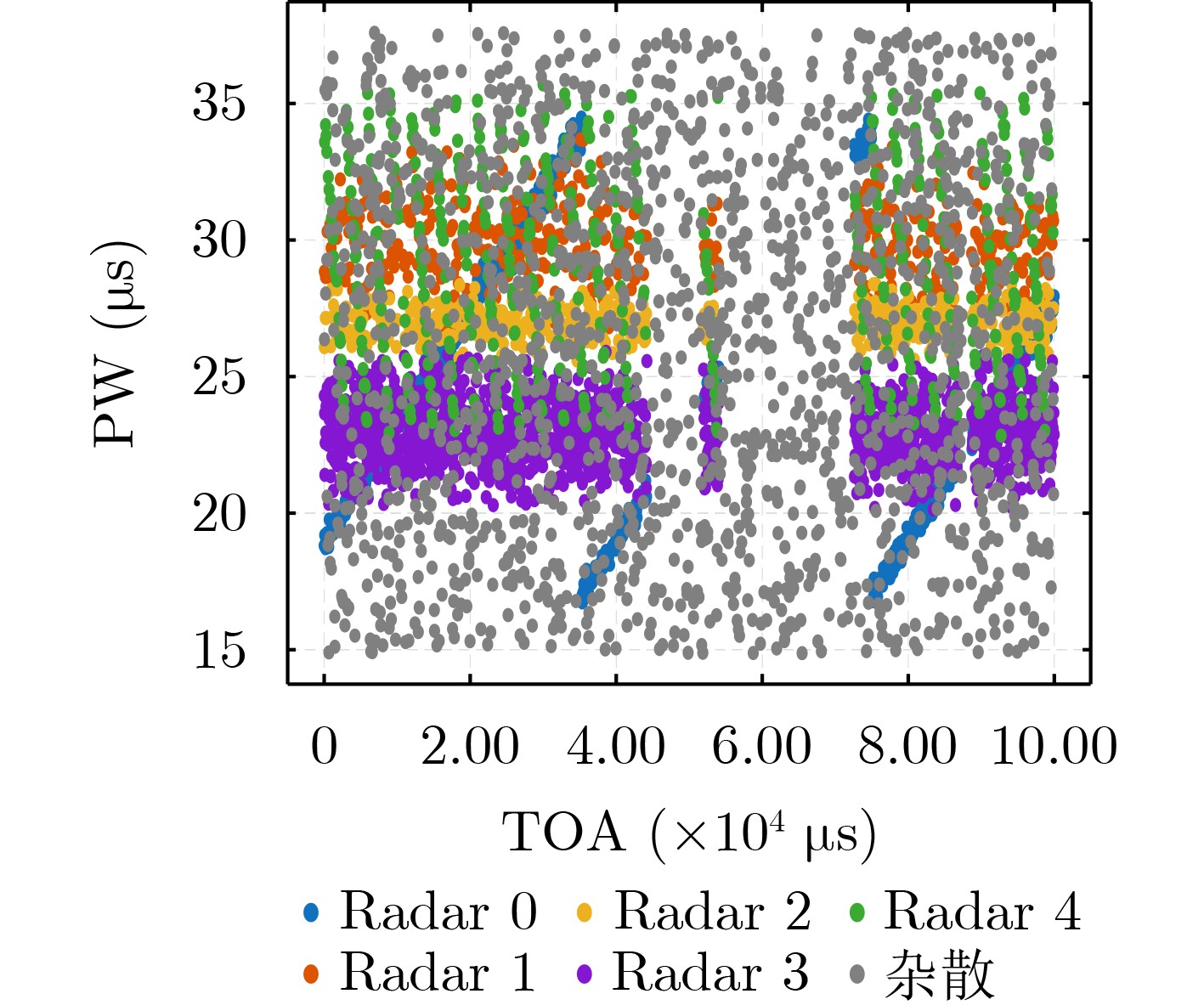
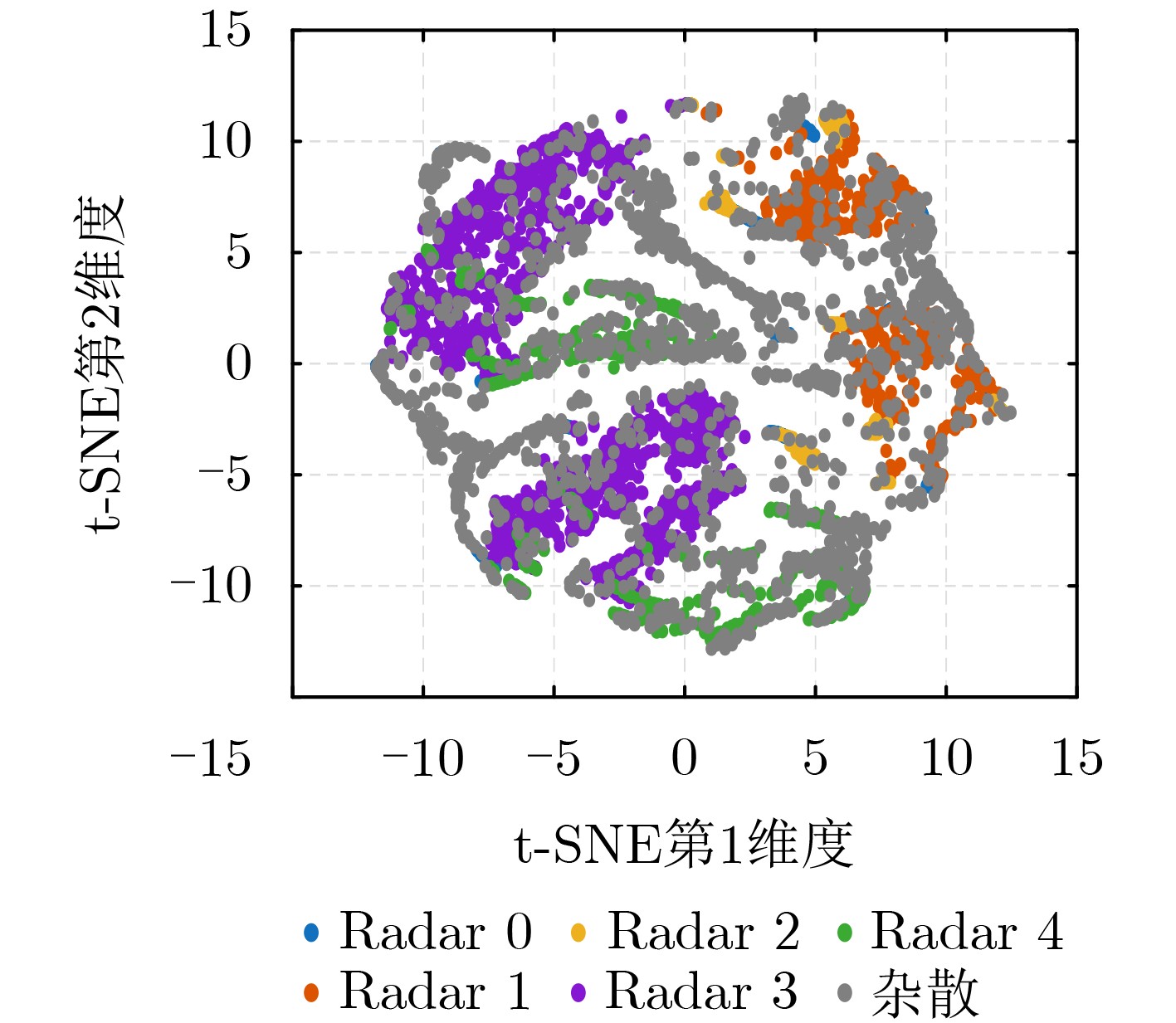
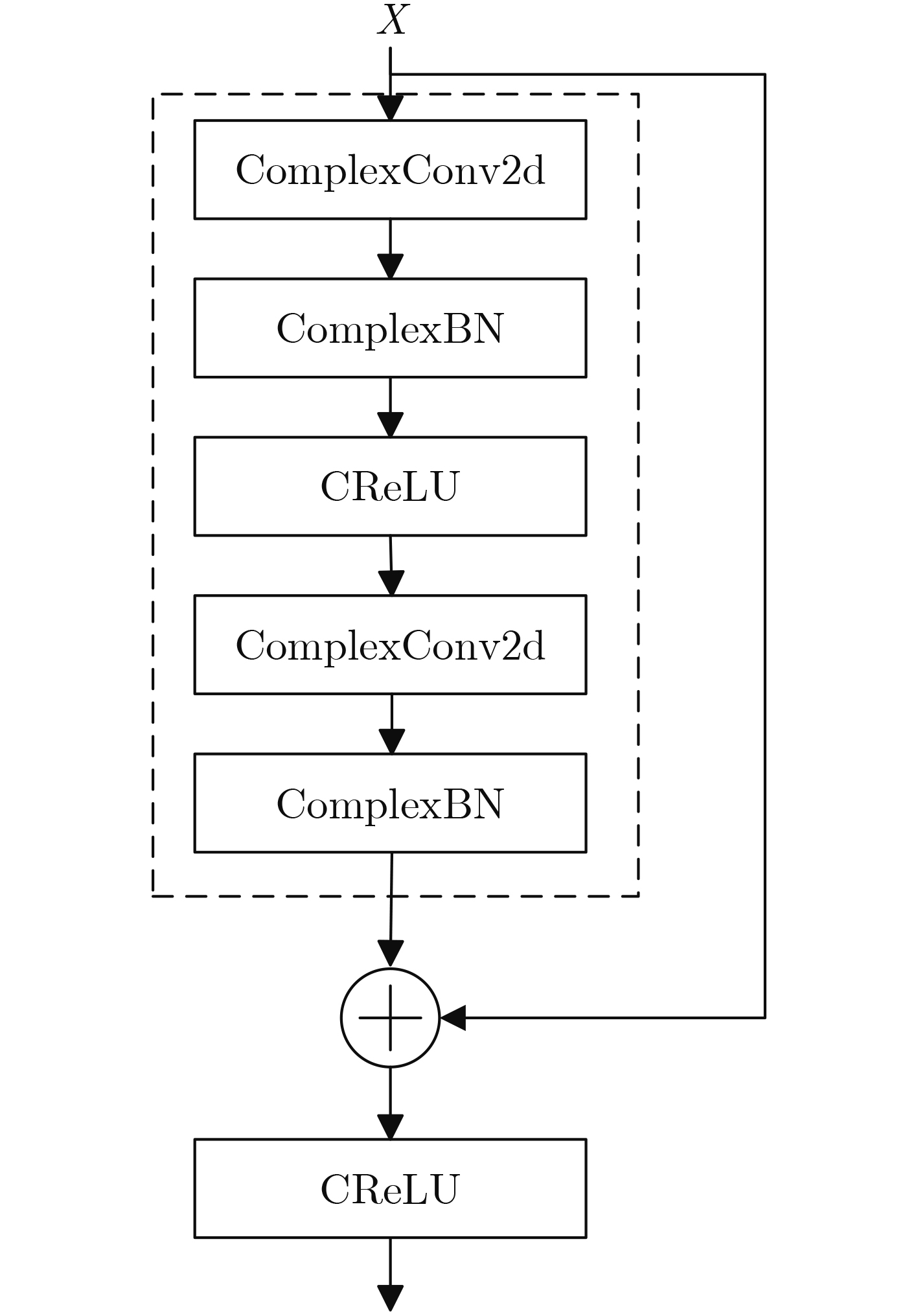
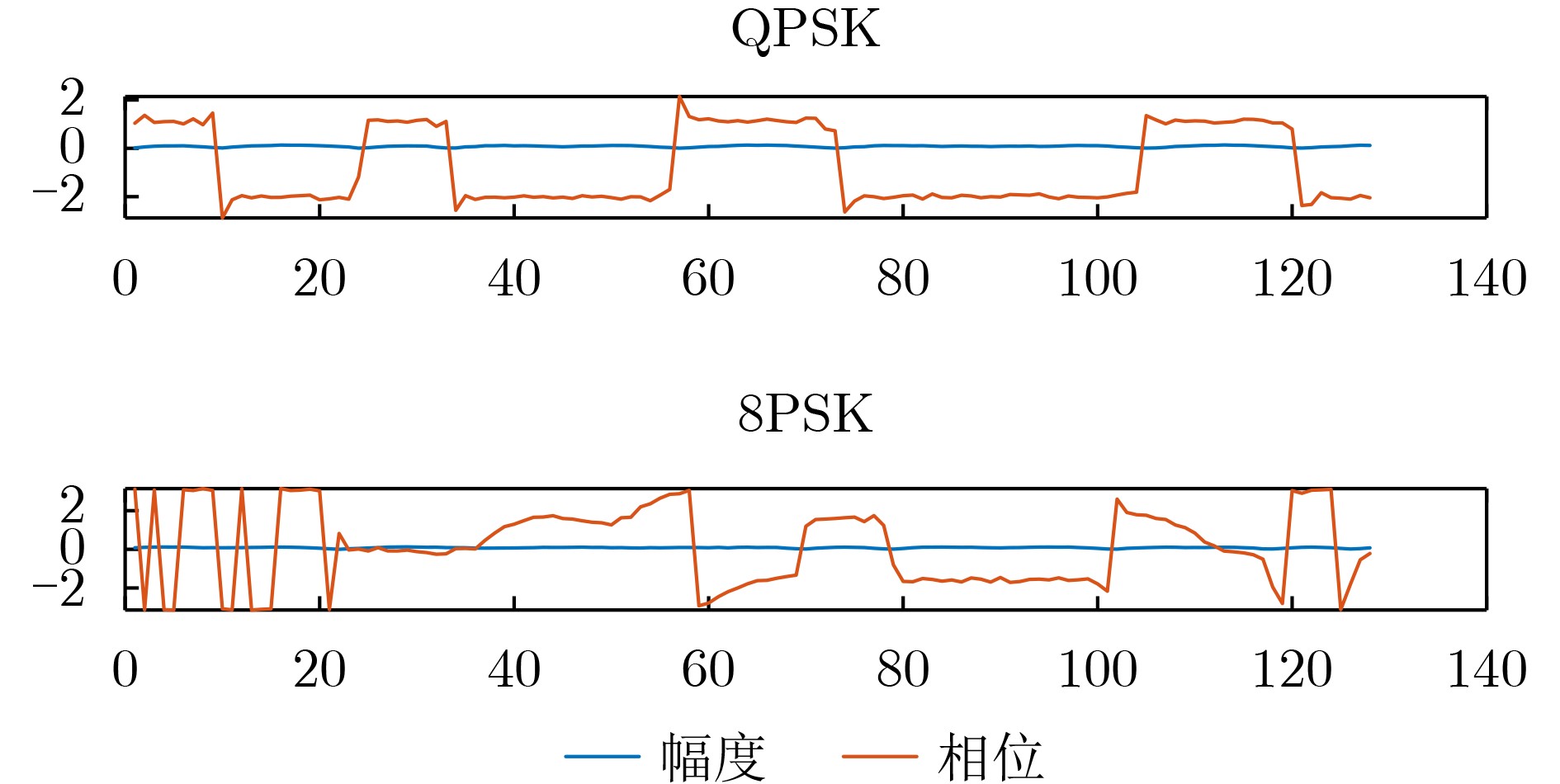
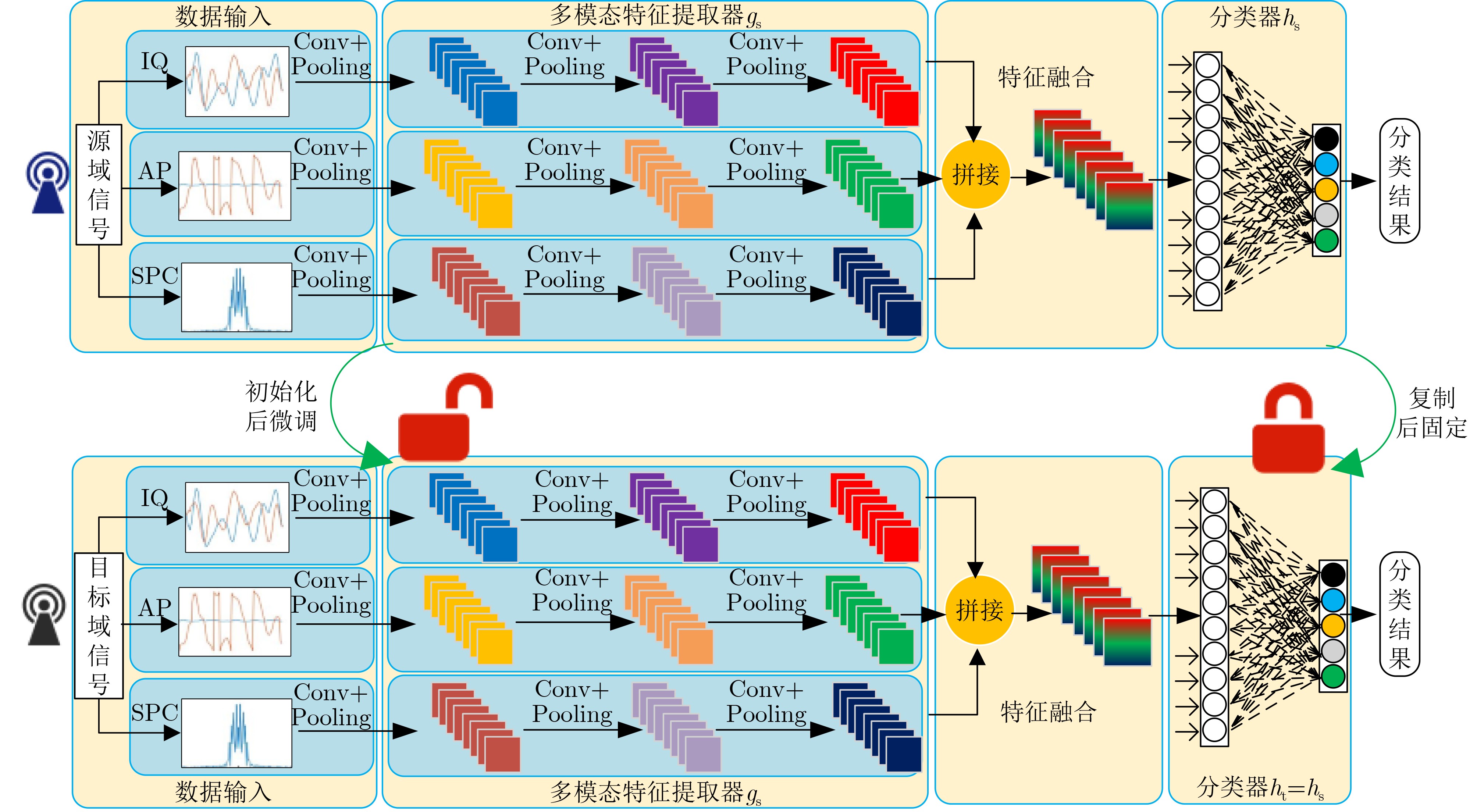
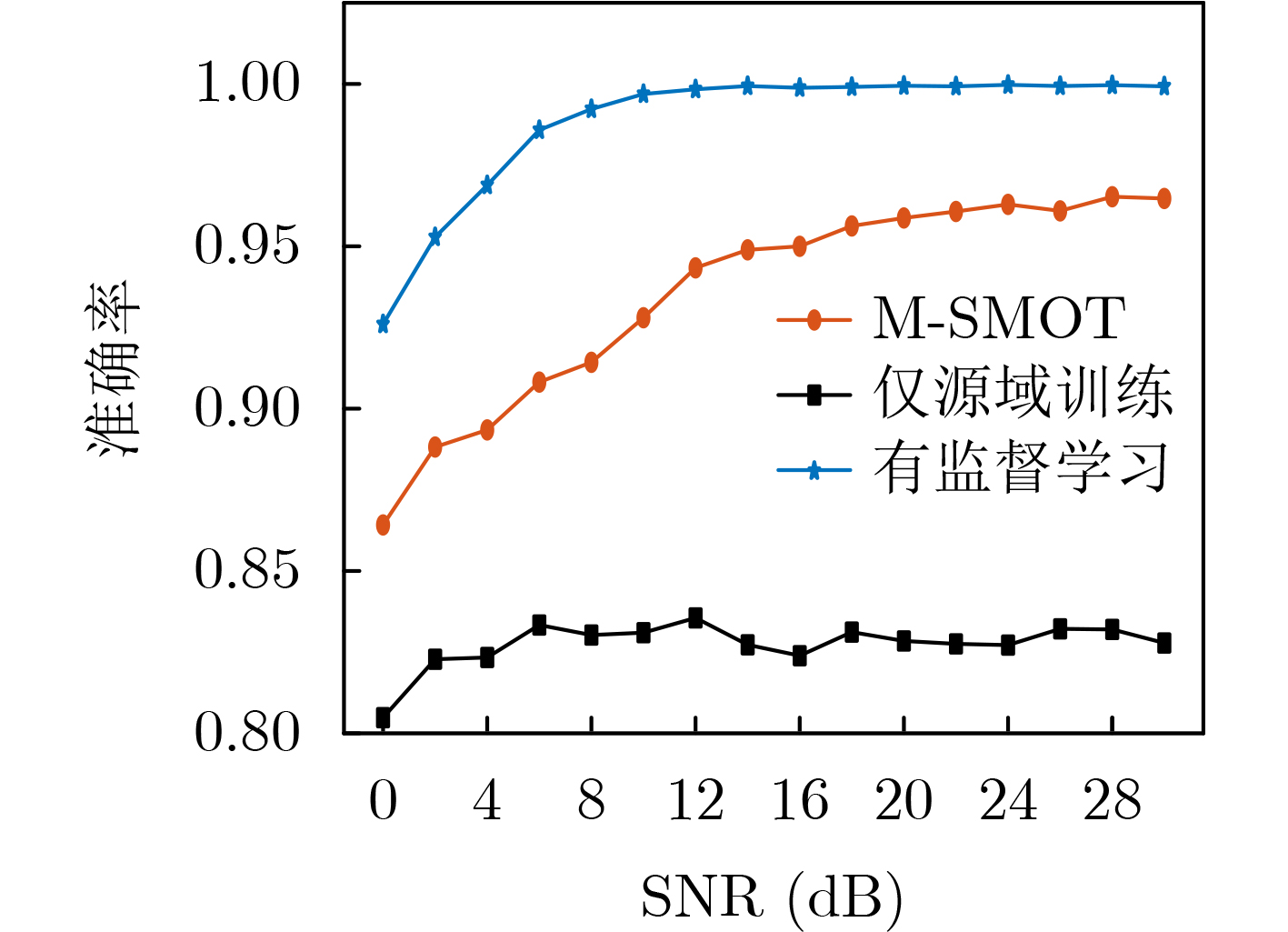
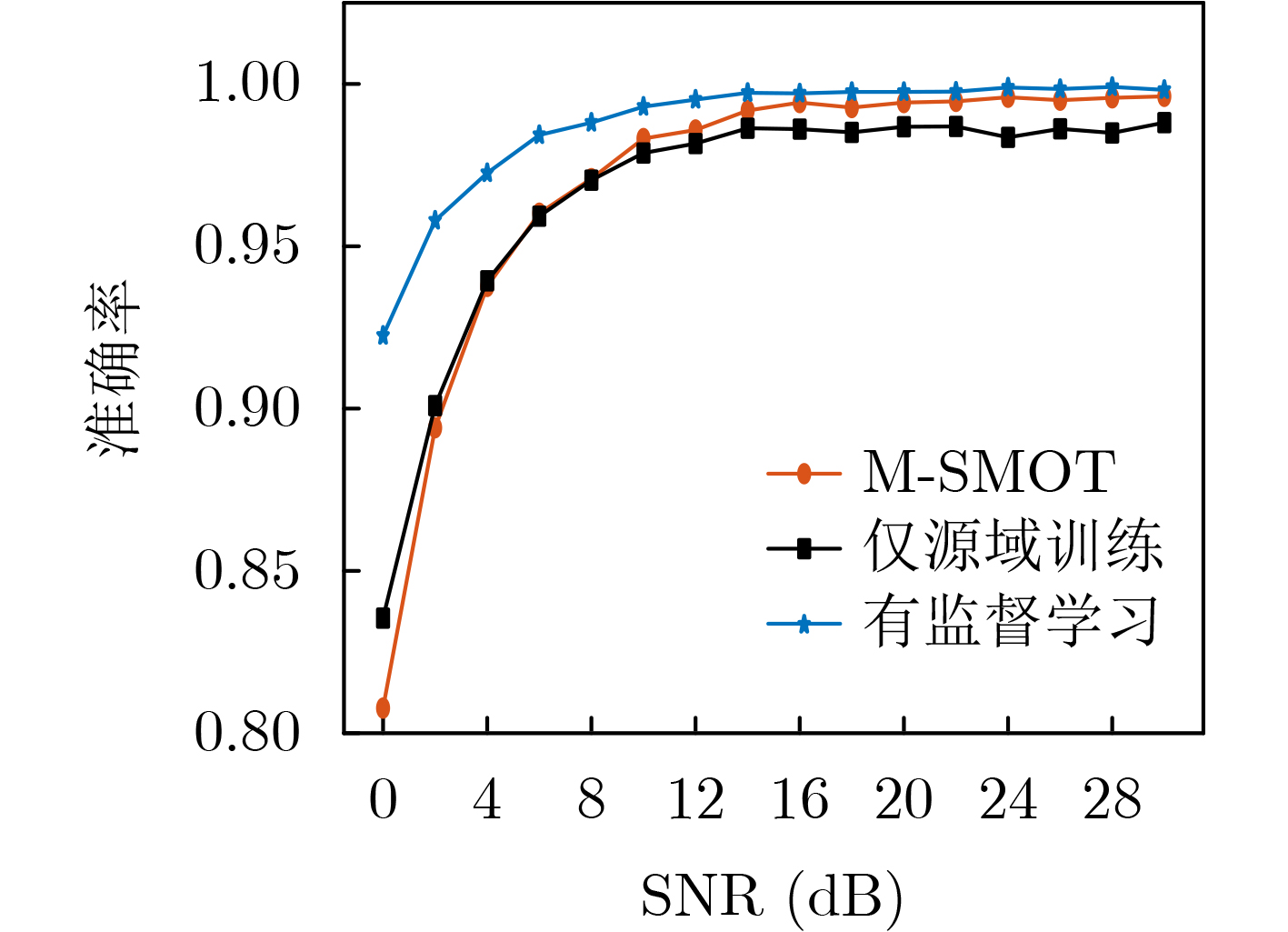
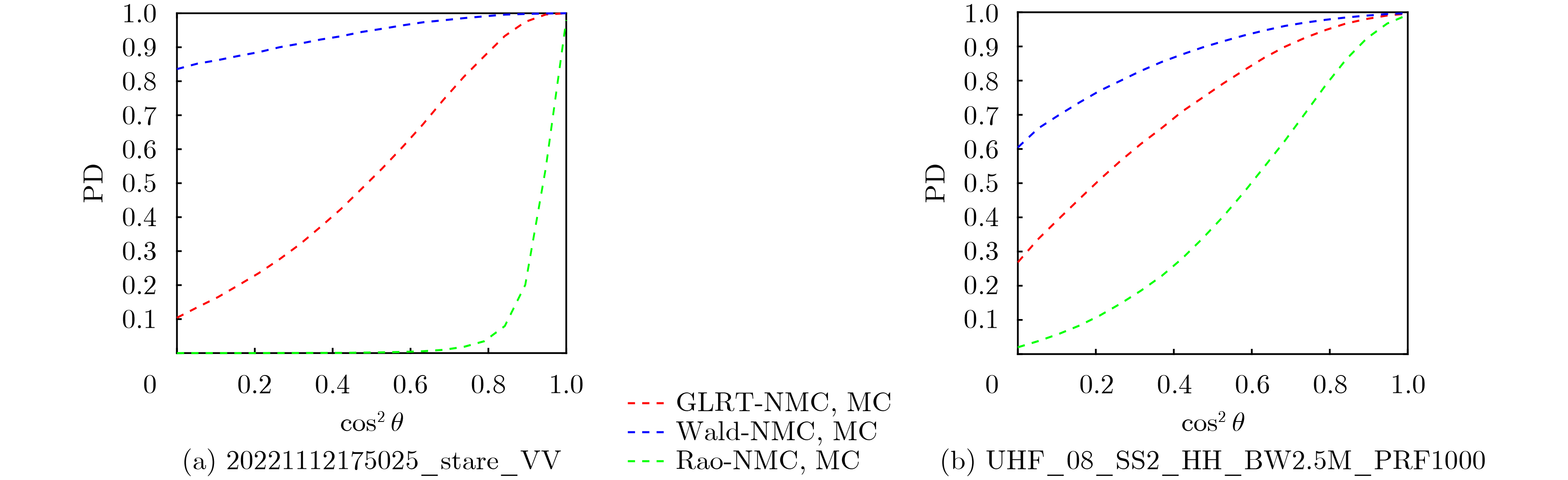
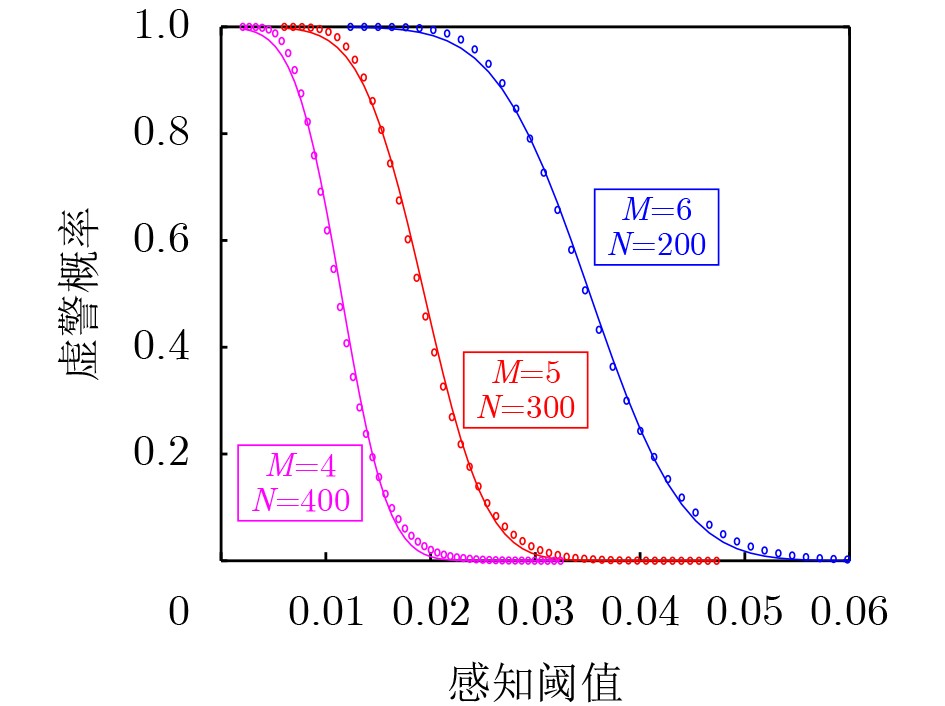
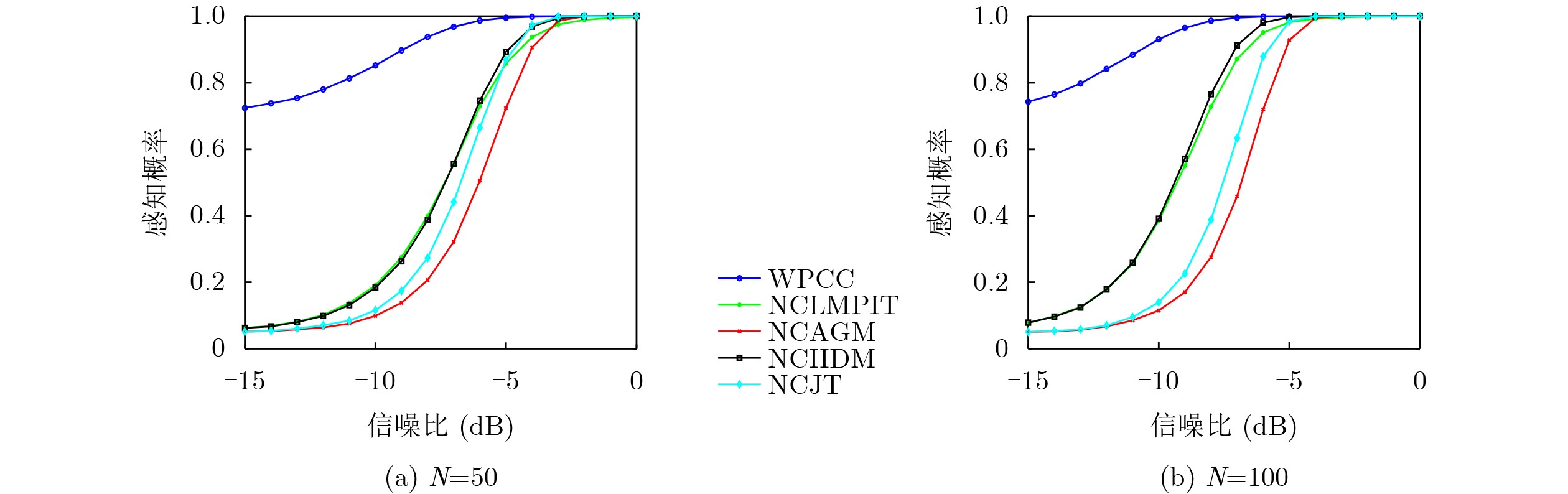
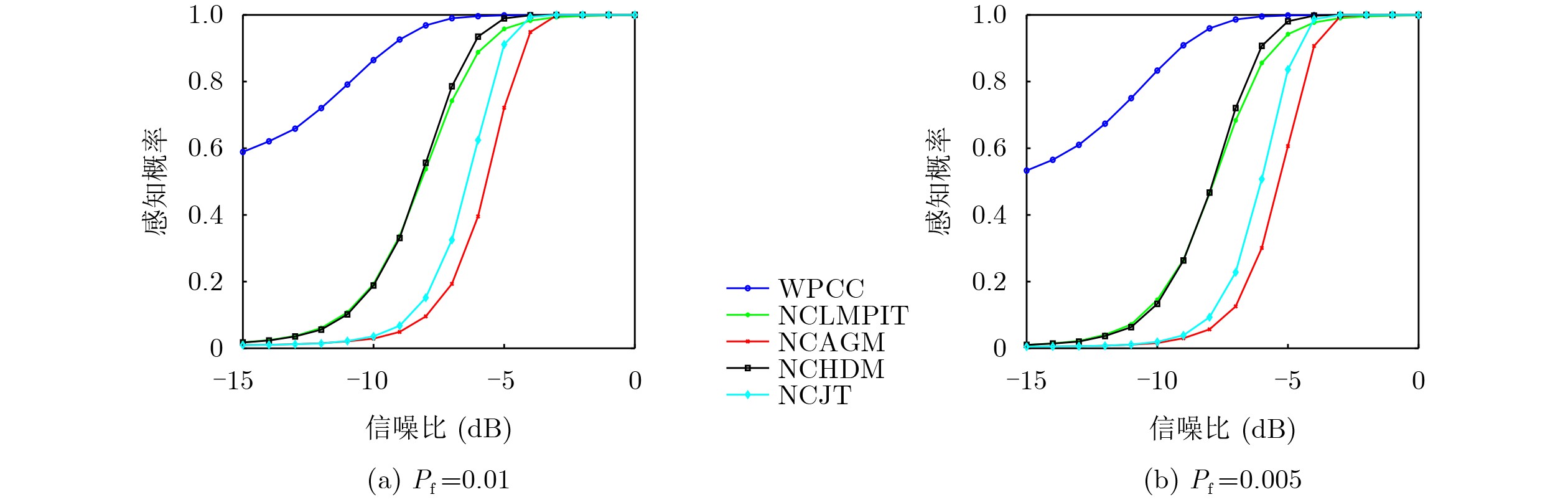
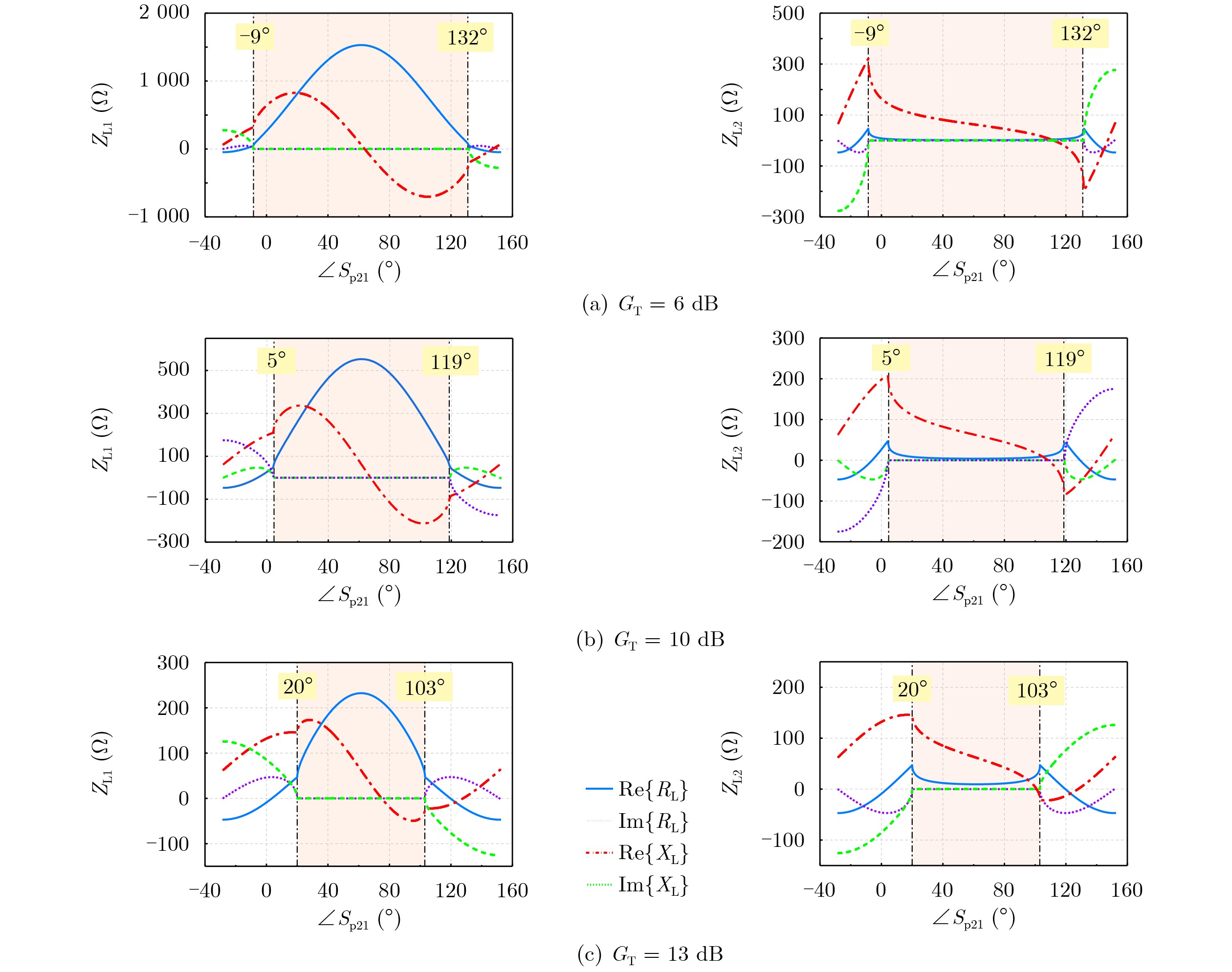
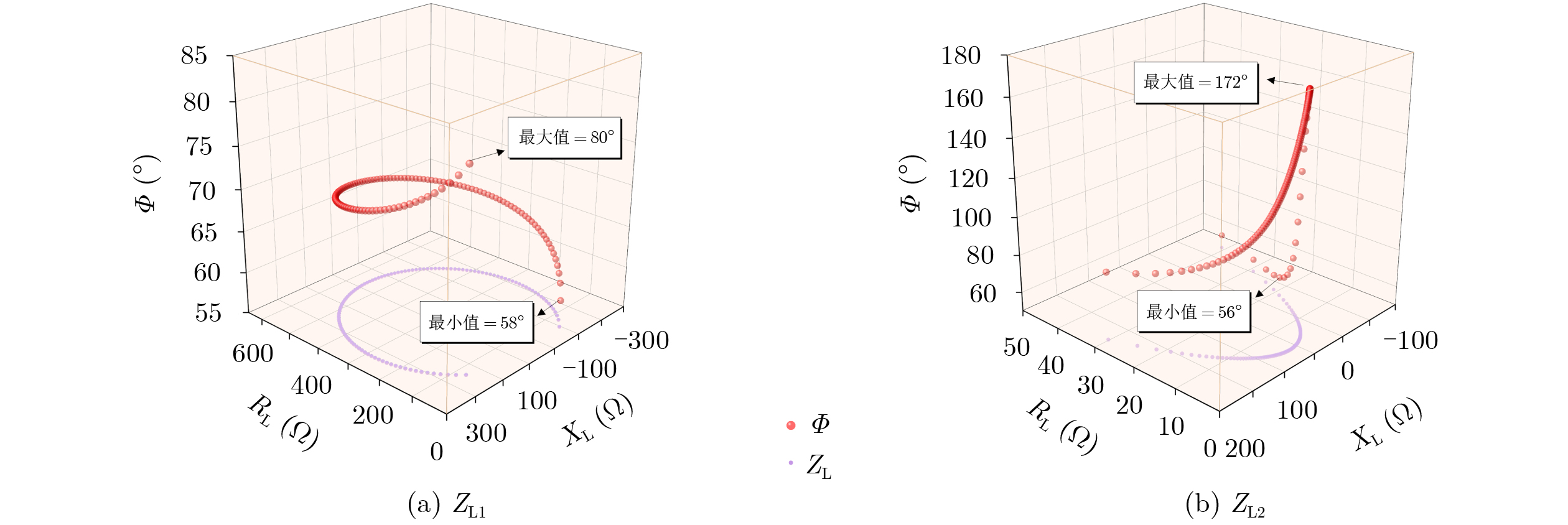
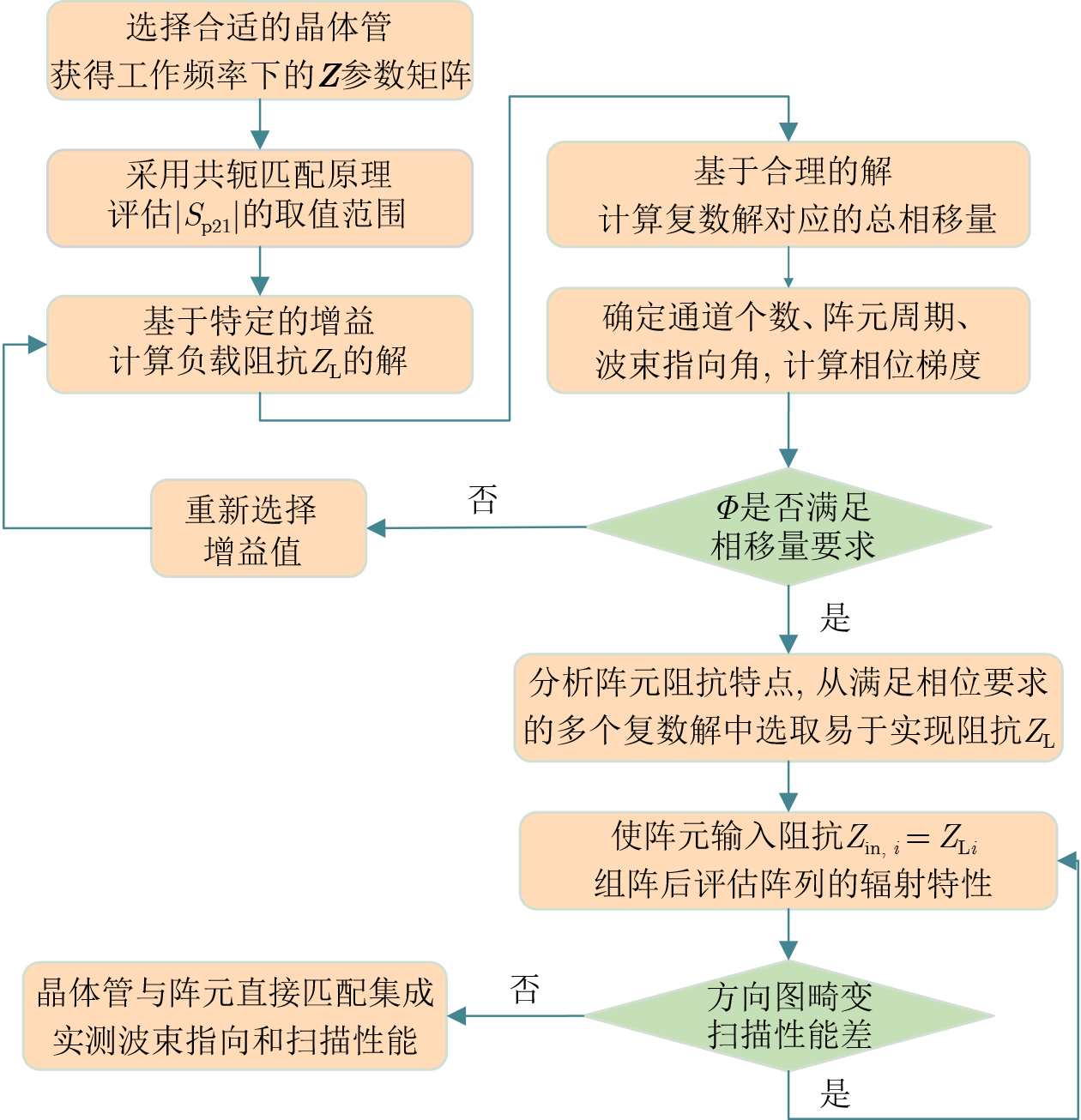
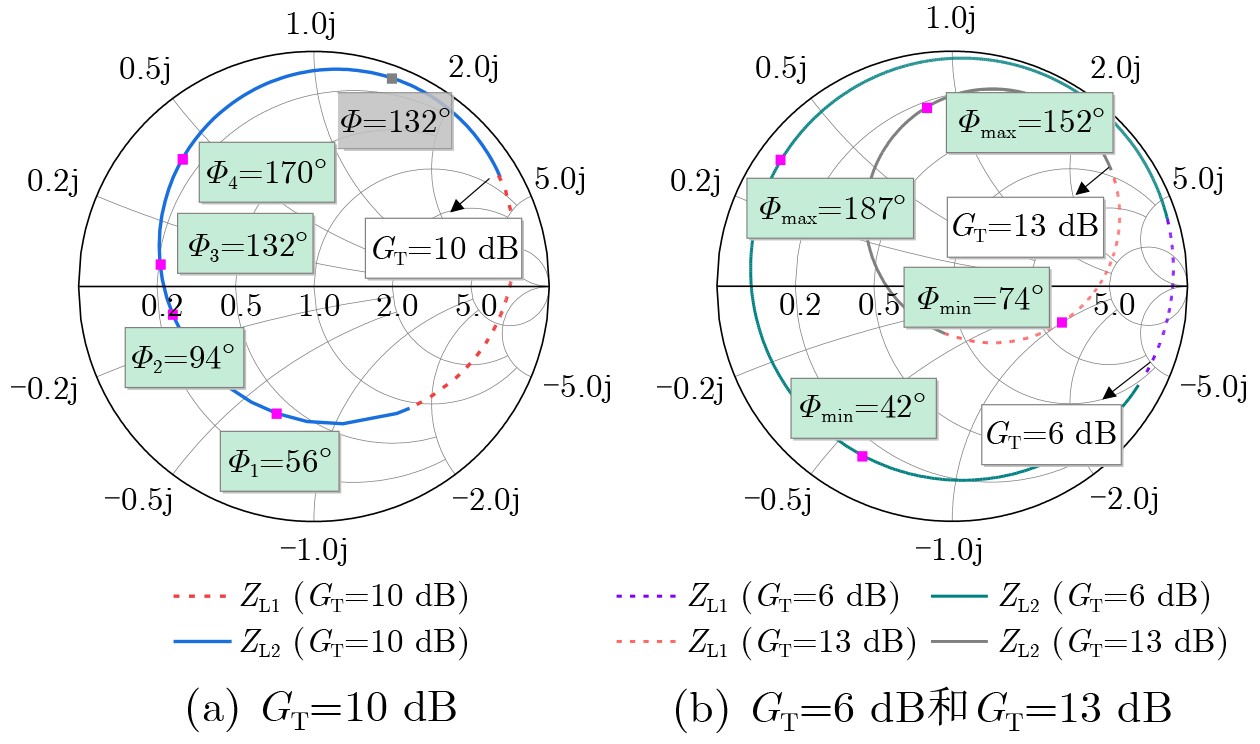
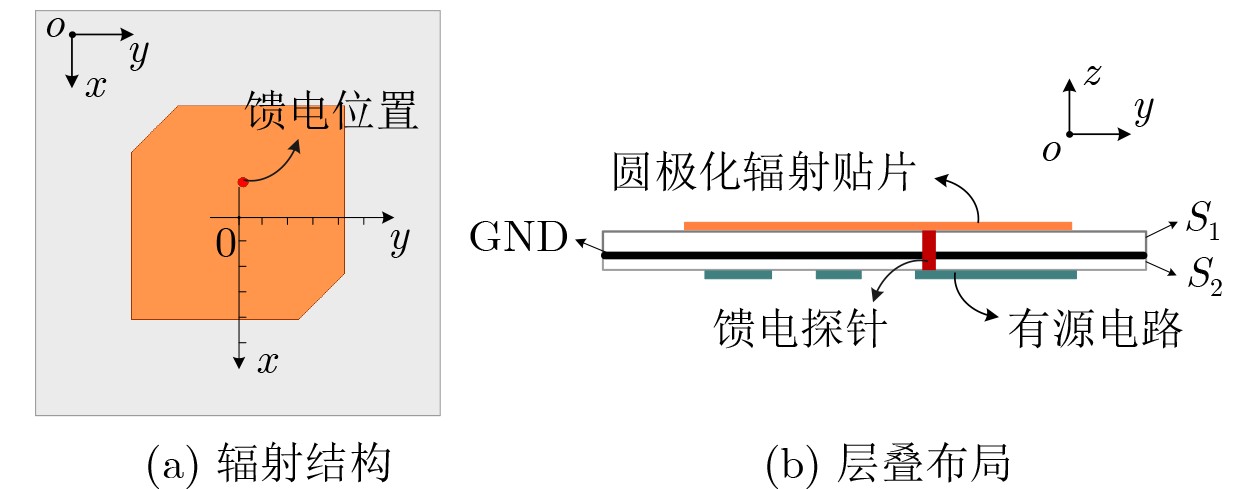
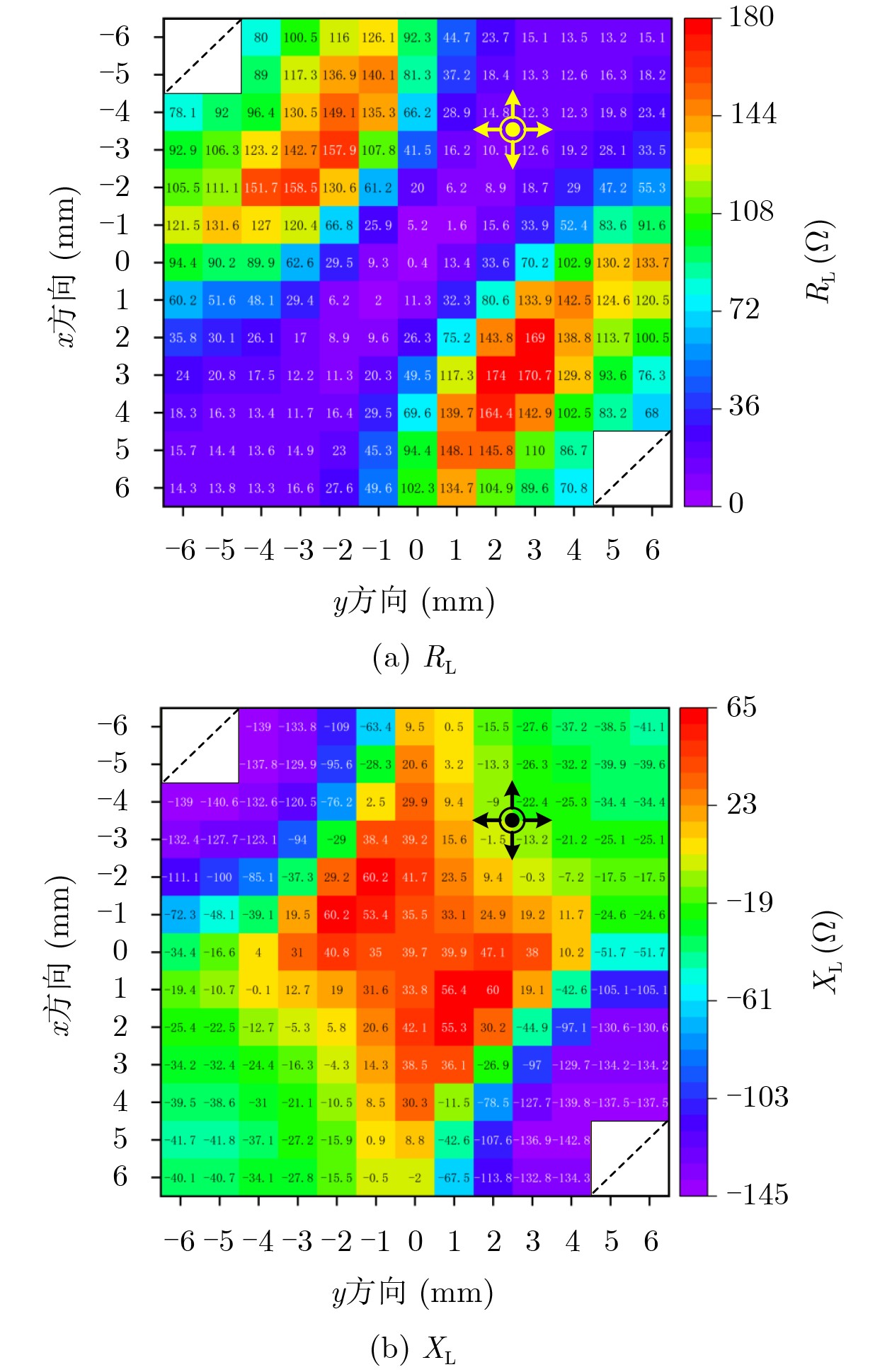
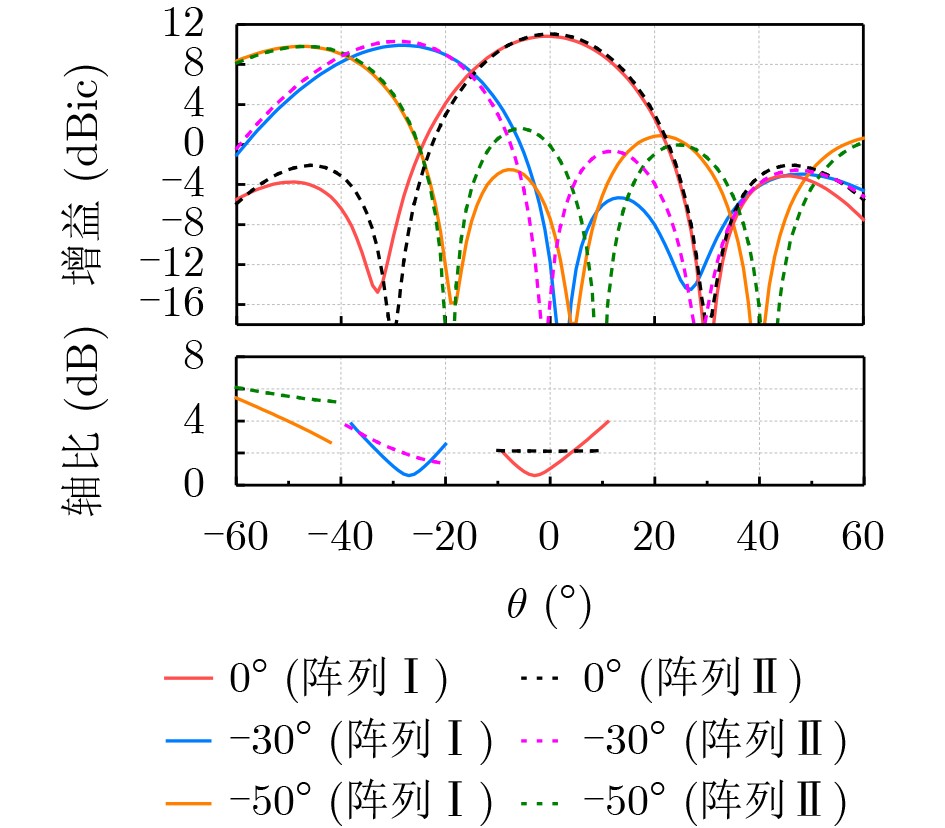
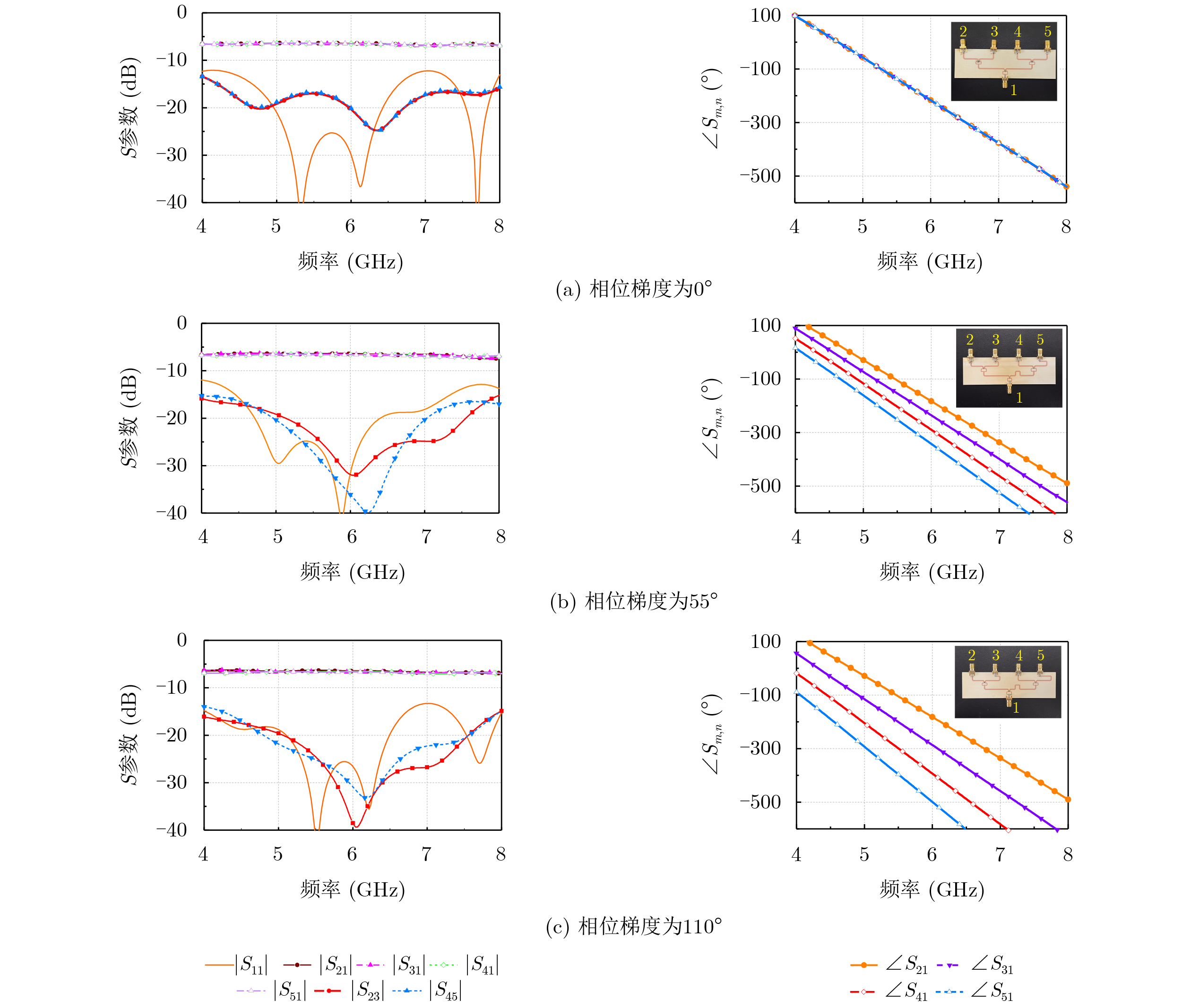
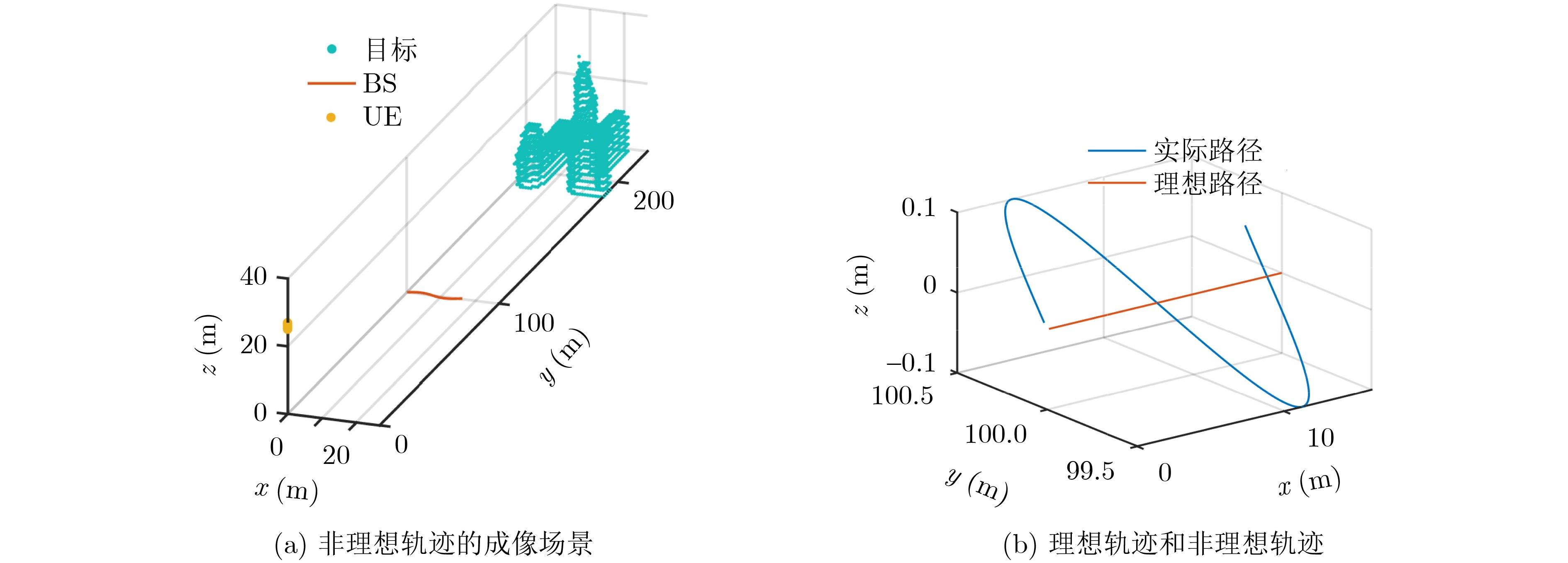
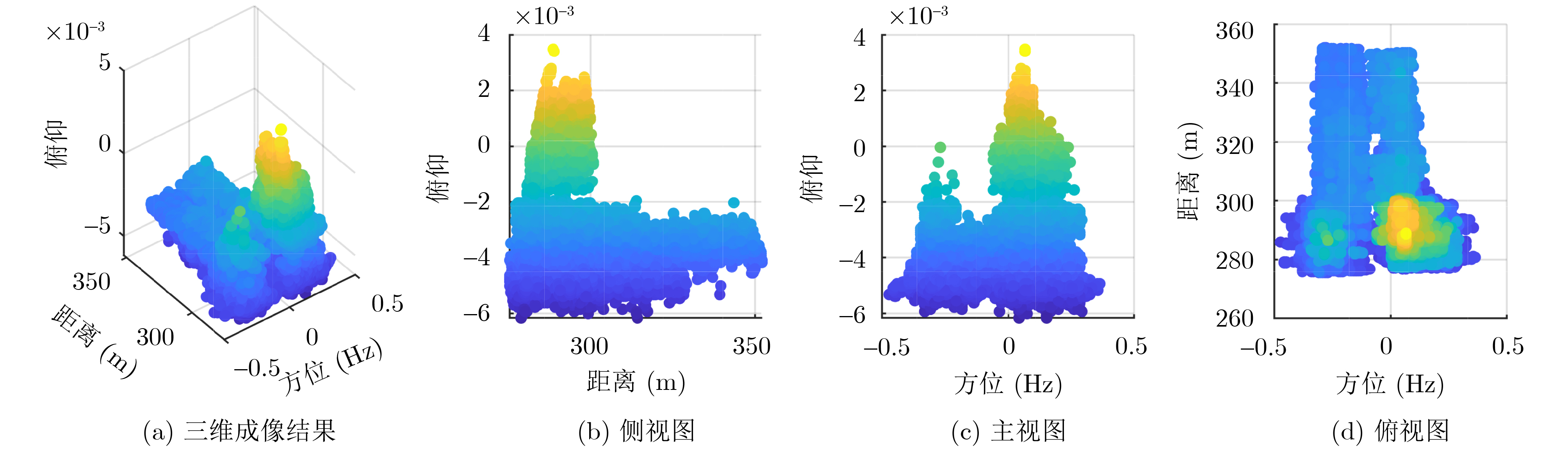
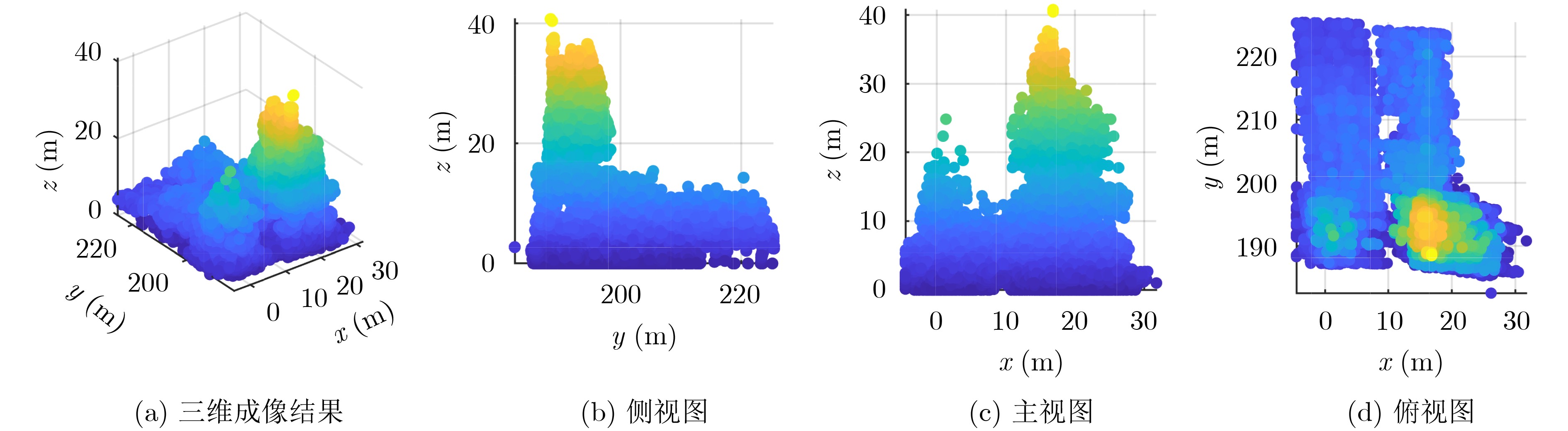
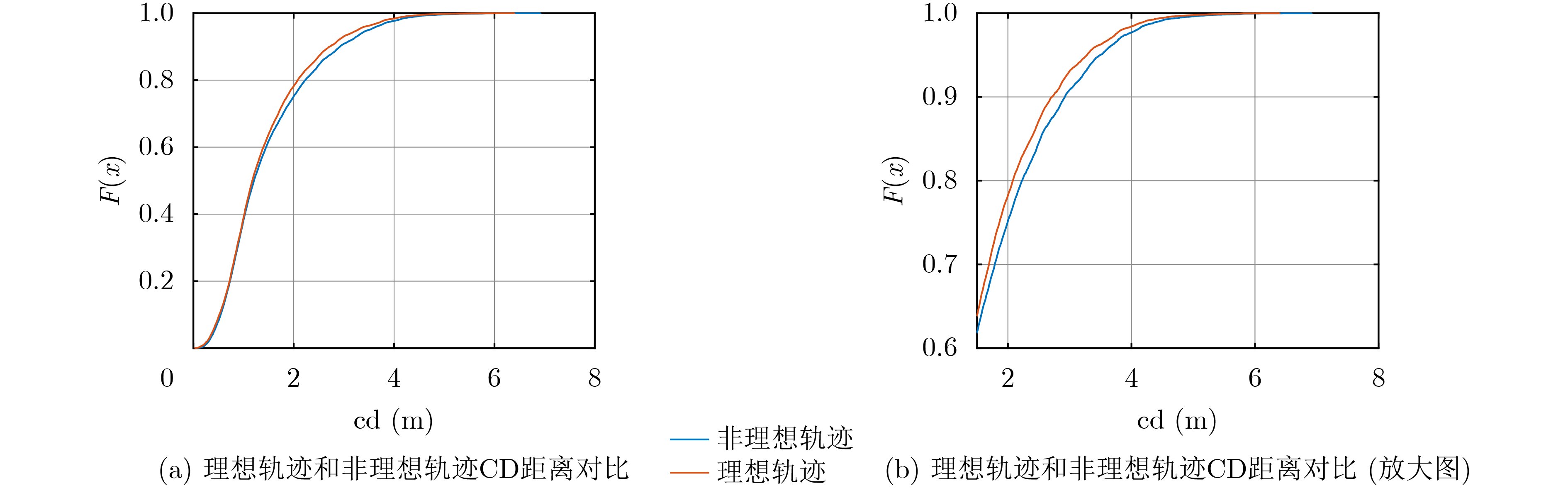
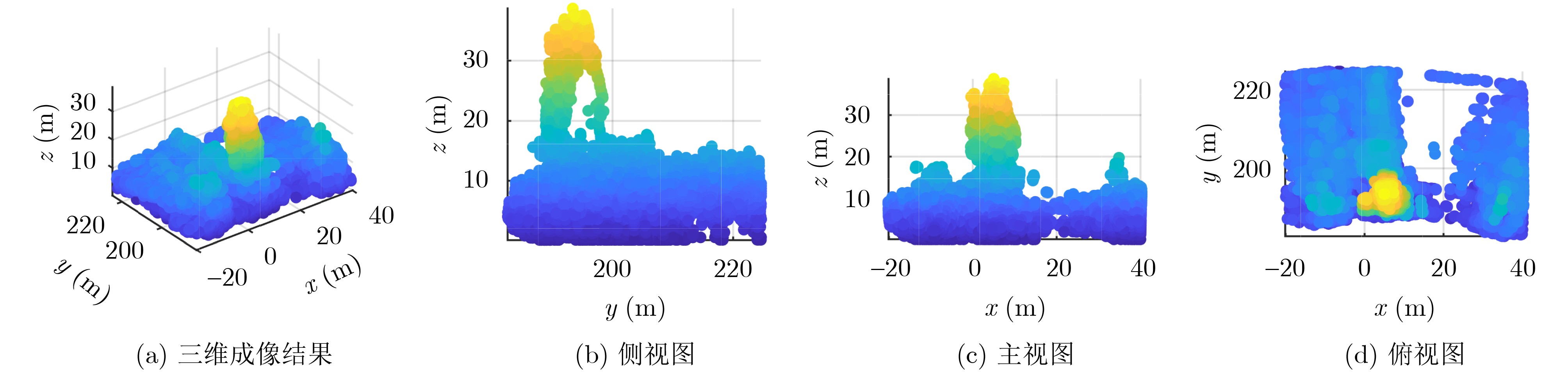
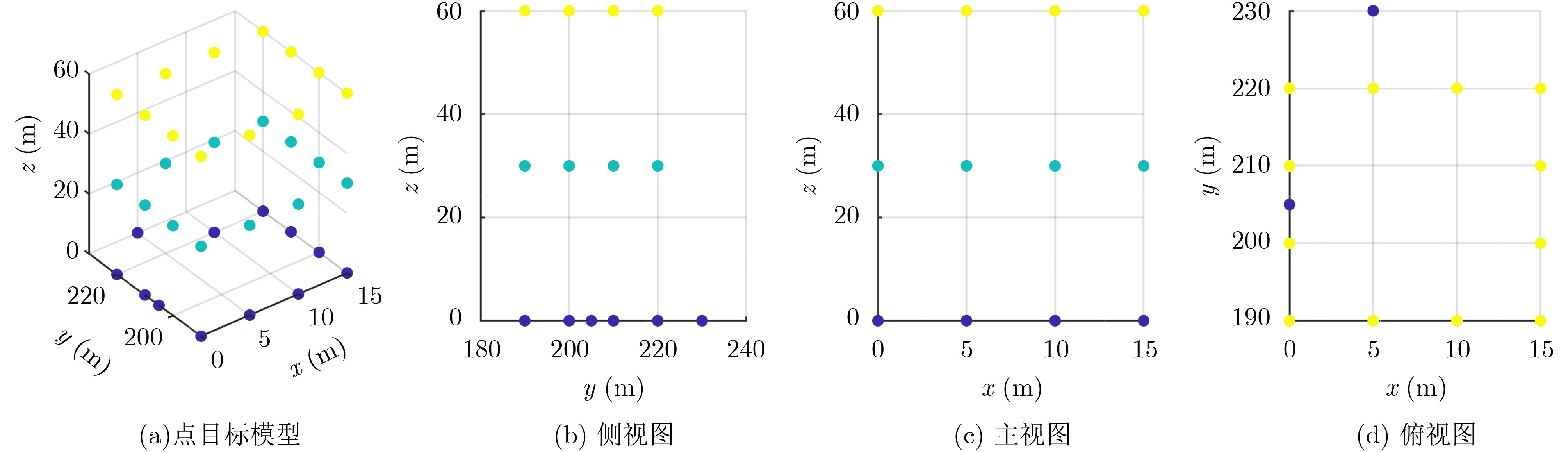
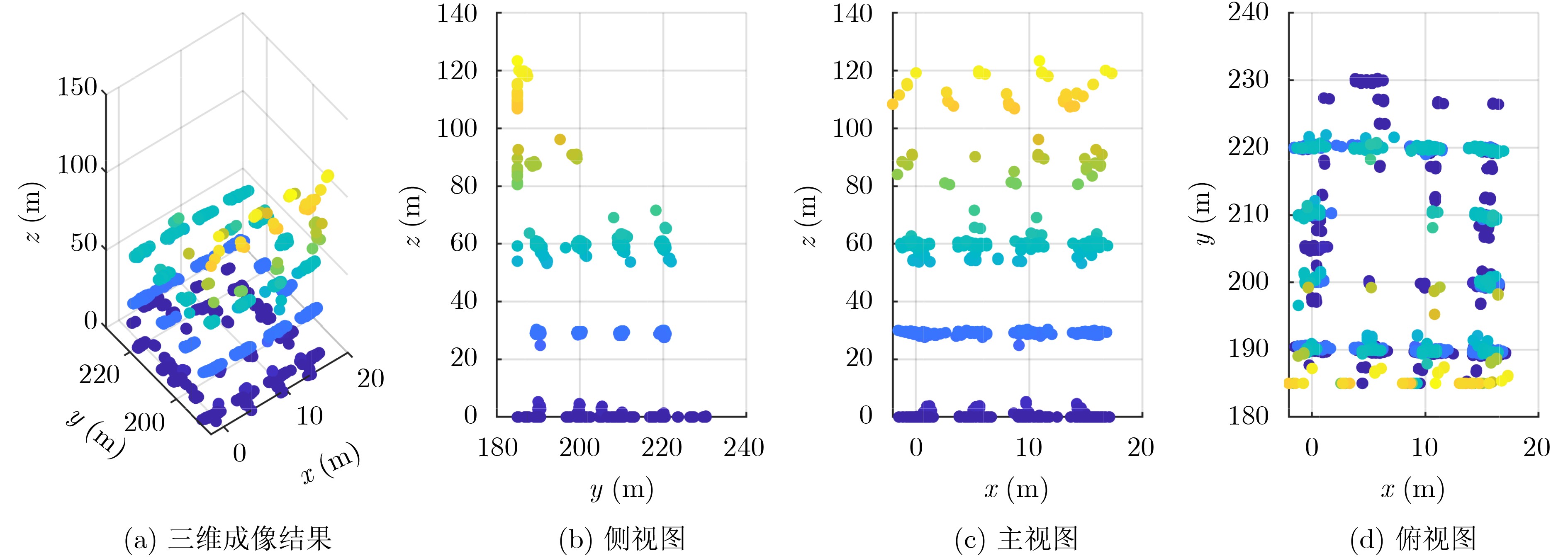
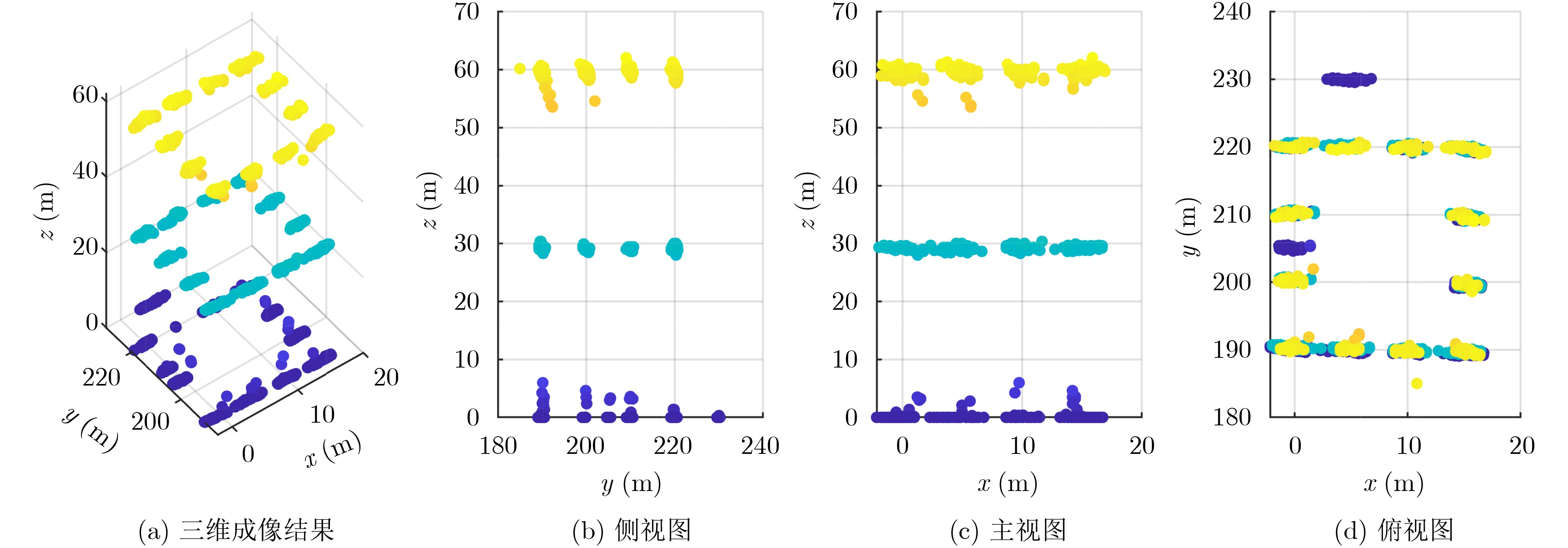
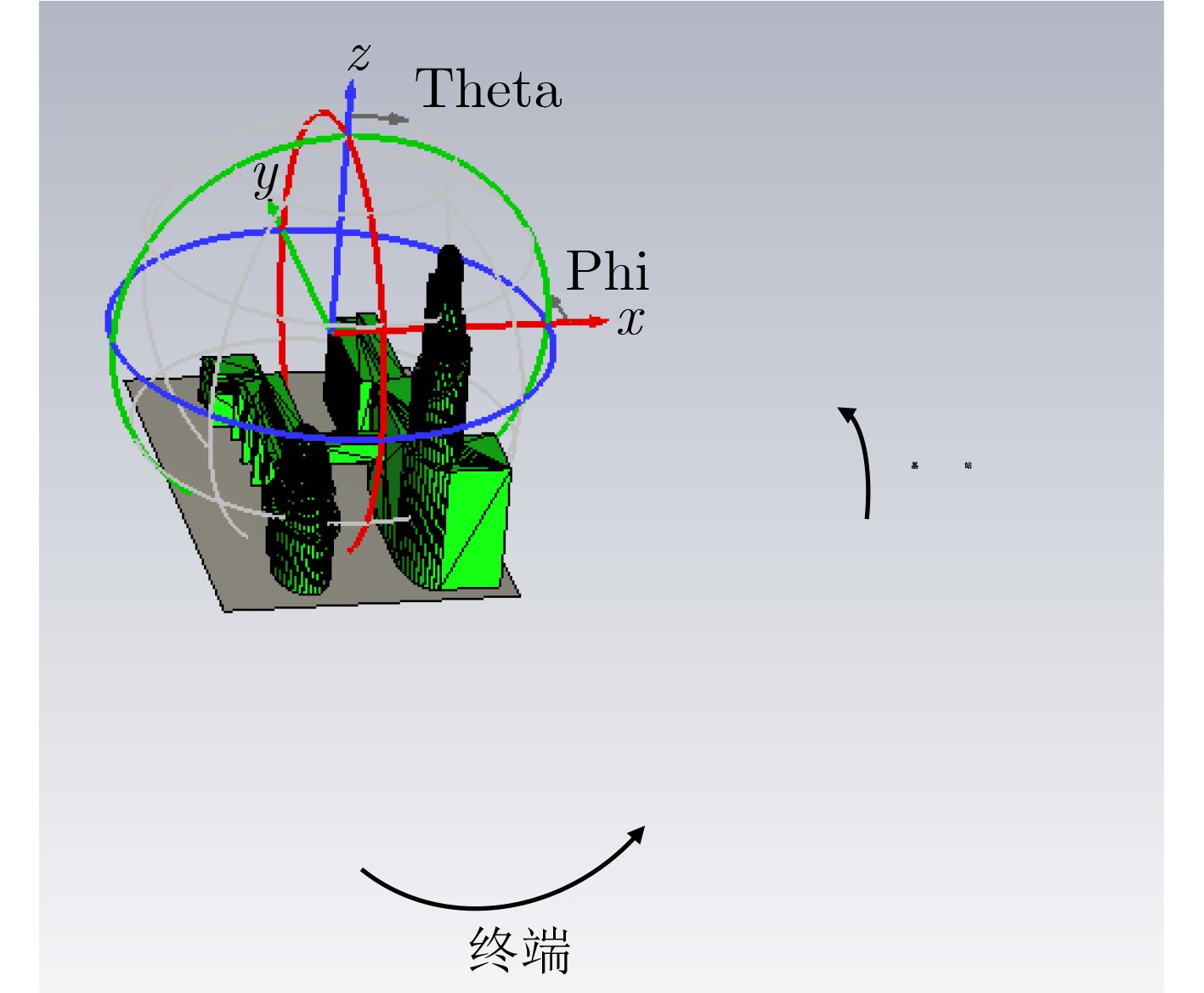
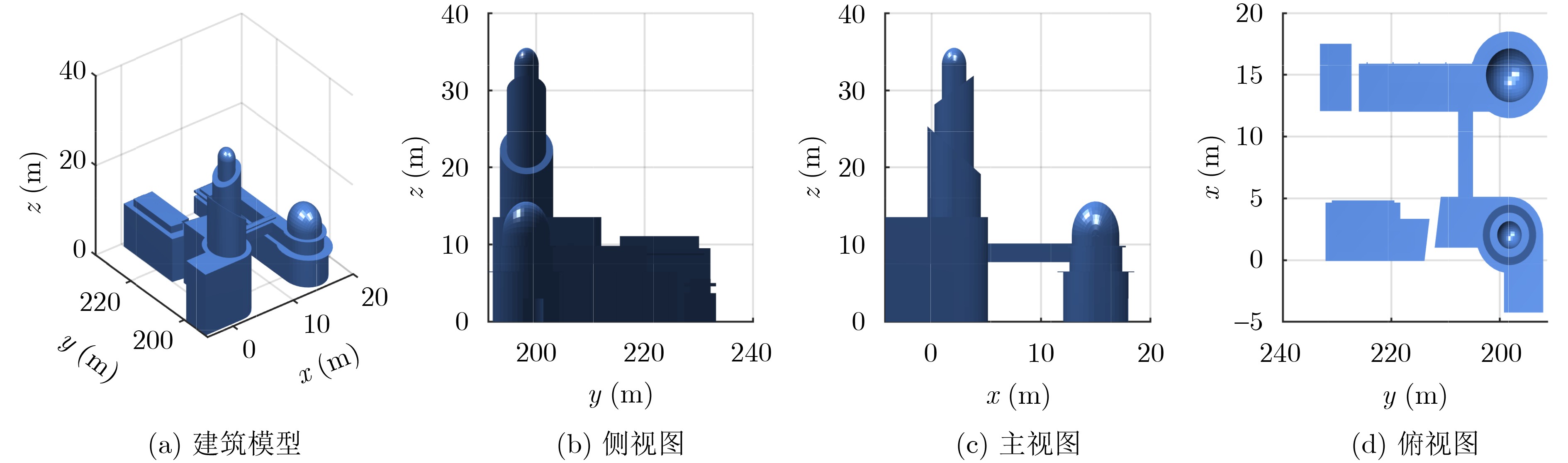
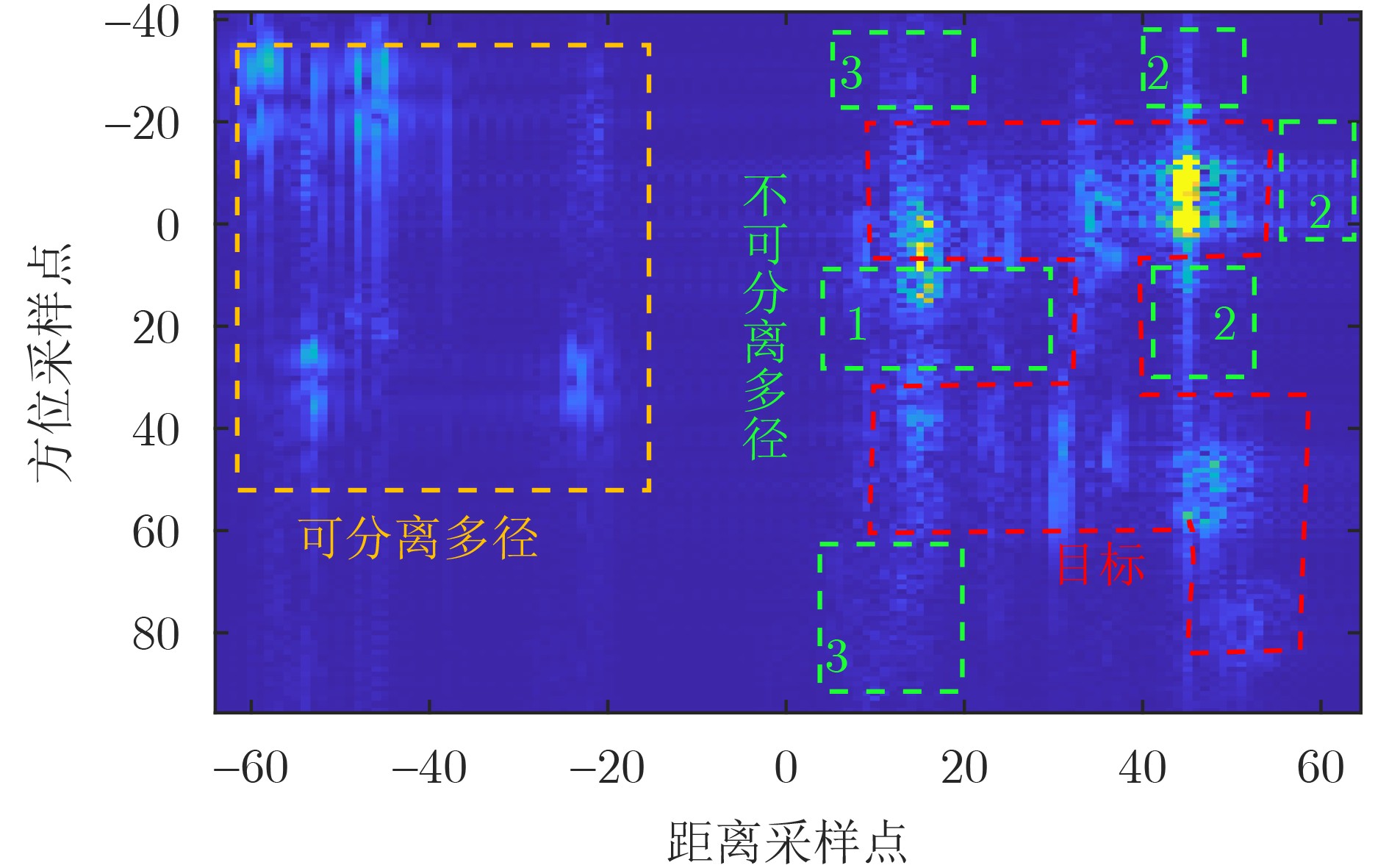
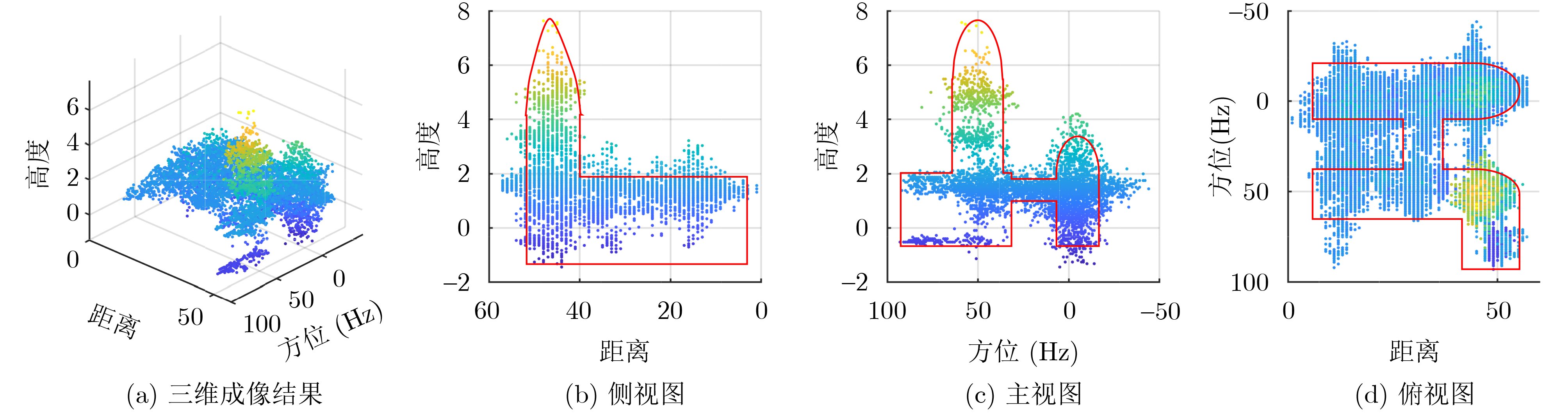
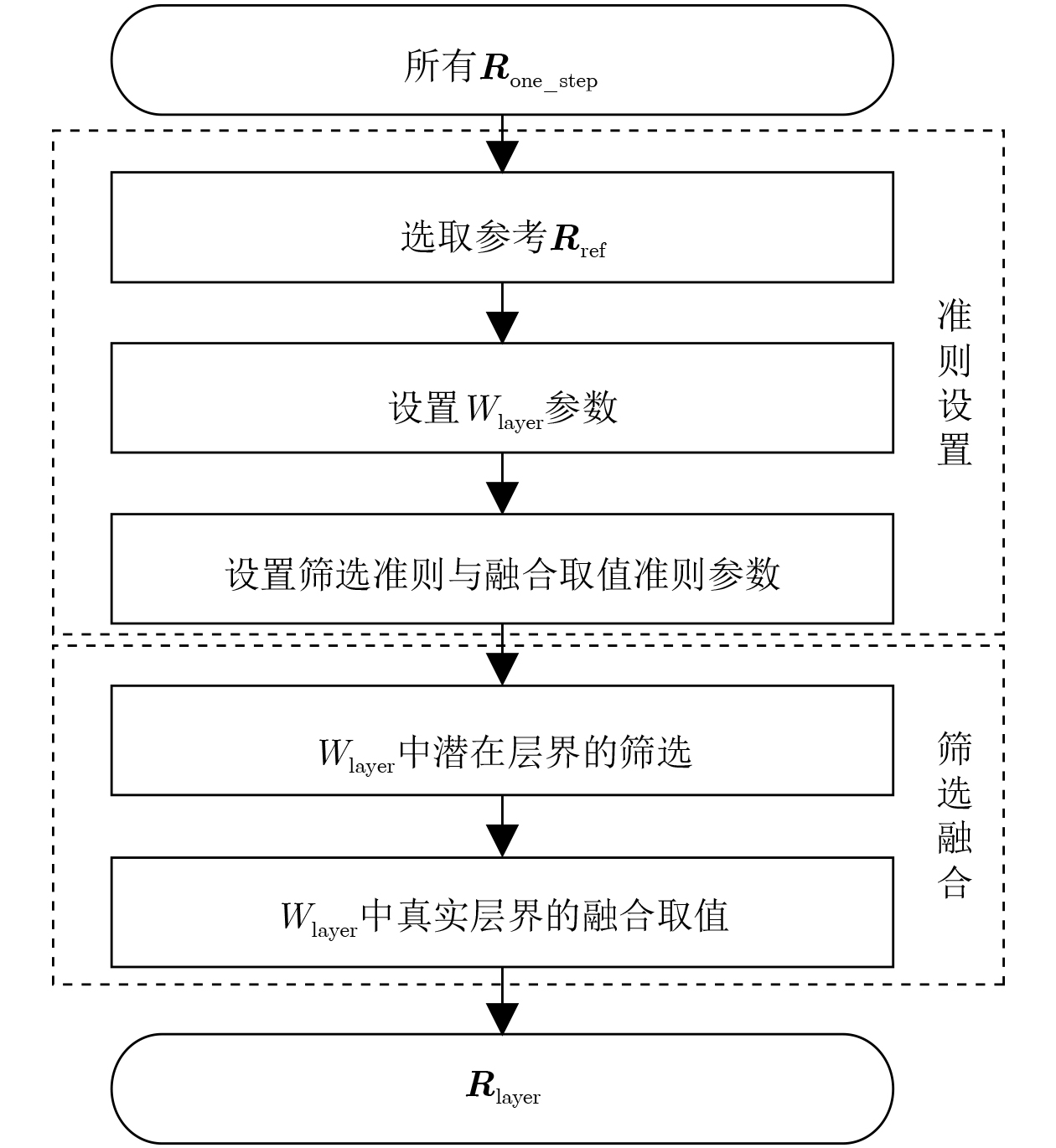
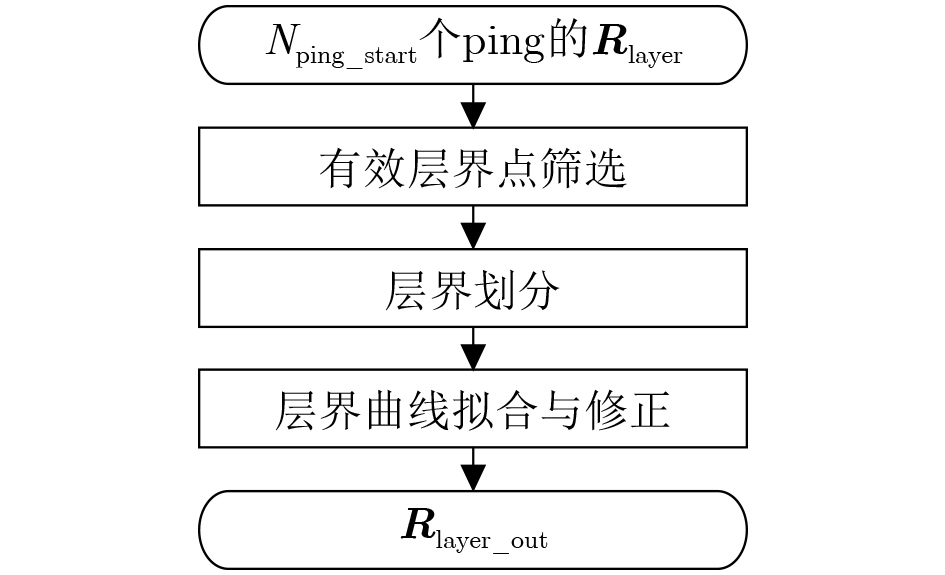
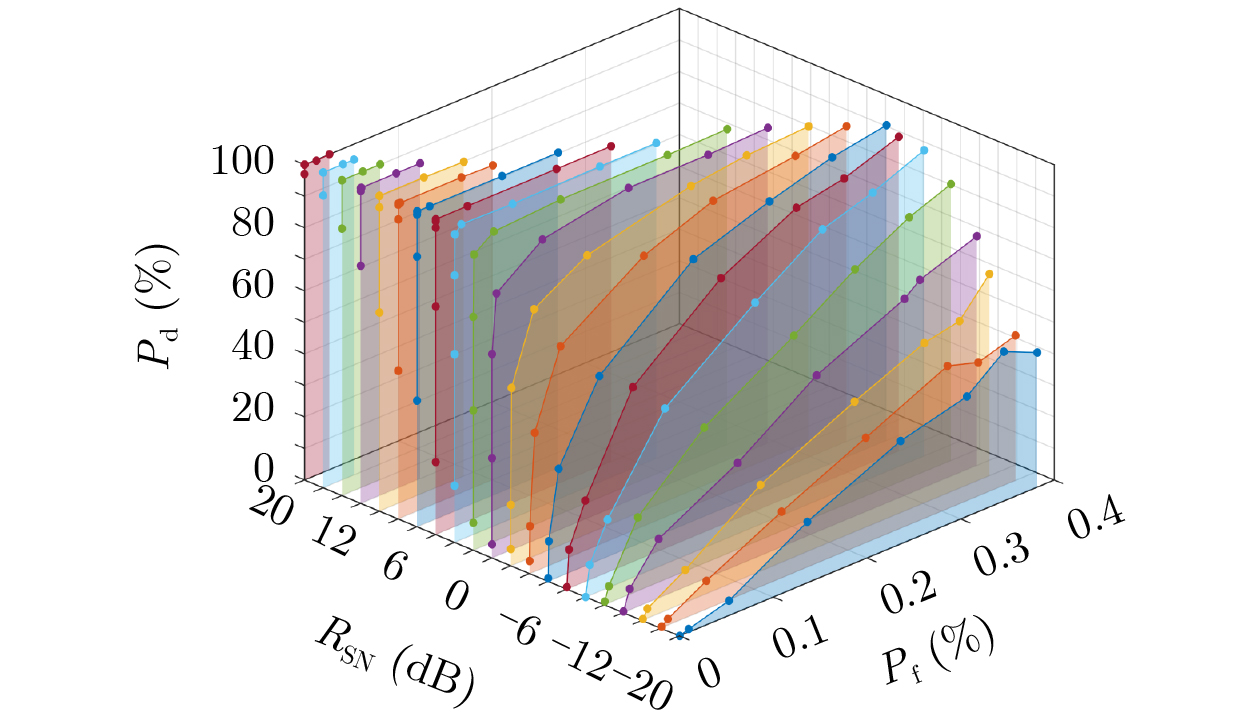
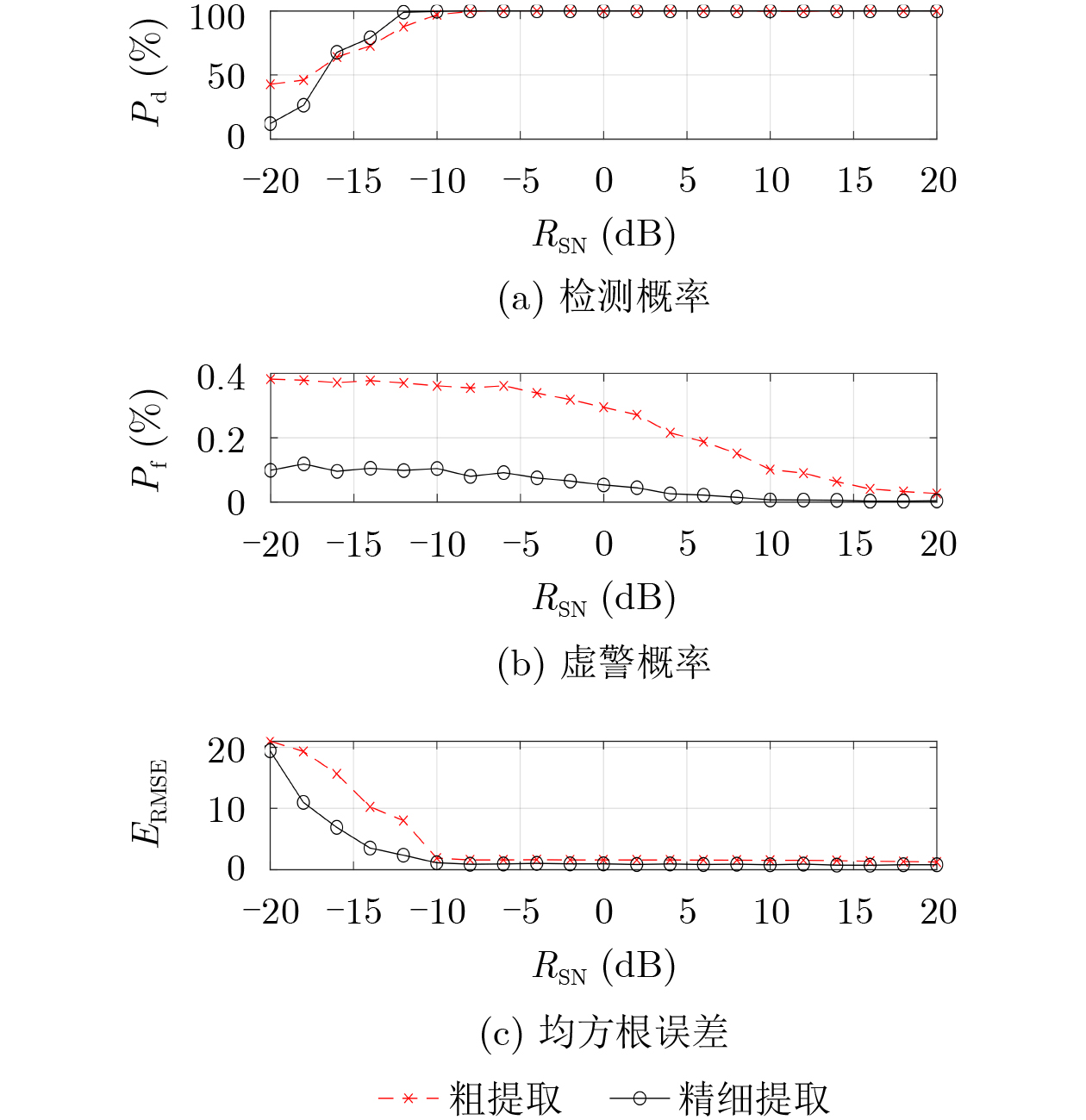
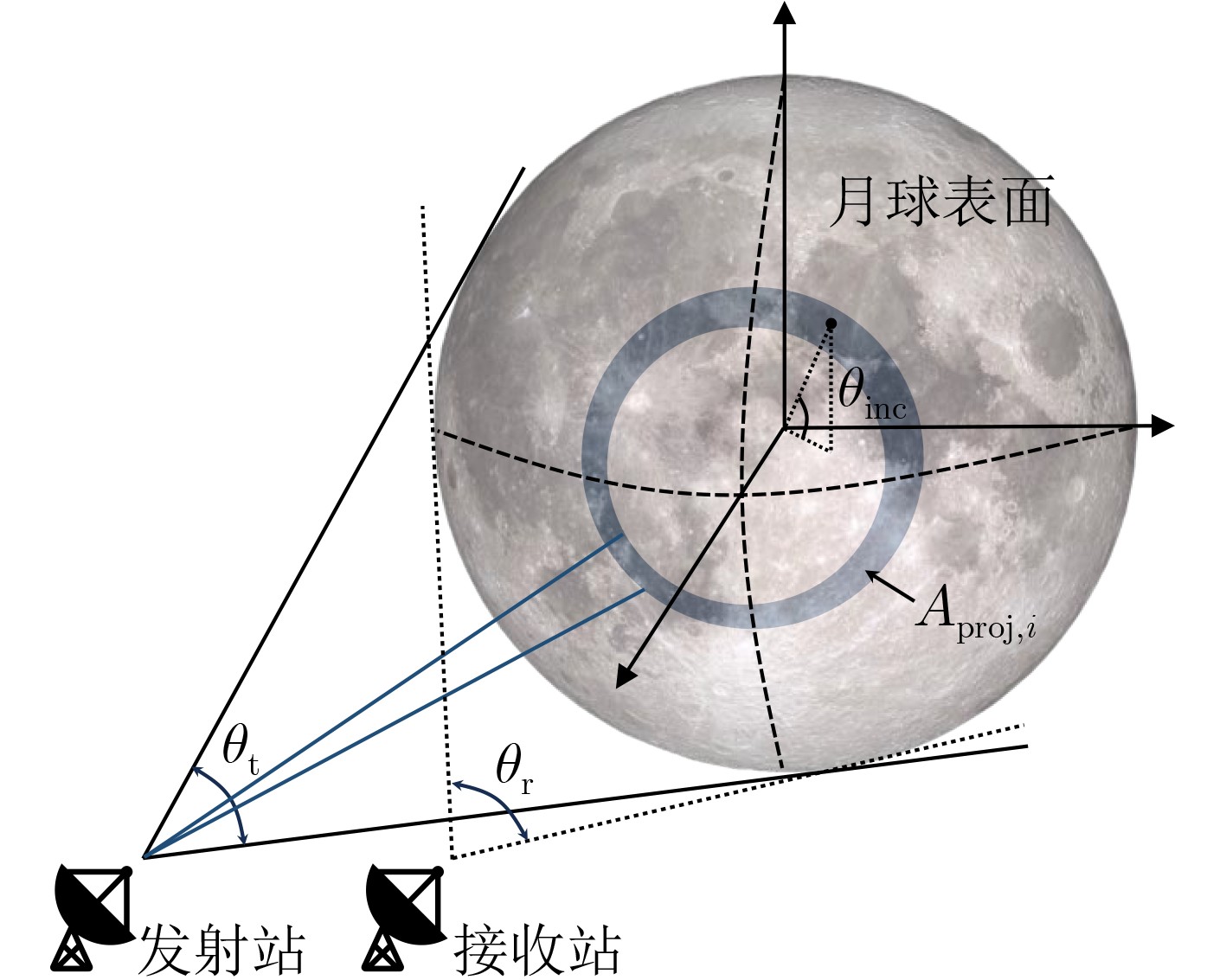
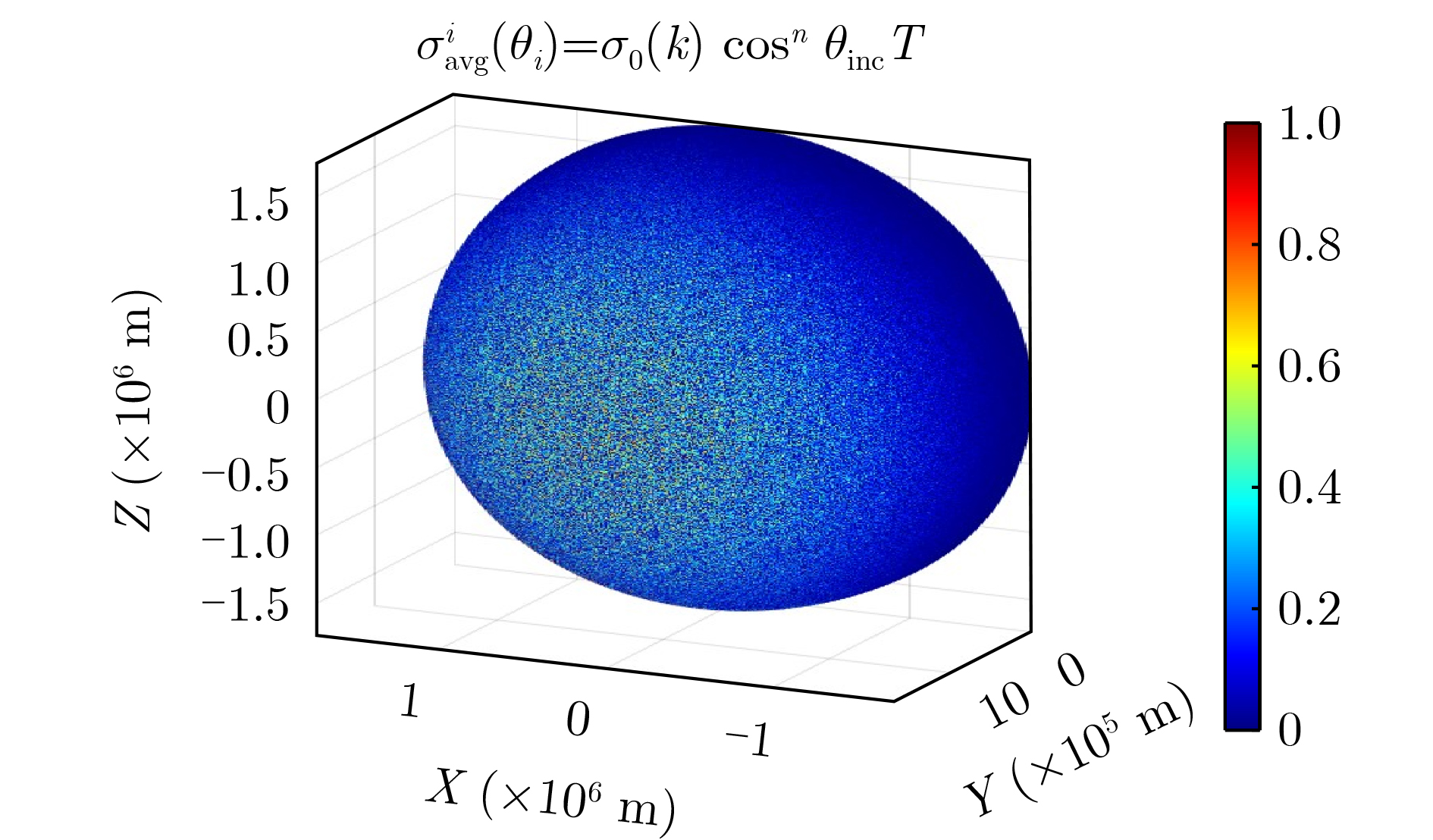
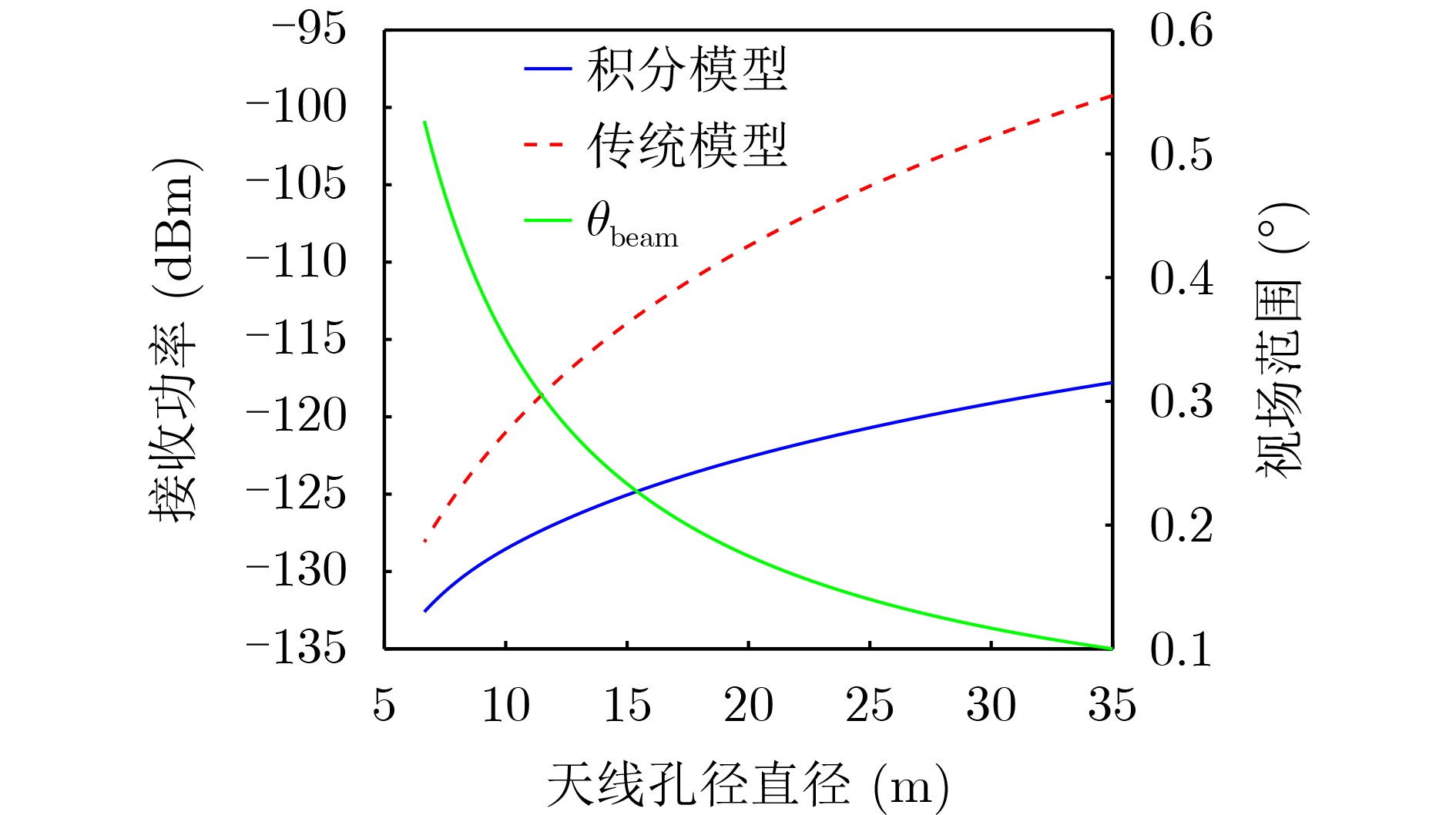
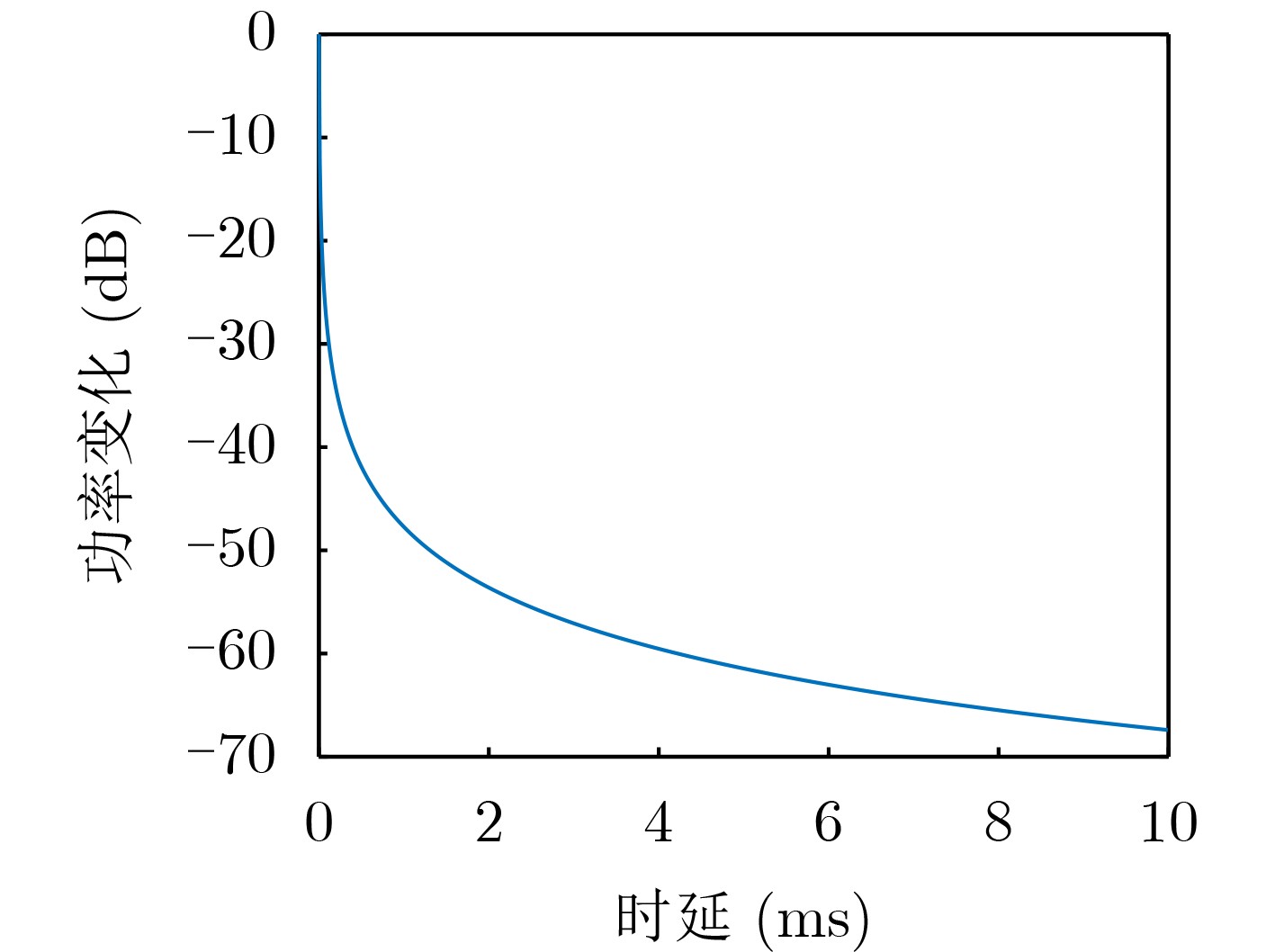
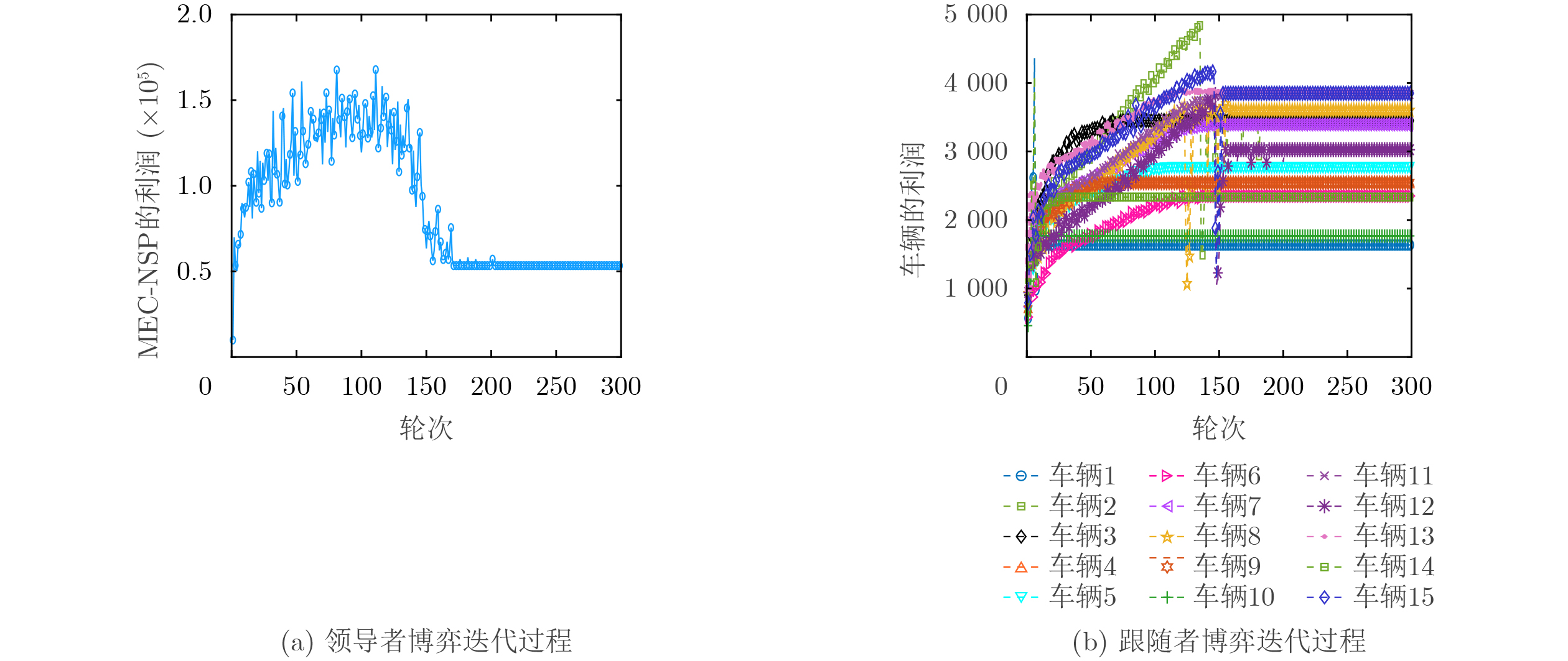
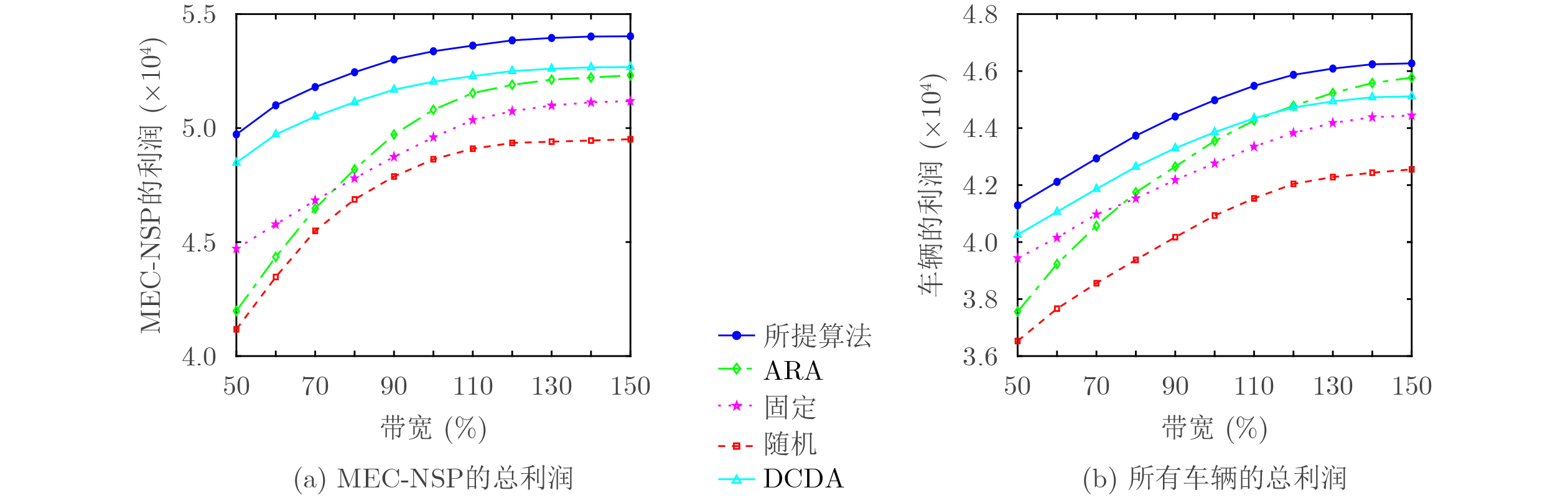
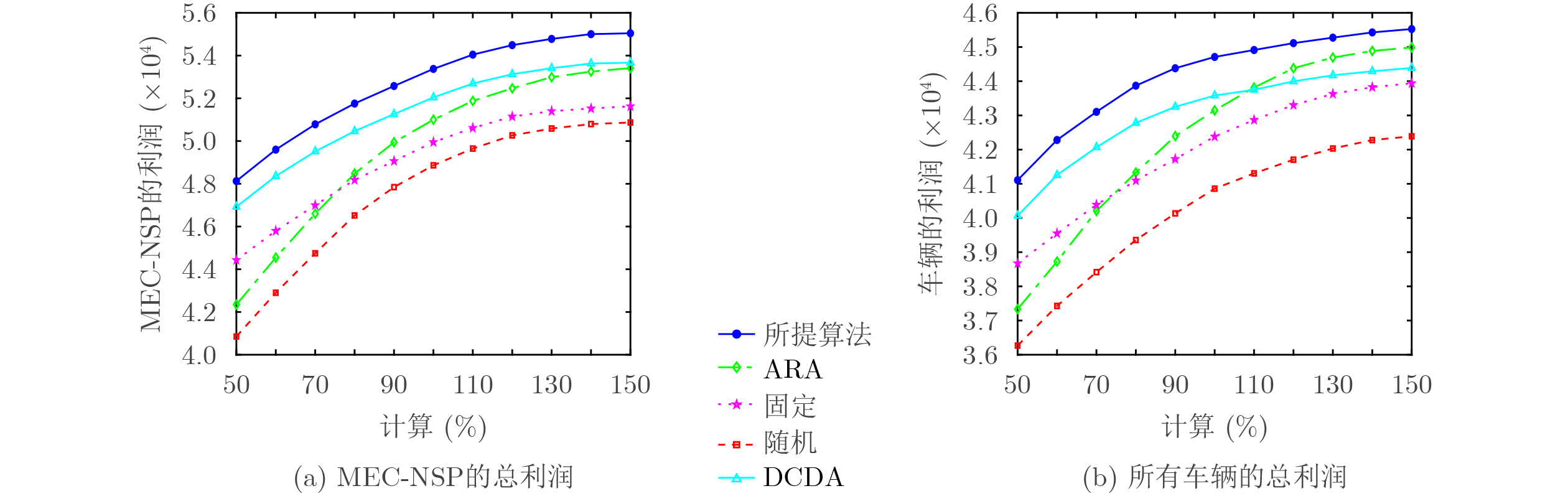
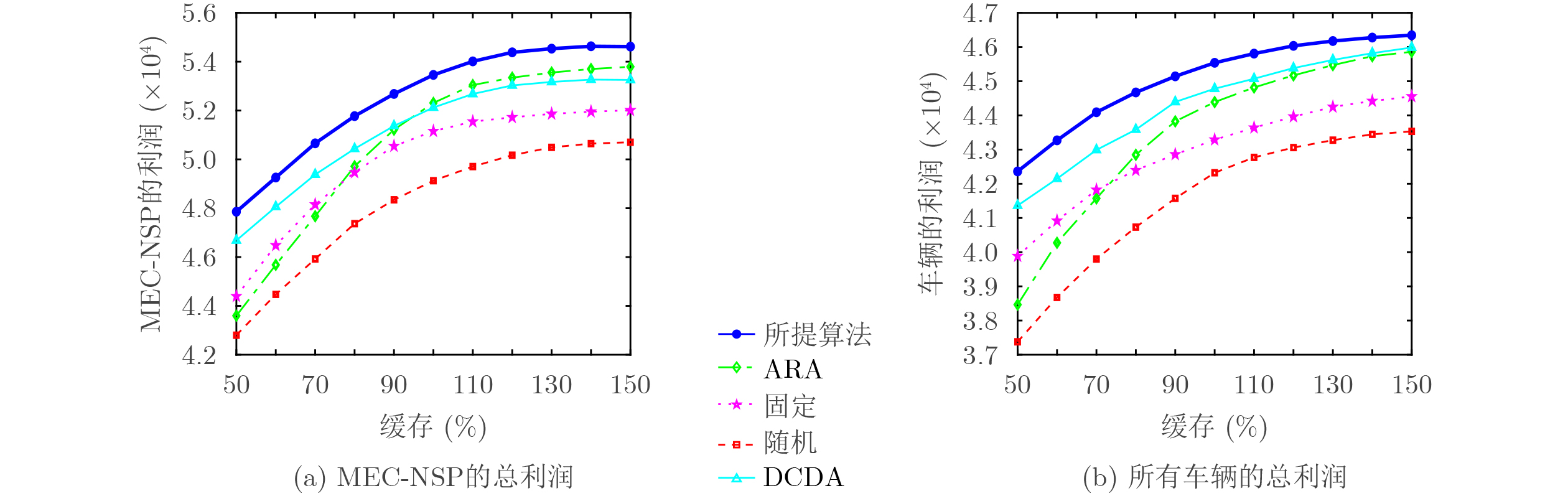
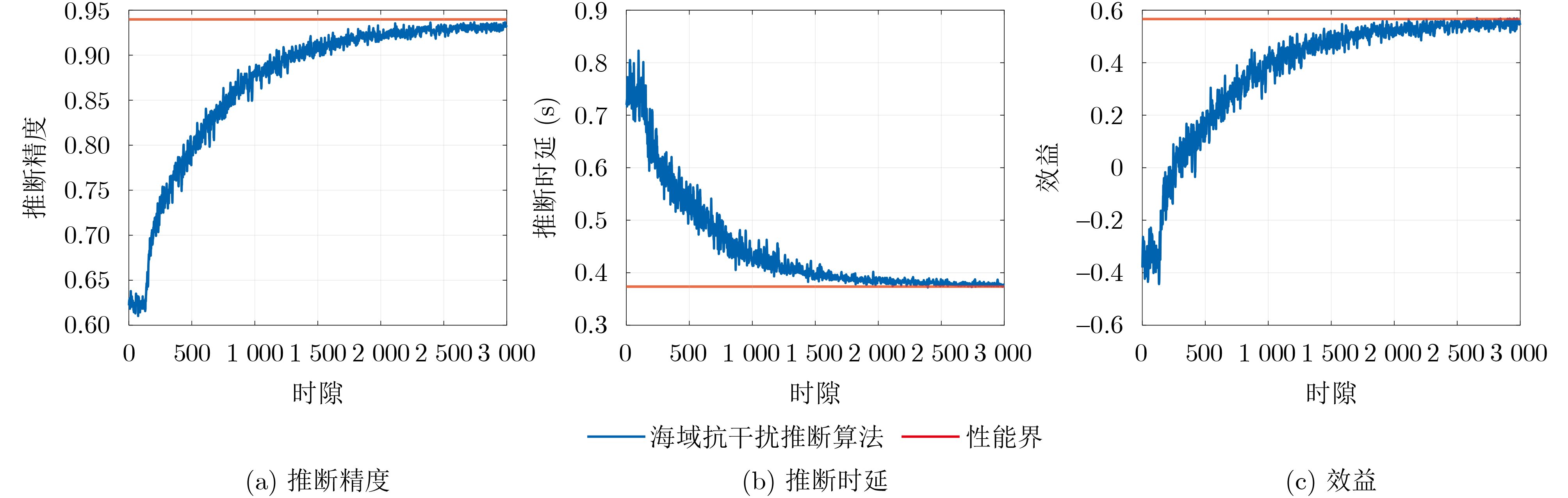
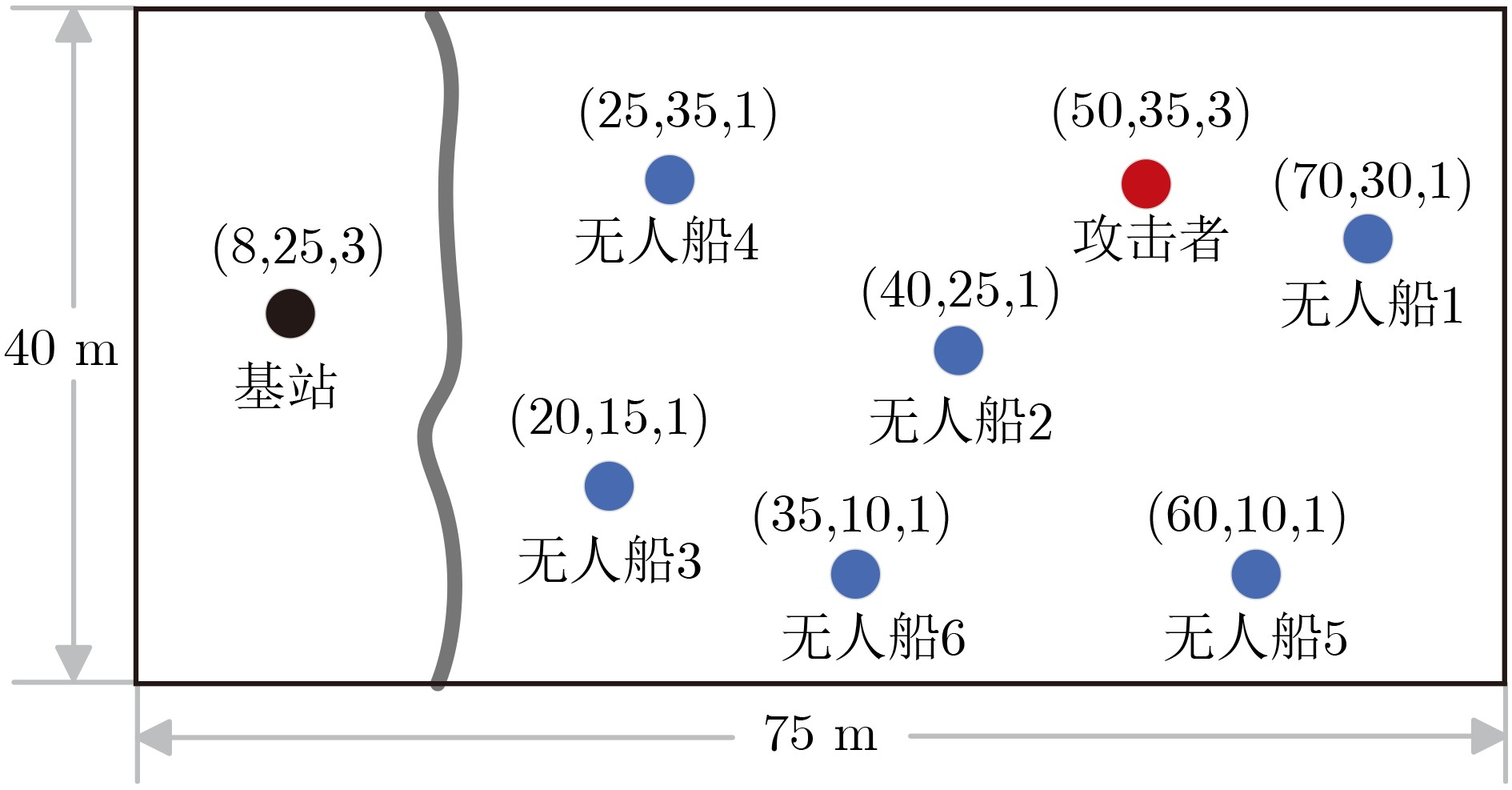
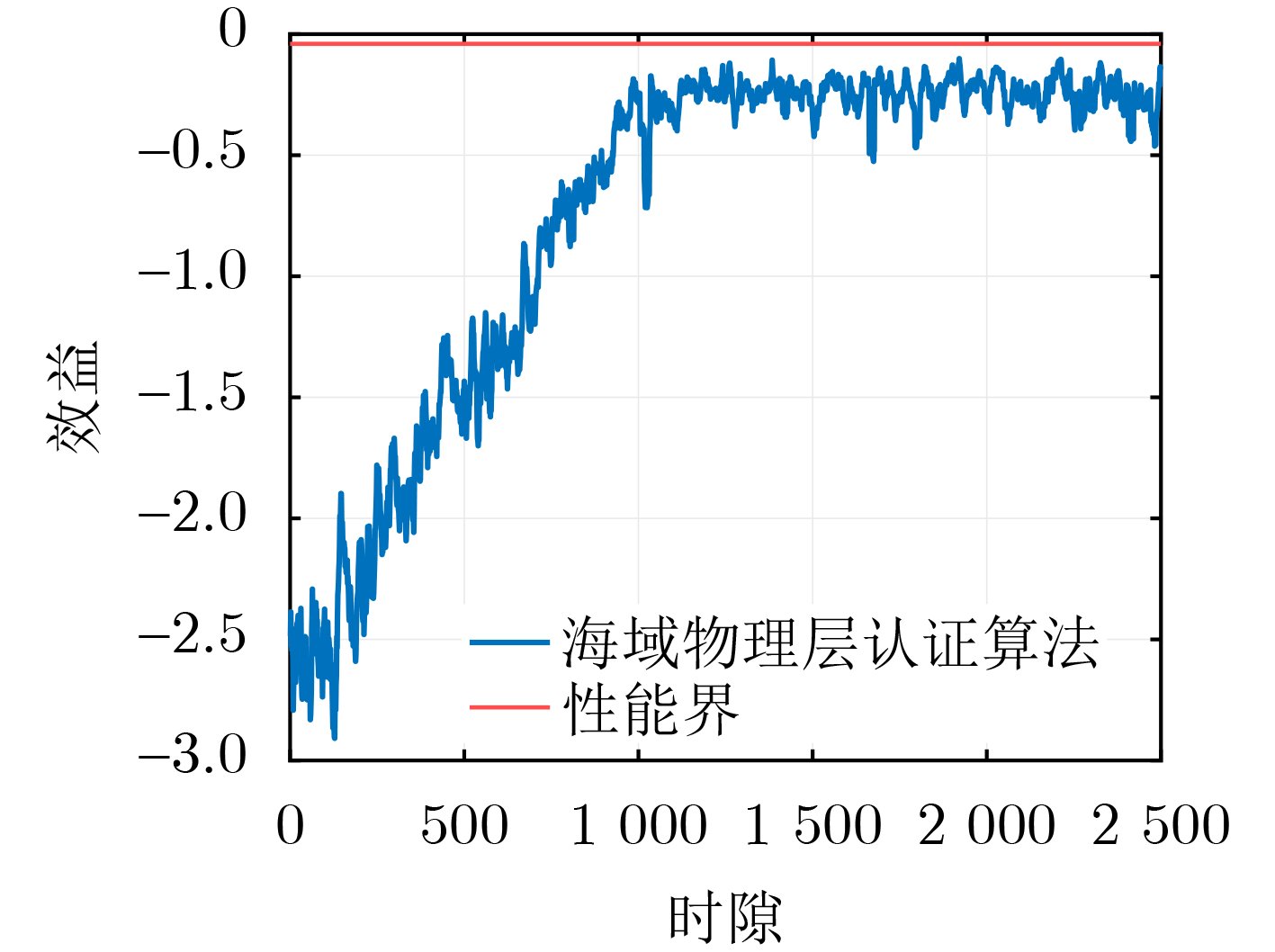
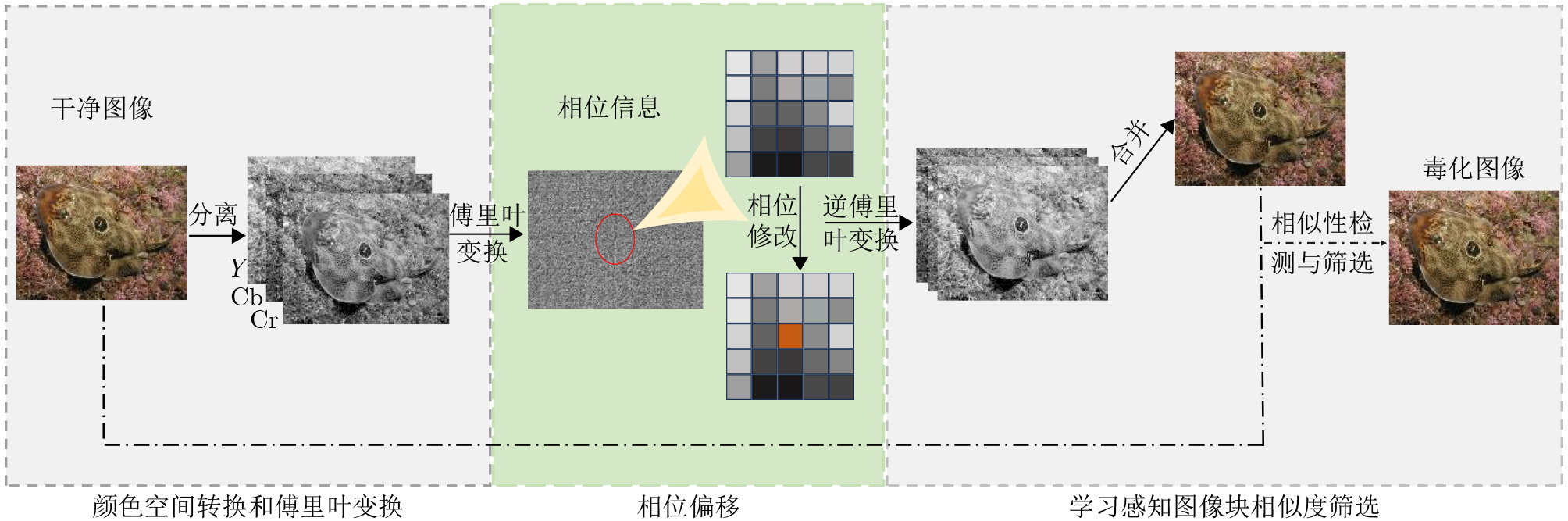
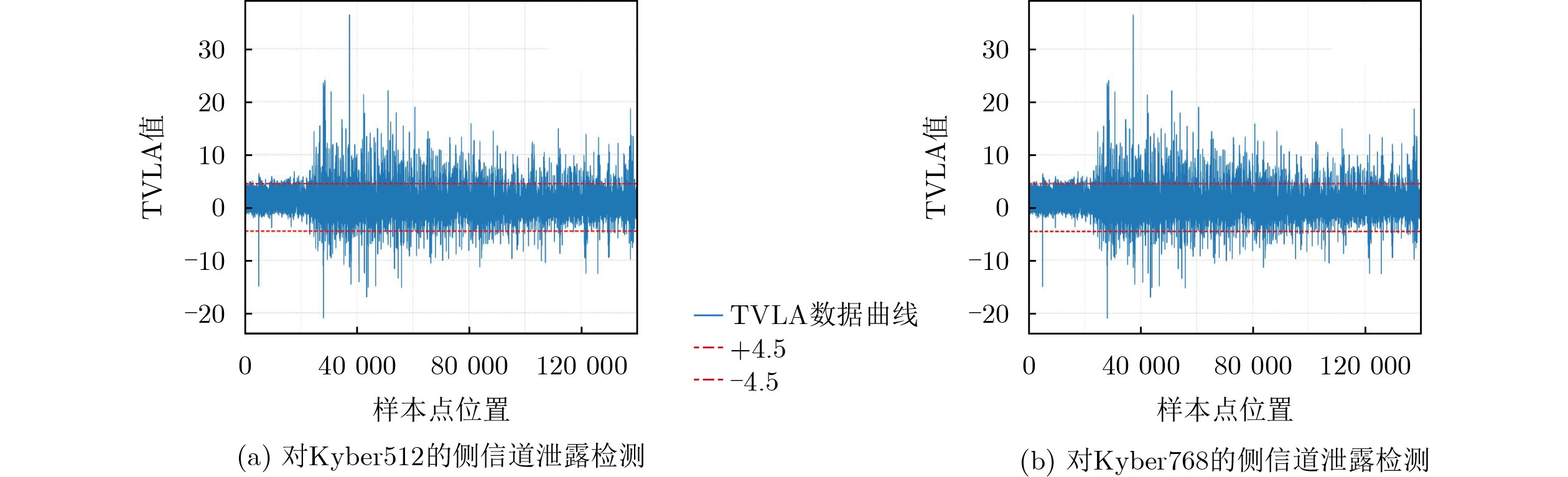
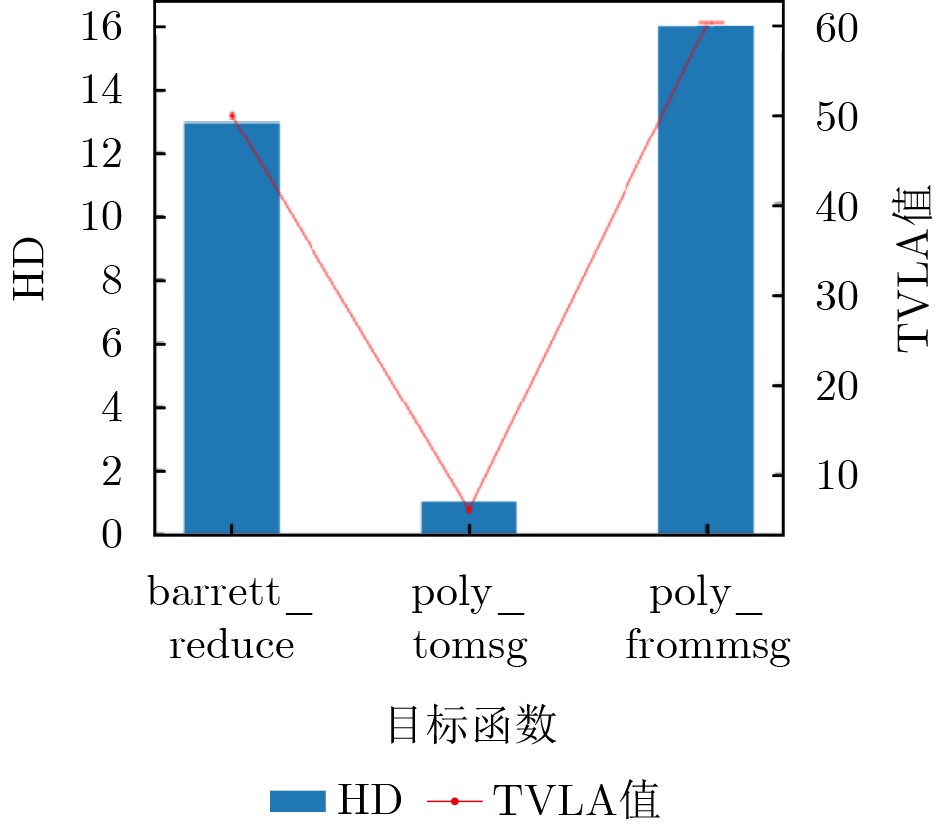
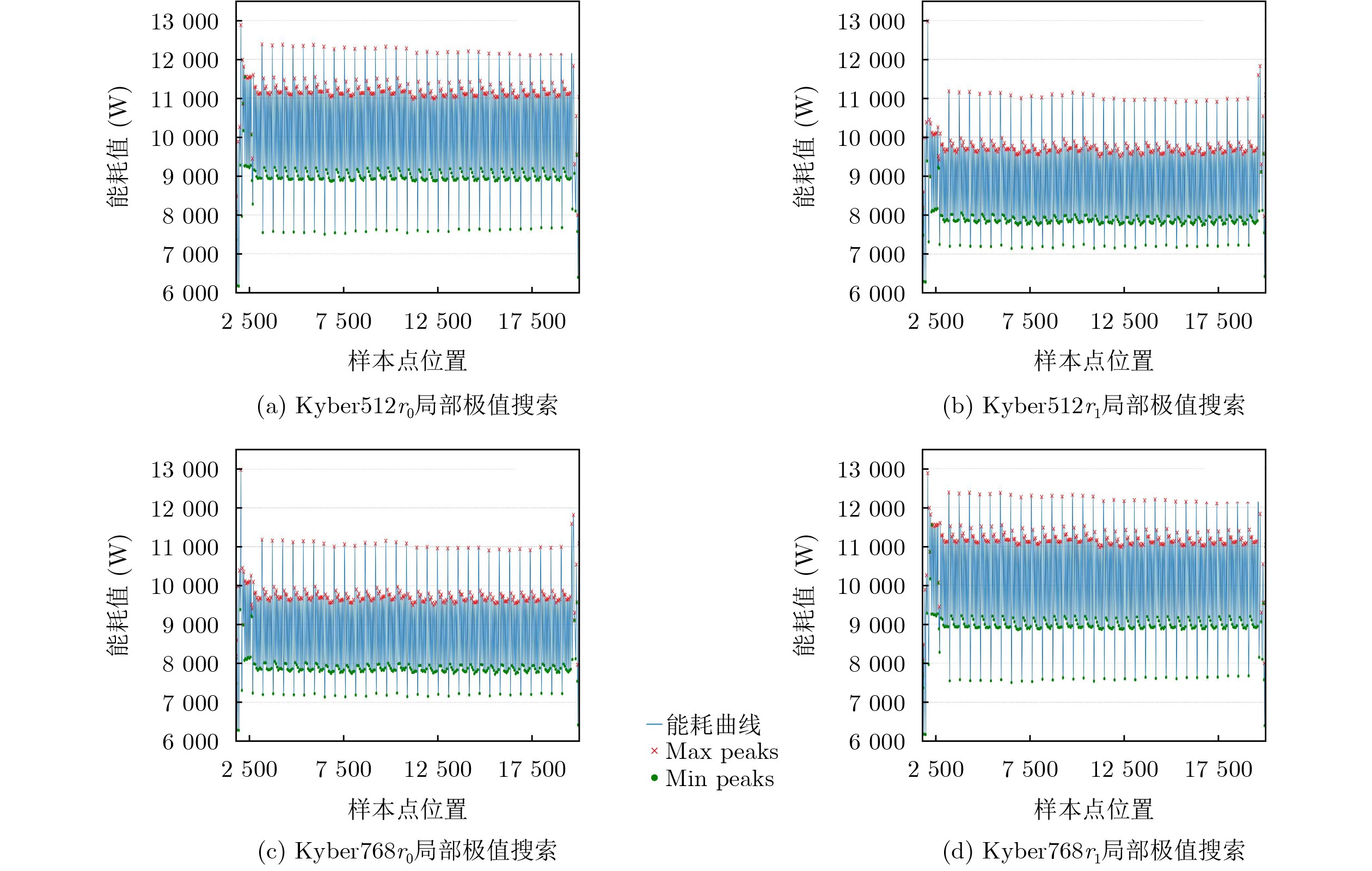
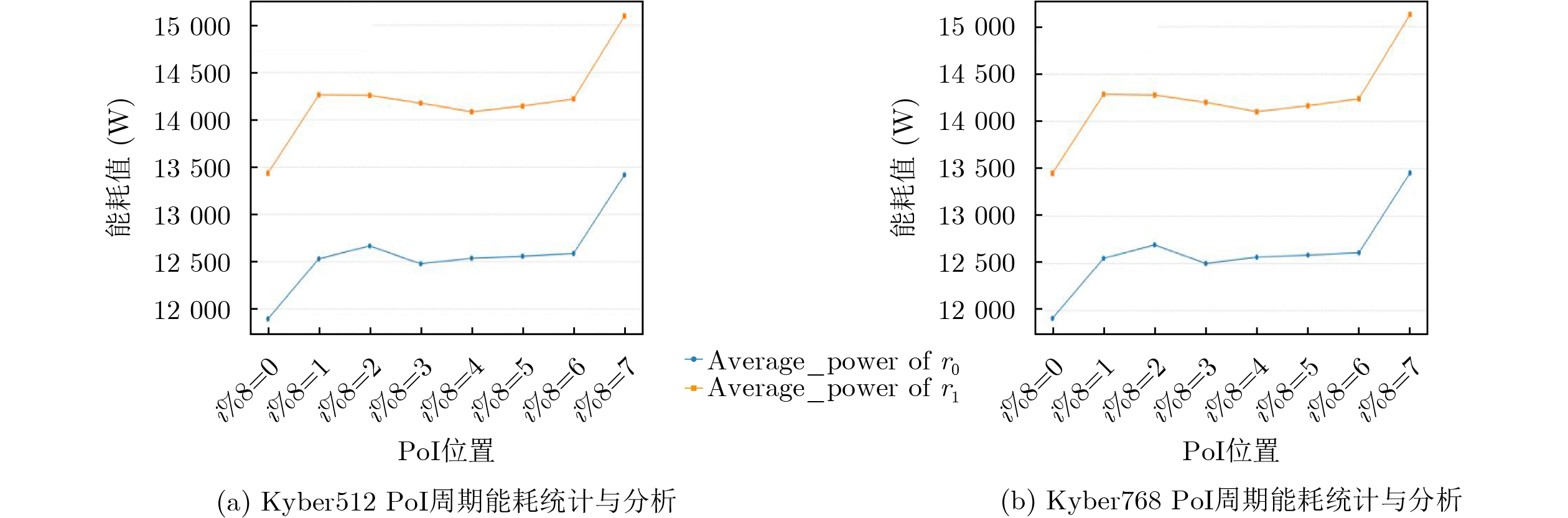
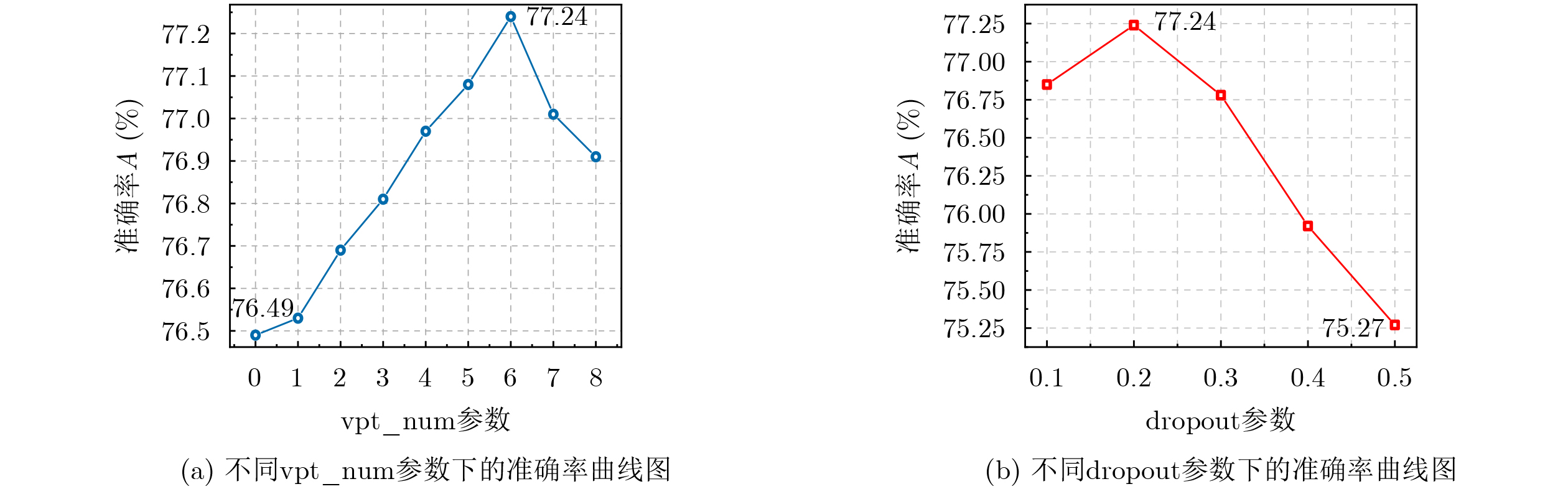
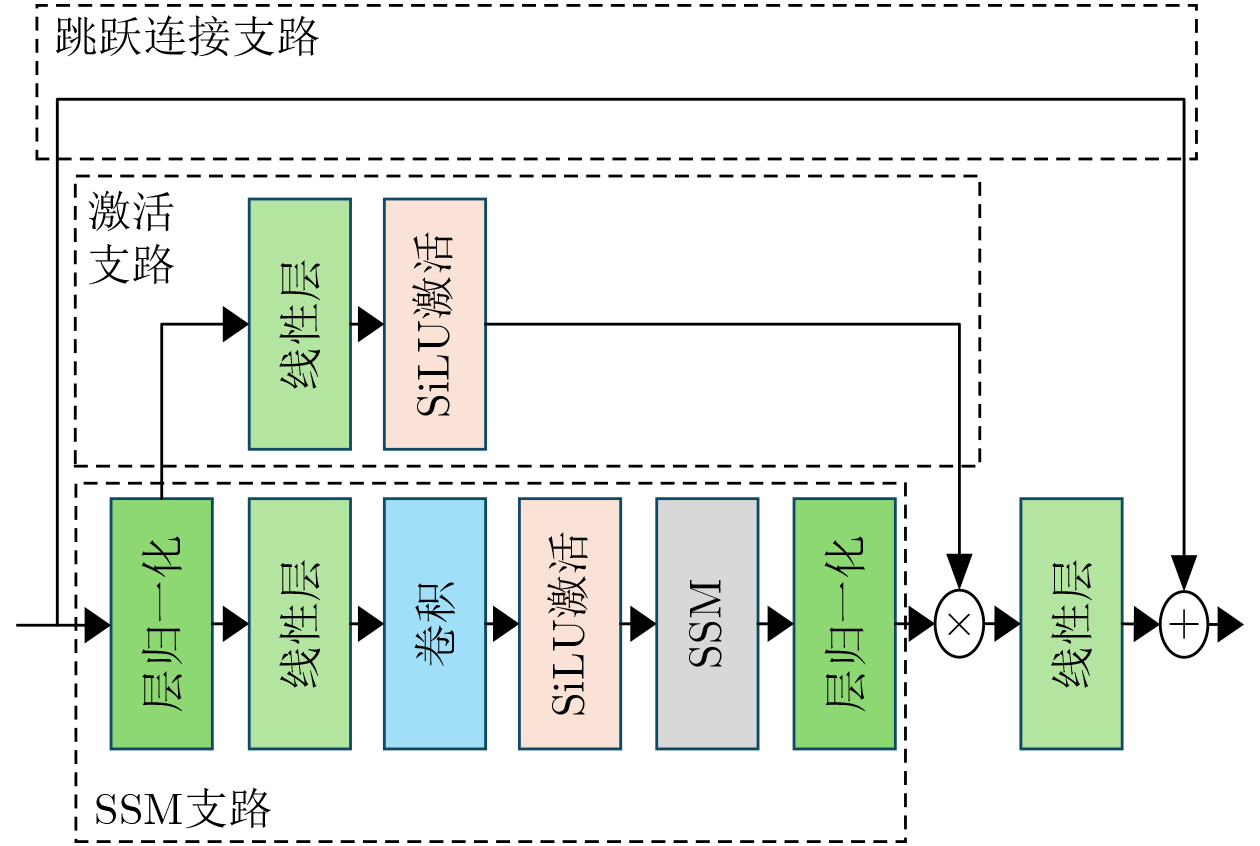
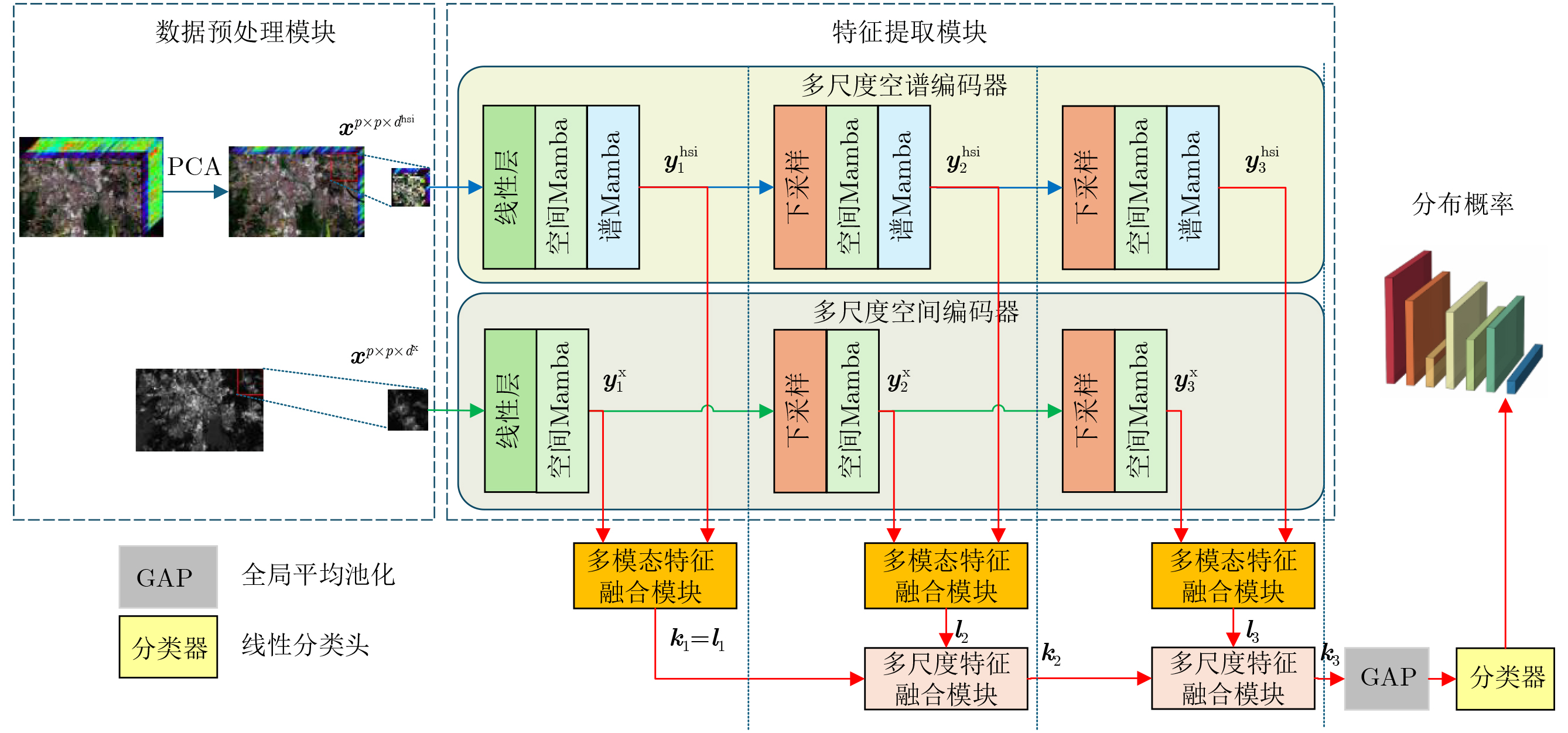
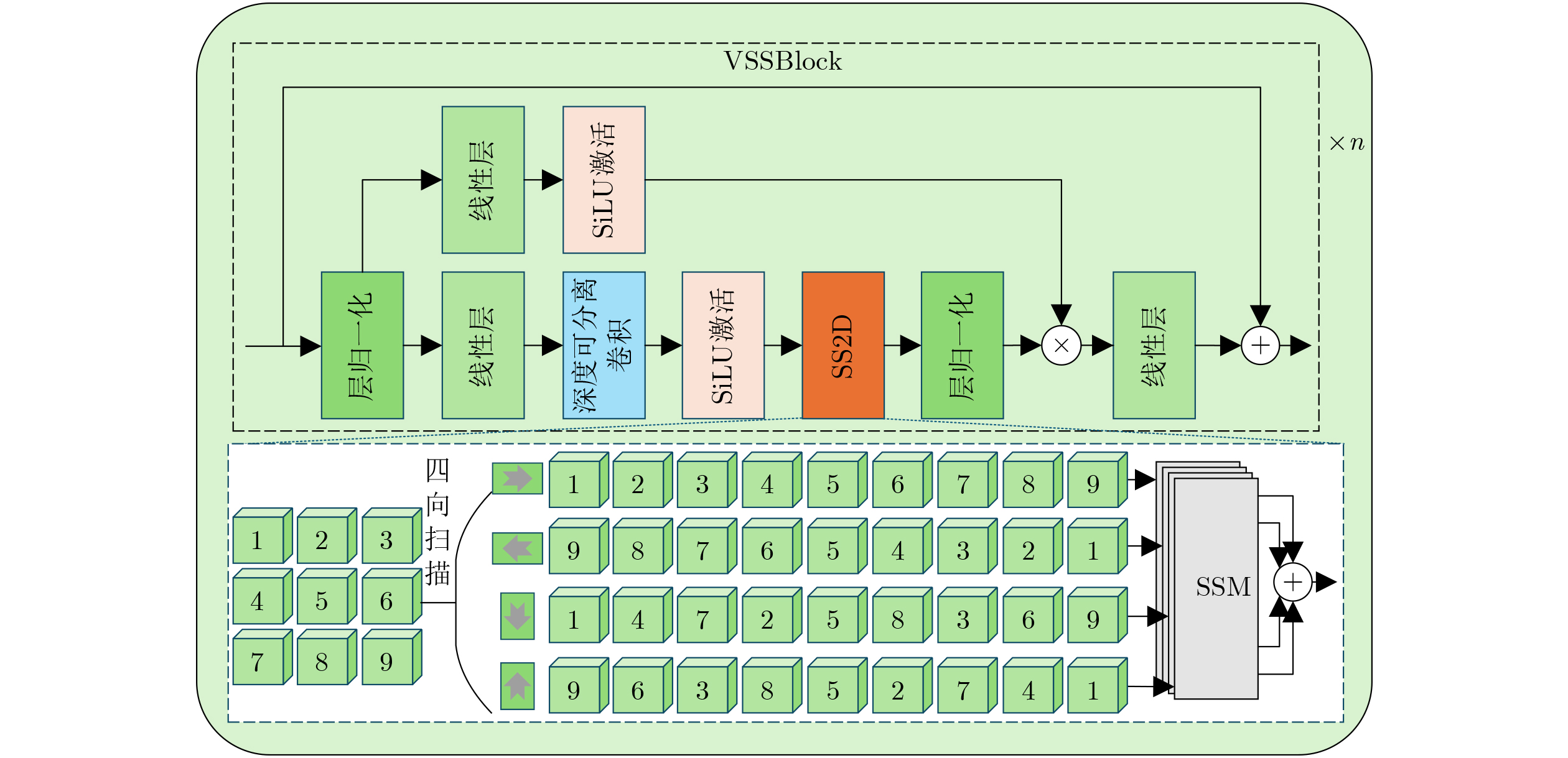
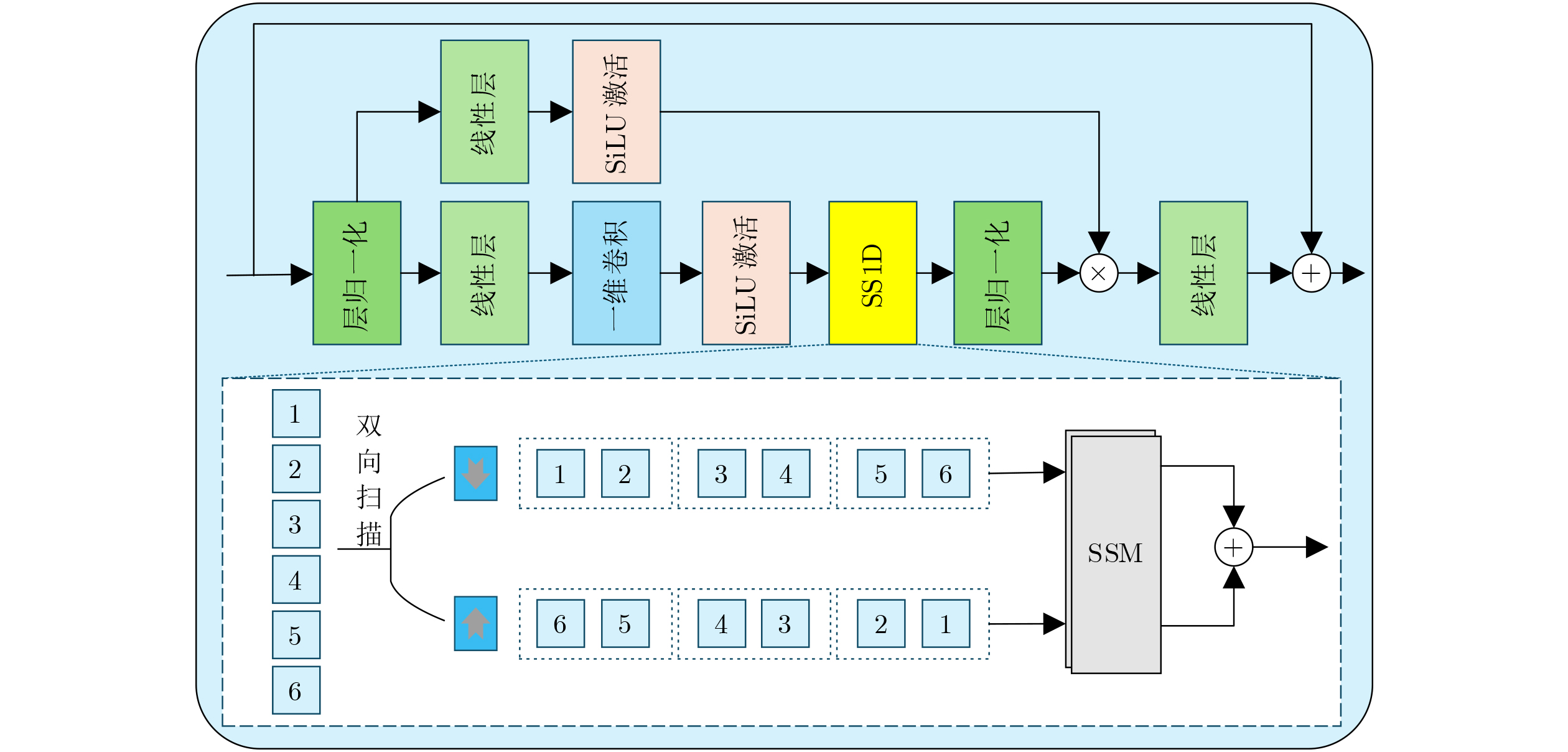
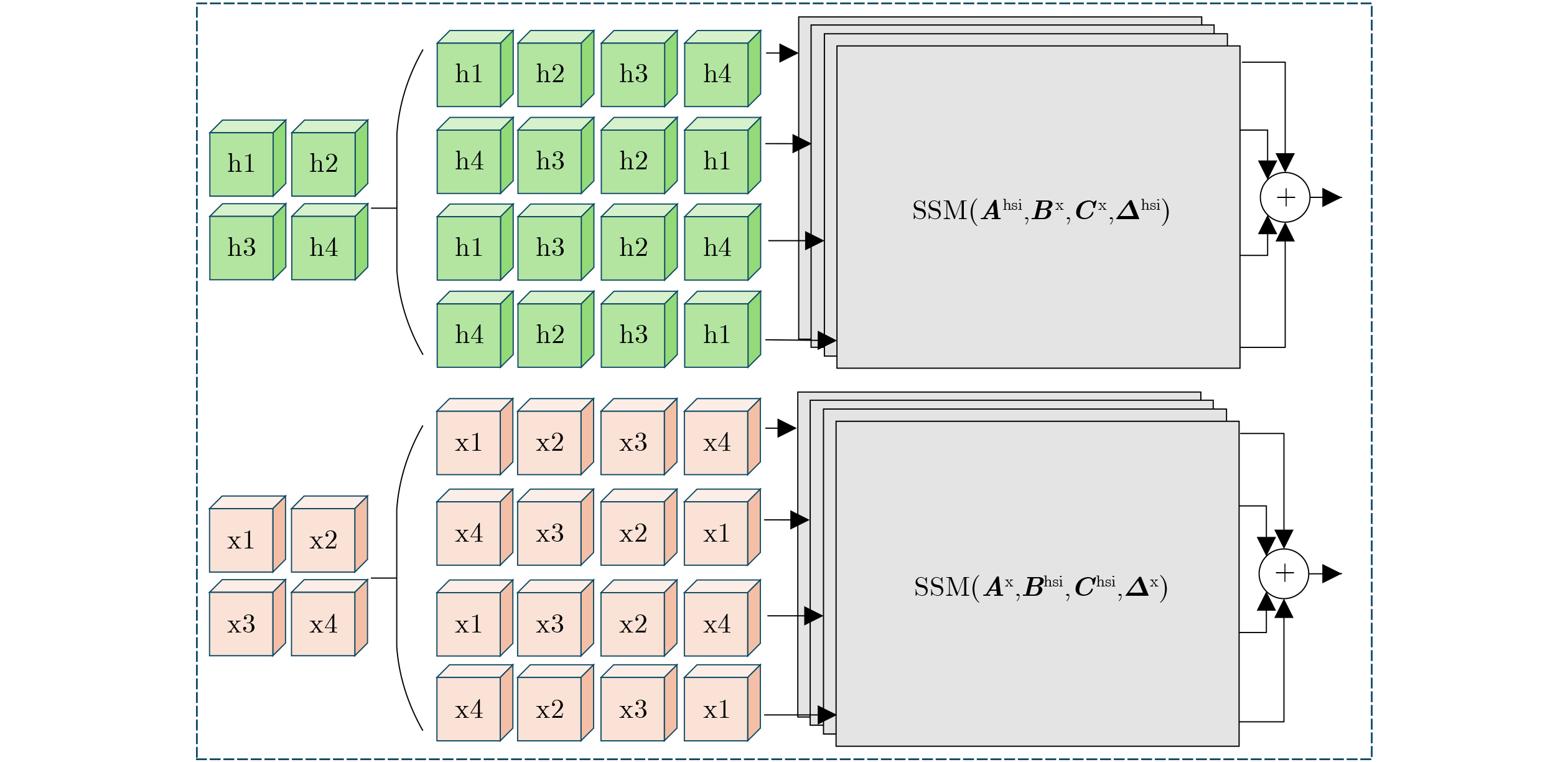
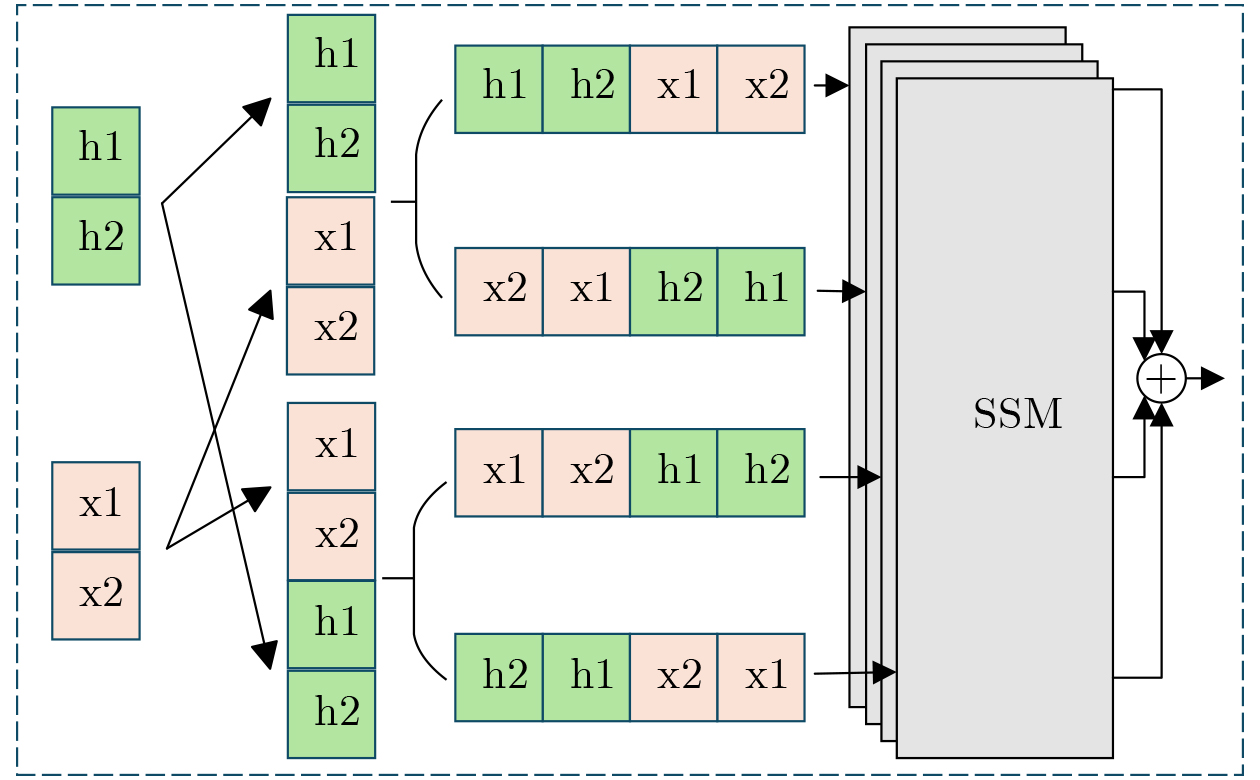
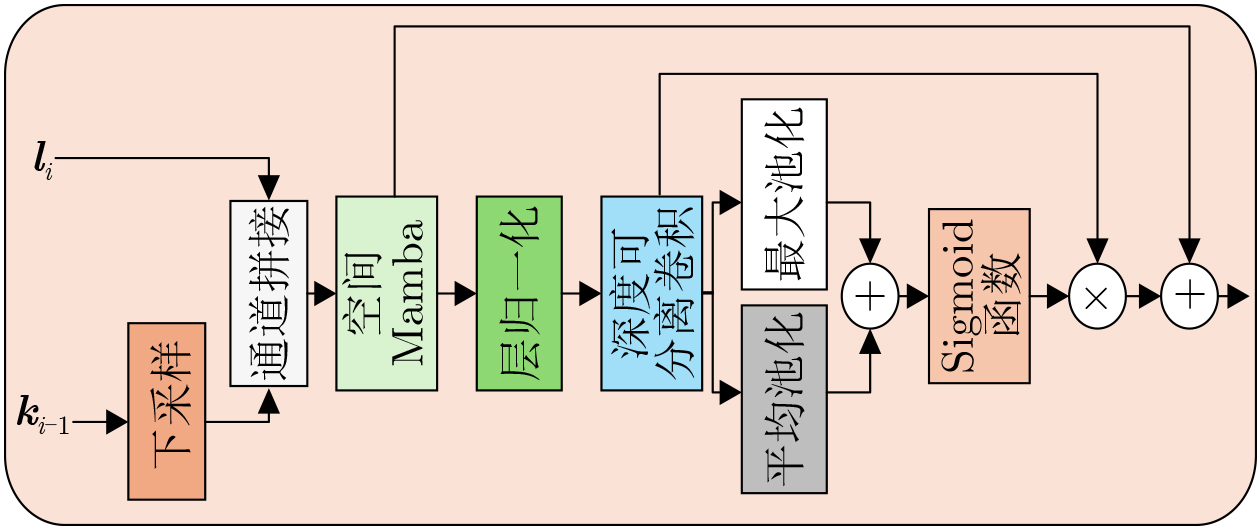
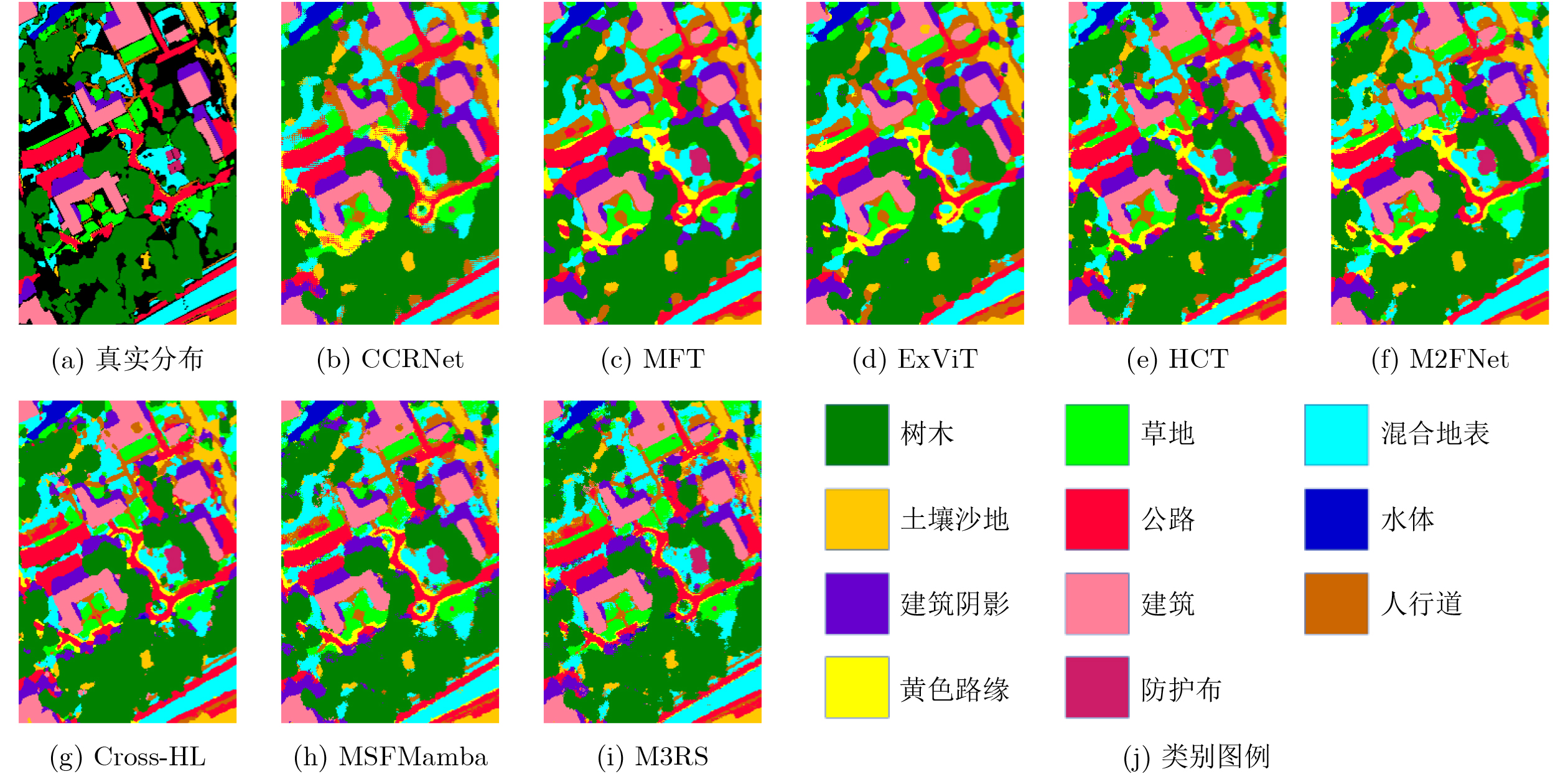
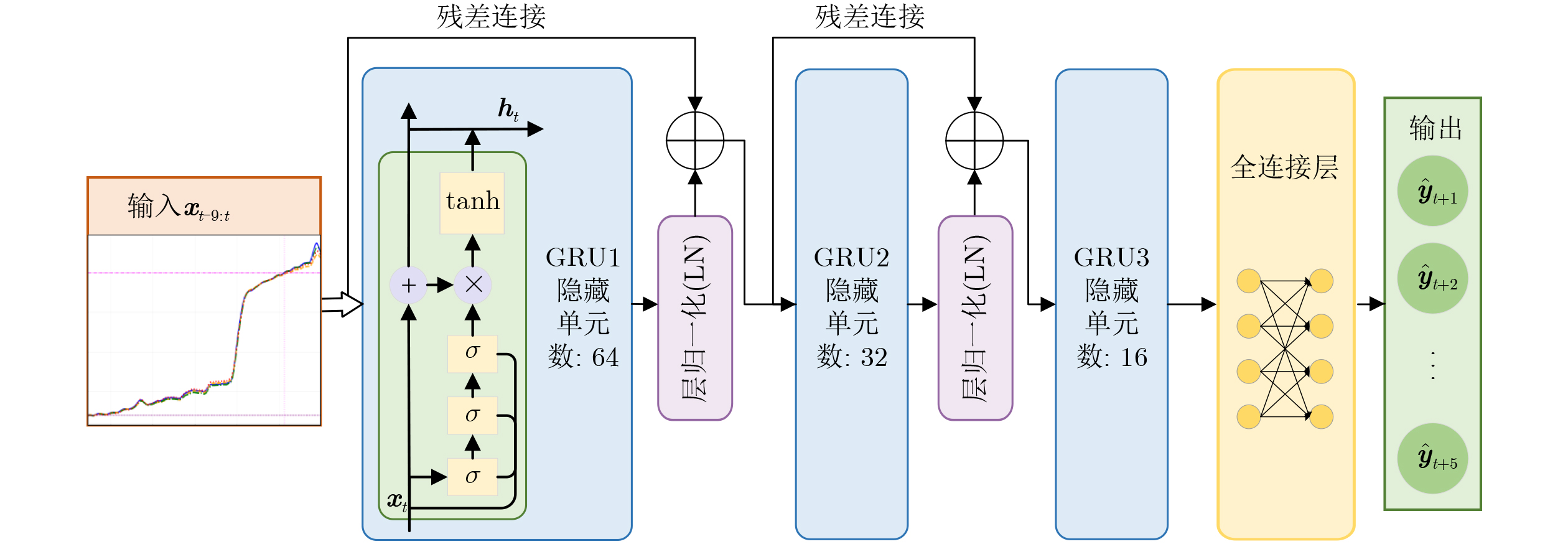
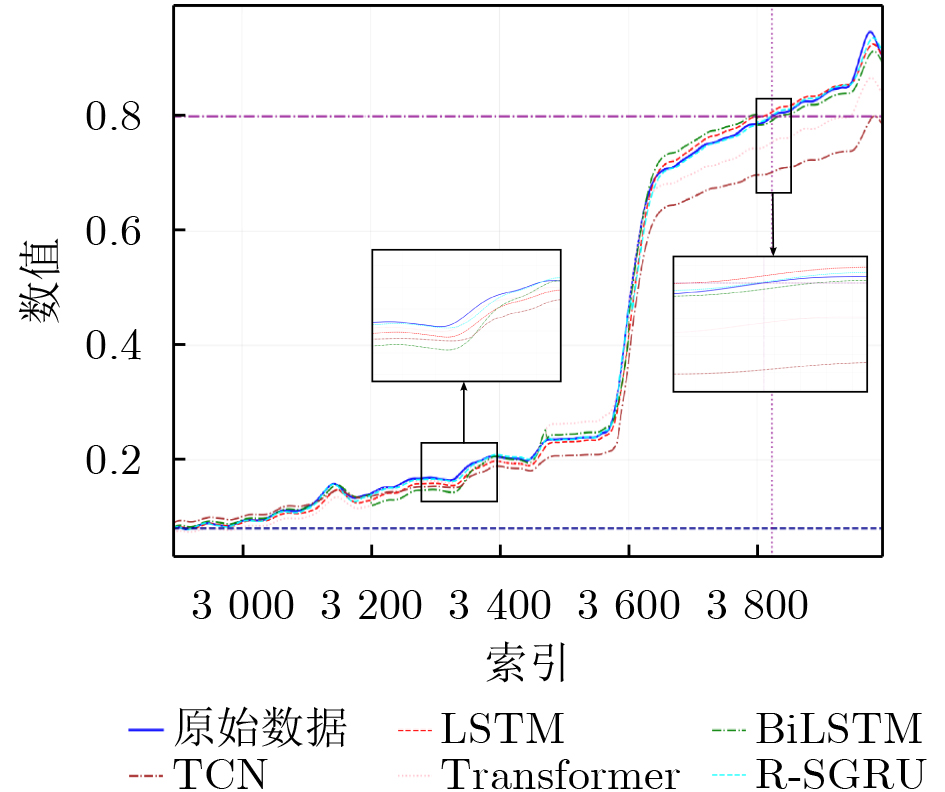
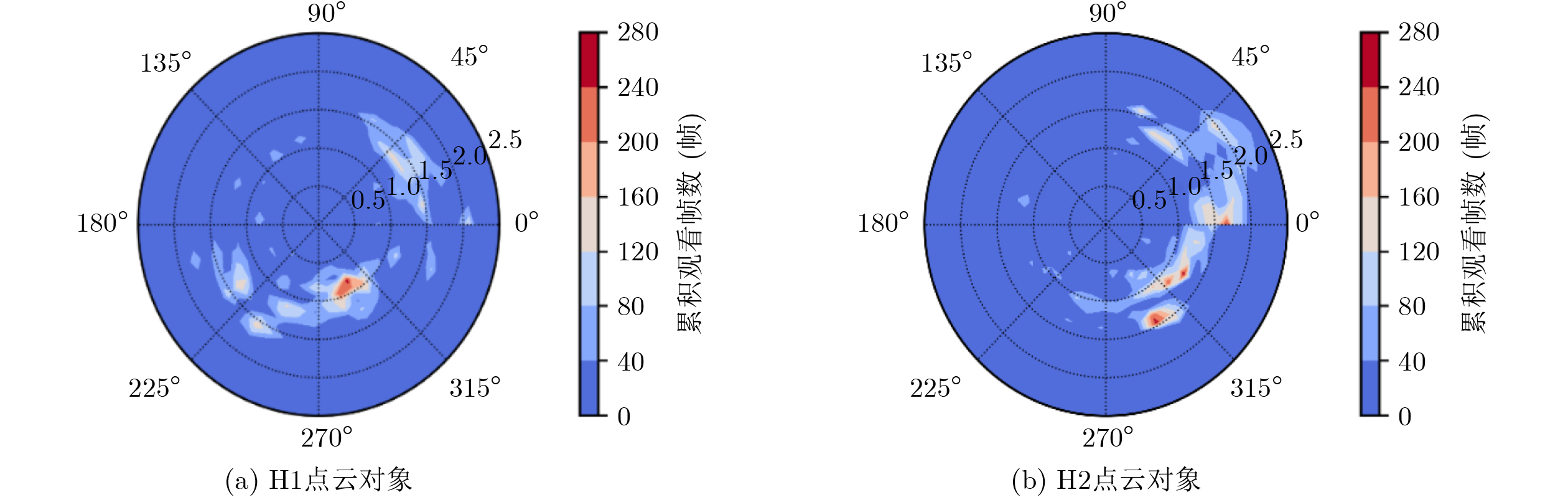
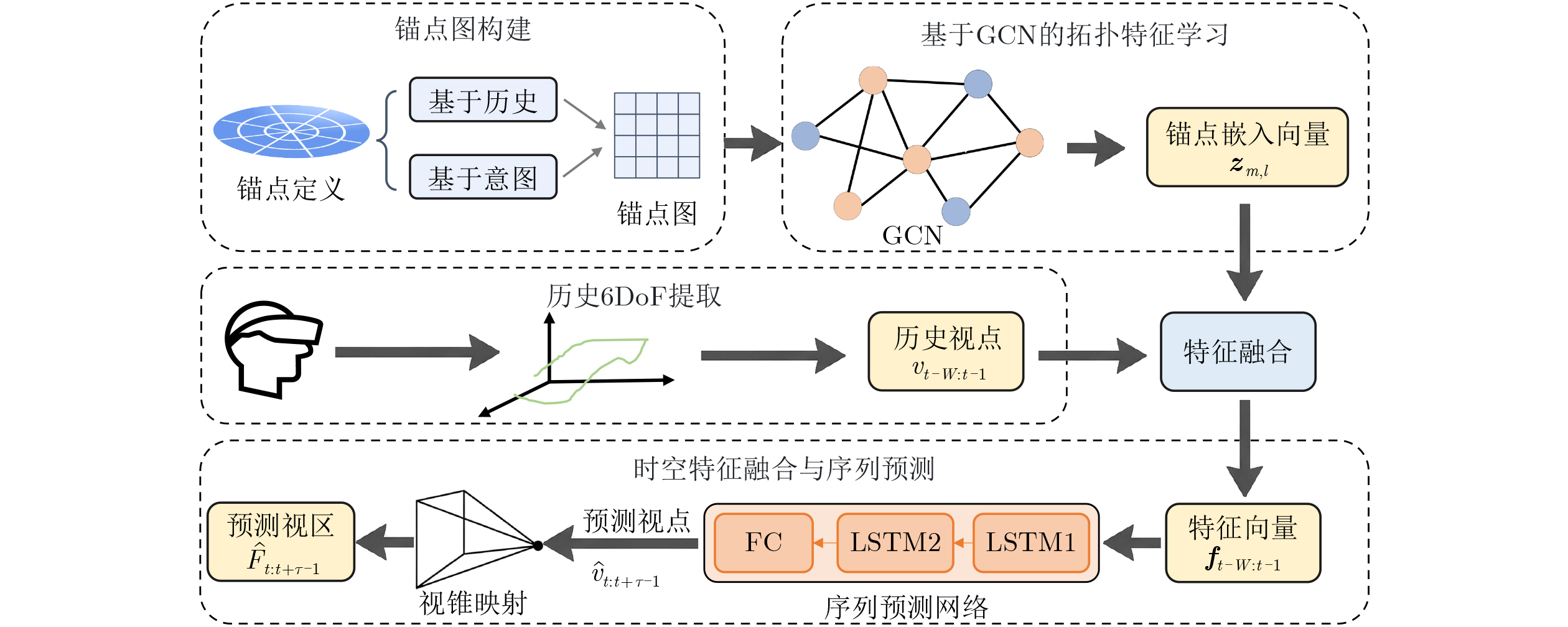
2026, 48(6): 2712-2721.
doi: 10.11999/JEIT250868
摘要:
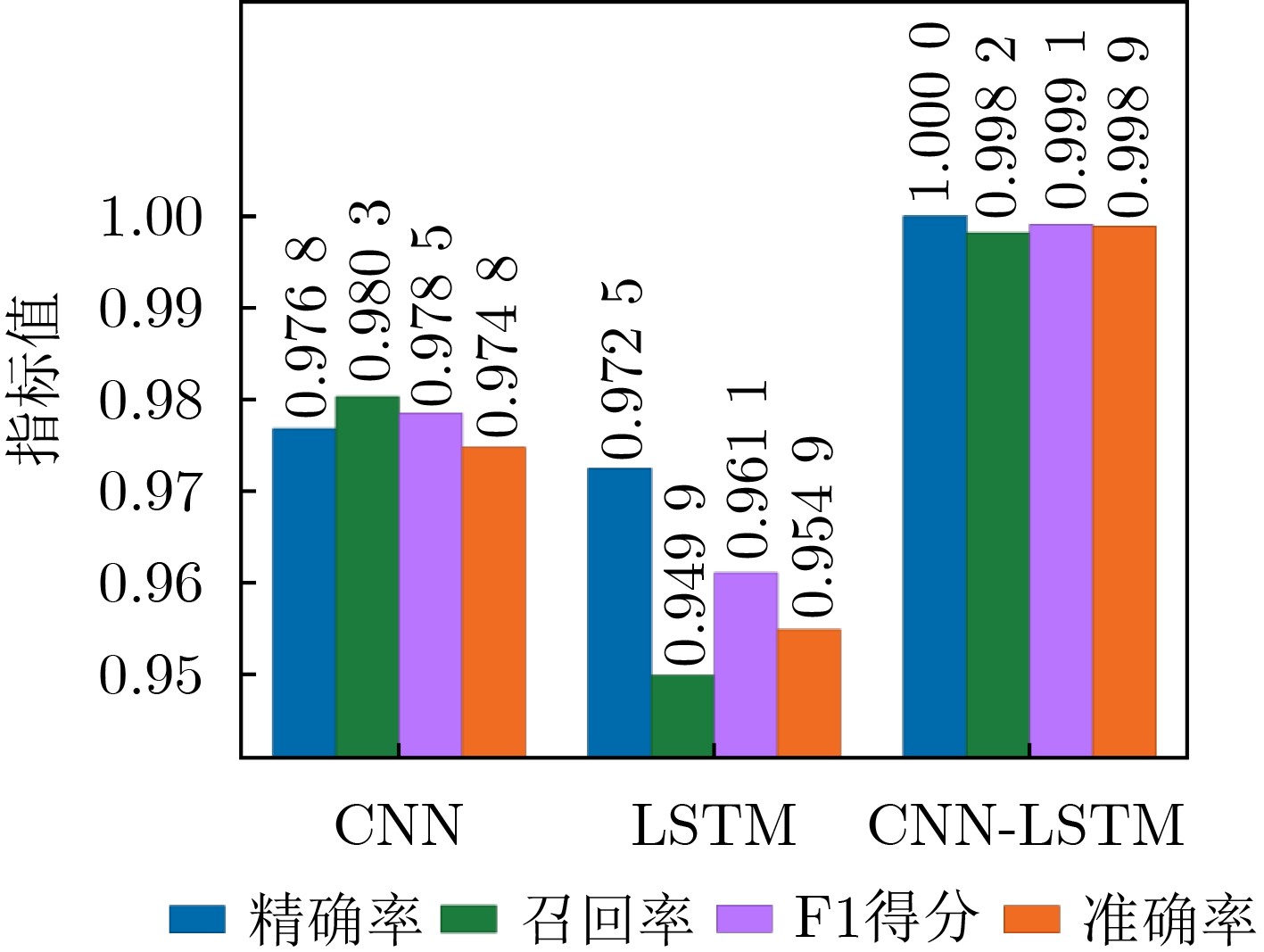
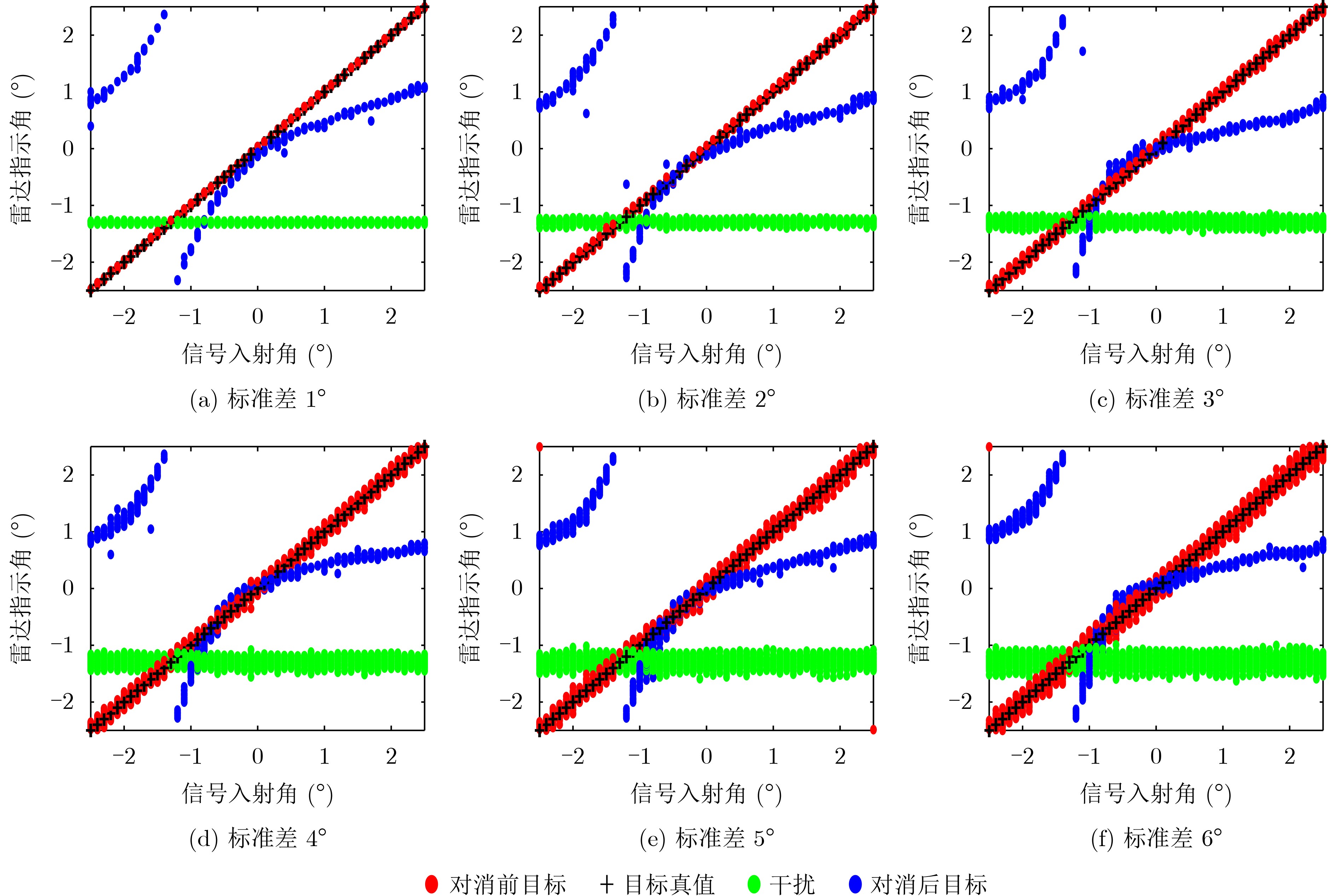
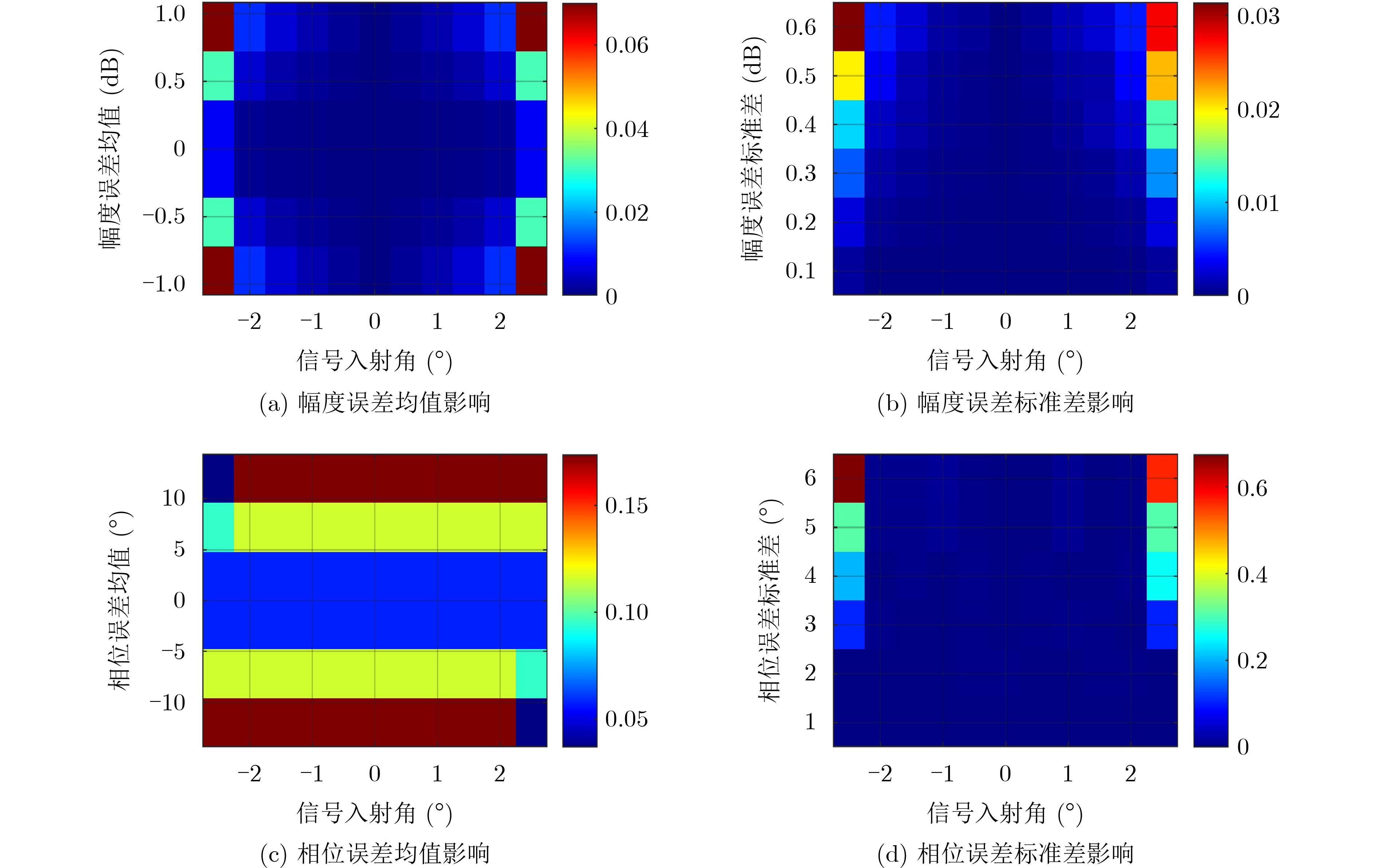
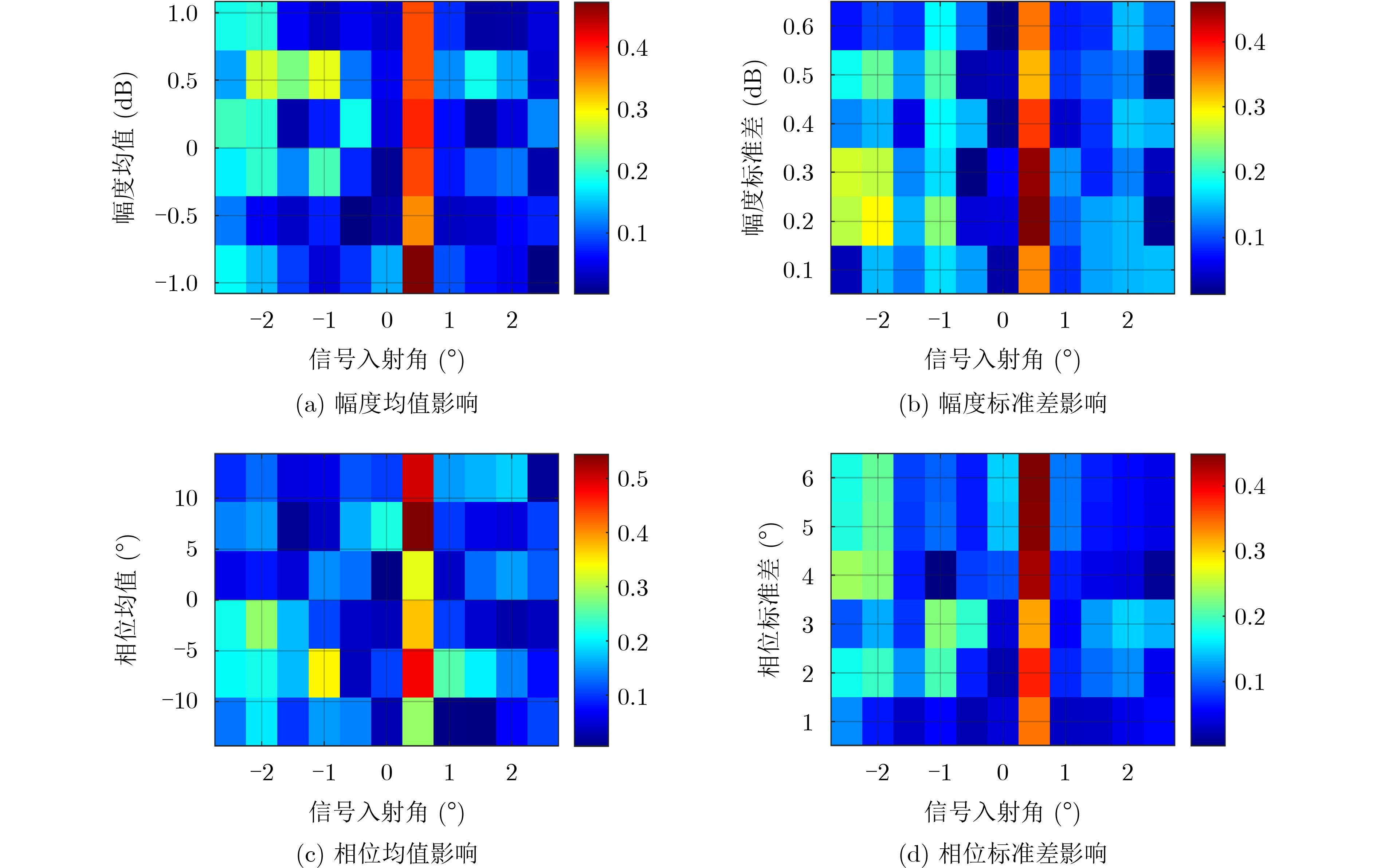
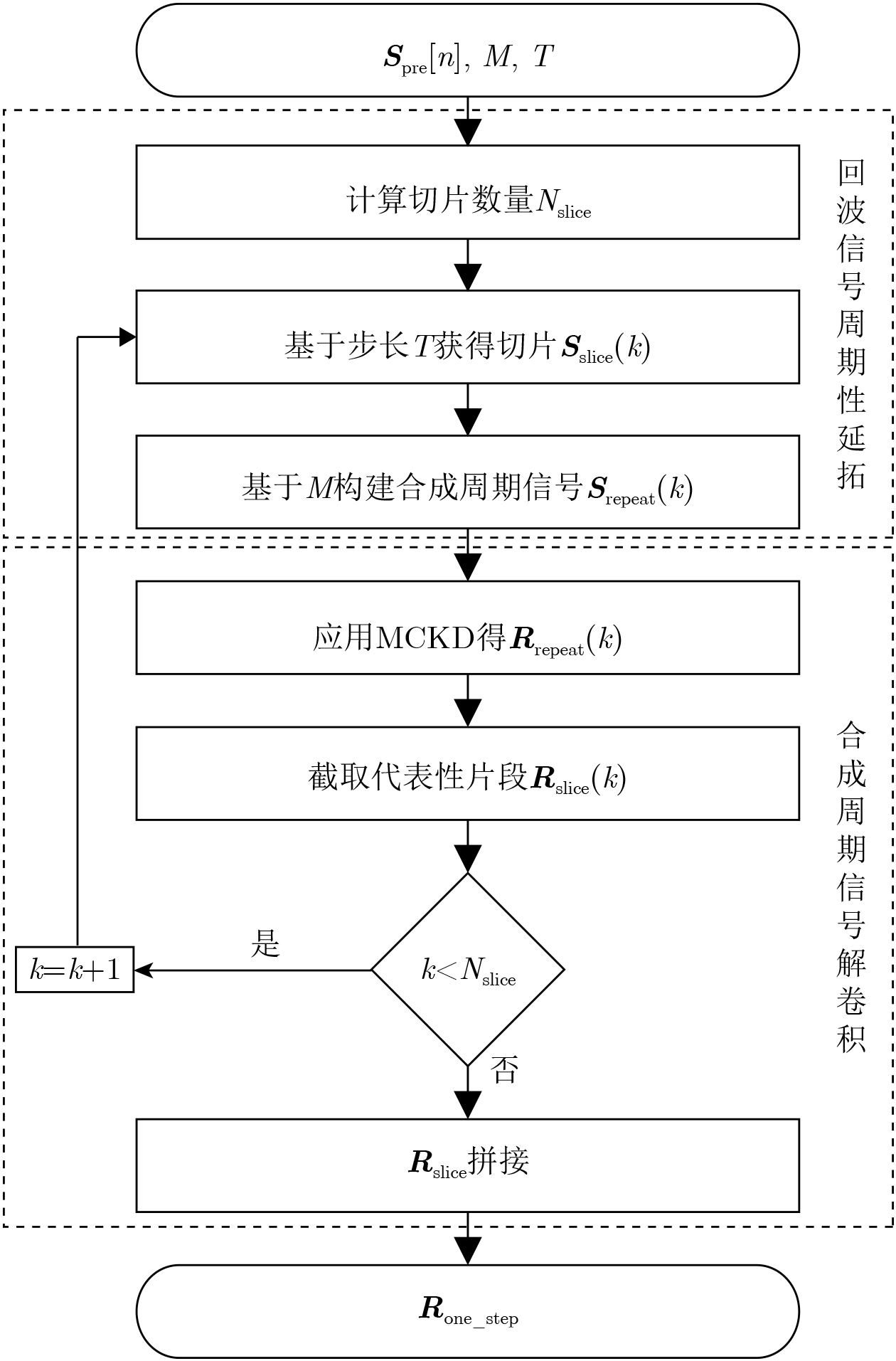
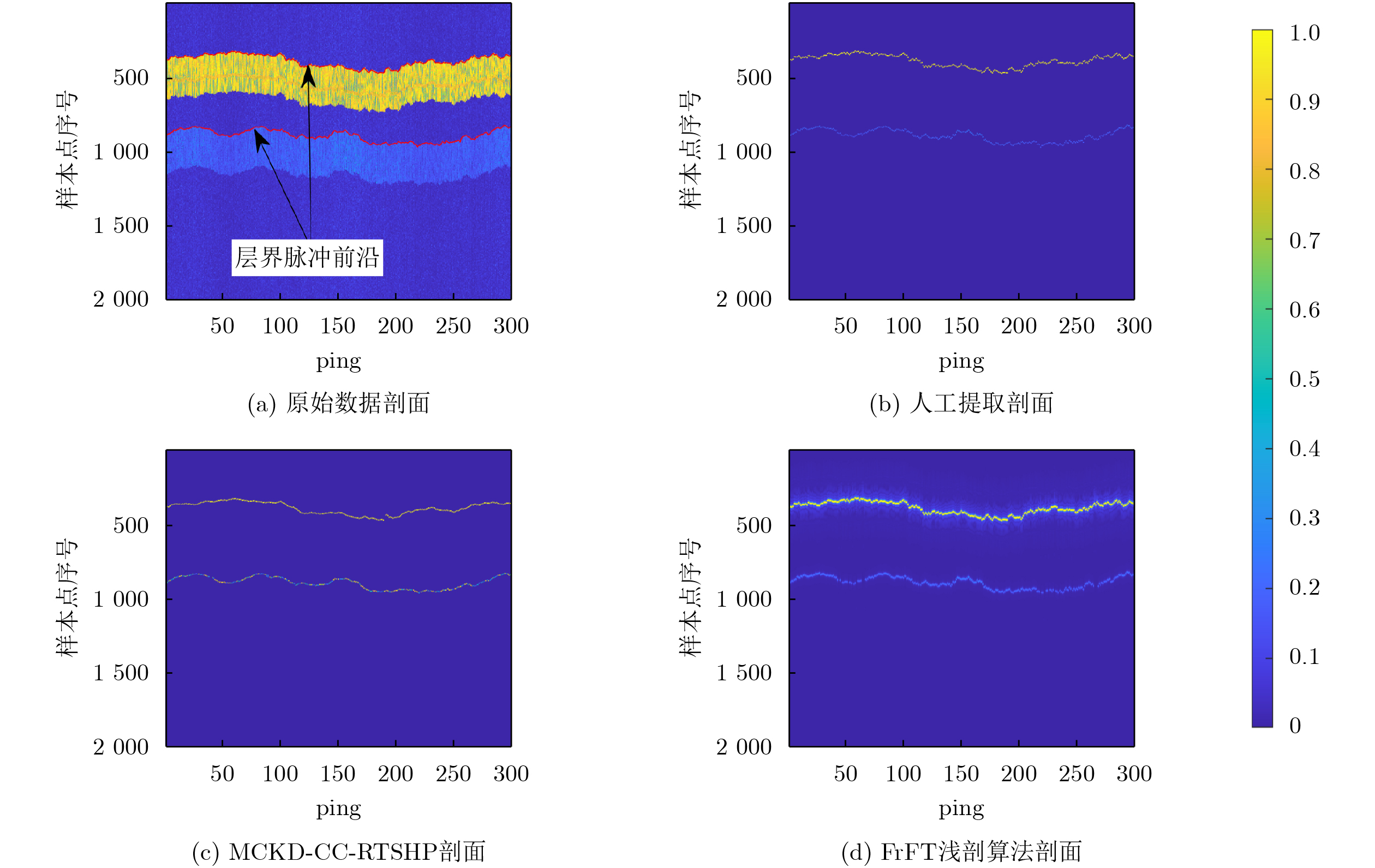
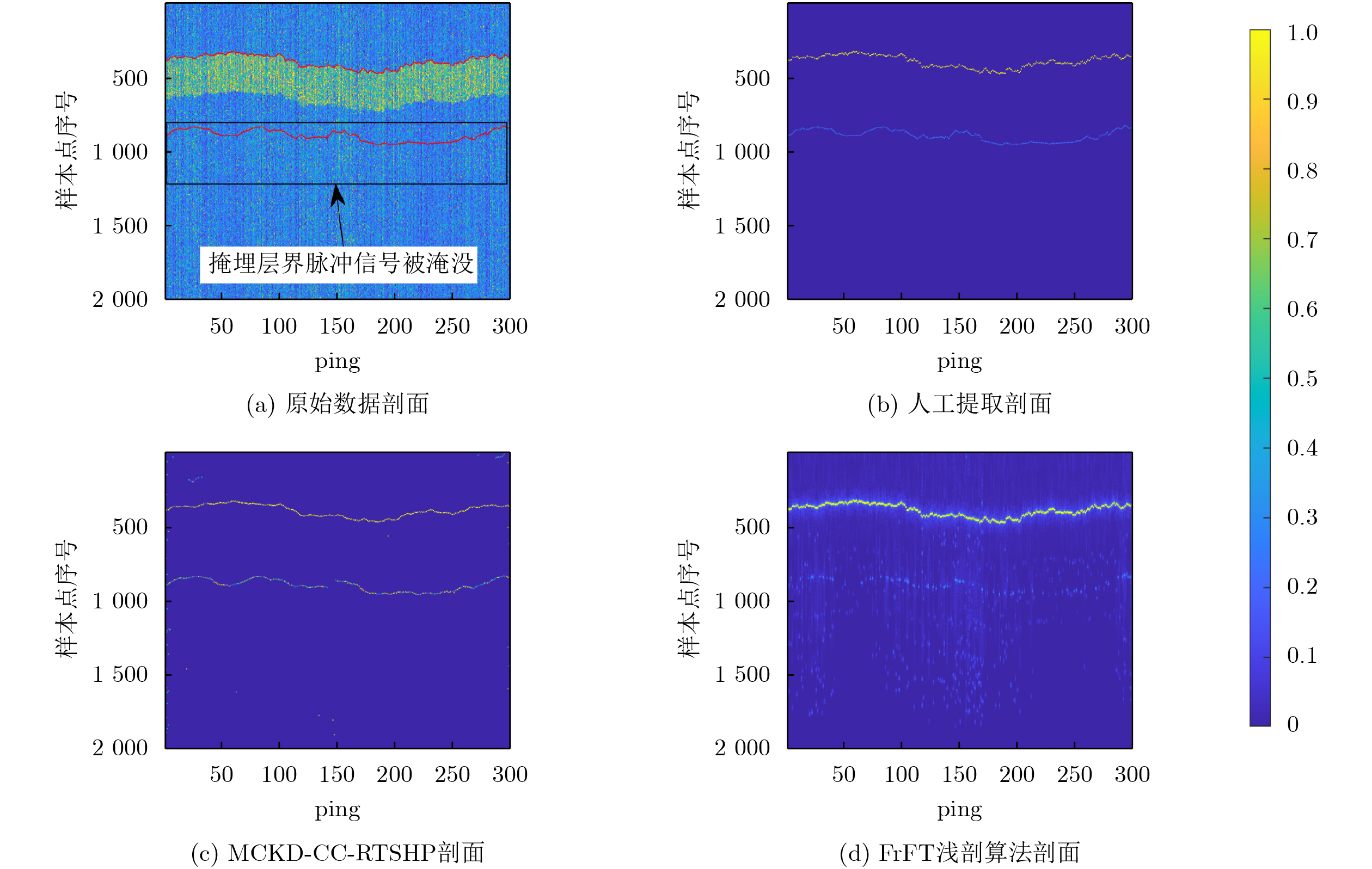
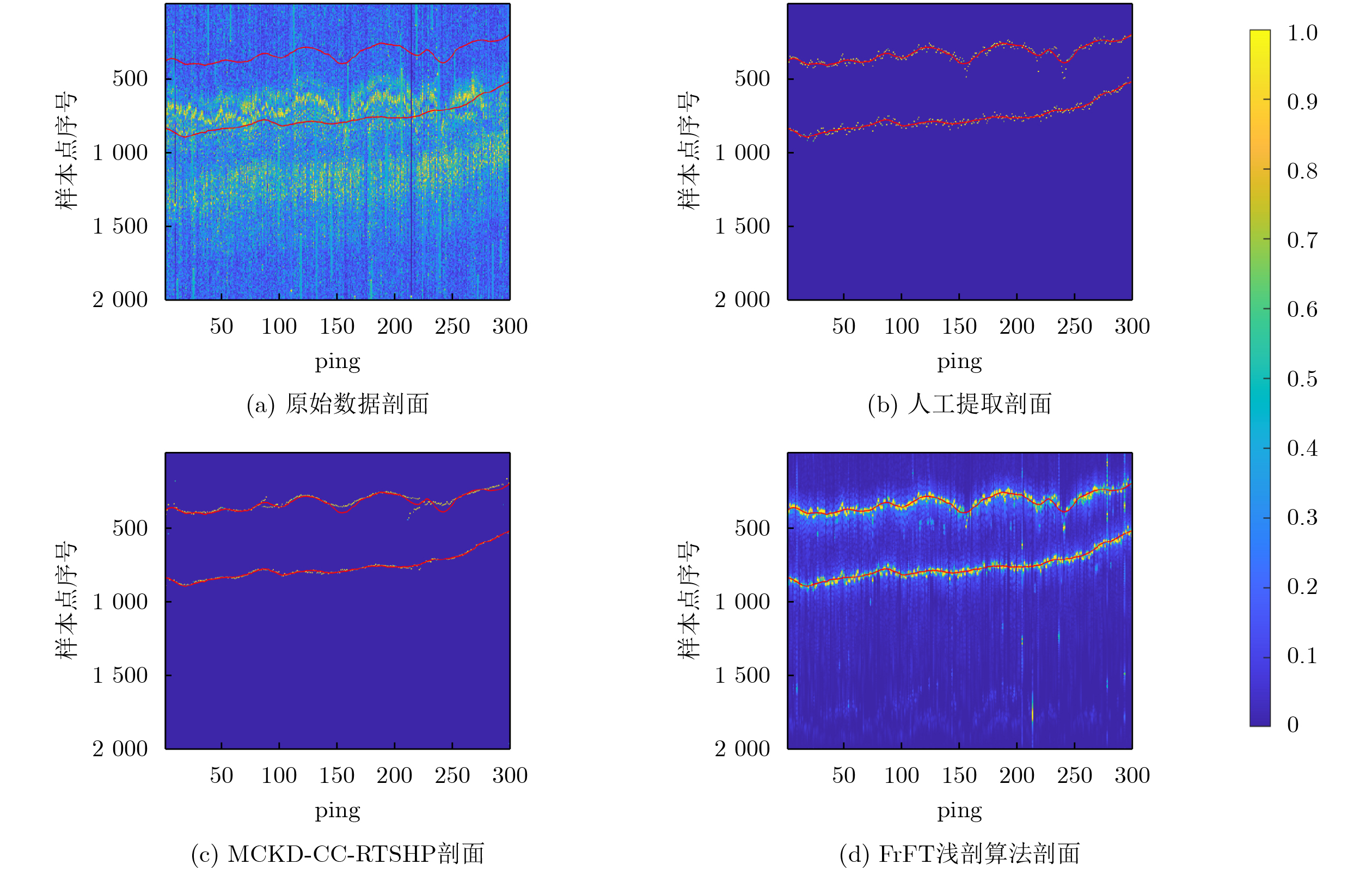
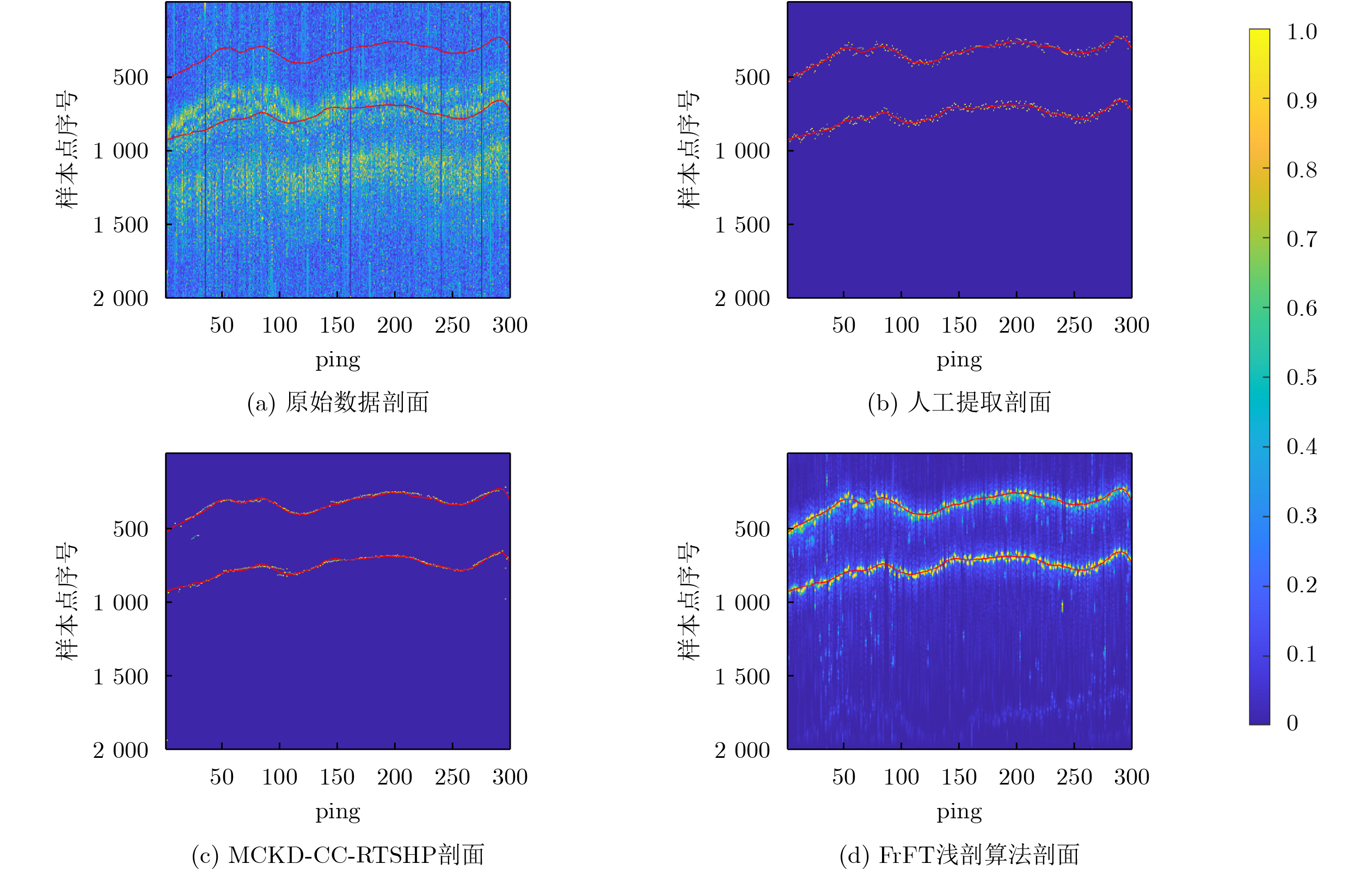
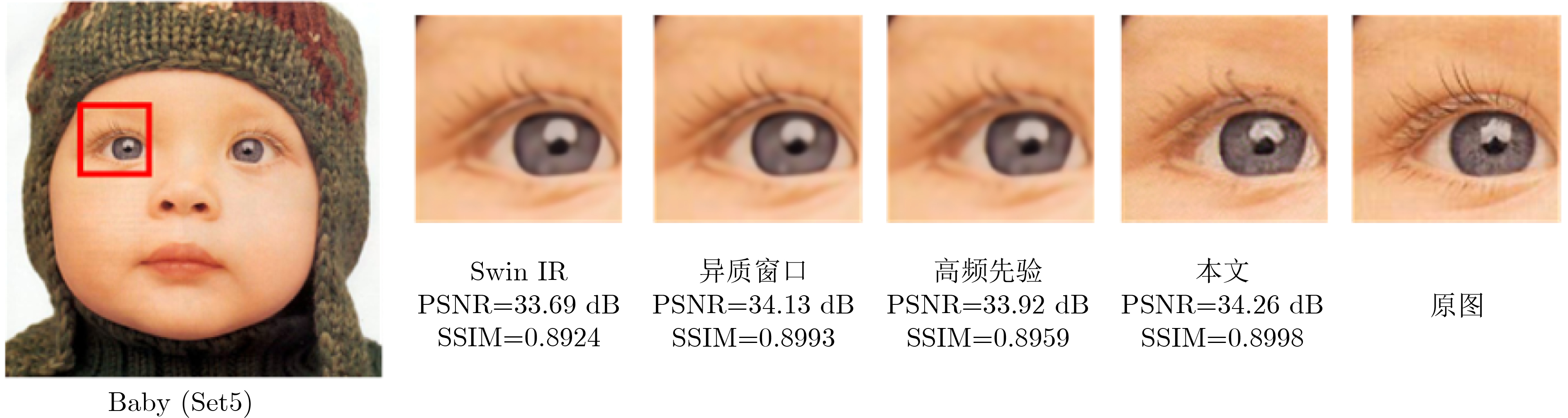
在大数据时代,图像质量参差不齐,对低质量图像进行高分辨率重建具有重要的研究与应用价值。基于 Transformer的单图像超分辨率方法通常将自注意力机制限制在局部非重叠窗口中,导致感受野受限、窗口边界失真以及高频细节重构能力不足等问题。为此,该文提出一种基于Swin IR的异质窗口注意力网络(Heterogeneous Window Transformer Network for image Super-Resolution, HWT-SRNet)。首先,设计异质窗口注意力机制,充分融合多尺度特征,以缓解窗口边界失真问题并有效扩大感受野。其次,针对Transformer在高频信息重构能力上的不足,提出一种高频先验特征提取网络,增强网络对边缘与纹理细节的恢复能力。实验结果表明,HWT-SRNet在Set5, Set14, BSD100, Urban100, Manga109 5个基准测试集上,PSNR指标相比基线模型Swin IR提升0.10~0.37 dB,同时,与其他具有代表性的超分模型CAT, ACT, ART等相比,在图像细节和纹理方面也取得了更优的视觉效果。