

A Method for Named Entity Recognition in Military Intelligence Domain Using Large Language Models
-
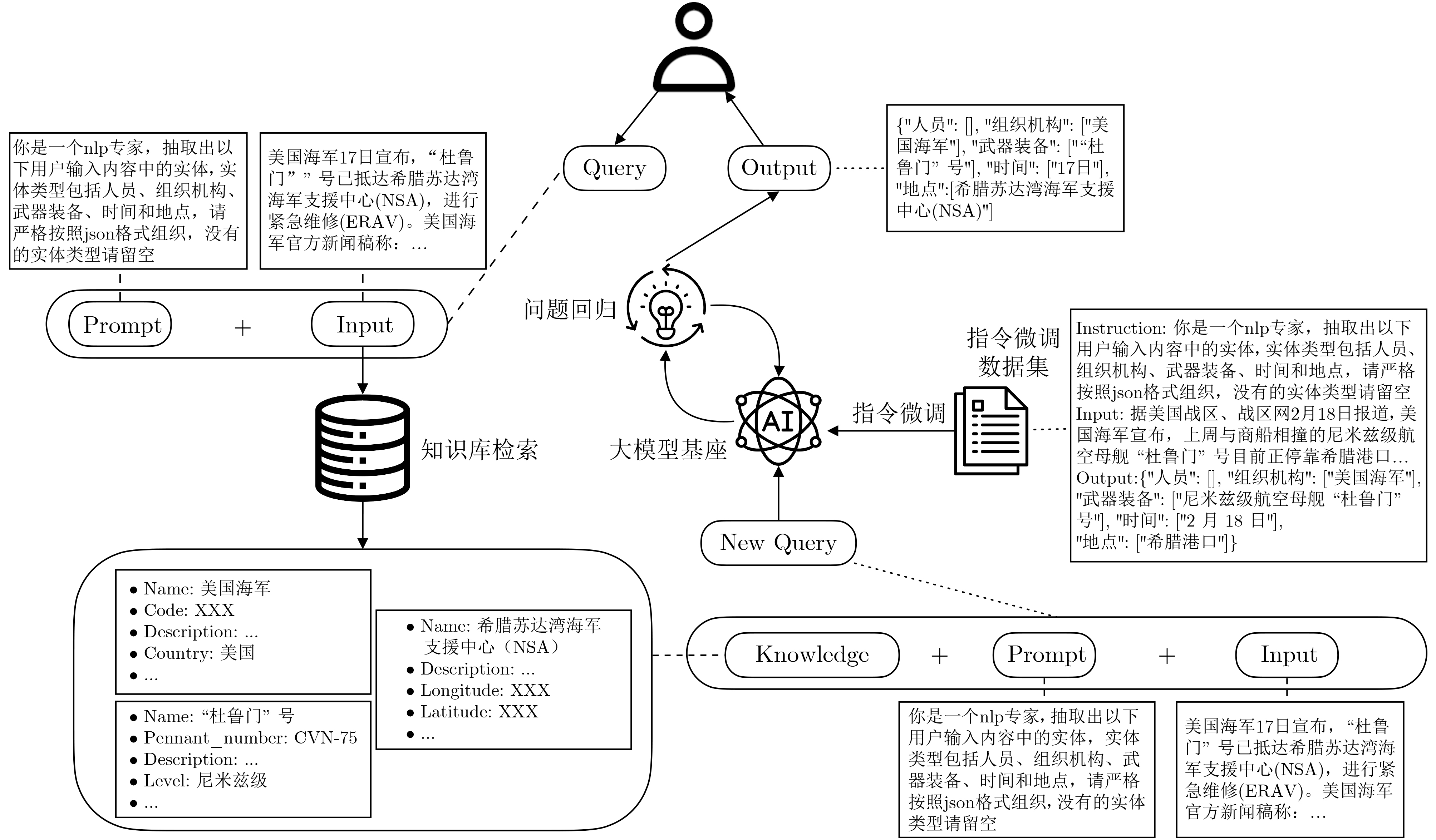
摘要: 在特定信息领域,尤其是开源信息领域,传统模型命名实体识别面临缺乏充足标注数据、难以满足复杂信息抽取任务等困难。该文聚焦开源信息领域,提出一种基于大语言模型的命名实体识别方法,旨在通过大语言模型强大的语义推理能力准确理解复杂的抽取要求,并自动完成抽取任务。通过指令微调和利用检索增强生成将专家知识融入模型,结合问题回归模块,使低参数通用型大模型基座能够快速适应开源信息这一特定领域,形成领域专家模型。实验结果表明,仅需少量的成本,便能构建一个高效的领域专家系统,为开源信息领域的命名实体识别提供了一种更为有效的解决方案。Abstract:
Objective Named Entity Recognition (NER) is a fundamental task in information extraction within specialized domains, particularly military intelligence. It plays a critical role in situation assessment, threat analysis, and decision support. However, conventional NER models face major challenges. First, the scarcity of high-quality annotated data in the military intelligence domain is a persistent limitation. Due to the sensitivity and confidentiality of military information, acquiring large-scale, accurately labeled datasets is extremely difficult, which severely restricts the training performance and generalization ability of supervised learning-based NER models. Second, military intelligence requires handling complex and diverse information extraction tasks. The entities to be recognized often possess domain-specific meanings, ambiguous boundaries, and complex relationships, making it difficult for traditional models with fixed architectures to adapt flexibly to such complexity or achieve accurate extraction. This study aims to address these limitations by developing a more effective NER method tailored to the military intelligence domain, leveraging Large Language Models (LLMs) to enhance recognition accuracy and efficiency in this specialized field. Methods To achieve the above objective, this study focuses on the military intelligence domain and proposes a NER method based on LLMs. The central concept is to harness the strong semantic reasoning capabilities of LLMs, which enable deep contextual understanding of military texts, accurate interpretation of complex domain-specific extraction requirements, and autonomous execution of extraction tasks without heavy reliance on large annotated datasets. To ensure that general-purpose LLMs can rapidly adapt to the specialized needs of military intelligence, two key strategies are employed. First, instruction fine-tuning is applied. Domain-specific instruction datasets are constructed to include diverse entity types, extraction rules, and representative examples relevant to military intelligence. Through fine-tuning with these datasets, the LLMs acquire a more precise understanding of the characteristics and requirements of NER in this field, thereby improving their ability to follow targeted extraction instructions. Second, Retrieval-Augmented Generation (RAG) is incorporated. A domain knowledge base is developed containing expert knowledge such as entity dictionaries, military terminology, and historical extraction cases. During the NER process, the LLM retrieves relevant knowledge from this base in real time to support entity recognition. This strategy compensates for the limited domain-specific knowledge of general LLMs and enhances recognition accuracy, particularly for rare or complex entities. Results and Discussions Experimental results indicate that the proposed LLM-based NER method, which integrates instruction fine-tuning and RAG, achieves strong performance in military intelligence NER tasks. Compared with conventional NER models, it demonstrates higher precision, recall, and F1-score, particularly in recognizing complex entities and managing scenarios with limited annotated data. The effectiveness of this method arises from several key factors. The powerful semantic reasoning capability of LLMs enables a deeper understanding of contextual nuances and ambiguous expressions in military texts, thereby reducing missed and false recognitions commonly caused by rigid pattern-matching approaches. Instruction fine-tuning allows the model to better align with domain-specific extraction requirements, ensuring that the recognition results correspond more closely to the practical needs of military intelligence analysis. Furthermore, the incorporation of RAG provides real-time access to domain expert knowledge, markedly enhancing the recognition of entities that are highly specialized or morphologically variable within military contexts. This integration effectively mitigates the limitations of traditional models that lack sufficient domain knowledge. Conclusions This study proposes a LLM-based NER method for the military intelligence domain, effectively addressing the challenges of limited annotated data and complex extraction requirements encountered by traditional models. By combining instruction fine-tuning and RAG, general-purpose LLMs can be rapidly adapted to the specialized demands of military intelligence, enabling the construction of an efficient domain-specific expert system at relatively low cost. The proposed method provides an effective and scalable solution for NER tasks in military intelligence scenarios, enhancing both the efficiency and accuracy of information extraction in this field. It offers not only practical value for military intelligence analysis and decision support but also methodological insight for NER research in other specialized domains facing similar data and complexity constraints, such as aerospace and national security. Future research will focus on optimizing instruction fine-tuning strategies, expanding the domain knowledge base, and reducing computational cost to further improve model performance and applicability. -
表 1 指令数据集样例
样例 Instruction 你是一个nlp专家,抽取出以下用户输入内容中的实体,实体类型包括人员、组织机构、武器装备、时间、地点,其中将文本中关于武器装备对应的状态和数量拼接到武器装备名称后,武器装备的状态和数量通过分隔符**拼接,如果没有则不拼接,同一个武器装备的数量进行合并,数量如果没有说明默认为一个,输出按照json格式,没有的实体类型留空。 Input 2月18日报道,美国海军宣布,上周与商船相撞的尼米兹级航空母舰“杜鲁门”号目前正在停靠希腊港口进行紧急维修。 Output {"人员": [],"组织机构": ["美国海军"],"武器装备": ["尼米兹级航空母舰“杜鲁门”号**1**紧急维修”],"时间": ["2月18日"],"地点": ["希腊港口"]}  下载: 导出CSV
下载: 导出CSV
表 2 固定目标知识库数据库表字段信息
序号 字段名称 描述 1 longitude 经度 2 latitude 纬度 3 name_target 固定目标名称 4 name_alias 固定目标别名 5 description 固定目标描述 6 country 国家 7 arm_force 部署部队编号
下载: 导出CSV
表 4 编制序列知识库数据库表字段信息
序号 字段名称 描述 1 country 国家 2 code 编码 3 name 名称 4 description 描述 5 parent 上级部门 6 equipments_names 部署装备名称
下载: 导出CSV
表 3 移动目标知识库数据库表字段信息
序号 字段名称 描述 1 pennant_number 舷号 2 name 移动目标名称 3 name_en 移动目标英文名称 4 name_alias 移动目标别名 5 level 级别 6 country 国家 7 construct_shipyard 造船厂 8 builder 建造商 9 major_experience 主要经历 10 member_of 隶属部队 11 home_port 母港 12 construct_date 建造日期 13 service_date 服役日期 14 retire_date 退役日期
下载: 导出CSV
表 6 标注样例
样例文本 原始文本 6月15日报道称,两架美国空军的F-22战斗机于当地时间6月13日下午4点左右从珍珠港-希卡姆联合基地起飞,
第三架F-22战斗机在它们起飞约一小时后起飞,期间一架KC-135空中加油机也起飞为这些战斗机提供支援标注结果 {"人员": [],"组织机构": ["美国空军"],"武器装备": ["F-22战斗机**起飞**3","KC-135空中加油机**起飞**1"],
"时间": ["6月15日","6月13日下午4点左右"],"地点": ["珍珠港-希卡姆联合基地"]}
下载: 导出CSV
表 7 模型总体性能对比(%)
精确率 召回率 F1值 BiLSTM-CRF 55.7 53.2 54.5 BERT-CRF 75.2 72.1 73.6 UIE 70.4 73.8 72.0 本文 95.8 73.5 83.2
下载: 导出CSV
表 8 “人员”实体类别识别模型性能对比(%)
精确率 召回率 F1值 BiLSTM-CRF 8.9 7.6 8.2 BERT-CRF 72.5 68.3 70.3 UIE 100.0 93.7 96.7 本文 90.6 42.8 58.2
下载: 导出CSV
表 12 模型“地点”实体类别性能对比(%)
精确率 召回率 F1值 BiLSTM+CRF 63.4 75.4 68.9 BERT-CRF 85.6 84.2 84.9 UIE 92.4 91.8 92.1 本文 100.0 98.2 99.1
下载: 导出CSV
表 9 模型“组织机构”实体类别性能对比(%)
精确率 召回率 F1值 BiLSTM-CRF 61.8 73.3 67.0 BERT-CRF 75.0 74.2 74.6 UIE 59.6 73.7 65.9 本文 99.5 72.5 83.9
下载: 导出CSV
表 10 模型“武器装备”实体类别性能对比(%)
精确率 召回率 F1值 BiLSTM-CRF 41.6 29.7 34.7 BERT-CRF 72.3 60.5 65.9 UIE 53.4 52.0 52.7 本文 90.0 65.0 75.5
下载: 导出CSV
表 11 模型“时间”实体类别性能对比(%)
精确率 召回率 F1值 BiLSTM+CRF 99.6 100.0 99.8 BERT-CRF 99.8 99.5 99.6 UIE 100.0 100.0 100.0 本文 100.0 98.9 99.4
下载: 导出CSV
表 13 消融实验结果对比(%)
精确率 召回率 F1值 本文(-Instruction Tuning) 79.6 68.2 73.5 本文(-RAG) 91.2 54.8 68.5 本文 95.8 73.5 83.2
下载: 导出CSV
表 14 本文模型与DeepSeek671B模型抽取结果对比
案例 Input 2024年12月5日,美国五角大楼宣布,在中东地区的军事行动中,美军特种部队于伊拉克巴格达市附近执行任务。此次行动涉及美军中央司令部指挥,行动人员包括由队长约翰·米勒带领的30人特种作战小组。行动中动用了5架AH - 64“阿帕奇”武装直升机,其中3架状态良好,可随时投入战斗,另外2架在前期执行任务后需要进行简单维护;还投入了10辆M1A2“艾布拉姆斯”主战坦克,所有坦克均处于正常战备状态。 Prompt 你是一个nlp专家,抽取出以下内容中的实体,实体类型包括人员、组织机构、武器装备、时间、地点,其中文本中关于武器装备对应的状态和数量抽取后以字典格式进行组织,装备状态为词语,内容不要过长,同一个武器装备不同状态分别罗列输出,请将输出严格按照json格式组织,其他无关信息不要输出,如果有其他实体类型请抽取出来,没有的实体请留空。 DeepSeek671B {"人员": [{"姓名": "约翰·米勒","职务": "队长"},{"描述": "30人特种作战小组"}],"组织机构": ["美国五角大楼","美军中央司令部"],"武器装备": [{"名称": "AH-64“阿帕奇”武装直升机","数量": 3,"状态": "良好"},{"名称": "AH-64“阿帕奇”武装直升机","数量": 2,"状态": "需维护"},{"名称": "M1A2“艾布拉姆斯”主战坦克","数量": 10,"状态": "正常战备"}],"时间": "2024年12月5日","地点": ["中东地区","伊拉克巴格达市附近"],"其他实体": []} 本文(Qwen2.5B) {"人员": ["约翰·米勒"],"组织机构": ["美国五角大楼"],"武器装备": ["阿帕奇**3**状态良好","阿帕奇**2**需要维护","艾布拉姆斯**10**正常战备状态"],"时间": ["2024年12月5日"],"地点": ["中东地区","伊拉克巴格达市"]} 本文(DeepSeek7B) {"人员": ["约翰·米勒"],"组织机构": [],"武器装备": ["AH-64阿帕奇武装直升机**3**良好","AH-64阿帕奇武装直升机**2**需要简单维护","M1A2艾布拉姆斯主战坦克**10**正常战备状态"],"时间": ["2024年12月5日"],"地点": ["伊拉克巴格达市附近"]} 本文(DeepSeek8B) {"人员": ["约翰·米勒"],"组织机构": ["美国五角大楼","美军中央司令部"],"武器装备": ["AH-64“阿帕奇”武装直升机**3**良好","AH-64“阿帕奇”武装直升机**2**简单维护","M1A2“艾布拉姆斯”主战坦克**10**正常战备"],"时间": ["2024年12月5日"],"地点": ["中东地区","伊拉克巴格达市附近"]}
下载: 导出CSV
-
[1] LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, et al. Neural architectures for named entity recognition[C]. The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, USA, 2016: 260–270. doi: 10.18653/v1/N16-1030. [2] DAI Zhenjin, WANG Xutao, NI Pin, et al. Named entity recognition using BERT BiLSTM CRF for Chinese electronic health records[C]. The 2019 12th International Congress on Image and Signal Processing, Biomedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 2019: 1–5. doi: 10.1109/CISP-BMEI48845.2019.8965823. [3] WANG Chenguang, LIU Xiao, CHEN Zui, et al. Zero-shot information extraction as a unified text-to-triple translation[C]. The 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 2021: 1225–1238. doi: 10.18653/v1/2021.emnlp-main.94. [4] YANG Qingping, HU Yingpeng, CAO Rongyu, et al. Zero-shot key information extraction from mixed-style tables: Pre-training on Wikipedia[C]. The 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 2021: 1451–1456. doi: 10.1109/icdm51629.2021.00187. [5] LU Yaojie, LIU Qing, DAI Dai, et al. Unified structure generation for universal information extraction[C]. The 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 2022: 5755–5772. doi: 10.18653/v1/2022.acl-long.395. [6] GUO Daya, YANG Dejian, ZHANG Haowei, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning[EB/OL]. https://arxiv.org/abs/2501.12948, 2025. [7] LIU Aixin, FENG Bei, XUE Bing, et al. Deepseek-v3 technical report[EB/OL]. https://arxiv.org/abs/2412.19437, 2024. [8] BI Xiao, CHEN Deli, CHEN Guanting, et al. DeepSeek LLM: scaling open-source language models with longtermism[EB/OL]. https://arxiv.org/abs/2401.02954, 2024. [9] YUAN Jingyang, GAO Huazuo, DAI Damai, et al. Native sparse attention: hardware-aligned and natively trainable sparse attention[C]. The 63rd Annual Meeting of the Association for Computational Linguistics, Vienna, Austria, 2025: 23078–23097. doi: 10.18653/v1/2025.acl-long.1126. [10] WANG Xiao, ZHOU Weikang, ZU Can, et al. InstructUIE: multi-task instruction tuning for unified information extraction[EB/OL]. https://arxiv.org/abs/2304.08085, 2023. [11] HU Danqing, LIU Bing, ZHU Xiaofeng, et al. Zero-shot information extraction from radiological reports using ChatGPT[J]. International Journal of Medical Informatics, 2024, 183: 105321. doi: 10.1016/j.ijmedinf.2023.105321. [12] KARTCHNER D, RAMALINGAM S, AL-HUSSAINI I, et al. Zero-shot information extraction for clinical meta-analysis using large language models[C]. The 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, Canada, 2023: 396–405. doi: 10.18653/v1/2023.bionlp-1.37. [13] 张国宾, 姬红兵, 王佳萌, 等. 基于通用信息抽取大模型的特定领域文本实体关系抽取研究[J]. 中国信息界, 2024(8): 159–161.ZHANG Guobin, JI Hongbing, WANG Jiameng, et al. Research on entity-relationship extraction from domain-specific texts leveraging generalized information extraction large models[J]. Information China, 2024(8): 159–161. [14] 皮乾坤, 卢记仓, 祝涛杰, 等. 一种基于大语言模型增强的零样本知识抽取方法[J/OL]. 计算机科学. https://link.cnki.net/urlid/50.1075.TP.20250123.1638.012, 2025.PI Qiankun, LU Jicang, ZHU Taojie, et al. A zero-shot knowledge extraction method based on large language model enhanced[J/OL]. Computer Science. https://link.cnki.net/urlid/50.1075.TP.20250123.1638.012, 2025. [15] 户才顺. 基于大语言模型的审计领域命名实体识别算法研究[J]. 计算机科学, 2025, 52(S1): 72–75.LU Caishun. Study on named entity recognition algorithms in audit domain based on large language models[J]. Computer Science, 2025, 52(S1): 72–75. [16] 胡慧云, 葛杨, 崔凌潇, 等. 融合多模态信息与大语言模型的生成式命名实体识别方法[J/OL]. 计算机工程与应用. https://doi.org/10.3778/j.issn.1002-8331.2503-0243, 2025.HU Huiyun, GE Yang, CUI Lingxiao, et al. Generative named entity recognition method integrating multimodal information and large language models[J/OL]. Computer Engineering and Applications. https://doi.org/10.3778/j.issn.1002-8331.2503-0243, 2025. [17] HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. https://arxiv.org/abs/2106.09685, 2021. [18] LEWIS P, PEREZ E, PIKTUS A, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 793. doi: 10.5555/3495724.3496517. -




计量
- 文章访问数: 712
- HTML全文浏览量: 541
- PDF下载量: 109
- 被引次数: 0
 下载:
下载:
