

Research on Monophonic Speech Separation Method Using Time-Frequency Domain Multi-scale Information Interaction Strategy
-
摘要: 针对现有基于注意力机制的单声道语音分离模型在多尺度特征交互与时频信息融合方面的不足,该文提出一种融合时频域信息的多尺度注意力模型(MSA-TF)。该模型通过构建时频融合模块与多尺度交互分离器,引入频带分裂、动态门控与交叉注意力机制,实现时域与频域特征的高效互补;并借助跨尺度残差连接与自适应池化策略,促进全局语义与局部细节之间的双向流动,从而增强对语音信号中长短时依赖的联合建模能力。利用信号失真比(SDR)、尺度不变信噪比(SI-SNR)评价指标,在WSJ0-2mix和Libri-2mix数据集进行实验测试。研究表明,MSA-TF在WSJ0-2mix数据集上,测试结果相较于Conv-Tasnet基线模型在SI-SNR上平均提升2.3 dB,在未训练的Libri-2mix测试集上,泛化性能与在该集上训练的基线性能相当。由此可见,该文方法能通过提取不同尺度下的时域信息与频域信息进行互补与融合,促进全局语义与局部细节建模,获得更好更具泛化性的分离结果。Abstract:
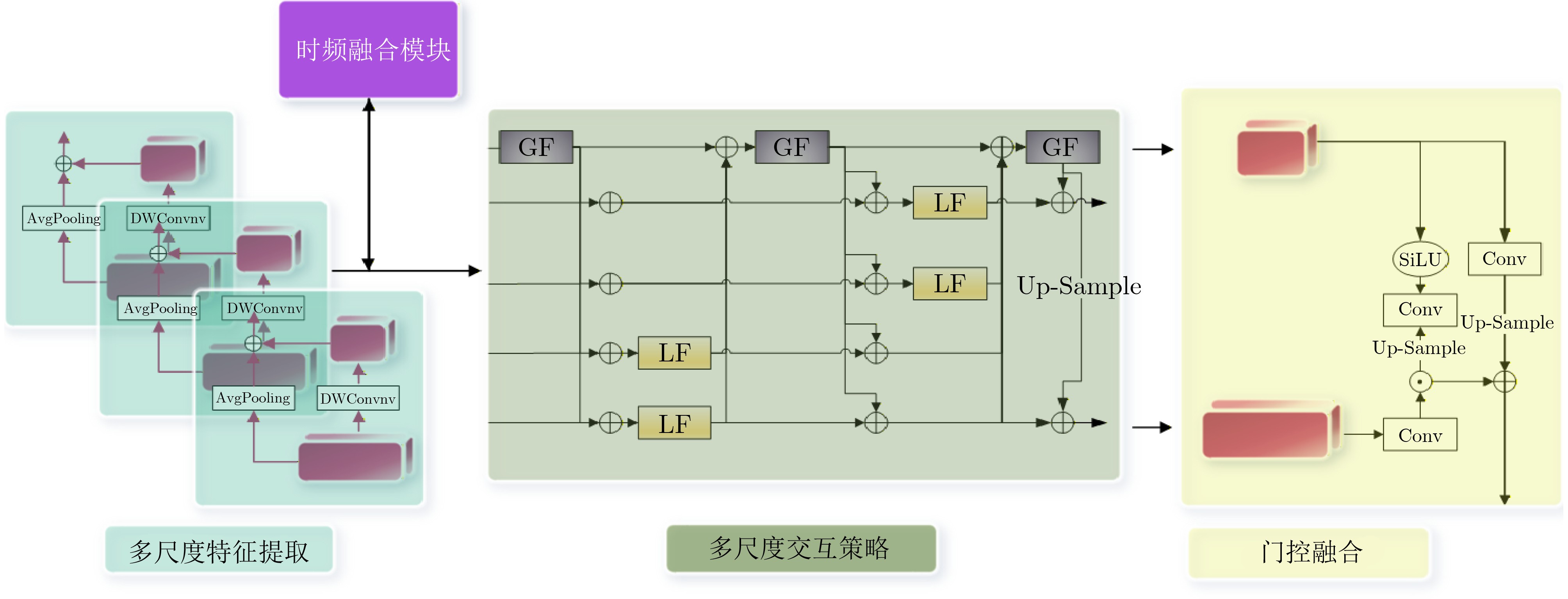
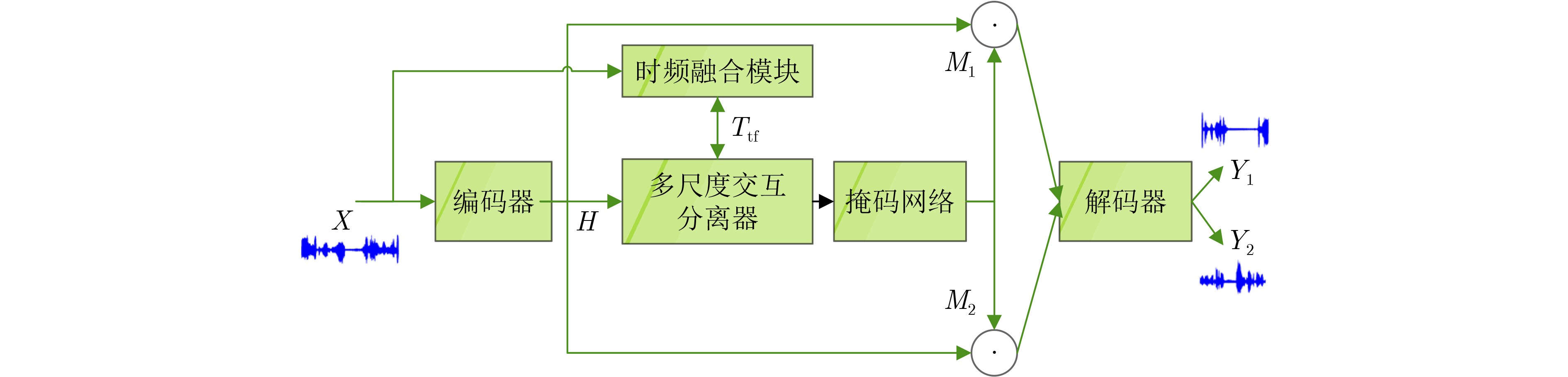
Objective Monaural speech separation aims to extract individual speaker signals from a single-channel mixture. It is a core technology for addressing the “cocktail party problem” and has substantial application value in low-resource, low-latency scenarios such as mobile voice assistants, teleconferencing, and hearing aids. However, the lack of spatial cues in single-channel signals, together with the substantial overlap of multiple speakers in both time-domain waveforms and frequency-domain spectra, makes accurate separation highly challenging, especially when the integrity and clarity of the target speech must be preserved. Current deep learning-based models often show limitations in three closely related aspects: effective coordination of multi-scale dependencies, efficient fusion of time-frequency information, and control of computational complexity. To address these challenges, a novel Multi-Scale Attention model integrating Time-Frequency domain information (MSA-TF) is proposed to improve separation performance, computational efficiency, and generalization capability. Methods The MSA-TF model contains three key components. First, a lightweight Time-Frequency fusion module is designed. The module first divides the frequency band into four subbands on the basis of speech priors, such as low-frequency energy concentration and high-frequency detail sensitivity, to extract spectral features efficiently. A dynamic gating mechanism with decomposed convolutions and SiLU activation is then applied to adaptively enhance speaker-discriminative features and suppress redundant channels associated with noise. Finally, a cross-attention mechanism is used to promote deep interaction between time-domain and frequency-domain features during the encoding stage. Global semantic information from the time domain guides the selection and weighting of useful frequency-domain features, allowing mutual correction and complementarity. This module adds only 0.8 M parameters. Second, a Multi-scale Interaction Separator is proposed to address the limitations of sequential or loosely coupled multi-scale processing in models such as SepFormer. Multi-granularity features, ranging from frame-level F 1 to syllable-level semantic F 4, are extracted through cascaded dilated convolutions. Its core is the “GF-LF Iterative Feedback” mechanism. The Global Flash module, based on efficient FLASH attention, captures long-range dependencies and syllable-level context. This global information is upsampled and injected into local features ( F k) through residual connections. Local Flash modules, also based on FLASH attention, then process the enhanced local features ($ {\boldsymbol{F}}_k^{\prime} $) to model fine-grained structures and suppress frame-level noise. The updated local features are subsequently fed back through adaptive pooling to refine the global representation in the next iteration. This closed-loop bidirectional flow enables deep synergy between global semantics and local details. A gated fusion mechanism at the end dynamically balances the contributions of different scales. Third, to control computational complexity, an efficient hierarchical grouped attention mechanism is adopted, reducing the complexity from quadratic to nearly linear with sequence length. The overall MSA-TF architecture is end-to-end and consists of a 1D convolutional encoder, the integrated time-frequency and multi-scale modules, a mask network, and a symmetric decoder. Results and Discussions Extensive experiments are conducted on the standard WSJ0-2mix and Libri-2mix datasets, with Scale-Invariant Signal-to-Noise Ratio (SI-SNR) and Signal-to-Distortion Ratio (SDR) used as evaluation metrics. Ablation studies ( Table 1 ) confirm the individual and joint contributions of the proposed modules. When only the time-frequency module is added to the TDAnet baseline, SI-SNR increases by 0.3 dB and SDR by 0.4 dB with only a small increase in parameters, confirming its contribution to signal structure modeling, particularly for high-frequency details. When only the multi-scale interaction module is incorporated, SI-SNR increases by 2.5 dB and SDR by 2.7 dB, highlighting its central role in modeling long-term dependencies. When the time-frequency and multi-scale modules are combined in the complete MSA-TF core, a synergistic effect is obtained, reaching 17.6 dB SI-SNR, which exceeds the sum of the individual gains. This result indicates that the dual-dimensional features provided by time-frequency fusion and the deep dependency modeling enabled by multi-scale interaction strengthen each other. Spectrogram analysis (Fig. 3 ) further shows that the time-frequency module effectively suppresses residual high-frequency noise and produces clearer spectral contours for the target speech. On the WSJ0-2mix test set (Table 2 ), MSA-TF achieves state-of-the-art performance, with 17.6 dB SI-SNR and 17.8 dB SDR. It matches the performance of SuperFormer and substantially outperforms strong baselines such as Conv-Tasnet by 2.3 dB SI-SNR, while maintaining a reasonable parameter count of 15.6 M. Compared with models with larger parameter sizes, such as SignPredictionNet at 55.2 M, MSA-TF shows more efficient modeling. For generalization evaluation on the completely unseen Libri-2mix dataset (Table 4 ), MSA-TF, trained only on WSJ0-2mix, achieves 14.2 dB SI-SNR and 14.7 dB SDR. Its performance is comparable to that of Conv-Tasnet models trained specifically on Libri-2mix, which achieve 14.4 dB SI-SNR, and it outperforms BLSTM-Tasnet trained on Libri-2mix. This strong cross-dataset adaptability indicates that the model captures universal time-frequency characteristics and multi-scale dependency structures in speech signals rather than overfitting to a specific dataset distribution.Conclusions An MSA-TF model is presented to address key challenges in monaural speech separation through deep integration of multi-scale time-frequency information interaction. The proposed lightweight Time-Frequency fusion module efficiently supplements time-domain features with discriminative frequency-domain information. The Multi-scale Interaction Separator, with its iterative feedback mechanism, enables dynamic bidirectional information flow across scales and substantially improves the joint modeling of short-term details and long-term dependencies. Combined with an efficient attention design, the model achieves superior performance without excessive computational cost. Experimental results show that MSA-TF achieves leading separation performance on standard benchmarks and shows strong generalization ability on unseen data distributions, confirming the effectiveness of this comprehensive design. The model provides an efficient, robust, and generalizable solution for practical low-resource application scenarios. Future work may examine advanced cross-modal fusion techniques and dynamic scale adjustment strategies to further improve robustness and performance in more complex and variable acoustic environments. -
表 1 消融实验的结果
模型 SI-SNR(dB) SDR(dB) Param(M) TDAnet 14.5 14.8 2.3 TDAnet+TF 14.8 15.2 3.1 TDAnet+MS 17.0 17.5 14.8 TDAnet+TF+MS 17.6 17.8 15.6  下载: 导出CSV
下载: 导出CSV
表 2 不同GF-LF迭代次数下的性能与效率对比
模型配置 迭代次数N SI-SNR(dB) SDR(dB) GMACs TDAnet+TF+MS 1 15.1 15.5 17.47 TDAnet+TF+MS 3 16.8 17.2 52.21 TDAnet+TF+MS 6 17.6 17.8 104.32
下载: 导出CSV
表 5 各模型的计算效率与资源消耗对比
模型 Params (M) GMACs 显存占用(MB) Conv-TasNet 5.1 20.47 1290.29 SepFormer 26.0 145.87 8159.30 MSA-TF 15.62 104.32 3179.57
下载: 导出CSV
表 6 MSA-TF 在不同输入语音长度下的鲁棒性分析
音频时长(s) 样本数 SI-SNR(dB) 平均推理时间(s) 3~4 12 18.44 0.1048 4~5 87 17.35 0.1142 5~6 285 17.31 0.1217 6~7 497 17.49 0.1361 7~8 357 17.44 0.1503 8~9 427 17.65 0.1693 9~10 439 17.54 0.1871 10~15 857 17.33 0.2259 15~20 39 18.31 0.3441
下载: 导出CSV
-
[1] LI Kai, CHEN Guo, SANG Wendi, et al. Advances in speech separation: Techniques, challenges, and future trends[J]. arXiv preprint arXiv: 2508.10830, 2025. doi: 10.48550/arXiv.2508.10830. [2] LUO Yi and MESGARANI N. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256–1266. doi: 10.1109/TASLP.2019.2915167. [3] ZHANG Liwen, SHI Ziqiang, HAN Jiqing, et al. FurcaNeXt: End-to-end monaural speech separation with dynamic gated dilated temporal convolutional networks[C]. The 26th International Conference on Multimedia Modeling, Daejeon, South Korea, 2020: 653–665. doi: 10.1007/978-3-030-37731-1_53. [4] SHI Huiyu, CHEN Xi, KONG Tianlong, et al. GLMSnet: Single channel speech separation framework in noisy and reverberant environments[C]. 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 2021: 663–670. doi: 10.1109/ASRU51503.2021.9688217. [5] LUO Yi, CHEN Zhuo, and YOSHIOKA T. Dual-Path RNN: Efficient long sequence modeling for time-domain single-channel speech separation[C]. The ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 46–50. doi: 10.1109/ICASSP40776.2020.9054266. [6] SUBAKAN C, RAVANELLI M, CORNELL S, et al. Attention is all you need in speech separation[C]. The ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, Canada, 2021: 21–25. doi: 10.1109/ICASSP39728.2021.9413901. [7] ZHAO Yucheng, LUO Chong, ZHA Zhengjun, et al. Multi-scale group transformer for long sequence modeling in speech separation[C]. The Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 2021: 450. [8] RIXEN J and RENZ M. SFSRNet: Super-resolution for single-channel audio source separation[C]. The 36th AAAI Conference on Artificial Intelligence, 2022: 11220–11228. doi: 10.1609/aaai.v36i10.21372. ,, [9] TONG Weinan, ZHU Jiaxu, CHEN Jun, et al. TFCnet: Time-frequency domain corrector for speech separation[C]. The ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10096785. [10] ROUARD S, MASSA F, and DÉFOSSEZ A. Hybrid transformers for music source separation[C]. The ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10096956. [11] TZINIS E, WANG Zhepei, and SMARAGDIS P. Sudo RM -RF: Efficient networks for universal audio source separation[C].2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP), Espoo, Finland, 2020: 1–6. doi: 10.1109/MLSP49062.2020.9231900. [12] LI Kai, YANG Runxuan, and HU Xiaolin. An efficient encoder-decoder architecture with top-down attention for speech separation[J]. arXiv preprint arXiv: 2209.15200, 2022. doi: 10.48550/arXiv.2209.15200. [13] GOEL K, GU A, DONAHUE C, et al. It’s raw! Audio generation with state-space models[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 7616–7633. [14] CHEN Chen, YANG C H H, LI Kai, et al. A neural state-space modeling approach to efficient speech separation[C]. The 24th Annual Conference of the International Speech Communication Association, Dublin, Ireland, 2023: 3784–3788. [15] XU Mohan, LI Kai, CHEN Guo, et al. TIGER: Time-frequency interleaved gain extraction and reconstruction for efficient speech separation[C]. The 13th International Conference on Learning Representations, Singapore, Singapore, 2025. [16] OH H, YI J, and LEE Y. Papez: Resource-efficient speech separation with auditory working memory[C]. The ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10095136. [17] HUA Weizhe, DAI Zihang, LIU Hanxiao, et al. Transformer quality in linear time[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 9099–9117. [18] ZHAO Shengkui and MA Bin. MossFormer: Pushing the performance limit of monaural speech separation using gated single-head transformer with convolution-augmented joint self-attentions[C]. The ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10096646. [19] ZHAO Shengkui, MA Yukun, NI Chongjia, et al. MossFormer2: Combining transformer and RNN-free recurrent network for enhanced time-domain monaural speech separation[C]. The ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024: 10356–10360. doi: 10.1109/ICASSP48485.2024.10445985. [20] HU Xiaolin, LI Kai, ZHANG Weiyi, et al. Speech separation using an asynchronous fully recurrent convolutional neural network[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 1724. . [21] PAN Zexu, WICHERN G, GERMAIN F G, et al. PARIS: Pseudo-AutoRegressIve Siamese training for online speech separation[C]. The 25th Annual Conference of the International Speech Communication Association, Kos, Greece, 2024. [22] TAN H M, VU D Q, and WANG J C. Selinet: A lightweight model for single channel speech separation[C]. The ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10097121. [23] TZINIS E, VENKATARAMANI S, WANG Zhepei, et al. Two-step sound source separation: Training on learned latent targets[C]. The IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 2020: 31–35. doi: 10.1109/ICASSP40776.2020.9054172. [24] LUO Jian, WANG Jianzong, CHENG Ning, et al. Tiny-Sepformer: A tiny time-domain transformer network for speech separation[J]. arXiv preprint arXiv: 2206.13689, 2022. doi: 10.48550/arXiv.2206.13689. . [25] JIANG Yanji, QIU Youli, SHEN Xueli, et al. SuperFormer: Enhanced multi-speaker speech separation network combining channel and spatial adaptability[J]. Applied Sciences, 2022, 12(15): 7650. doi: 10.3390/app12157650. [26] LIU Debang, ZHANG Tianqi, CHRISTENSEN M G, et al. Efficient time-domain speech separation using short encoded sequence network[J]. Speech Communication, 2025, 166: 103150. doi: 10.1016/j.specom.2024.103150. [27] 侯进, 盛尧宝, 张波. 基于二阶统计特性的方向向量估计算法的DOA估计[J]. 电子与信息学报, 2024, 46(2): 697–704. doi: 10.11999/JEIT230172.HOU Jin, SHENG Yaobao, and ZHANG Bo. DOA estimation of direction vector estimation algorithm based on second-order statistical properties[J]. Journal of Electronics & Information Technology, 2024, 46(2): 697–704. doi: 10.11999/JEIT230172. [28] 田浩原, 陈宇轩, 陈北京, 等. 抵抗语音转换伪造的扩散重构式主动防御方法[J]. 电子与信息学报, 2026, 48(2): 818–828. doi: 10.11999/JEIT250709.TIAN Haoyuan, CHEN Yuxuan, CHEN Beijing, et al. Defeating voice conversion forgery by active defense with diffusion reconstruction[J]. Journal of Electronics & Information Technology, 2026, 48(2): 818–828. doi: 10.11999/JEIT250709. [29] 刘佳, 张洋瑞, 陈大鹏, 等. 结合双流注意力与对抗互重建的双模态情绪识别方法[J]. 电子与信息学报, 2026, 48(1): 277–286. doi: 10.11999/JEIT250424.LIU Jia, ZHANG Yangrui, CHEN Dapeng, et al. Bimodal emotion recognition method based on dual-stream attention and adversarial mutual reconstruction[J]. Journal of Electronics & Information Technology, 2026, 48(1): 277–286. doi: 10.11999/JEIT250424. -




图(3) / 表(6)
计量
- 文章访问数: 203
- HTML全文浏览量: 127
- PDF下载量: 32
- 被引次数: 0
 下载:
下载:
