

BIRD1445: Large-scale Multimodal Bird Dataset for Ecological Monitoring
-
摘要: 随着人工智能技术的快速发展,基于深度学习的计算机视觉、声学智能分析和多模态融合技术为生态监测领域提供了重要技术手段,广泛应用于鸟类物种识别与调查等业务场景。然而,现有鸟类数据集存在实采数据获取难度大、专业标注人力成本高、珍稀物种数据样本少且数据模态单一等诸多问题,难以满足大模型等人工智能技术在生态监测与保护领域的训练与应用需求。针对此问题,该文提出一种面向专业领域的大规模多模态数据集高效构建方法,通过多源异构数据采集、智能化半自动标注和基于异构注意力融合的多模型协同校验机制,有效降低专业标注成本并保证数据质量。该文设计了基于多尺度注意力融合的数据集校验方法,通过构建多模型协同校验系统,利用类别敏感权重分配机制提升数据集校验的准确度和效率。基于以上方法,该文构建了大规模多模态鸟类数据集BIRD1445,涵盖1 445种鸟类物种,包含图像、视频、音频和文本4种模态,共计354万个样本,能够支持目标检测、密度估计、细粒度识别等智能分析任务,为人工智能技术在生态监测与保护领域的应用提供了重要数据基础。Abstract:
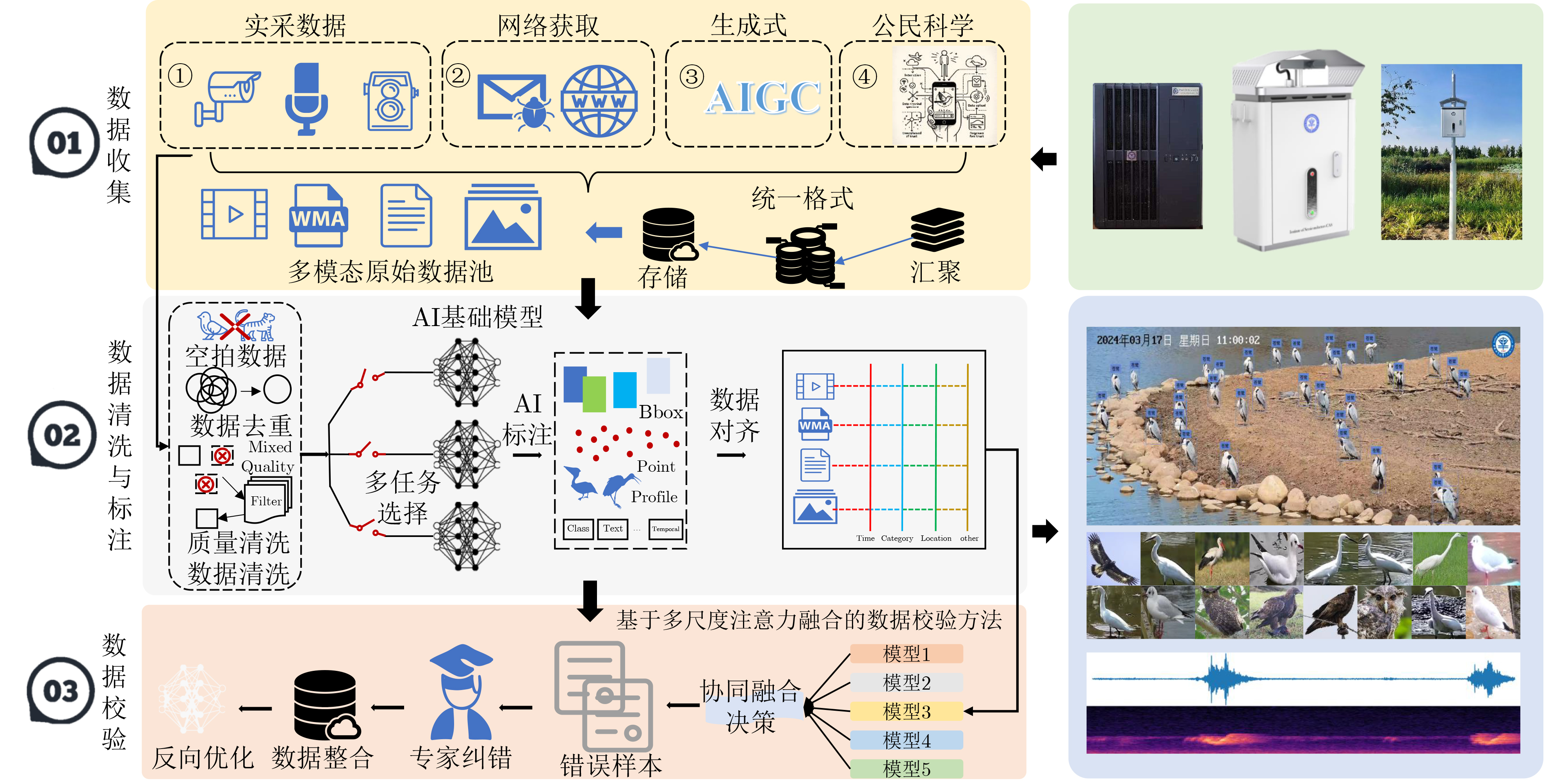
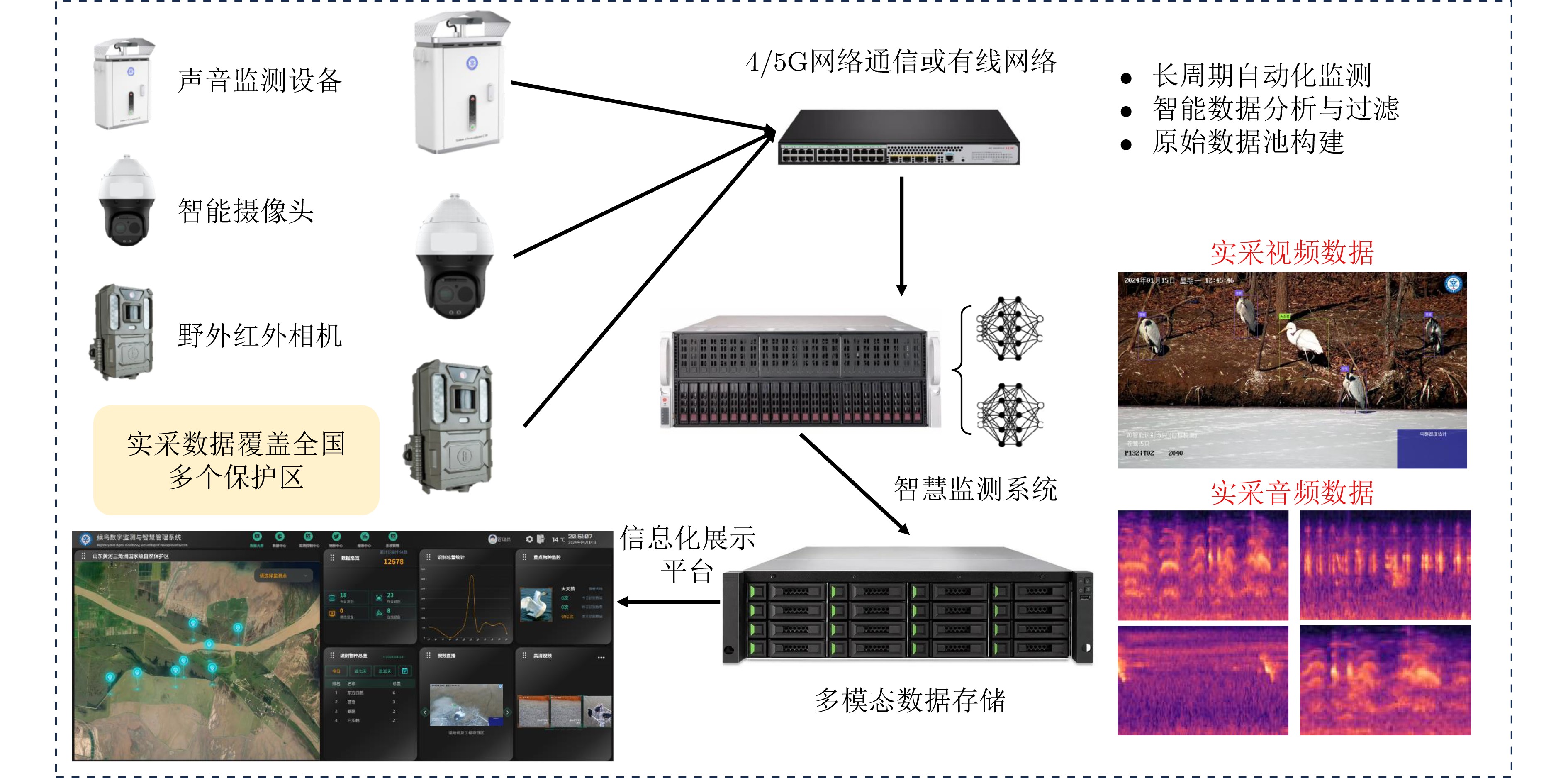
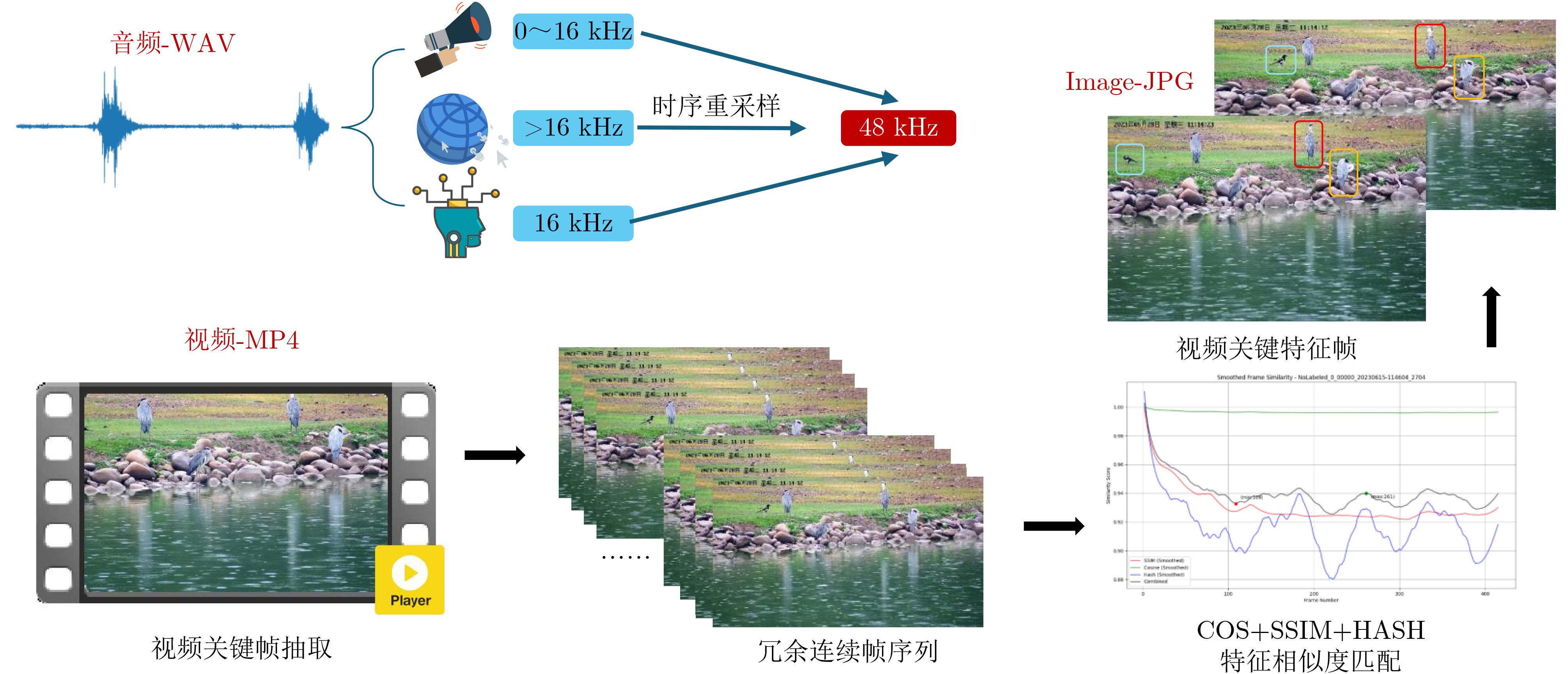
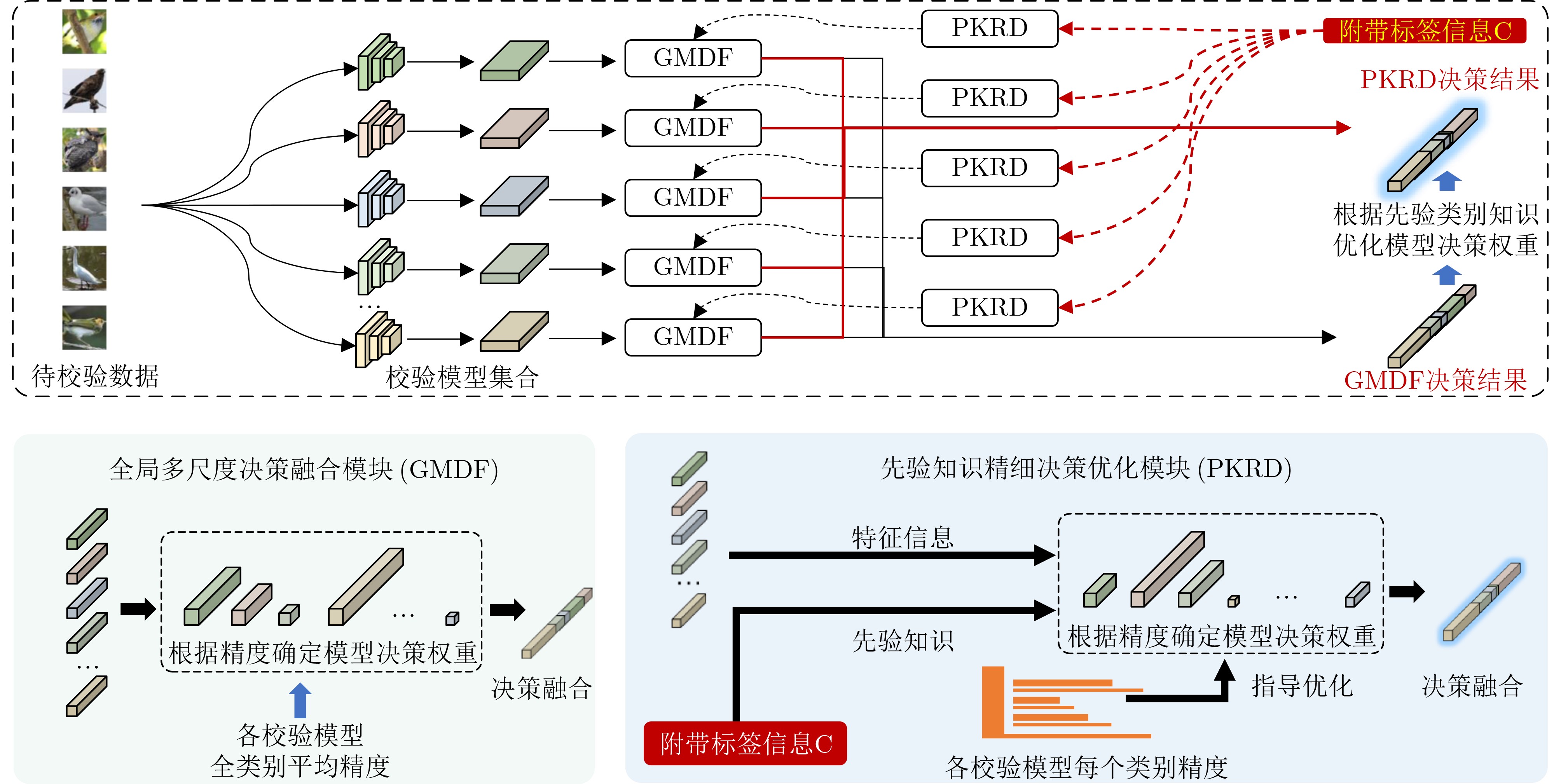
Objective With the rapid advancement of Artificial Intelligence (AI) and growing demands in ecological monitoring, high-quality multimodal datasets have become essential for training and deploying AI models in specialized domains. Existing bird datasets, however, face notable limitations, including challenges in field data acquisition, high costs of expert annotation, limited representation of rare species, and reliance on single-modal data. To overcome these constraints, this study proposes an efficient framework for constructing large-scale multimodal datasets tailored to ecological monitoring. By integrating heterogeneous data sources, employing intelligent semi-automatic annotation pipelines, and adopting multi-model collaborative validation based on heterogeneous attention fusion, the proposed approach markedly reduces the cost of expert annotation while maintaining high data quality and extensive modality coverage. This work offers a scalable and intelligent strategy for dataset development in professional settings and provides a robust data foundation for advancing AI applications in ecological conservation and biodiversity monitoring. Methods The proposed multimodal dataset construction framework integrates multi-source heterogeneous data acquisition, intelligent semi-automatic annotation, and multi-model collaborative verification to enable efficient large-scale dataset development. The data acquisition system comprises distributed sensing networks deployed across natural reserves, incorporating high-definition intelligent cameras, custom-built acoustic monitoring devices, and infrared imaging systems, supplemented by standardizedpublic data to enhance species coverage and modality diversity. The intelligent annotation pipeline is built upon four core automated tools: (1) spatial localization annotation leverages object detection algorithms to generate bounding boxes; (2) fine-grained classification employs Vision Transformer models for hierarchical species identification; (3) pixel-level segmentation combines detection outputs with SegGPT models to produce instance-level masks; and (4) multimodal semantic annotation uses Qwen large language models to generate structured textual descriptions. To ensure annotation quality and minimize manual verification costs, a multi-scale attention fusion verification mechanism is introduced. This mechanism integrates seven heterogeneous deep learning models, each with different feature perception capacities across local detail, mid-level semantic, and global contextual scales. A global weighted voting module dynamically assigns fusion weights based on model performance, while a prior knowledge-guided fine-grained decision module applies category-specific accuracy metrics and Top-K model selection to enhance verification precision and computational efficiency. Results and Discussions The proposed multi-scale attention fusion verification method dynamically assesses data quality based on heterogeneous model predictions, forming the basis for automated annotation validation. Through optimized weight allocation and category-specific verification strategies, the collaborative verification framework evaluates the effect of different model combinations on annotation accuracy. Experimental results demonstrate that the optimal verification strategy—achieved by integrating seven specialized models—outperforms all baseline configurations across evaluation metrics. Specifically, the method attains a Top-1 accuracy of 95.39% on the CUB-200-2011 dataset, exceeding the best-performing single-model baseline, which achieves 91.79%, thereby yielding a 3.60% improvement in recognition precision. The constructed BIRD1445 dataset, comprising 3.54 million samples spanning 1 445 bird species and four modalities, outperforms existing datasets in terms of coverage, quality, and annotation accuracy. It serves as a robust benchmark for fine-grained classification, density estimation, and multimodal learning tasks in ecological monitoring. Conclusions This study addresses the challenge of constructing large-scale multimodal datasets for ecological monitoring by integrating multi-source data acquisition, intelligent semi-automatic annotation, and multi-model collaborative verification. The proposed approach advances beyond traditional manual annotation workflows by incorporating automated labeling pipelines and heterogeneous attention fusion mechanisms as the core quality control strategy. Comprehensive evaluations on benchmark datasets and real-world scenarios demonstrate the effectiveness of the method: (1) the verification strategy improves annotation accuracy by 3.60% compared to single-model baselines on the CUB-200-2011 dataset; (2) optimal trade-offs between precision and computational efficiency are achieved using Top-K = 3 model selection, based on performance-complexity alignment; and (3) in large-scale annotation scenarios, the system ensures high reliability across 1 445 species categories. Despite its effectiveness, the current approach primarily targets species with sufficient data. Future work should address the representation of rare and endangered species by incorporating advanced data augmentation and few-shot learning techniques to mitigate the limitations posed by long-tail distributions. -
表 1 主流数据集汇总
数据集 数据集类型 发布年份 数据类型 类别数 数据总数 主要任务 主要特点 PASCAL VOC[16] AI算法通用 2010 图像 21 1.15×104 分类、检测、分割 高精度标注;标准评估协议;
难度分级与遮挡标记MS COCO[17] AI算法通用 2014 图像 80 3.30×105 检测、实例分割、
图像描述、关键点检测像素级分割标注;复杂多样场景;多任务;
物体关系与语言描述ImageNet[18] AI算法通用 2009 图像 20,000+ 2.10×107 分类、检测 超大规模;类别广泛且结构化 Open Images[19] AI算法通用 2020 图像 600 9.00×106 多标签分类、检测、
实例分割、视觉关系检测标注类型全面;真实场景分布广;
支持细粒度视觉理解任务VQA v2[20] 大模型评测 2017 问答对 \ 2.14×105 视觉问答 平衡设计,消除语言偏见 GQA[21] 大模型评测 2023 问答对 \ 2.20×107 组合推理 多步推理,场景图结构 OK-VQA[22] 大模型评测 2019 问答对 \ 2.50×104 知识推理 外部知识整合,跨领域推理 CUB-200-2011[11] 专业领域
应用2011 图像 200 1.18×104 细粒度识别、部位定位 精细标注,场景单一 NABirds[12] 专业领域
应用2015 图像 1,011 4.86×104 层级分类、
细粒度识别北美鸟类覆盖全面,包含分类层级 iNaturalist Birds[13] 专业领域
应用2018 图像 1,203 2.70×105 野外识别、生物多样性监测 自然场景真实,数据分布不均衡 Species196 专业领域
应用2023 图像 196 1.22×106 入侵物种生物识别 120万无标注+19,236精细标注 TreeOfLife-1M 专业领域
应用2023 图像 454,000 1.00×107 生物学图像
识别附带详细的分类层级标签 BIRD1445
(本文)专业领域
应用2025 图像
音频
视频
文本1,445 3.54×106 多种AI任务 包含全国18个自然保护地实采数据、
全国鸟类物种、多任务、
智能化专业标注、文本模态包含100万条
结构化观测记录,关联经纬度、
时间戳等元数据 下载: 导出CSV
下载: 导出CSV
表 3 核心模块消融实验结果(%)
模型 Top-1准确率 相对提升 MPSA[32] 91.79 - AVE(本文) 94.19 +2.40 GWV(本文) 94.46 +2.67 PKFD(本文) 95.39 +3.60
下载: 导出CSV
-
[1] ZHU Ruizhe, JIN Hai, HAN Yonghua, et al. Aircraft target detection in remote sensing images based on improved YOLOv7-tiny network[J]. IEEE Access, 2025, 13: 48904–48922. doi: 10.1109/ACCESS.2025.3551320. [2] 侯志强, 董佳乐, 马素刚, 等. 基于多尺度特征增强与全局-局部特征聚合的视频目标分割算法[J]. 电子与信息学报, 2024, 46(11): 4198–4207. doi: 10.11999/JEIT231394.HOU Zhiqiang, DONG Jiale, MA Sugang, et al. Video object segmentation algorithm based on multi-scale feature enhancement and global-local feature aggregation[J]. Journal of Electronics & Information Technology, 2024, 46(11): 4198–4207. doi: 10.11999/JEIT231394. [3] 查志远, 袁鑫, 张嘉超, 等. 基于低秩正则联合稀疏建模的图像去噪算法[J]. 电子与信息学报, 2025, 47(2): 561–572. doi: 10.11999/JEIT240324.ZHA Zhiyuan, YUAN Xin, ZHANG Jiachao, et al. Low-rank regularized joint sparsity modeling for image denoising[J]. Journal of Electronics & Information Technology, 2025, 47(2): 561–572. doi: 10.11999/JEIT240324. [4] TUIA D, KELLENBERGER B, BEERY S, et al. Perspectives in machine learning for wildlife conservation[J]. Nature Communications, 2022, 13(1): 792. doi: 10.1038/s41467-022-27980-y. [5] WANG Hongchang, LU Huaxiang, GUO Huimin, et al. Bird-Count: A multi-modality benchmark and system for bird population counting in the wild[J]. Multimedia Tools and Applications, 2023, 82(29): 45293–45315. doi: 10.1007/s11042-023-14833-z. [6] 王洪昌, 夏舫, 张渊媛, 等. 基于深度学习算法的鸟类及其栖息地识别——以北京翠湖国家城市湿地公园为例[J]. 生态学杂志, 2024, 43(7): 2231–2238. doi: 10.13292/j.1000-4890.202407.045.WANG Hongchang, XIA Fang, ZHANG Yuanyuan, et al. Bird and habitat recognition based on deep learning algorithm: A case study of Beijing Cuihu National Urban Wetland Park[J]. Chinese Journal of Ecology, 2024, 43(7): 2231–2238. doi: 10.13292/j.1000-4890.202407.045. [7] GUO Huimin, JIAN Haifang, WANG Yiyu, et al. CDPNet: Conformer-based dual path joint modeling network for bird sound recognition[J]. Applied Intelligence, 2024, 54(4): 3152–3168. doi: 10.1007/s10489-024-05362-9. [8] NICHOLS J D and WILLIAMS B K. Monitoring for conservation[J]. Trends in Ecology & Evolution, 2006, 21(12): 668–673. doi: 10.1016/j.tree.2006.08.007. [9] NOROUZZADEH M S, NGUYEN A, KOSMALA M, et al. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning[J]. Proceedings of the National Academy of Sciences, 2018, 115(25): E5716–E5725. doi: 10.1073/pnas.1719367115. [10] HAMPTON S E, STRASSER C A, TEWKSBURY J J, et al. Big data and the future of ecology[J]. Frontiers in Ecology and the Environment, 2013, 11(3): 156–162. doi: 10.1890/120103. [11] WAH C, BRANSON S, WELINDER P, et al. The Caltech-UCSD birds-200-2011 dataset[R]. 2011. [12] VAN HORN G, BRANSON S, FARRELL R, et al. Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection[C]. The 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 595–604. doi: 10.1109/CVPR.2015.7298658. [13] VAN HORN G, MAC AODHA O, SONG Yang, et al. The iNaturalist species classification and detection dataset[C]. The 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8769–8778. doi: 10.1109/CVPR.2018.00914. [14] STEVENS S, WU Jiaman, THOMPSON M J, et al. BioCLIP: A vision foundation model for the tree of life[C]. The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA, 2024: 19412–19424. doi: 10.1109/CVPR52733.2024.01836. [15] FERGUS P, CHALMERS C, LONGMORE S, et al. Harnessing artificial intelligence for wildlife conservation[J]. Conservation, 2024, 4(4): 685–702. doi: 10.3390/conservation4040041. [16] EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL Visual Object Classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4. [17] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]. The 13th European Conference on Computer Vision -- ECCV 2014, Zurich, Switzerland, 2014: 740–755. doi: 10.1007/978-3-319-10602-1_48. [18] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. [19] KUZNETSOVA A, ROM H, ALLDRIN N, et al. The open images dataset V4: Unified image classification, object detection, and visual relationship detection at scale[J]. International Journal of Computer Vision, 2020, 128(7): 1956–1981. doi: 10.1007/s11263-020-01316-z. [20] GOYAL Y, KHOT T, SUMMERS-STAY D, et al. Making the V in VQA matter: Elevating the role of image understanding in visual question answering[C]. The 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6325–6334. doi: 10.1109/CVPR.2017.670. [21] AINSLIE J, LEE-THORP J, DE JONG M, et al. GQA: Training generalized multi-query transformer models from multi-head checkpoints[C]. The 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 2023: 4895–4901. doi: 10.18653/v1/2023.emnlp-main.298. [22] MARINO K, RASTEGARI M, FARHADI A, et al. OK-VQA: A visual question answering benchmark requiring external knowledge[C]. The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3190–3199. doi: 10.1109/CVPR.2019.00331. [23] KAHL S, WILHELM-STEIN T, KLINCK H, et al. Recognizing birds from sound-the 2018 BirdCLEF baseline system[J]. arXiv preprint arXiv: 1804.07177, 2018. doi: 10.48550/arXiv.1804.07177. [24] HE Wei, HAN Kai, NIE Ying, et al. Species196: A one-million semi-supervised dataset for fine-grained species recognition[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1949. doi: 10.5555/3666122.3668071. [25] GUO Huimin, JIAN Haifang, WANG Yequan, et al. MAMGAN: Multiscale attention metric GAN for monaural speech enhancement in the time domain[J]. Applied Acoustics, 2023, 209: 109385. doi: 10.1016/j.apacoust.2023.109385. [26] BAI Shuai, CHEN Keqin, LIU Xuejing, et al. Qwen2.5-VL technical report[J]. arXiv preprint arXiv: 2502.13923, 2025. doi: 10.48550/arXiv.2502.13923. [27] WANG Xinlong, ZHANG Xiaosong, CAO Yue, et al. SegGPT: Towards segmenting everything in context[C]. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 1130–1140. doi: 10.1109/ICCV51070.2023.00110. [28] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021. [29] CHEN Yue, BAI Yalong, ZHANG Wei, et al. Destruction and construction learning for fine-grained image recognition[C]. The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5152–5161. doi: 10.1109/CVPR.2019.00530. [30] CHOU P Y, LIN C H, and KAO W C. A novel plug-in module for fine-grained visual classification[J]. arxiv preprint arXiv: 2202.03822, 2022. doi: 10.48550/arXiv.2202.03822. [31] LUO Wei, YANG Xitong, MO Xianjie, et al. Cross-X learning for fine-grained visual categorization[C]. The 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 8241–8250. doi: 10.1109/ICCV.2019.00833. [32] WANG Jiahui, XU Qin, JIANG Bo, et al. Multi-granularity part sampling attention for fine-grained visual classification[J]. IEEE Transactions on Image Processing, 2024, 33: 4529–4542. doi: 10.1109/TIP.2024.3441813. [33] LIU Zhuang, MAO Hanzi, WU Chaoyuan, et al. A ConvNet for the 2020s[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 11966–11976. doi: 10.1109/CVPR52688.2022.01167. [34] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [35] HE Ju, CHEN Jieneng, LIU Shuai, et al. TransFG: A transformer architecture for fine-grained recognition[C/OL]. The 36th AAAI Conference on Artificial Intelligence, 2022: 852–860. doi: 10.1609/aaai.v36i1.19967. [36] DU Ruoyi, CHANG Dongliang, BHUNIA A K, et al. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 153–168. doi: 10.1007/978-3-030-58565-5_10. -





图(10) / 表(5)
计量
- 文章访问数: 1426
- HTML全文浏览量: 860
- PDF下载量: 174
- 被引次数: 0
 下载:
下载:
