

TTSPD: A Multimodal Traffic Scene Perception Dataset Integrating Tire Data
-
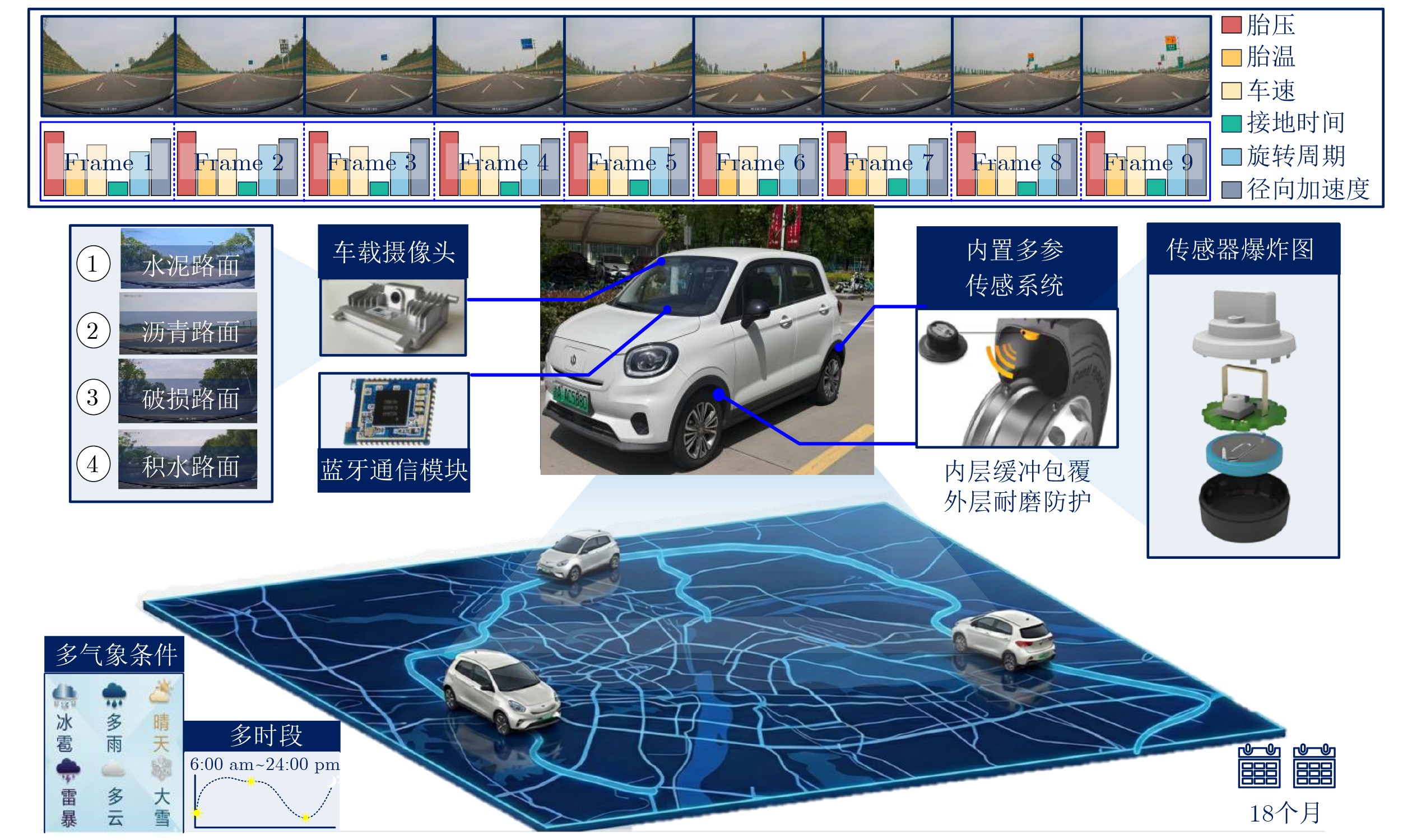
摘要: 当前交通场景感知依赖大规模高分辨率图像与雷达点云数据,在“感知-存储-计算”链路上面临采集成本高、存储压力大及计算资源消耗高等瓶颈。基于此,该文创新性地从轮胎视角出发,构建了一种新的多模态交通场景感知数据集(TTSPD)。具体地,该文采用橡胶基复合材料封装策略与低功耗蓝牙5.0自适应跳频技术,构建了一套集轮胎内置多参数传感与车载摄像头为一体的多模态传感器系统。该系统可在车辆行驶过程中同步采集径向加速度、胎温和胎压等6类轮胎传感器数据(约
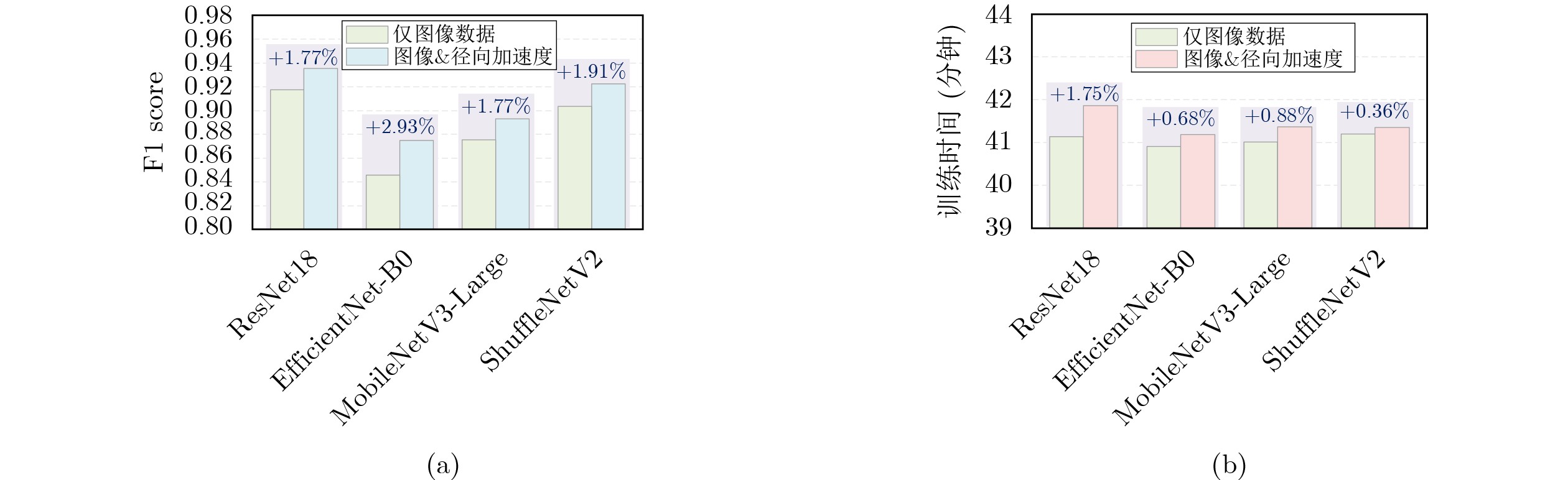
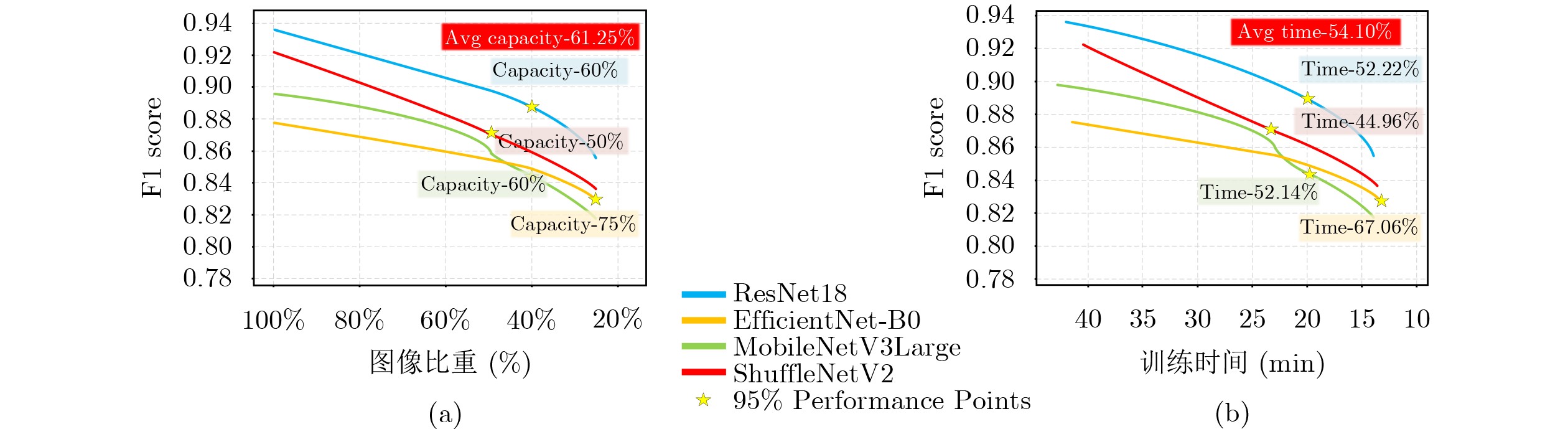
1 550 万字节,超过180万个传感器采样点),并同时获取309 GB的交通场景图像数据(涵盖水泥、沥青、破损与积水4类典型路面)。通过对轮胎传感器数据与交通场景图像数据进行统一时间标记与跨模态关联,构建了具有场景一致性的多模态交通场景感知数据集TTSPD。进一步,为验证数据集的合理性和有效性,该文将TTSPD数据集应用于路面分类任务。实验结果表明,主流路面分类算法在该数据集上能够实现较高的分类精度(精度范围87.25%~93.75%)。同时,融合轮胎传感器数据(低维度)使模型在仅使用约38.75%原始数据量的情况下即可达到全量数据95%的分类精度,显著降低对高维度图像数据的依赖,减少了数据存储压力(存储规模下降约61.25%)、降低了计算资源开销,缩短了整体训练时间(缩短约54.10%)。该数据集为构建车规级算力约束下多模态环境感知与智能决策系统提供了新的数据形态,为我国智能交通技术的自主创新与可持续发展提供了助力。Abstract:Objective With the rapid development of Intelligent Transportation Systems (ITS) and autonomous driving technologies, accurate traffic environment perception is a fundamental prerequisite for vehicle safety and decision making. Current perception frameworks primarily rely on high-resolution cameras and LiDAR sensors. Although these sensors provide rich information, they create severe challenges across the Perception-Storage-Calculation pipeline. High acquisition costs limit large-scale deployment. In addition, the massive data volume produced by high-dimensional sensors places heavy pressure on onboard storage and computational resources, often exceeding the power and thermal budgets of vehicle-grade edge platforms. These constraints motivate the exploration of alternative sensing paradigms that are cost-effective, compact, and computationally efficient while maintaining reliable perception accuracy. In response, the present study shifts the perception perspective from conventional external sensors to the tire-road contact interface, where abundant physical interaction information naturally exists. The objective is to construct a novel multimodal dataset, termed the Tire-integrated Traffic Scene Perception Dataset (TTSPD), which combines internal tire dynamics with external visual observations. This dataset is used to examine whether low-dimensional tire sensing data can complement or partially substitute high-dimensional visual data for accurate road surface classification. The study also aims to establish a new data morphology that balances perception performance and system efficiency for future intelligent vehicles. Methods To construct a high-quality and practically usable multimodal dataset, an integrated hardware-software acquisition framework is developed. From a hardware perspective, a specialized sensing system is designed by coupling tire-mounted multi-parameter sensors with a vehicle-mounted camera. To ensure reliable operation under the harsh mechanical conditions of a rotating tire, sensing nodes are encapsulated using a rubber-based composite material that provides mechanical protection and long-term stability. Wireless transmission is implemented using Bluetooth Low Energy (BLE) 5.0 with an adaptive frequency-hopping mechanism, enabling low-power and reliable communication during high-speed rotation. During data acquisition, the system synchronously collects six types of internal tire signals, including radial acceleration, tire temperature, and tire pressure, producing approximately 1.8 million sampling points. In parallel, a dashboard-mounted camera records high-resolution traffic scene images totaling 309 GB across four representative road surface conditions. To address the heterogeneity between high-frequency one-dimensional tire signals and two-dimensional visual data, a timestamp-based association strategy is adopted to achieve scene-level temporal alignment rather than strict frame-by-frame correspondence. Sensor sequences and image segments are grouped according to shared temporal windows and driving scenarios. This approach ensures semantic and temporal consistency at the scene level. The alignment strategy reflects practical deployment conditions and forms the basis of the final TTSPD dataset for multimodal fusion research. Results and Discussions The effectiveness of the proposed TTSPD is evaluated through comprehensive road surface classification experiments using mainstream deep learning models. Initial experiments based solely on visual data demonstrate strong baseline performance, with classification accuracies ranging from 87.25% to 93.75% ( Table 7 ). These results confirm the quality and diversity of the visual modality in the dataset. The primary contribution of this study is the quantification of efficiency gains enabled by tire-based sensing. Comparative experiments progressively reduce the amount of visual data while integrating low-dimensional tire signals, particularly radial acceleration (Table 9 ). The results show that the multimodal model achieves approximately 95% of the full-data baseline accuracy while using only about 38.75% of the original data volume. This reduction in data dependency produces significant system-level benefits. Storage requirements decrease by approximately 61.25%, and overall model training time decreases by about 54.10% (Fig. 8 ). These findings indicate that tire dynamics encode high-value physical features related to road texture and surface conditions that complement visual cues. The proposed dataset therefore supports the development of lighter perception pipelines without reducing recognition performance.Conclusions This study addresses the long-standing Perception-Storage-Calculation bottleneck in vision-dominated autonomous driving systems by proposing the TTSPD. Multi-parameter sensors are embedded within tires using rubber-based encapsulation, and stable wireless communication is achieved through BLE 5.0. A robust tire-camera data acquisition system is therefore established. The resulting dataset covers four common and safety-critical road surface types: cement, asphalt, damaged, and water-covered roads. It provides a comprehensive foundation for multimodal perception research. Experimental results show that combining low-dimensional tire sensing data with visual information significantly improves perception efficiency. Approximately 95% of peak classification accuracy is achieved using only about 38.75% of the original data volume. This result effectively reduces storage pressure and computational cost, reflected in a 61.25% reduction in data storage and a 54.10% reduction in training time. The TTSPD dataset therefore proposes a practical data morphology that supports efficient and high-performance perception under vehicle-grade computational constraints. It also provides valuable resources for the future development of ITS. -
表 1 主流交通场景感知数据集对比
数据集 传感器配置 数据类型 样本规模 样本覆盖度 存储I/O负载 nuScenes[18] 相机+雷达+LiDAR 图像+点云+雷达 约140万图像,
39万帧雷达城市道路 高(的多模态并行读取) WOD[19] 相机+LiDAR 图像+稠密点云 1 150个场景,千万级帧数 高速、城市、郊区多类型道路 极高(大规模点云流) FCDD[20] 单目前视相机 RGB图像 500张图像 海岸城市道路、行人密集区域 极低 RSCD[21–23] 单目相机 路面图像 约100万张图像 多种路面材质 低 RDD[24,25] 相机 道路缺陷图像 约4.7万张图像 多国家、多路面类型缺陷 低 Cityscapes[26] 车载相机 高分辨率图像 约2.5万张图像 欧洲城市街景 中(高分辨率) TTSPD
(本文数据集)摄像头、
轮胎专用传感器路面图像+轮胎传感数据 约6万张图像,
180万余传感器采样点高速、城市道路 低  下载: 导出CSV
下载: 导出CSV
1 完整流程及分工
流程起始:车载数据采集与处理
流程结果:多模态交通场景感知数据集Begin
步骤 1: (人员A)完成采集前准备工作,包括车载摄像头状态确认、蓝牙模块供电与连接检查,并对车胎内多参数传感器进行零点校准与量程确认;步骤 2: (人员A)启动车辆并验证实验路线;同时检查车载摄像头的显示屏清晰度及指示灯状态,确保采集区域覆盖完整;
步骤 3: (自动化)中央控制单元发送同步指令,触发所有传感器按照设定周期采
集视频数据与轮胎状态数据,实现多模态同步采集;
步骤 4: (人员B)实时监控数据流与传输质量,每30 min进行1次中期数据暂存,并对采集完整性进行初步核查;
步骤 5: (人员B)执行数据整理与预处理工作,包括数据清洗、缺失值标记与类型分类,并上传至云端服务器;
步骤 6: (双人协作)核验采集数据的完整性与一致性,归档日志并配置下一阶段采集参数。
End
下载: 导出CSV
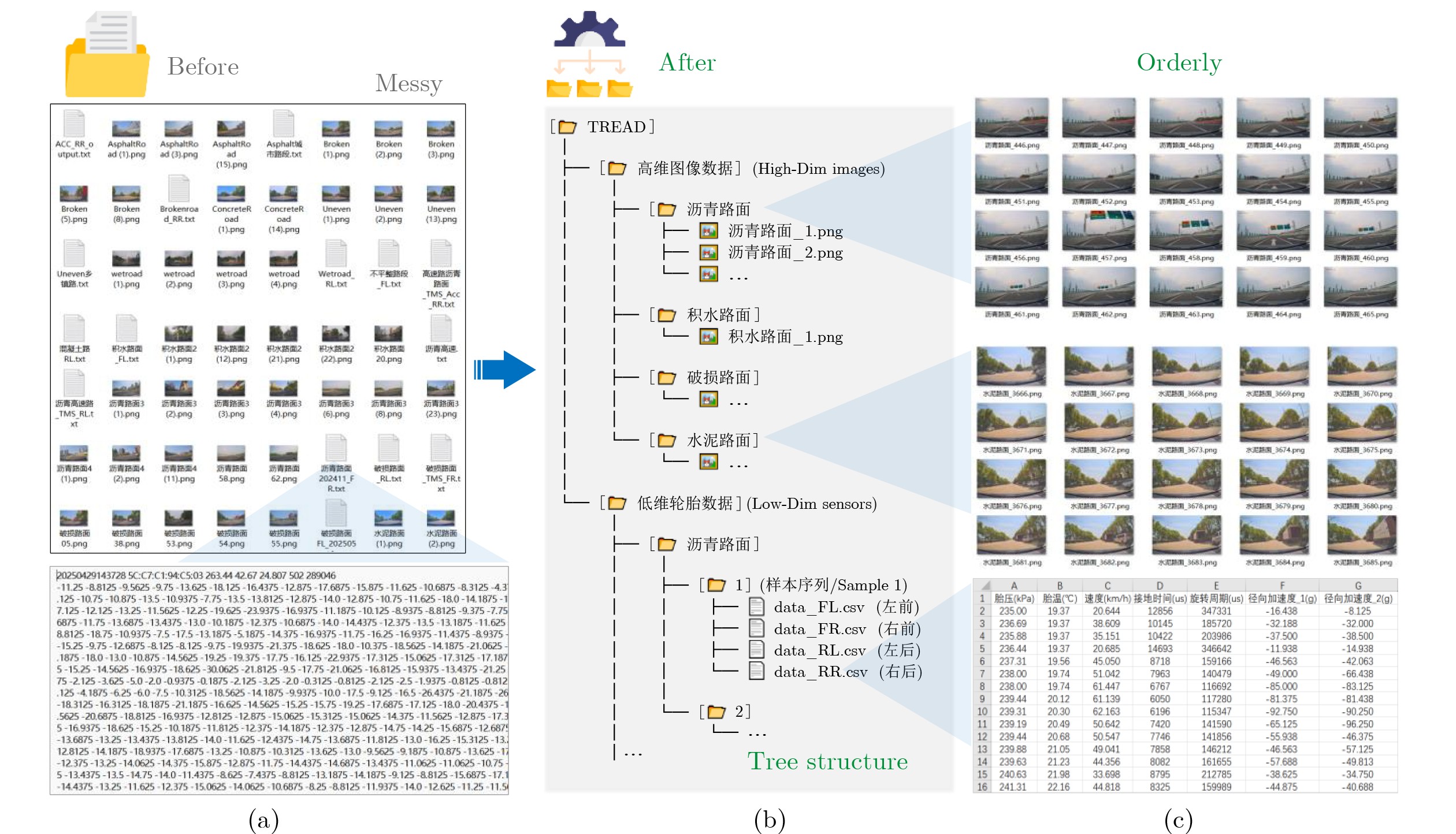
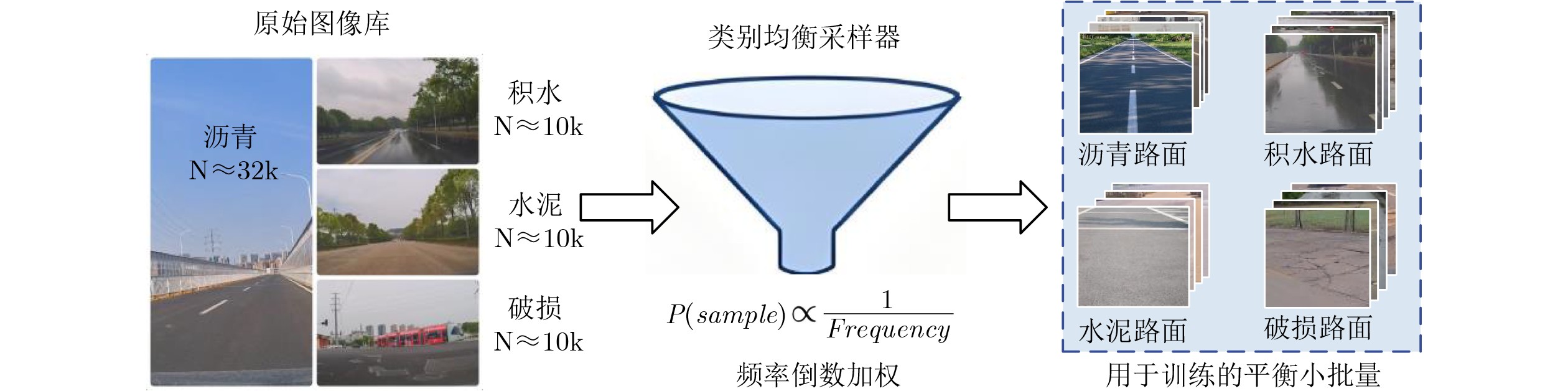
表 2 TTSPD中数据分布情况
类别ID 交通场景图像数据帧数 轮胎传感器数据 路面类型 A 10 280 302 143 积水路面 B 10 003 326 536 破损路面 C 9 816 318 397 水泥路面 D 32 230 935 670 沥青路面
下载: 导出CSV
表 3 数据集字段介绍
字段顺序 字段名称 数据类型 示例值 1 胎压(kPa) 浮点数 257.19 2 胎温(℃) 浮点数 22.91 3 车速(km/h) 浮点数 57.48 4 接地时间(μs) 整数 7184 5 旋转周期(μs) 整数 151111 6 径向加速度_1~径向加速度_N(g) 浮点数 – 12.8125
下载: 导出CSV
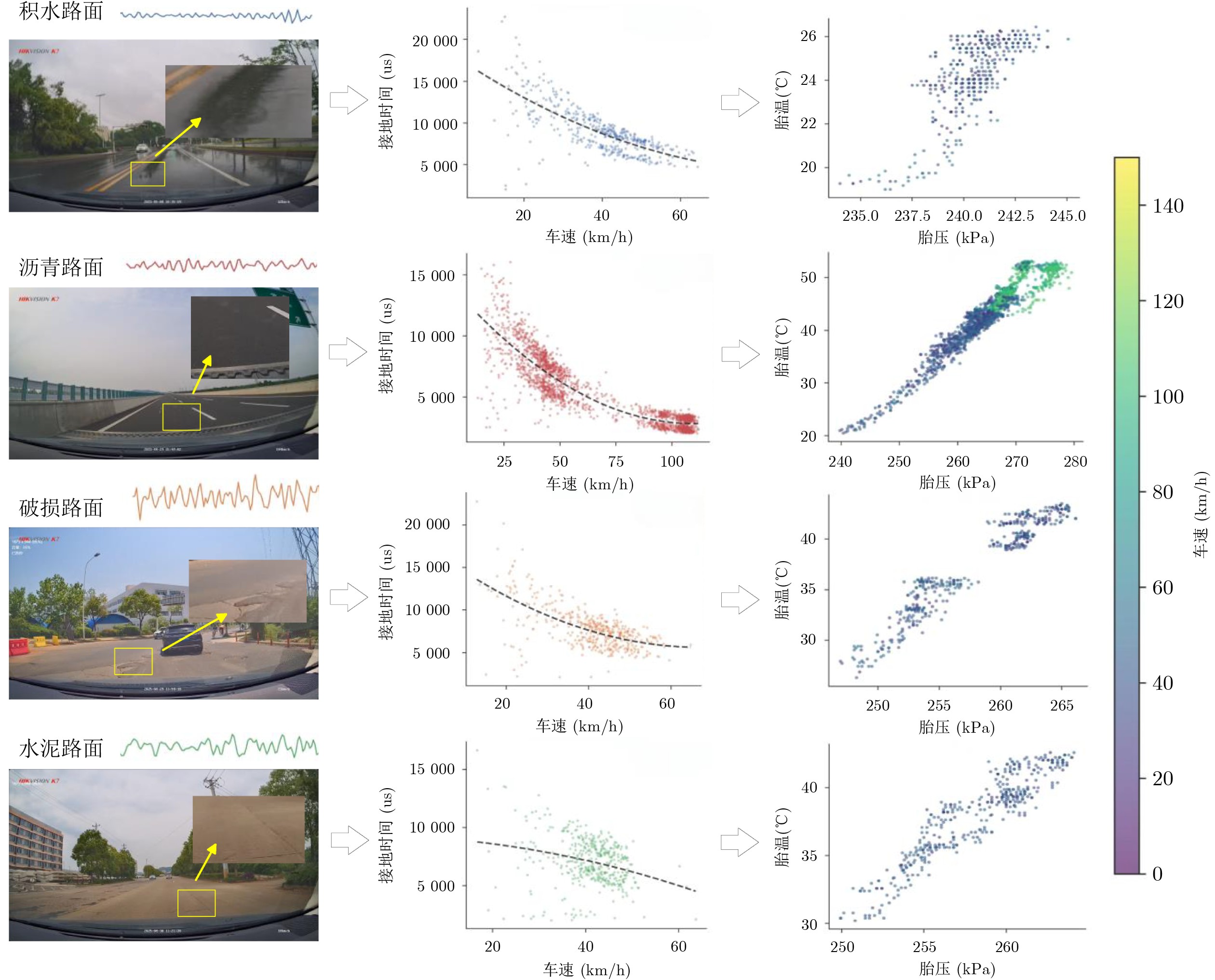
表 4 轮胎感知特征的物理含义及应用场景
参数名 物理机制 潜在适用领域 轮胎径向加速度 路面激励下的轮胎结构振动特性 路面分类;粗糙度评估;异常路面检测 车速与旋转周期 接触激励的时空尺度映射 振动信号尺度校正;跨车速路面识别 轮胎接地时间 接触斑长度与等效刚度表征 路面分类;轮胎载荷估计 胎压与胎温 轮胎结构与摩擦状态调制 摩擦系数估计;轮胎健康监测
下载: 导出CSV
表 5 4类主流模型架构参数设置
关键参数 主流路面分类模型 ResNet18[40] EfficientNet-B0[41] MobileNetV3-Large[42] ShuffleNetV2[43] 输出类别数 4 4 4 4 学习率 5e–5 5e-5 5e–5 5e–5 权重衰减 1e–4 1e–4 1e–4 5e–4 批次大小 64 64 64 64 损失函数 CrossEntropyLoss CrossEntropyLoss CrossEntropyLoss CrossEntropyLoss 优化器 AdamW AdamW AdamW AdamW 中间层维度 576→256 1344 →2561024 →2561088 →256注:模型采用迁移学习策略[44],使用在ImageNet数据集[45]上预训练的权重进行初始化。
下载: 导出CSV
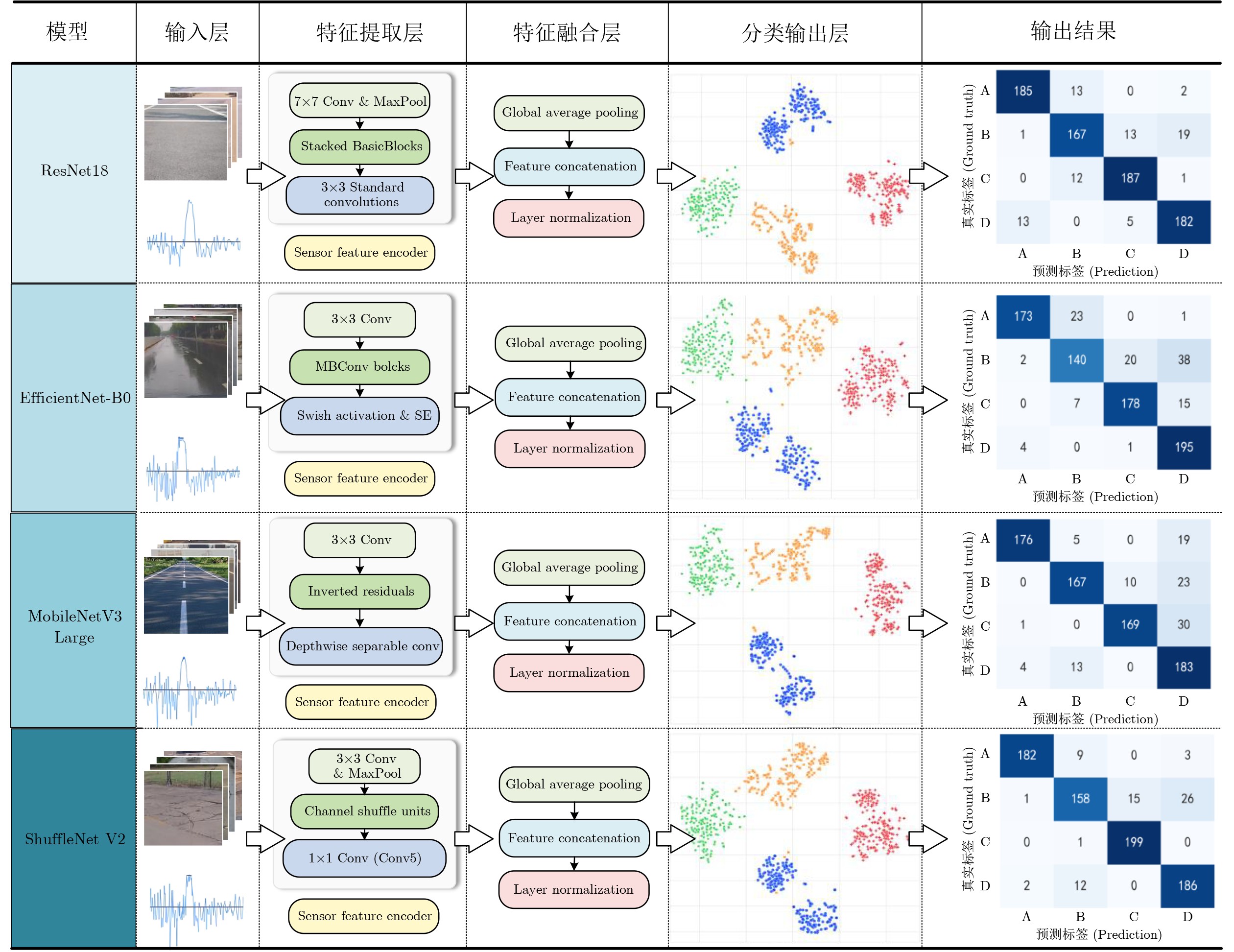
表 6 4种主流模型性能对比(输入:图像数据)
模型 精确率
(%)召回率
(%)F1-score
(%)准确率
(%)耗时
(min)ResNet18 93.43 92.13 91.75 92.13 41.14 EfficientNet-B0 89.71 86.13 84.58 86.12 40.91 MobileNetV3-Large 91.15 88.50 87.54 88.50 41.01 ShuffleNetV2 92.46 90.88 90.35 90.88 41.20
下载: 导出CSV
表 7 4种主流模型性能对比(输入:图像数据+径向加速度数据)
模型 精确率(%) 召回率(%) F1-score
(%)准确率(%) 耗时(min) ResNet18 94.54 93.75 93.52 93.75 41.86 EfficientNet-B0 91.04 88.50 87.51 88.50 41.19 MobileNetV3-Large 92.00 90.00 89.31 90.00 41.37 ShuffleNetV2 93.63 92.63 92.26 92.63 41.35
下载: 导出CSV
表 8 不同图像输入比例下模型性能对比
模型 图像比重(%) 精确率(%) 召回率(%) F1-score
(%)准确率(%) 耗时
(min)ResNet18 100
(基准)94.54 93.75 93.52 93.75 41.86 50 92.28 90.38 89.84 90.38 23.07 40 91.44 89.50 88.86 89.50 20.00 25 89.37 86.50 85.50 86.50 13.73 EfficientNet-B0 100 91.04 88.50 87.51 88.50 41.19 50 89.24 86.75 85.45 86.75 22.55 40 88.90 85.88 84.42 85.88 19.87 25 88.50 84.88 83.05 84.88 13.57 MobileNetV3-Large 100 92.00 90.00 89.31 90.00 41.37 50 90.54 87.25 86.03 87.25 23.02 40 88.90 85.88 84.42 85.88 19.80 25 89.01 84.00 81.75 84.00 13.80 ShuffleNetV2 100 93.63 92.63 92.26 92.63 41.35 50 91.19 88.00 87.04 88.00 22.76 40 91.18 87.00 85.75 87.00 19.93 25 88.88 85.25 83.70 85.25 13.58
下载: 导出CSV
表 9 纯图像模型与多模态模型再数据依赖性与训练耗时上关键节点对比
模型 输入模态 图像数据量(%) 准确率(%) F1-score
(%)耗时(min) ResNet18 纯图像 90 85.46 86.99 37.43 多模态 40 89.50 88.86 20.00 EfficientNet-B0 纯图像 85 79.38 79.85 35.81 多模态 25 84.88 83.05 13.57 MobileNetV3-Large 纯图像 85 81.63 82.07 36.13 多模态 40 85.88 84.42 19.80 ShuffleNetV2 纯图像 92 84.21 85.36 38.13 多模态 50 88.00 87.04 22.76 注:关键节点选择为F值性能保留率约为95%时的实验结果
下载: 导出CSV
-
[1] QIAN Hui, WANG Mingchen, ZHU Maotao, et al. A review of multi-sensor fusion in autonomous driving[J]. Sensors, 2025, 25(19): 6033. doi: 10.3390/s25196033. [2] 党宏社, 肖利霞, 张选德. 不良光照场景下的交通标志识别算法[J]. 半导体光电, 2025, 46(1): 142–148. doi: 10.16818/j.issn1001-5868.20240924001.DANG Hongshe, XIAO Lixia, and ZHANG Xuande. Traffic sign recognition algorithm under adverse lighting conditions[J]. Semiconductor Optoelectronics, 2025, 46(1): 142–148. doi: 10.16818/j.issn1001-5868.20240924001. [3] YAO Shanliang, GUAN Runwei, HUANG Xiaoyu, et al. Radar-camera fusion for object detection and semantic segmentation in autonomous driving: A comprehensive review[J]. IEEE Transactions on Intelligent Vehicles, 2024, 9(1): 2094–2128. doi: 10.1109/TIV.2023.3307157. [4] 李奕, 张明, 段文瑞, 等. 光学参数计量评估在道路交通场景中的应用及研究进展(特邀)[J]. 光子学报, 2025, 54(11): 1154304. doi: 10.3788/gzxb20255411.1154304.LI Yi, ZHANG Ming, DUAN Wenrui, et al. Application and research progress of optical parameter metrology and evaluation in traffic scenarios (invited)[J]. Acta Photonica Sinica, 2025, 54(11): 1154304. doi: 10.3788/gzxb20255411.1154304. [5] 曲立国, 张鑫, 卢自宝, 等. 基于改进YOLOv5的交通标志识别方法[J]. 光电工程, 2024, 51(6): 240055. doi: 10.12086/oee.2024.240055.QU Liguo, ZHANG Xin, LU Zibao, et al. A traffic sign recognition method based on improved YOLOv5[J]. Opto-Electronic Engineering, 2024, 51(6): 240055. doi: 10.12086/oee.2024.240055. [6] DONG Zhekang, GU Shenyu, ZHOU Shiqi, et al. Periodic segmentation transformer-based internal short circuit detection method for battery packs[J]. IEEE Transactions on Transportation Electrification, 2025, 11(1): 3655–3666. doi: 10.1109/TTE.2024.3444453. [7] WANG Yan, YIN Guodong, HANG Peng, et al. Fundamental estimation for tire road friction coefficient: A model-based learning framework[J]. IEEE Transactions on Vehicular Technology, 2025, 74(1): 481–493. doi: 10.1109/TVT.2024.3464524. [8] GU Tianli, LI Bo, QUAN Zhenqiang, et al. A novel estimation method for tire-road friction coefficient using intelligent tire and tire dynamics[J]. Mechanical Systems and Signal Processing, 2025, 235: 112872. doi: 10.1016/j.ymssp.2025.112872. [9] TAO Siyou, JU Zhiyang, LI Liang, et al. Tire road friction coefficient estimation for individual wheel based on two robust PMI observers and a multilayer perceptron[J]. IEEE Transactions on Vehicular Technology, 2024, 73(9): 12530–12541. doi: 10.1109/TVT.2024.3390032. [10] JI Xiaoyue, HAN Yifeng, LAI C S, et al. ViP-HMNN: A visual pathway-inspired hybrid neural network incorporated with in-memory computing for object recognition[J]. Information Fusion, 2026, 130: 104086. doi: 10.1016/j.inffus.2025.104086. [11] KIM S, KIM Y J, LEE D, et al. Robust road surface classification using time series augmented intelligent tire sensor data and 1-D CNN[J]. IEEE Access, 2025, 13: 76508–76515. doi: 10.1109/ACCESS.2025.3565656. [12] HAN Zongzhi, LIU Weidong, GAO Zhenhai, et al. A method for real-time road surface identification of intelligent tire systems based on random convolutional kernel neural network[J]. IEEE Transactions on Intelligent Vehicles, 2024, 9(10): 6487–6501. doi: 10.1109/TIV.2024.3369951. [13] KARKARIA V, CHEN Jie, LUEY C, et al. A digital twin framework utilizing machine learning for robust predictive maintenance: Enhancing tire health monitoring[J]. Journal of Computing and Information Science in Engineering, 2025, 25(7): 071003. doi: 10.1115/1.4067270. [14] YANG Yiting, XIAO Yao, TAN Yingqi, et al. Multimodal sensor fusion for road surface identification considering vehicle dynamic characteristics[C]. 2025 IEEE Intelligent Vehicles Symposium (IV), Cluj-Napoca, Romania, 2025: 1825–1832. doi: 10.1109/IV64158.2025.11097345. [15] YOON Y, KIM H, LEE S K, et al. Tire–road friction estimation and classification based on a CNN using tire acoustical signals for autonomous driving vehicles[R]. SAE Technical Paper 2025-01-8761, 2025. doi: 10.4271/2025-01-8761. [16] DONG Zhekang, ZHU Liyan, ZHOU Shiqi, et al. FE-SpikeFormer: A camera-based facial expression recognition method for hospital health monitoring[J]. IEEE Journal of Biomedical and Health Informatics, 2025: 1–11. doi: 10.1109/JBHI.2025.3589267. [17] 杨宇翔, 曹旗, 高明煜, 等. 基于多阶段多尺度彩色图像引导的道路场景深度图像补全[J]. 电子与信息学报, 2022, 44(11): 3951–3959. doi: 10.11999/JEIT210967.YANG Yuxiang, CAO Qi, GAO Mingyu, et al. Multi-stage multi-scale color guided depth image completion for road scenes[J]. Journal of Electronics & Information Technology, 2022, 44(11): 3951–3959. doi: 10.11999/JEIT210967. [18] CAESAR H, BANKITI V, LANG A H, et al. nuScenes: A multimodal dataset for autonomous driving[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11618–11628. doi: 10.1109/CVPR42600.2020.01164. [19] SUN Pei, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo open dataset[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 2443–2451. doi: 10.1109/CVPR42600.2020.00252. [20] DE S. TOLEDO R, DE OLIVEIRA C S, ANDALÓ F, et al. FCDD: A high-resolution unstructured environment dataset with multiple sand roads[J]. IEEE Access, 2025, 13: 191531–191542. doi: 10.1109/ACCESS.2025.3630348. [21] ZHAO Tong, HE Junxiang, LV Jingcheng, et al. A comprehensive implementation of road surface classification for vehicle driving assistance: Dataset, models, and deployment[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(8): 8361–8370. doi: 10.1109/TITS.2023.3264588. [22] ZHAO Tong, GUO Peilin, and WEI Yintao. Road friction estimation based on vision for safe autonomous driving[J]. Mechanical Systems and Signal Processing, 2024, 208: 111019. doi: 10.1016/j.ymssp.2023.111019. [23] ZHAO Tong. RSCD: Road surface classification dataset with detailed annotations for driving assistance[DB/OL]. IEEE Dataport. https://doi.org/10.21227/446p-xr65, 2022. [24] ARYA D, MAEDA H, GHOSH S K, et al. Deep learning-based road damage detection and classification for multiple countries[J]. Automation in Construction, 2021, 132: 103935. doi: 10.1016/j.autcon.2021.103935. [25] ARYA D, MAEDA H, GHOSH S K, et al. Global road damage detection: State-of-the-art solutions[C]. 2020 IEEE International Conference on Big Data, Atlanta, USA, 2020: 5533–5542. doi: 10.1109/BigData50022.2020.9377790. [26] GÄHLERT N, JOURDAN N, CORDTS M, et al. Cityscapes 3D: Dataset and benchmark for 9 DoF vehicle detection[C]. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2021: 1886–1895. doi: 10.1109/WACV48630.2021.00193. [27] FENG Di, HAASE-SCHUTZ C, ROSENBAUM L, et al. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(3): 1341–1360. doi: 10.1109/TITS.2020.2972974. [28] YEONG D J, VELASCO-HERNANDEZ G, BARRY J, et al. Sensor and sensor fusion technology in autonomous vehicles: A review[J]. Sensors, 2021, 21(6): 2140. doi: 10.3390/s21062140. [29] KUUTTI S, FALLAH S, KATSAROS K, et al. A survey of the state-of-the-art localization techniques and their potentials for autonomous vehicle applications[J]. IEEE Internet of Things Journal, 2018, 5(2): 829–846. doi: 10.1109/JIOT.2018.2812300. [30] HUANG Jiye, CHEN Xinshi, JIN Qingsong, et al. A fusion estimation method for tire-road friction coefficient based on weather and road images[J]. Lubricants, 2025, 13(10): 459. doi: 10.3390/lubricants13100459. [31] QIU Zhimin, SHAO Jinju, GUO Dong, et al. A multi-feature fusion approach for road surface recognition leveraging millimeter-wave radar[J]. Sensors, 2025, 25(12): 3802. doi: 10.3390/s25123802. [32] LIU Shaoshan, LIU Liangkai, TANG Jie, et al. Edge computing for autonomous driving: Opportunities and challenges[J]. Proceedings of the IEEE, 2019, 107(8): 1697–1716. doi: 10.1109/JPROC.2019.2915983. [33] BUDA M, MAKI A, and MAZUROWSKI M A. A systematic study of the class imbalance problem in convolutional neural networks[J]. Neural Networks, 2018, 106: 249–259. doi: 10.1016/j.neunet.2018.07.011. [34] KANG Bingyi, XIE Saining, ROHRBACH M, et al. Decoupling representation and classifier for long-tailed recognition[C]. The 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 2020. [35] DÓZSA T, JURDANA V, ŠEGOTA S B, et al. Road type classification using time-frequency representations of tire sensor signals[J]. IEEE Access, 2024, 12: 53361–53372. doi: 10.1109/ACCESS.2024.3382931. [36] WU Ti, ZHANG Xiaolong, WANG Dong, et al. Comparative study and real-world validation of vertical load estimation techniques for intelligent tire systems[J]. Sensors, 2025, 25(7): 2100. doi: 10.3390/s25072100. [37] THARWAT A. Classification assessment methods[J]. Applied Computing and Informatics, 2021, 17(1): 168–192. doi: 10.1016/j.aci.2018.08.003. [38] 任俊宇, 俞宁宁, 周成伟, 等. DroneRFb-DIR: 用于非合作无人机个体识别的射频信号数据集[J]. 电子与信息学报, 2025, 47(3): 573–581. doi: 10.11999/JEIT240804.REN Junyu, YU Ningning, ZHOU Chengwei, et al. DroneRFb-DIR: An RF signal dataset for non-cooperative drone individual identification[J]. Journal of Electronics & Information Technology, 2025, 47(3): 573–581. doi: 10.11999/JEIT240804. [39] 俞宁宁, 毛盛健, 周成伟, 等. DroneRFa: 用于侦测低空无人机的大规模无人机射频信号数据集[J]. 电子与信息学报, 2024, 46(4): 1147–1156. doi: 10.11999/JEIT230570.YU Ningning, MAO Shengjian, ZHOU Chengwei, et al. DroneRFa: A large-scale dataset of drone radio frequency signals for detecting low-altitude drones[J]. Journal of Electronics & Information Technology, 2024, 46(4): 1147–1156. doi: 10.11999/JEIT230570. [40] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [41] TAN Mingxing and LE Q V. EfficientNet: Rethinking model scaling for convolutional neural networks[C]. The 36th International Conference on Machine Learning, Long Beach, USA, 2019: 6105–6114. [42] HOWARD A, SANDLER M, CHEN Bo, et al. Searching for MobileNetV3[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 1314–1324. doi: 10.1109/ICCV.2019.00140. [43] MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. ShuffleNet V2: Practical guidelines for efficient CNN architecture design[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 122–138. doi: 10.1007/978-3-030-01264-9_8. [44] PAN S J and YANG Qiang. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345–1359. doi: 10.1109/TKDE.2009.191. [45] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: A large-scale hierarchical image database[C]. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248–255. doi: 10.1109/CVPR.2009.5206848. -



图(8) / 表(10)
计量
- 文章访问数: 260
- HTML全文浏览量: 195
- PDF下载量: 53
- 被引次数: 0
 下载:
下载:
