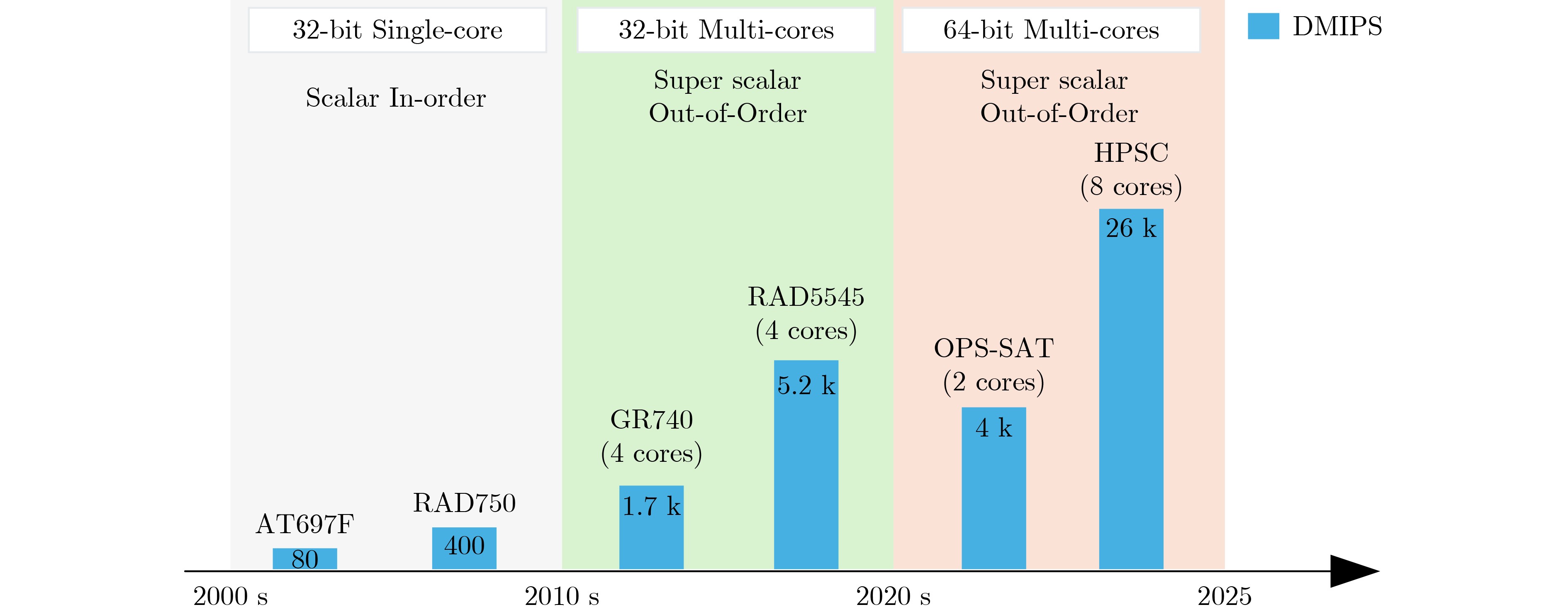
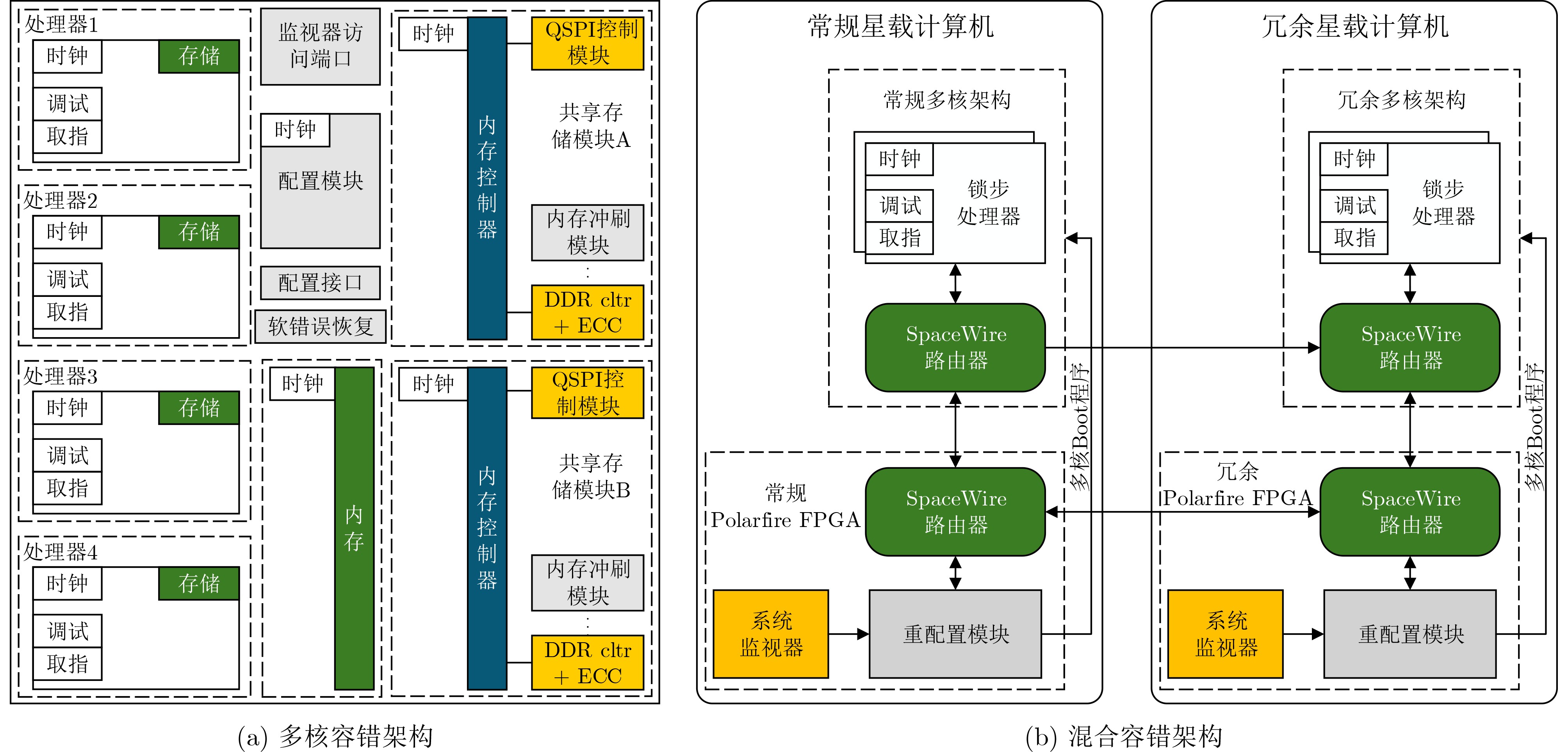
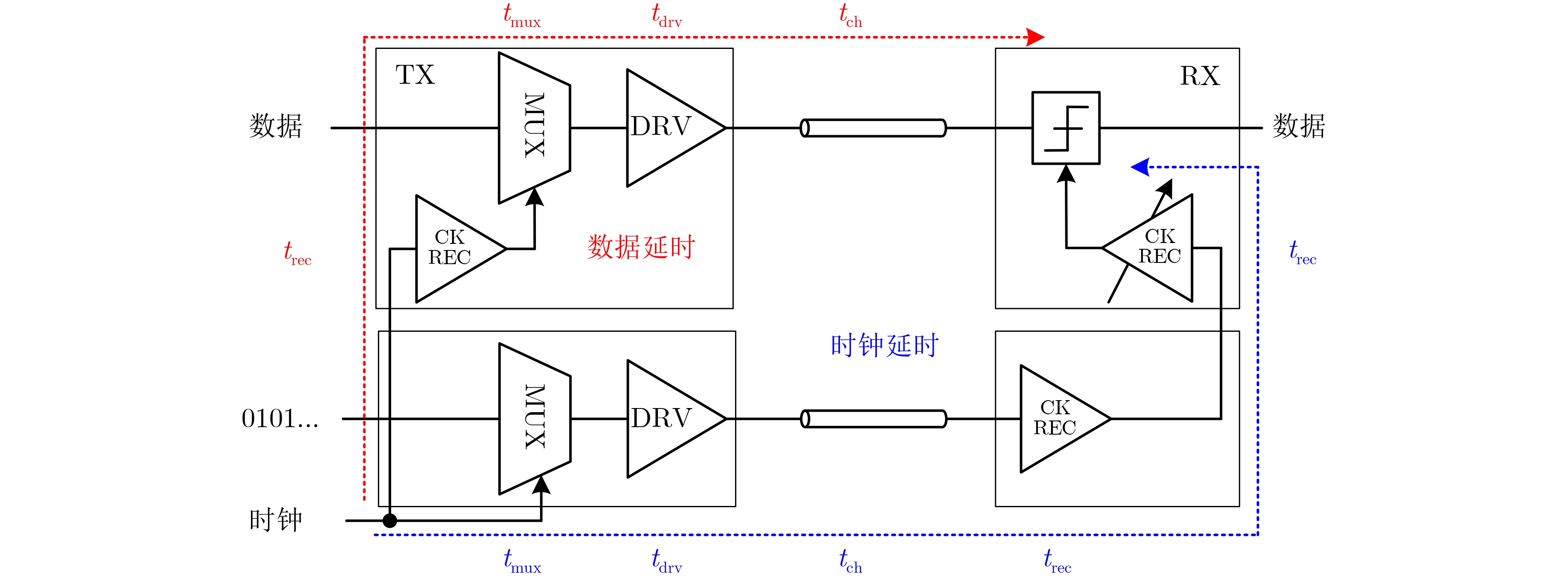
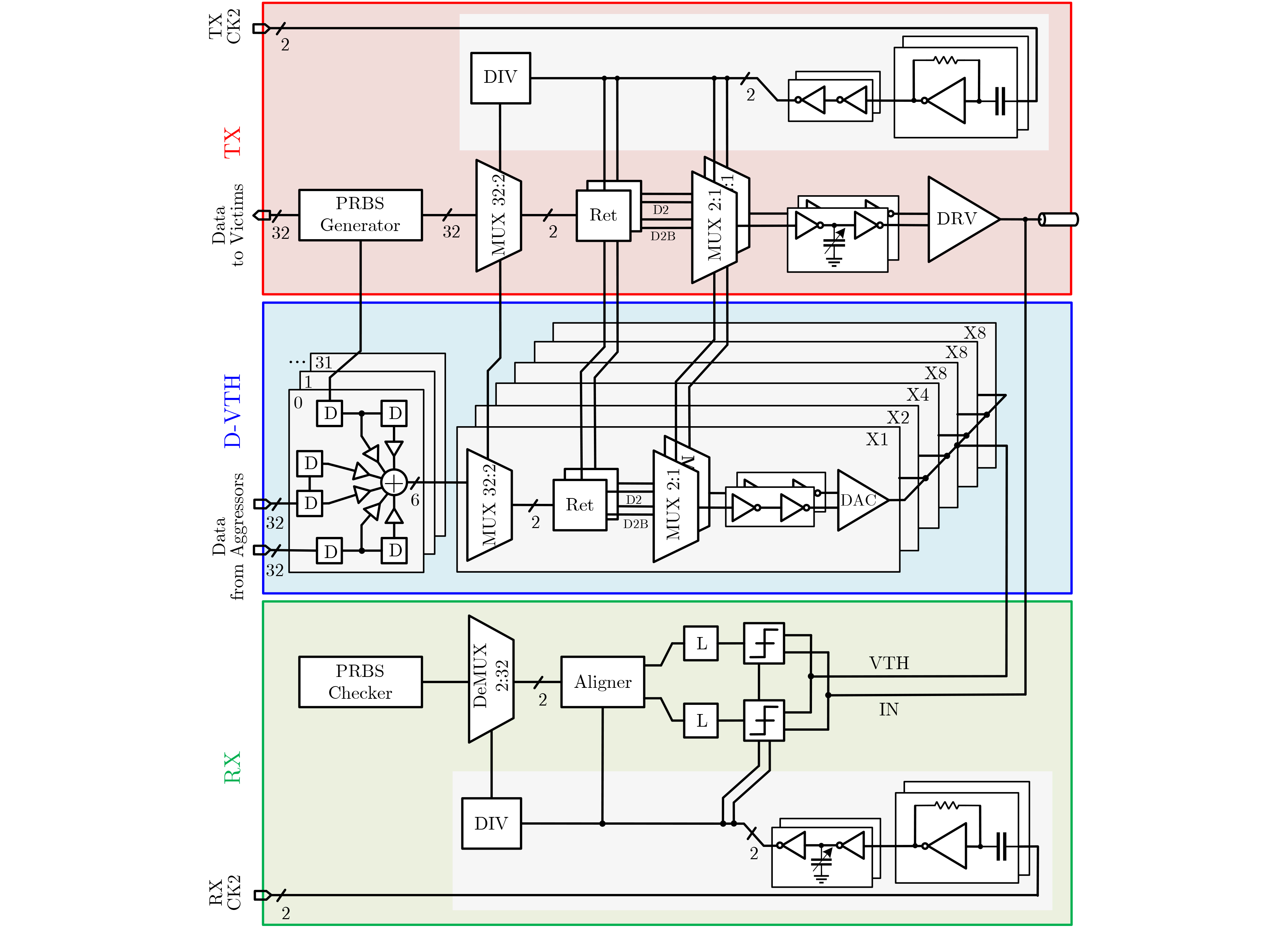
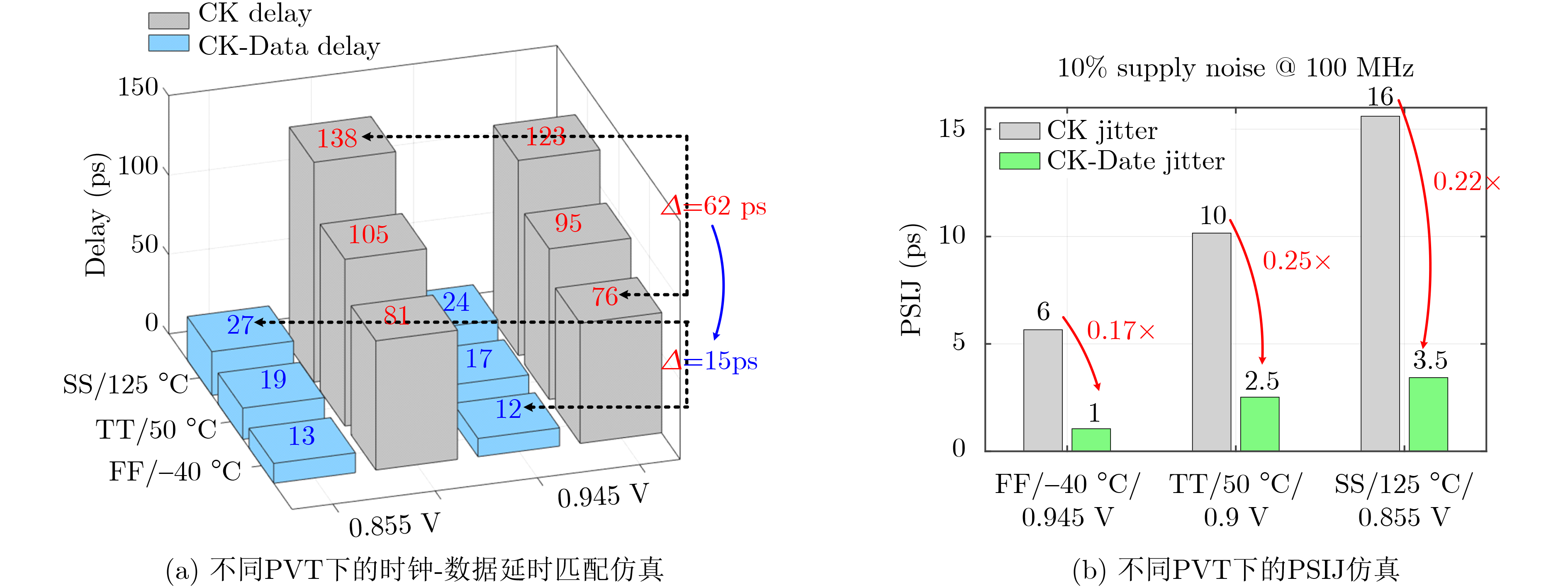
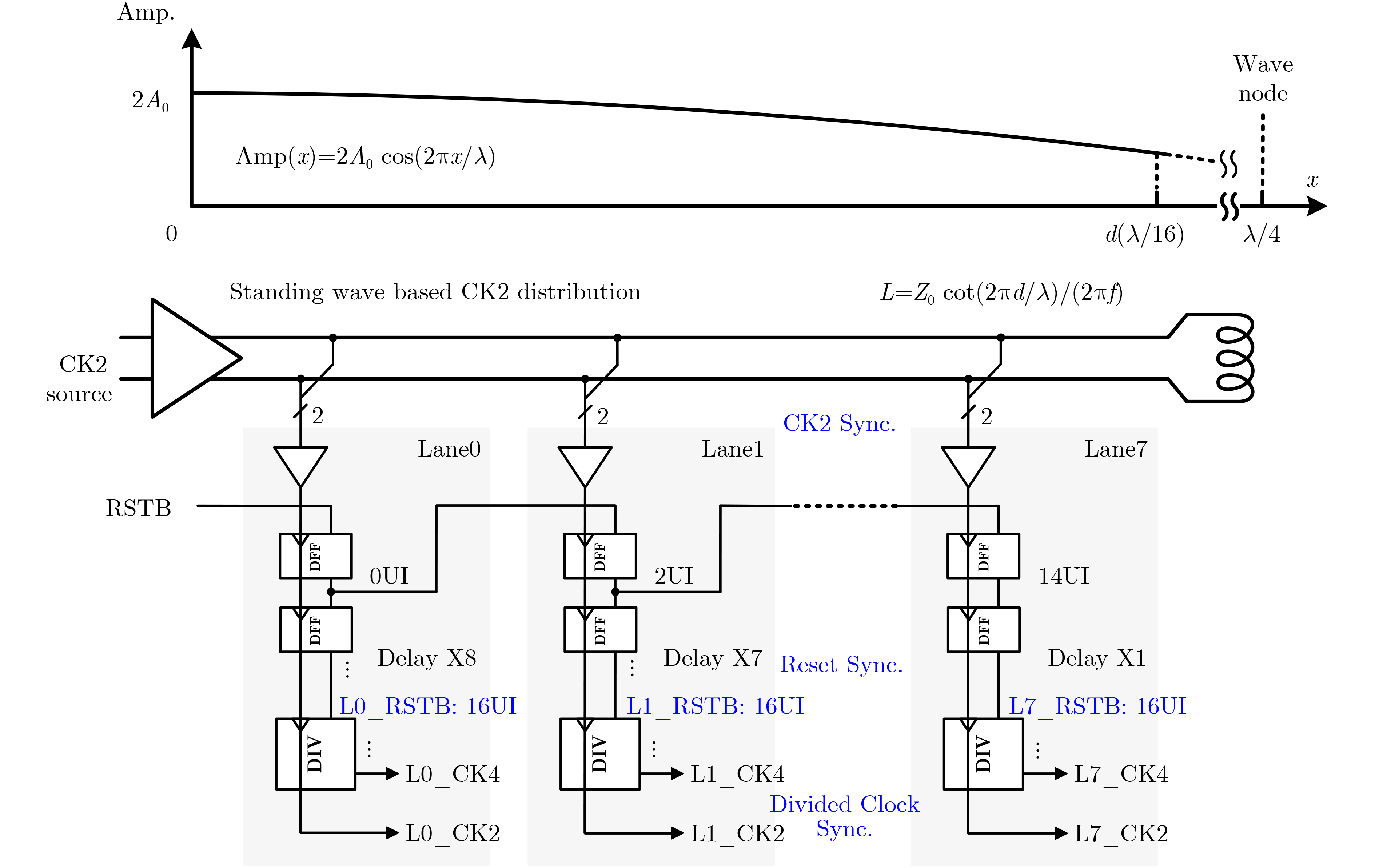
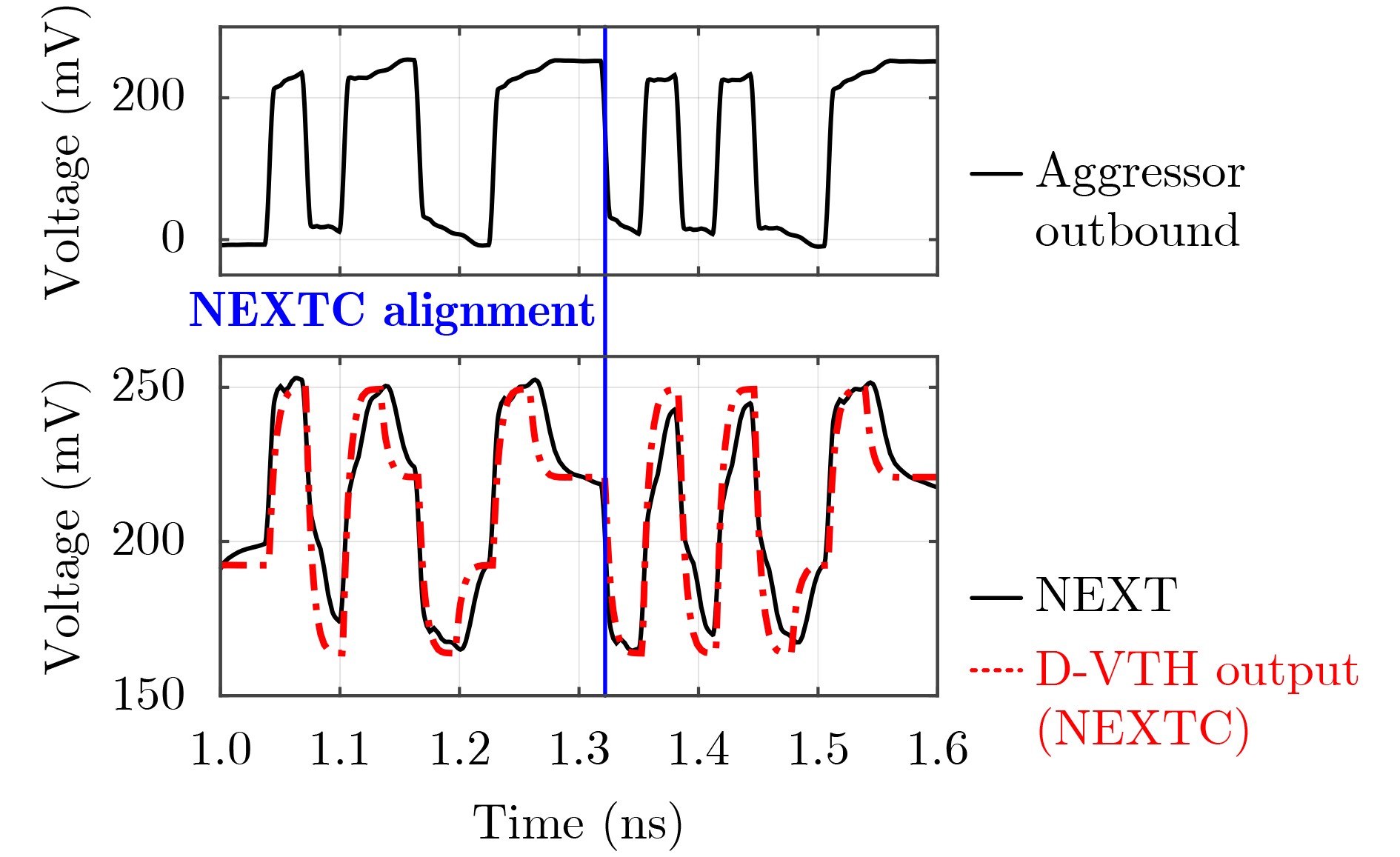
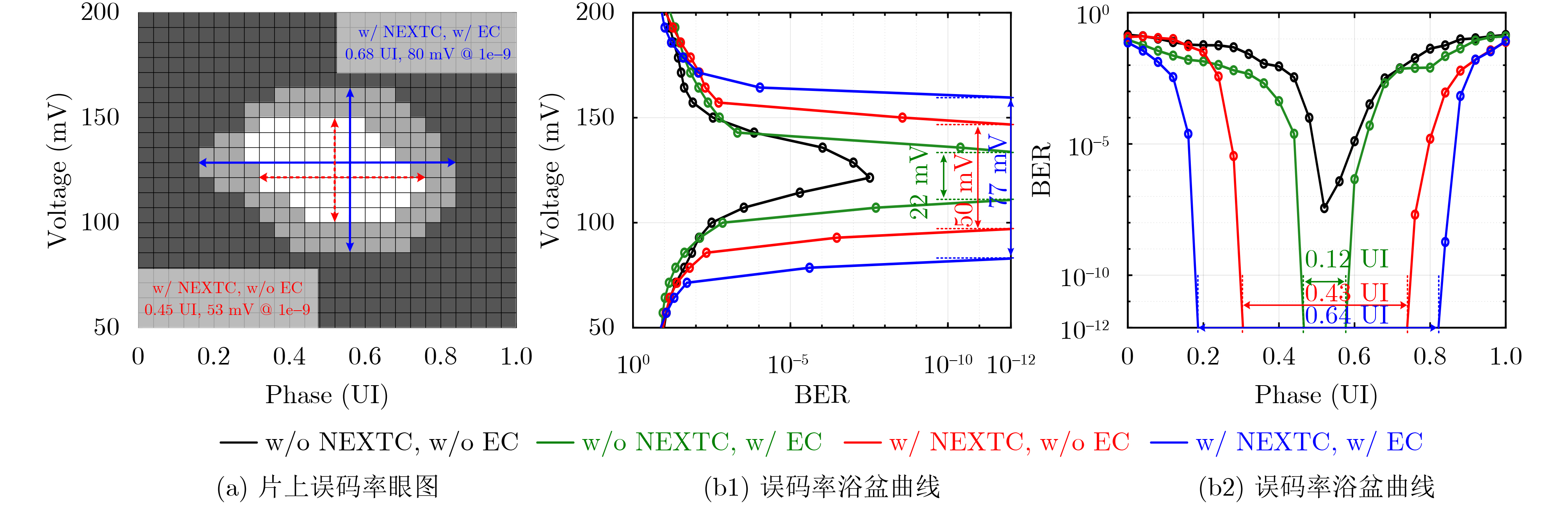
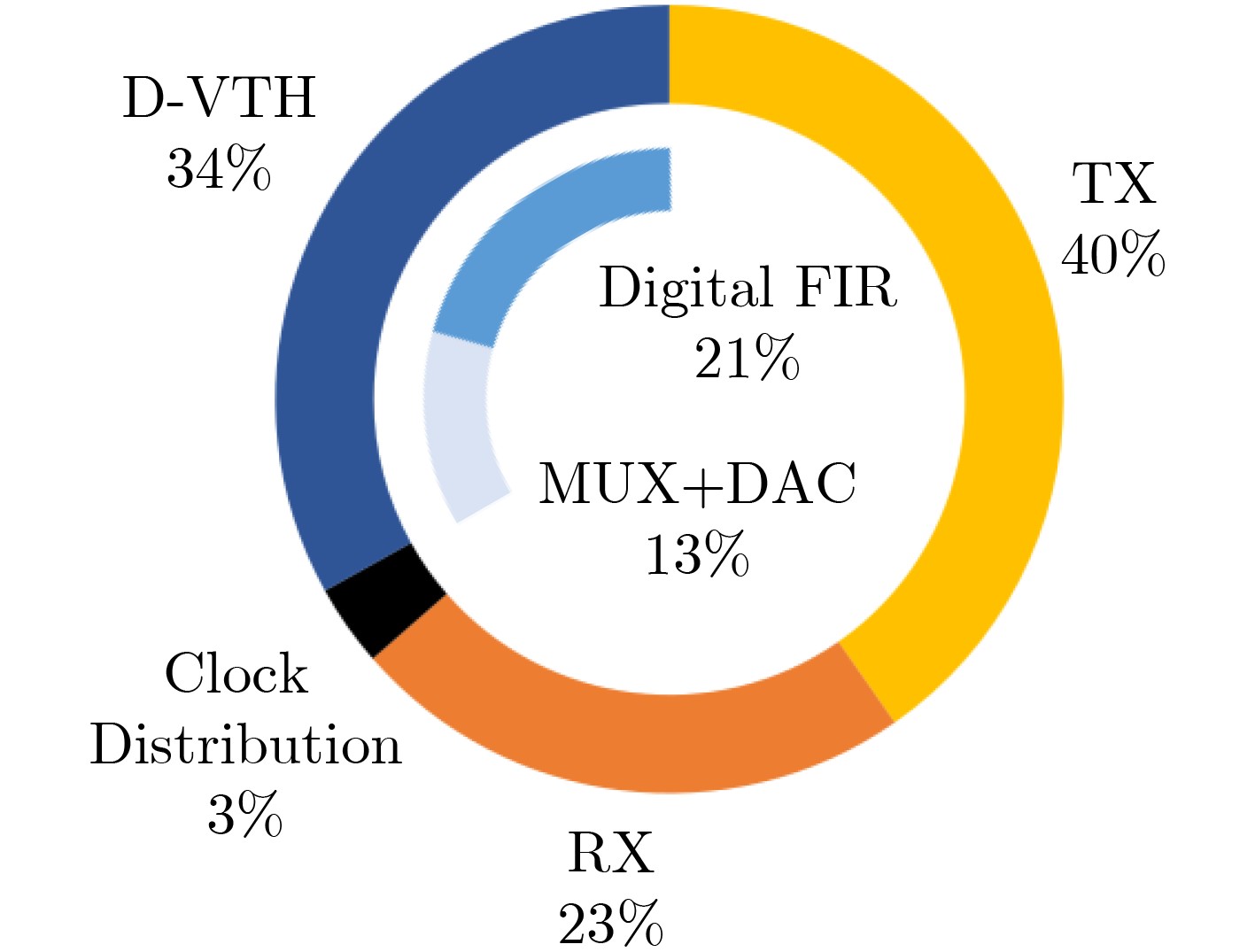
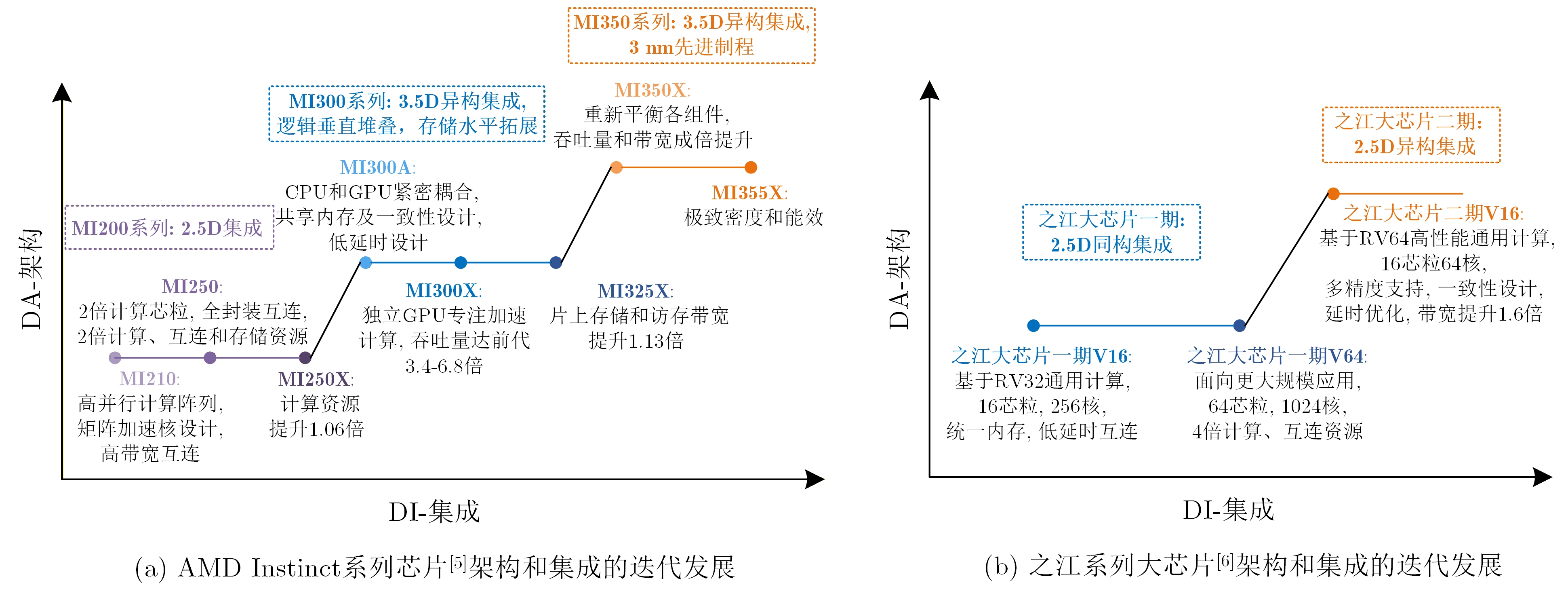
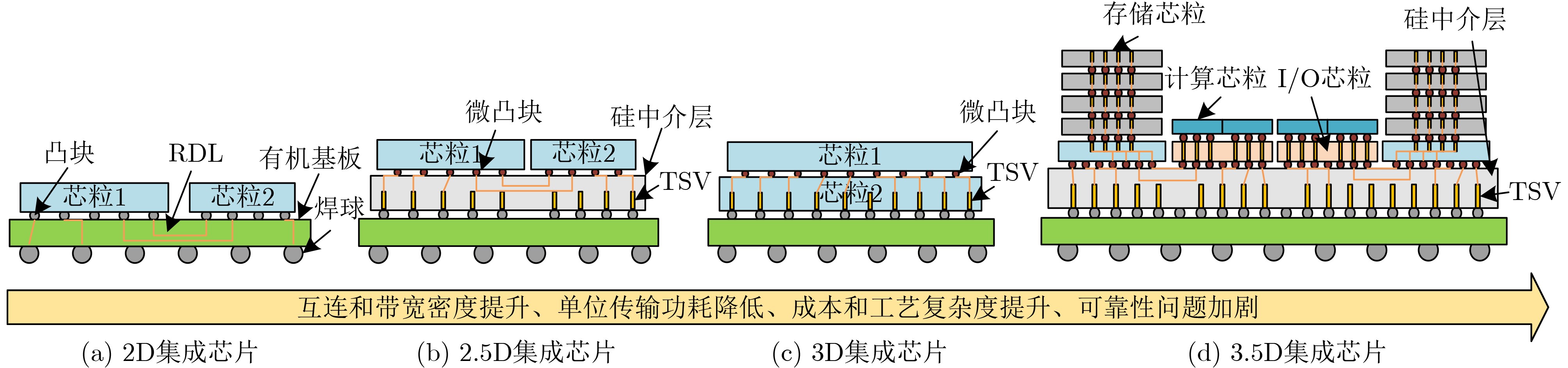
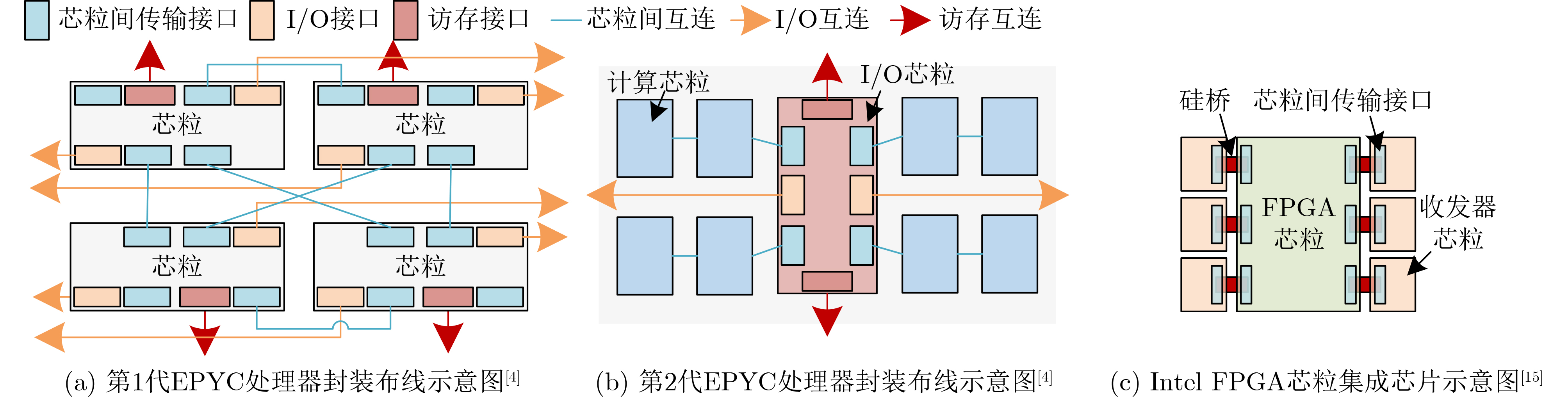
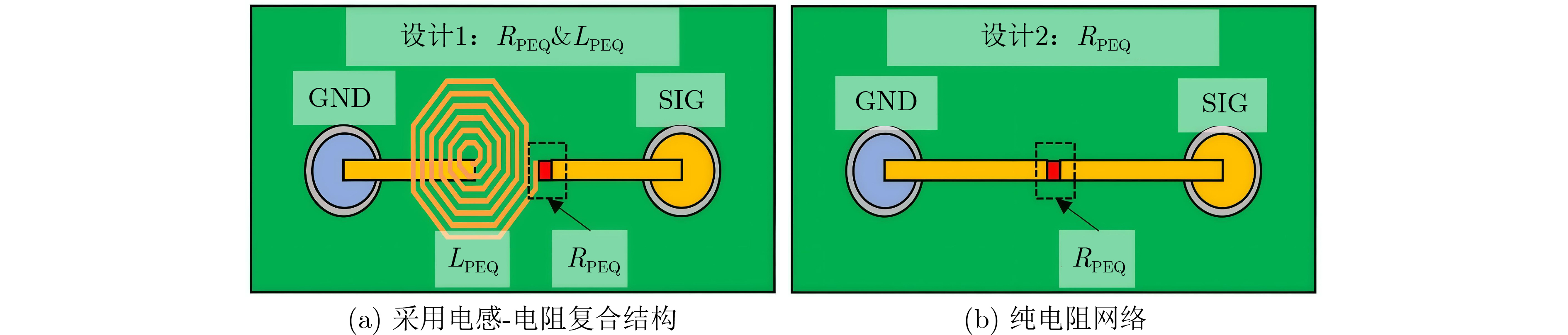
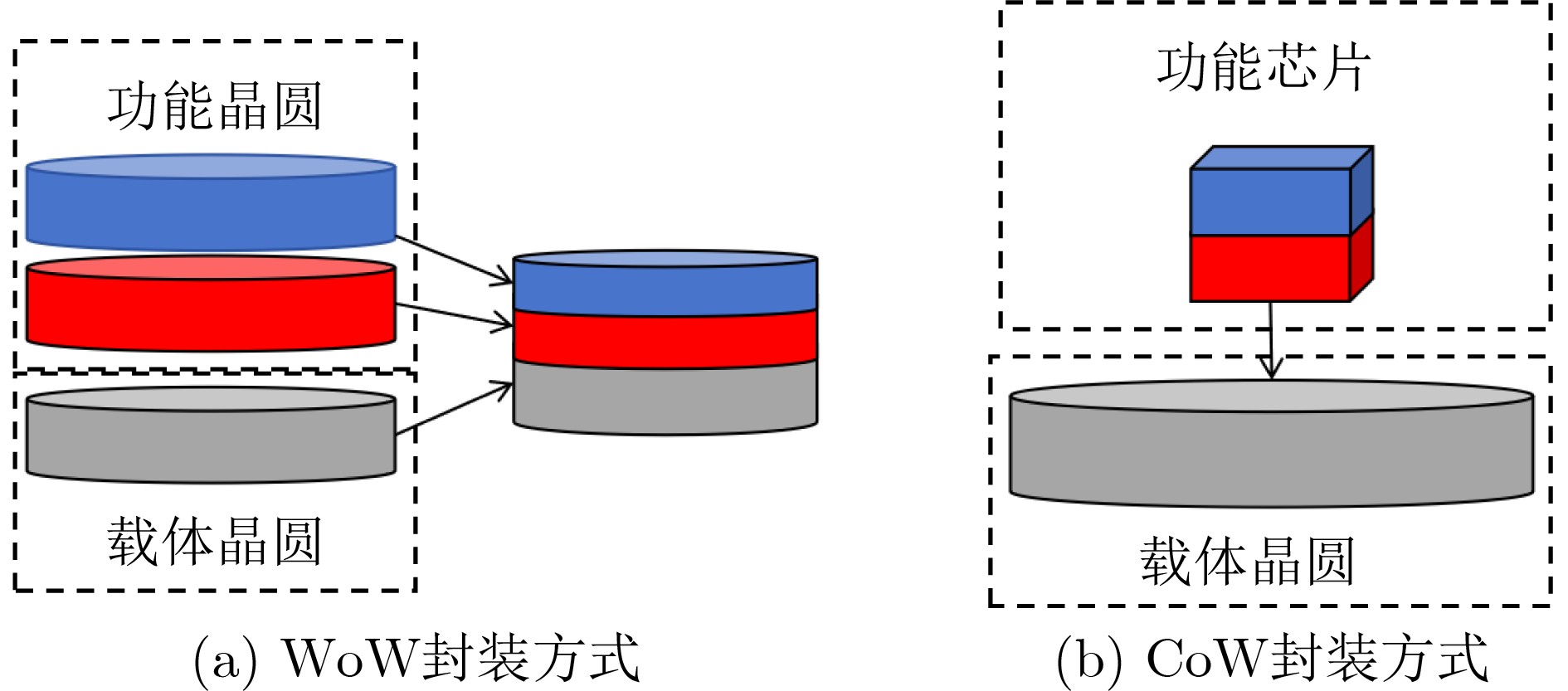
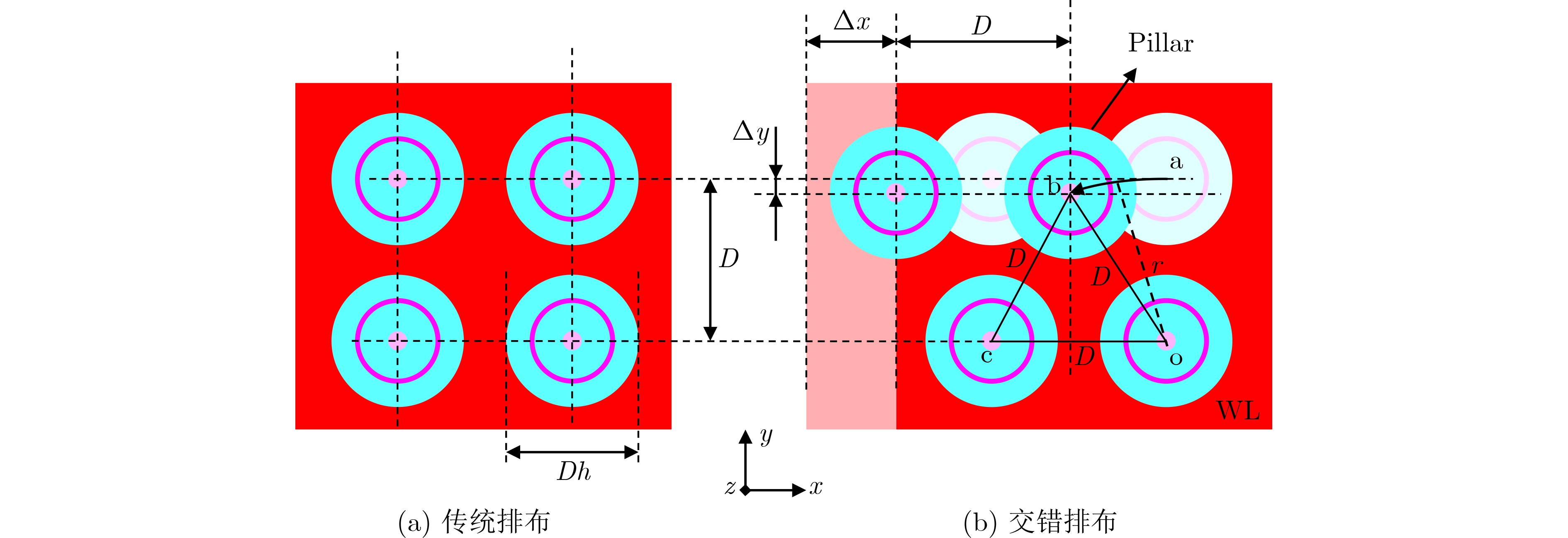
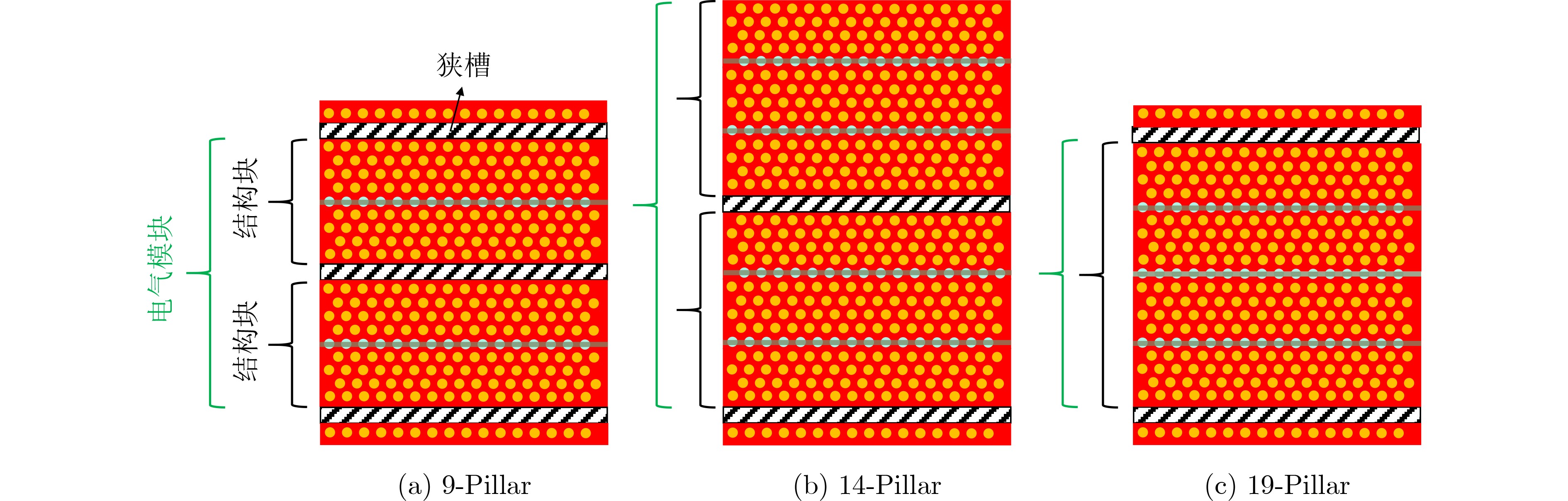
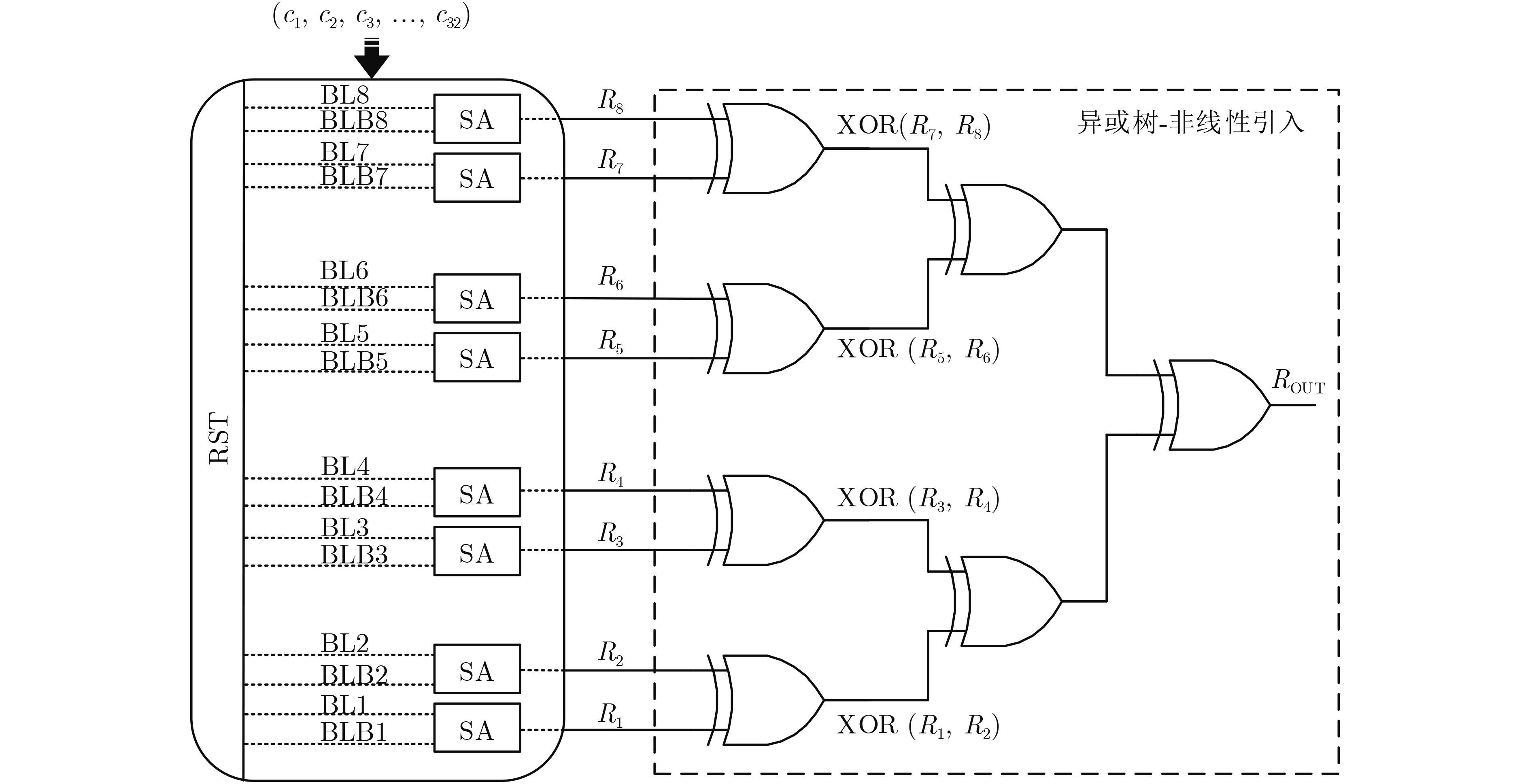
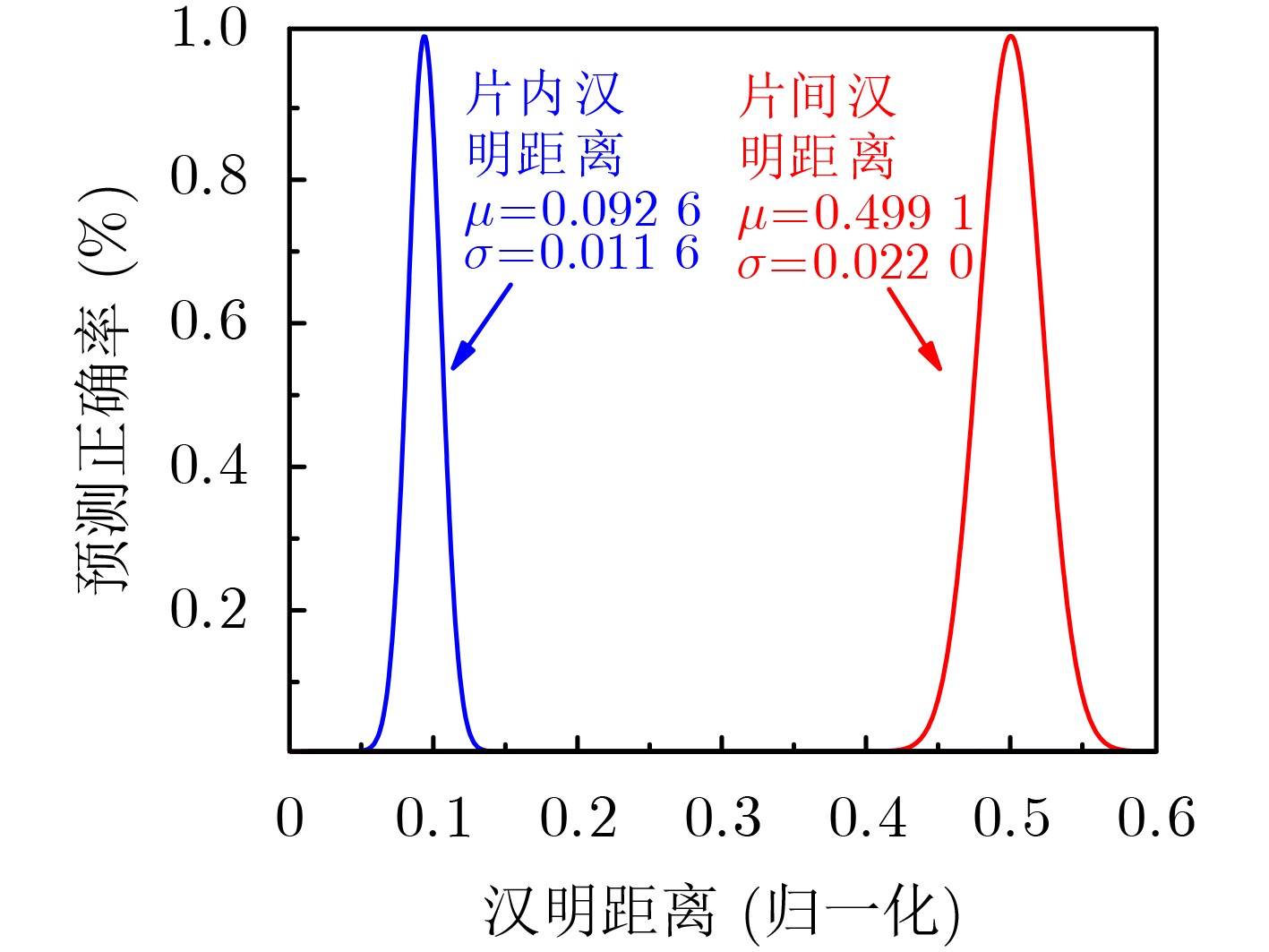
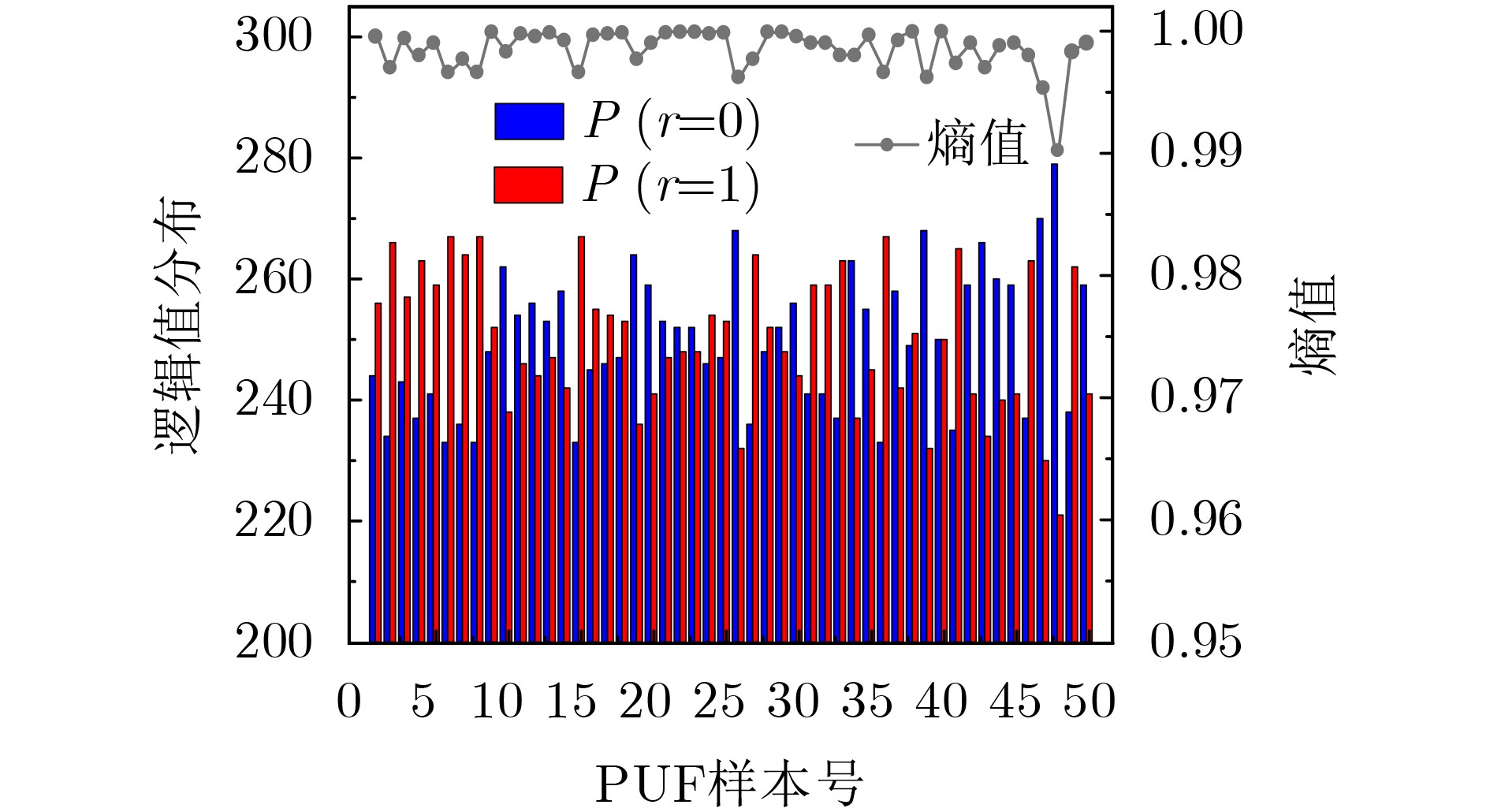
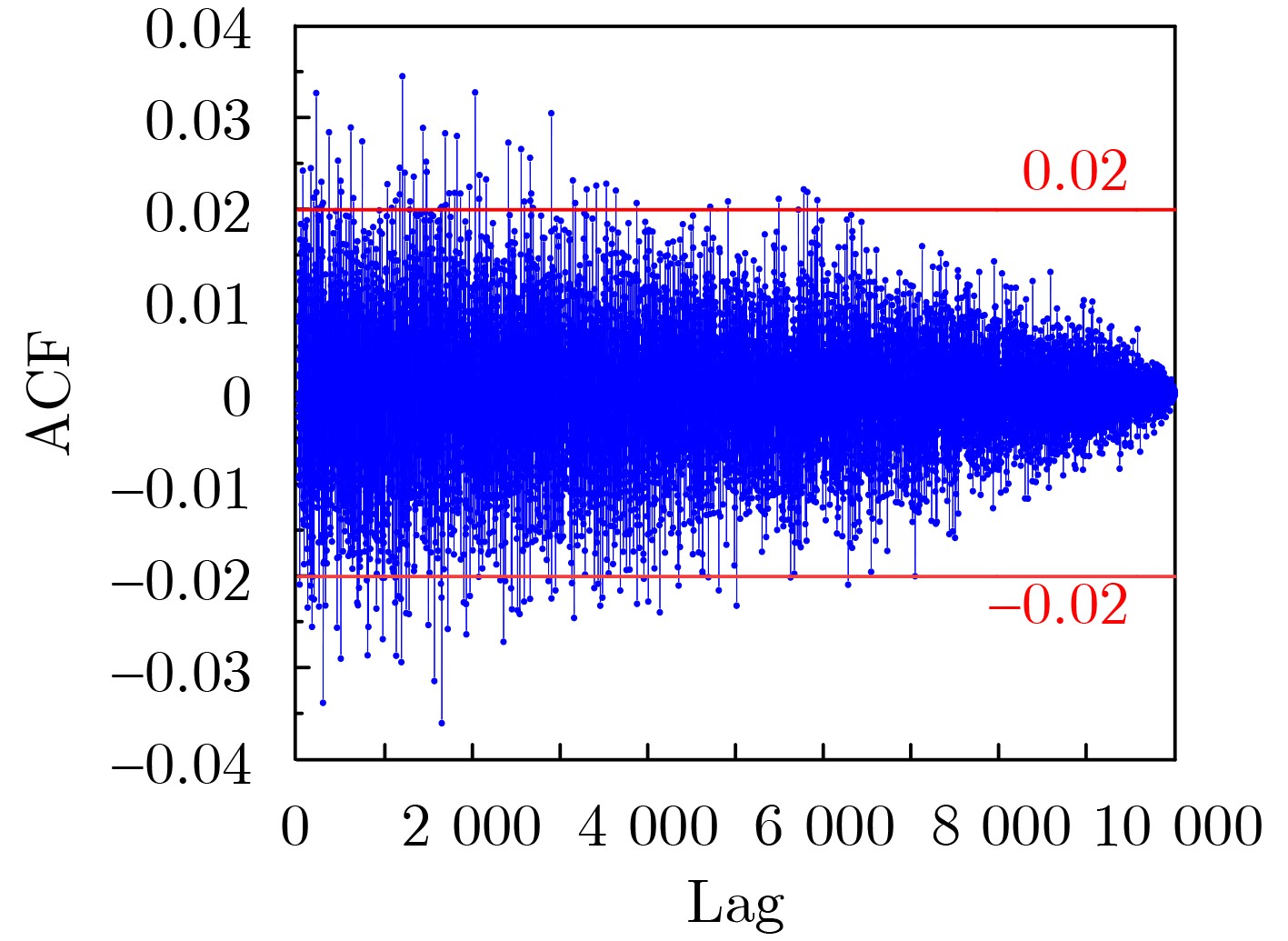
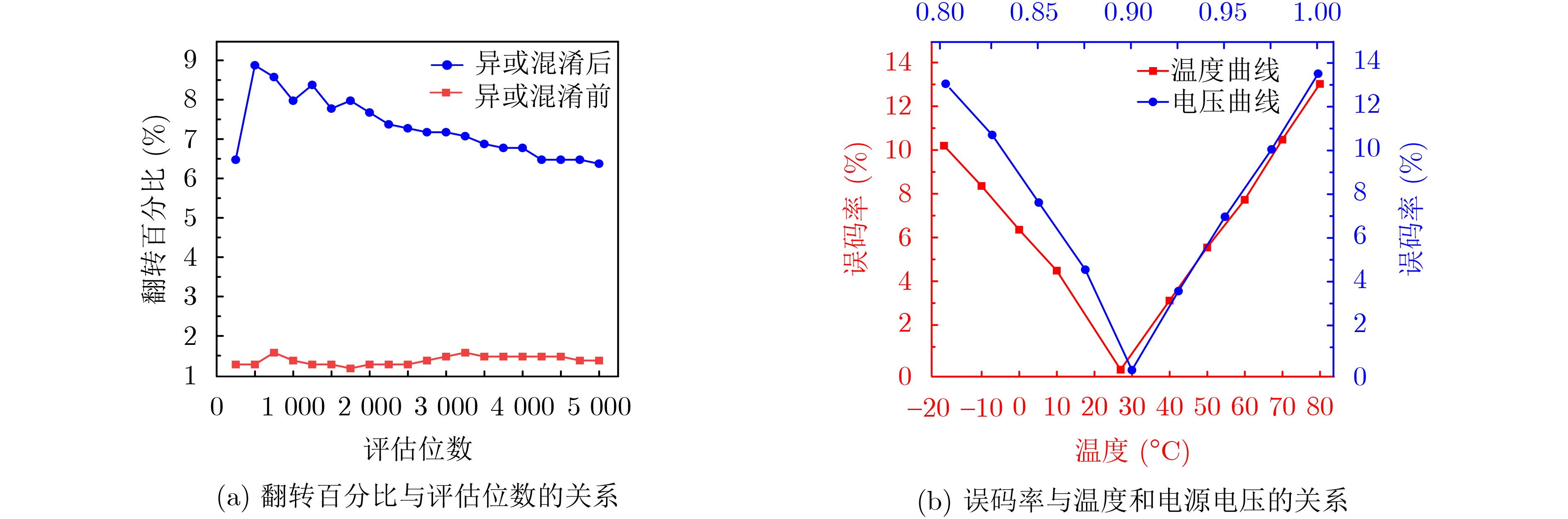
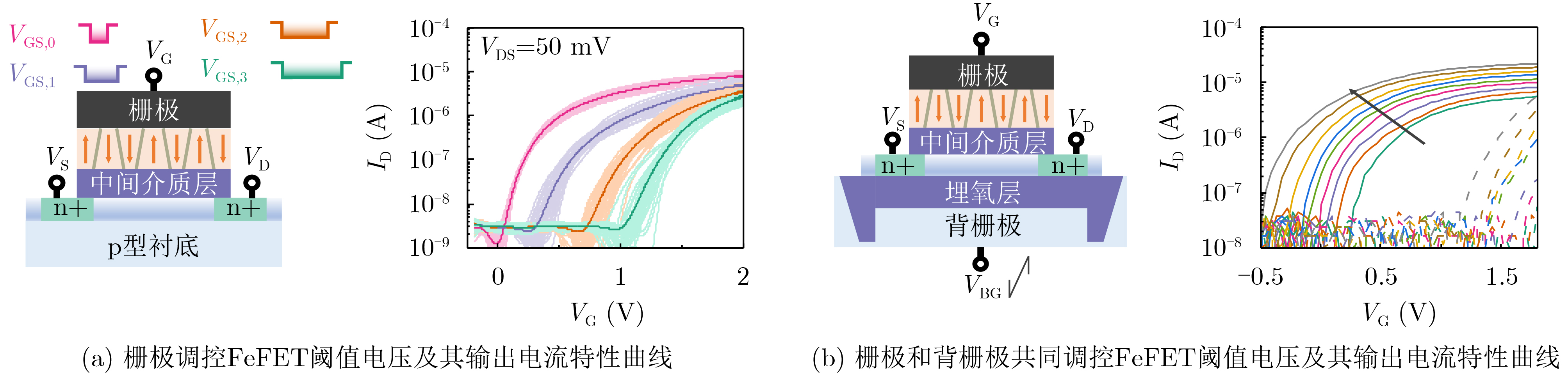
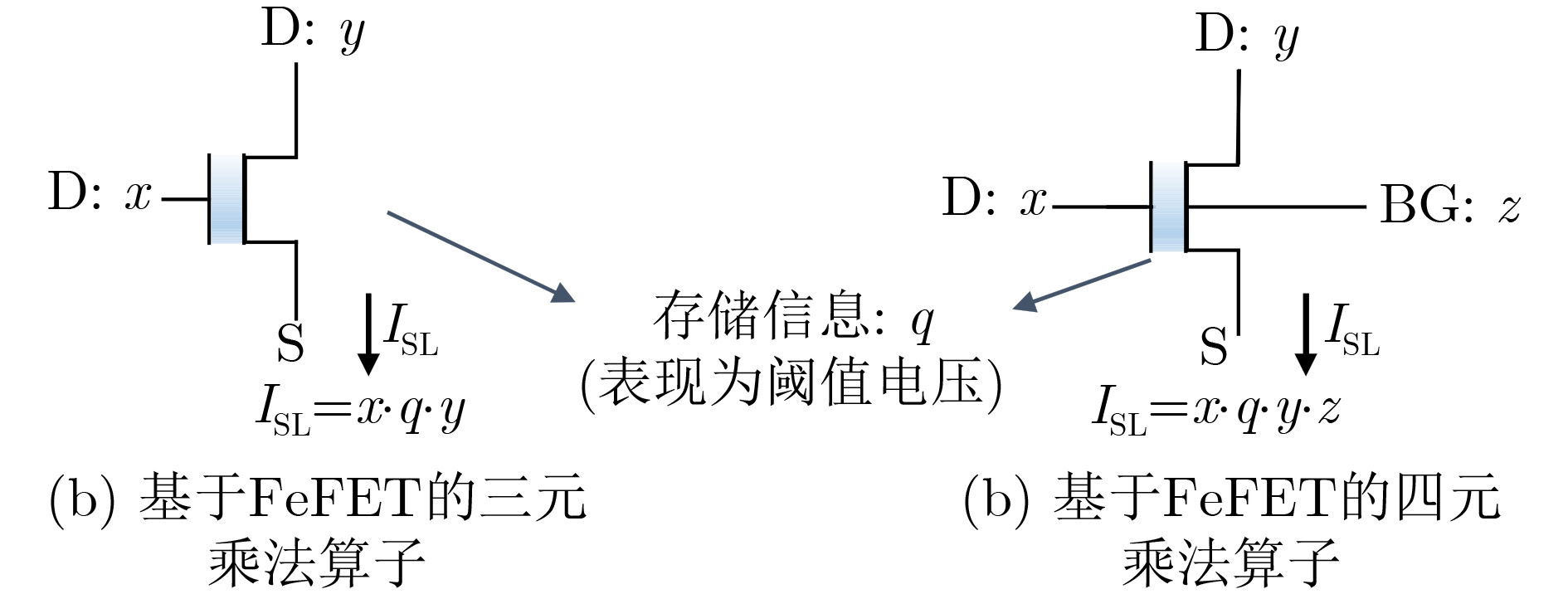
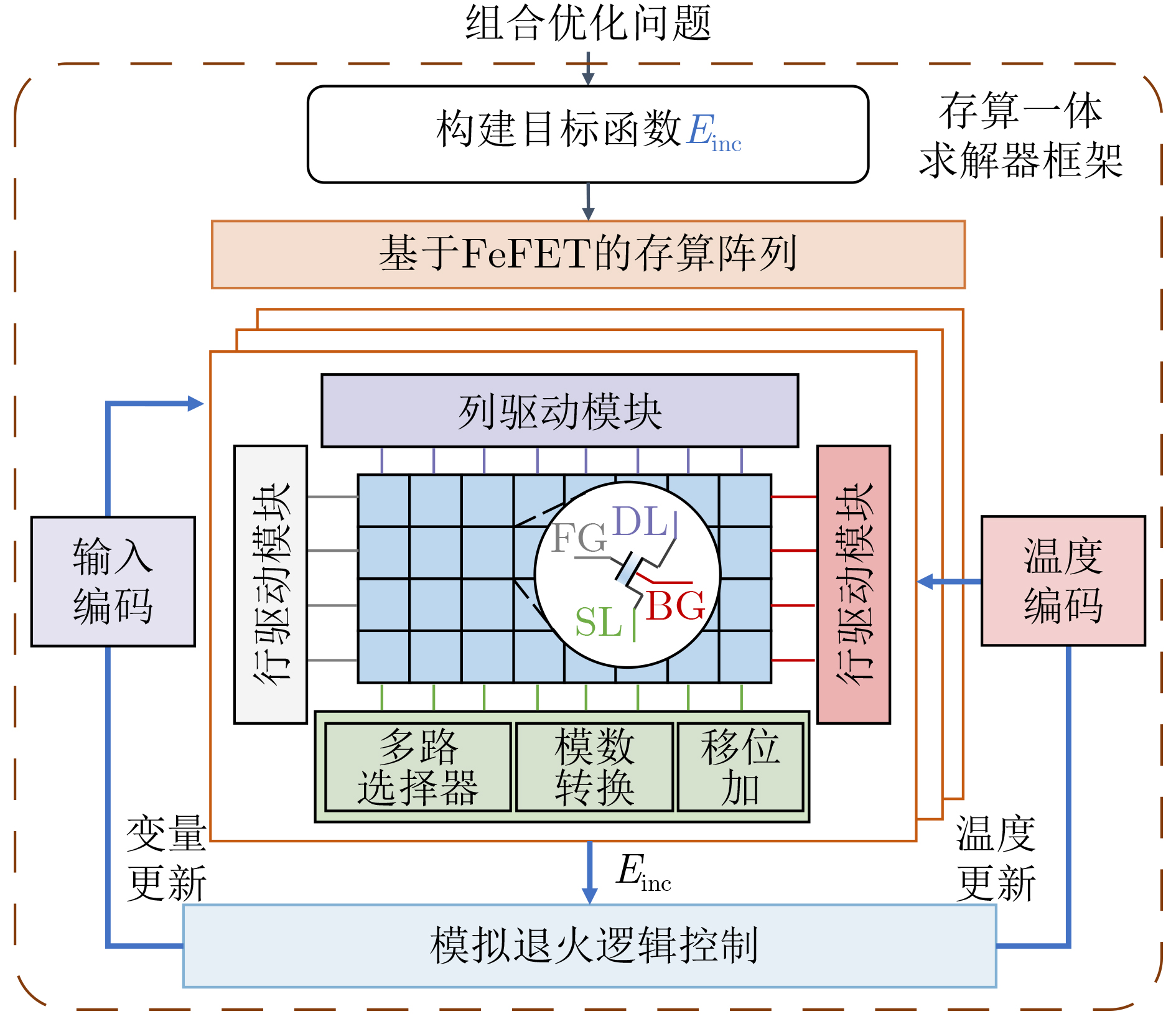
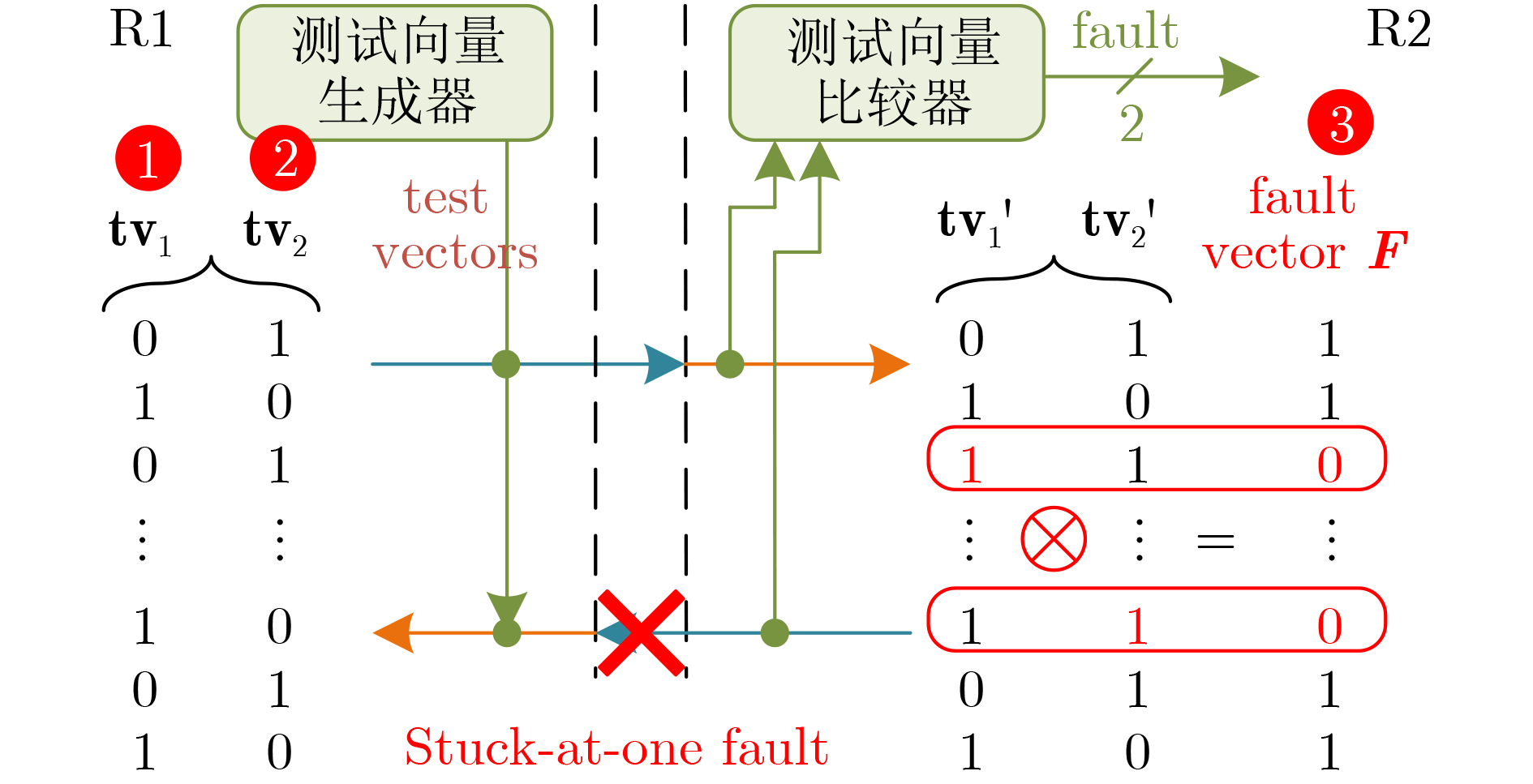
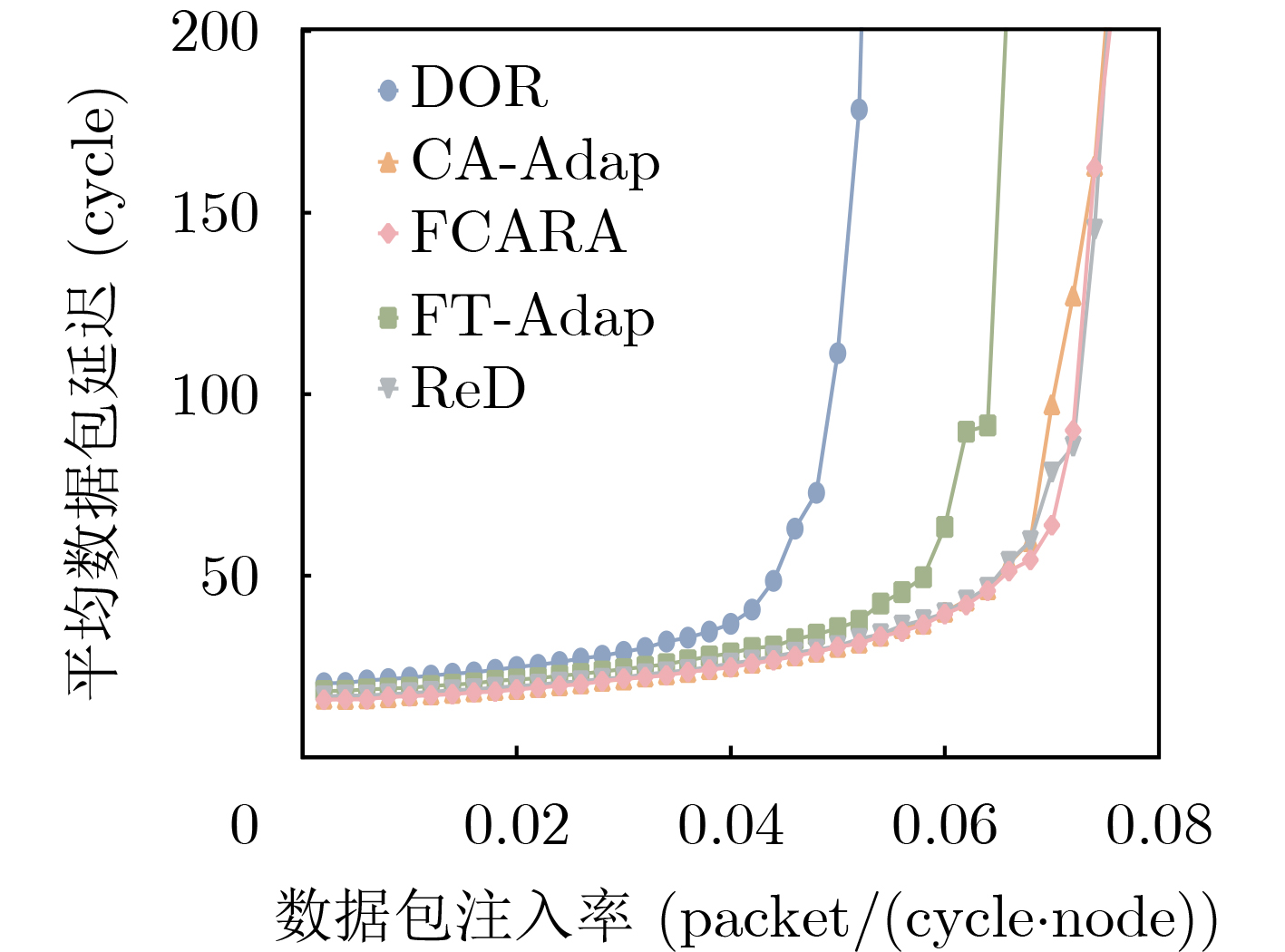
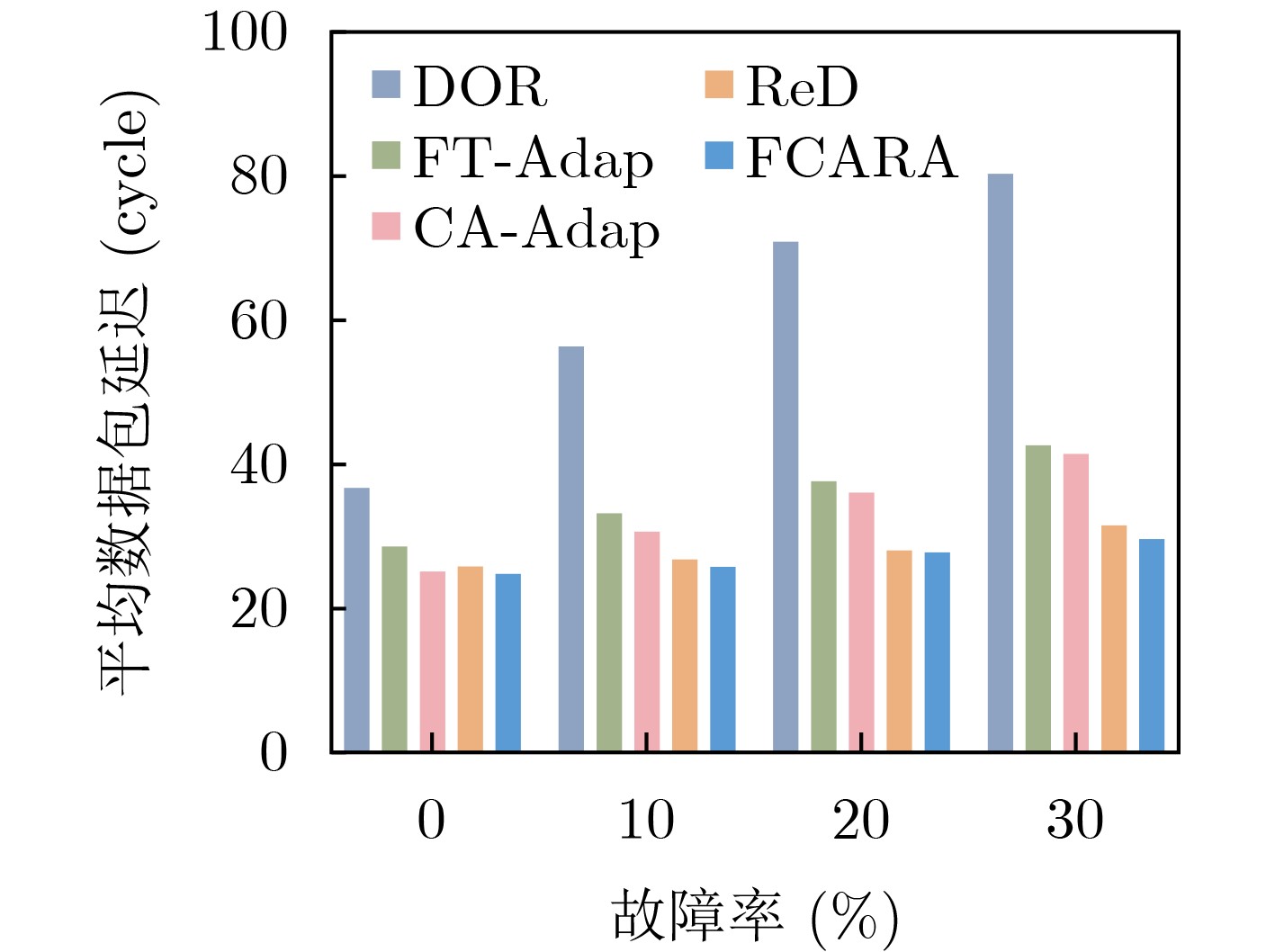
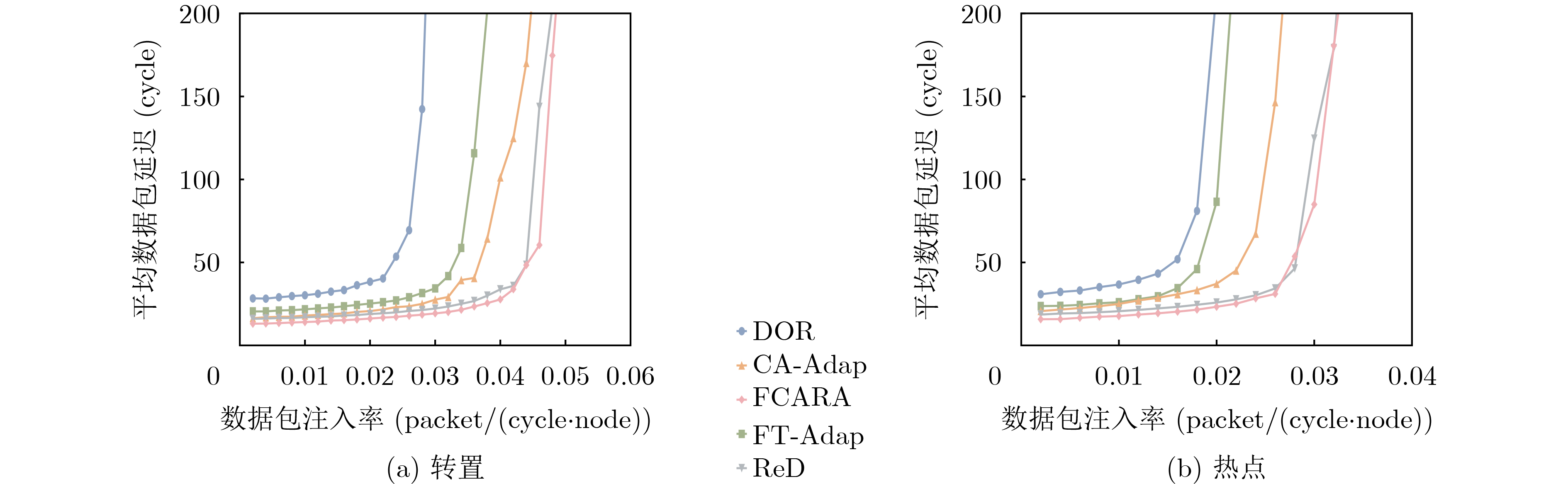
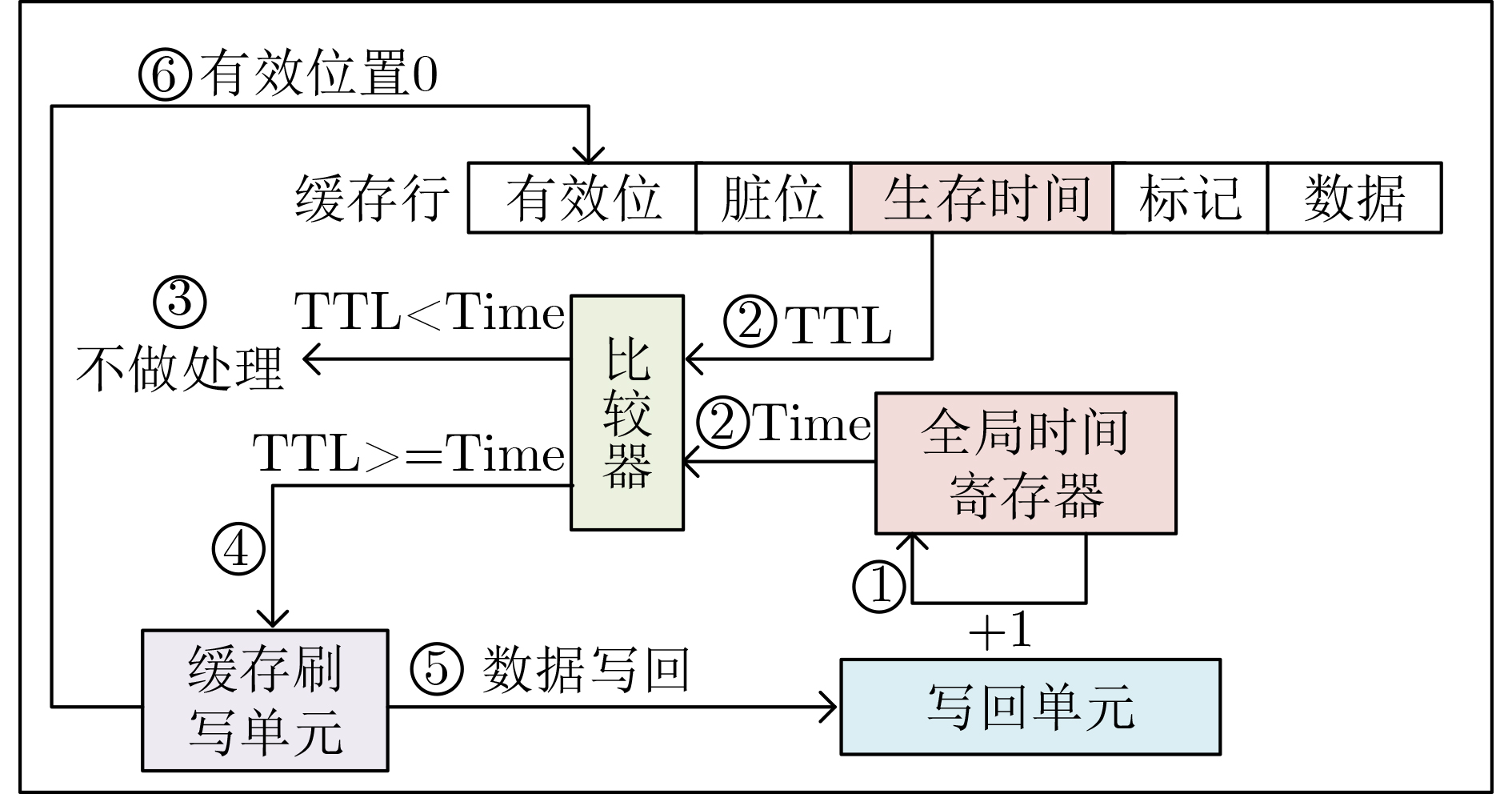
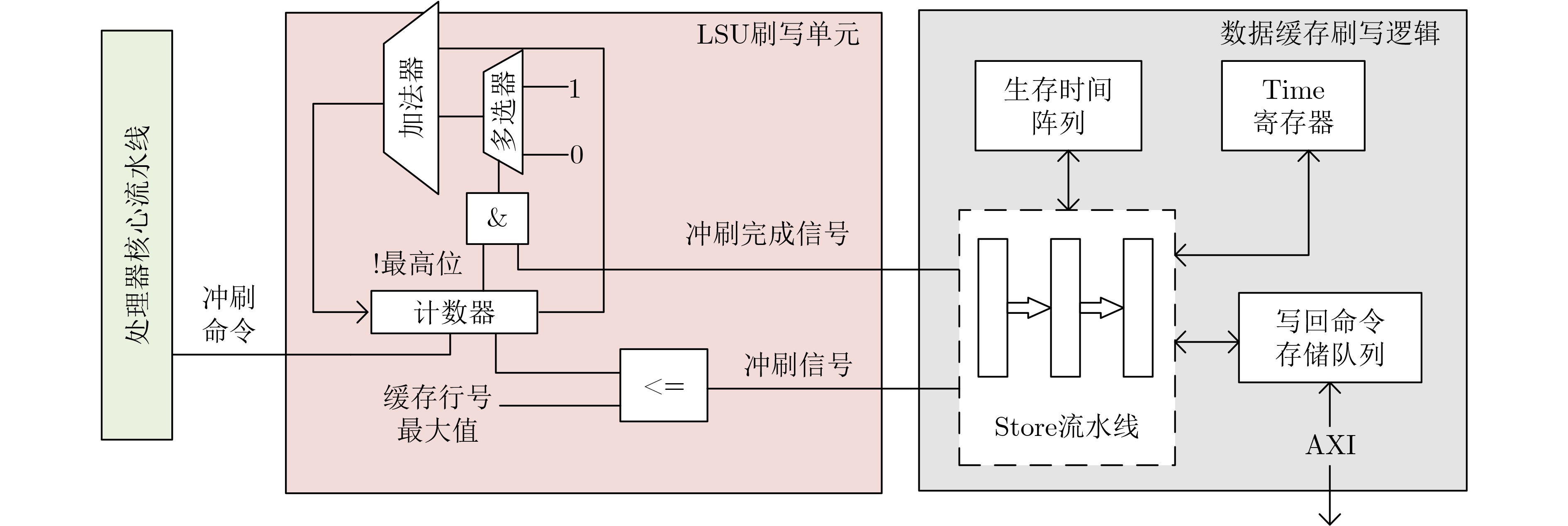
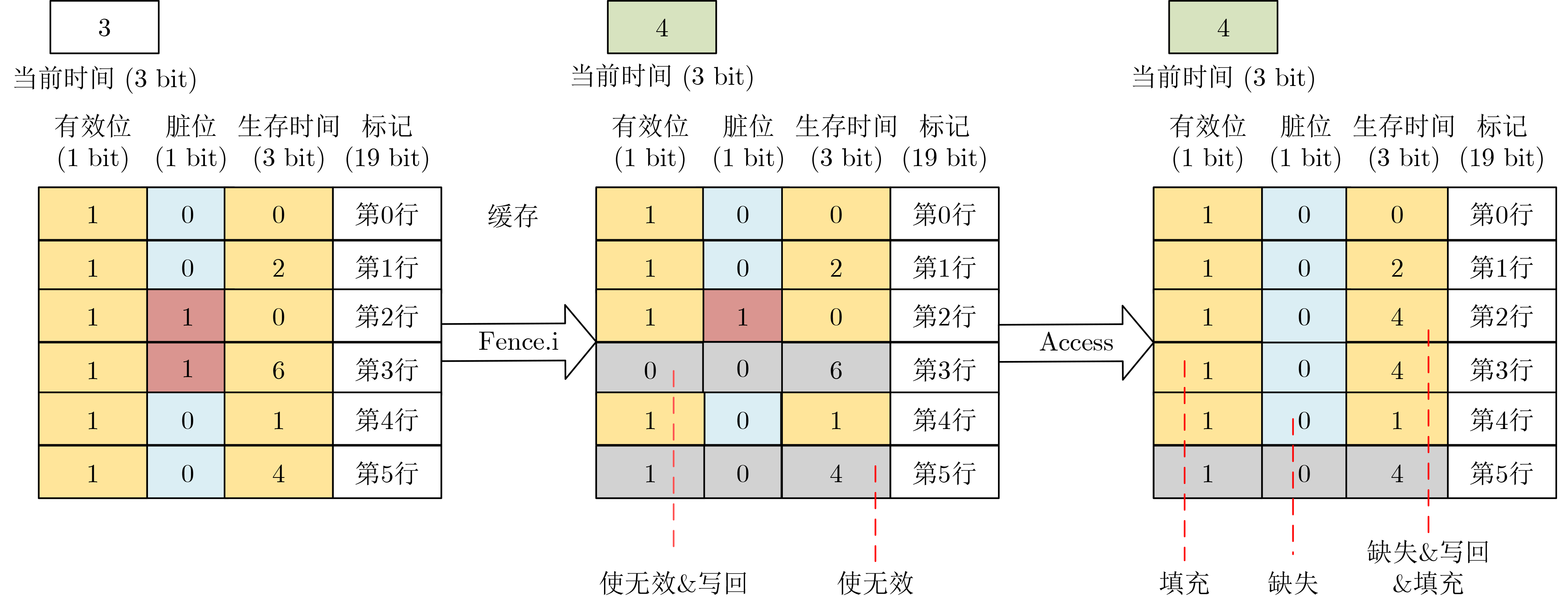
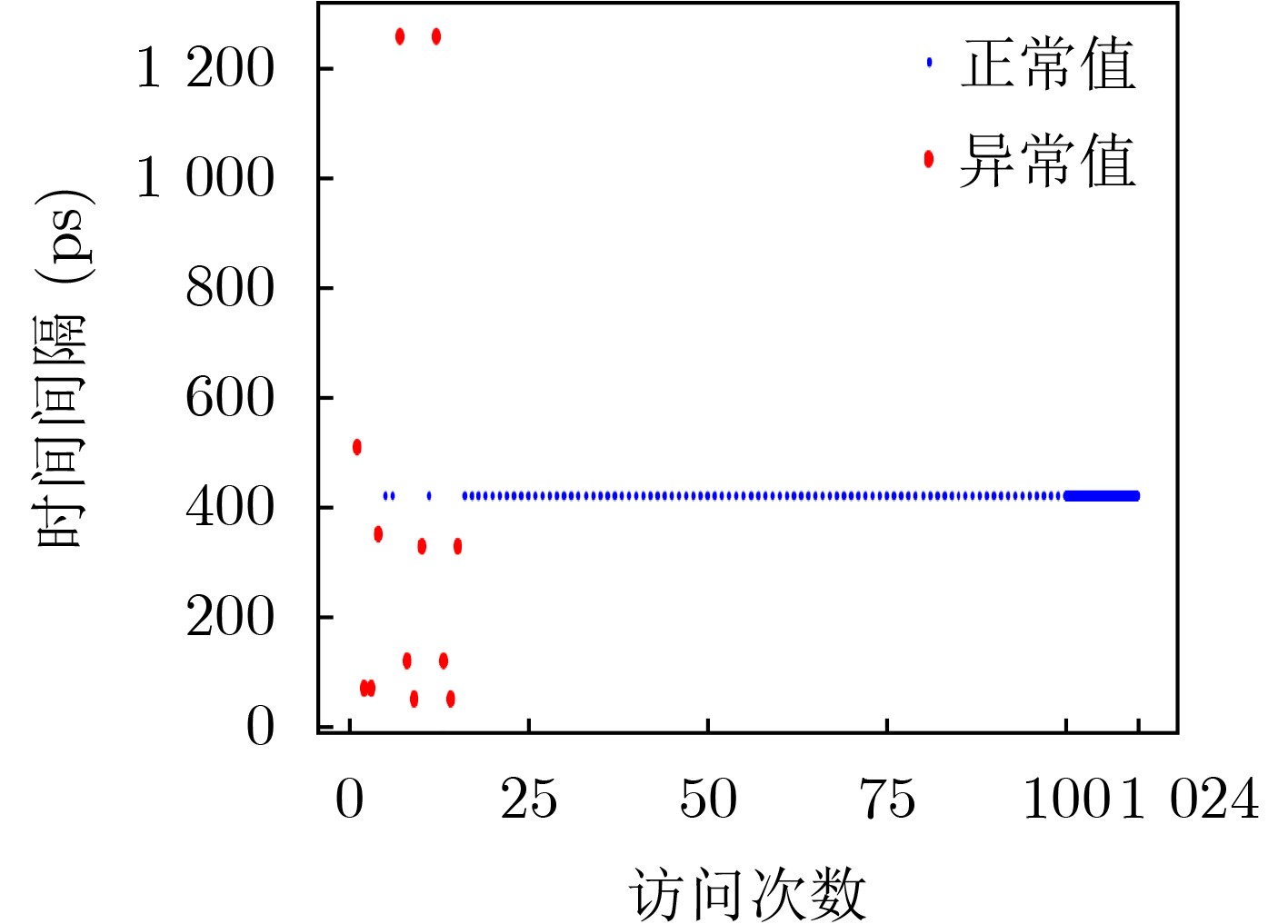
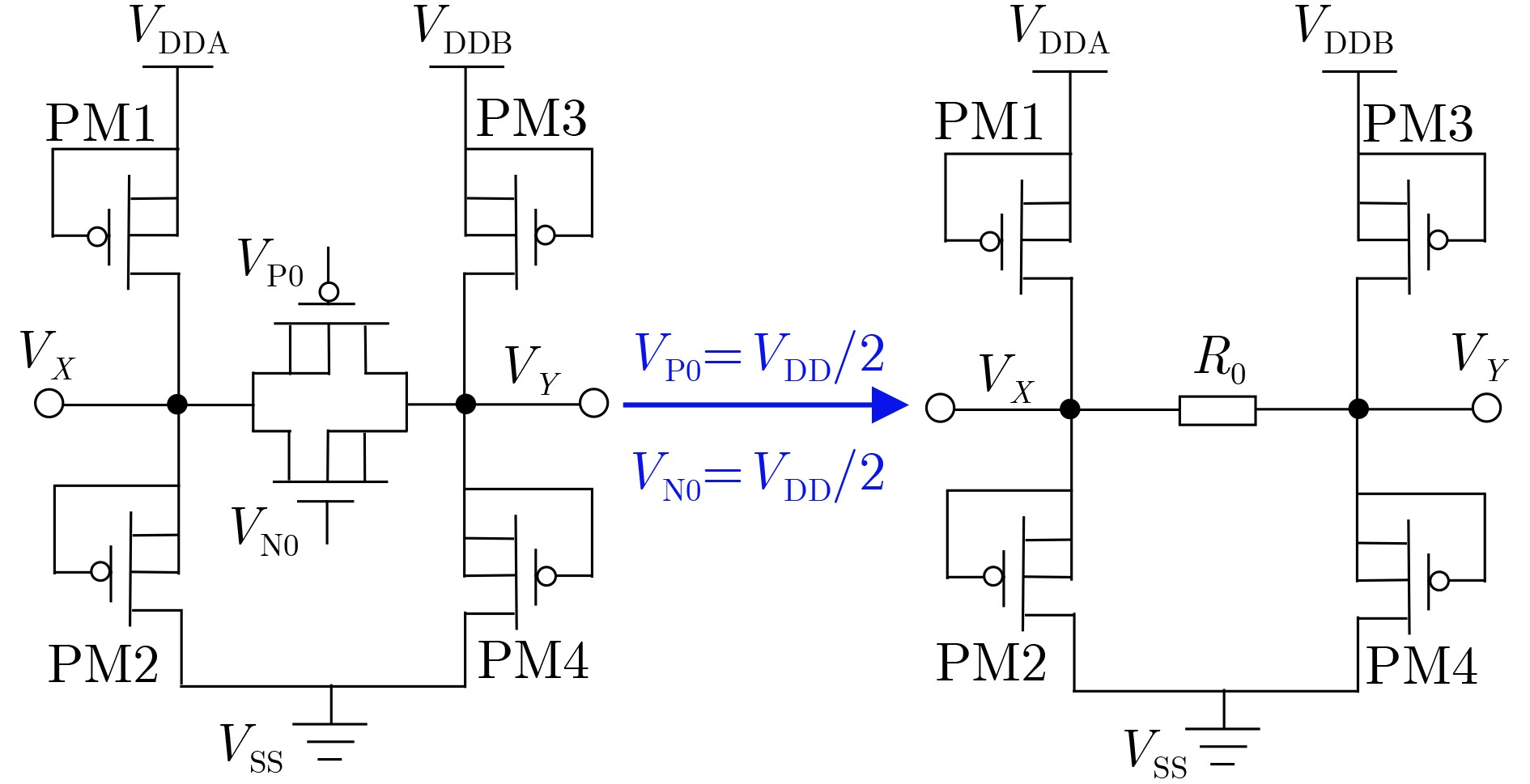
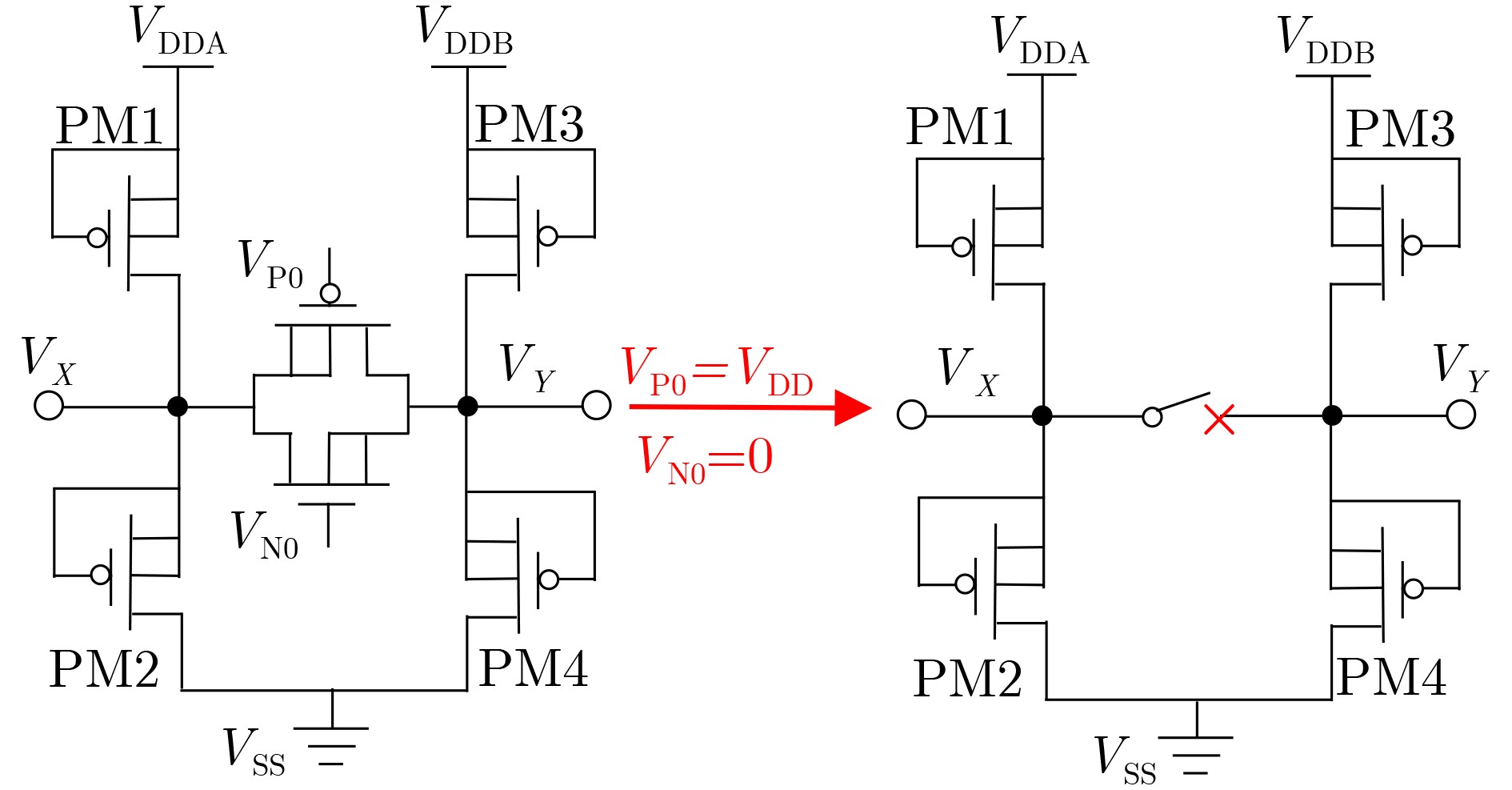
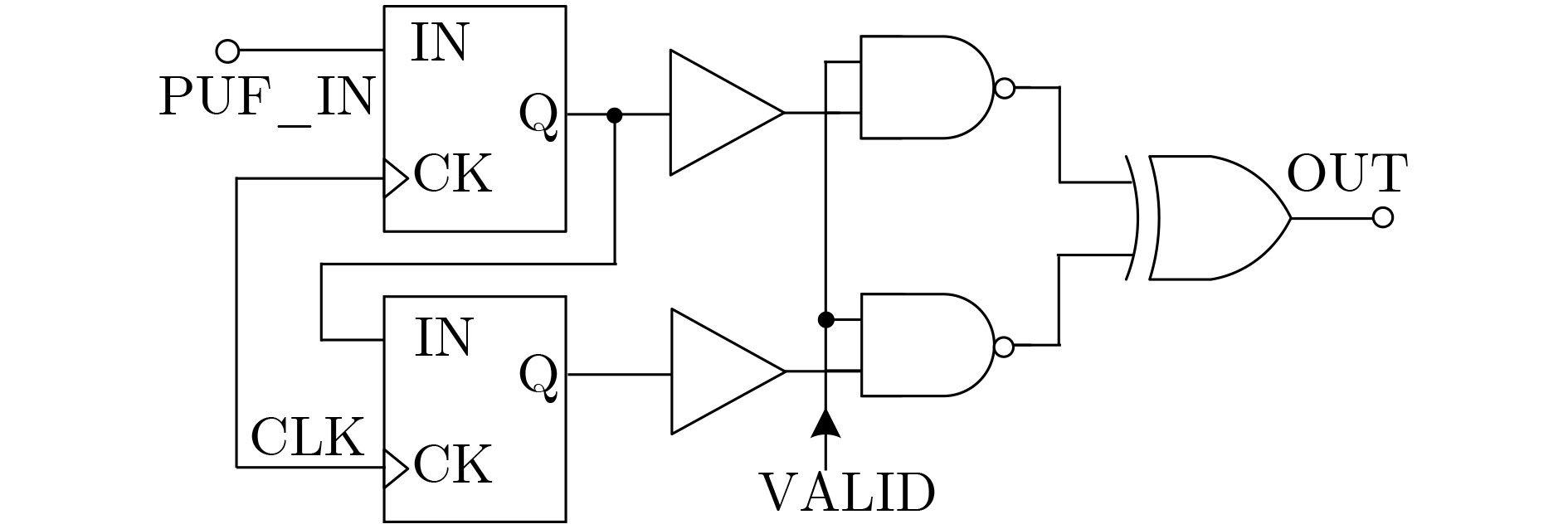
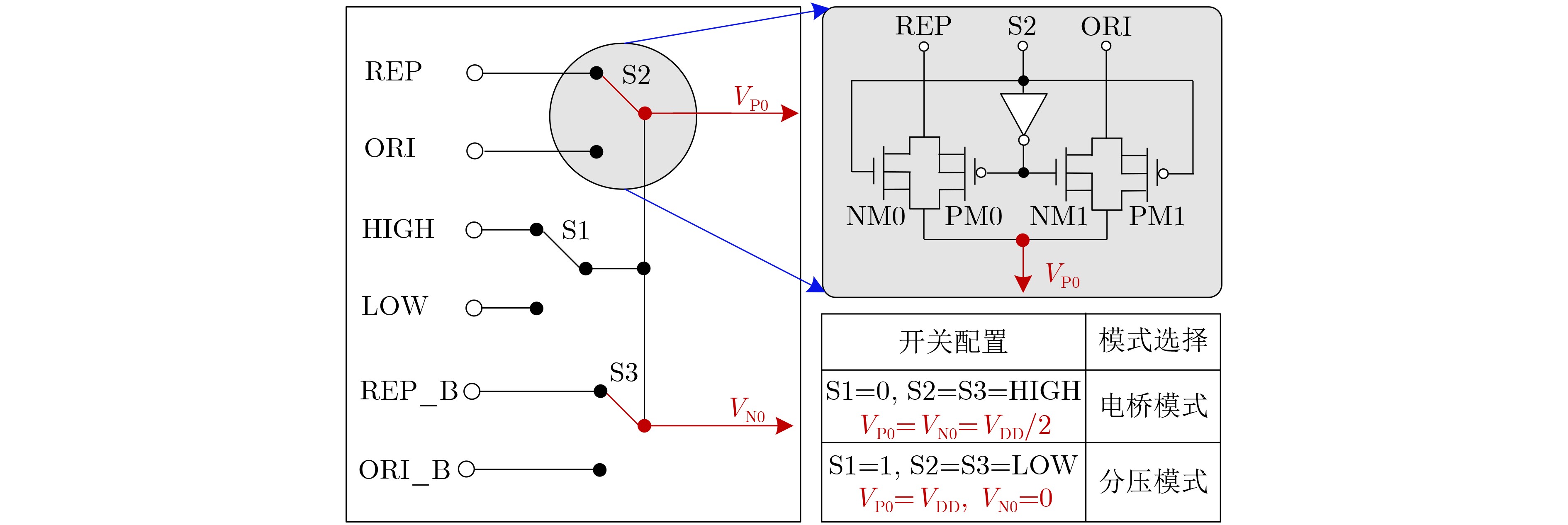
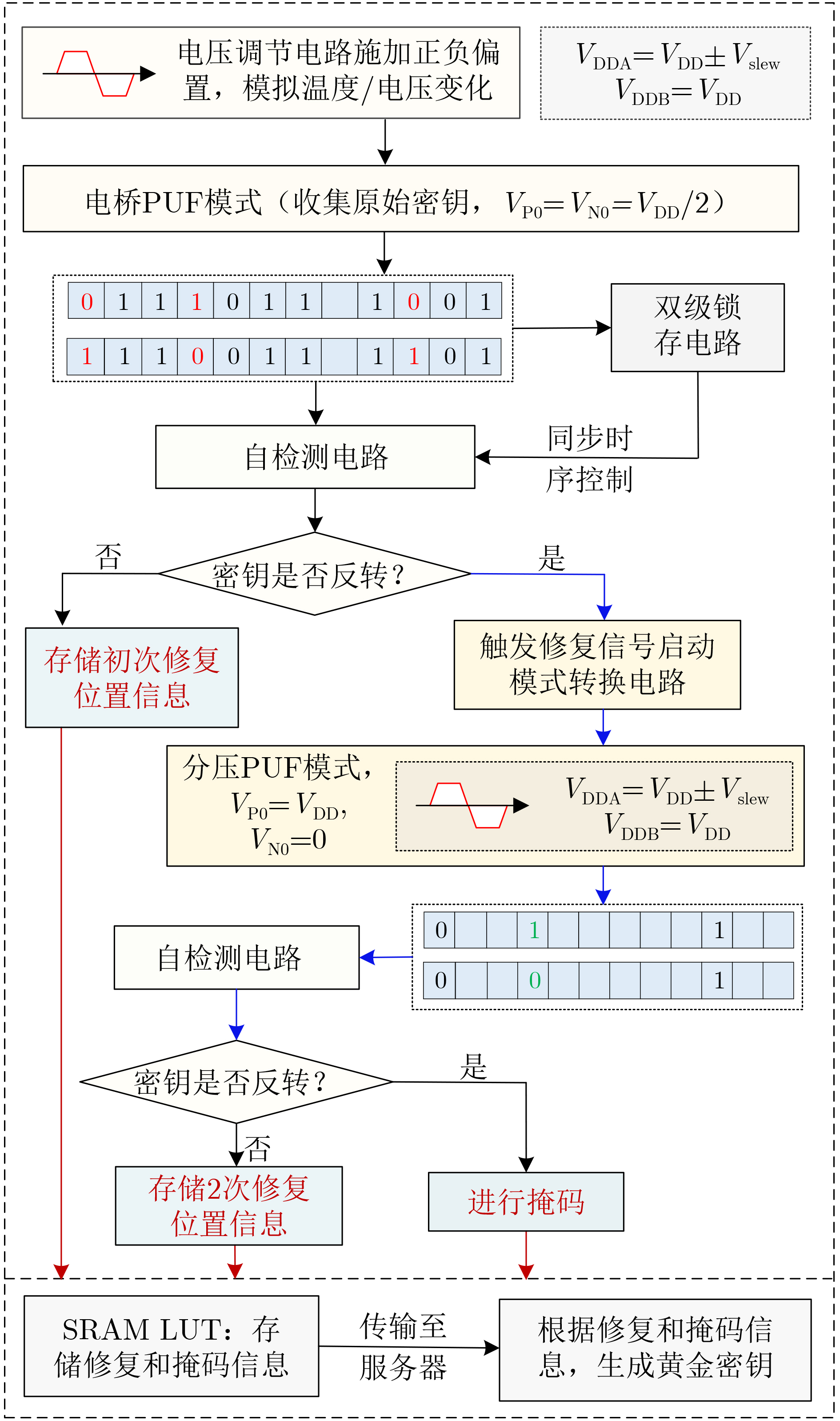
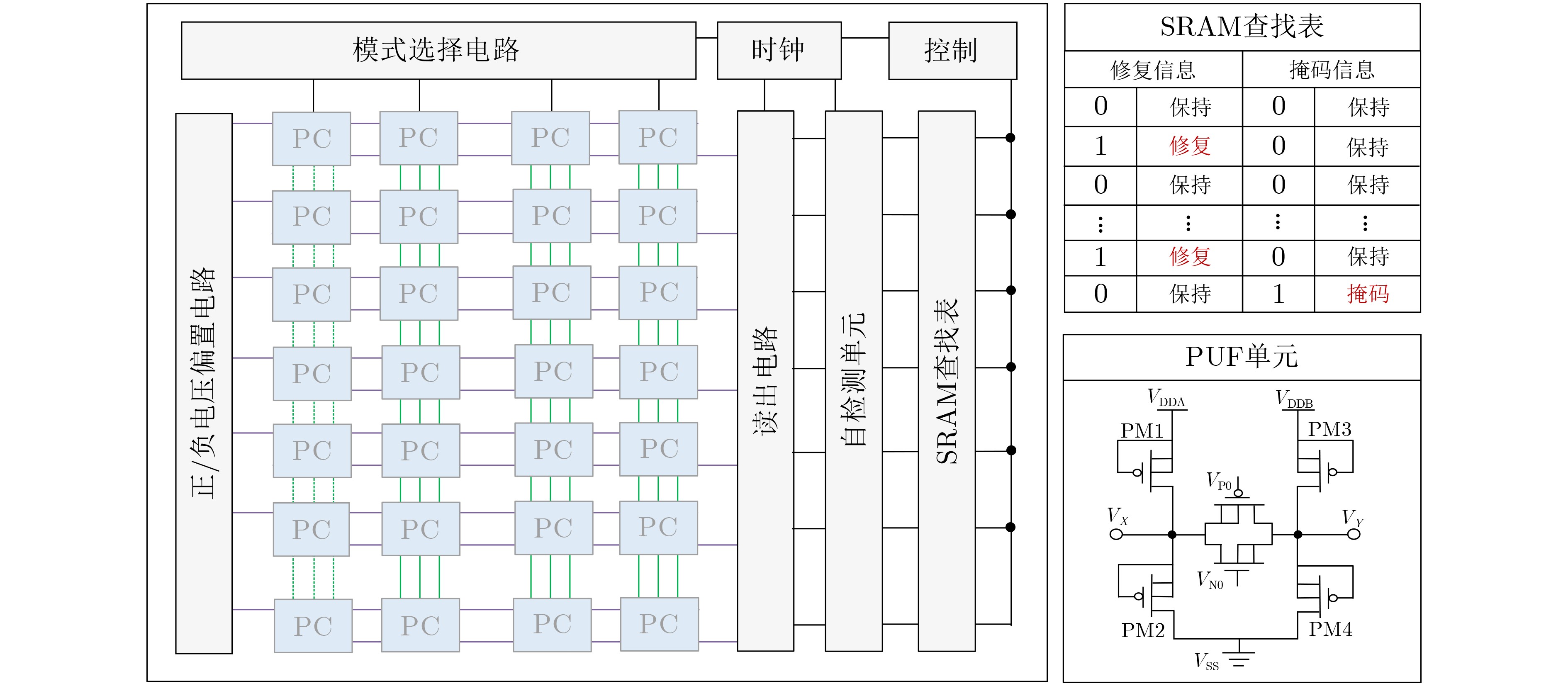
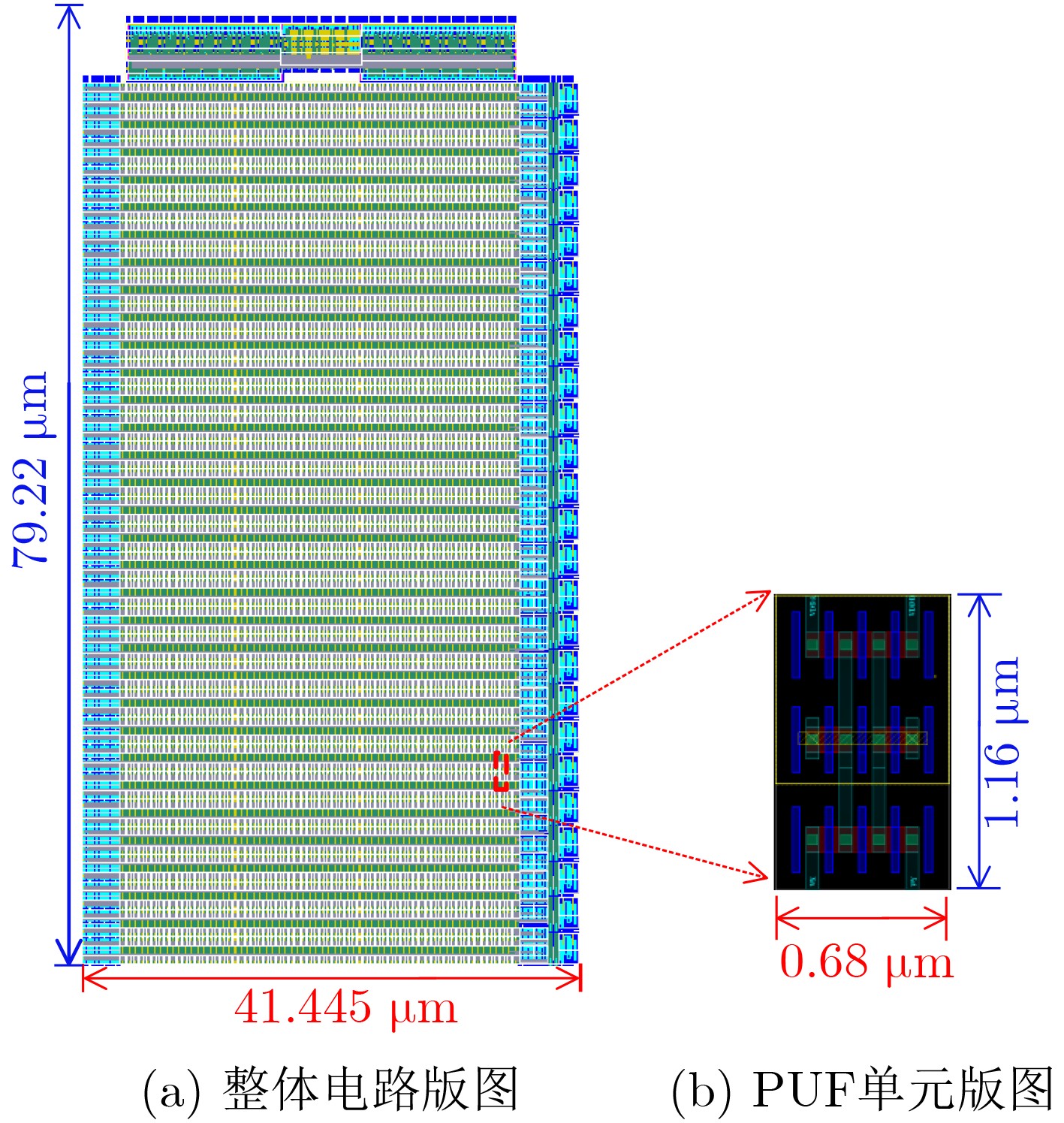
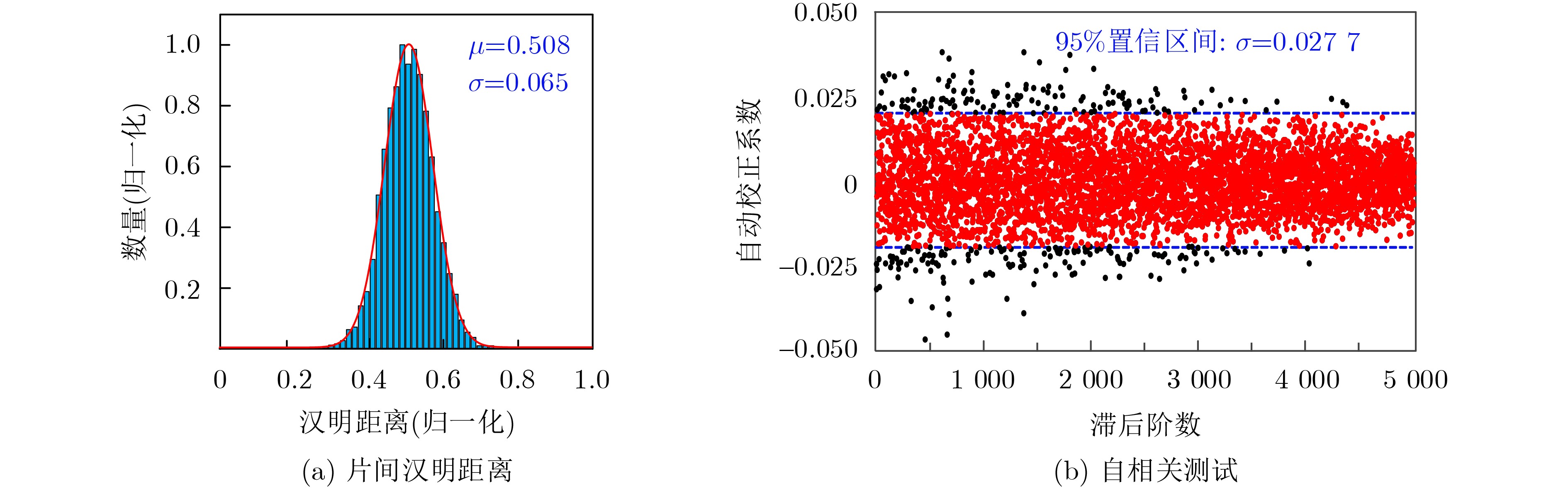
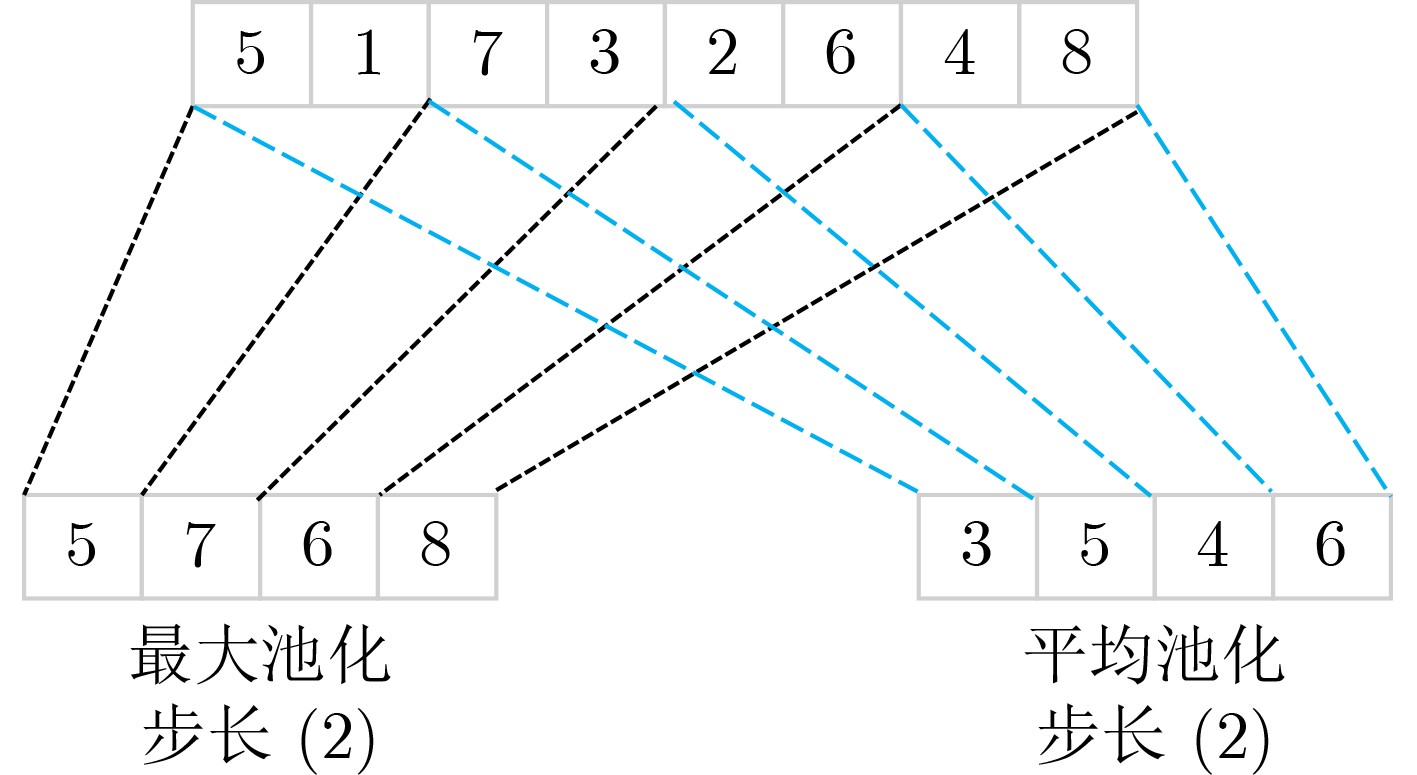
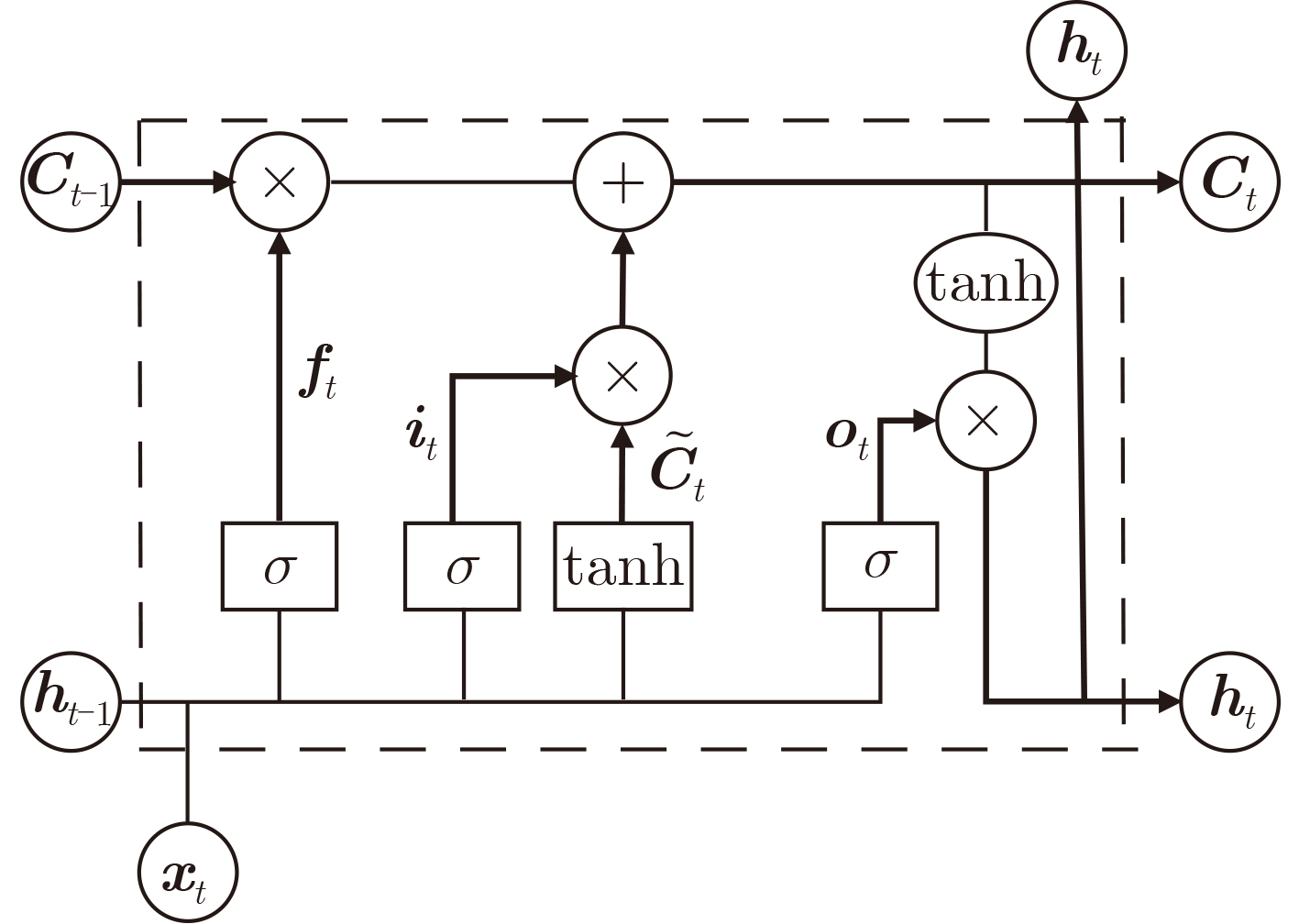
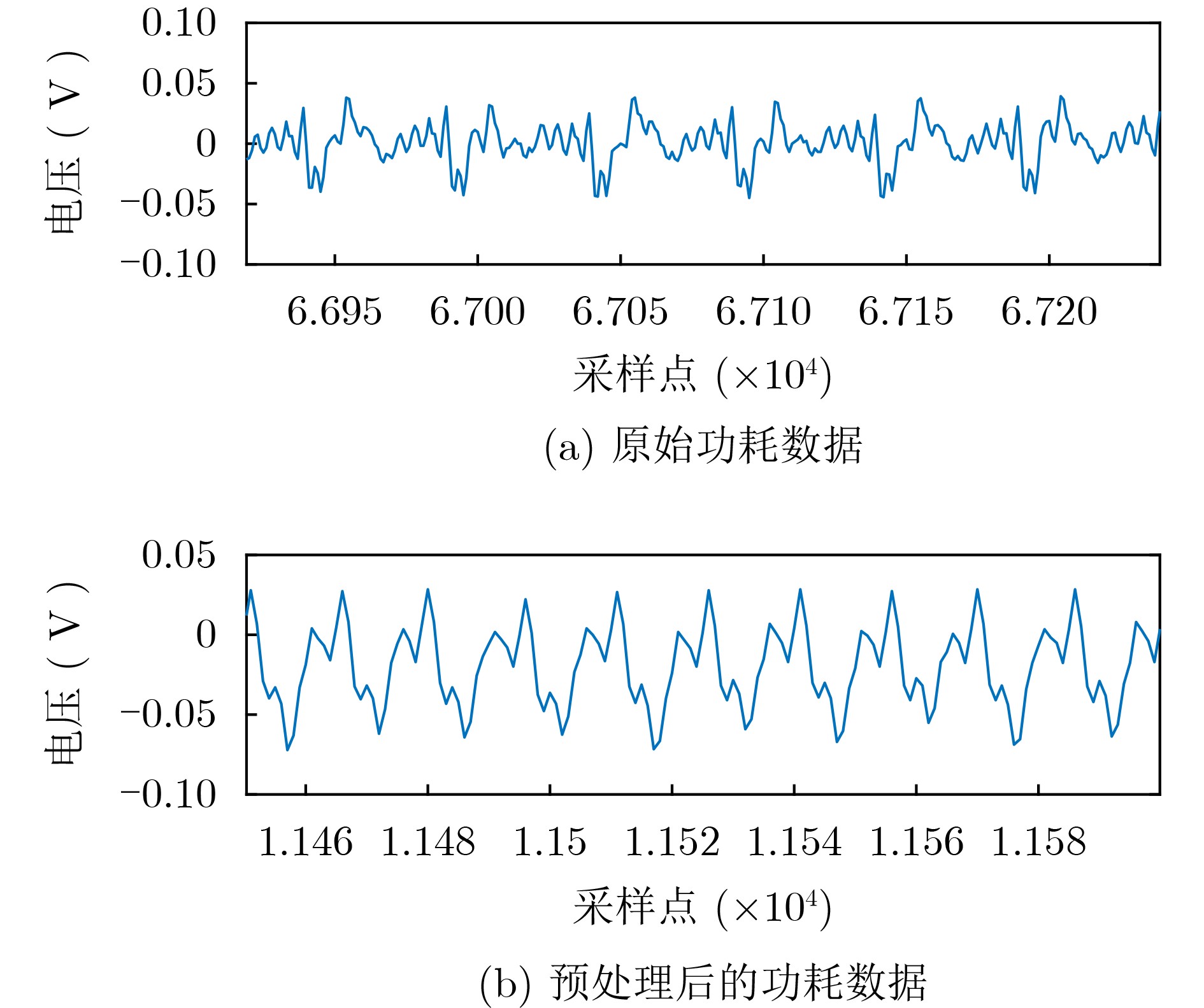
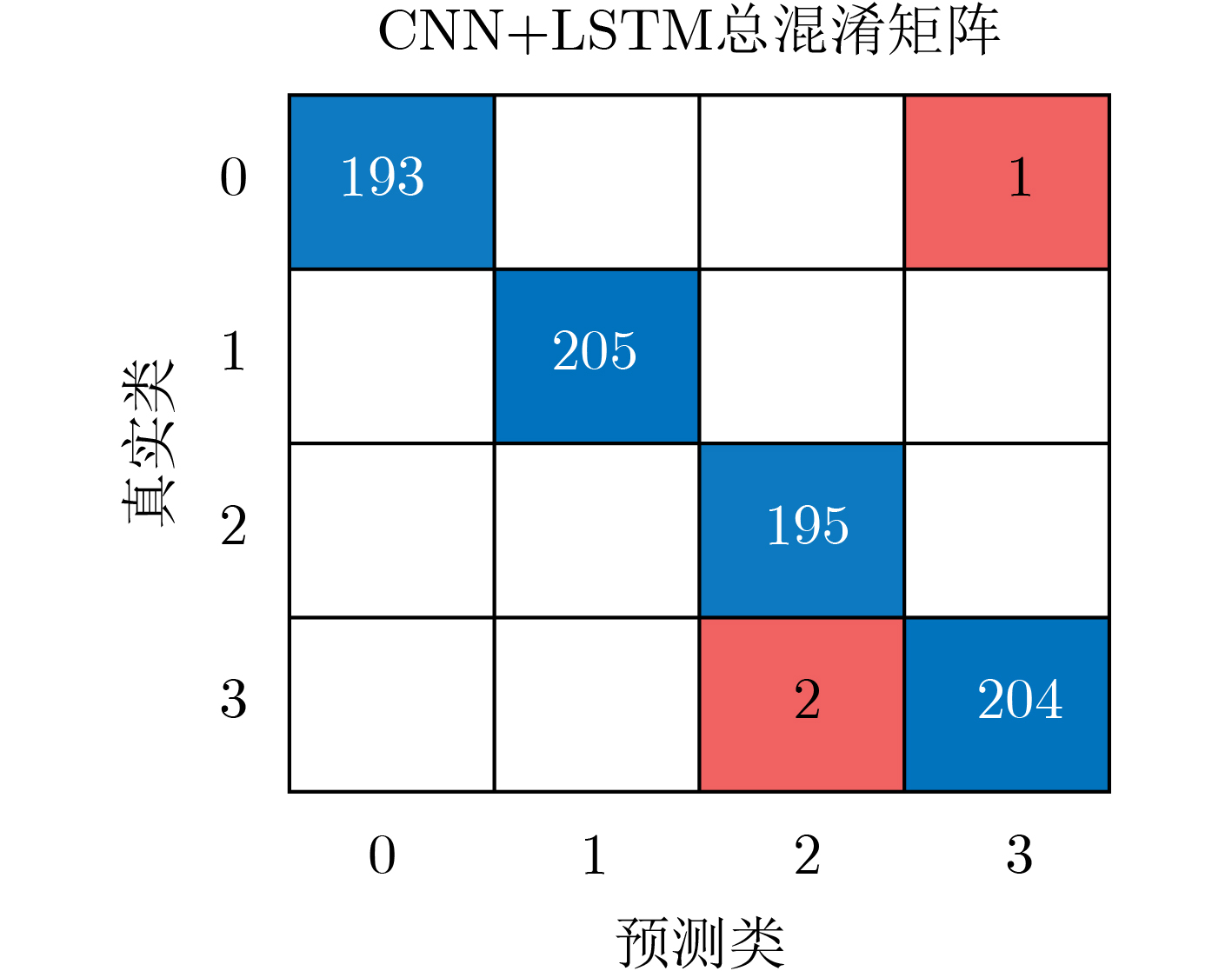
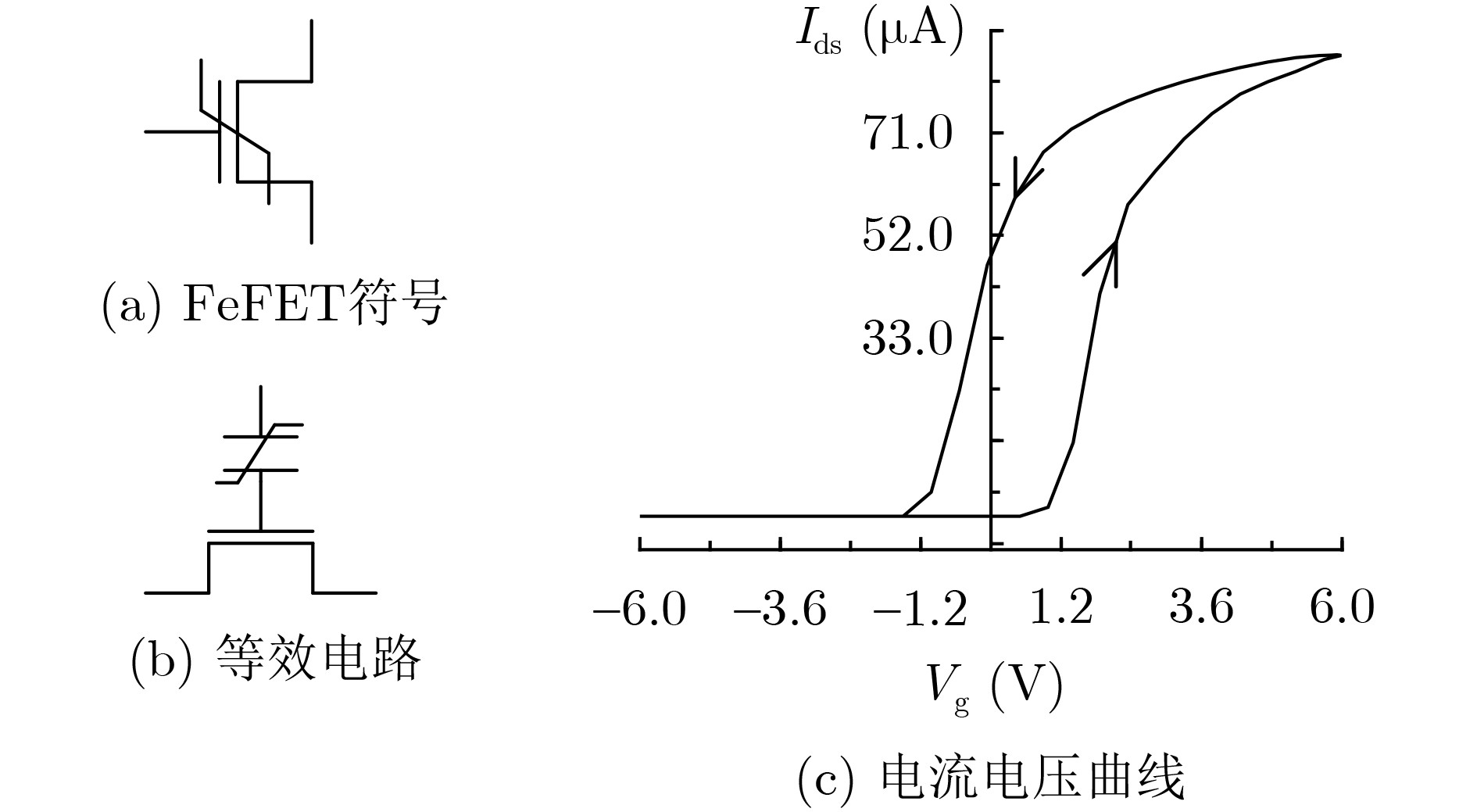
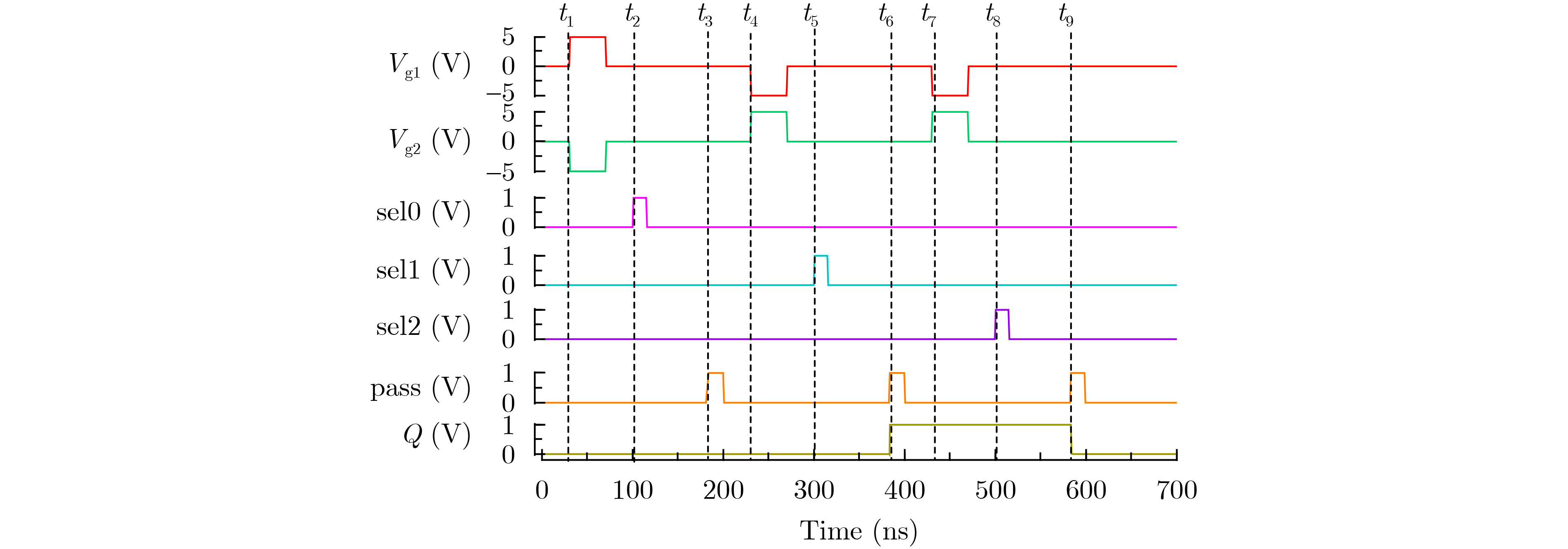
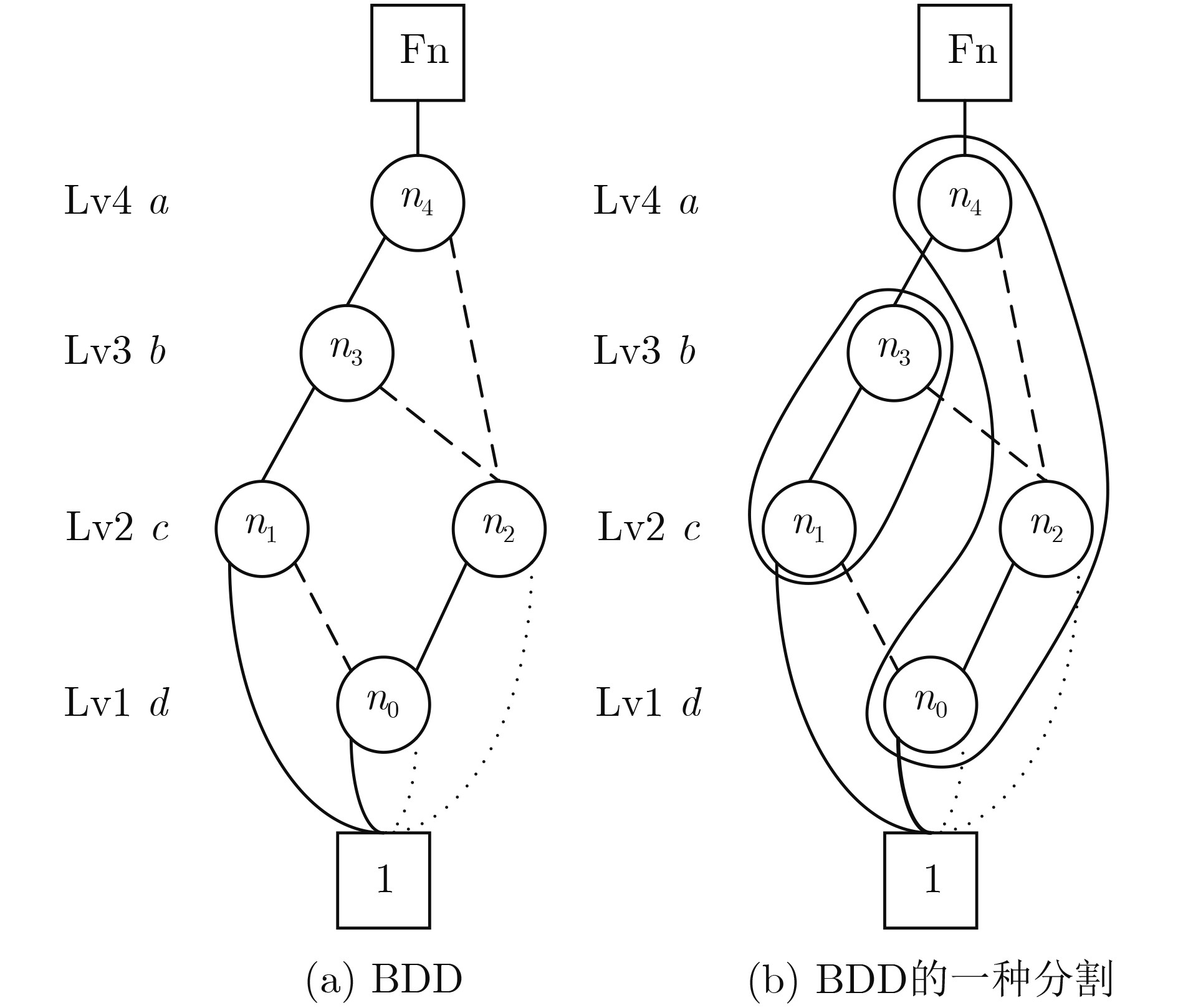
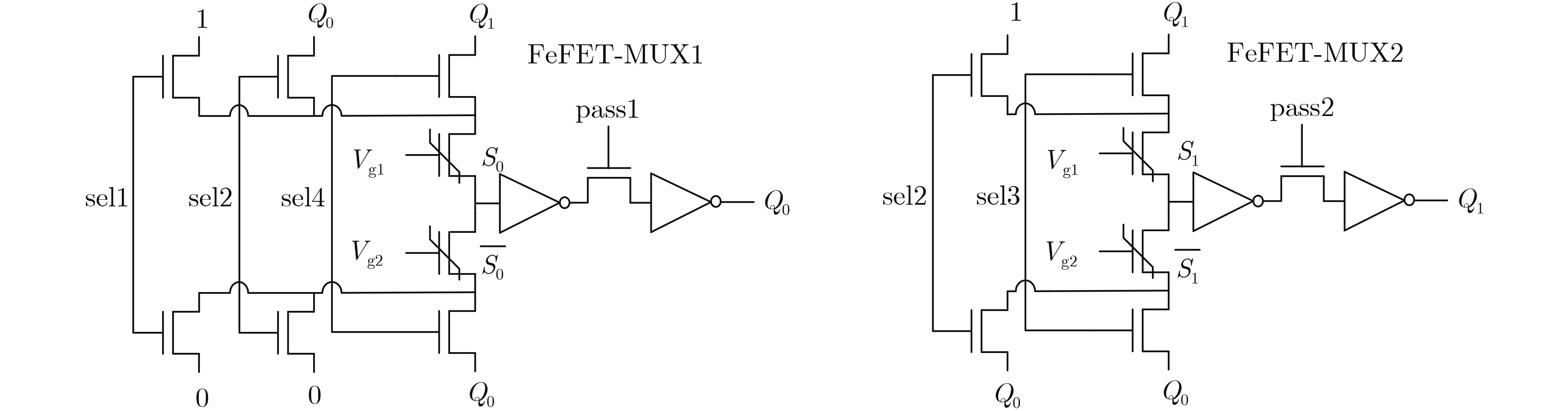
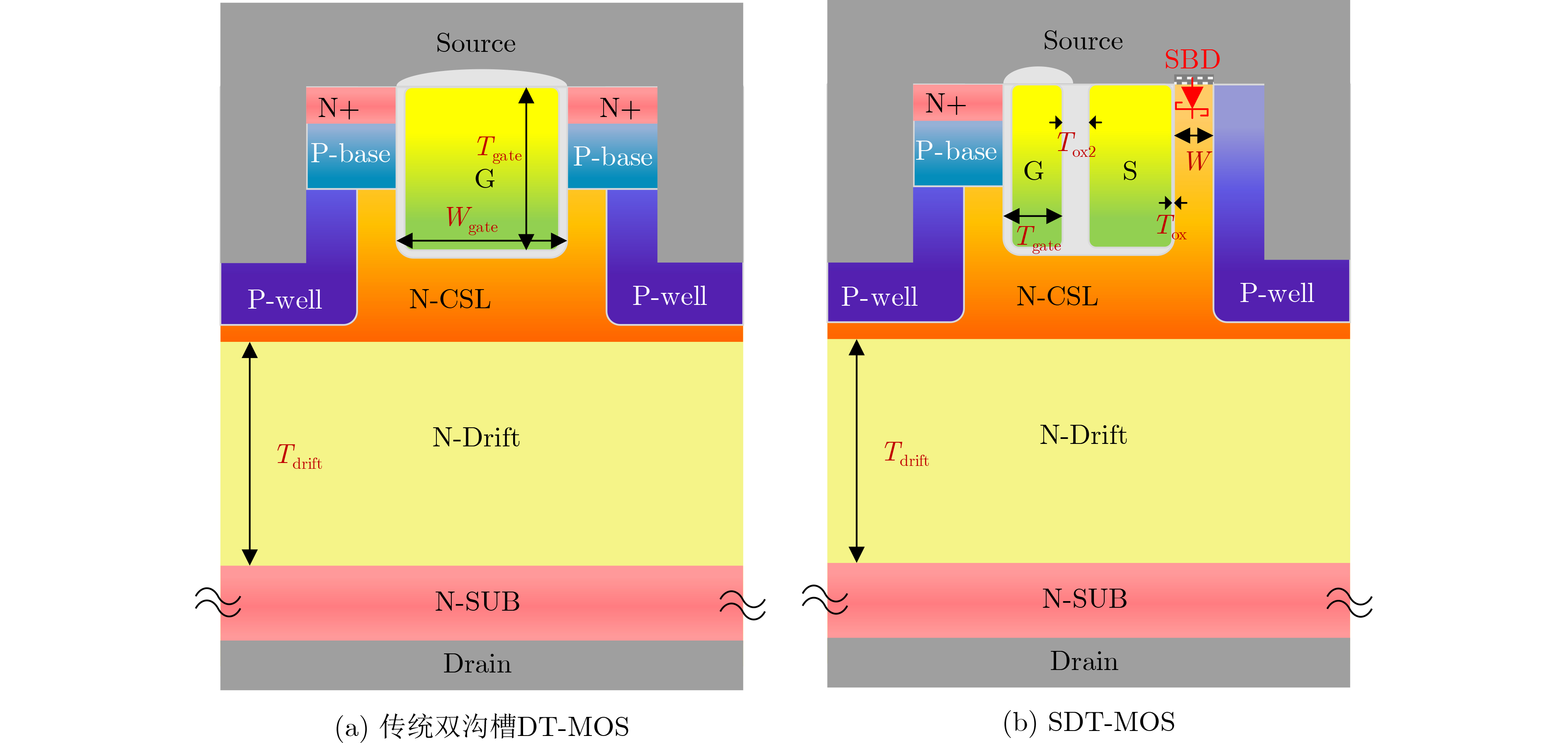
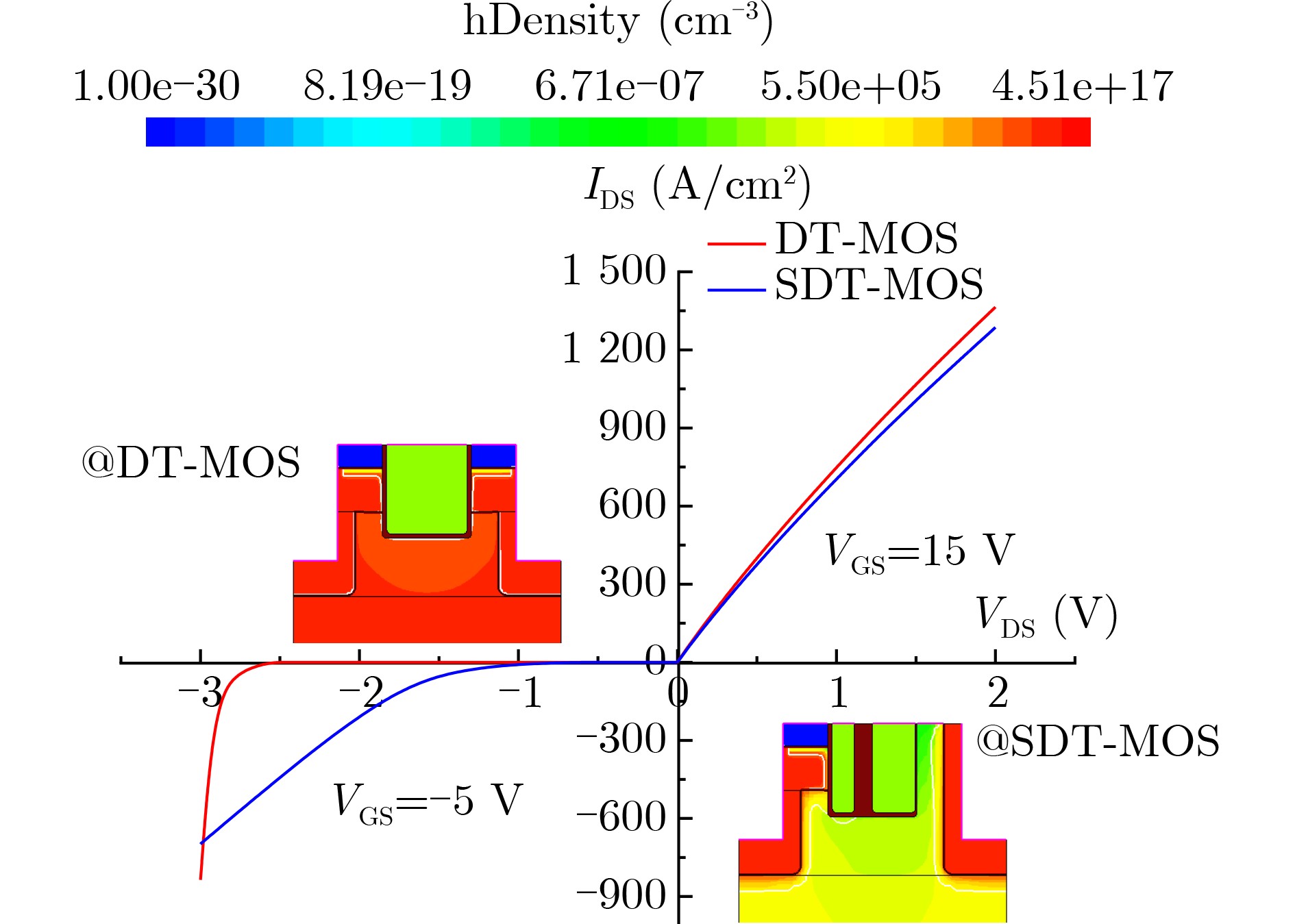
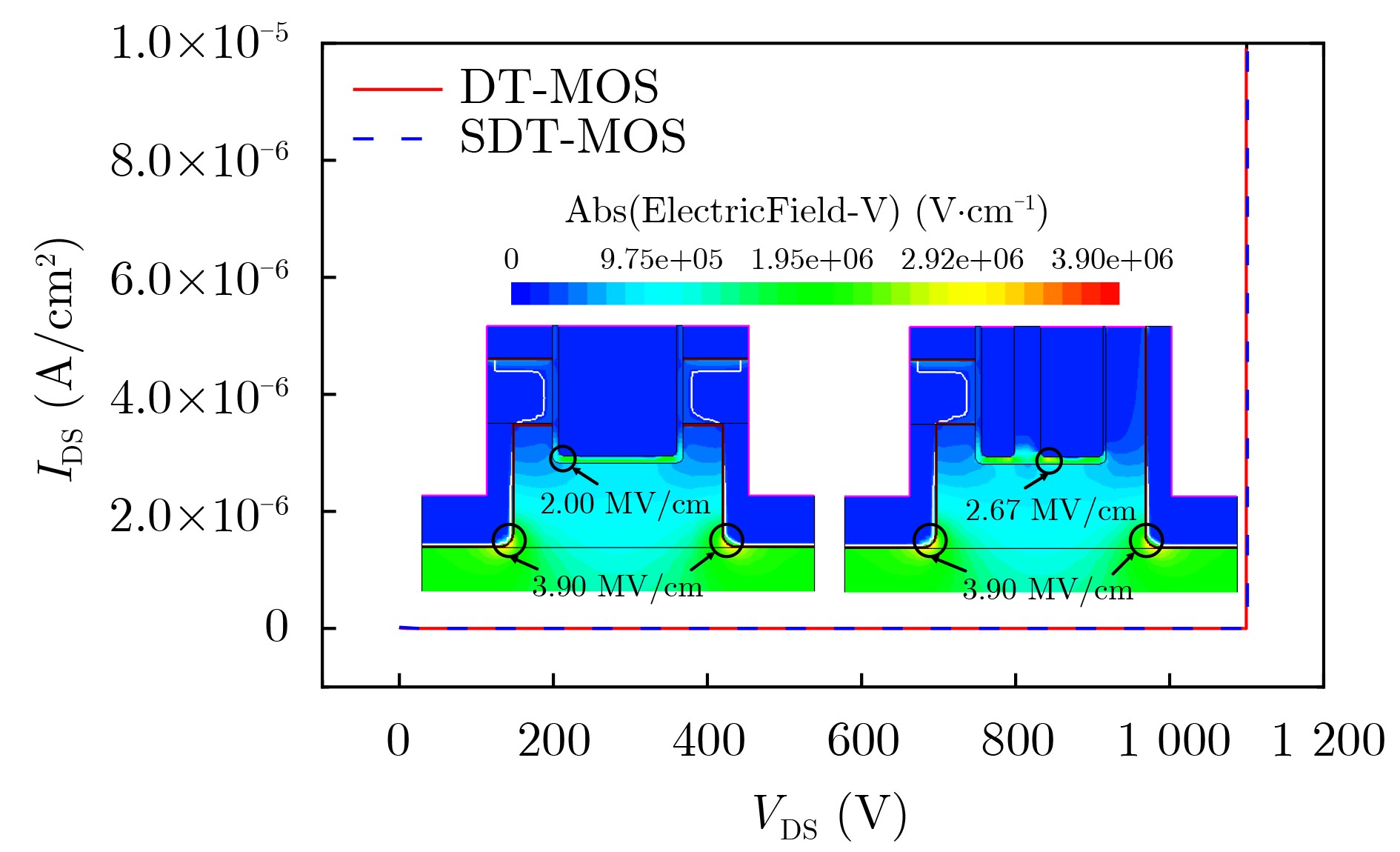
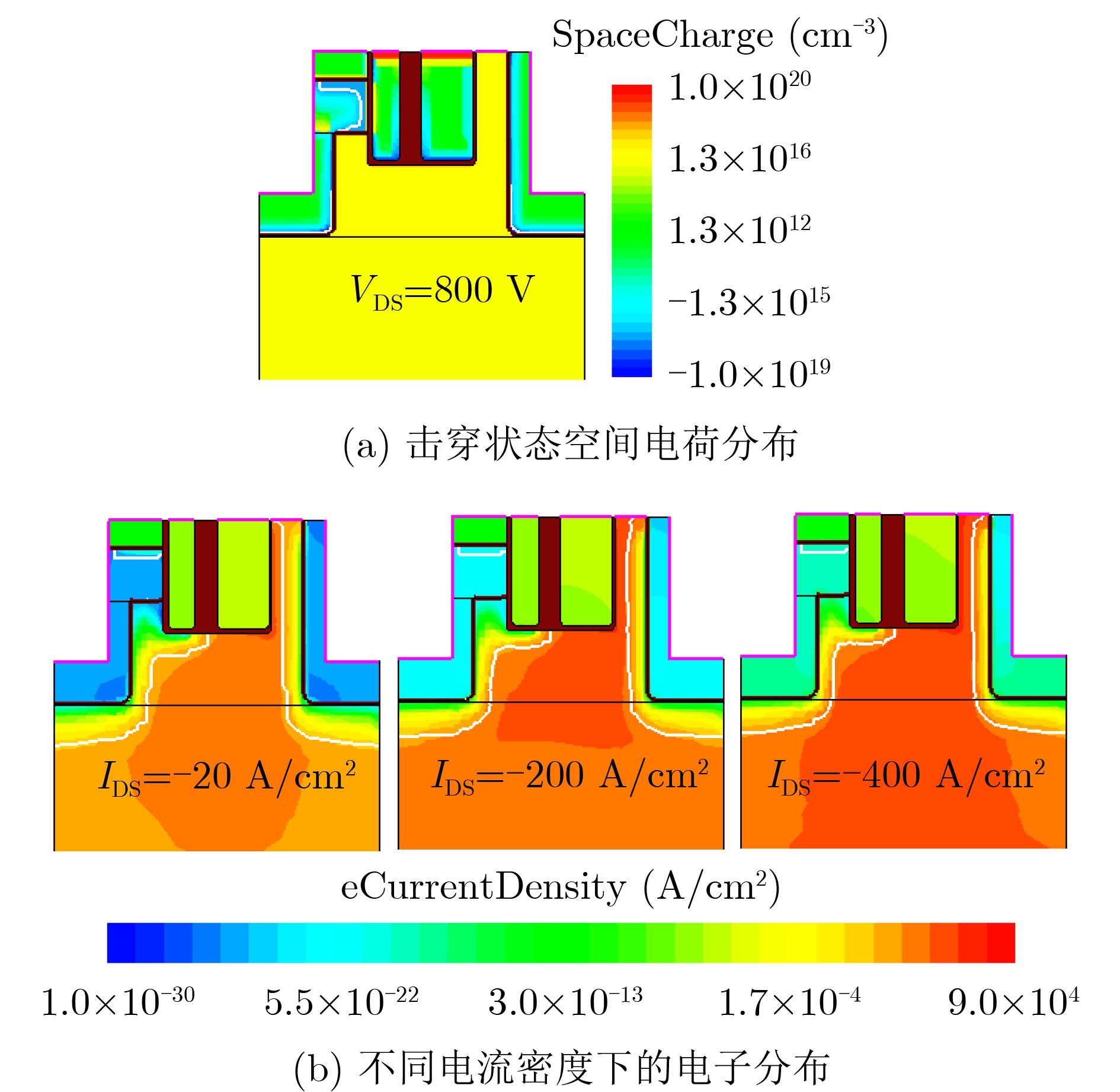
2025, 47(9): 3241-3251.
doi: 10.11999/JEIT250366
摘要:
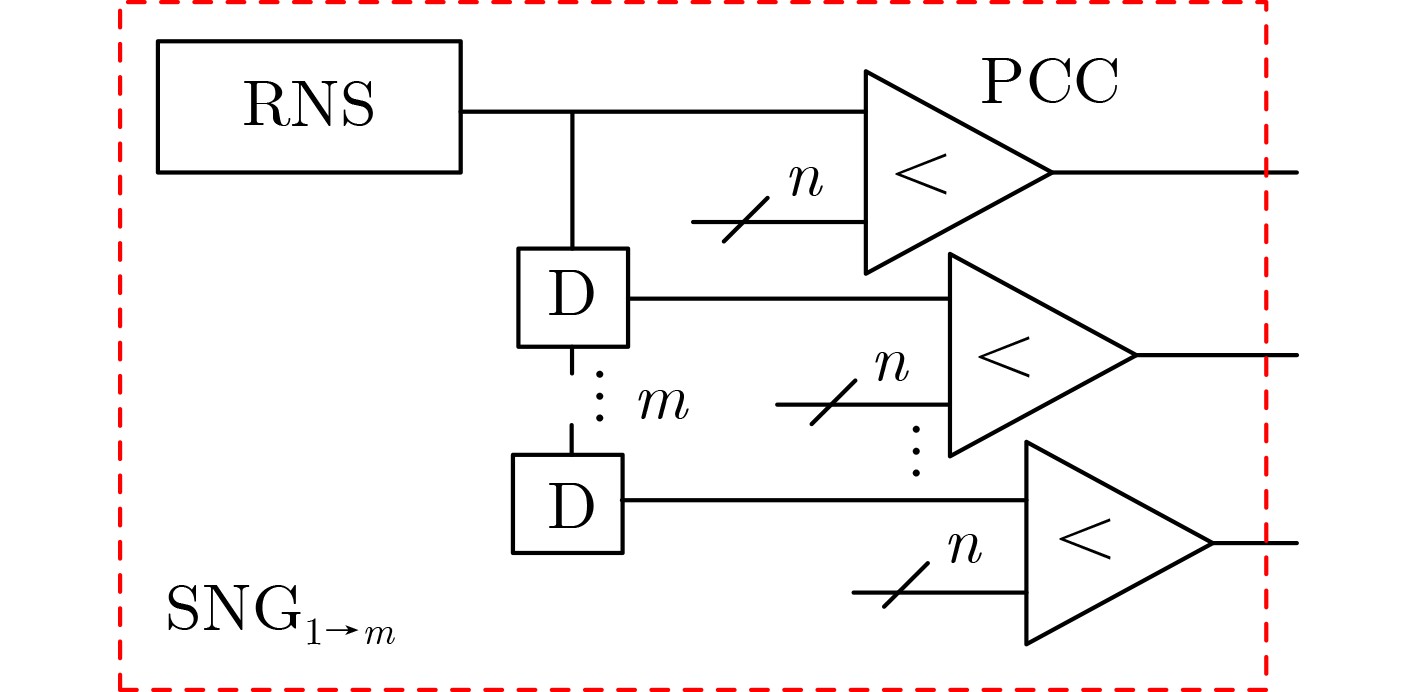
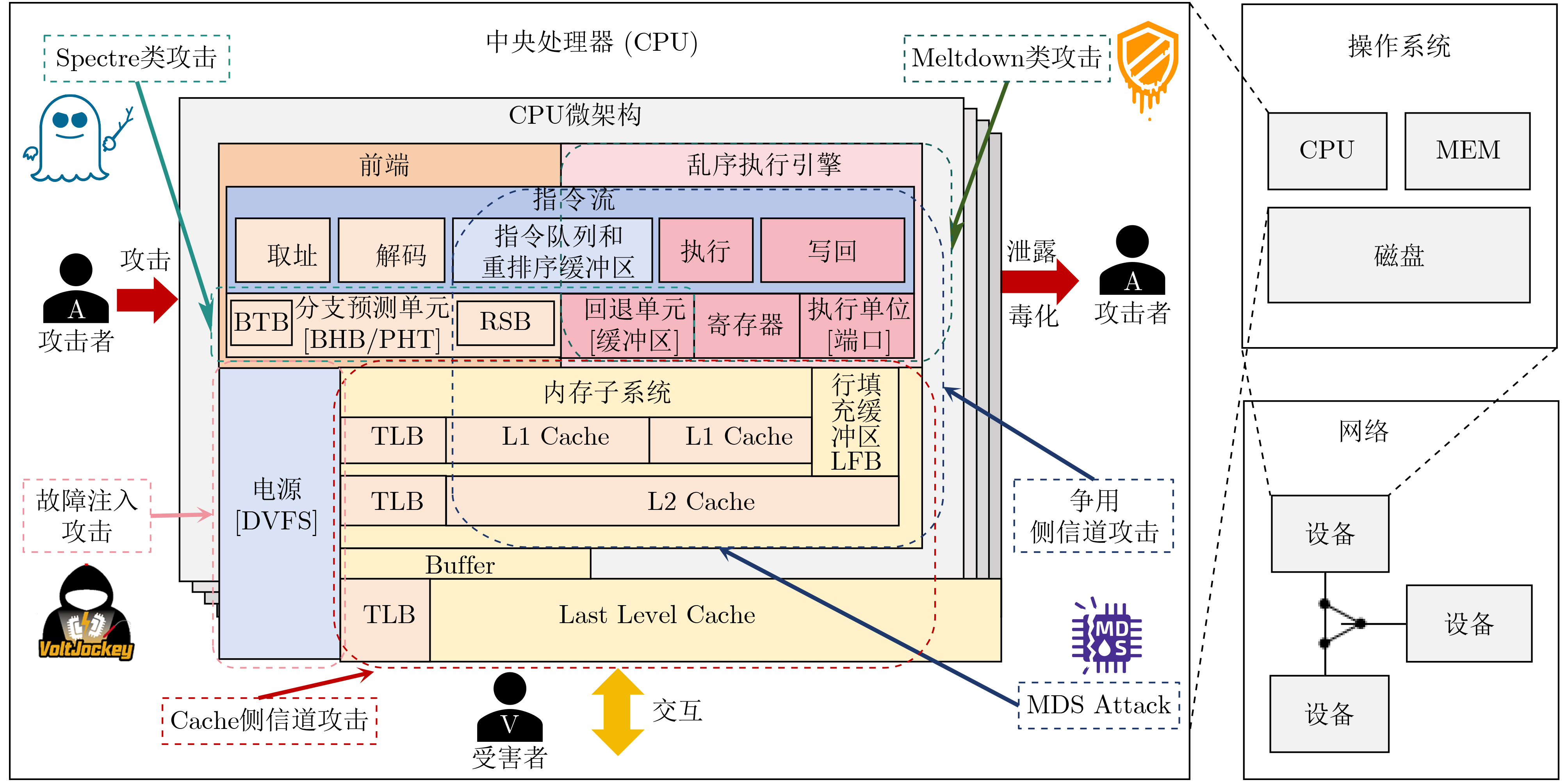
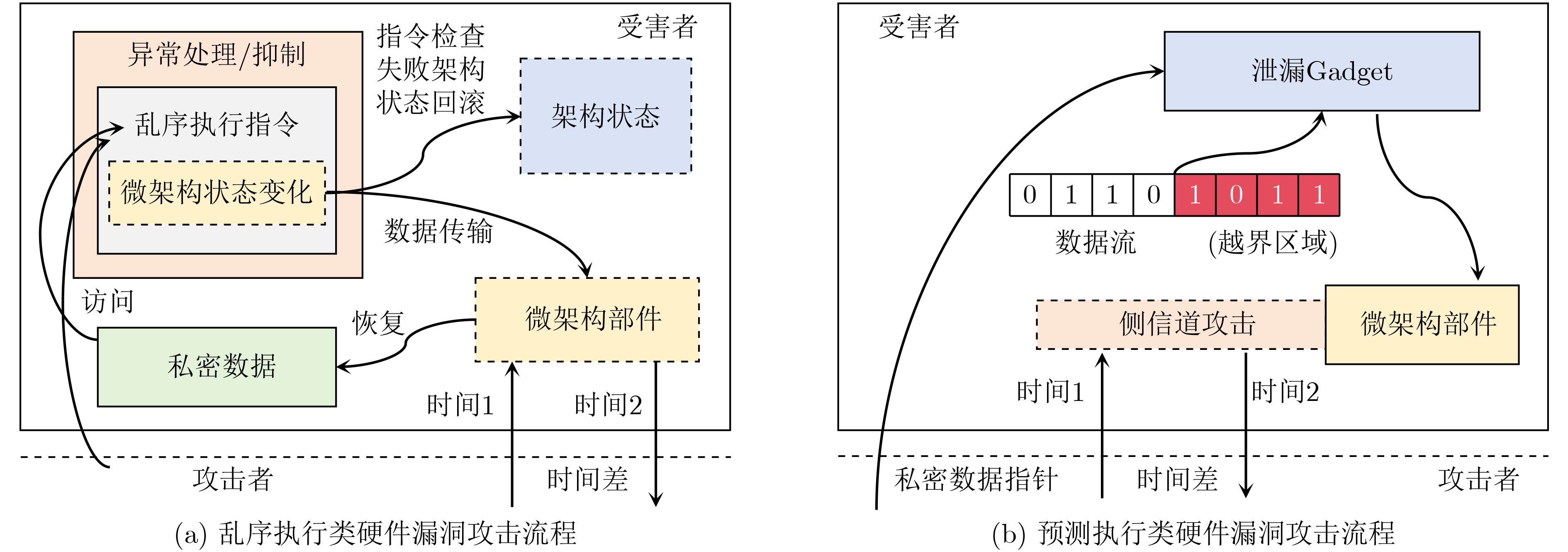
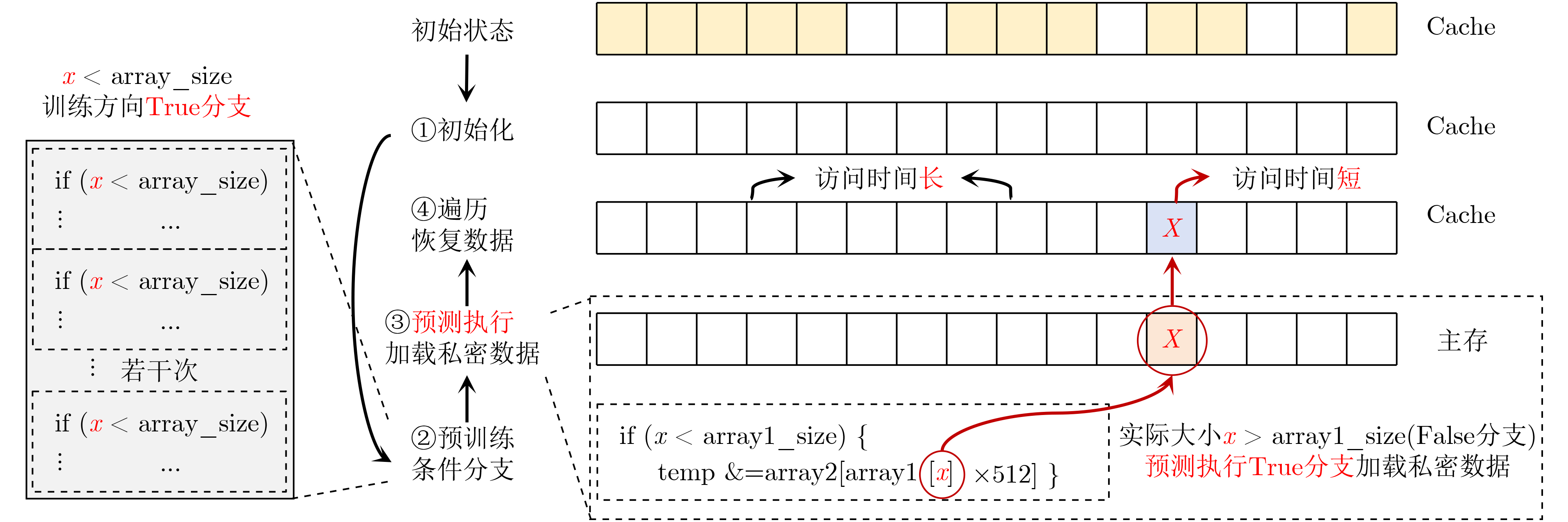
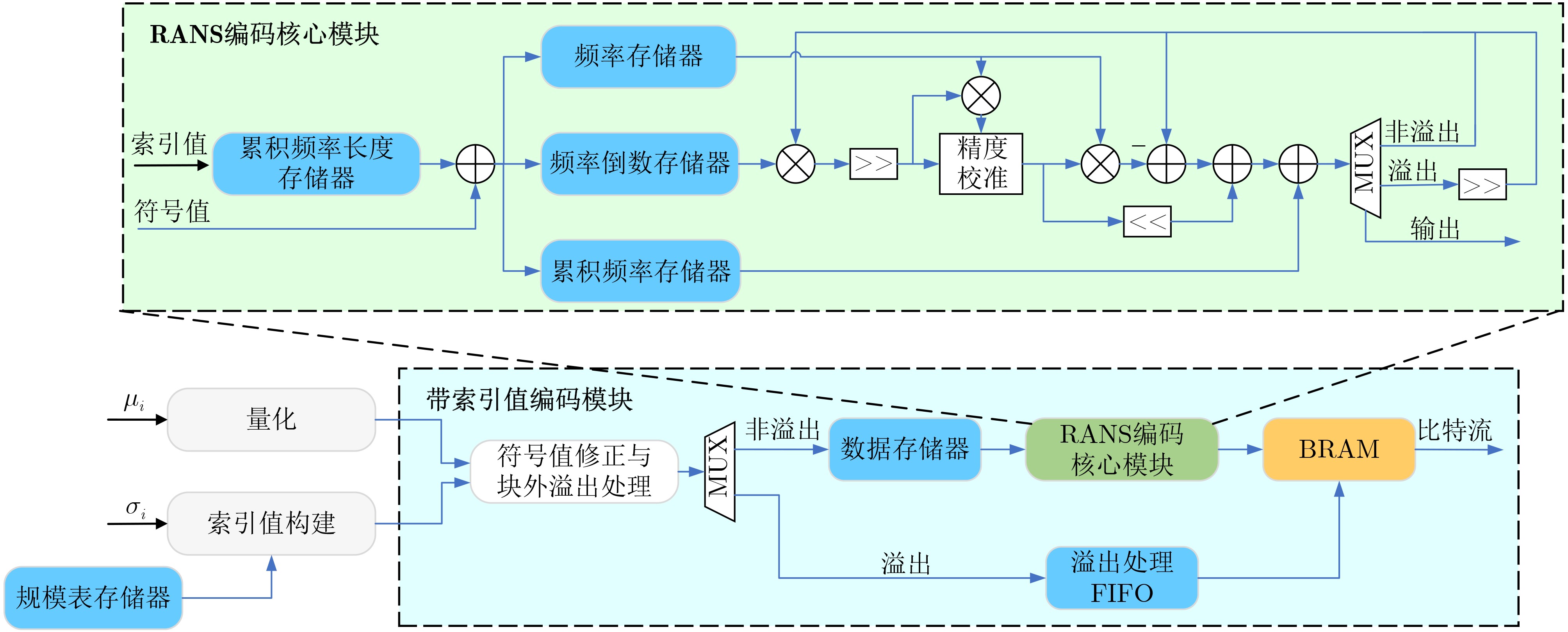
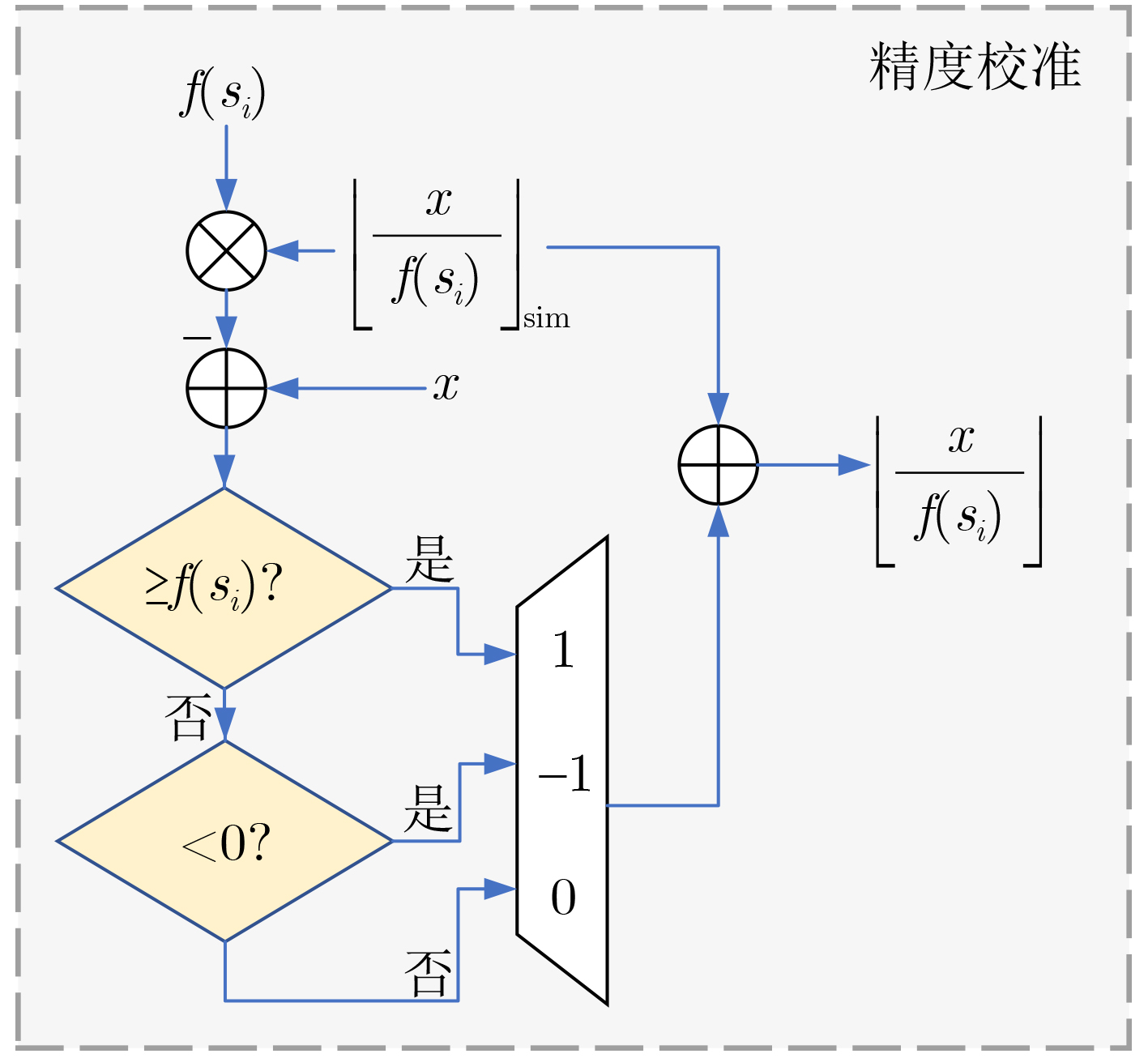
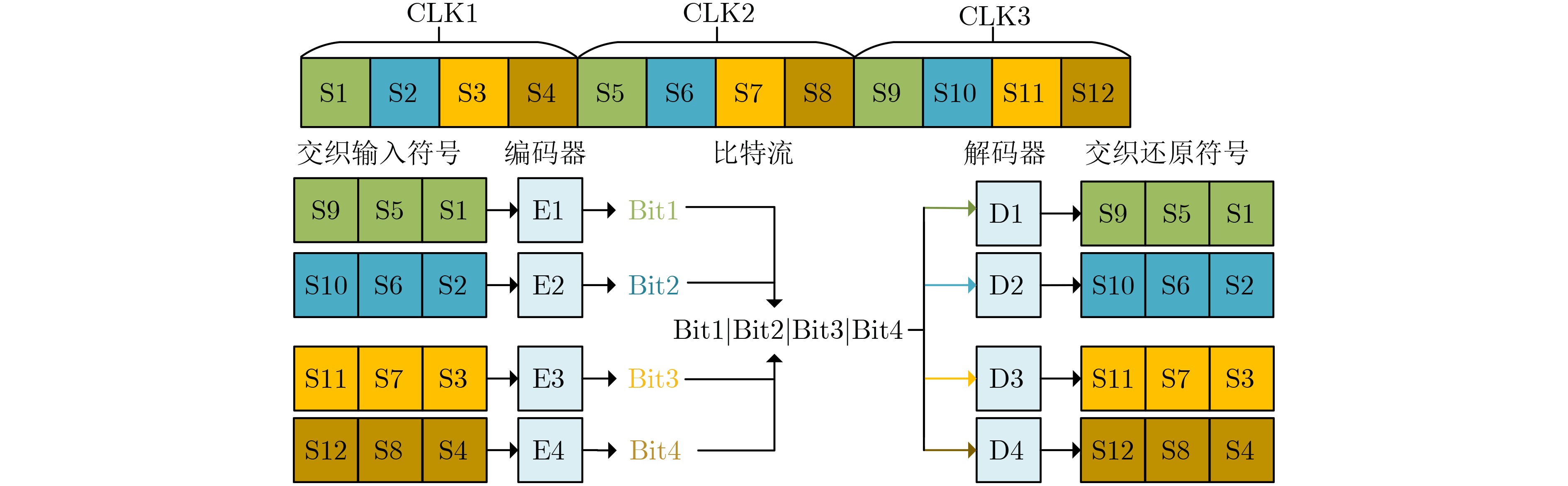
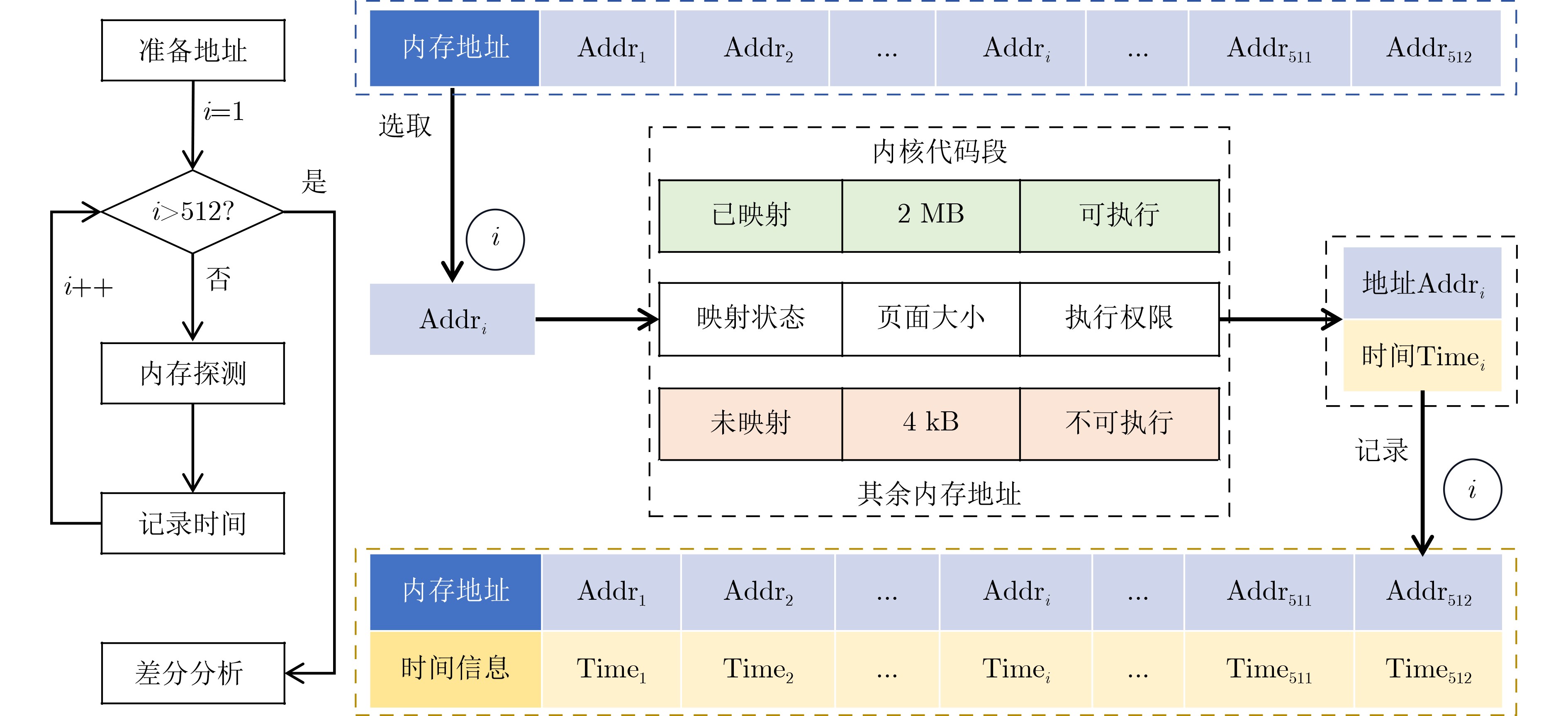
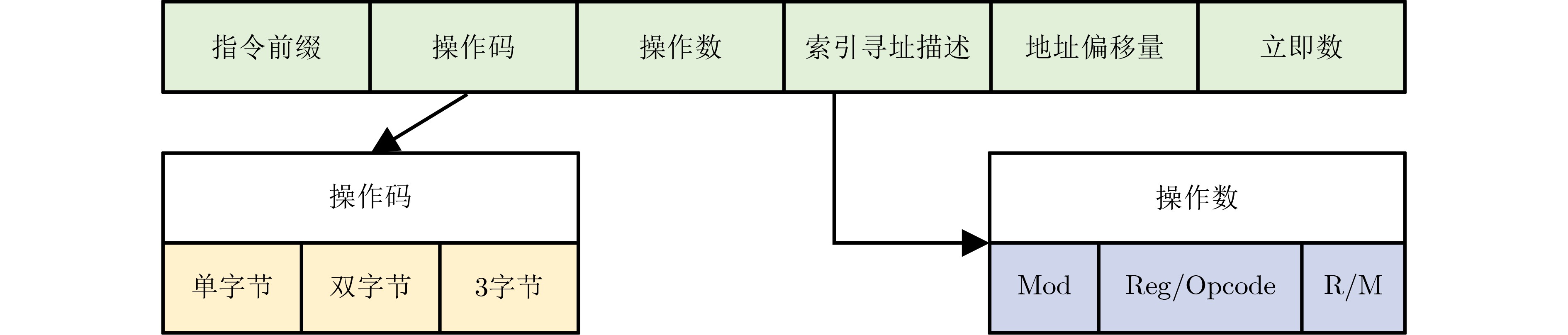
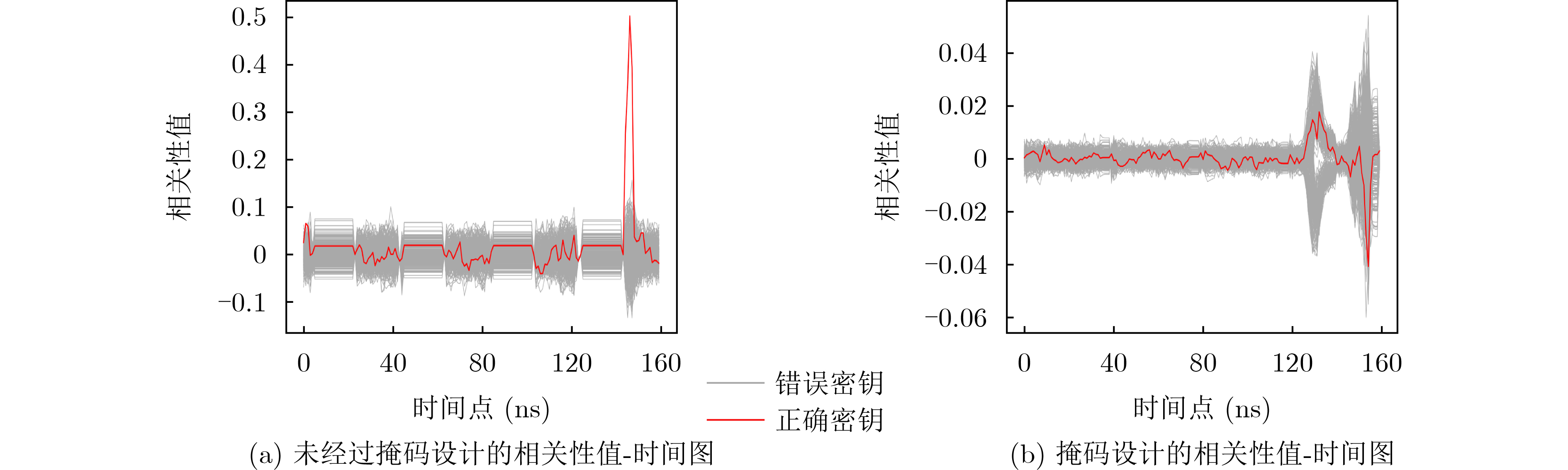
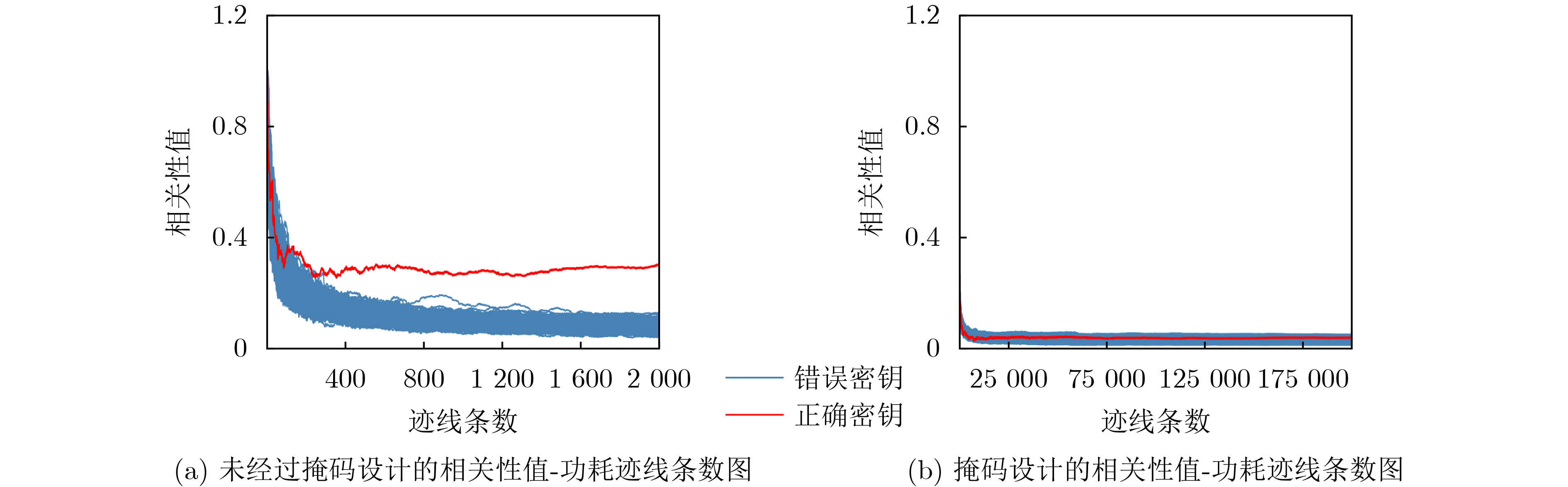
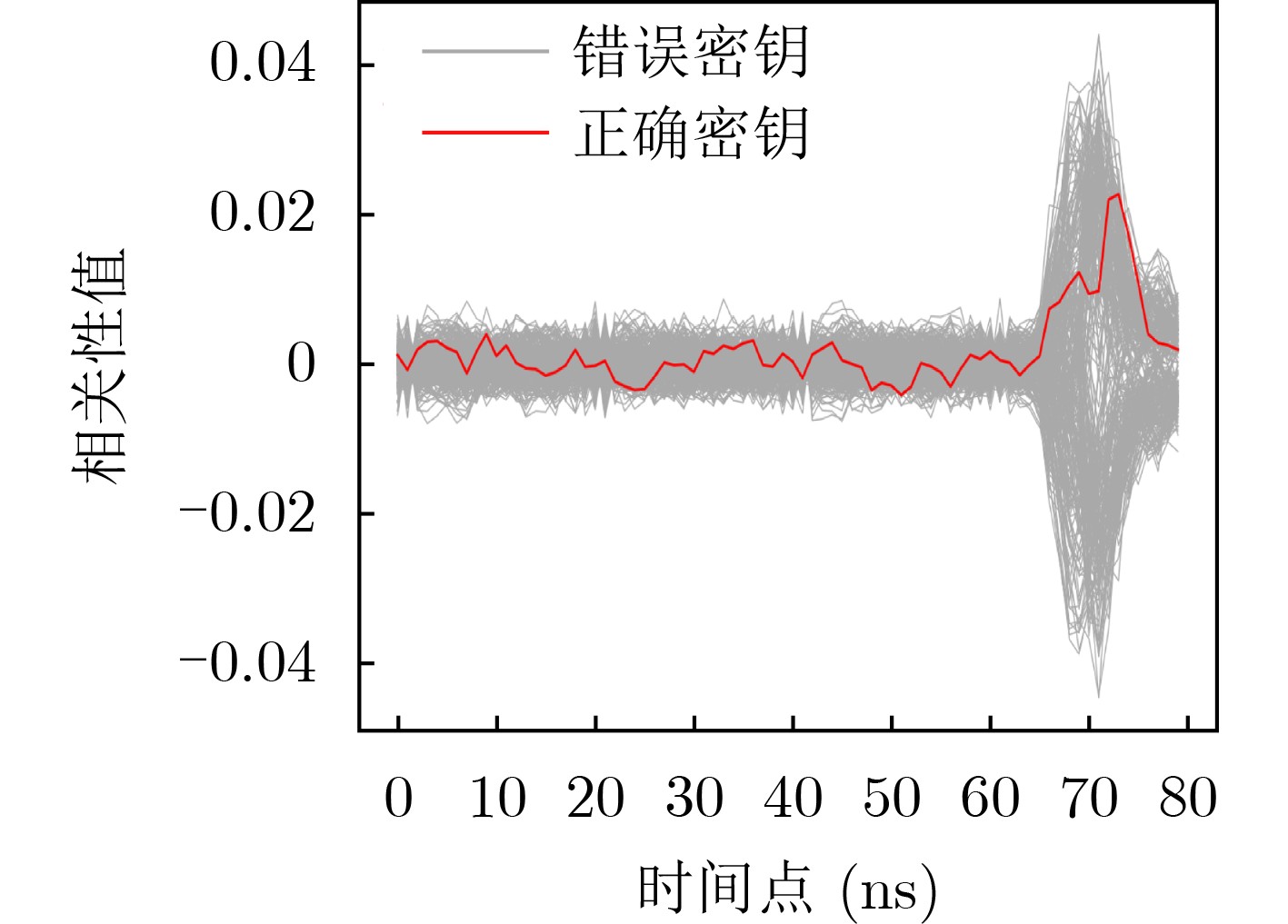
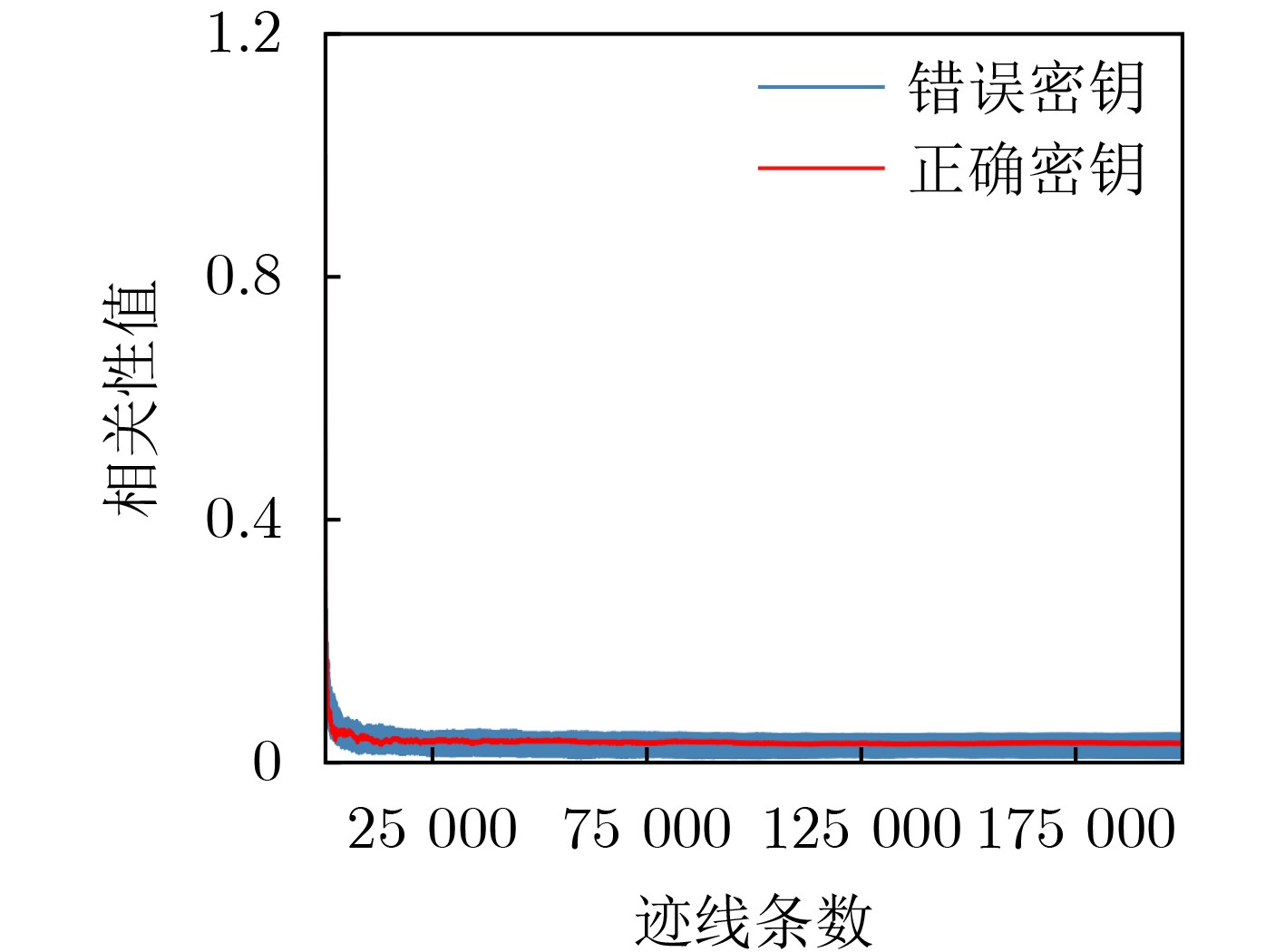
现代操作系统采用内核地址空间随机化(KASLR)技术来抵御内核代码重用攻击。处理器微架构侧信道能够泄露内核代码段的页表信息,进而可以被用来绕过KASLR保护,但是现有研究局限于MOV, CMASKMOV, PREFETCHNTA和CLDEMOTE等少数的几条指令来探测内核地址,攻击面有限。为系统评估KASLR攻击面,该文从指令多样性出发,设计一个自动化分析框架,挖掘可以绕过KASLR保护并暴露计算机系统安全脆弱性的指令。该框架不需要逆向微架构部件的实现细节,专注于攻击任务本身,首先将攻击流程抽象为环境准备、内存探测、微架构信息记录和差分分析4个阶段,然后定位绕过KASLR保护的关键攻击代码,最后研究不同指令在替换关键代码后的攻击效果。该文分别从指令的汇编形式和字节形式出发提出两套KASLR攻击面的评估算法,互相验证和补充。实验结果表明,该文在Intel x86指令集挖掘出699条可实现KASLR绕过的汇编指令,相比现有研究依赖的6条指令,实现了KASLR脆弱性指令的跨数量级增长。此外,从字节形式出发的实验数据表明,Intel x86指令集有39个单字节操作码、121个双字节操作码和24个3字节操作码指令可以实现KASLR绕过。该文的发现不仅显著扩展了KASLR的攻击面,更为基于特征检测的防御机制带来挑战和新思路。