

A Joint Fault and Congestion-Aware Adaptive Routing Algorithm for Chiplet Interconnect Networks
-
摘要: 芯粒技术作为后摩尔时代提升计算性能与实现异构集成的关键途径,其内部互连网络的性能与可靠性直接影响系统整体效能。然而,芯粒互连网络面临链路故障频发与动态网络拥塞并发存在且相互耦合的严峻挑战,难以满足高性能和高可靠芯粒系统的需求。针对此问题,该文提出一种故障与拥塞联合感知自适应路由算法,通过实时感知链路故障状态与网络拥塞程度,创新性地构建了综合评估故障、拥塞及距离因素的联合代价函数,动态地选择最优路径。通过详细的仿真评估,与多种基准算法对比,结果表明:该算法能够显著降低平均包延迟,提高网络饱和吞吐率。尤其在高故障率和非均衡流量等恶劣条件下展现出优越的性能和鲁棒性。基于65 nm工艺的硬件综合与功耗分析显示,该算法体现了良好的性能和成本效益。研究表明,该算法为应对芯粒互连网络中故障与拥塞并发的关键挑战提供了一种有效且实用的解决方案。Abstract:
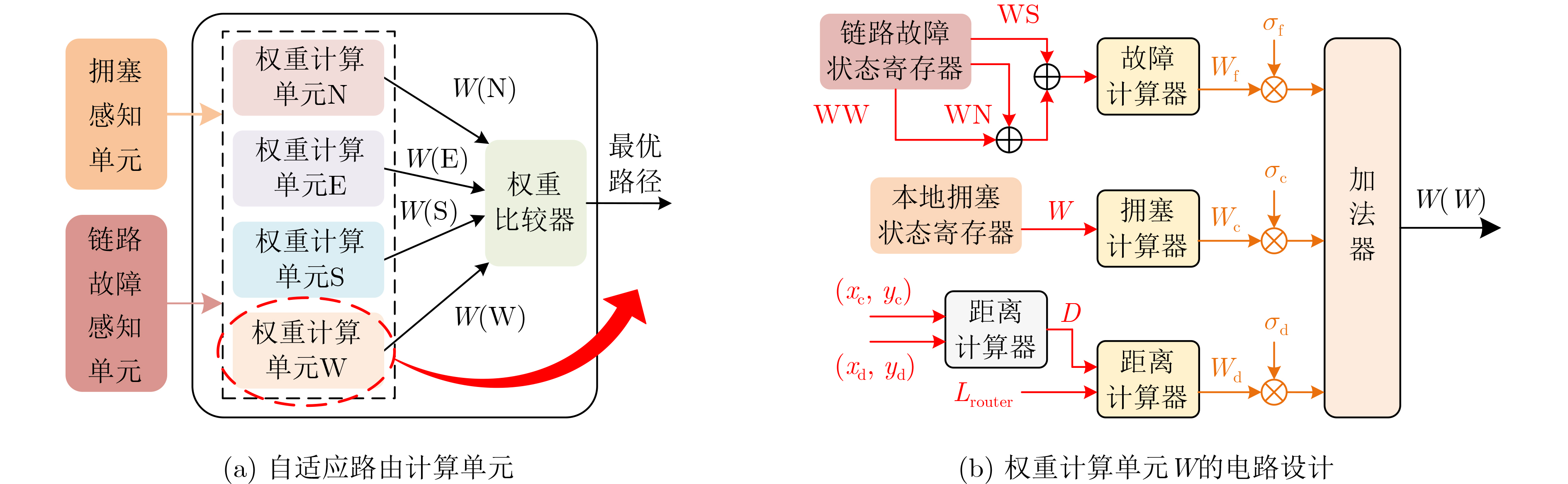
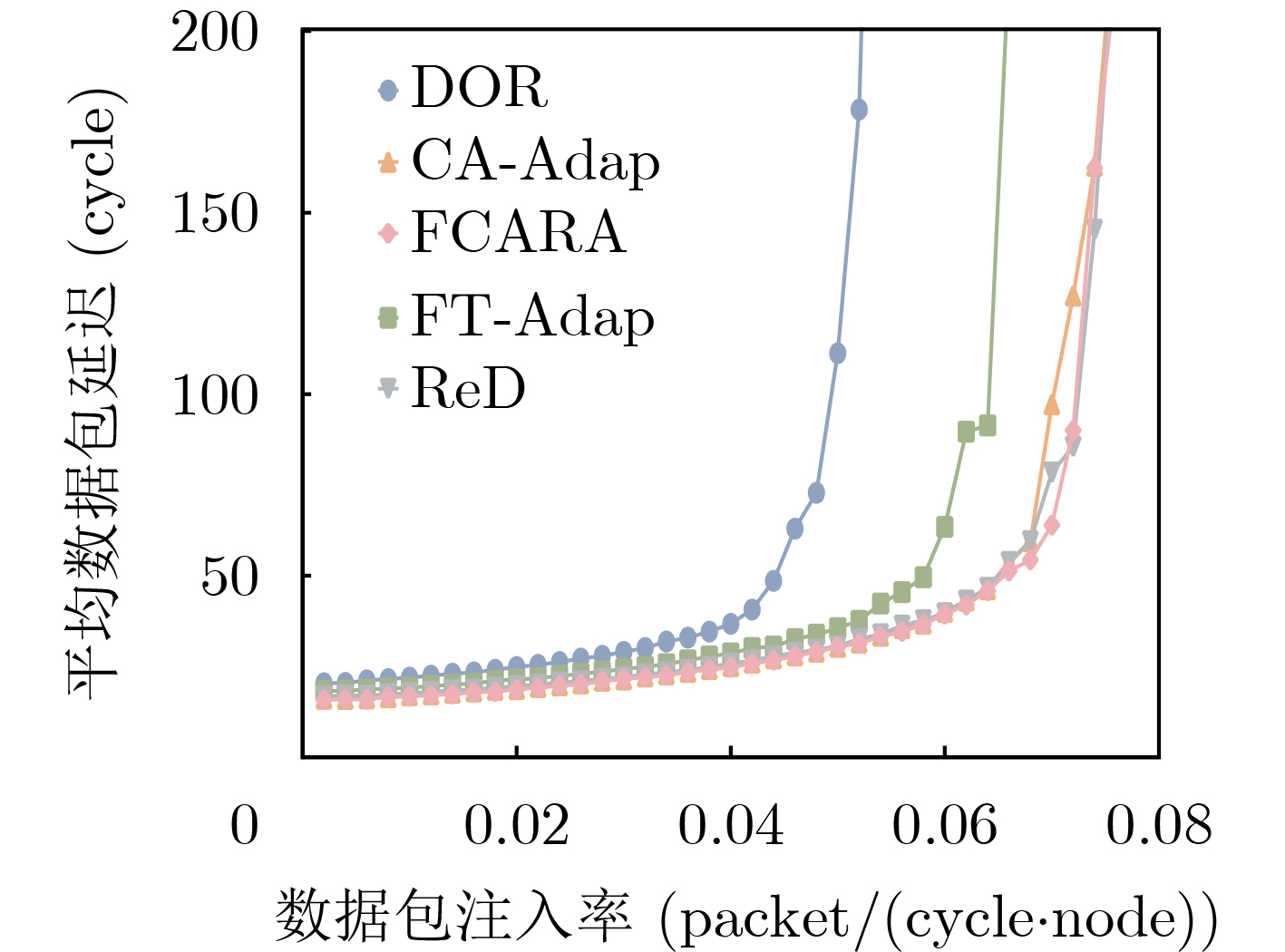
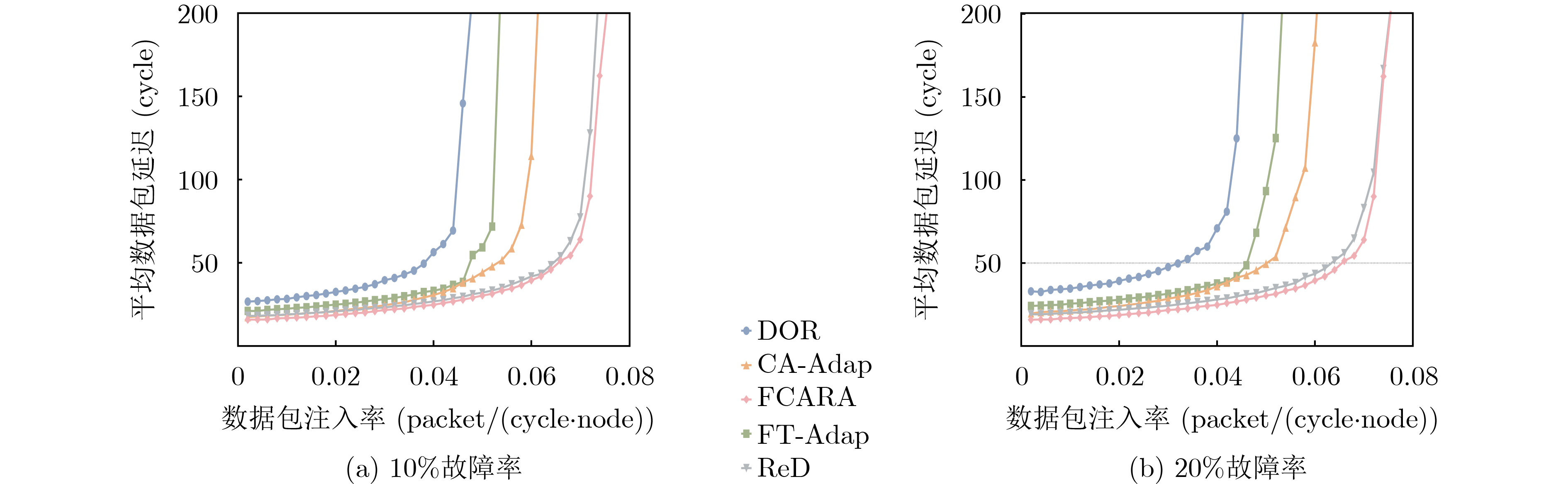
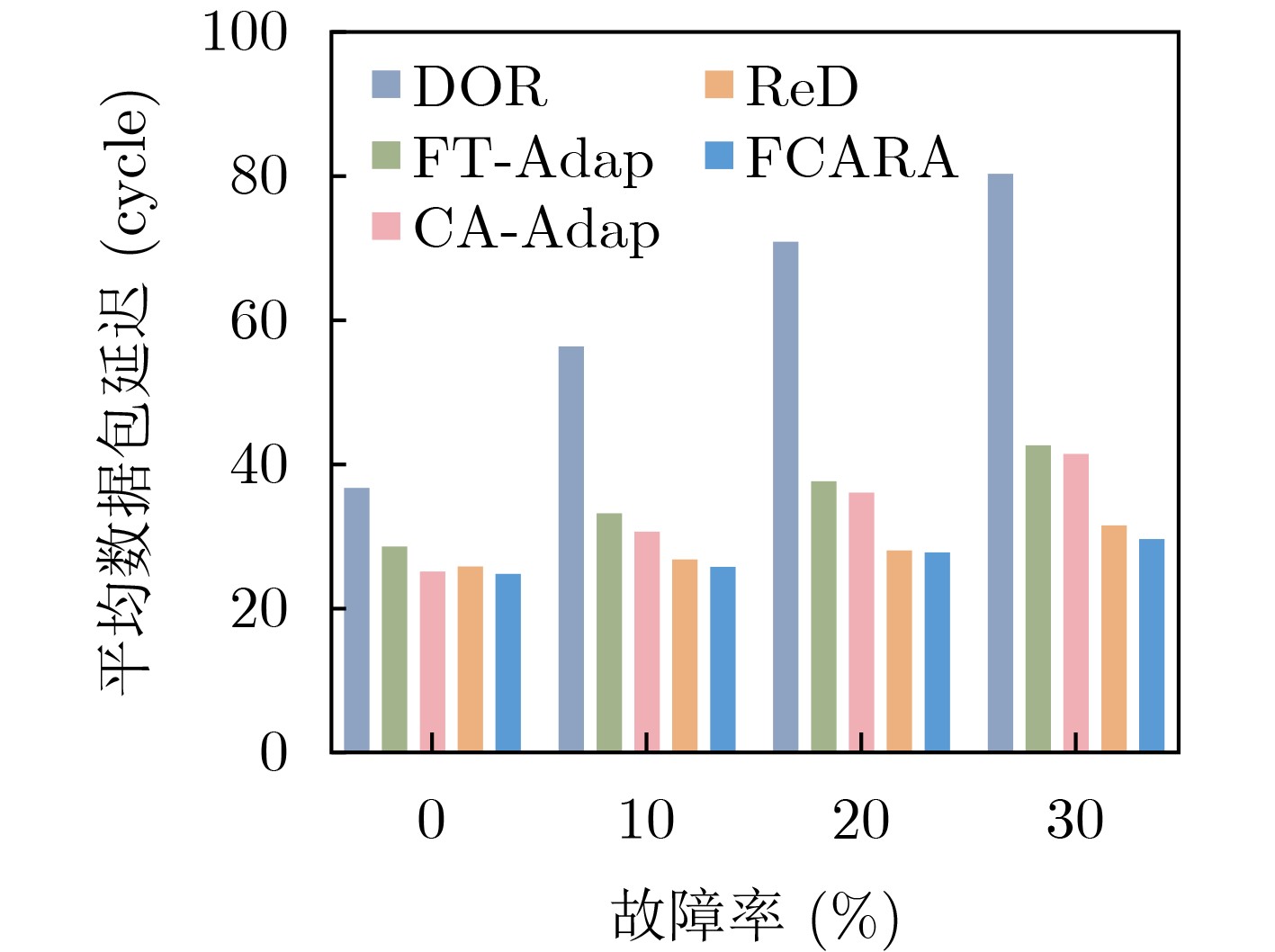
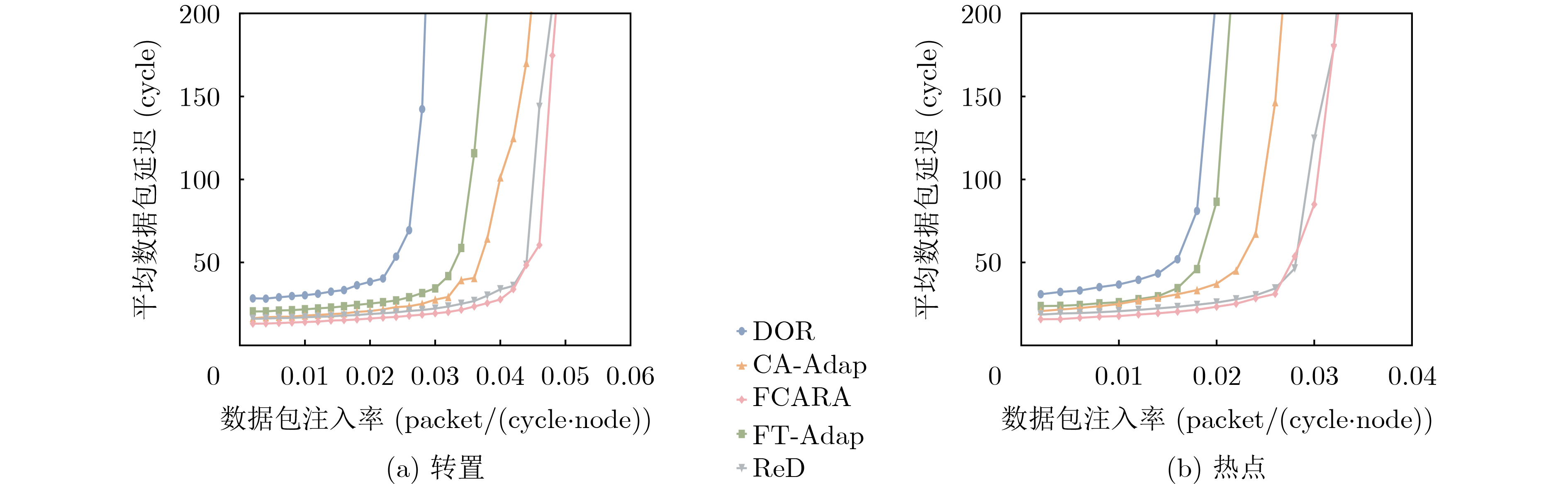
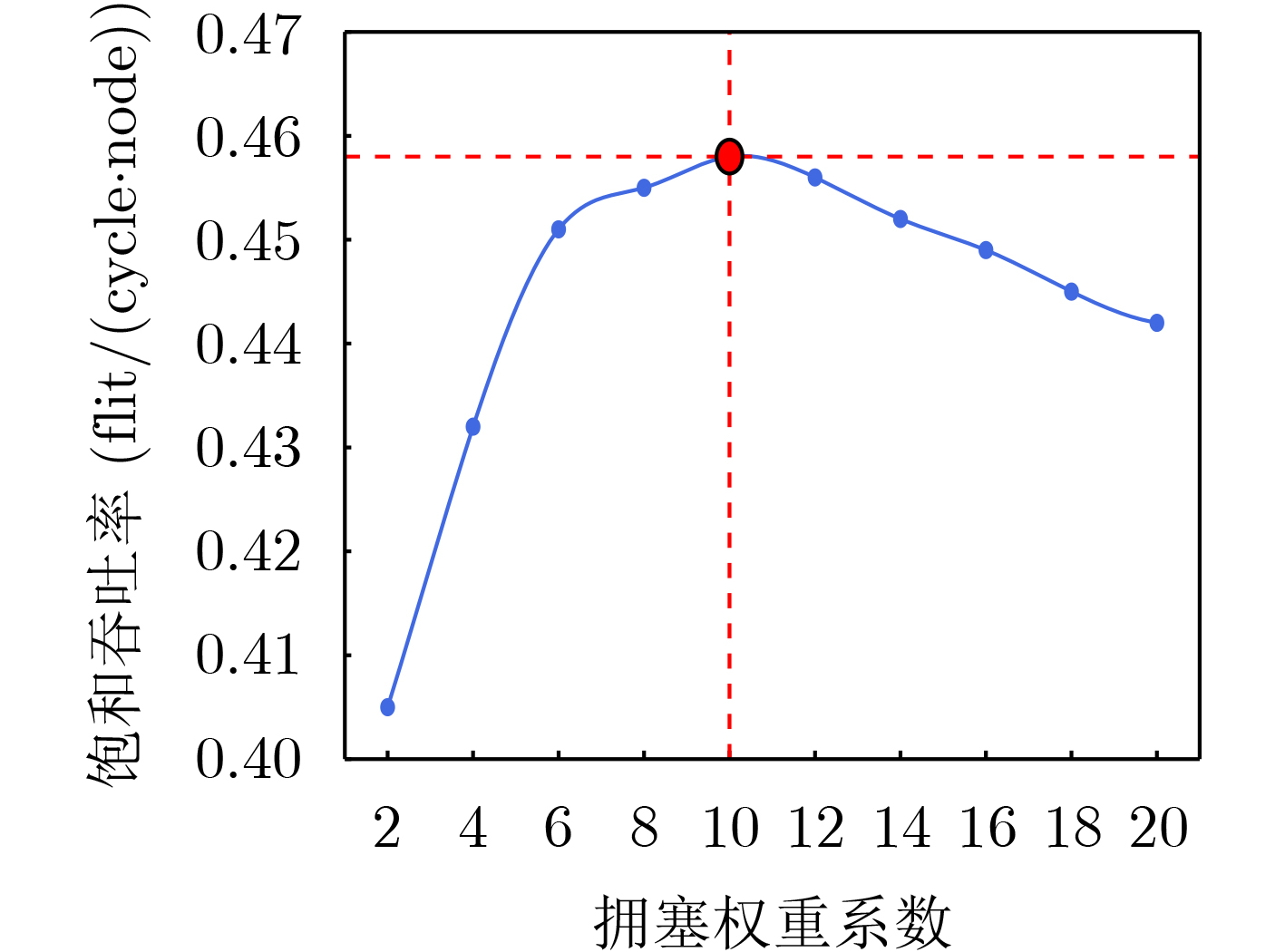
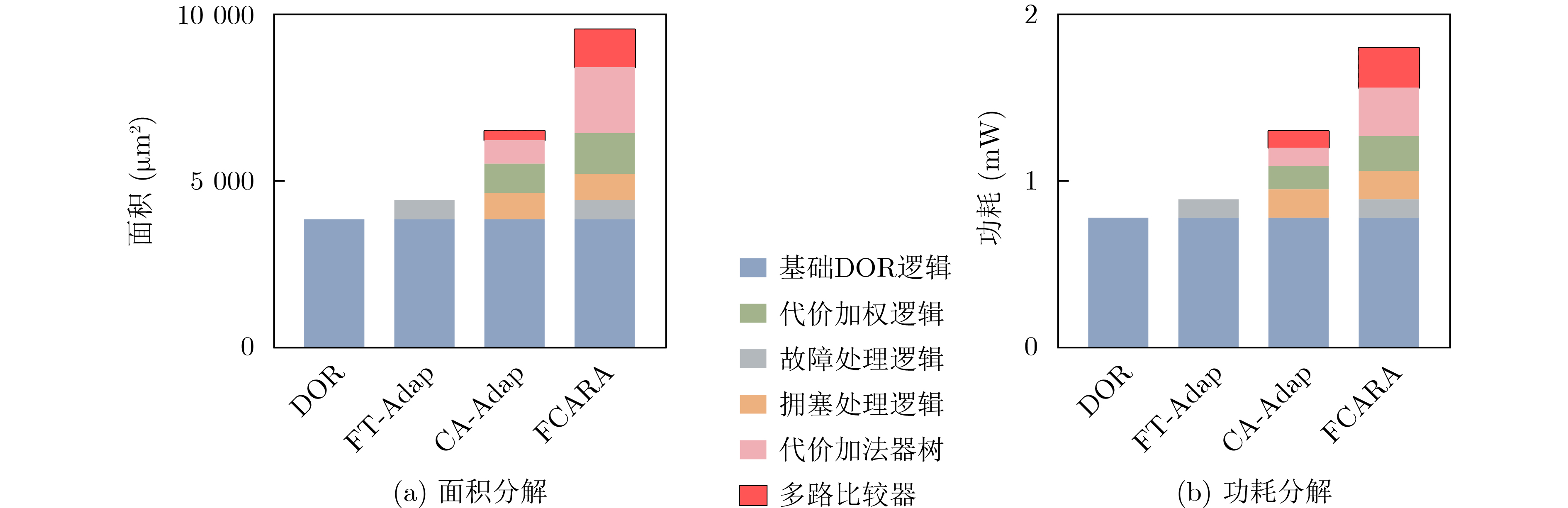
As a key approach to enhancing computing performance and enabling heterogeneous integration in the post-Moore era, chiplet technology relies heavily on the efficiency and reliability of its internal interconnection networks. However, these networks face severe challenges, as frequent link failures and dynamic congestion often coexist and interact, making it difficult to meet the requirements of high-performance and high-reliability systems. To address this issue, this paper proposes a joint Fault- and Congestion-aware Adaptive Routing Algorithm (FCARA). By sensing link status and congestion levels in real time, the algorithm constructs a joint cost function that integrates fault, congestion, and distance factors to dynamically select the optimal path. Simulation-based evaluations and comparisons with benchmark algorithms show that the proposed method markedly reduces average packet delay and improves network saturation throughput. It demonstrates particularly strong performance and robustness under high fault rates and unbalanced traffic conditions. Hardware synthesis and power analysis based on a 65 nm process confirm that the algorithm achieves favorable trade-offs between performance and cost. These findings indicate that the proposed algorithm offers an effective and practical solution to the concurrent challenges of faults and congestion in chiplet interconnect networks. Objective With the rapid advancement of chiplet technology as a key solution for post-Moore era computing, the performance and reliability of its internal interconnect network (NoC) have become critical determinants of overall system efficiency. However, chiplet NoCs face unique challenges arising from the concurrent occurrence and coupling of frequent link faults, caused by advanced packaging and high-density interconnects, and dynamic network congestion. Existing routing algorithms typically address these issues in isolation: fault-tolerant methods often overlook the performance degradation introduced by detours under congestion, whereas congestion-aware methods generally assume fault-free networks and fail to adapt when faults occur. These limitations hinder the realization of truly high-performance and highly reliable chiplet systems. Therefore, developing an adaptive routing algorithm that simultaneously and effectively addresses both link faults and network congestion in chiplet interconnects is a crucial requirement. Methods To address the challenge, a joint FCARA is proposed for chiplet NoCs. The method is based on real-time, distributed perception of the network state at each router. Information on the fault status of local outgoing links (e.g., normal, partial fault, complete fault) and the congestion level of the input port at the next-hop router is collected. A joint cost function is then employed to quantitatively evaluate potential next-hop directions by integrating three weighted factors: severity of link fault, degree of downstream congestion, and distance to the destination. Using the calculated costs for all available deadlock-free paths, the optimal path with the lowest cost is dynamically selected for forwarding incoming flits. The effectiveness of FCARA is evaluated through extensive cycle-accurate simulations on the ChipletSimulator platform. Performance is compared with baseline algorithms including Dimension-Order Routing (DOR), a representative Fault-tolerant Adaptive Algorithm (FT-Adap), and a representative Congestion-aware Adaptive Algorithm (CA-Adap). Hardware overhead is further assessed through RTL modeling and synthesis using a commercial 65 nm standard cell library, and power consumption is analyzed with Synopsys tools. Results and Discussions Simulation results demonstrate the clear advantages of the proposed FCARA algorithm. Across a wide range of fault rates (0%~30%) and traffic patterns, FCARA consistently outperforms baseline algorithms in key performance metrics. In particular, it achieves markedly lower average packet latency and higher network saturation throughput ( Fig. 6 ,Fig. 7 ). The performance gap becomes especially pronounced under harsh conditions such as high fault rates (≥20%) and non-uniform traffic loads (Fig. 9 ), highlighting FCARA’s robustness. This improvement results from its joint cost function and adaptive decision-making, which enable it to simultaneously bypass faulty links and congested regions (Algorithm 1). Hardware overhead analysis, based on synthesis and power estimation (Table 2 ,Table 3 ), shows that FCARA increases router area by 13.1% and total power consumption by 15.6% compared with the baseline DOR router.Conclusions This study developed and evaluated FCARA, a novel adaptive routing strategy tailored for chiplet interconnect networks operating under concurrent link faults and network congestion. The results demonstrate that by jointly incorporating fault and congestion information into routing decisions, FCARA substantially improves network performance in terms of latency and throughput while enhancing robustness compared with conventional approaches that address these issues separately. With its proven effectiveness and moderate hardware overhead, FCARA offers a practical and efficient solution for achieving high-performance, high-reliability communication in next-generation chiplet-based systems. -
Key words:
- Chiplet /
- Interconnect network /
- Adaptive routing /
- Fault tolerance /
- Congestion awareness
-
1 FCARA Route Computation
输入:c, d, p, $ {\mathit{F}}_{\rm{c}\rm{o}\rm{d}\rm{e}} $, $ {\mathit{C}}_{\rm{s}\rm{t}\rm{a}\rm{t}\rm{u}\rm{s}} $ 1. CandidateDirs = GetDirections(c, d); 2. MinWeight = INF; 3. for each dir in CandidateDirs do 4. if ! IsDeadlock(p.currentVC, dir) then 5. $ {W}_{\mathrm{f}} $ = FaultCost($ {F}_{\mathrm{c}\mathrm{o}\mathrm{d}\mathrm{e}} $(dir)); 6. if $ {W}_{\mathrm{f}} $ == INF then 7. continue; 8. $ {W}_{\mathrm{c}} $ = CongestionCost($ {C}_{\mathrm{s}\mathrm{t}\mathrm{a}\mathrm{t}\mathrm{u}\mathrm{s}}\left(\mathrm{d}\mathrm{i}\mathrm{r}\right) $); 9. $ {W}_{\mathrm{d}} $ = DistanceCost(c, d, dir); 10. $ W={\sigma }_{\mathrm{f}}\times {W}_{\mathrm{f}}+{\sigma }_{\mathrm{c}}\times {W}_{\mathrm{c}}+{\sigma }_{\mathrm{d}}\times {W}_{\mathrm{d}} $; 11. if $ W $ < MinWeight then 12. MinWeight = $ W $; 13. SelectedDir = dir; 14. $ {\mathrm{n}\mathrm{e}\mathrm{x}\mathrm{t}}_{\mathrm{d}\mathrm{i}\mathrm{r}} $ = SelectedDir; 输出:$ {\rm{n}\rm{e}\rm{x}\rm{t}}_{\rm{d}\rm{i}\rm{r}} $  下载: 导出CSV
下载: 导出CSV
表 1 仿真参数配置
参数 值 芯粒数量 4 芯粒和基板网络尺寸 4×4 Mesh 虚通道数量 4 缓冲区深度 8 flit Flit位宽 64 bit 数据包大小 1~5 flit 预热时间 1000 周期仿真时间 20000 周期流量模式 均匀随机、转置、热点
下载: 导出CSV
表 2 不同路由算法下主要组件的面积开销(μm2)
主要组件 DOR FT-Adap CA-Adap FCARA 相对值(vs. DOR)(%) 输入缓冲区 29875.5 29875.5 29875.5 29875.5 100.0 路由计算单元 3850.2 4420.8 6510.5 9550.7 248.1 虚通道分配器 3420.1 3475.3 3580.6 3710.9 108.5 交换仲裁器 3420.1 3475.3 3580.6 3710.9 108.5 交叉开关 7450.3 7450.3 7450.3 7450.3 100.0 其他控制逻辑 1480.6 1530.1 1585.2 1670.1 112.8 总面积 49496.8 50227.3 52582.7 55968.4 113.1
下载: 导出CSV
表 3 不同路由算法下主要组件的功耗开销(mW)
主要组件 DOR FT-Adap CA-Adap FCARA 相对值(vs. DOR)(%) 输入缓冲区 3.95 3.97 4.03 4.08 103.3 路由计算单元 0.78 0.89 1.30 1.80 230.8 虚通道分配器 0.88 0.90 0.95 0.99 112.5 交换仲裁器 0.88 0.90 0.95 0.99 112.5 交叉开关 2.95 2.96 2.98 3.01 102.0 其他控制逻辑 0.39 0.41 0.45 0.49 125.6 总功耗 9.83 10.03 10.66 11.36 115.6
下载: 导出CSV
-
[1] 陈云霁, 蔡一茂, 汪玉, 等. 集成电路未来发展与关键问题——第347期“双清论坛(青年)”学术综述[J]. 中国科学: 信息科学, 2024, 54(1): 1–15. doi: 10.1360/SSI-2023-0356.CHEN Yunji, CAI Yimao, WANG Yu, et al. Integrated circuit technology: Future development and key issues–review of the 347th “Shuangqing Forum(Youth)”[J]. Scientia Sinica Informationis, 2024, 54(1): 1–15. doi: 10.1360/SSI-2023-0356. [2] 王梦迪, 王颖, 刘成, 等. Puzzle: 面向深度学习集成芯片的可扩展框架[J]. 计算机研究与发展, 2023, 60(6): 1216–1231. doi: 10.7544/issn1000-1239.202330059.WANG Mengdi, WANG Ying, LIU Cheng, et al. Puzzle: A scalable framework for deep learning integrated chips[J]. Journal of Computer Research and Development, 2023, 60(6): 1216–1231. doi: 10.7544/issn1000-1239.202330059. [3] 李韬, 杨惠, 厉俊男, 等. ChipletNP: 基于芯粒的敏捷可定制网络处理器架构[J]. 计算机研究与发展, 2024, 61(12): 2952–2968. doi: 10.7544/issn1000-1239.202220998.LI Tao, YANG Hui, LI Junnan, et al. ChipletNP: Chiplet-based agile customizable network processor architecture[J]. Journal of Computer Research and Development, 2024, 61(12): 2952–2968. doi: 10.7544/issn1000-1239.202220998. [4] 李雯, 王颖, 何银涛, 等. SMCA: 基于芯粒集成的存算一体加速器扩展框架[J]. 电子与信息学报, 2024, 46(11): 4081–4091. doi: 10.11999/JEIT240284.LI Wen, WANG Ying, HE Yintao, et al. SMCA: A framework for scaling chiplet-based computing-in-memory accelerators[J]. Journal of Electronics & Information Technology, 2024, 46(11): 4081–4091. doi: 10.11999/JEIT240284. [5] 陈桂林, 王观武, 胡健, 等. Chiplet封装结构与通信结构综述[J]. 计算机研究与发展, 2022, 59(1): 22–30. doi: 10.7544/issn1000-1239.20200314.CHEN Guilin, WANG Guanwu, HU Jian, et al. Survey on chiplet packaging structure and communication structure[J]. Journal of Computer Research and Development, 2022, 59(1): 22–30. doi: 10.7544/issn1000-1239.20200314. [6] LAU J H. Chiplet Design and Heterogeneous Integration Packaging[M]. Singapore: Springer, 2023: 1–542. doi: 10.1007/978-981-19-9917-8. [7] FENG Yinxiao, XIANG Dong, and MA Kaisheng. A scalable methodology for designing efficient interconnection network of chiplets[C]. 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Montreal, Canada, 2023: 1059–1071. doi: 10.1109/HPCA56546.2023.10070981. [8] MA Xiaohan, WANG Ying, WANG Yujie, et al. Survey on chiplets: Interface, interconnect and integration methodology[J]. CCF Transactions on High Performance Computing, 2022, 4(1): 43–52. doi: 10.1007/s42514-022-00093-0. [9] WANG Tianqi, FENG Fan, XIANG Shaolin, et al. Application defined on-chip networks for heterogeneous chiplets: An implementation perspective[C]. 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Republic of Korea, 2022: 1198–1210. doi: 10.1109/HPCA53966.2022.00091. [10] LIU Yafei, LI Xiangyu, and YIN Shouyi. Review of chiplet-based design: System architecture and interconnection[J]. Science China Information Sciences, 2024, 67(10): 200401. doi: 10.1007/s11432-023-3926-8. [11] HAN Yinhe, XU Haobo, LU Meixuan, et al. The big chip: Challenge, model and architecture[J]. Fundamental Research, 2024, 4(6): 1431–1441. doi: 10.1016/j.fmre.2023.10.020. [12] NAFFZIGER S, BECK N, BURD T, et al. Pioneering chiplet technology and design for the AMD EPYCTM and RyzenTM processor families: Industrial product[C]. 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 2021: 57–70. doi: 10.1109/ISCA52012.2021.00014. [13] SINGH T, RANGARAJAN S, JOHN D, et al. 2.1 Zen 2: The AMD 7nm energy-efficient high-performance x86-64 microprocessor core[C]. 2020 IEEE International Solid-State Circuits Conference - (ISSCC), San Francisco, USA, 2020, 42–44. doi: 10.1109/ISSCC19947.2020.9063113. [14] NAFFZIGER S, LEPAK K, PARASCHOU M, et al. 2.2 AMD chiplet architecture for high-performance server and desktop products[C]. 2020 IEEE International Solid-State Circuits Conference - (ISSCC), San Francisco, USA, 2020: 44–45. doi: 10.1109/ISSCC19947.2020.9063103. [15] WANG Xiaohang, WANG Yifan, JIANG Yingtao, et al. On task mapping in multi-chiplet based many-core systems to optimize inter- and intra-chiplet communications[J]. IEEE Transactions on Computers, 2025, 74(2): 510–525. doi: 10.1109/TC.2024.3500354. [16] CHEN Chixiao, YIN Jieming, PENG Yarui, et al. Design challenges of intrachiplet and interchiplet interconnection[J]. IEEE Design & Test, 2022, 39(6): 99–109. doi: 10.1109/MDAT.2022.3203005. [17] ZHENG Hao, WANG Ke, and LOURI A. A versatile and flexible chiplet-based system design for heterogeneous manycore architectures[C]. 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, USA, 2020: 1–6. doi: 10.1109/DAC18072.2020.9218654. [18] HUANG Letian, ZHAO Tianjin, WANG Ziren, et al. Component dependencies based network-on-chip test[J]. IEEE Transactions on Computers, 2024, 73(12): 2805–2816. doi: 10.1109/TC.2024.3457732. [19] FENG Yinxiao and MA Kaisheng. Chiplet actuary: A quantitative cost model and multi-chiplet architecture exploration[C]. Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, USA, 2022: 121–126. doi: 10.1145/3489517.3530428. [20] DONG Xiao, SUN Songyu, JIANG Yangfan, et al. SPIRAL+: Efficient signal-power integrity co-analysis for inter-chiplet links validation[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025, 44(8): 3140–3153. doi: 10.1109/TCAD.2025.3532822. [21] EHRETT P, AUSTIN T, and BERTACCO V. SiPterposer: A fault-tolerant substrate for flexible system-in-package design[C]. 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 2019: 510–515. doi: 10.23919/DATE.2019.8714998. [22] TAHERI E, PASRICHA S, and NIKDAST M. DeFT: A deadlock-free and fault-tolerant routing algorithm for 2.5D chiplet networks[C]. 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 2022: 1047–1052. doi: 10.23919/DATE54114.2022.9774617. [23] XIONG Ruoting, REN Wei, ZHANG Chengzhuo, et al. A sampling-based acceleration method for heterogeneous chiplet noc simulations[J]. Future Generation Computer Systems, 2025, 166: 107643. doi: 10.1016/j.future.2024.107643. [24] FU Yuxiang, ZHANG Chuan, SONG Wenqing, et al. Optimizing vertical link placement and congestion aware dynamic elevator assignment for partially connected 3D-NoCs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2021, 40(10): 1957–1970. doi: 10.1109/TCAD.2020.3038338. [25] NEZARAT M and MOMENI M. TCAR: Thermal and congestion-aware routing algorithm in a partially connected 3D network on chip[C]. 2022 12th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 2022: 106–111. doi: 10.1109/ICCKE57176.2022.9960056. [26] TAHERI E, KIM R G, and NIKDAST M. AdEle+: An adaptive congestion-and-energy-aware elevator selection for partially connected 3D networks-on-chip[J]. IEEE Transactions on Computers, 2023, 72(8): 2278–2292. doi: 10.1109/TC.2023.3248260. [27] VIVET P, GUTHMULLER E, THONNART Y, et al. IntAct: A 96-core processor with six chiplets 3D-stacked on an active interposer with distributed interconnects and integrated power management[J]. IEEE Journal of Solid-State Circuits, 2021, 56(1): 79–97. doi: 10.1109/JSSC.2020.3036341. [28] ZHI Changle, DONG Gang, YANG Deguang, et al. Electrical and thermal characteristics optimization in interposer-based 2.5-D integrated circuits[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2025, 33(3): 627–637. doi: 10.1109/TVLSI.2024.3478846. [29] LIAO Chengyi, HE Huimin, LIU Fengman, et al. Enhanced fabrication and assembly of 3-D chiplets based on active interposer with frontside via-last TSVs[J]. IEEE Transactions on Components, Packaging and Manufacturing Technology, 2024, 14(9): 1692–1700. doi: 10.1109/TCPMT.2024.3443858. [30] FENG Yinxiao, XIANG Dong, and MA Kaisheng. Heterogeneous die-to-die interfaces: Enabling more flexible chiplet interconnection systems[C]. 2023 56th IEEE/ACM International Symposium on Microarchitecture (MICRO), Toronto, Canada, 2023: 930–943. [31] YIN Jieming, LIN Zhifeng, KAYIRAN O, et al. Modular routing design for chiplet-based systems[C]. 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, USA, 2018: 726–738. doi: 10.1109/ISCA.2018.00066. [32] TAHERI E, PASRICHA S, and NIKDAST M. ReD: A reliable and deadlock-free routing for 2.5-D chiplet-based interposer networks[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024, 43(12): 4599–4612. doi: 10.1109/TCAD.2024.3399660. -

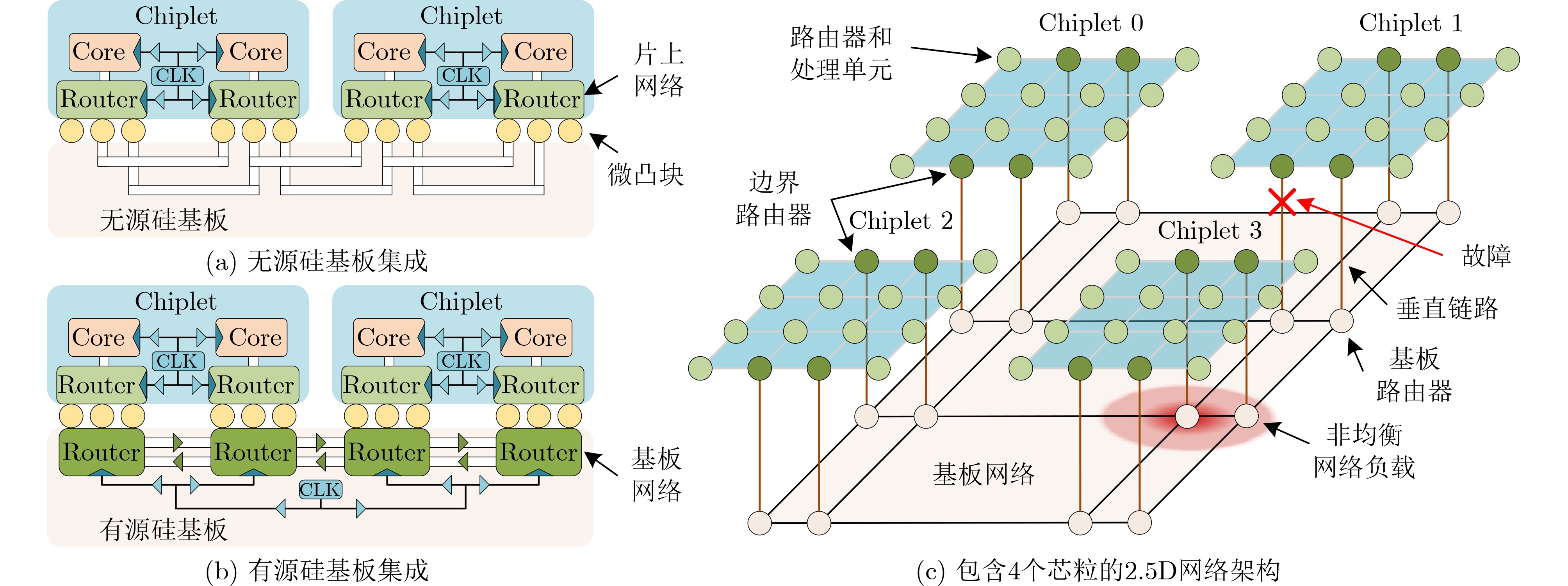
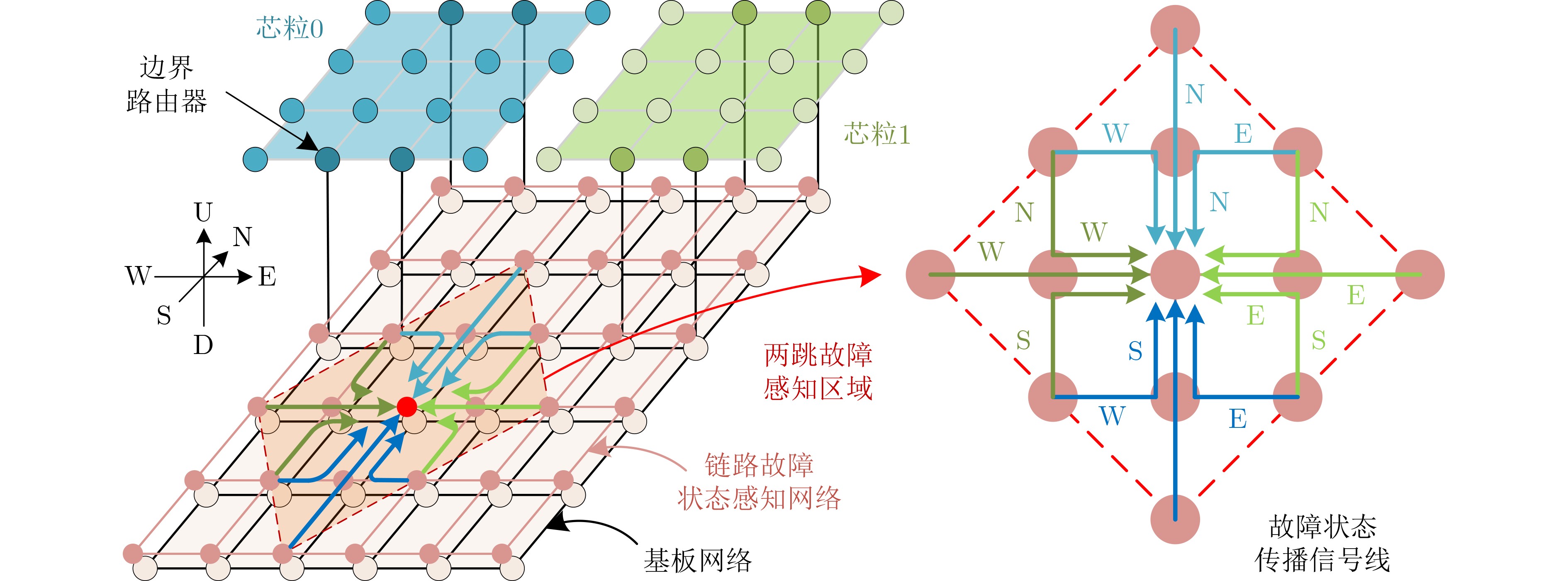
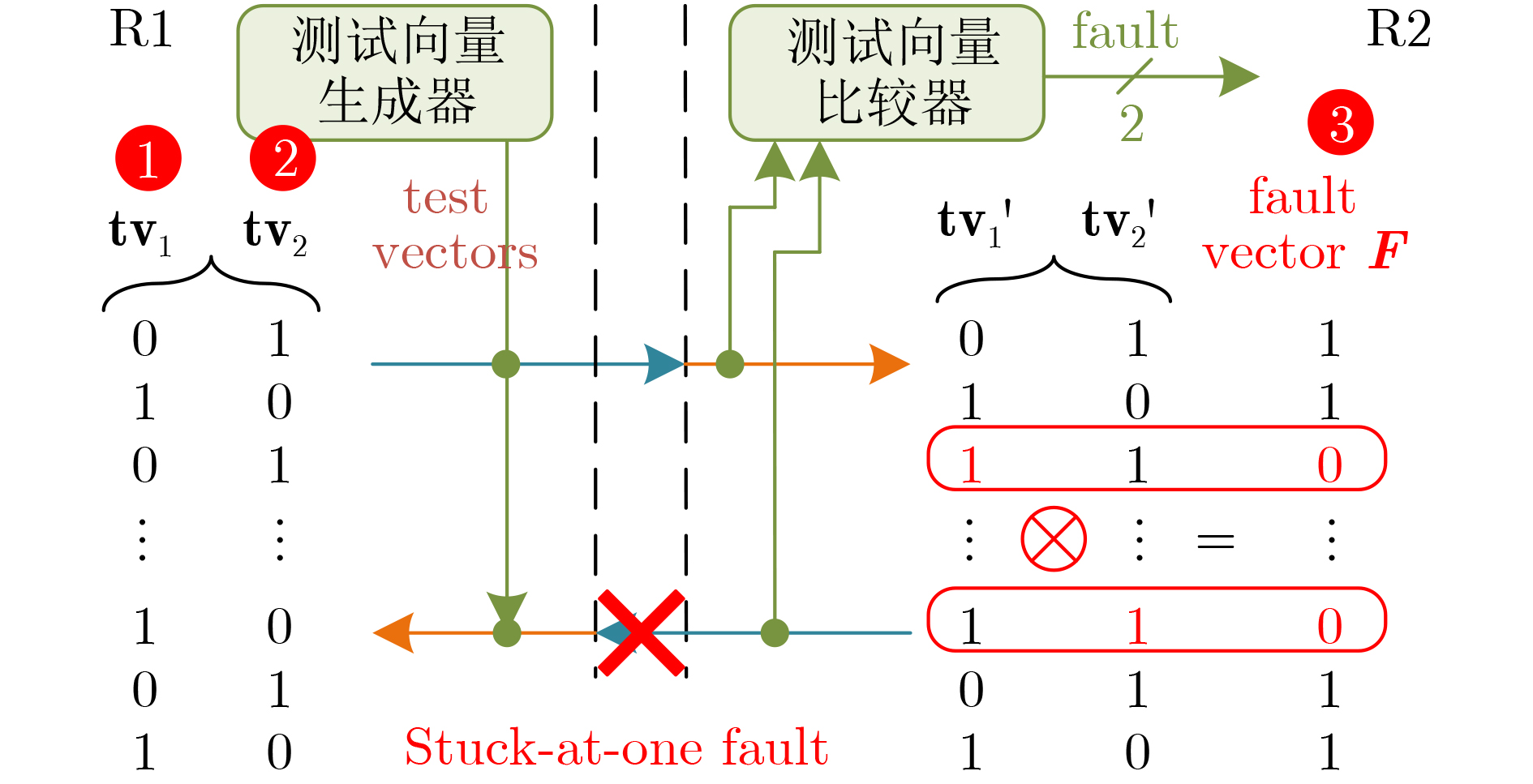
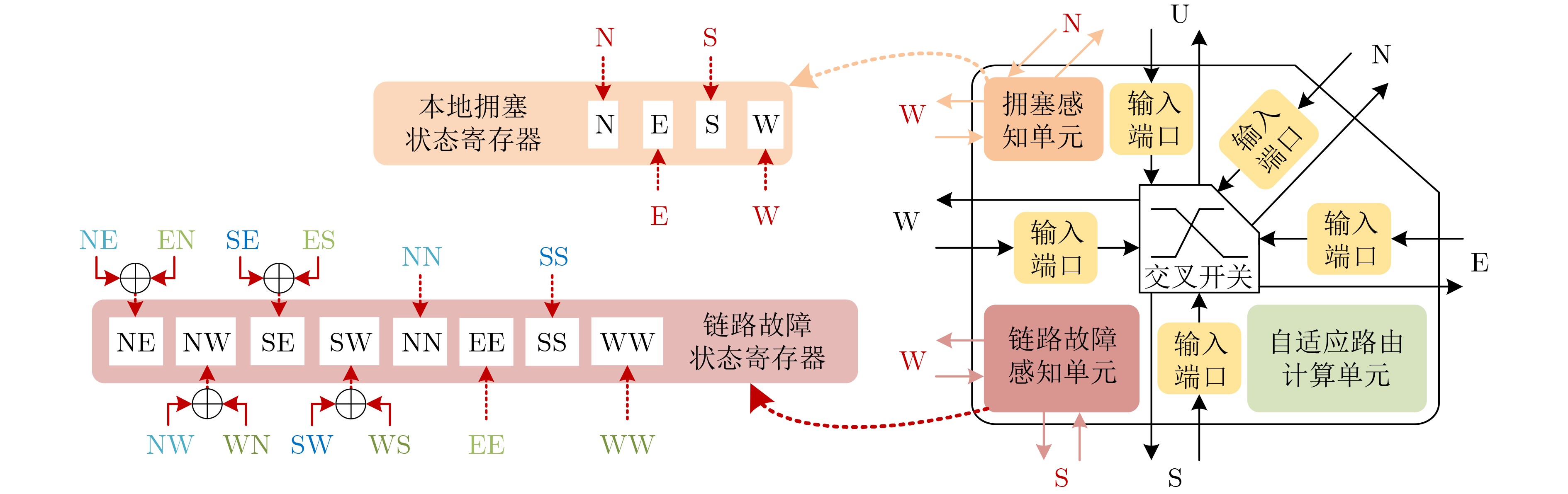


图(11) / 表(4)
计量
- 文章访问数: 729
- HTML全文浏览量: 495
- PDF下载量: 93
- 被引次数: 0
 下载:
下载:
