

Mitigating Cache Side-channel Attacks via Fast Flushing Mechanism
-
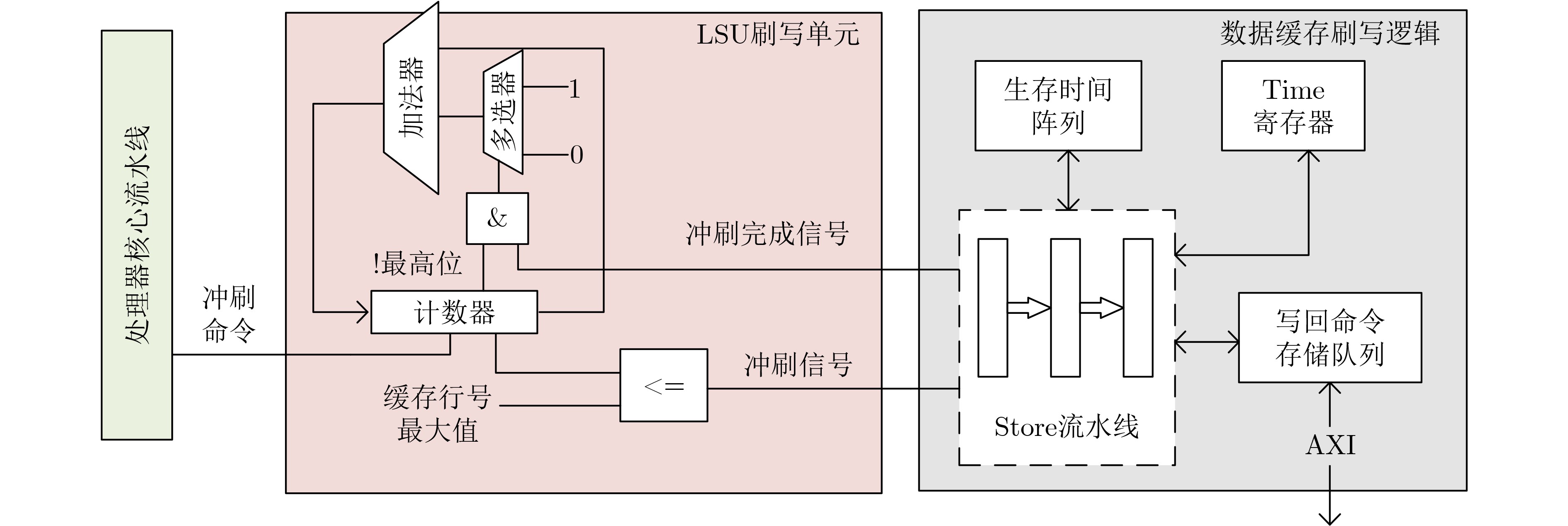
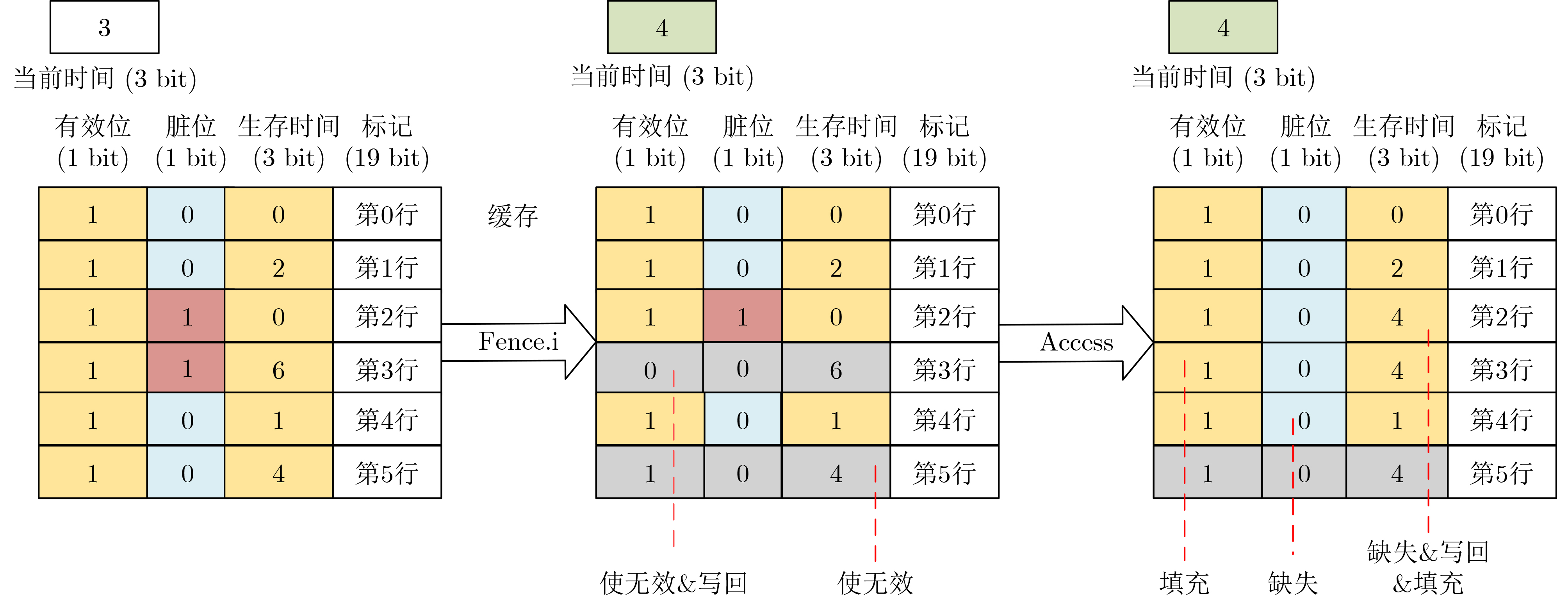
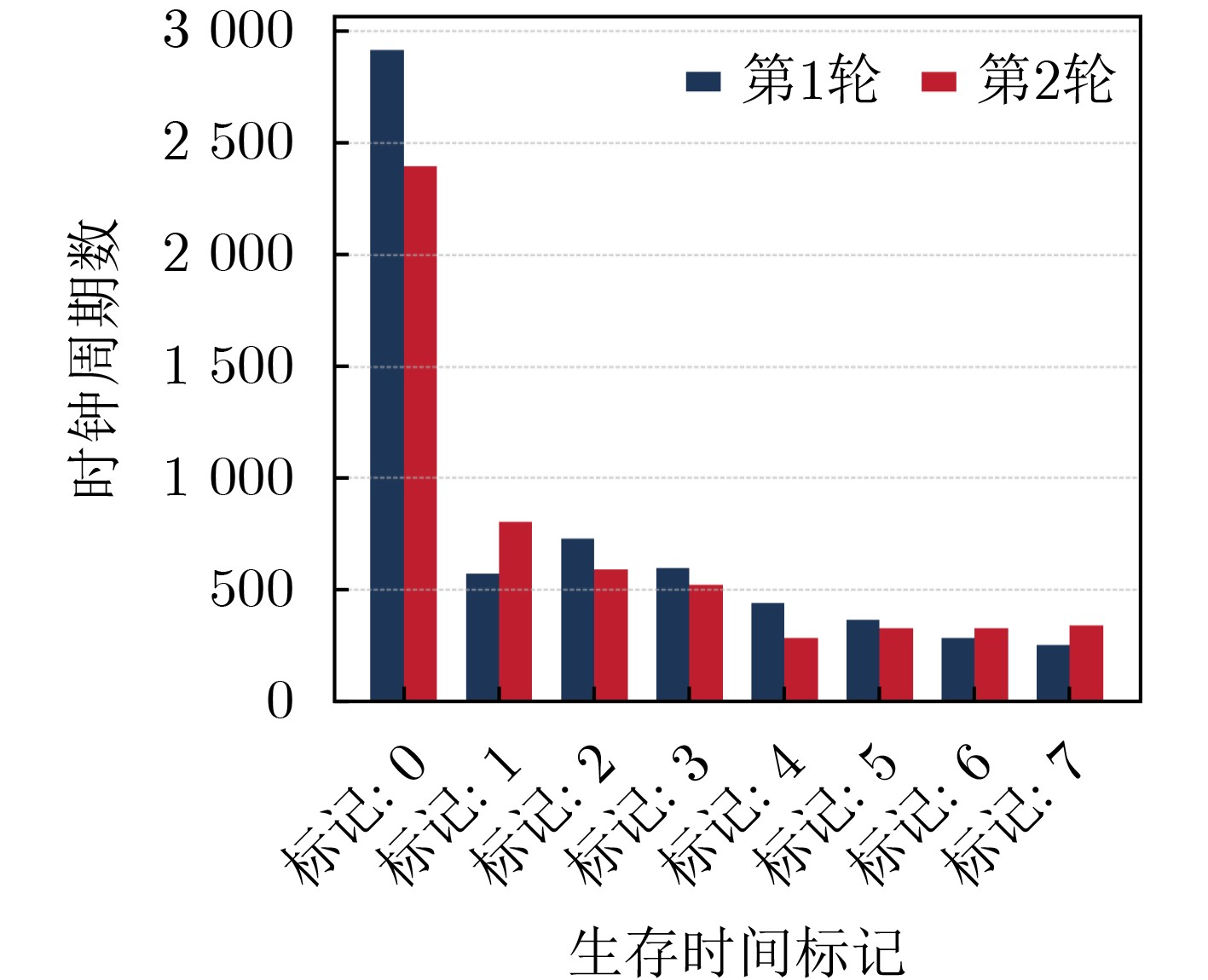
摘要: 缓存作为处理器中缓解主存访问延迟的重要结构,在提升系统性能的同时,其共享性也为攻击者实施侧信道攻击提供了条件。近年来,针对数据缓存的多种侧信道攻击手段相继被提出,严重威胁处理器系统的安全性。为应对此类威胁,各类防护策略也不断涌现。现有基于缓存映射随机化的方案通常伴随较高的硬件开销,不适用于资源受限的一级缓存;而基于缓存刷写的方案则存在效率较低的问题。针对上述问题,该文提出基于快速刷写的缓存侧信道攻击缓解技术,通过在数据缓存中引入生存时间标识,在执行缓存刷写时,有选择地执行缓存写回操作,提高缓存刷写效率。该文基于 (RISC-V)架构处理器对上述防护策略进行了实现,并在FPGA平台上对其硬件开销进行了评估,相较于原始缓存刷写方法可减少70%左右的刷写执行时间,相比于原有数据缓存结构,所带来的额外硬件逻辑开销为8%左右,引入标记位的额外存储开销仅为0.01%左右。Abstract:
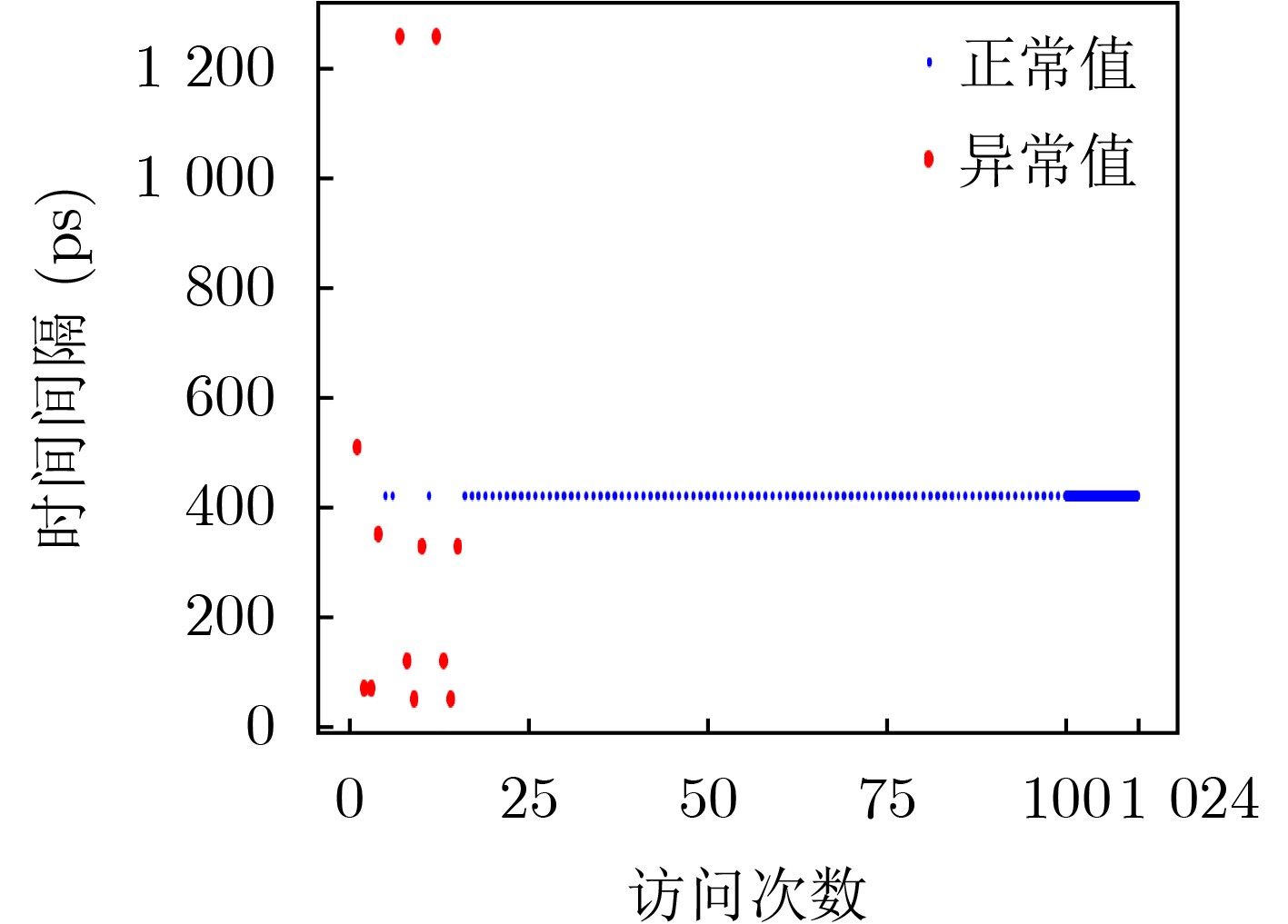
Objective With the rising demand for secure computing, cache-based side-channel attacks have become a critical threat to modern processors. Conventional data cache designs do not account for information leakage caused by malicious memory access patterns, enabling adversaries to infer sensitive data from subtle variations in cache access latency. Existing countermeasures, such as cache mapping randomization and cache flushing, provide partial protection but incur considerable hardware overhead and performance degradation, particularly in resource-constrained private caches such as L1 and L2. To address this limitation, this study focuses on L1 data caches and proposes a fast flushing mechanism based on Time-To-Live (TTL) control. The method mitigates side-channel leakage while minimizing additional hardware complexity and performance cost. Methods This study proposes a fast cache flushing method that introduces a lightweight 3-bit TTL field into each cache line, together with a global time register (Time), to enable efficient cache invalidation. When a flush instruction is issued, the Time register is incremented, and all cache lines are checked against their TTL values. Only lines that remain valid and contain modified data are invalidated and written back, thereby reducing flushing overhead. To ensure robustness and correctness, several auxiliary strategies are incorporated, including mechanisms to handle TTL wraparound, preserve data consistency, and strengthen resistance against advanced side-channel attacks. The proposed mechanism is realized through custom instruction set extensions on an RISC-V processor platform. Results and Discussions The proposed cache flushing mechanism exhibits significant performance benefits in representative application scenarios. Experimental evaluation shows that it reduces average flushing latency by approximately 70% relative to conventional flushing techniques. In side-channel security tests based on the Prime+Probe attack model, an adversary probing 1024 cache lines after the victim executes a flush operation is unable to recover valid sensitive information patterns, thereby confirming the security effectiveness of the proposed architecture. Regarding hardware overhead, the design introduces only about 8% additional logic and approximately 0.01% extra storage cost for TTL fields compared with conventional cache structures.Conclusions This paper presents a fast cache flushing mechanism to defend against cache-based side-channel attacks. The proposed method achieves a balanced trade-off between security and performance. Experimental results show that it substantially reduces cache flushing latency while effectively mitigating typical side-channel threats. The design is particularly suited for deployment in resource-constrained private caches such as L1 and L2. Hardware implementation further confirms the lightweight nature and engineering feasibility of the approach, indicating strong potential for practical application. -
Key words:
- Cache side-channel attacks /
- RISC-V security /
- Cache flushing
-
表 1 处理器配置
处理器参数 配置 位数 64位 指令集 RISC-V IMACFD 执行单元 2-Decode, 3-issue, 2-commit ROB/LDQ/STQ 64/16/16 entries 分支预测单元 BTB+GSHARE+RAS MMU SV39 L1 ICache 64 kB, 4-way, 256 B line L1 DCache 64 kB, 4-way, 256 B line L2 Cache 512 kB, 8-way, 256 B line L1-L2 Cache总线平均时延 5 cycle l2-Memory总线平均时延 96 cycle  下载: 导出CSV
下载: 导出CSV
-
[1] WANG Zhenghong and LEE R B. New cache designs for thwarting software cache-based side channel attacks[C]. The 34th Annual International Symposium on Computer Architecture, San Diego, USA, 2007: 494–505. doi: 10.1145/1250662.1250723. [2] KOCHER P, HORN J, FOGH A, et al. Spectre attacks: Exploiting speculative execution[J]. Communications of the ACM, 2020, 63(7): 93–101. doi: 10.1145/3399742. [3] LIPP M, SCHWARZ M, GRUSS D, et al. Meltdown: Reading kernel memory from user space[J]. Communications of the ACM, 2020, 63(6): 46–56. doi: 10.1145/3357033. [4] CHEN Yun, PASHRASHID A, WU Yongzheng, et al. Prime+reset: Introducing a novel cross-world covert-channel through comprehensive security analysis on ARM TrustZone[C]. The 2024 Design, Automation & Test in Europe Conference & Exhibition (DATE 2024), Valencia, Spain, 2024: 1–6. doi: 10.23919/DATE58400.2024.10546531. [5] QURESHI M K. New attacks and defense for encrypted-address Cache[C]. The 46th International Symposium on Computer Architecture (ISCA 2019), Phoenix, USA, 2019: 360–371. [6] LI Tuo and PARAMESWARAN S. FaSe: Fast selective flushing to mitigate contention-based cache timing attacks[C]. The 59th ACM/IEEE Design Automation Conference, San Francisco, USA, 2022: 541–546. doi: 10.1145/3489517.3530491. [7] SONG Wei, XUE Zihan, HAN Jinchi, et al. Randomizing set-associative caches against conflict-based cache side-channel attacks[J]. IEEE Transactions on Computers, 2024, 73(4): 1019–1033. doi: 10.1109/TC.2024.3349659. [8] DOMNITSER L, JALEEL A, LOEW J, et al. Non-monopolizable caches: Low-complexity mitigation of cache side channel attacks[J]. ACM Transactions on Architecture and Code Optimization, 2012, 8(4): 35. doi: 10.1145/2086696.2086714. [9] YAN Mengjia, GOPIREDDY B, SHULL T, et al. Secure Hierarchy-Aware Cache Replacement Policy (SHARP): Defending against cache-based side channel atacks[C]. The 44th Annual International Symposium on Computer Architecture, Toronto, Canada, 2017: 347–360. doi: 10.1145/3079856.3080222. [10] WERNER M, UNTERLUGGAUER T, GINER L, et al. SCATTERCACHE: Thwarting cache attacks via cache set randomization[C]. The 28th USENIX Conference on Security Symposium, Santa Clara, USA, 2019: 675–692. [11] QURESHI M K. CEASER: Mitigating conflict-based cache attacks via encrypted-address and remapping[C]. The 51st Annual IEEE/ACM International Symposium on Microarchitecture, Fukuoka, Japan, 2018: 775–787. doi: 10.1109/MICRO.2018.00068. [12] SONG Wei, LI Boya, XUE Zihan, et al. Randomized last-level caches are still vulnerable to cache side-channel attacks! But we can fix it[C]. The 2021 IEEE Symposium on Security and Privacy, San Francisco, USA, 2021: 955–969. doi: 10.1109/SP40001.2021.00050. [13] OLEKSENKO O, TRACH B, KRAHN R, et al. Varys: Protecting SGX enclaves from practical side-channel attacks[C]. The 2018 USENIX Conference on USENIX Annual Technical Conference, Boston, USA, 2018: 227–239. [14] BOURGEAT T, LEBEDEV I, WRIGHT A, et al. MI6: Secure enclaves in a speculative out-of-order processor[C]. The 52nd Annual IEEE/ACM International Symposium on Microarchitecture, Columbus, USA, 2019: 42–56. doi: 10.1145/3352460.3358310. [15] GE Qian, YAROM Y, CHOTHIA T, et al. Time protection: The missing OS abstraction[C]. The Fourteenth EuroSys Conference 2019, Dresden, Germany, 2019: 1. doi: 10.1145/3302424.3303976. [16] CHOWDHURYY M H I and YAO Fan. IvLeague: Side channel-resistant secure architectures using isolated domains of dynamic integrity trees[C]. 2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), Austin, USA, 2024: 1153–1168. doi: 10.1109/MICRO61859.2024.00087. [17] BHATLA A, NAVNEET, and PANDA B. The Maya cache: A storage-efficient and secure fully-associative last-level cache[C]. 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), Buenos Aires, Argentina, 2024: 32–44. doi: 10.1109/ISCA59077.2024.00013. [18] Dolu1990. NaxRiscv[CP/OL]. GitHub, 2024-12-05[2025-04-15]. https://github.com/SpinalHDL/NaxRiscv. -






图(7) / 表(2)
计量
- 文章访问数: 521
- HTML全文浏览量: 363
- PDF下载量: 45
- 被引次数: 0
 下载:
下载:
