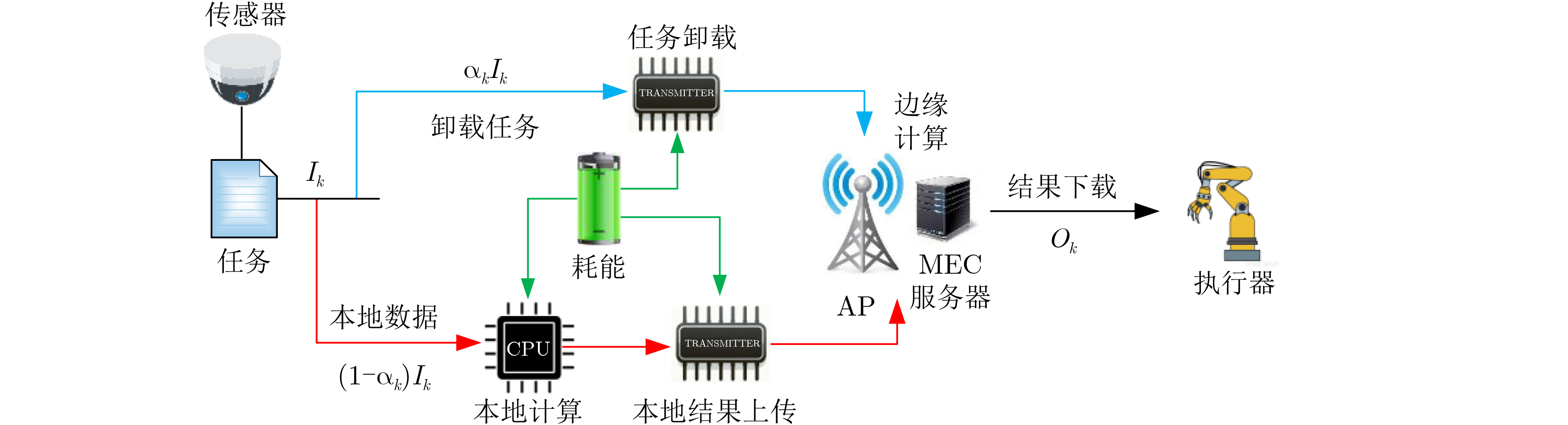
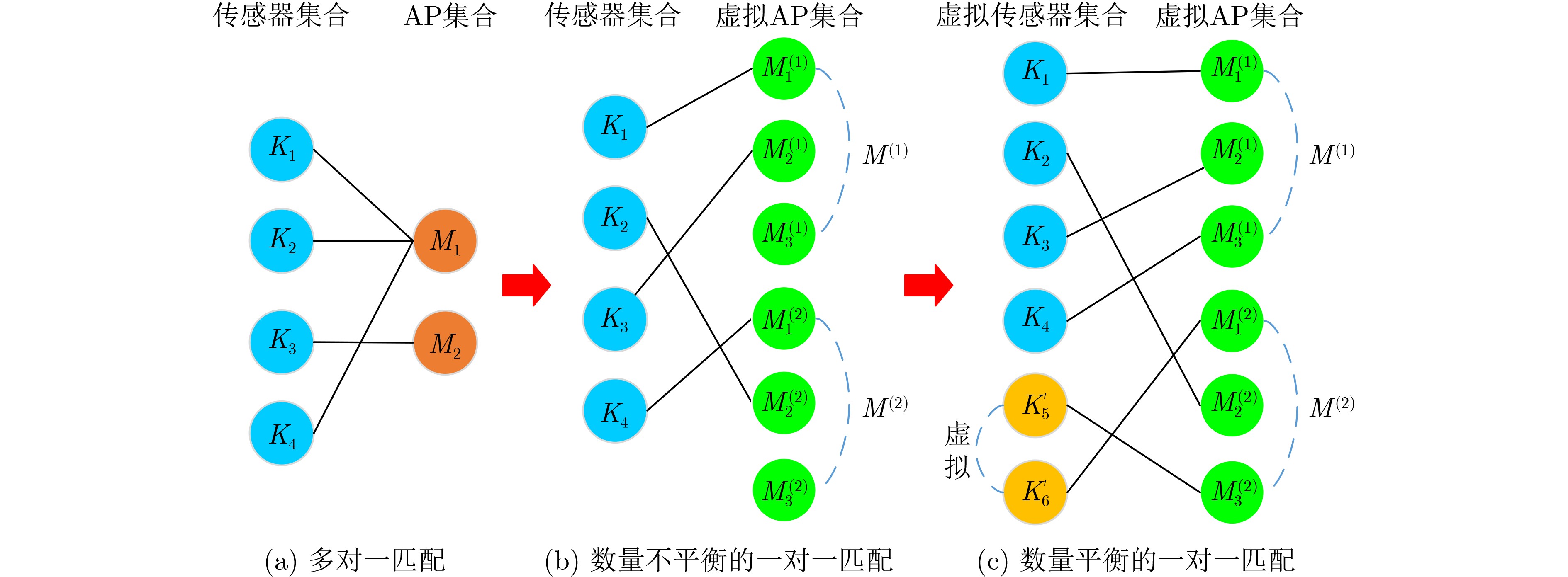
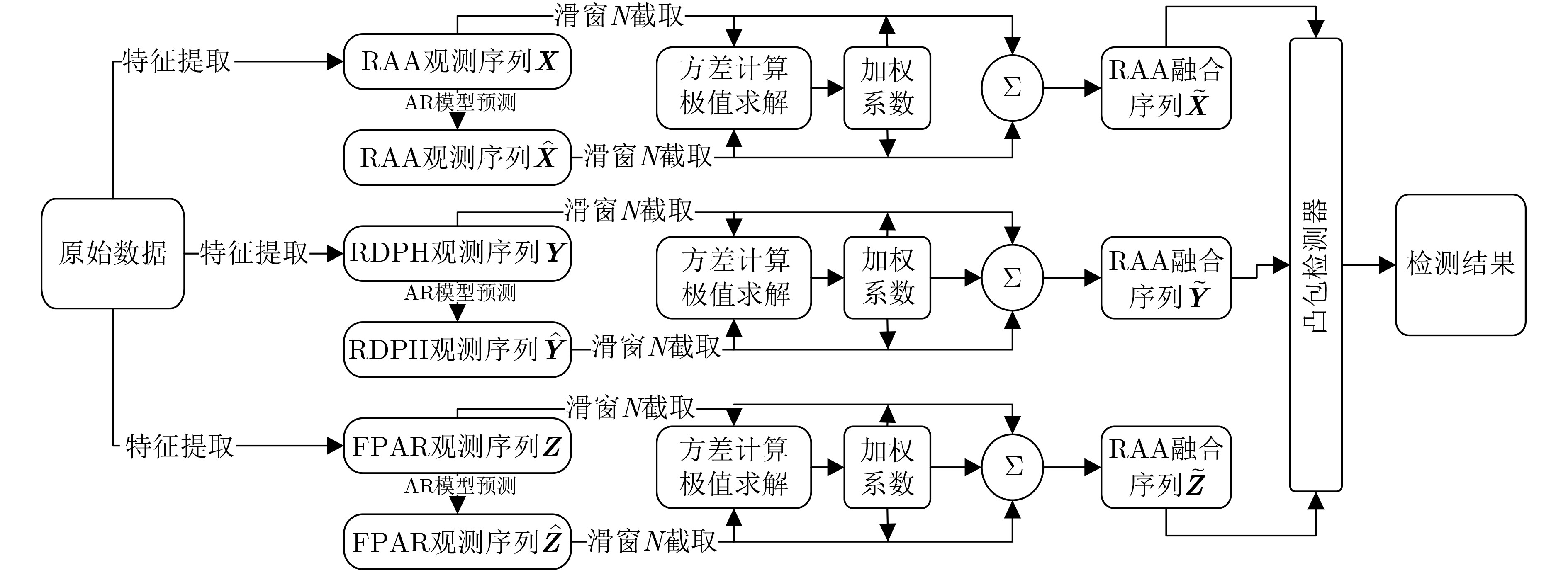
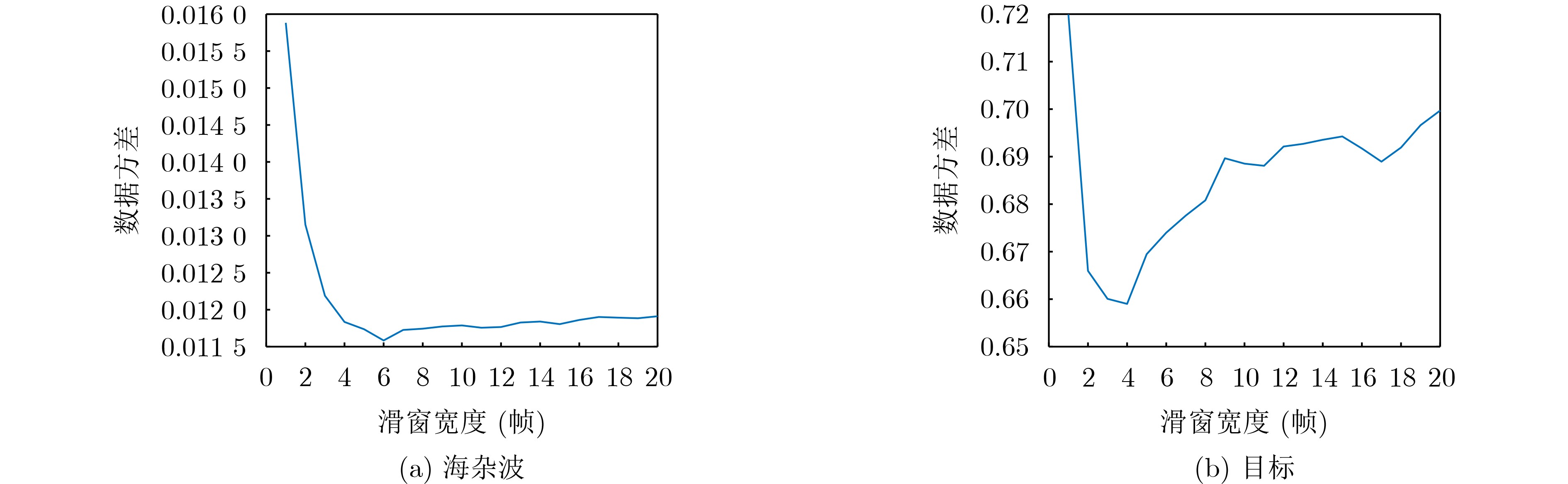
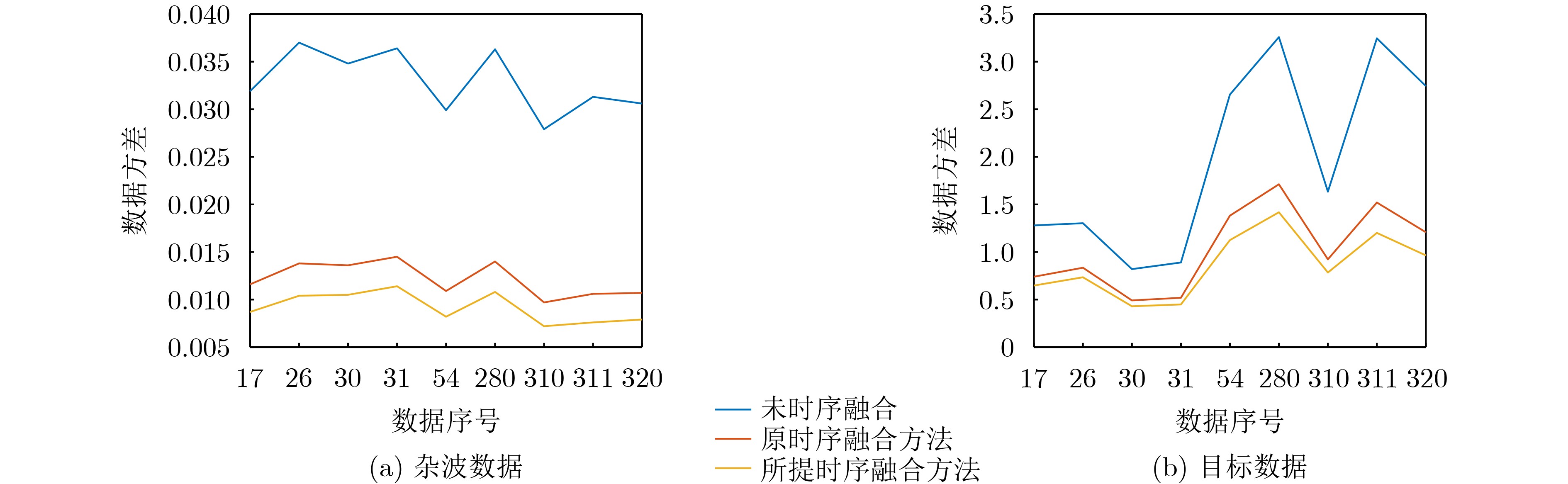
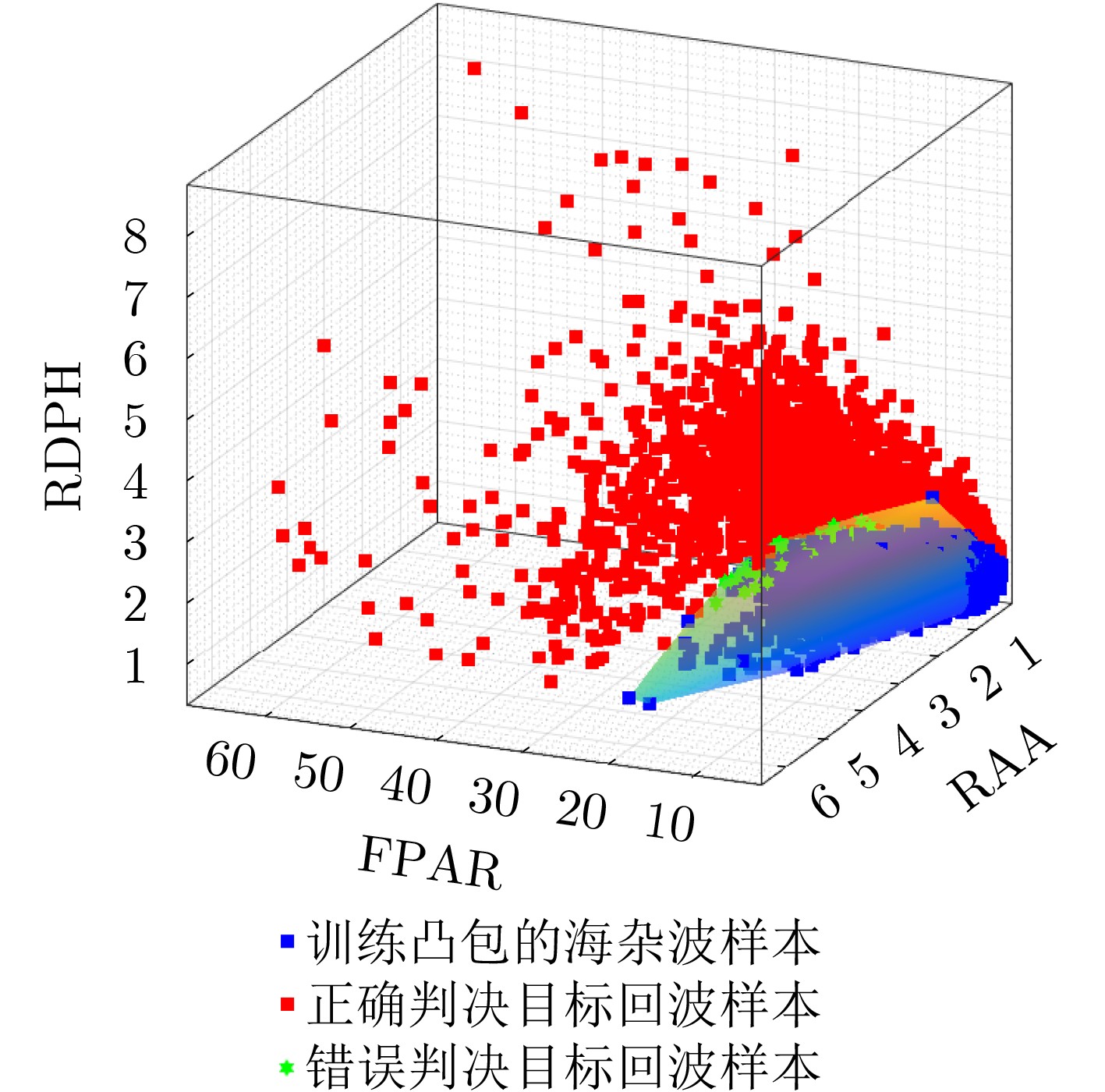
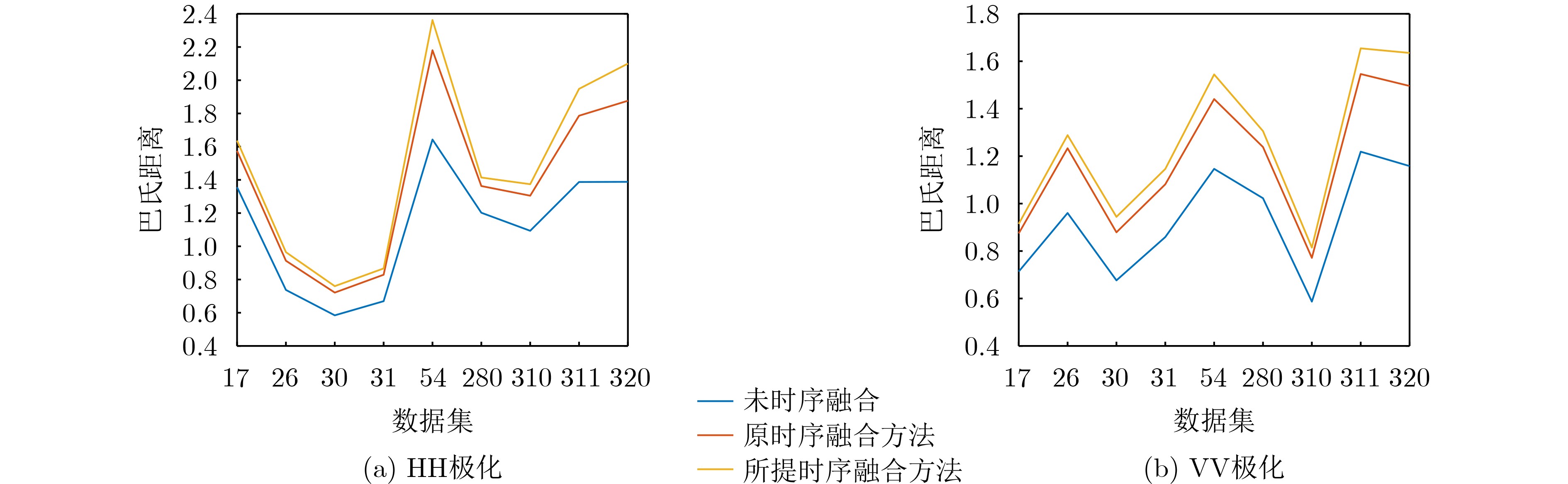
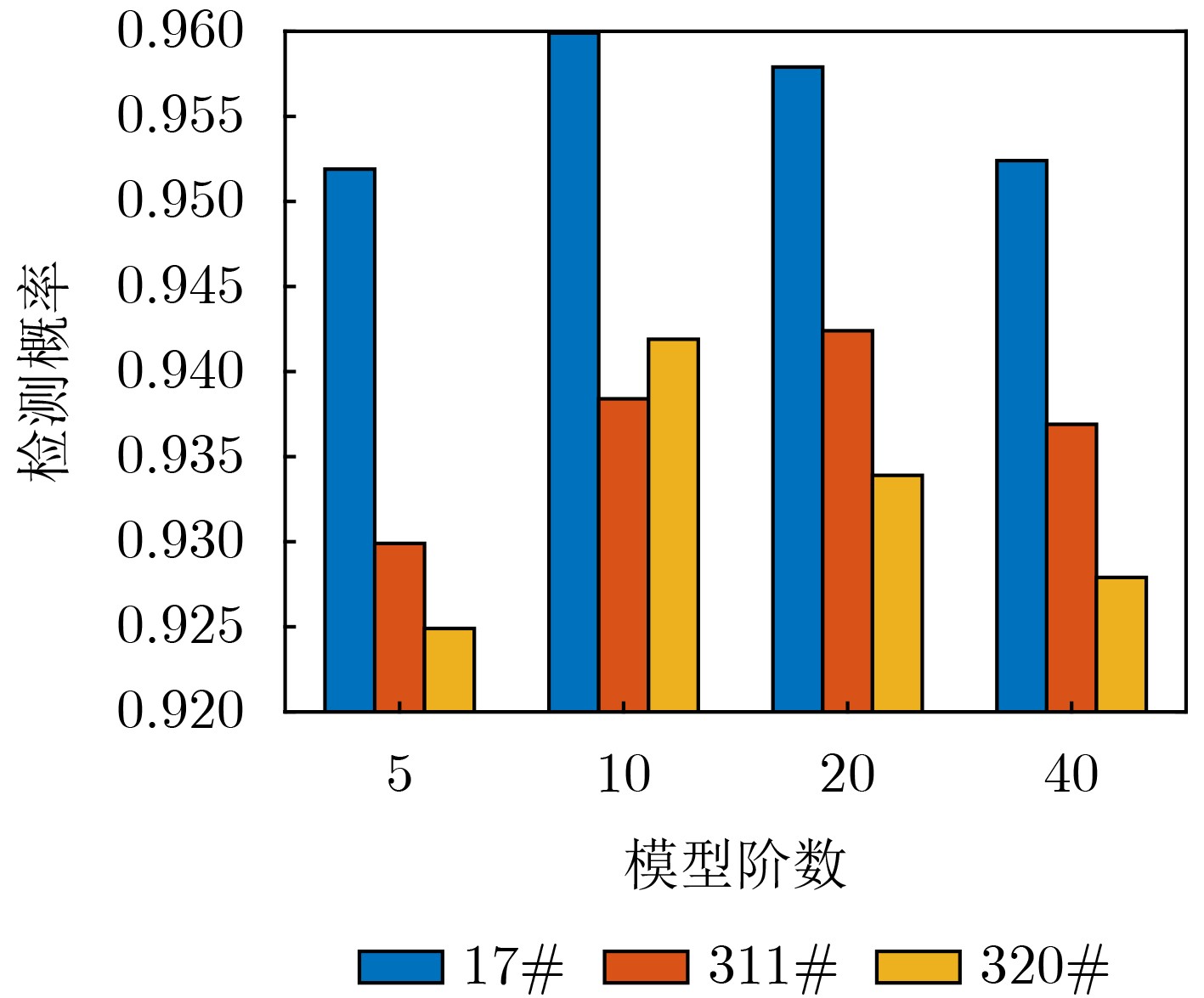
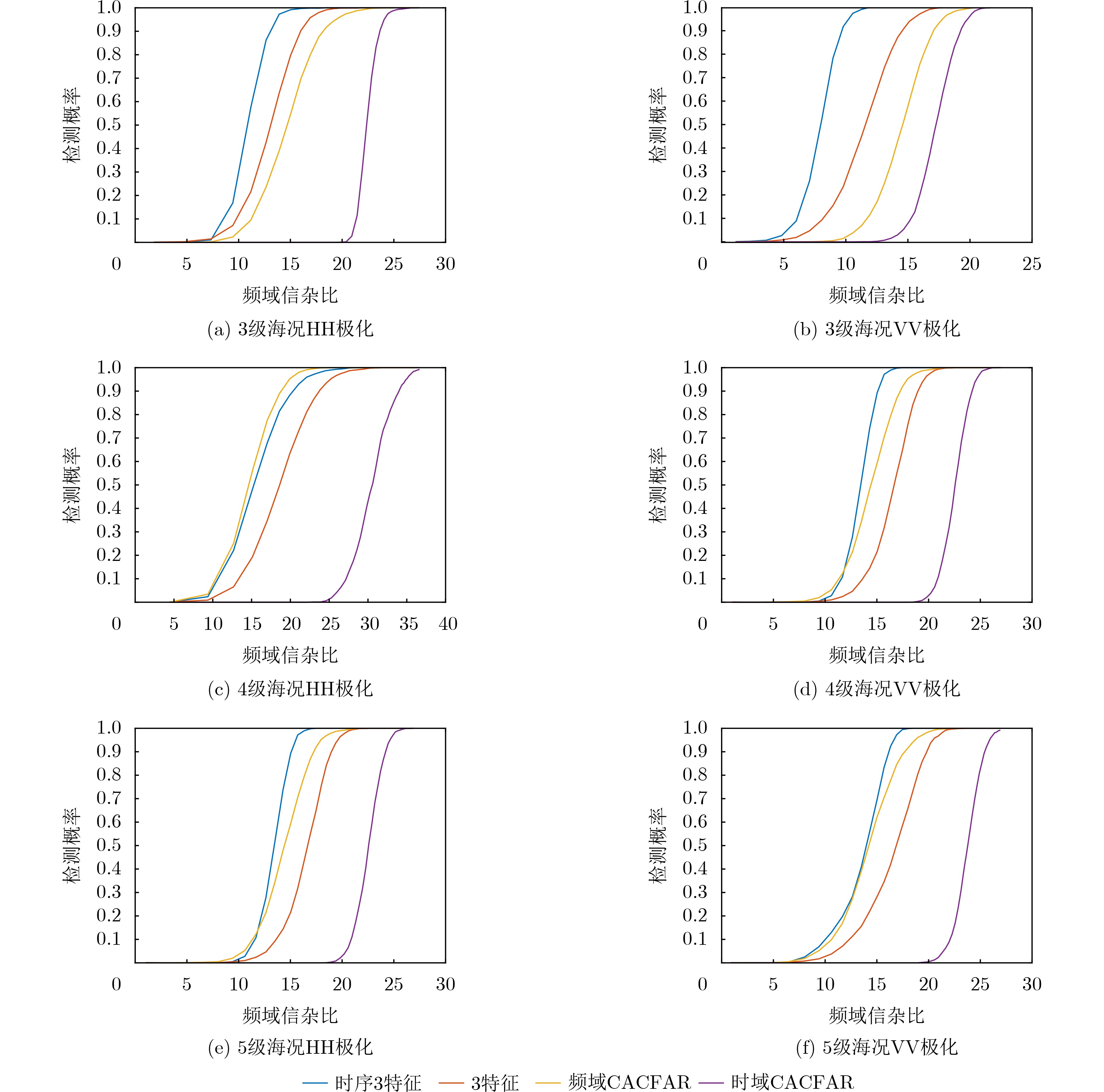
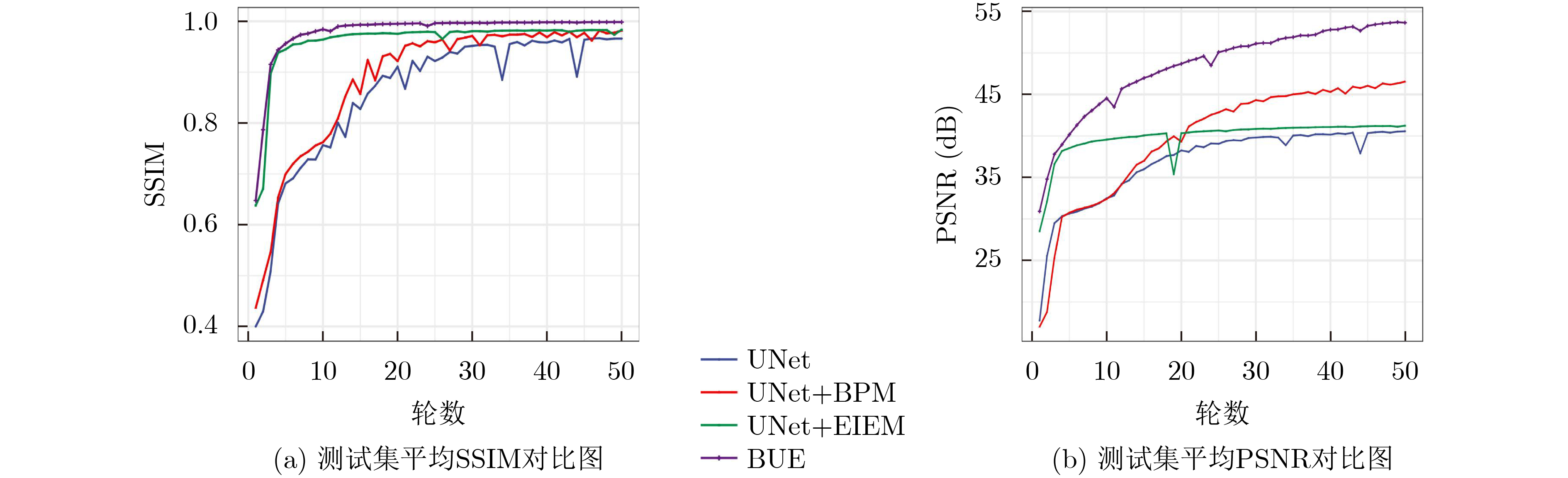
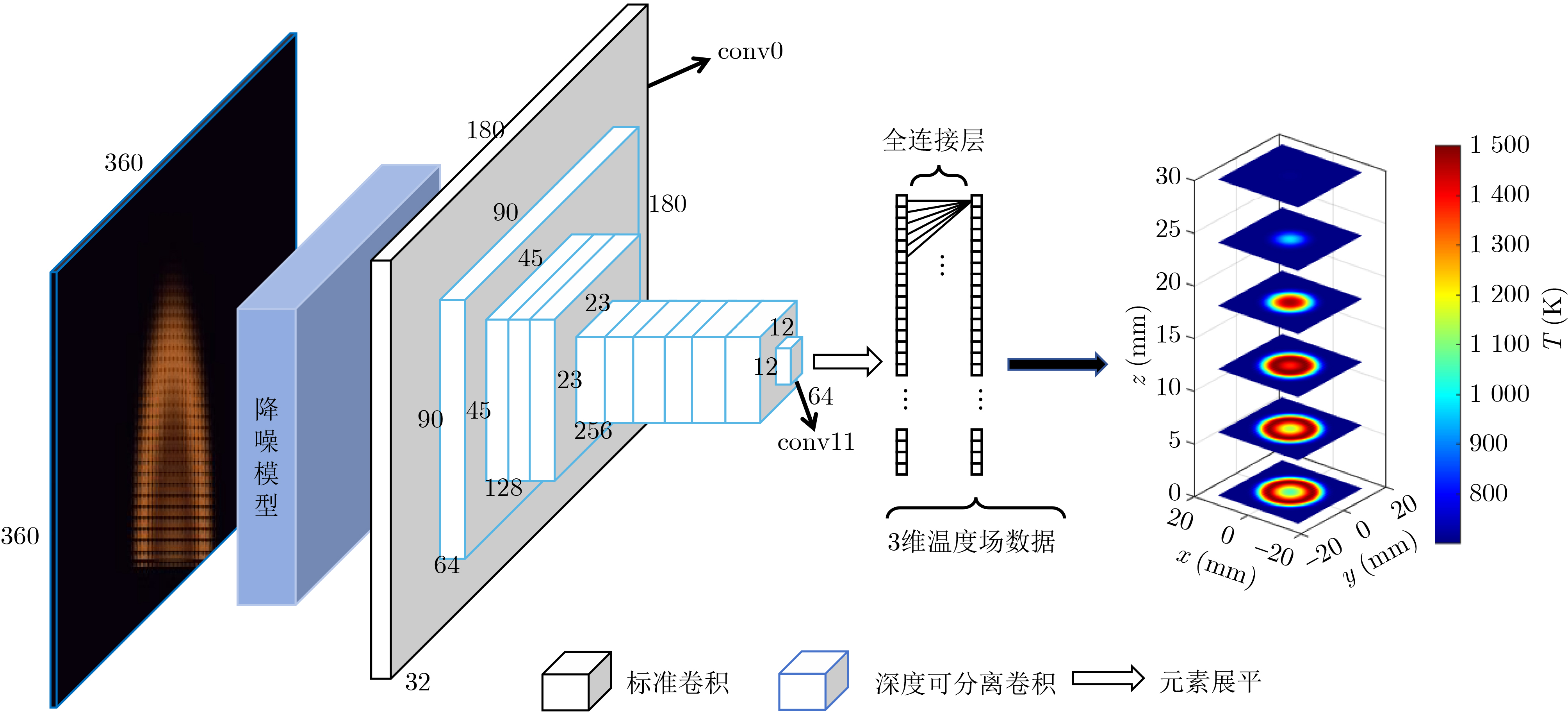
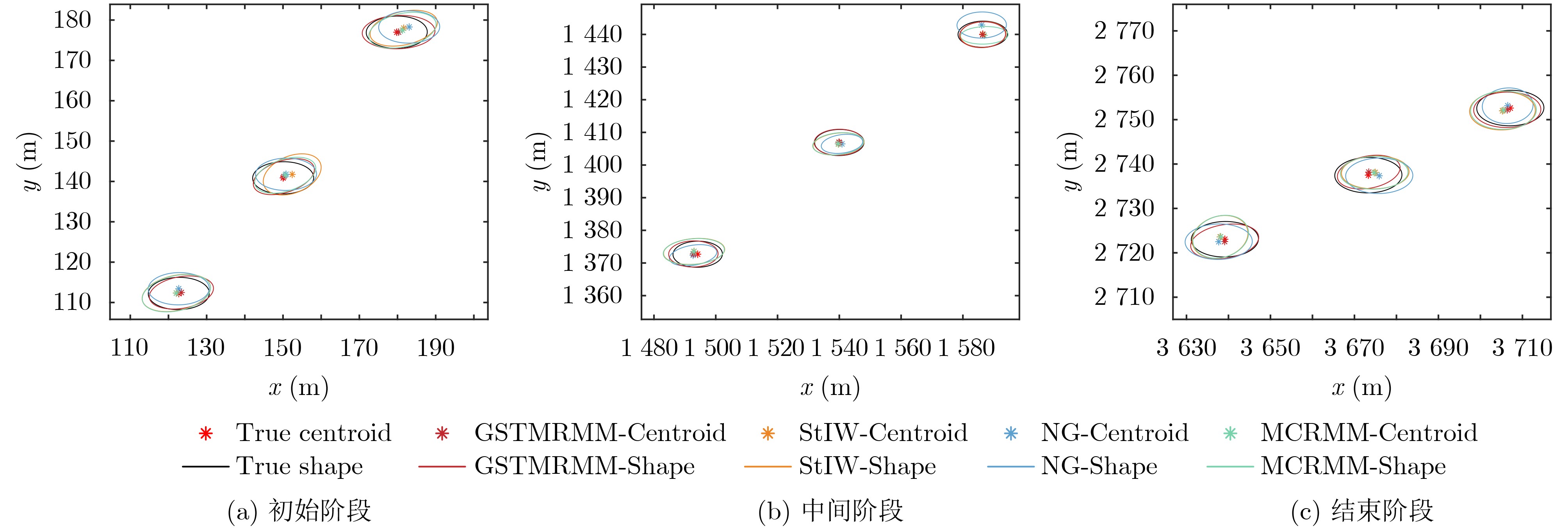
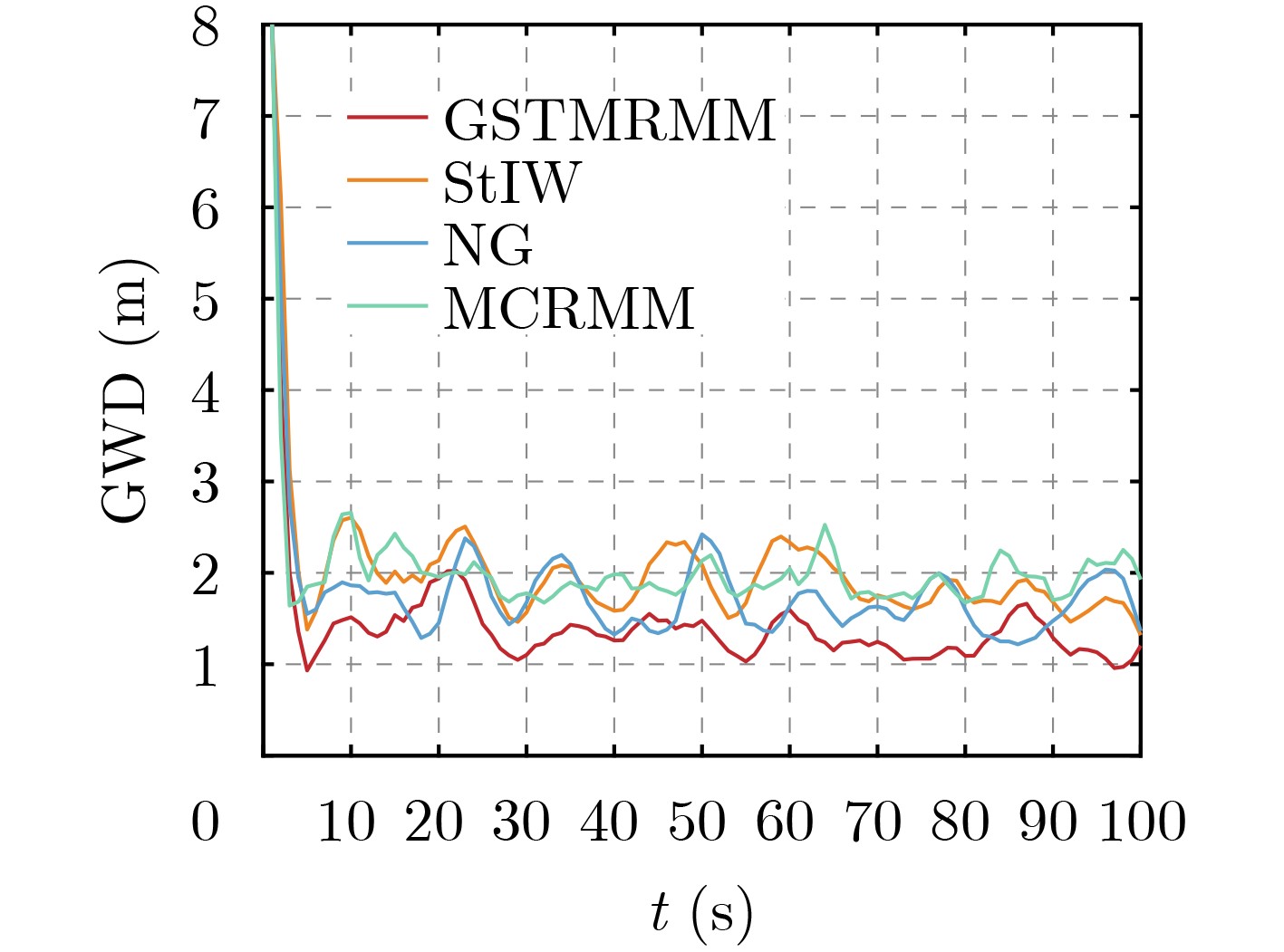
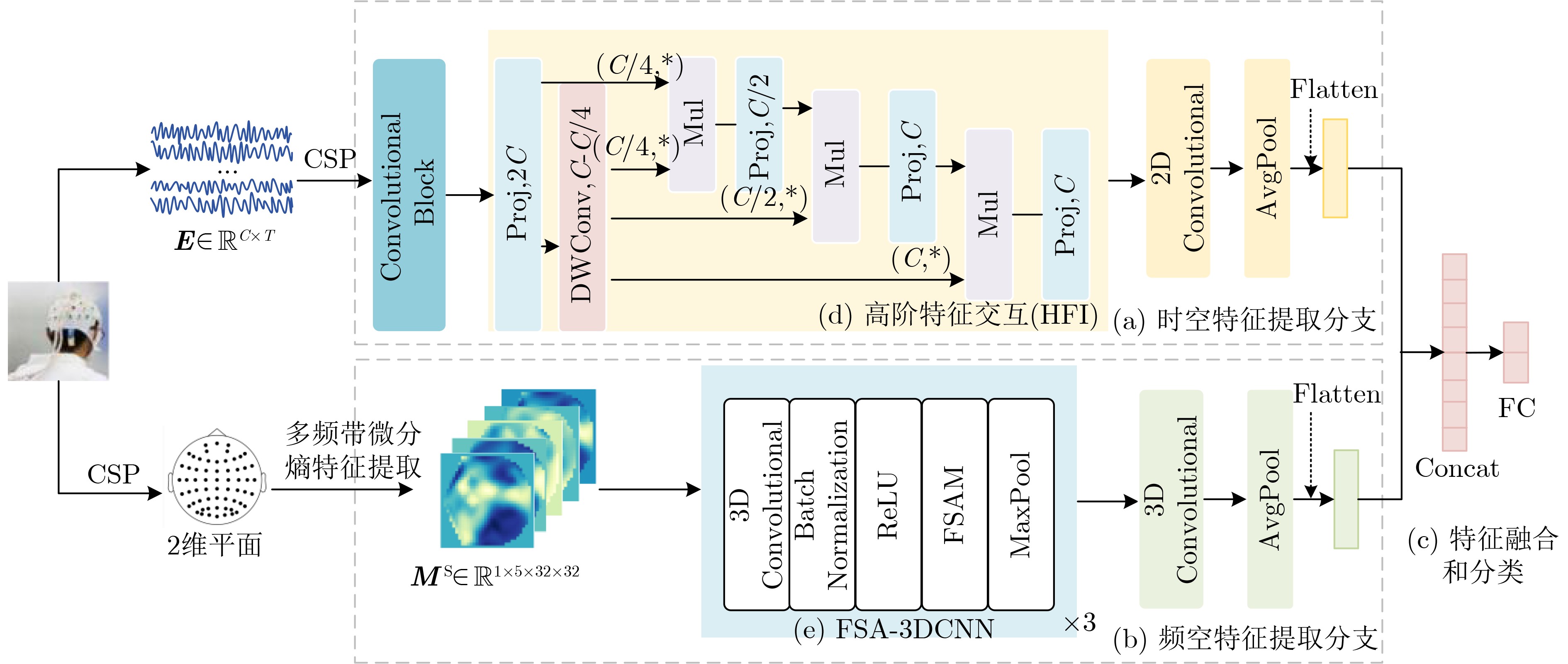
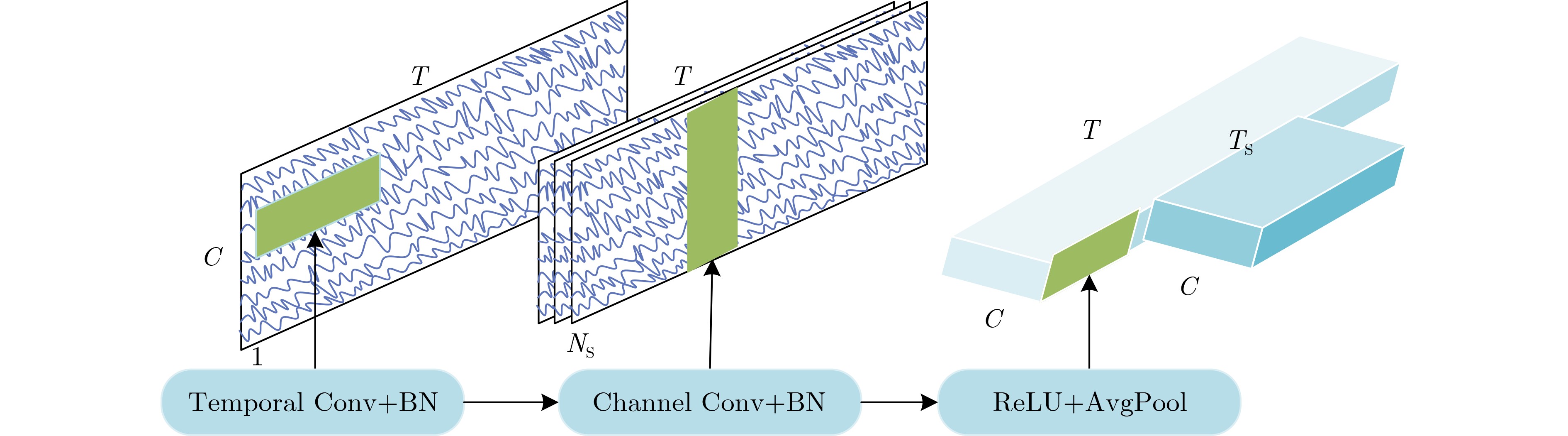
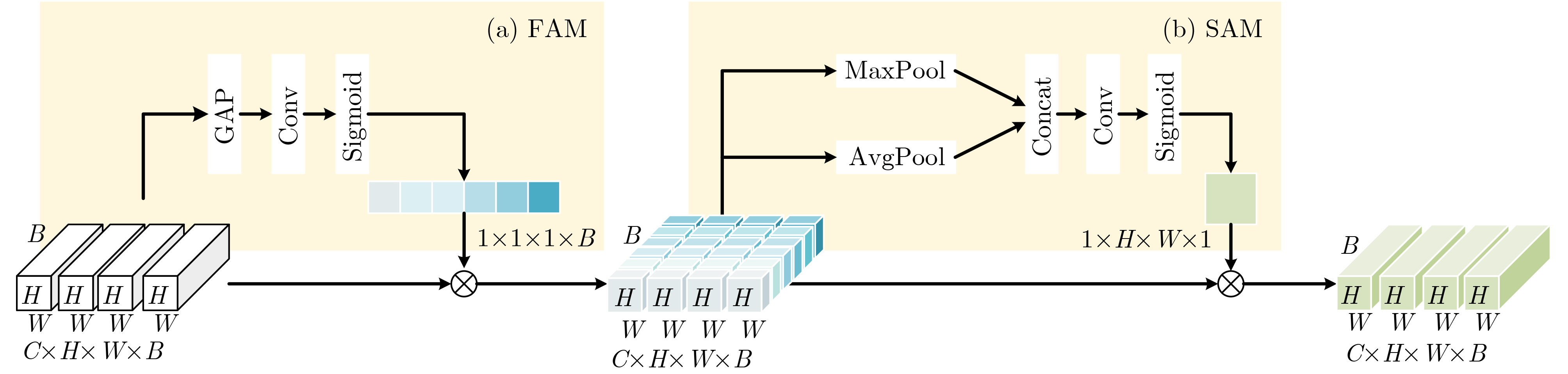
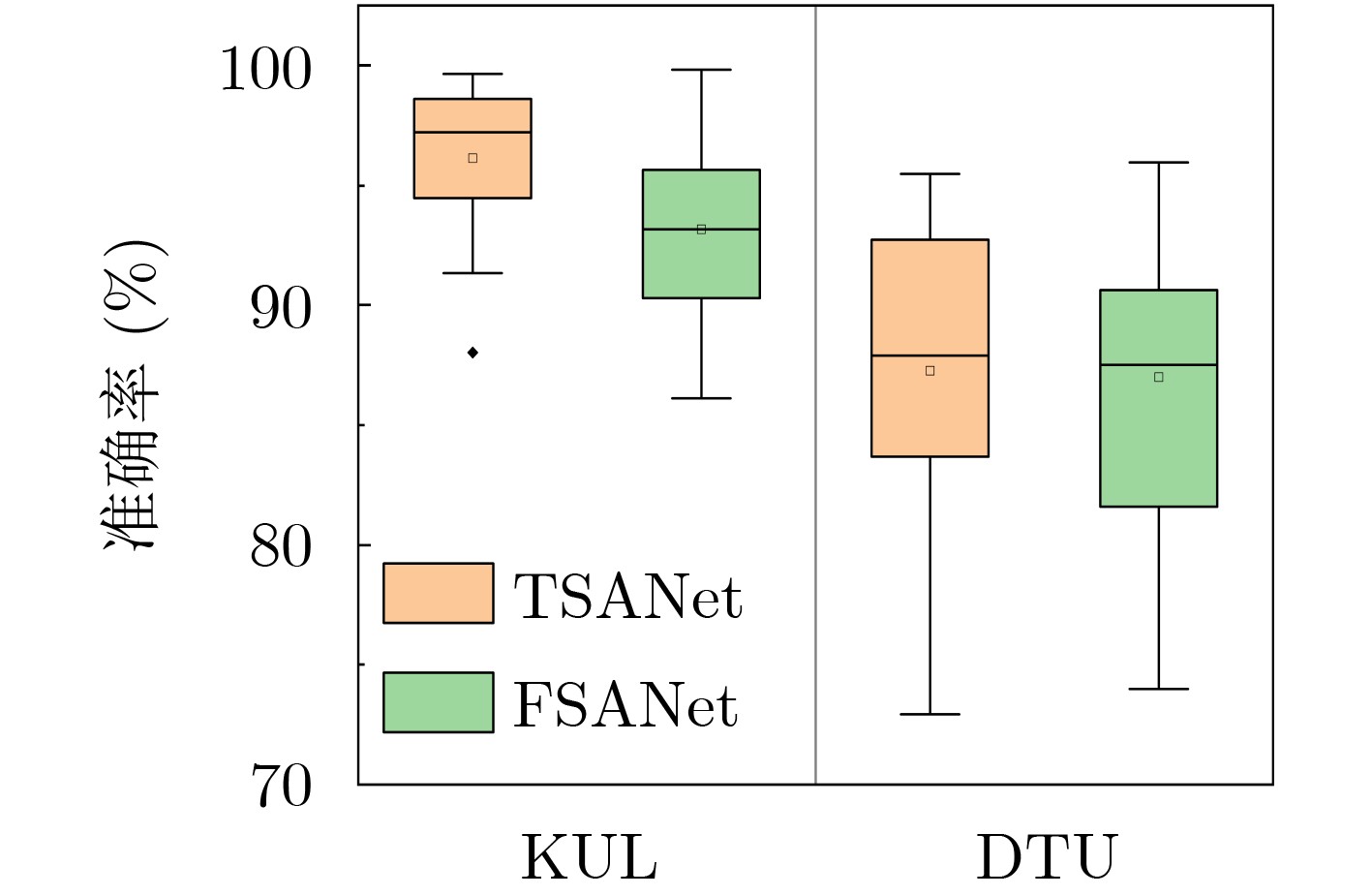
2025, 47(3): 720-728.
doi: 10.11999/JEIT240517
Abstract:
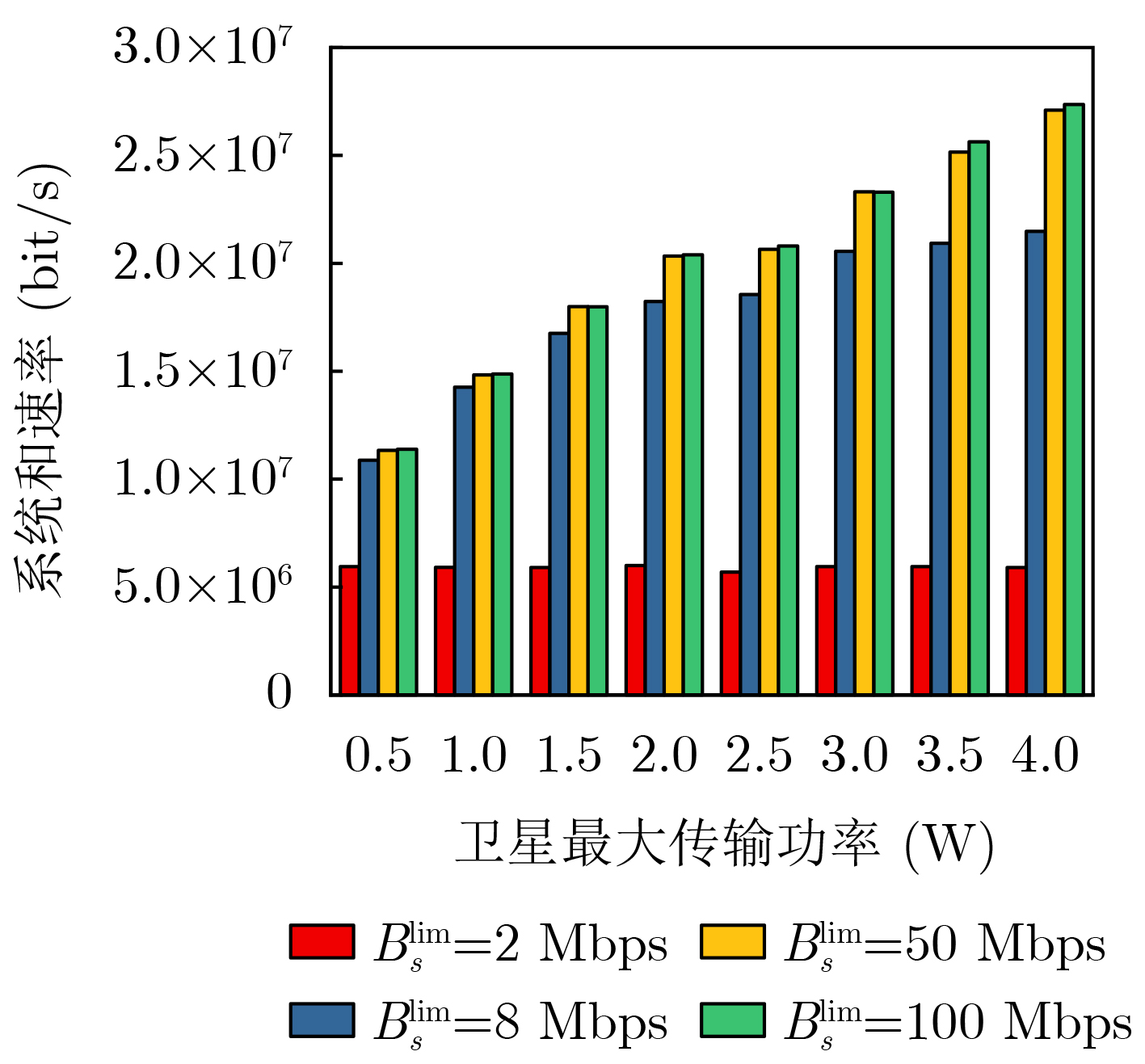
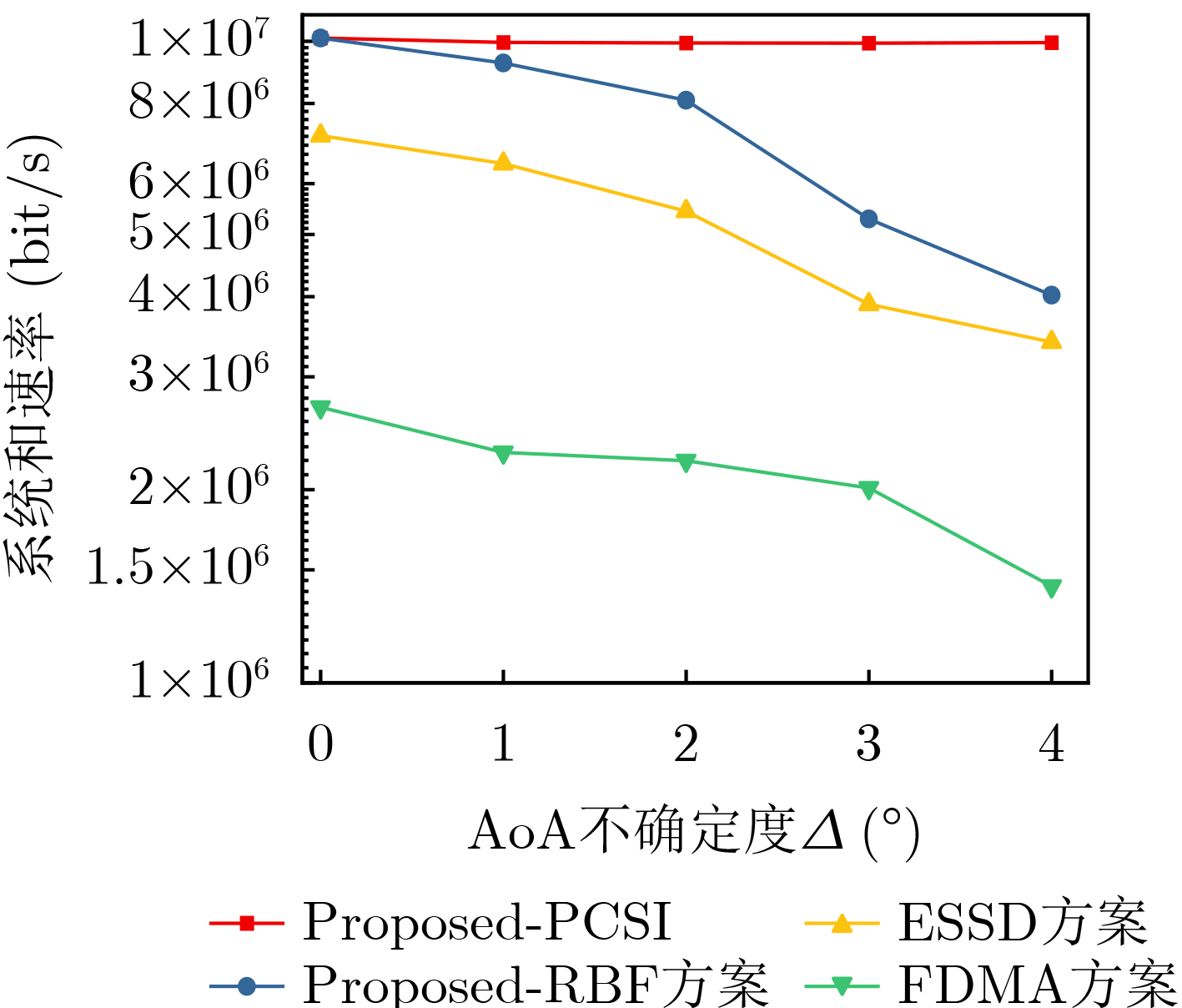
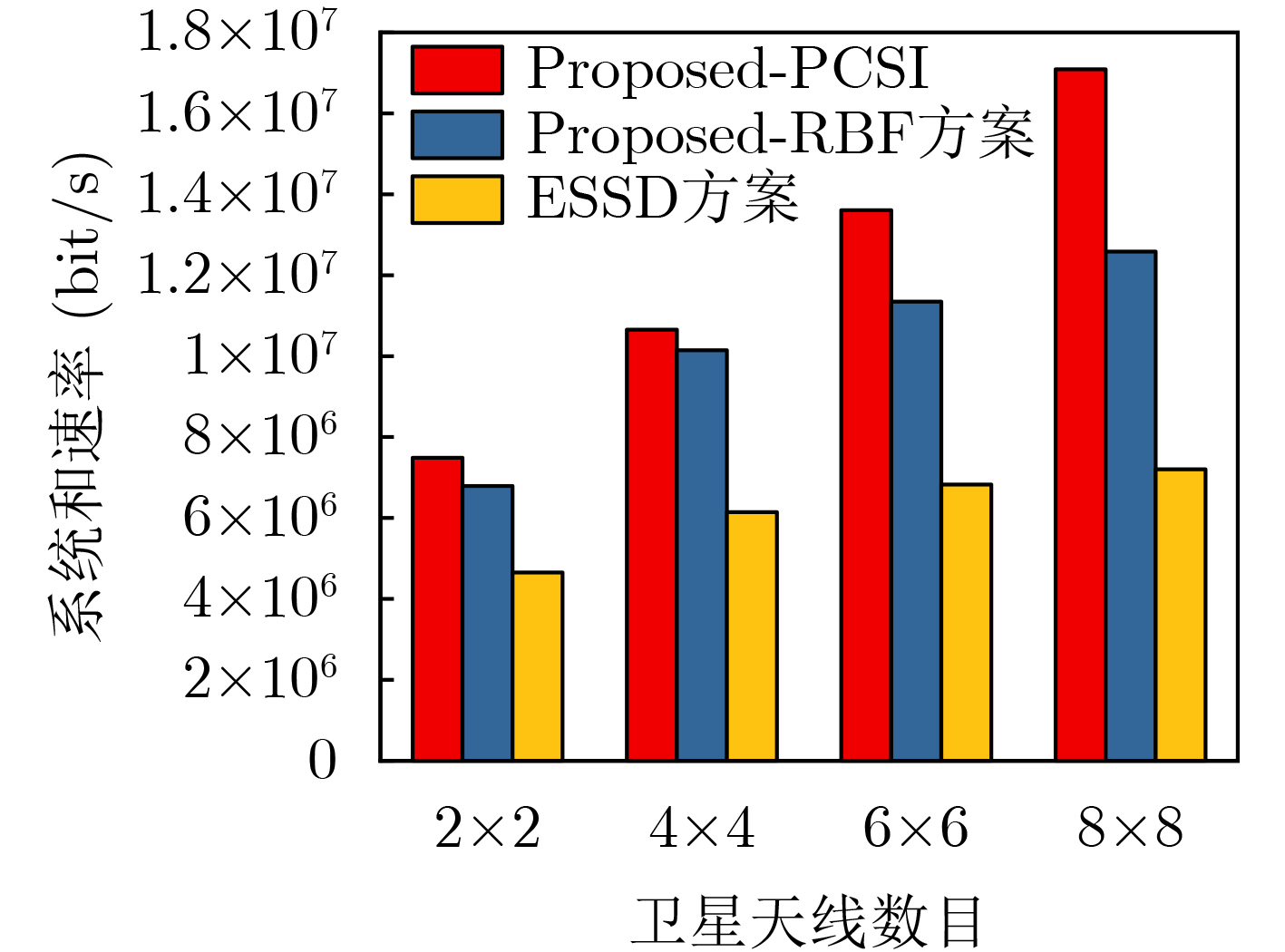
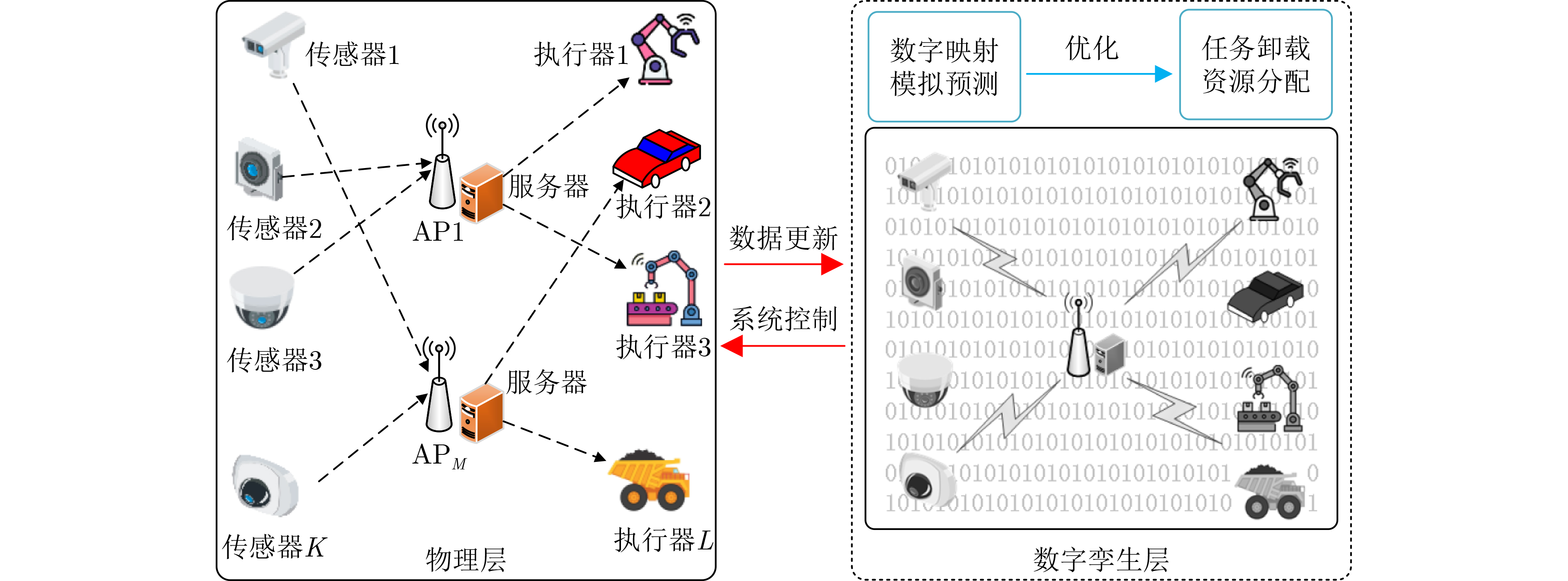
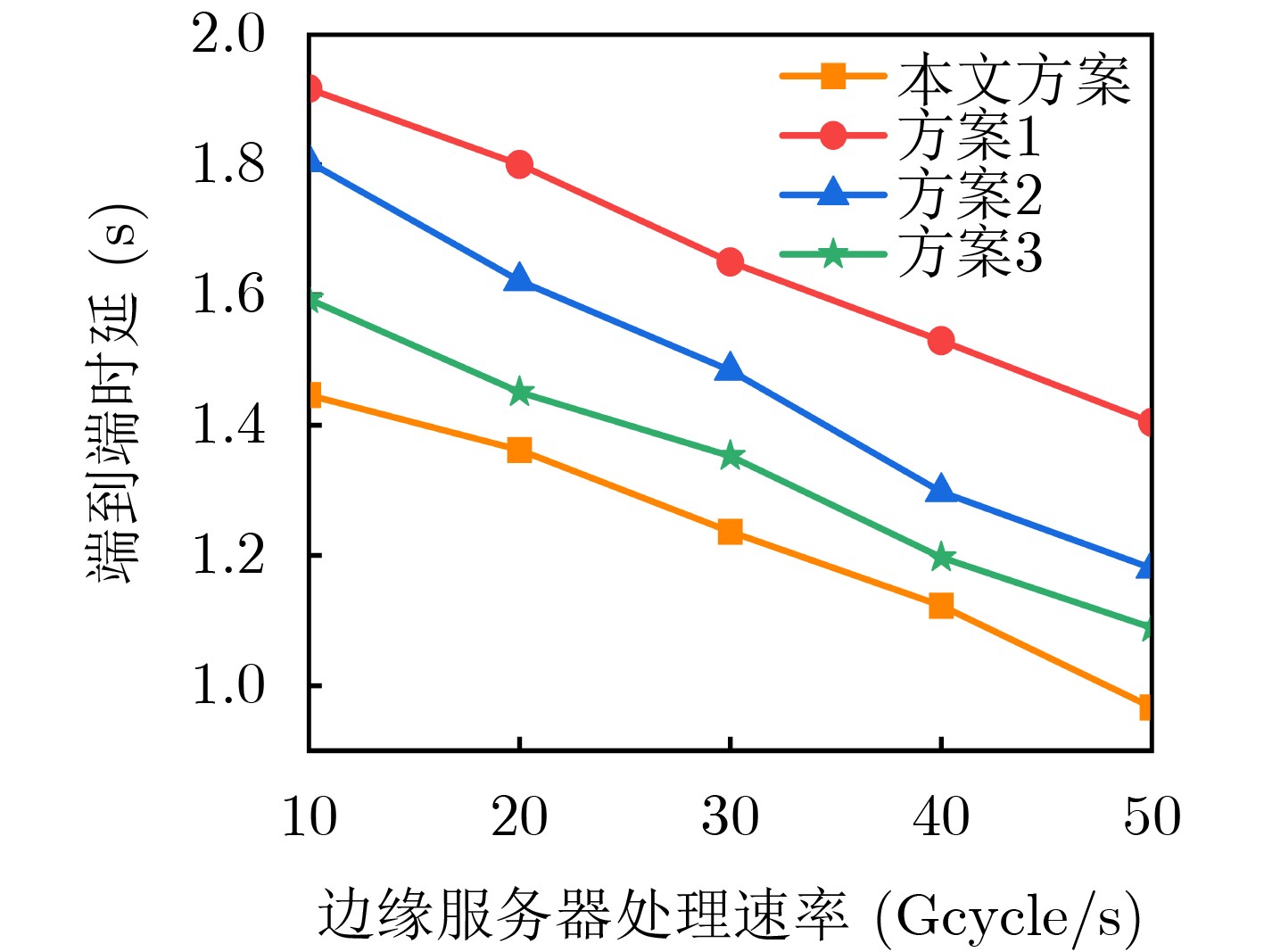
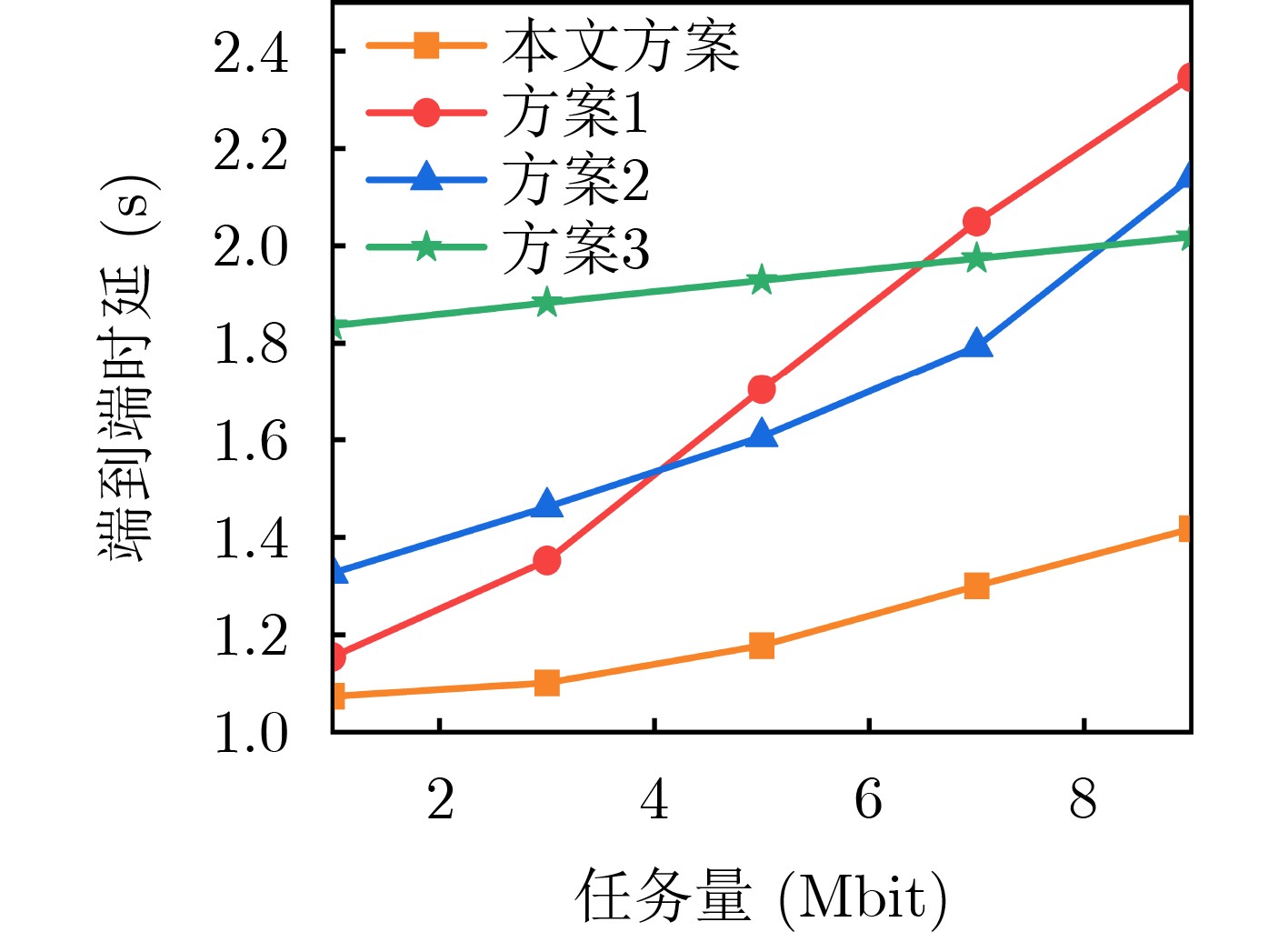
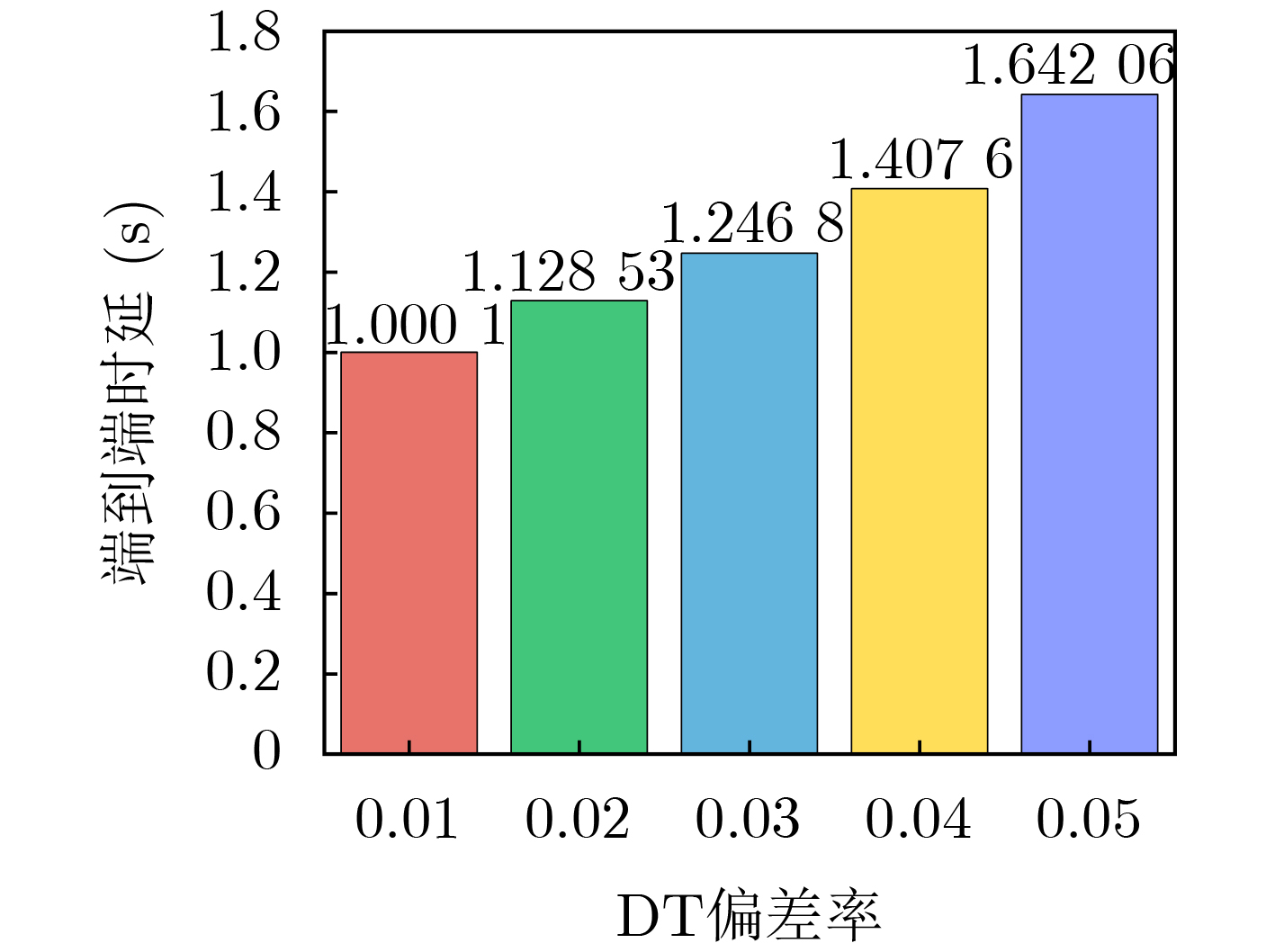
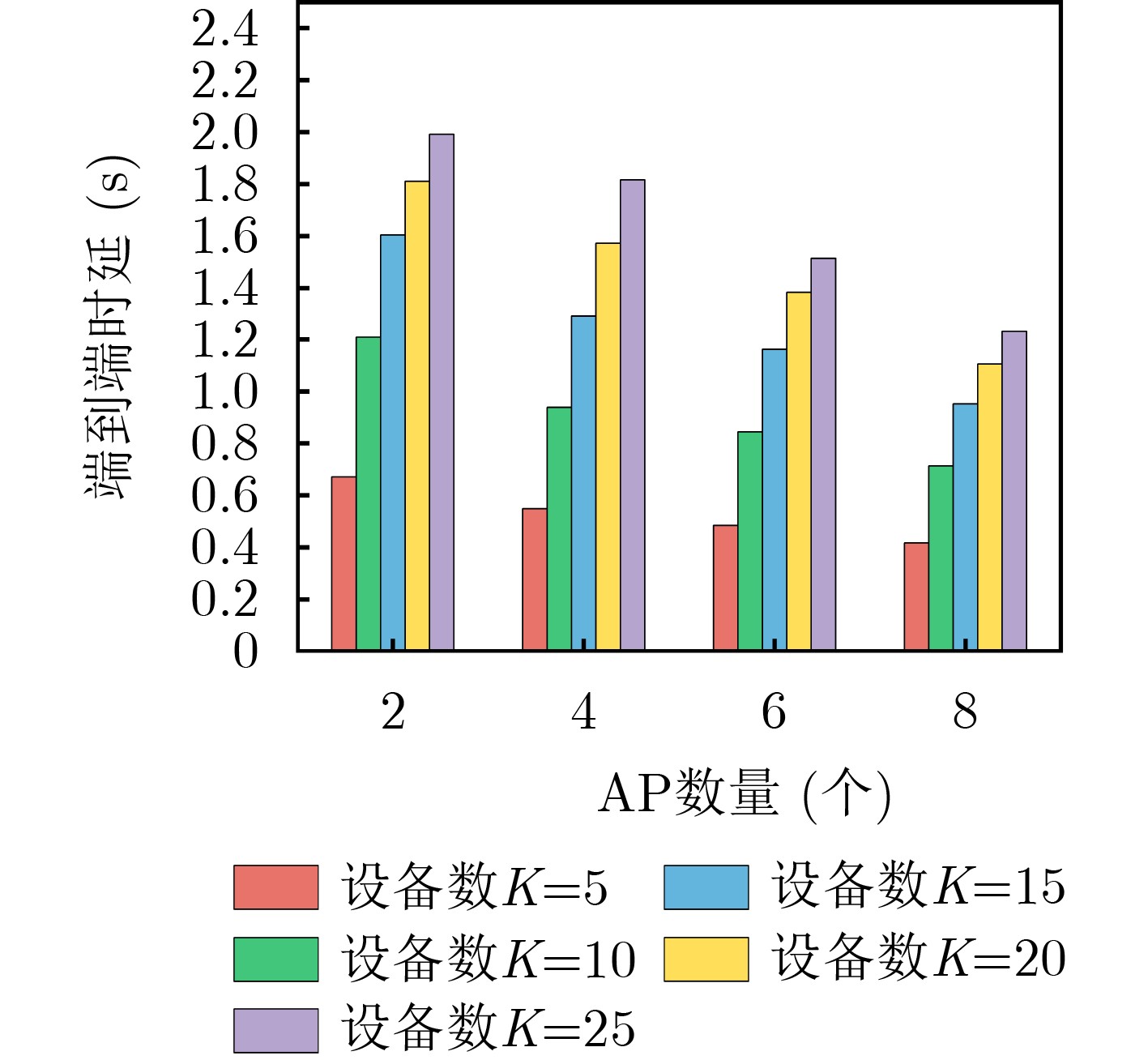
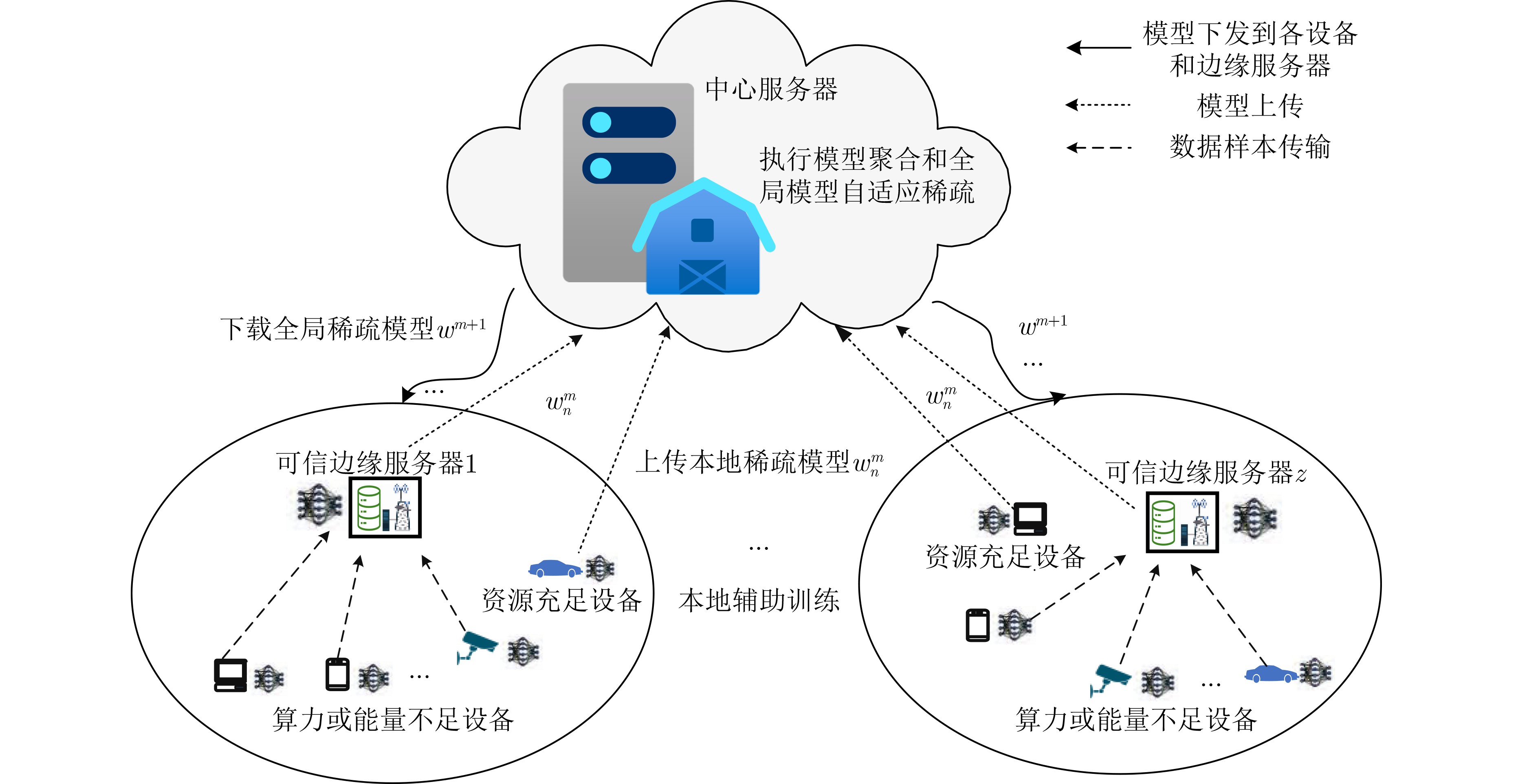
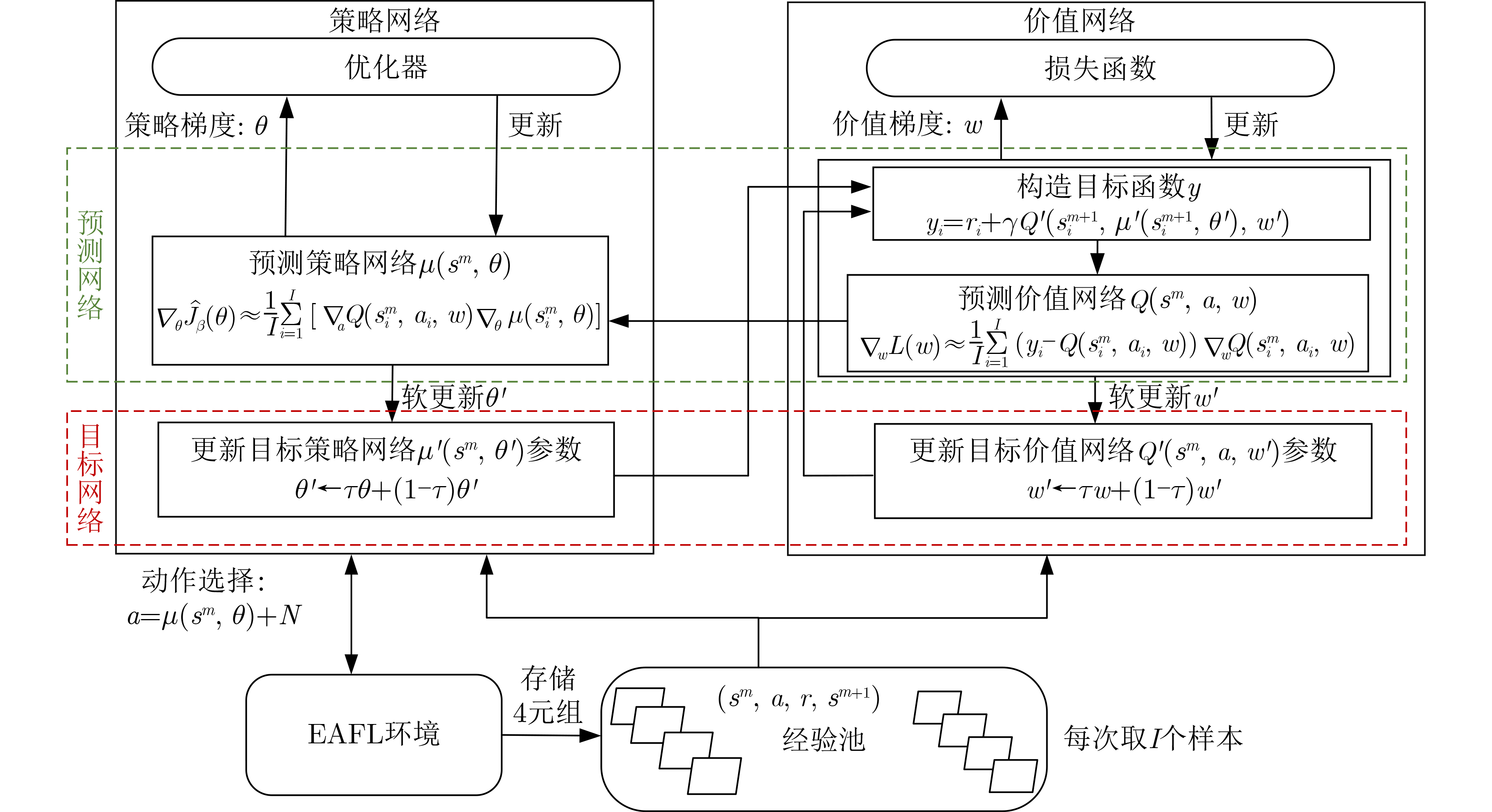
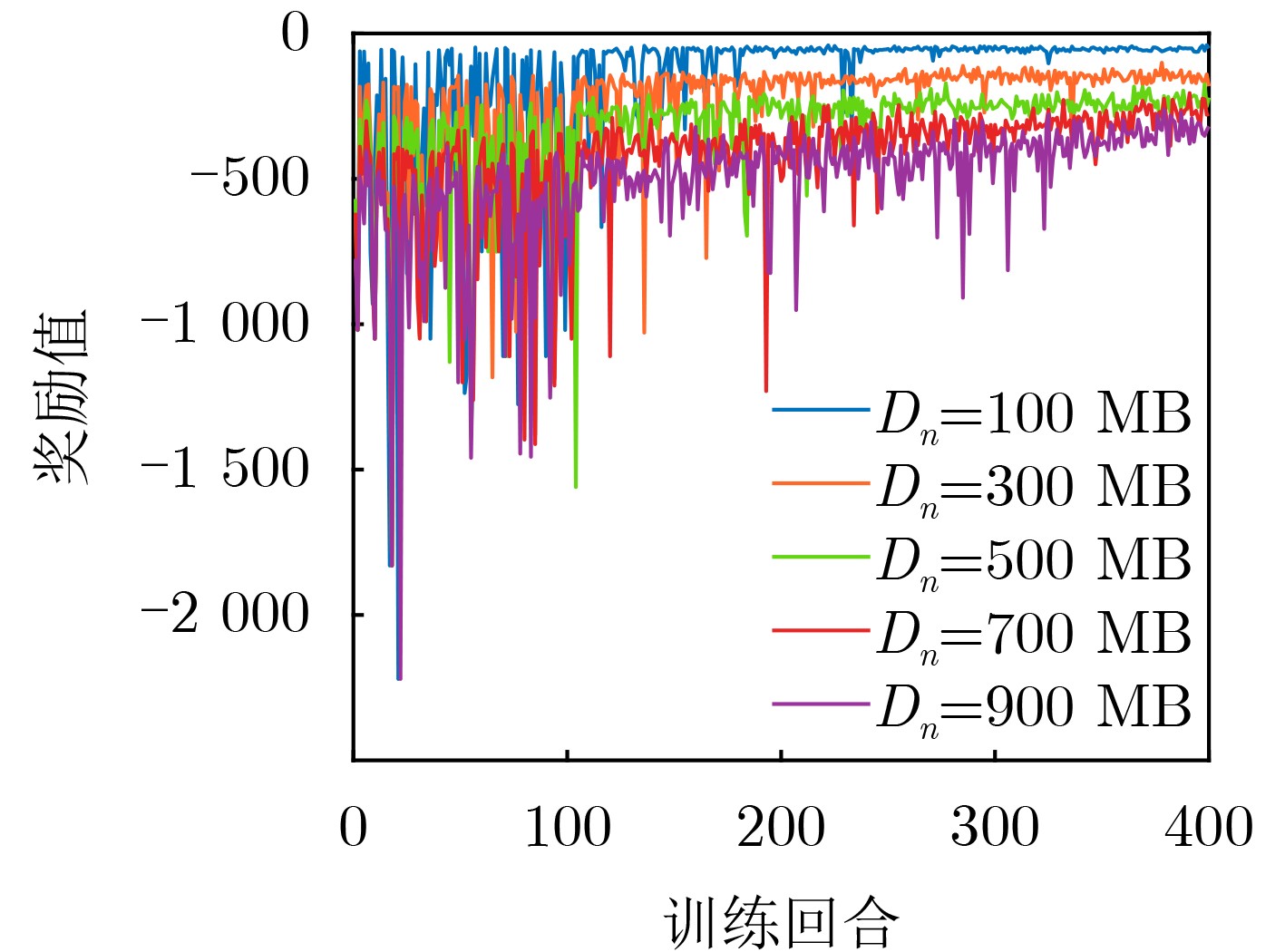
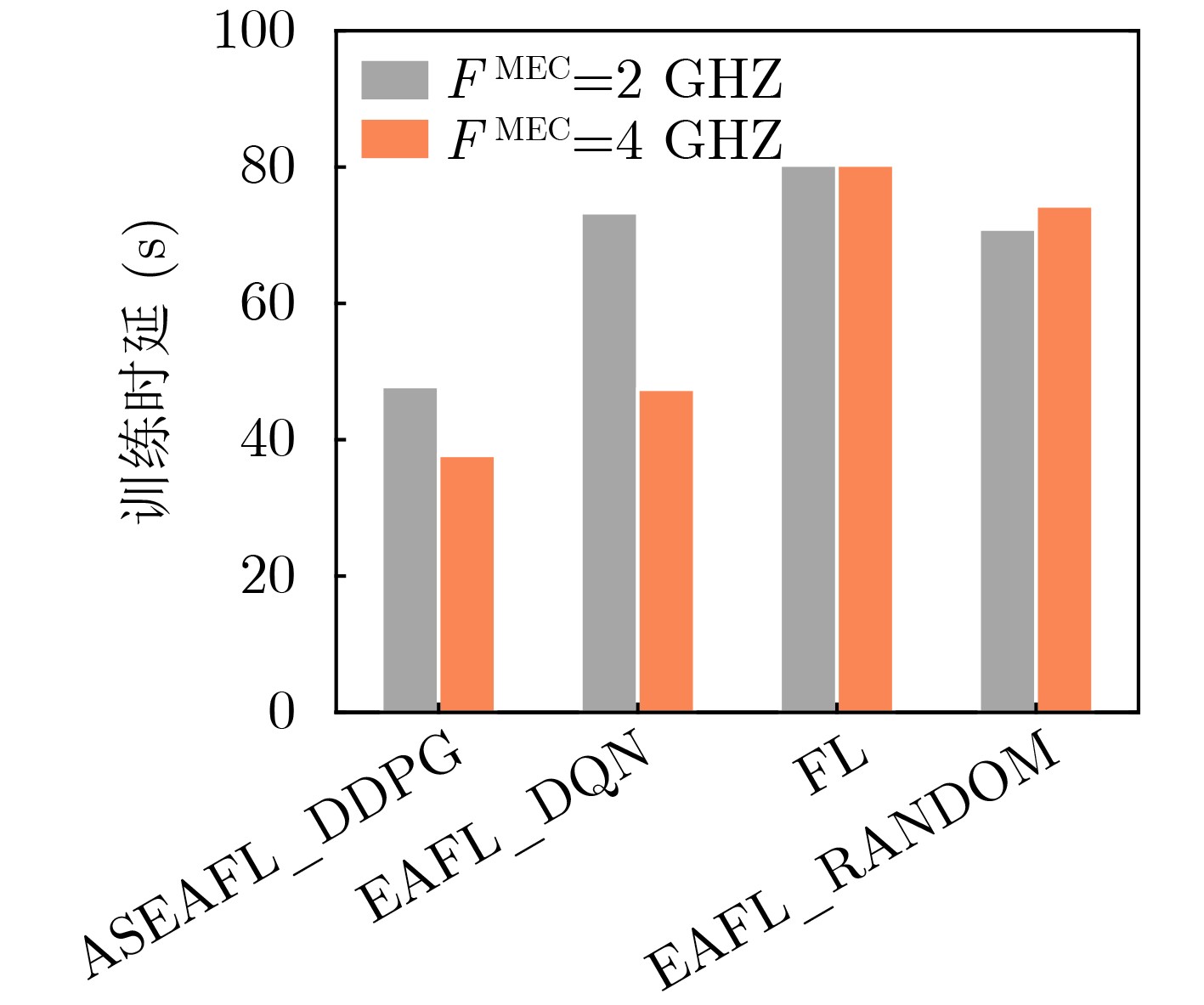
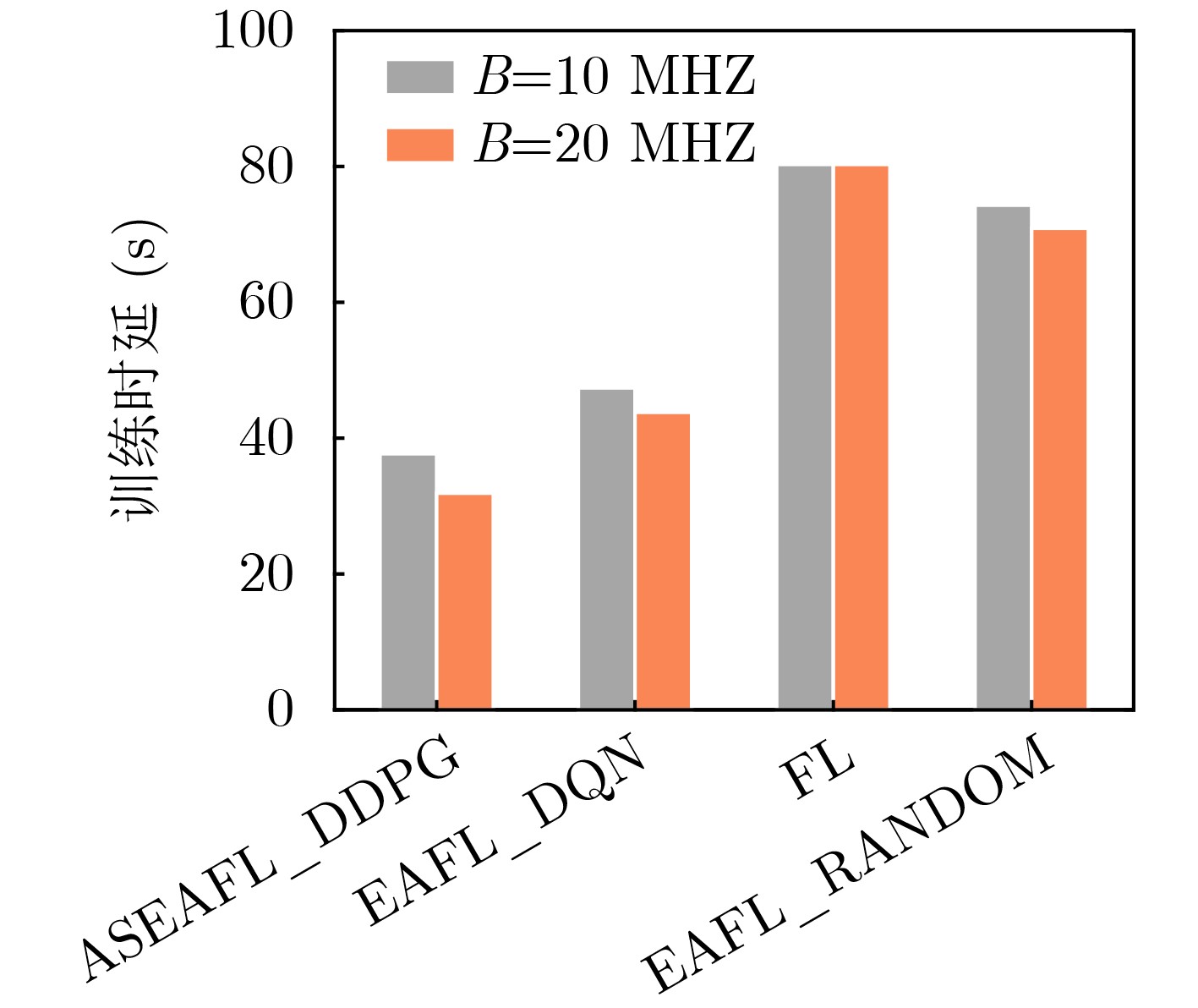
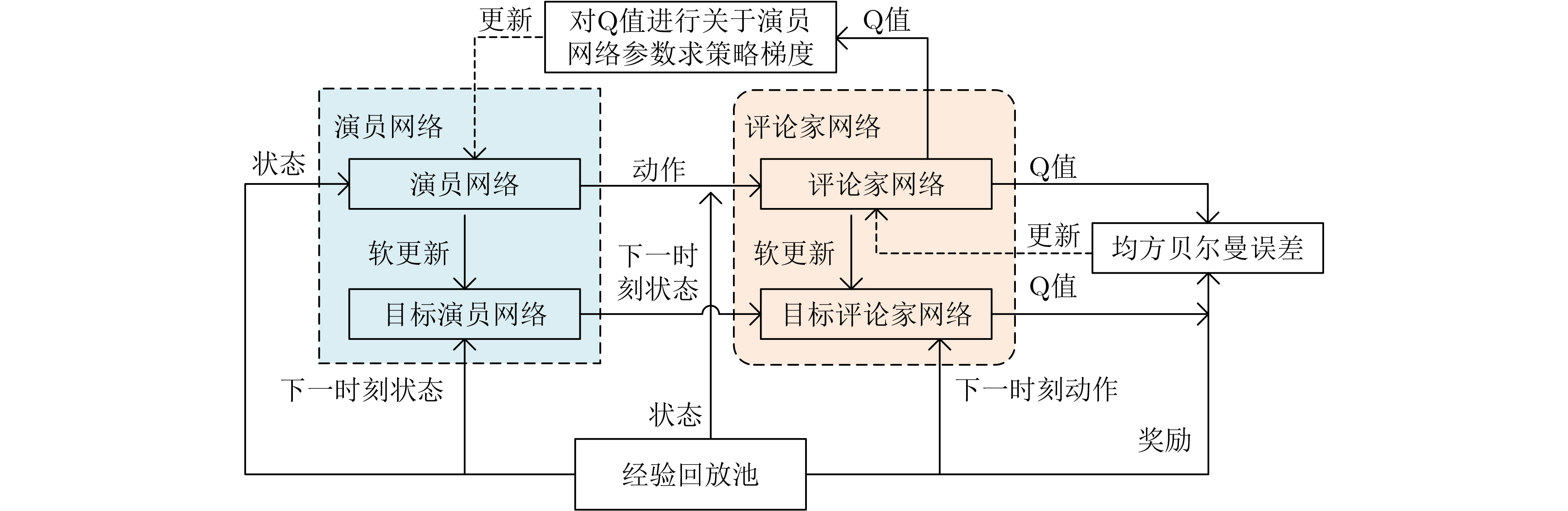
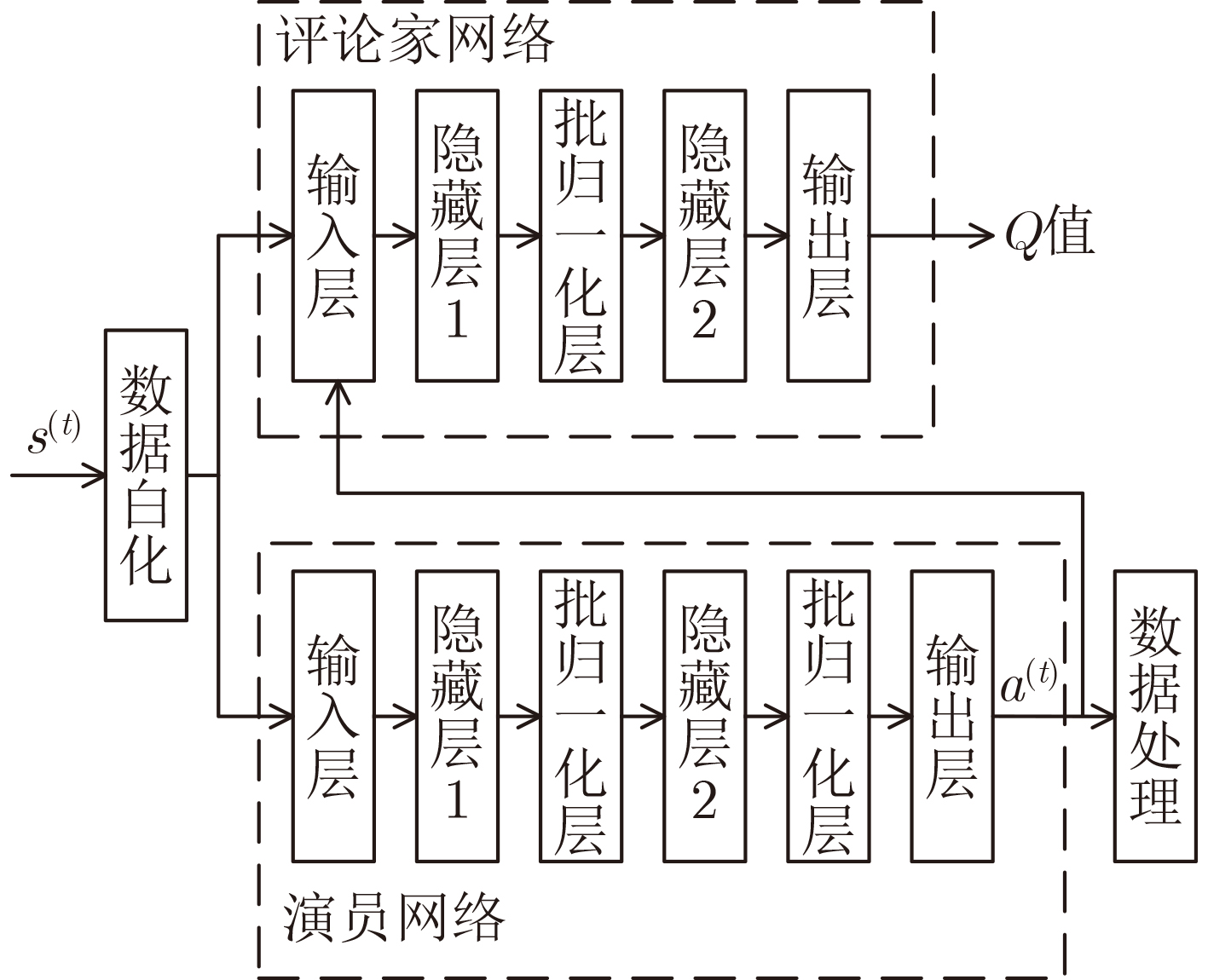
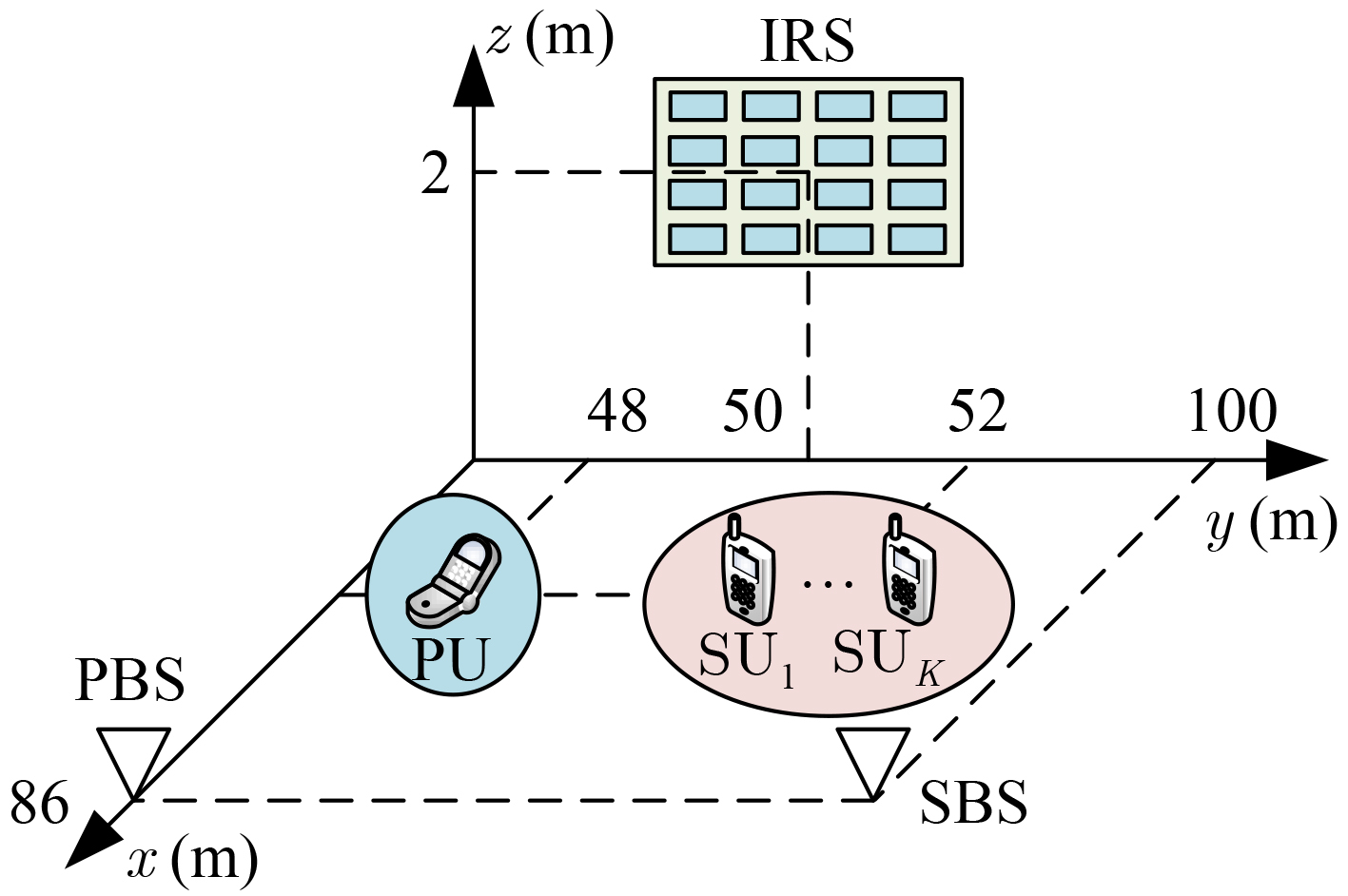
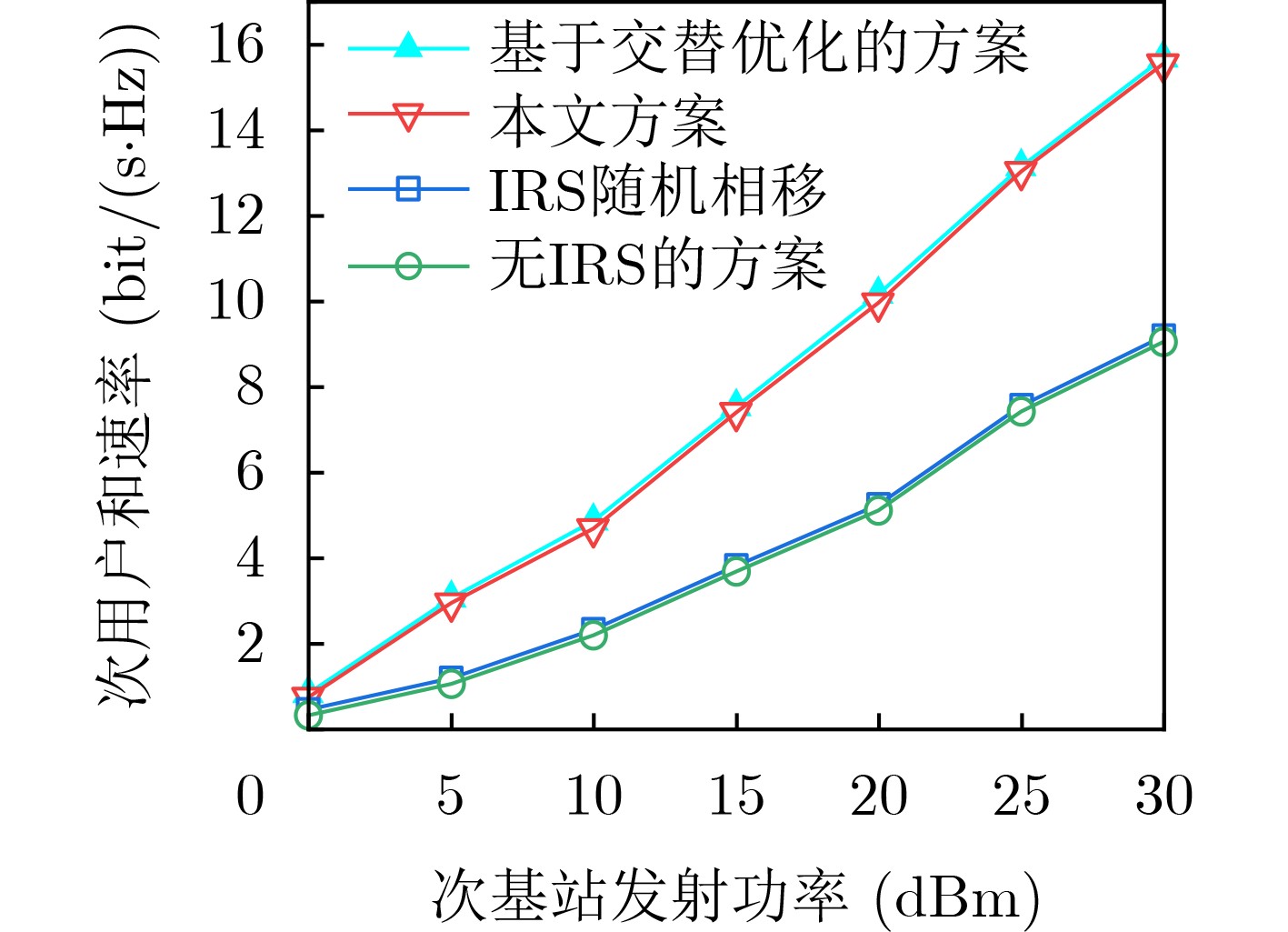
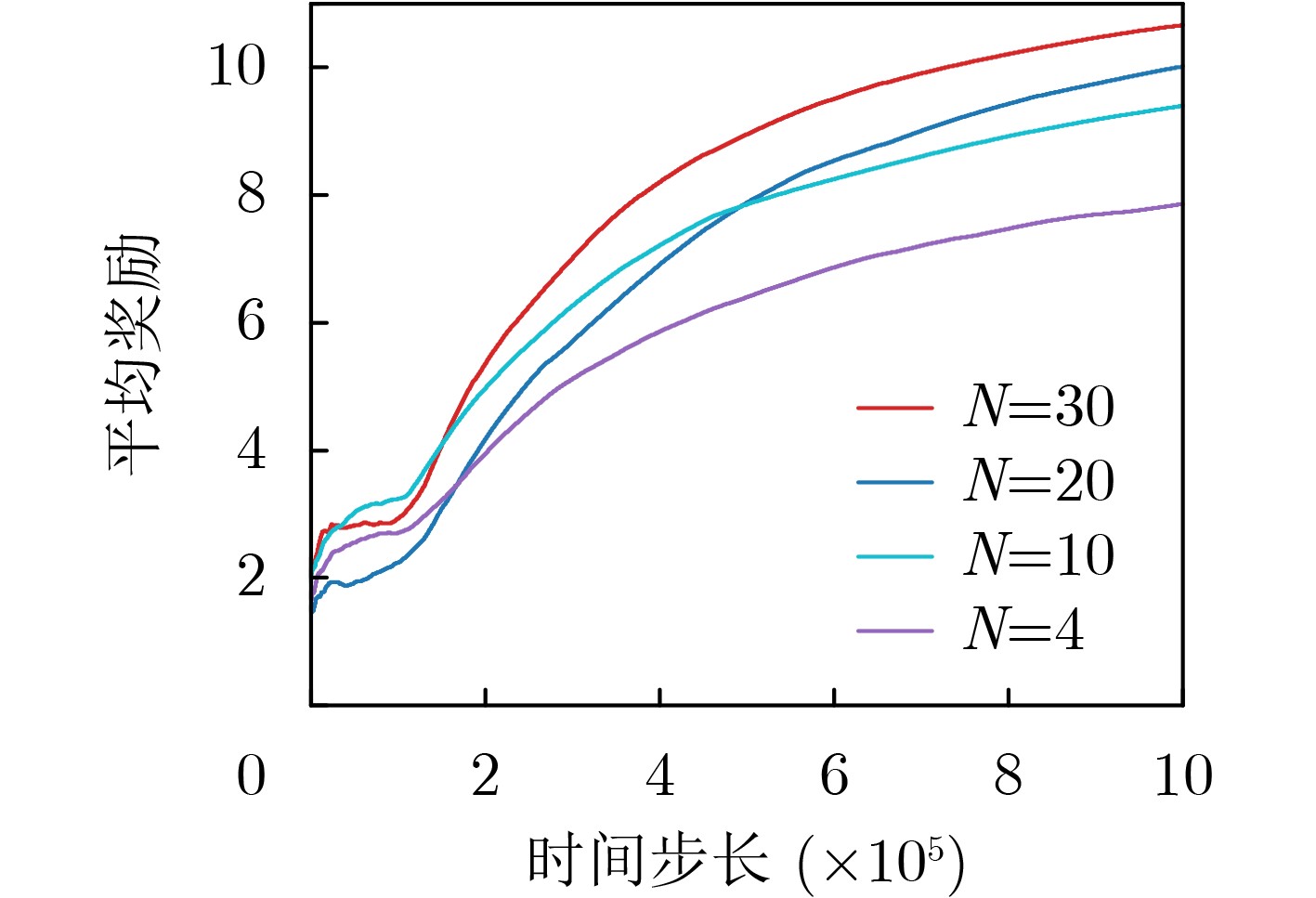
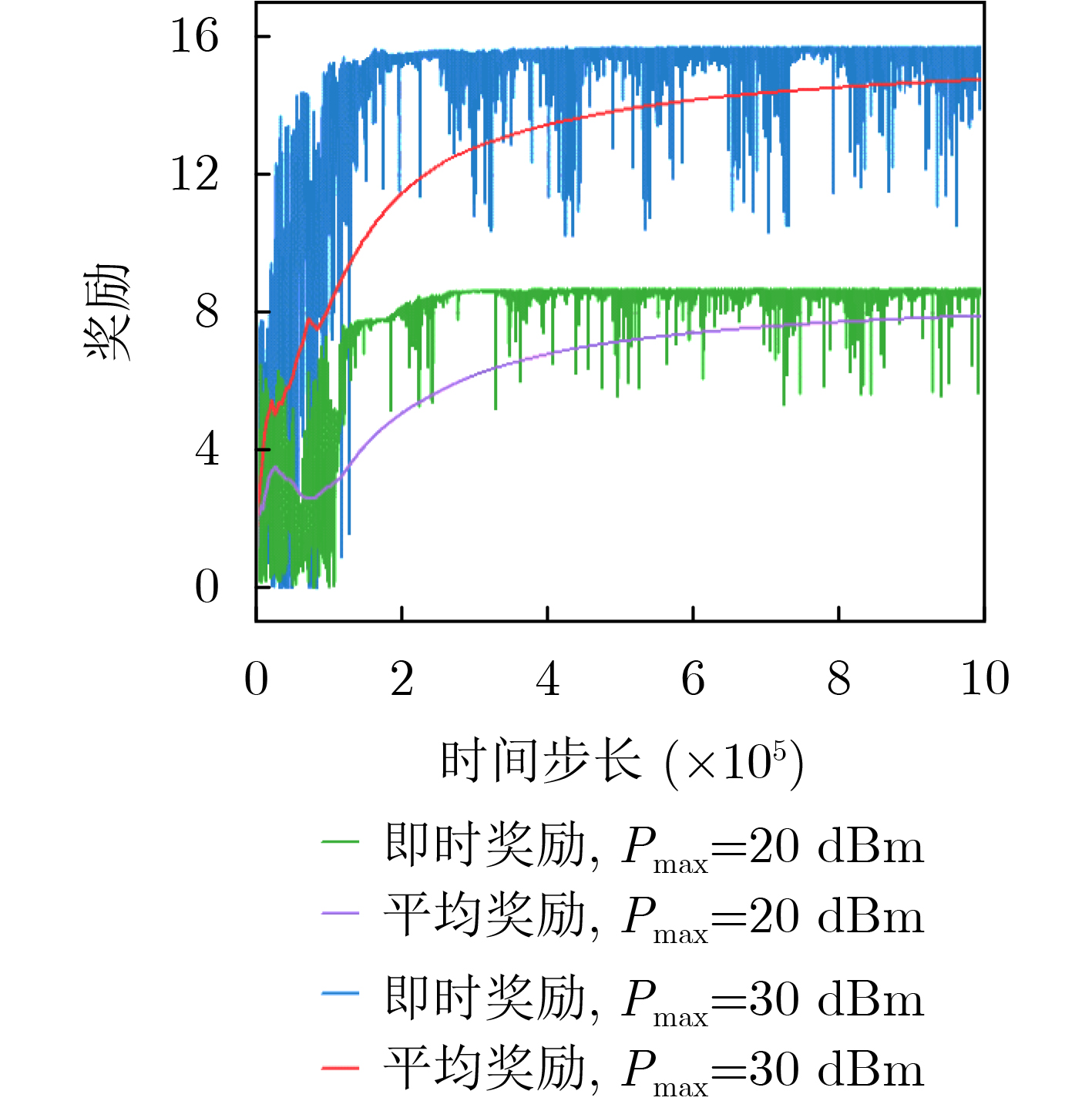
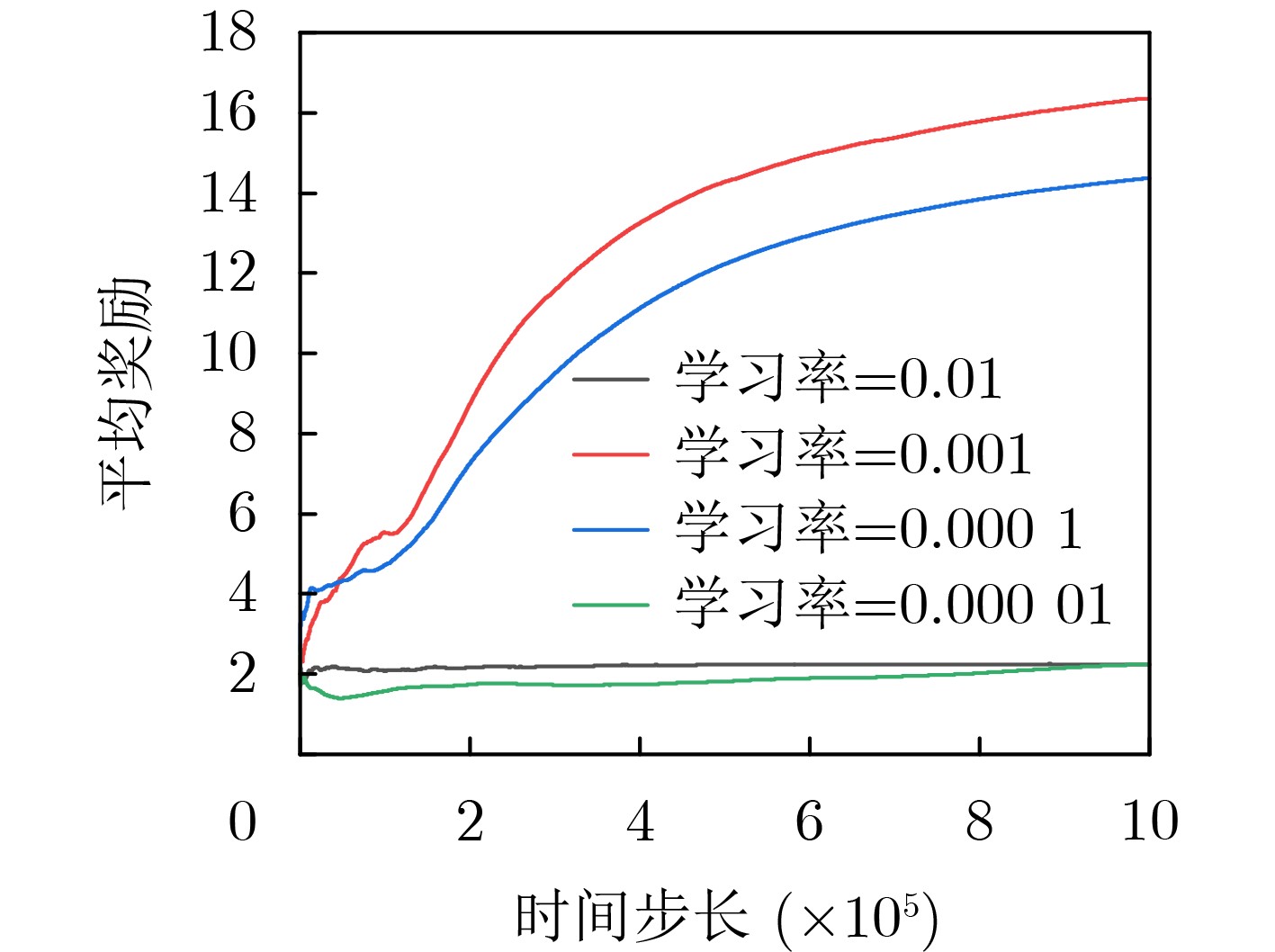
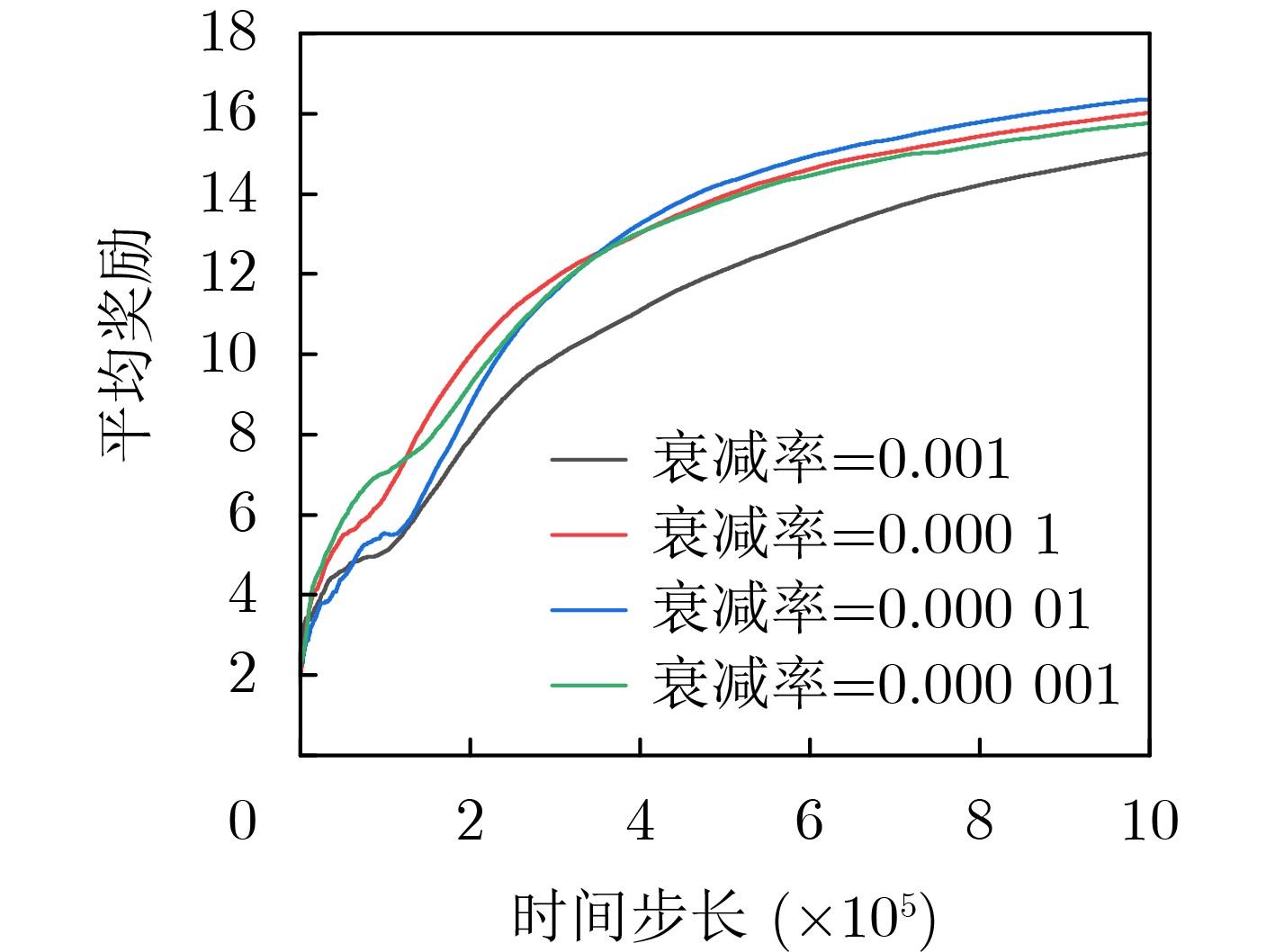
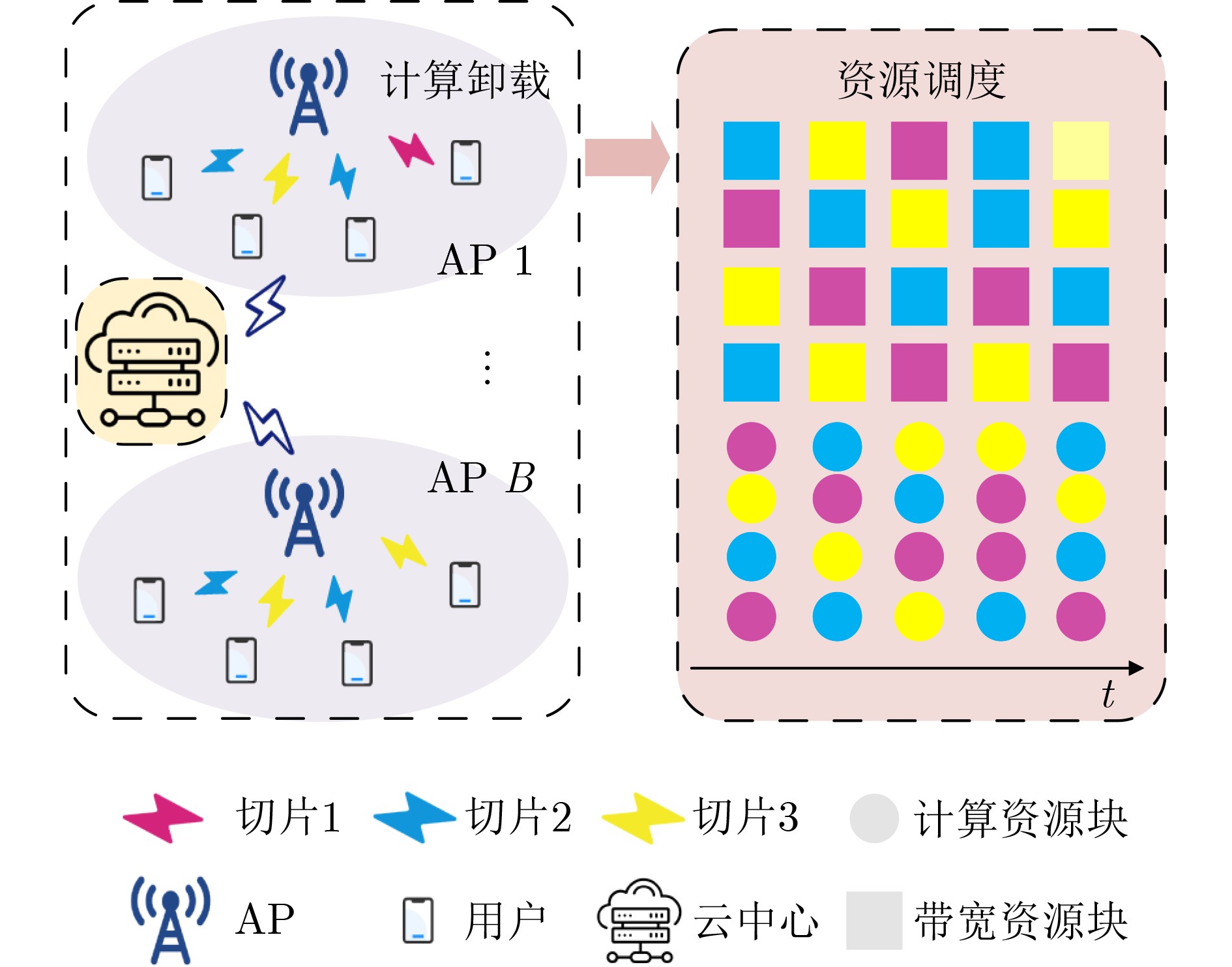
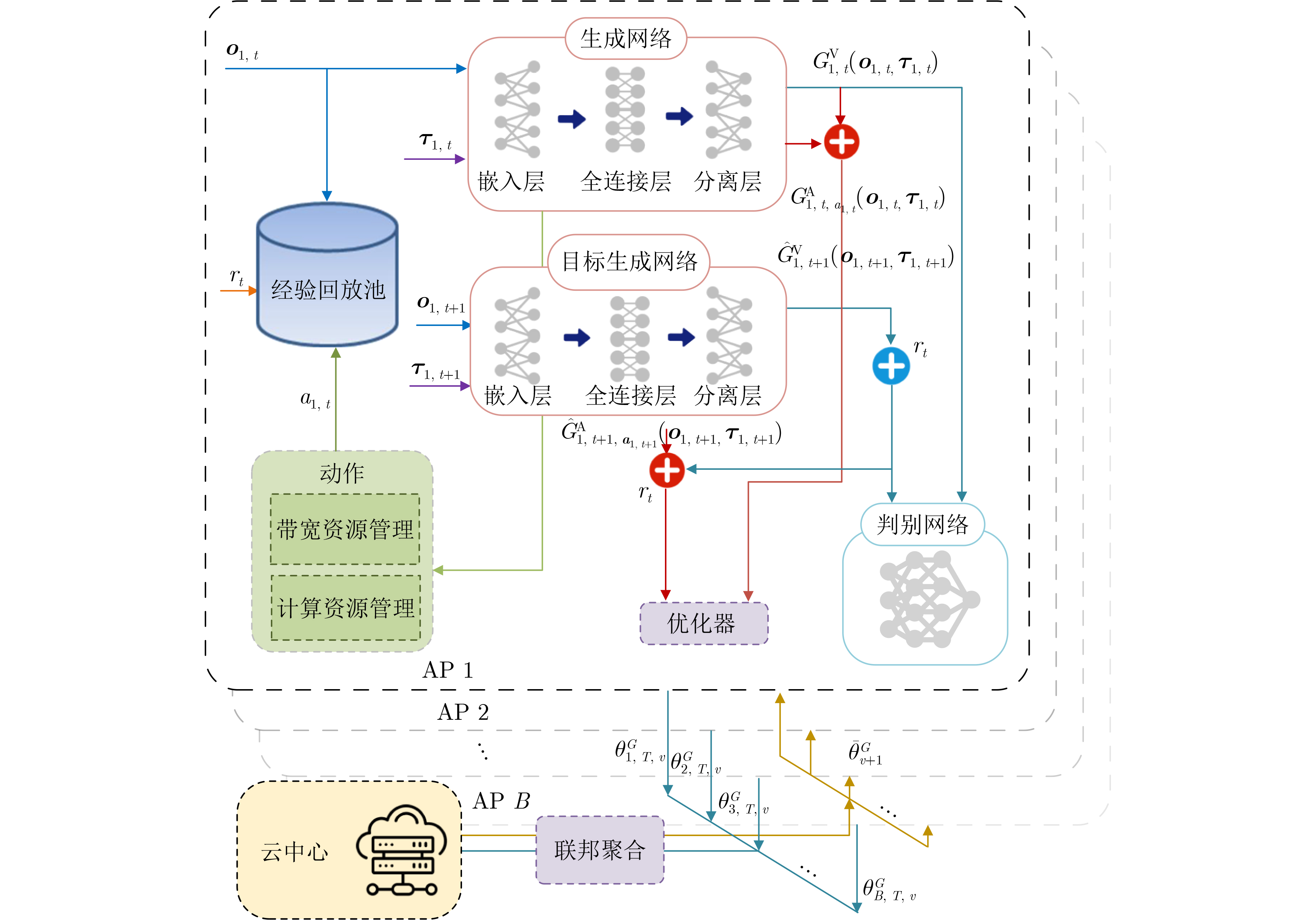
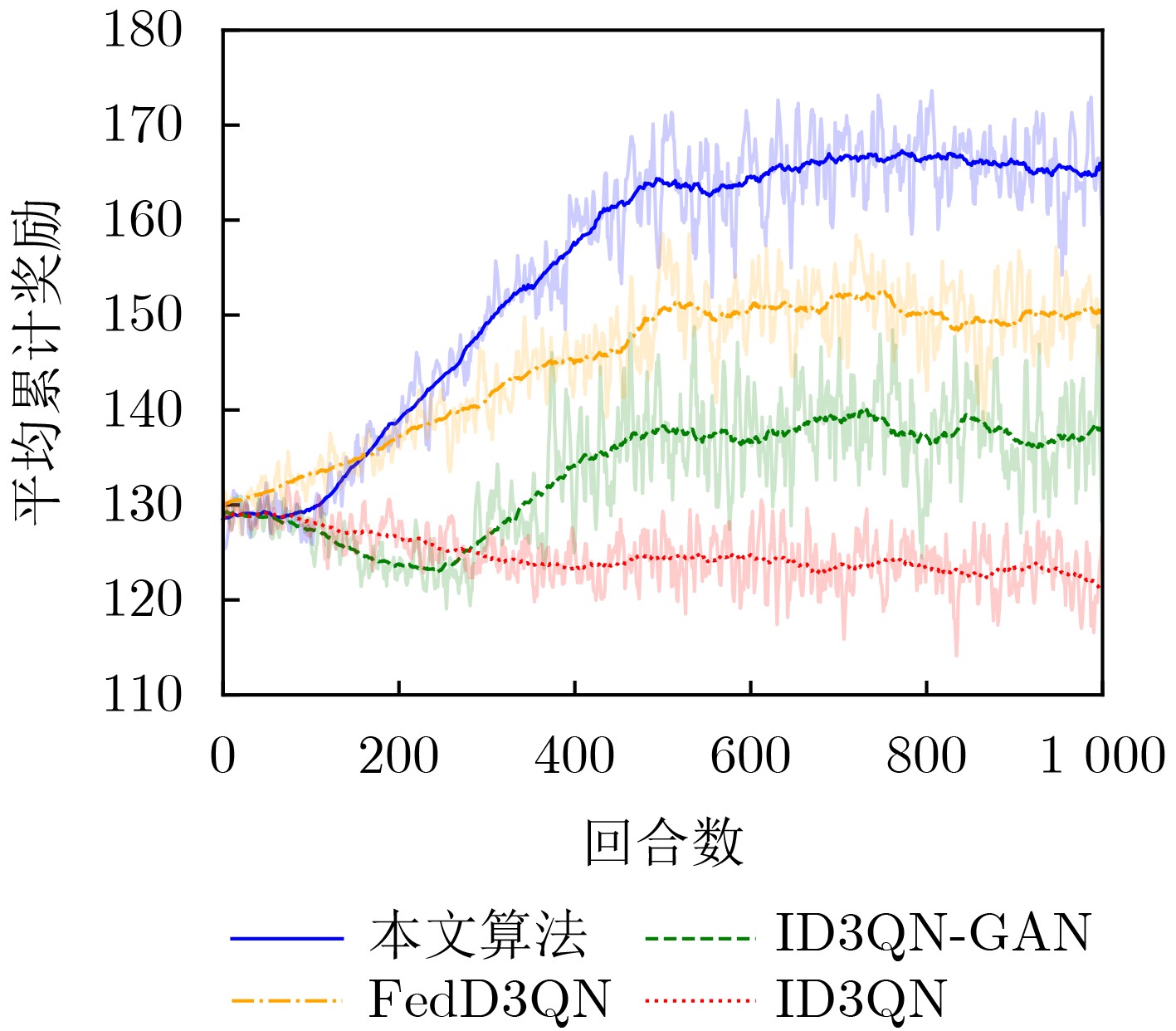
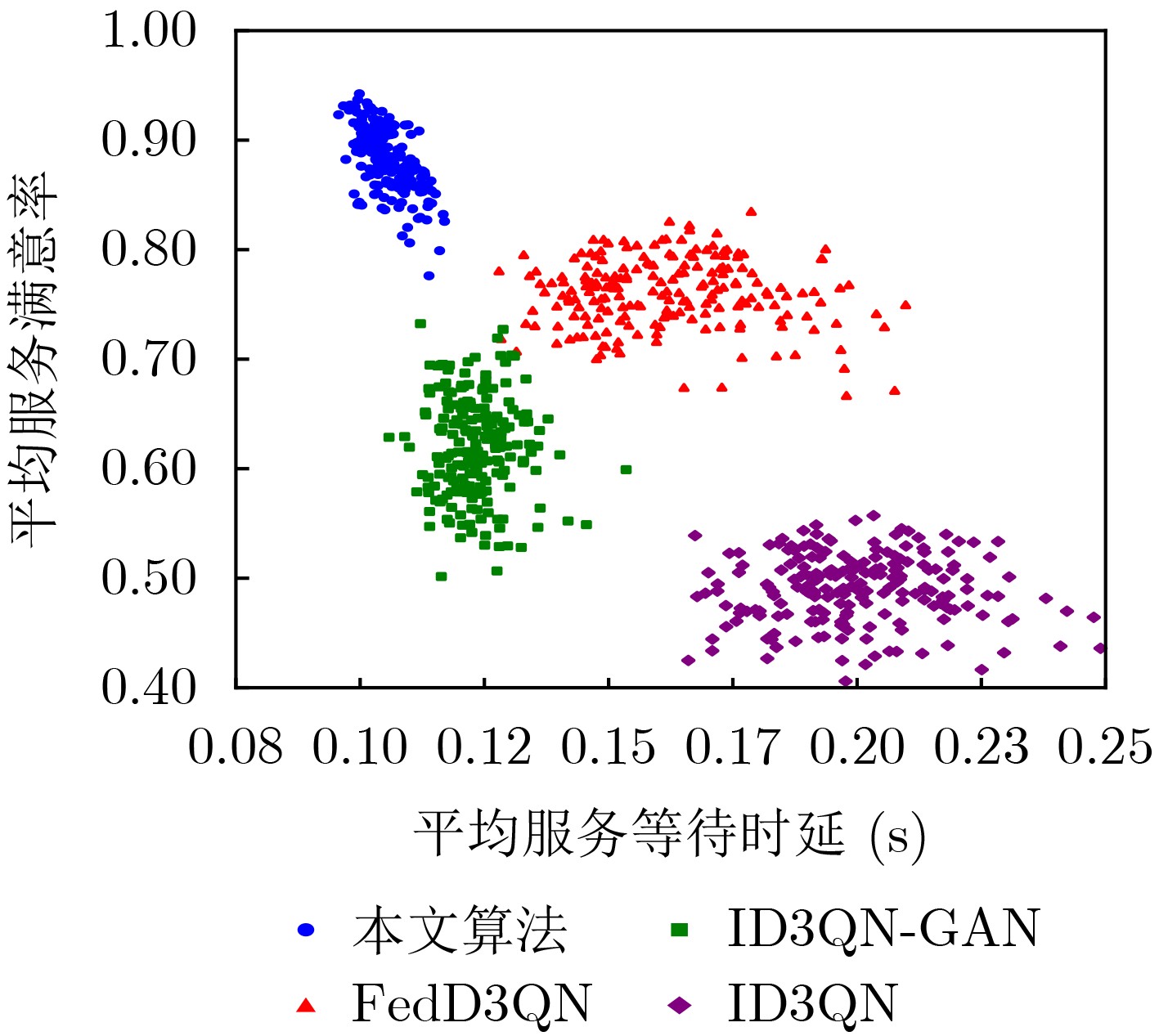
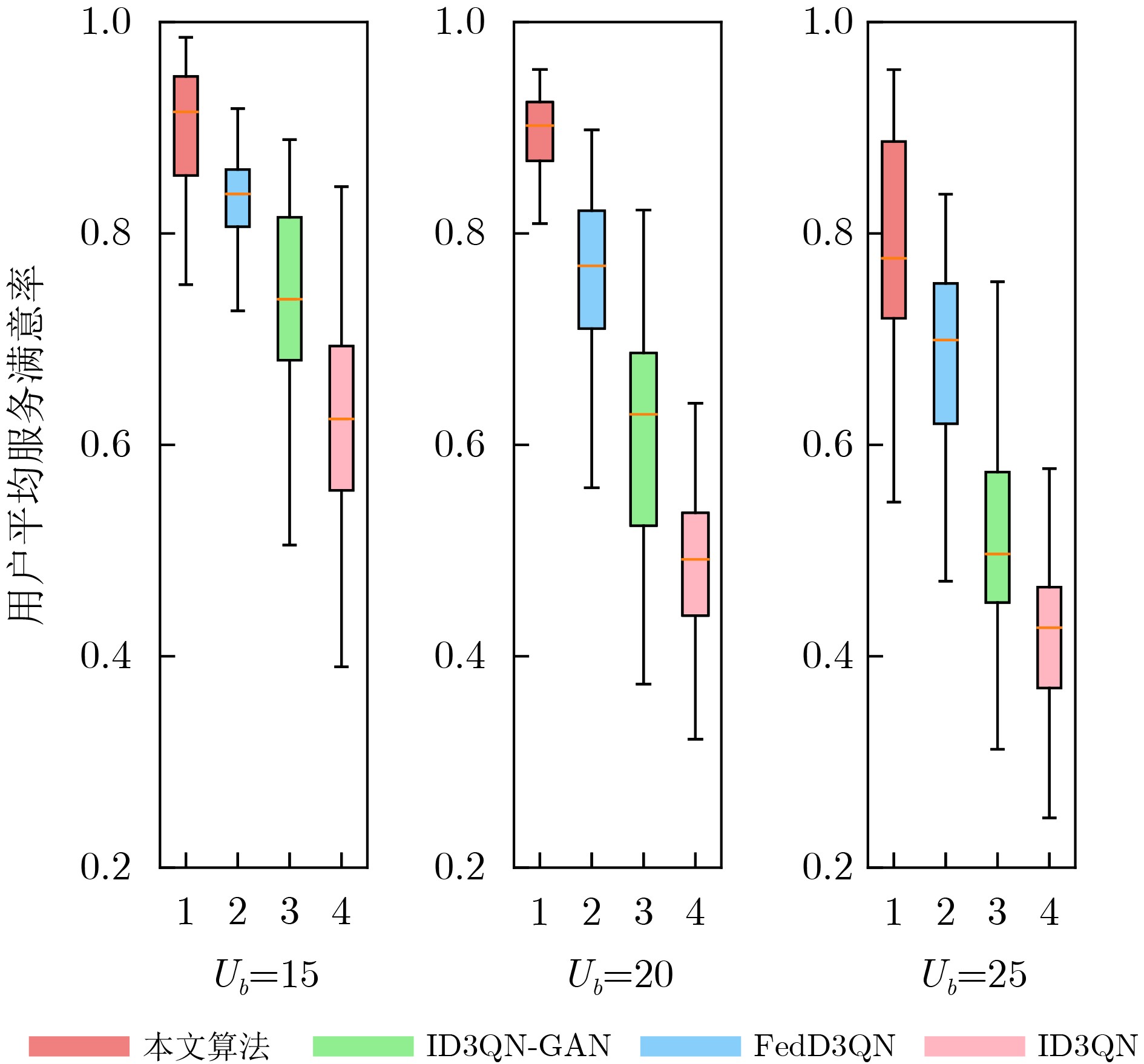
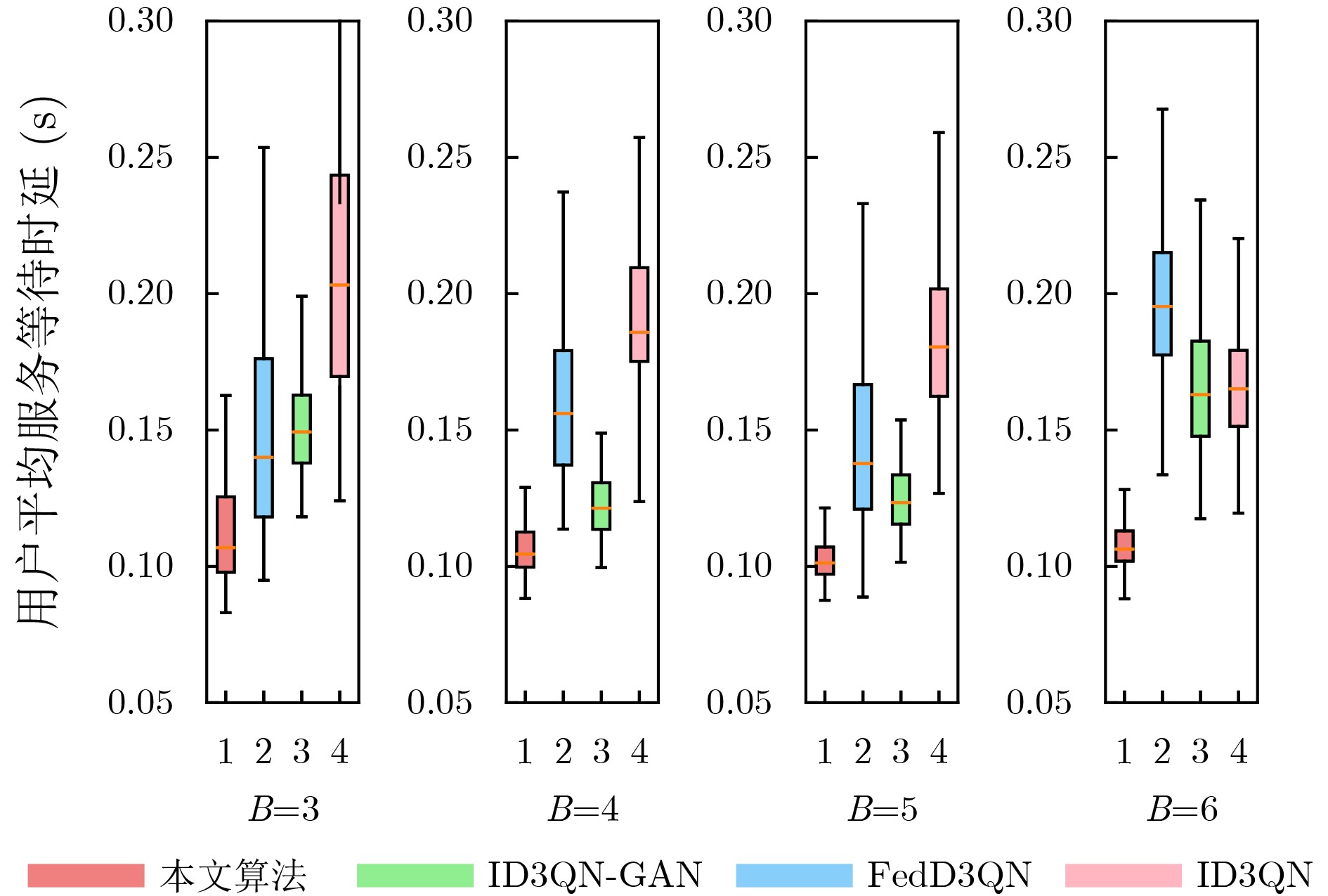
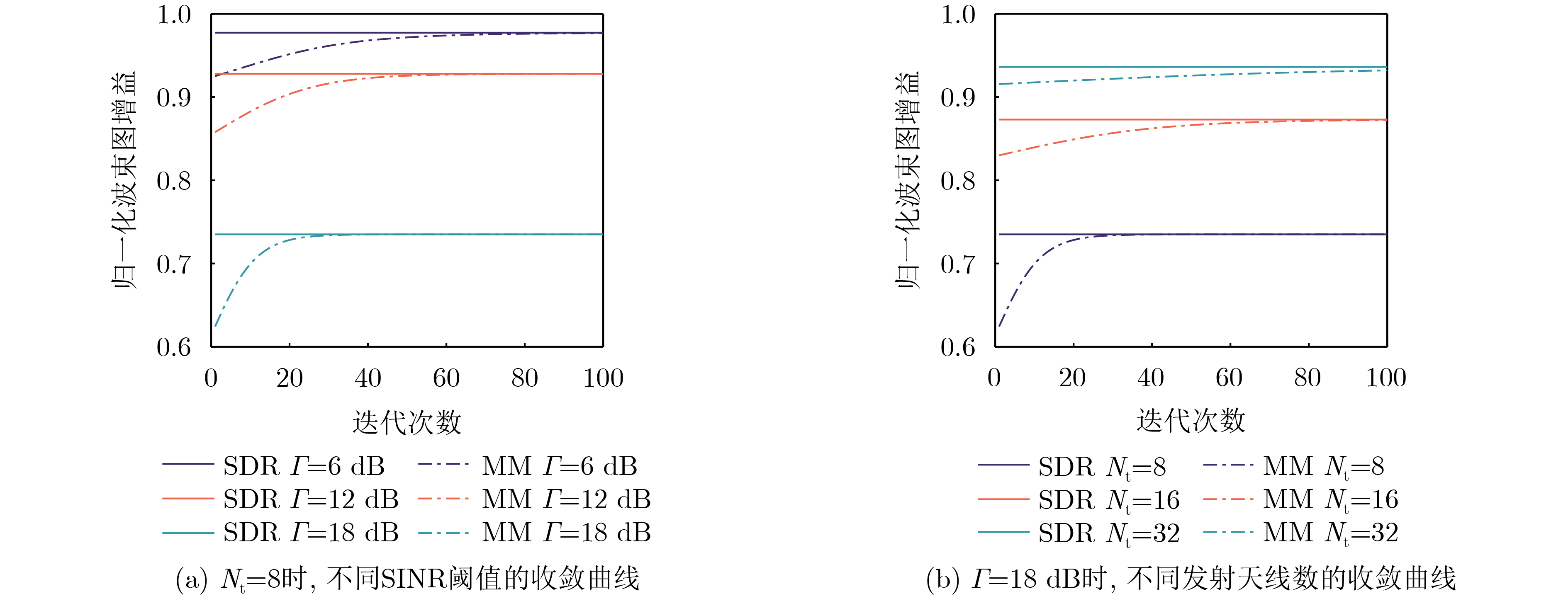
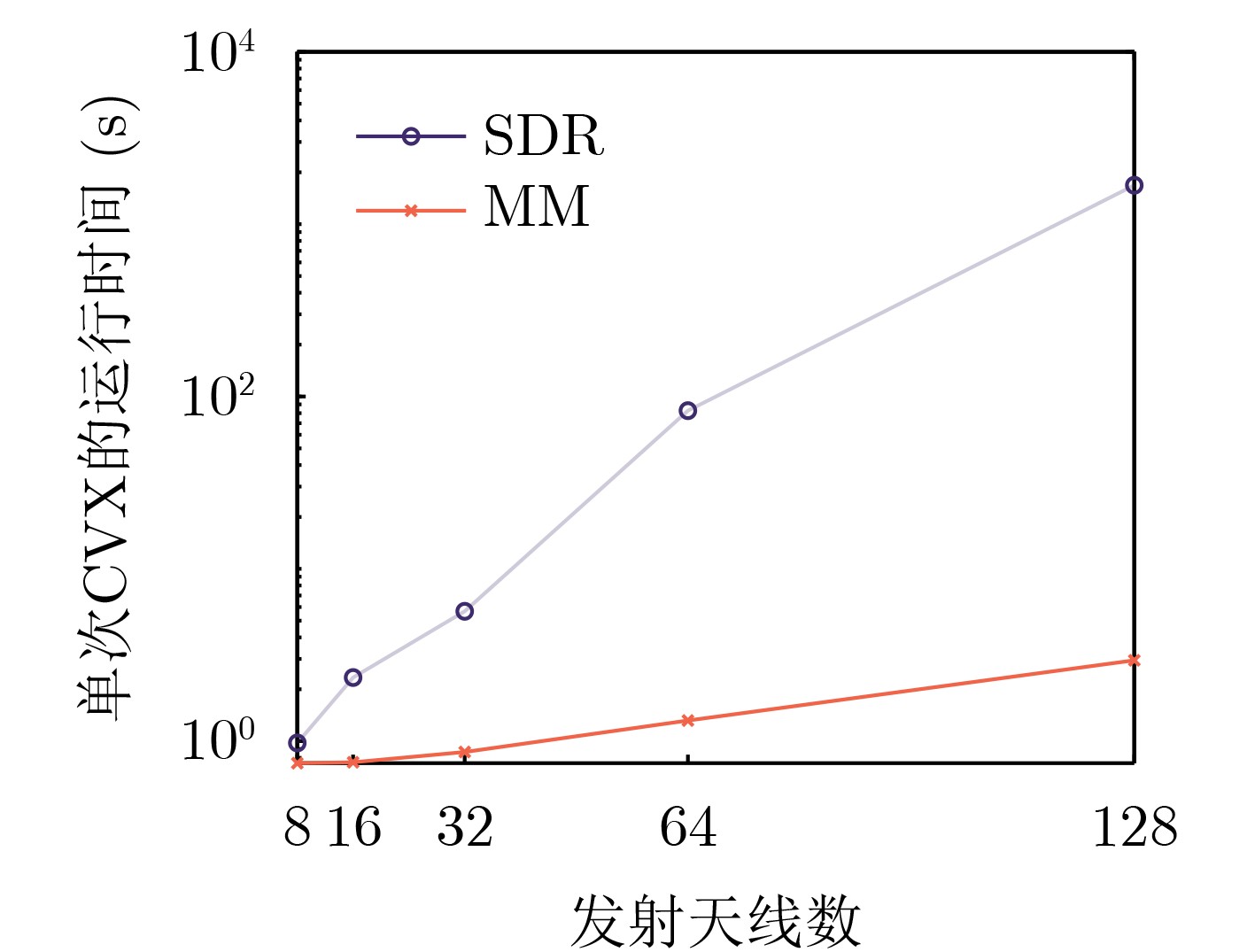
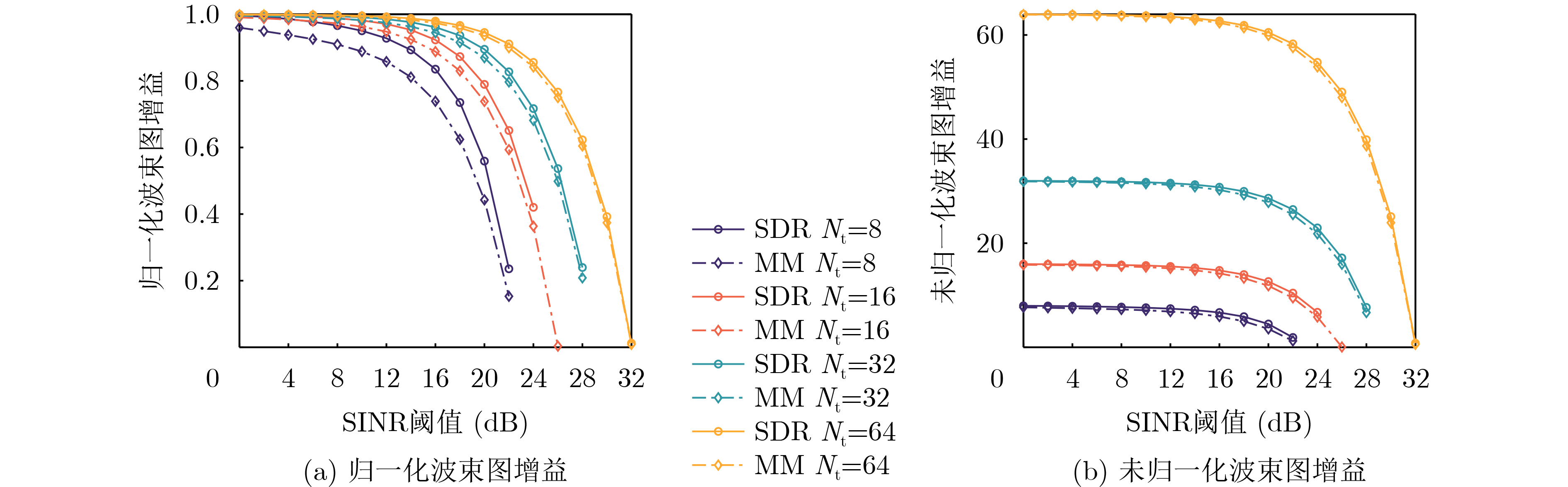
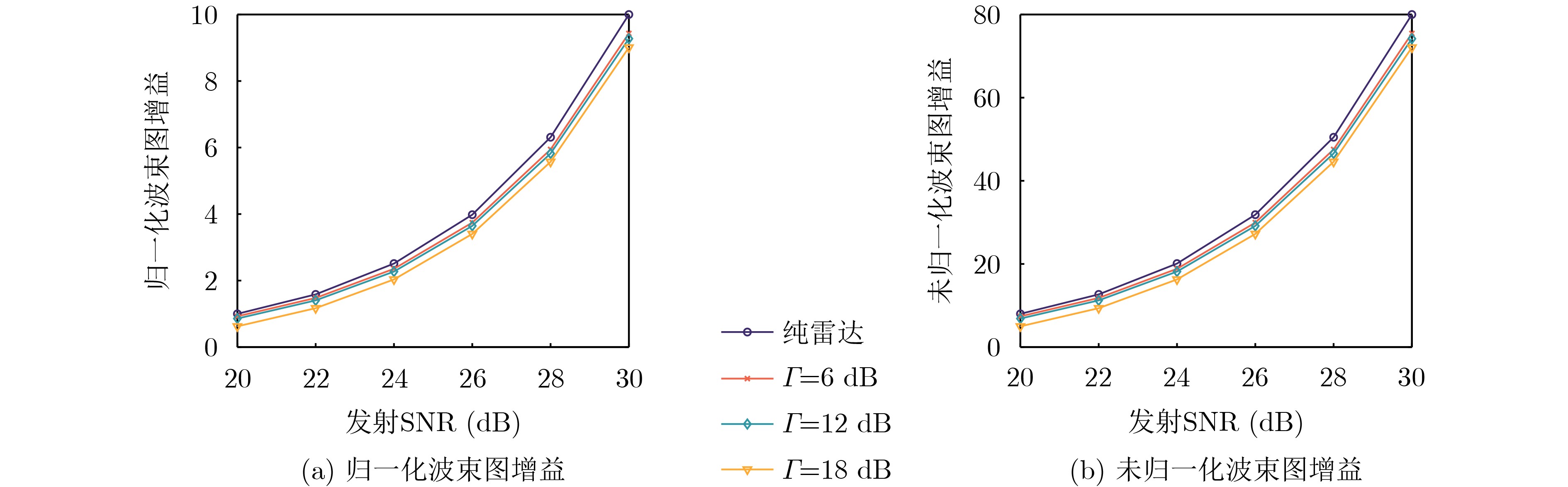
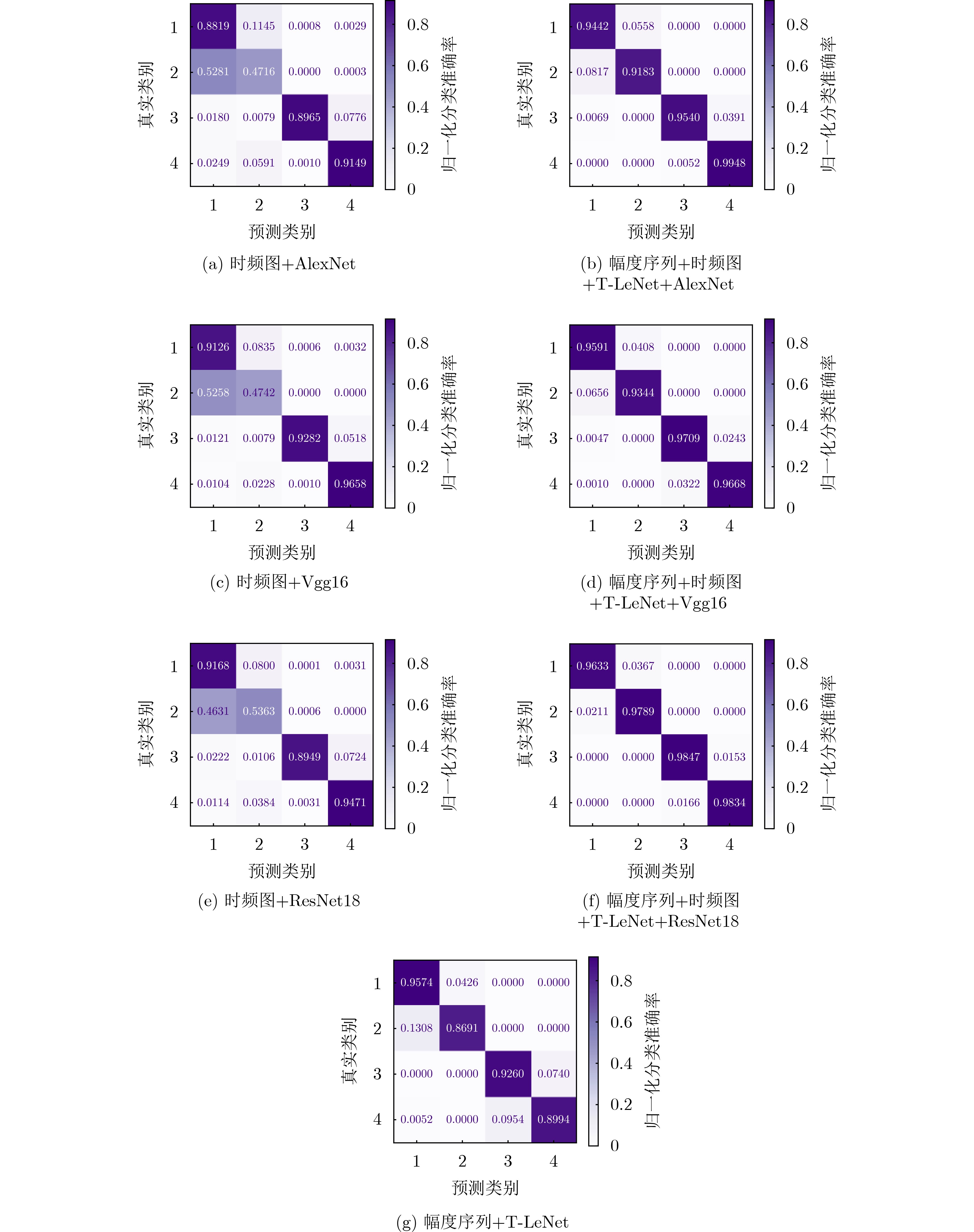
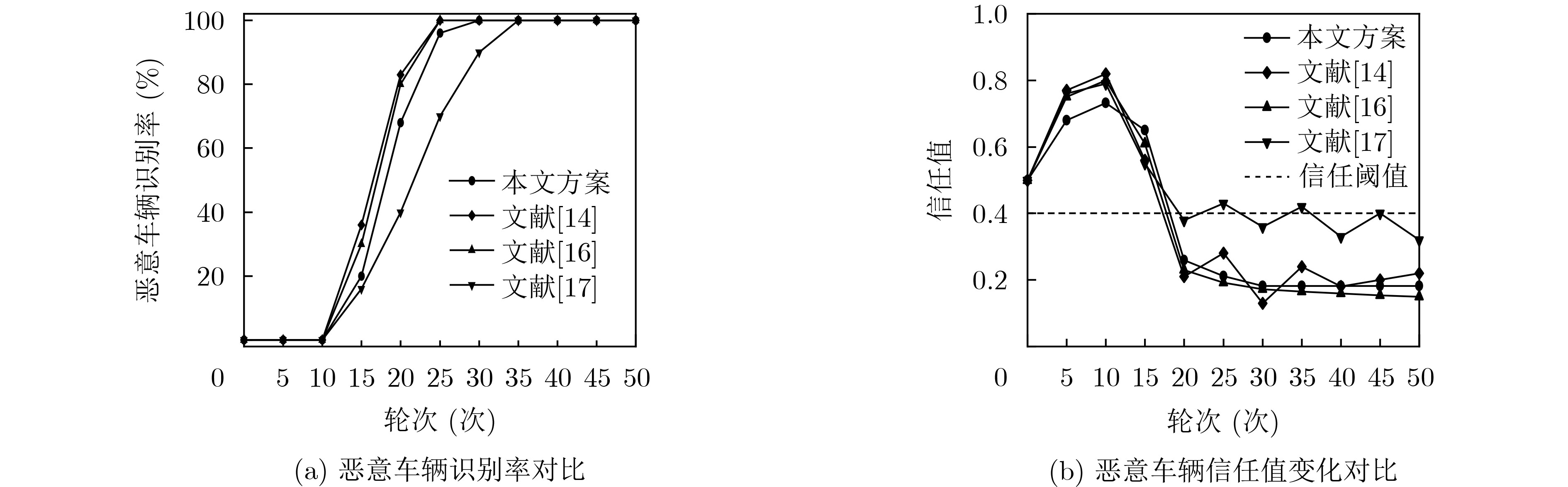
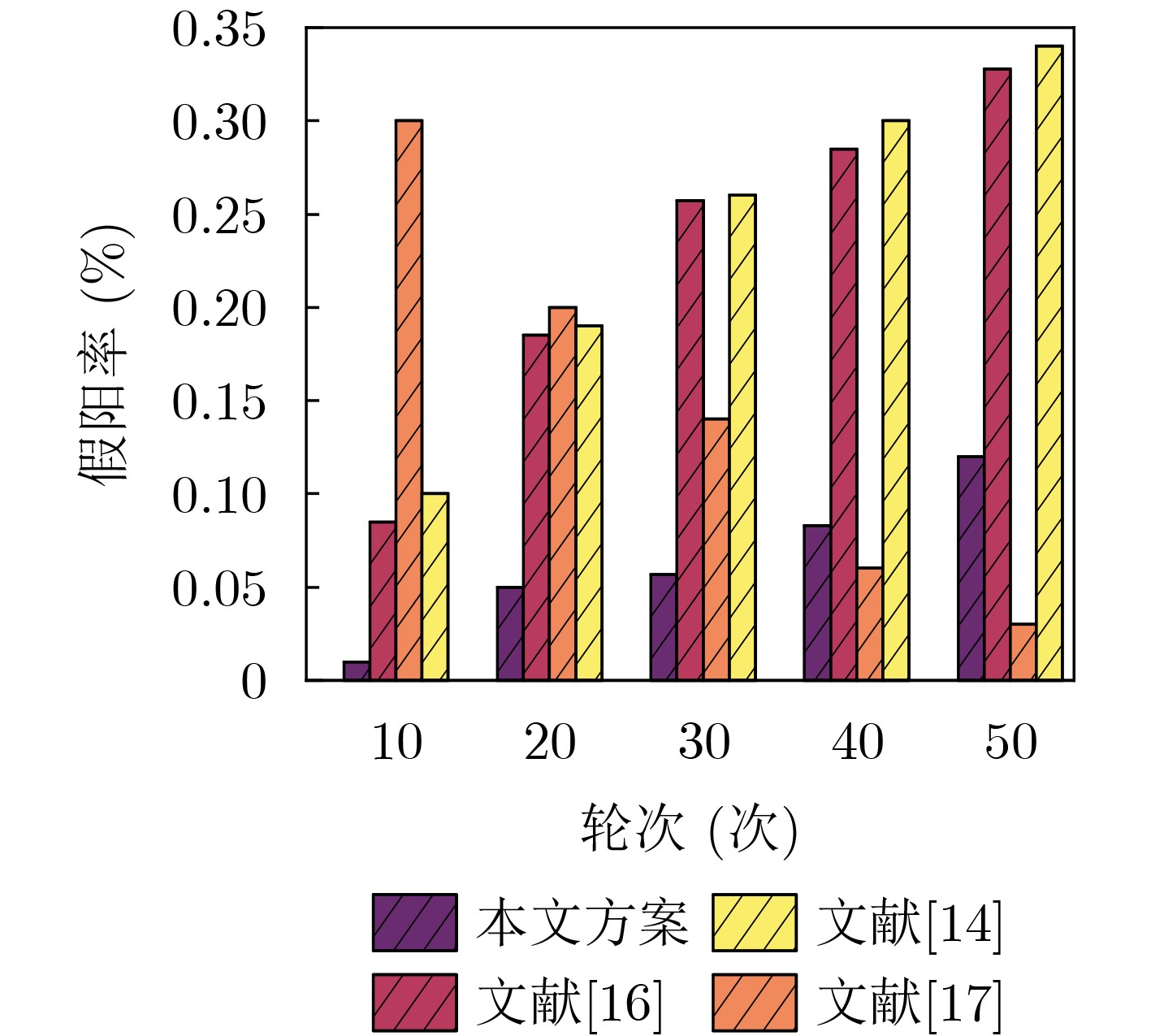
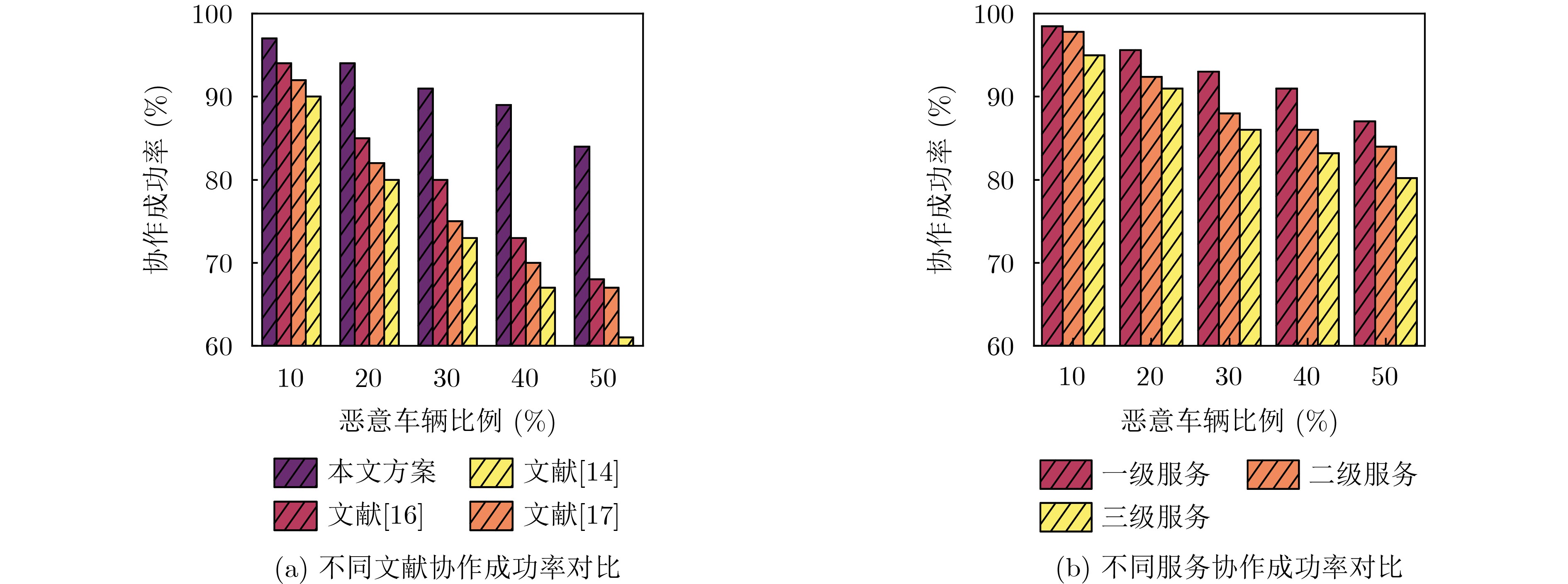
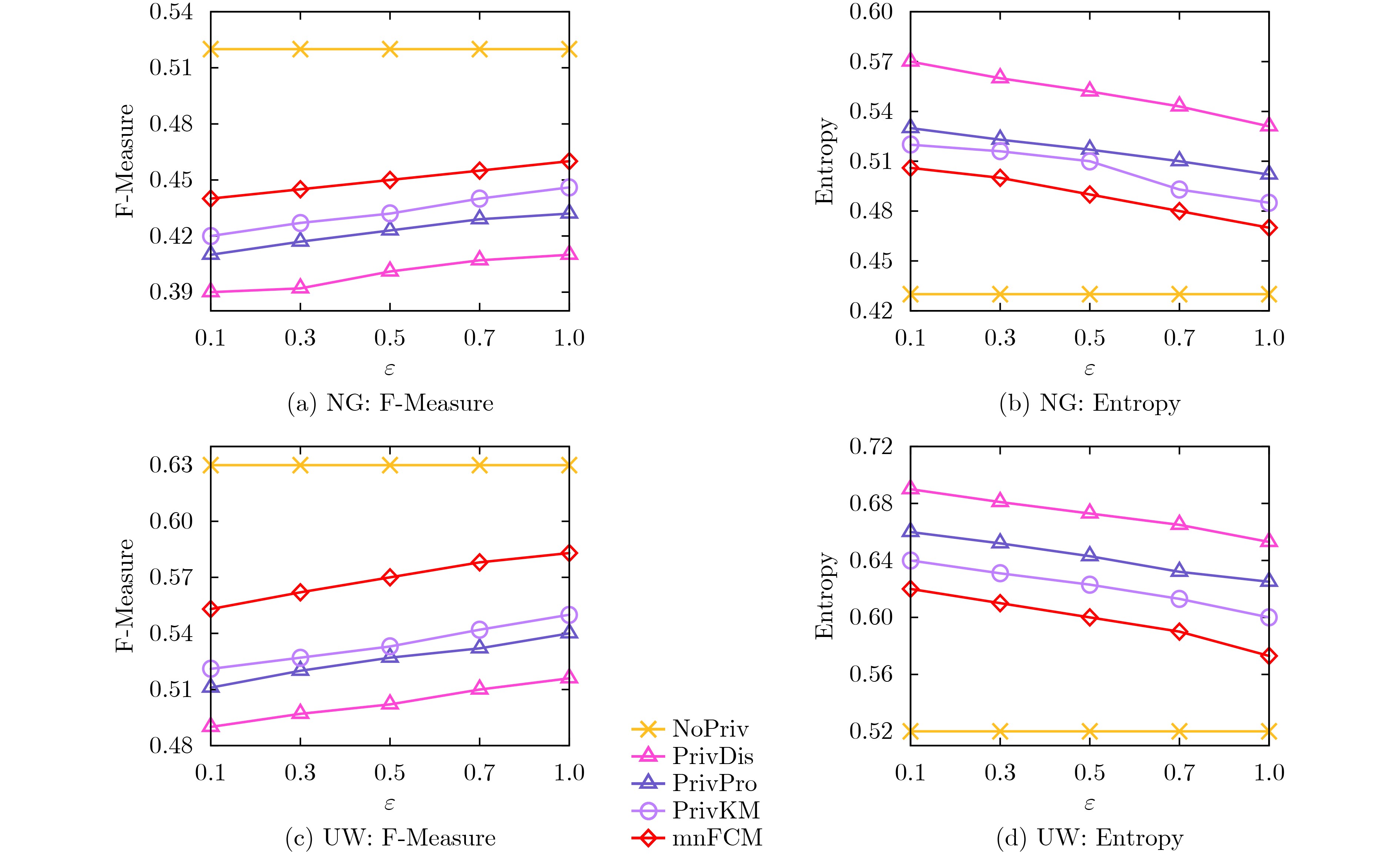
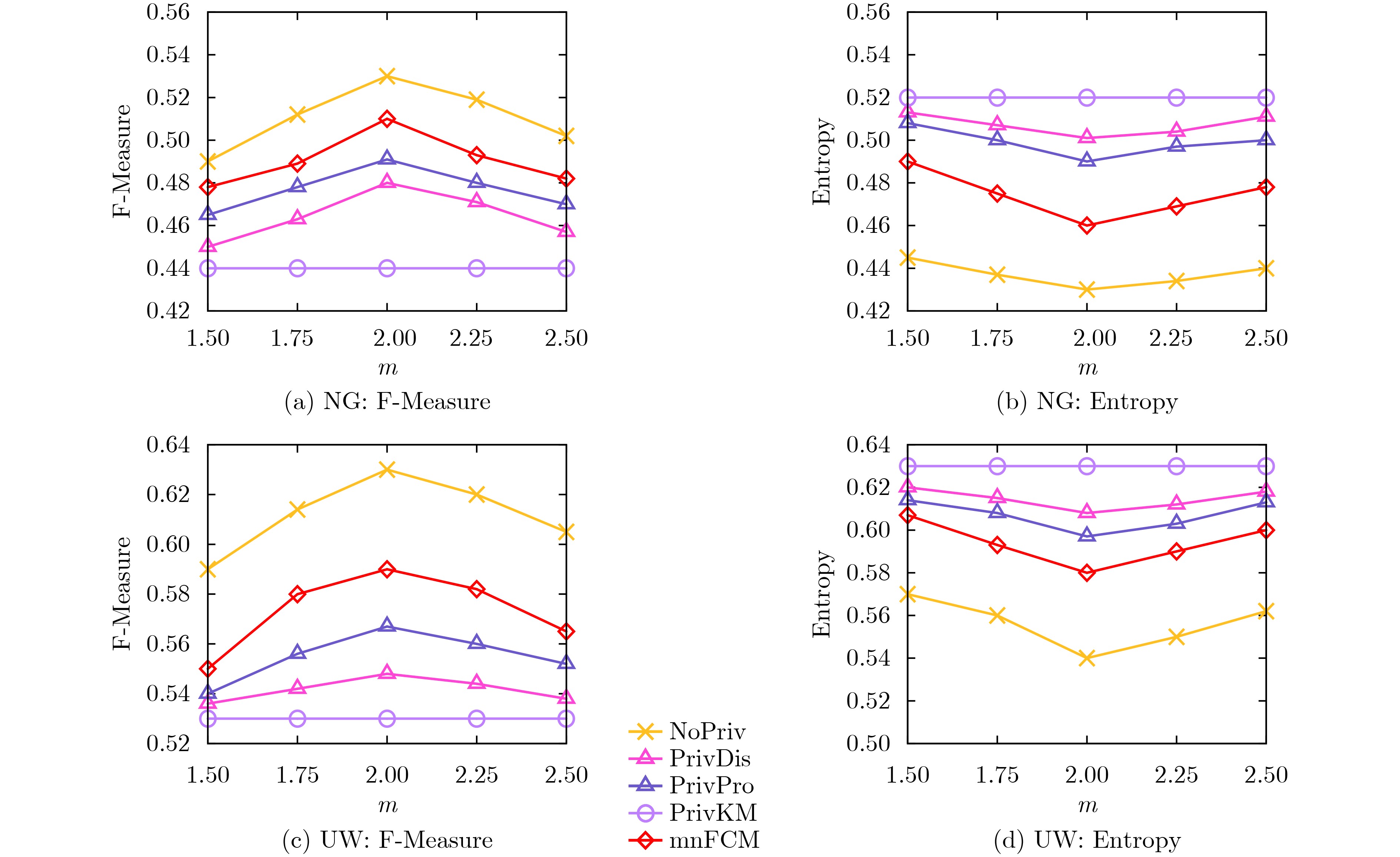
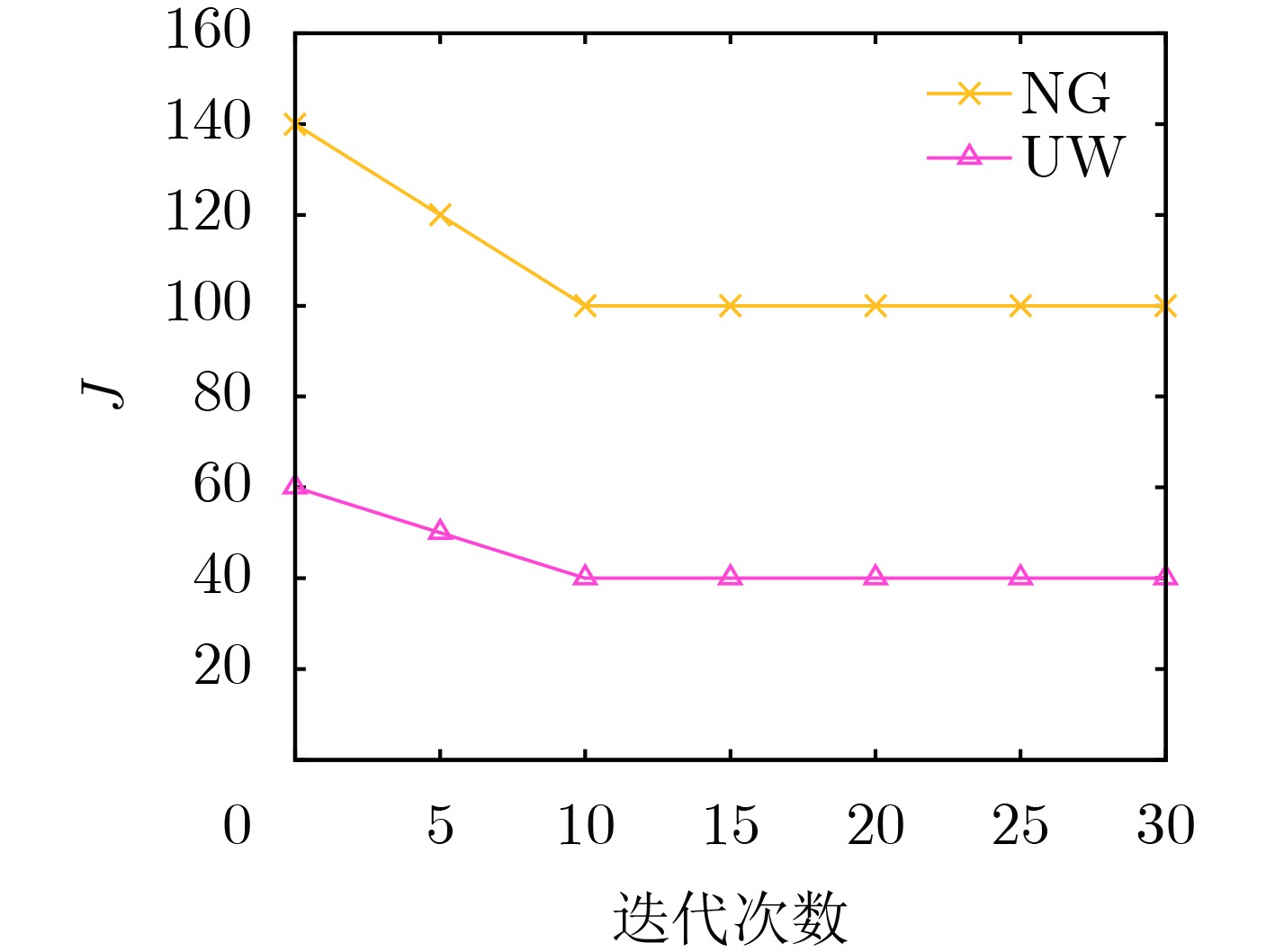
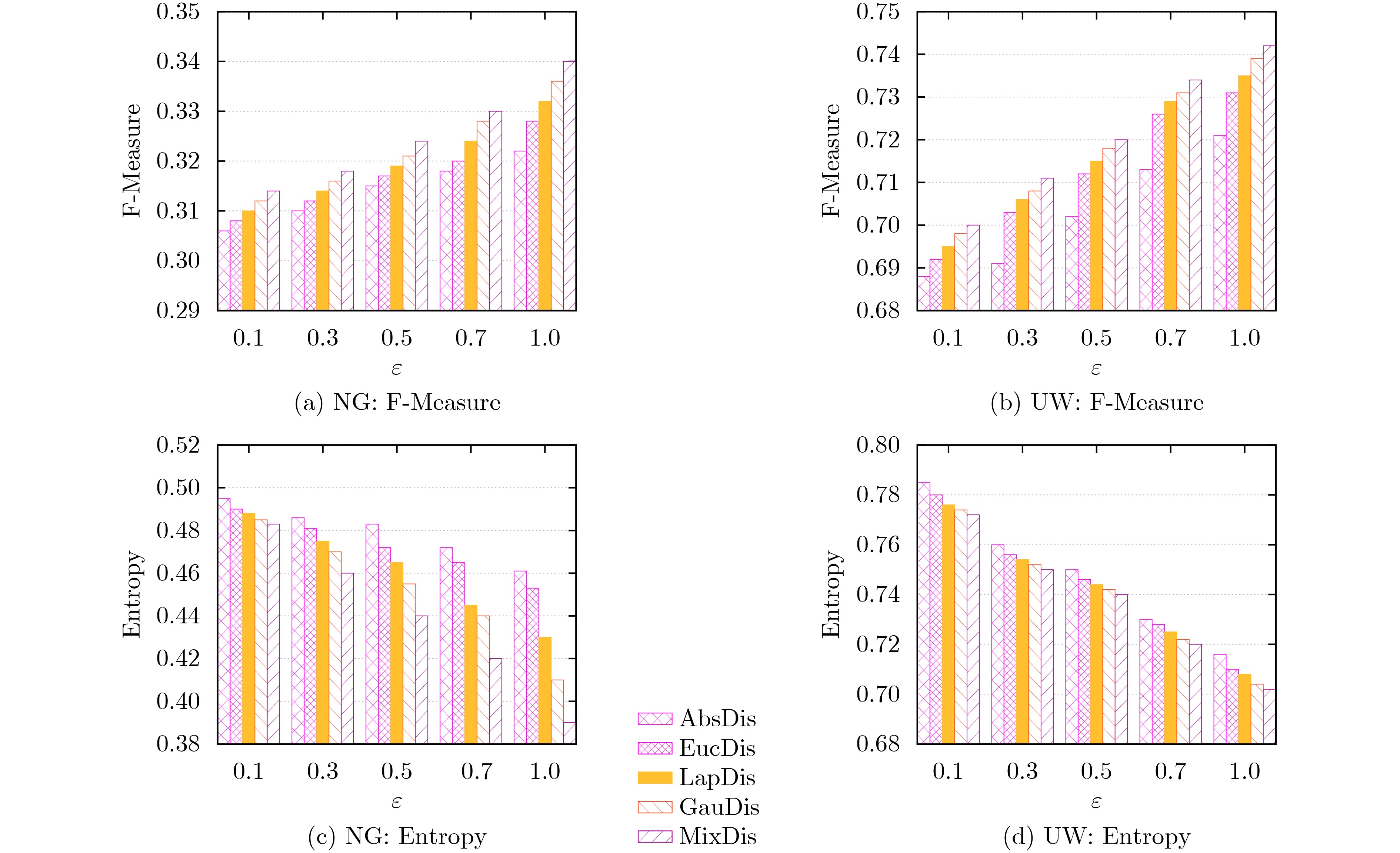
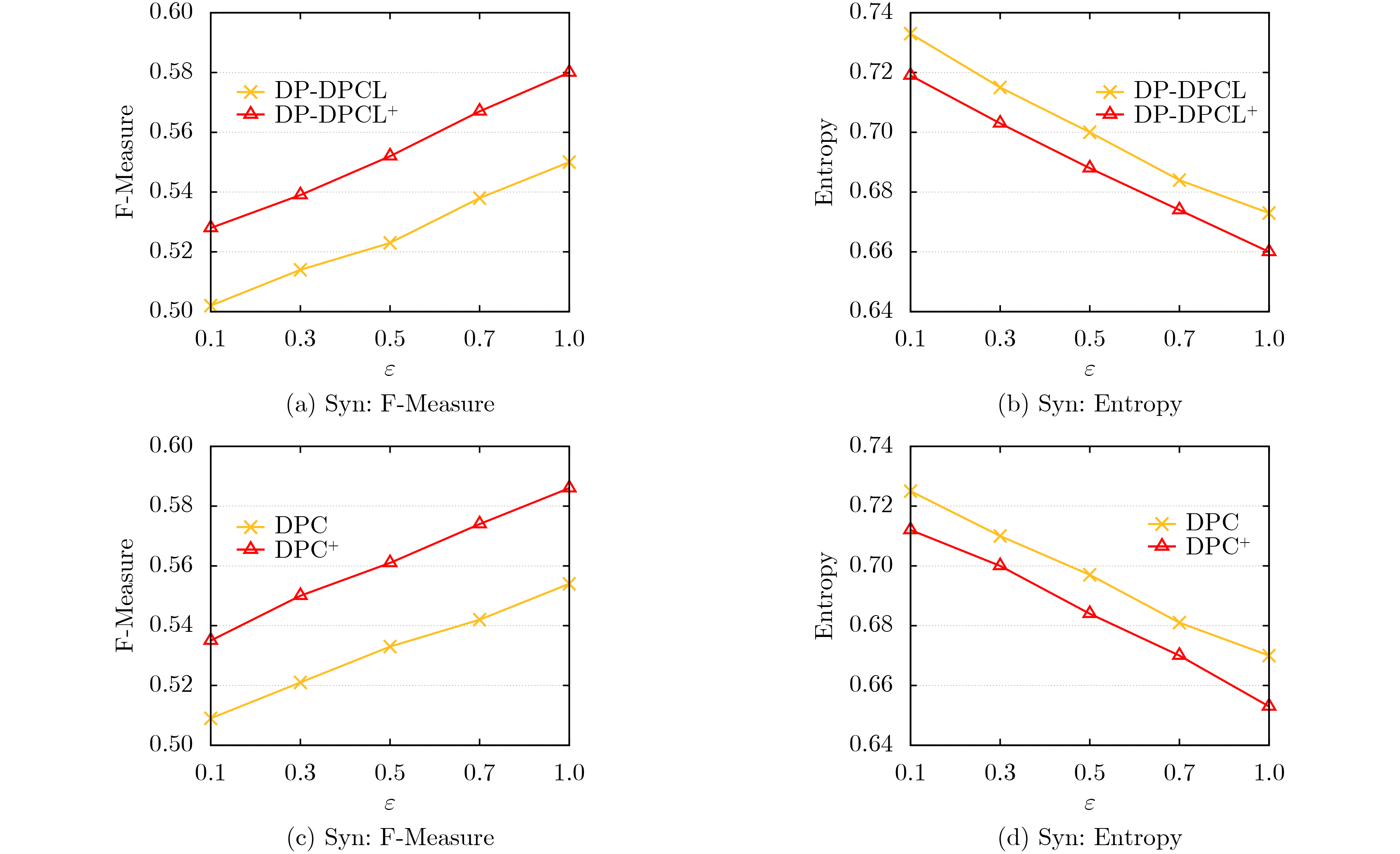
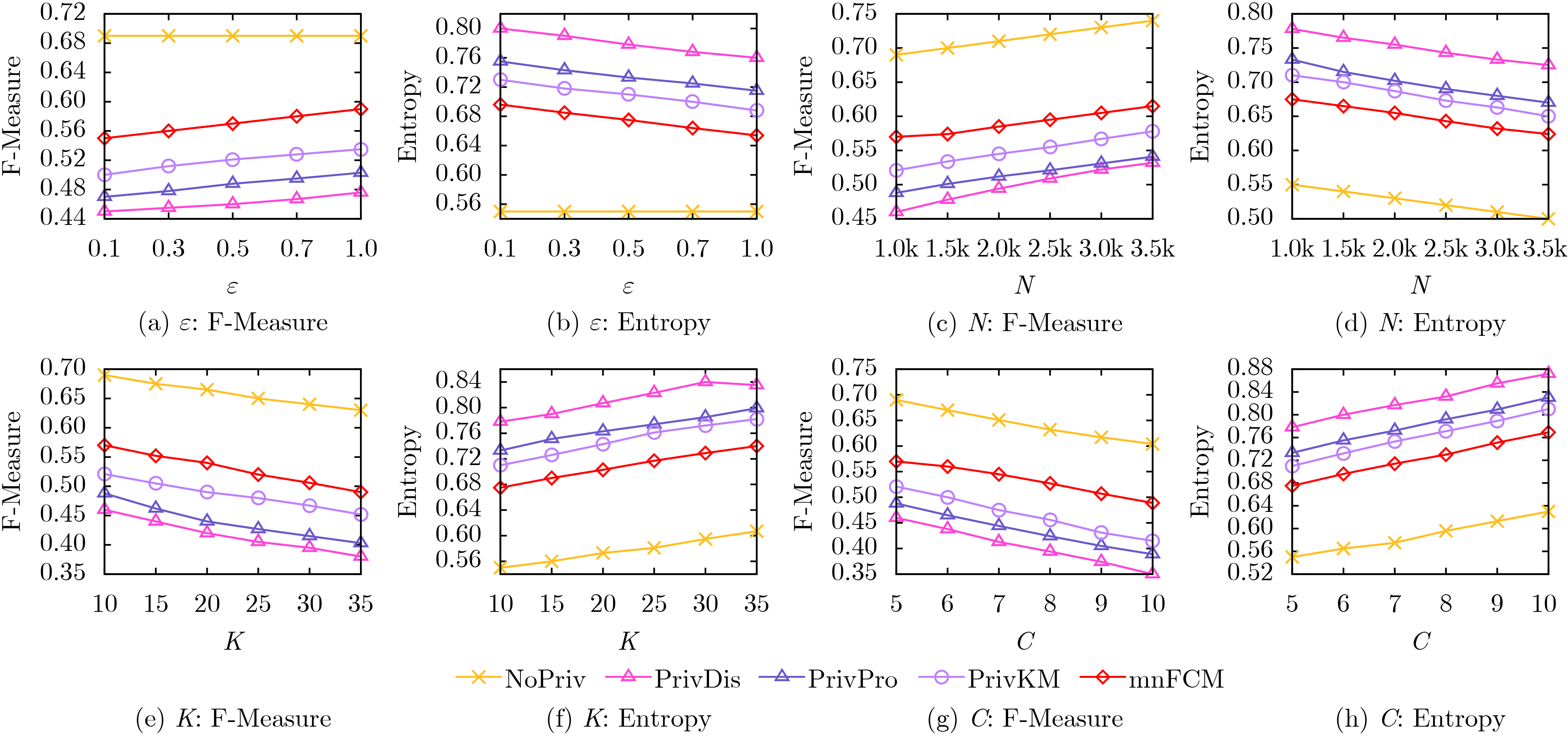
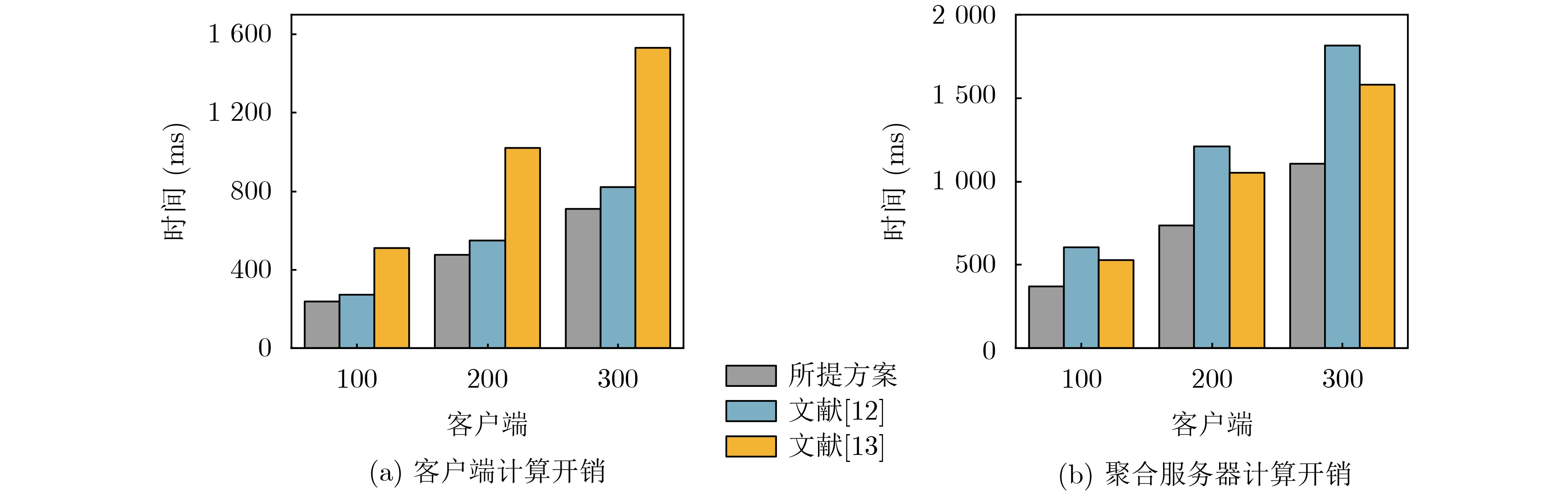
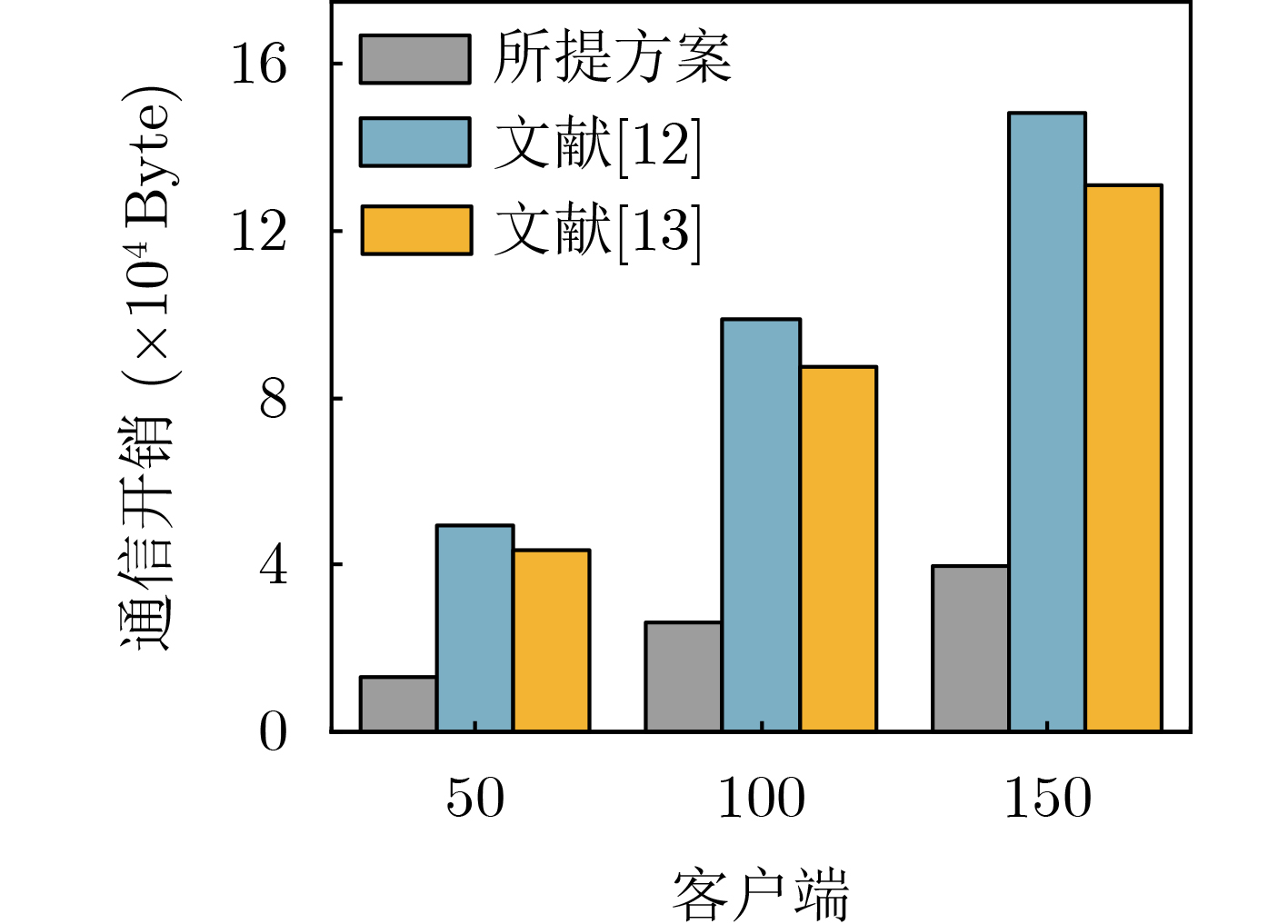
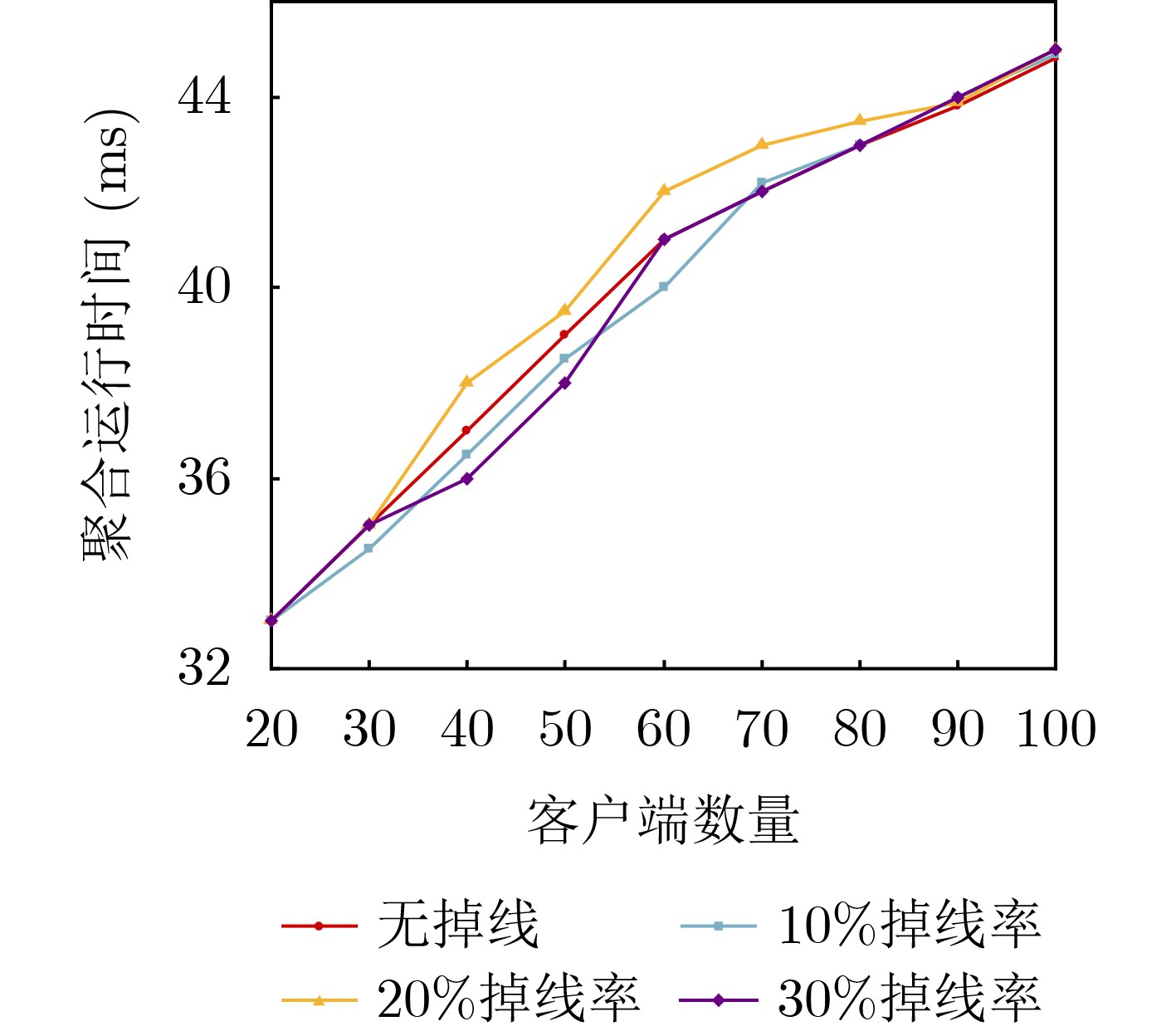
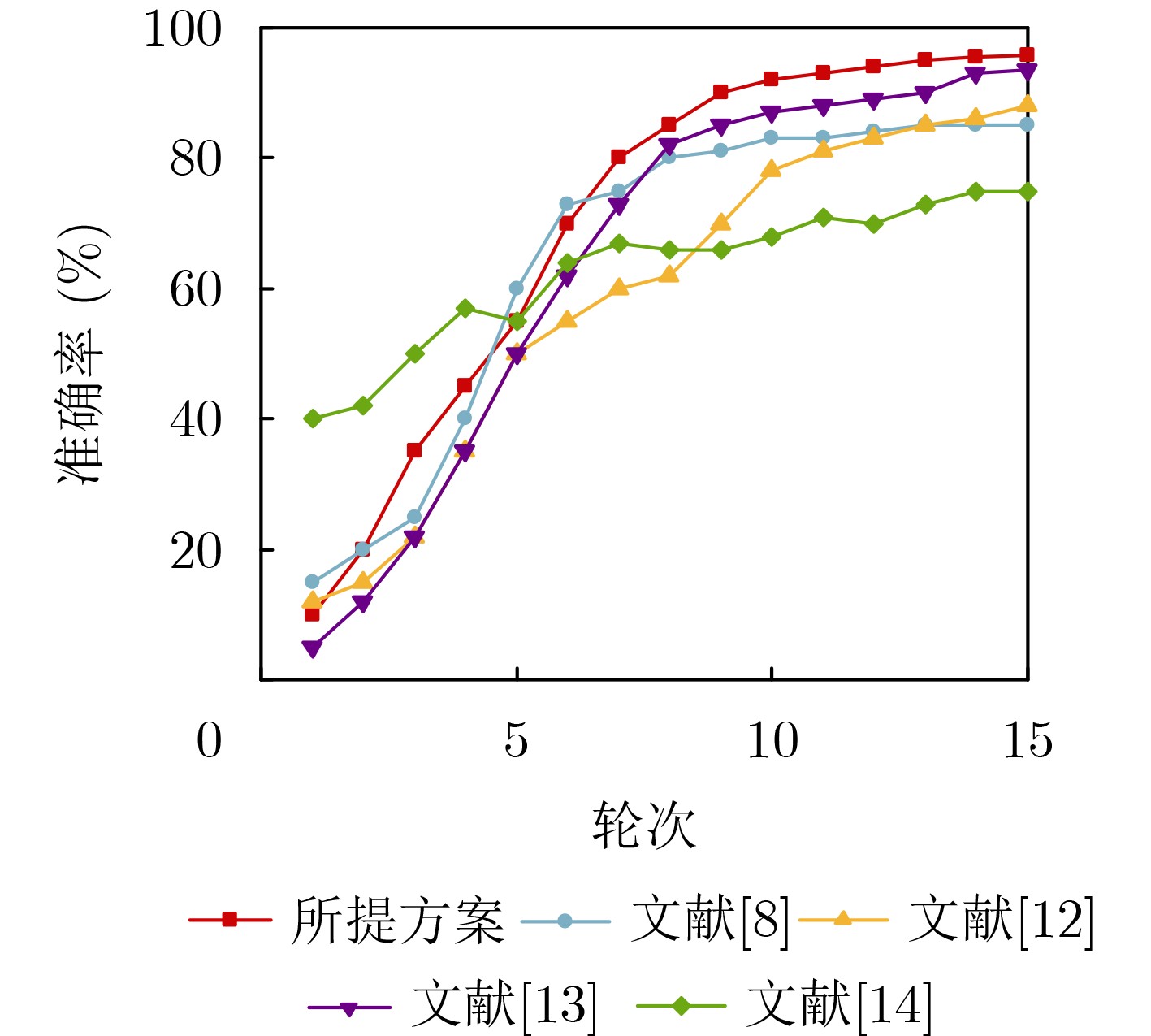
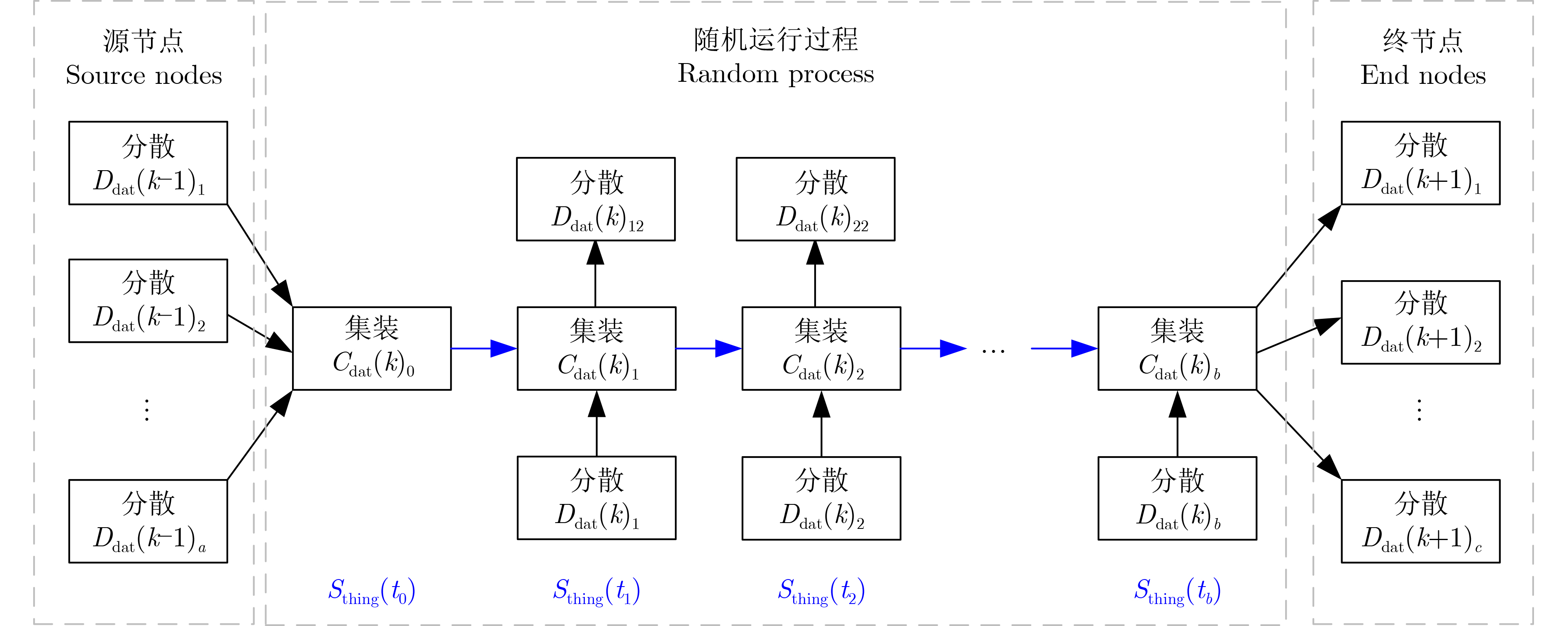
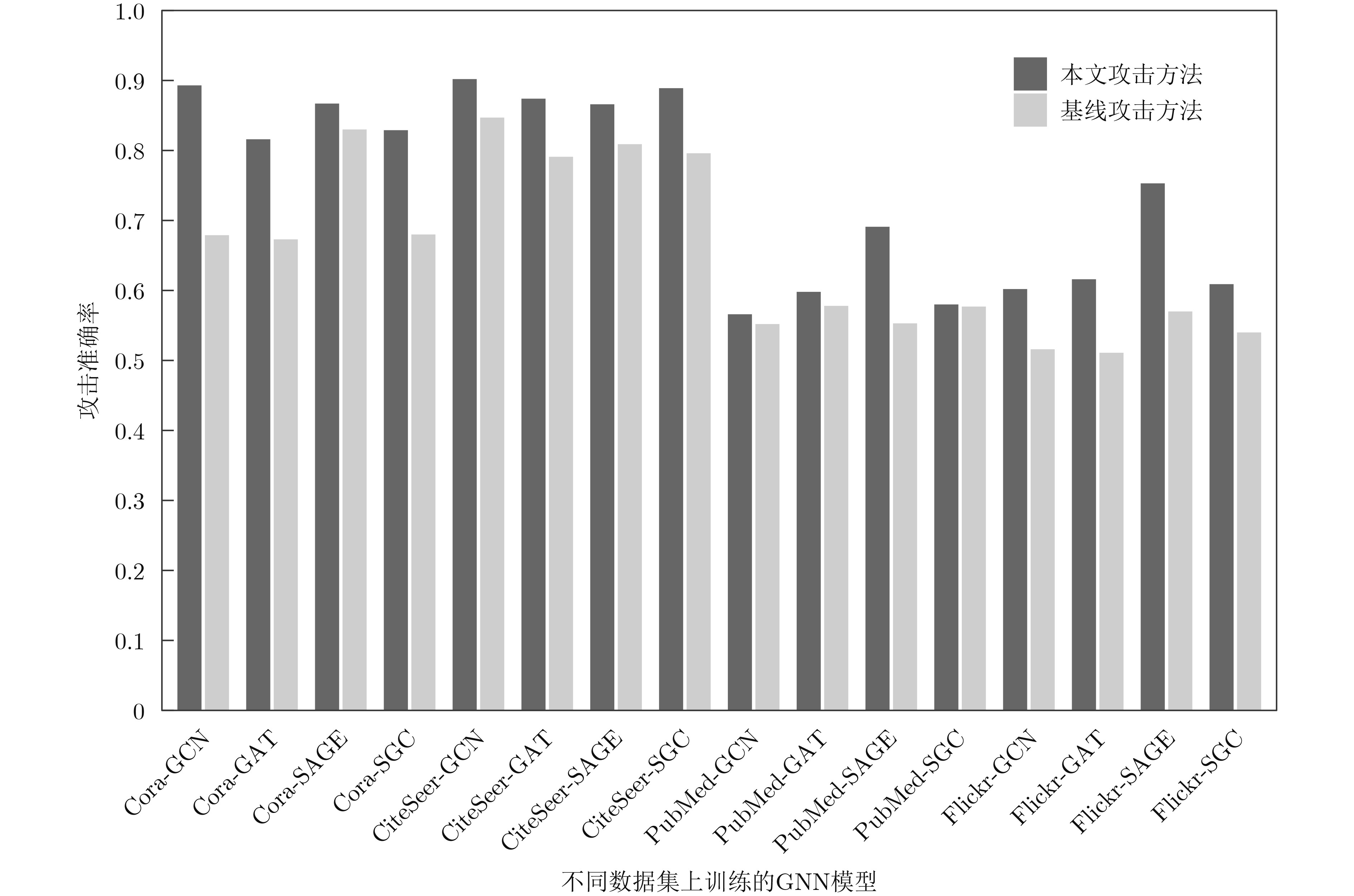
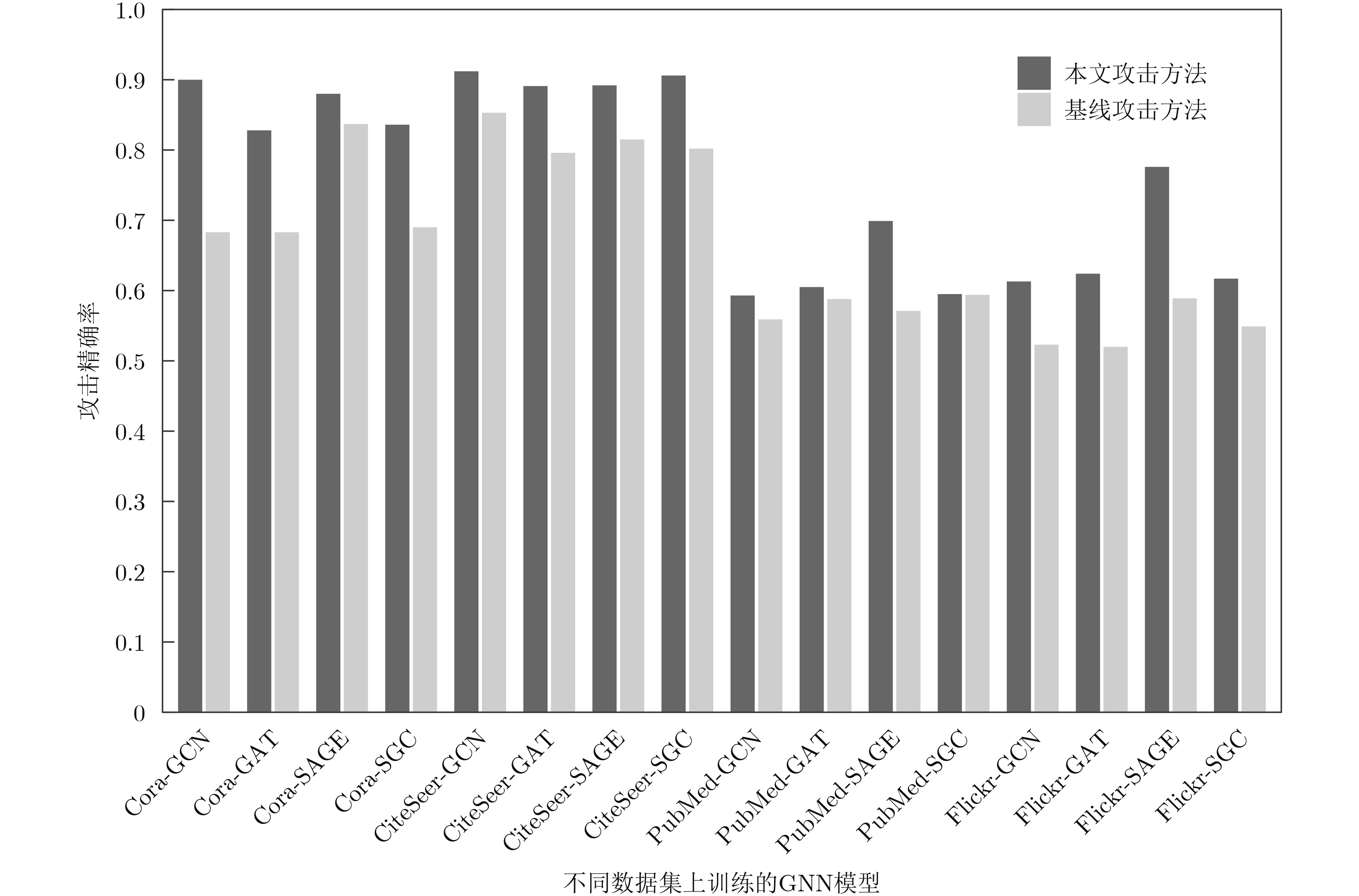
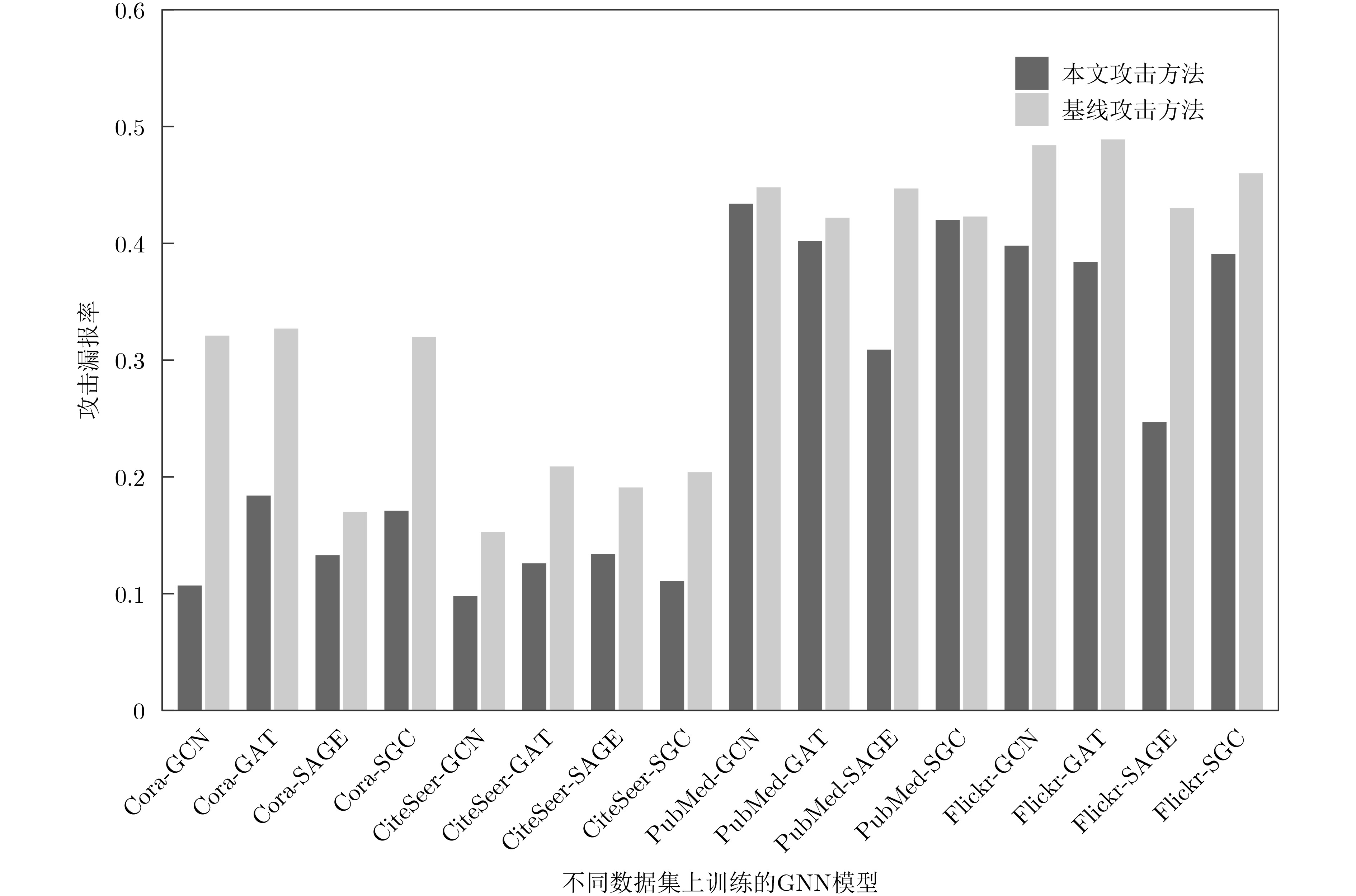
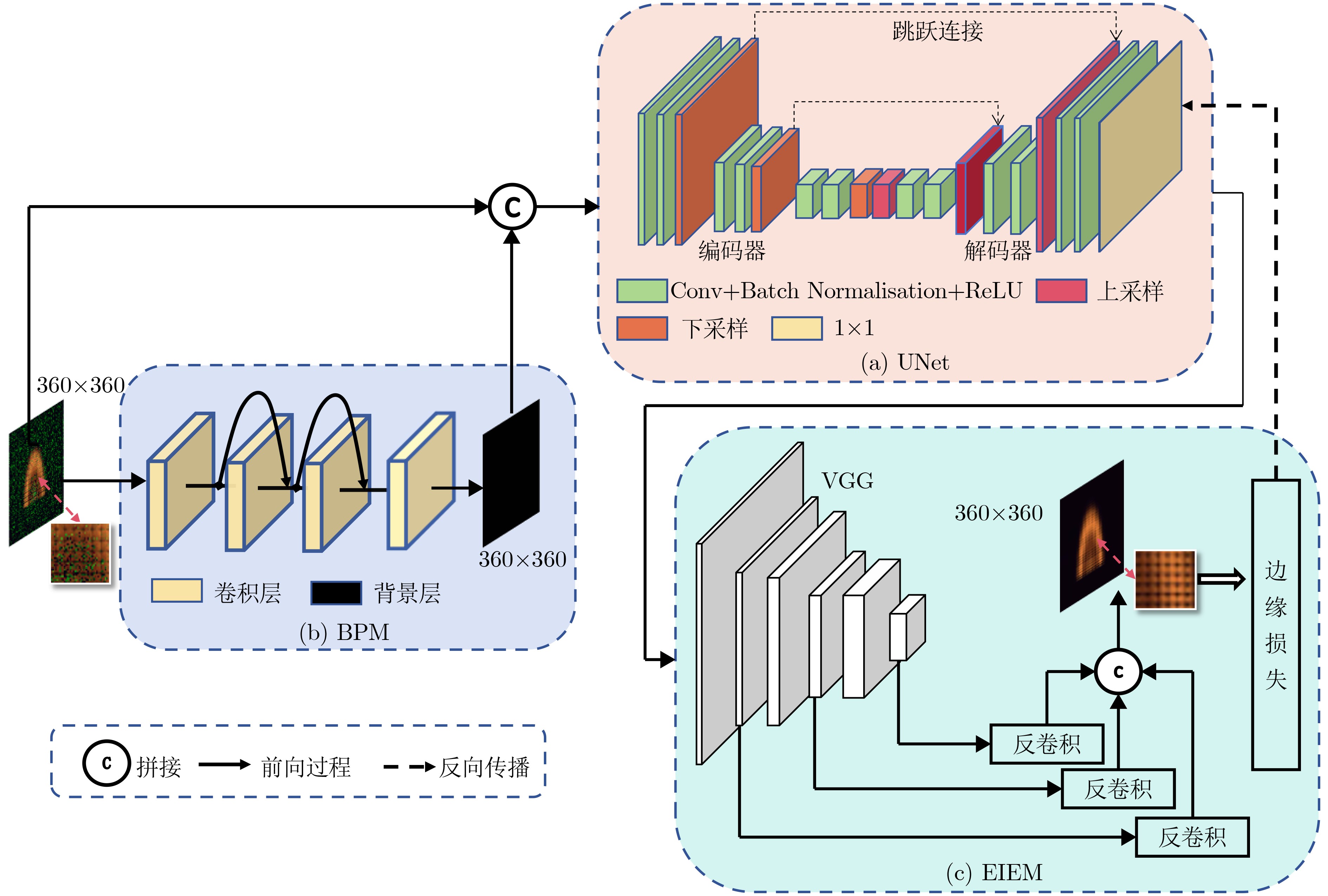
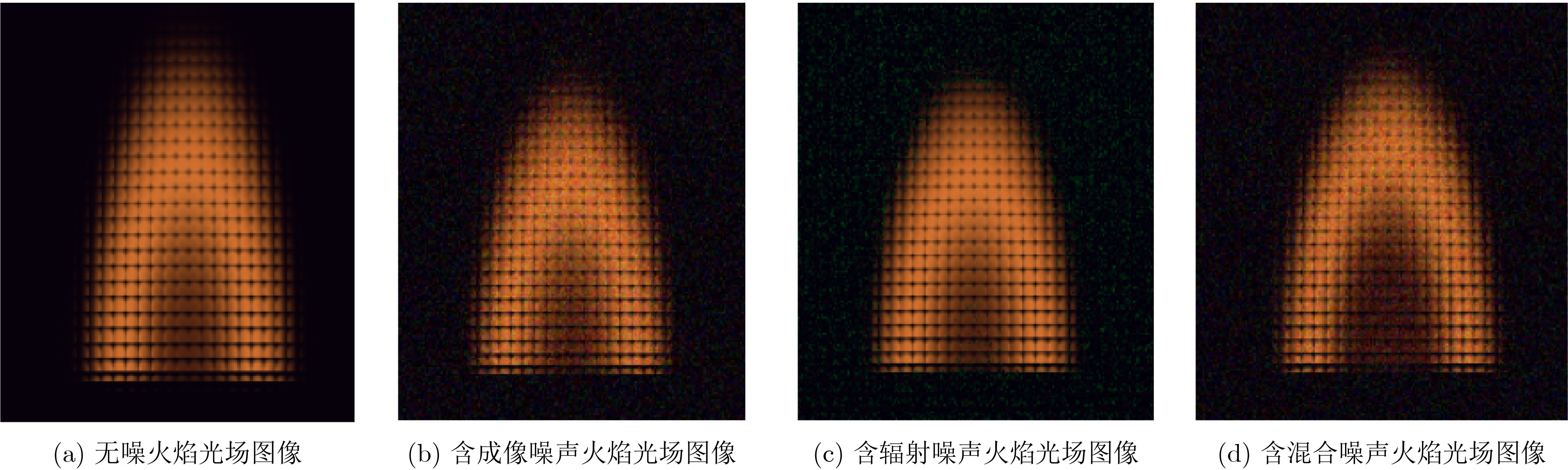
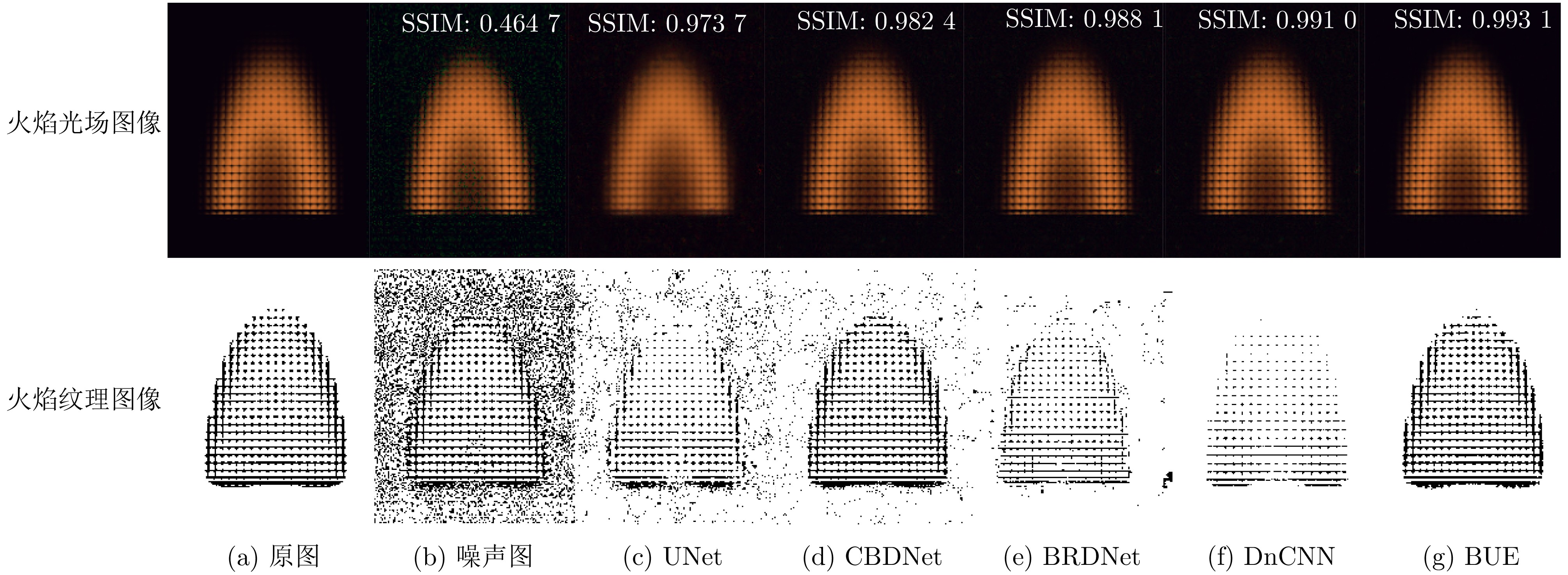
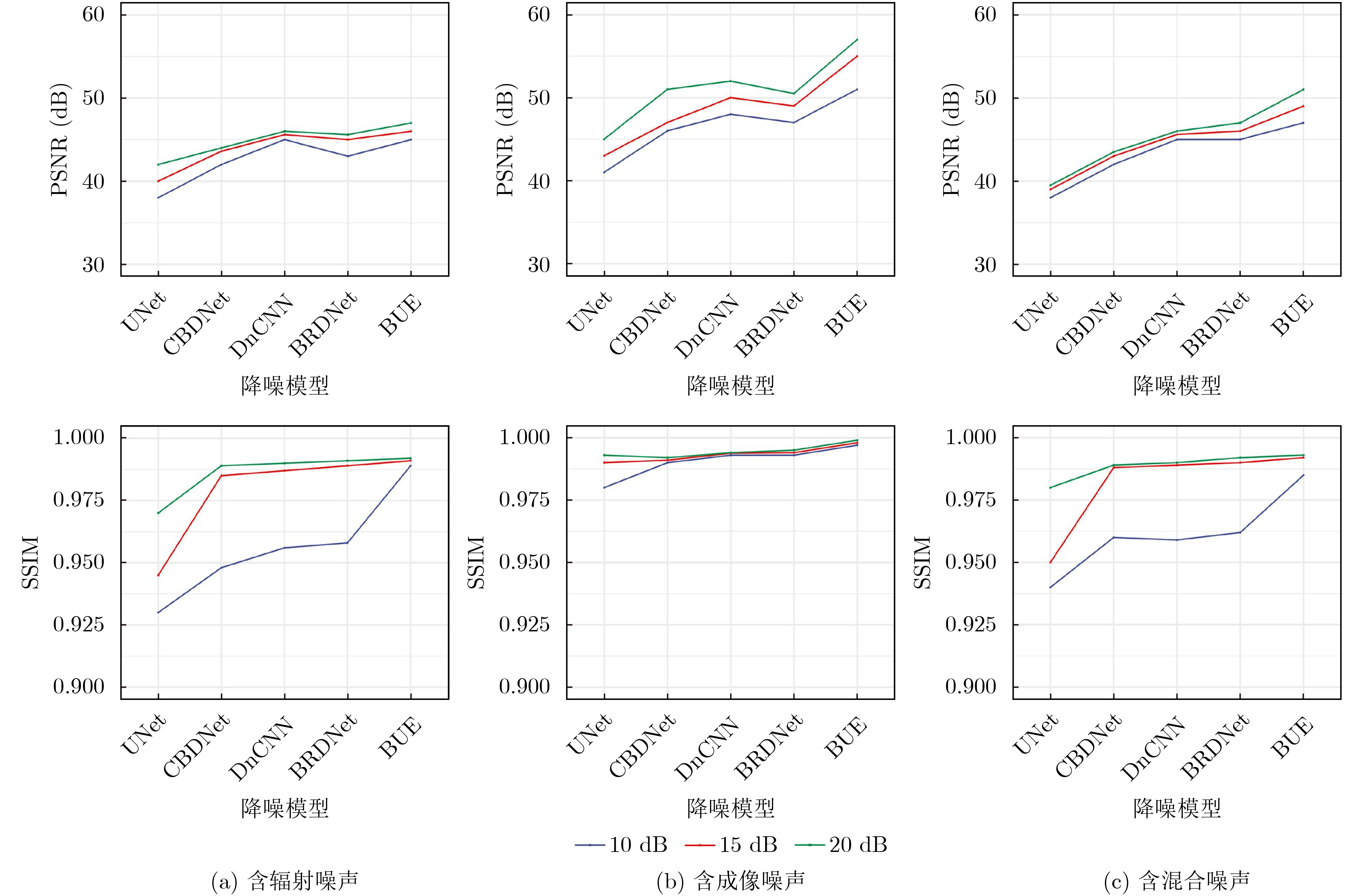
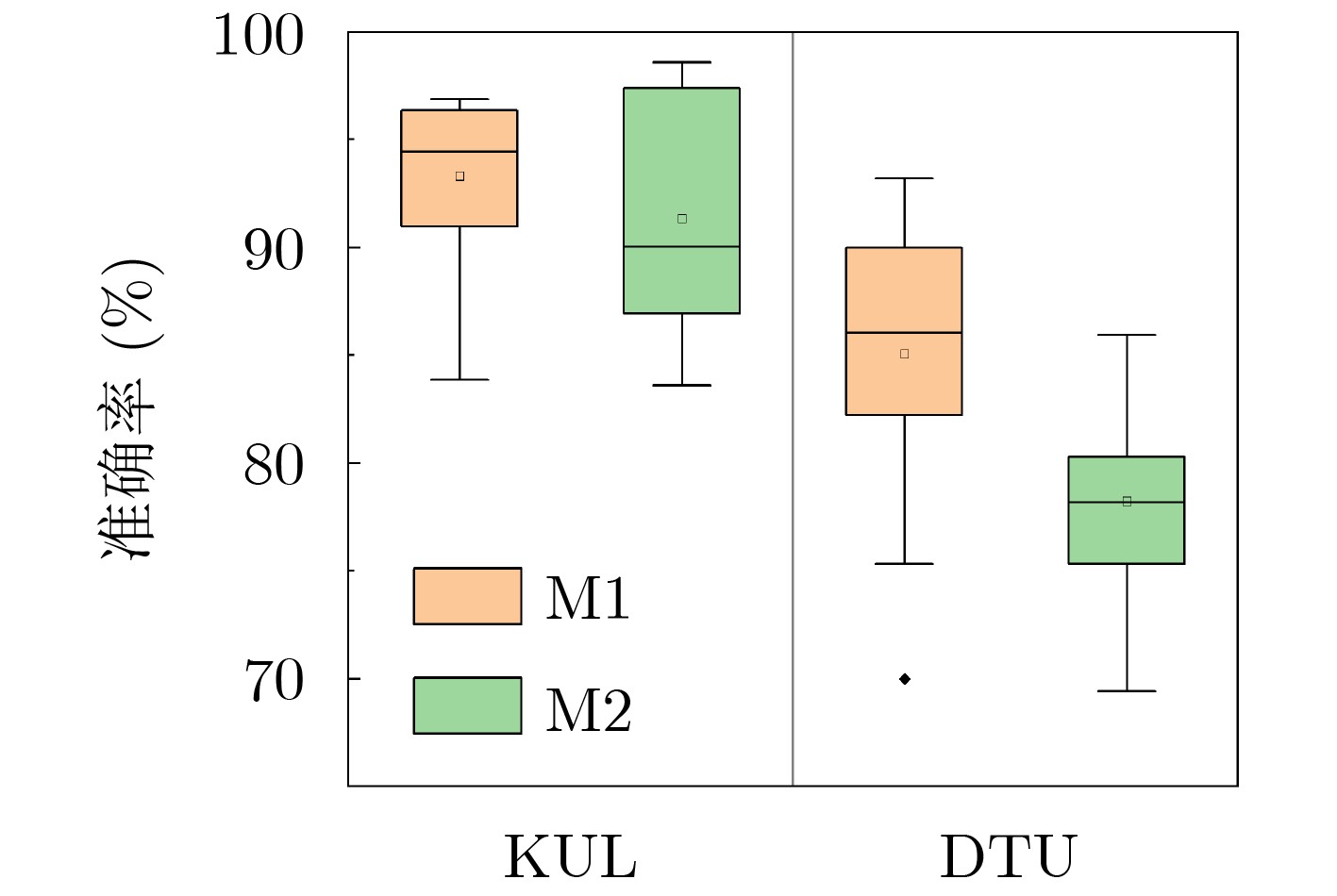
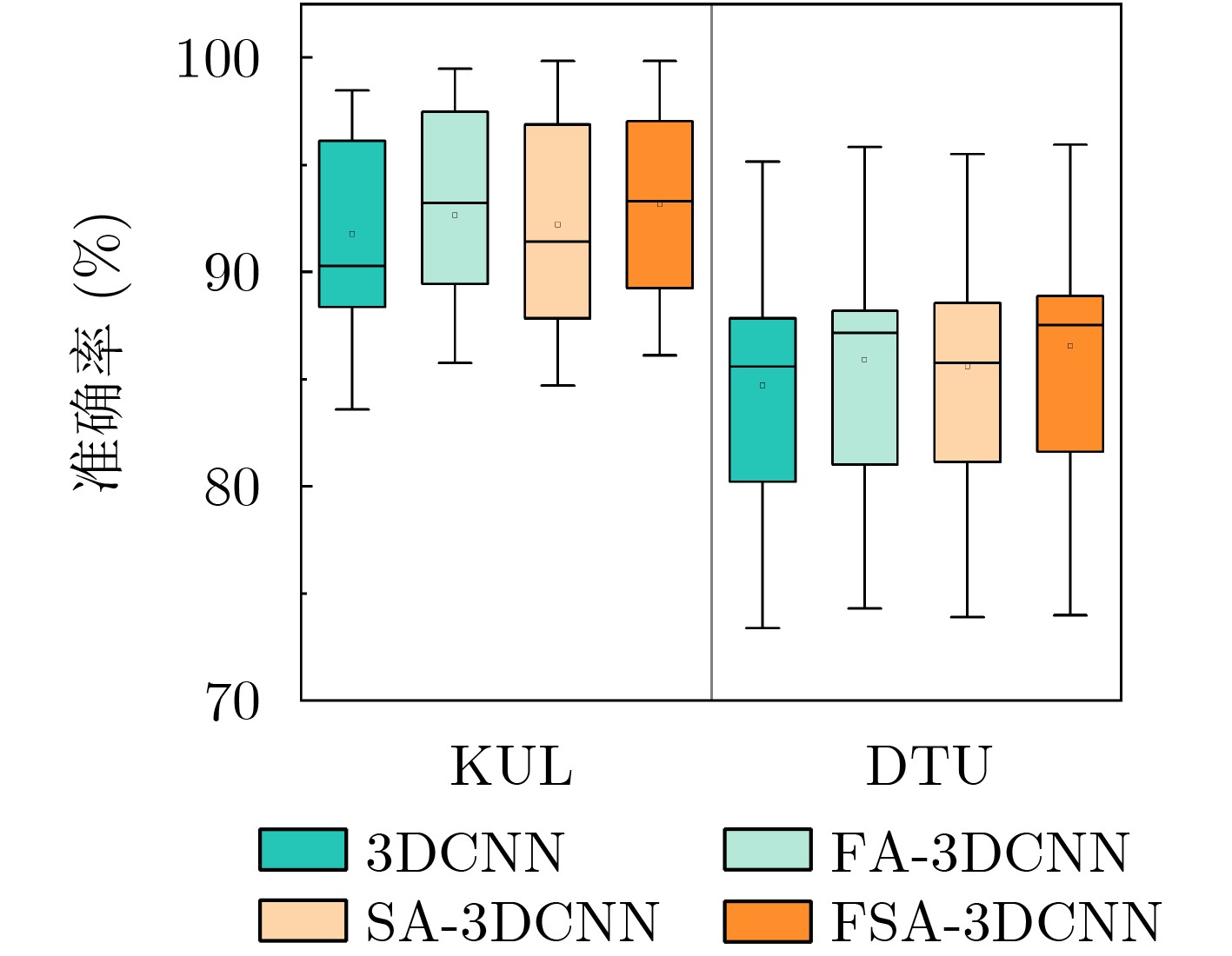
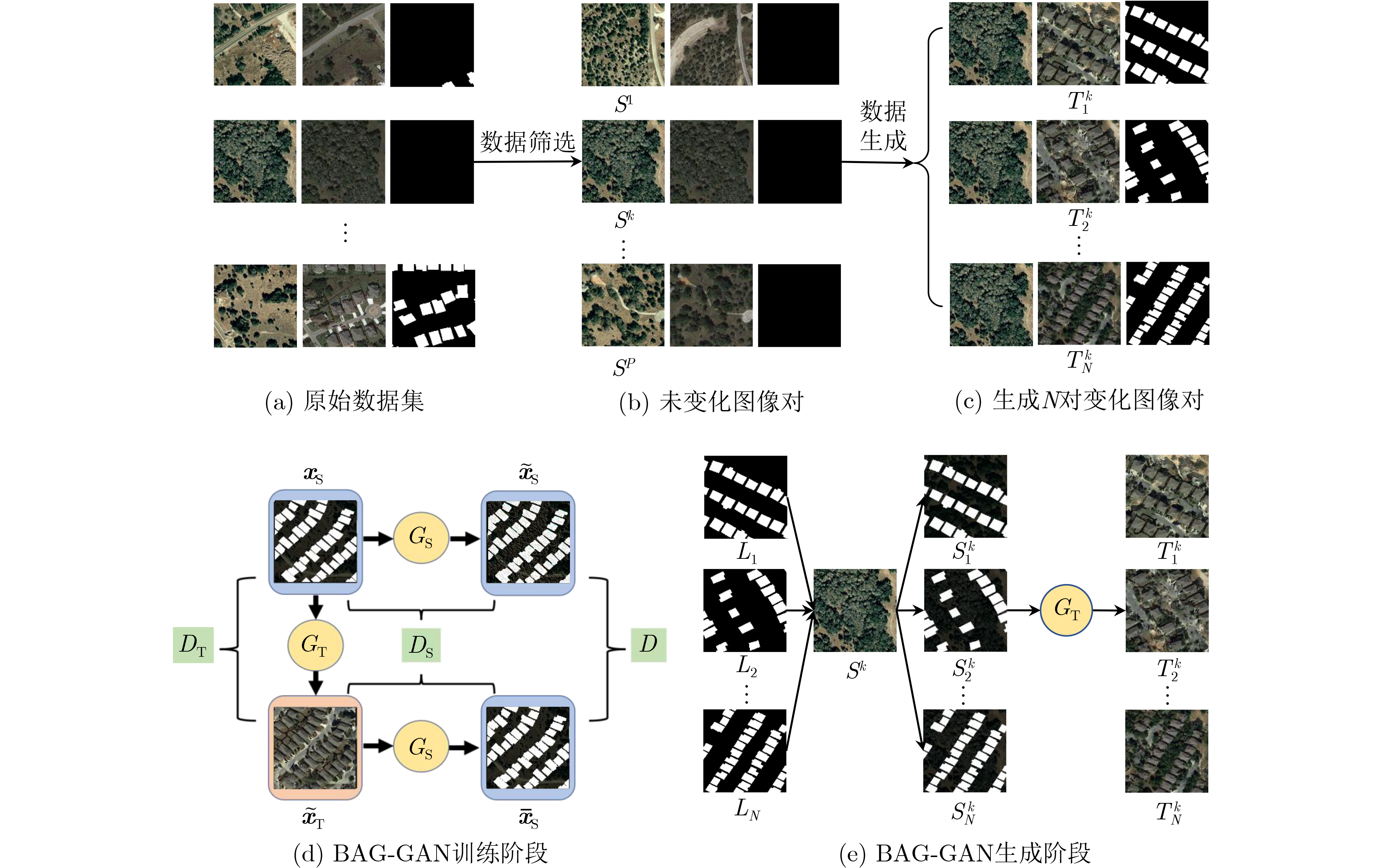
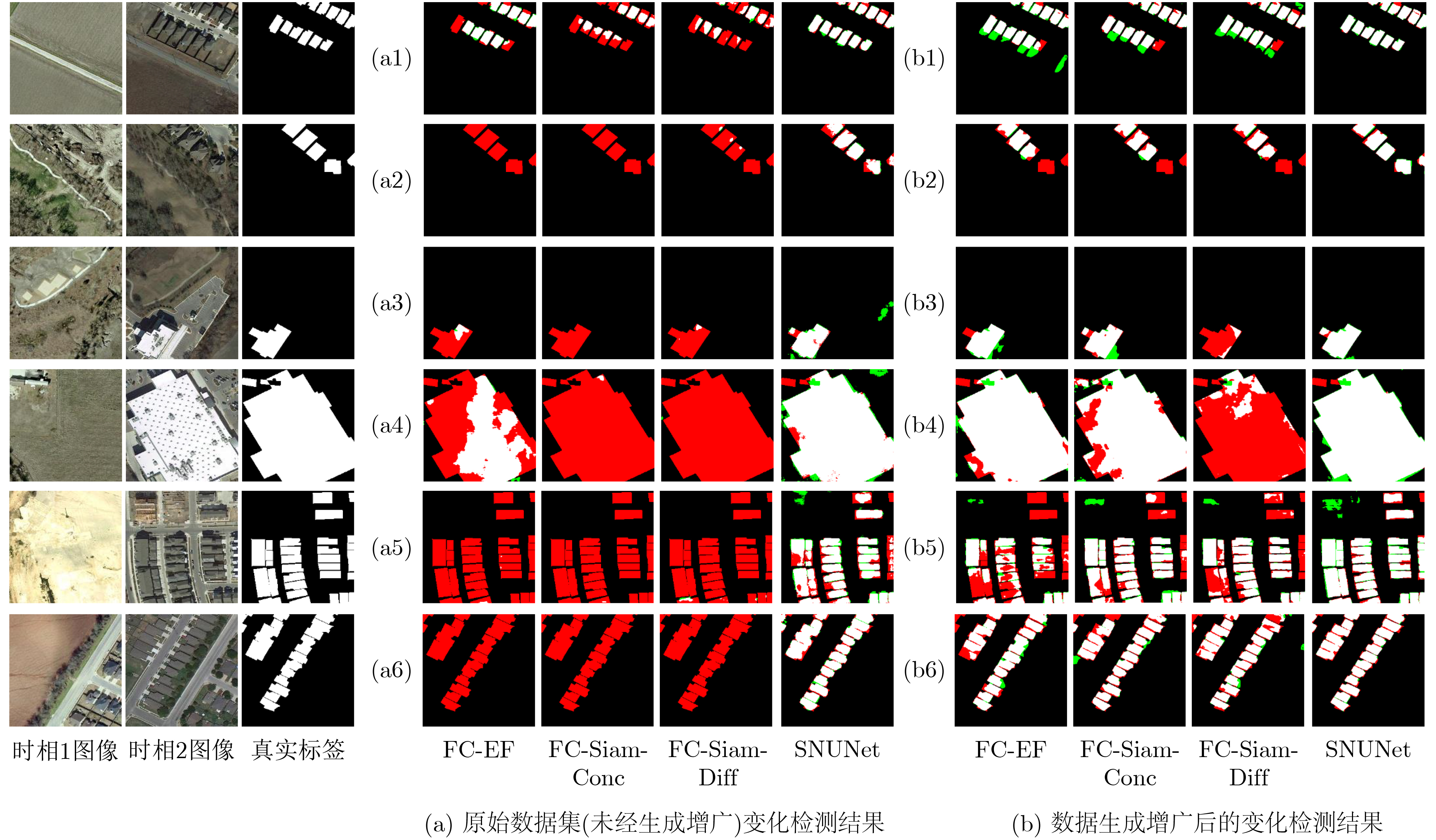
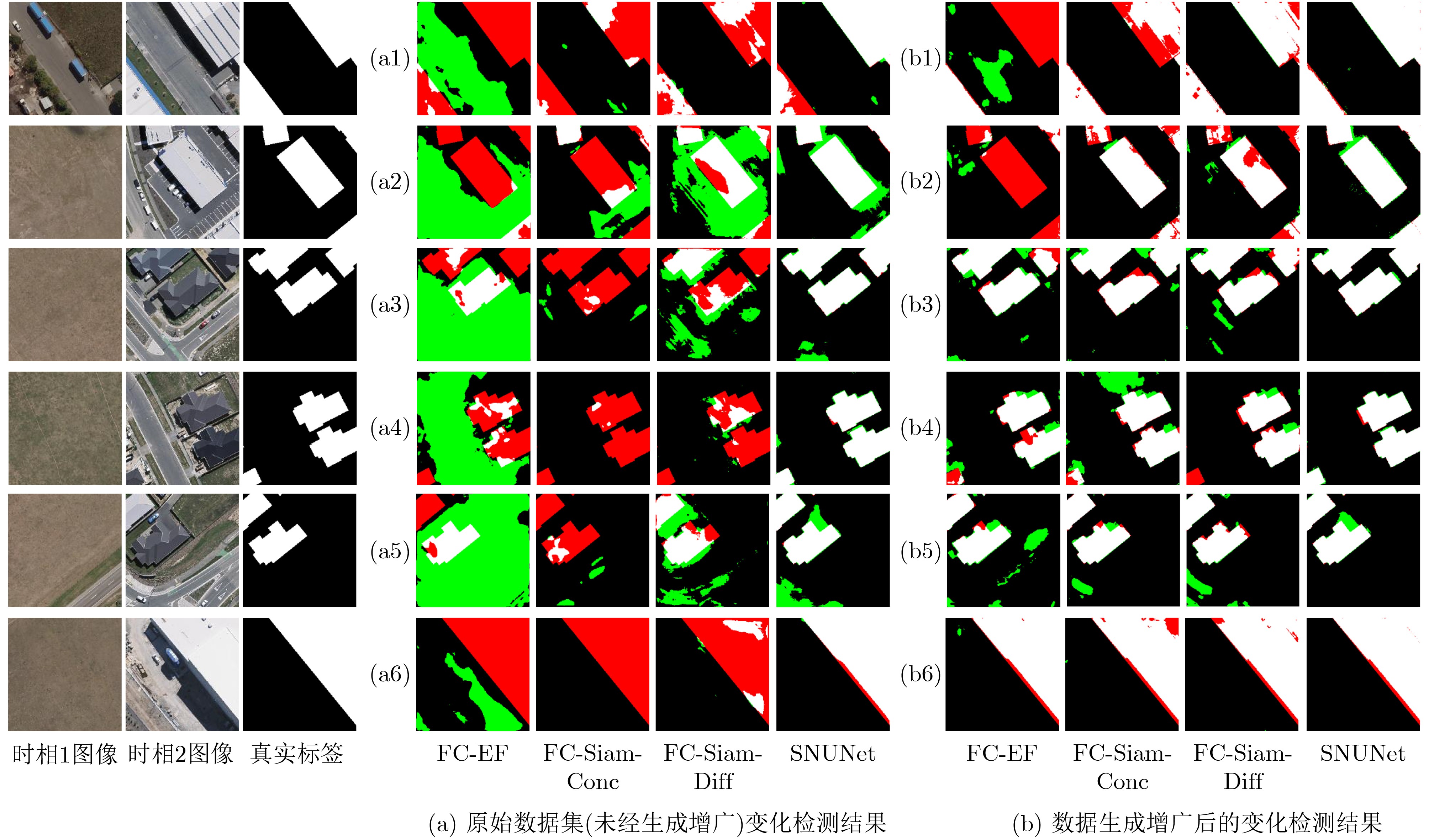
Objective The Internet of Vehicles (IoV) plays a pivotal role in the development of modern intelligent transportation systems. It enables seamless communication among vehicles, road infrastructure, and pedestrians, thereby improving traffic management, enhancing driving experiences, and optimizing resource utilization. However, existing IoV systems face a range of complex and urgent challenges. A major issue is the high false positive rate in identifying malicious vehicles. These vehicles, intending to disrupt network operations, may engage in harmful activities such as dropping packets or delaying transmissions. This not only compromises data transmission integrity but also poses a serious threat to the overall security and reliability of the IoV network. Furthermore, inaccurate identification may lead to the wrongful penalization of legitimate vehicles, disrupting their normal operations. Another challenge stems from the diverse and complex service requirements within IoV. These range from entertainment services that enhance user experience, to traffic efficiency services aimed at optimizing traffic flow, and highly sensitive services related to traffic safety and privacy. Unfortunately, existing solutions fail to adequately address these varied needs, leading to suboptimal service delivery and potential security risks. Traditional consensus algorithms also face significant limitations in the dynamic IoV environment. The high resource consumption and low efficiency of these algorithms not only waste valuable computational resources but also hinder timely and accurate information processing, affecting the overall performance of the IoV system. To address these issues, it is critical to develop an innovative solution to enhance the security, reliability, and adaptability of IoV systems. This paper proposes a collaborative trust management scheme based on blockchain technology, which aims to address these challenges and improve the overall performance of IoV. Methods To address the challenges outlined above, a comprehensive set of methods is designed. First, a trust management model based on the Dirichlet distribution is developed. This model classifies vehicle trust and collaborative services into multiple levels, each representing a different degree of trustworthiness and service quality. The trust level thresholds for different service types are finely tuned. For example, traffic safety and privacy-related services, which require high security and reliability, are assigned higher trust level thresholds, ensuring that only vehicles with a sufficient trust level can provide these critical services. Second, a trust level evaluation algorithm integrated with a feedback mechanism is developed. This algorithm considers four key factors: the current state of the collaborating vehicle, neighbor recommendations, historical trust data, and service quality. The evaluation process occurs in two distinct but complementary stages: before and after collaboration.Before collaboration, the vehicle’s current state is thoroughly assessed, including its computing power, which determines its capacity to handle complex tasks; propagation delay, which indicates the timeliness of communication; and familiarity with the requesting vehicle, which can influence collaboration reliability. These factors, along with neighbor recommendations and historical trust data, contribute to an initial trustworthiness assessment. After collaboration, a feedback mechanism based on packet delivery ratio and time delay is applied. The packet delivery ratio measures the proportion of successfully delivered packets, while time delay reflects the responsiveness of the vehicle during communication. These metrics are used to adjust the vehicle’s trust level, providing a more dynamic and accurate evaluation of its trustworthiness. Third, the traditional Proof of Work (PoW) consensus algorithm is enhanced by introducing a task priority index. This dynamic adjustment of block creation difficulty for miner nodes allows blocks containing critical trust information or high-priority service data to be added to the blockchain more quickly. This enhancement improves blockchain efficiency. Results and Discussions The simulation results provide compelling evidence for the effectiveness of the proposed scheme. In terms of malicious vehicle identification, as shown in (Fig. 3), although the initial identification rate of malicious vehicles is slightly lower than that of some binary-evaluation-based schemes, the proposed scheme demonstrates a significant reduction in the false positive rate. The comparison of false positive rates, presented in (Fig. 4), clearly illustrates that the proposed scheme outperforms existing methods. This improvement is attributed to the carefully designed trust level thresholds, which prevent ordinary vehicles with low-quality services from being misclassified as malicious when performing high-level services. Regarding the collaboration success rate, (Fig. 5) indicates that the proposed scheme performs better across various service scenarios and different proportions of malicious vehicles. Even when the proportion of malicious vehicles reaches 50%, the collaboration success rate for the three-level services remains above 80%, emphasizing the robustness and reliability of the proposed scheme. In terms of consensus efficiency, as shown in (Fig. 6), the improved algorithm outperforms the traditional PoW consensus algorithm. By dynamically adjusting to the actual conditions, the enhanced algorithm allows the RoaSide Unit (RSU) responsible for the area to generate blocks more quickly when the task priority index is larger. This leads to faster processing of critical information and better alignment with the dynamic needs of the IoV collaborative scenario. Conclusions The collaborative trust management scheme based on blockchain proposed in this paper effectively addresses critical challenges in IoV systems, including malicious vehicle identification, service adaptability, and the applicability of consensus algorithms. By accurately classifying service types and vehicle trust levels, and by employing a comprehensive trust evaluation algorithm along with an enhanced consensus algorithm, this scheme significantly improves the security and trustworthiness of IoV systems. Furthermore, it provides a scalable solution for future IoV deployments, facilitating the broader adoption of IoV technology.