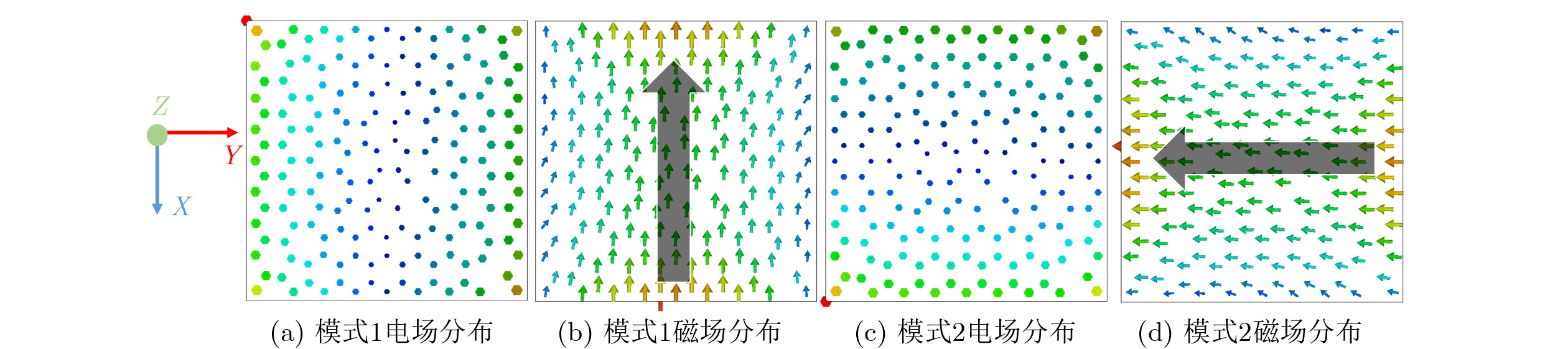
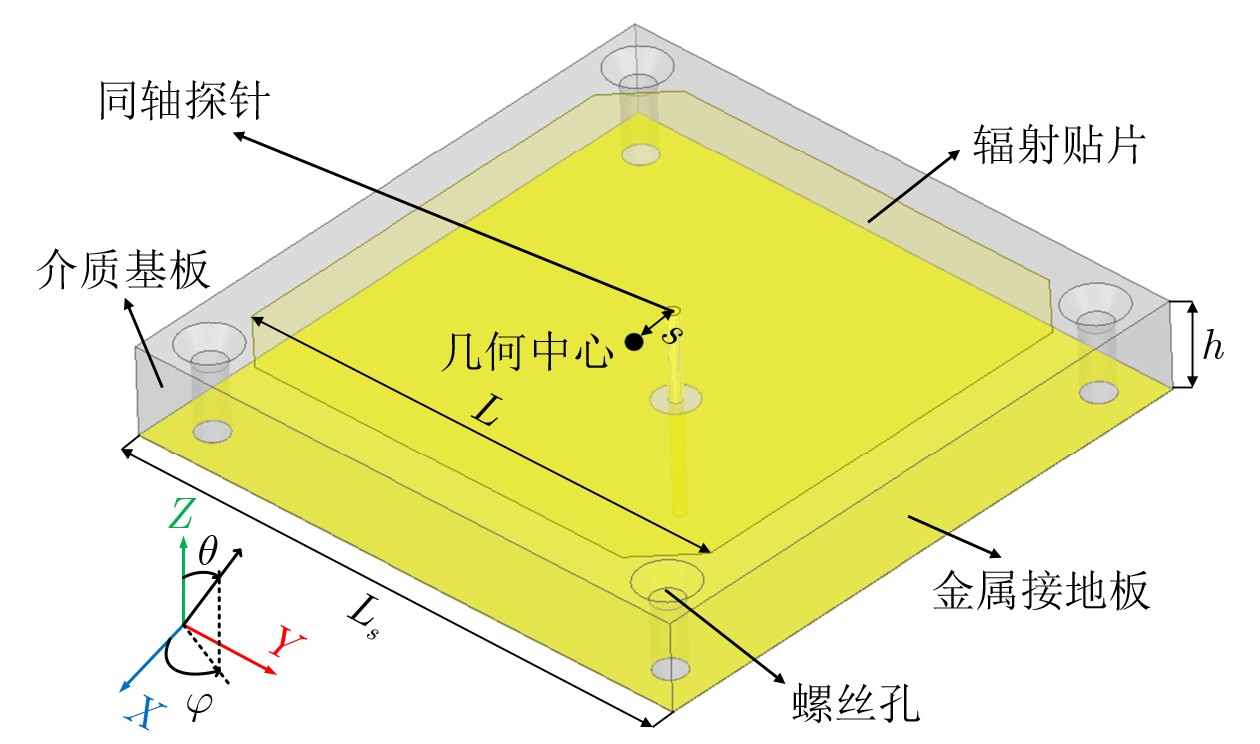
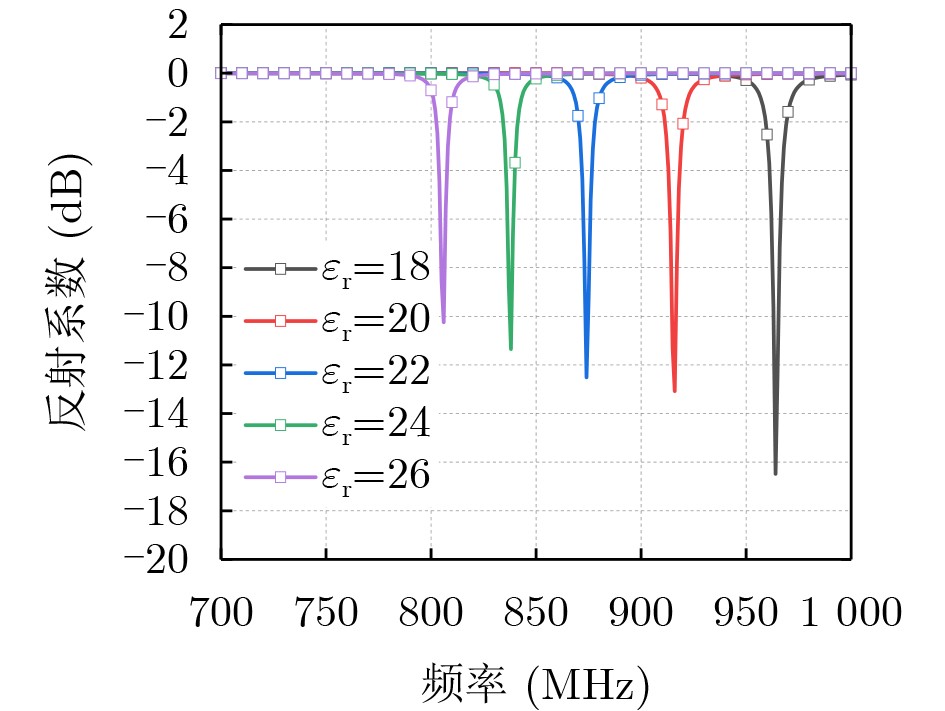
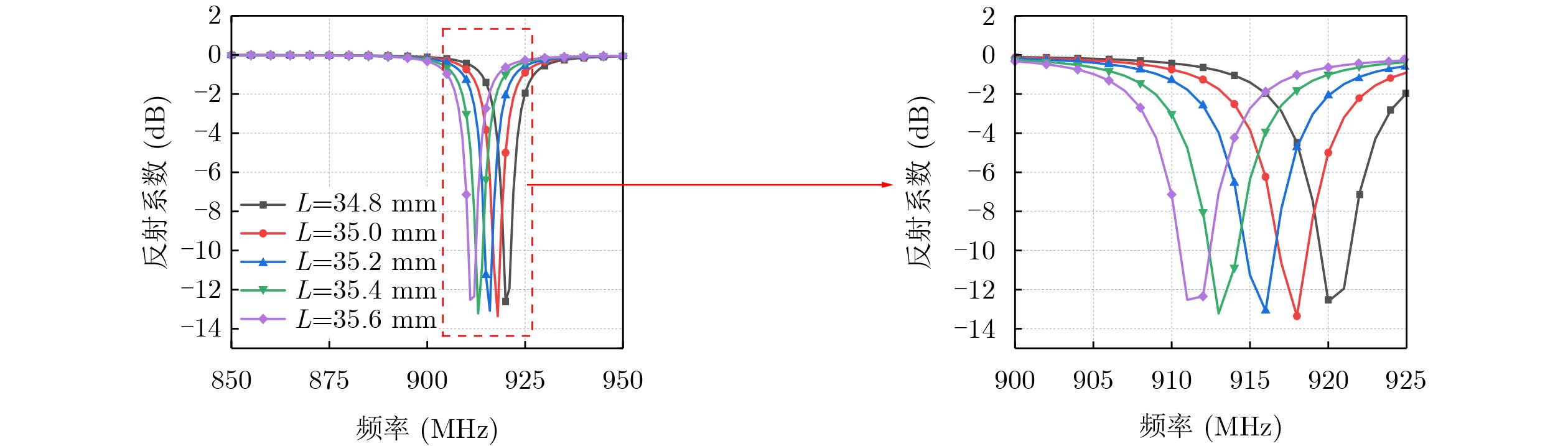
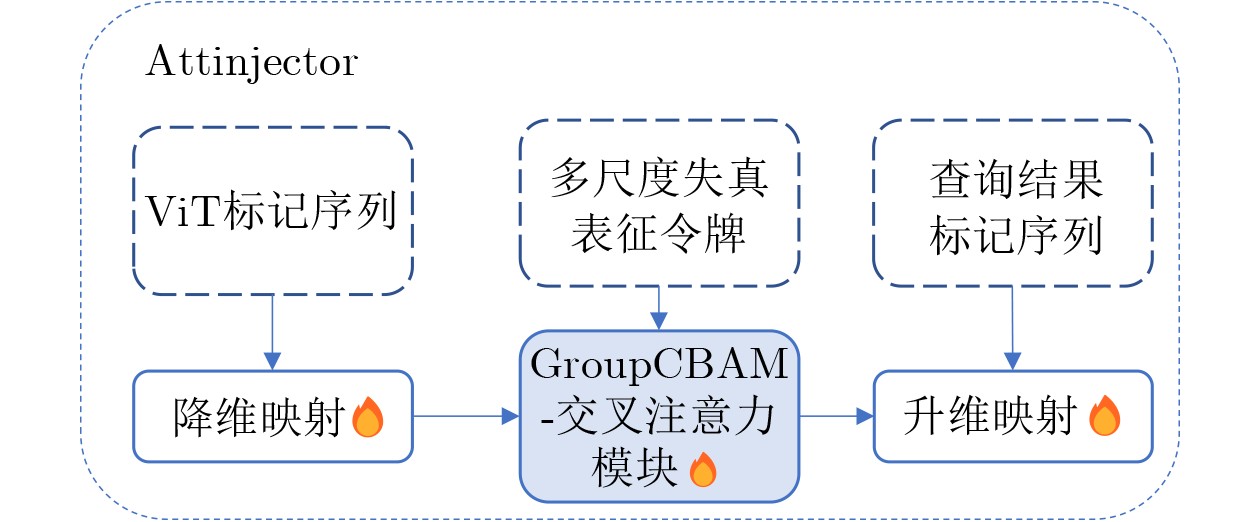
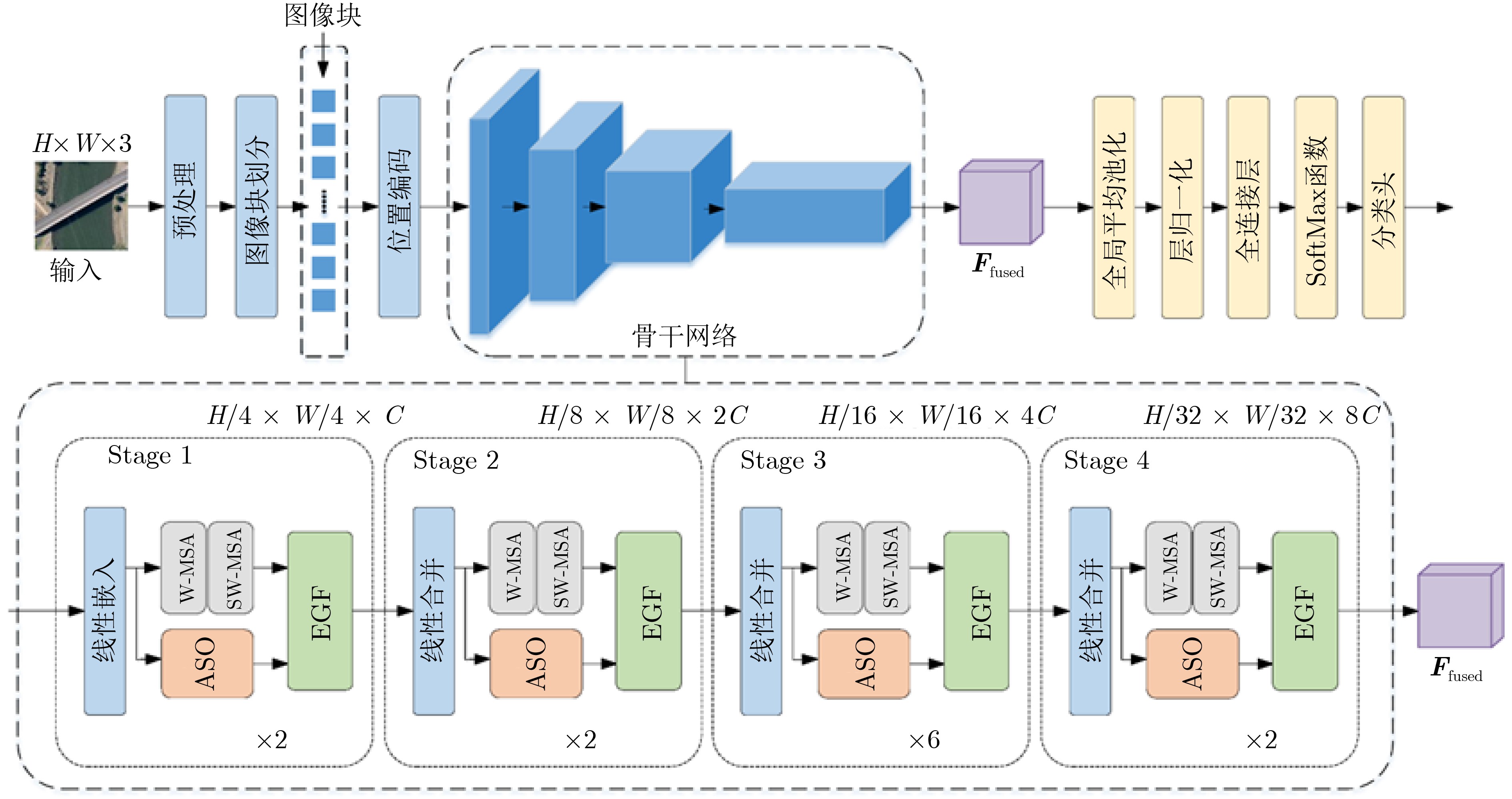
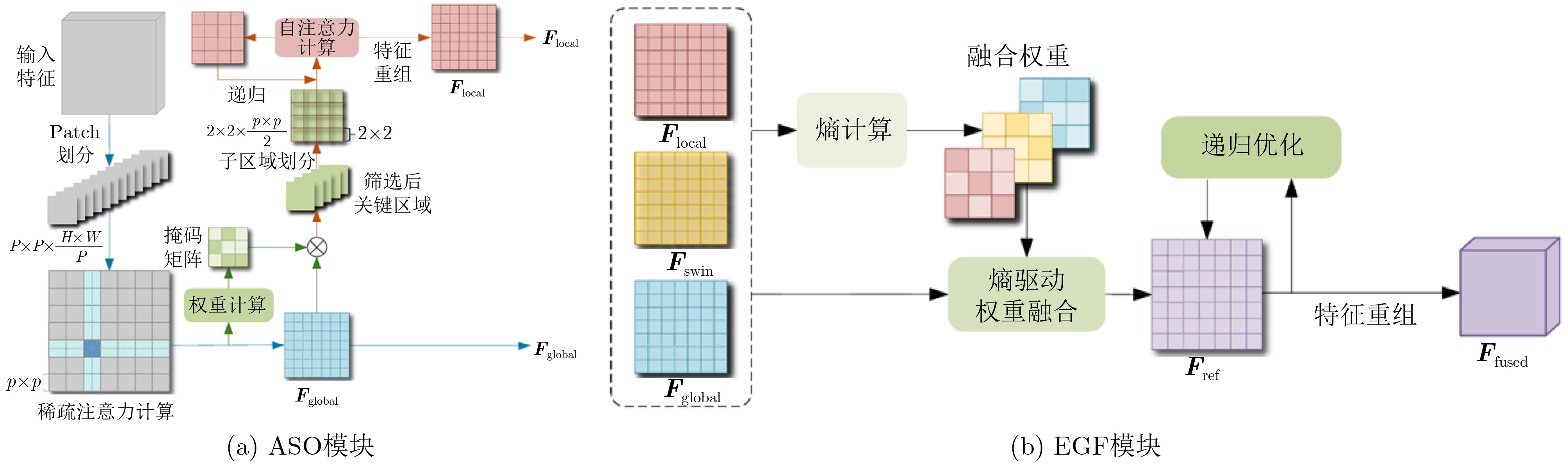
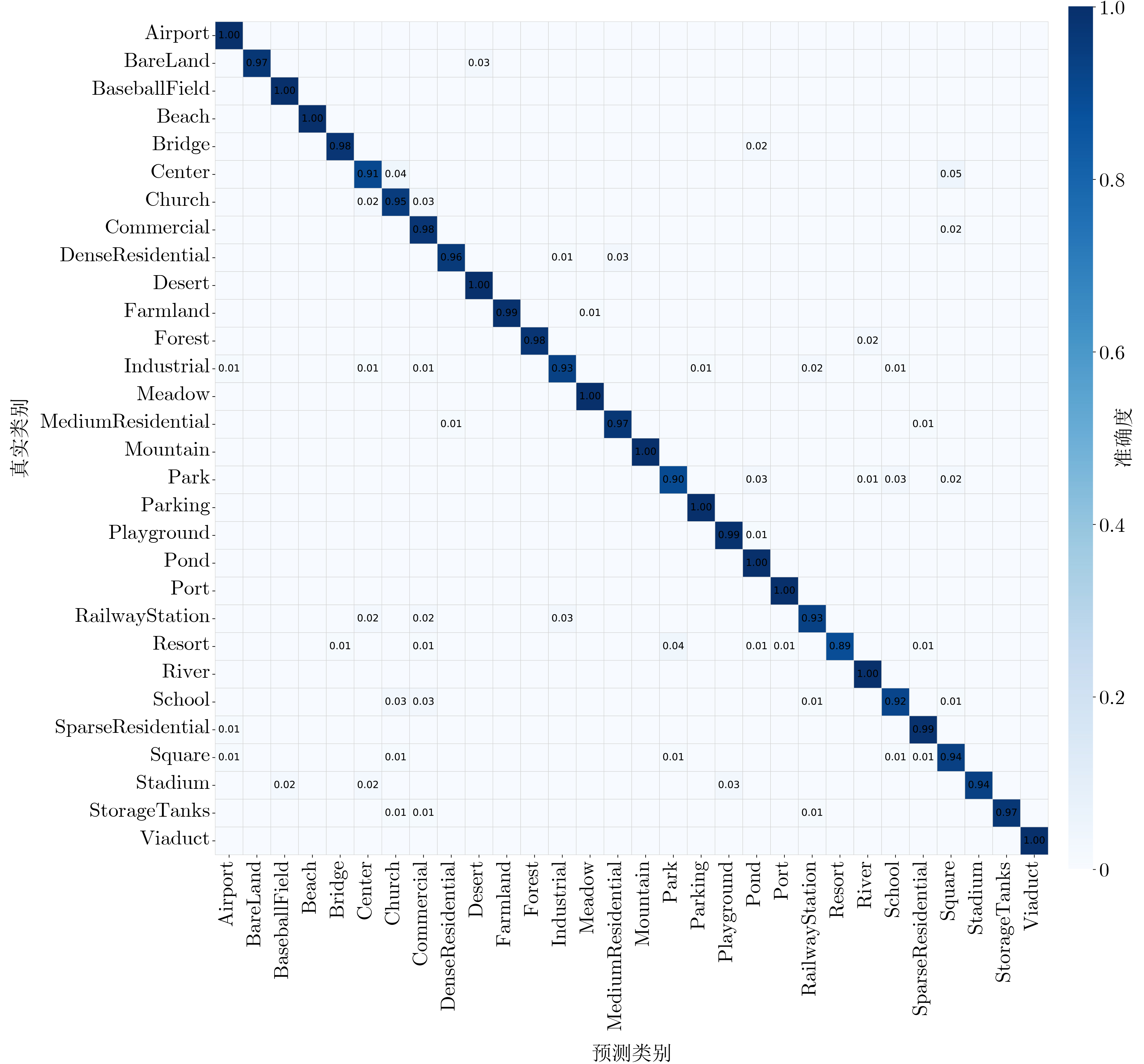
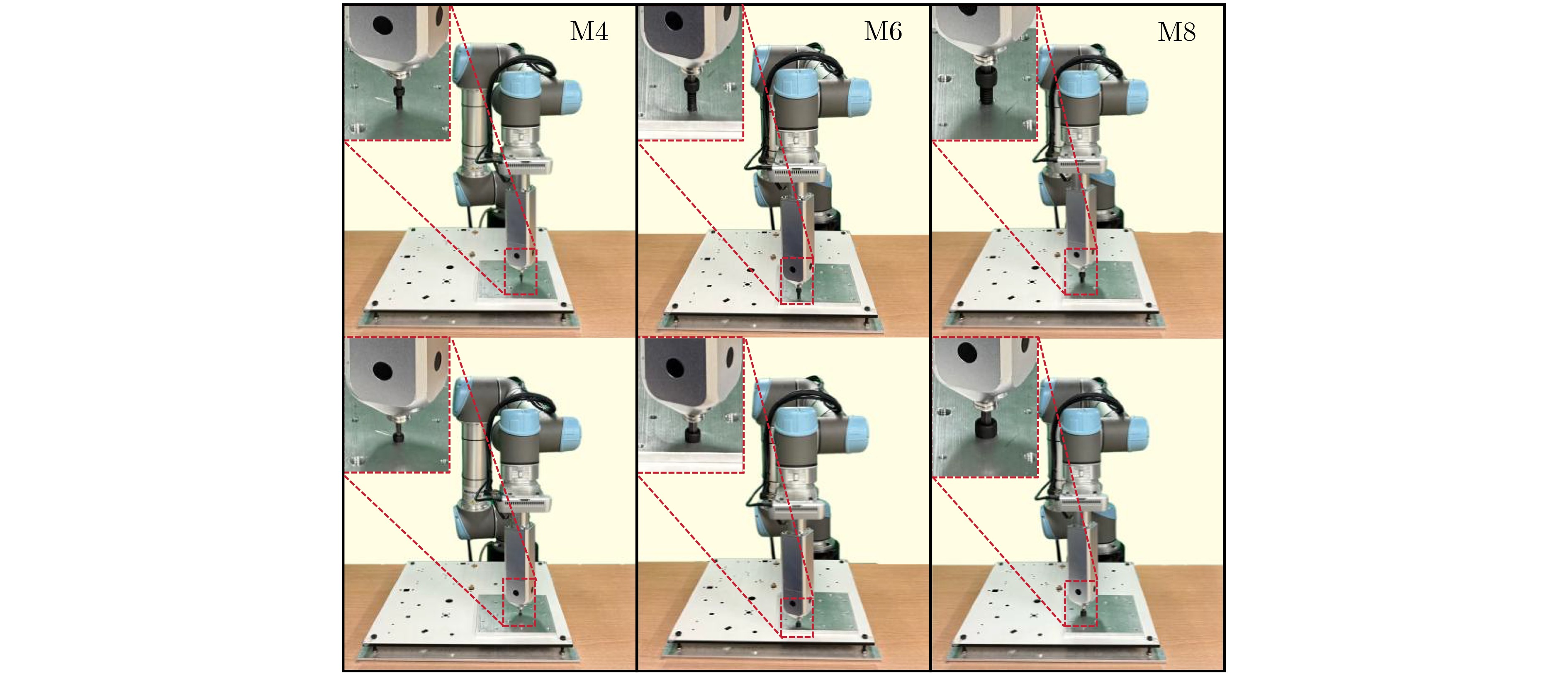
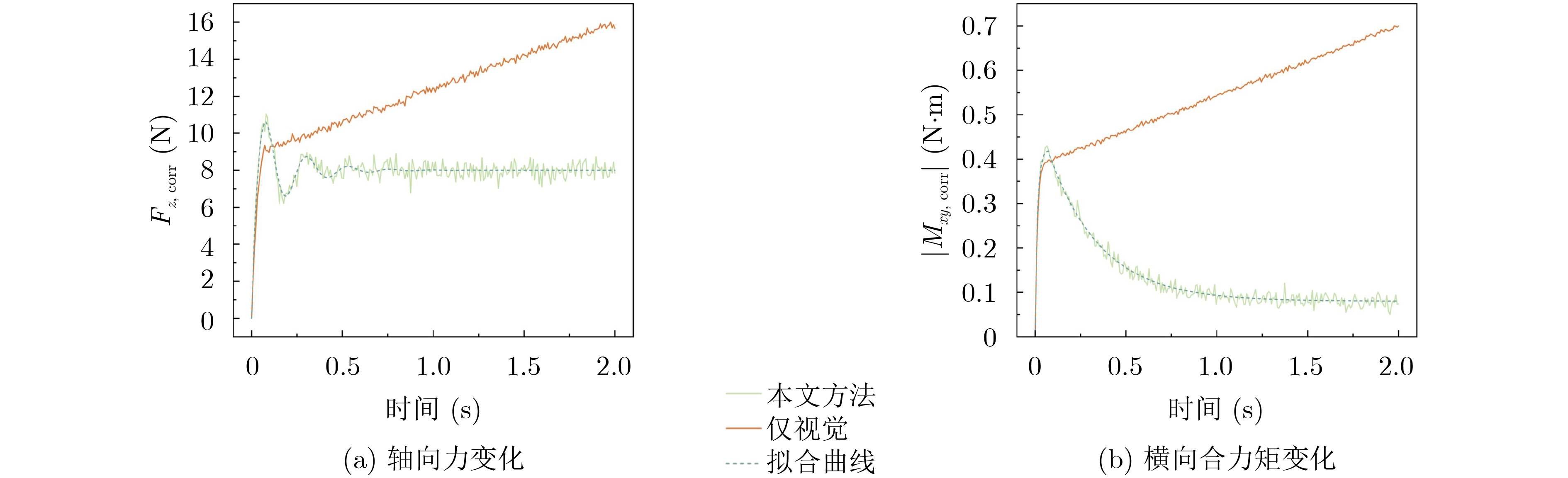
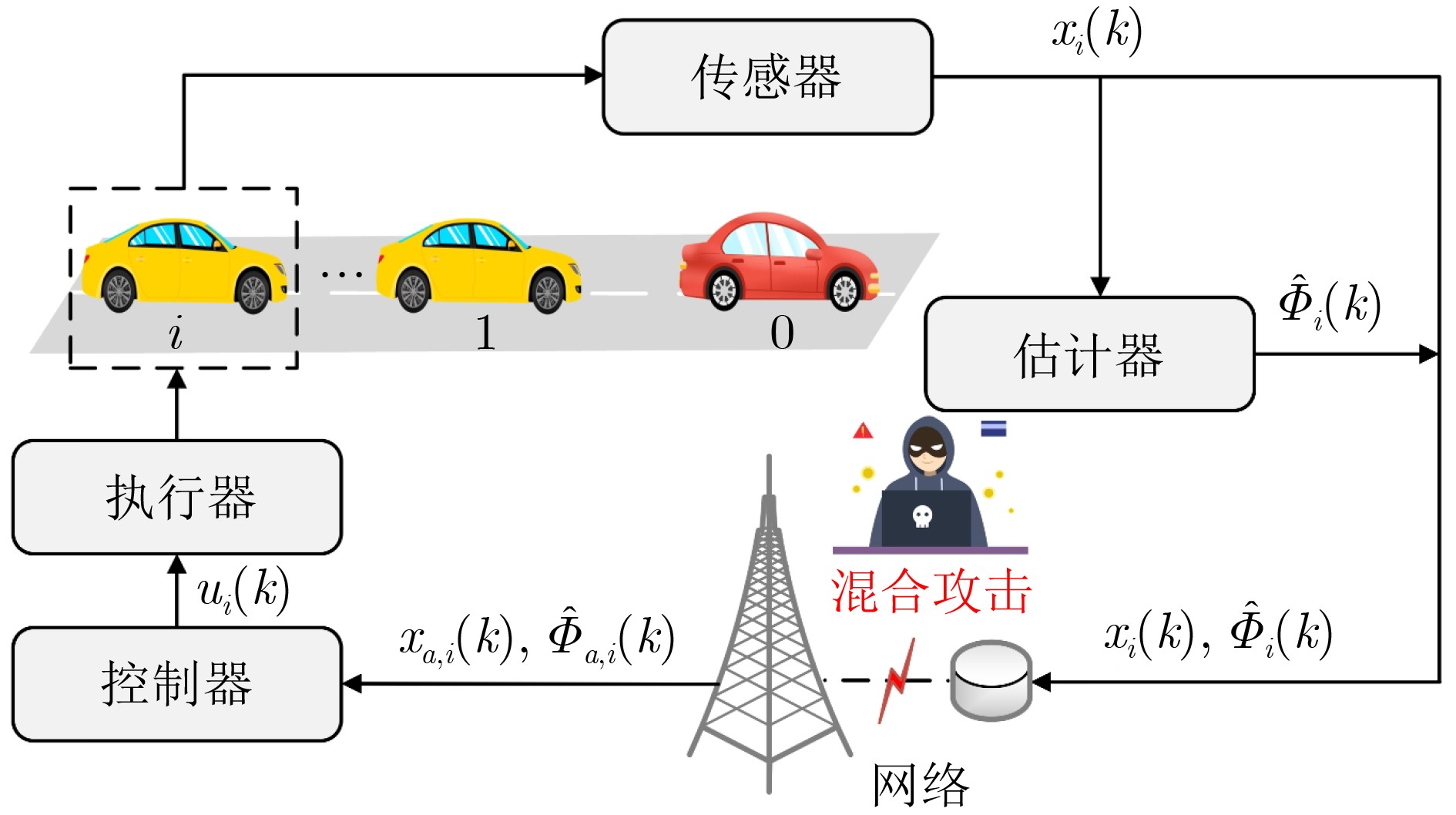
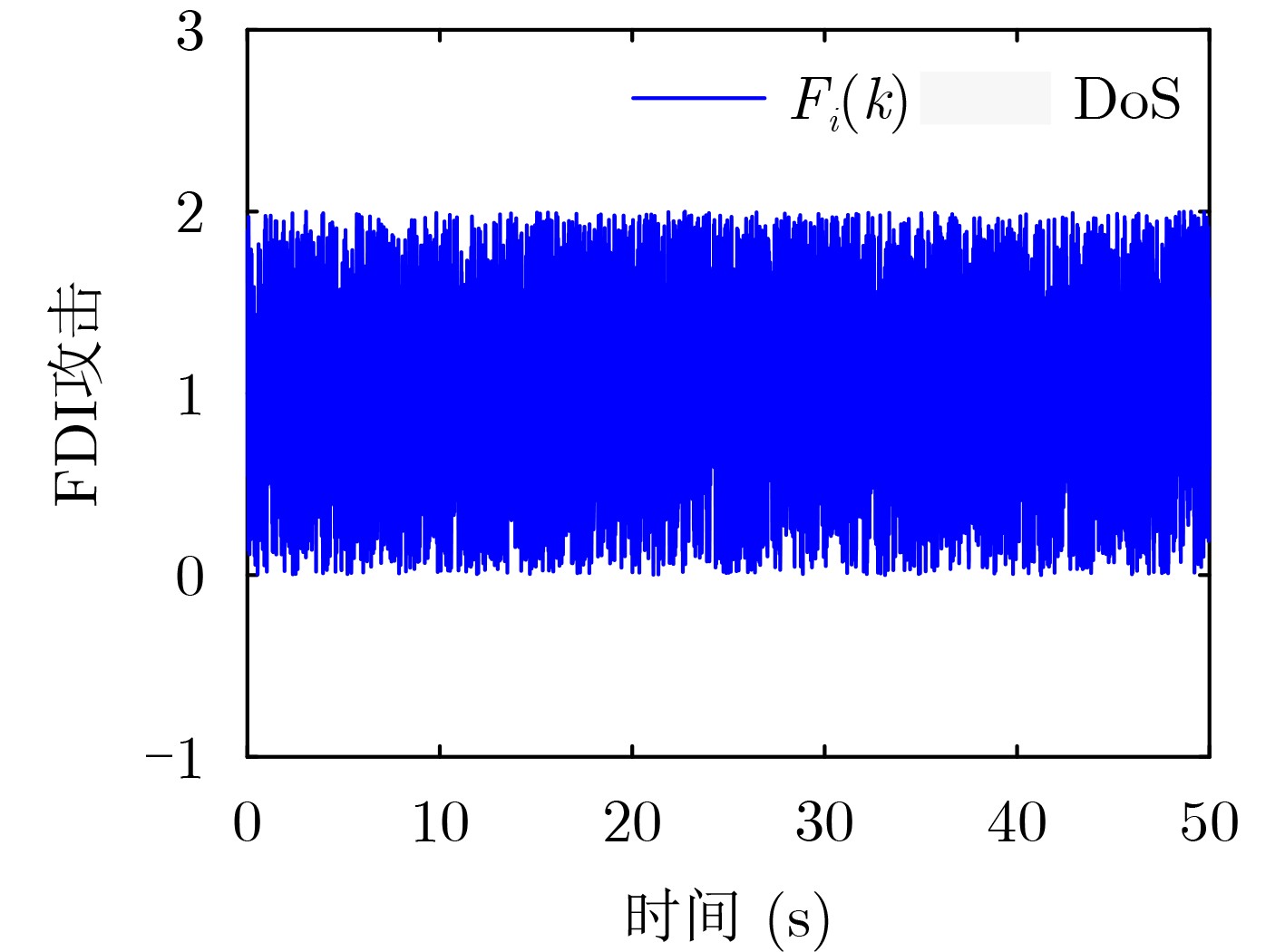
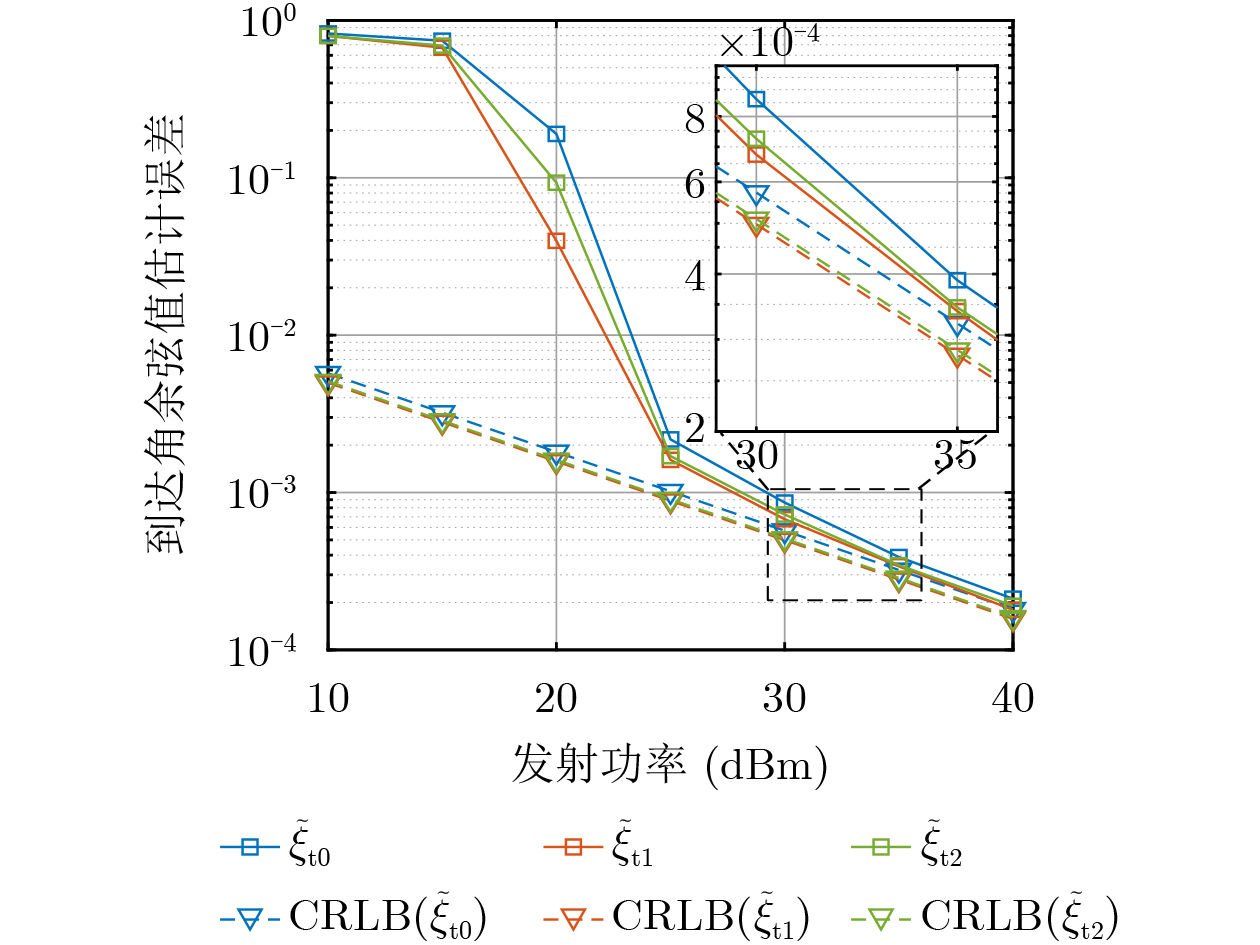
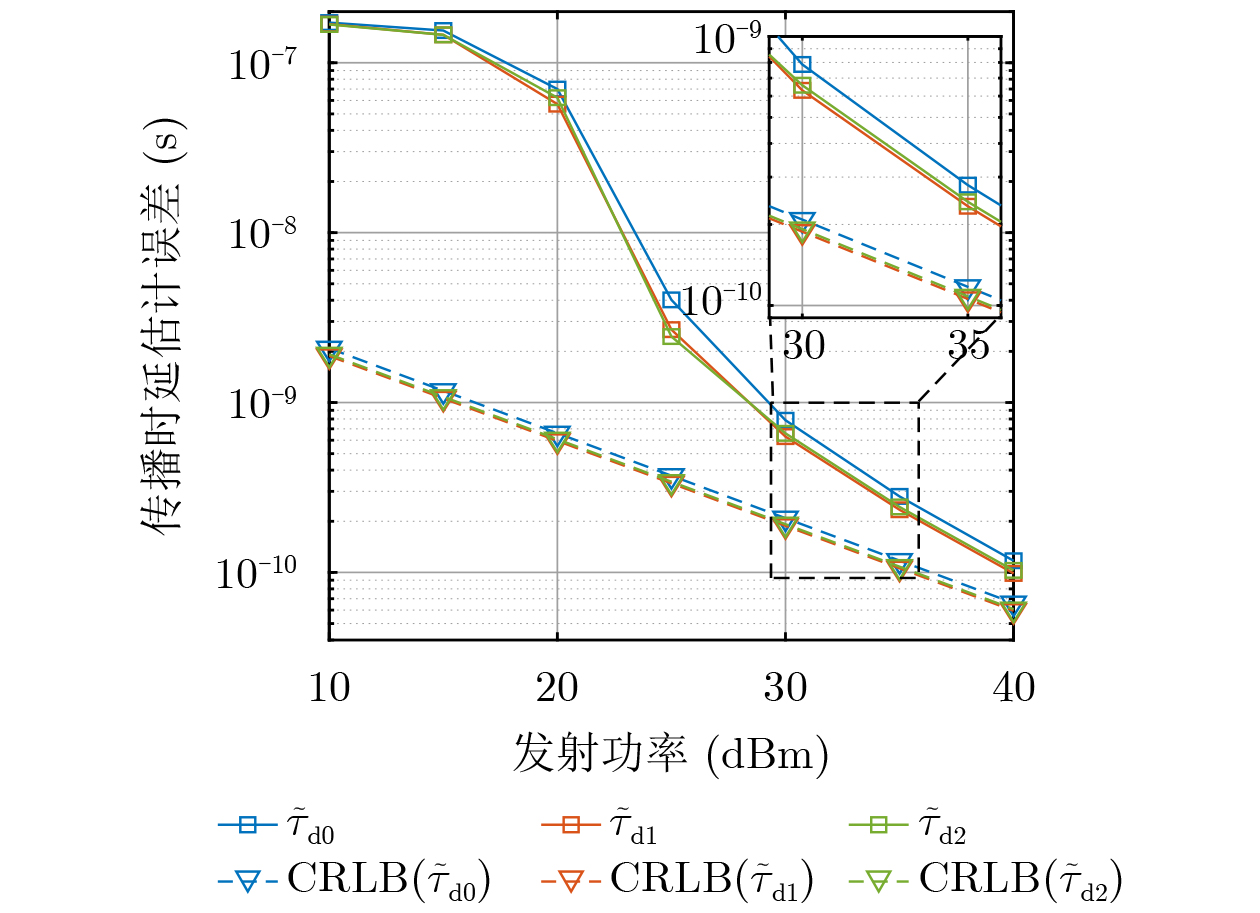
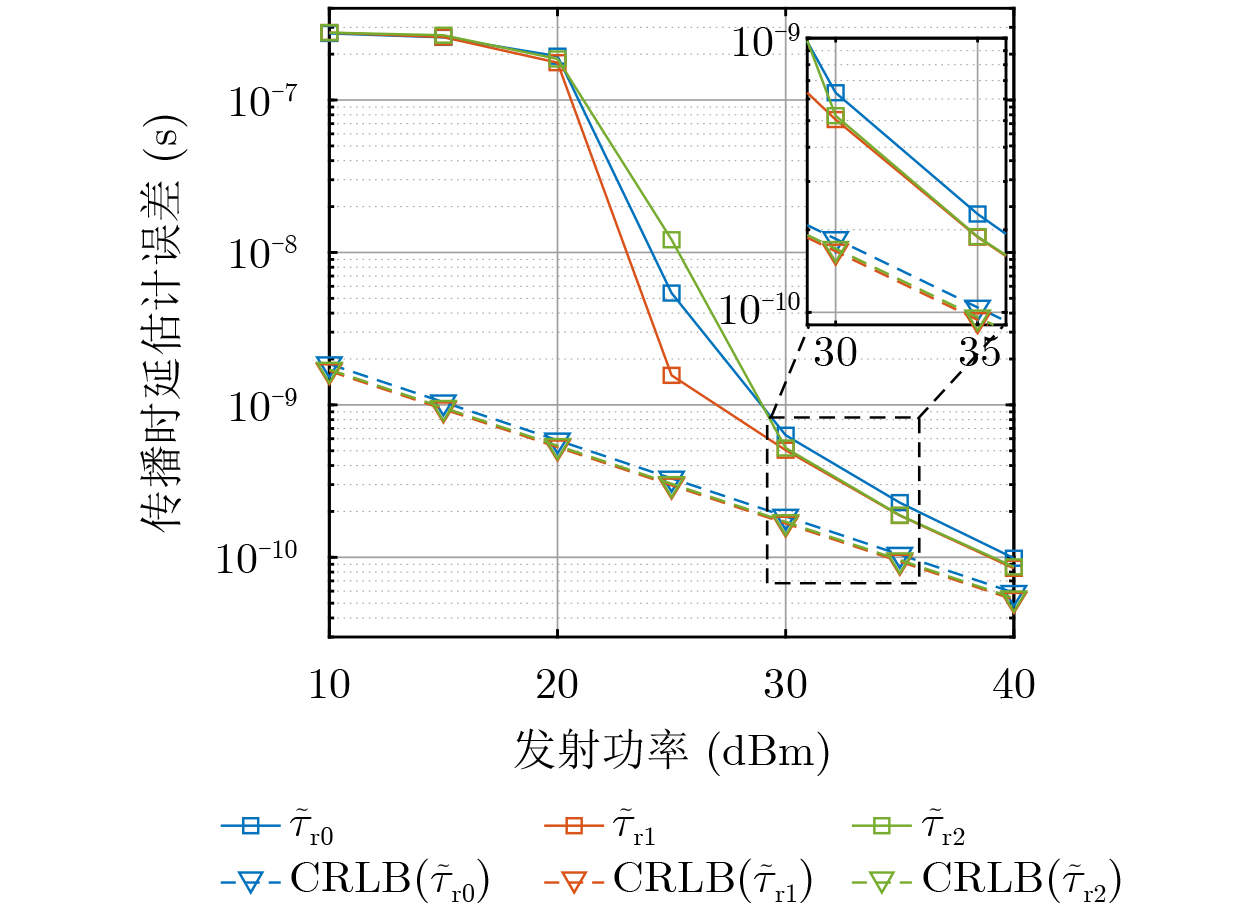
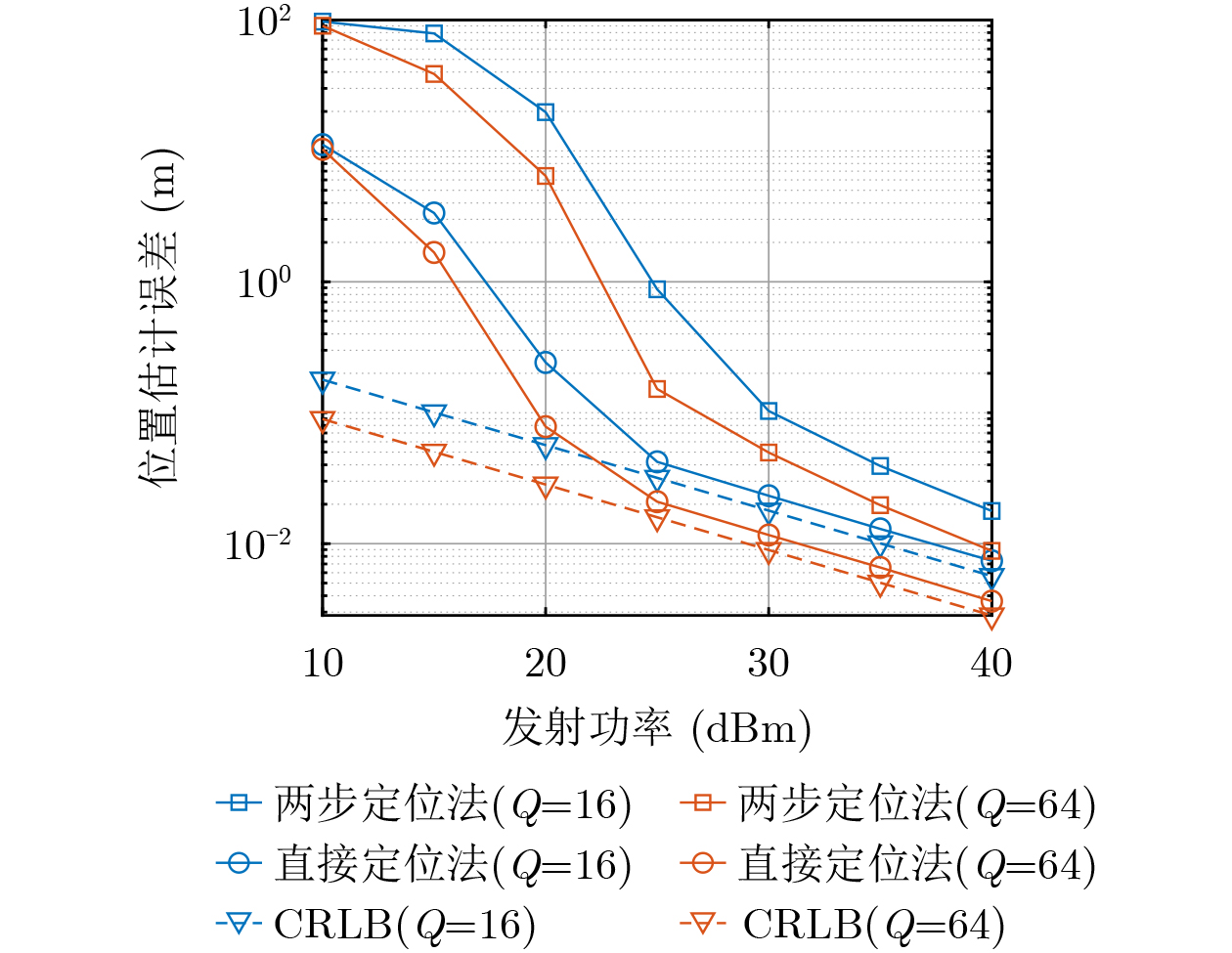
2026,
48(5):
2132-2143.
doi: 10.11999/JEIT251294
Abstract:
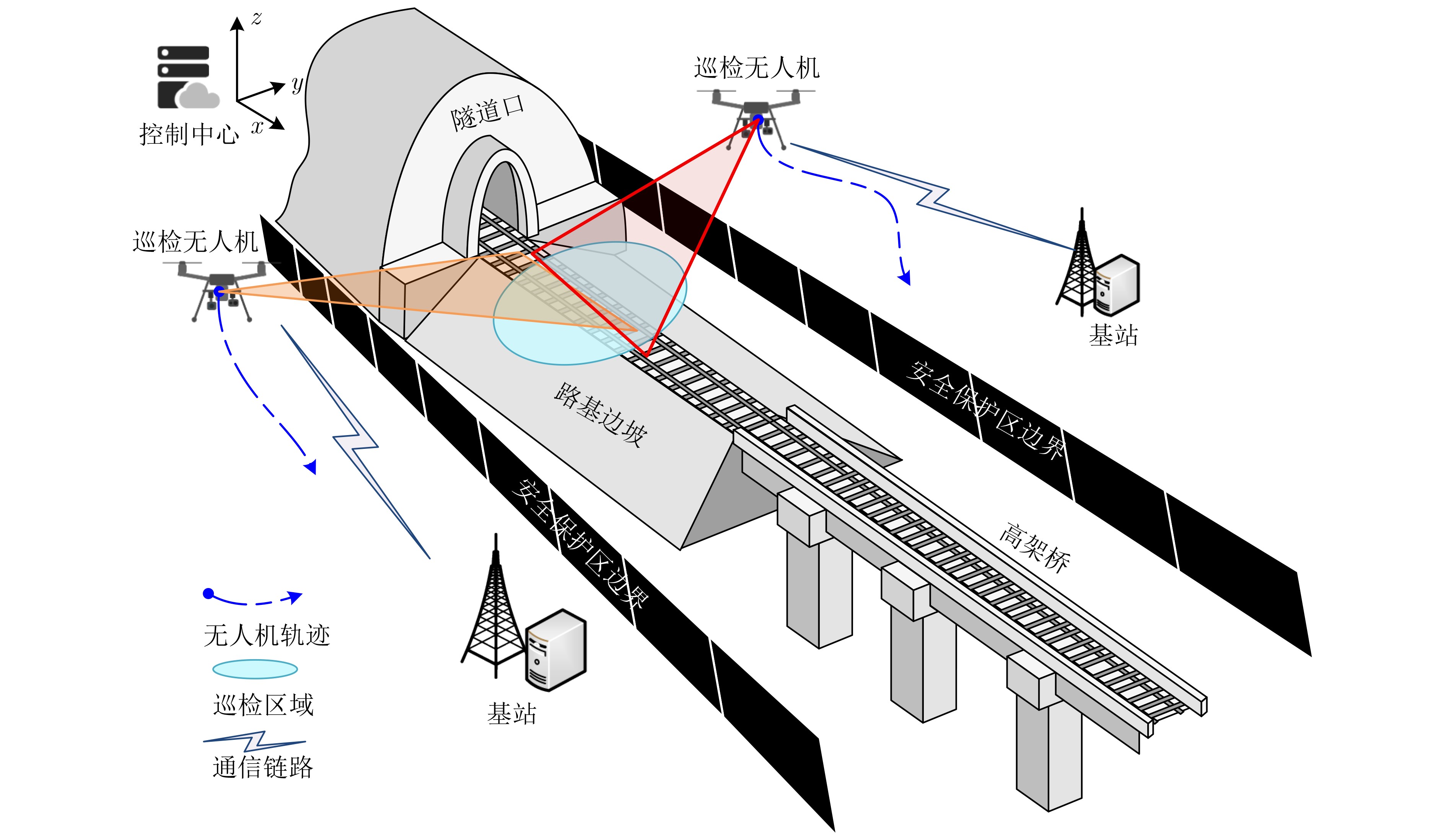
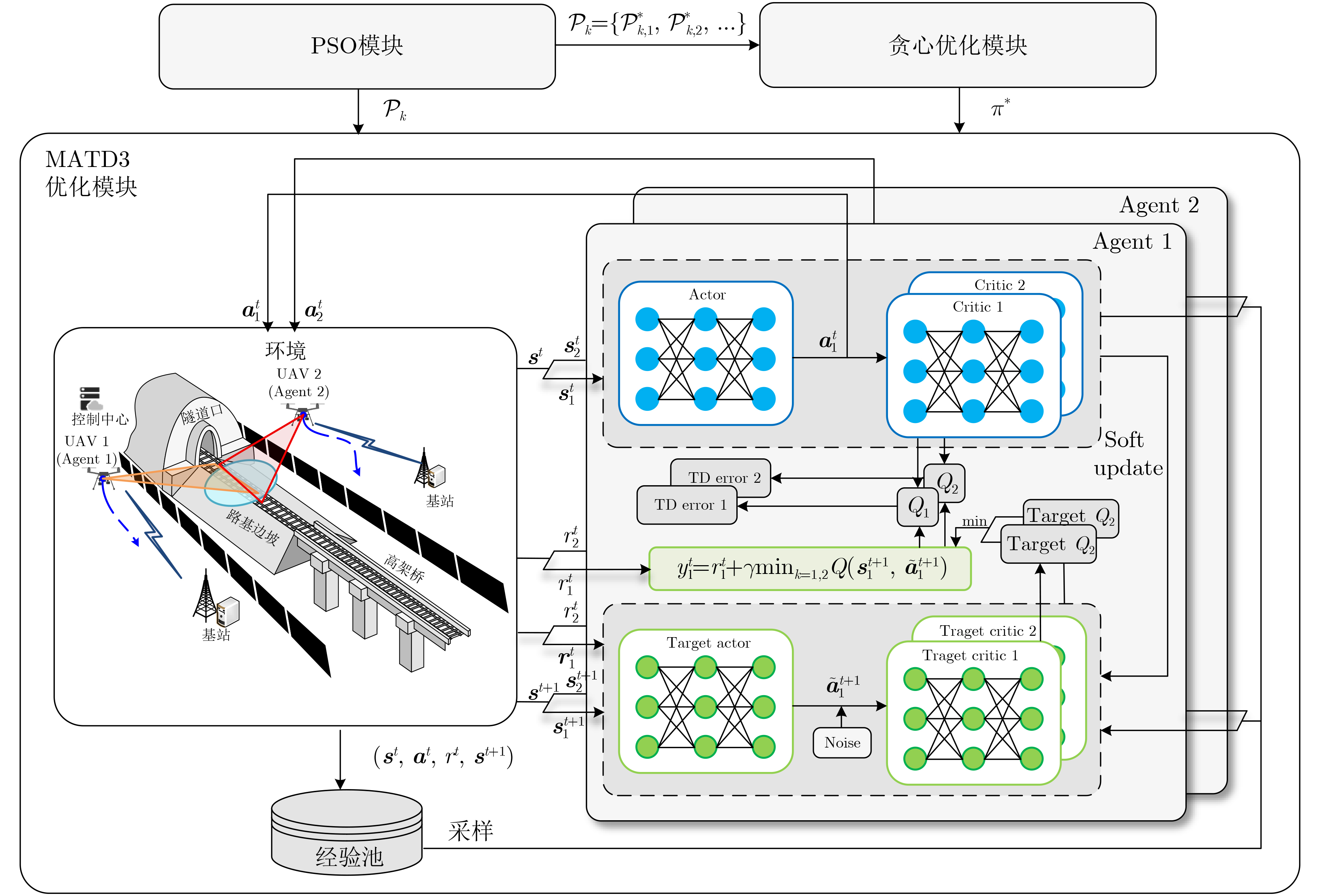
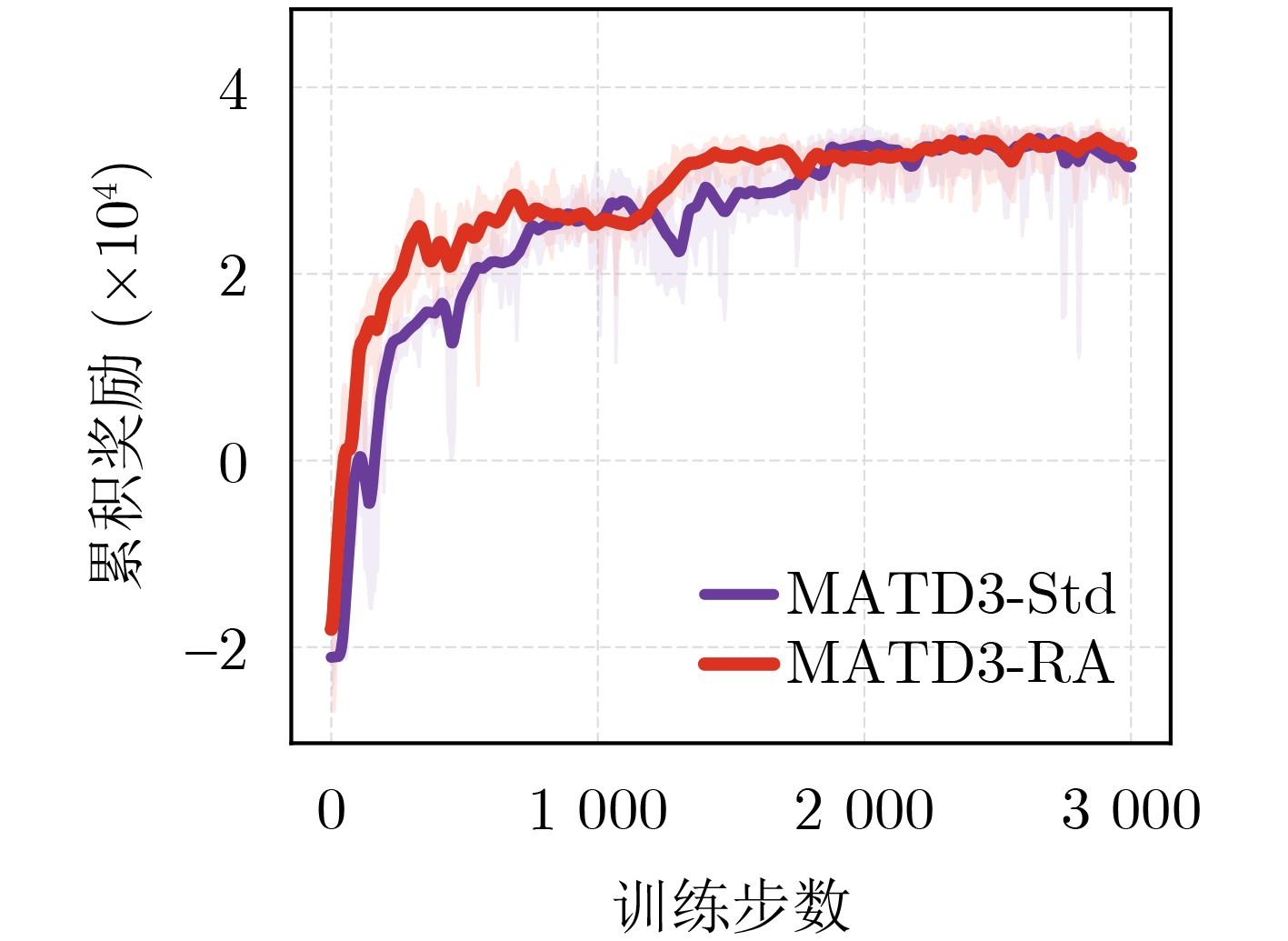
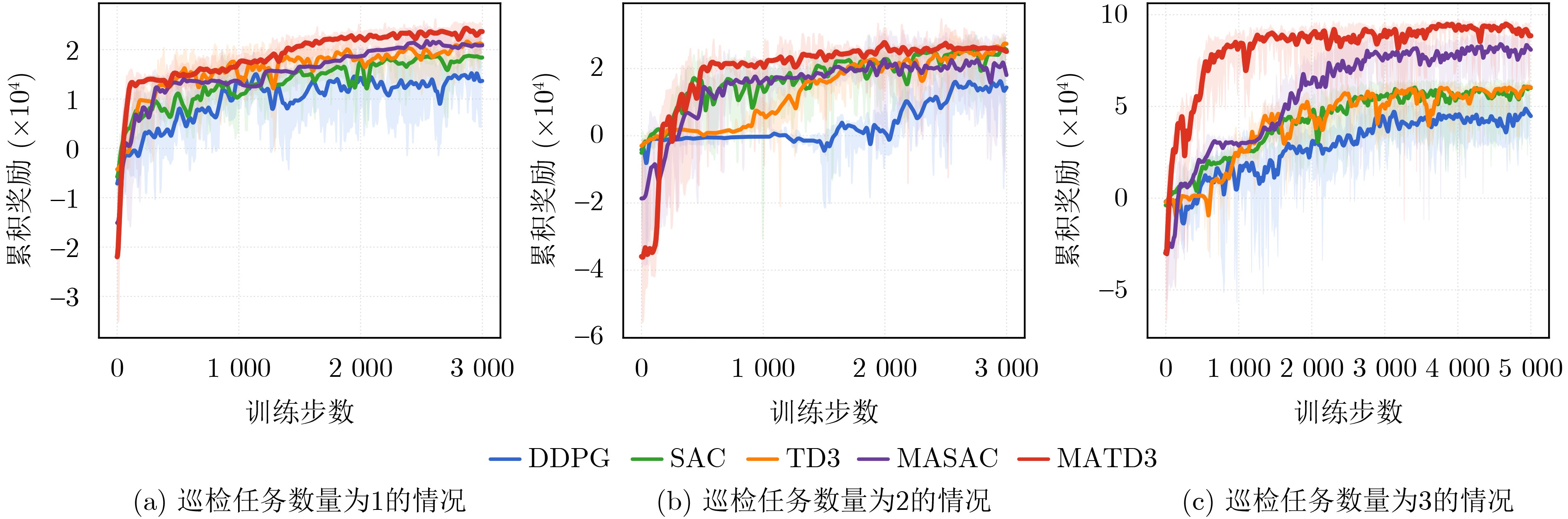
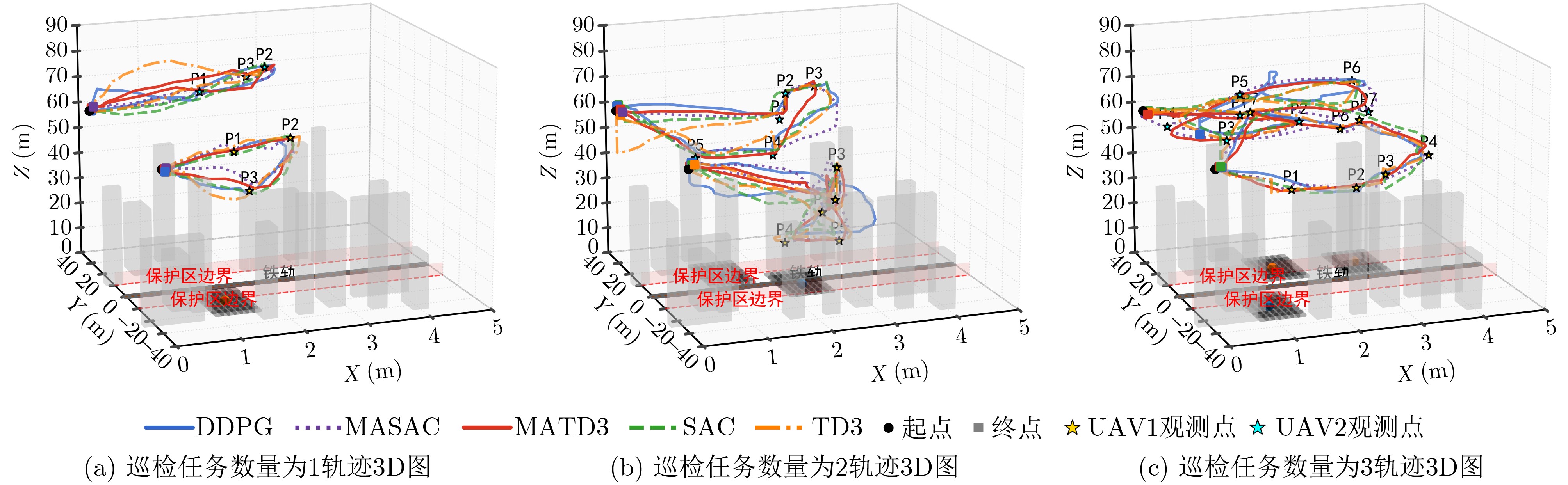
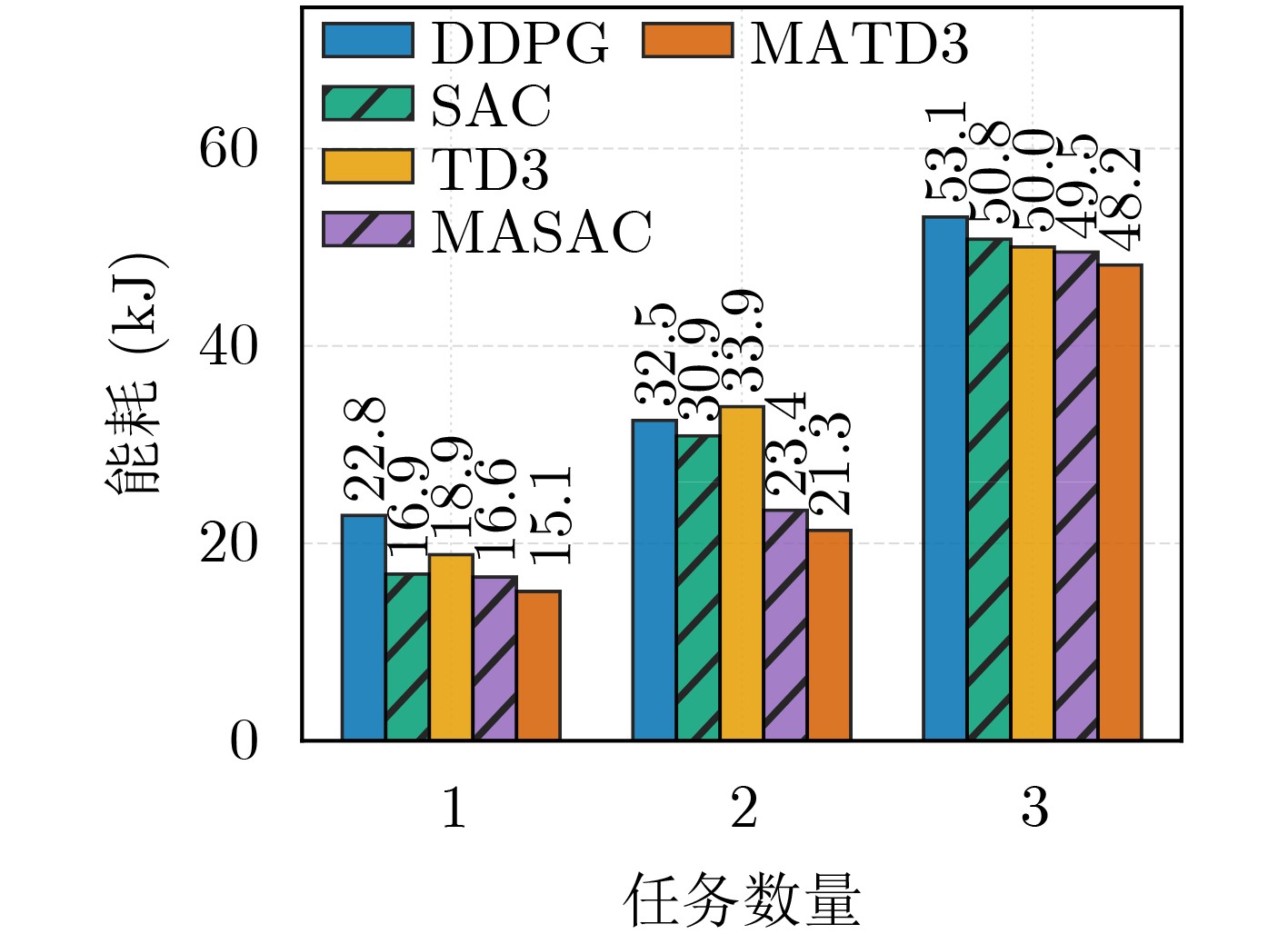
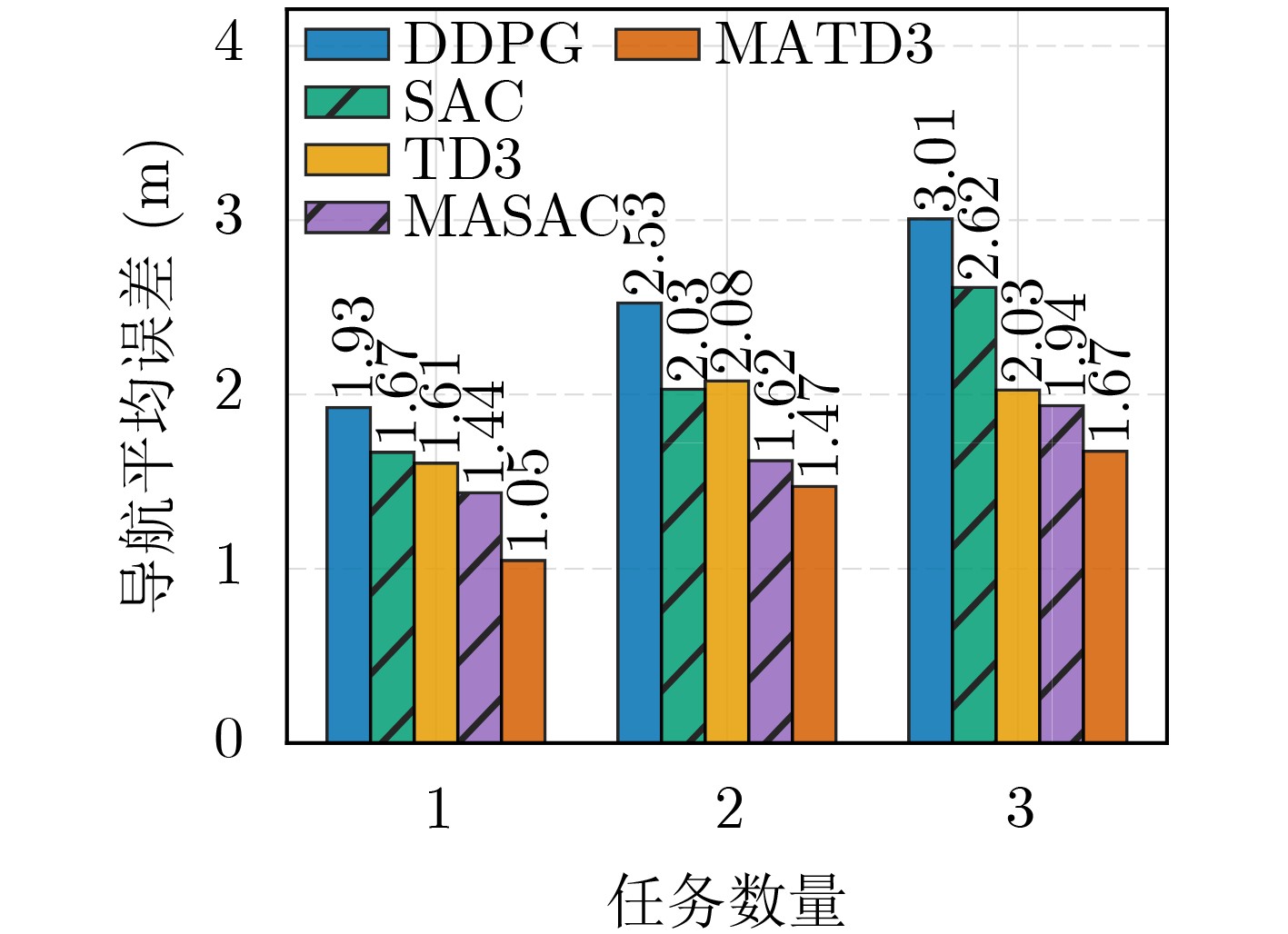
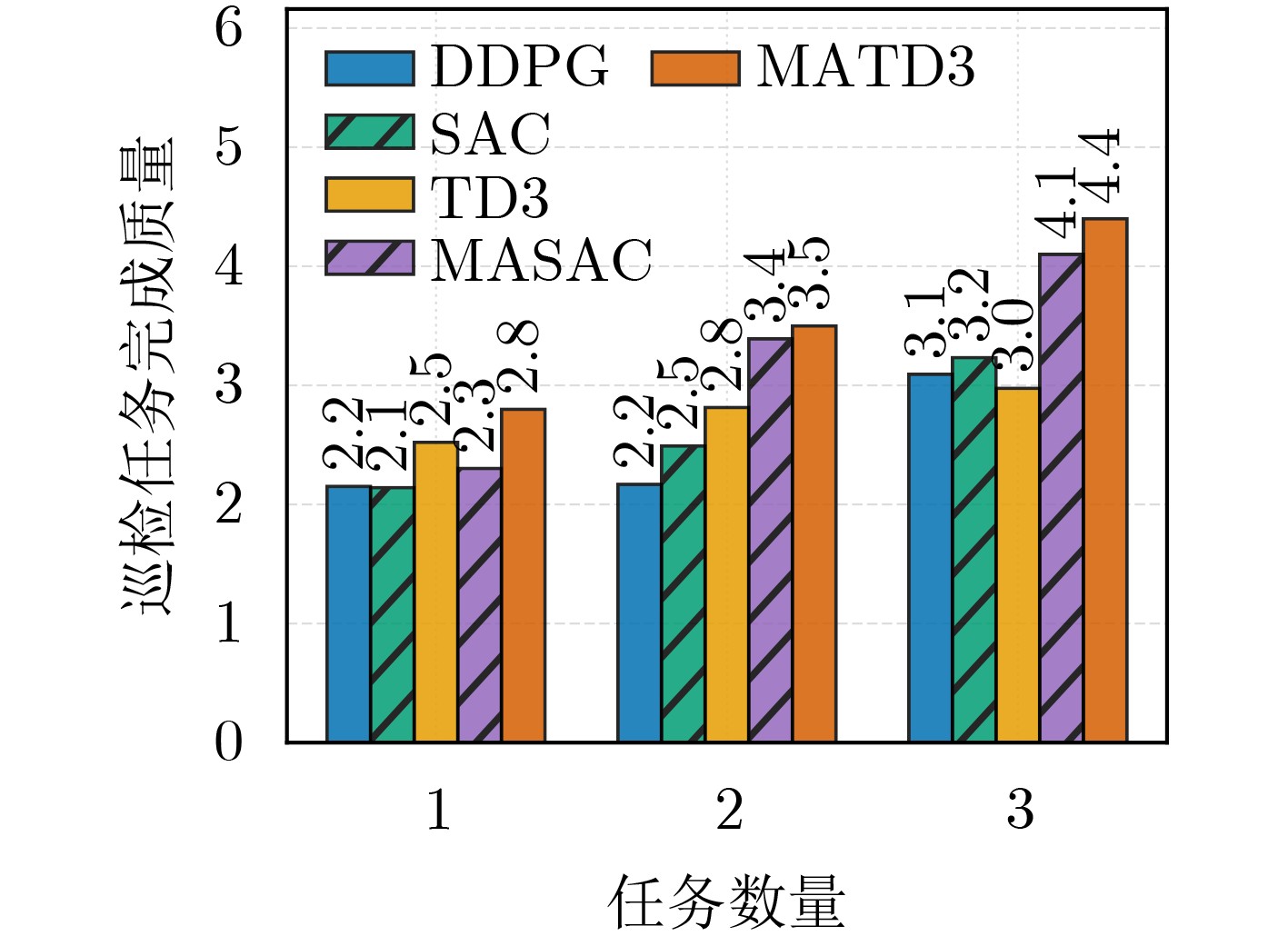
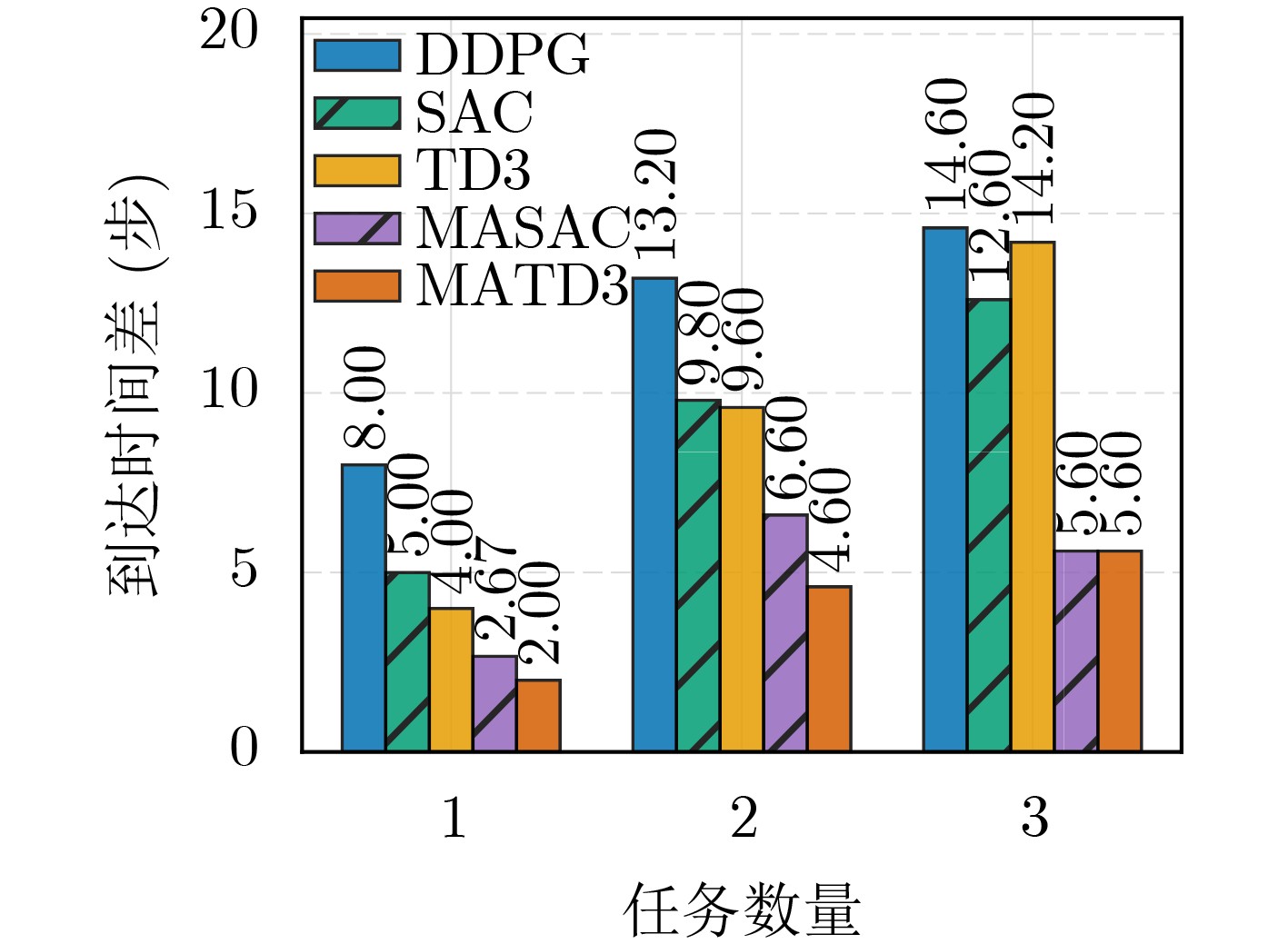
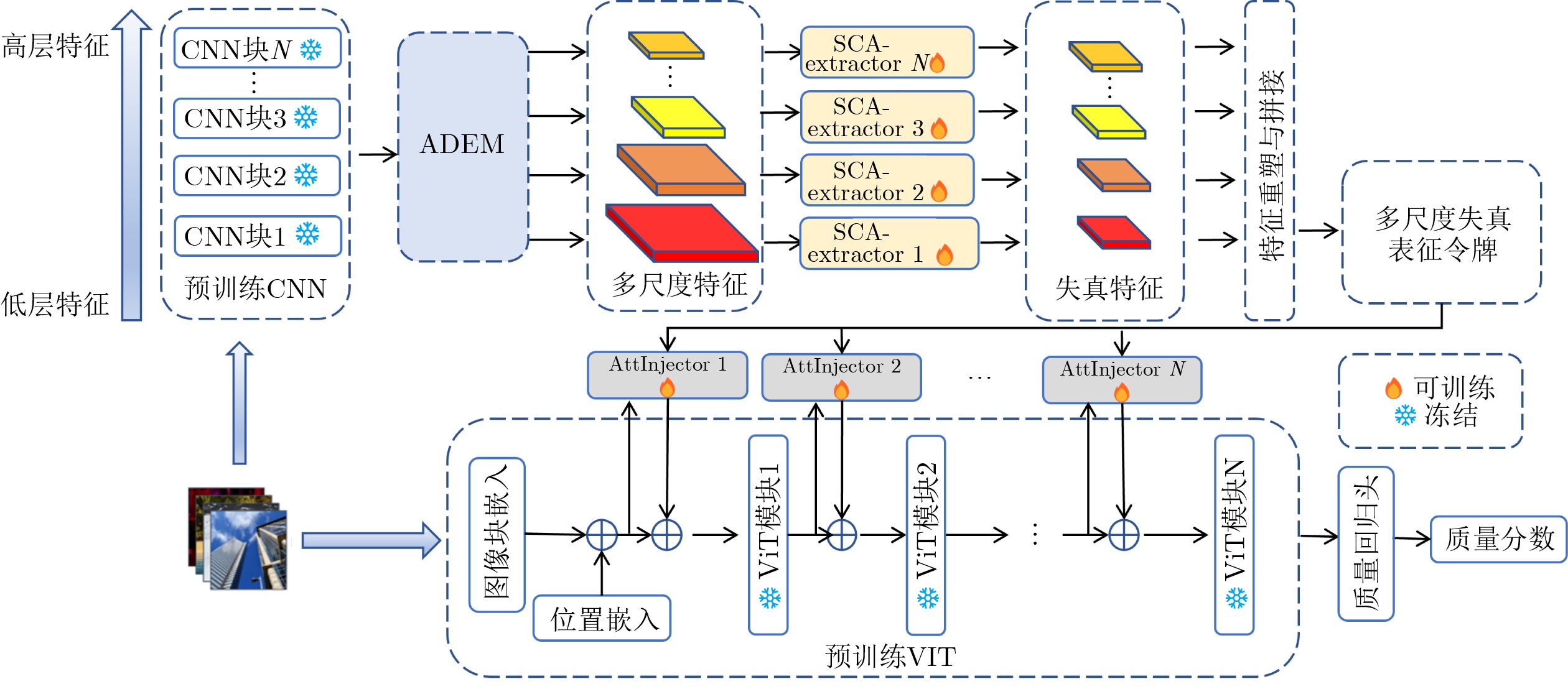
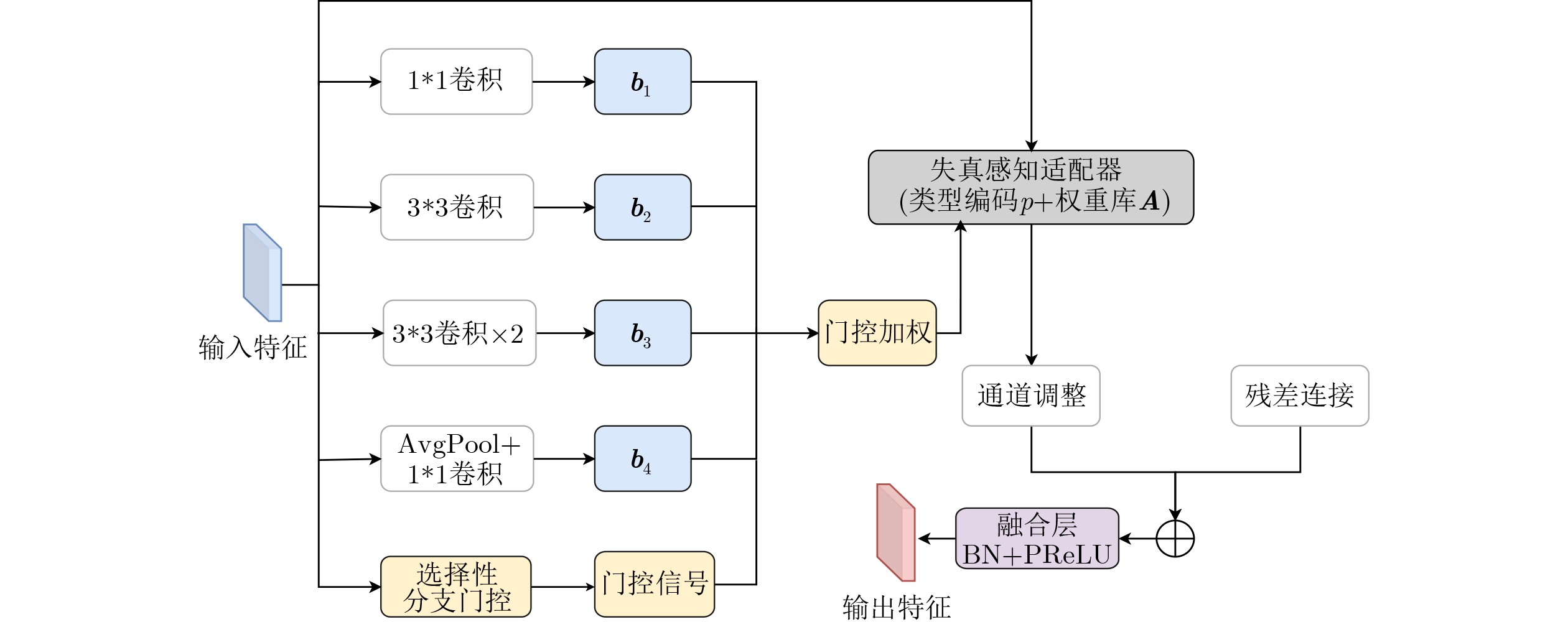
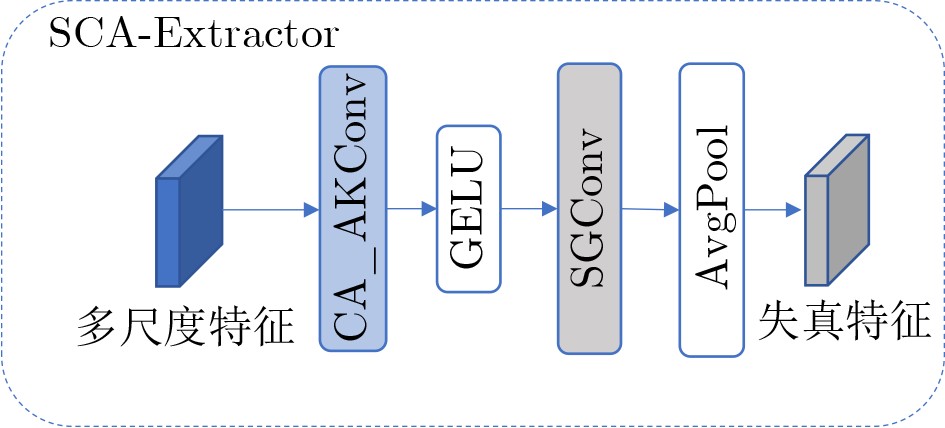
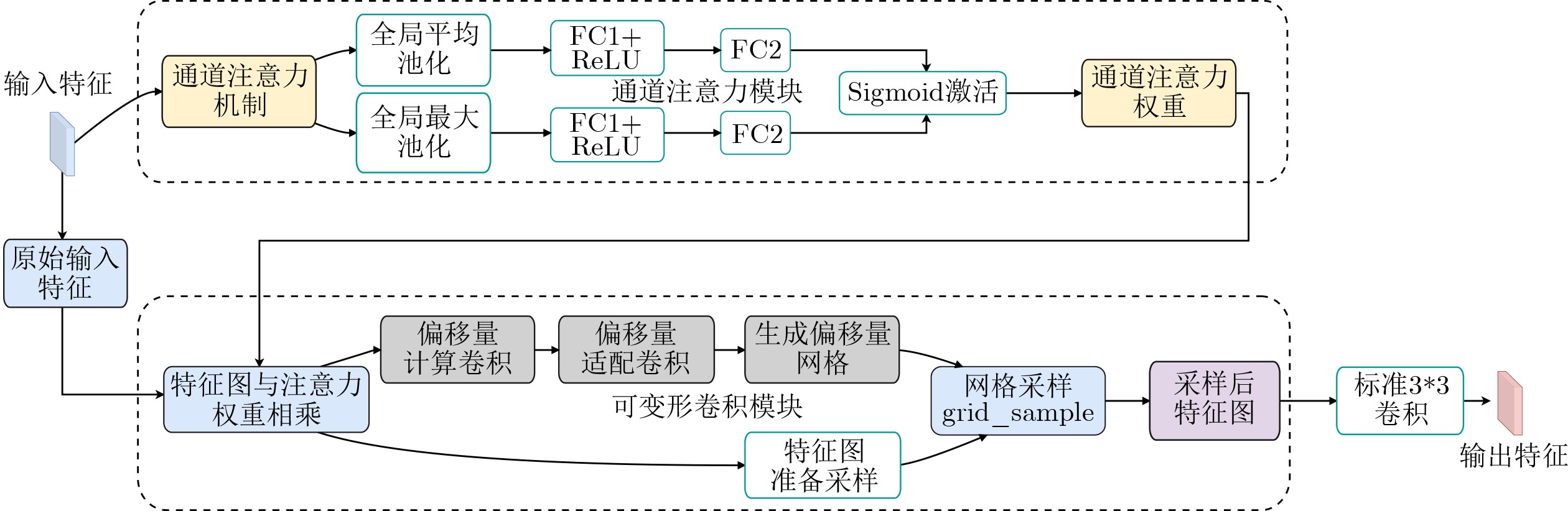
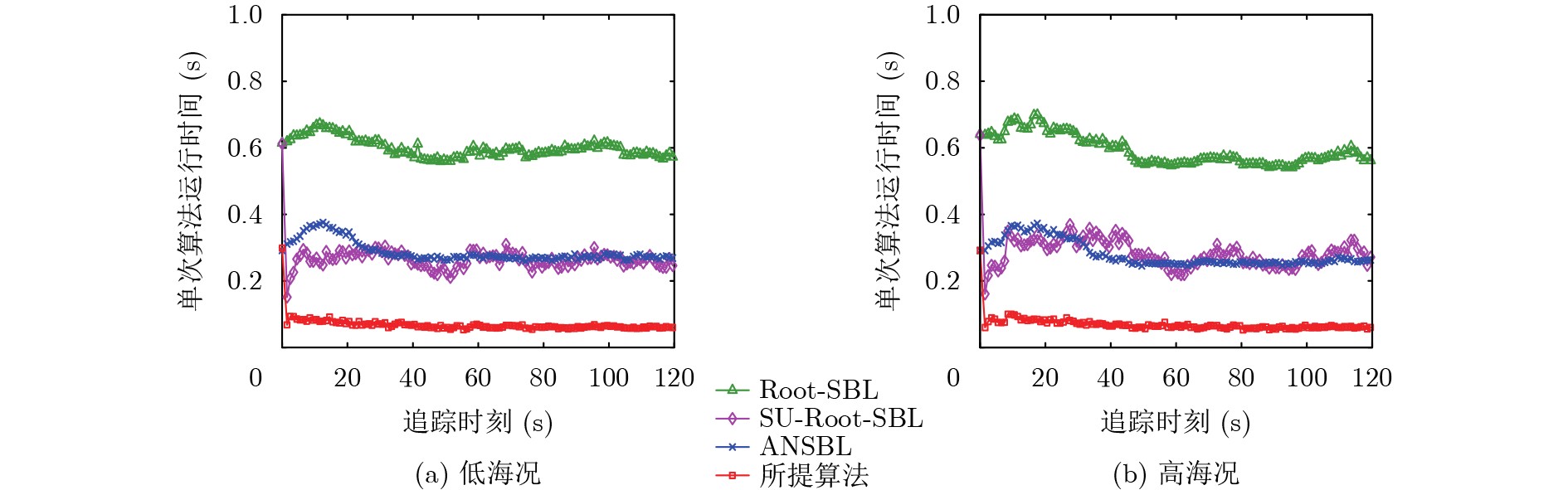
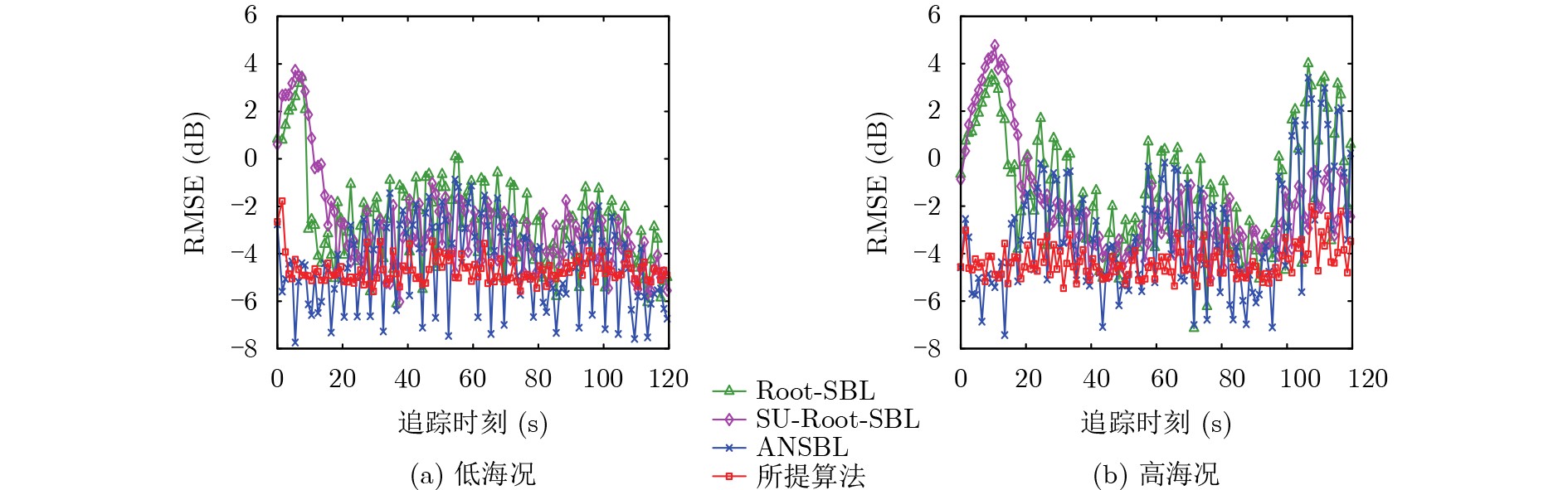
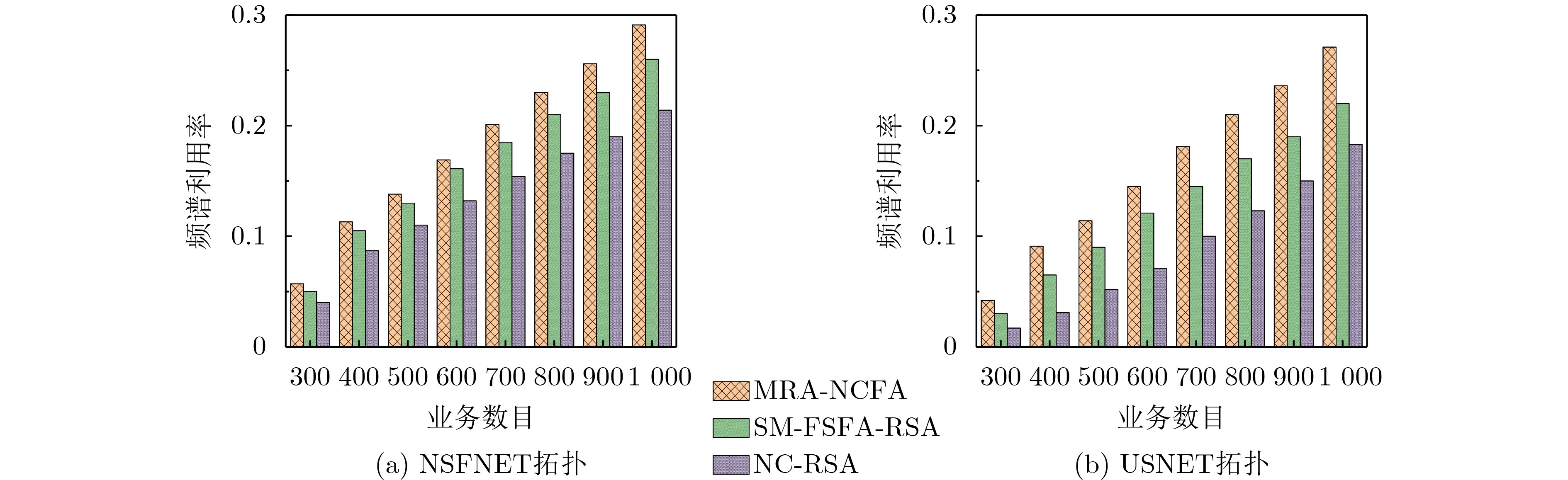
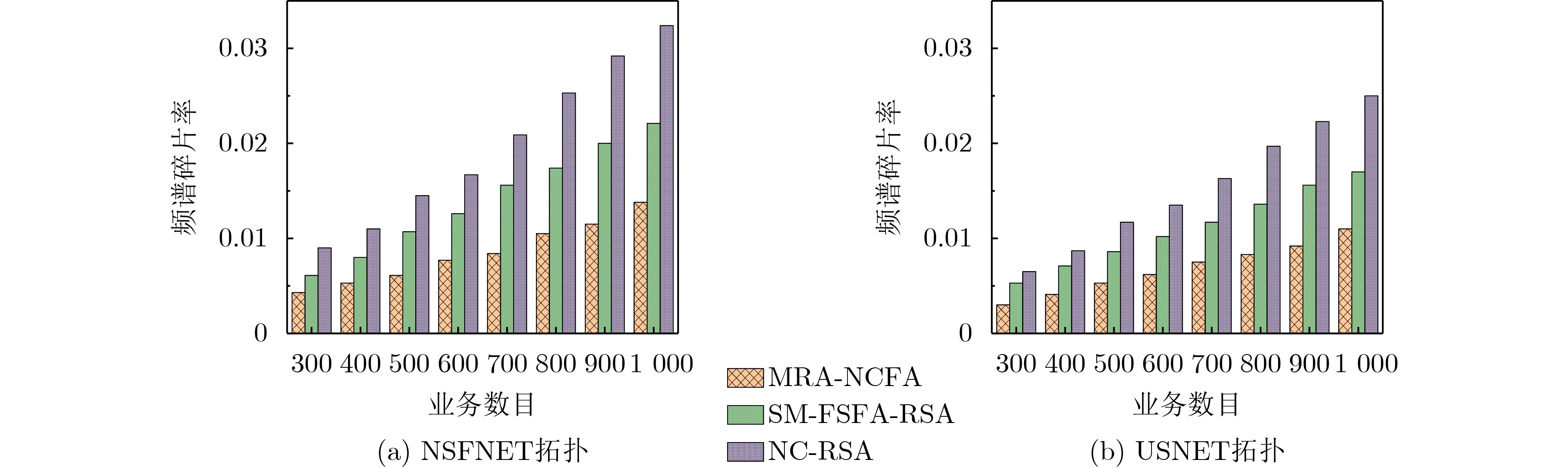
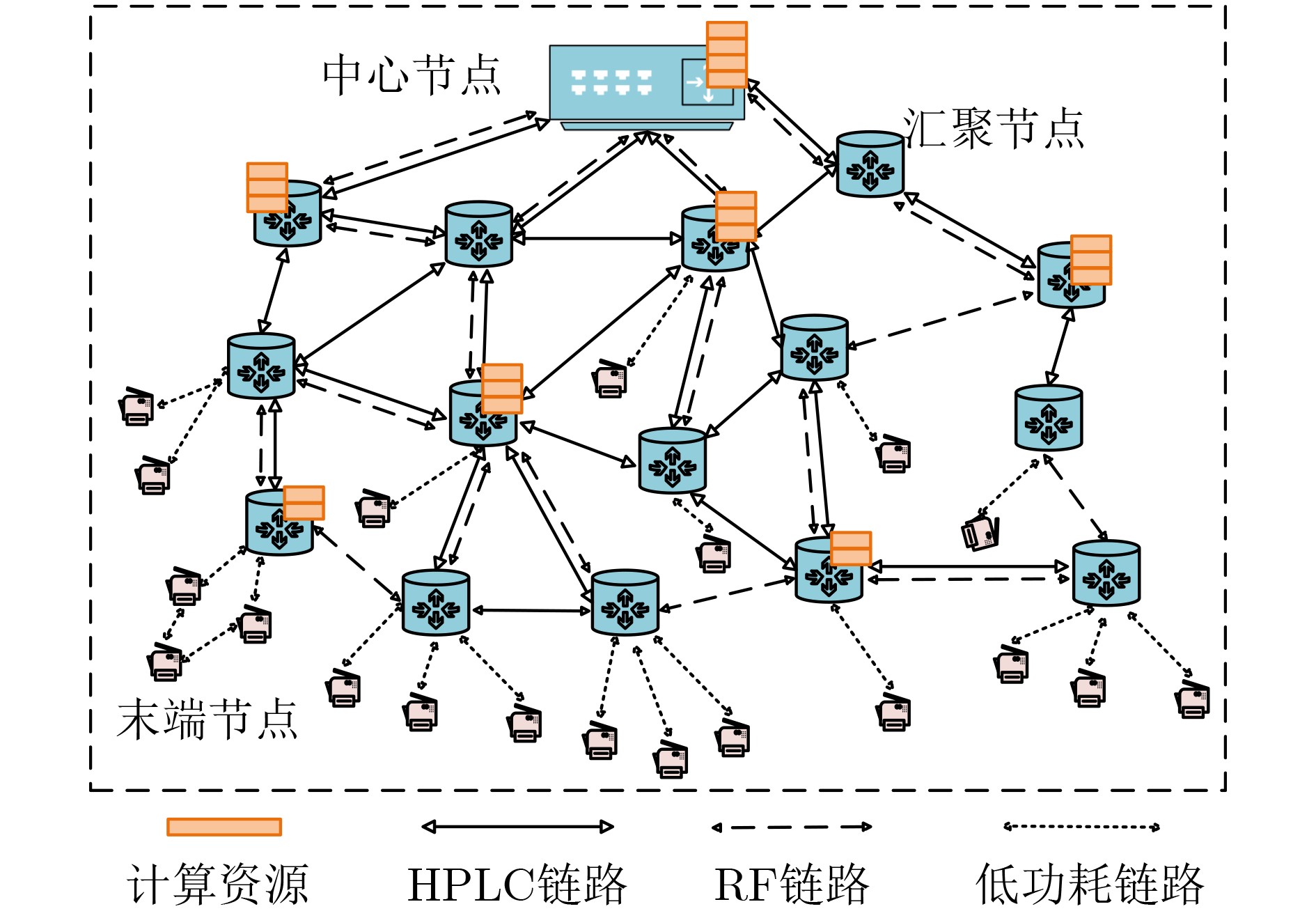
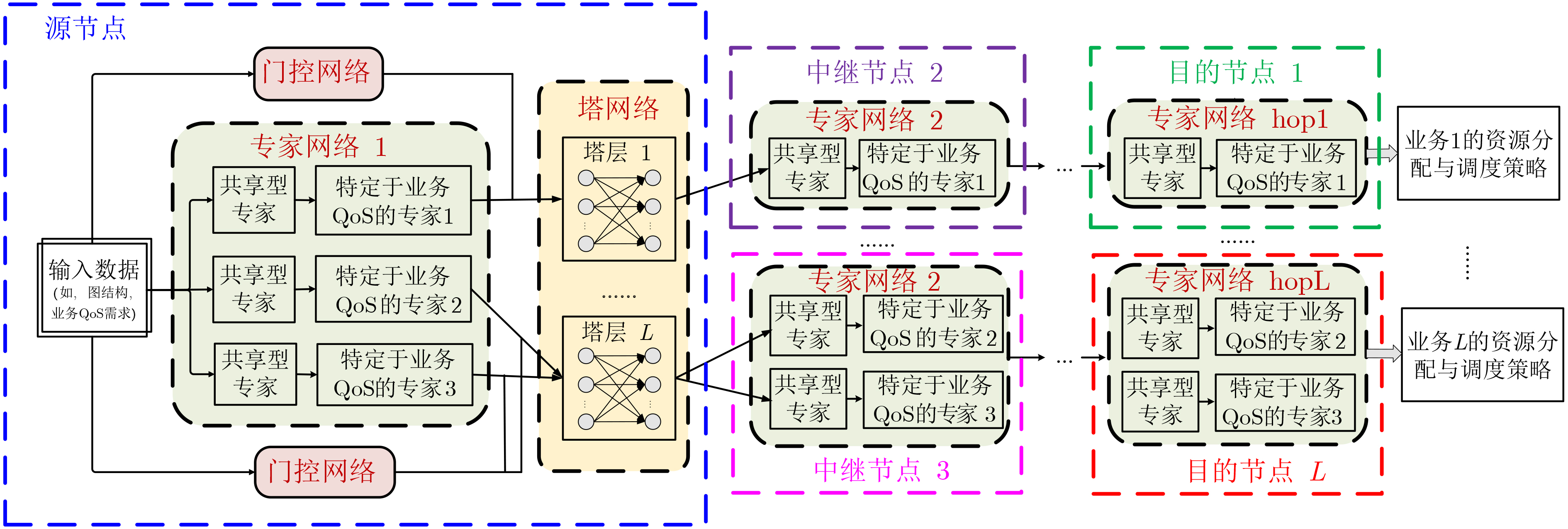
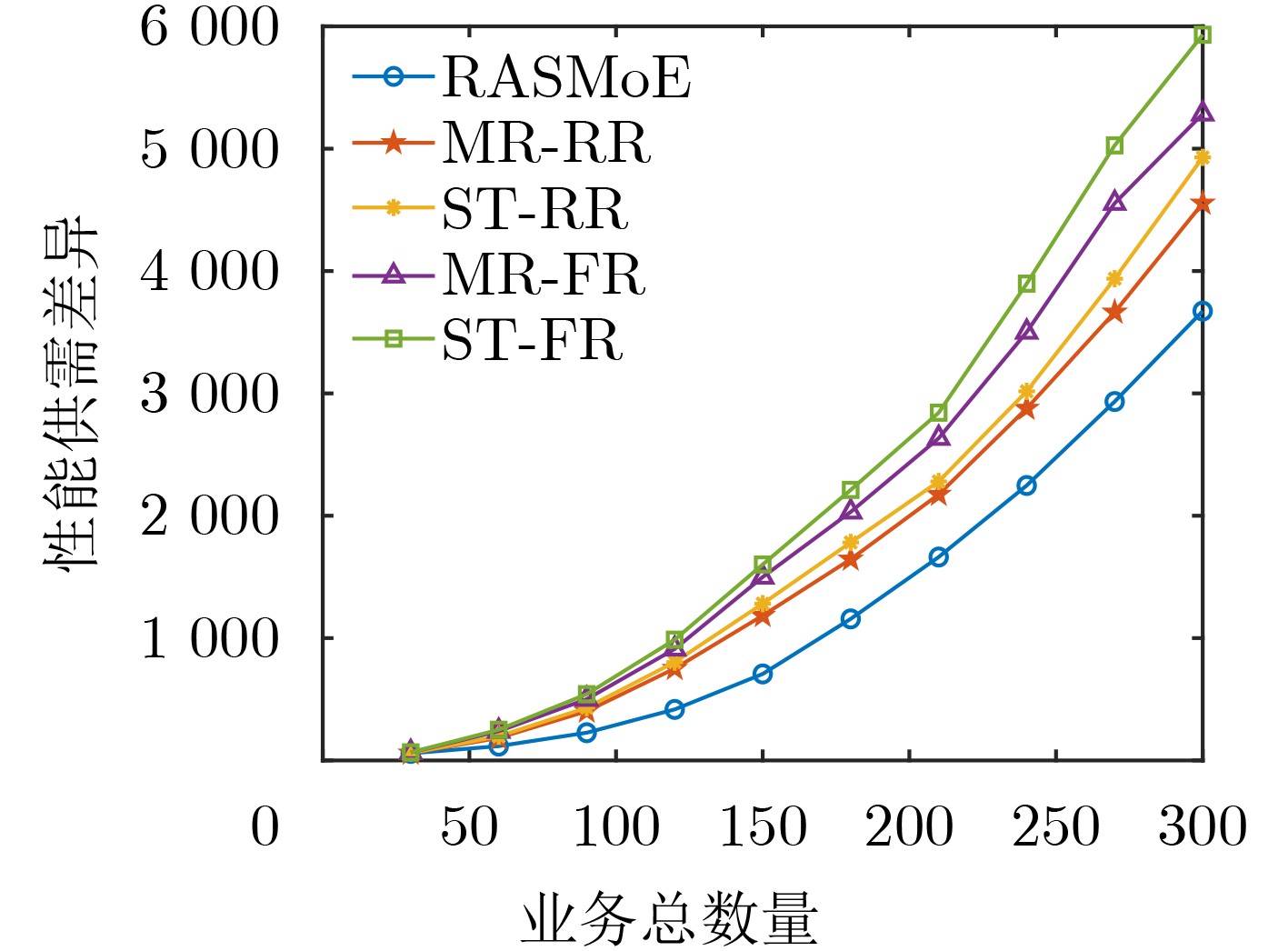
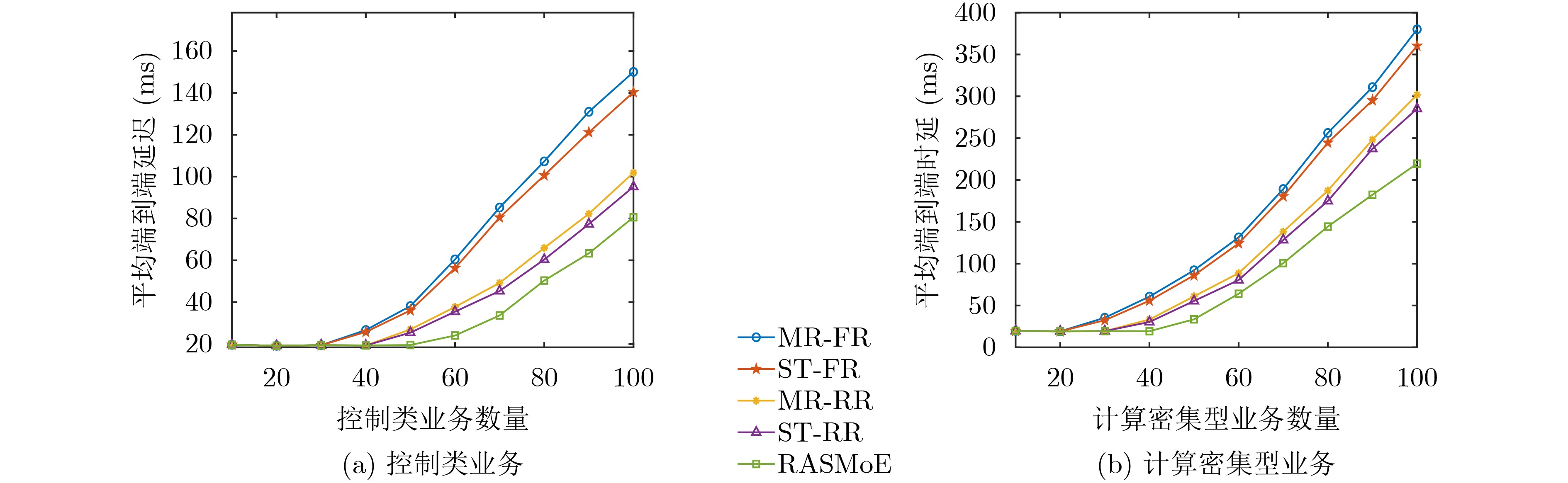
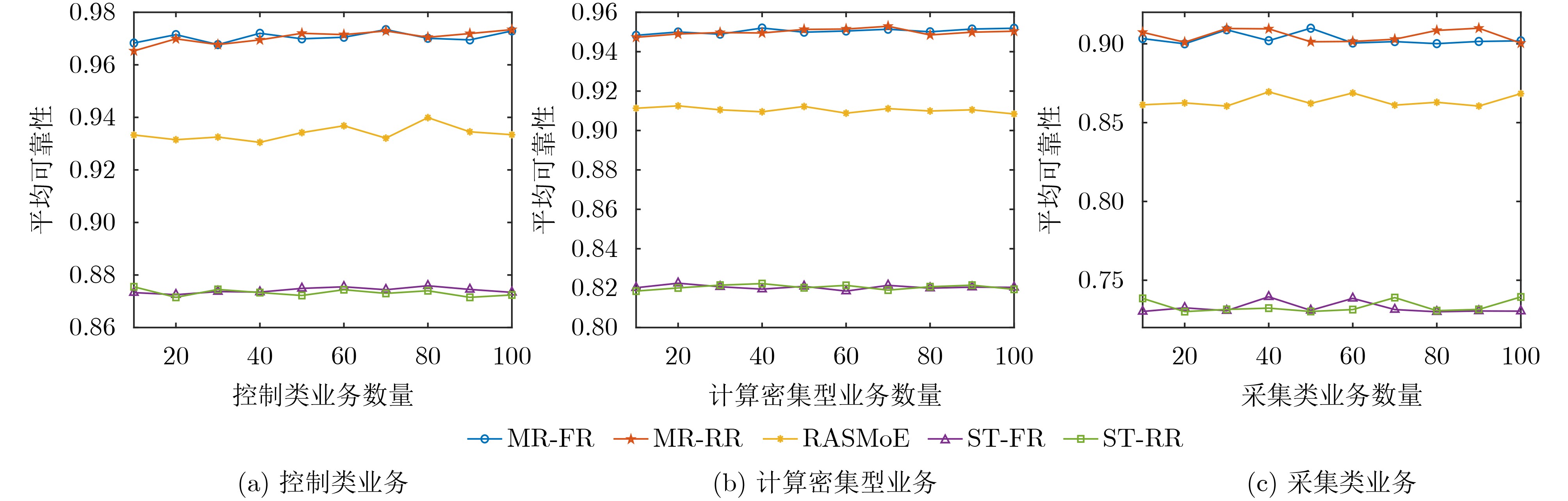
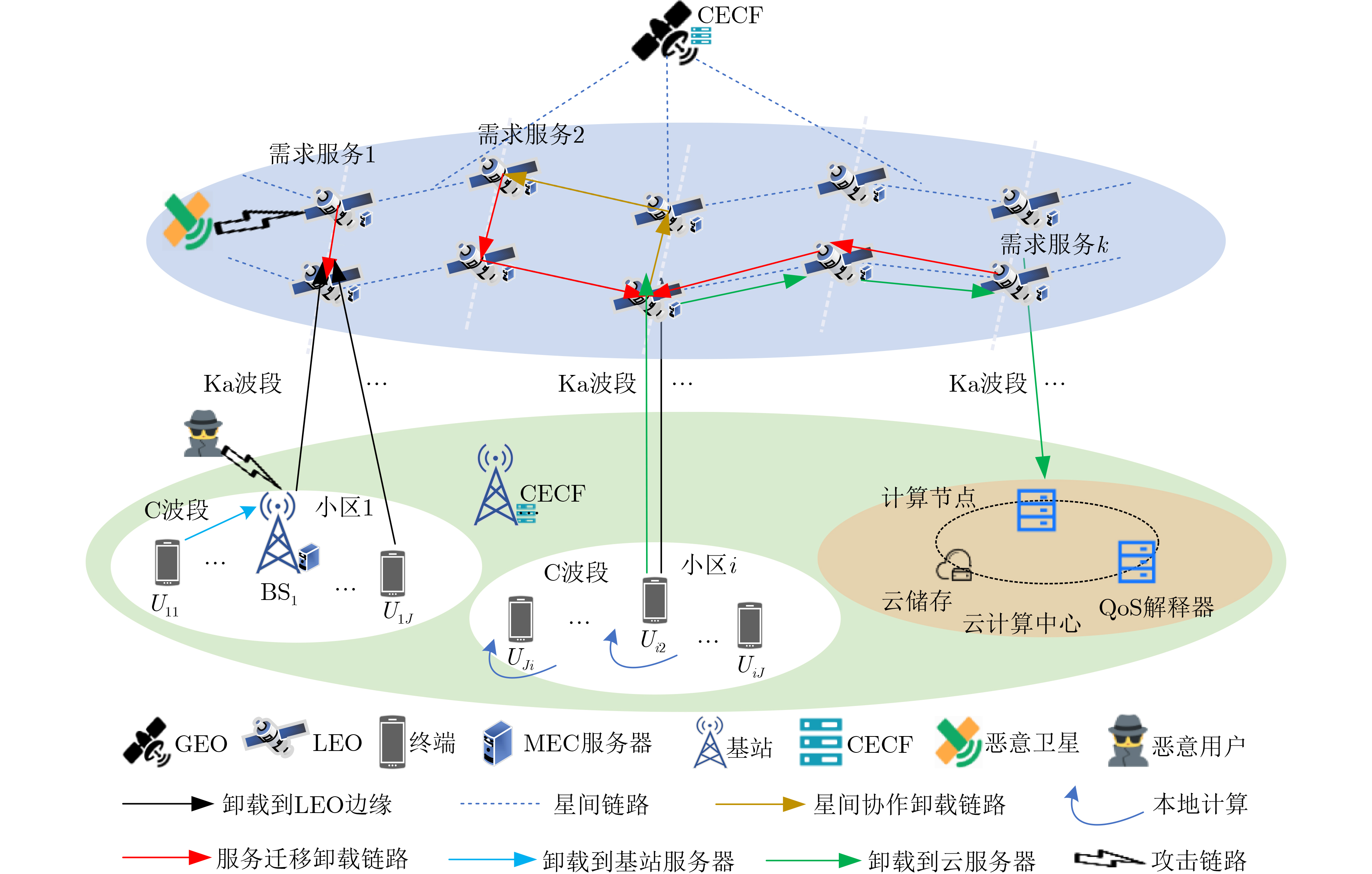
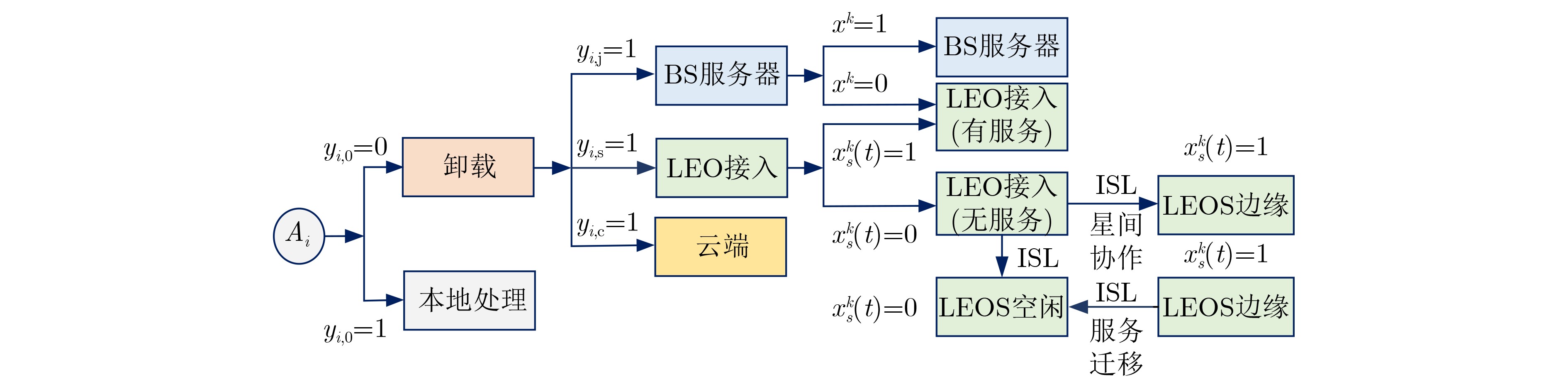
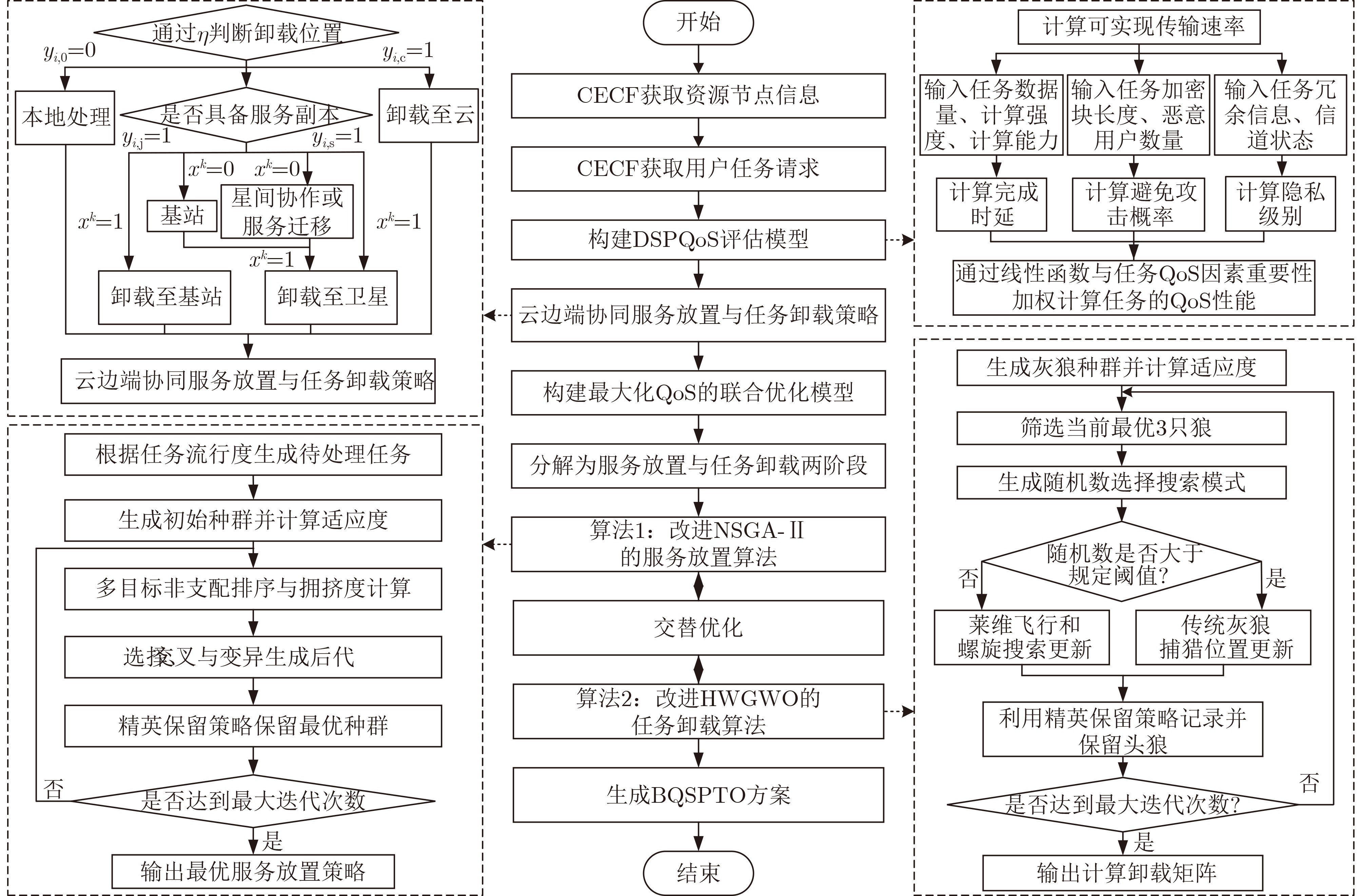
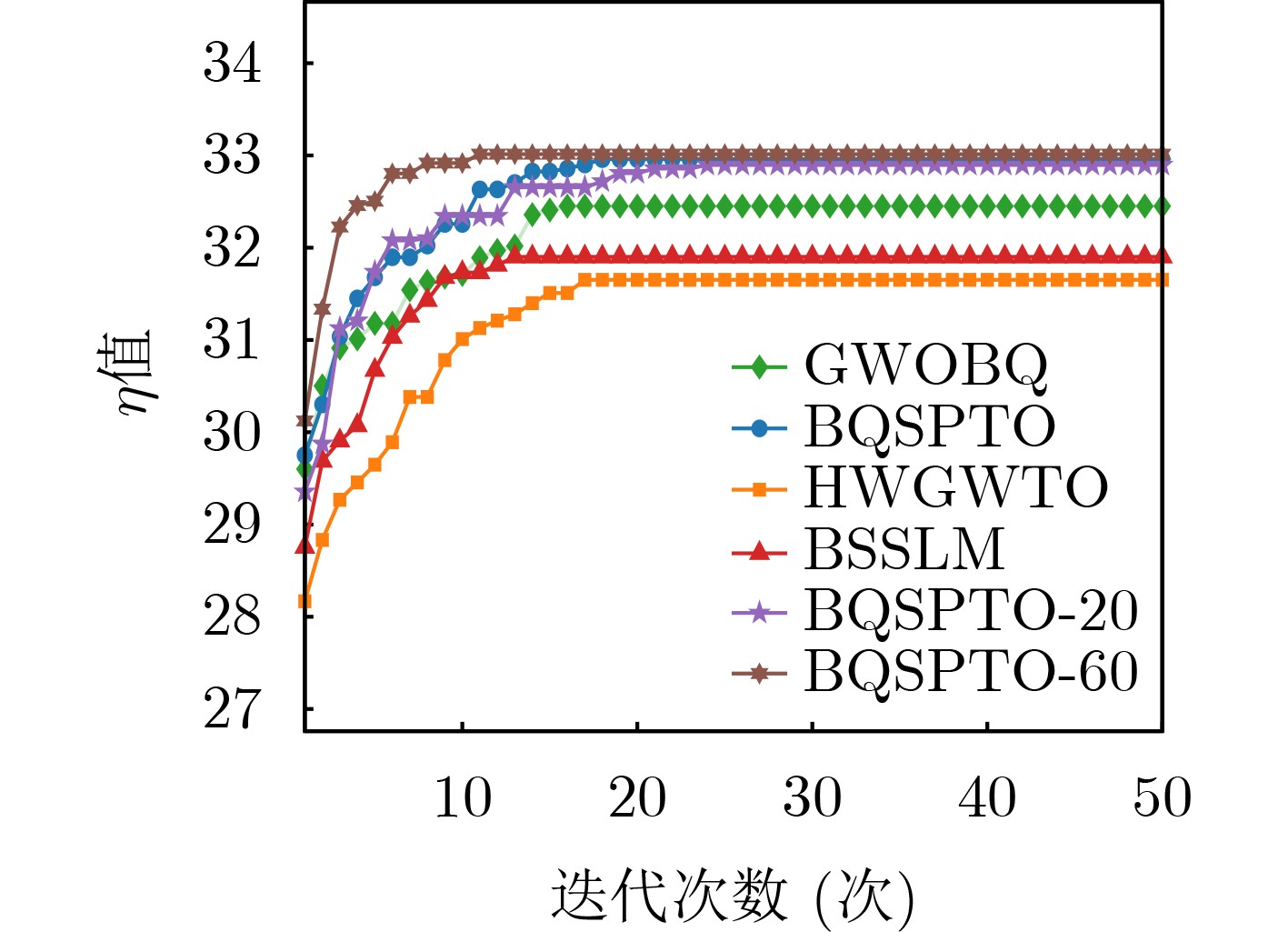
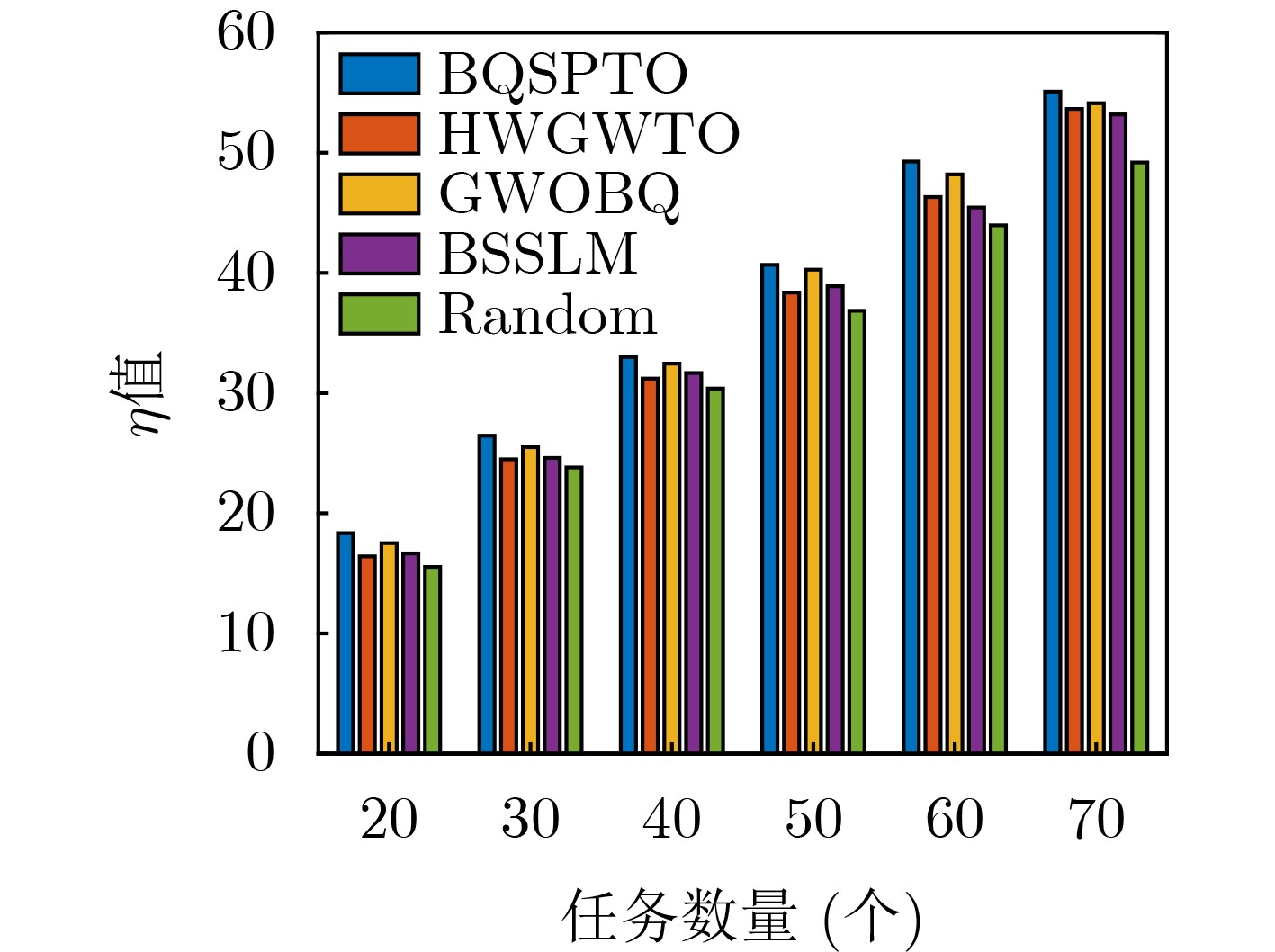
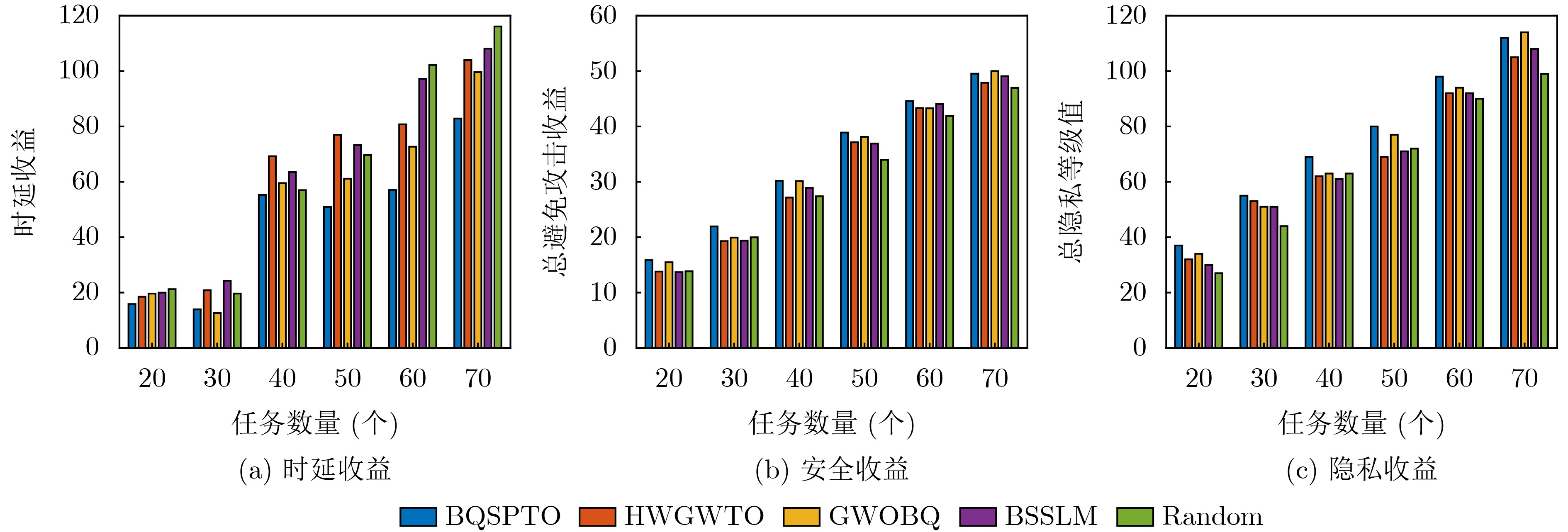
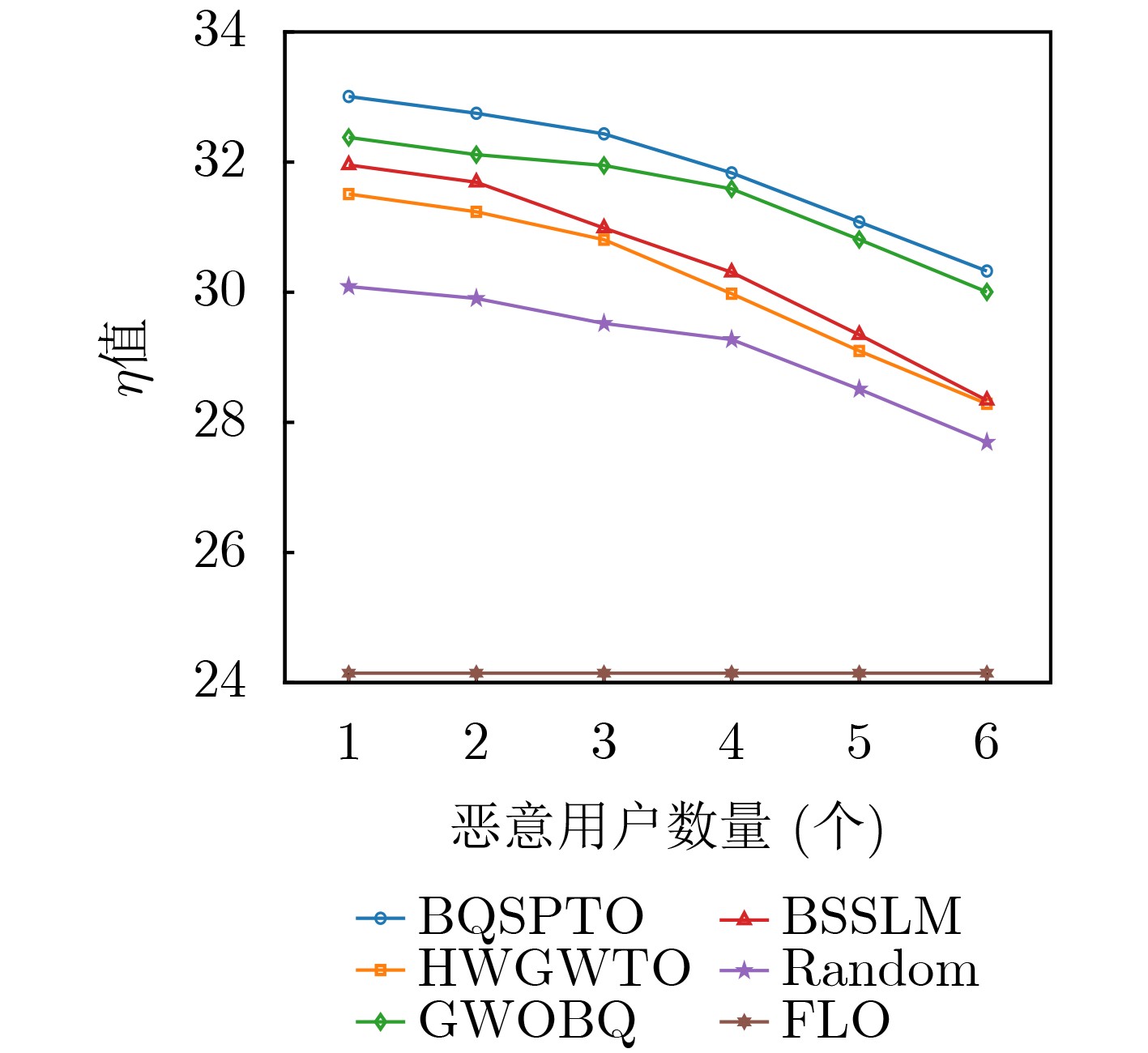
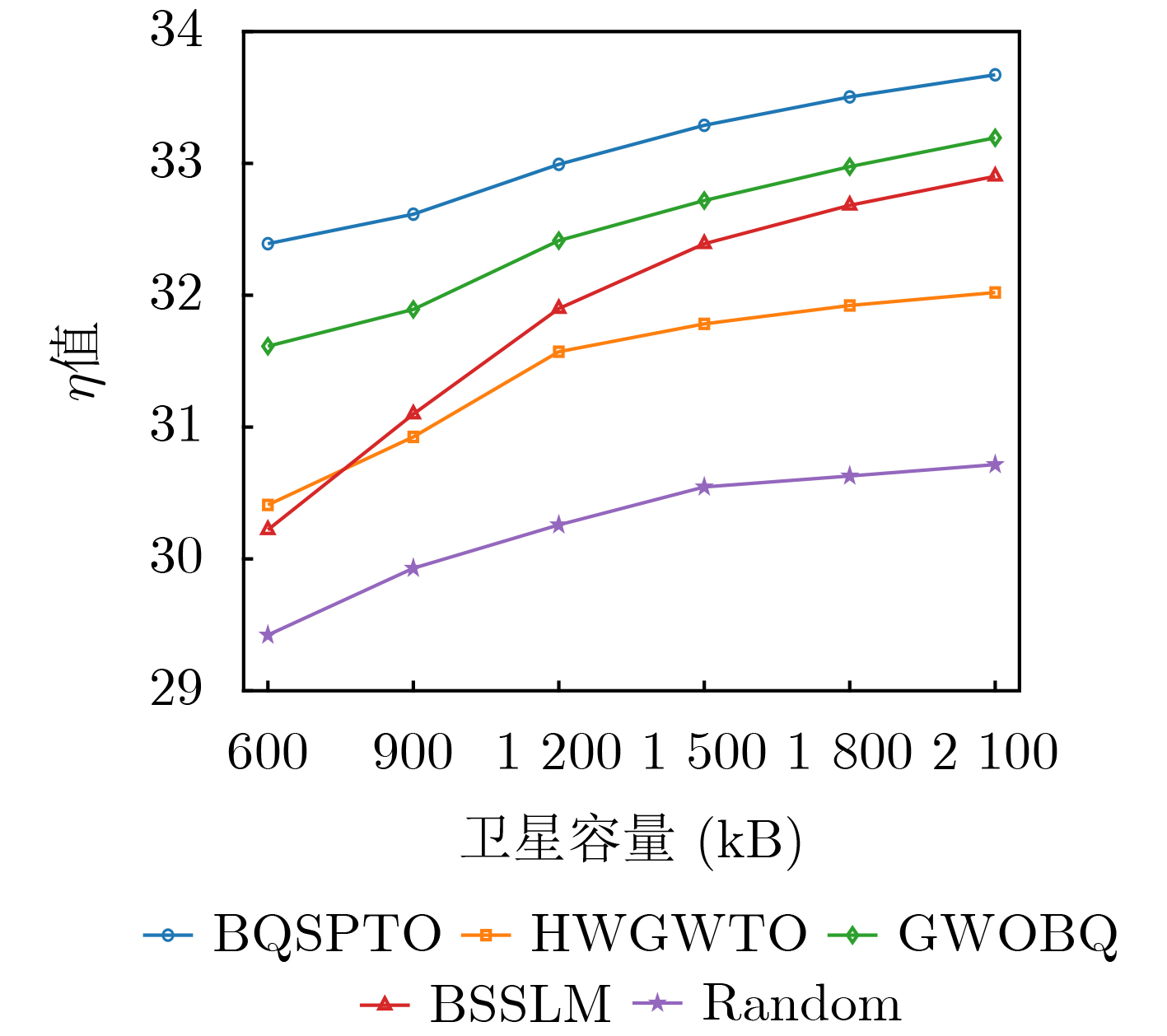
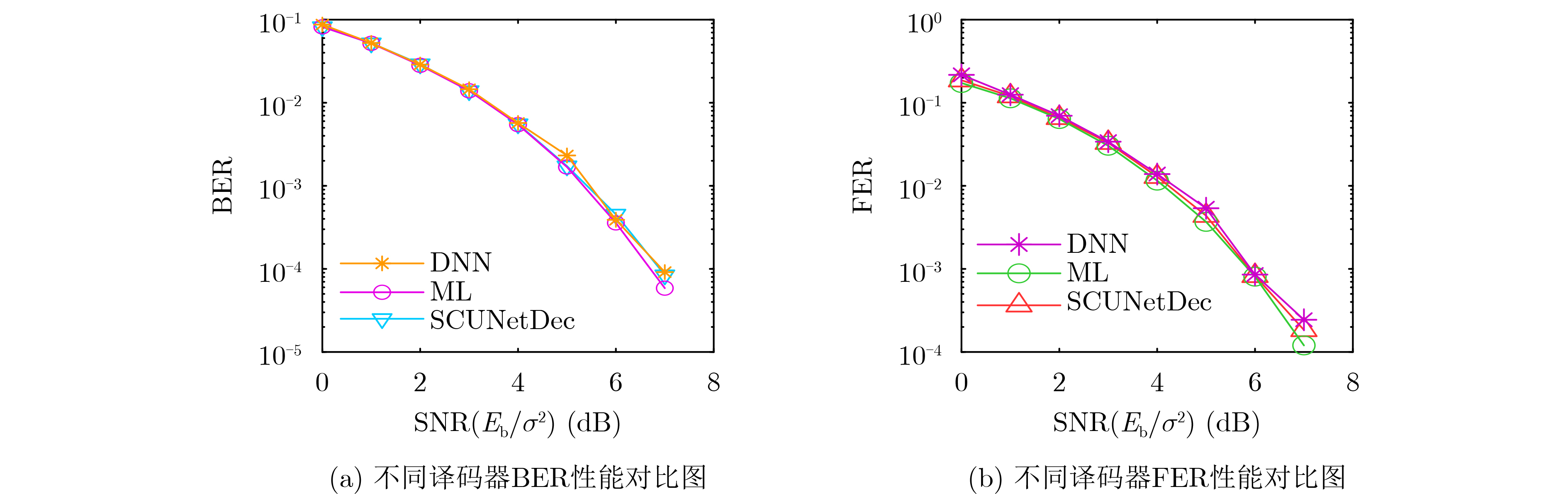
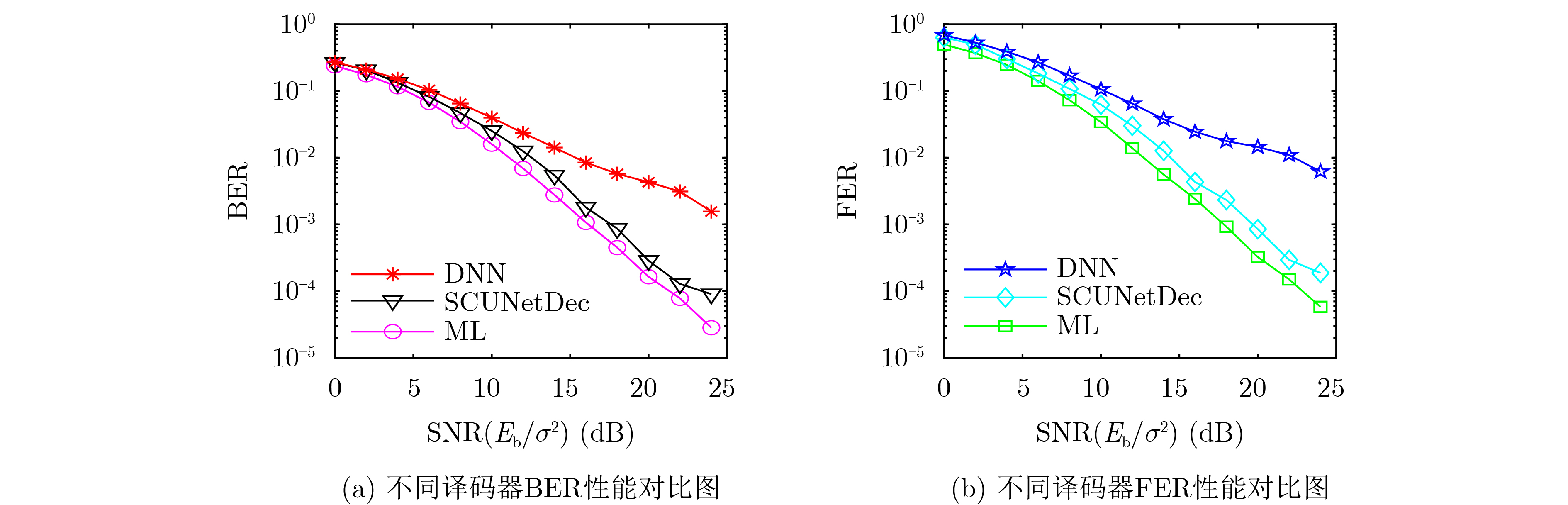
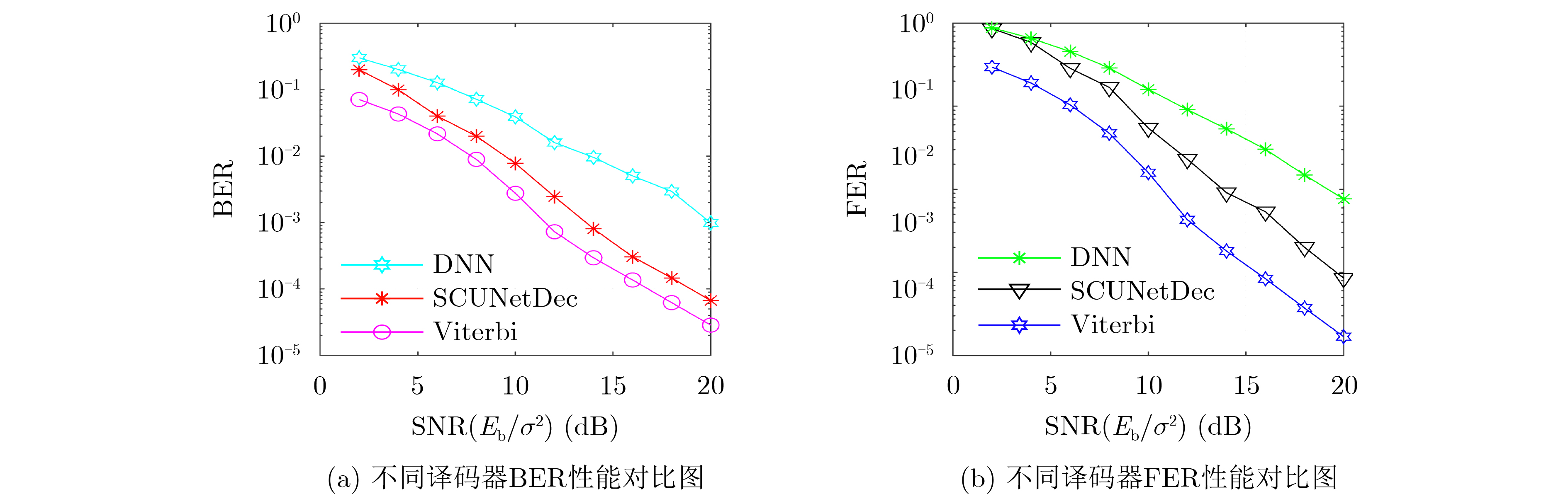
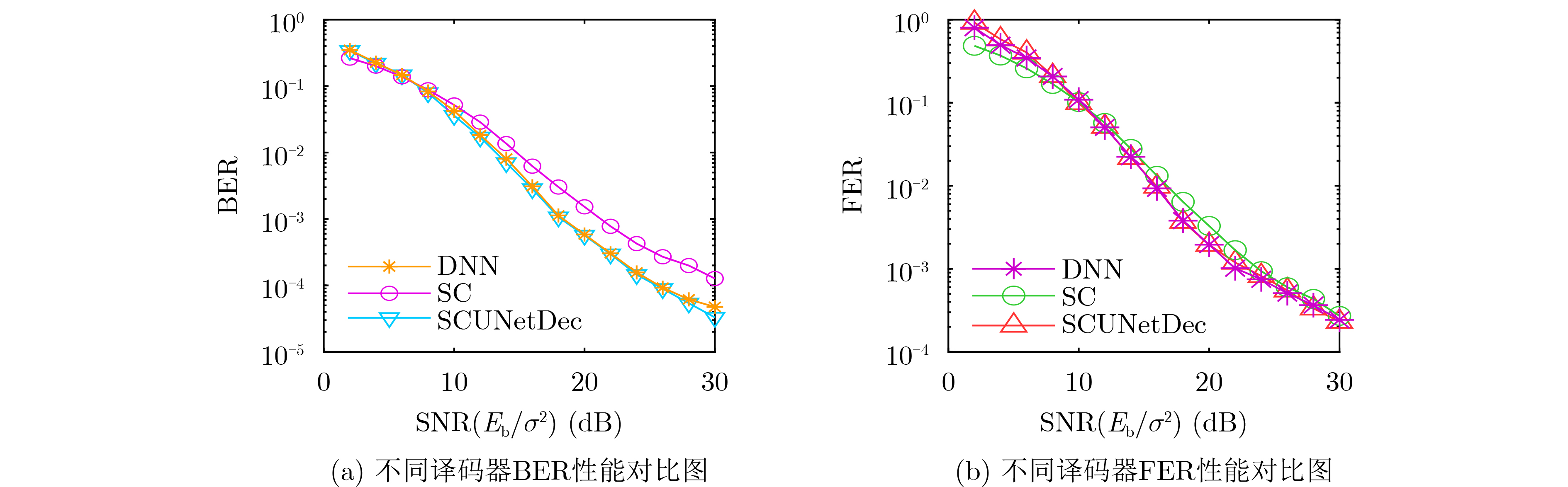
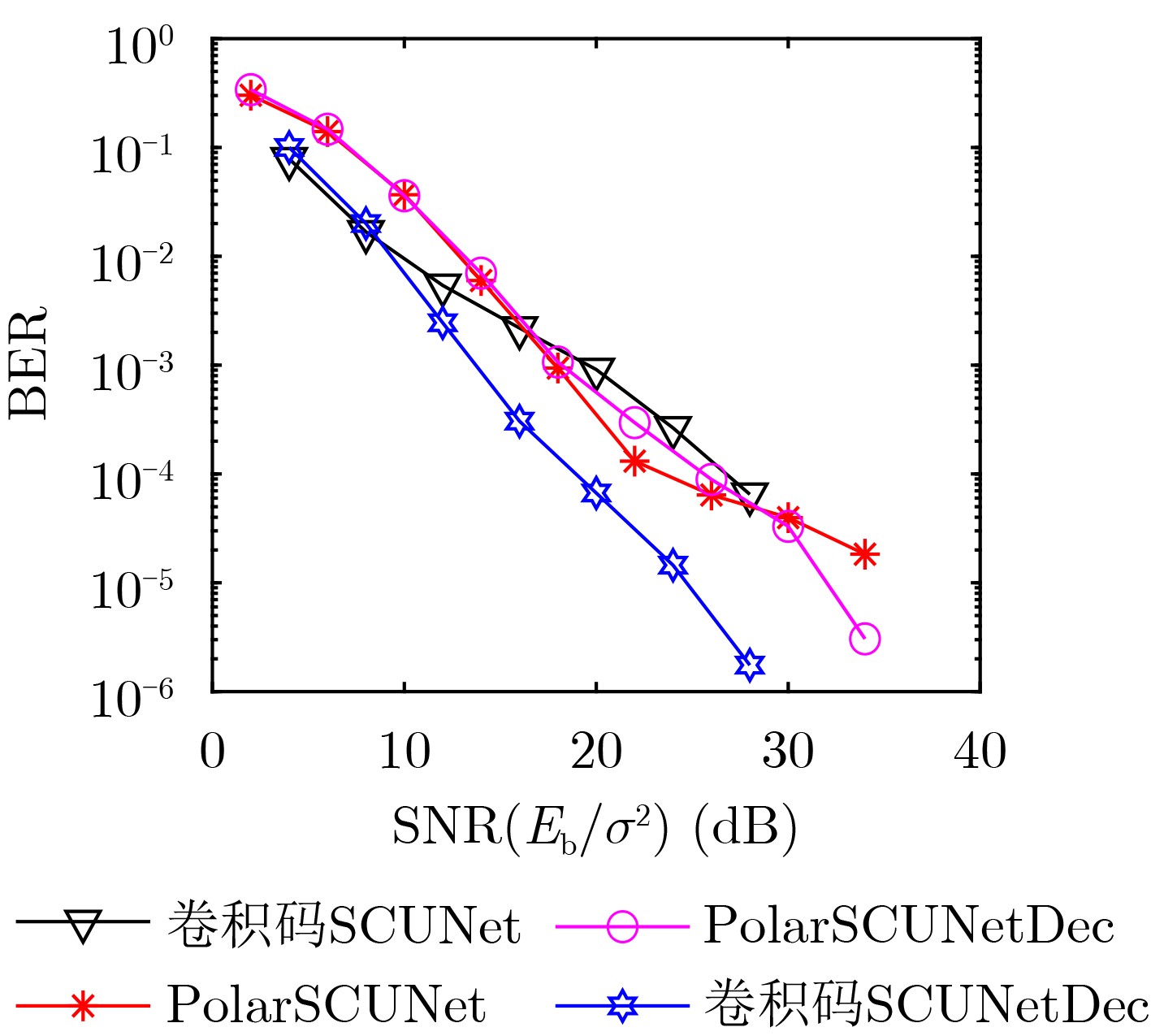
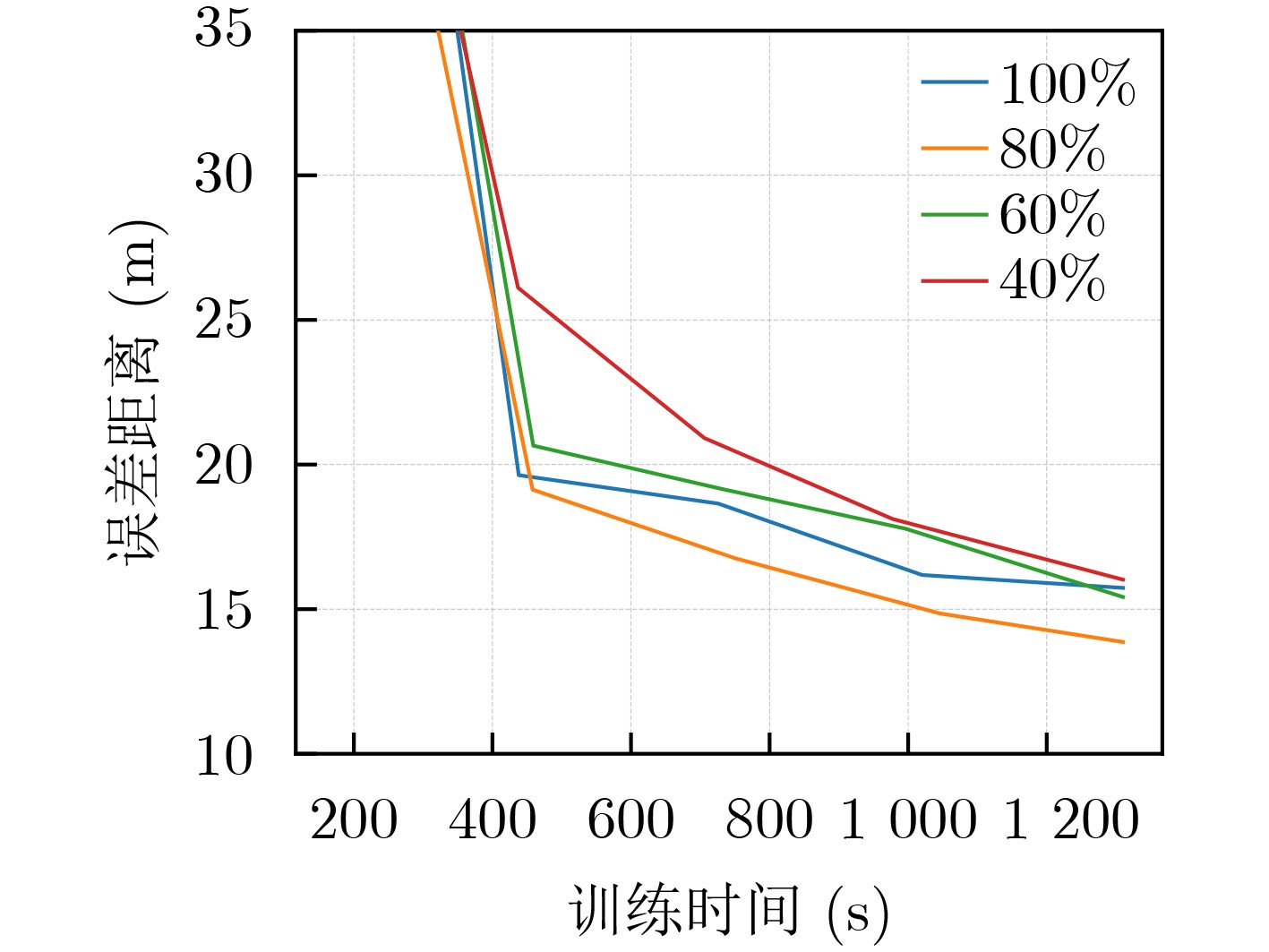
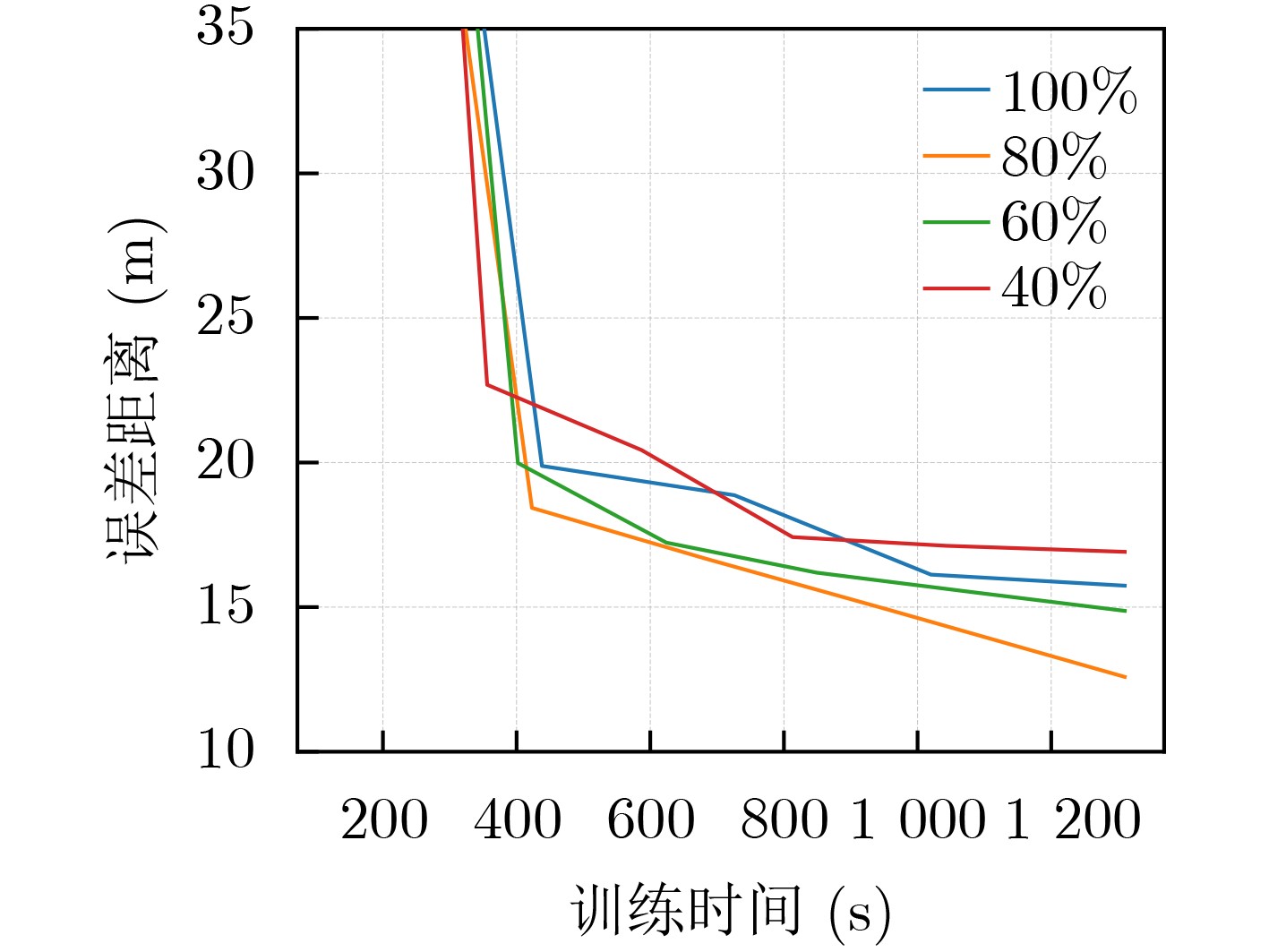
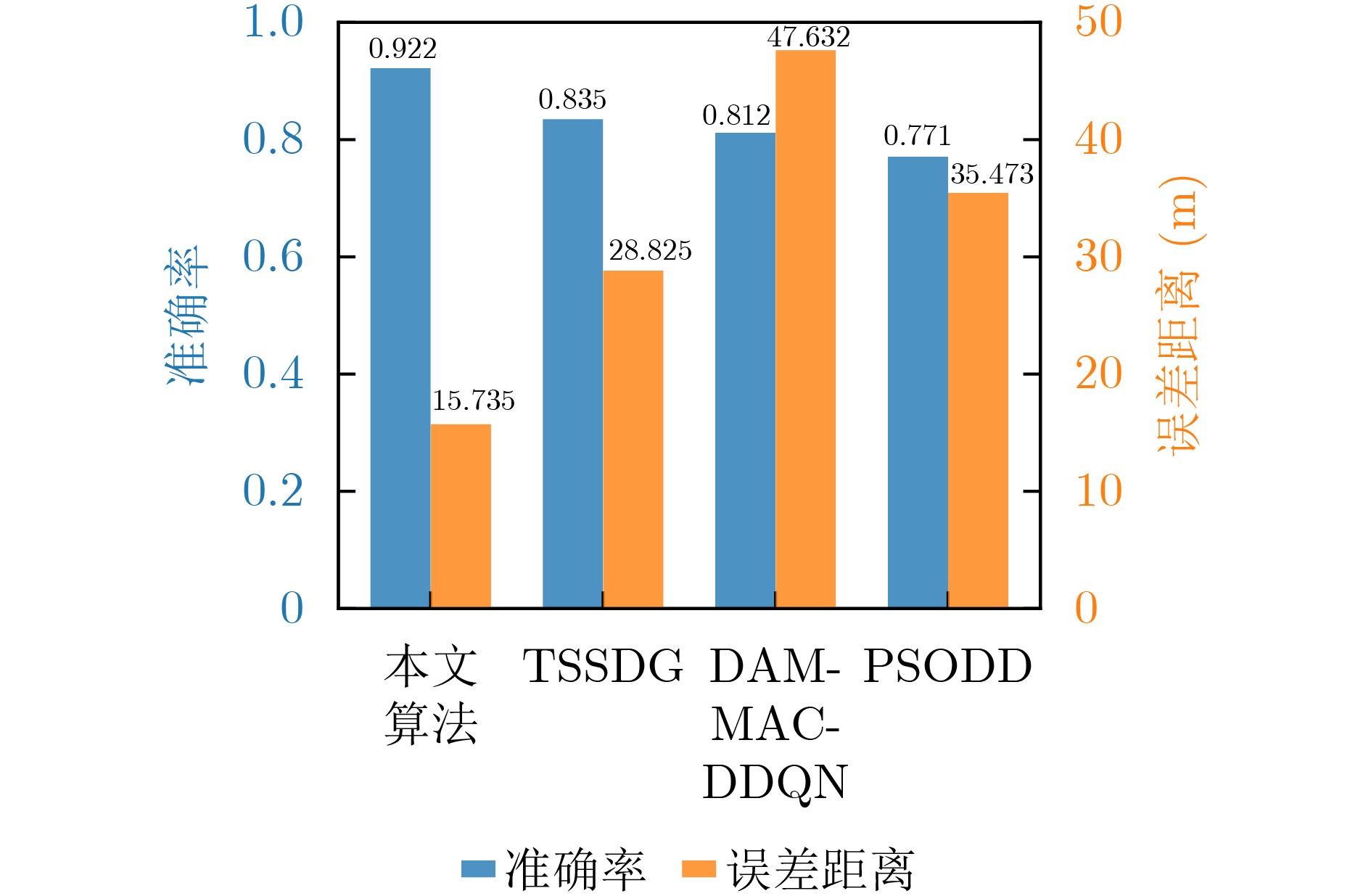
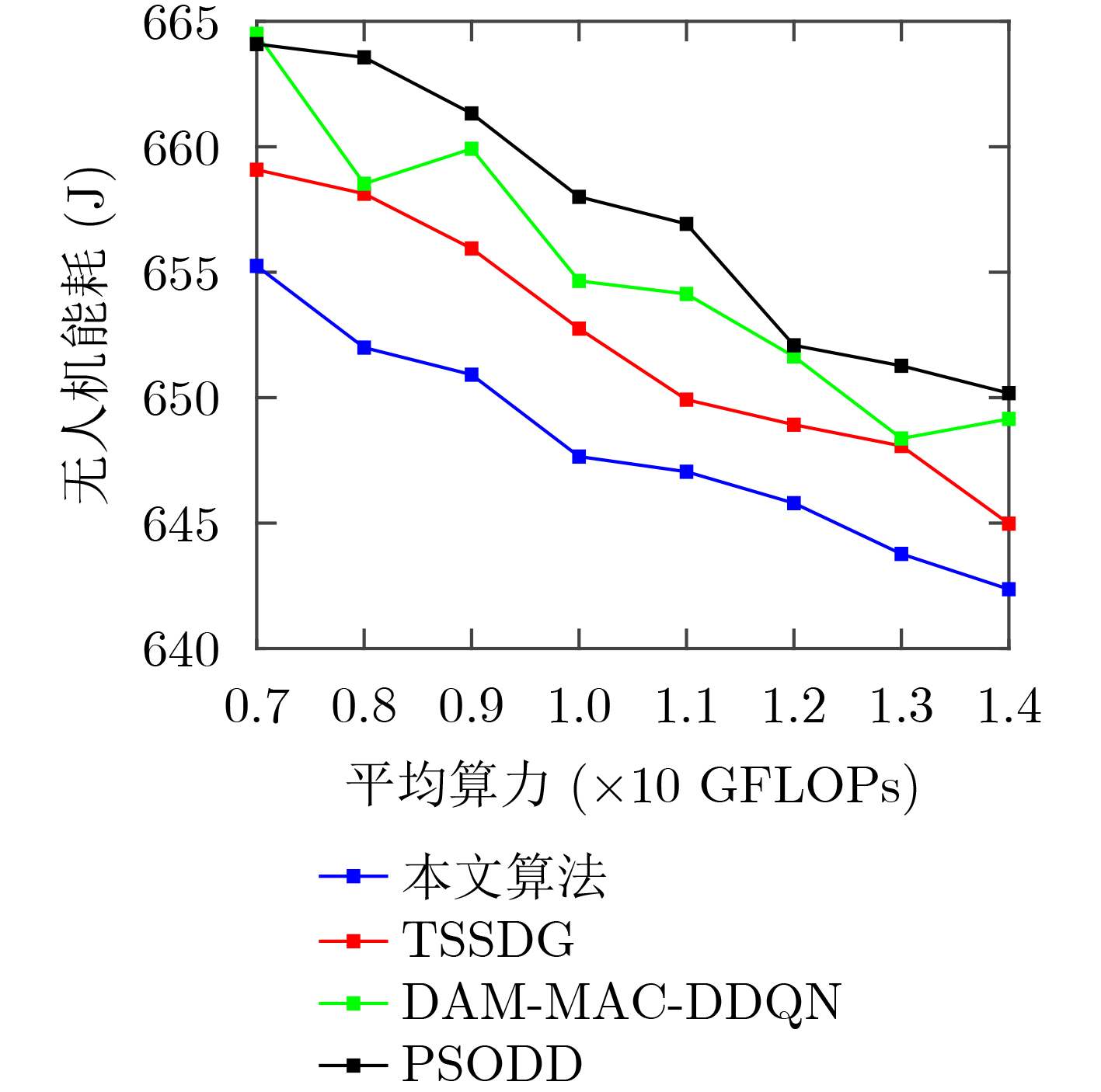
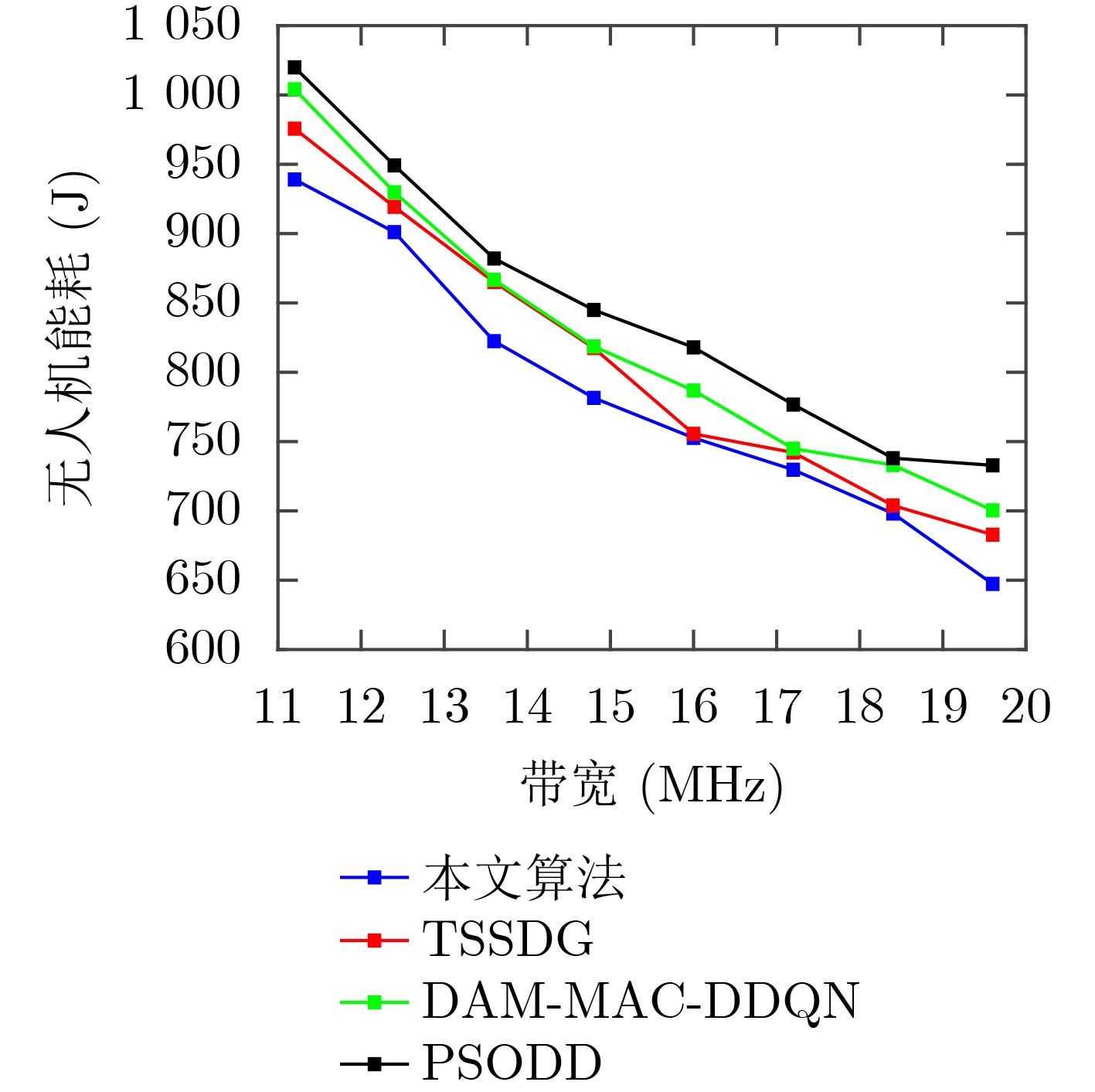
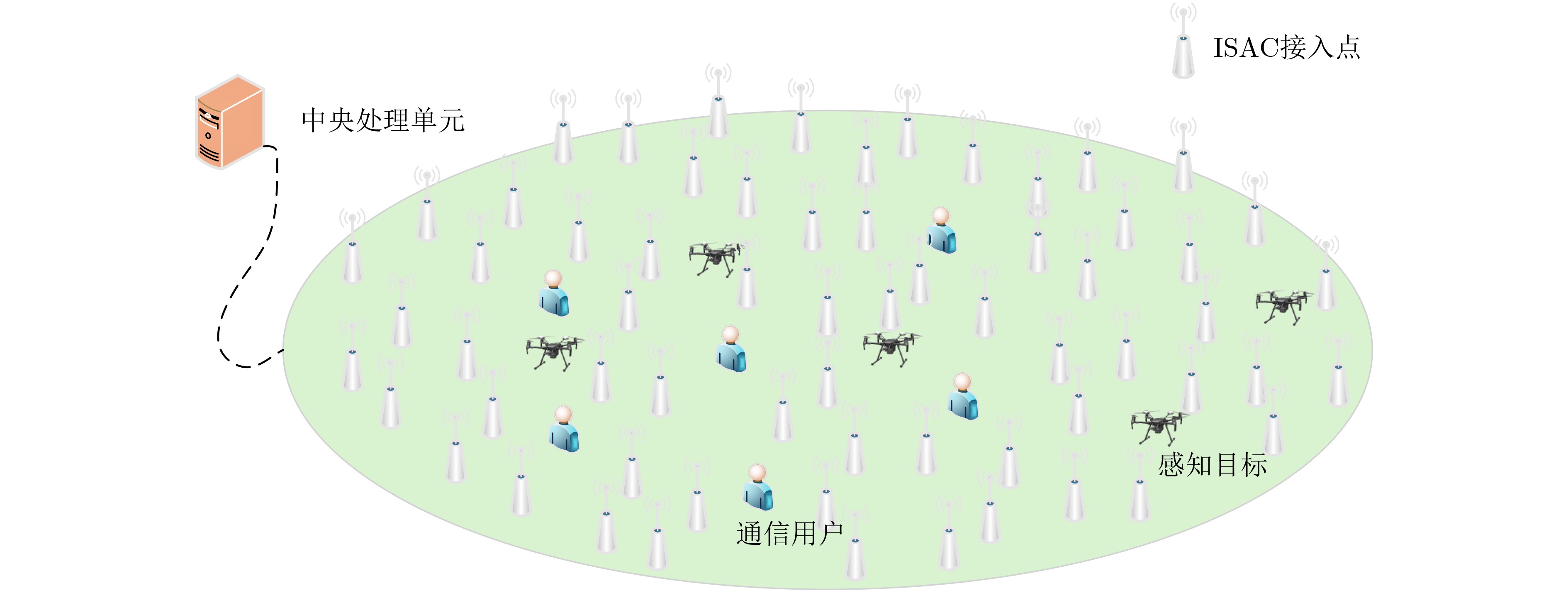
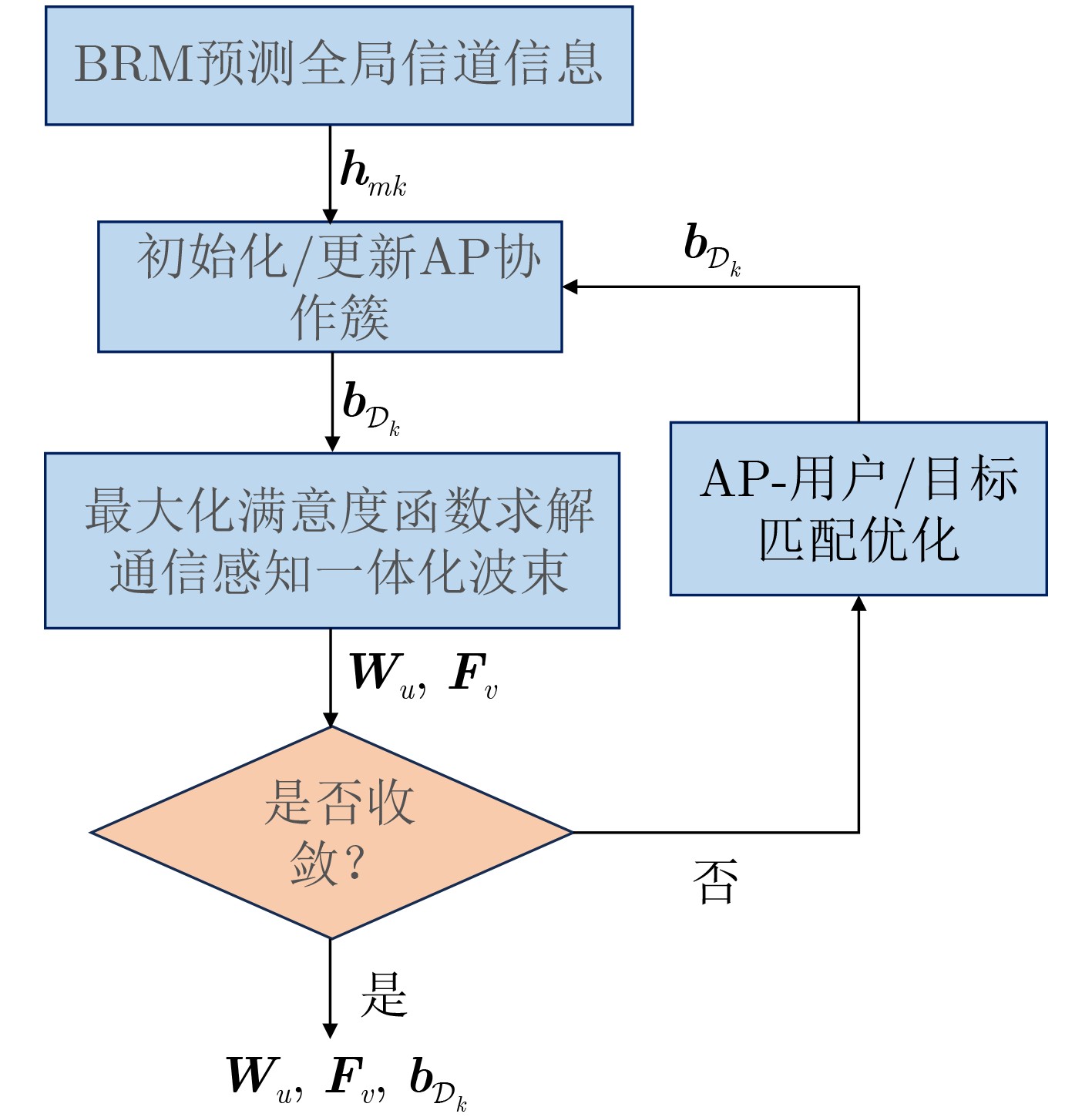
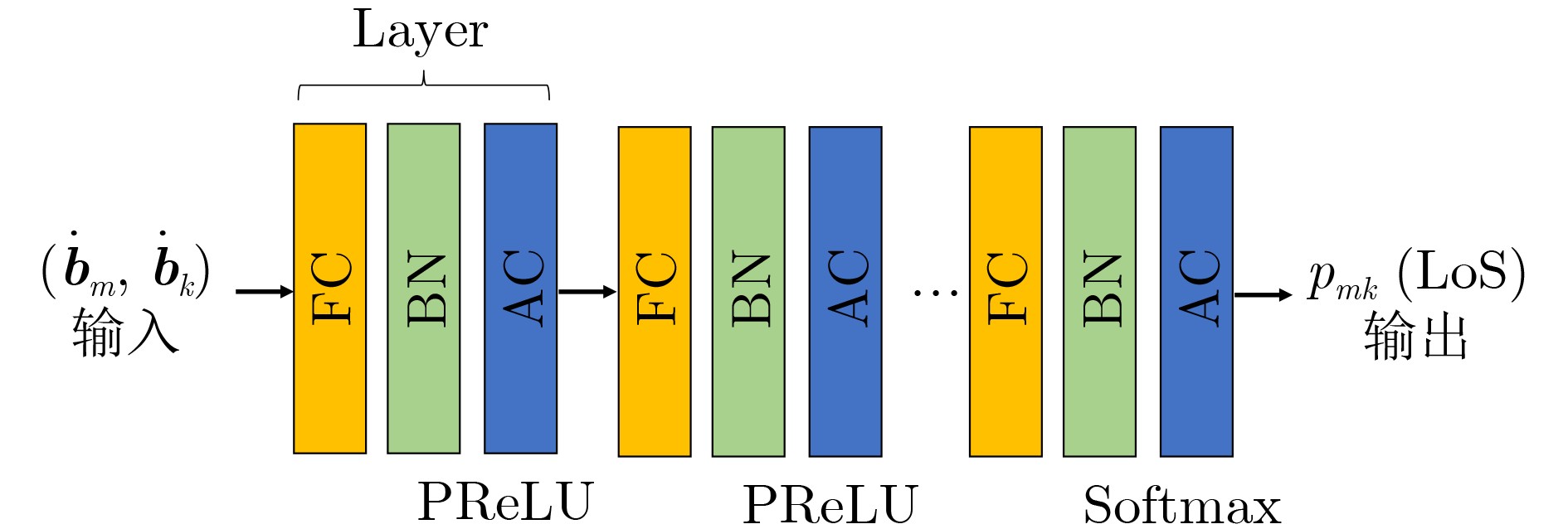
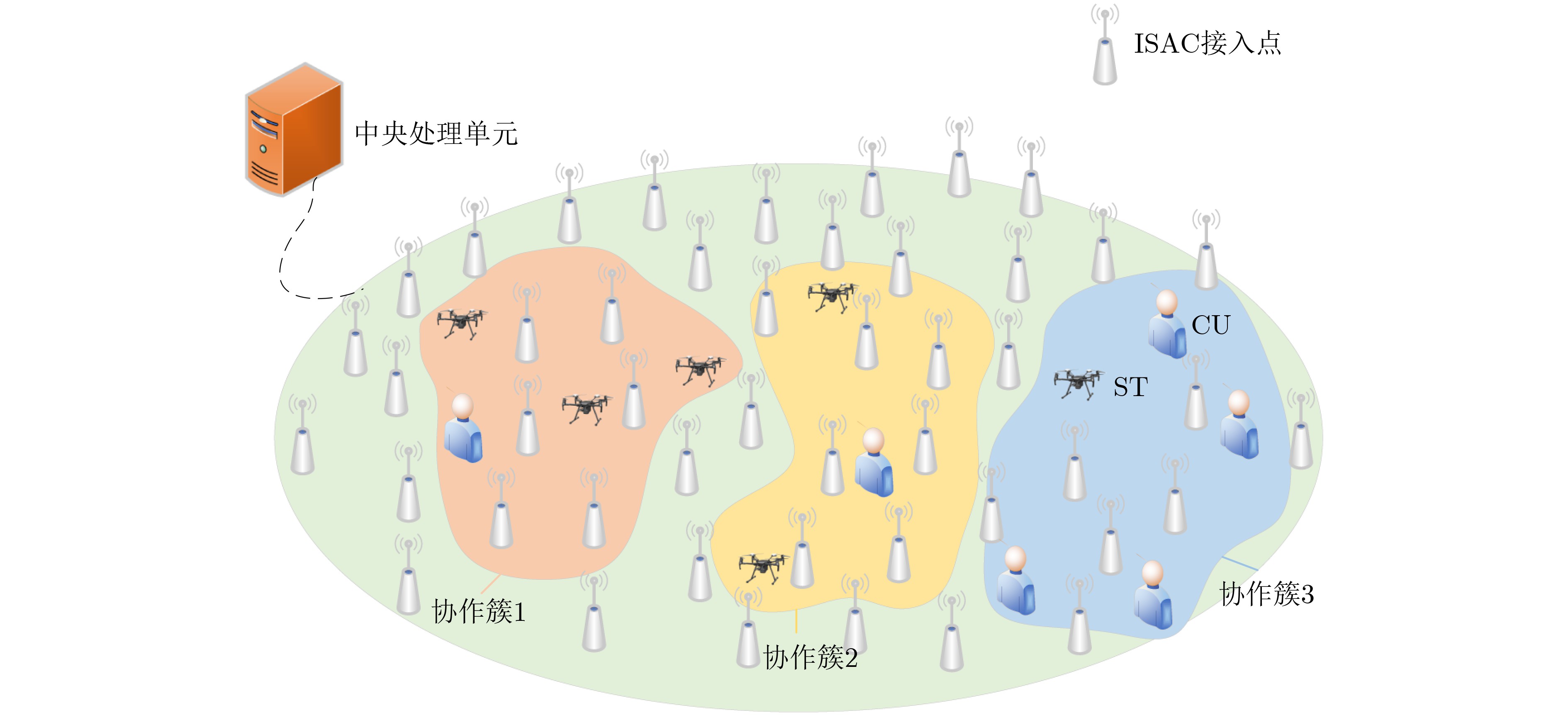
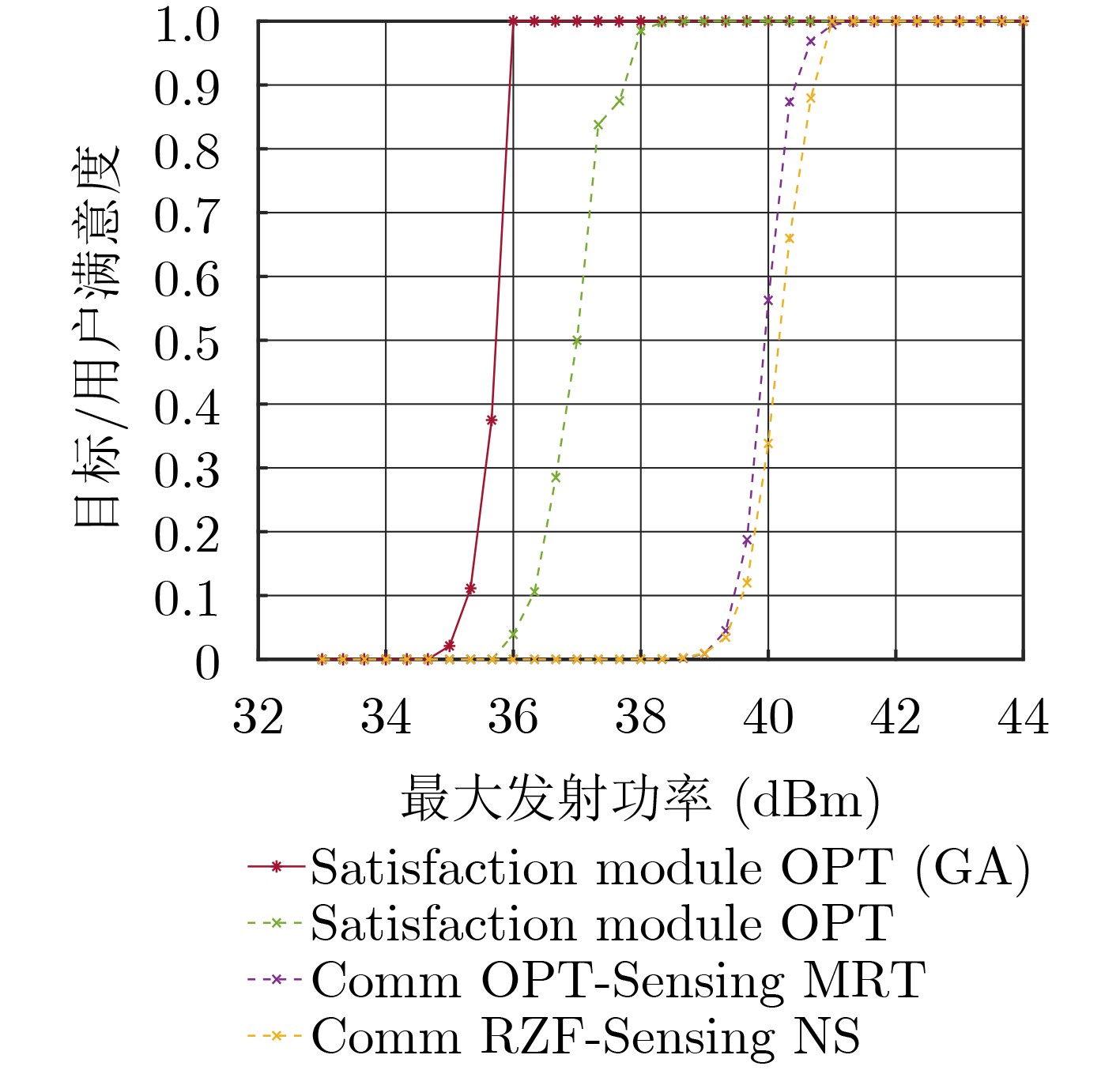
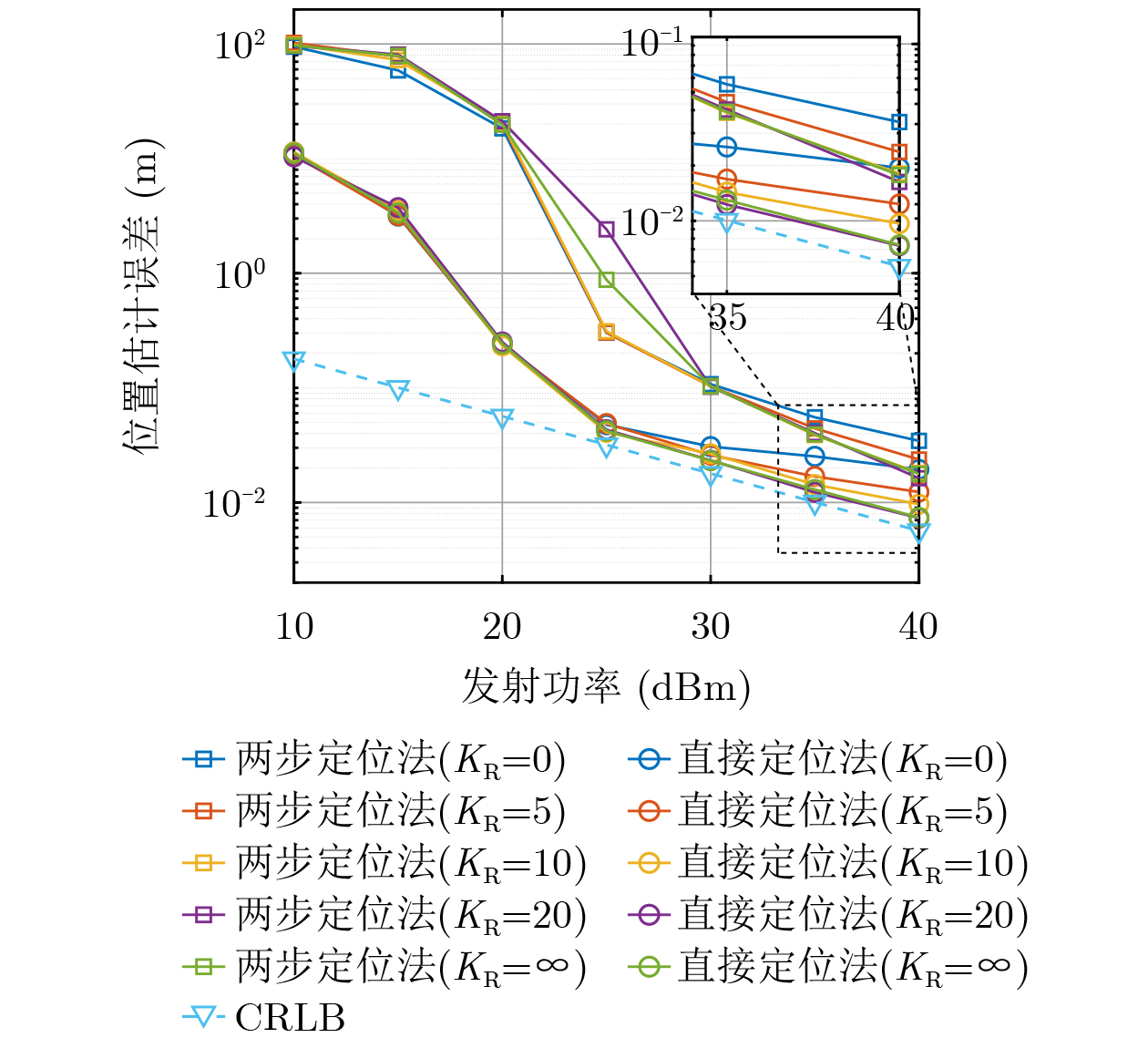
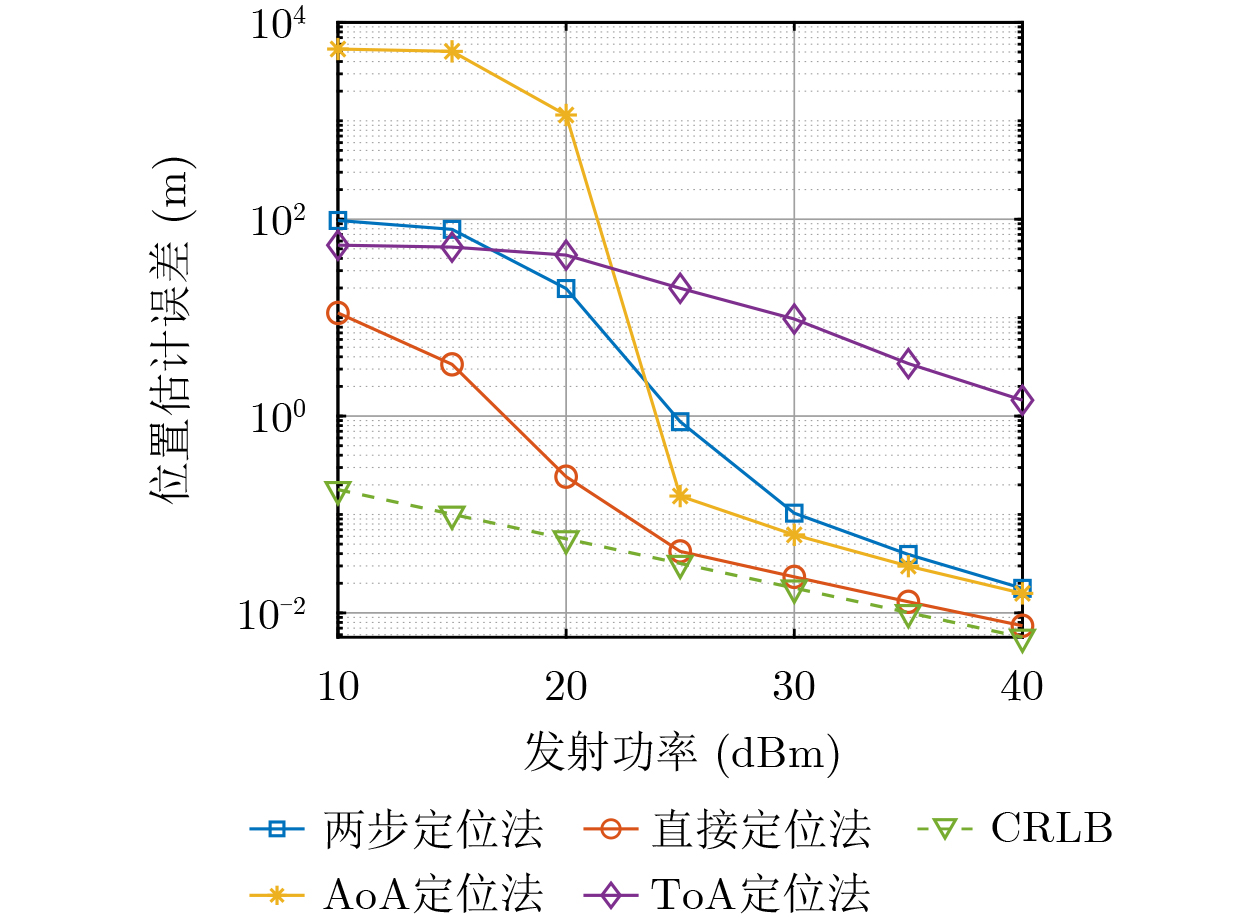
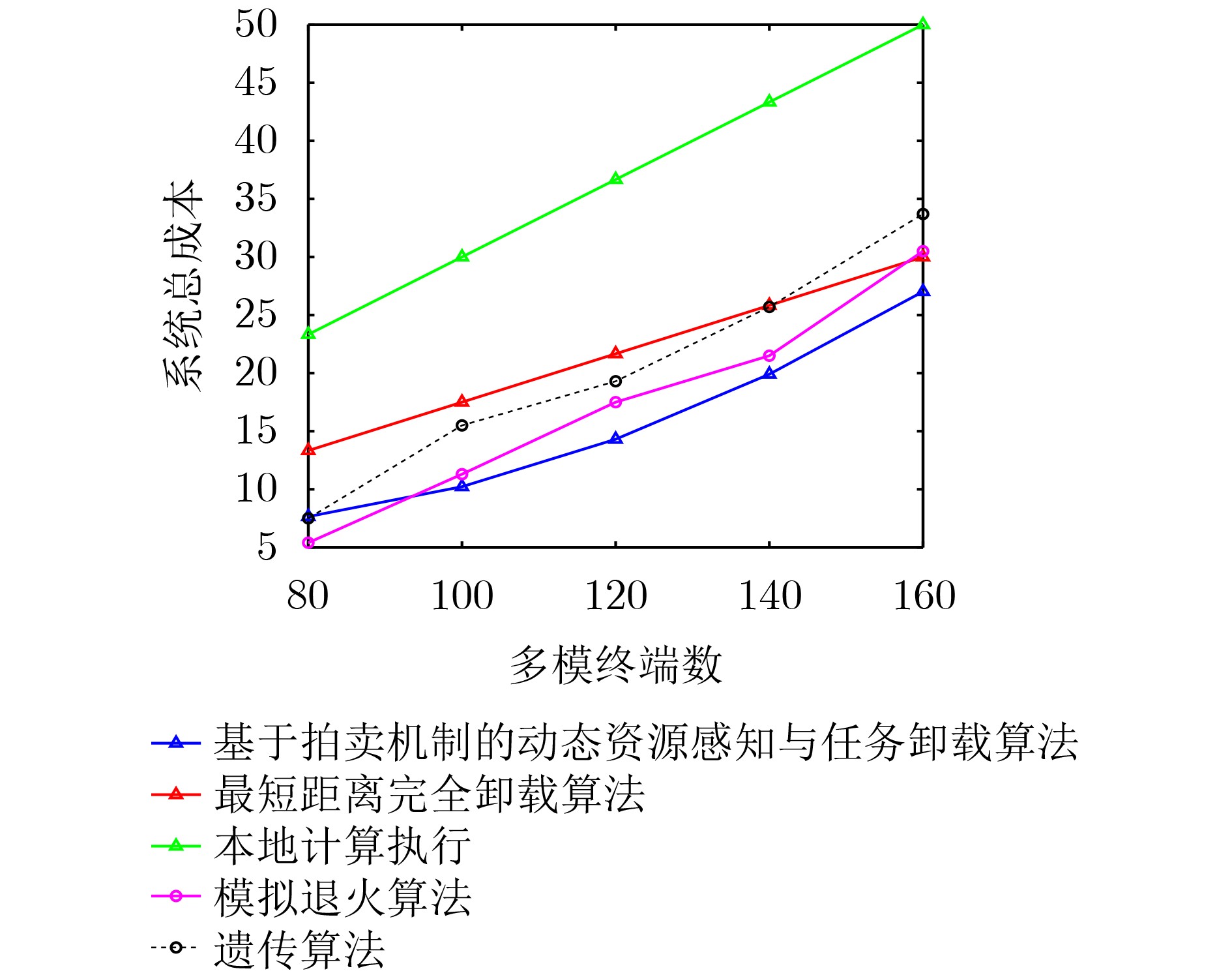
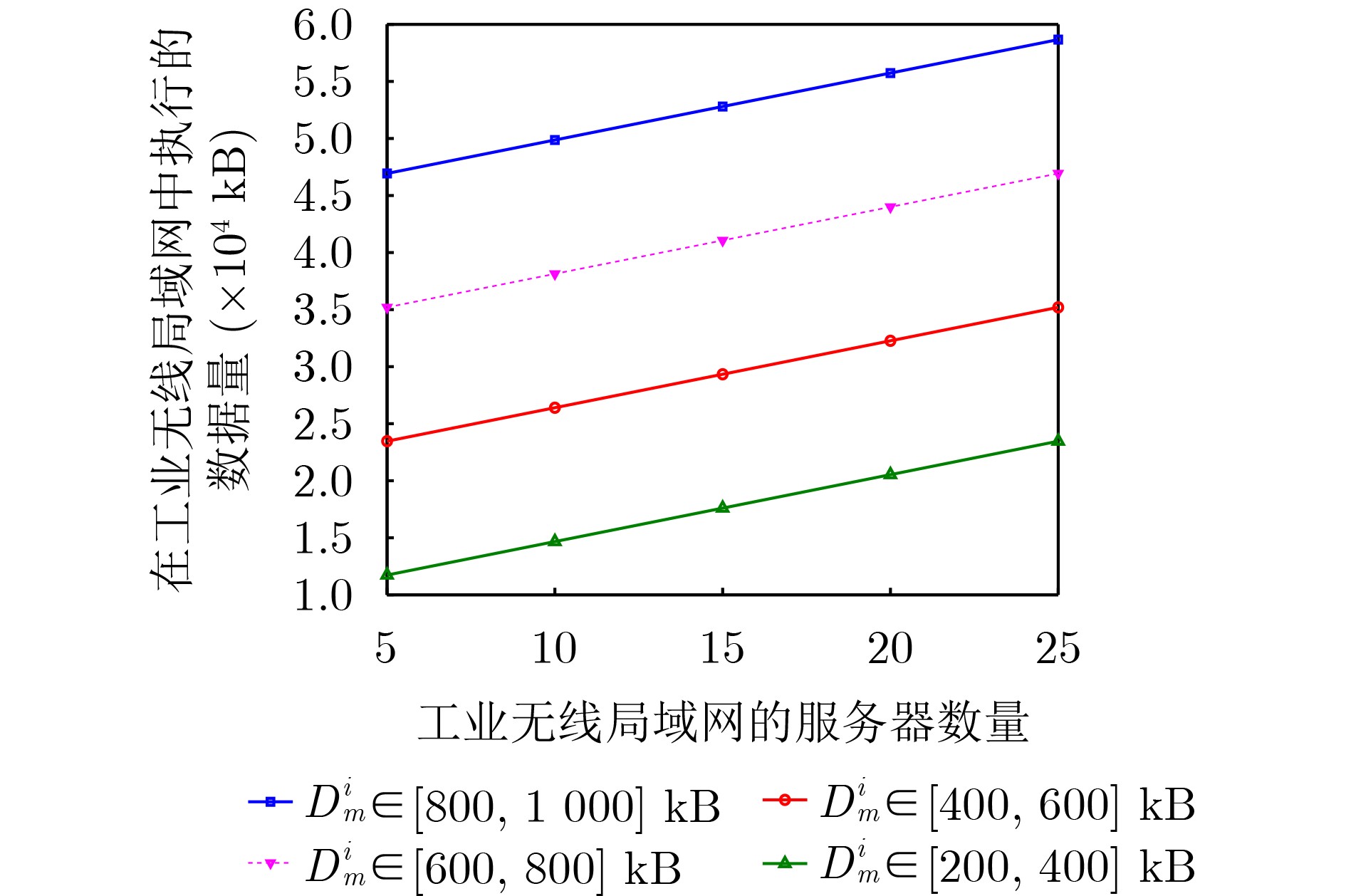
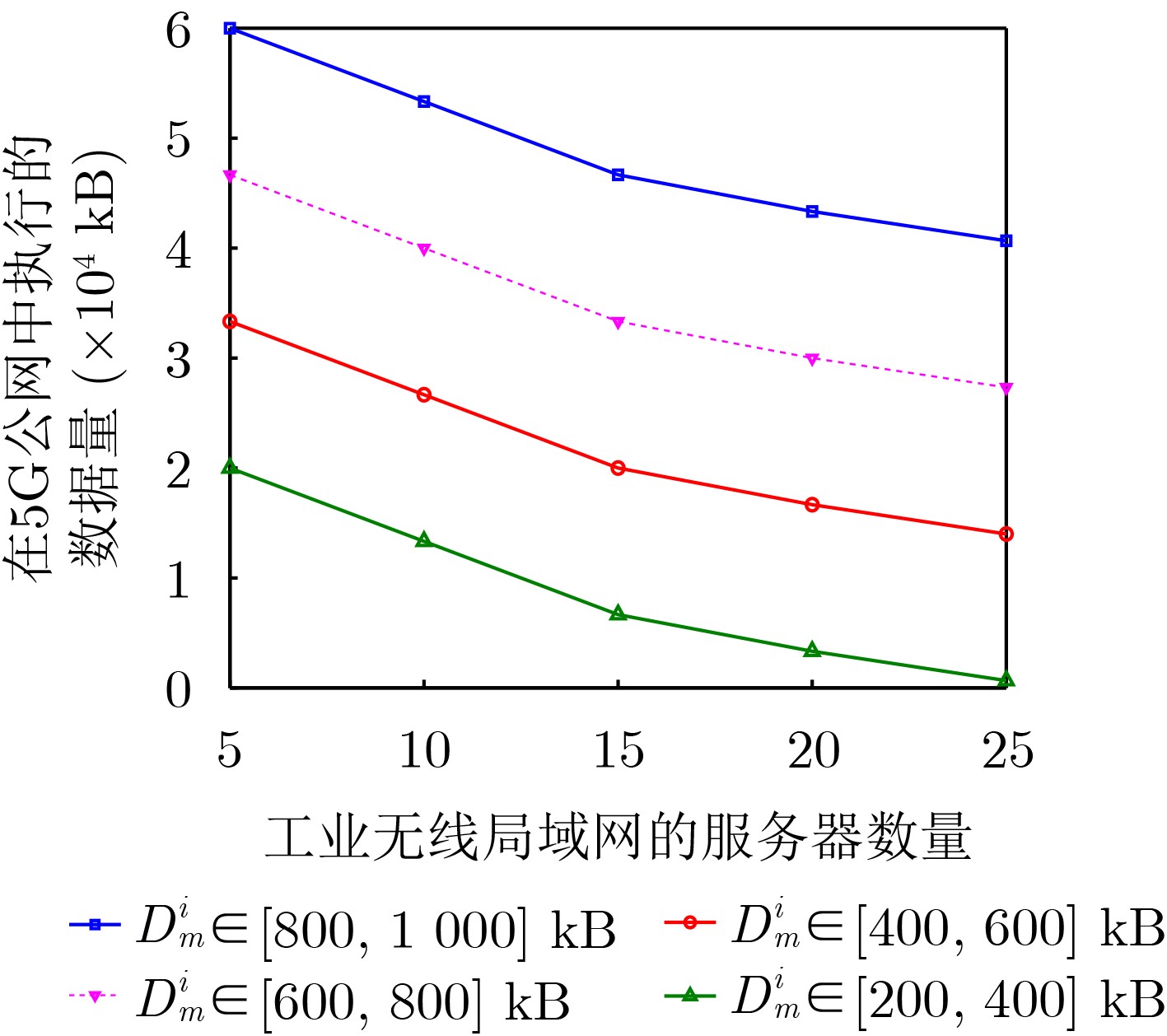
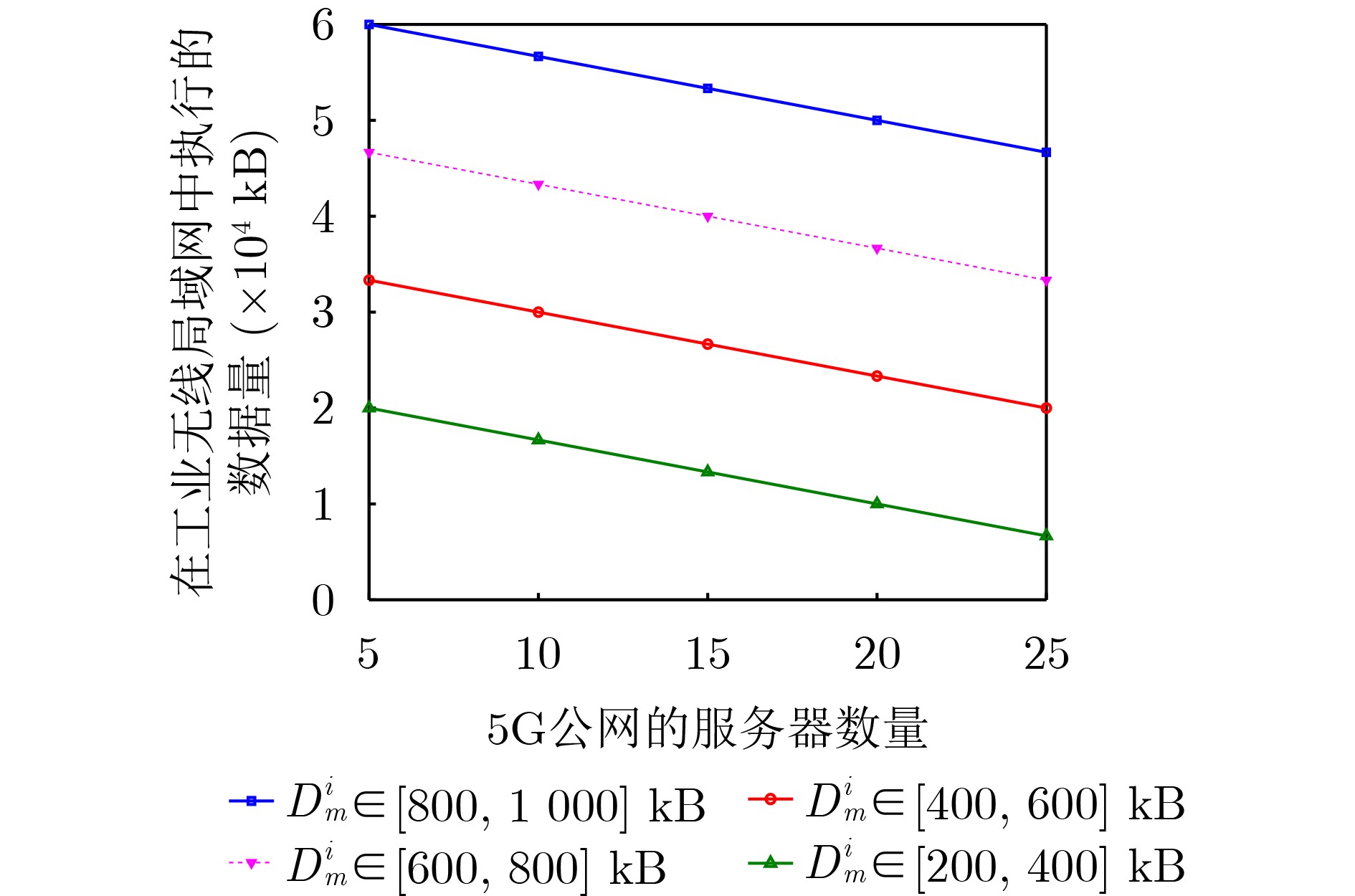
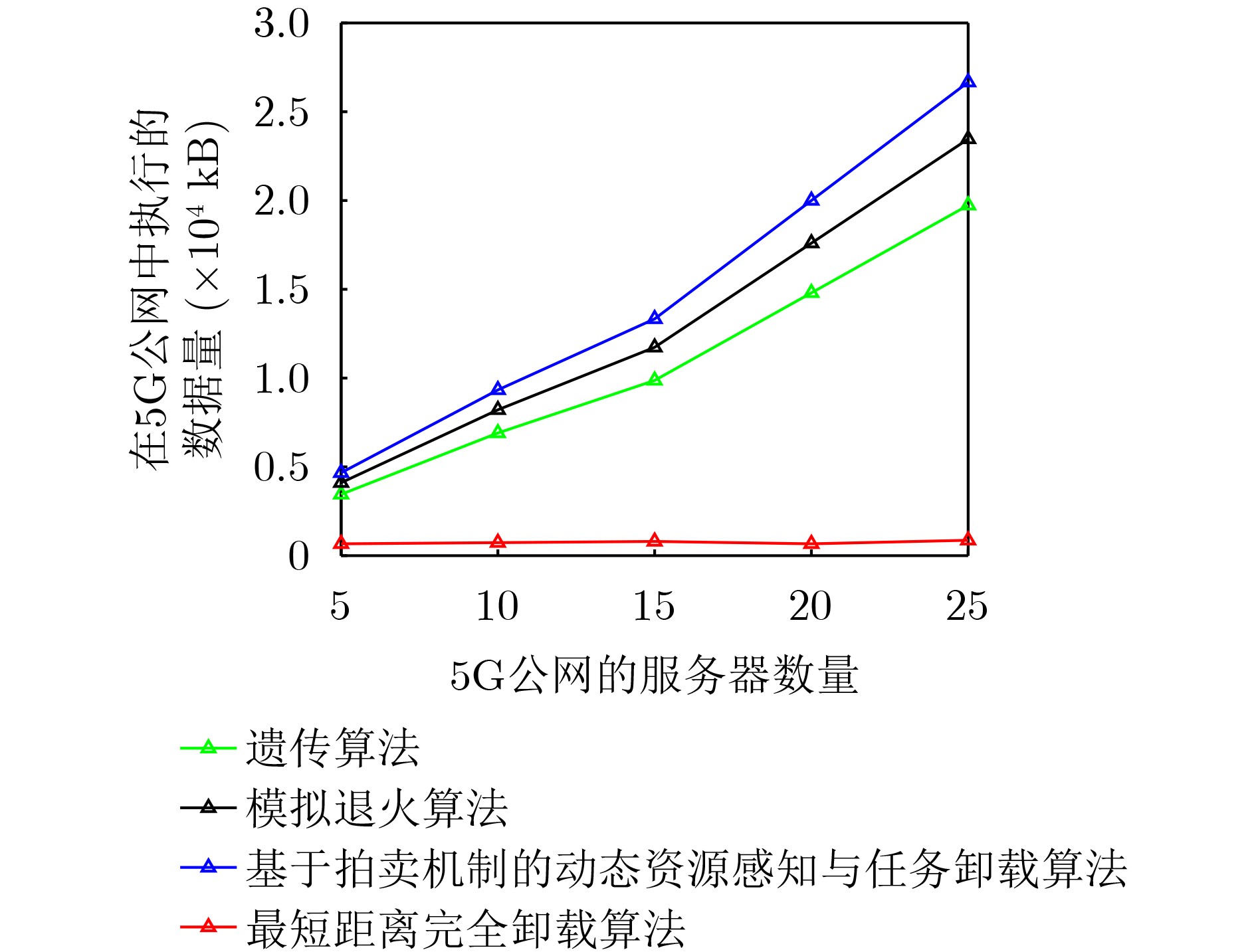
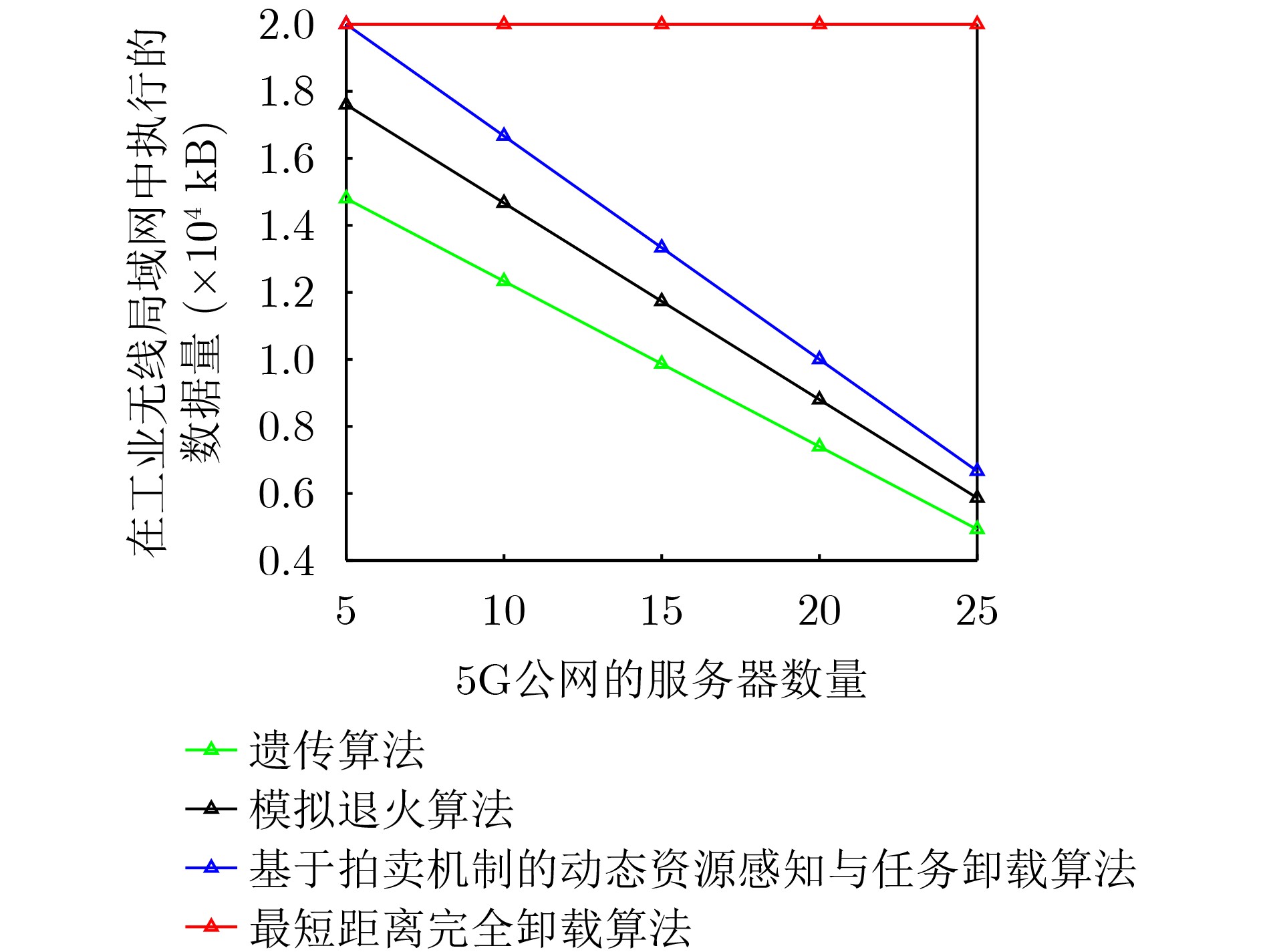
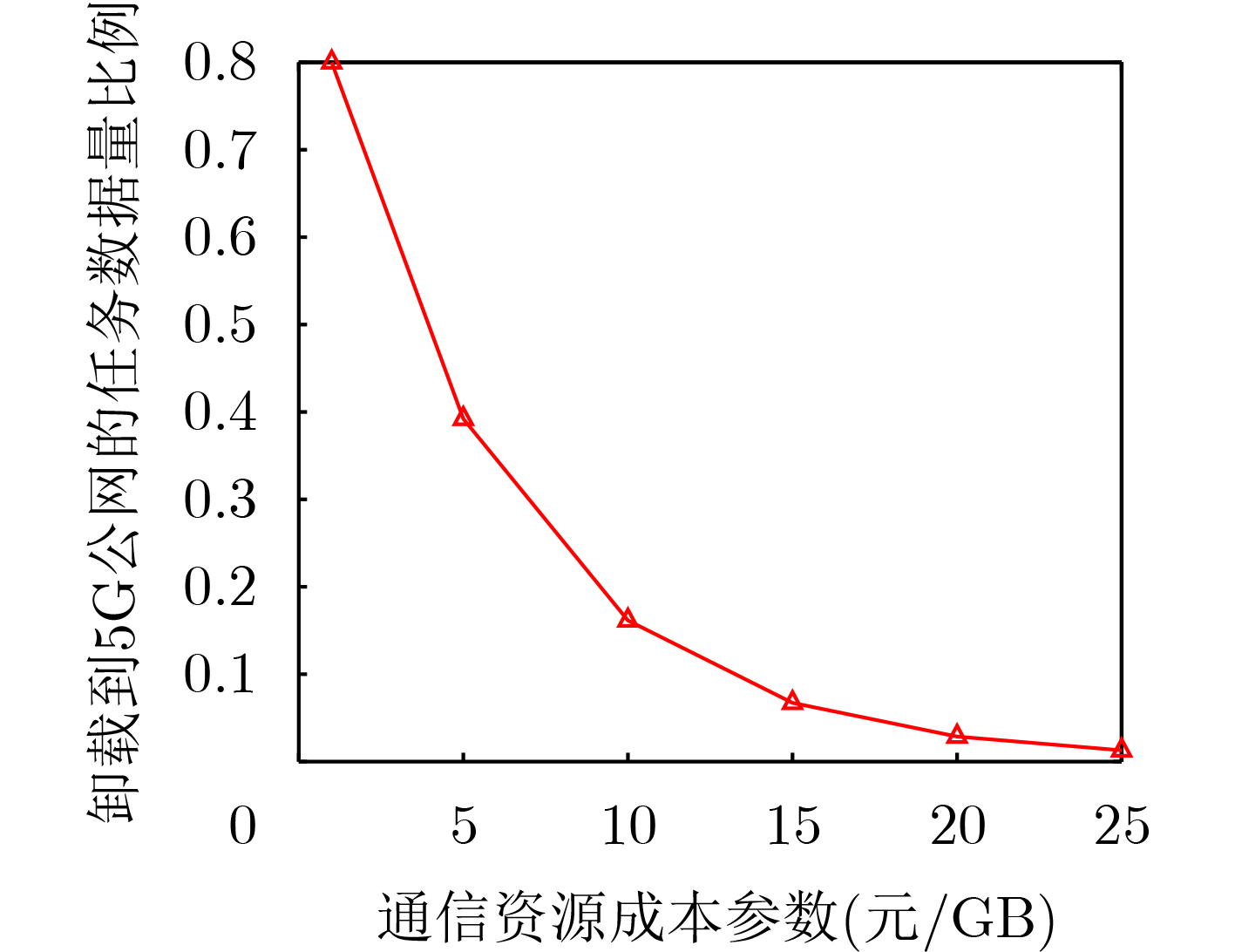
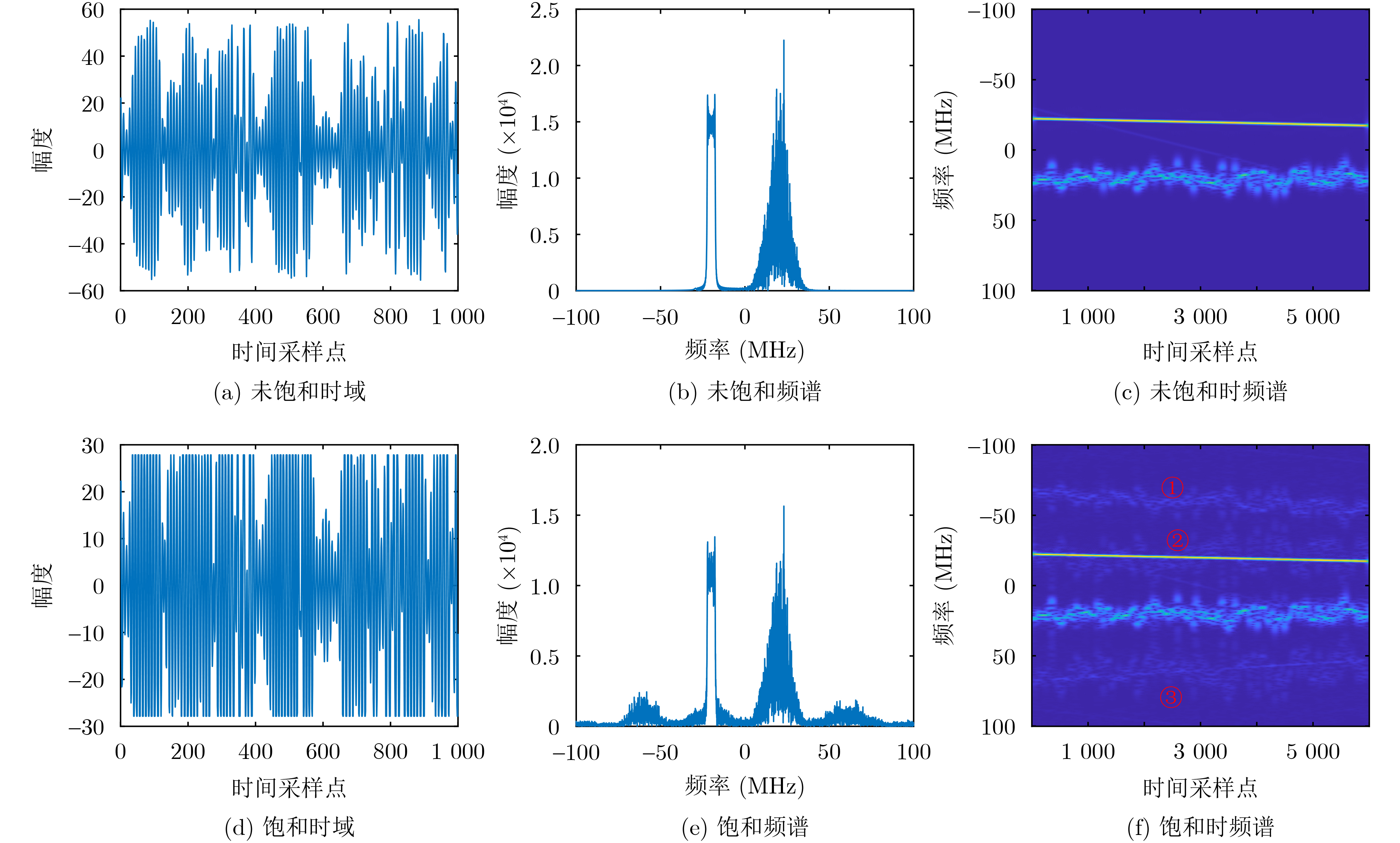
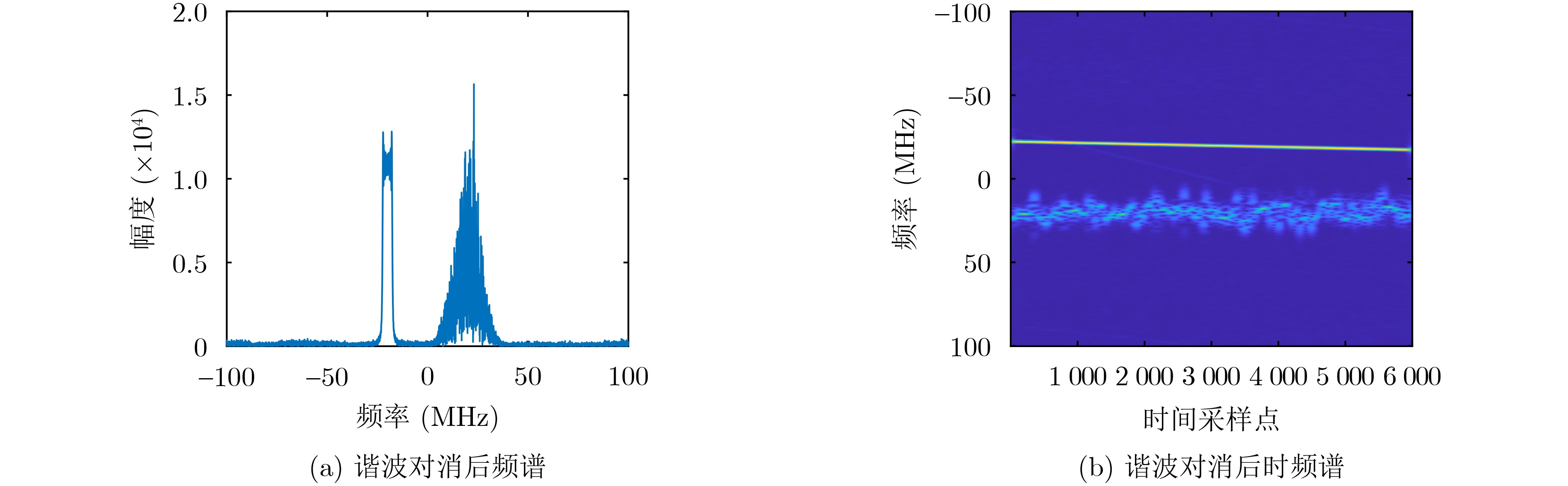
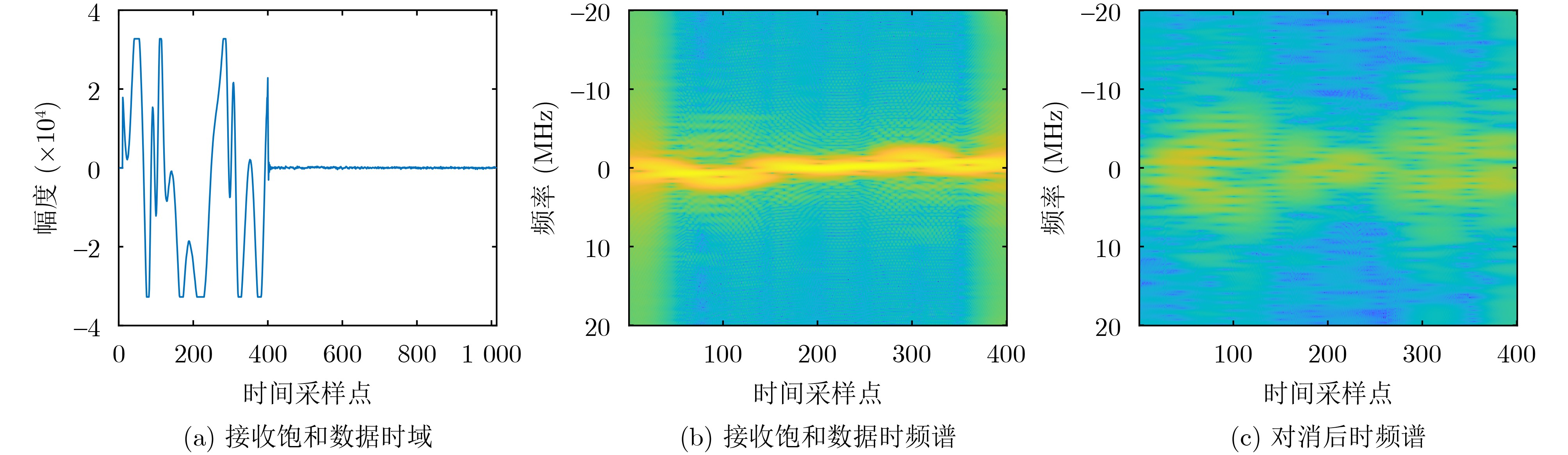
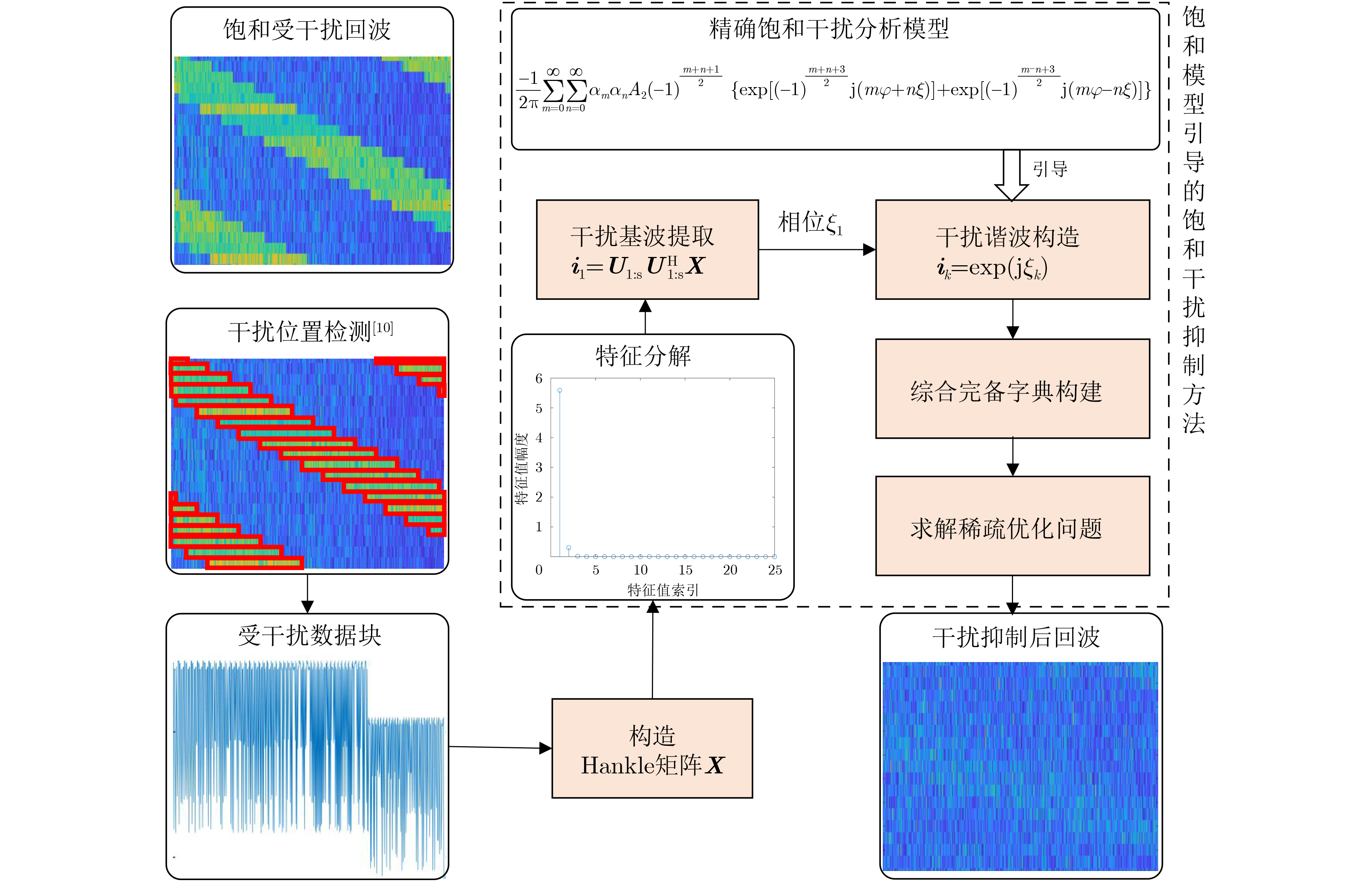
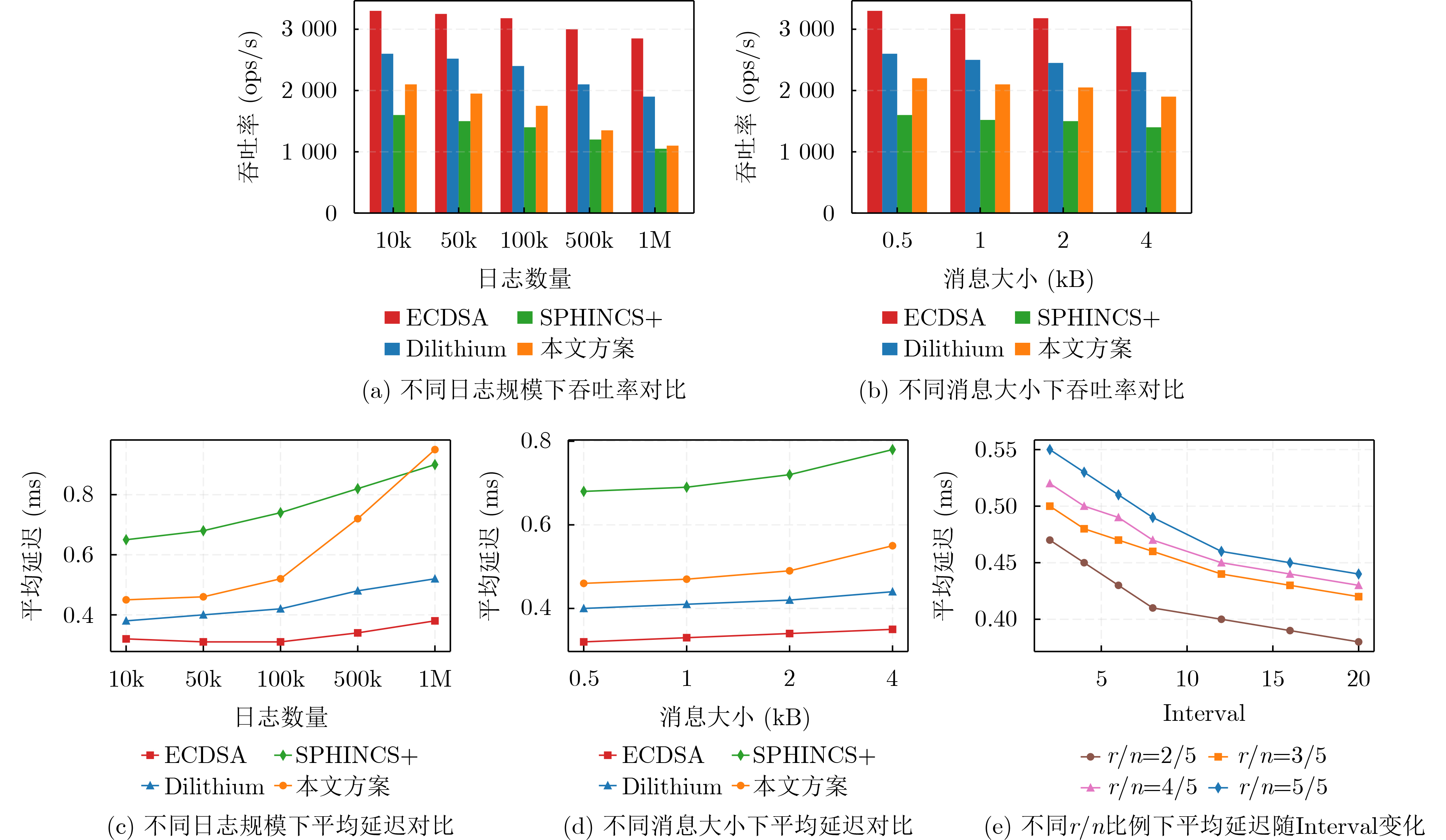
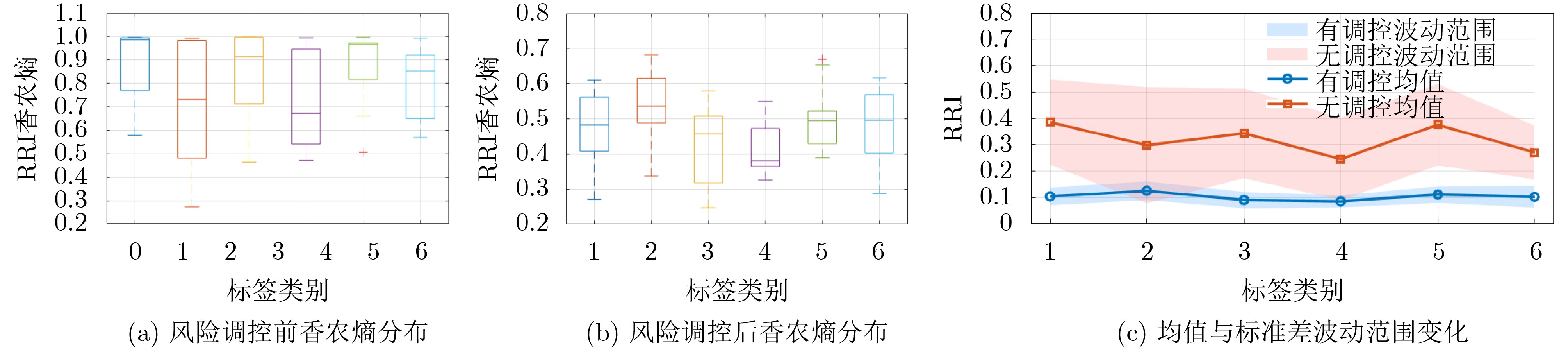
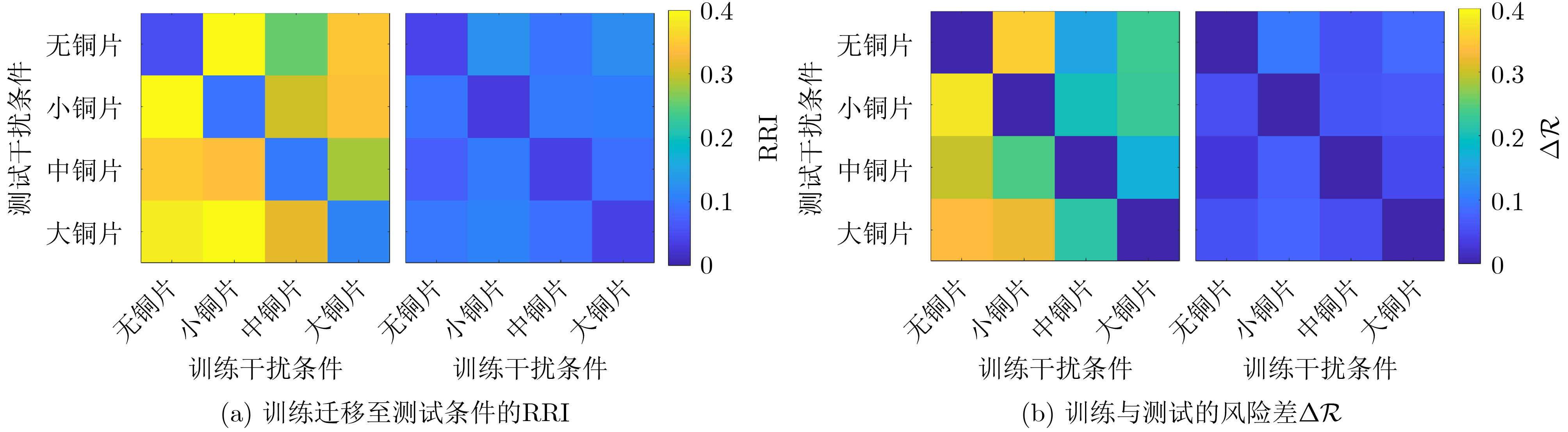
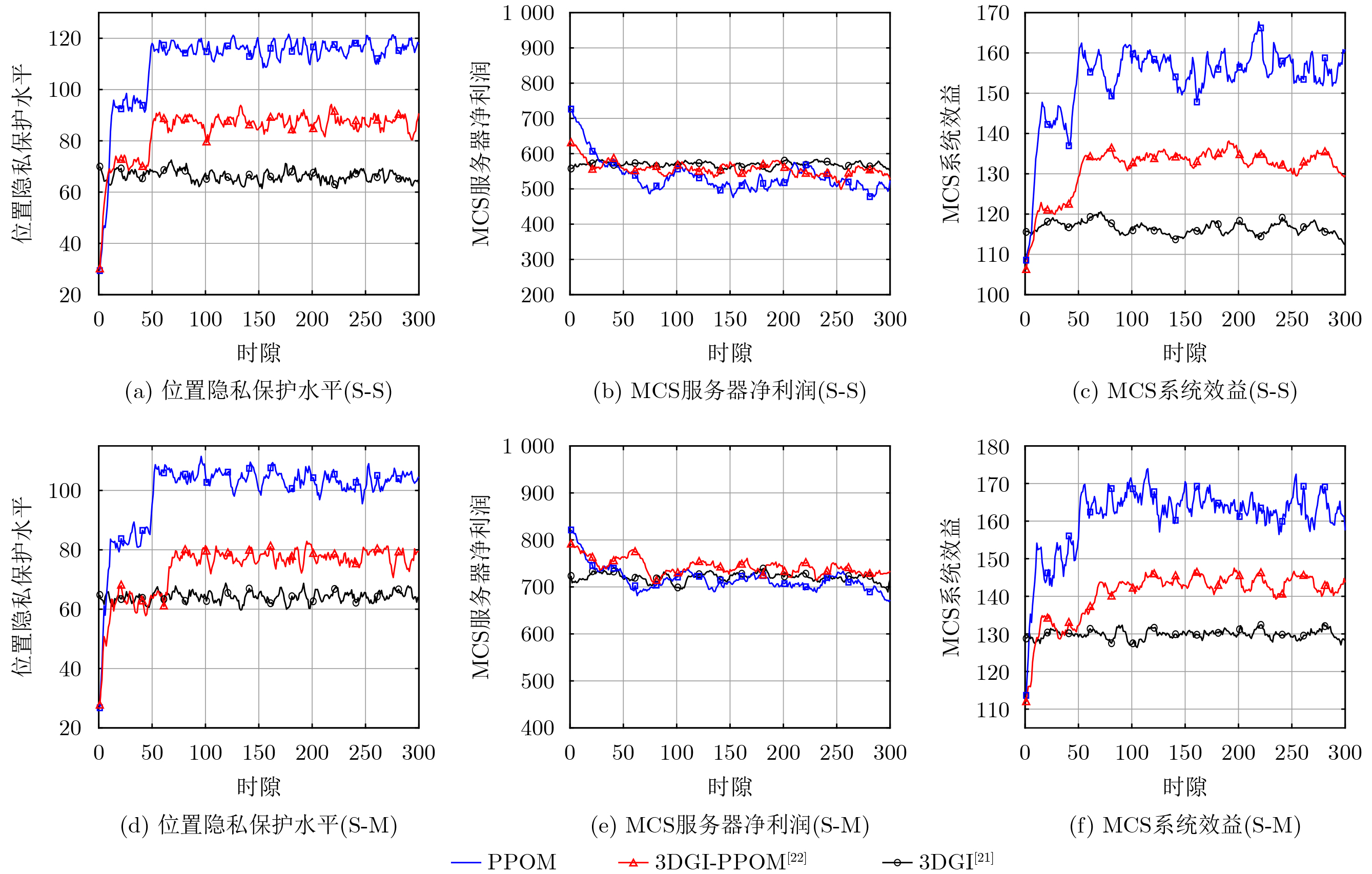
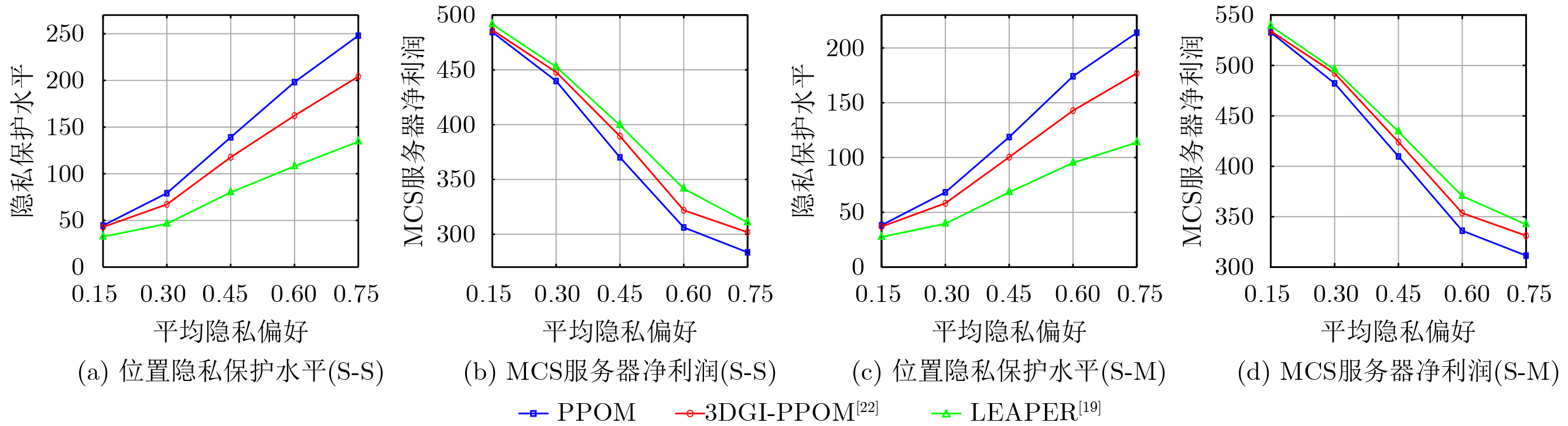
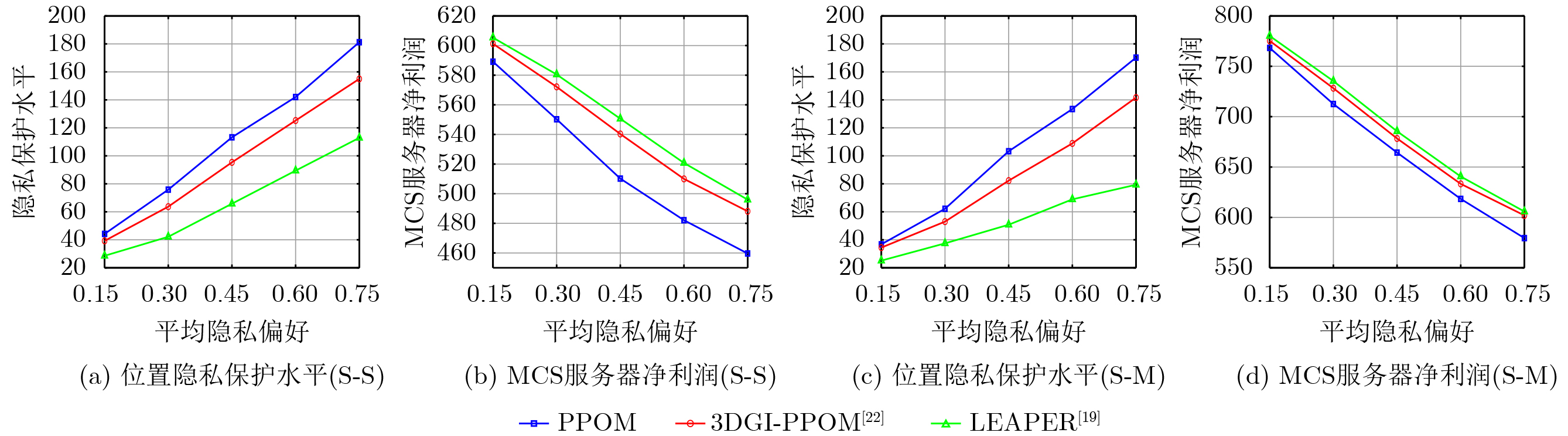
Objective Satellite-Terrestrial Integrated Networks (STIN) integrate multi-source and multi-dimensional services from terrestrial and satellite networks, providing wide coverage, large capacity, and flexible networking. These features support global coverage and ubiquitous access for diverse services. However, the dynamic topology and heterogeneous, resource-constrained nodes in STIN complicate service placement at satellite-terrestrial edge nodes. This further increases the difficulty of matching user service requests with edge computing resources during task offloading, making it difficult to satisfy Quality of Service (QoS) requirements. To address this issue, a joint optimization scheme for QoS-Balanced Service Placement and Task Offloading (BQSPTO) is proposed. The scheme integrates a Delay, Security, and Privacy-aware QoS (DSPQoS) evaluation model with satellite-terrestrial collaboration, inter-satellite cooperation, and service migration. It enables joint optimization of service placement and task offloading in a cloud-edge-end architecture, while satisfying task latency, security, and privacy requirements. Methods The proposed scheme integrates service placement, task offloading, and QoS evaluation into a unified framework. First, a cloud-edge-end collaborative STIN model is constructed, including terminal devices, terrestrial edge servers, satellite edge nodes, and cloud servers. Task security is quantified using the attack avoidance probability derived from key-cracking capability, and task privacy is characterized by usage-pattern privacy and location privacy. A DSPQoS evaluation model is established by combining task completion latency, attack avoidance probability, and privacy level. Second, a service placement strategy is designed based on task popularity prediction and service migration. A cloud-edge-end collaborative full offloading strategy is developed by determining offloading locations and multi-node cooperation modes according to QoS performance. Based on the service placement strategy and task offloading decisions, an optimization problem is formulated to maximize the total QoS performance under communication and computation resource constraints. Third, the joint optimization problem is decomposed into service placement and task offloading subproblems. A Non-dominated Sorting Genetic Algorithm II (NSGA-II) is applied to the service placement subproblem, while a hybrid Grey Wolf Optimization (GWO) and Whale Optimization Algorithm (WOA) is applied to the task offloading subproblem. Alternating optimization is employed to iteratively update both decisions and obtain the final solution. Results and Discussions The QoS performance of the proposed BQSPTO scheme is evaluated through MATLAB simulations. The cloud-edge-end collaborative task processing model (Fig. 2) and the overall BQSPTO framework (Fig. 3) are analyzed. The proposed scheme is compared with three baseline methods: GWOBQ (Grey Wolf Optimization Algorithm-based BQSPTO Scheme), BSSLM (BQSPTO Scheme Without Service Migration), and HWGWTO (Hybrid Grey Wolf Optimization with Whale Algorithm Fusion for Task Offloading). Results show that BQSPTO achieves faster convergence and better avoids local optima, resulting in higher QoS performance (Fig. 4). Compared with GWOBQ, HWGWTO, and BSSLM, the QoS performance is improved by approximately 2.1%, 5.4%, and 4.8%, respectively. As the number of tasks increases, QoS performance improves for all methods, while BQSPTO consistently achieves the highest performance (Fig. 5). Latency, security, and privacy metrics increase with task volume, and BQSPTO maintains superior performance across these metrics, although trade-offs appear due to multi-objective optimization (Fig. 6). QoS performance decreases as the number of malicious users increases, while BQSPTO shows stronger robustness and stability (Fig. 7). As satellite capacity increases, the number of deployable service types grows, and QoS performance improves for all methods. BQSPTO remains superior under different capacity settings (Fig. 8). Conclusions A joint optimization scheme for service placement and task offloading in STIN is proposed under multi-objective QoS constraints. The DSPQoS evaluation model integrates latency, security, and privacy into a unified evaluation framework. The joint optimization problem is decomposed and solved using alternating optimization, enabling effective coordination between service placement and task offloading. Simulation results demonstrate that the proposed scheme achieves higher QoS performance, better convergence stability, and improved multi-objective balance under varying task loads, malicious user scales, and satellite capacities.