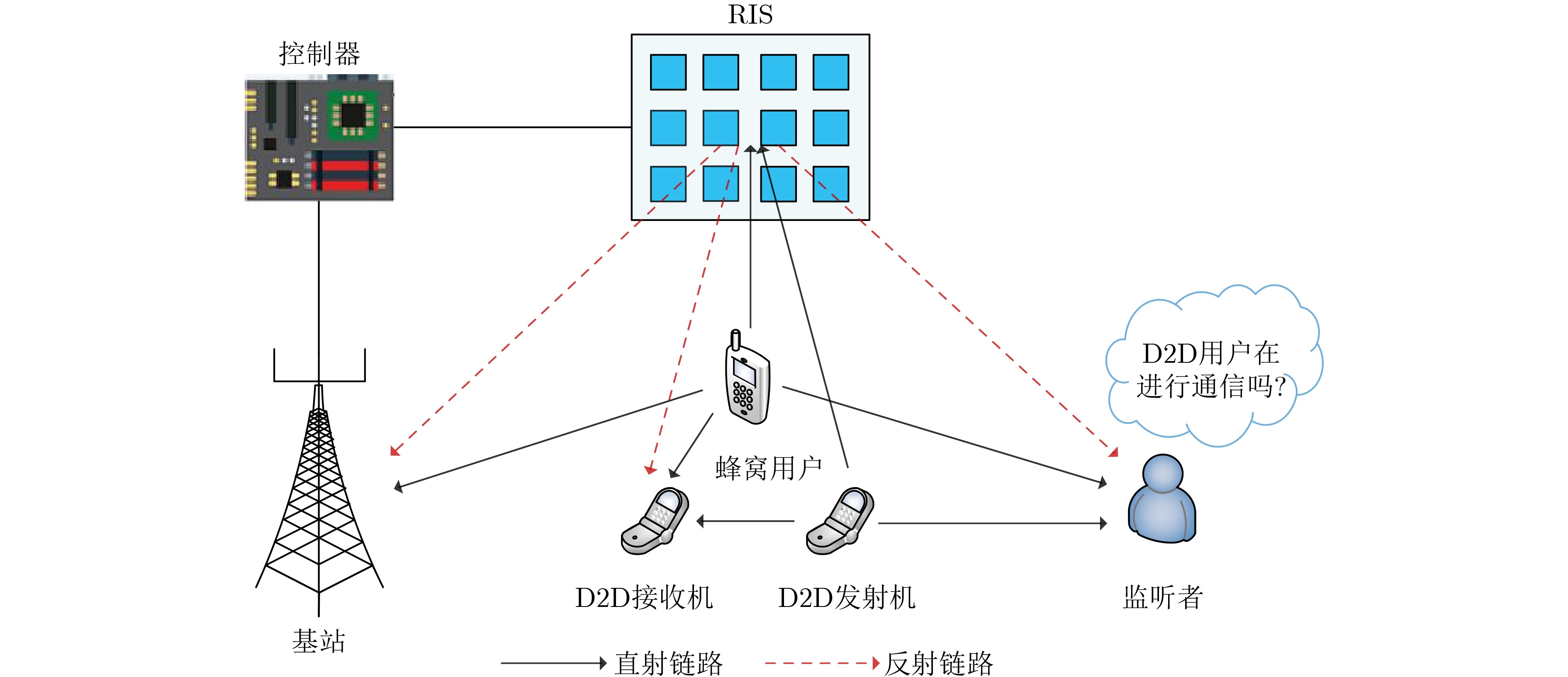
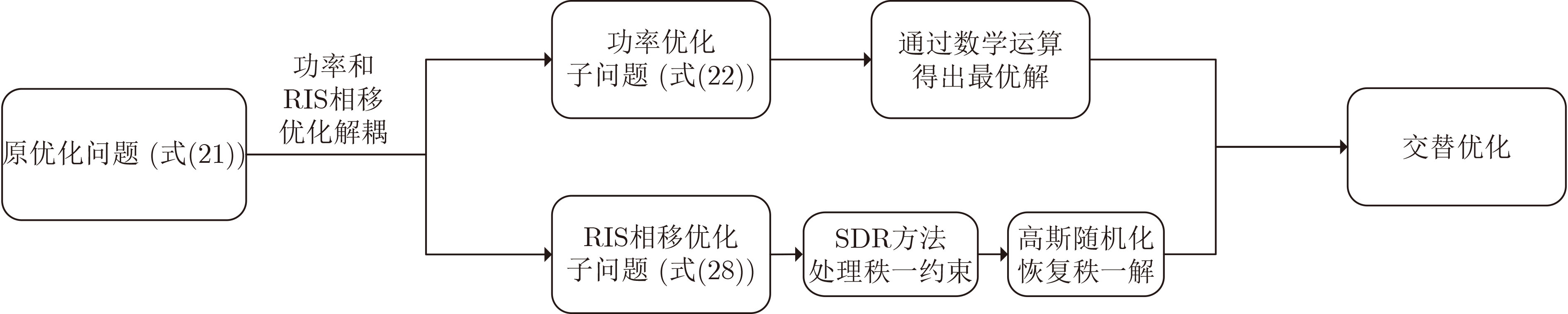
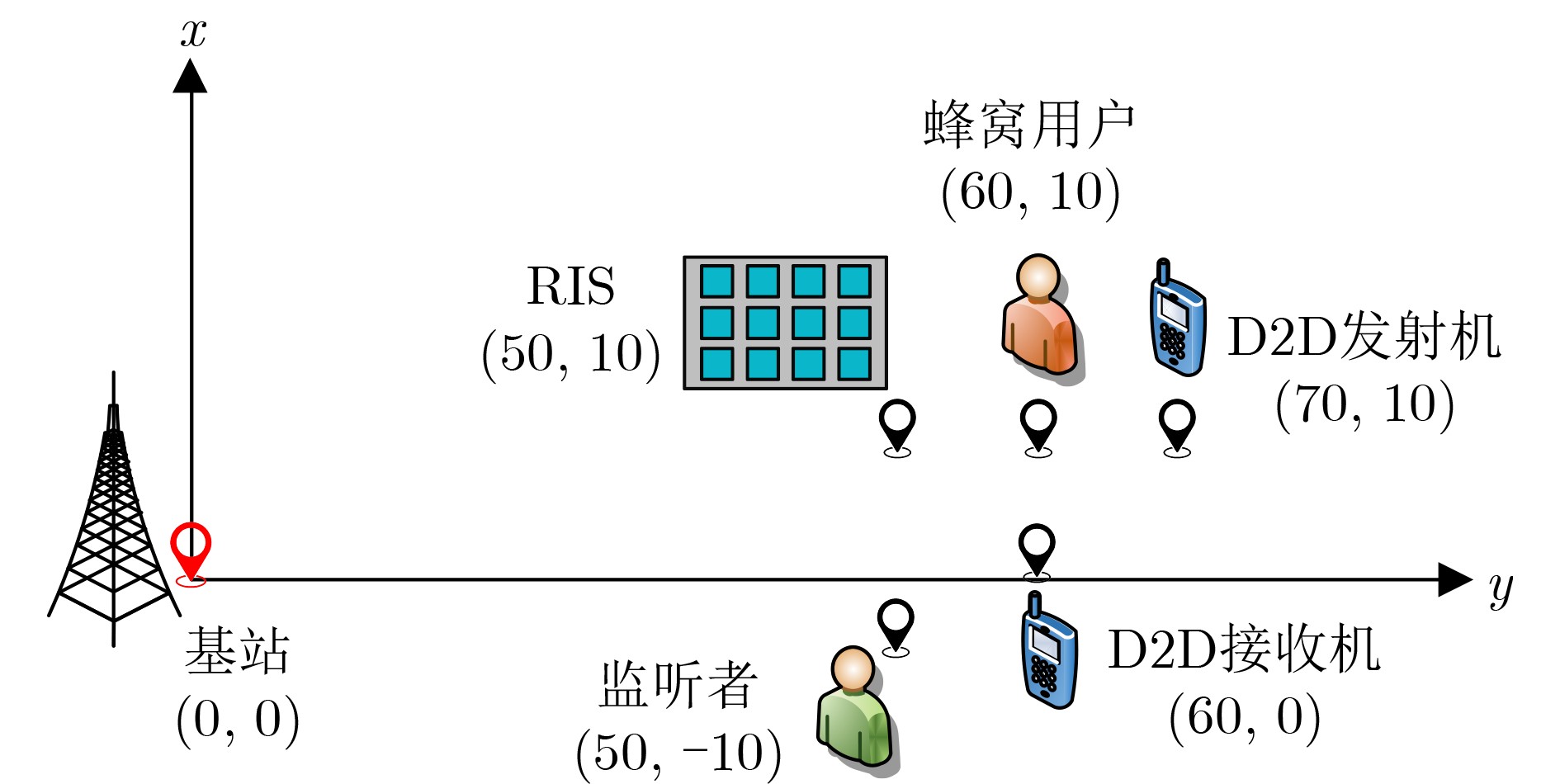
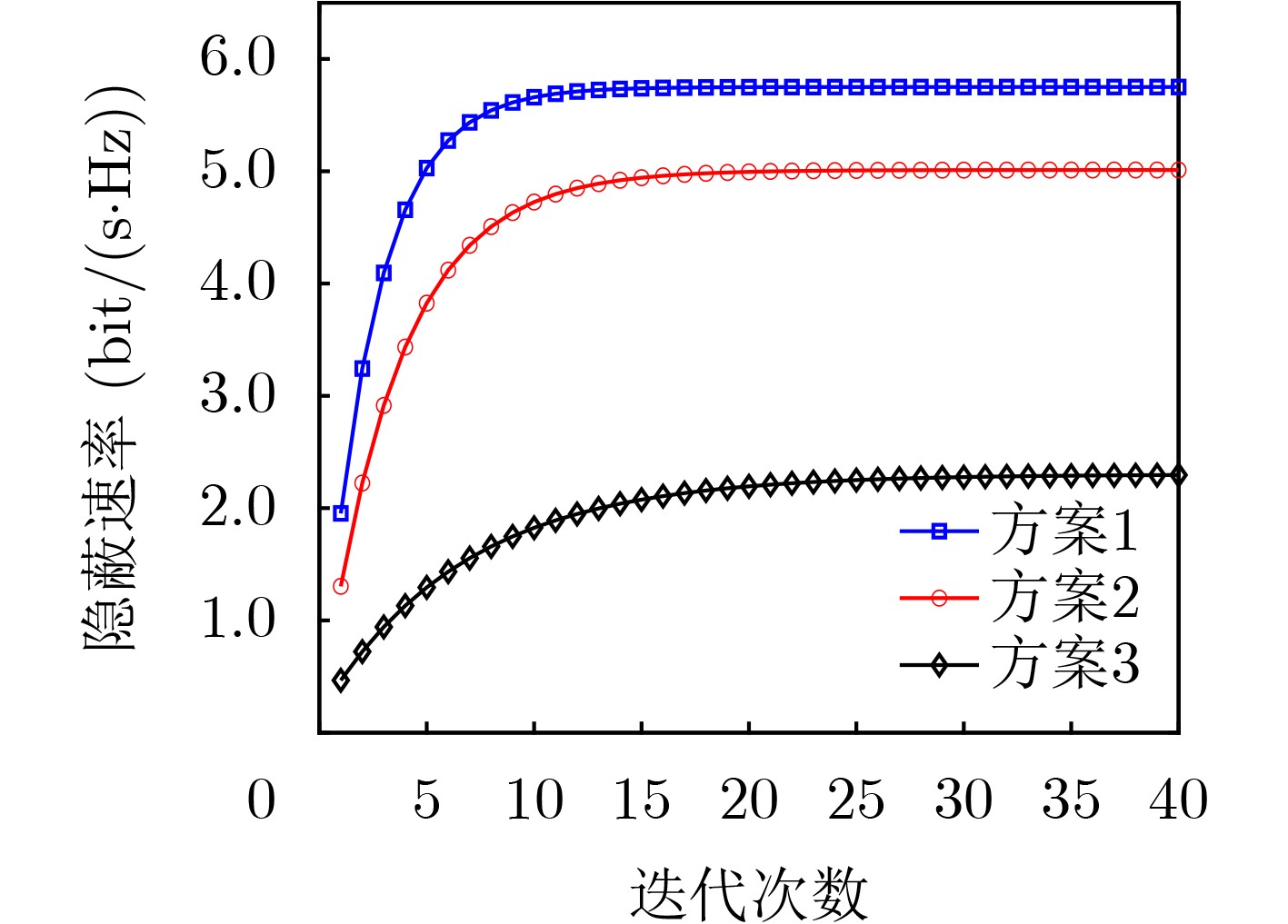
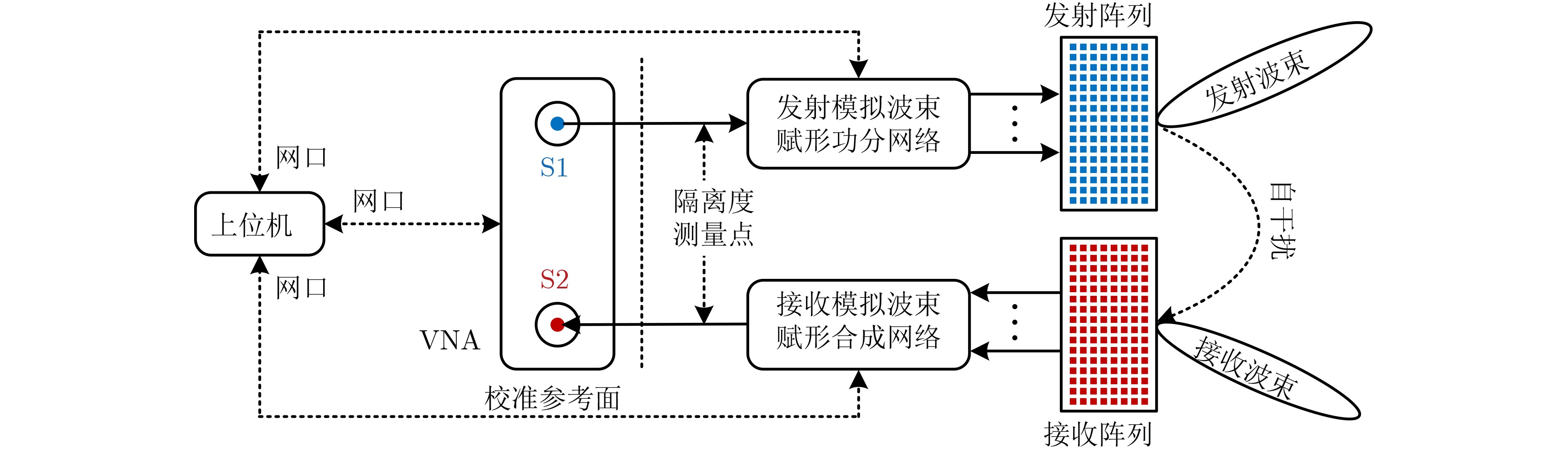
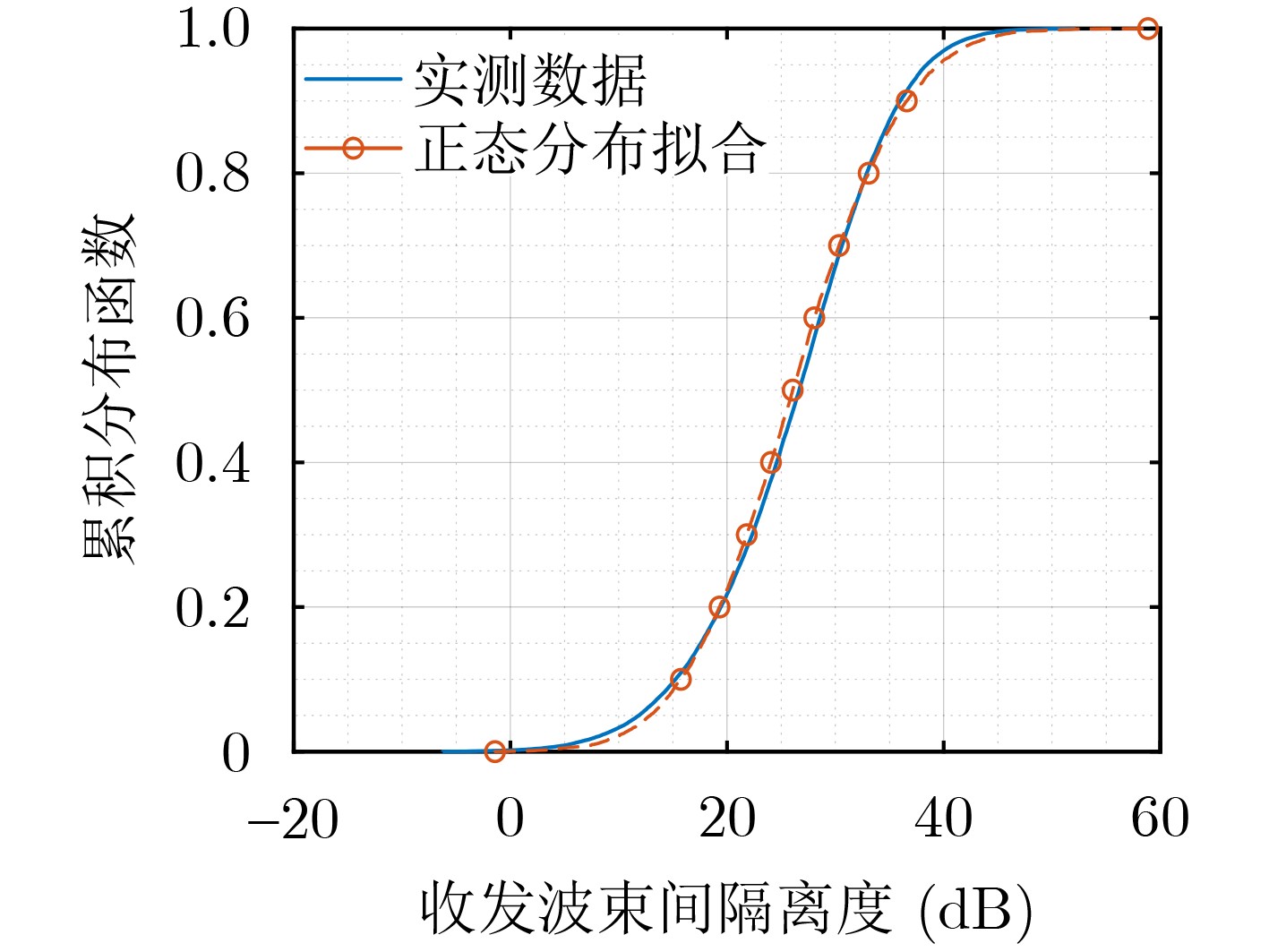
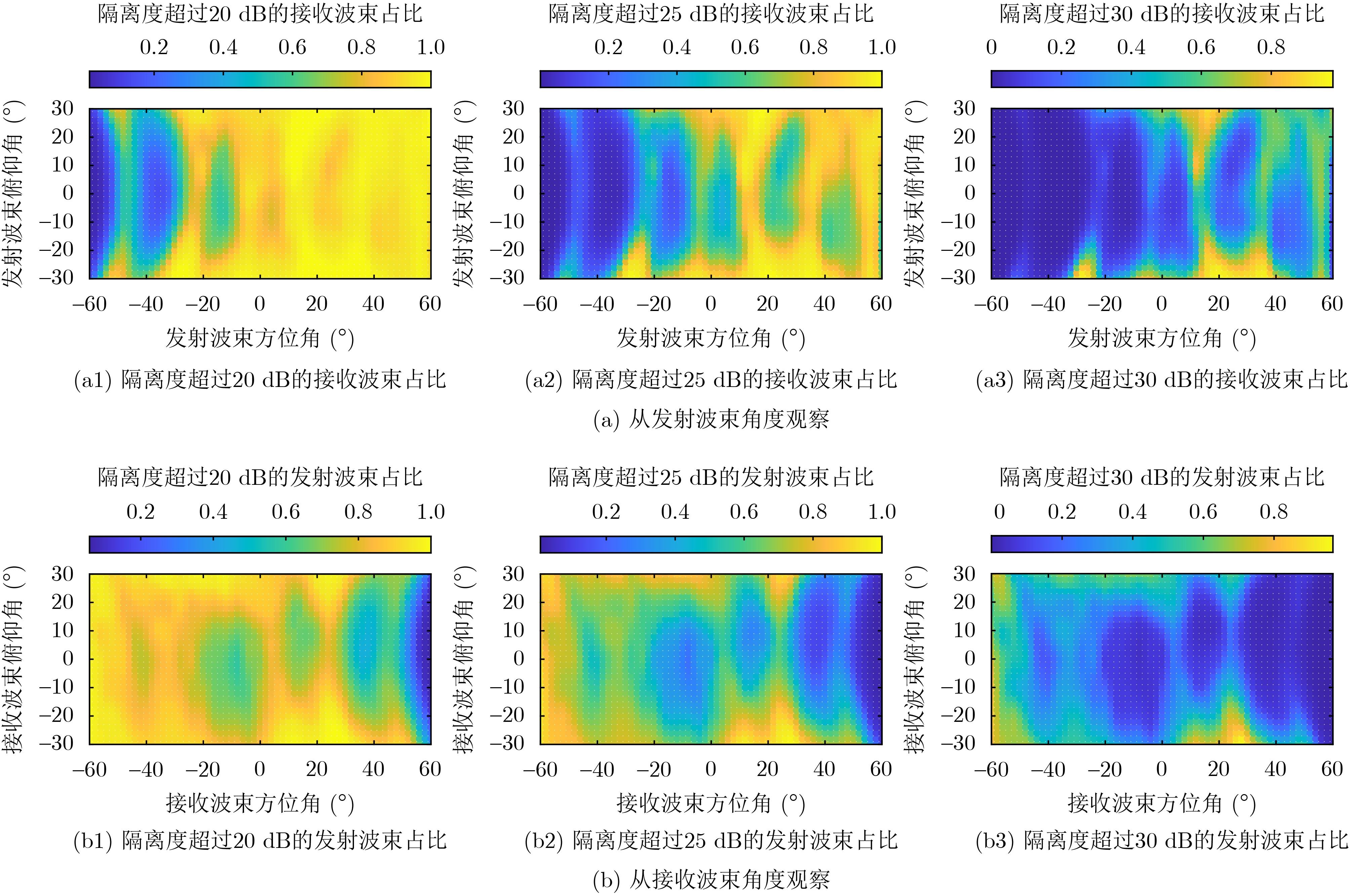
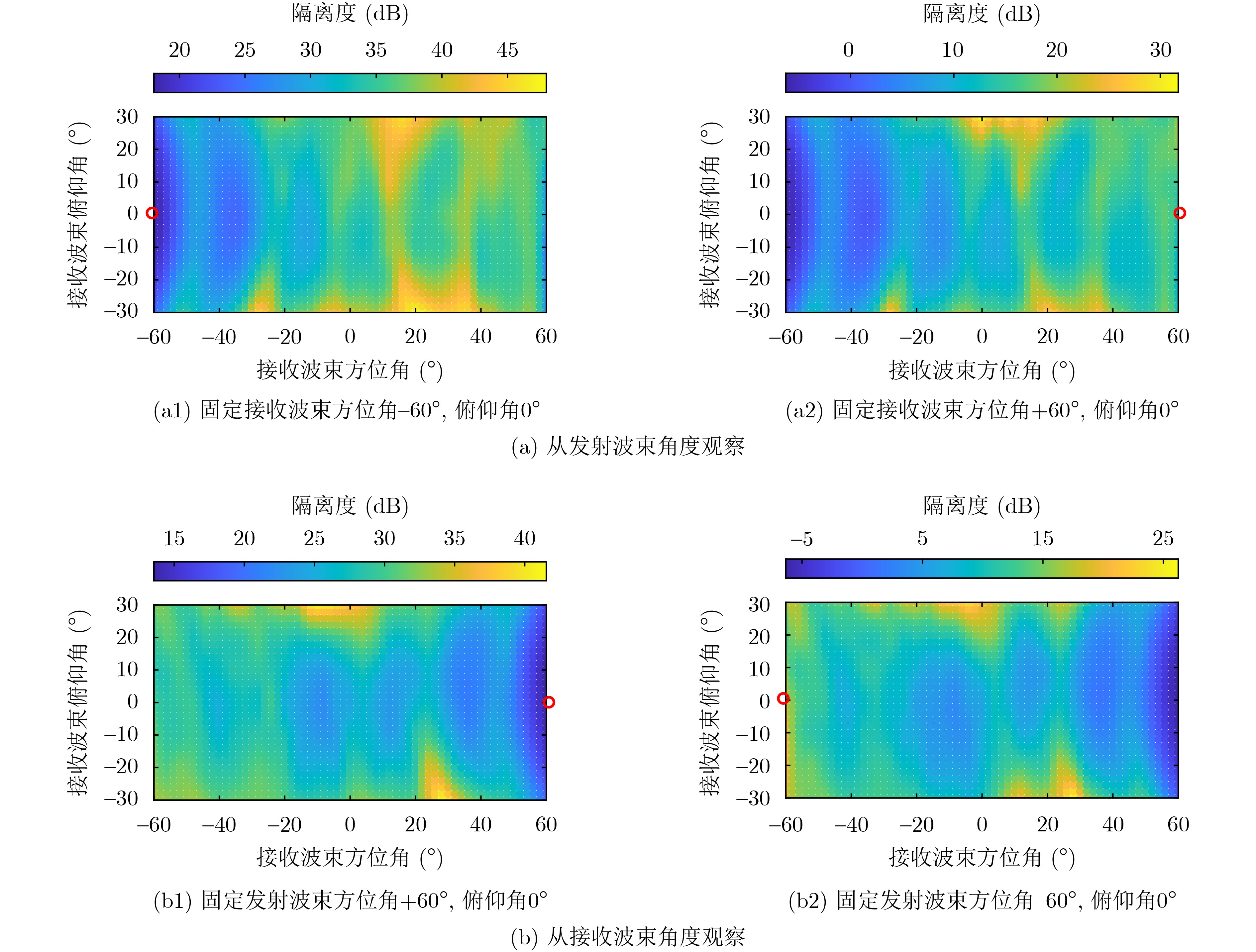
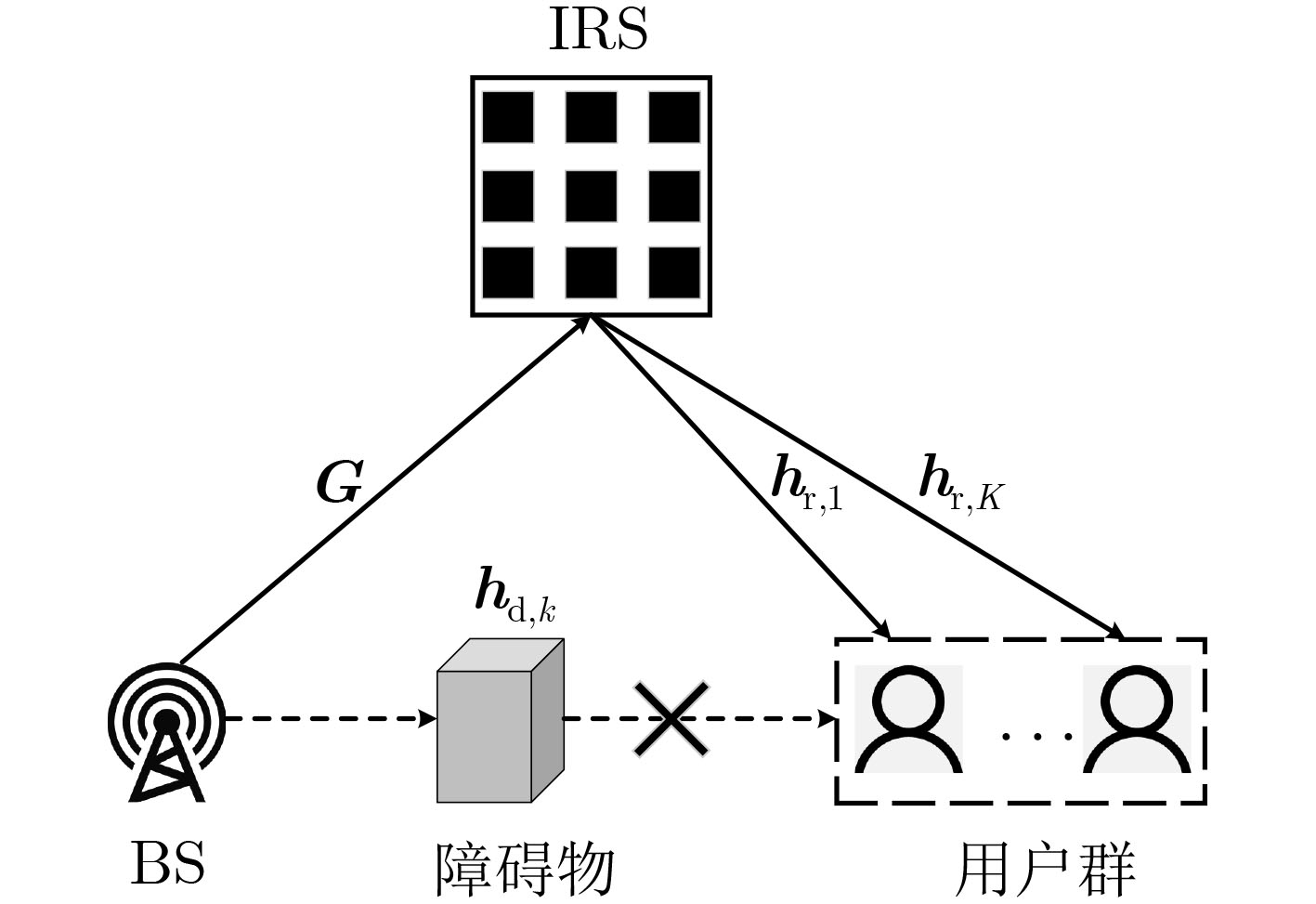
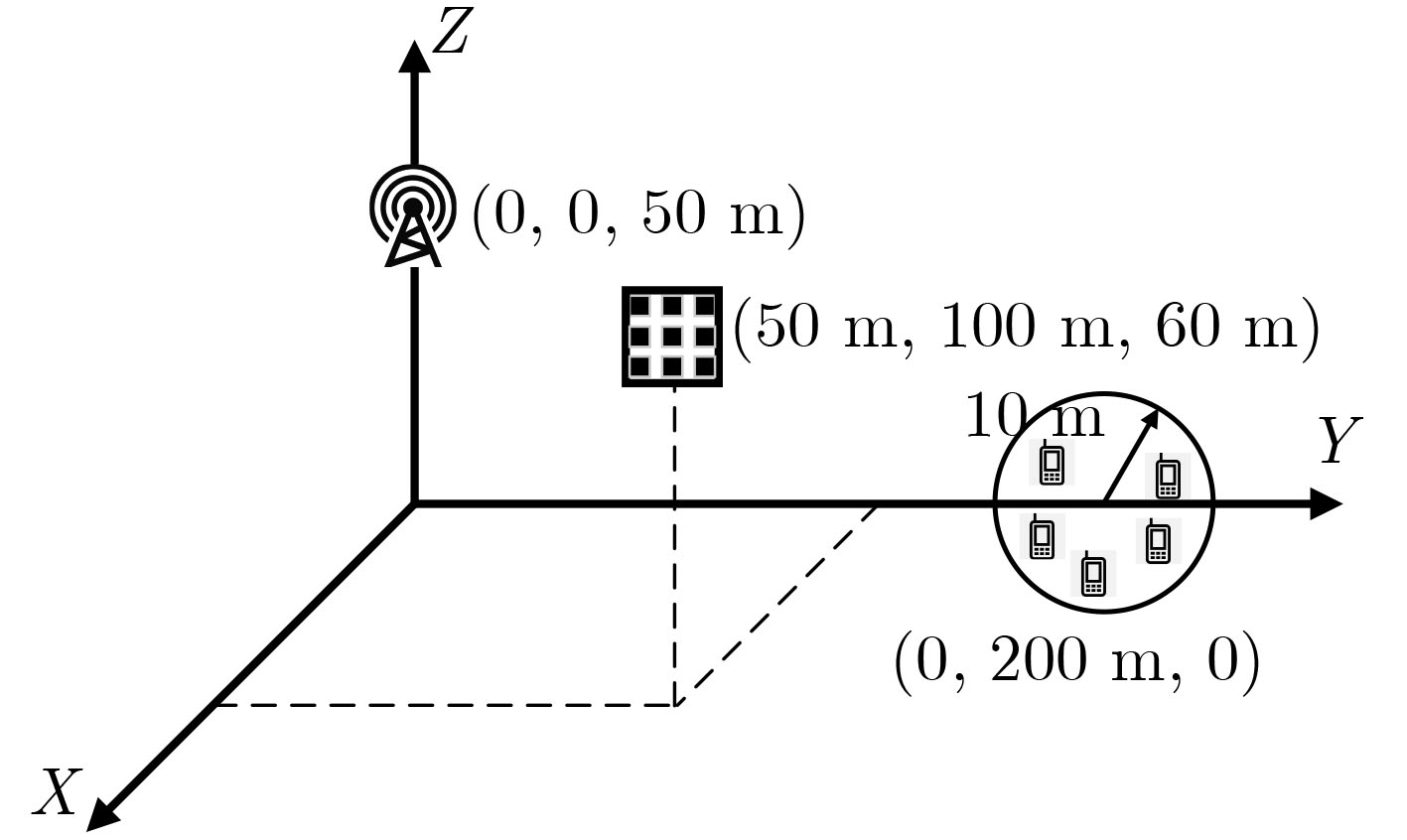
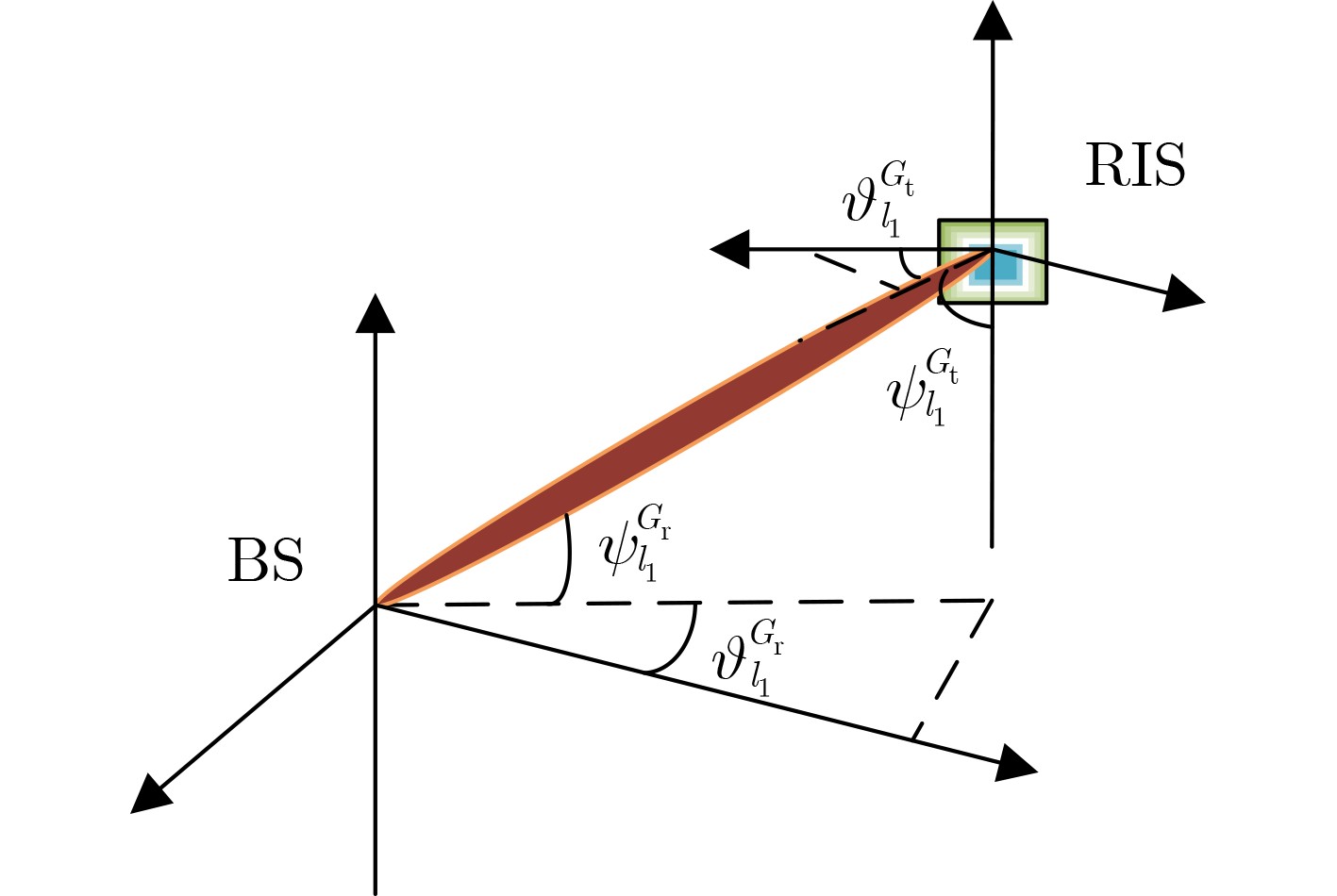
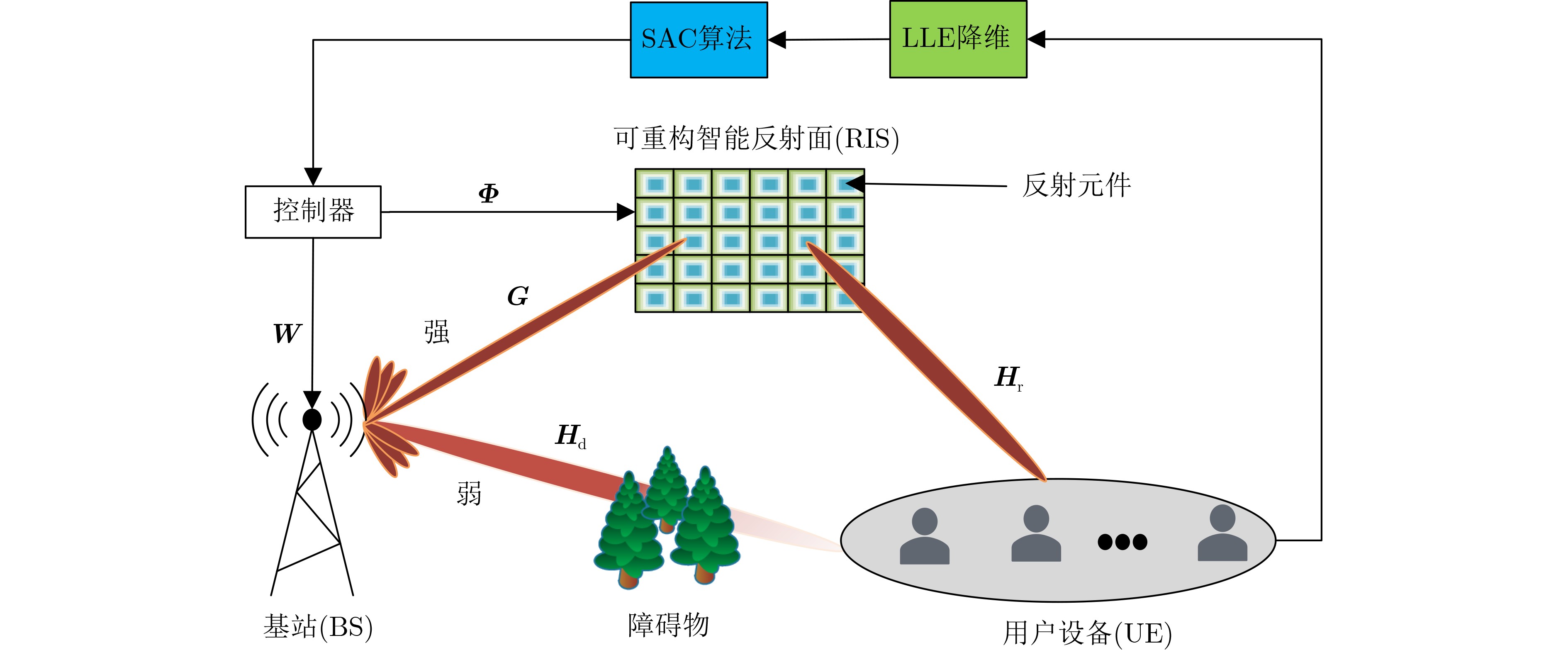
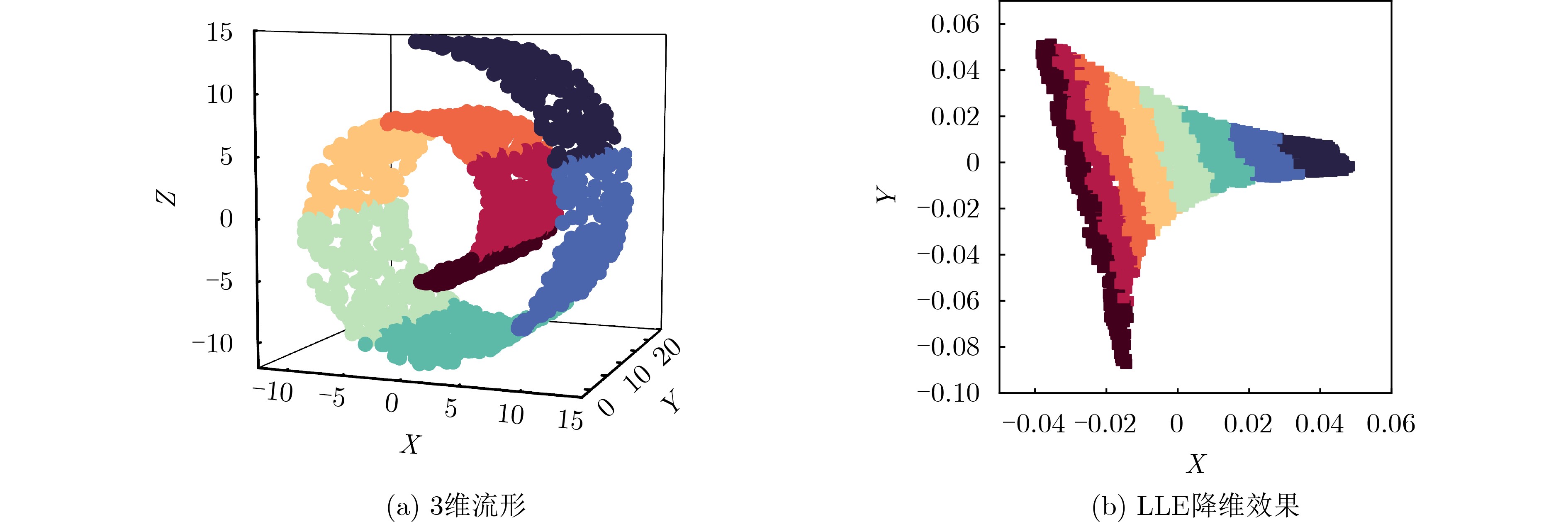
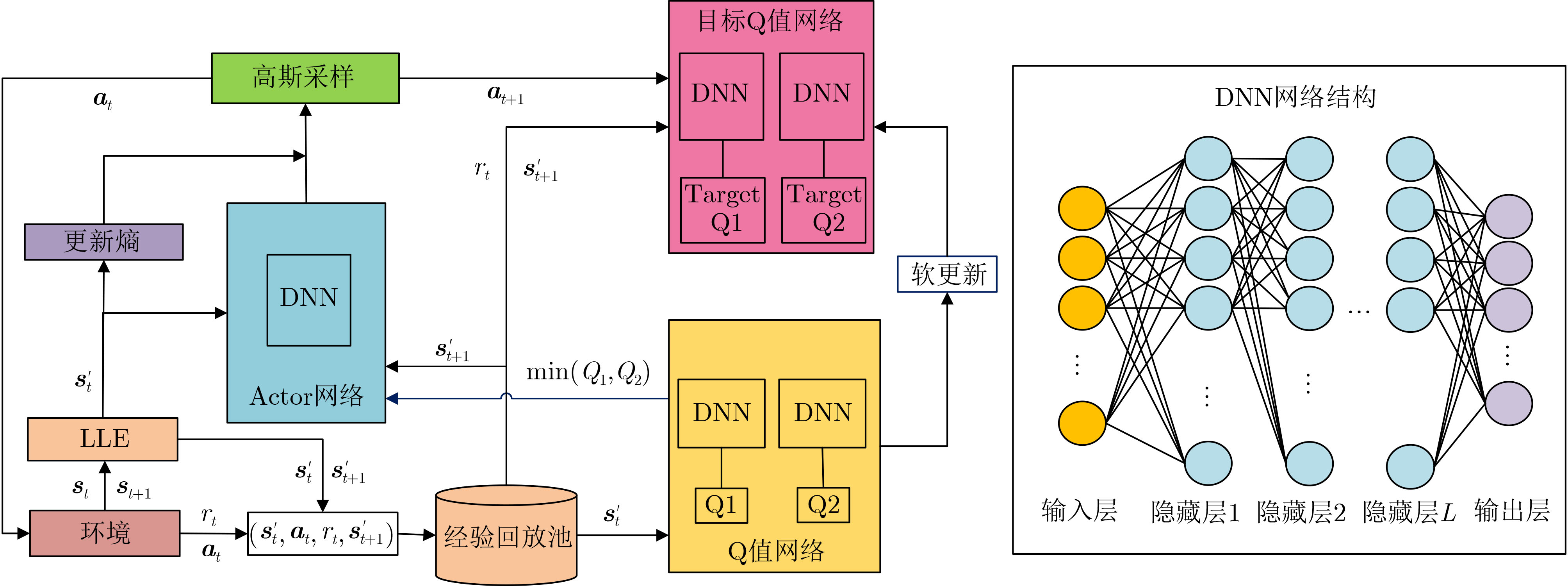
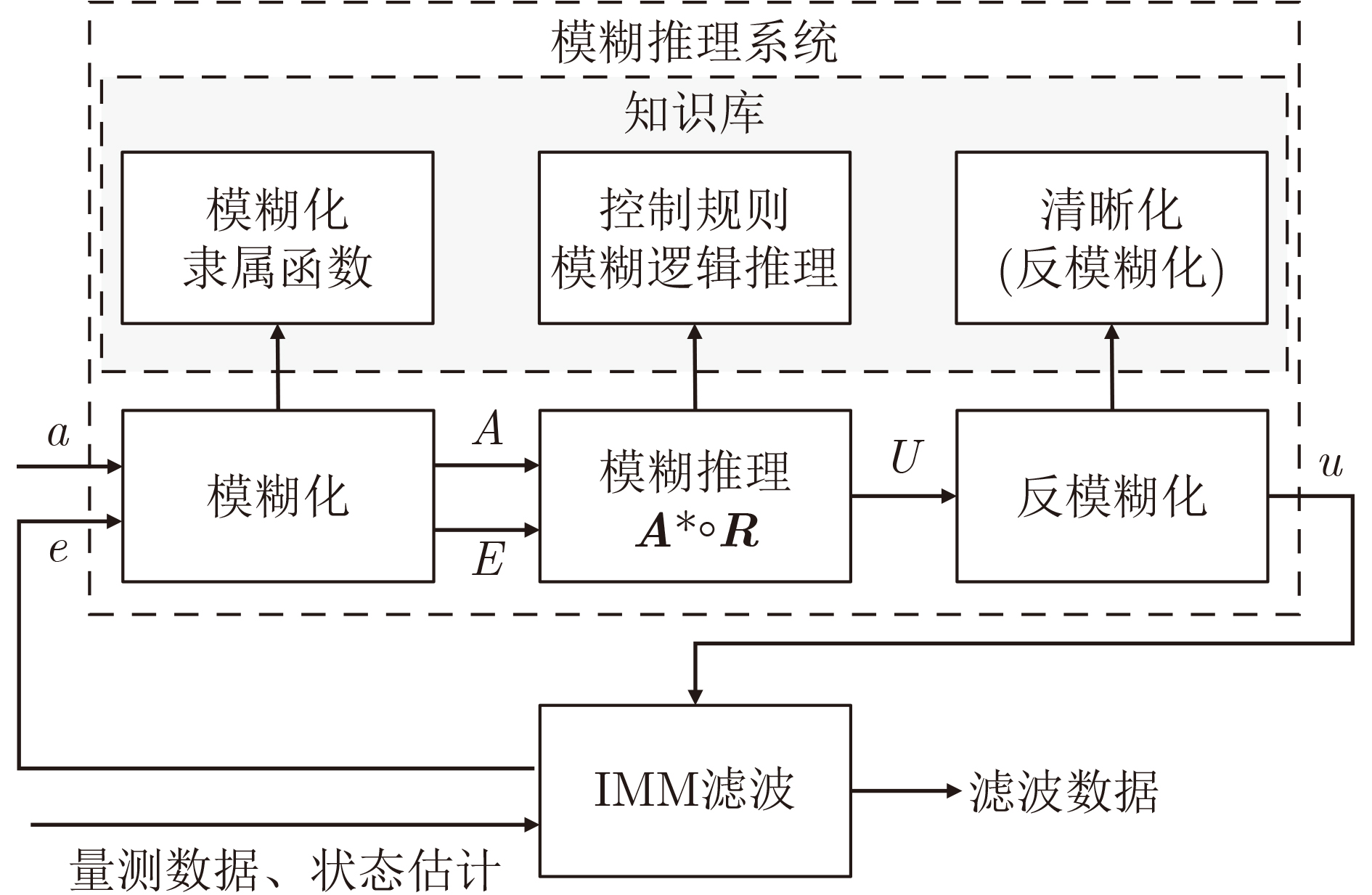
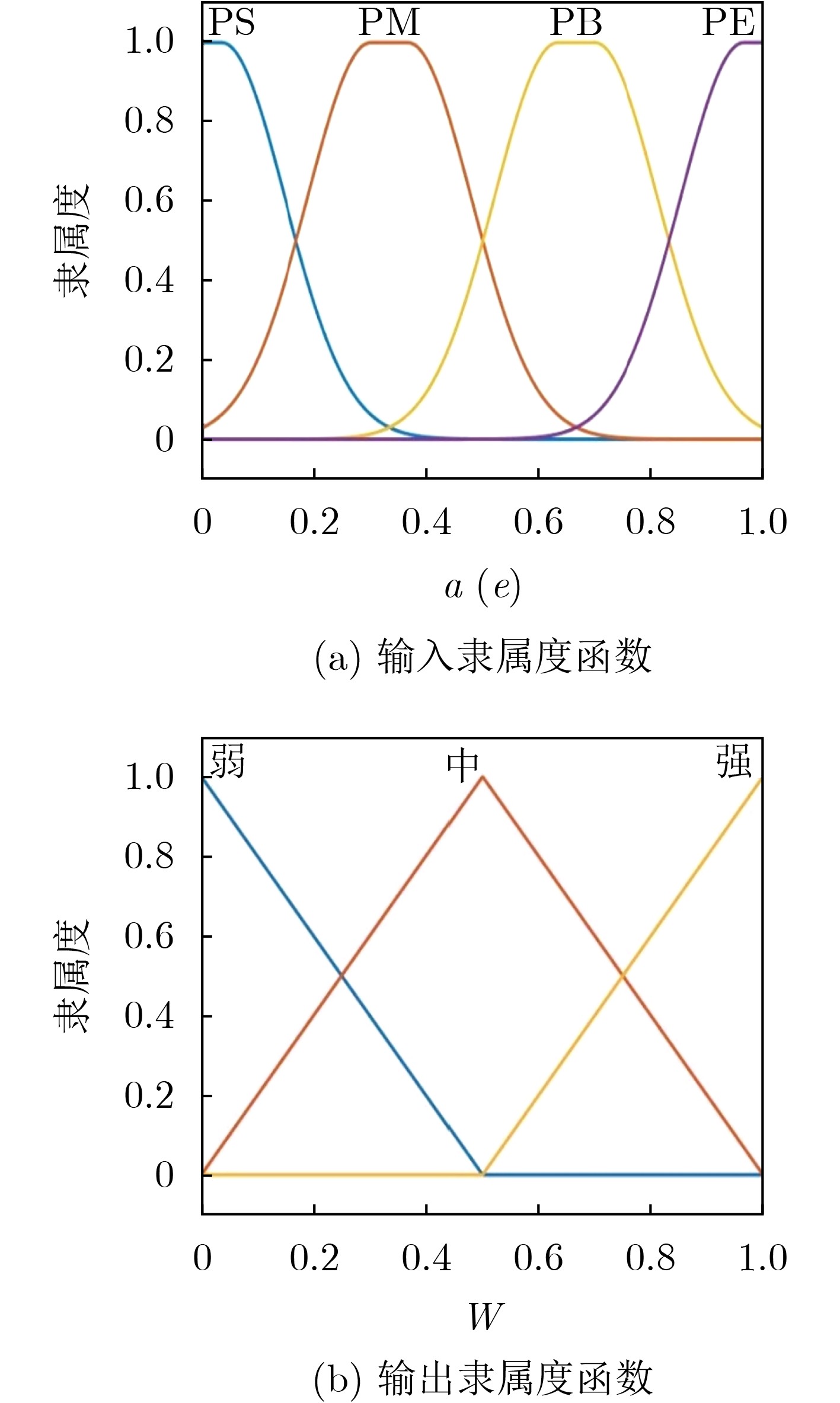
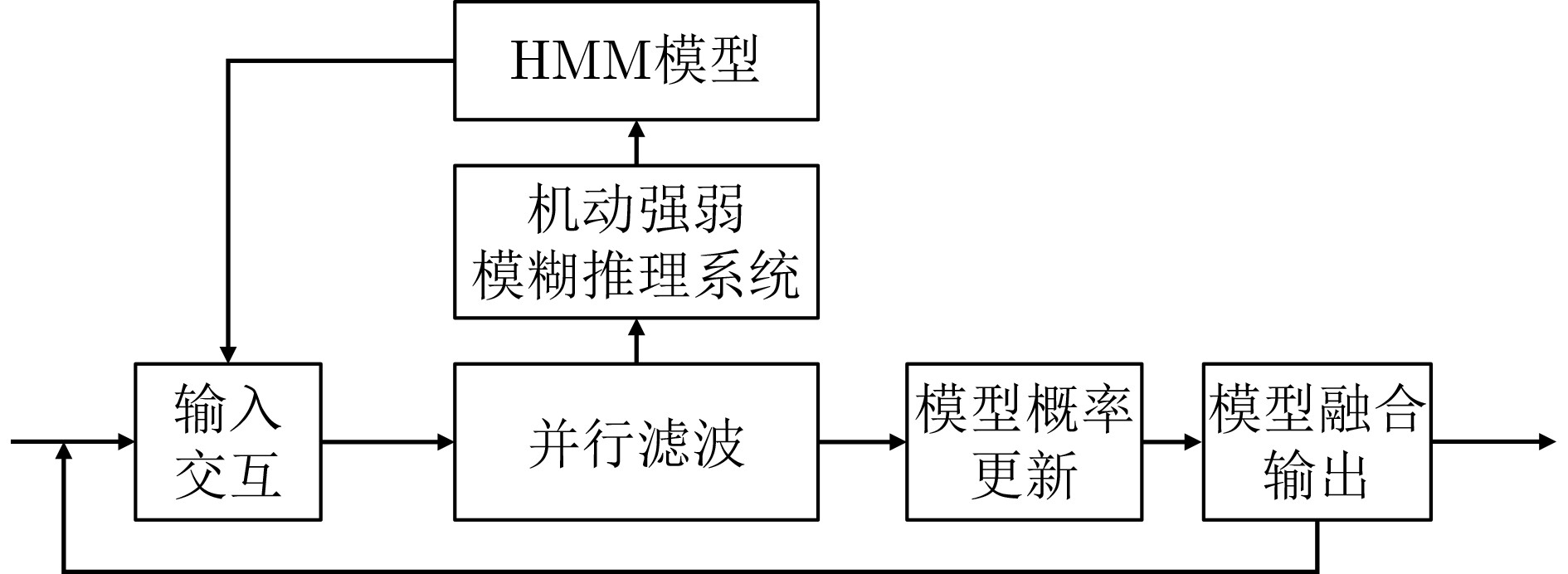
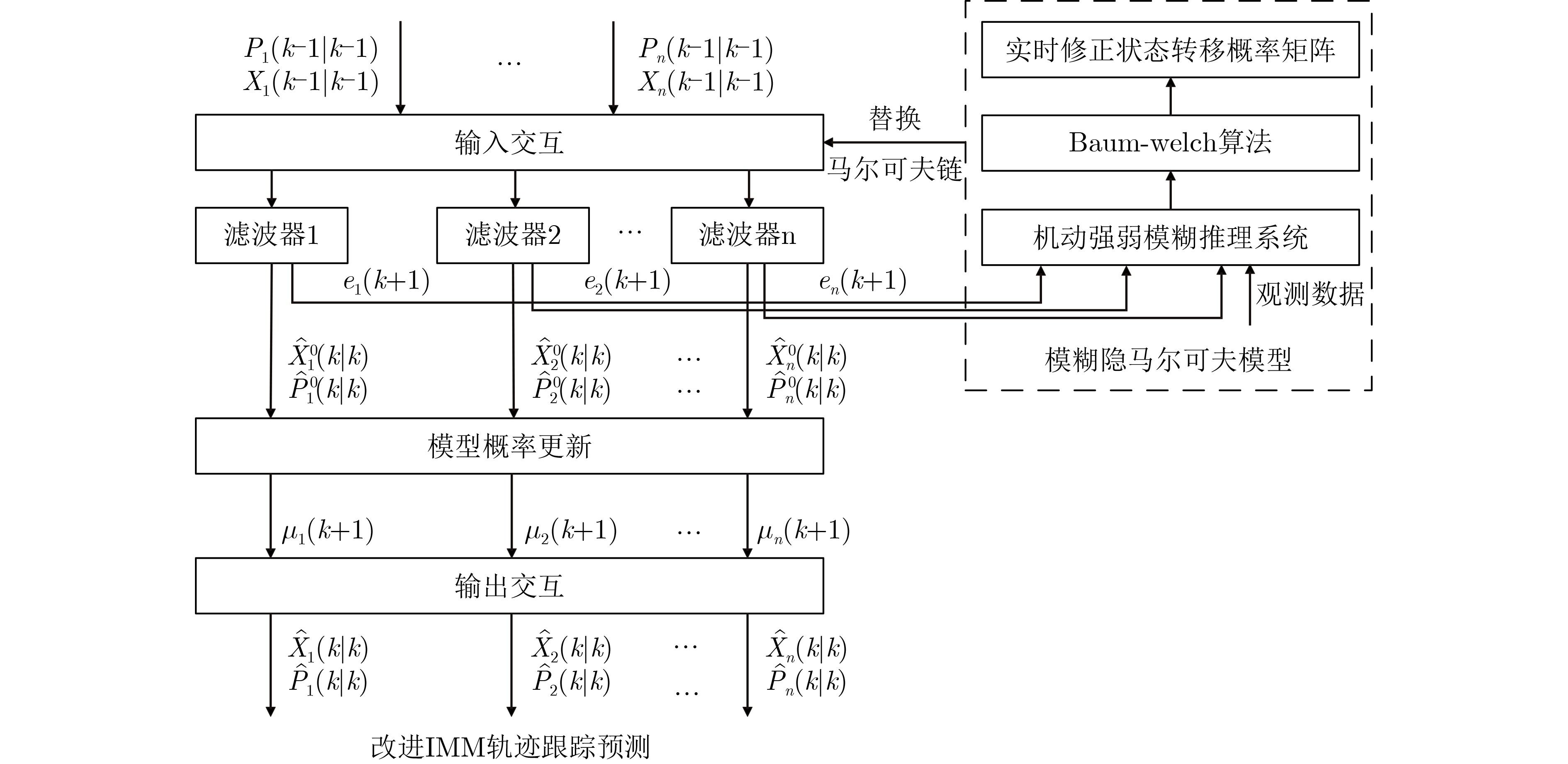
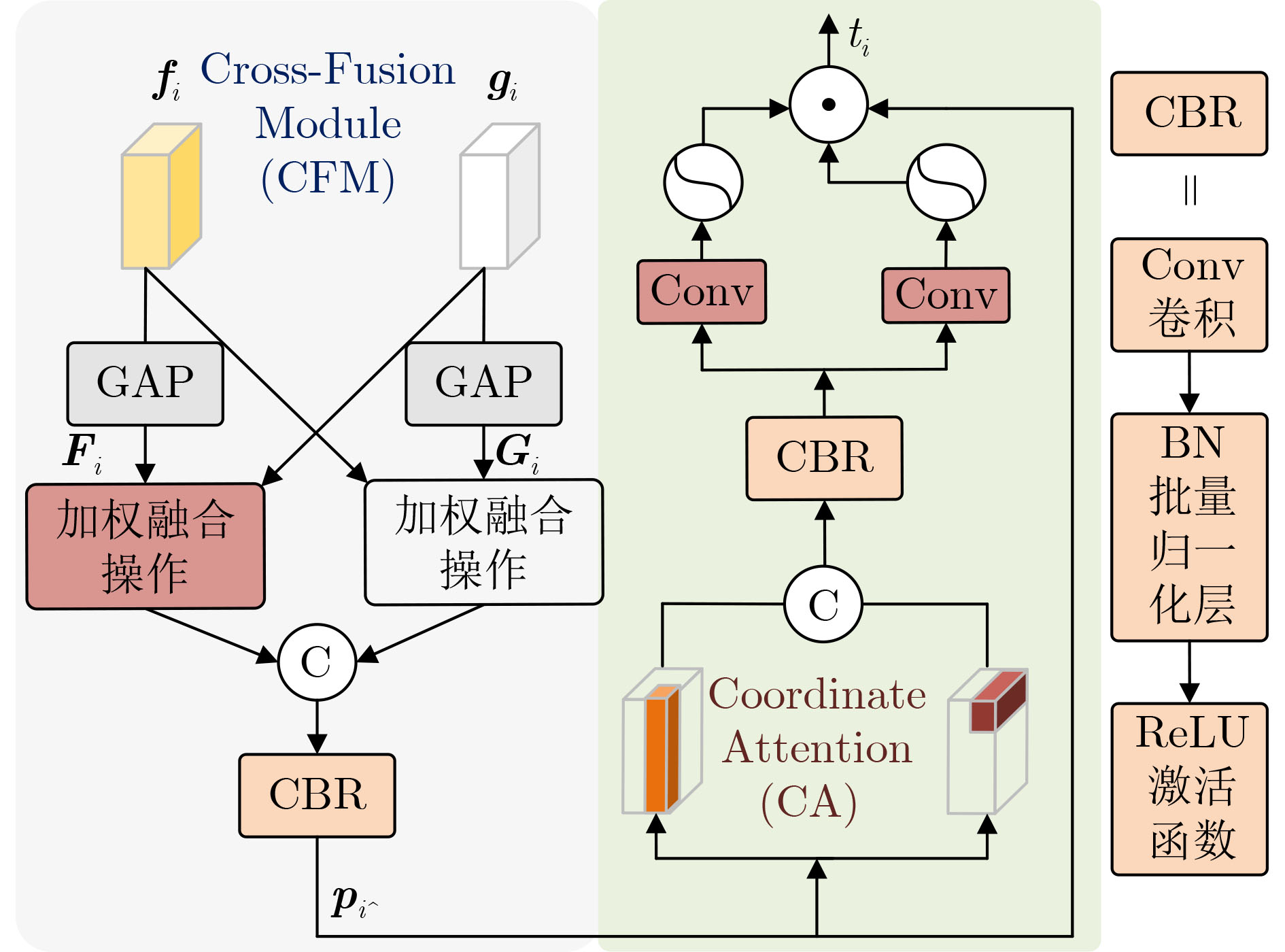
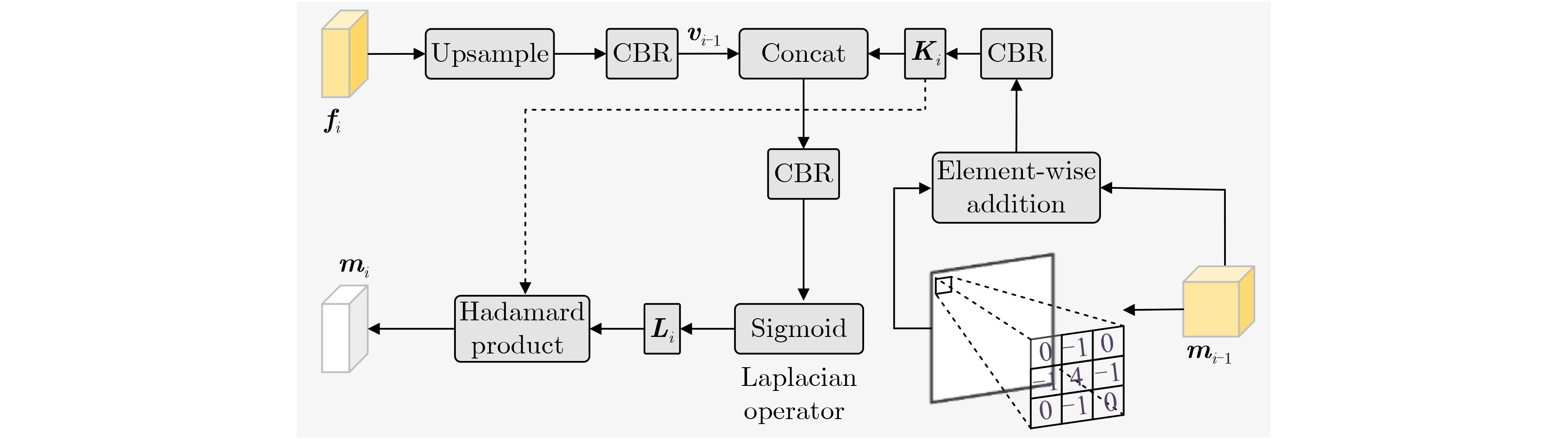
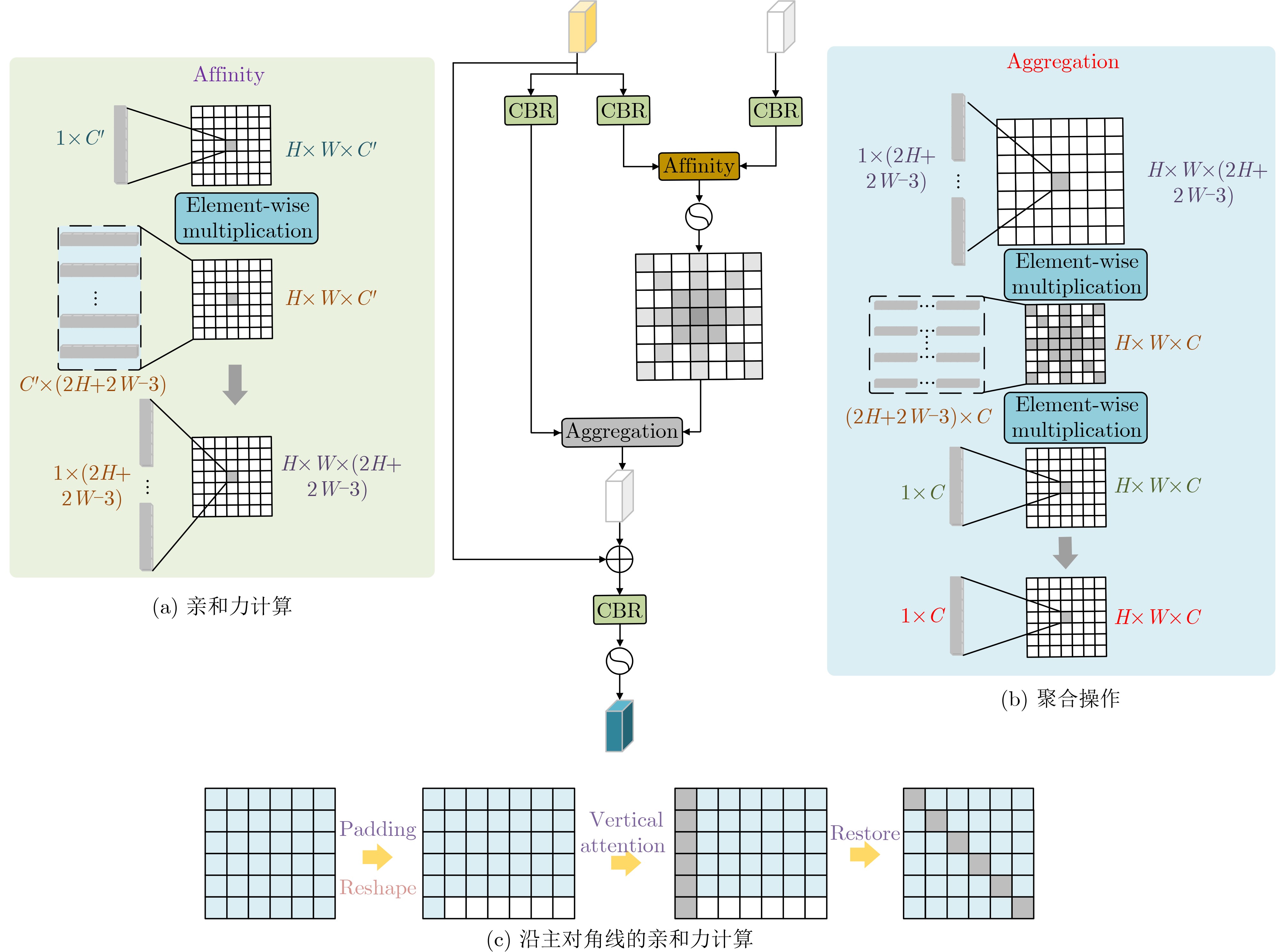
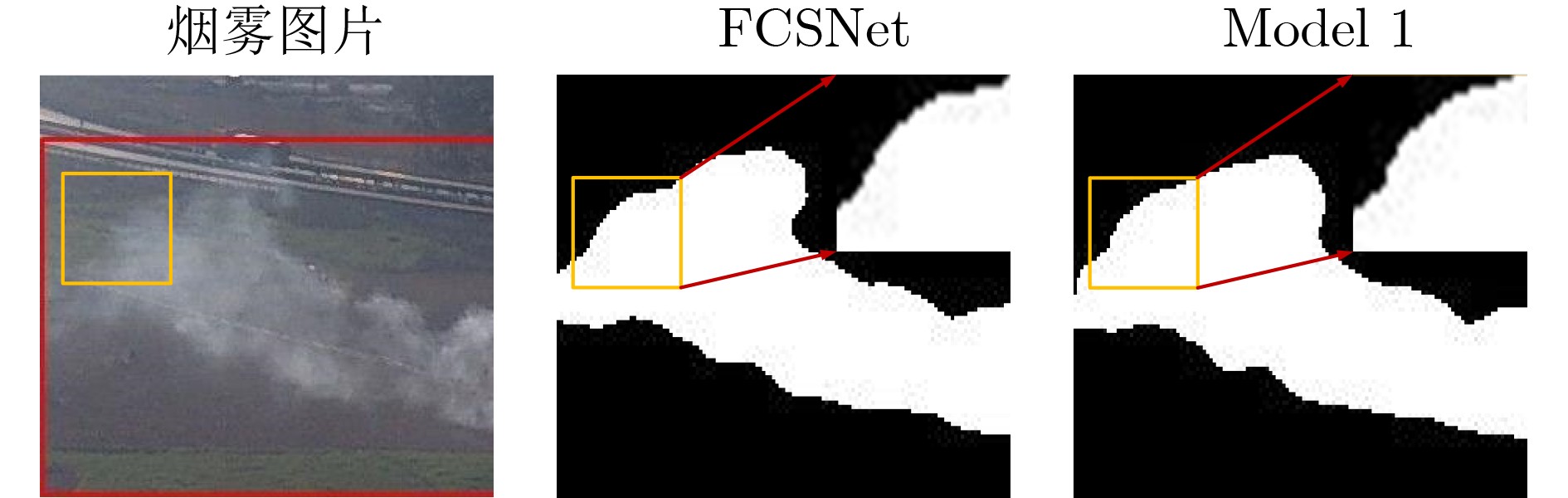
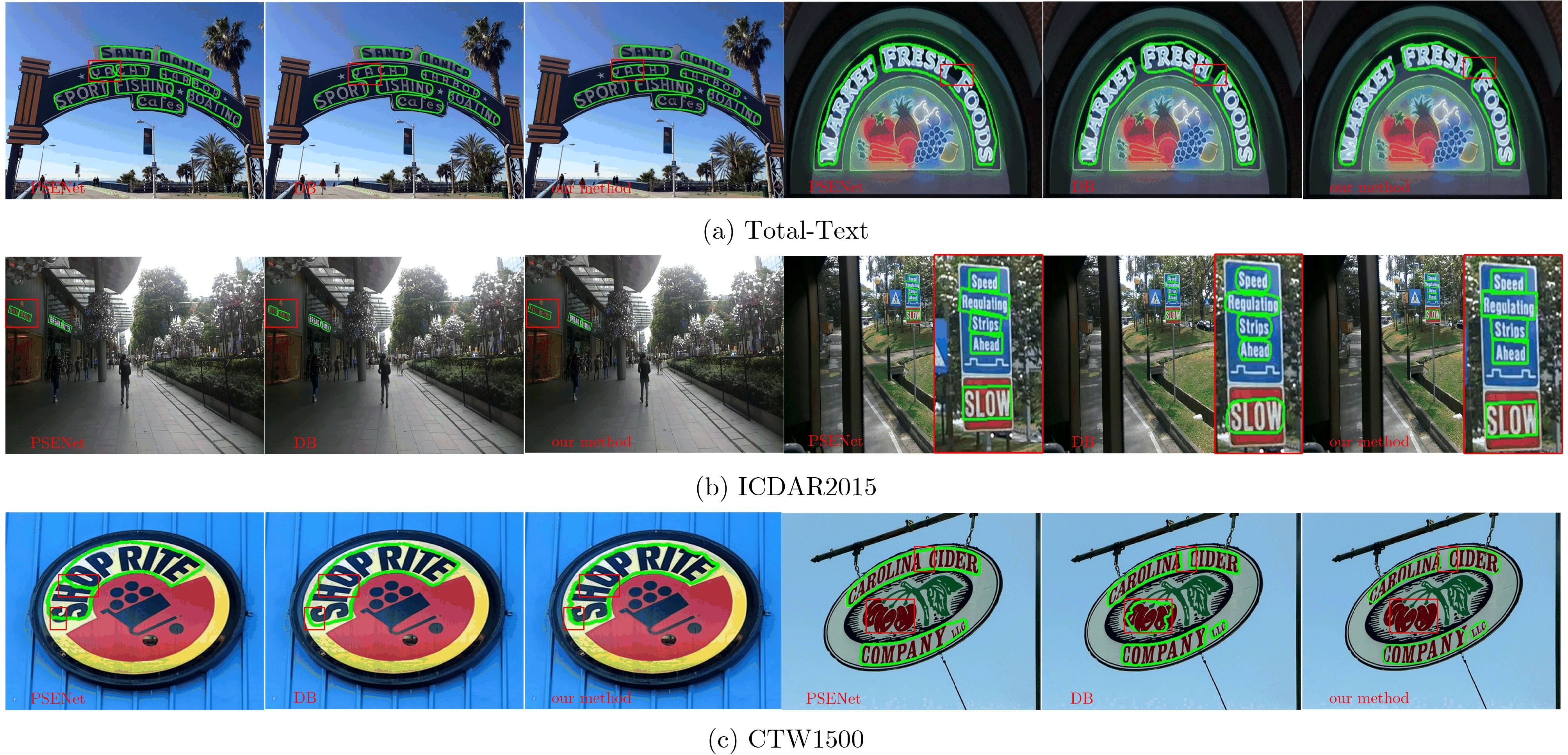
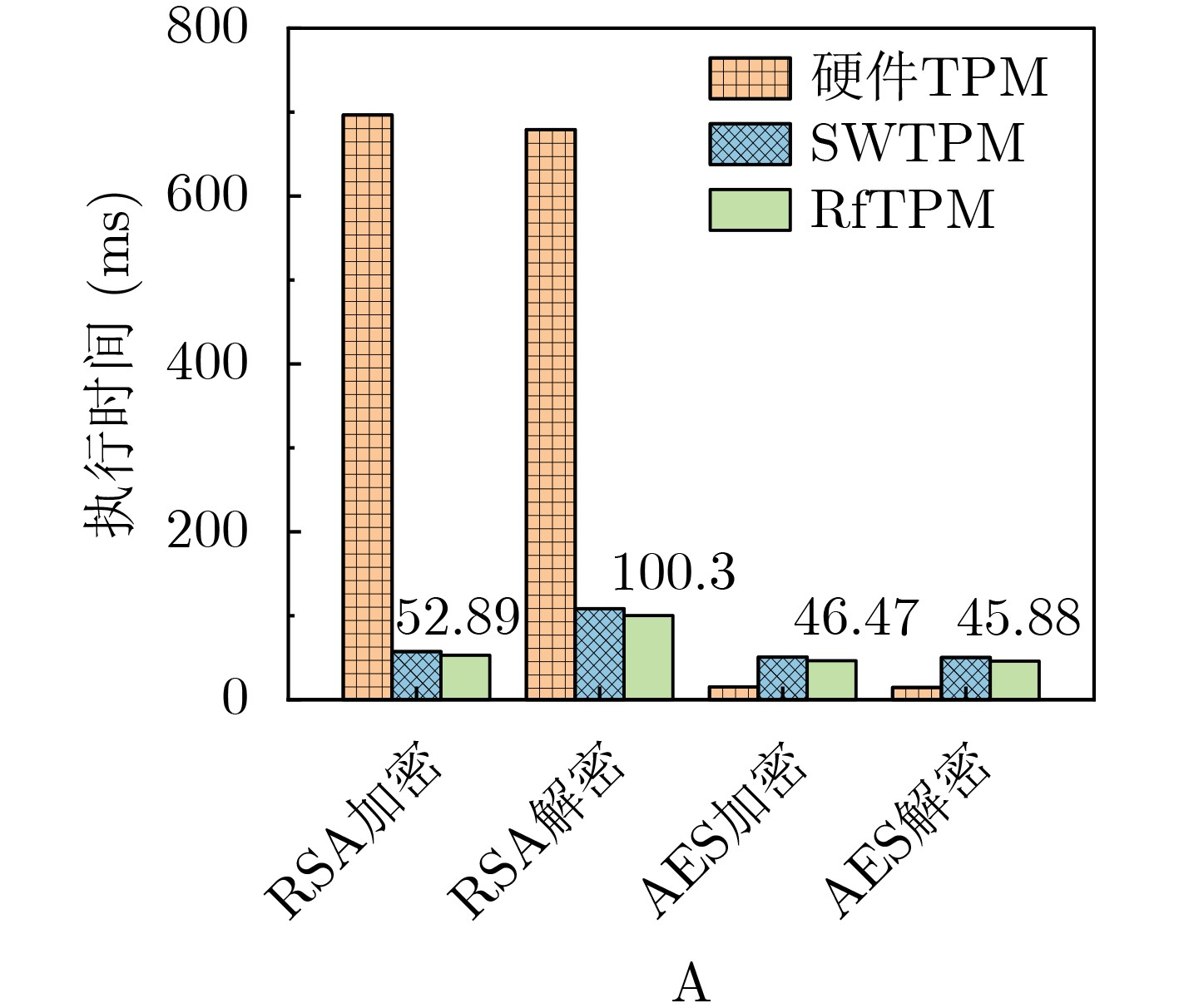
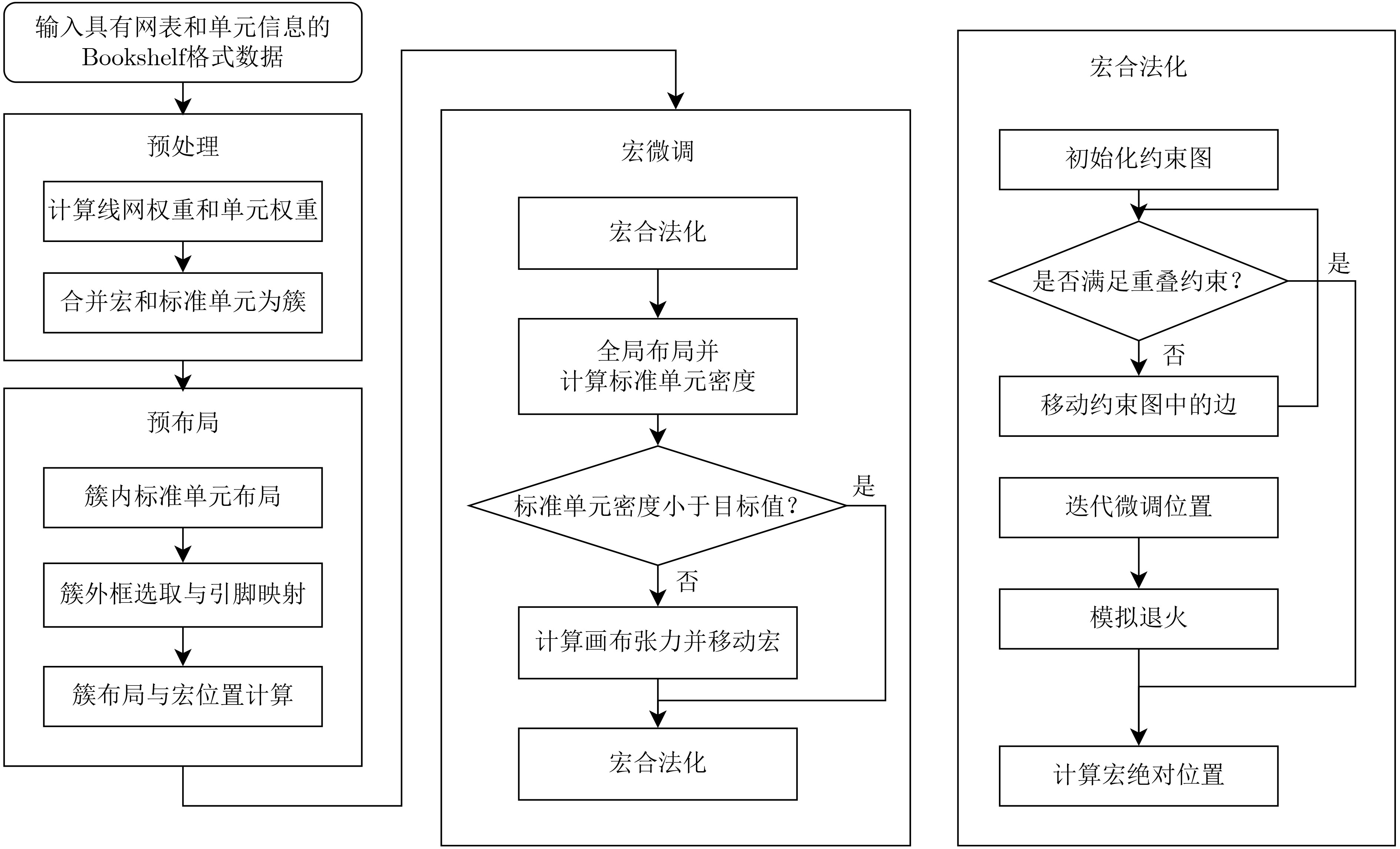
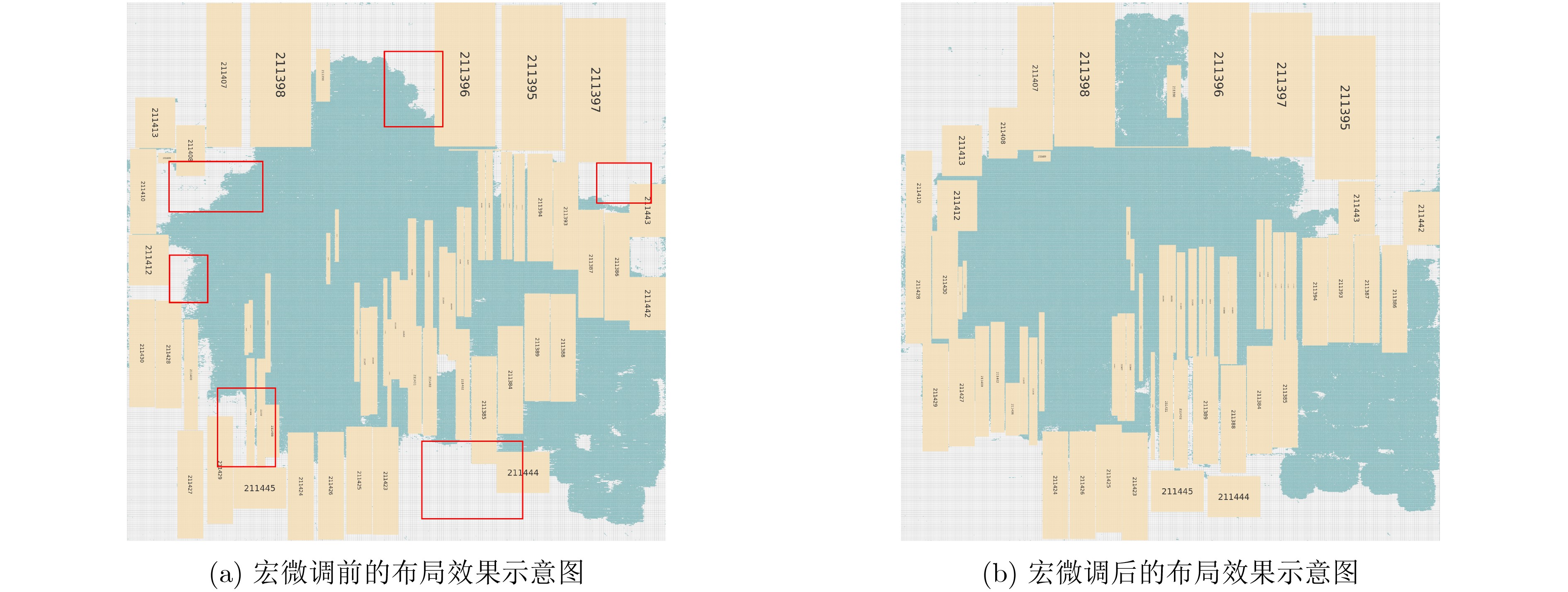
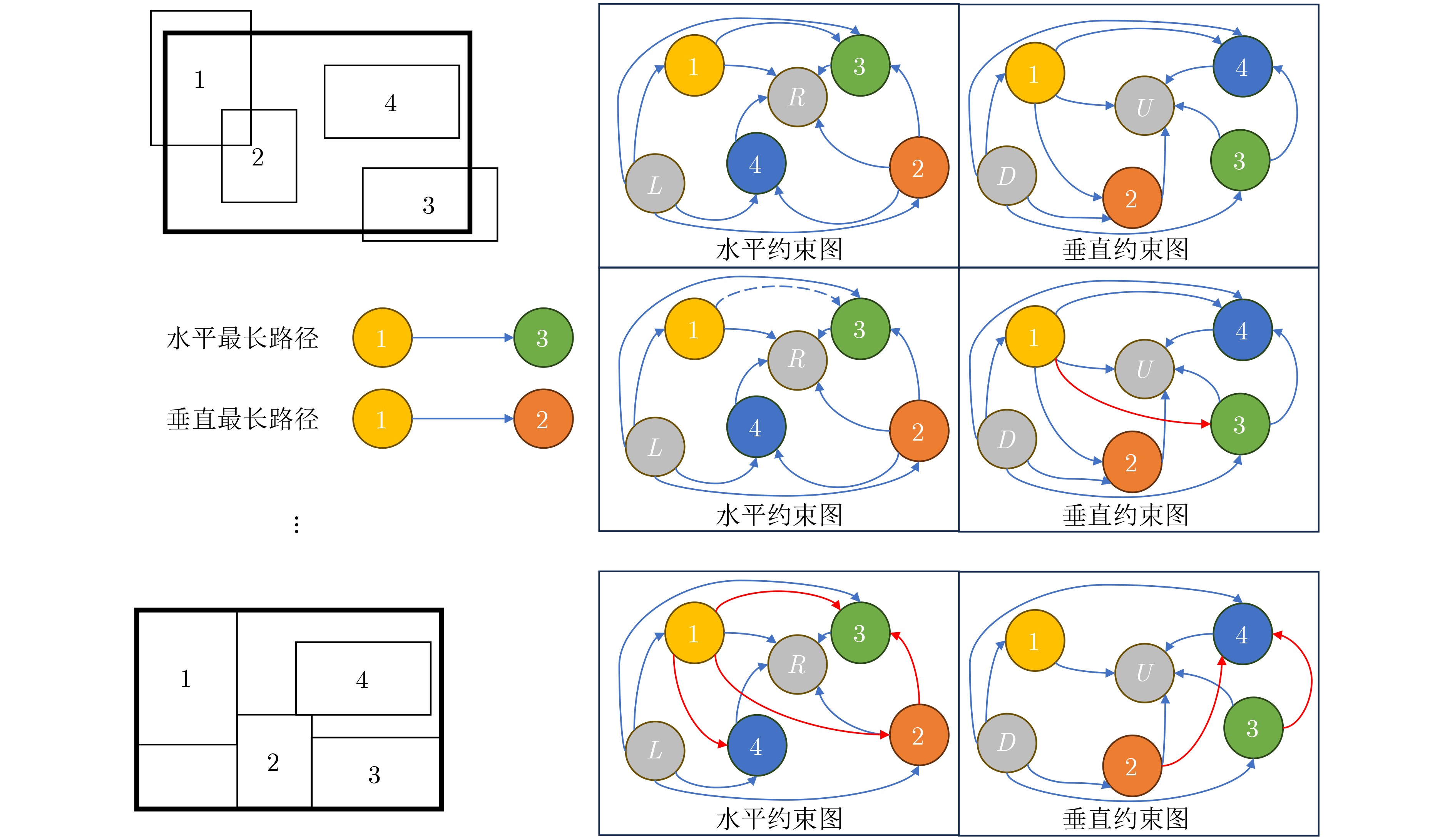
2025, 47(7): 2050-2061.
doi: 10.11999/JEIT250013
Abstract:
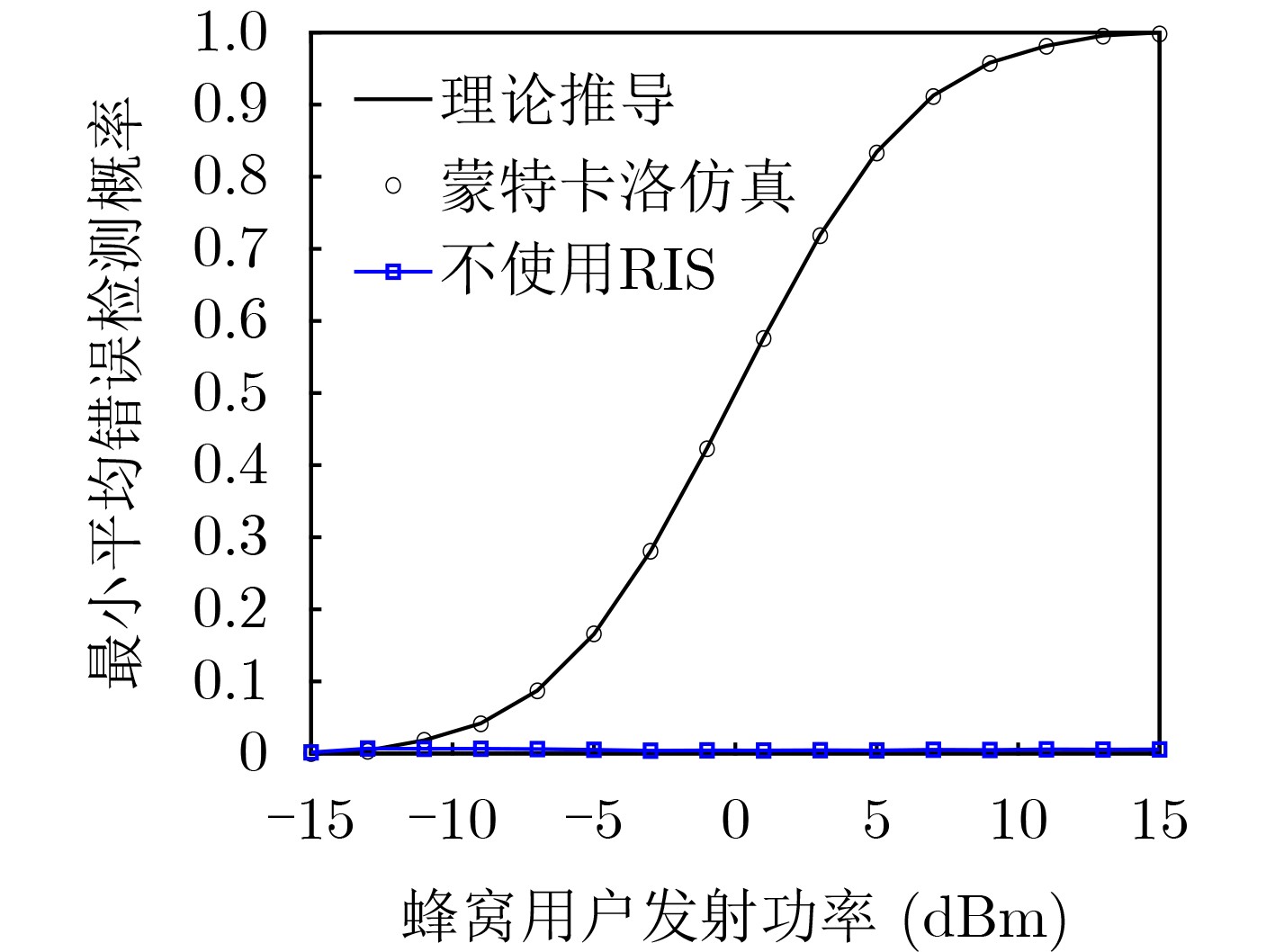
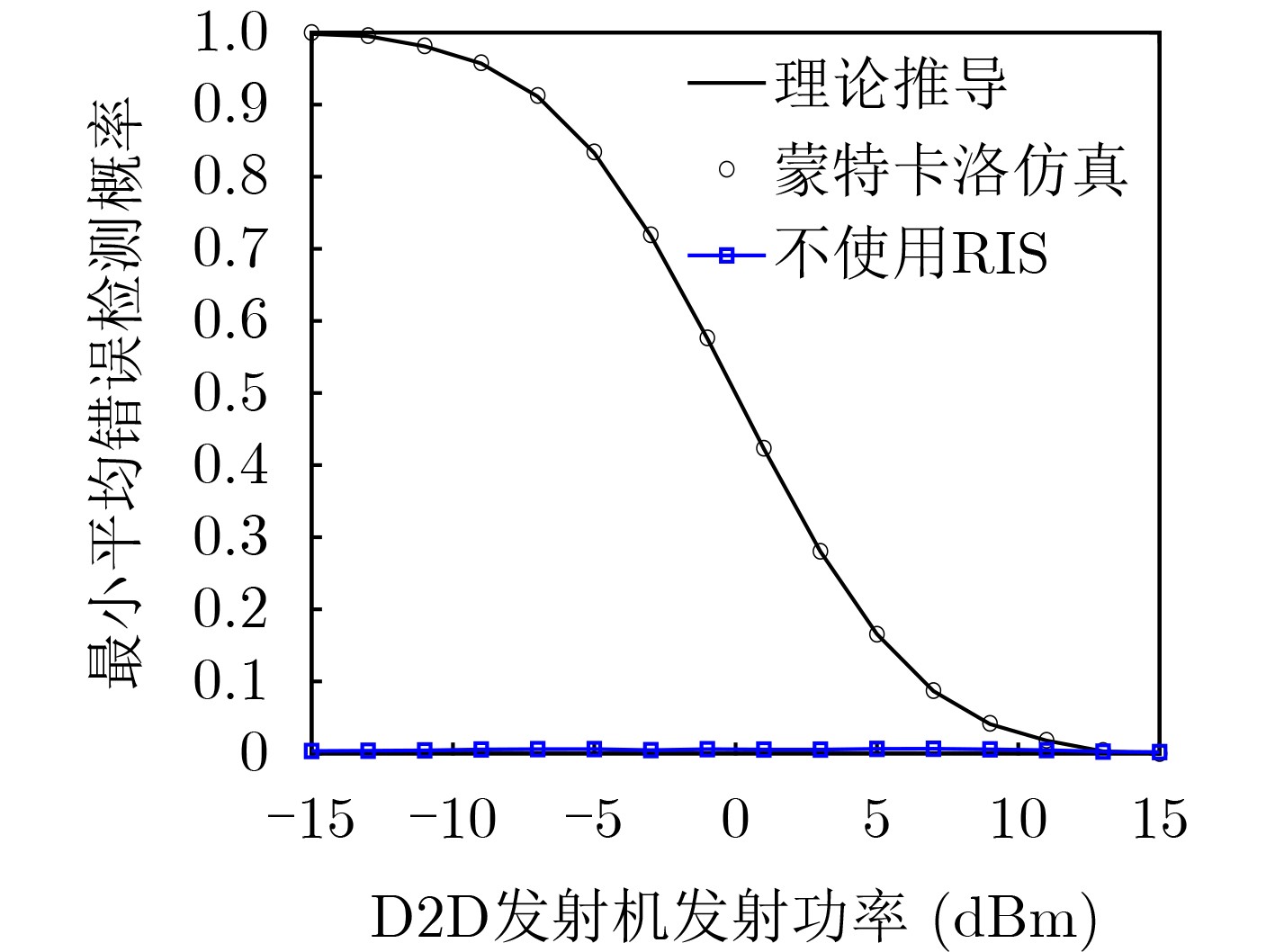
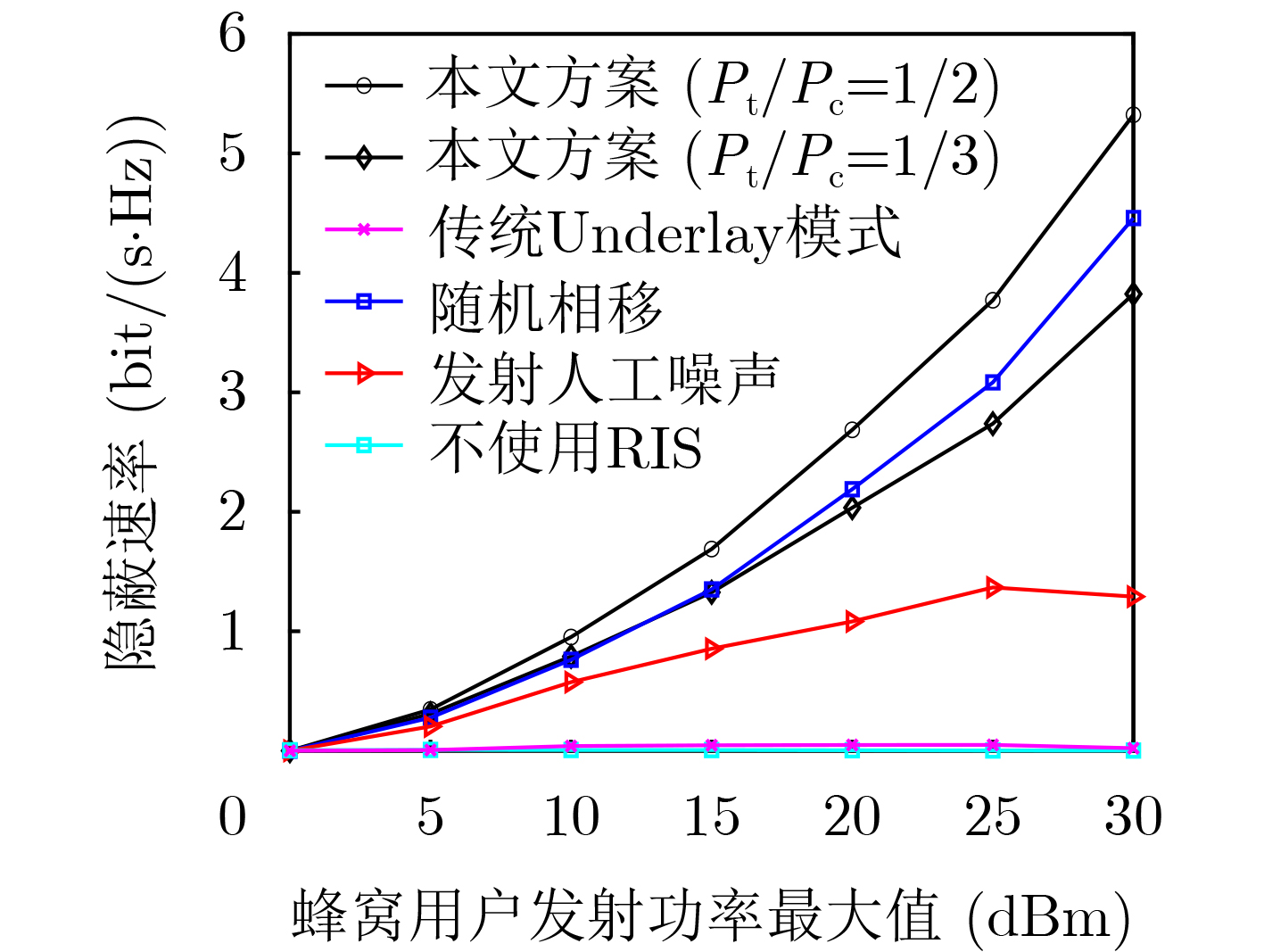
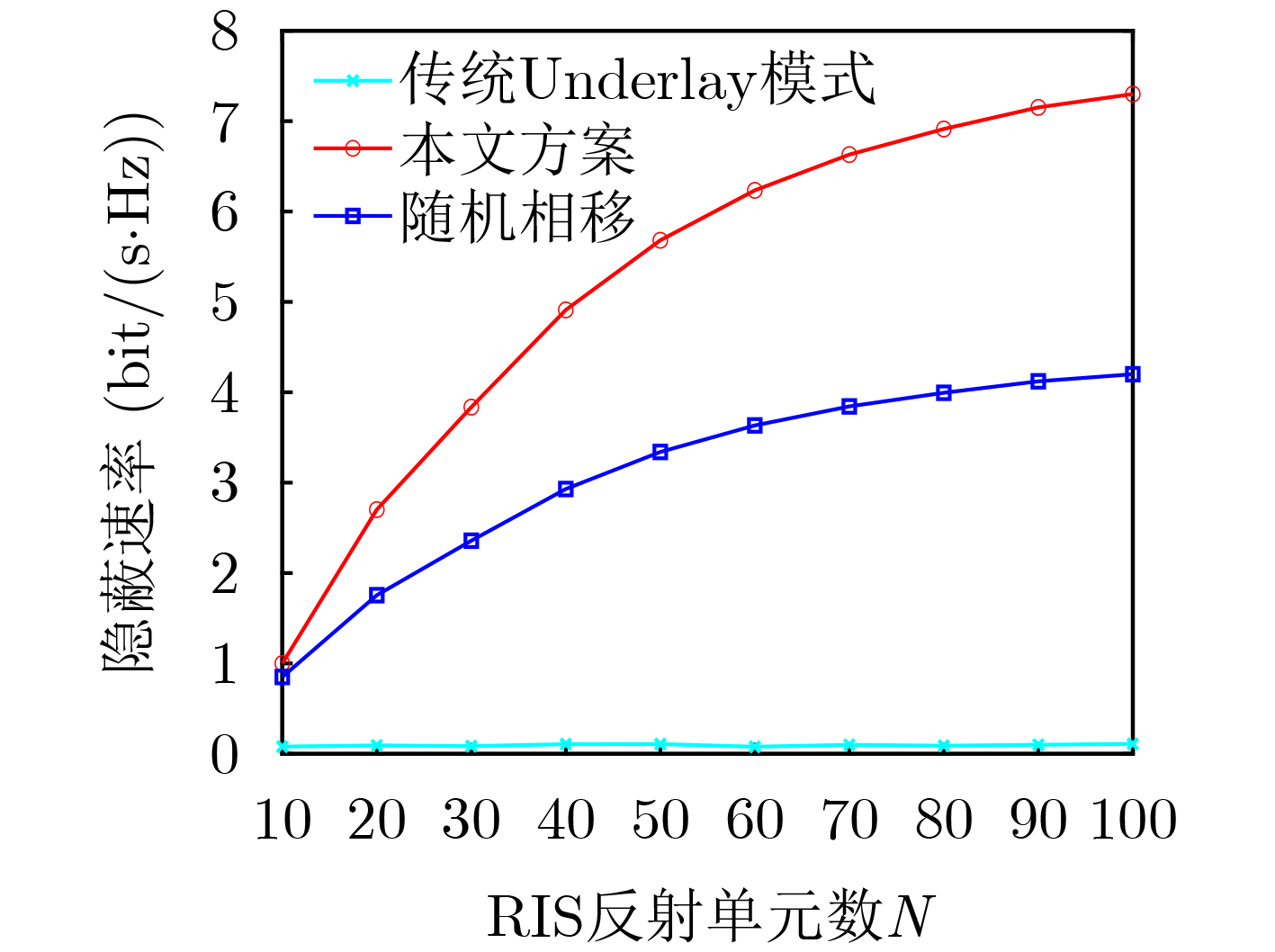
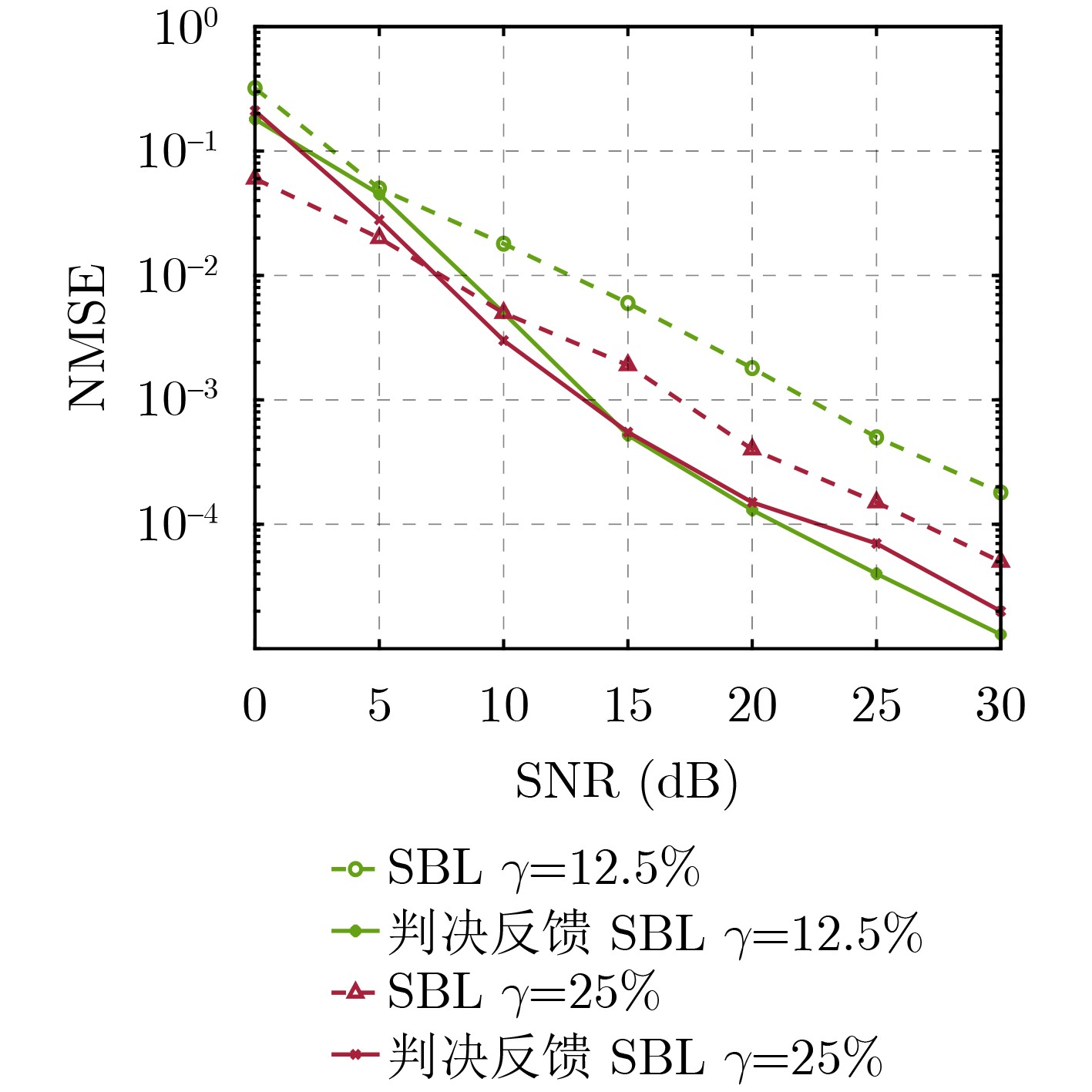
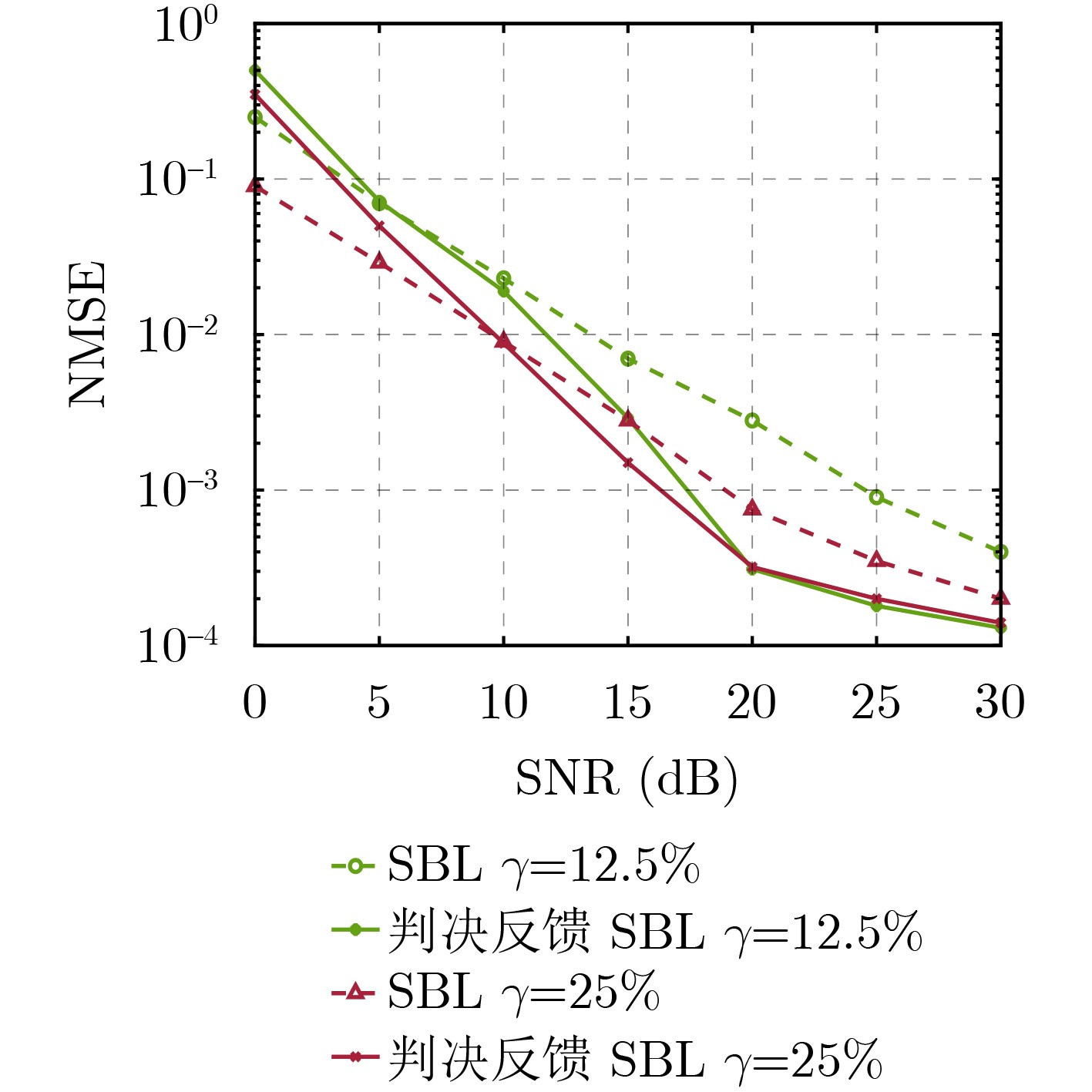
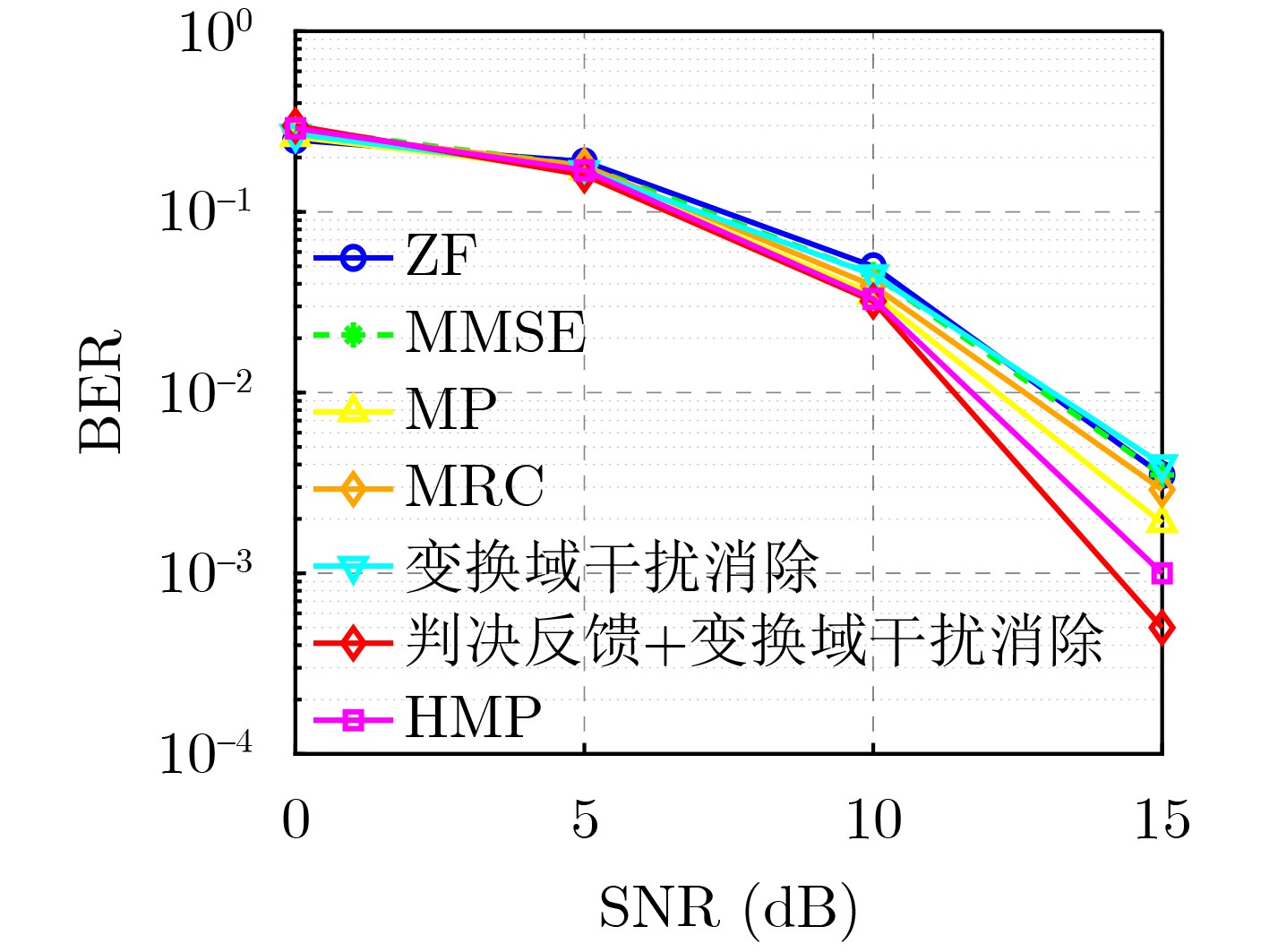
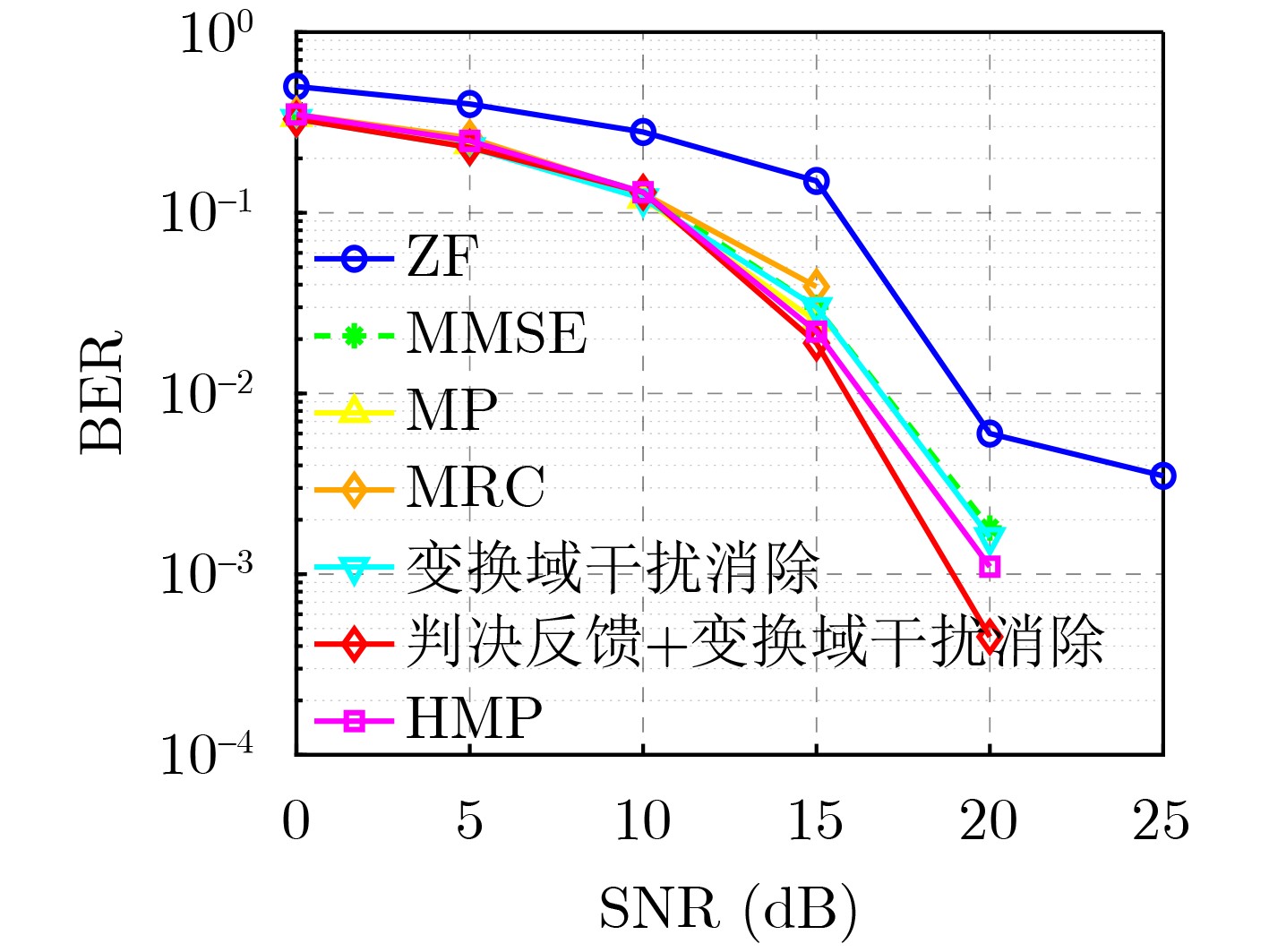
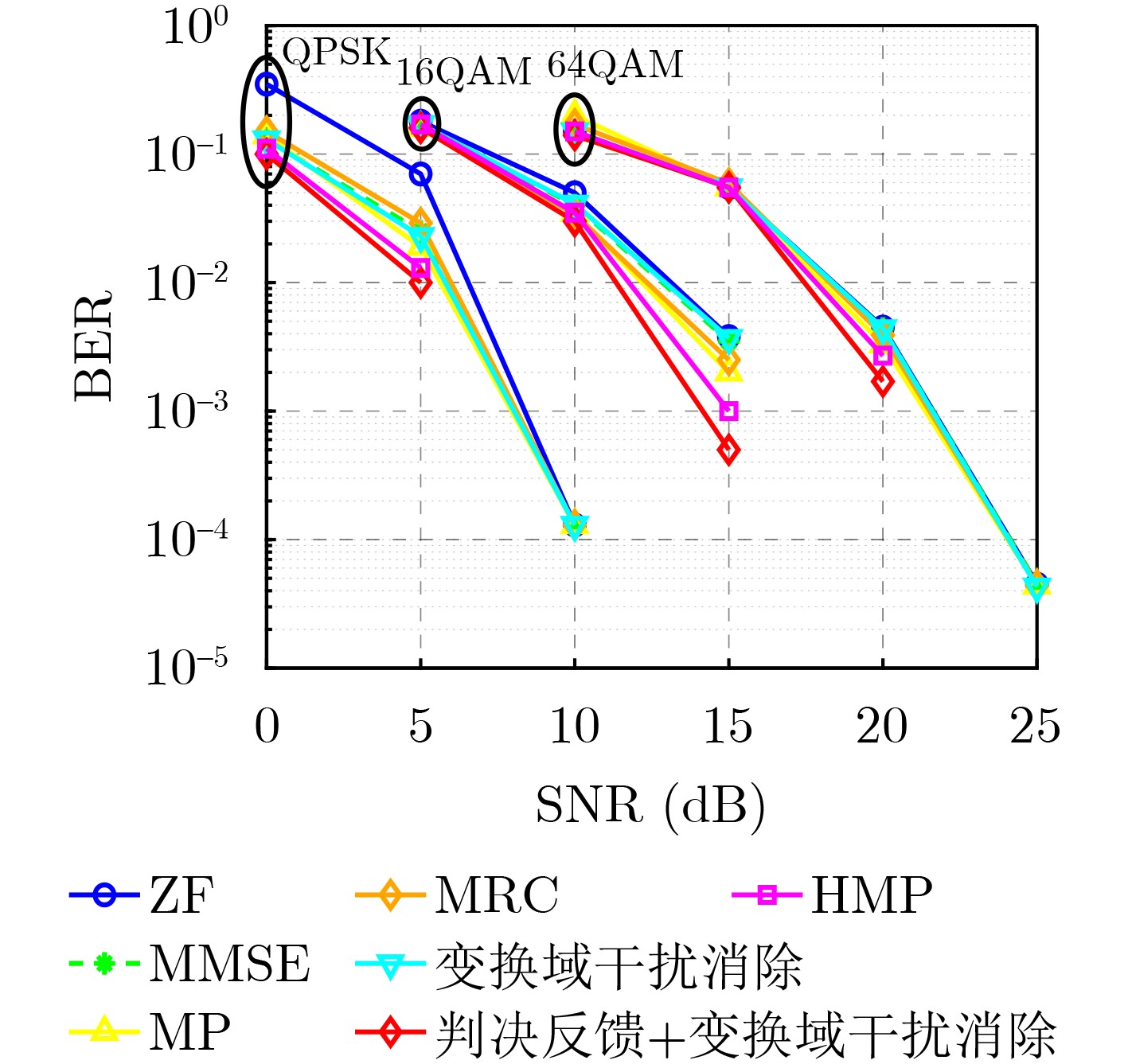
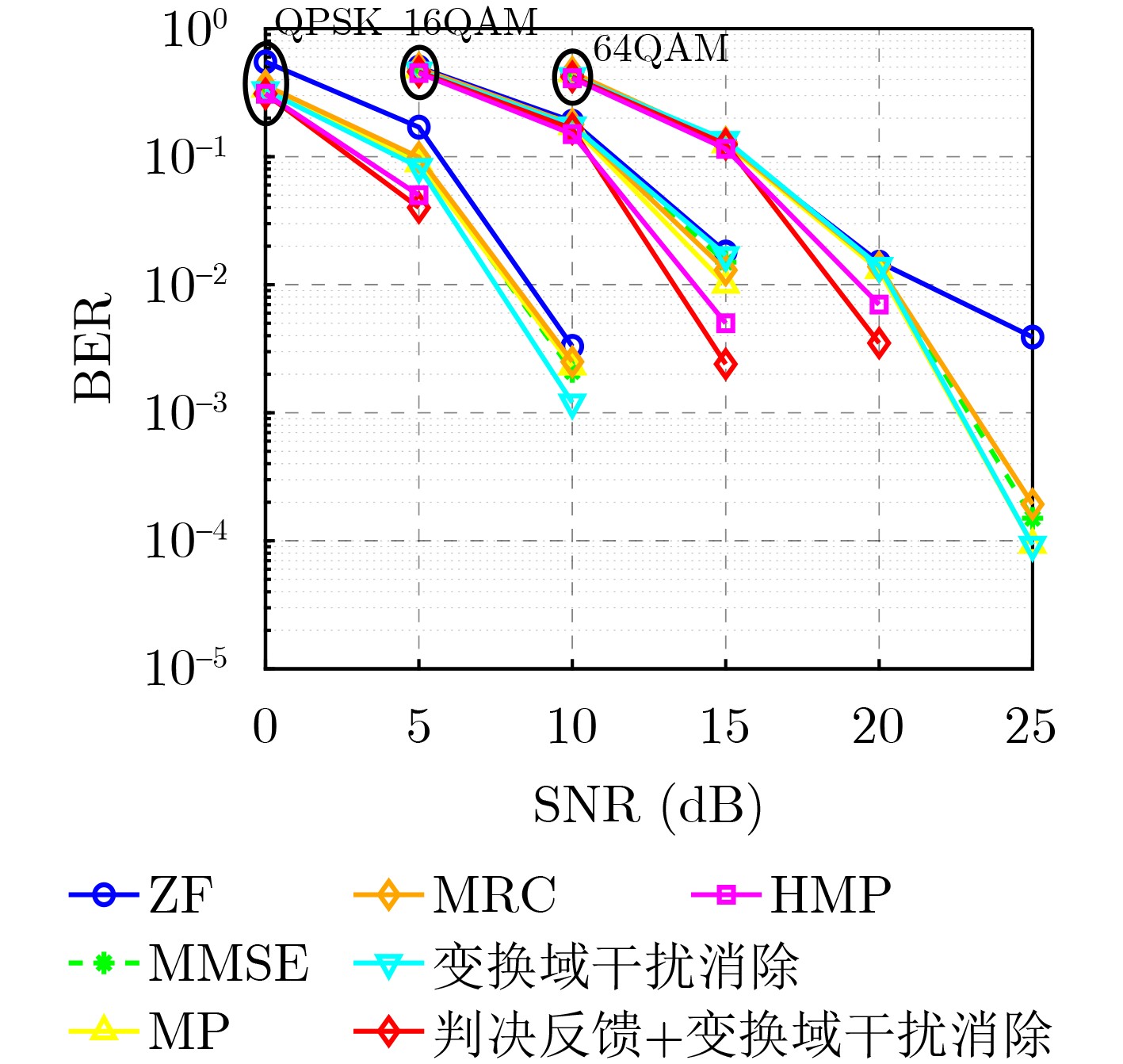
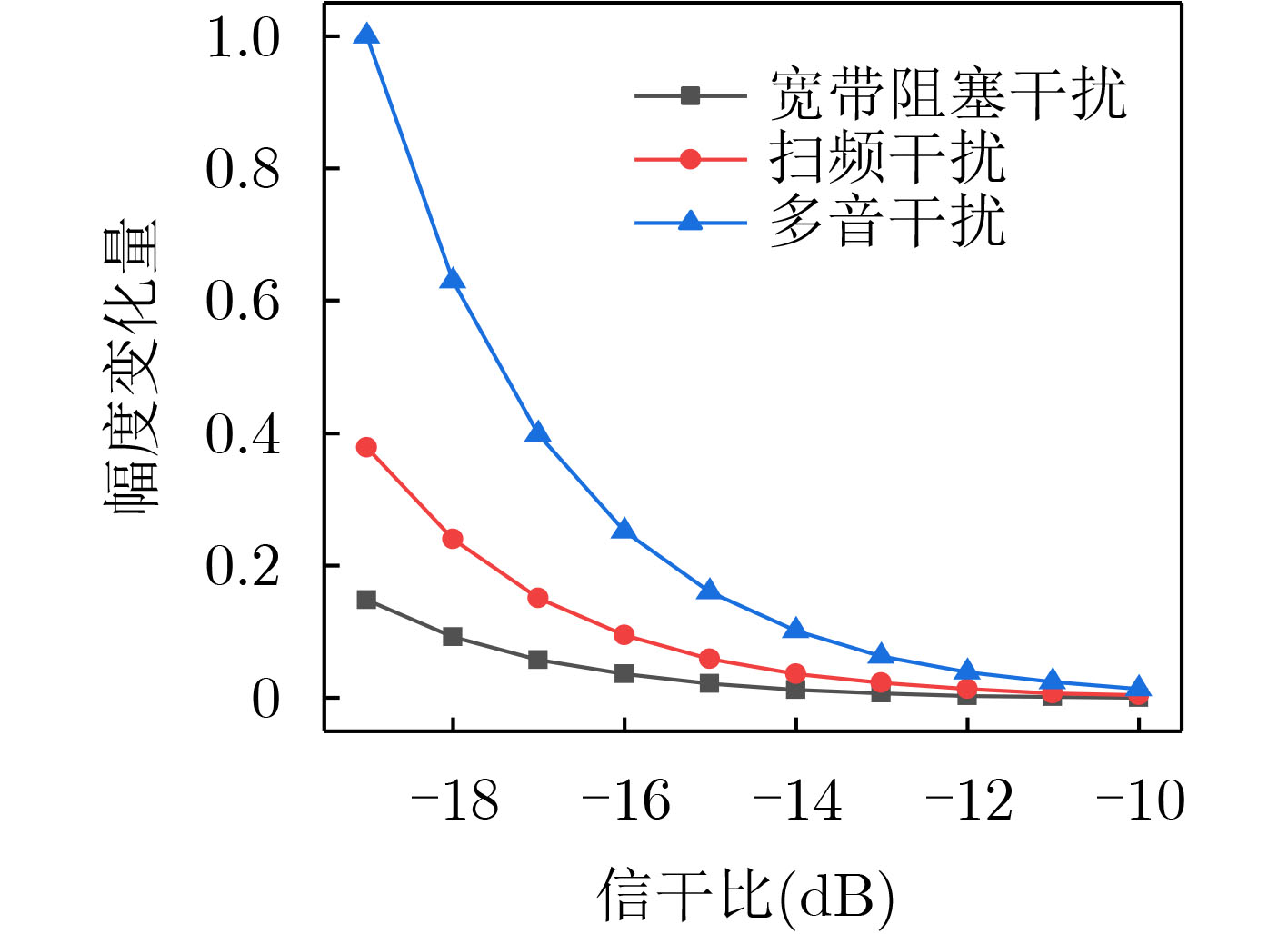
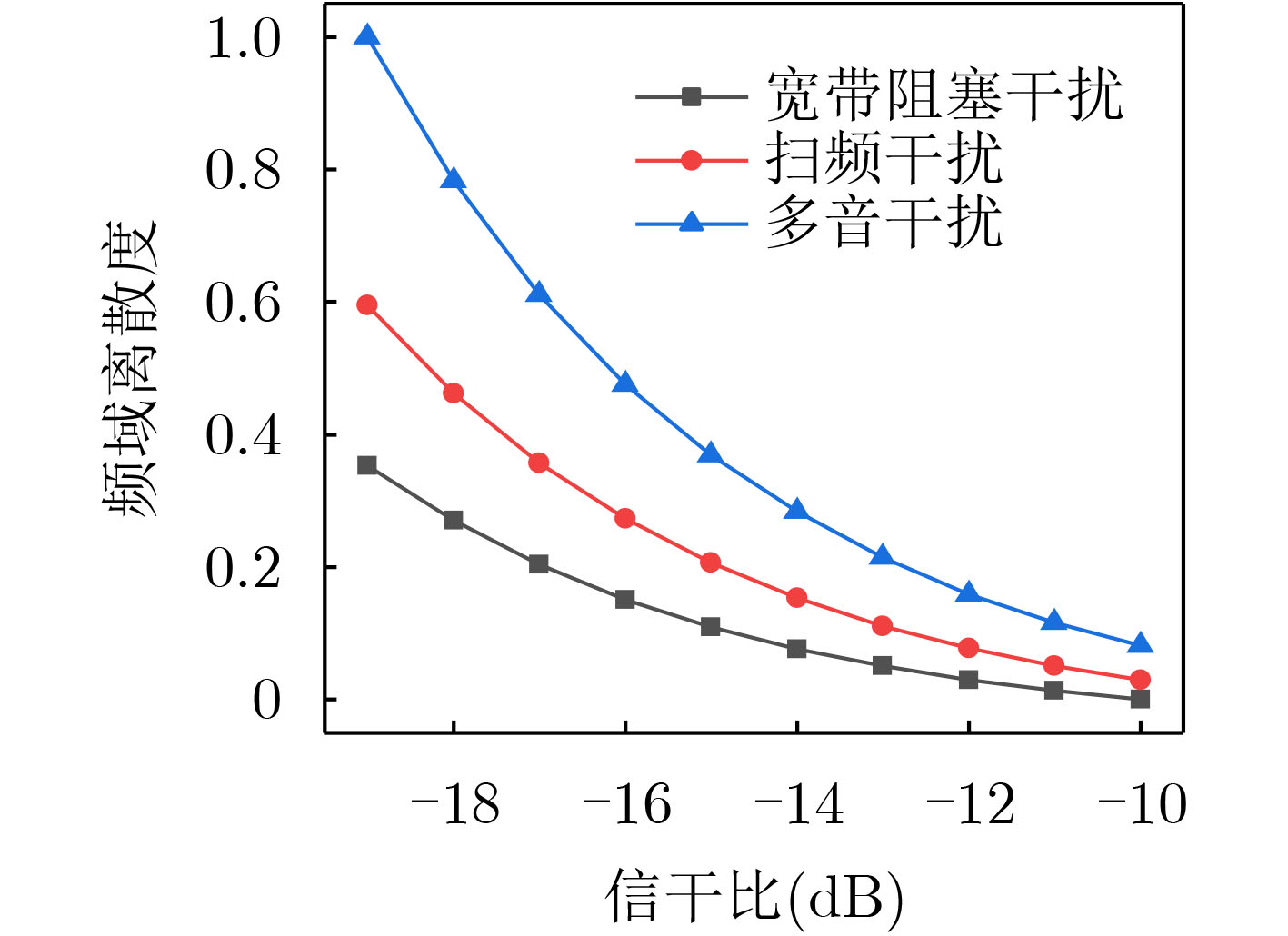
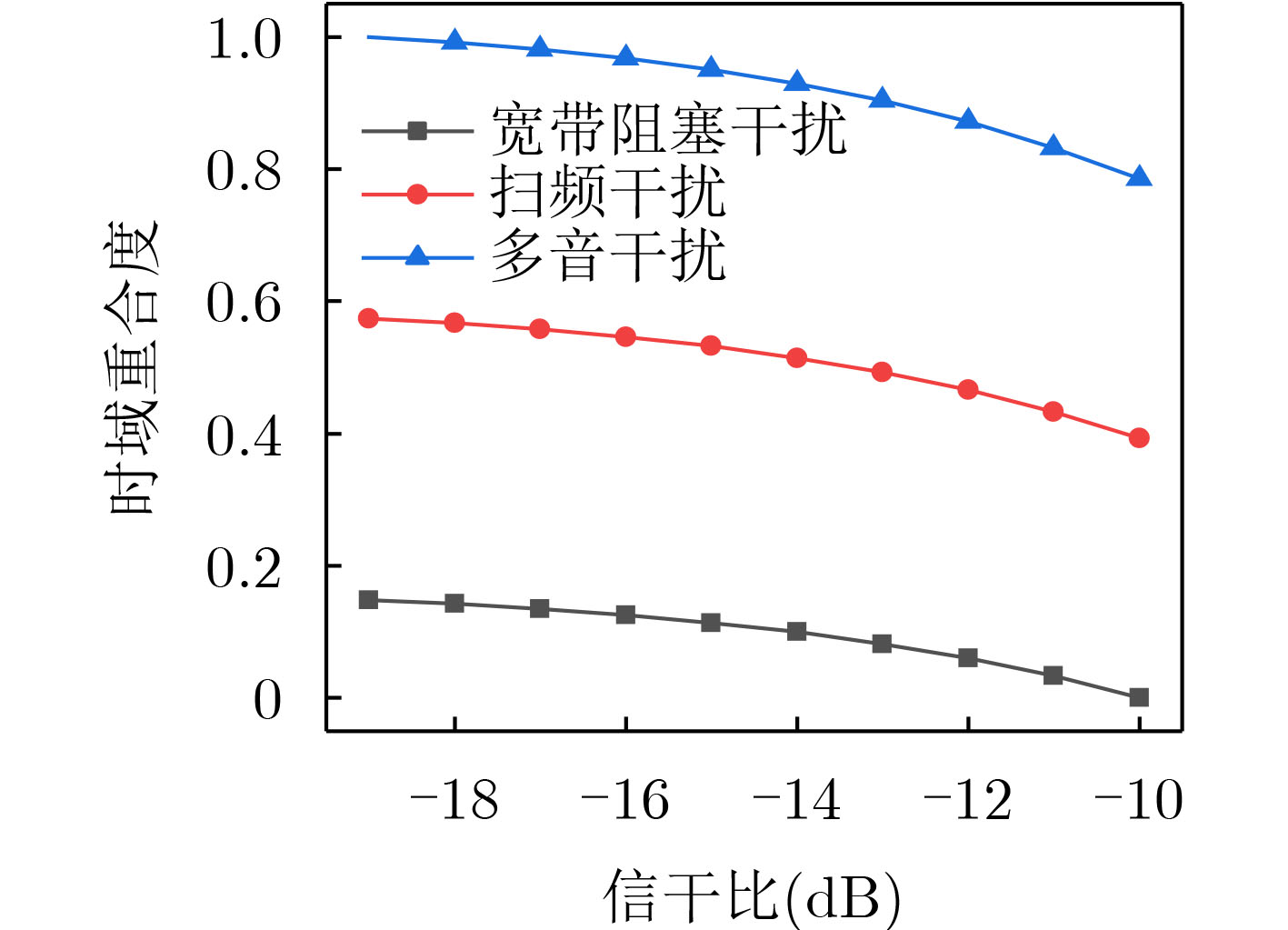
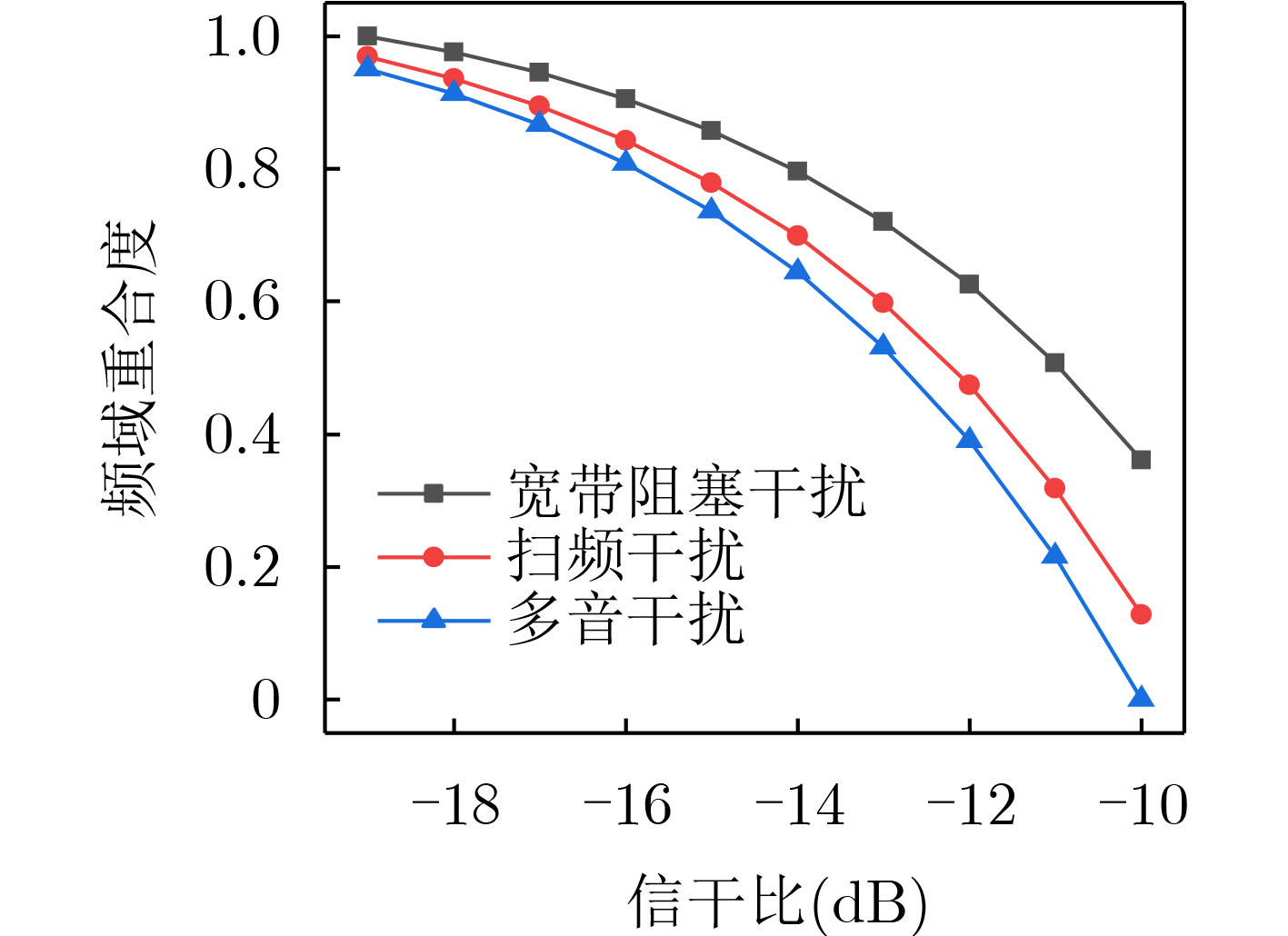
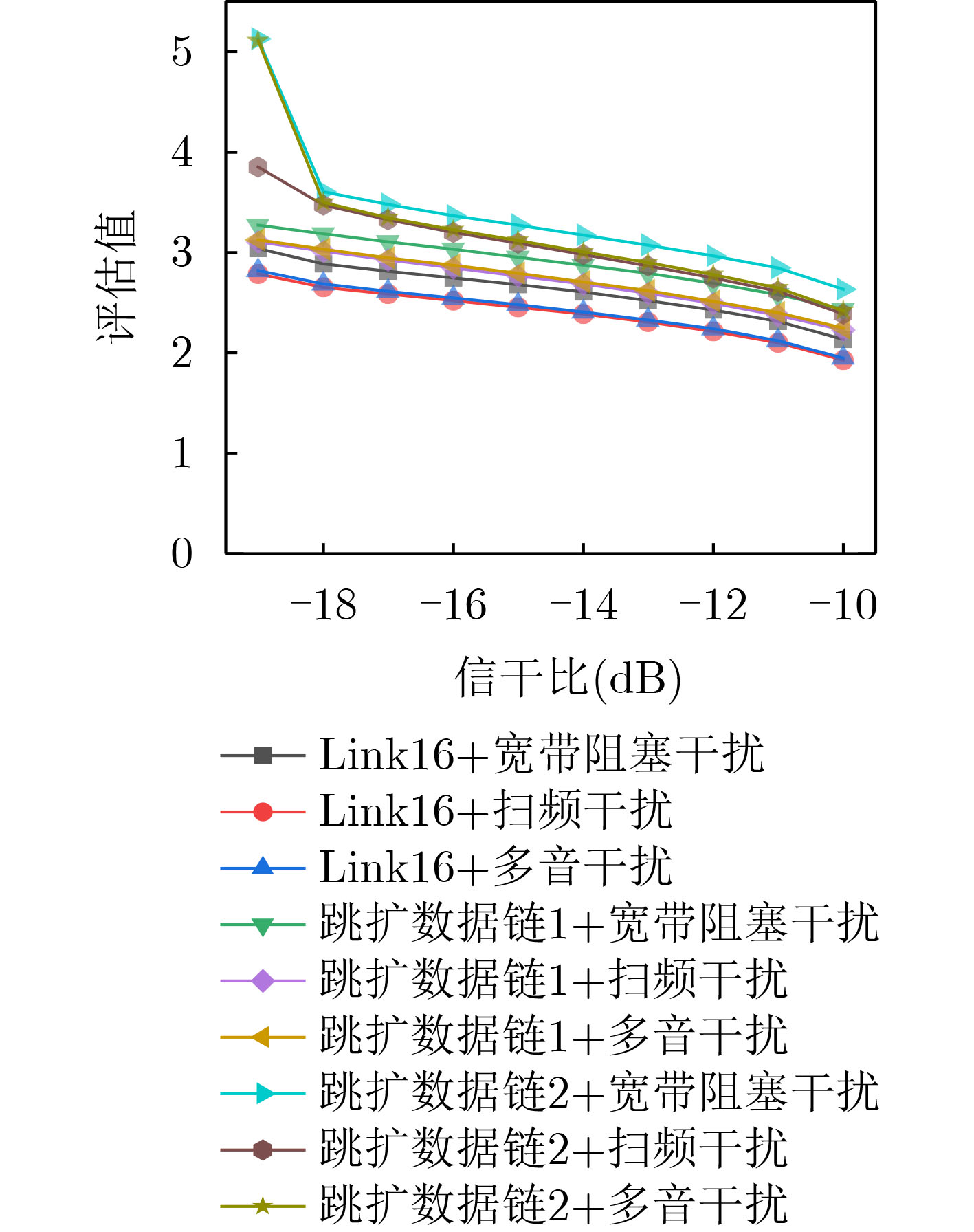
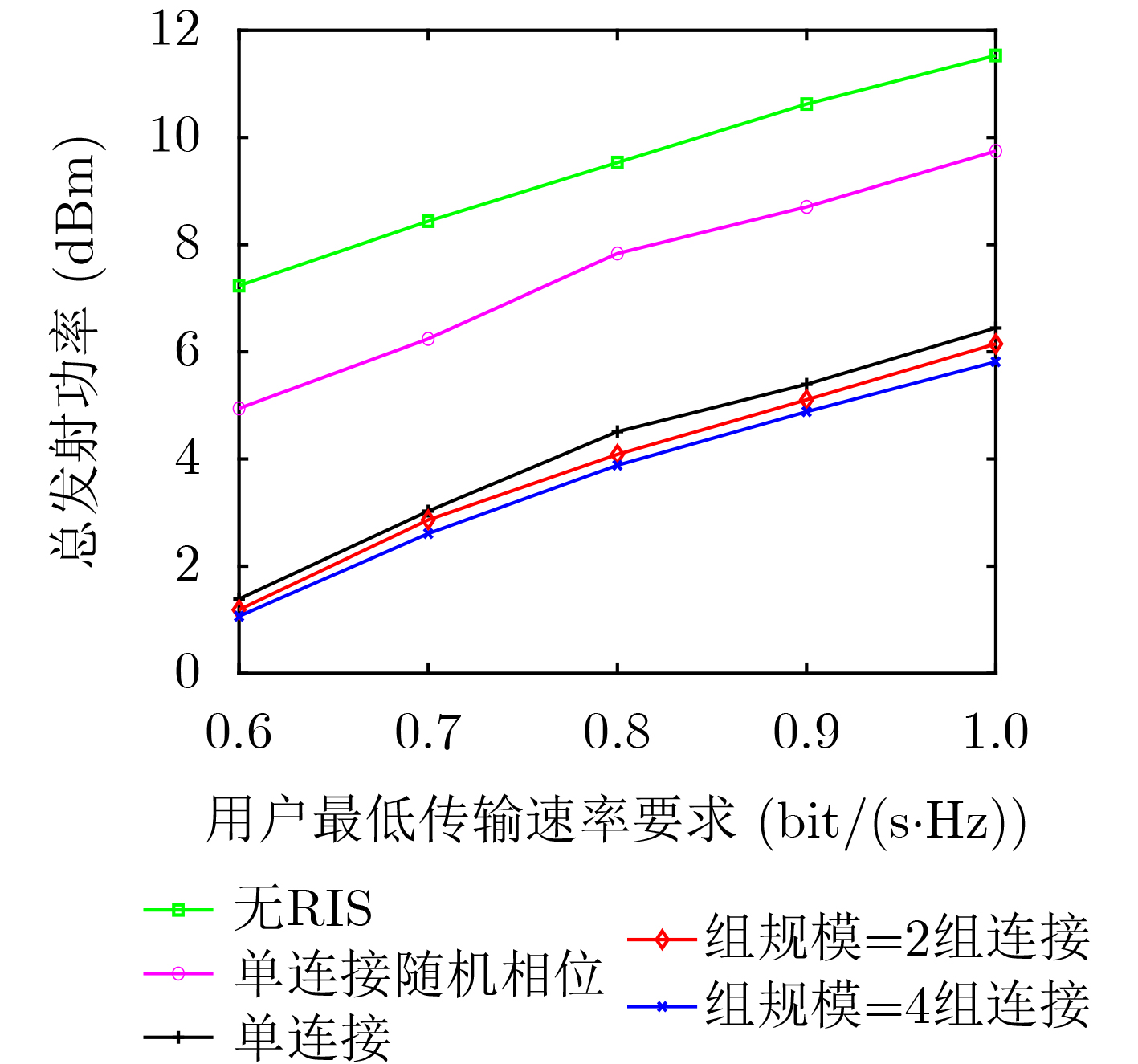
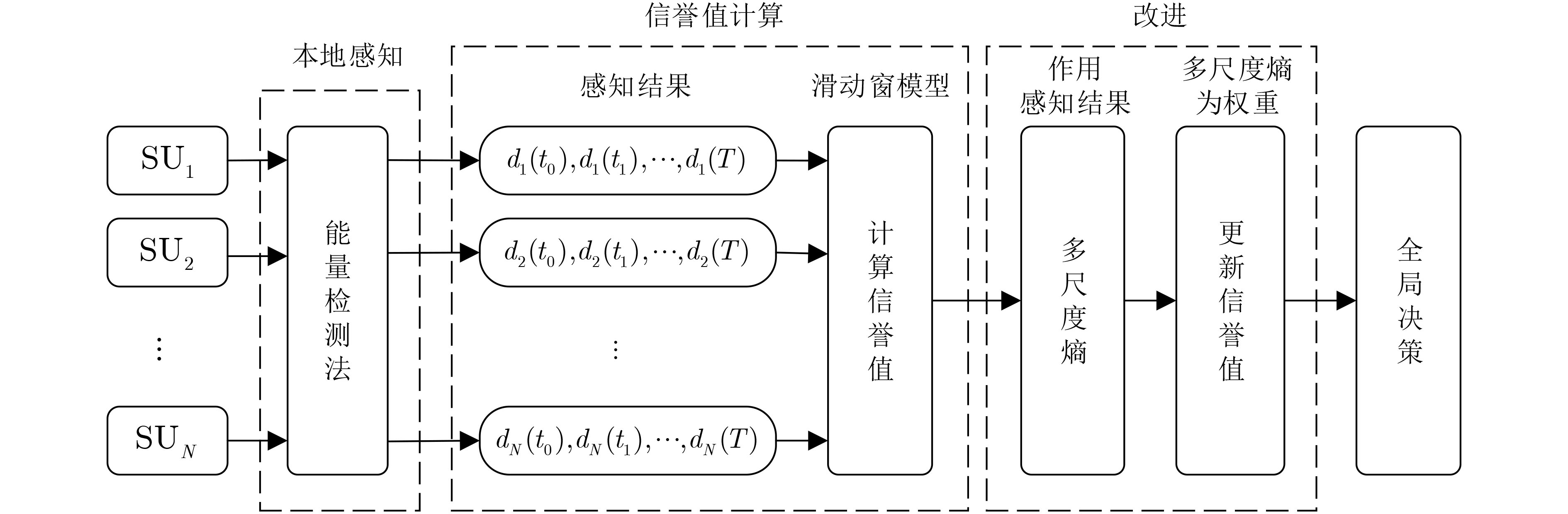
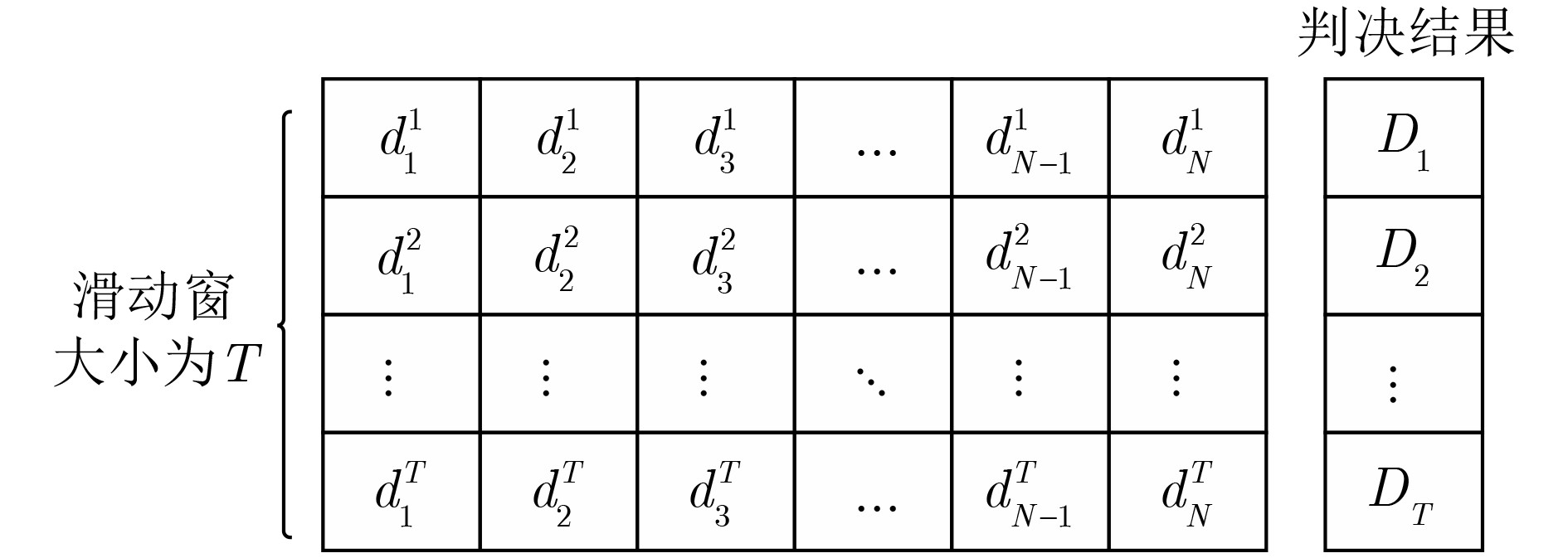
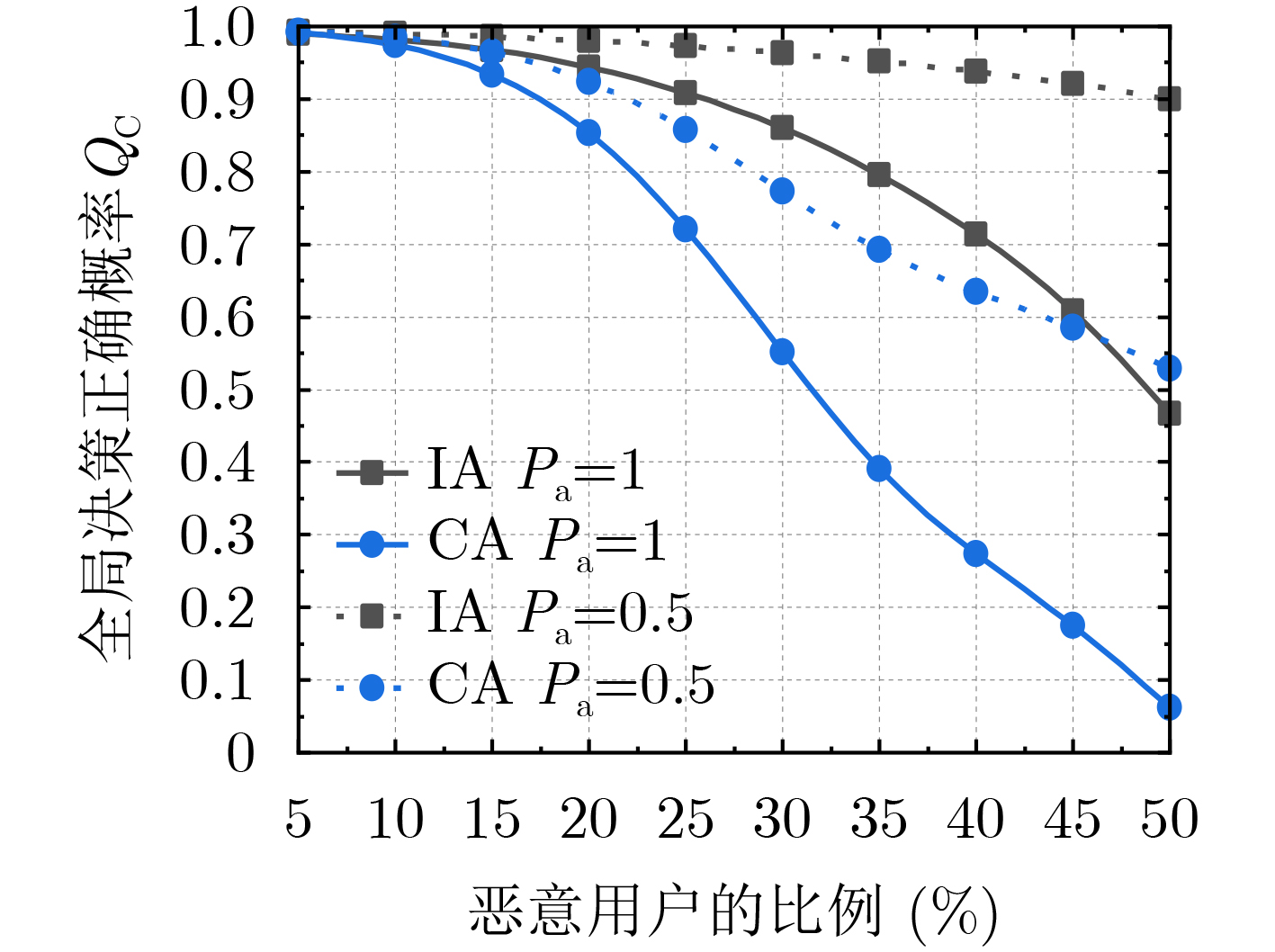
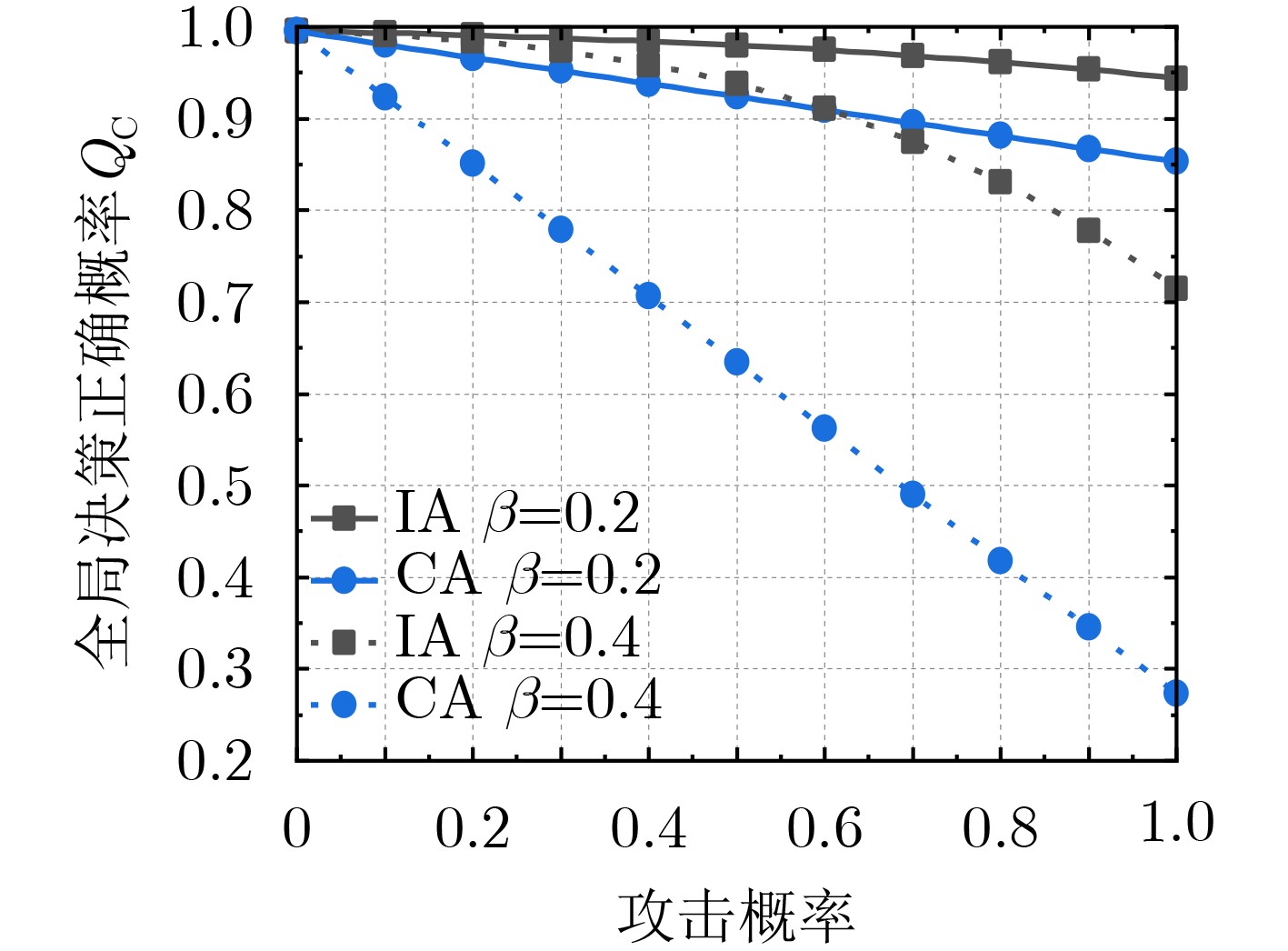
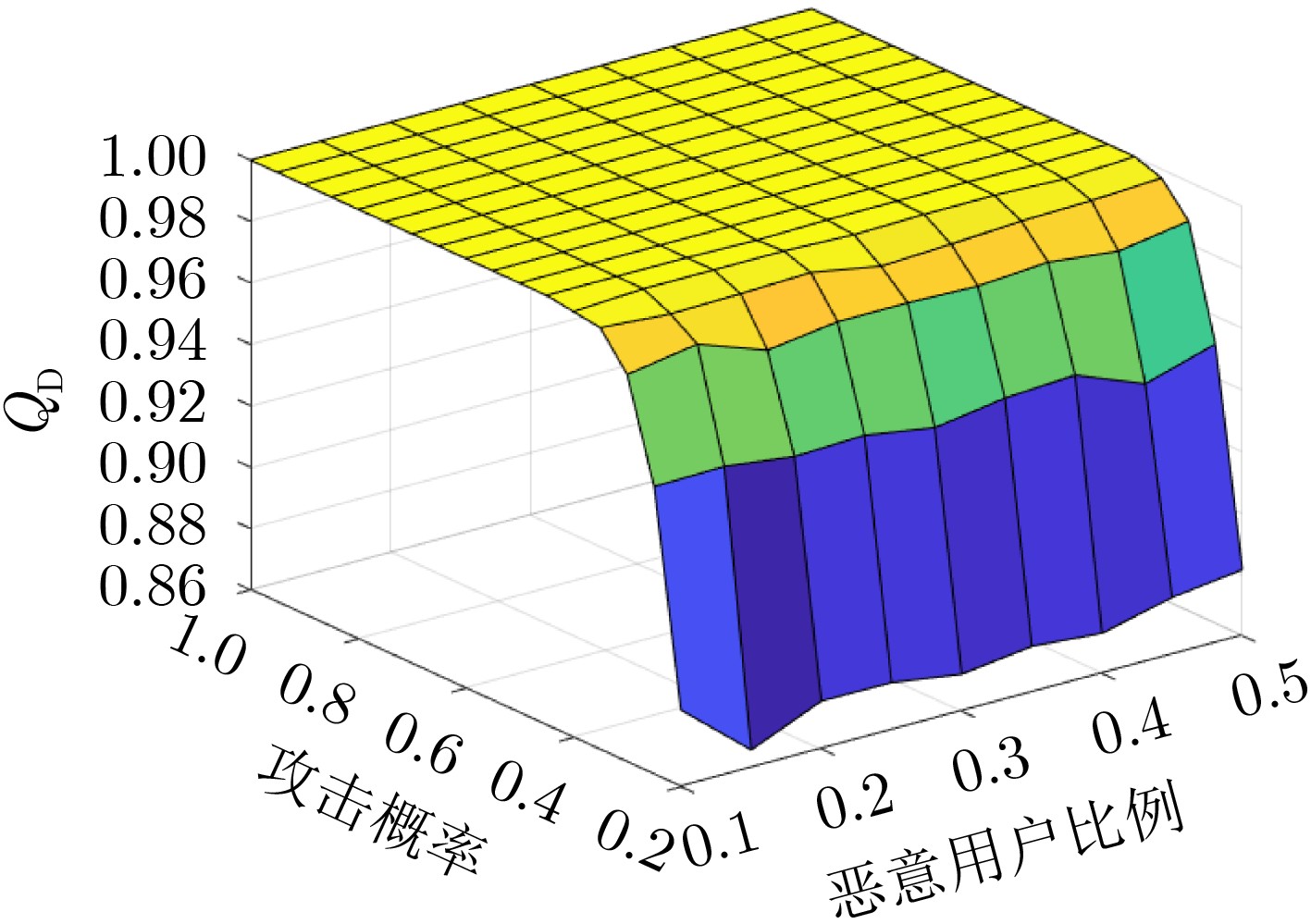
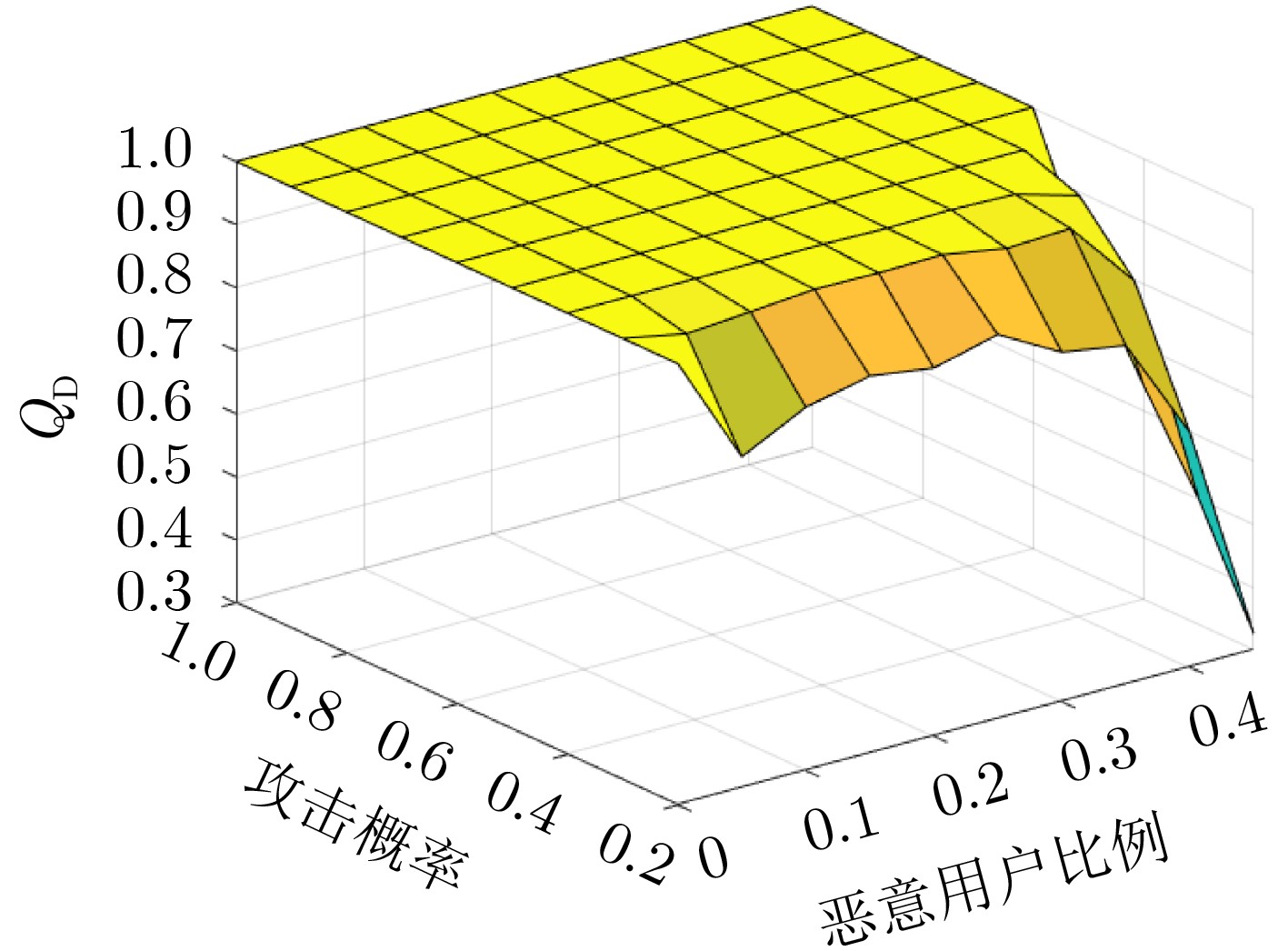
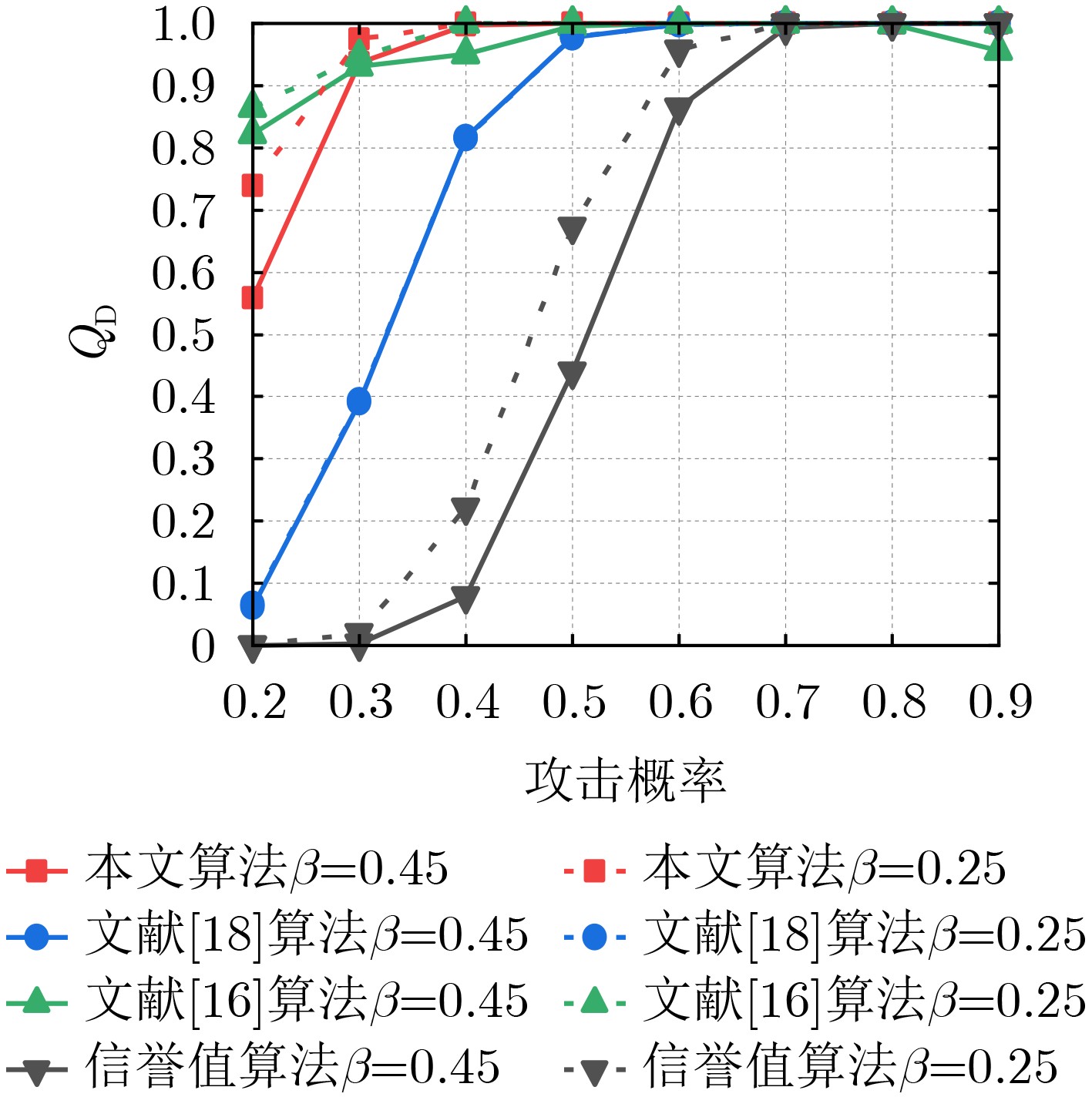
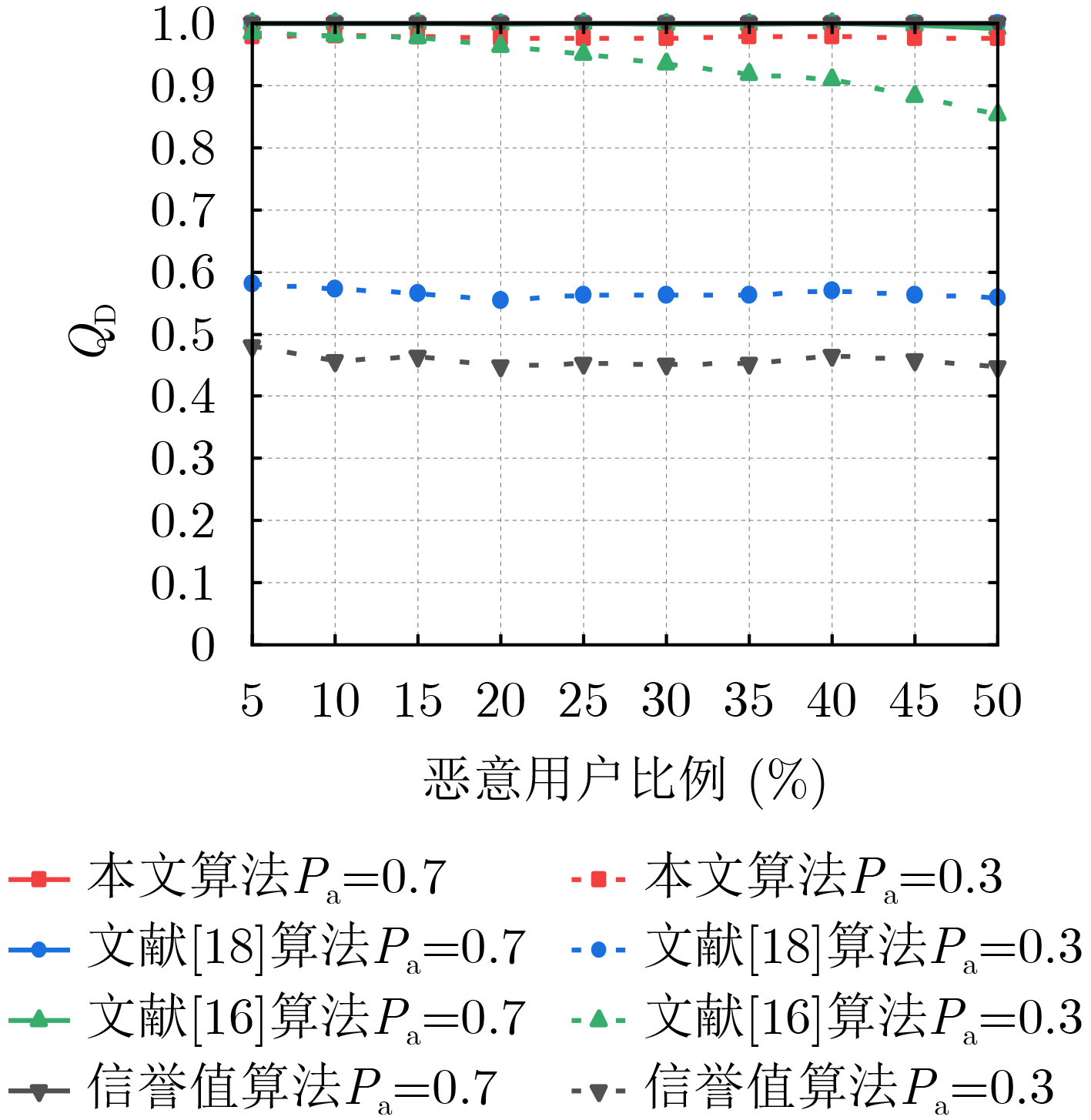
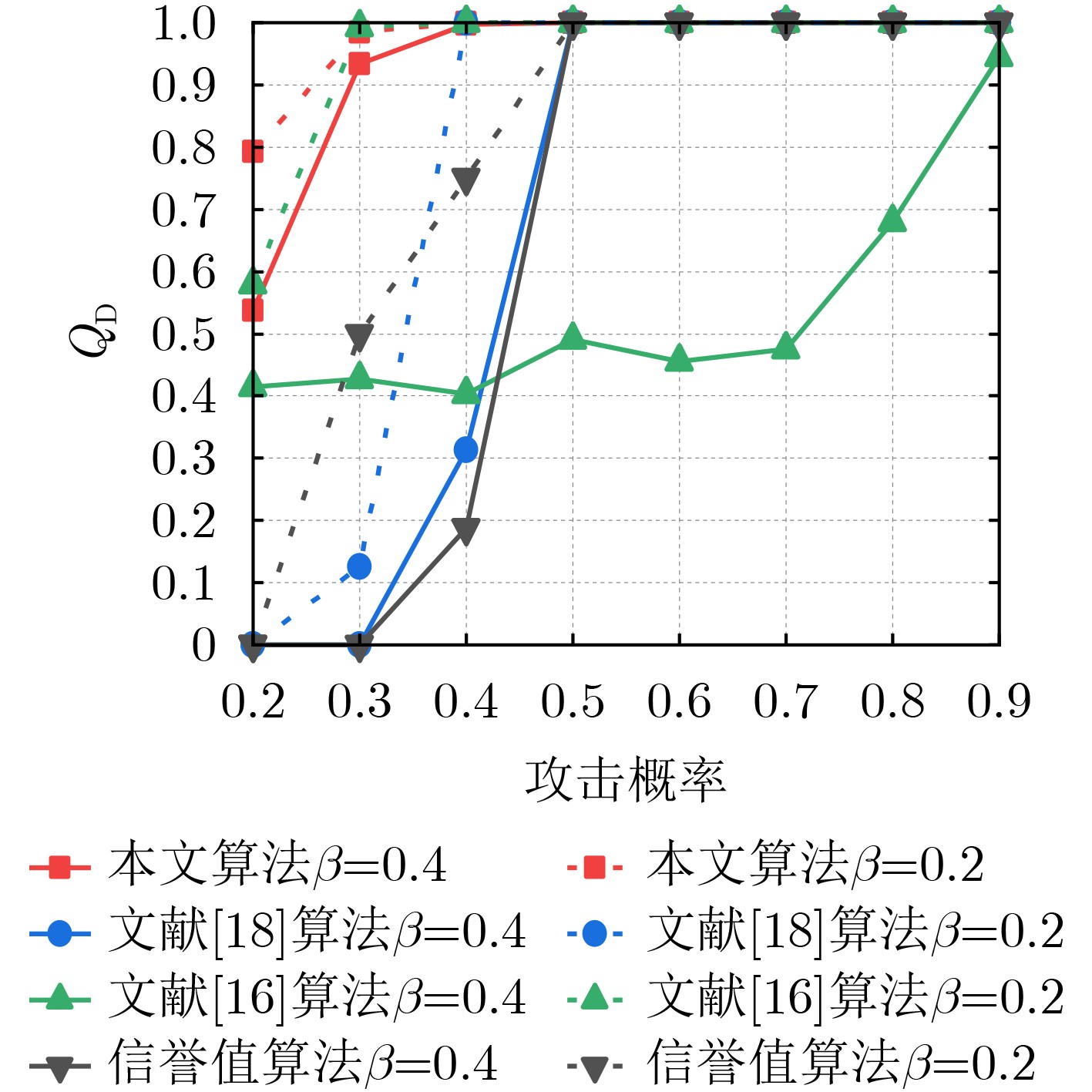
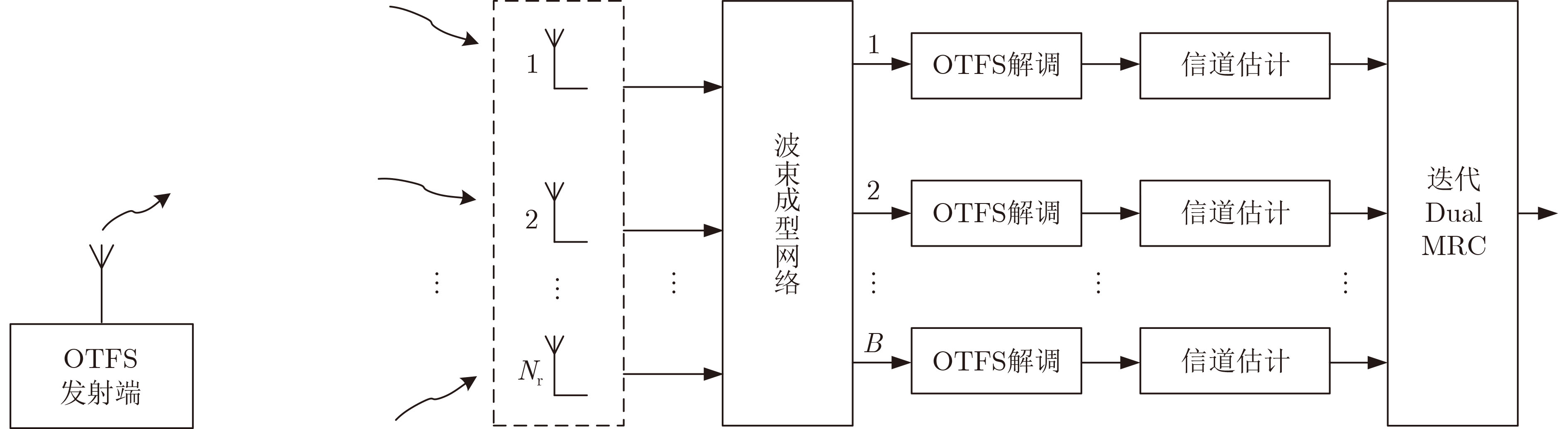
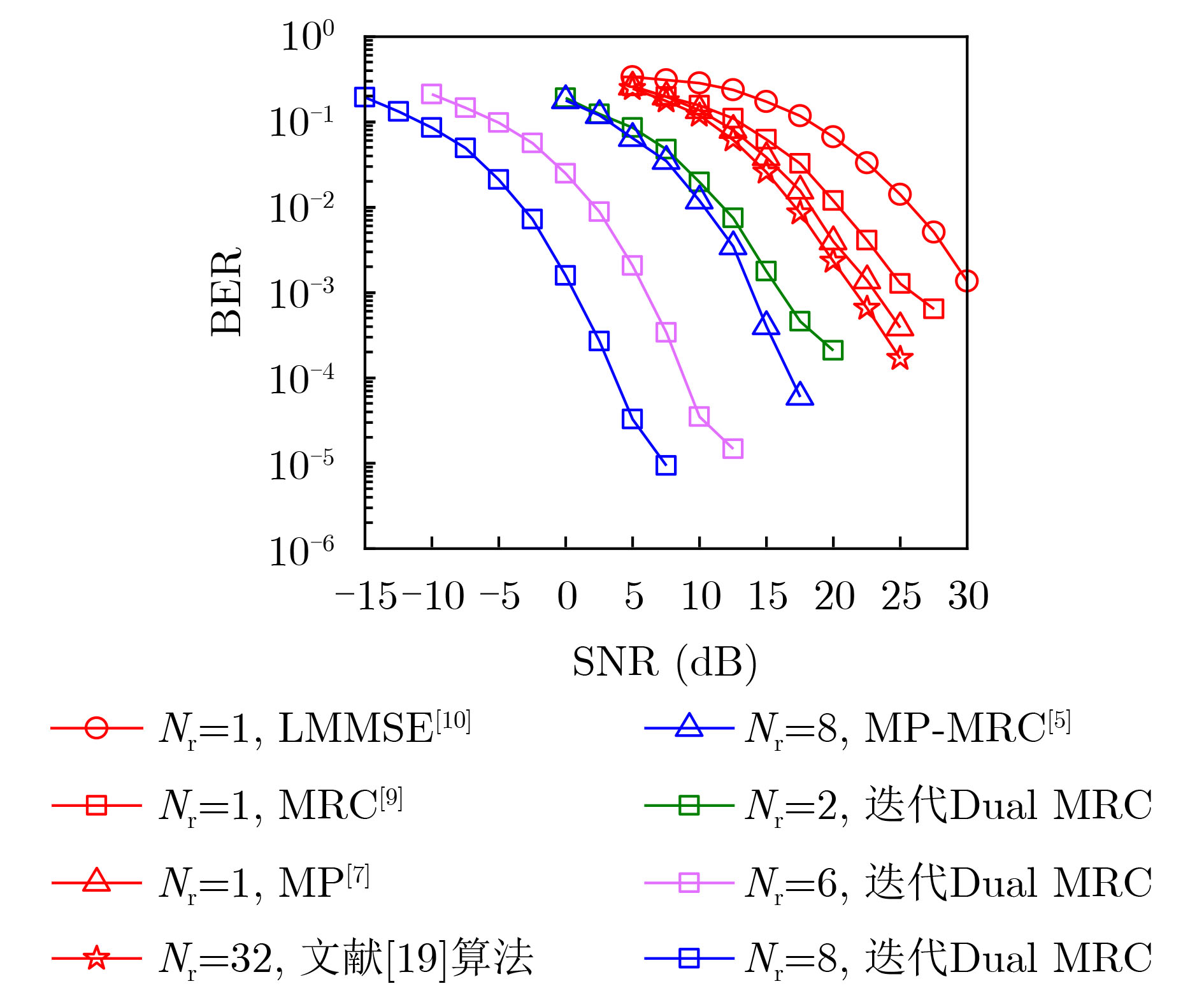
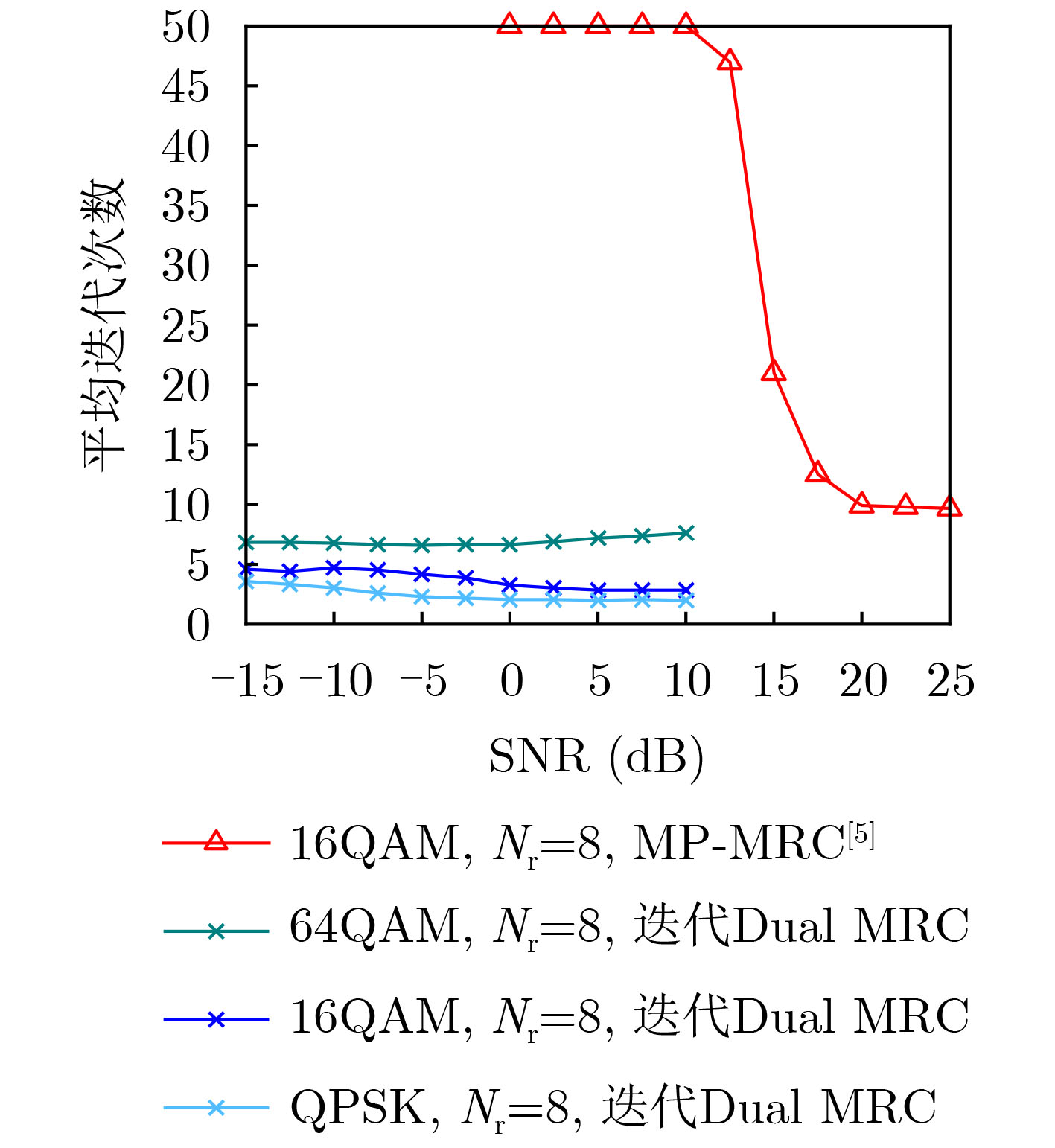
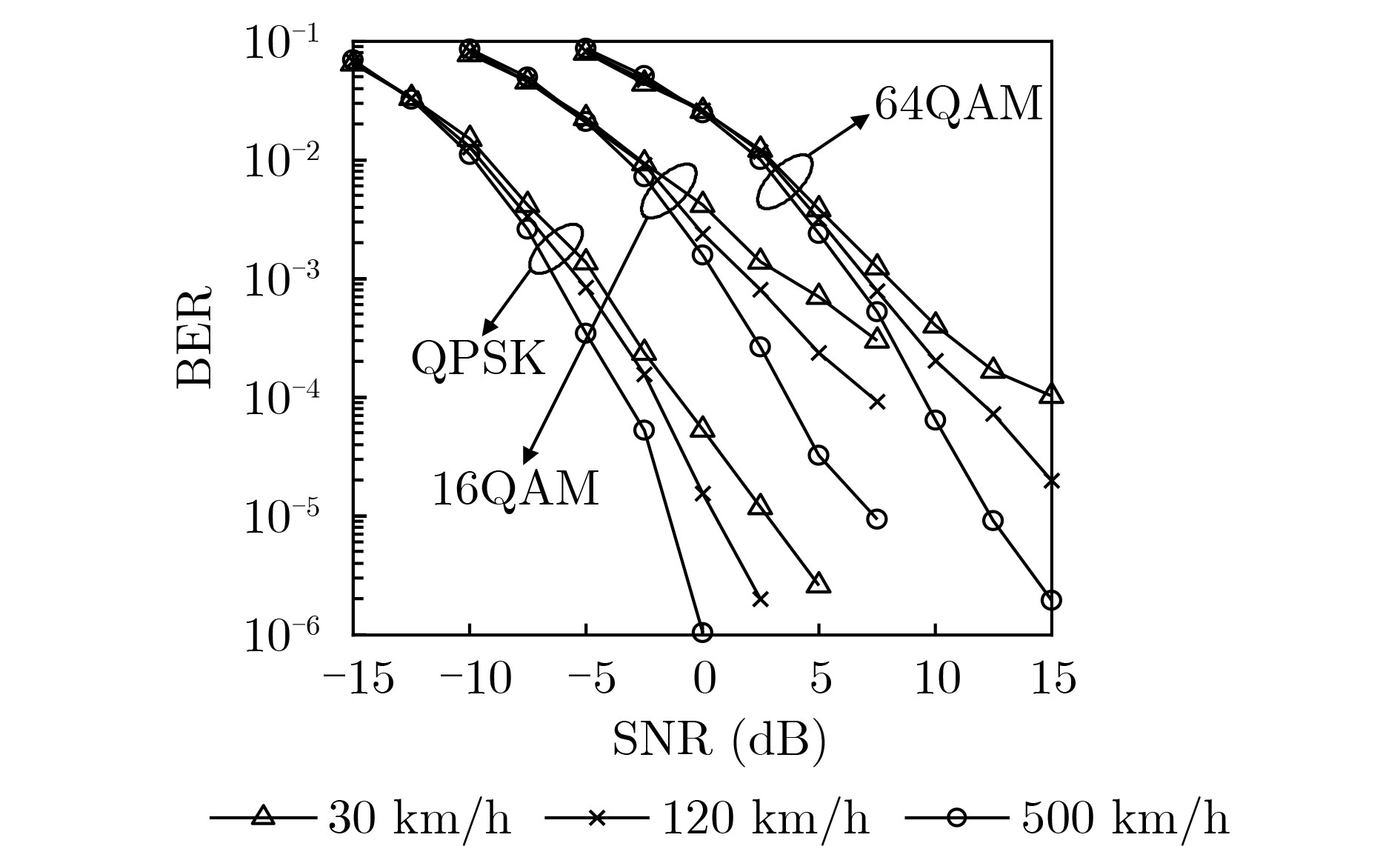
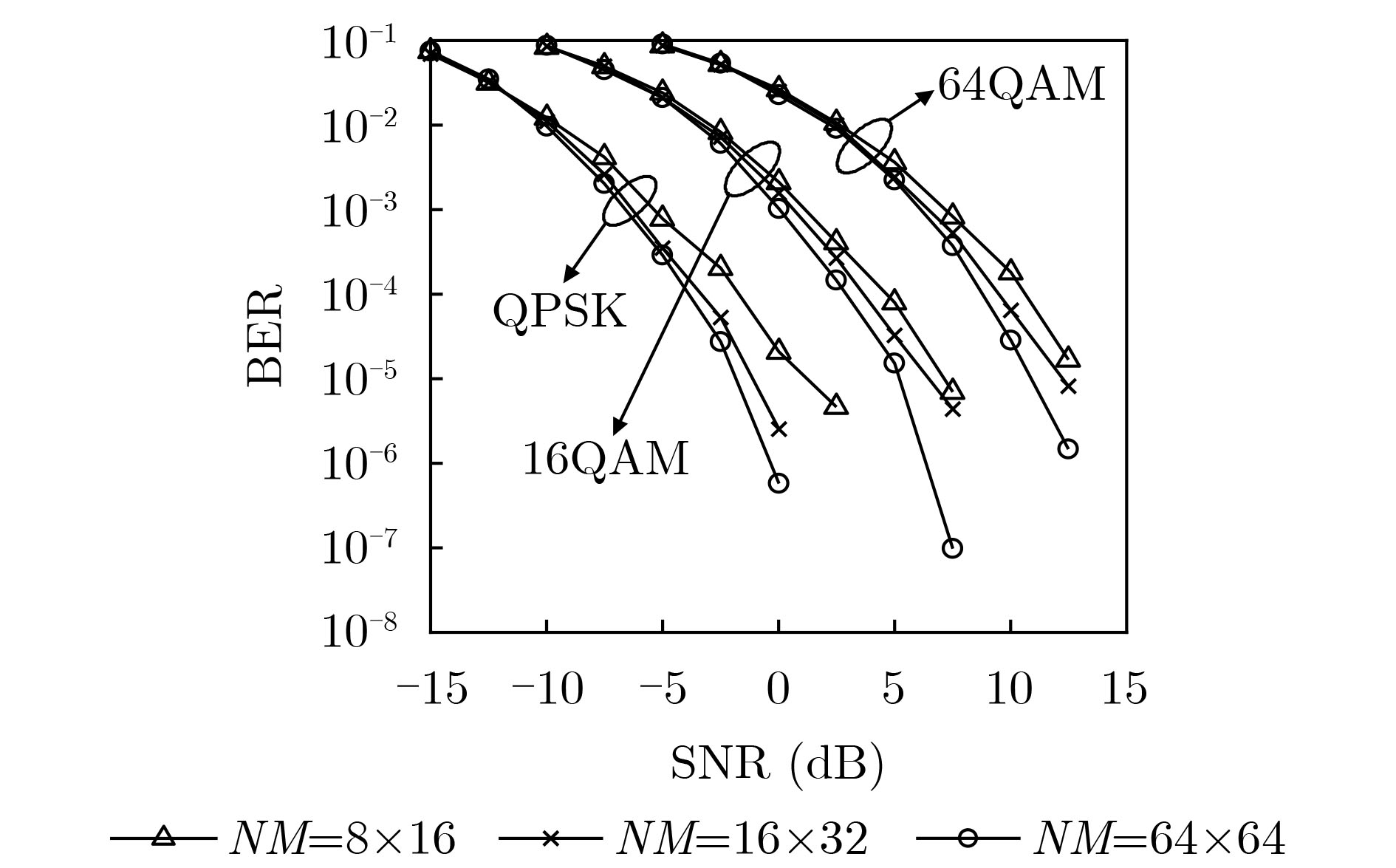
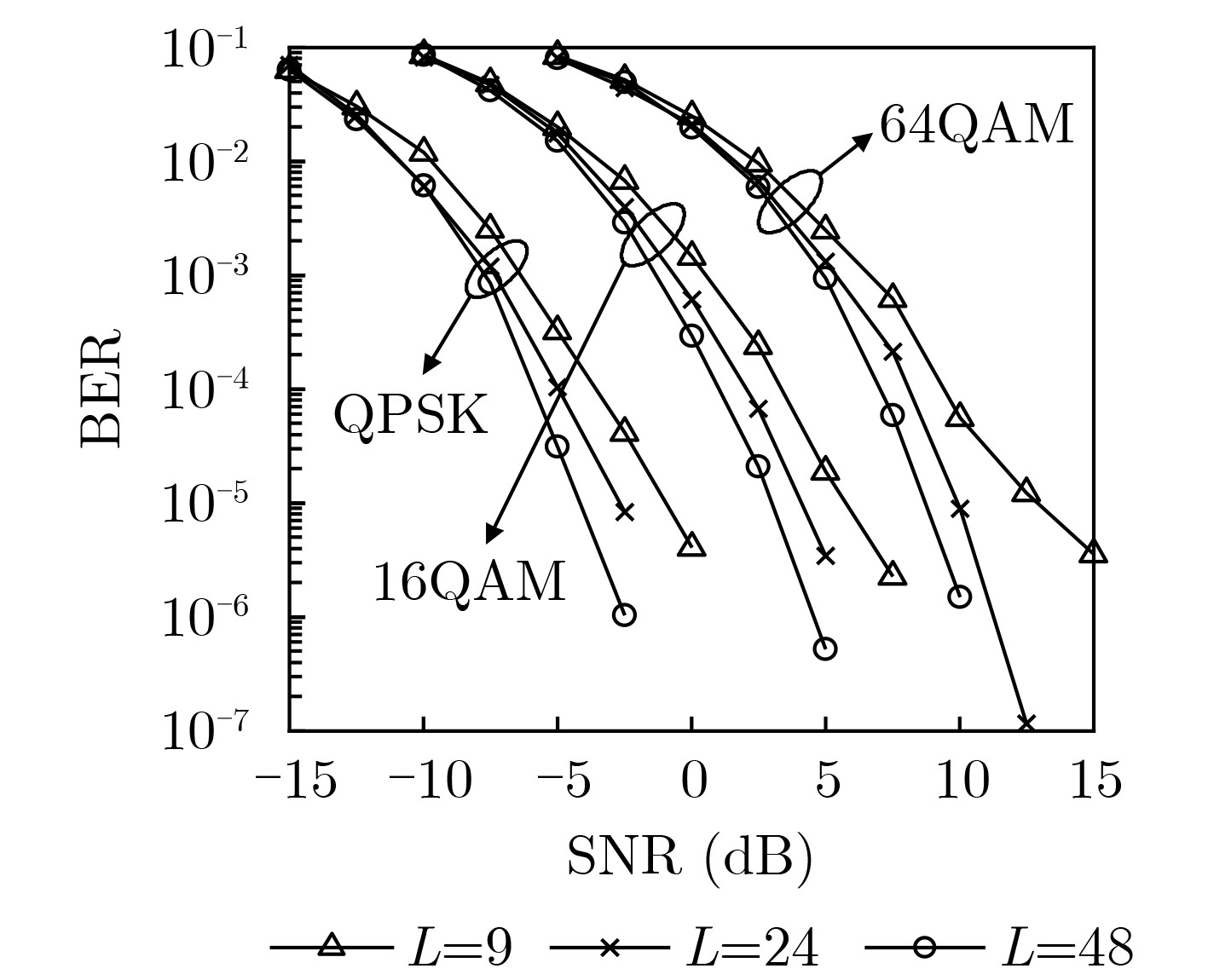
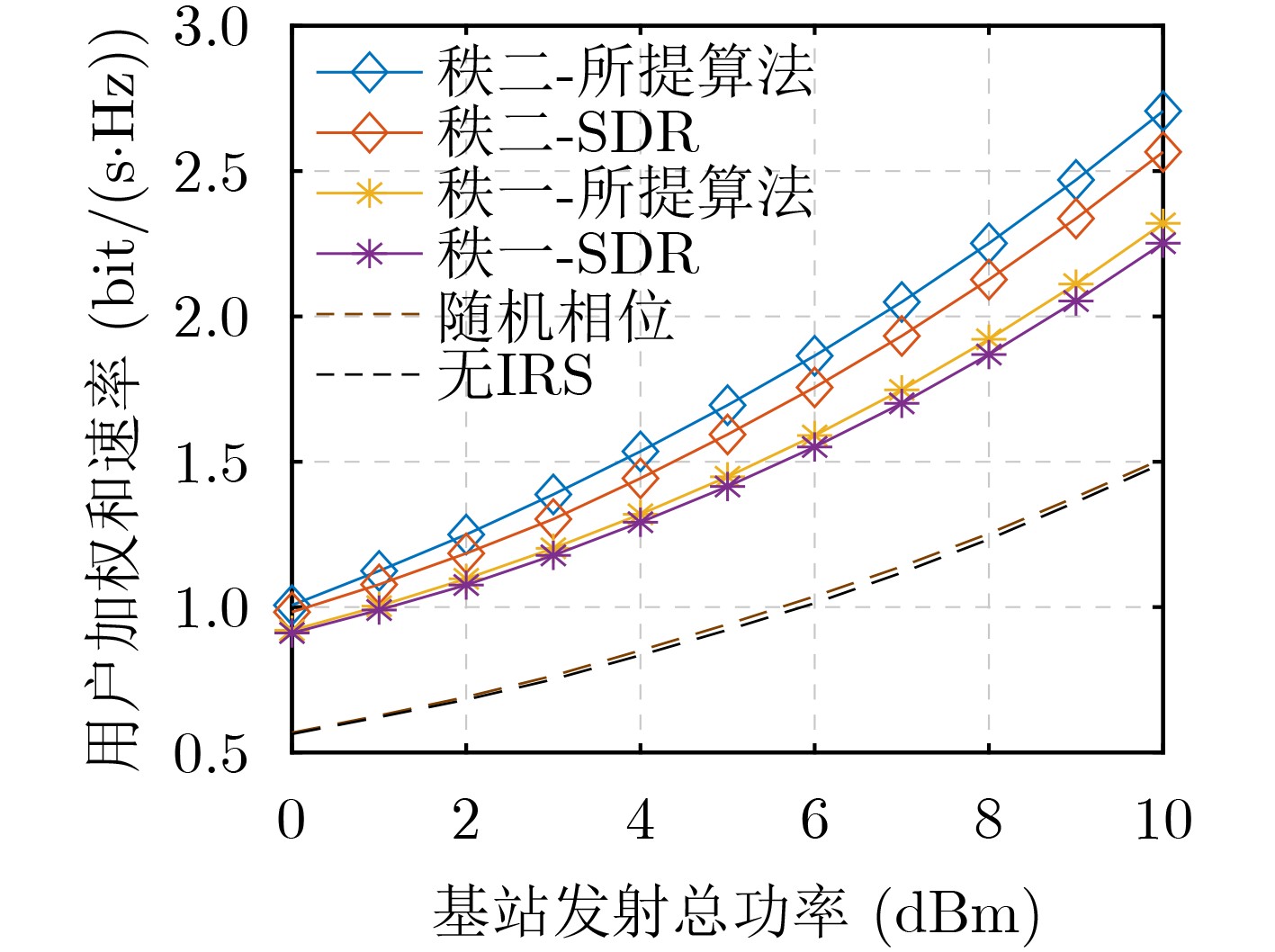
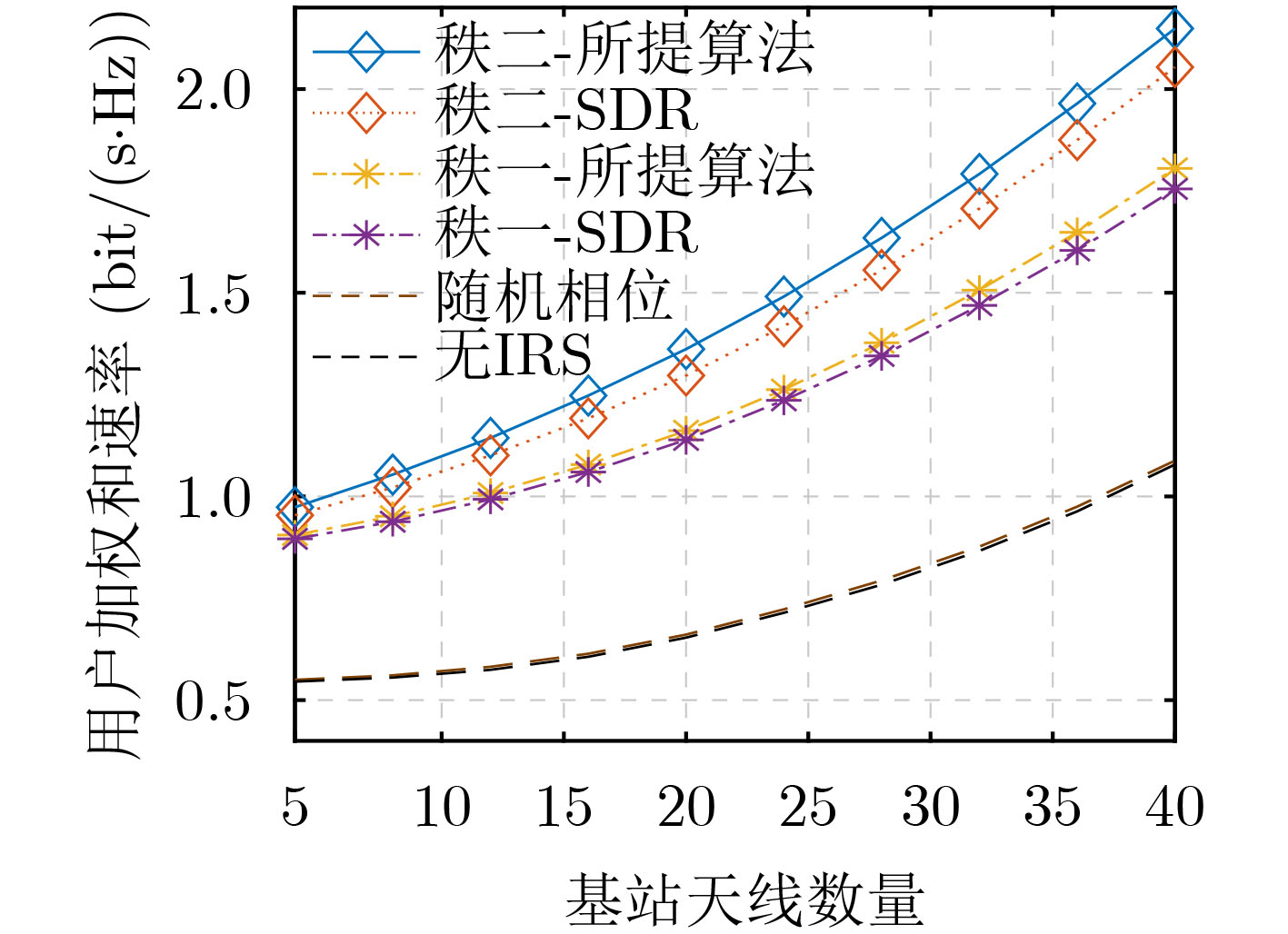
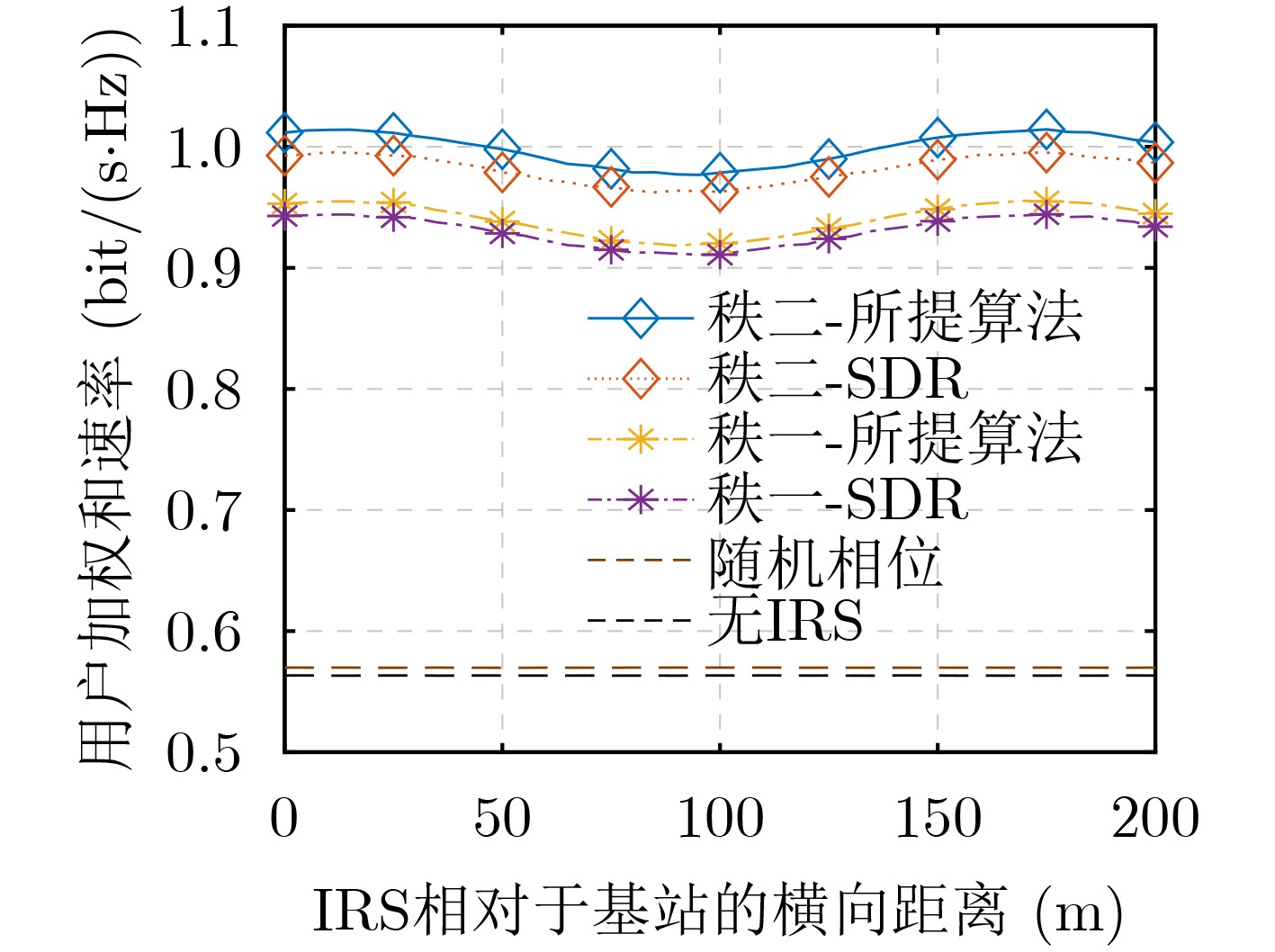
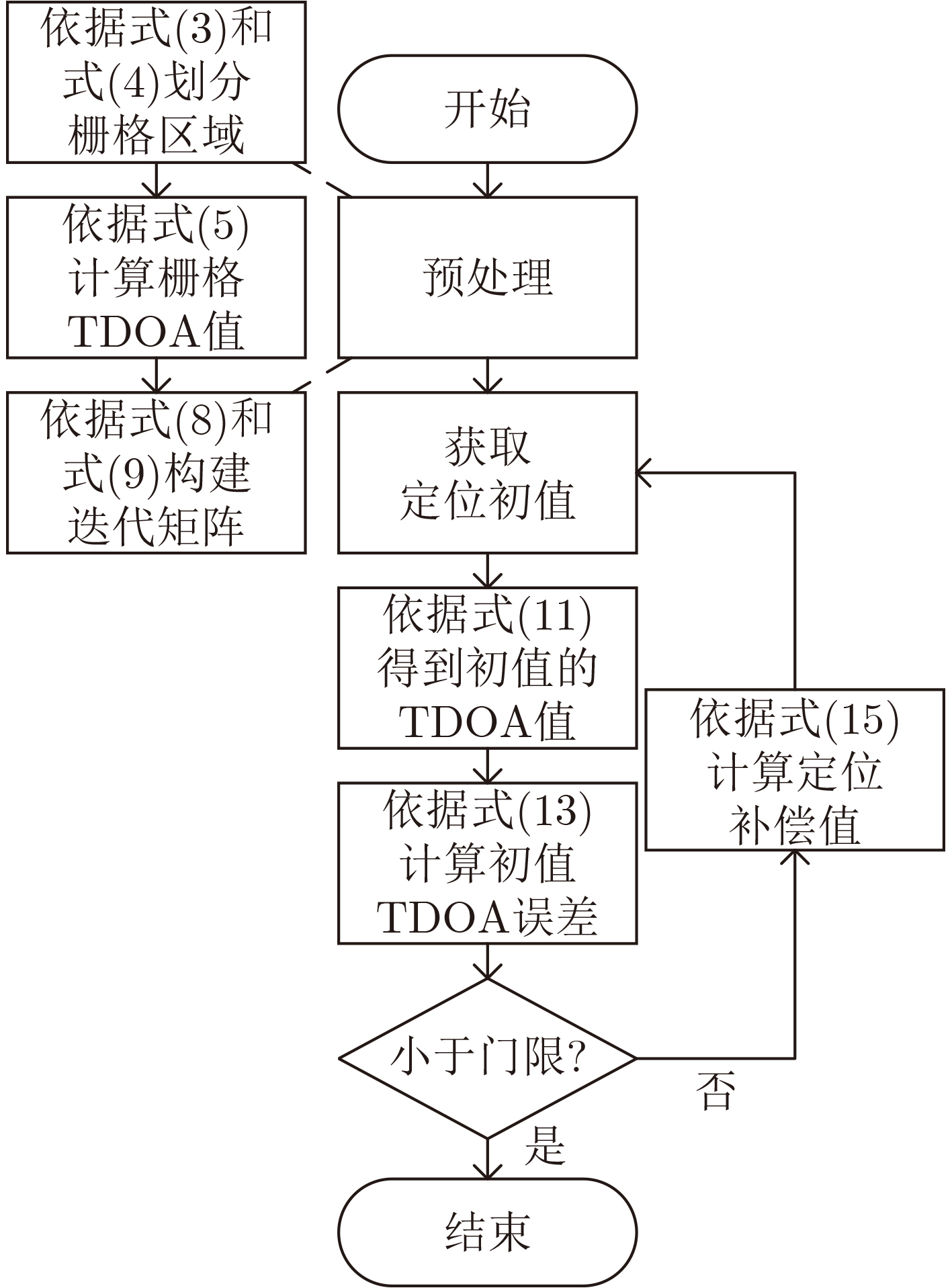
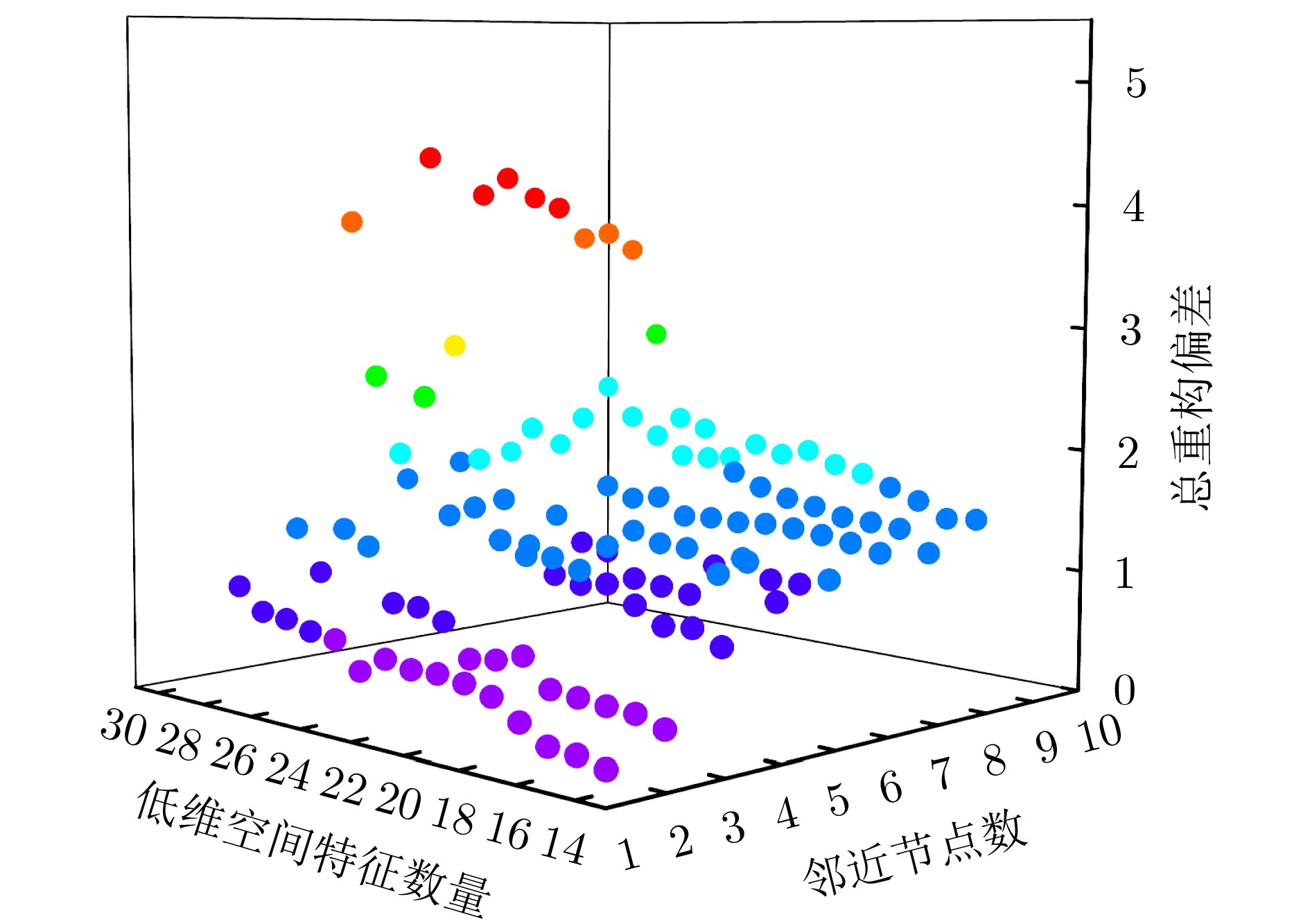
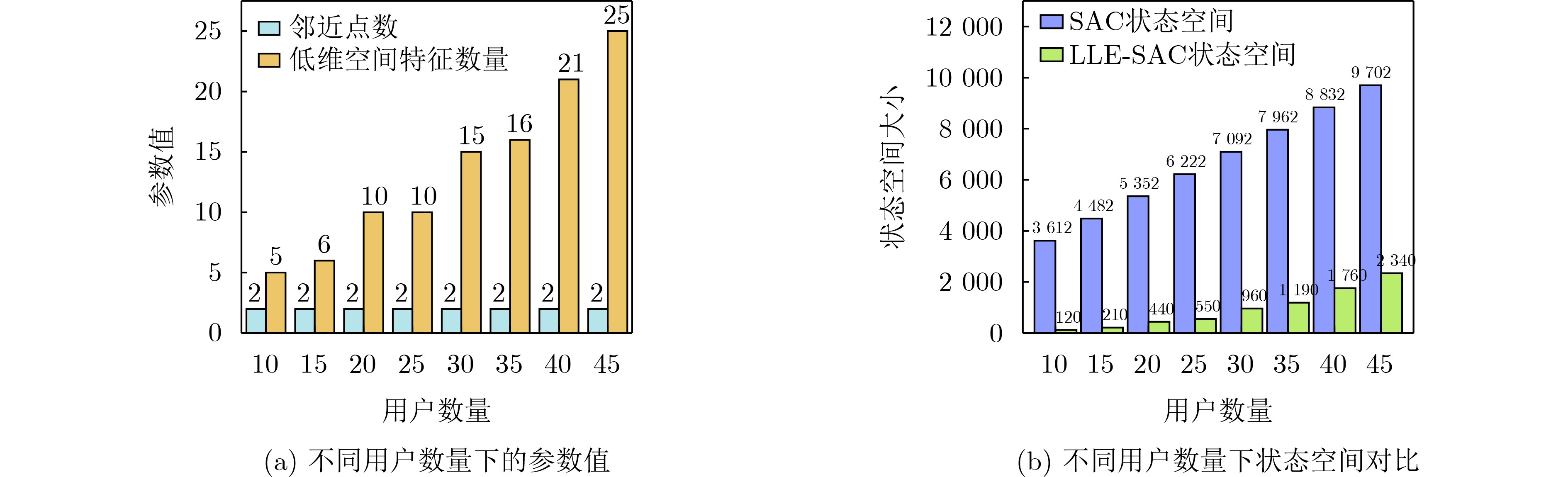
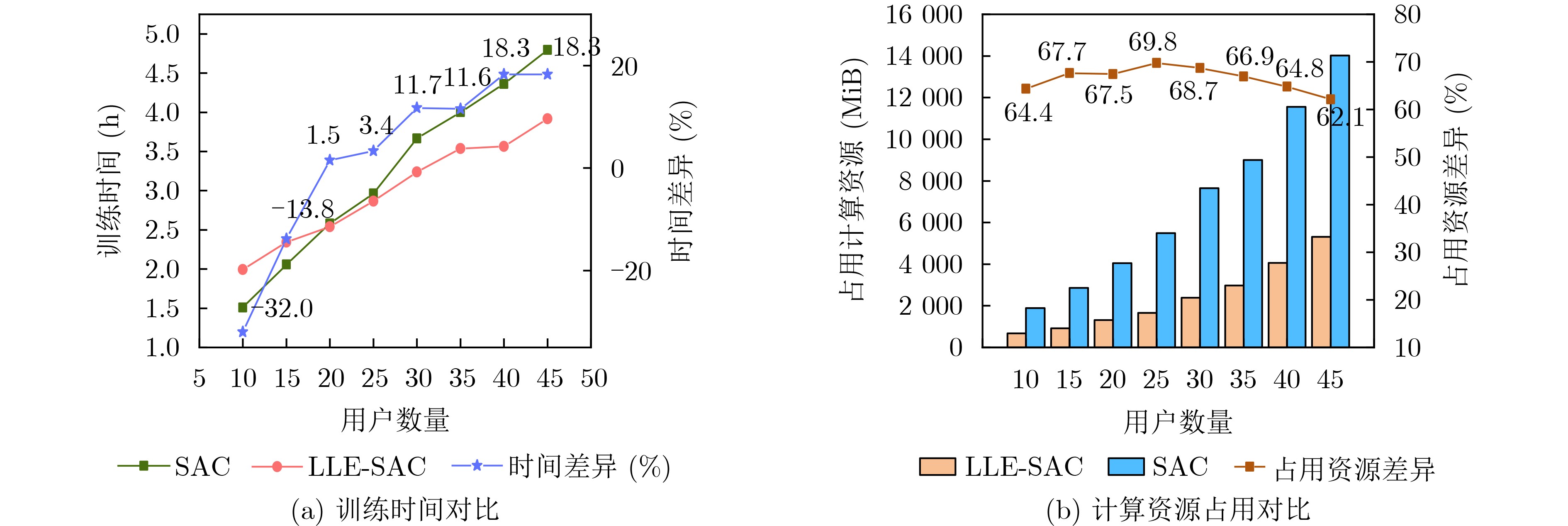
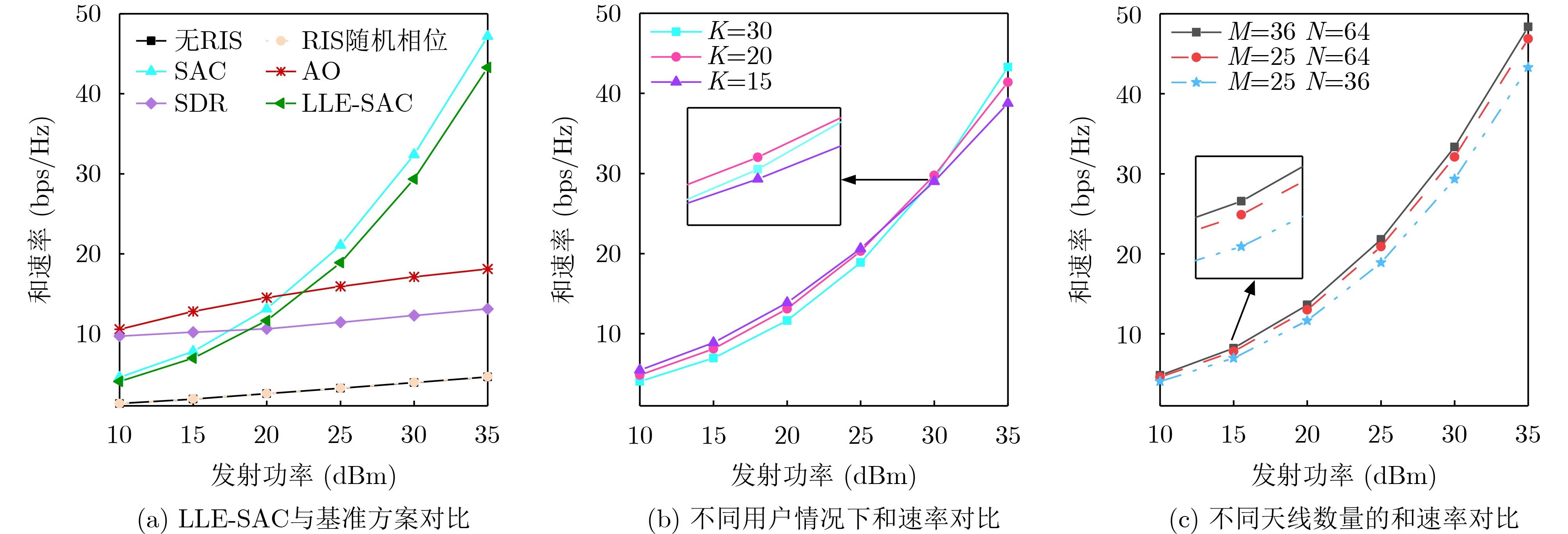
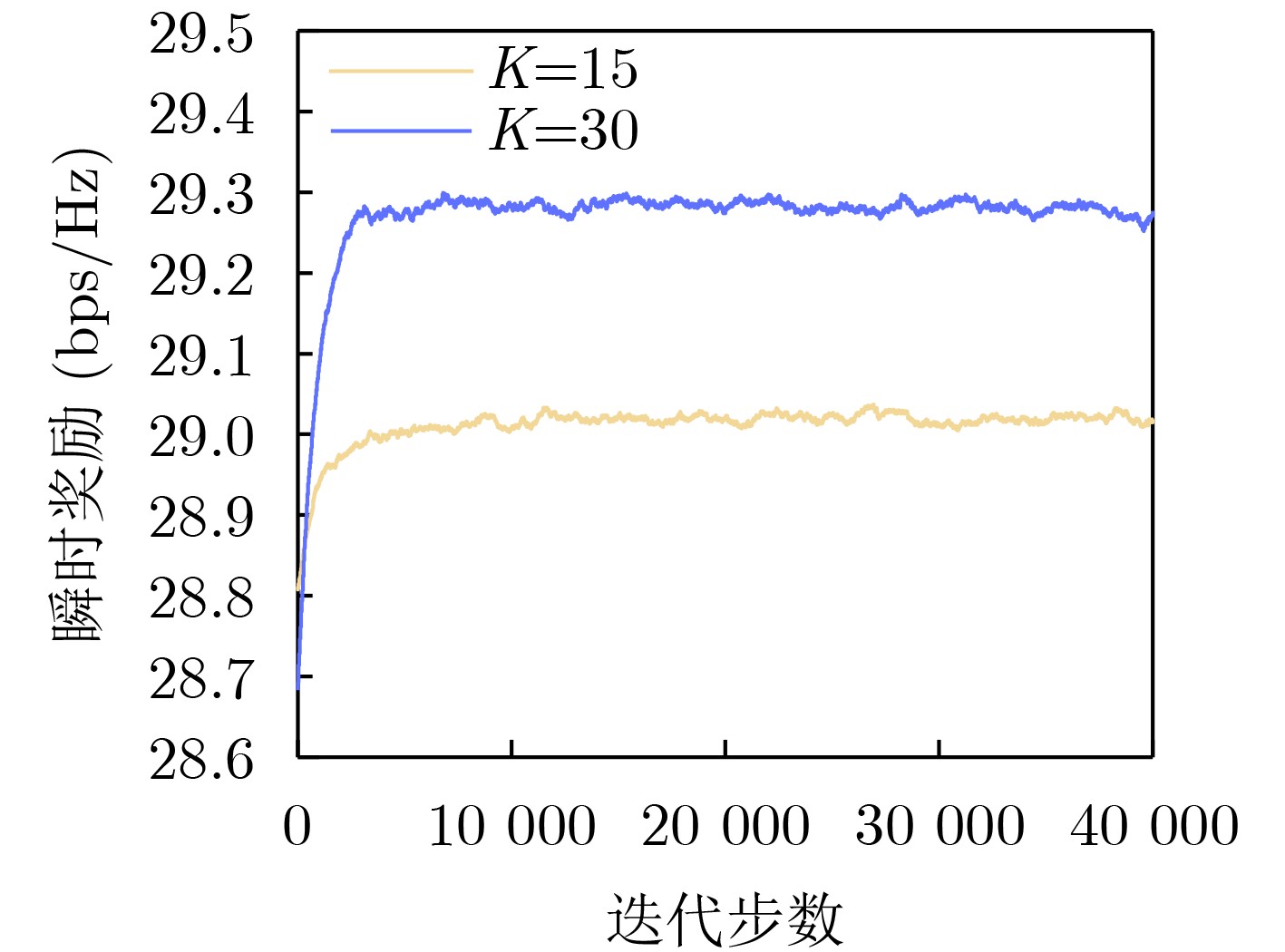
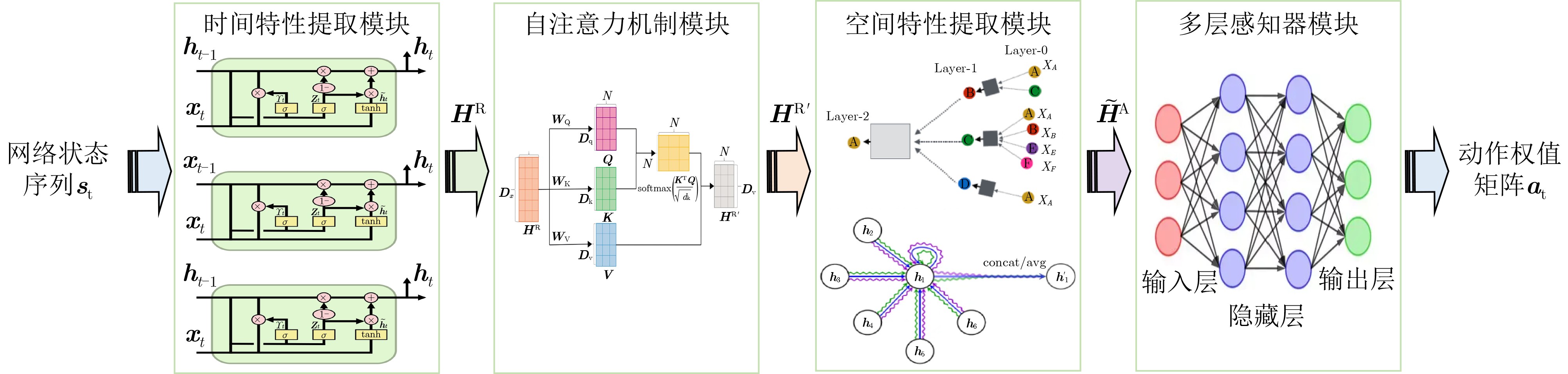
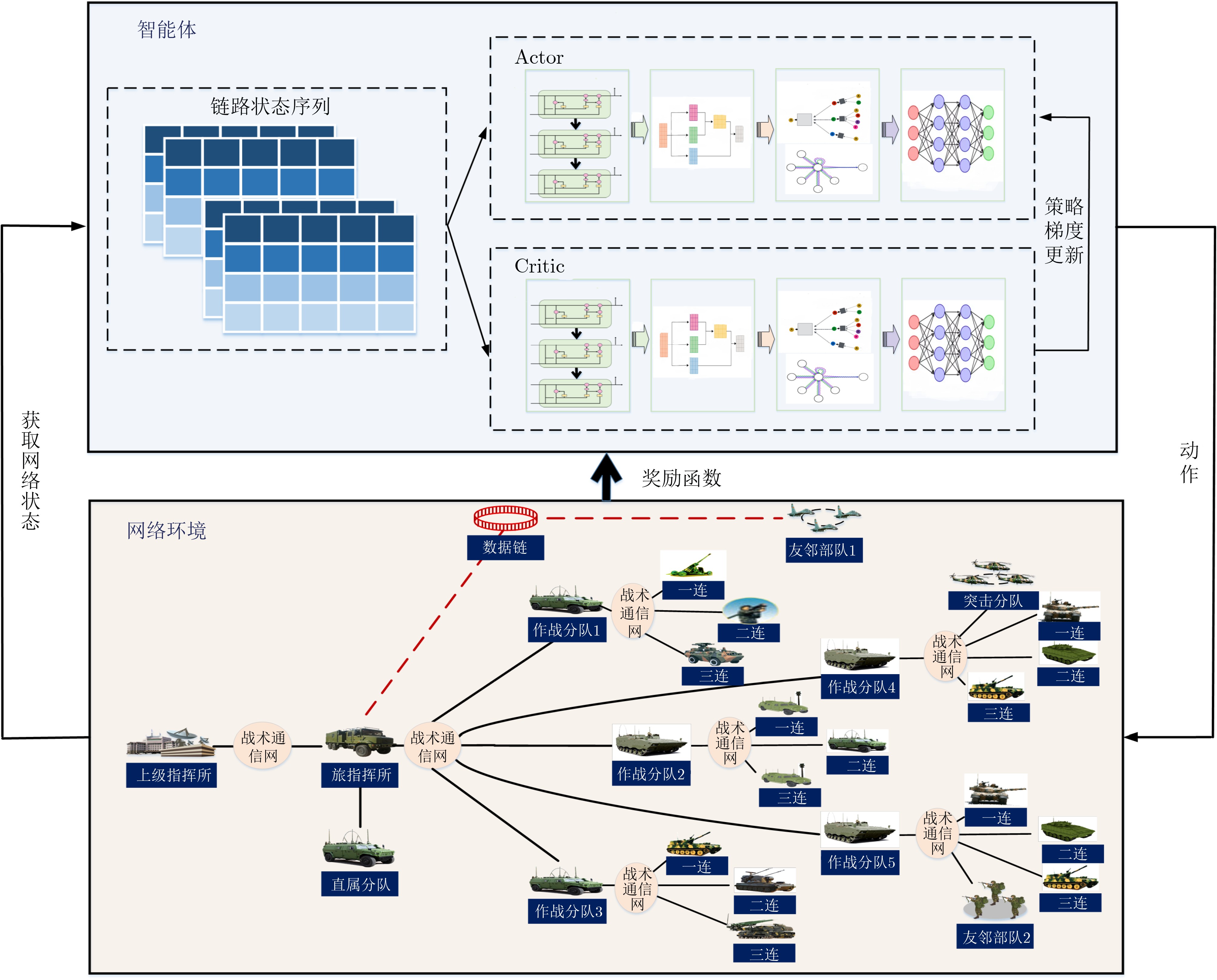
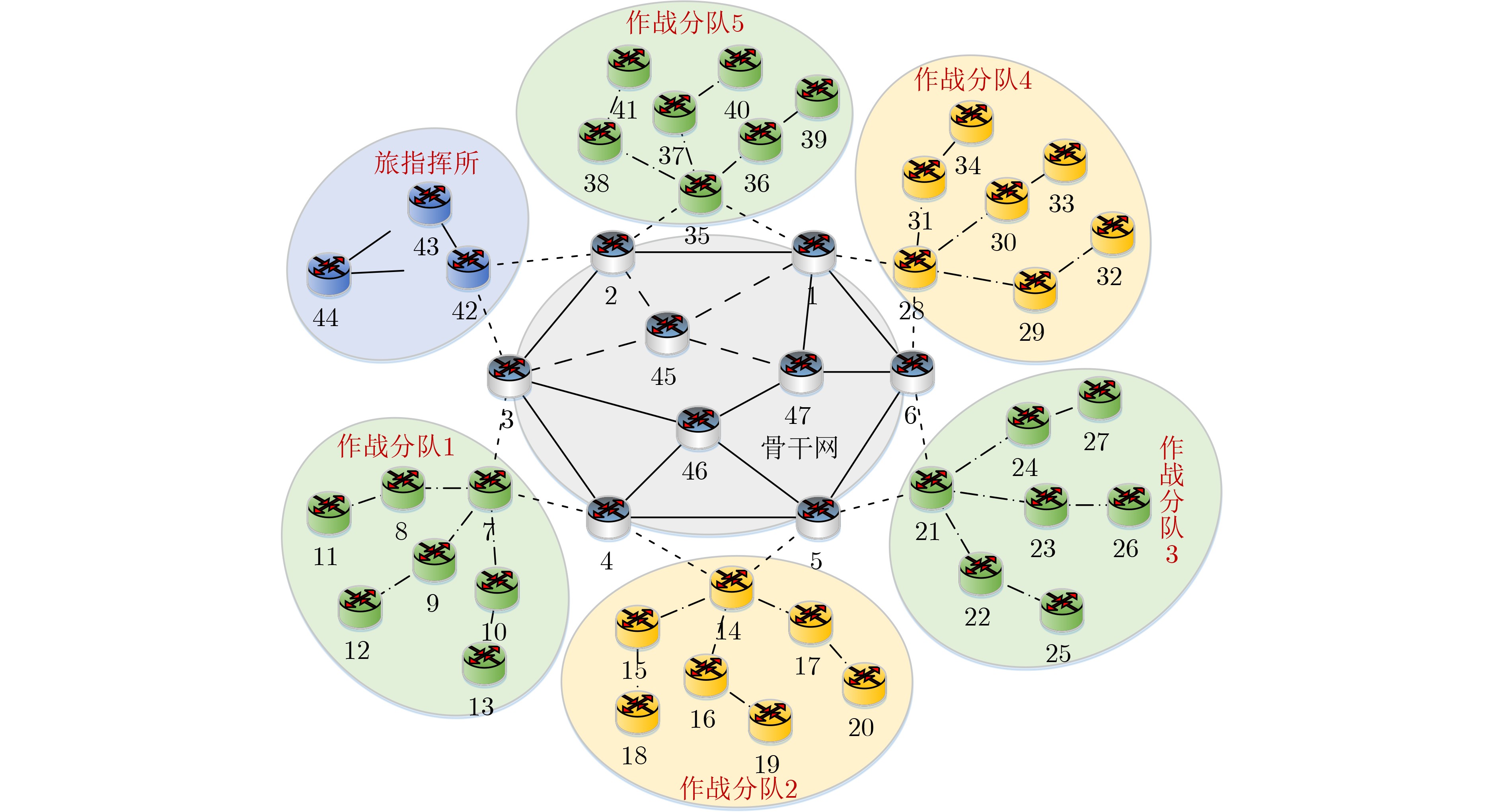
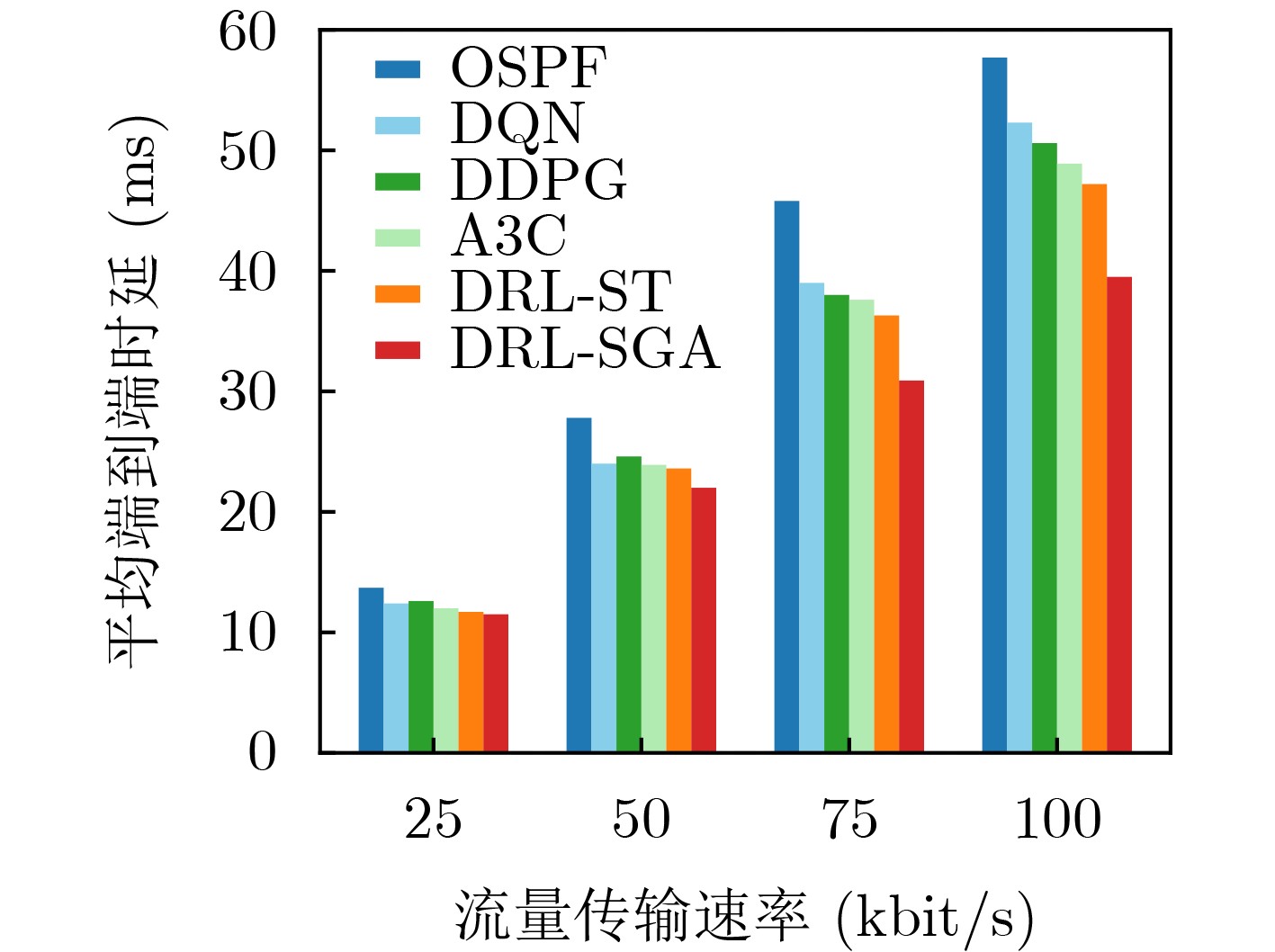
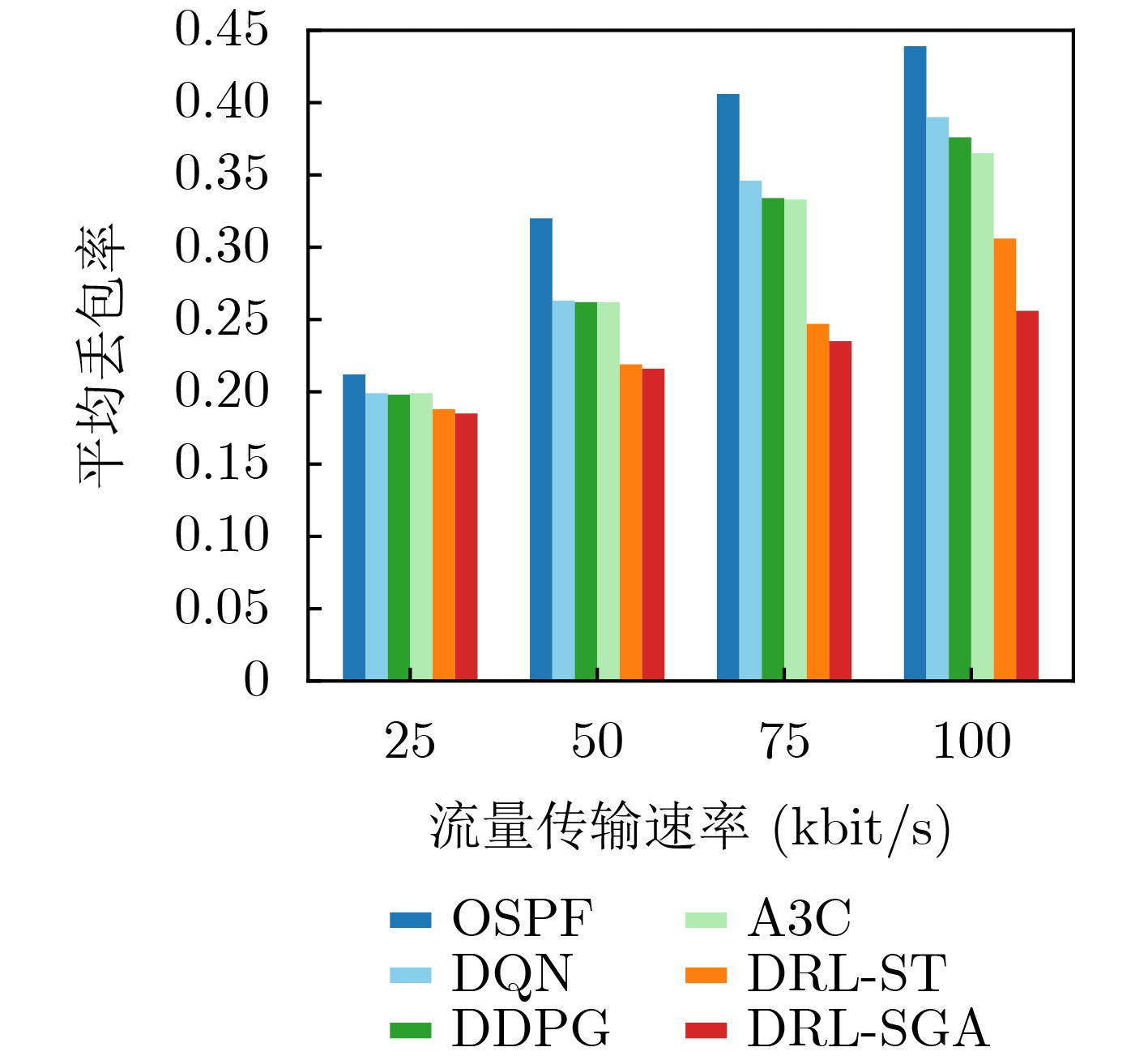
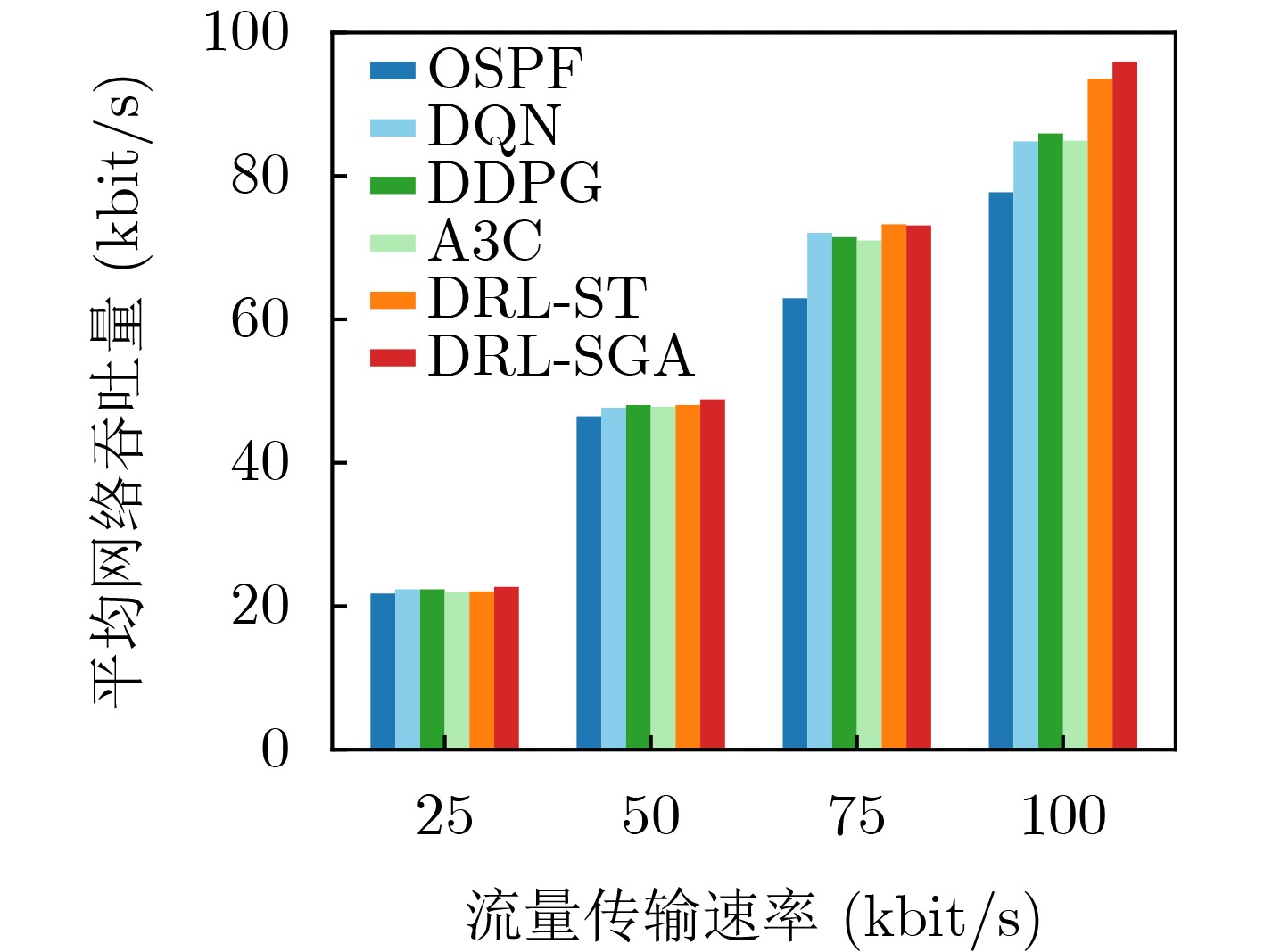
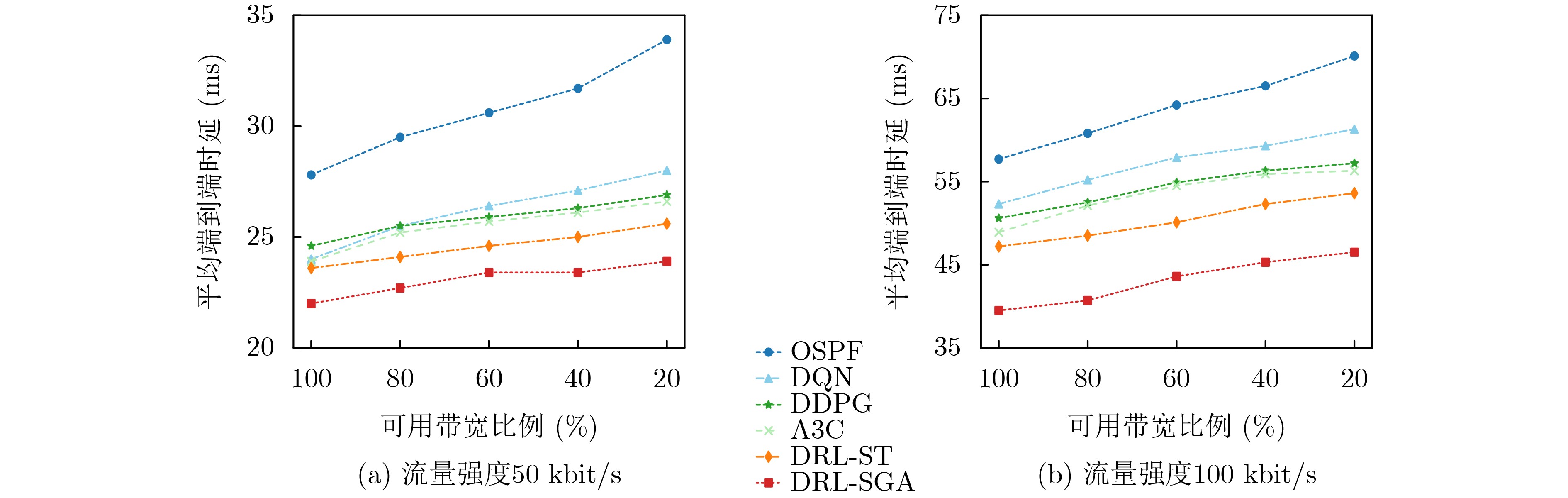
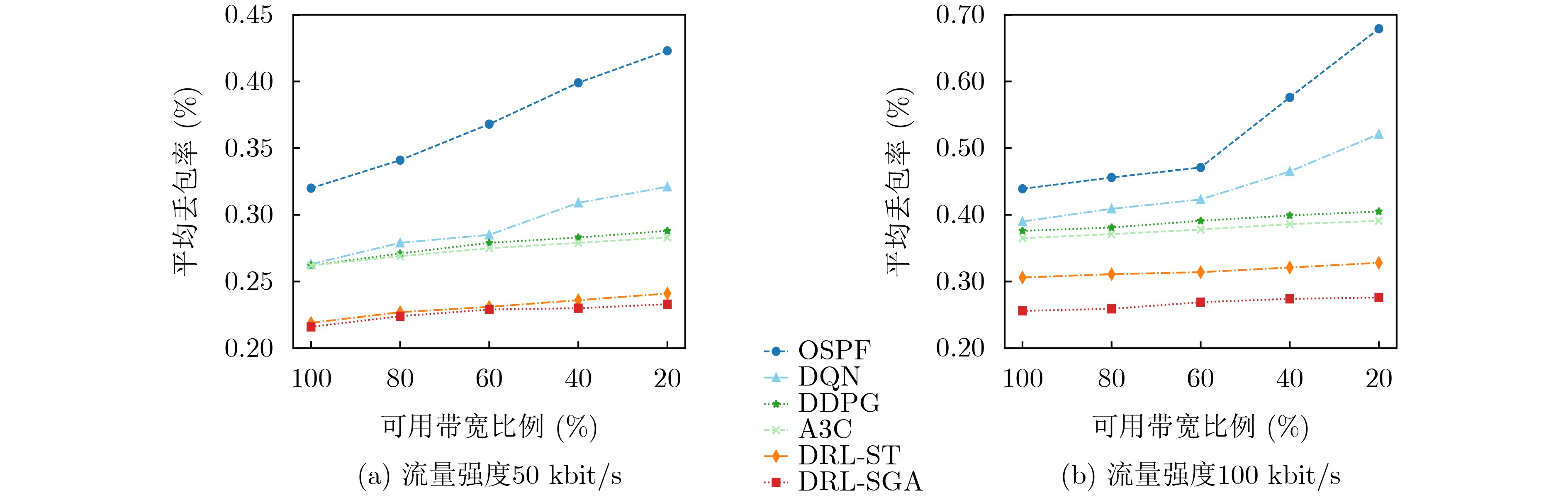
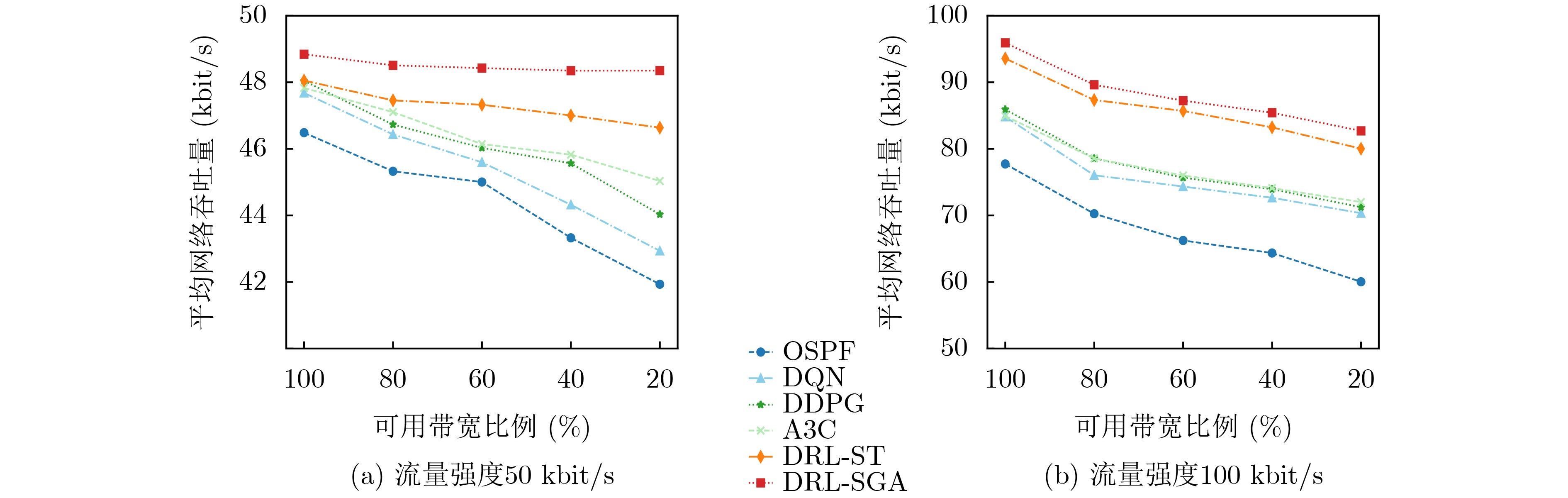
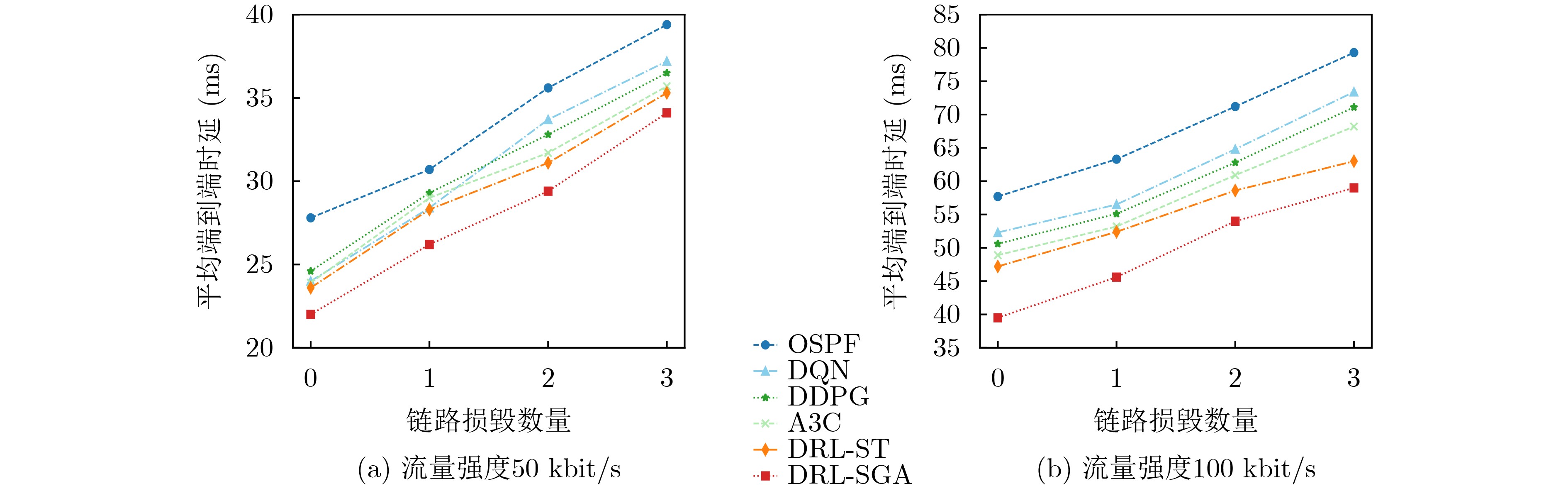
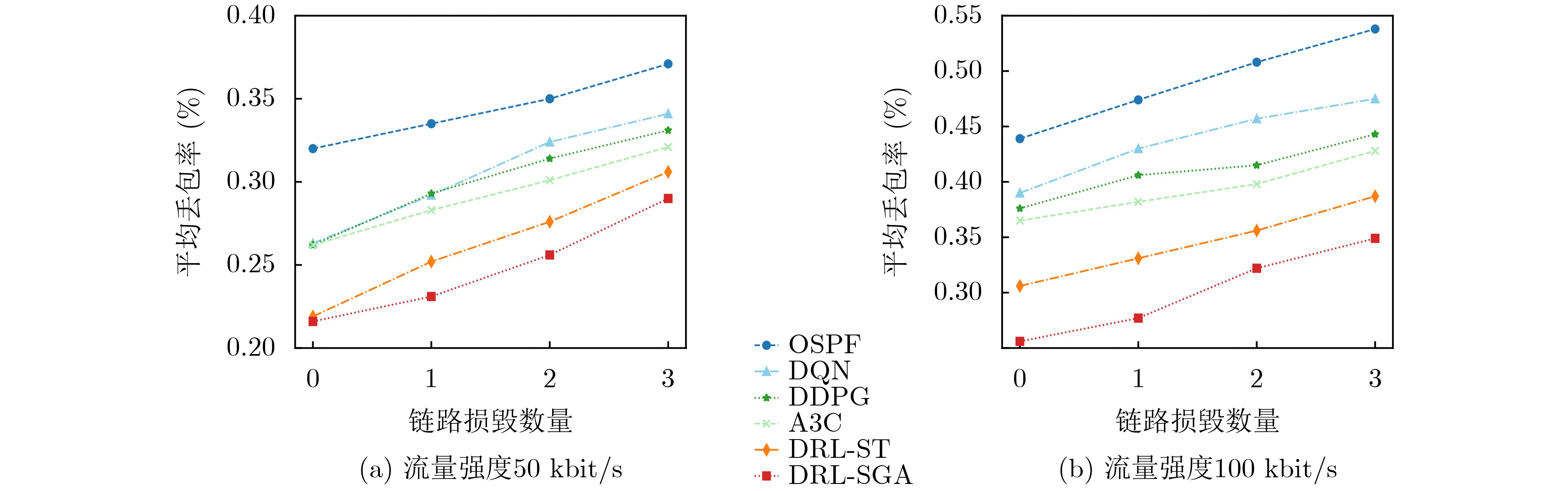
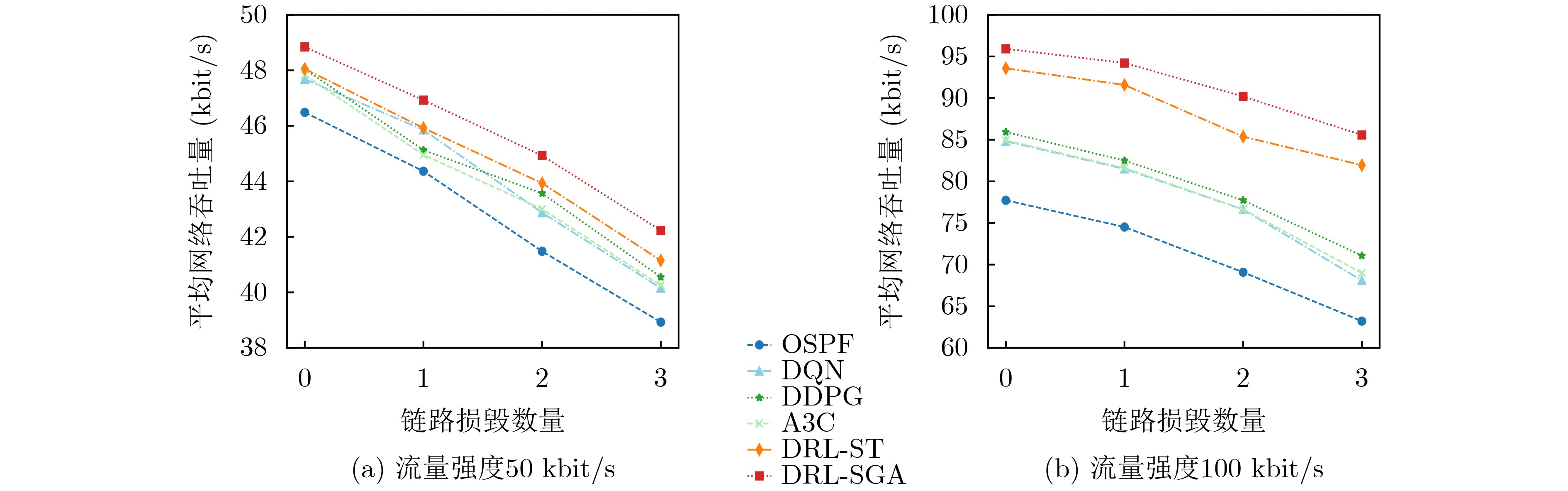
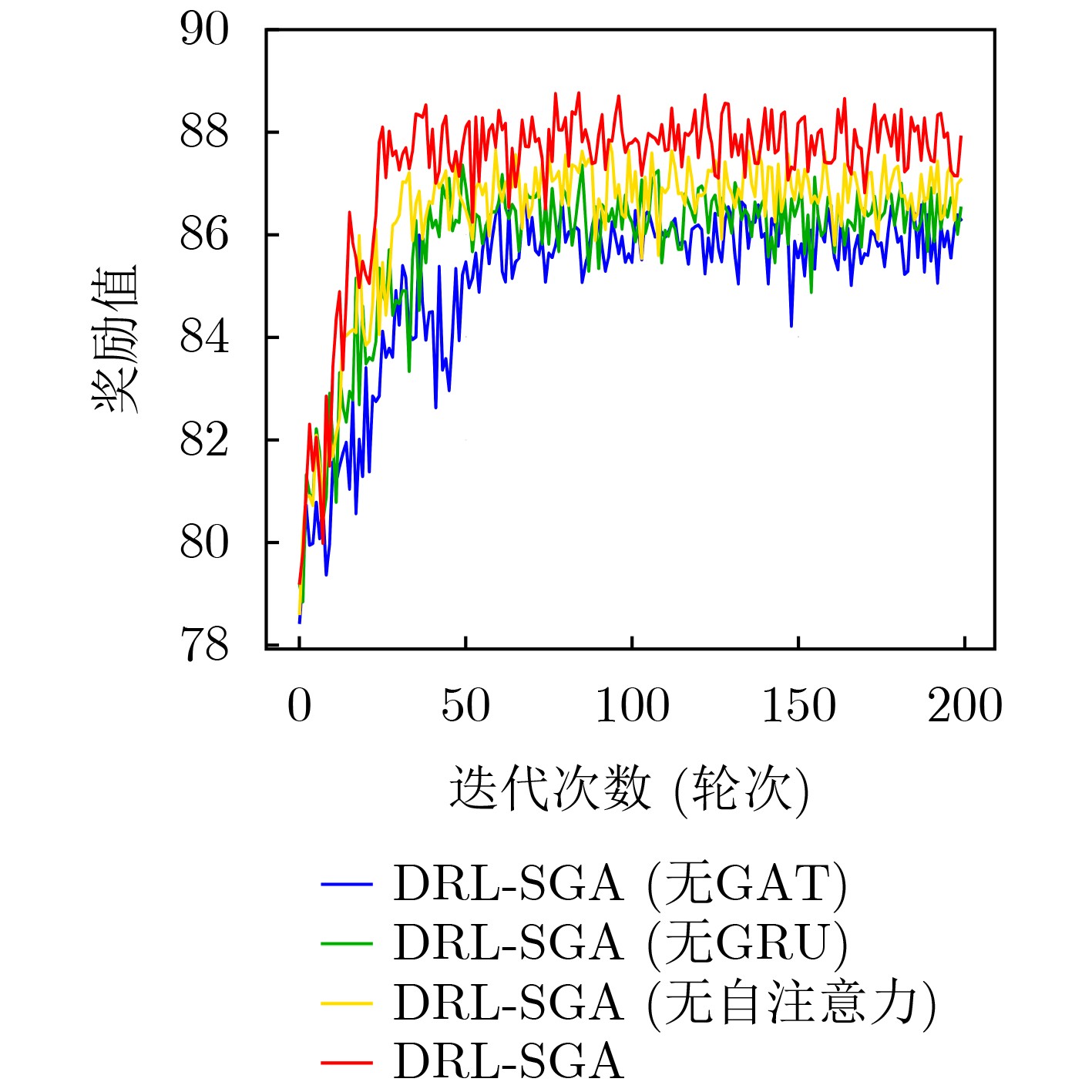
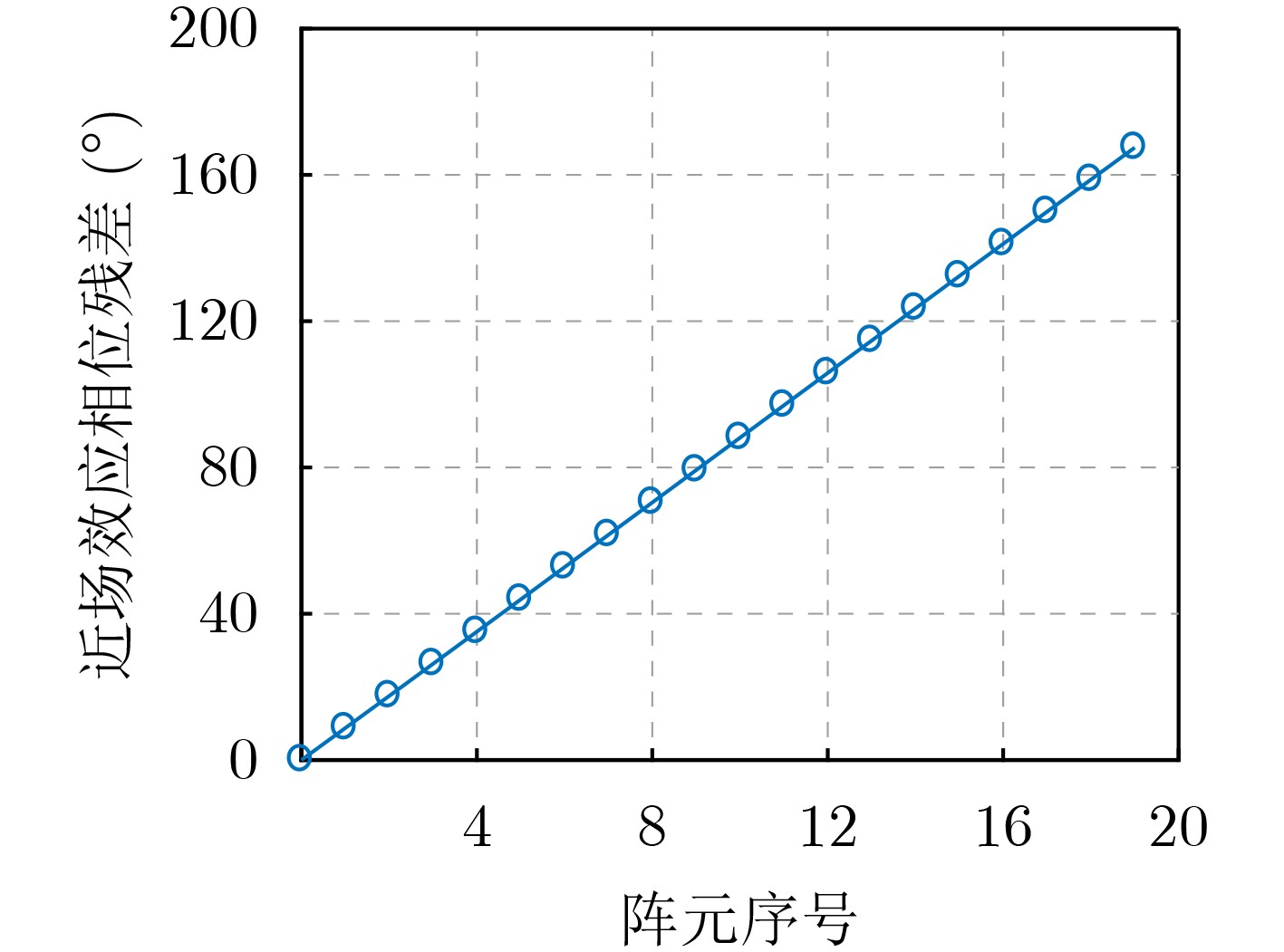
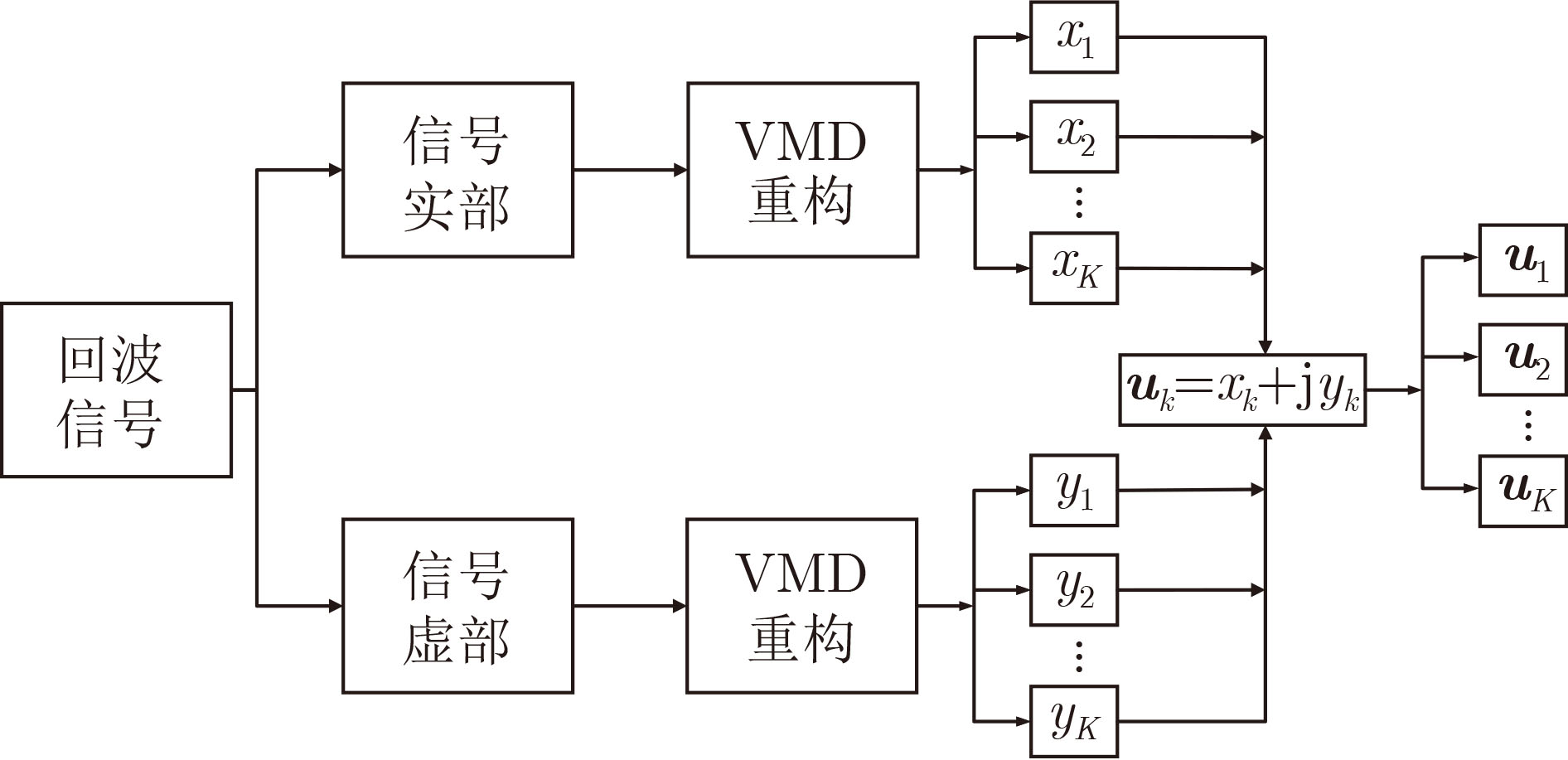
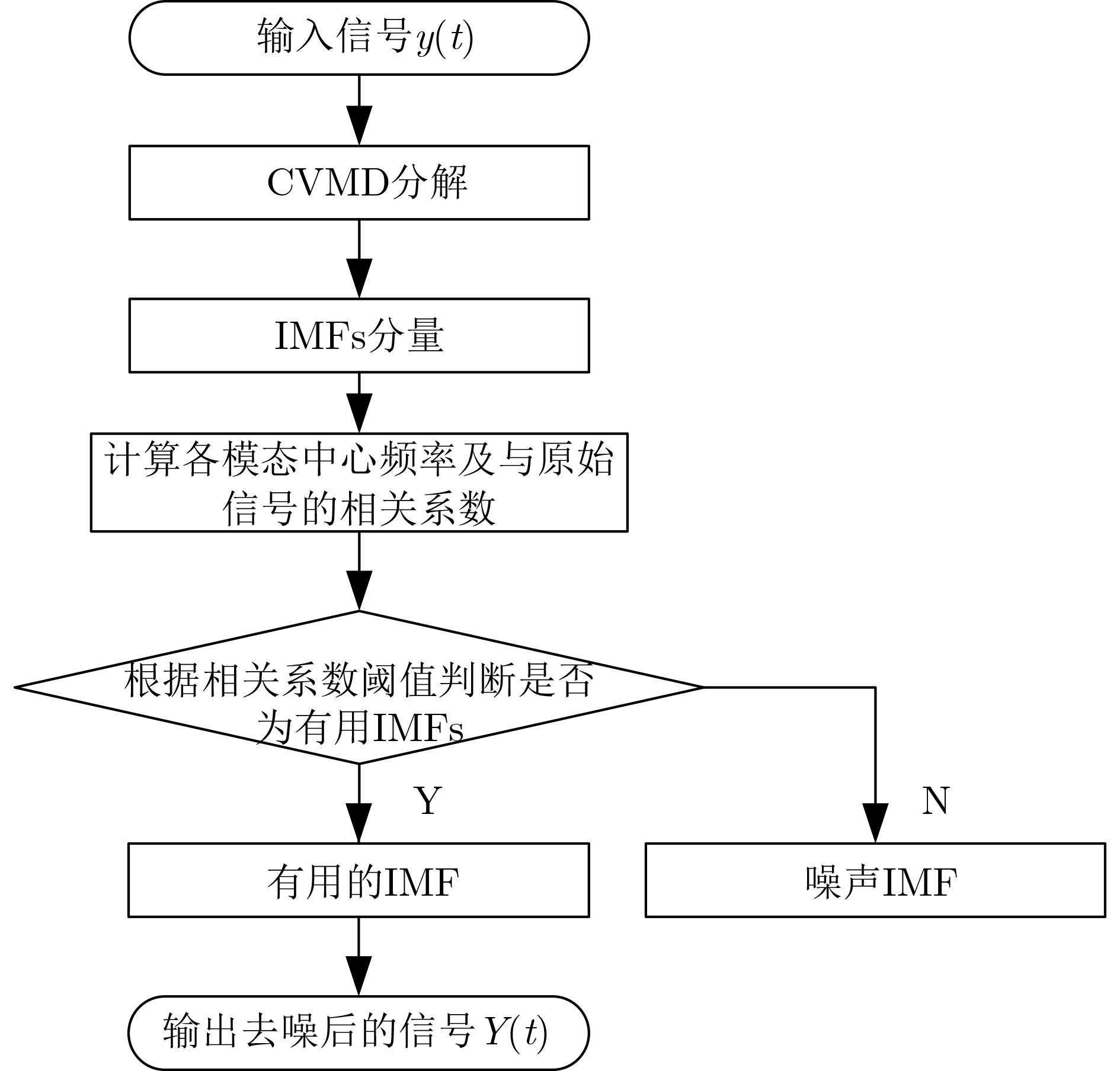
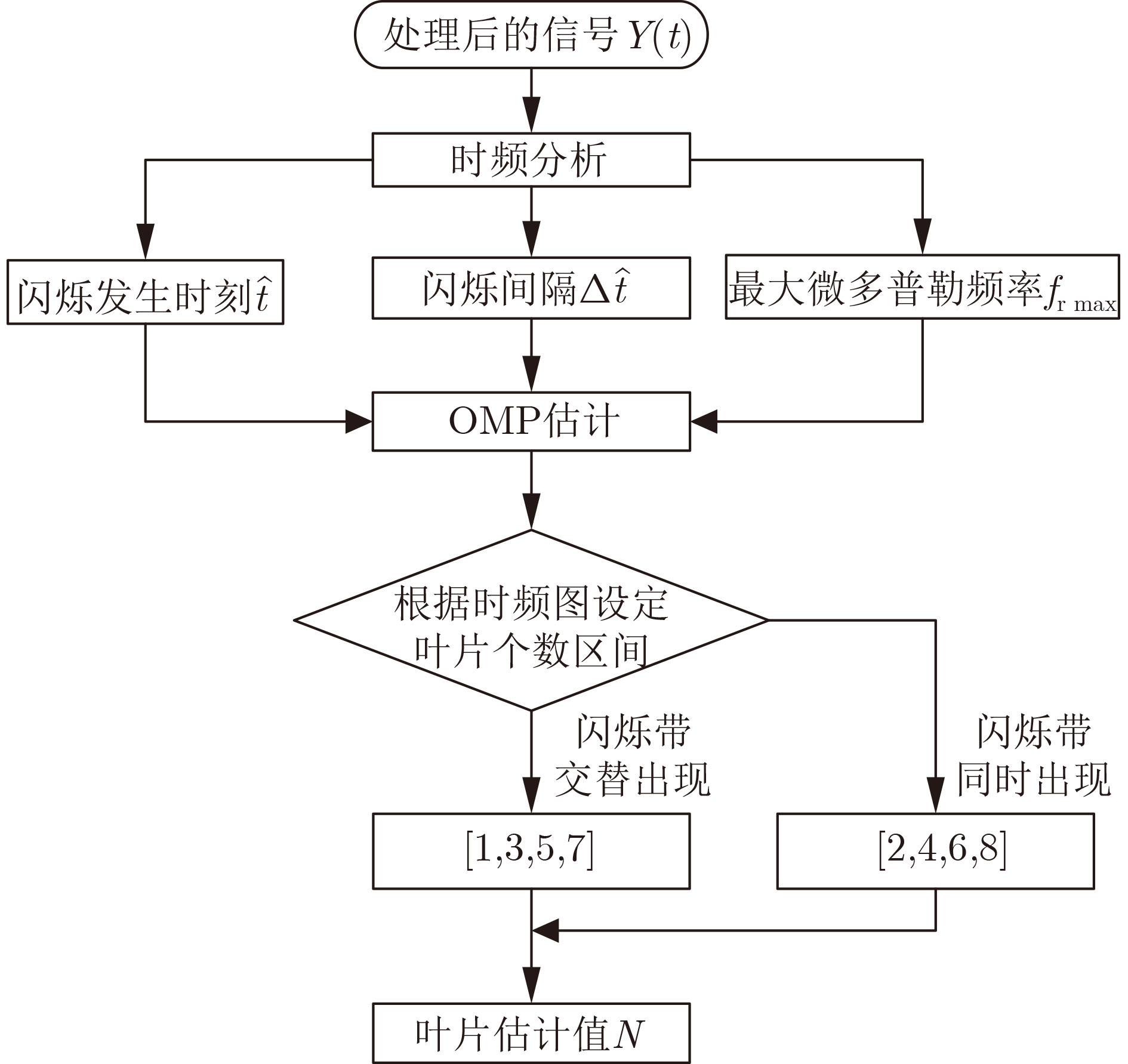
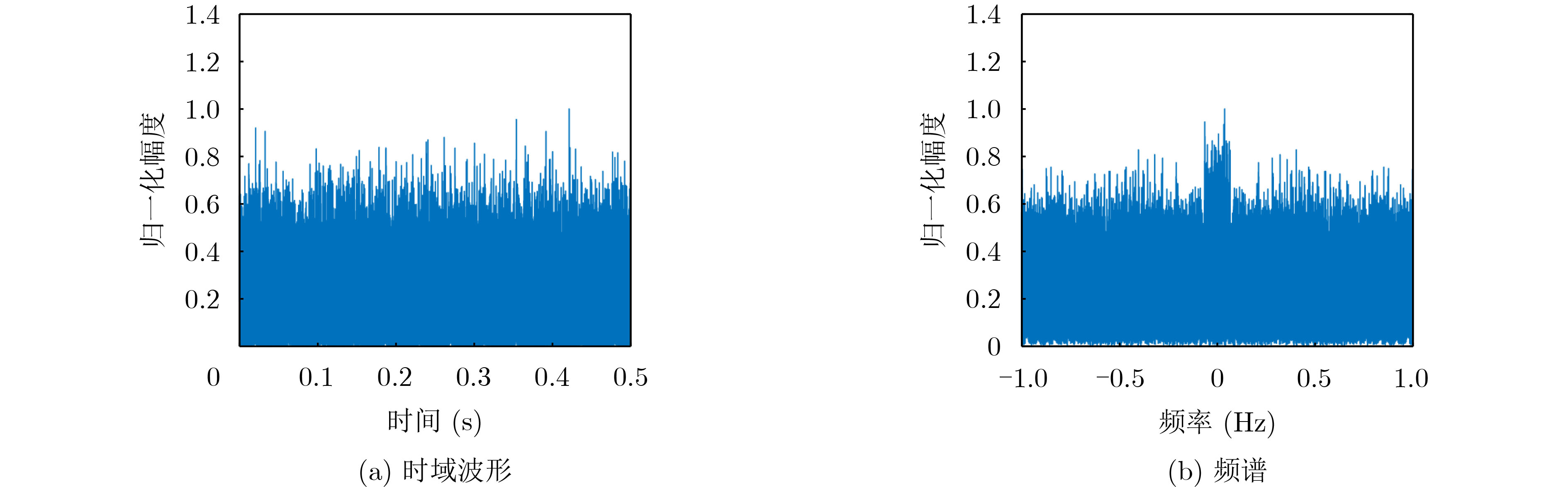
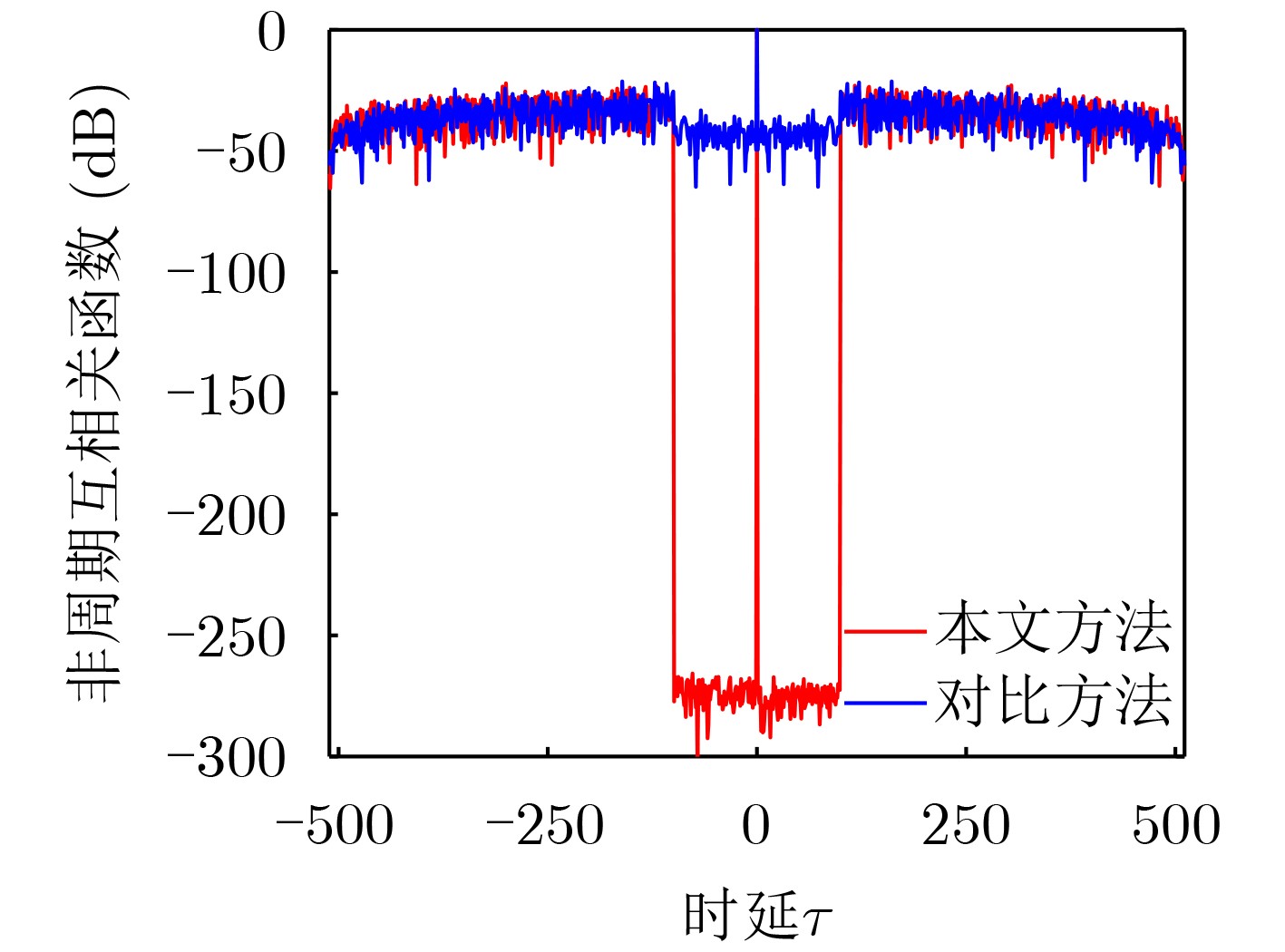
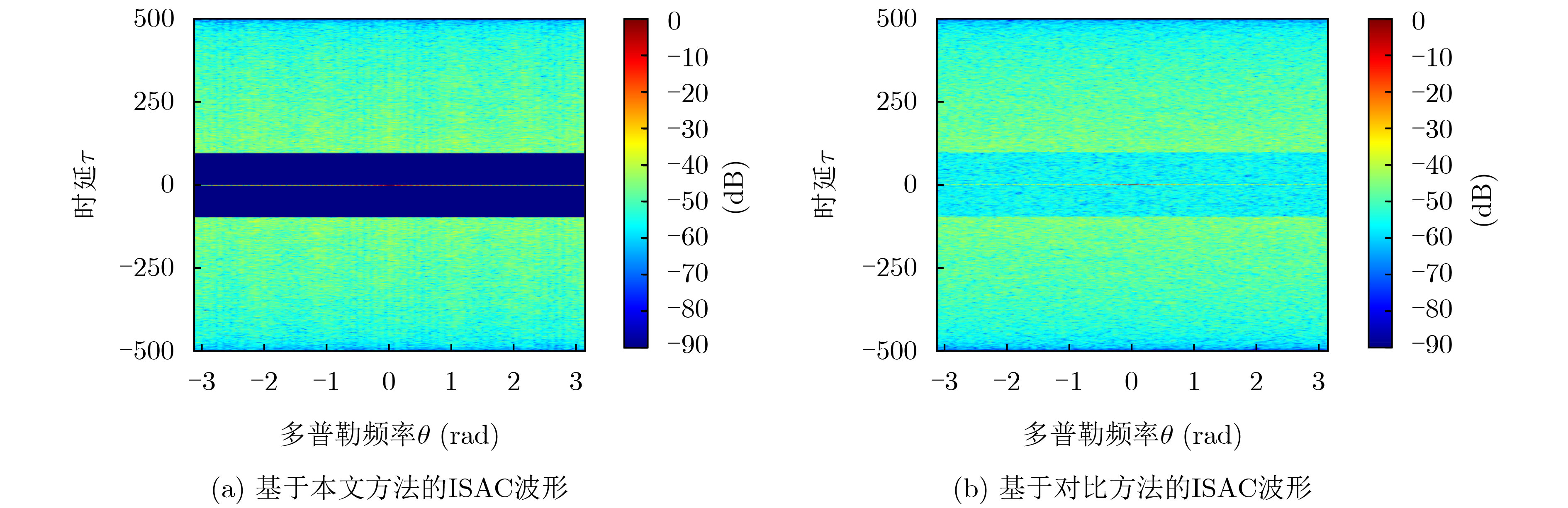
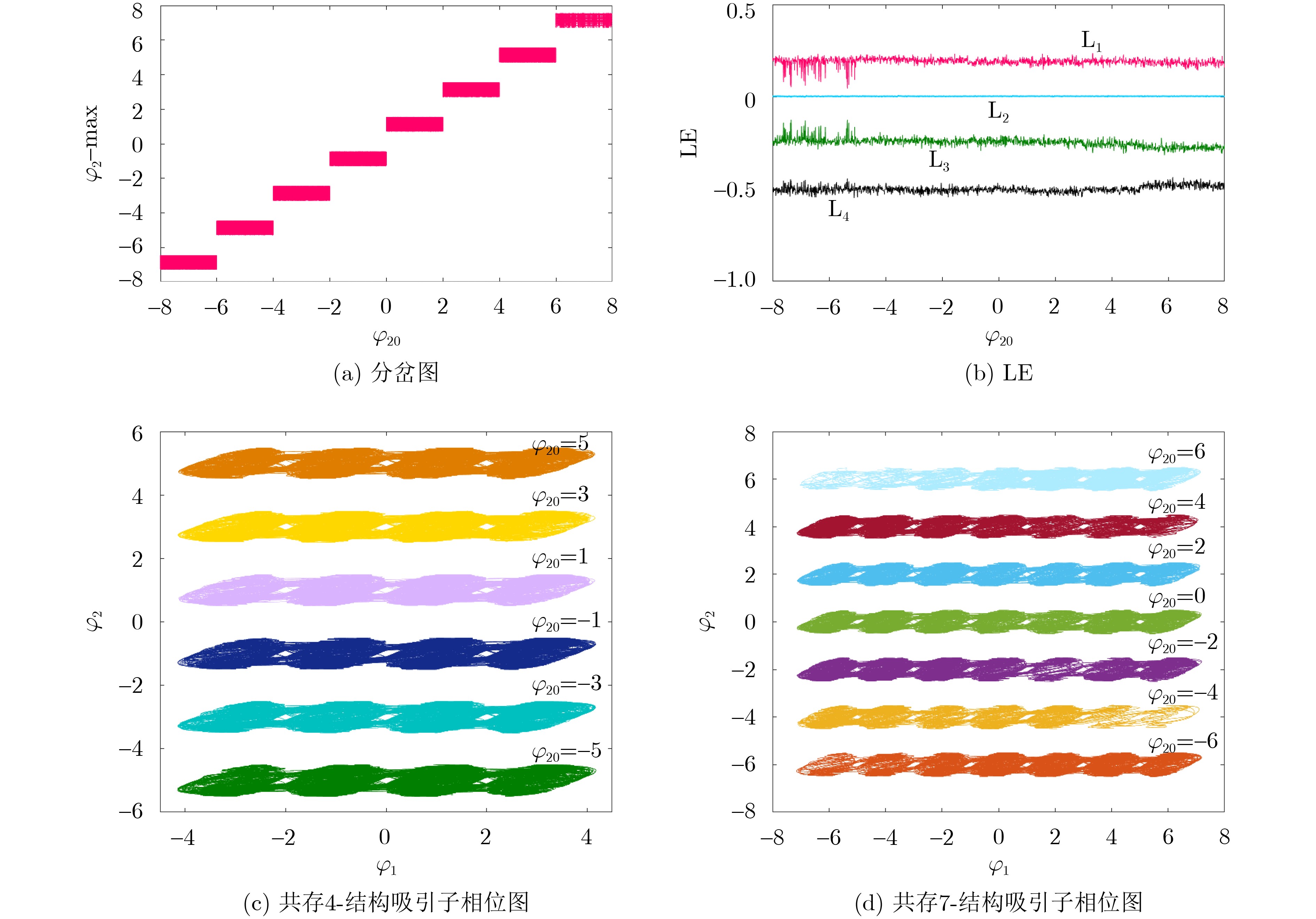
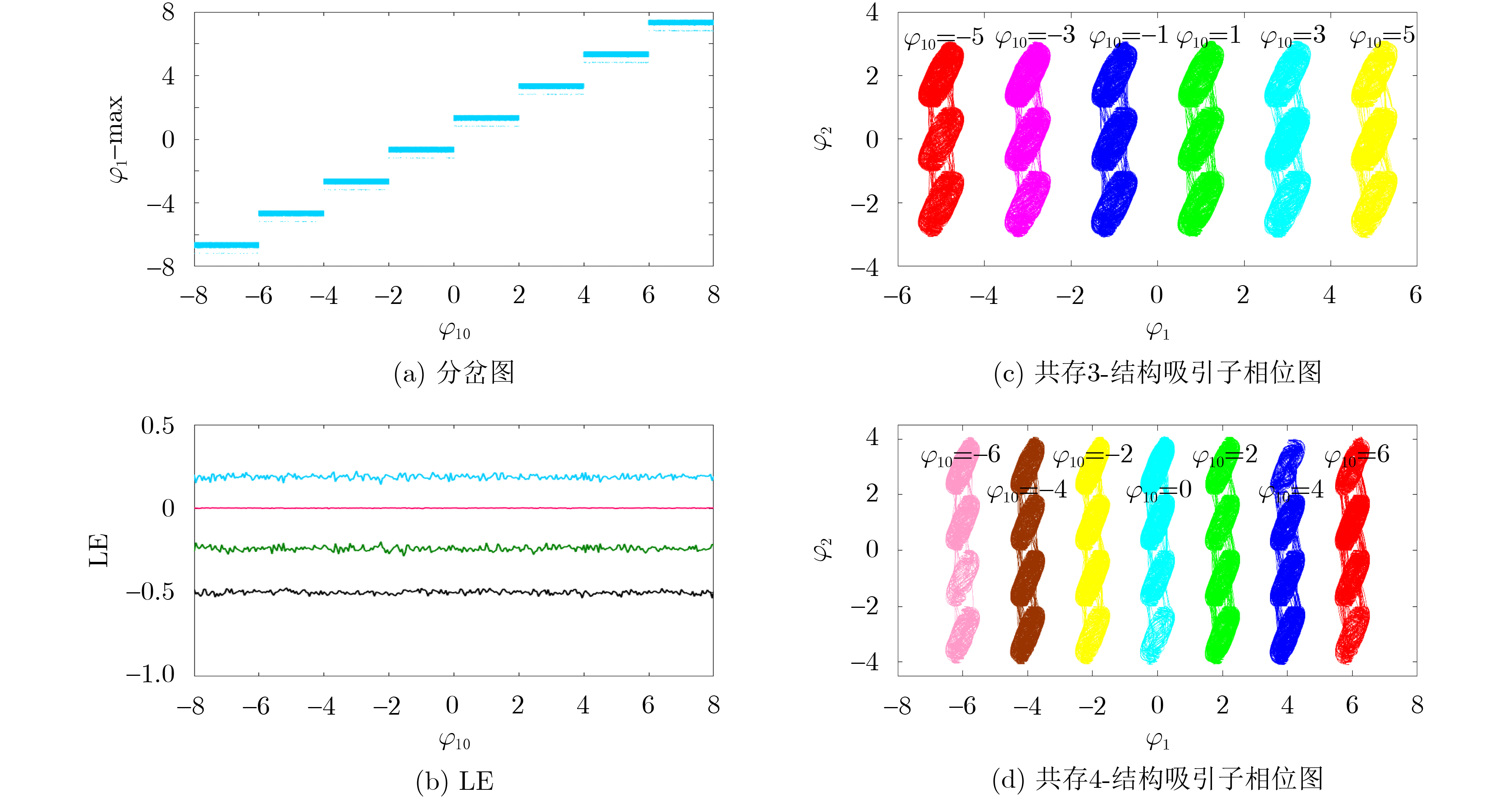
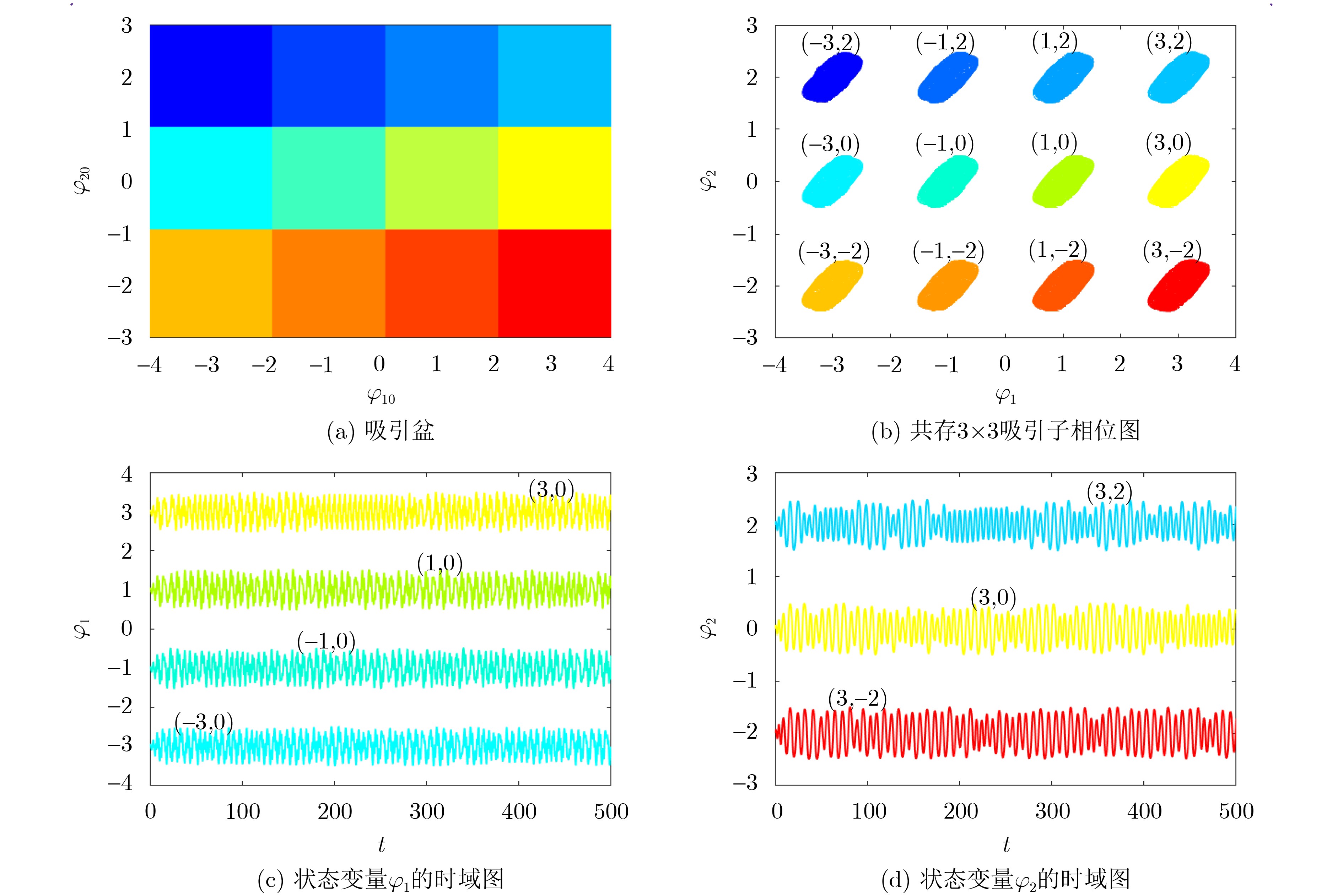
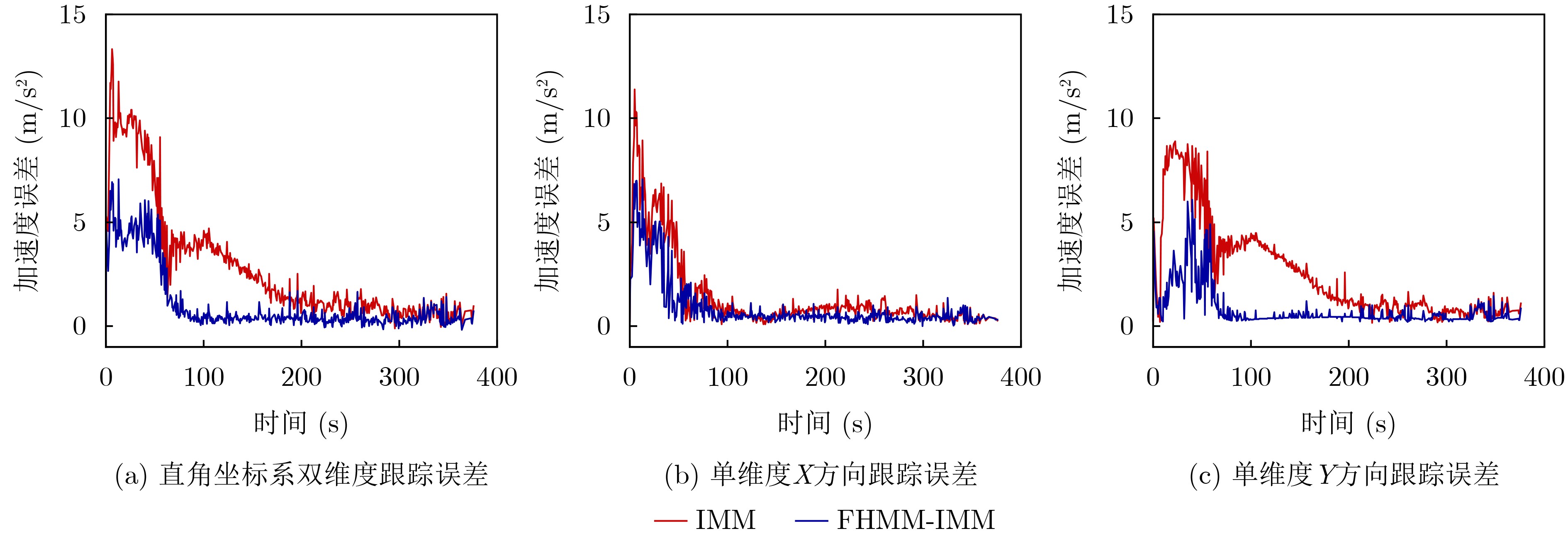
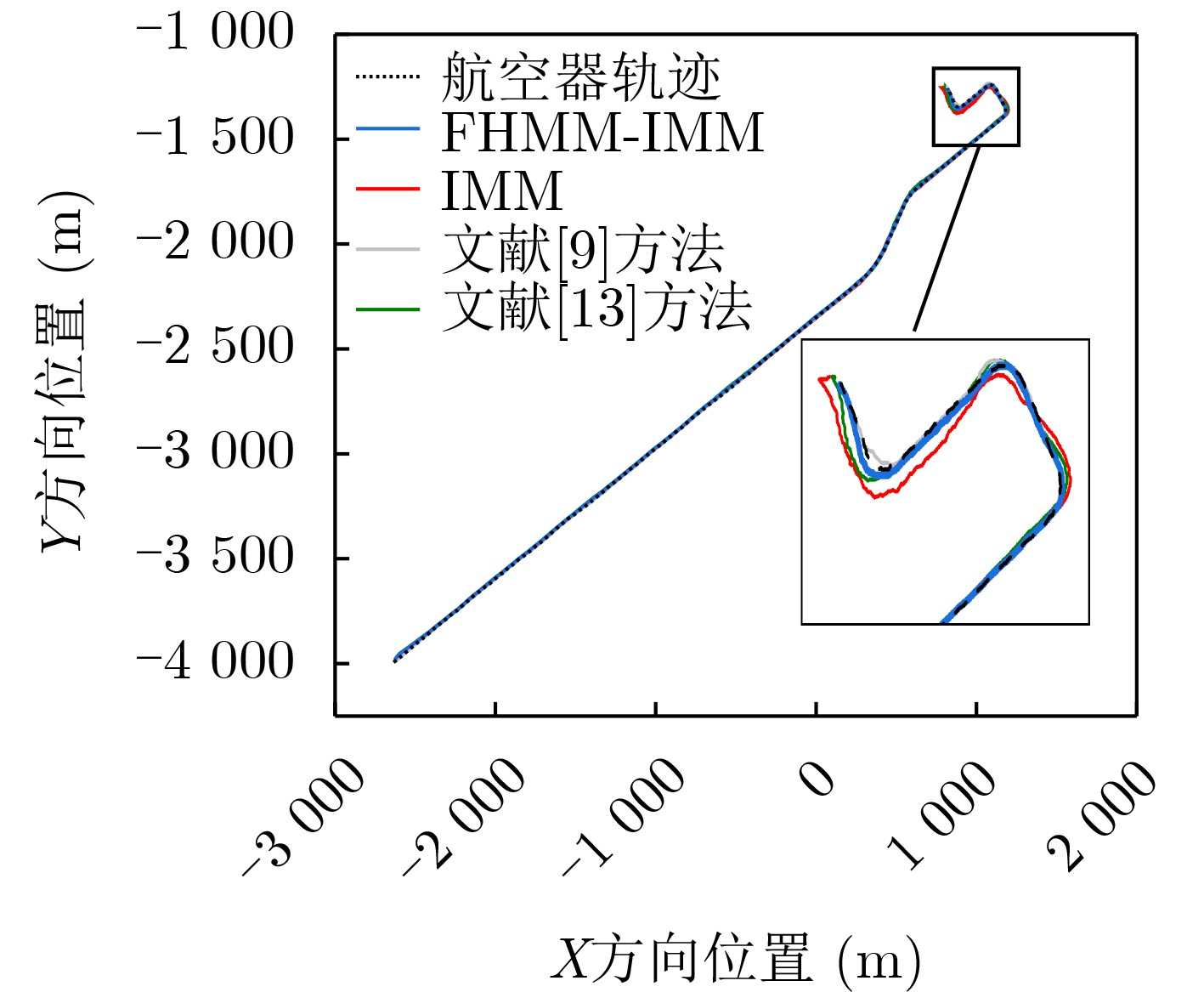
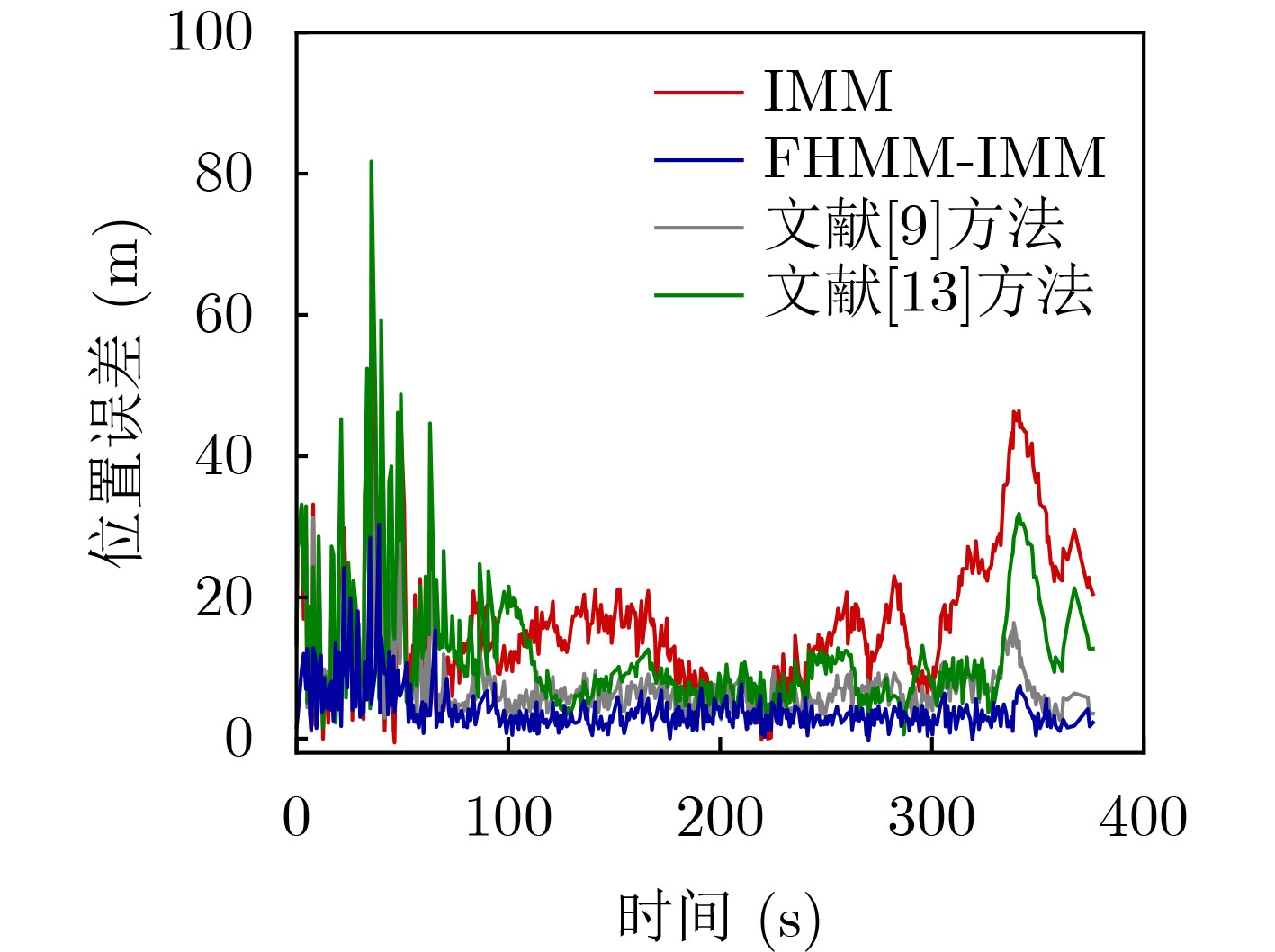
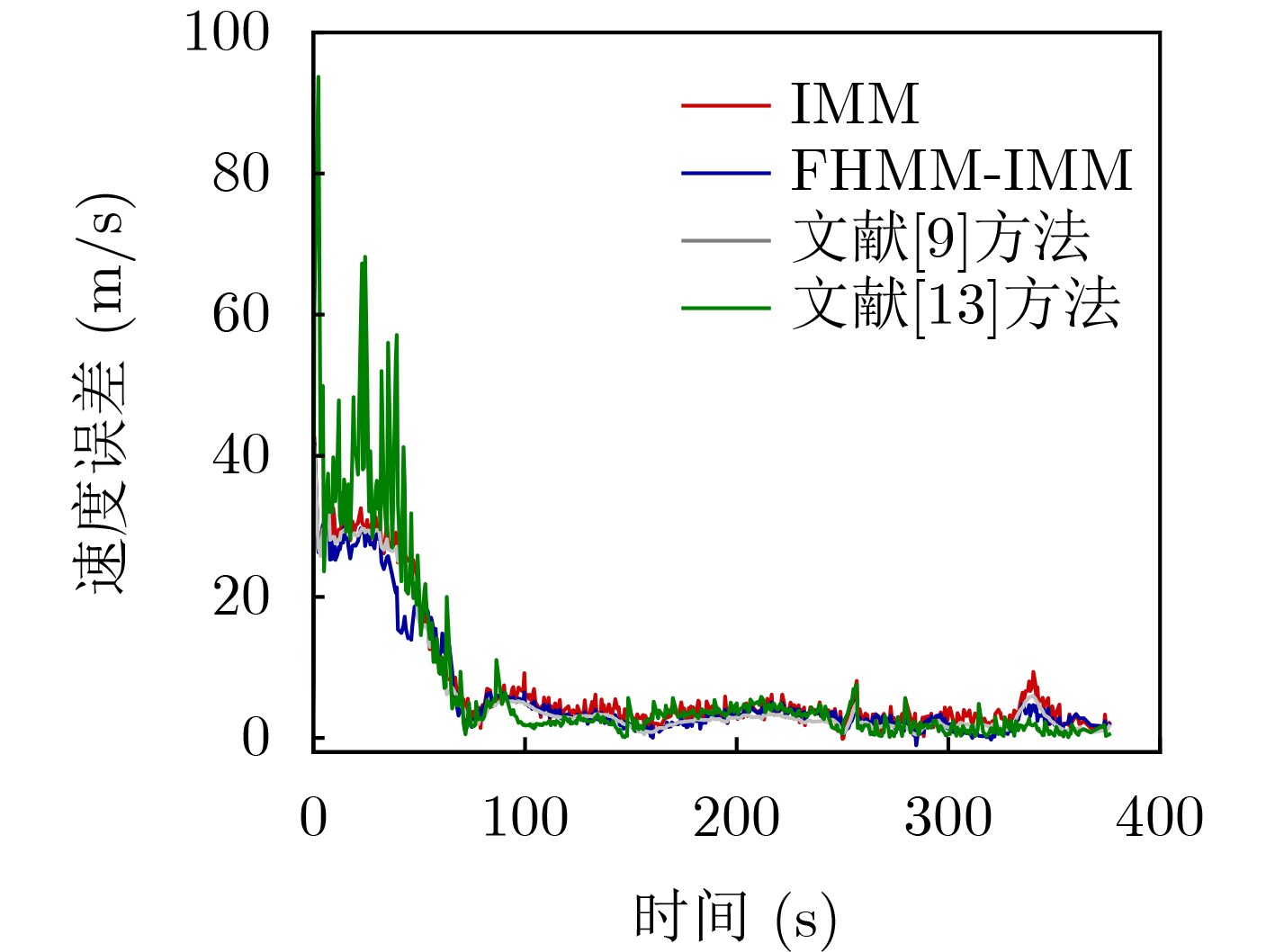
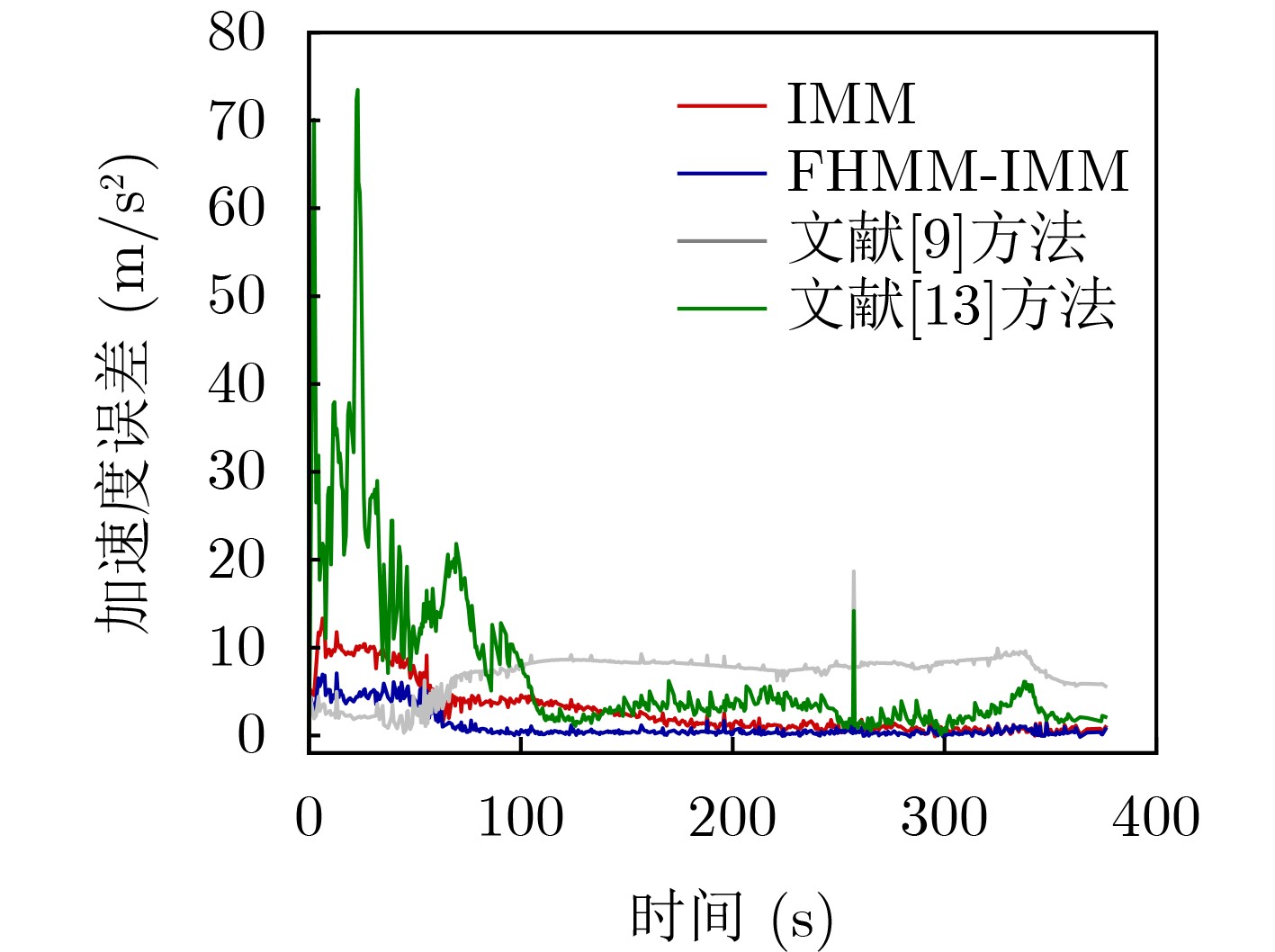
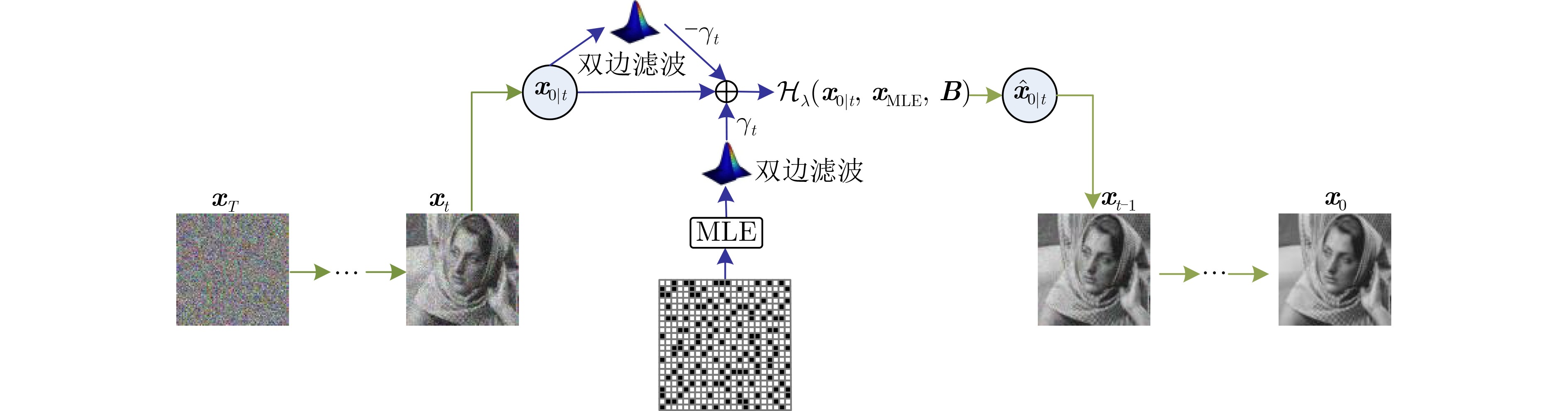
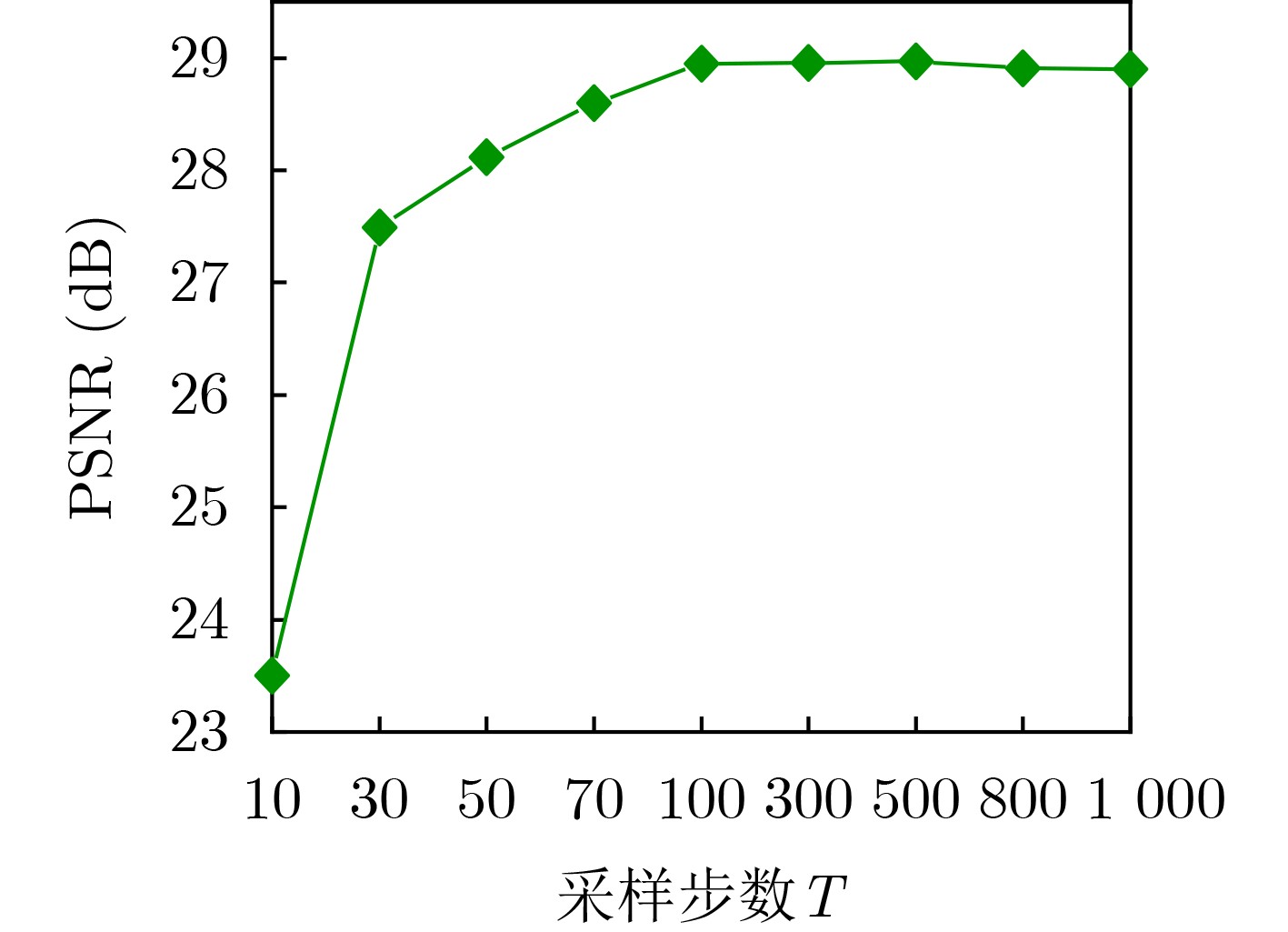
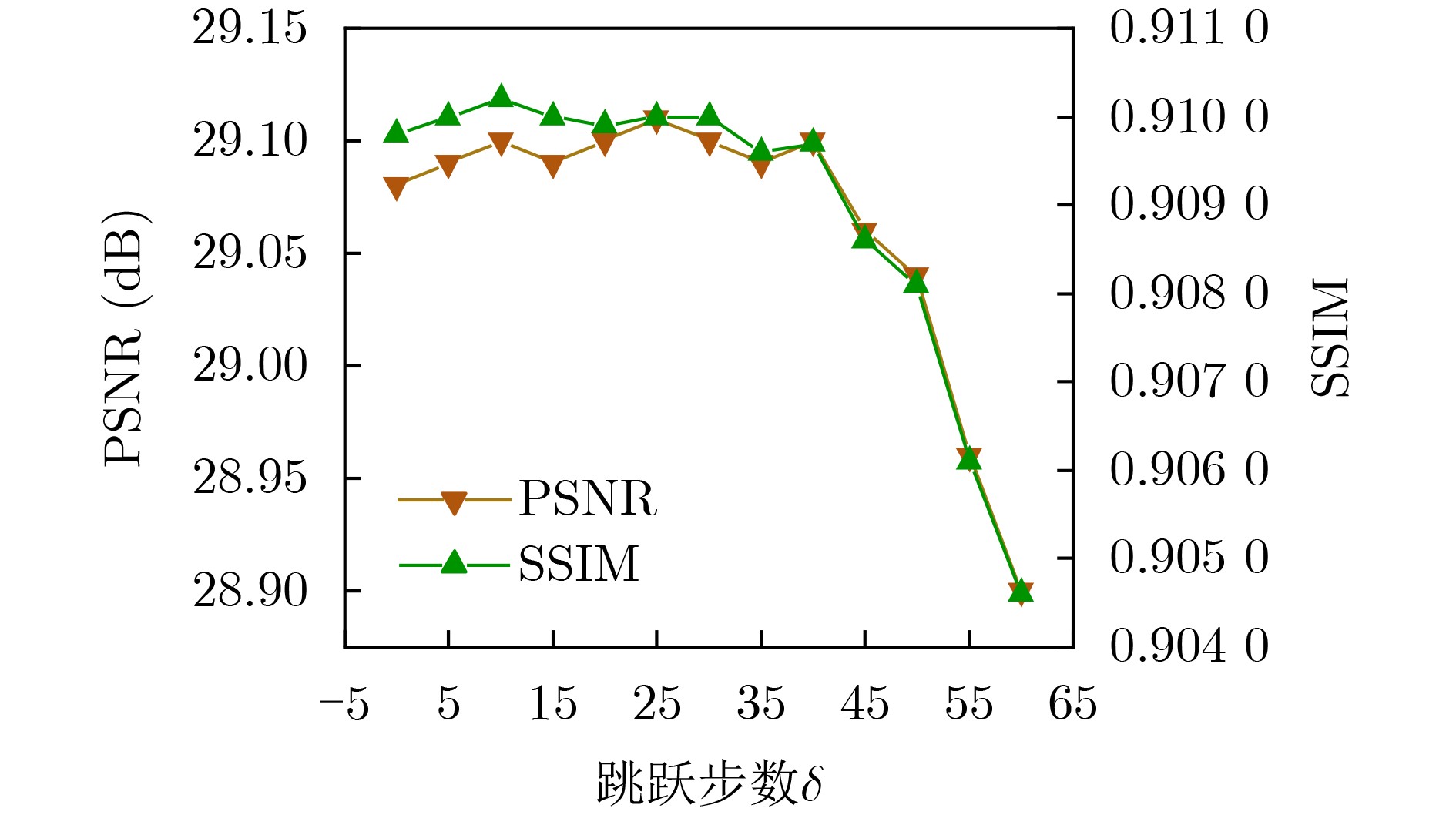
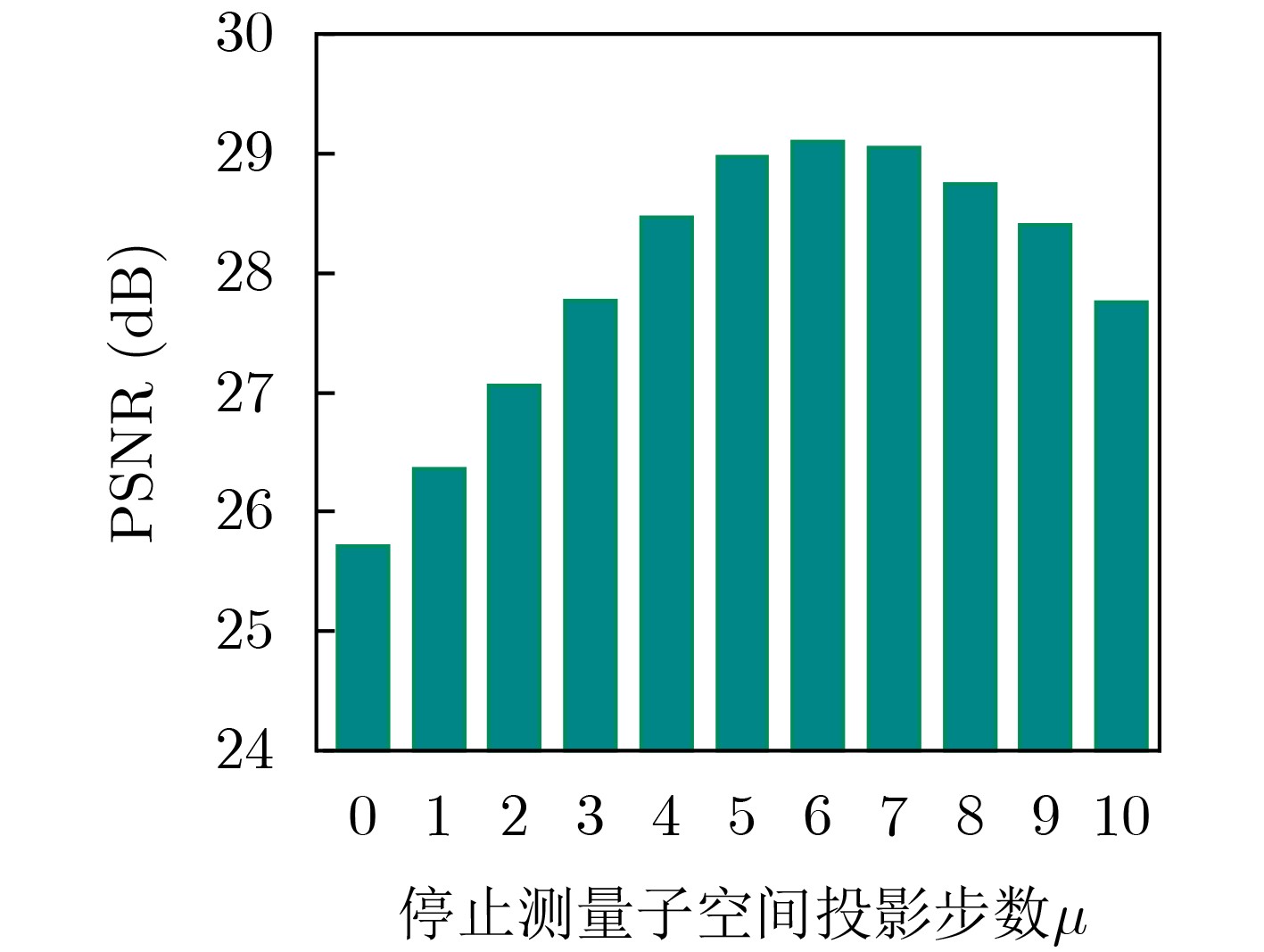
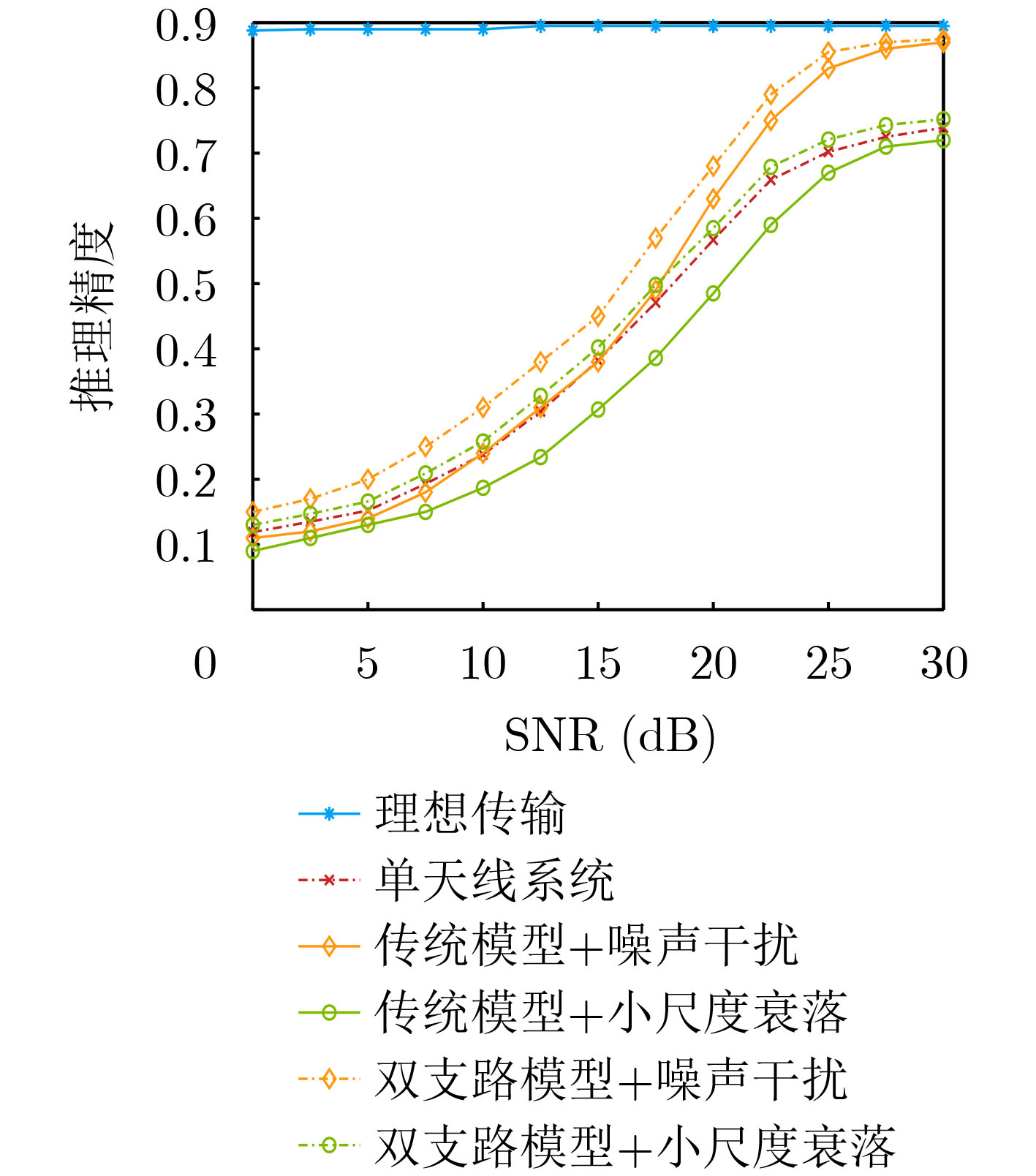
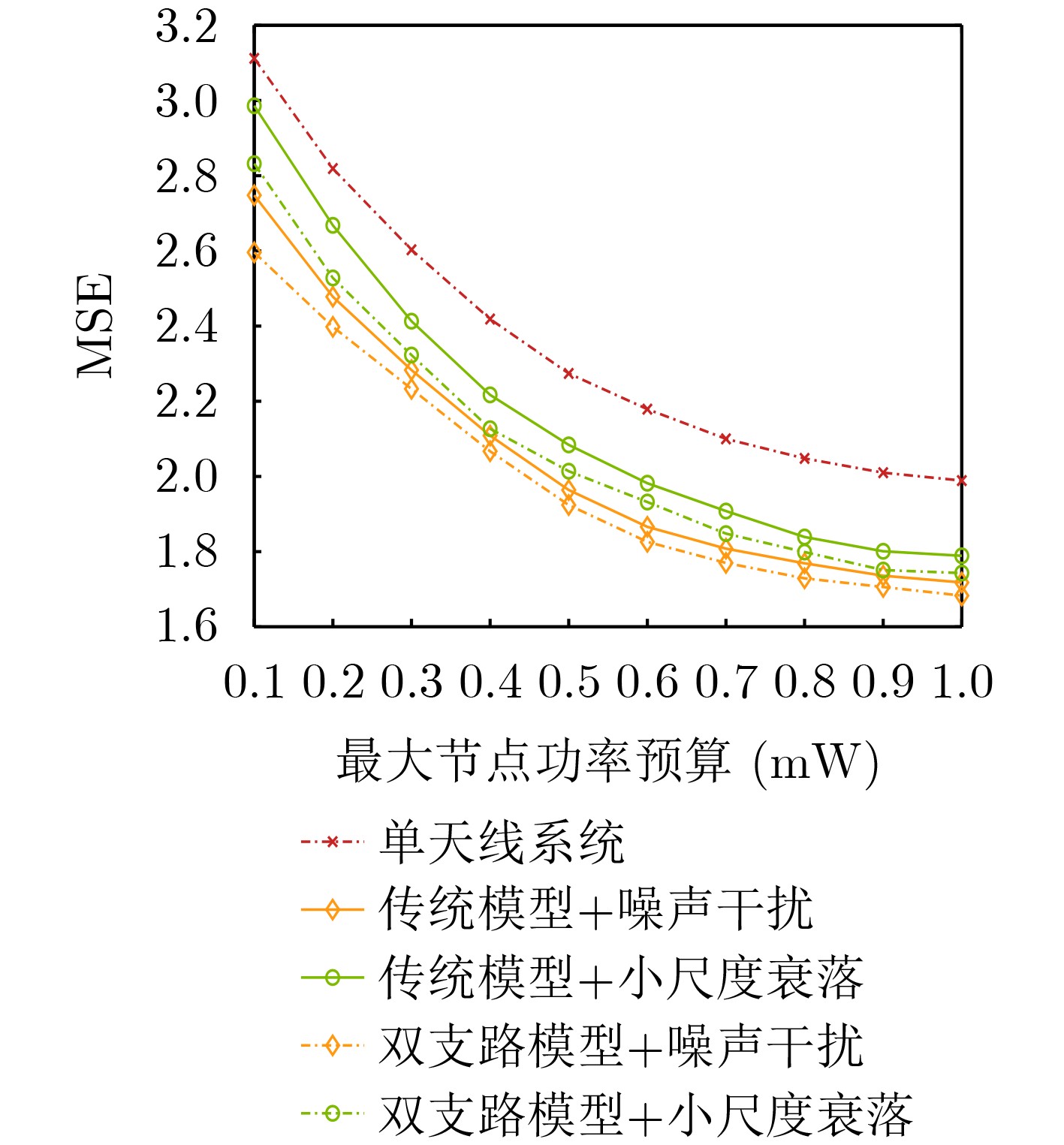
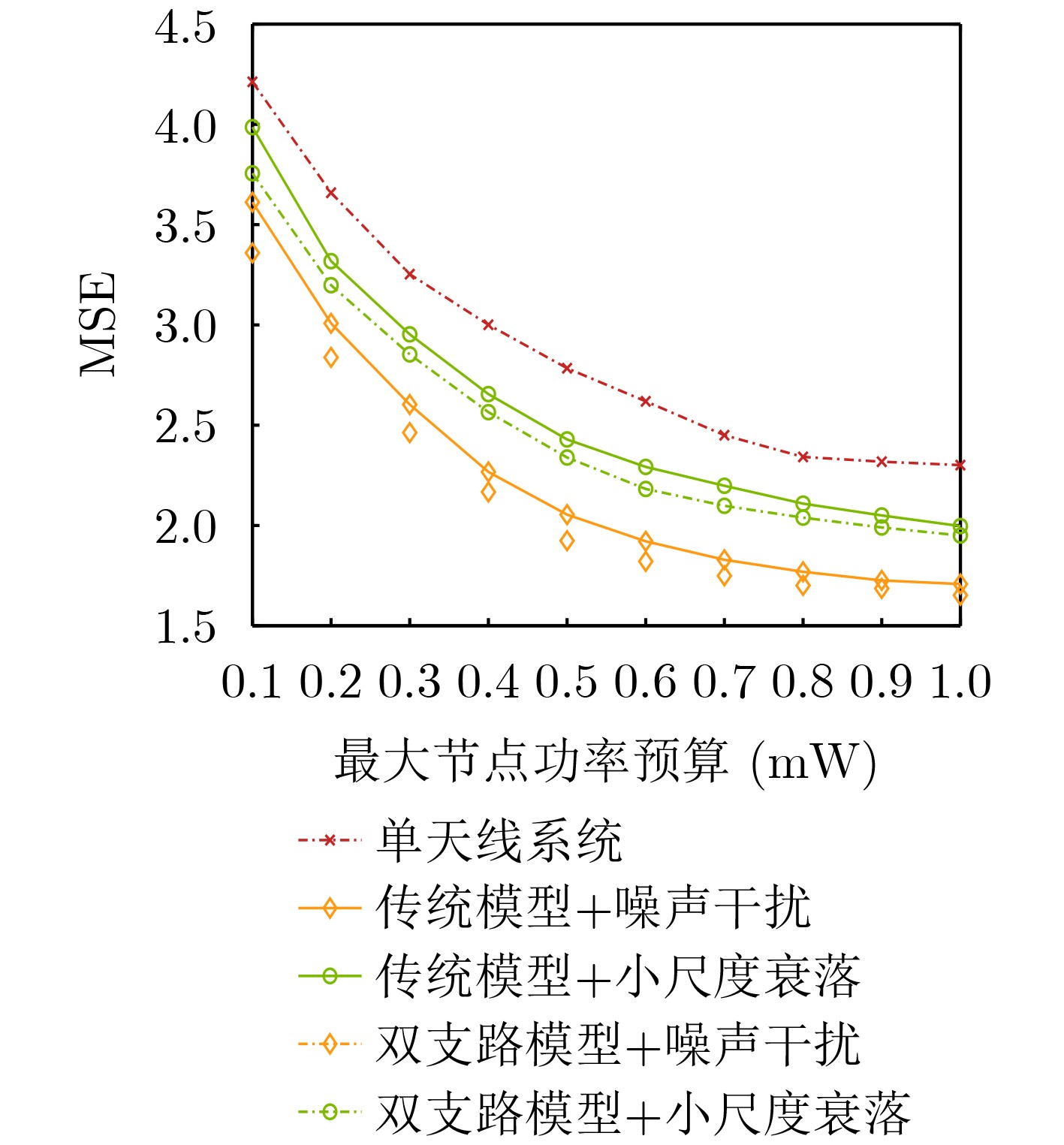
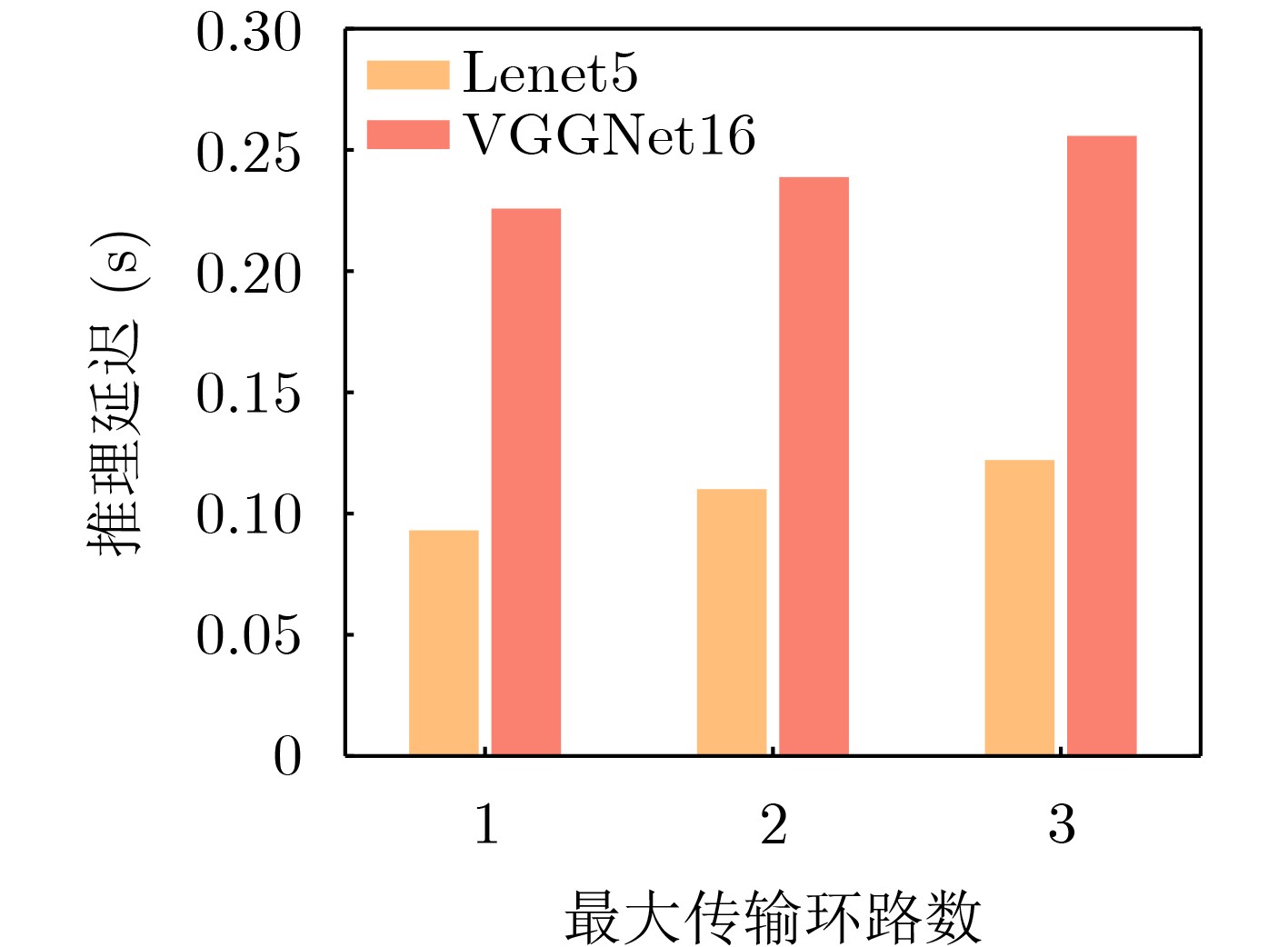
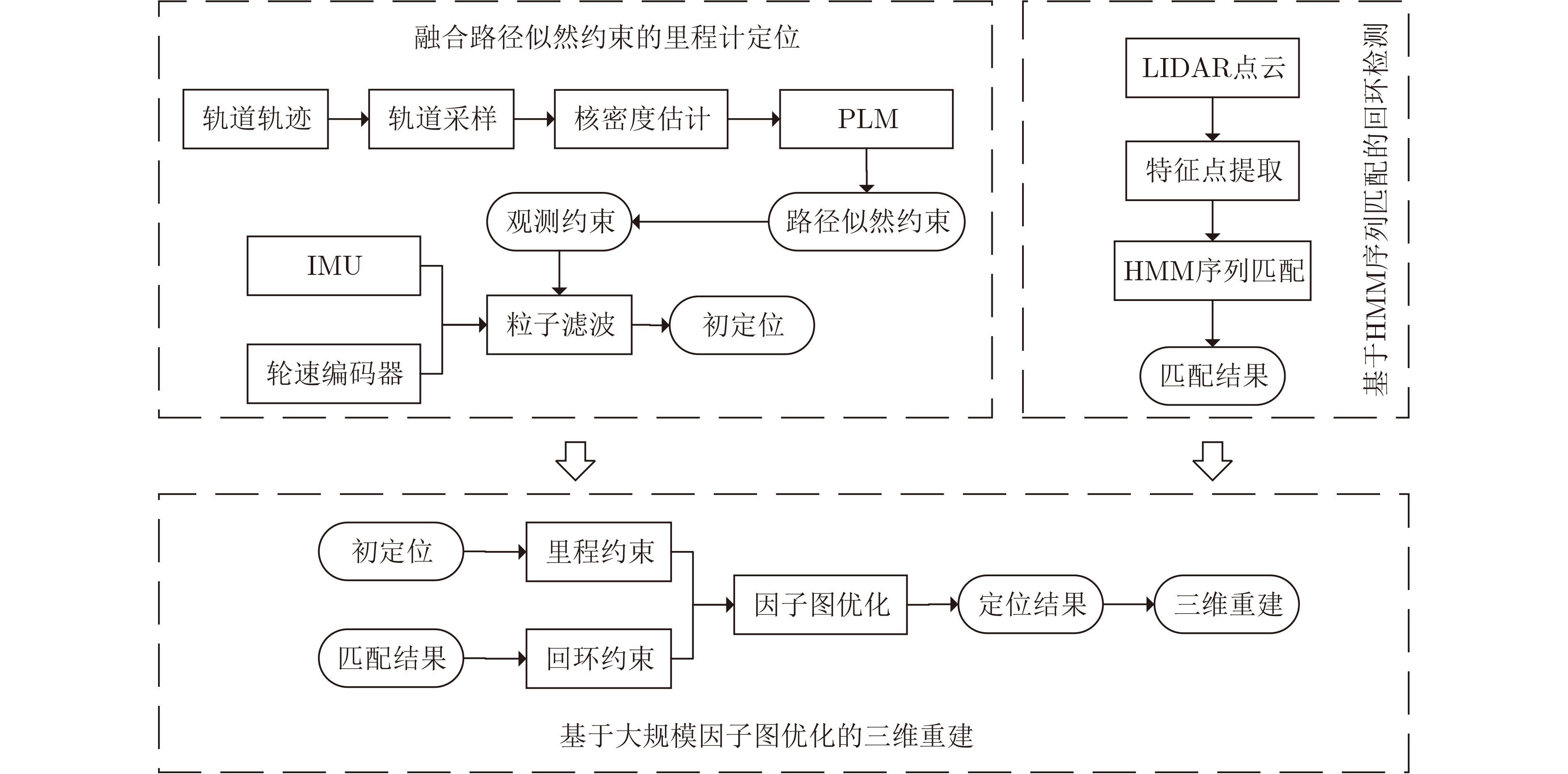
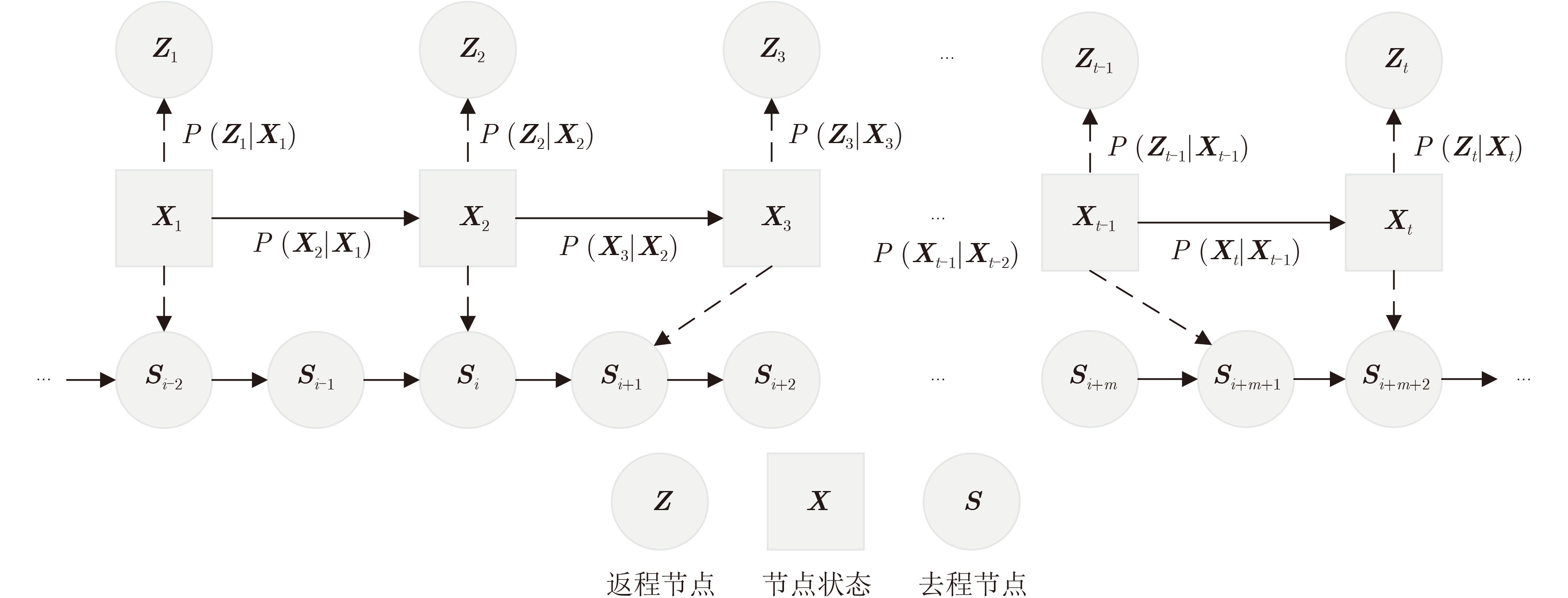
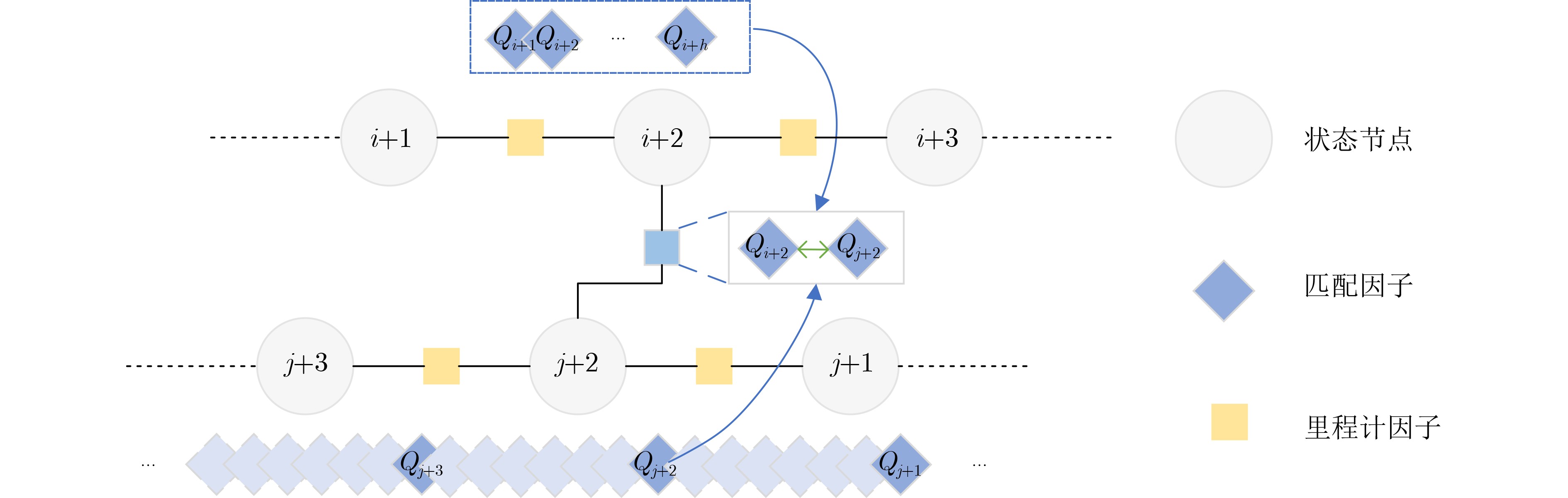
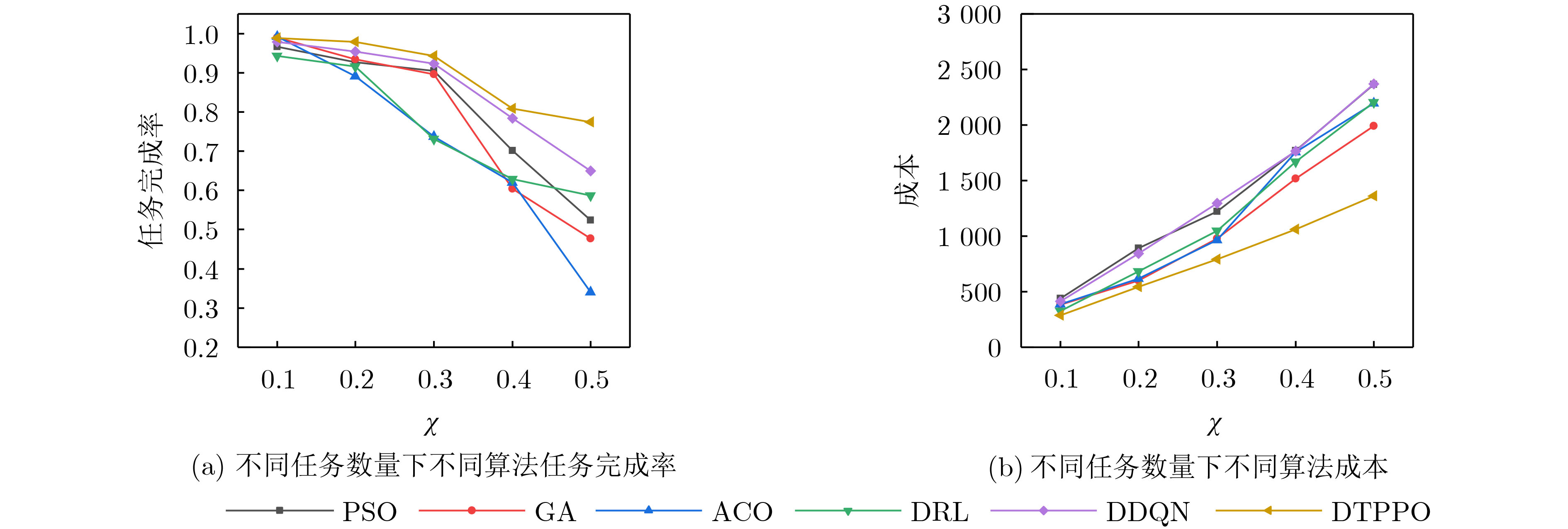
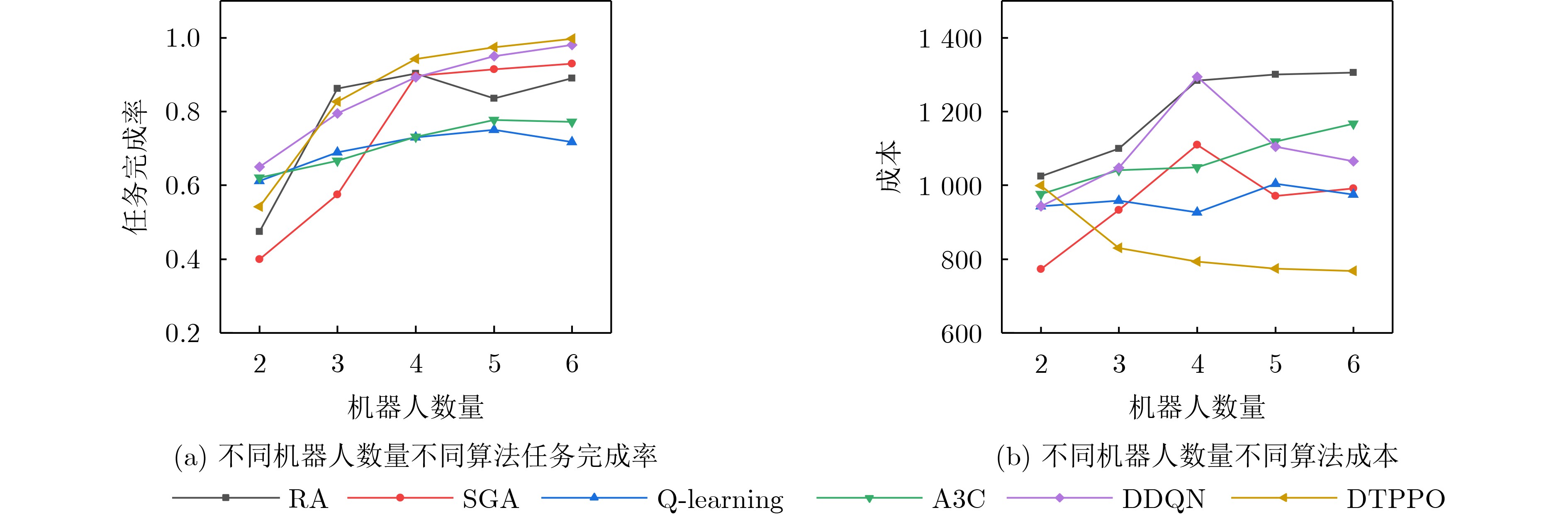
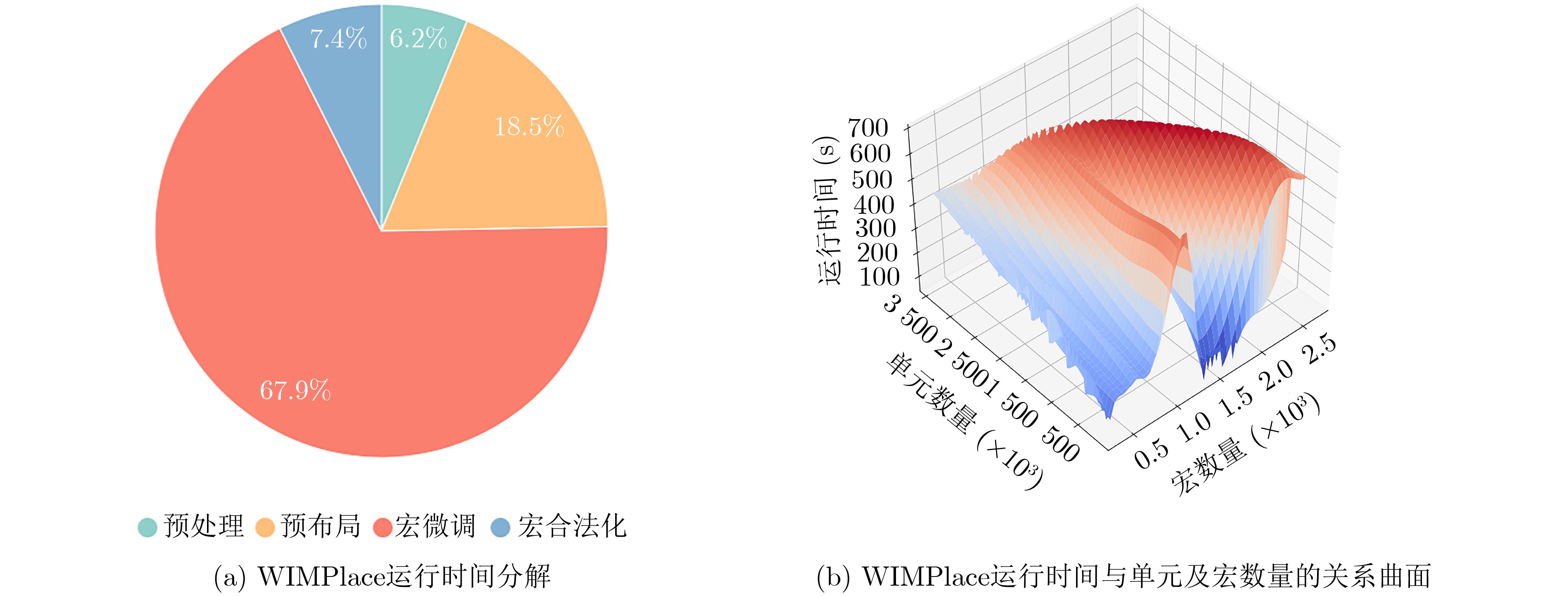
Objective Orthogonal Time Frequency Space (OTFS) modulation is a key technique for high-mobility communication systems, offering robustness against severe Doppler shifts and multipath fading. It provides notable advantages in dynamic environments such as vehicular networks, high-speed rail communications, and unmanned aerial vehicle systems, where conventional orthogonal frequency-division multiplexing fails due to rapid channel variations and dense scattering. However, standard equalization algorithms, including Zero Forcing (ZF) and Minimum Mean Square Error (MMSE), are often ineffective in mitigating Inter-Symbol Interference (ISI) and Inter-Doppler Interference (IDI) under rich-scatterer conditions. These methods also require large-scale matrix inversion, resulting in prohibitively high computational complexity, particularly on OTFS grids with high dimensionality (e.g., M = 32 subcarriers, N = 16 symbols per frame). Most existing studies adopt single-scatterer models that do not reflect the interference structure in practical multipath channels. This study proposes a low-complexity transform domain OTFS equalization algorithm that incorporates block matrix decomposition, transform domain diagonalization, and decision feedback strategies. The algorithm aims to (1) reduce complexity by exploiting block sparsity and structural features of the Delay-Doppler (DD) domain channel matrix, (2) improve interference suppression in time-varying Doppler and dense scattering environments, and (3) validate performance using the 3GPP Extended Vehicular A (EVA) channel model, which simulates realistic high-speed scenarios with user velocities ranging from 121.5 km/h to 607.5 km/h and multiple scattering paths. Methods The proposed algorithm operates in three key stages: (1) Block-Wise ISI Elimination: Leveraging the block-sparse structure of the DD-domain channel matrix, the algorithm partitions the channel into submatrices, each corresponding to a specific DD component. Guard intervals are introduced to suppress ISI arising from signal dispersion across the OTFS grid. Each submatrix K m,l is modeled as a Toeplitz circulant matrix, enabling iterative cancellation of interference by subtracting previously estimated symbols. (2) Transform Domain Diagonalization: Each Toeplitz circulant submatrix is diagonalized using Fourier-based operations. Specifically, the normalized FFT matrix F N is applied to K m,l , converting it into a diagonal form and transforming complex matrix inversion into element-wise division. This step reduces the computational complexity of MMSE equalization from \begin{document}$\mathcal{O}\left( M^3{{N^3}} \right)$\end{document} to \begin{document}$\mathcal{O}\left( {{N^3}} \right)$\end{document}, where N denotes the Doppler dimension of the OTFS resource grid. (3) Decision Feedback Refinement: A closed-loop decision feedback mechanism is introduced to iteratively improve symbol estimates. The demodulated symbols are re-modulated and fed back to update the channel matrix, thereby enhancing estimation accuracy and lowering pilot overhead. The algorithm is evaluated using the 3GPP EVA channel model, which reflects practical high-speed communication scenarios with user velocities between 121.5 km/h and 607.5 km/h, time-varying Doppler shifts, and multiple scatterers. Key system parameters include 32 subcarriers (M = 32), 16 symbols per frame (N = 16), and modulation formats ranging from QPSK to 64QAM. Results and Discussions The performance of the proposed algorithm is evaluated against ZF, MMSE, Message Passing (MP), Maximal Ratio Combining (MRC), and Hybrid MP (HMP) detectors under scenarios: Complexity reduction. The algorithm achieves a computational complexity of \begin{document}$\mathcal{O}\left( {{N^3}} \right)$\end{document}, markedly lower than that of ZF/MMSE and MP. Transform domain diagonalization simplifies matrix inversion into element-wise division, thereby eliminating \begin{document}$\mathcal{O}\left( {{N^3}} \right)$\end{document} operations.Interference Suppression: the algorithm yields a 2.5 dB Bit Error Ratio (BER) improvement over ZF and MMSE at 15 dB SNR under 16QAM modulation. The decision feedback mechanism further reduces the Normalized Mean Square Error (NMSE) by 12.5 dB while lowering pilot overhead by 50%. In high-speed scenarios, the algorithm maintains superior performance, outperforming MRC and HMP by 1.7 dB and 1.0 dB, respectively, under 64QAM modulation. Modulation Robustness: The algorithm consistently demonstrates performance gains across QPSK, 16QAM, and 64QAM. At high SNR with 64QAM, BER gains of 1.7 dB, 1.5 dB, and 1.0 dB are achieved over MRC, MP, and HMP, respectively. Transform domain processing efficiently diagonalizes the channel matrix and eliminates IDI, which is critical in scatterer-rich environments where non-diagonal components dominate interference.Practical Validation: Simulations using the 3GPP EVA model confirm the algorithm’s applicability in real-world high-mobility settings. Conclusions This study presents a low-complexity approach to OTFS channel equalization, addressing both computational and interference challenges in high-mobility scenarios. By leveraging the block-sparse structure of the DD-domain channel matrix and applying Fourier-based diagonalization, the algorithm achieves near-linear complexity while maintaining competitive BER performance. The decision feedback mechanism further enhances robustness, enabling adaptive channel estimation with reduced pilot overhead.Key contributions include: Block-sparse matrix decomposition that facilitates sequential ISI elimination through the use of guard intervals and Toeplitz circulant structures.Fourier-based diagonalization that replaces matrix inversion with element-wise division, reducing computational complexity by orders of magnitude.A closed-loop decision feedback scheme that improves NMSE by 12.5 dB while halving the required pilot overhead.Simulation results under the 3GPP EVA model confirm the algorithm’ suitability for high-speed applications, such as vehicular networks and high-speed rail communications. Future work will explore extensions to large-scale Multiple-Input Multiple-Output (MIMO) systems, adaptive channel tracking, and multi-user interference suppression, with the aim of integrating this framework into 6G URLLC systems.