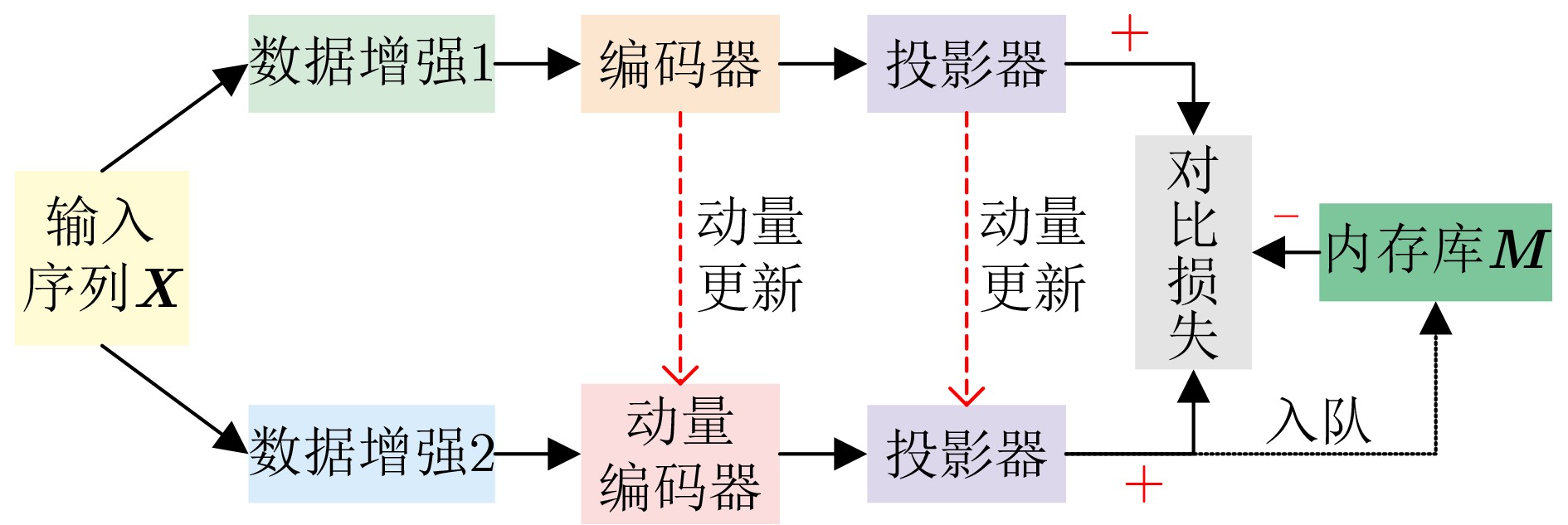
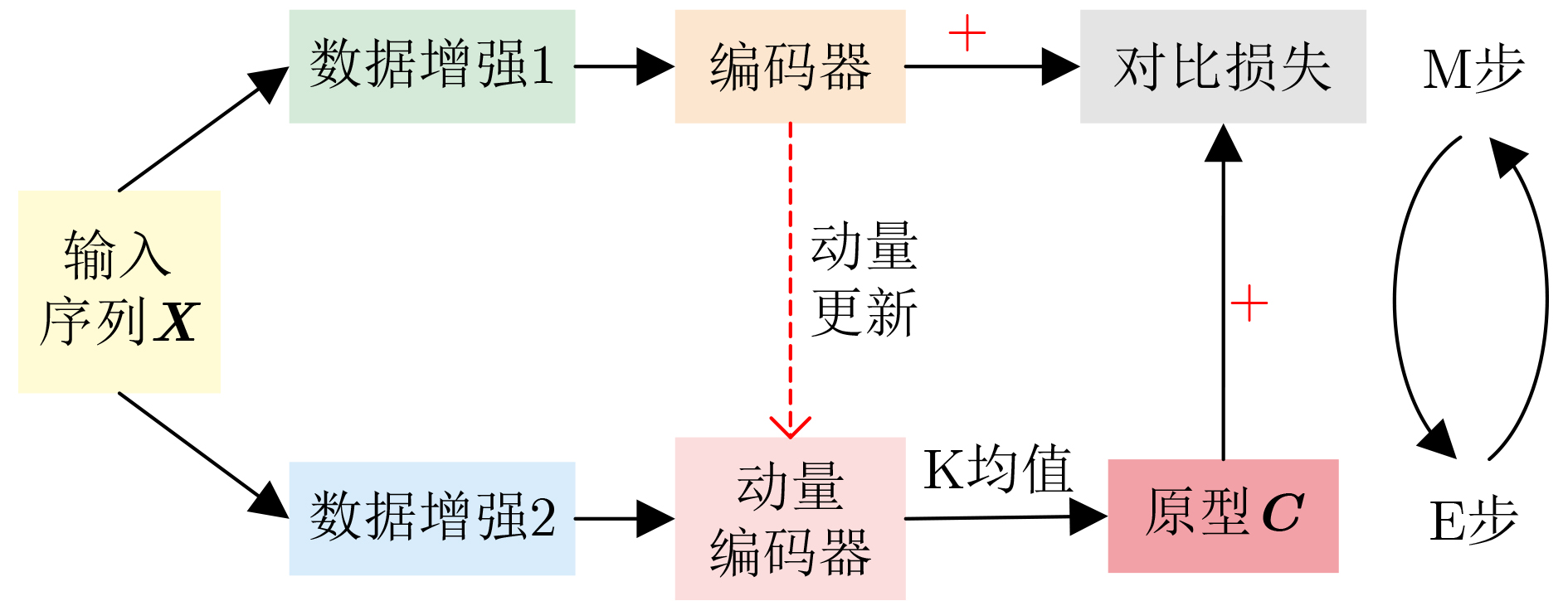
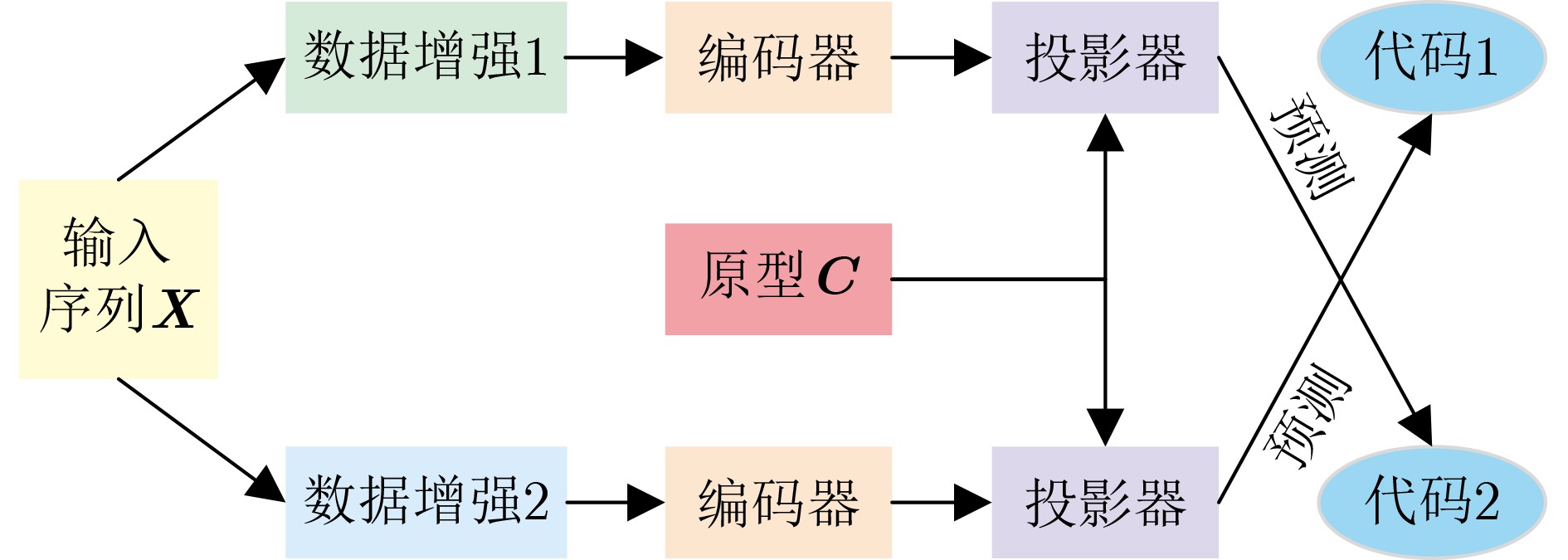
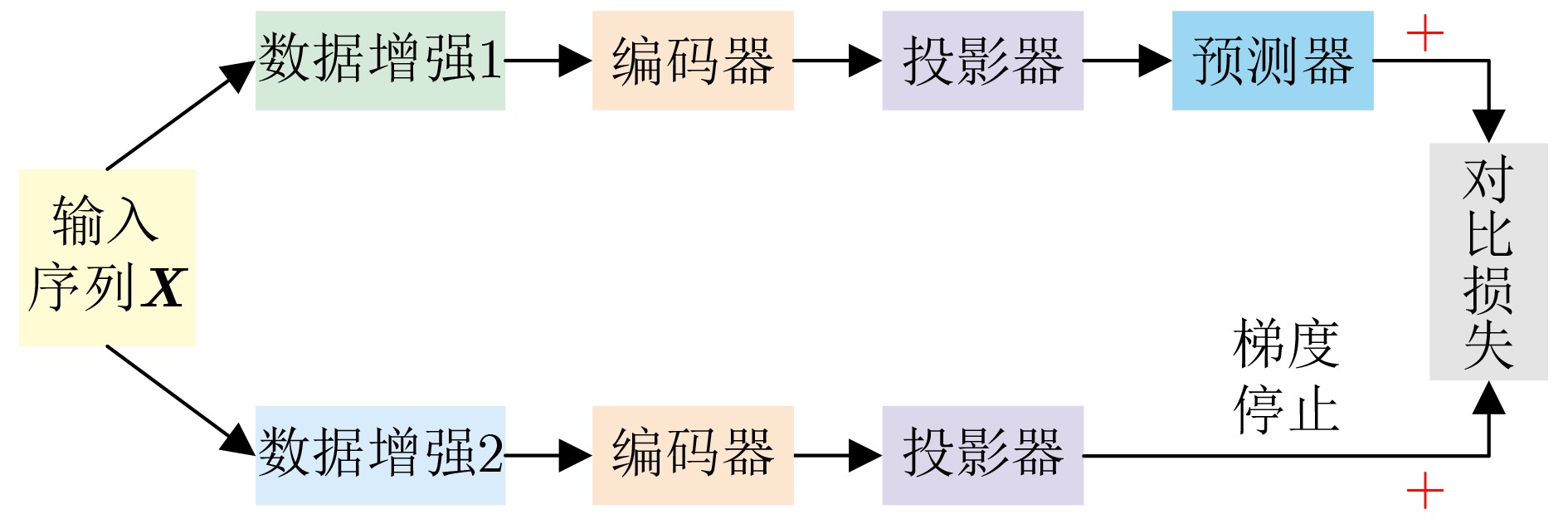
| Citation: | SUN Zhonghua, WU Shuang, JIA Kebin, FENG Jinchao, LIU Pengyu. A Review on Action Recognition Based on Contrastive Learning[J]. Journal of Electronics & Information Technology, 2025, 47(8): 2473-2485. doi: 10.11999/JEIT250131

|

| [1] |
CHEN Ting, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]. The 37th International Conference on Machine Learning, Vienna, Austria, 2020: 149.
|
| [2] |
CHEN Xinlei, FAN Haoqi, GIRSHICK R, et al. Improved baselines with momentum contrastive learning[EB/OL]. https://doi.org/10.48550/arXiv.2003.04297, 2020.
|
| [3] |
LIN Lilang, SONG Sijie, YANG Wenhan, et al. MS2L: Multi-task self-supervised learning for skeleton based action recognition[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 2490–2498. doi: 10.1145/3394171.3413548.
|
| [4] |
SINGH A, CHAKRABORTY O, VARSHNEY A, et al. Semi-supervised action recognition with temporal contrastive learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 10384–10394. doi: 10.1109/CVPR46437.2021.01025.
|
| [5] |
DAVE I R, RIZVE M N, CHEN C, et al. TimeBalance: Temporally-invariant and temporally-distinctive video representations for semi-supervised action recognition[C]. Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 2341–2352. doi: 10.1109/CVPR52729.2023.00232.
|
| [6] |
GAO Xuehao, YANG Yang, ZHANG Yimeng, et al. Efficient spatio-temporal contrastive learning for skeleton-based 3-D action recognition[J]. IEEE Transactions on Multimedia, 2023, 25: 405–417. doi: 10.1109/TMM.2021.3127040.
|
| [7] |
XU Binqian, SHU Xiangbo, ZHANG Jiachao, et al. Spatiotemporal decouple-and-squeeze contrastive learning for semisupervised skeleton-based action recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 11035–11048. doi: 10.1109/TNNLS.2023.3247103.
|
| [8] |
BIAN Cunling, FENG Wei, MENG Fanbo, et al. Global-local contrastive multiview representation learning for skeleton-based action recognition[J]. Computer Vision and Image Understanding, 2023, 229: 103655. doi: 10.1016/j.cviu.2023.103655.
|
| [9] |
WANG Xiang, ZHANG Shiwei, QING Zhiwu, et al. MoLo: Motion-augmented long-short contrastive learning for few-shot action recognition[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 18011–18021. doi: 10.1109/CVPR52729.2023.01727.
|
| [10] |
SHU Xiangbo, XU Binqian, ZHANG Liyan, et al. Multi-granularity anchor-contrastive representation learning for semi-supervised skeleton-based action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 7559–7576. doi: 10.1109/TPAMI.2022.3222871.
|
| [11] |
WU Zhirong, XIONG Yuanjun, YU S X, et al. Unsupervised feature learning via non-parametric instance discrimination[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3733–3742. doi: 10.1109/CVPR.2018.00393.
|
| [12] |
VAN DEN OORD A, LI Yazhe, and VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. http://arxiv.org/abs/1807.03748, 2018.
|
| [13] |
RAO Haocong, XU Shihao, HU Xiping, et al. Augmented skeleton based contrastive action learning with momentum LSTM for unsupervised action recognition[J]. Information Sciences, 2021, 569: 90–109. doi: 10.1016/j.ins.2021.04.023.
|
| [14] |
LI Linguo, WANG Minsi, NI Bingbing, et al. 3D human action representation learning via cross-view consistency pursuit[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 4739–4748. doi: 10.1109/CVPR46437.2021.00471.
|
| [15] |
HUA Yilei, WU Wenhan, ZHENG Ce, et al. Part aware contrastive learning for self-supervised action recognition[C]. The Thirty-Second International Joint Conference on Artificial Intelligence, Macao, China, 2023: 855–863. doi: 10.24963/ijcai.2023/95.
|
| [16] |
GUO Tianyu, LIU Hong, CHEN Zhan, et al. Contrastive learning from extremely augmented skeleton sequences for self-supervised action recognition[C]. The 36th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2022: 762–770. doi: 10.1609/aaai.v36i1.19957.
|
| [17] |
SHAH A, ROY A, SHAH K, et al. HaLP: Hallucinating latent positives for skeleton-based self-supervised learning of actions[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 18846–18856. doi: 10.1109/CVPR52729.2023.01807.
|
| [18] |
MAO Yunyao, ZHOU Wengang, LU Zhenbo, et al. CMD: Self-supervised 3D action representation learning with cross-modal mutual distillation[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 734–752. doi: 10.1007/978-3-031-20062-5_42.
|
| [19] |
ZHANG Jiahang, LIN Lilang, and LIU Jiaying. Prompted contrast with masked motion modeling: Towards versatile 3D action representation learning[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 7175–7183. doi: 10.1145/3581783.3611774.
|
| [20] |
LIN Lilang, ZHANG Jiahang, and LIU Jiaying. Mutual information driven equivariant contrastive learning for 3D action representation learning[J]. IEEE Transactions on Image Processing, 2024, 33: 1883–1897. doi: 10.1109/TIP.2024.3372451.
|
| [21] |
DONG Jianfeng, SUN Shengkai, LIU Zhonglin, et al. Hierarchical contrast for unsupervised skeleton-based action representation learning[C]. The Thirty-Seventh AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 525–533. doi: 10.1609/aaai.v37i1.25127.
|
| [22] |
CHEN Yuxiao, ZHAO Long, YUAN Jianbo, et al. Hierarchically self-supervised transformer for human skeleton representation learning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 185–202. doi: 10.1007/978-3-031-19809-0_11.
|
| [23] |
LI Junnan, ZHOU Pan, XIONG Caiming, et al. Prototypical contrastive learning of unsupervised representations[C]. The 9th International Conference on Learning Representations, Virtual Event, Austria, 2021.
|
| [24] |
DEMPSTER A P, LAIRD N M, and RUBIN D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statistical Society: Series B (Methodological), 1977, 39(1): 1–22. doi: 10.1111/j.2517-6161.1977.tb01600.x.
|
| [25] |
XU Shihao, RAO Haocong, HU Xiping, et al. Prototypical contrast and reverse prediction: Unsupervised skeleton based action recognition[J]. IEEE Transactions on Multimedia, 2023, 25: 624–634. doi: 10.1109/TMM.2021.3129616.
|
| [26] |
ZHOU Huanyu, LIU Qingjie, and WANG Yunhong. Learning discriminative representations for skeleton based action recognition[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 10608–10617. doi: 10.1109/CVPR52729.2023.01022.
|
| [27] |
CARON M, MISRA I, MAIRAL J, et al. Unsupervised learning of visual features by contrasting cluster assignments[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 831.
|
| [28] |
WANG Mingdao, LI Xueming, CHEN Siqi, et al. Learning representations by contrastive spatio-temporal clustering for skeleton-based action recognition[J]. IEEE Transactions on Multimedia, 2024, 26: 3207–3220. doi: 10.1109/TMM.2023.3307933.
|
| [29] |
HAN Haochen, ZHENG Qinghua, LUO Minnan, et al. Noise-tolerant learning for audio-visual action recognition[J]. IEEE Transactions on Multimedia, 2024, 26: 7761–7774. doi: 10.1109/TMM.2024.3371220.
|
| [30] |
GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent a new approach to self-supervised learning[C]. Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1786.
|
| [31] |
XU Binqian, SHU Xiangbo, and SONG Yan. X-invariant contrastive augmentation and representation learning for semi-supervised skeleton-based action recognition[J]. IEEE Transactions on Image Processing, 2022, 31: 3852–3867. doi: 10.1109/TIP.2022.3175605.
|
| [32] |
FRANCO L, MANDICA P, MUNJAL B, et al. Hyperbolic self-paced learning for self-supervised skeleton-based action representations[C]. The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 2023: 1–5.
|
| [33] |
KUMAR M P, PACKER B, and KOLLER D. Self-paced learning for latent variable models[C]. The 24th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2010: 1189–1197.
|
| [34] |
CHEN Xinlei and HE Kaiming. Exploring simple siamese representation learning[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 15745–15753. doi: 10.1109/CVPR46437.2021.01549.
|
| [35] |
ZHANG Haoyuan, HOU Yonghong, ZHANG Wenjing, et al. Contrastive positive mining for unsupervised 3D action representation learning[C]. Proceedings of the 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 36–51. doi: 10.1007/978-3-031-19772-7_3.
|
| [36] |
LIN Wei, DING Xinghao, HUANG Yue, et al. Self-supervised video-based action recognition with disturbances[J]. IEEE Transactions on Image Processing, 2023, 32: 2493–2507. doi: 10.1109/TIP.2023.3269228.
|
| [37] |
YUN S, HAN D, CHUN S, et al. CutMix: Regularization strategy to train strong classifiers with localizable features[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 6022–6031. doi: 10.1109/ICCV.2019.00612.
|
| [38] |
REN Sucheng, WANG Huiyu, GAO Zhengqi, et al. A simple data mixing prior for improving self-supervised learning[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 14575–14584. doi: 10.1109/CVPR52688.2022.01419.
|
| [39] |
ZHANG Hongyi, CISSE M, DAUPHIN Y N, et al. mixup: Beyond empirical risk minimization[C]. The 6th International Conference on Learning Representations, Vancouver, Canada, 2018.
|
| [40] |
SHI Lei, ZHANG Yifan, CHENG Jian, et al. Decoupled spatial-temporal attention network for skeleton-based action-gesture recognition[C]. Proceedings of the 15th Asian Conference on Computer Vision, Kyoto, Japan, 2020: 38–53. doi: 10.1007/978-3-030-69541-5_3.
|
| [41] |
ZHAN Chen, LIU Hong, GUO Tianyu, et al. Contrastive learning from spatio-temporal mixed skeleton sequences for self-supervised skeleton-based action recognition[EB/OL]. https://arxiv.org/abs/2207.03065, 2022.
|
| [42] |
LEE I, KIM D, KANG S, et al. Ensemble deep learning for skeleton-based action recognition using temporal sliding LSTM networks[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1012–1020. doi: 10.1109/ICCV.2017.115.
|
| [43] |
YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 912. doi: 10.1609/aaai.v32i1.12328.
|
| [44] |
LE-KHAC P H, HEALY G, and SMEATON A F. Contrastive representation learning: A framework and review[J]. IEEE Access, 2020, 8: 193907–193934. doi: 10.1109/ACCESS.2020.3031549.
|
| [45] |
张重生, 陈杰, 李岐龙, 等. 深度对比学习综述[J]. 自动化学报, 2023, 49(1): 15–39. doi: 10.16383/j.aas.c220421.
ZHANG Chongsheng, CHEN Jie, LI Qilong, et al. Deep contrastive learning: A survey[J]. Acta Automatica Sinica, 2023, 49(1): 15–39. doi: 10.16383/j.aas.c220421.
|
| [46] |
KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: A large video database for human motion recognition[C]. 2011 International Conference on Computer Vision, Barcelona, Spain, 2011: 2556–2563. doi: 10.1109/ICCV.2011.6126543.
|
| [47] |
SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[EB/OL]. https://doi.org/10.48550/arXiv.1212.0402, 2012.
|
| [48] |
WANG Jiang, NIE Xiaohan, XIA Yin, et al. Cross-view action modeling, learning, and recognition[C]. 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 2649–2656. doi: 10.1109/CVPR.2014.339.
|
| [49] |
SHAHROUDY A, LIU Jun, NG T-T, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115.
|
| [50] |
LIU Chunhui, HU Yueyu, LI Yanghao, et al. PKU-MMD: A large scale benchmark for skeleton-based human action understanding[C]. Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities, Mountain View, USA, 2017: 1–8. doi: 10.1145/3132734.3132739.
|
| [51] |
KAY W, CARREIRA J, SIMONYAN K, et al. The Kinetics human action video dataset[EB/OL]. http://arxiv.org/abs/1705.06950, 2017.
|
| [52] |
GOYAL R, KAHOU S E, MICHALSKI V, et al. The “Something Something” video database for learning and evaluating visual common sense[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5843–5851. doi: 10.1109/ICCV.2017.622.
|
| [53] |
LIU Jun, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684–2701. doi: 10.1109/TPAMI.2019.2916873.
|
| [54] |
MATERZYNSKA J, BERGER G, BAX I, et al. The Jester dataset: A large-scale video dataset of human gestures[C]. 2019 IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 2019: 2874–2882. doi: 10.1109/ICCVW.2019.00349.
|
| [55] |
CHEN C F R, PANDA R, RAMAKRISHNAN K, et al. Deep analysis of CNN-based spatio-temporal representations for action recognition[C]. Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 6161–6171. doi: 10.1109/CVPR46437.2021.00610.
|
Figures(6) / Tables(7)



 DownLoad:
DownLoad: