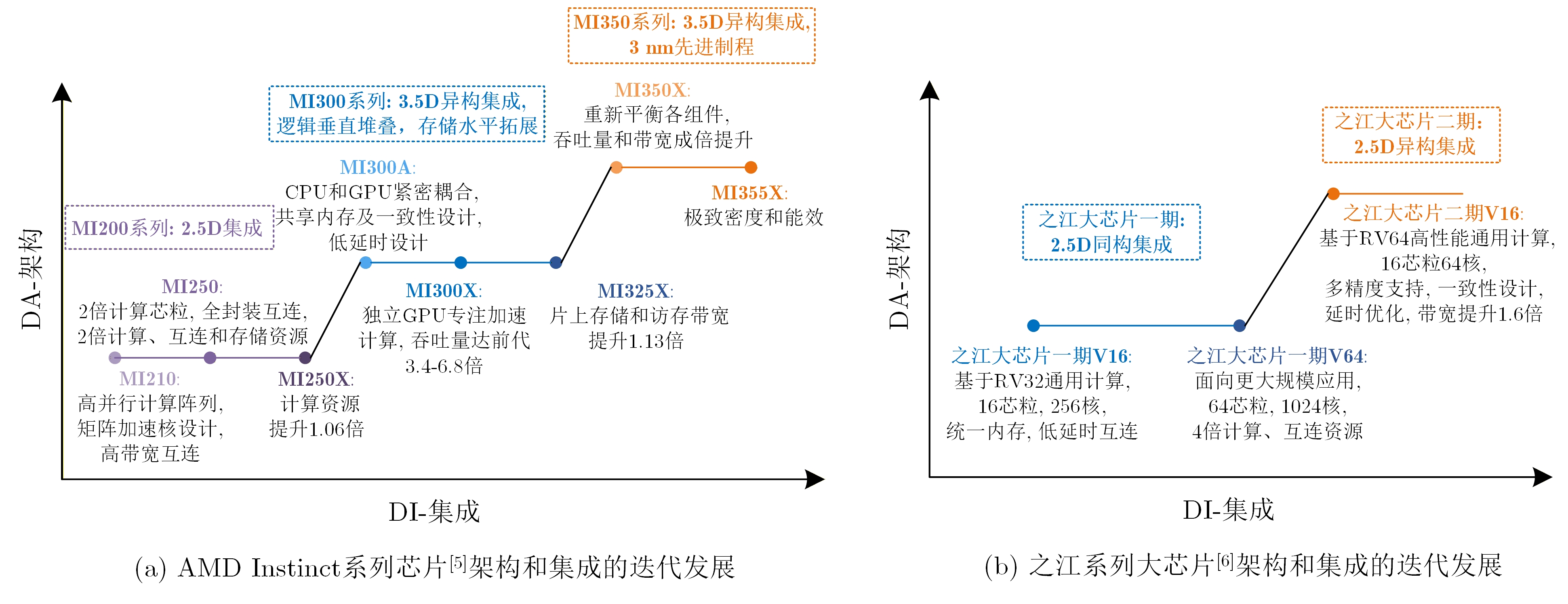
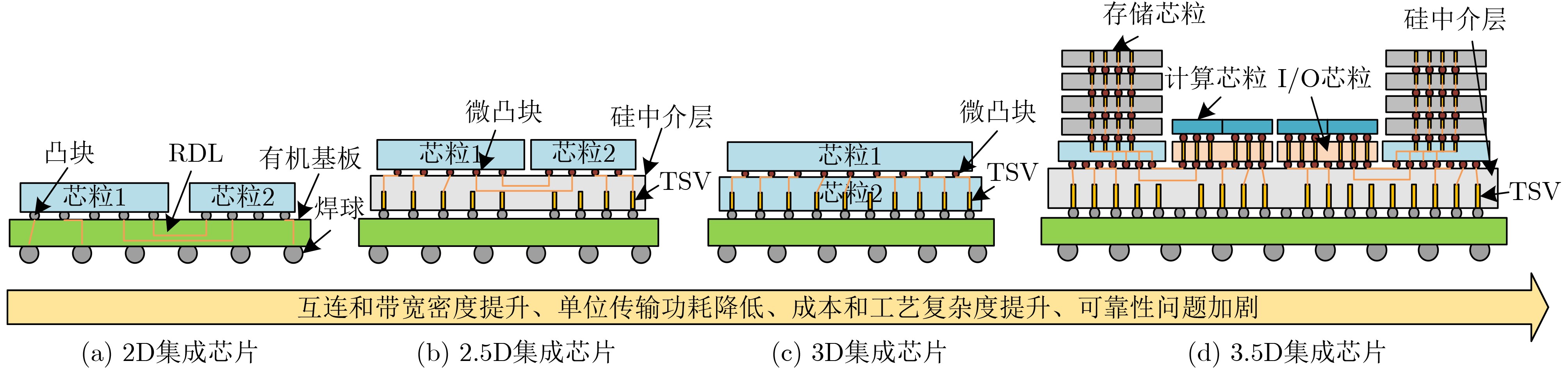
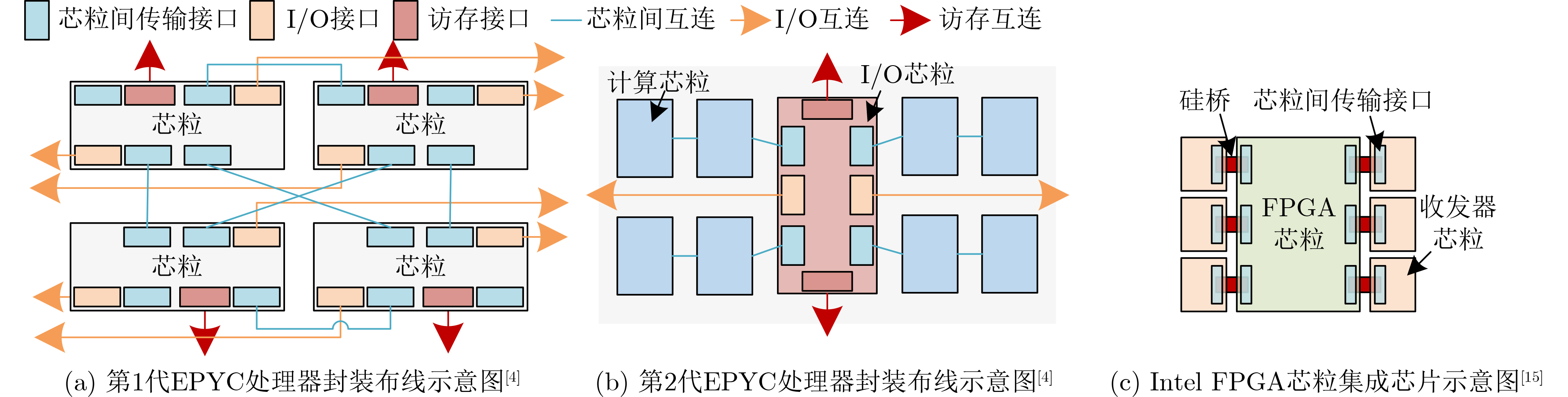
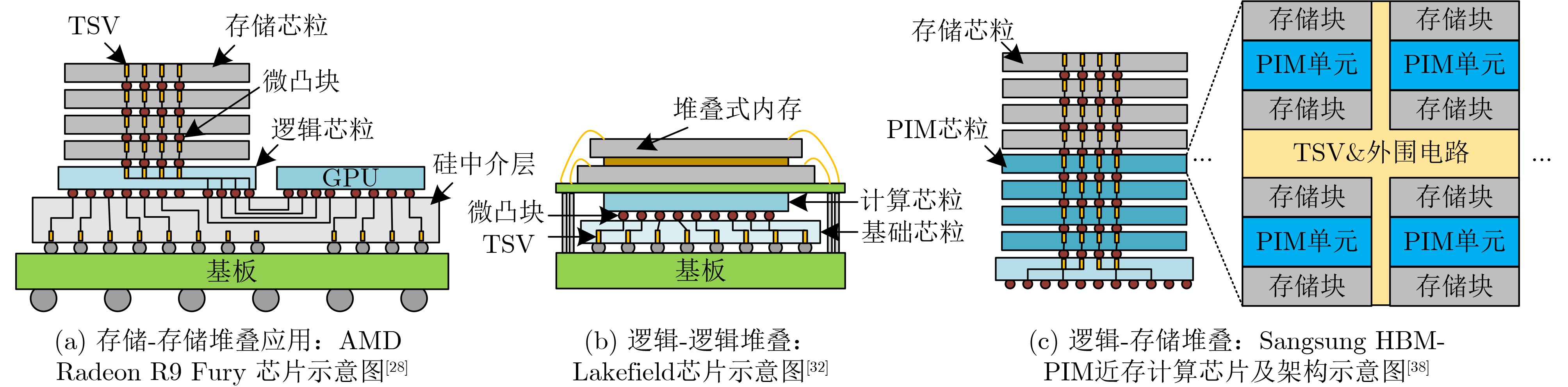
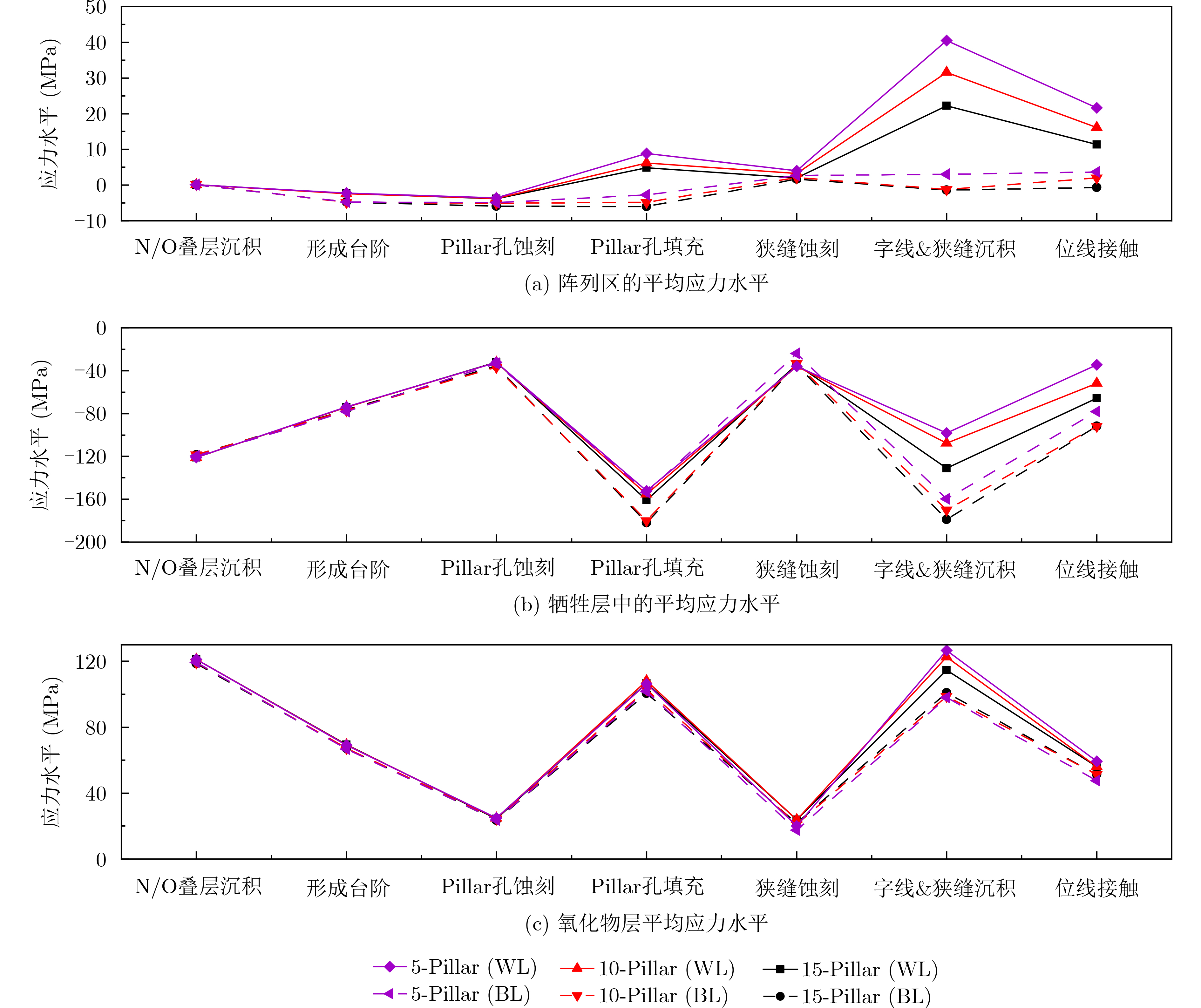
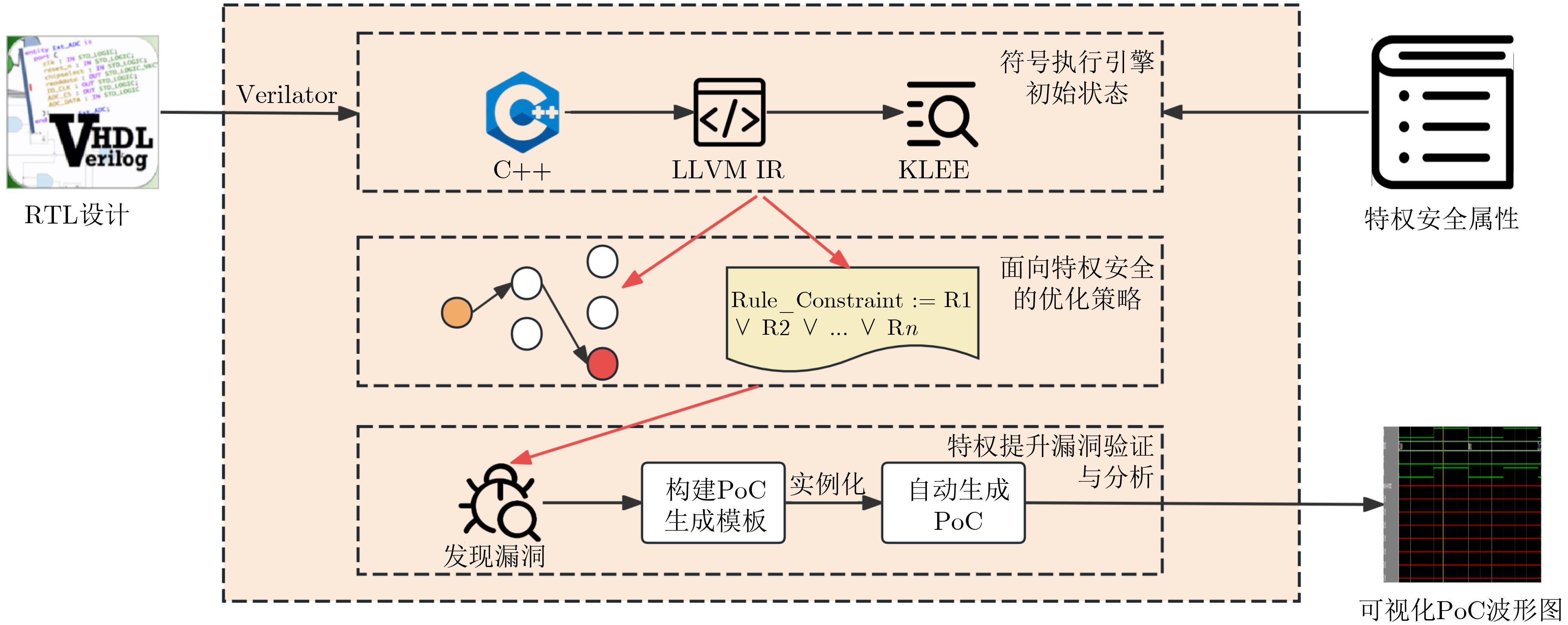
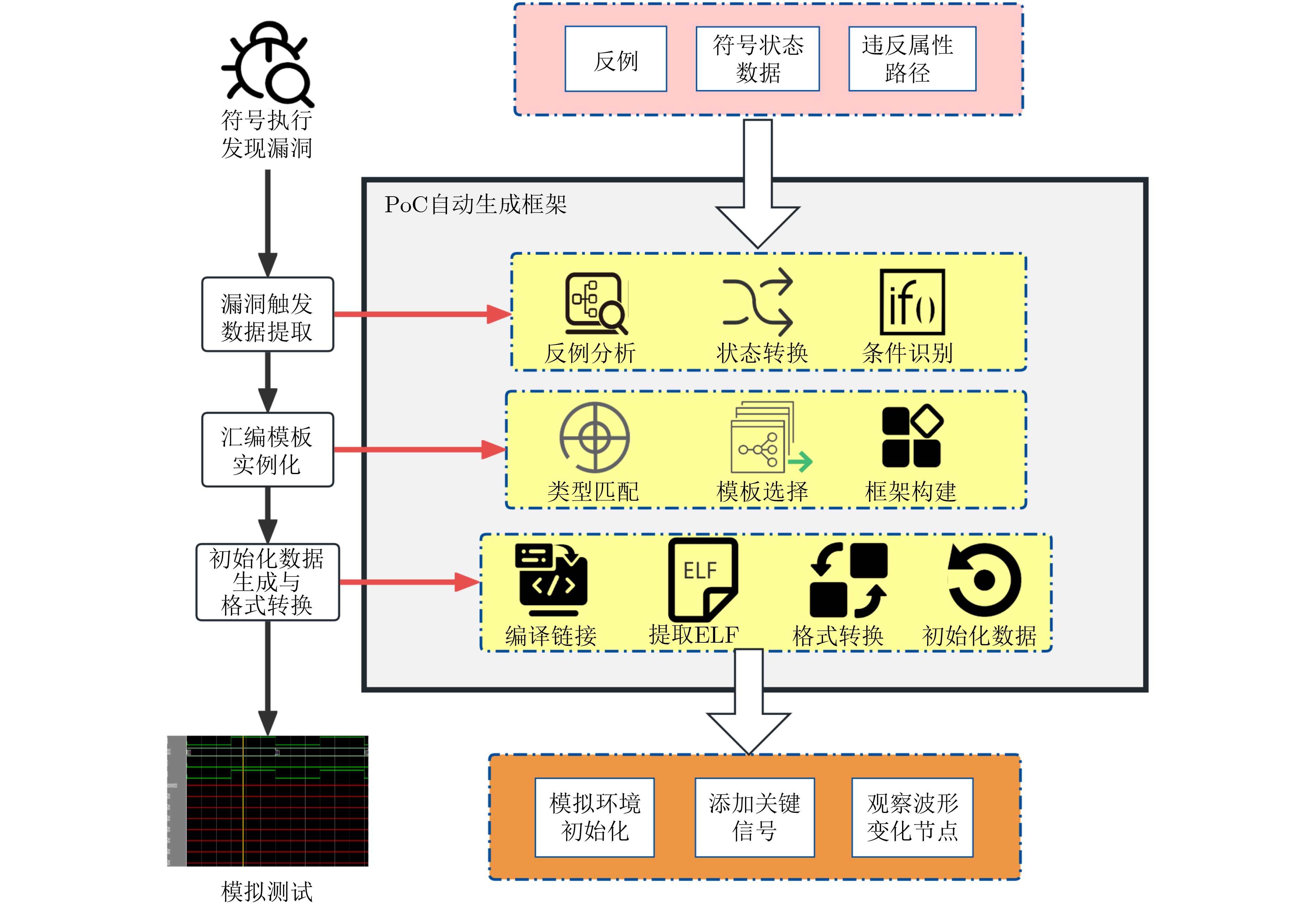
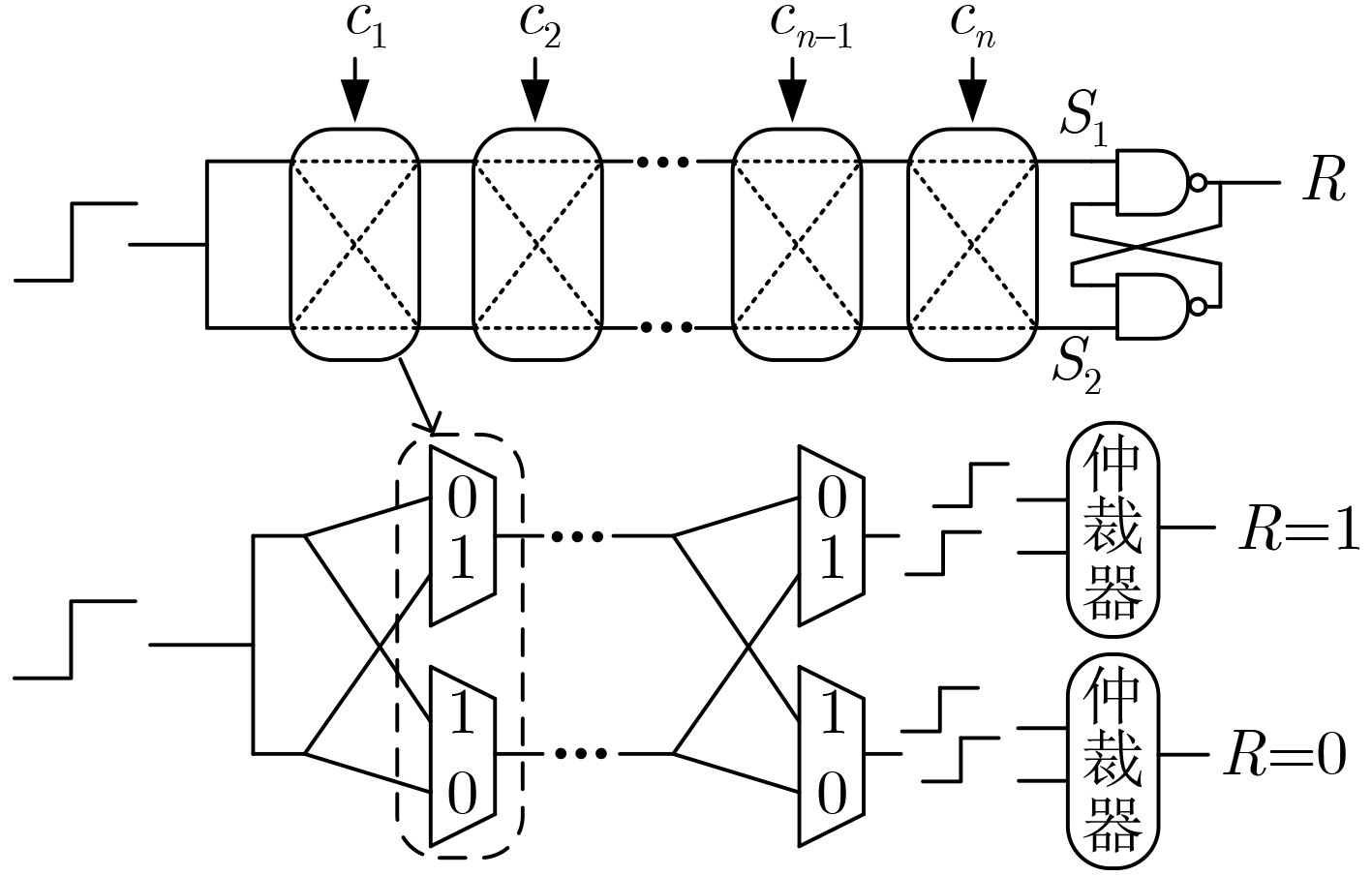
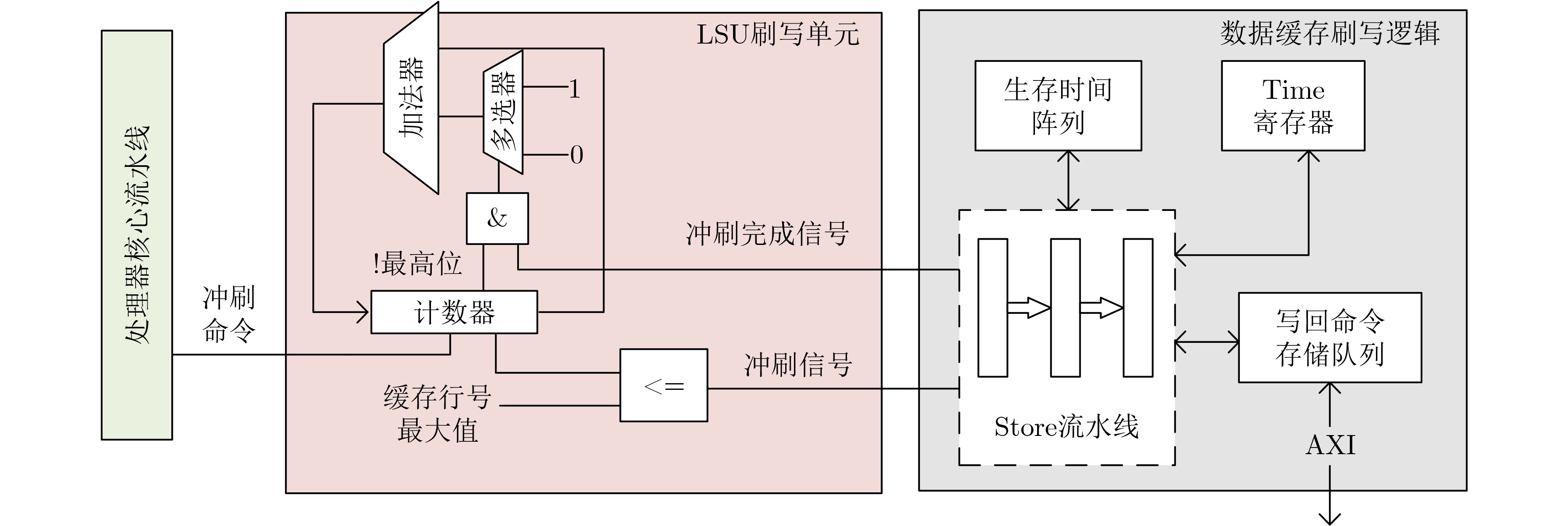
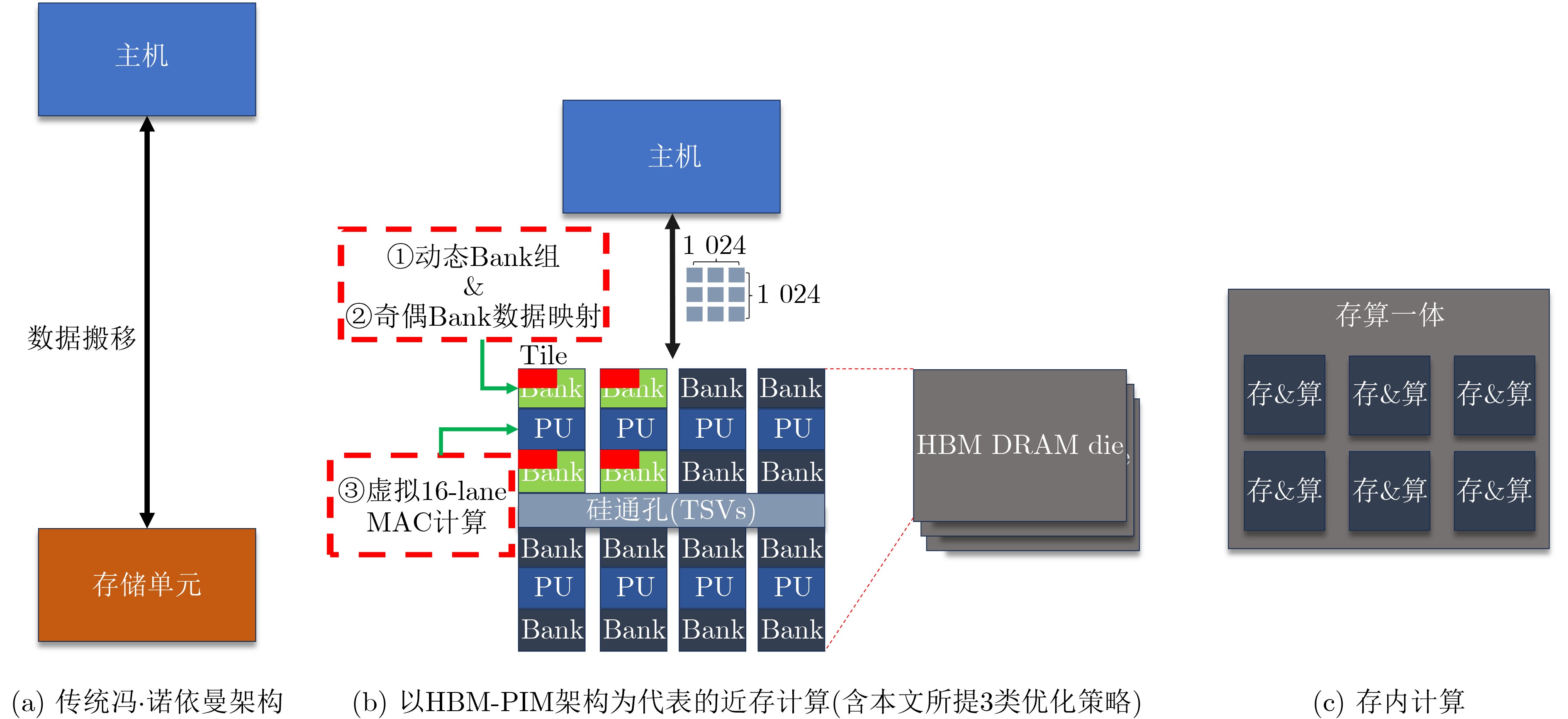
2025, 47(9): 3104-3115.
doi: 10.11999/JEIT250369
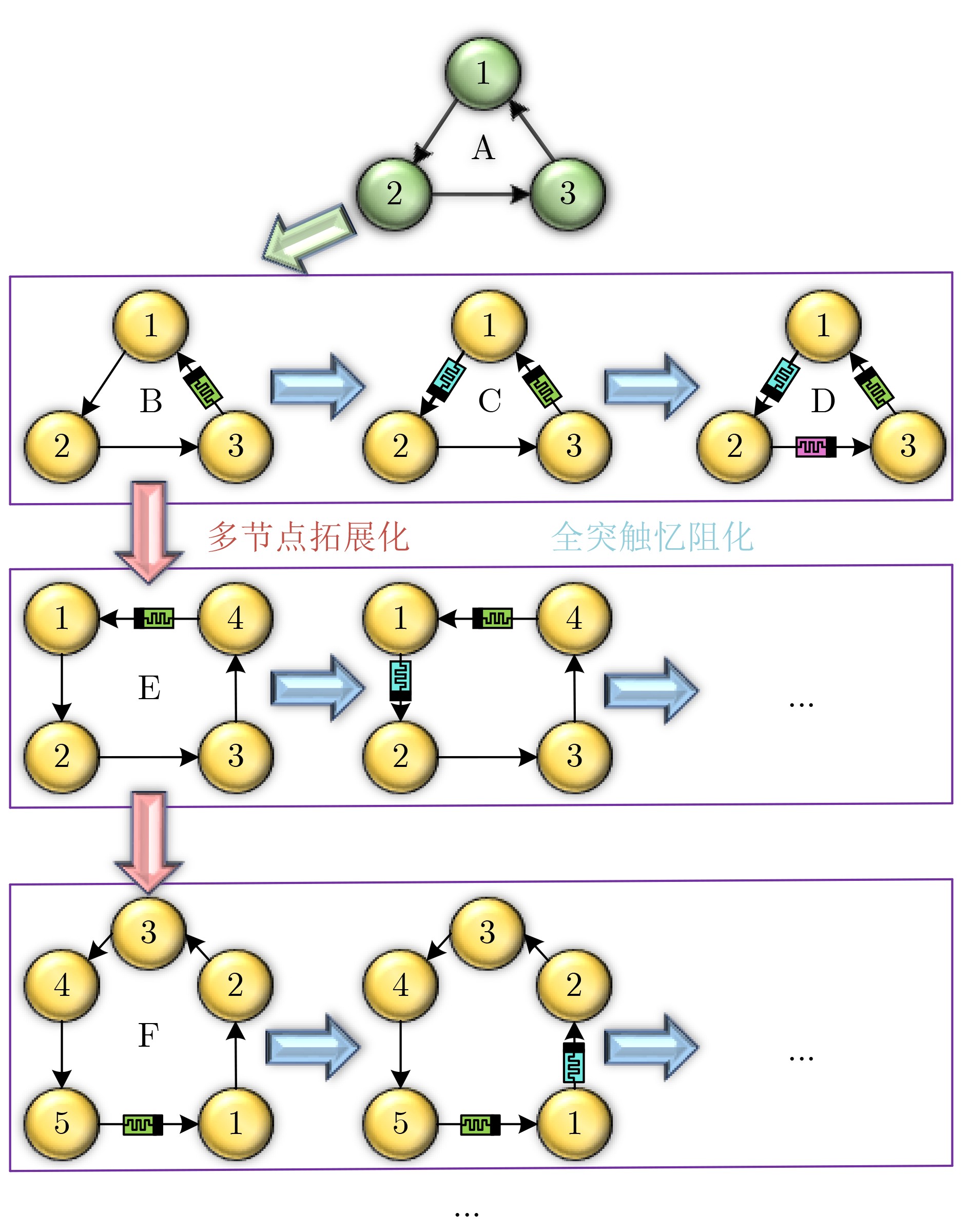
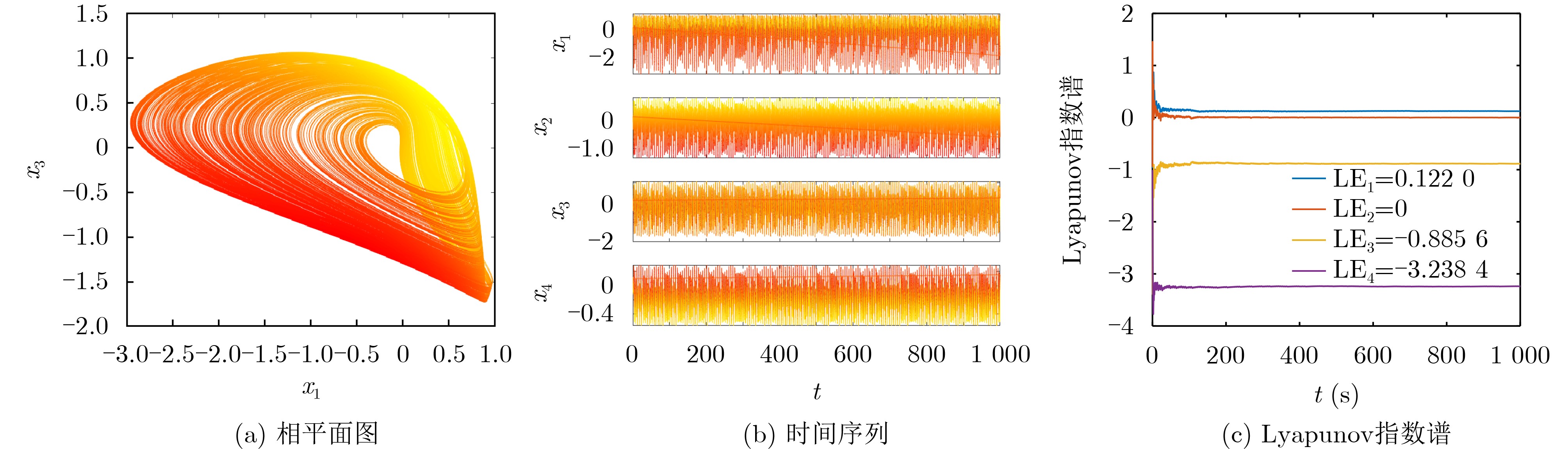
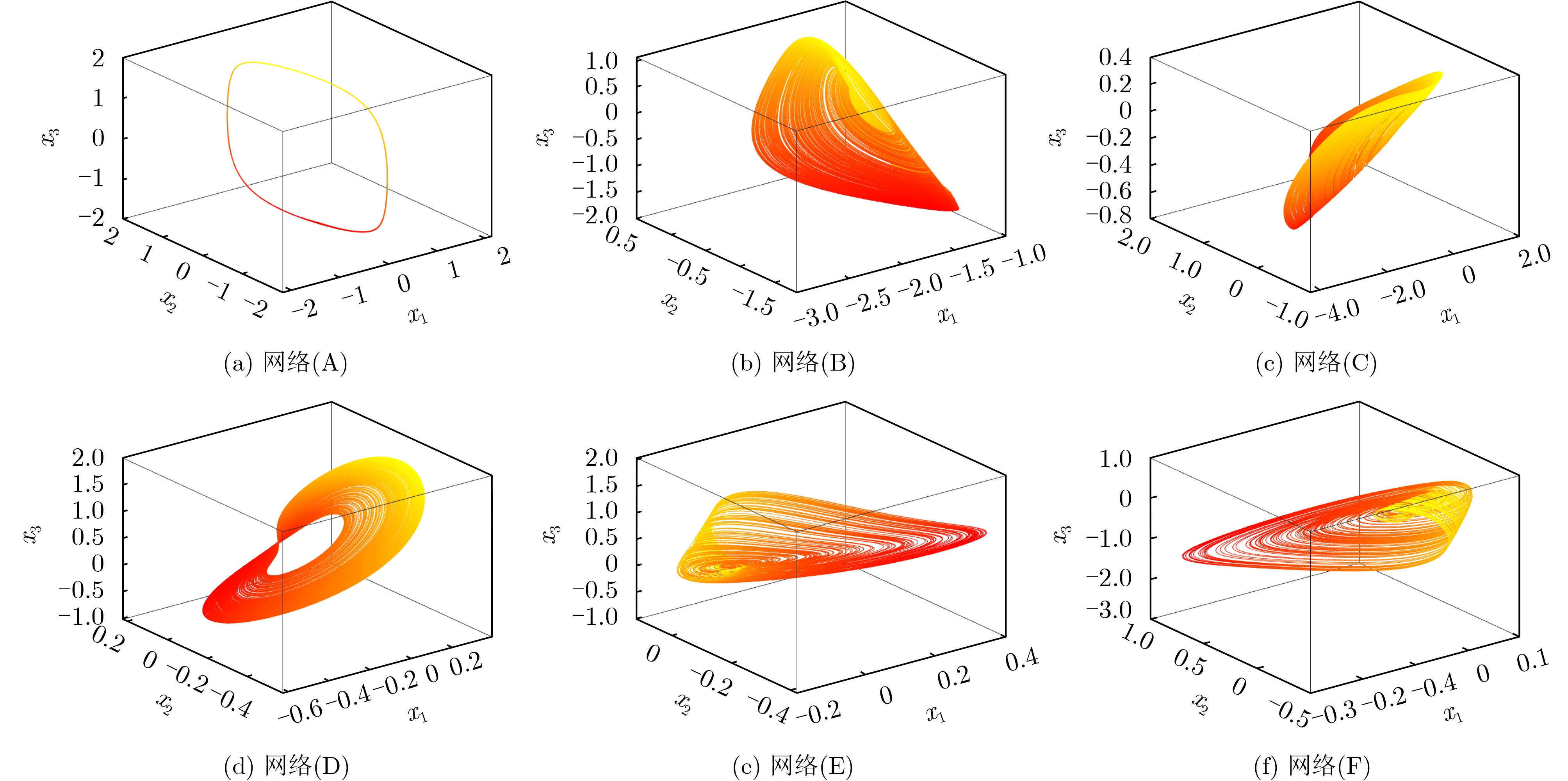
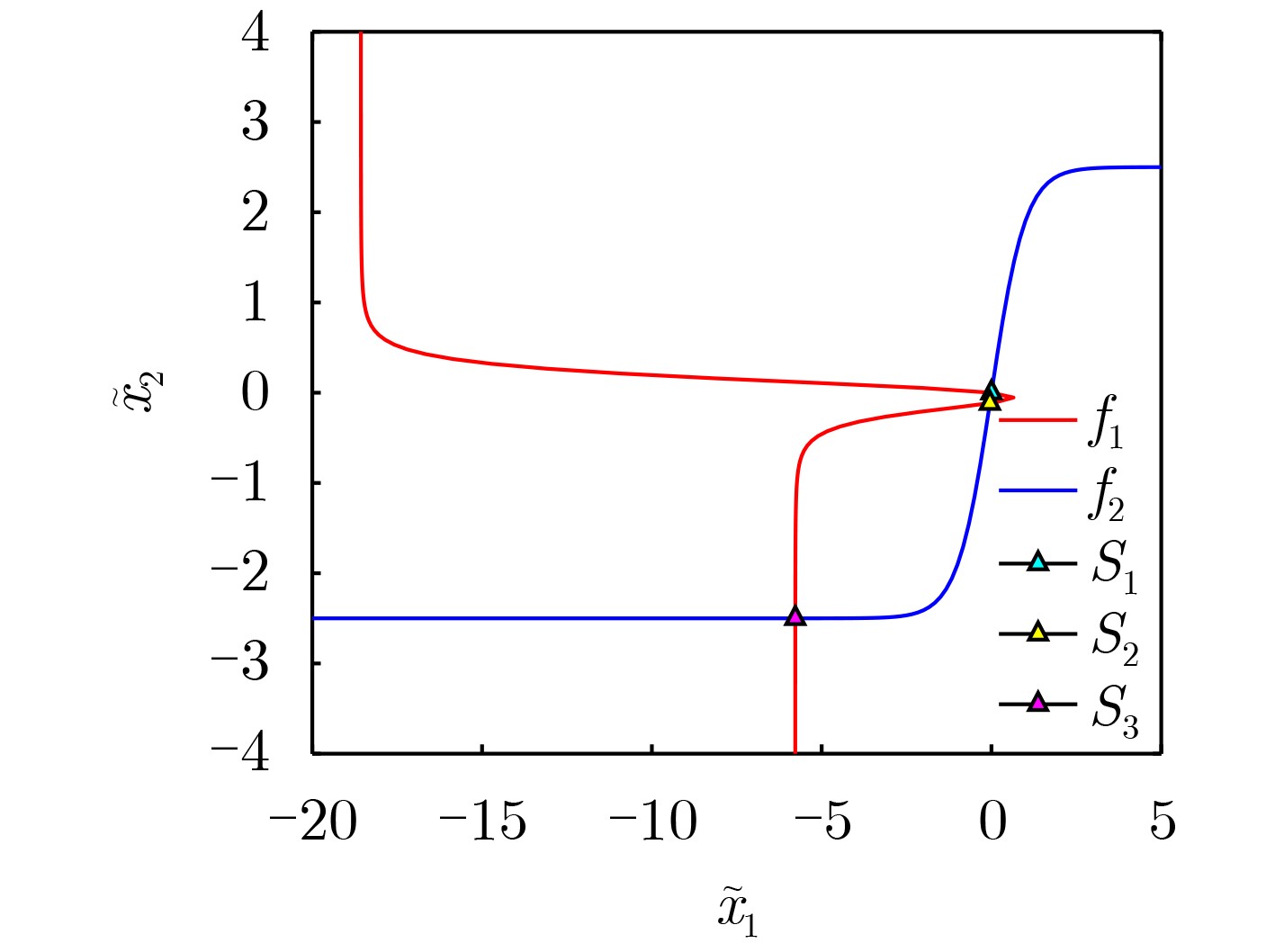
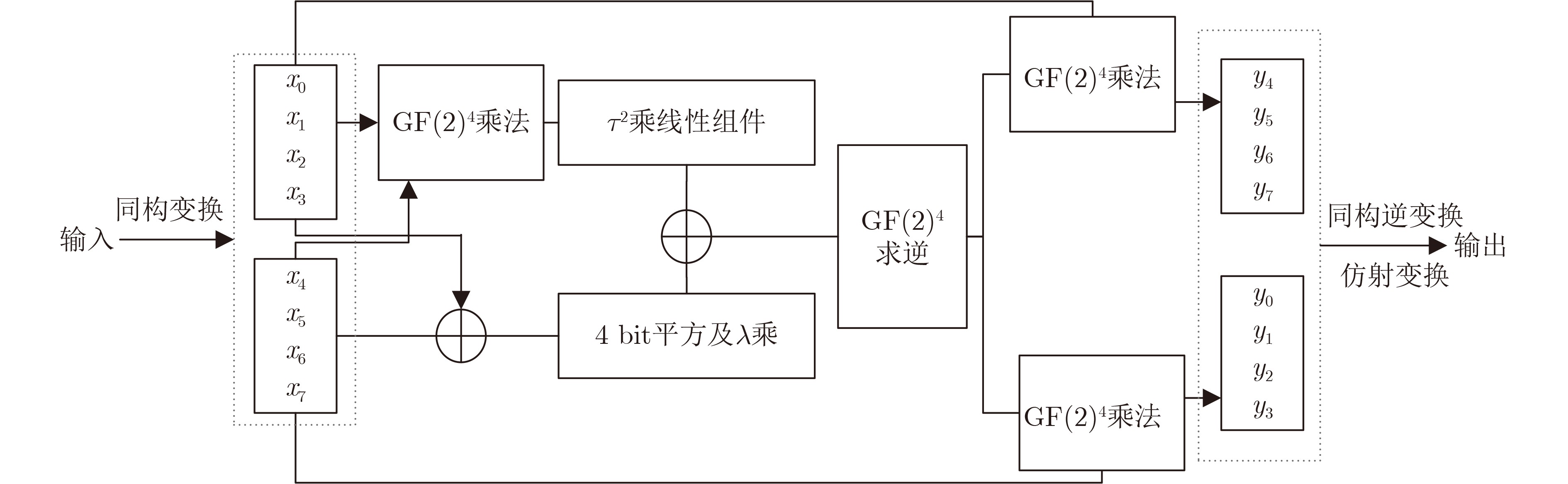
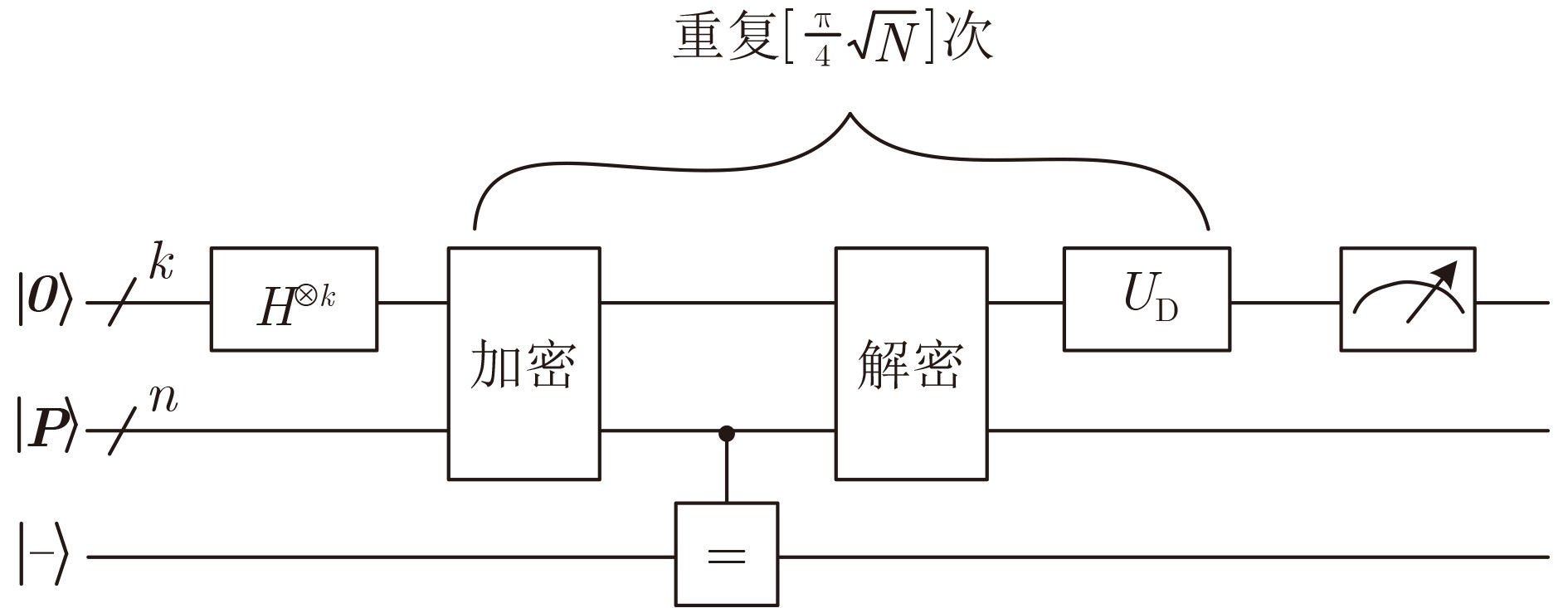
Abstract:
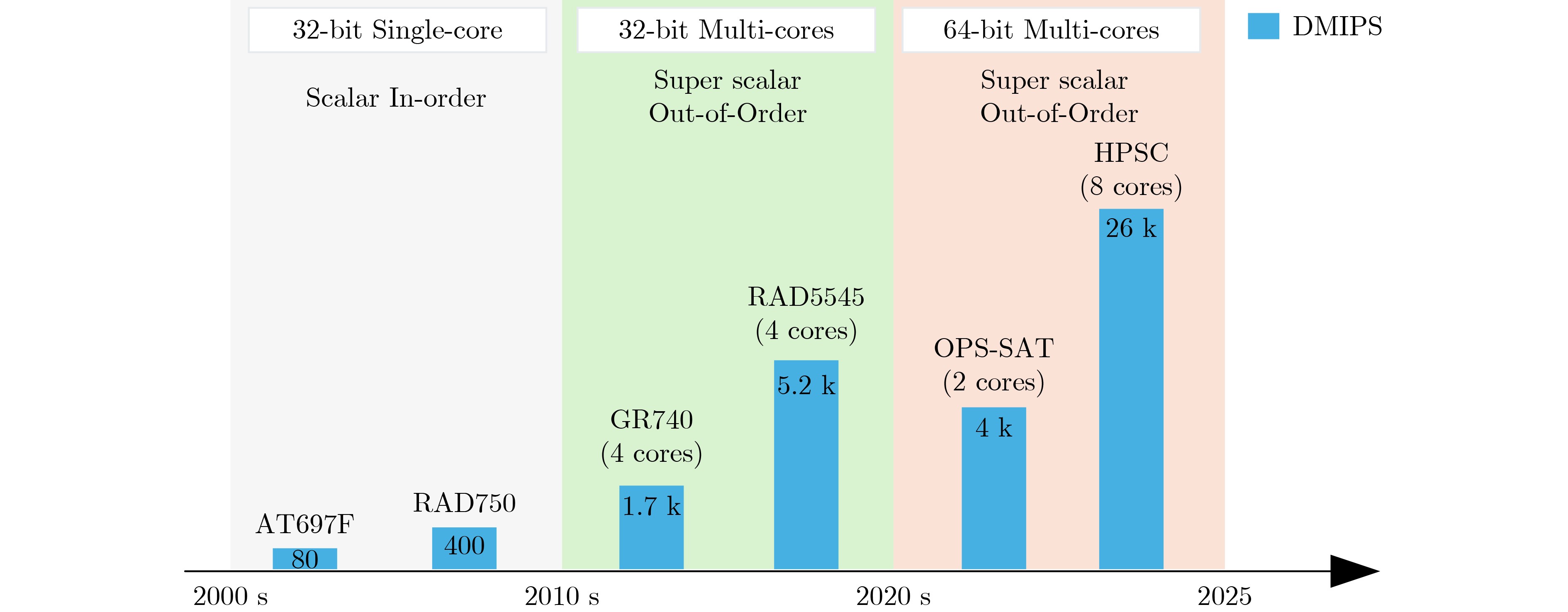
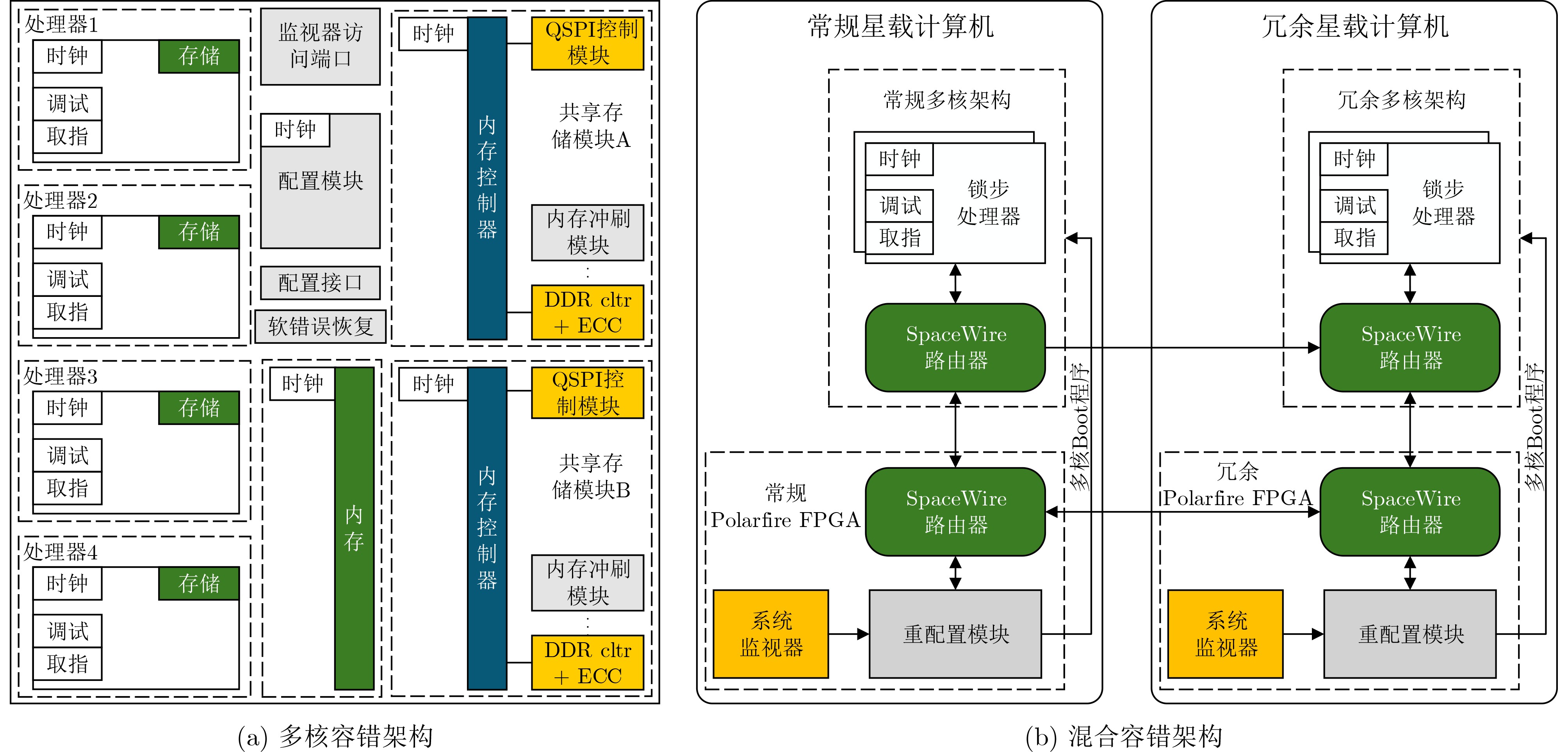
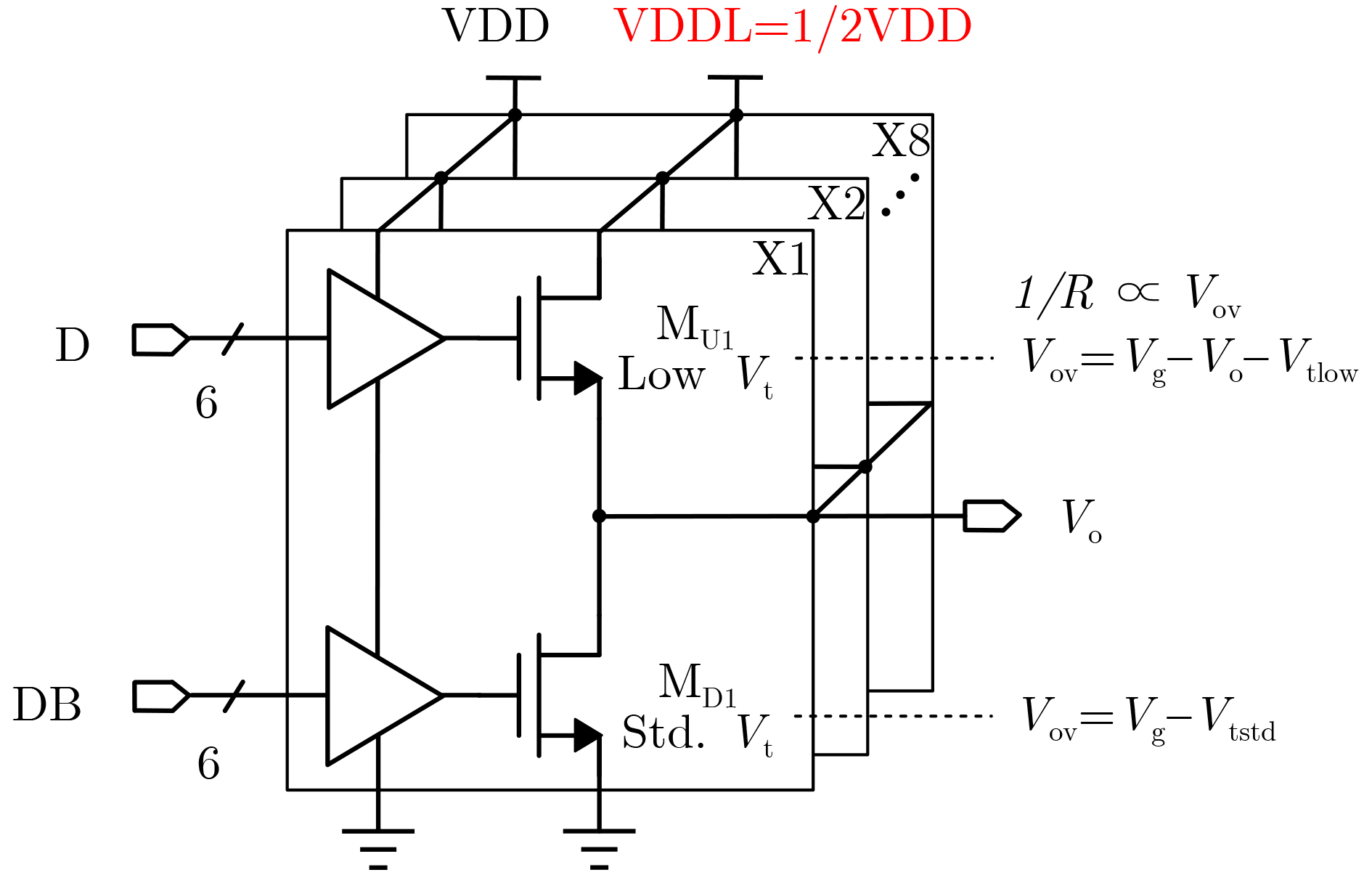
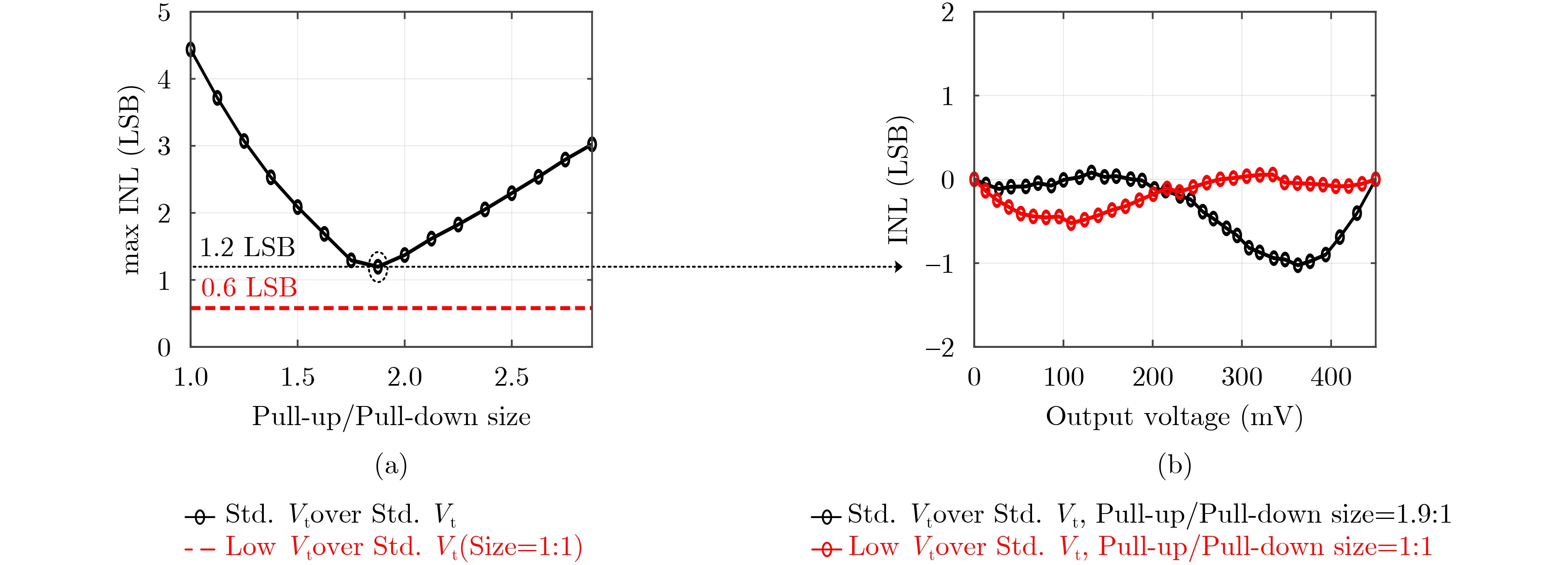
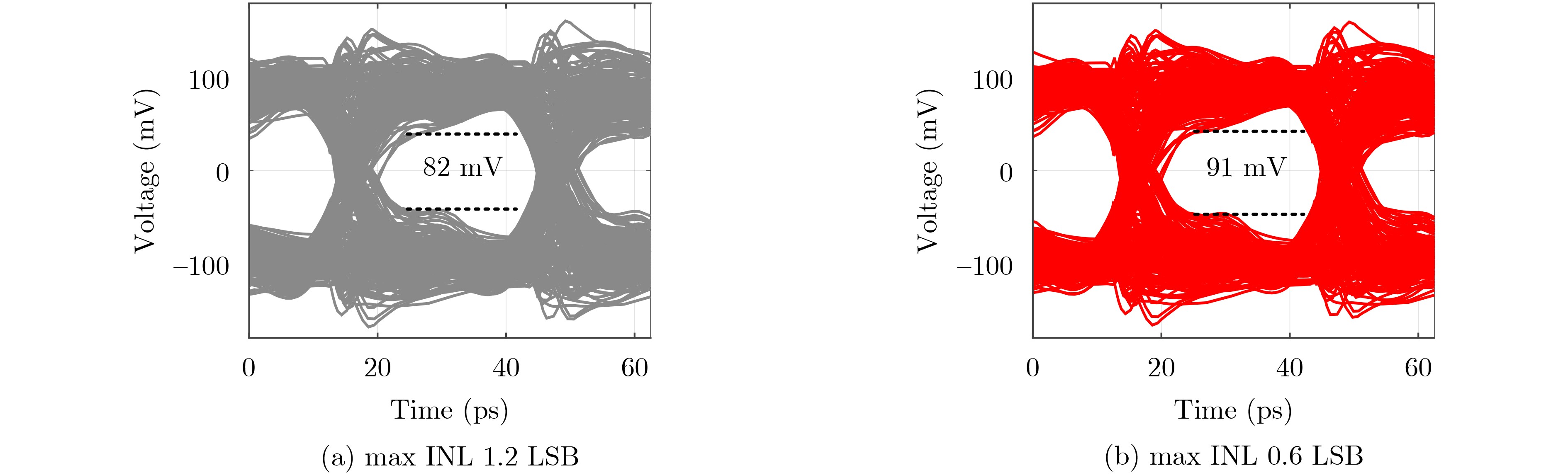
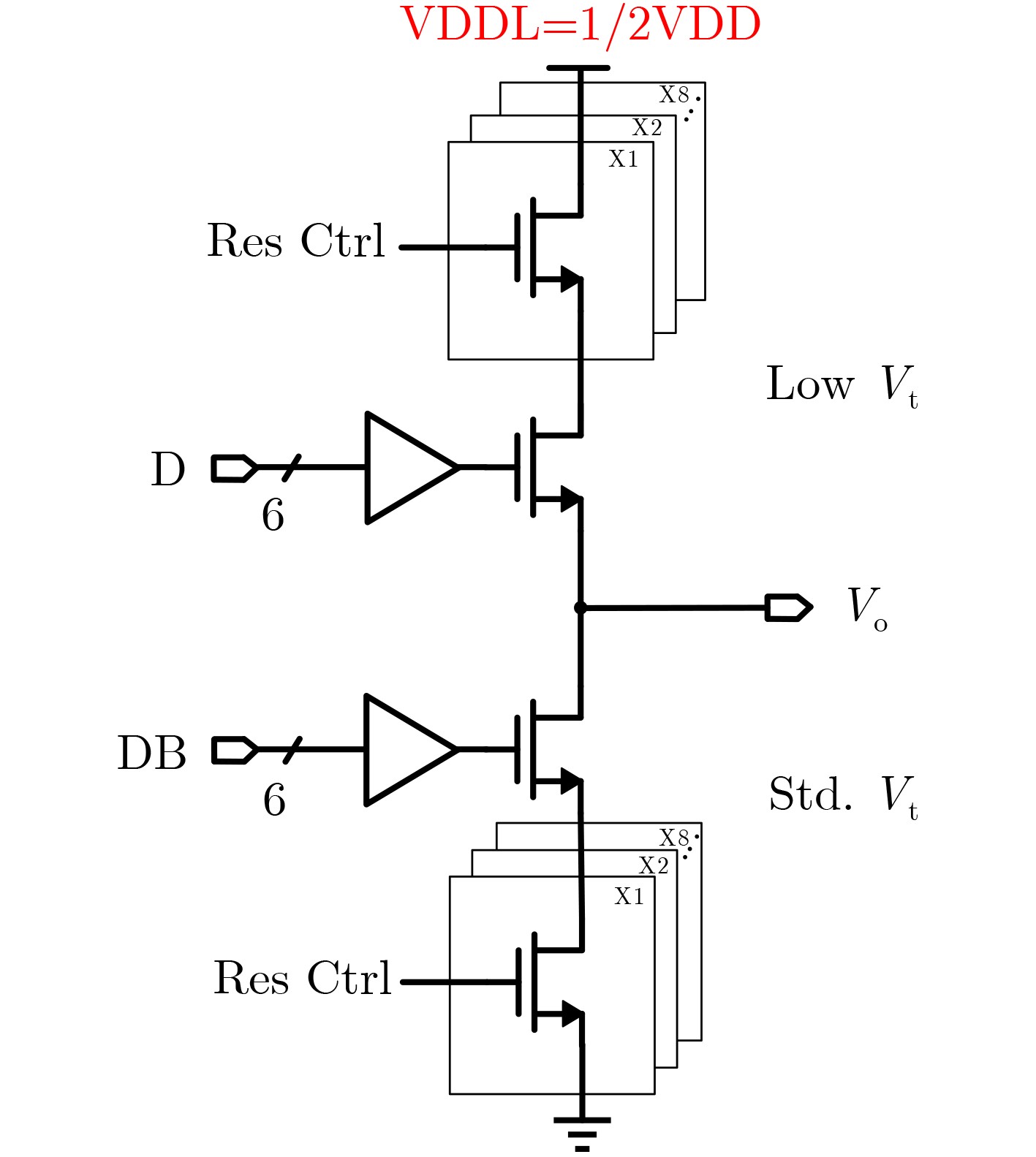
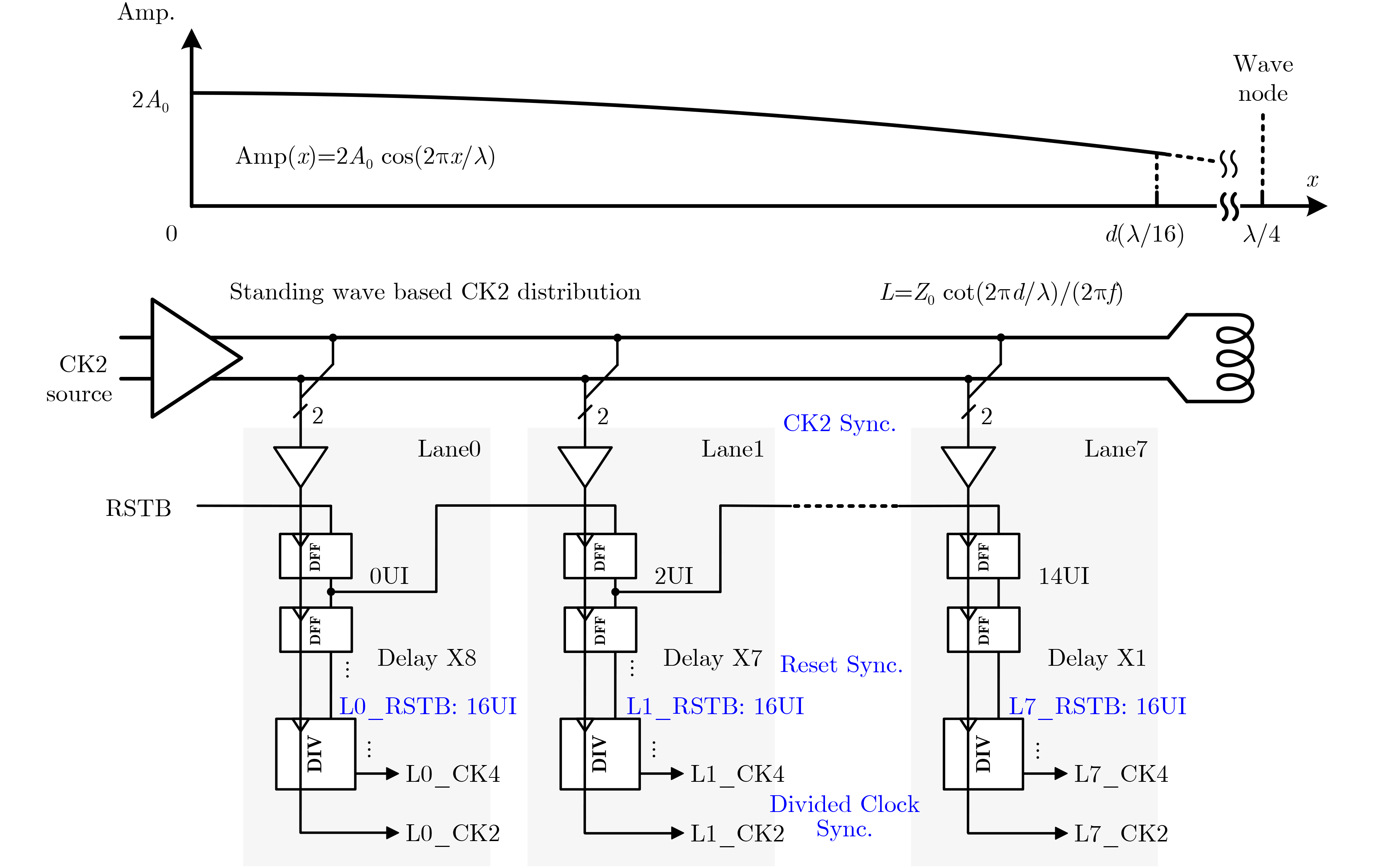
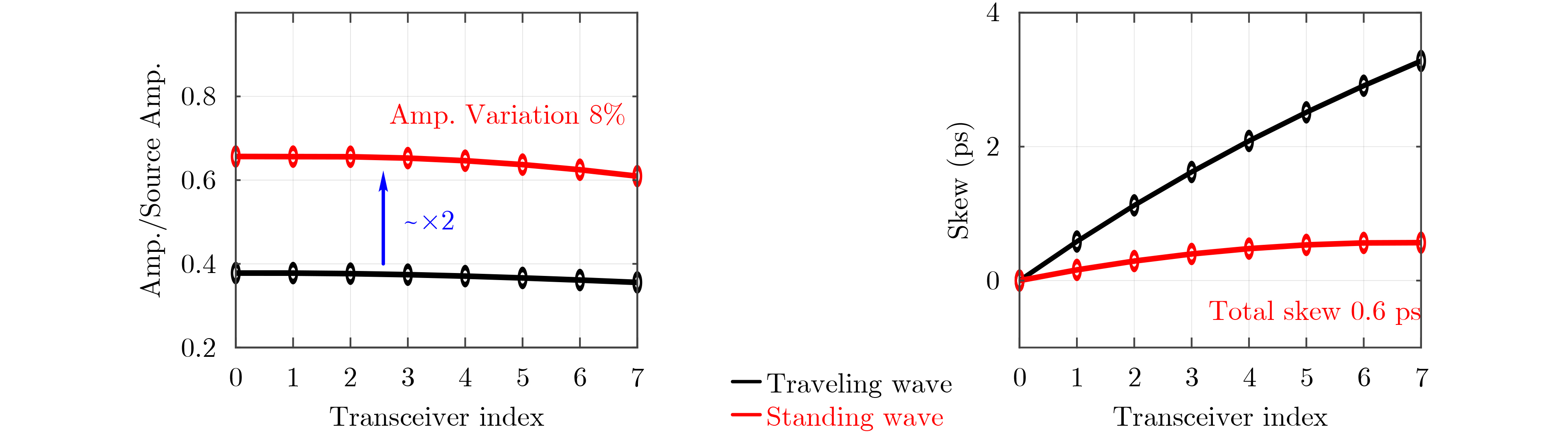
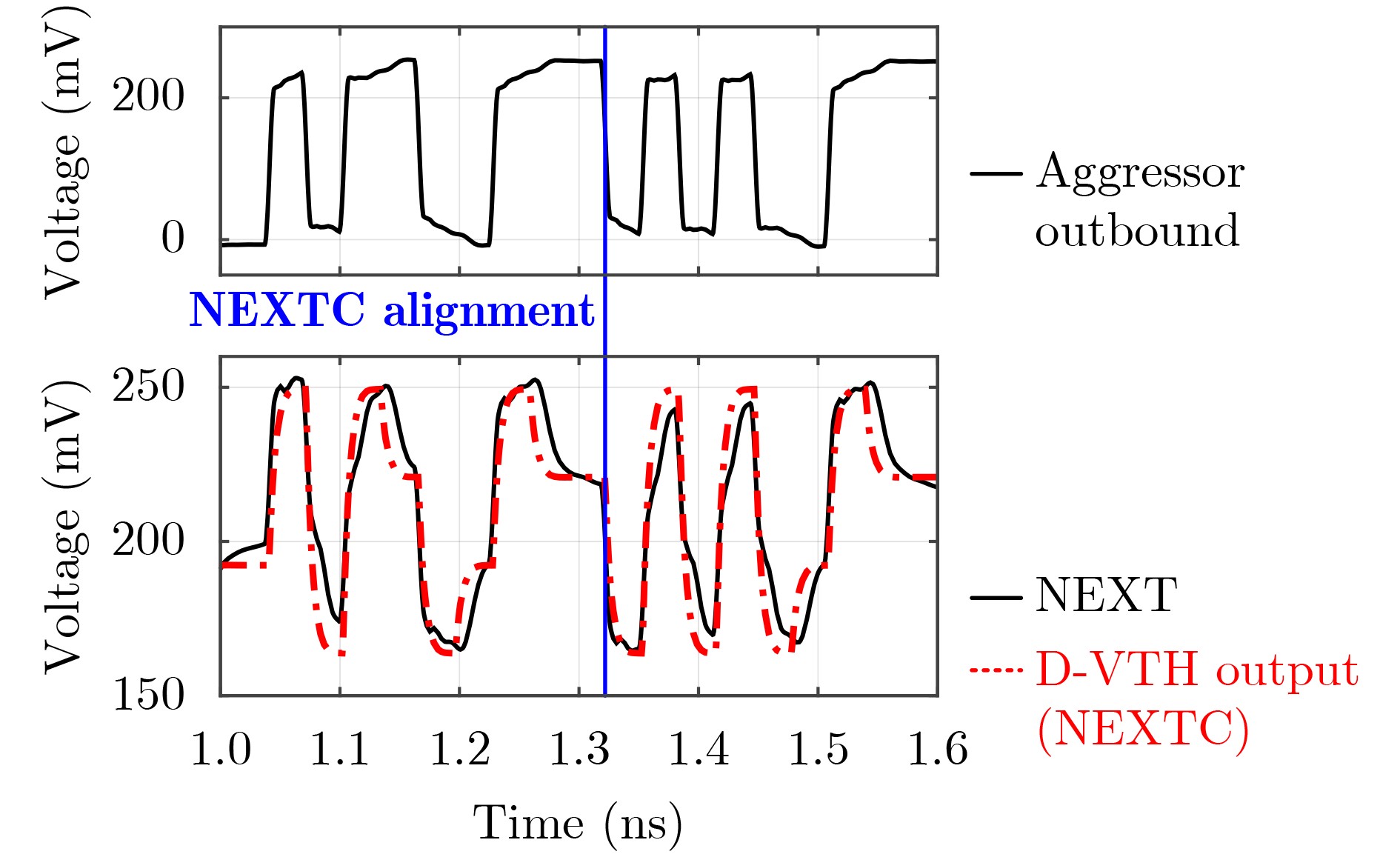
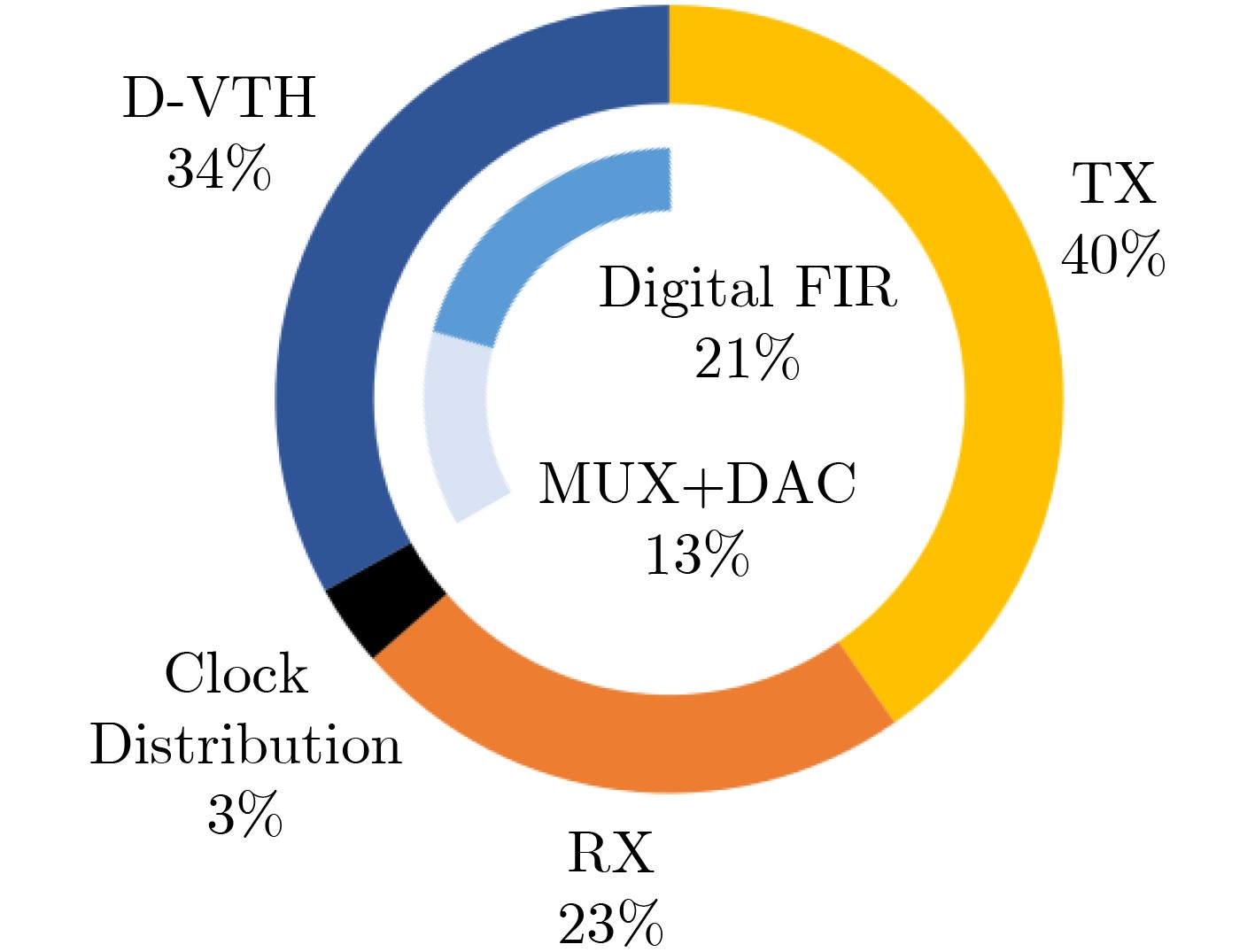
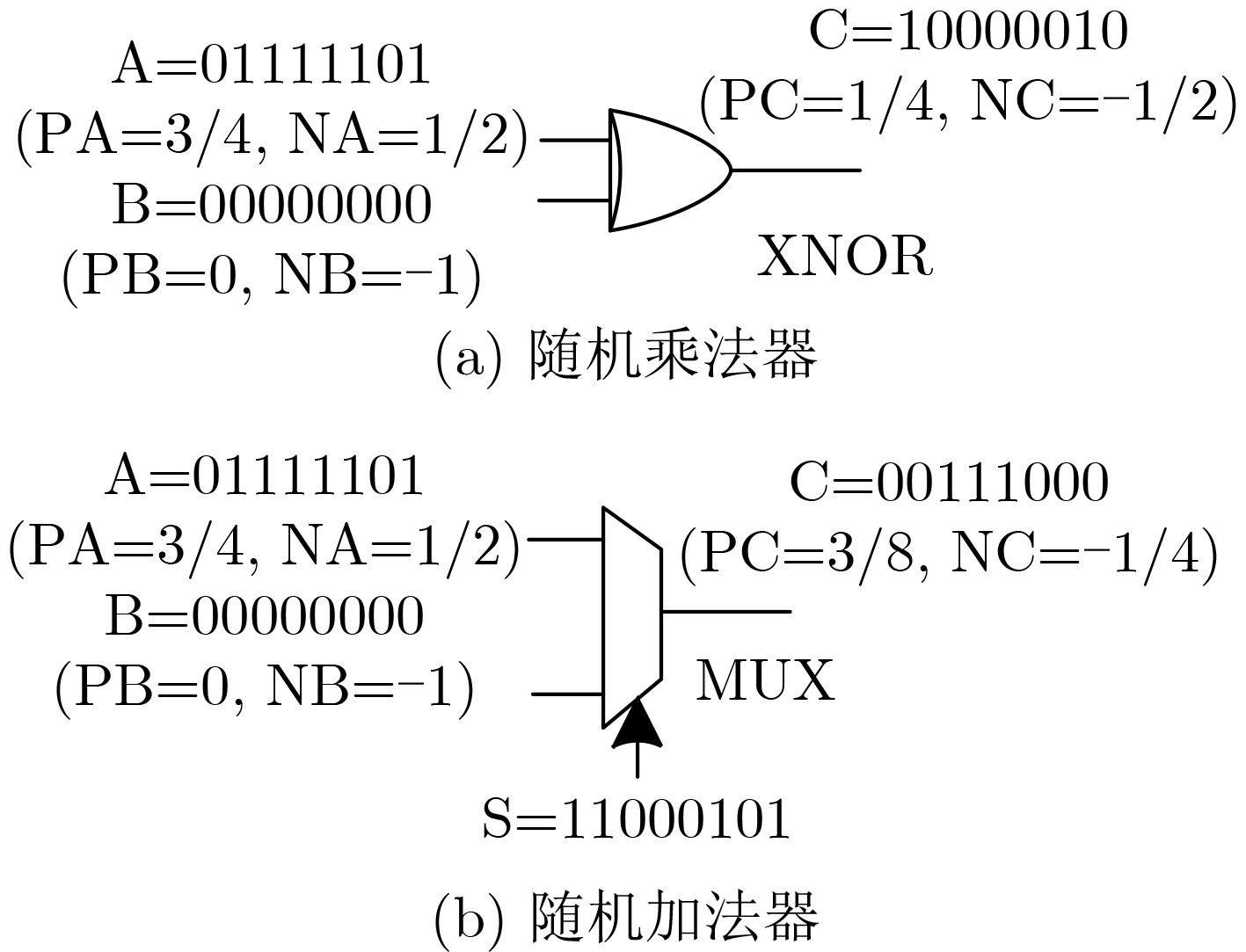
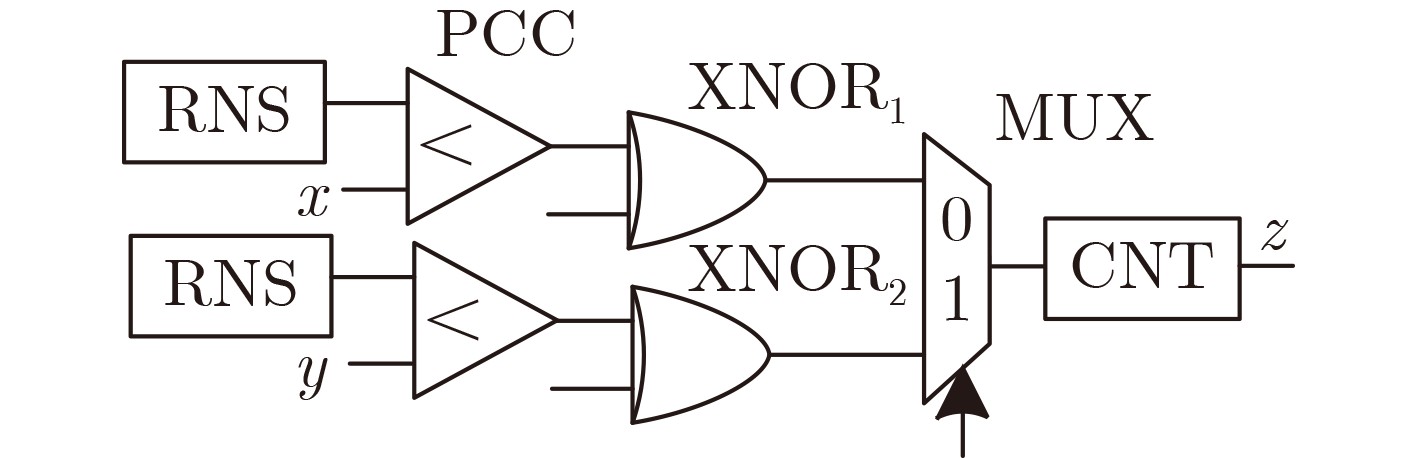
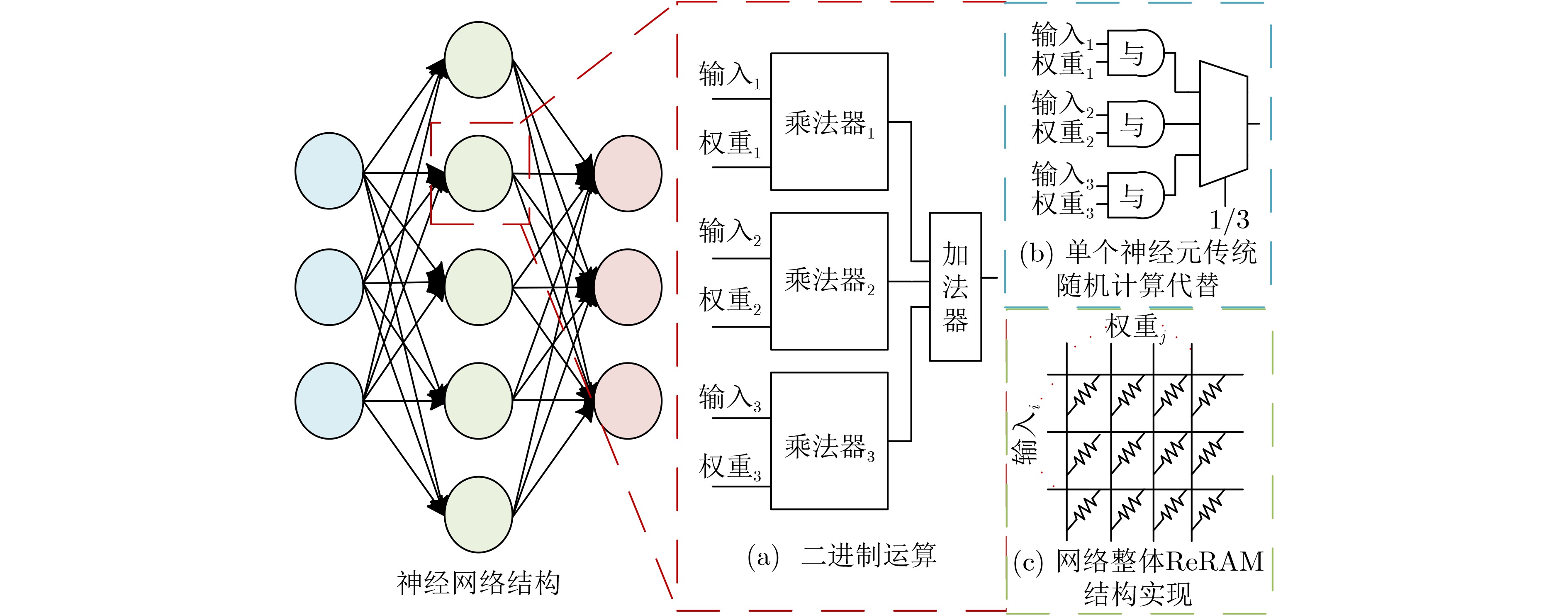
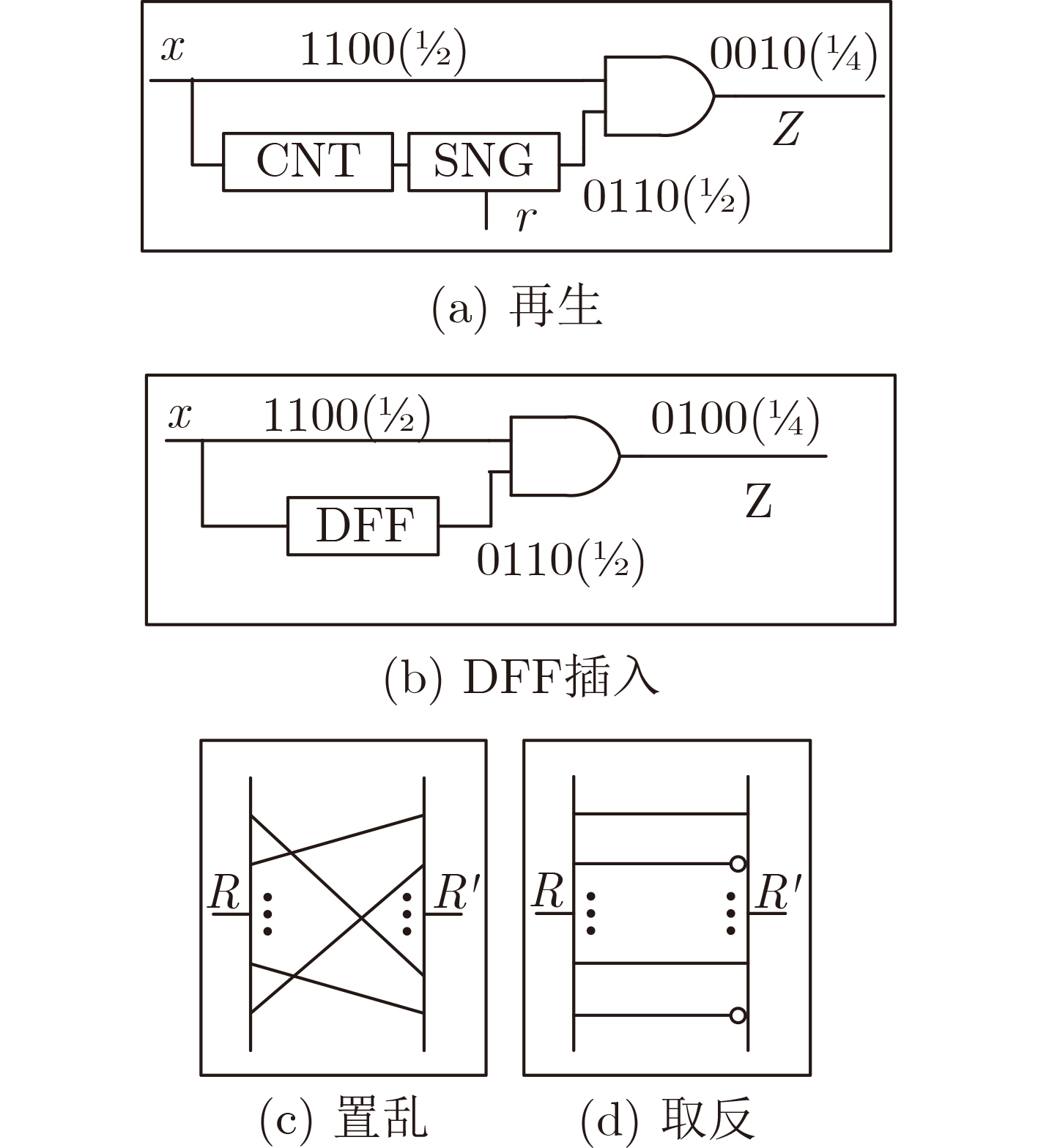
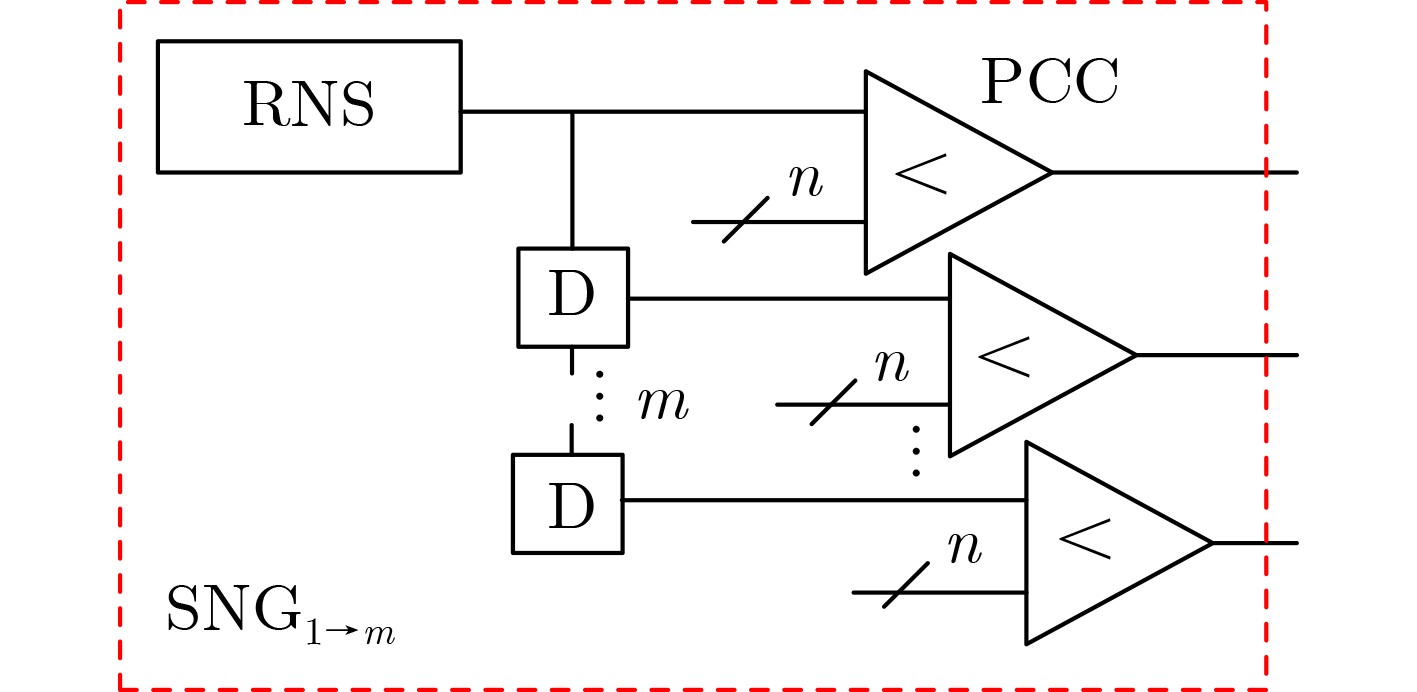
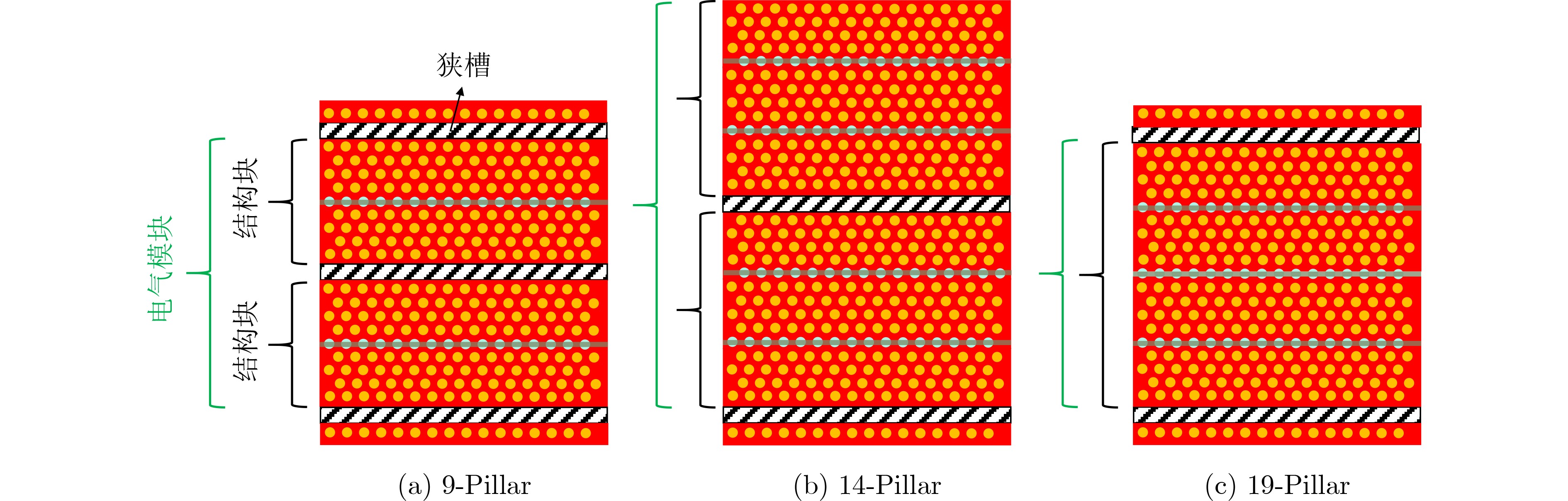
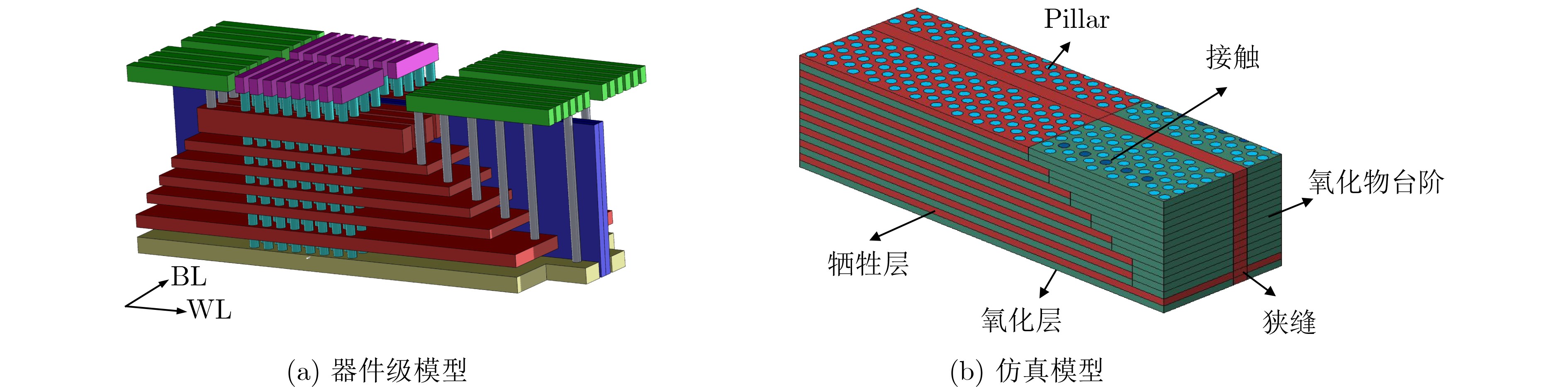
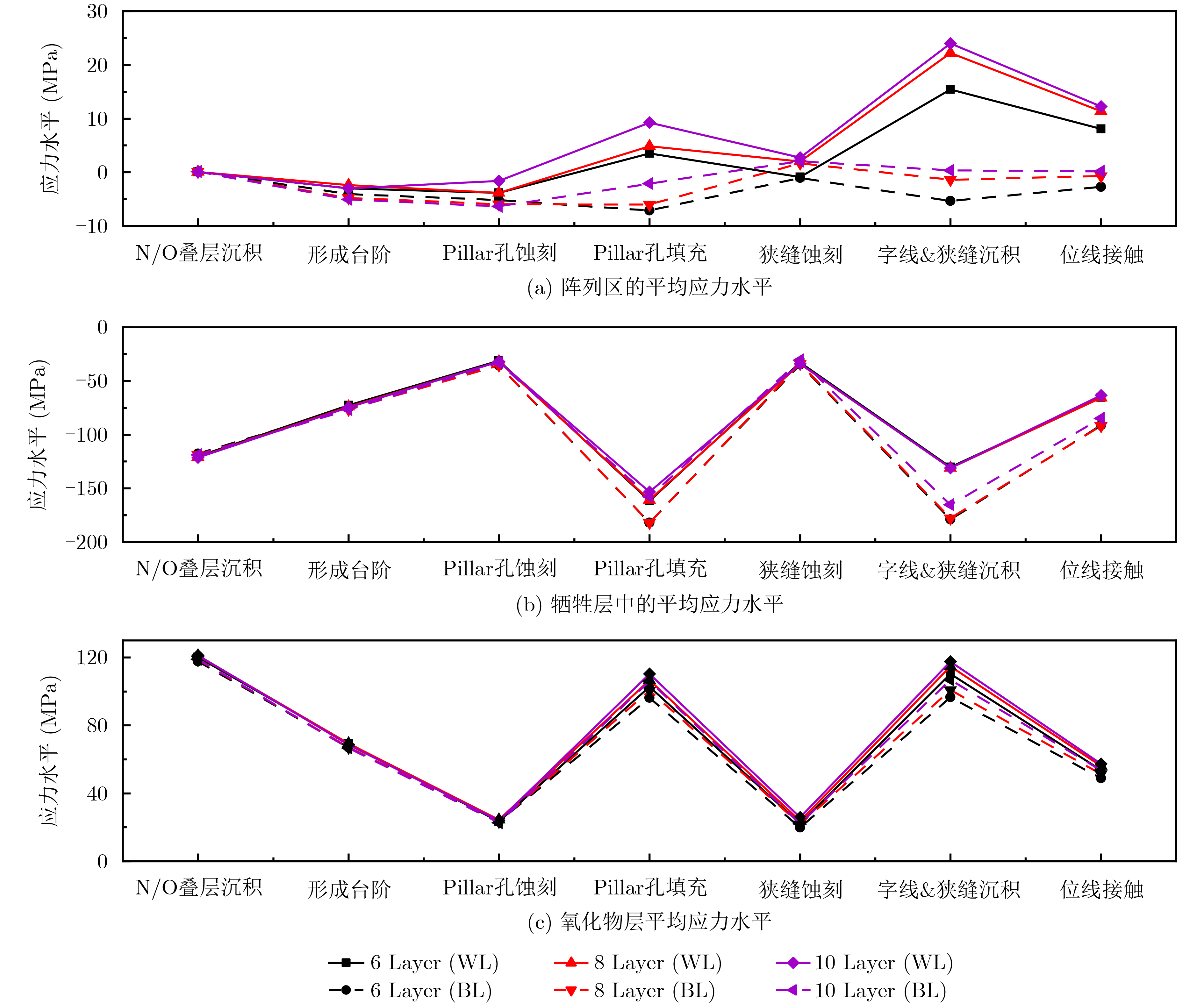
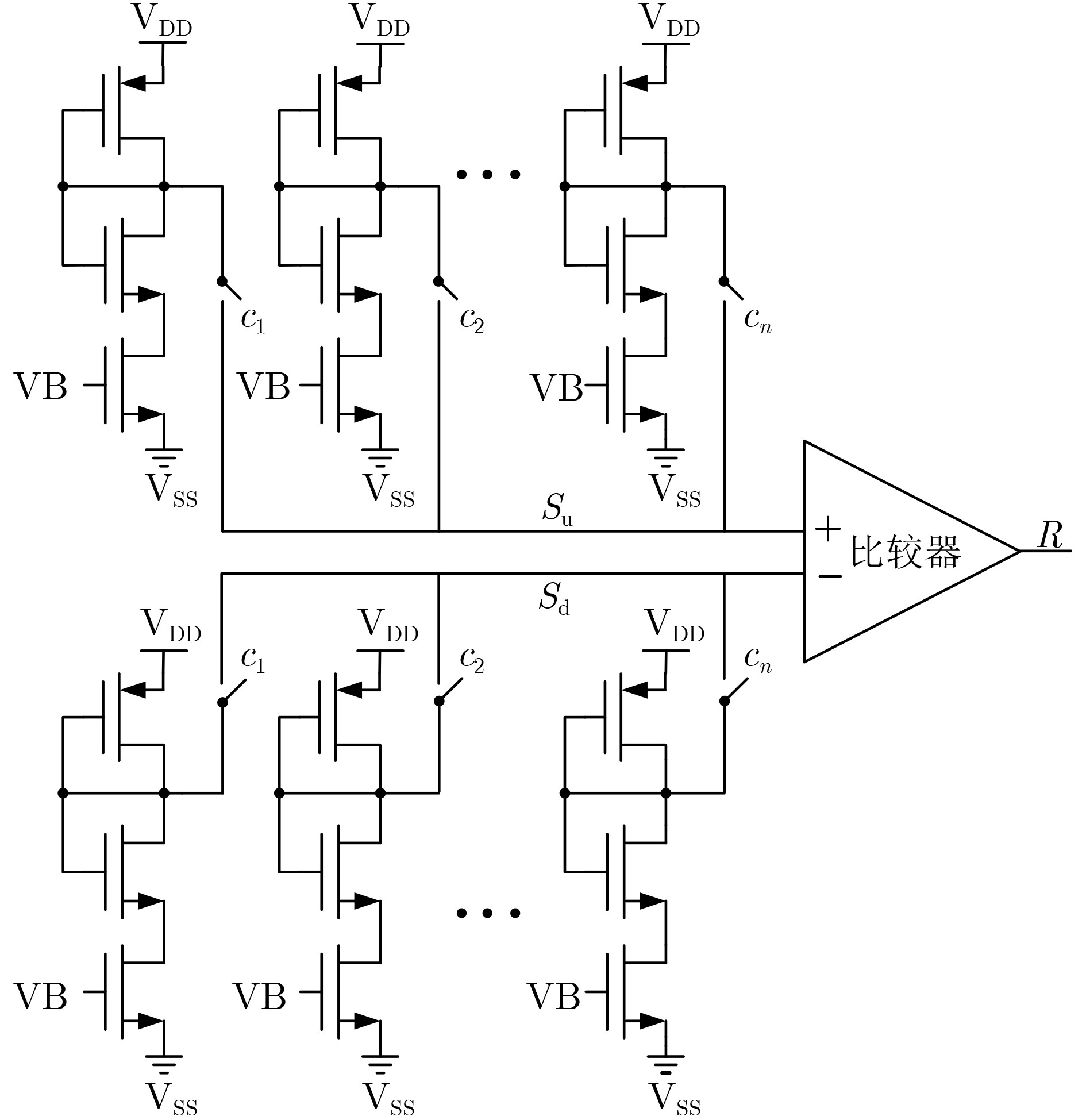
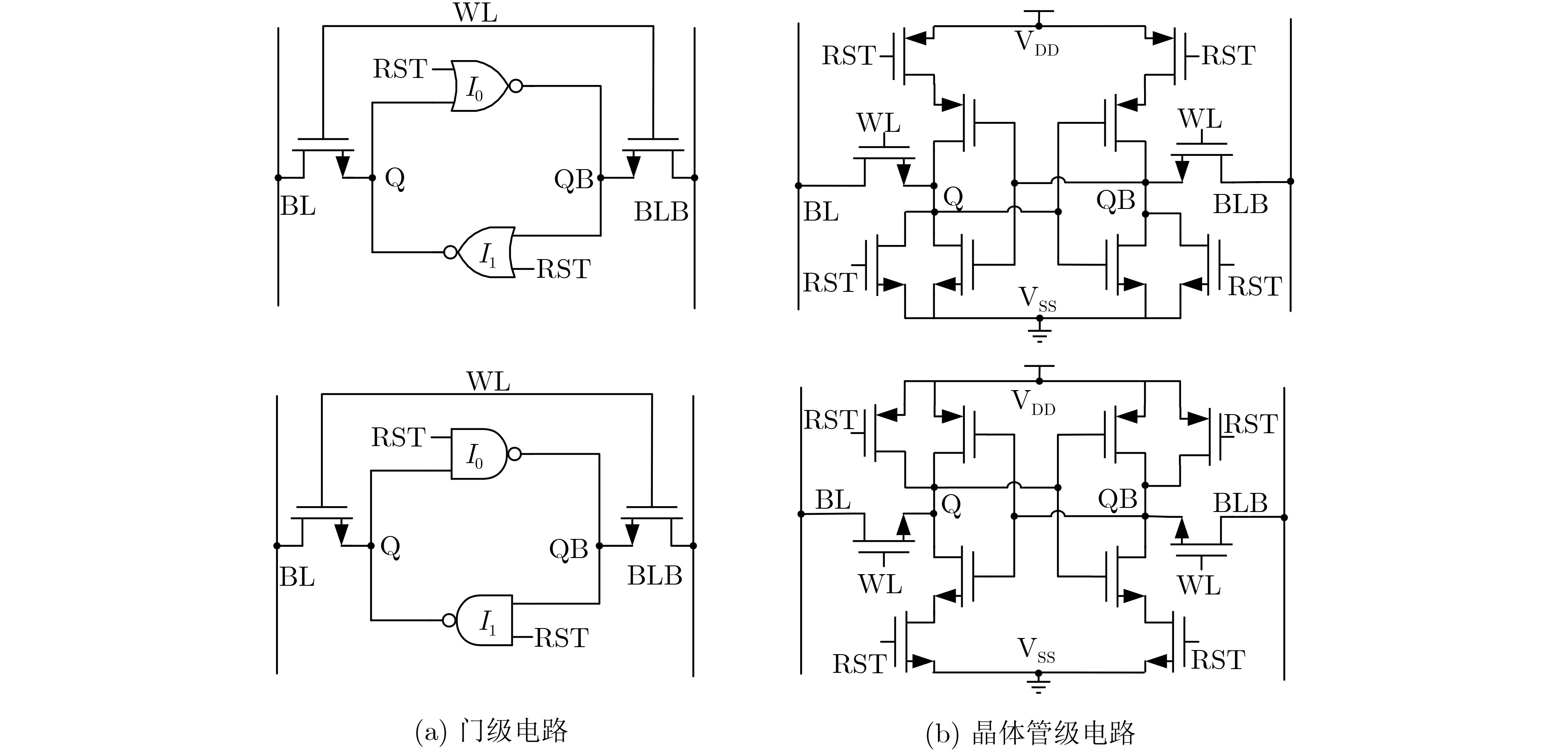
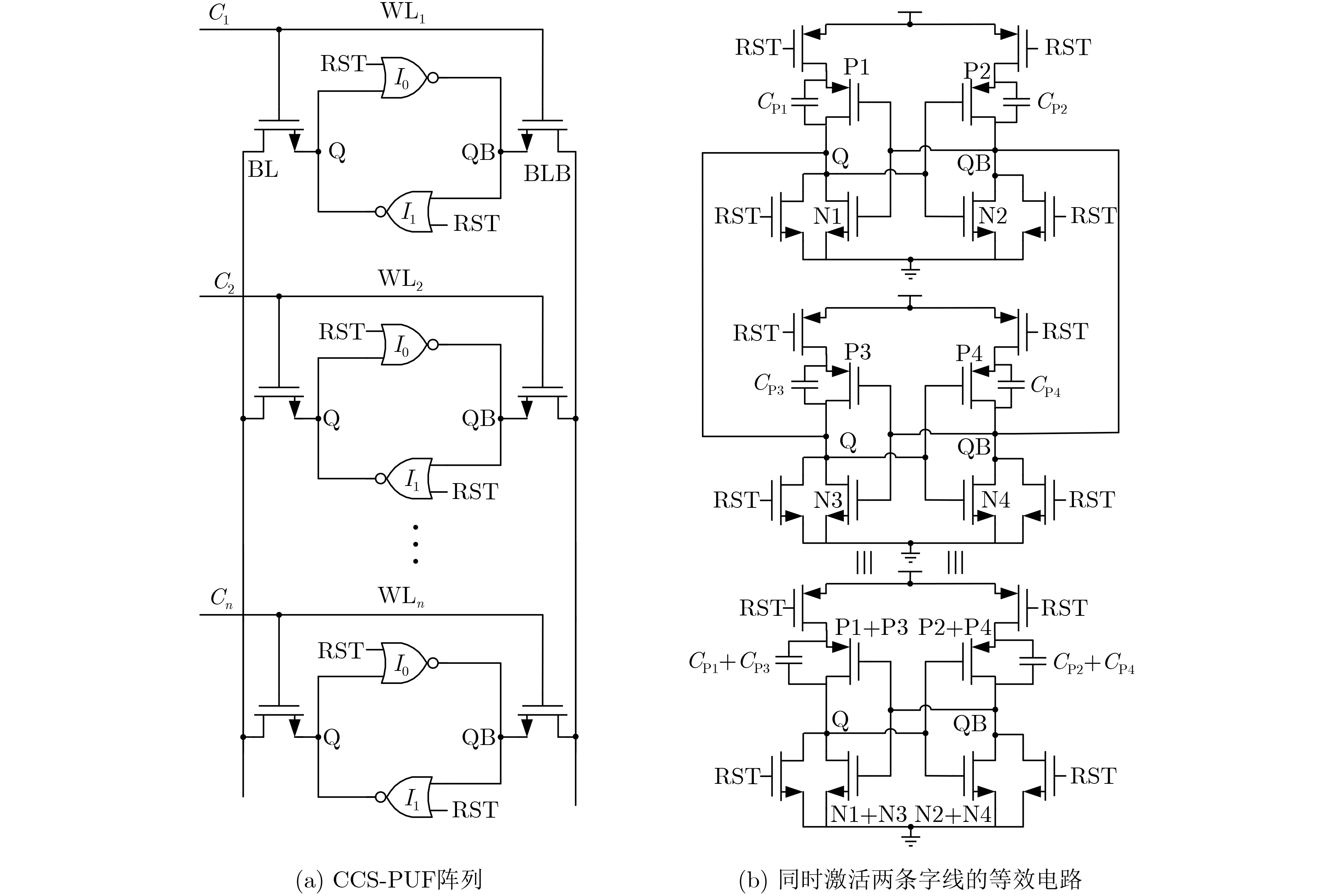
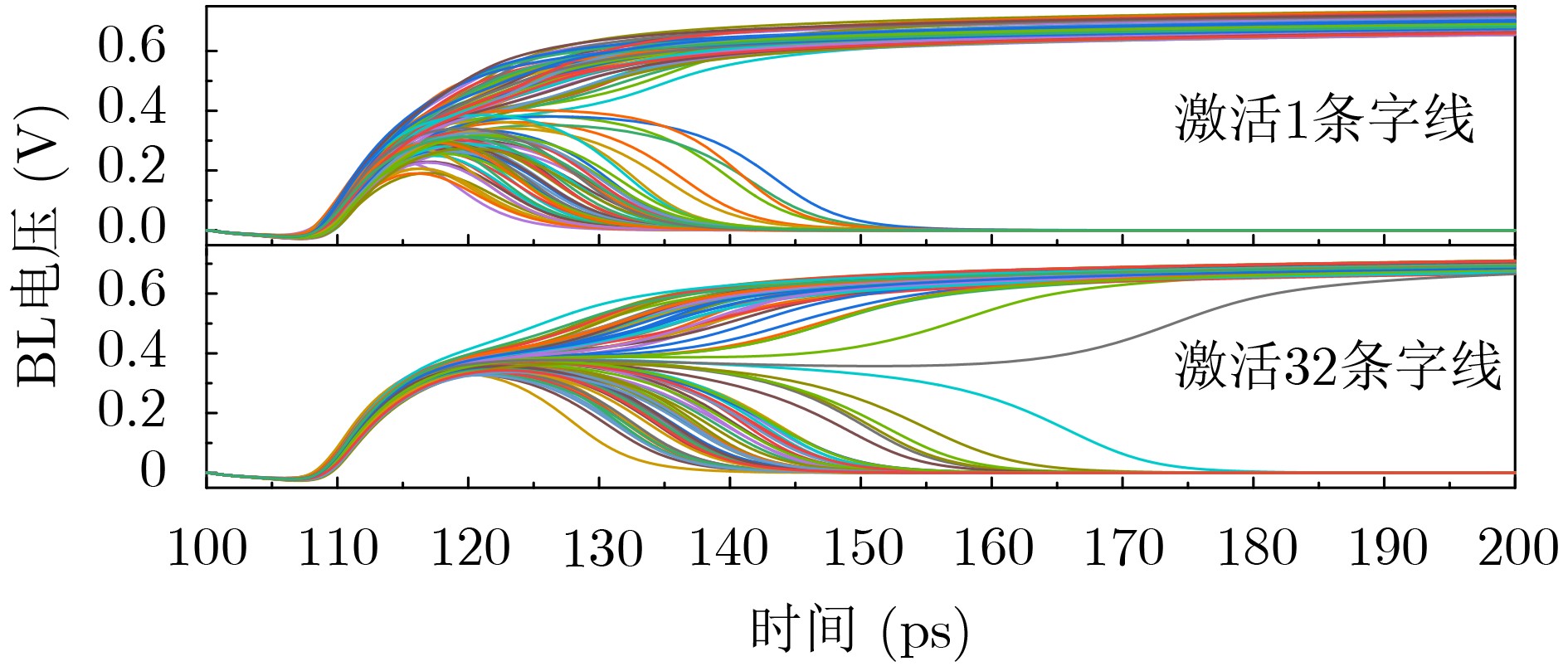
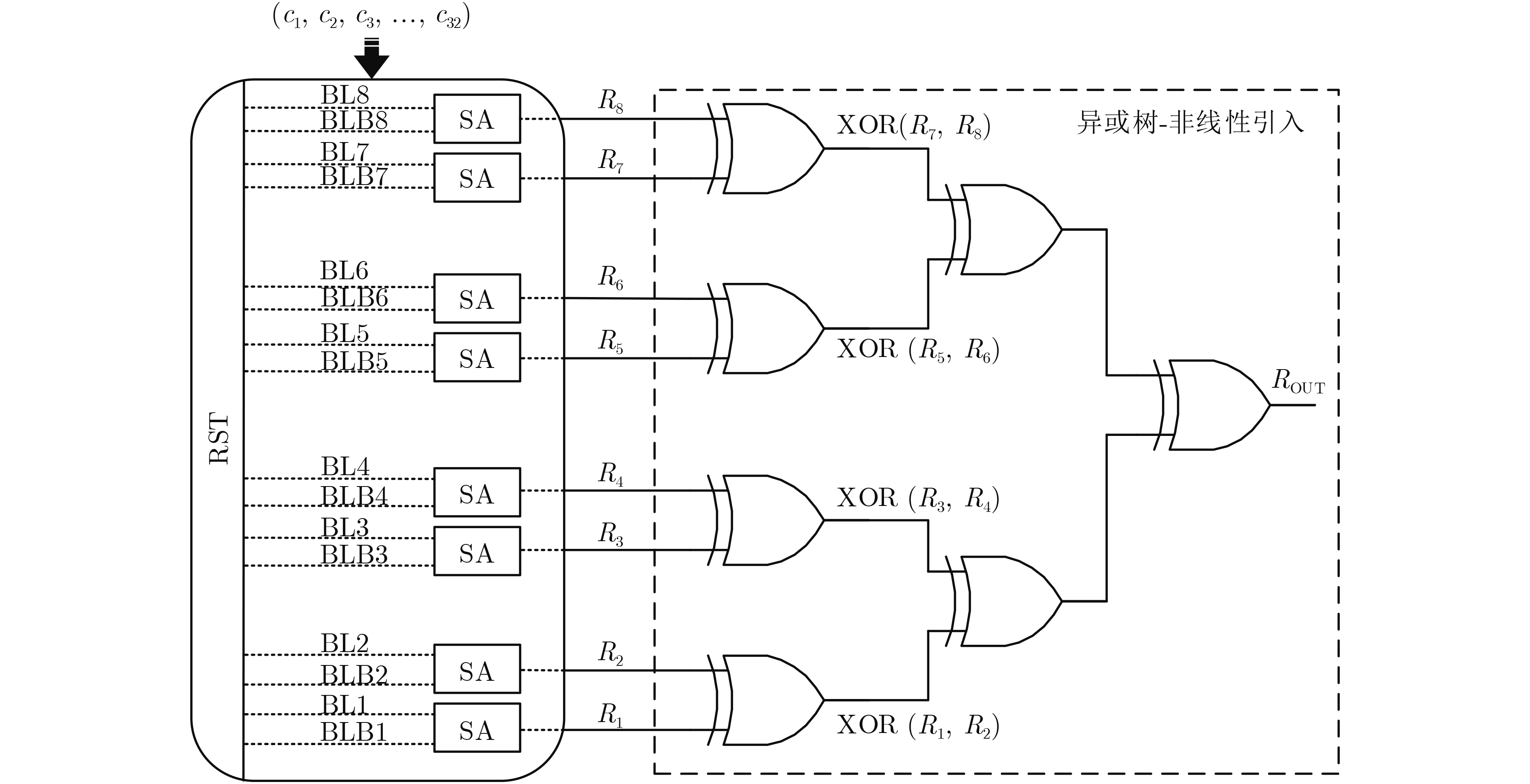
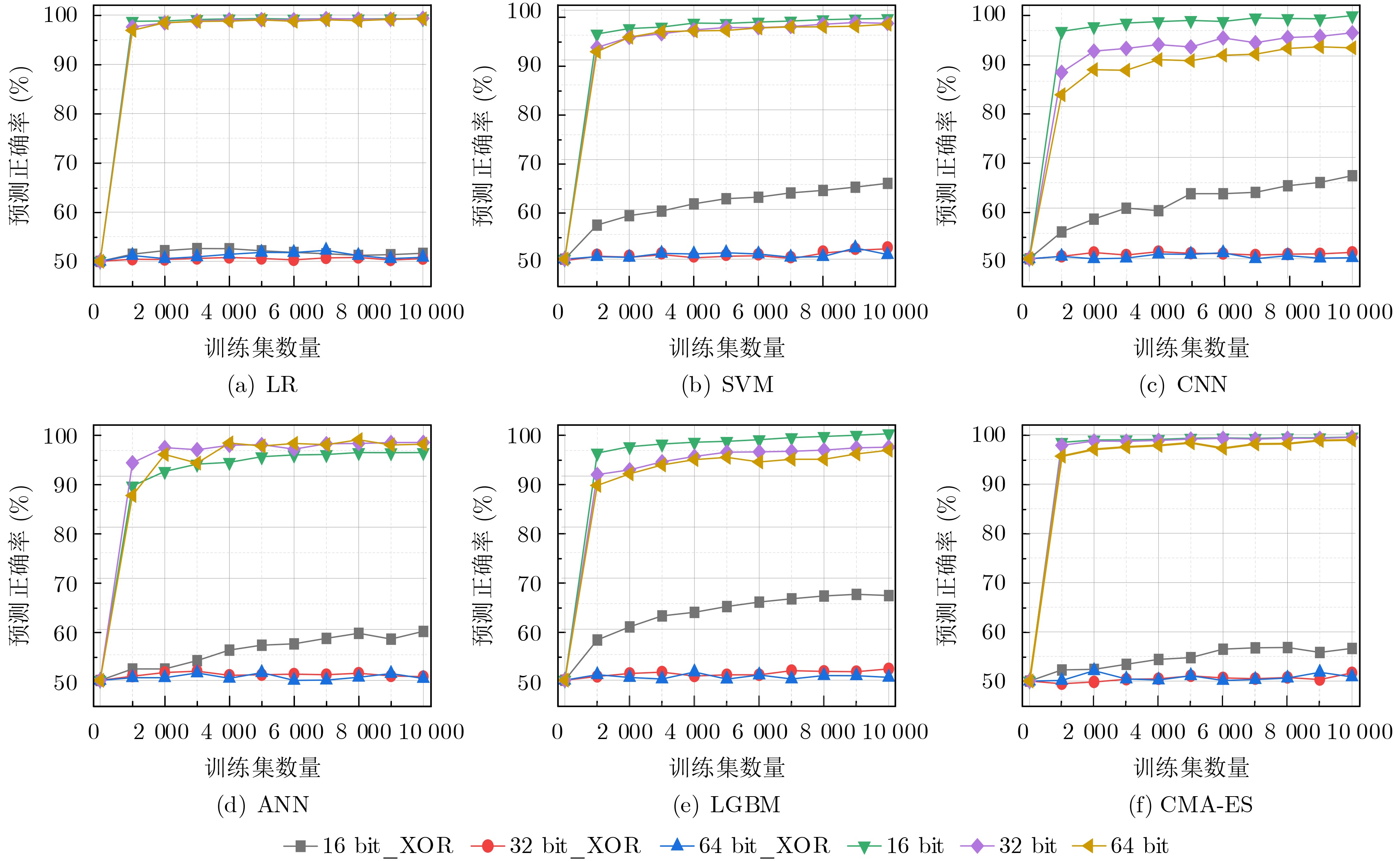
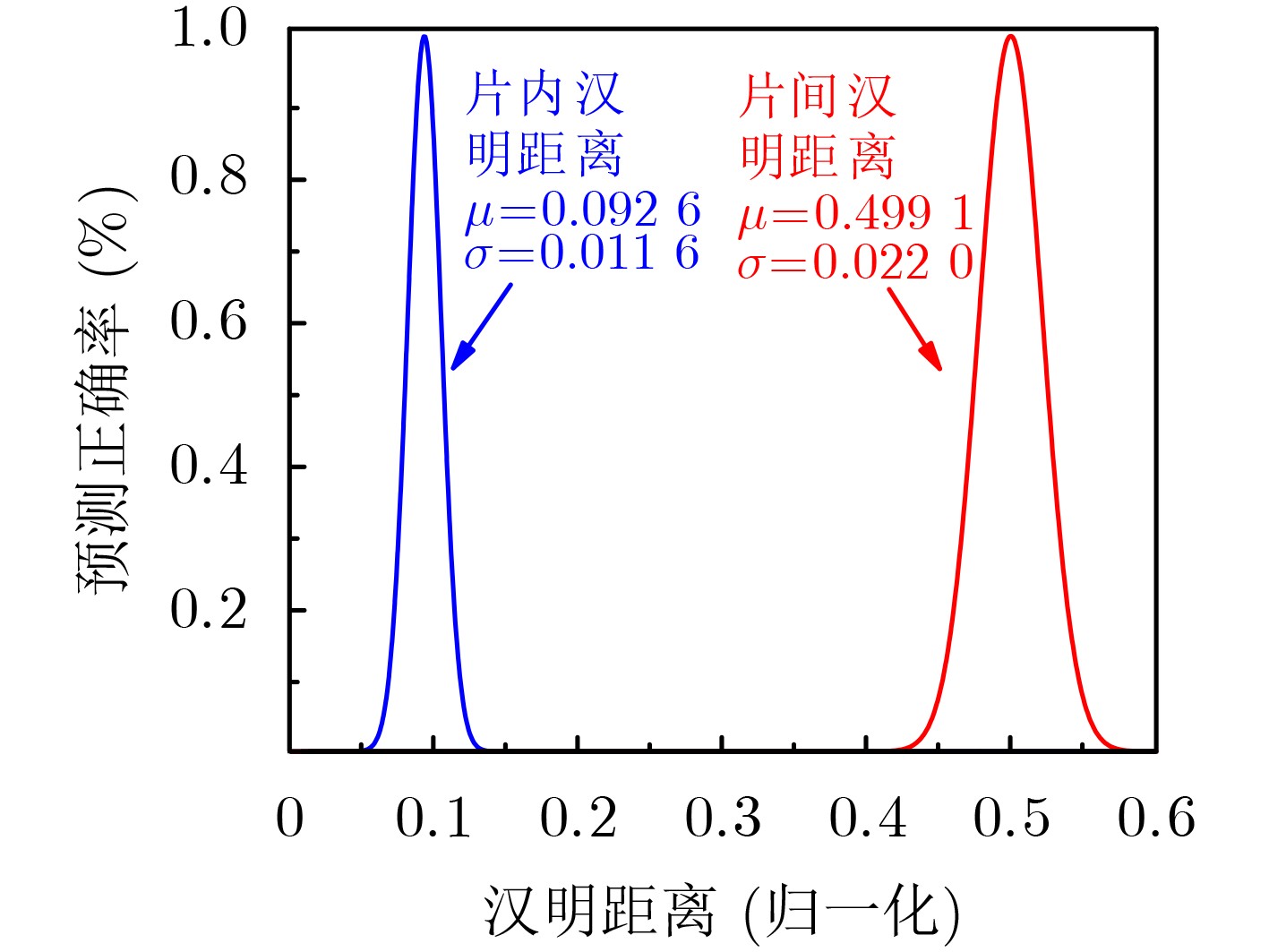
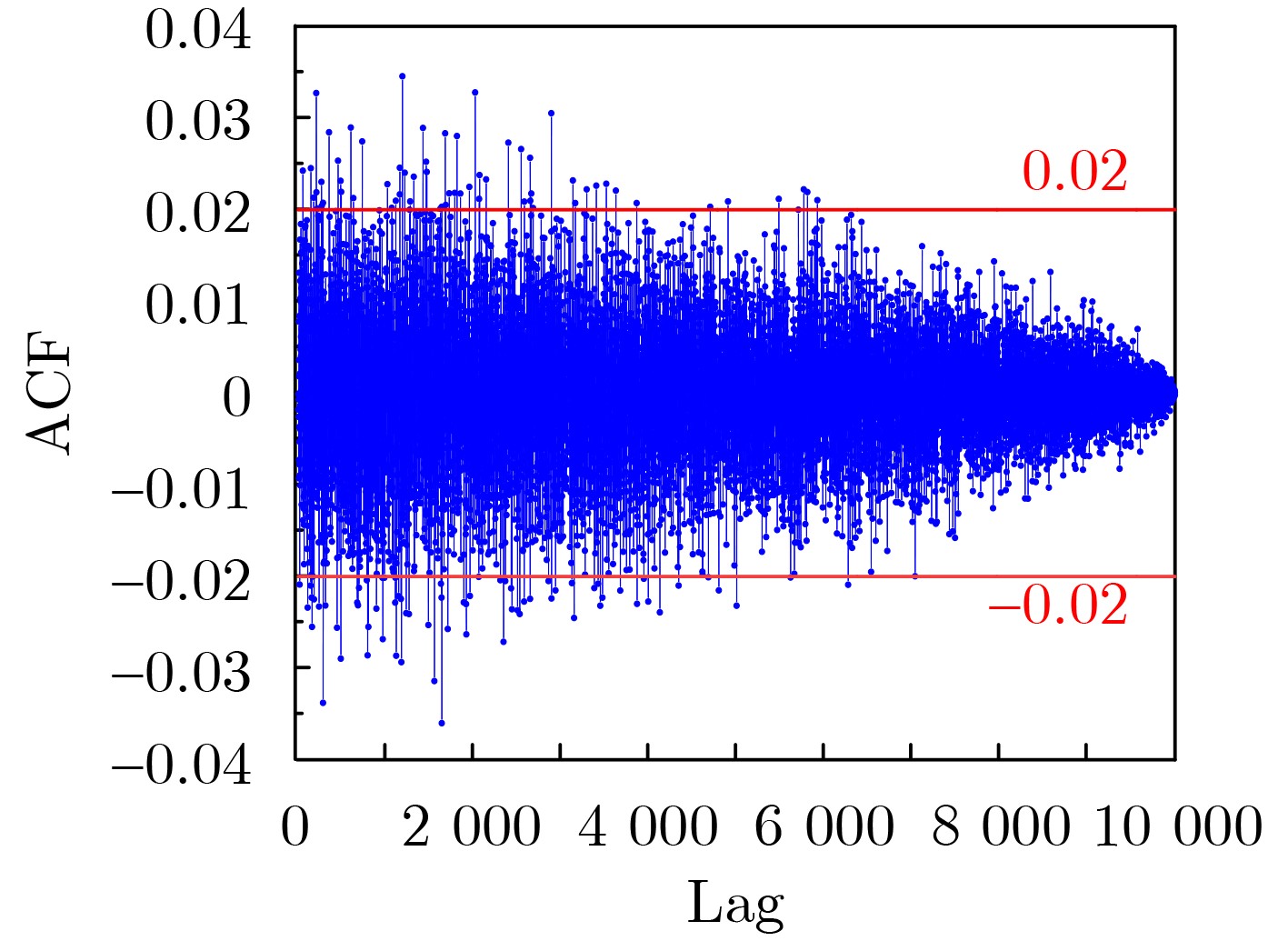
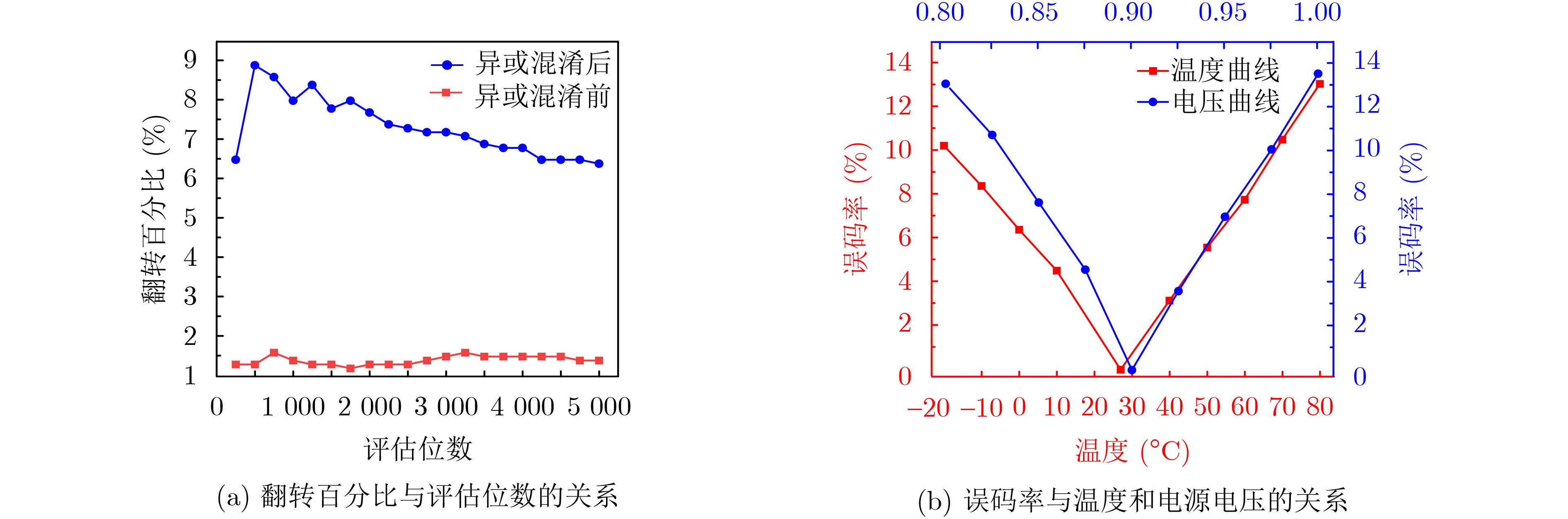
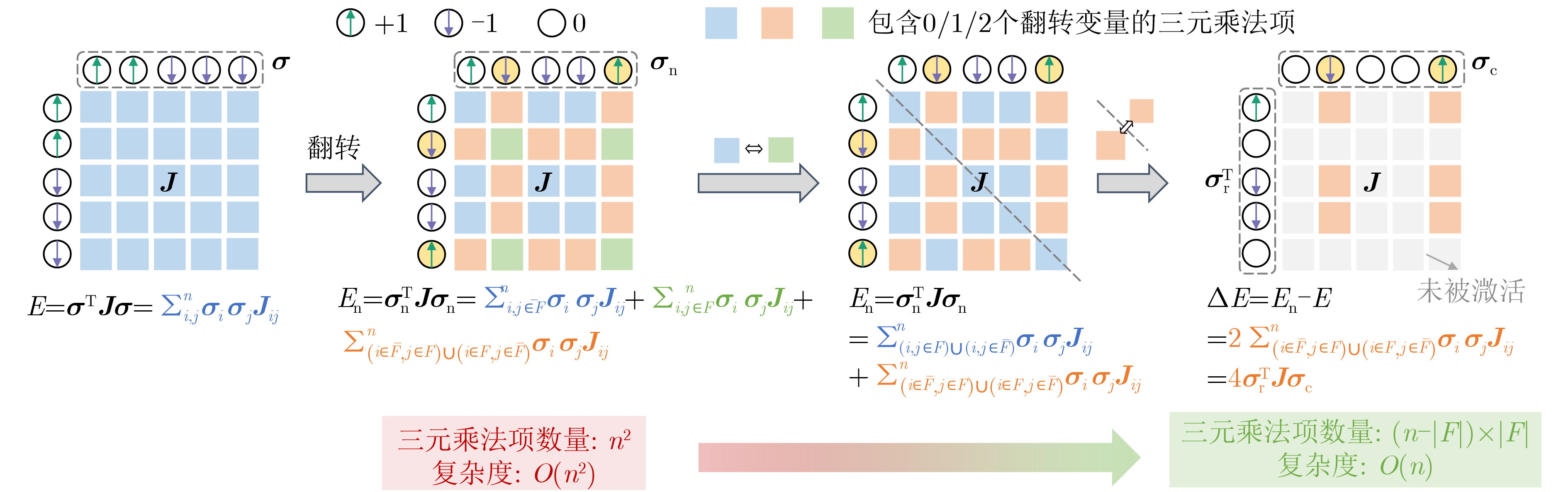
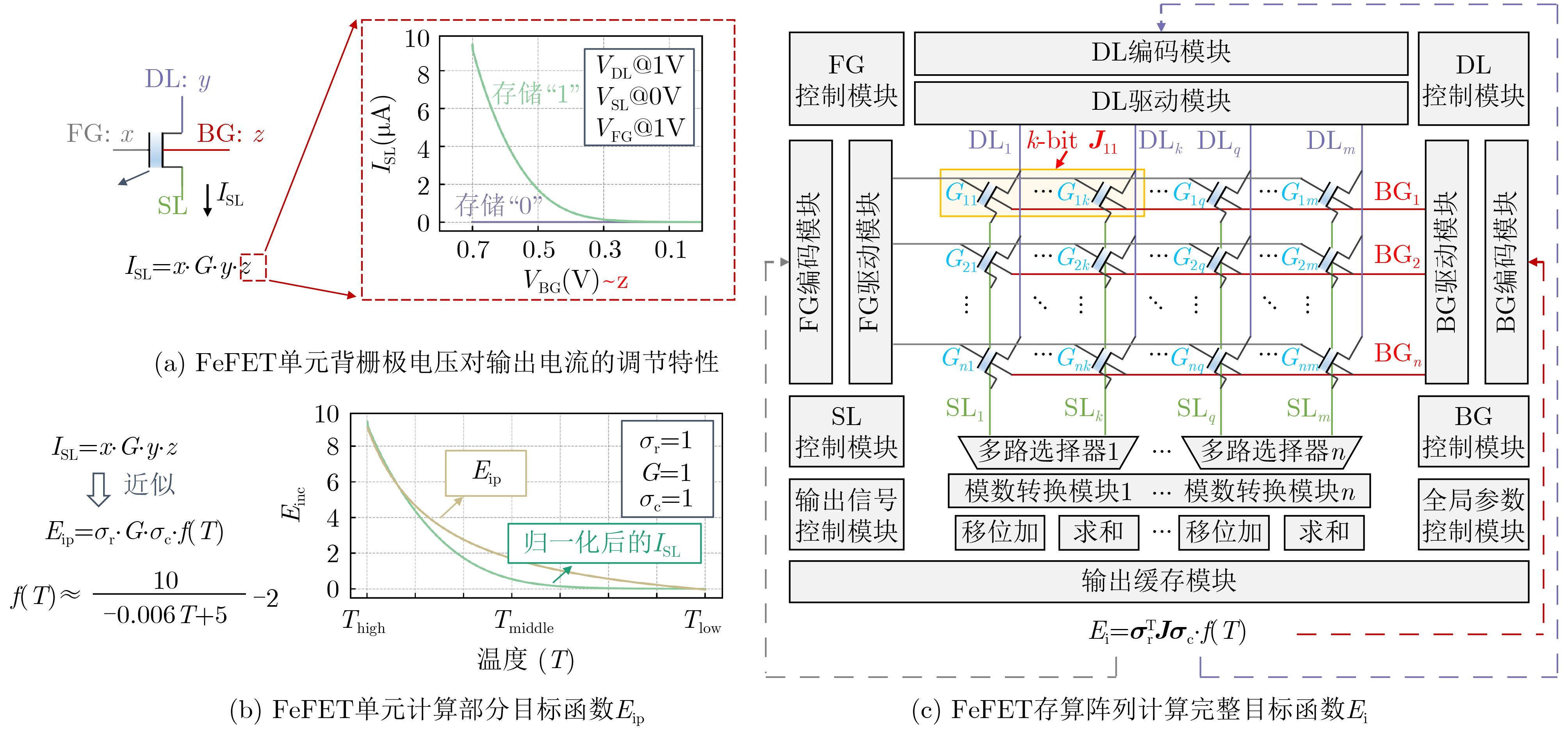
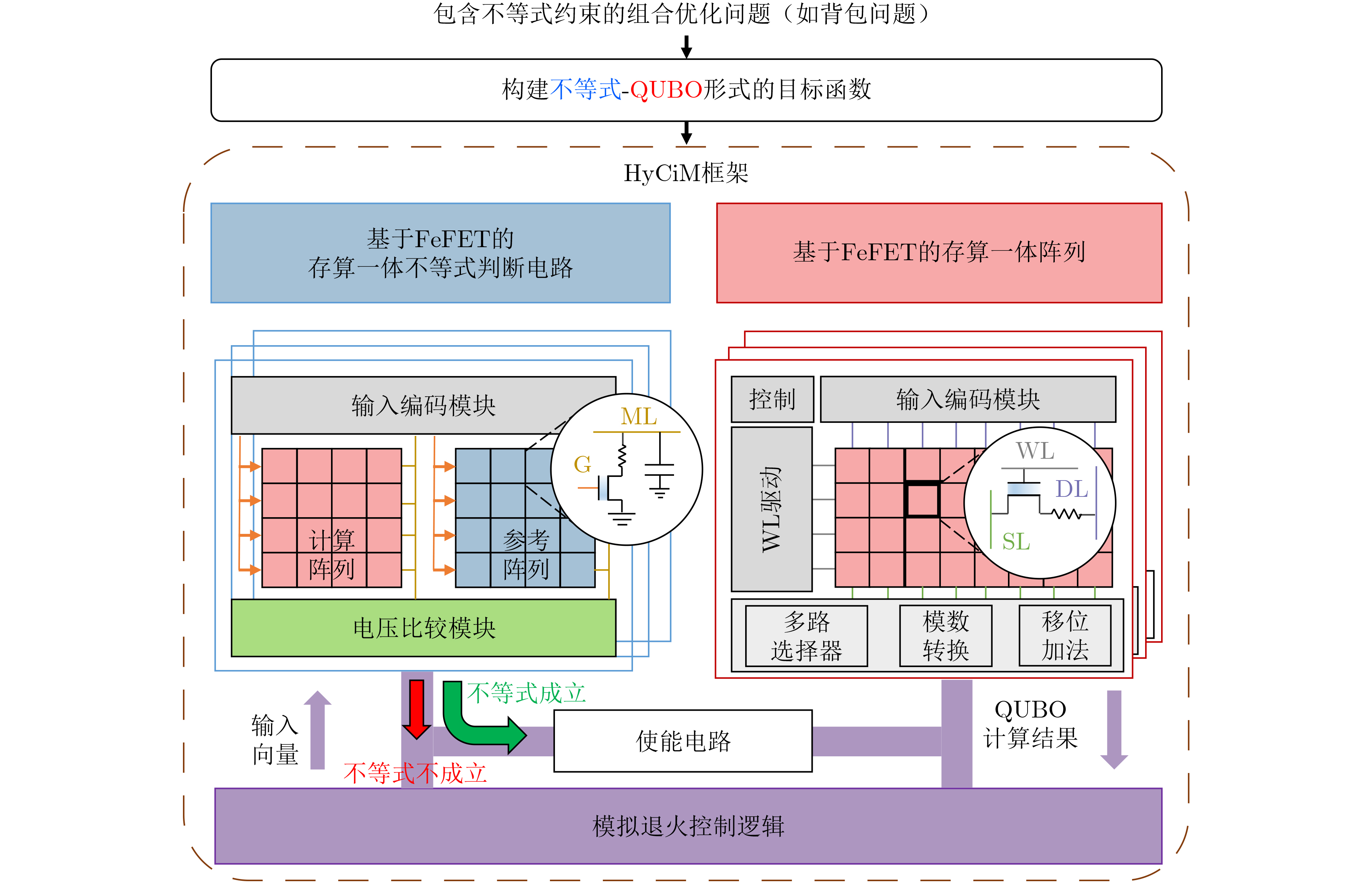
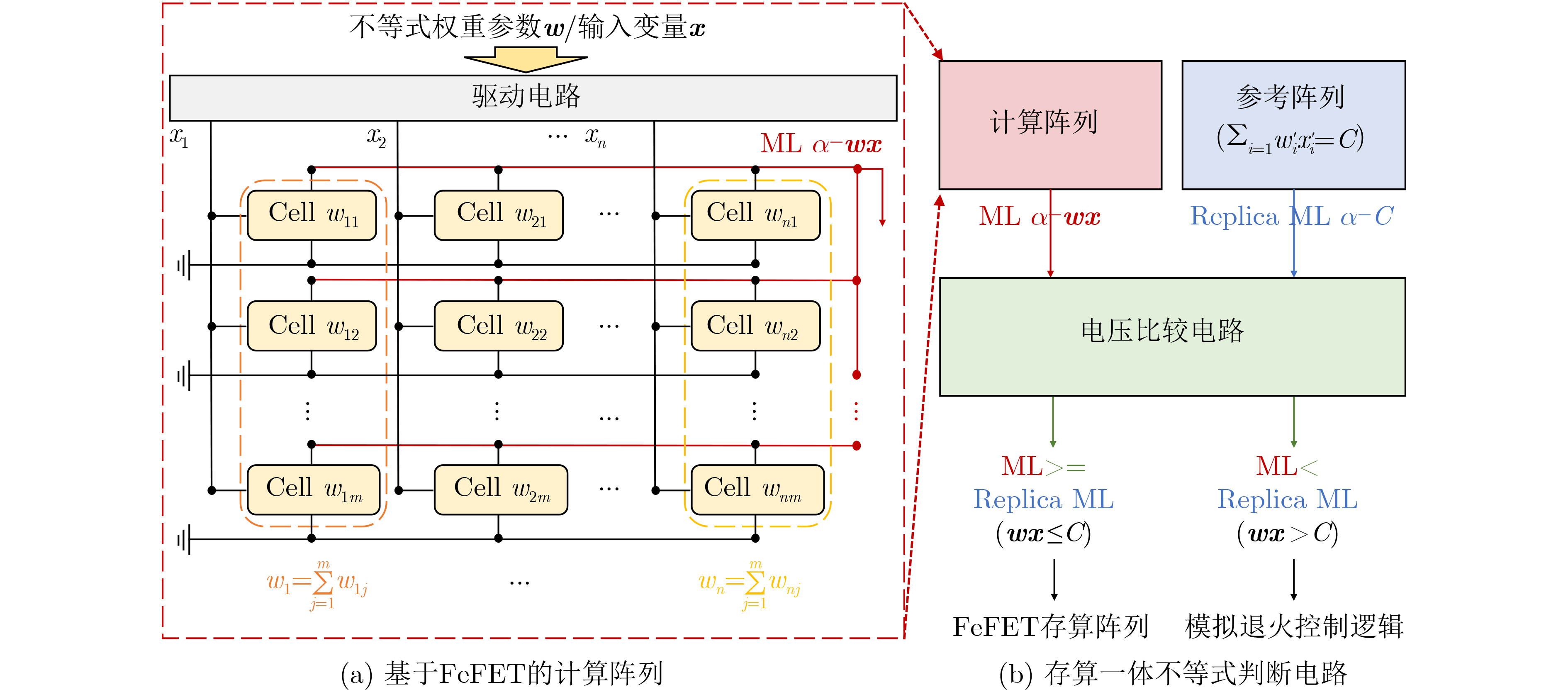
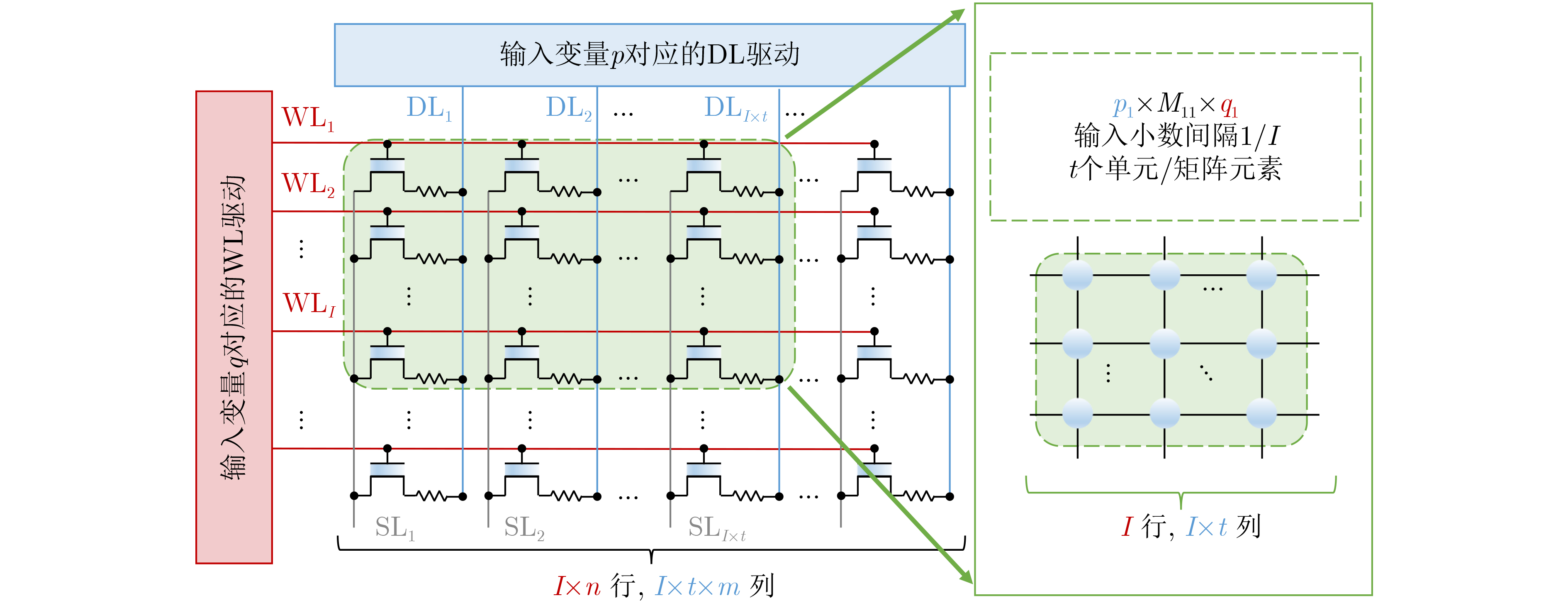
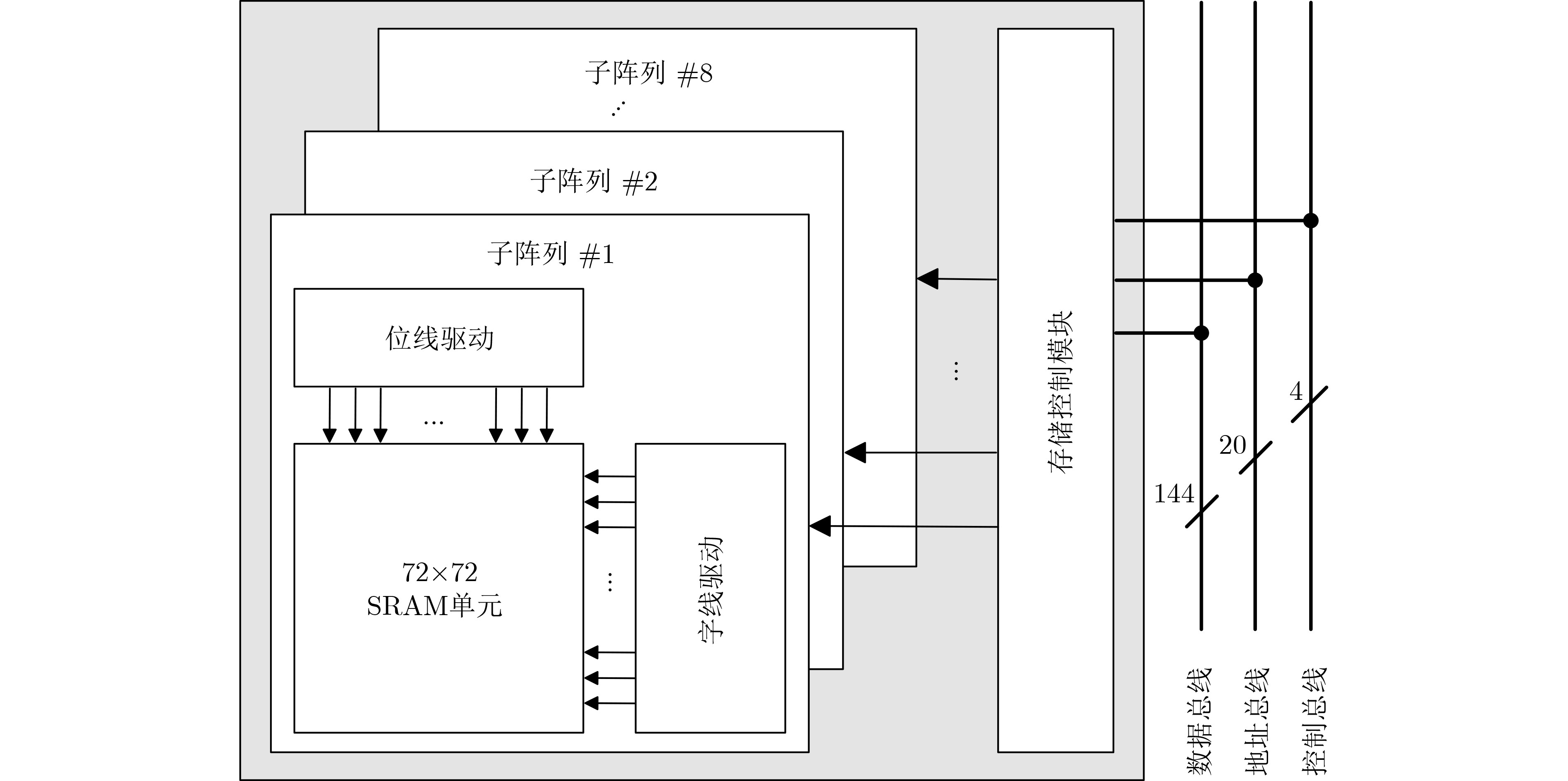
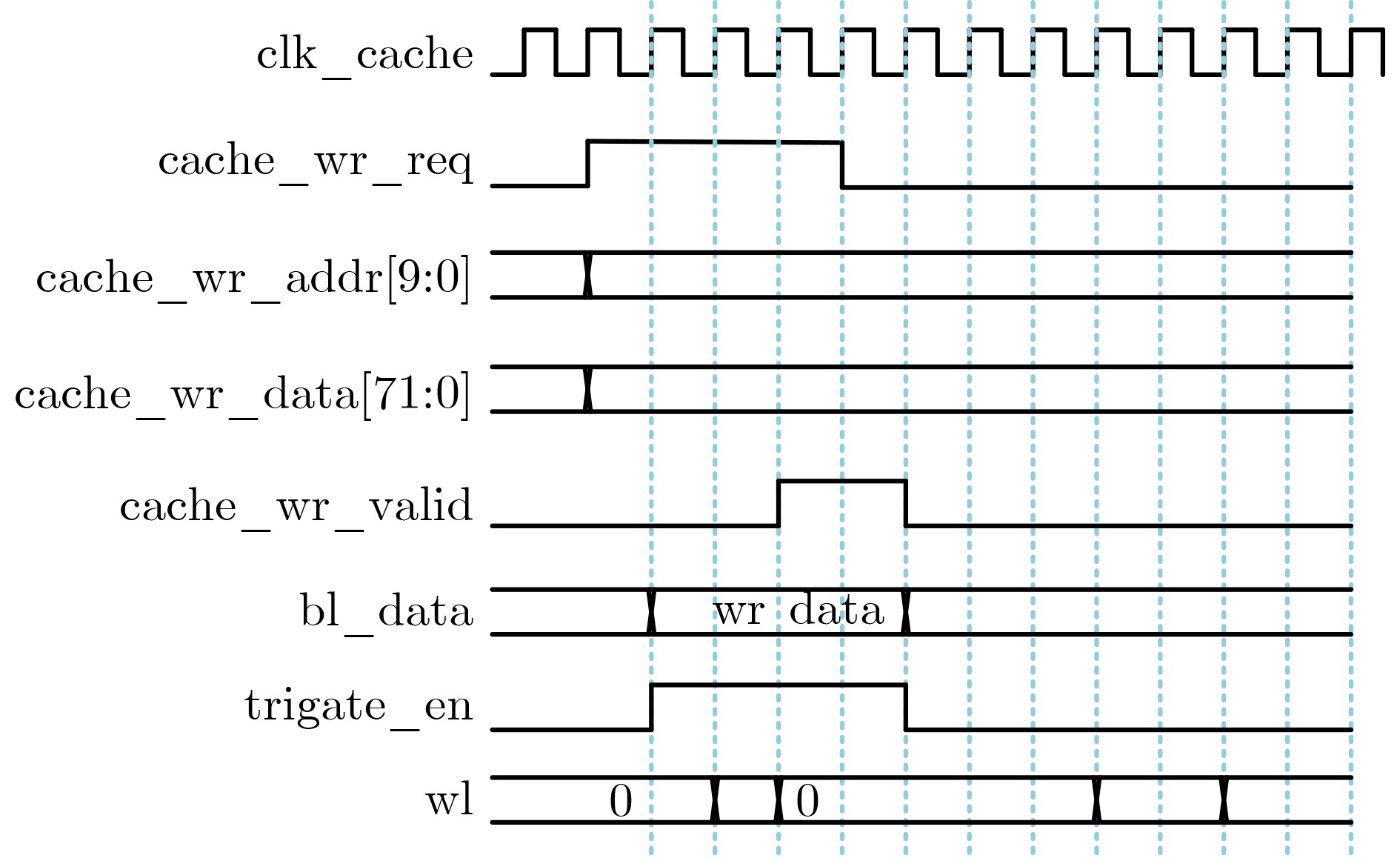
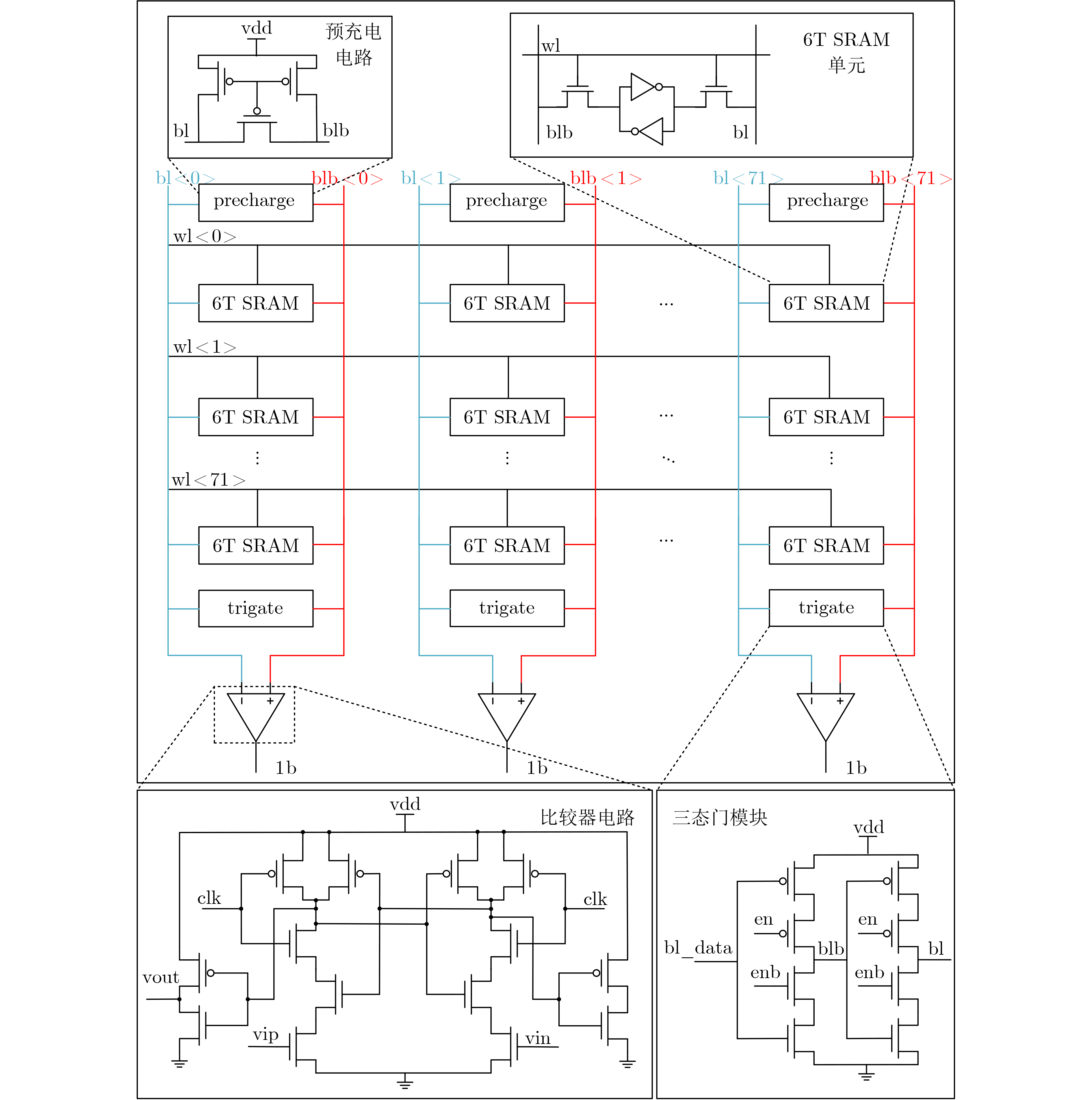
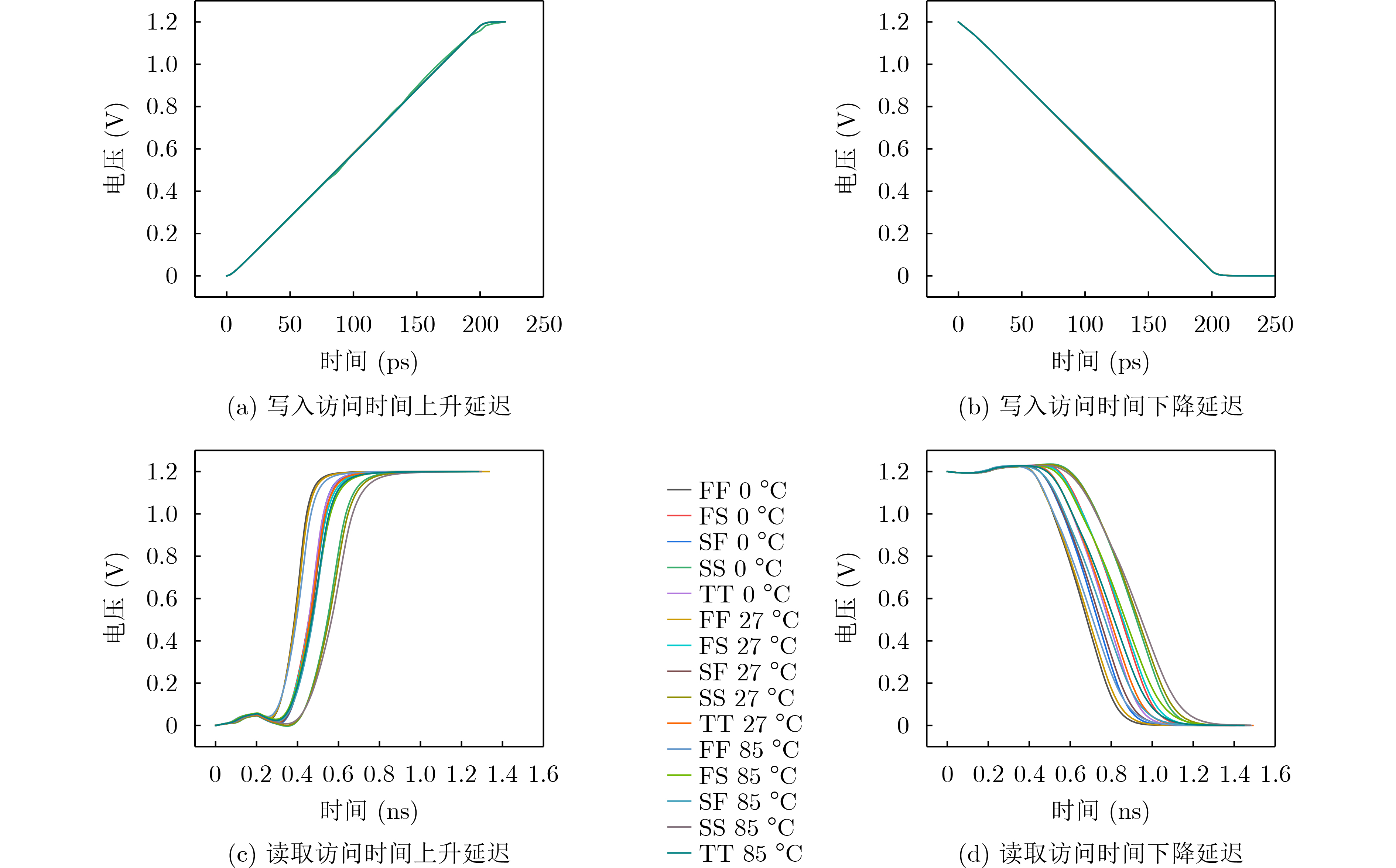
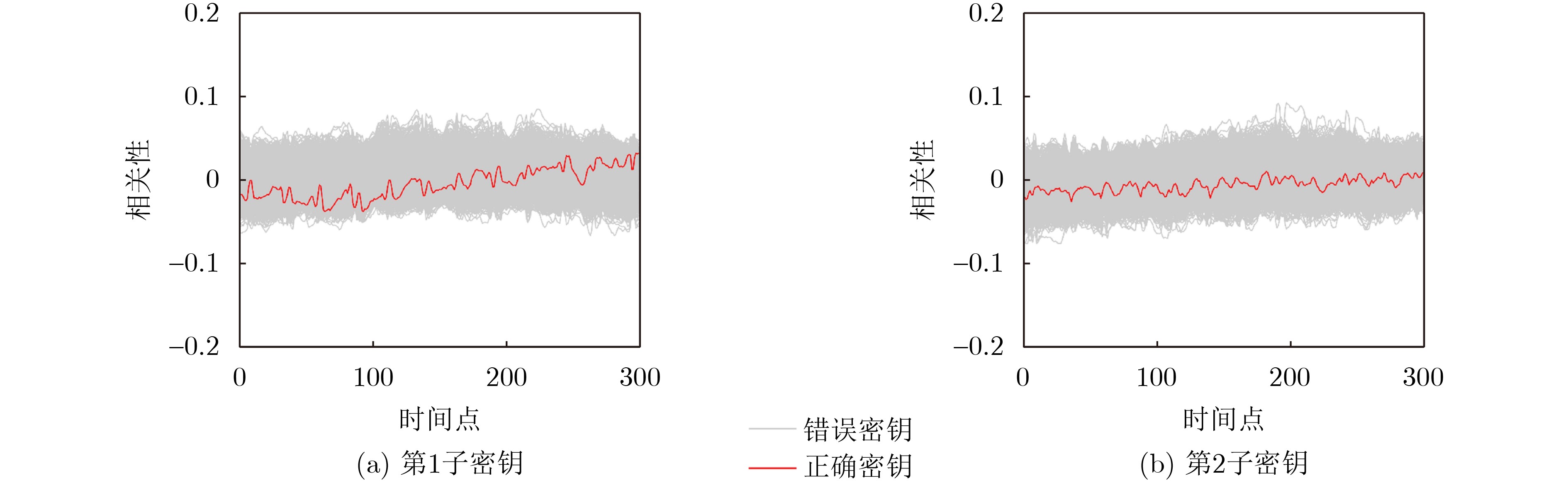
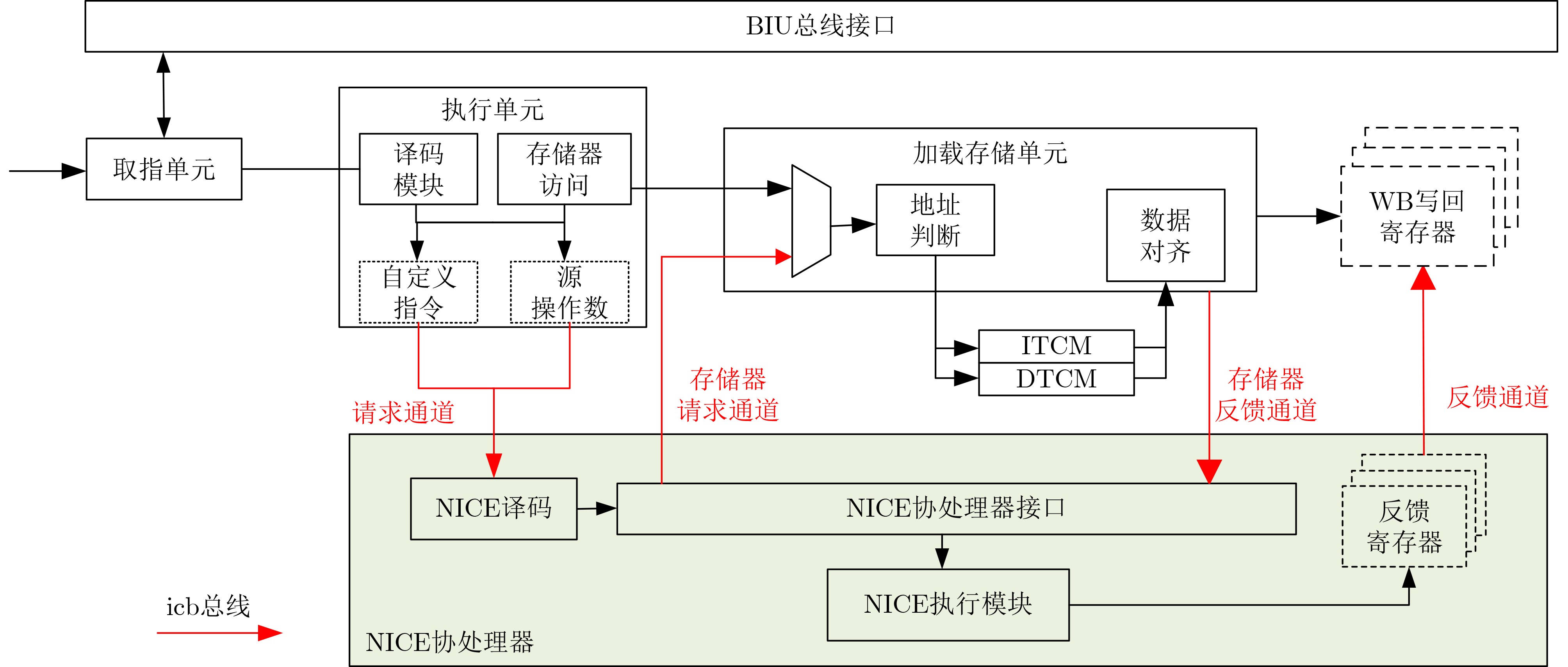
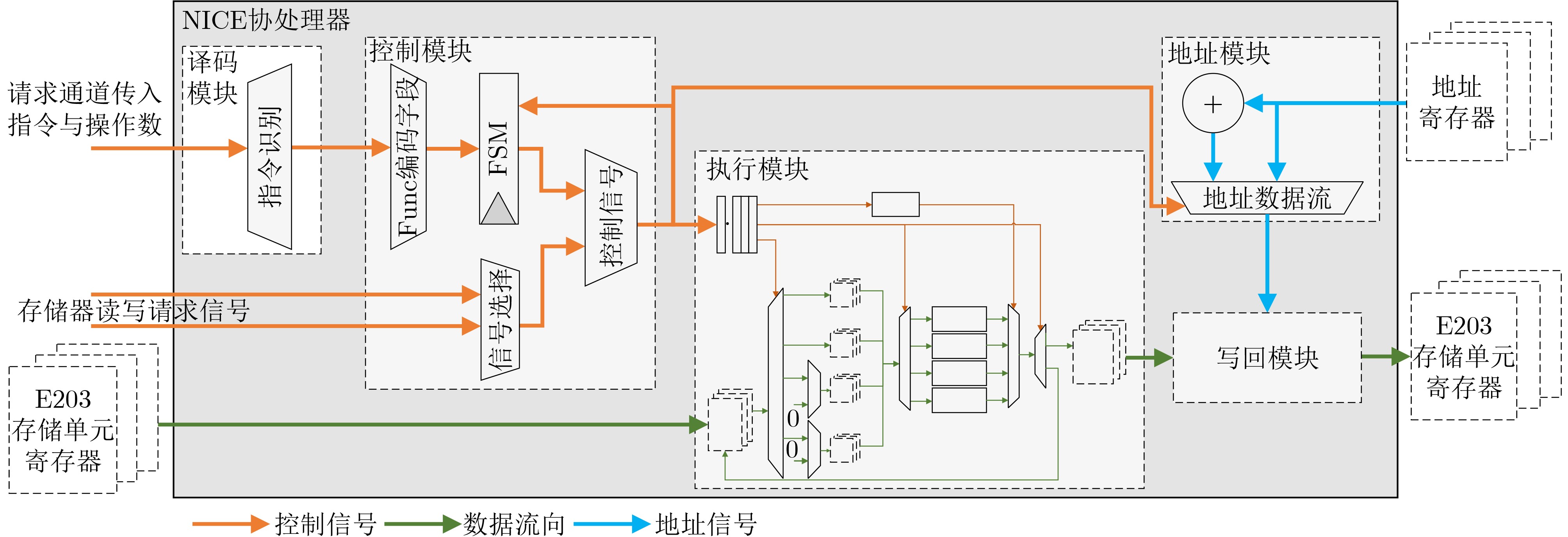
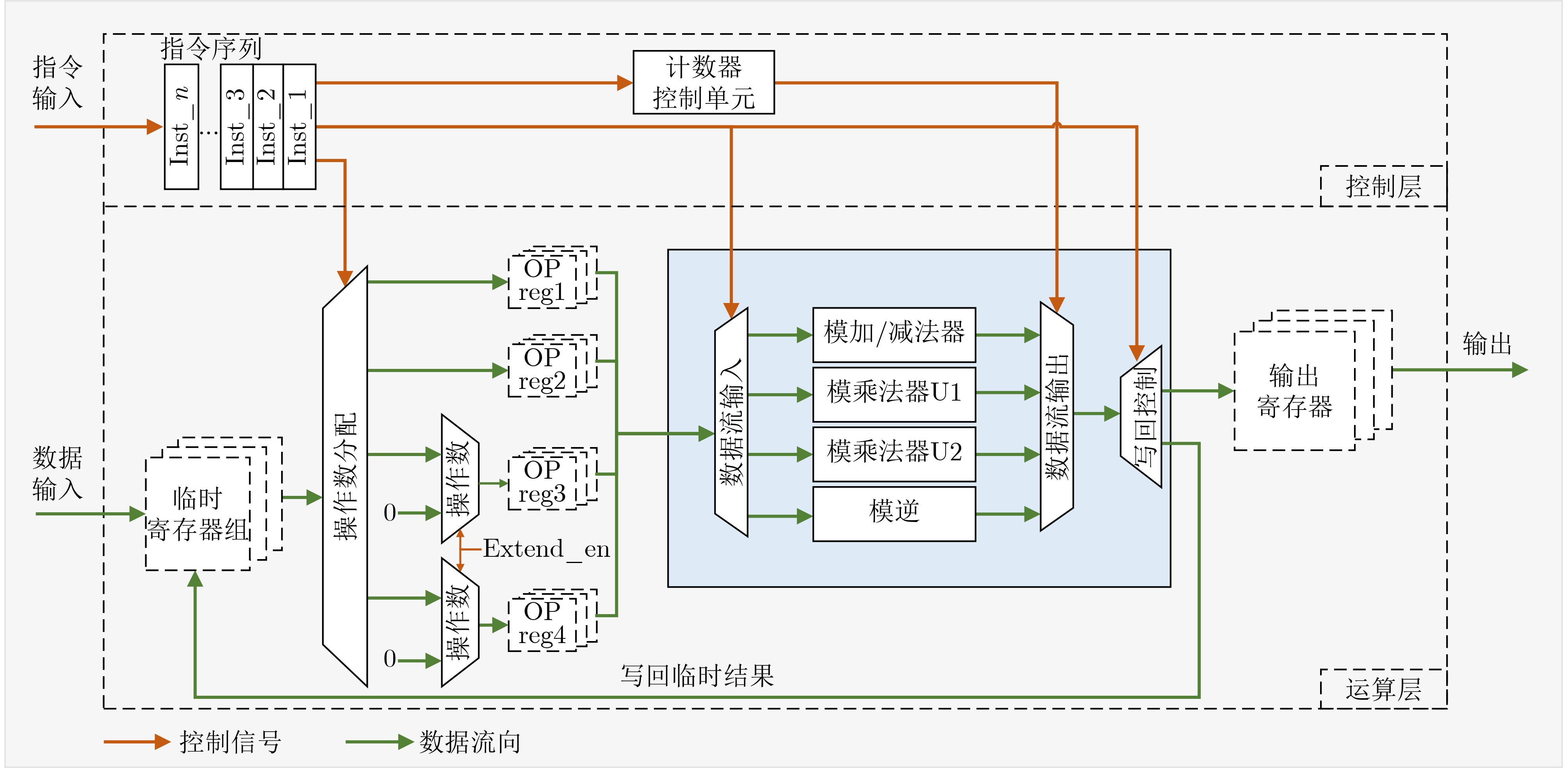
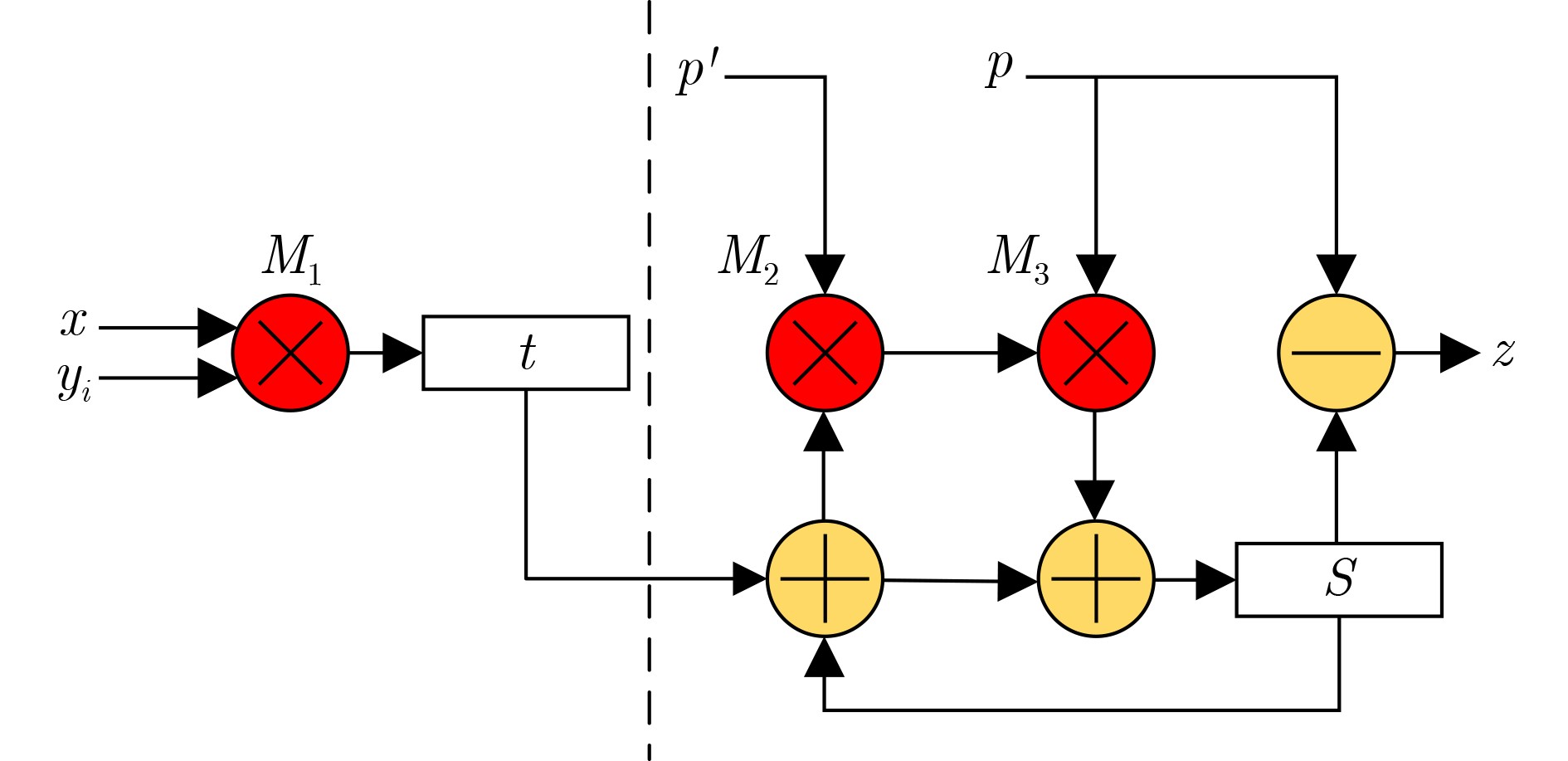
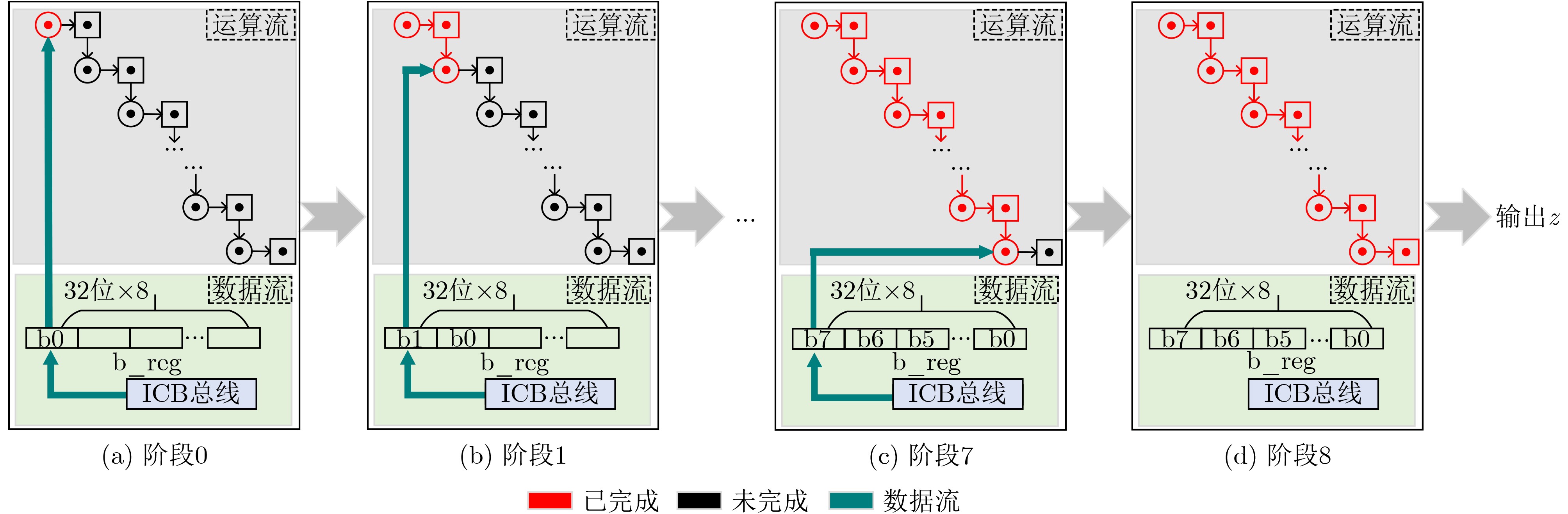
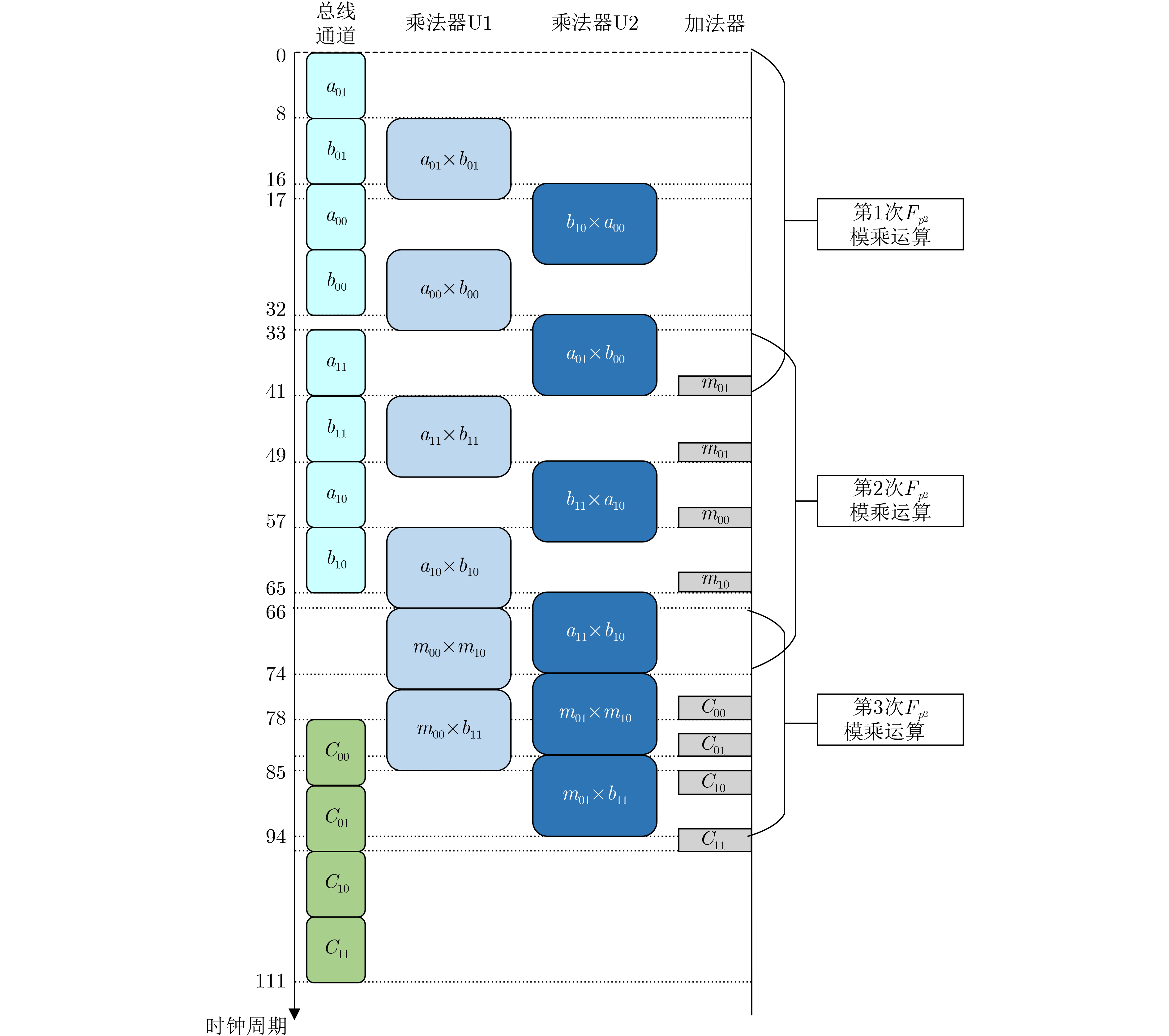
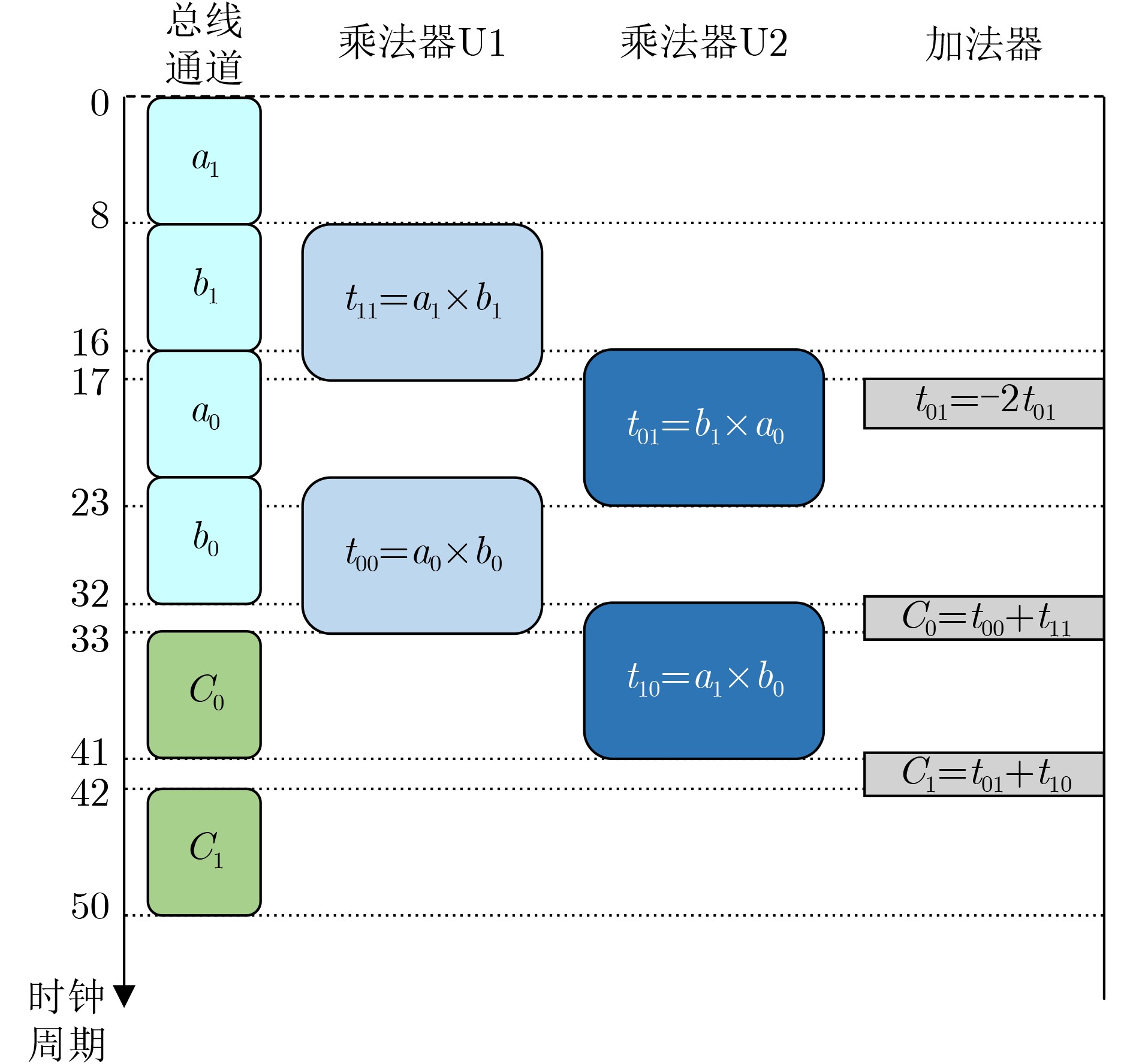
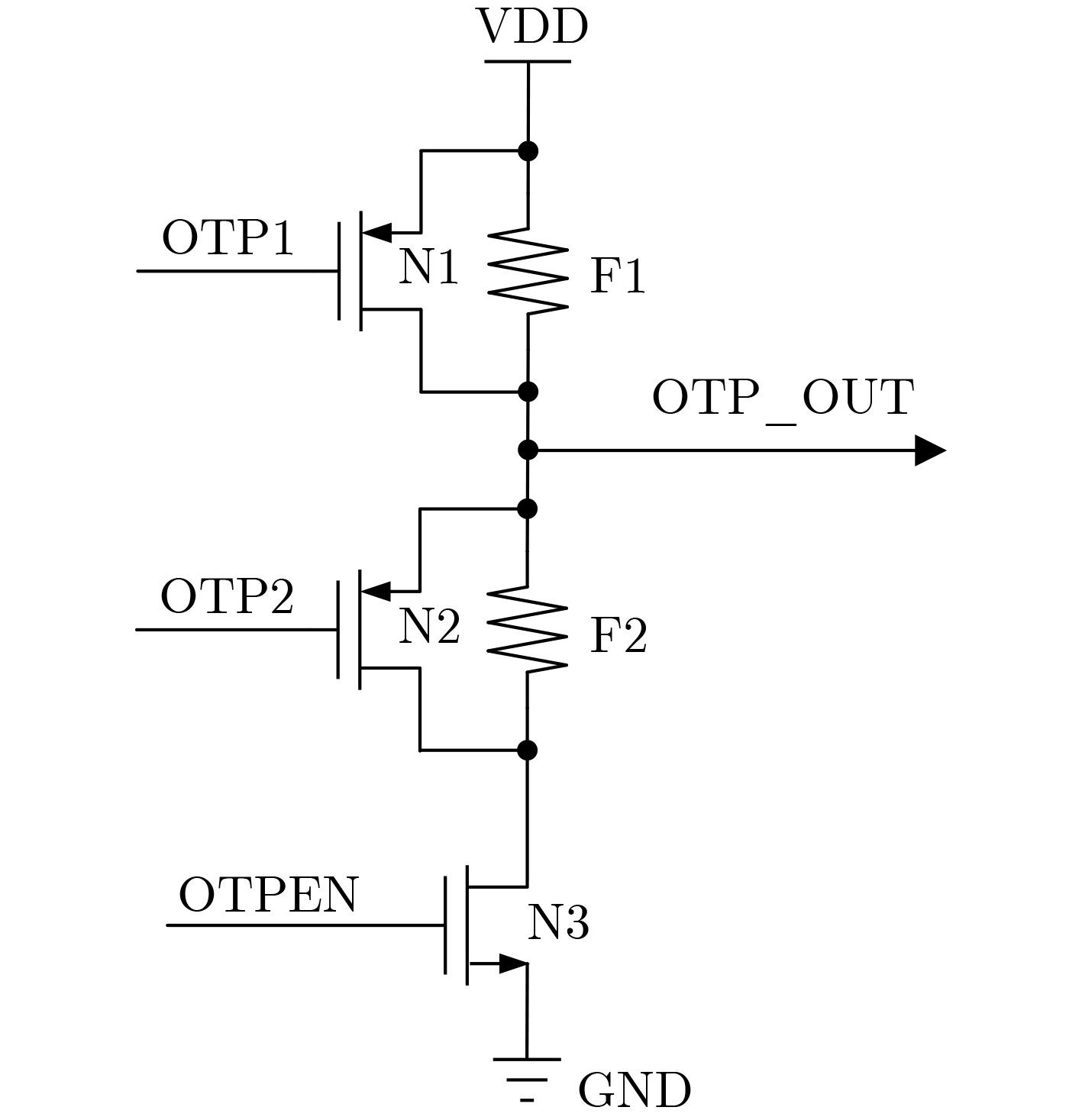
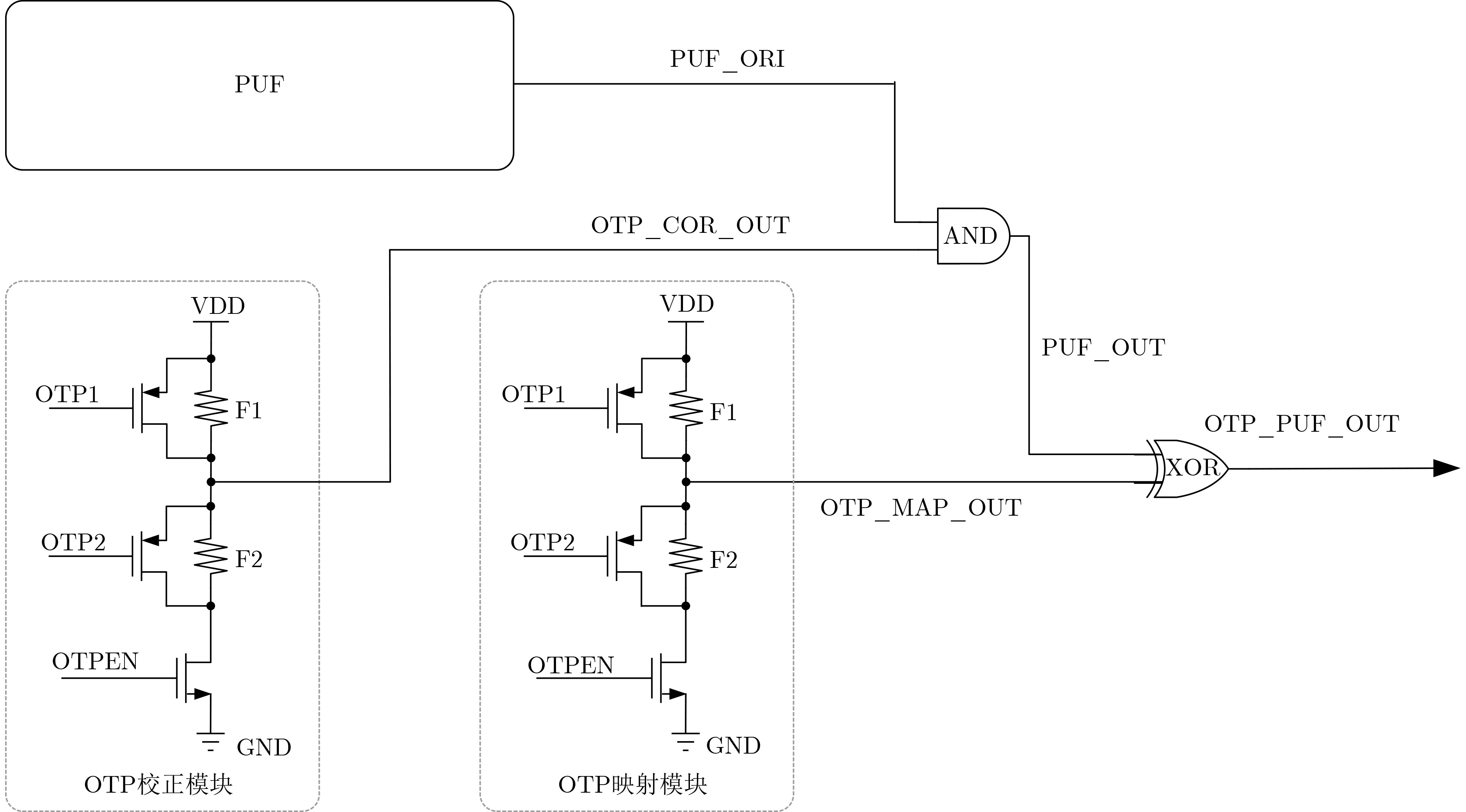
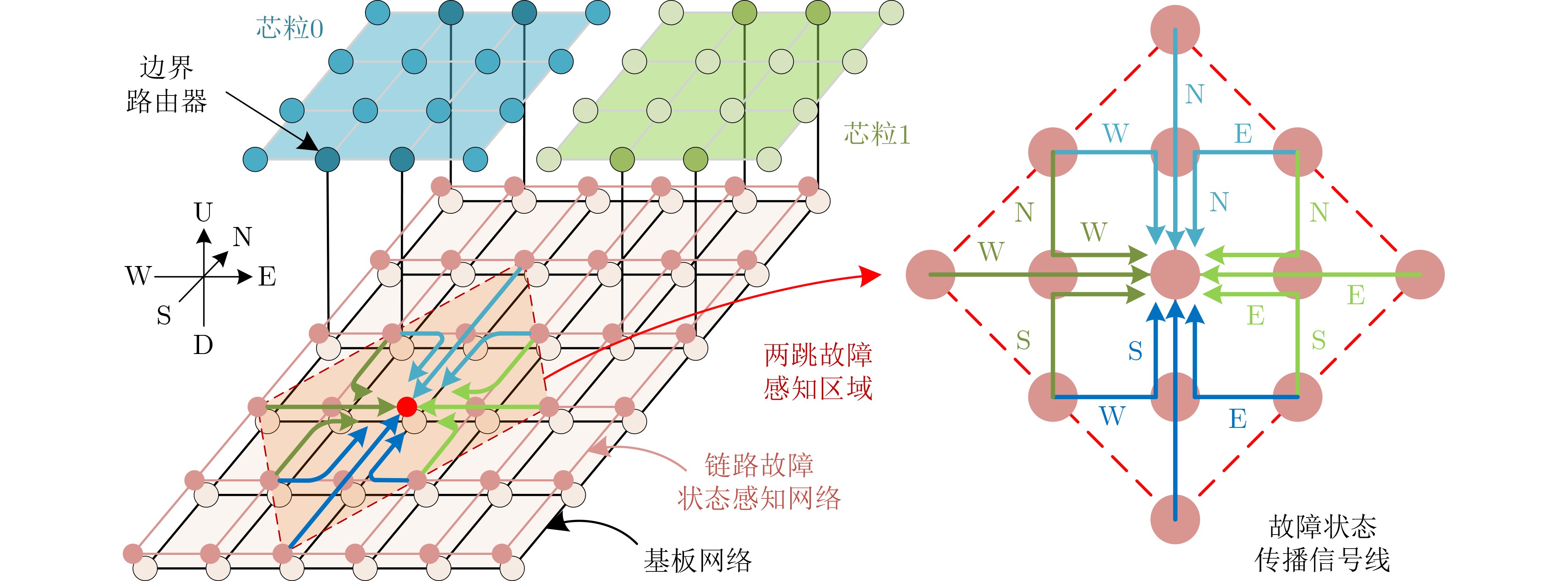
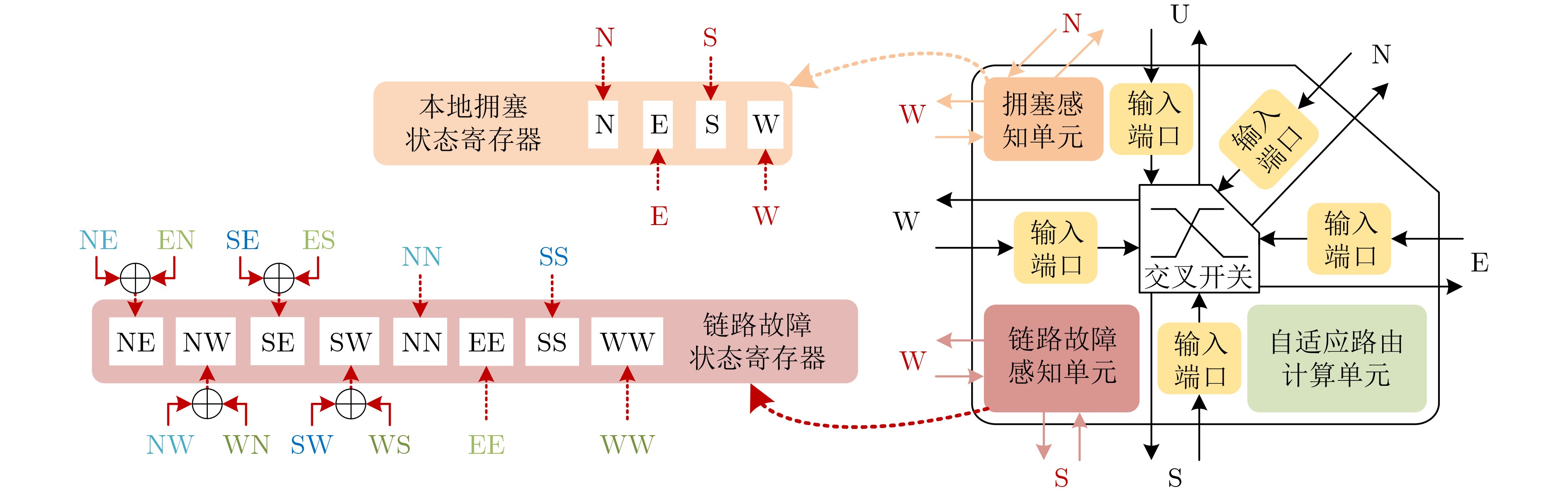
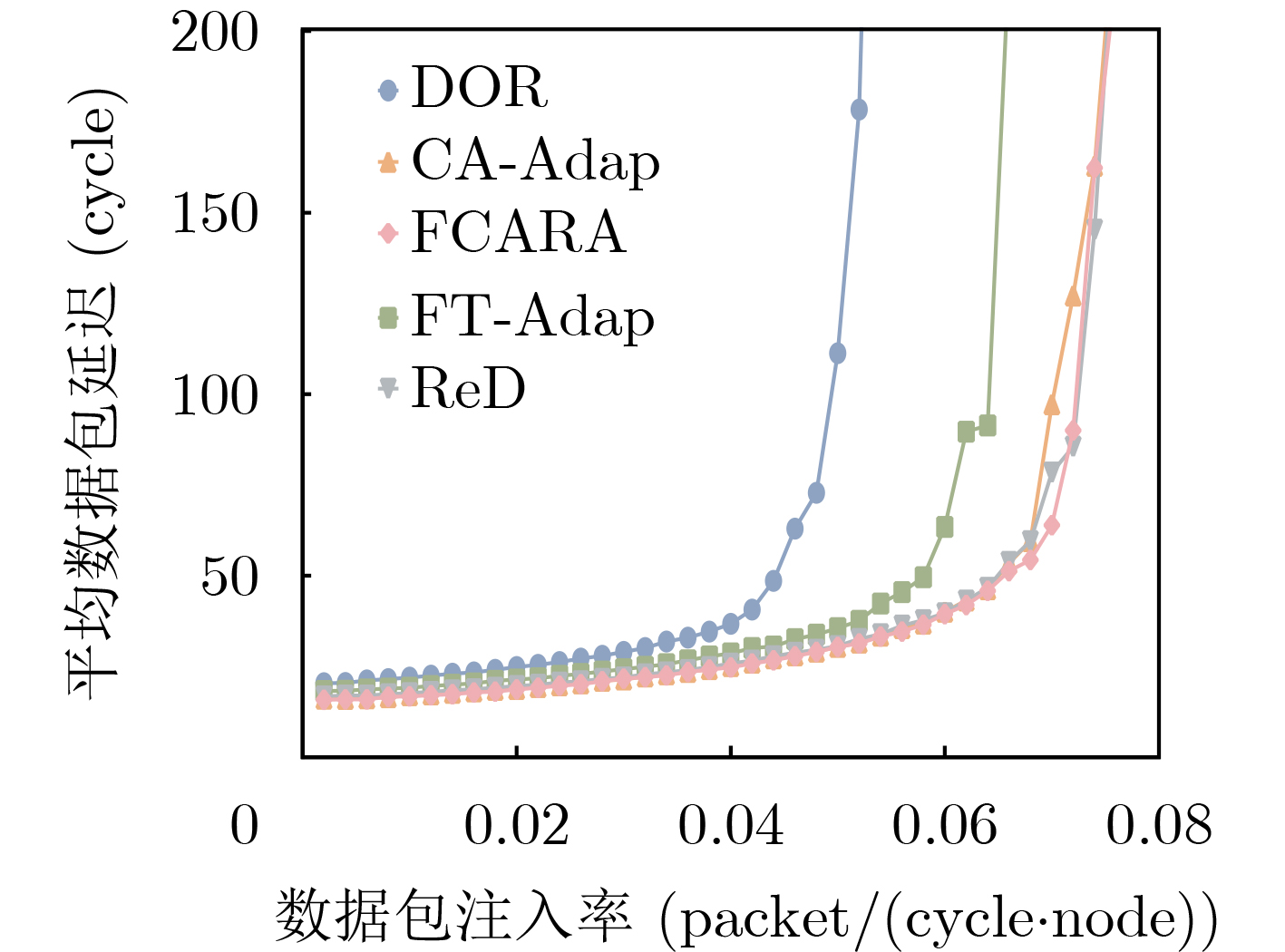
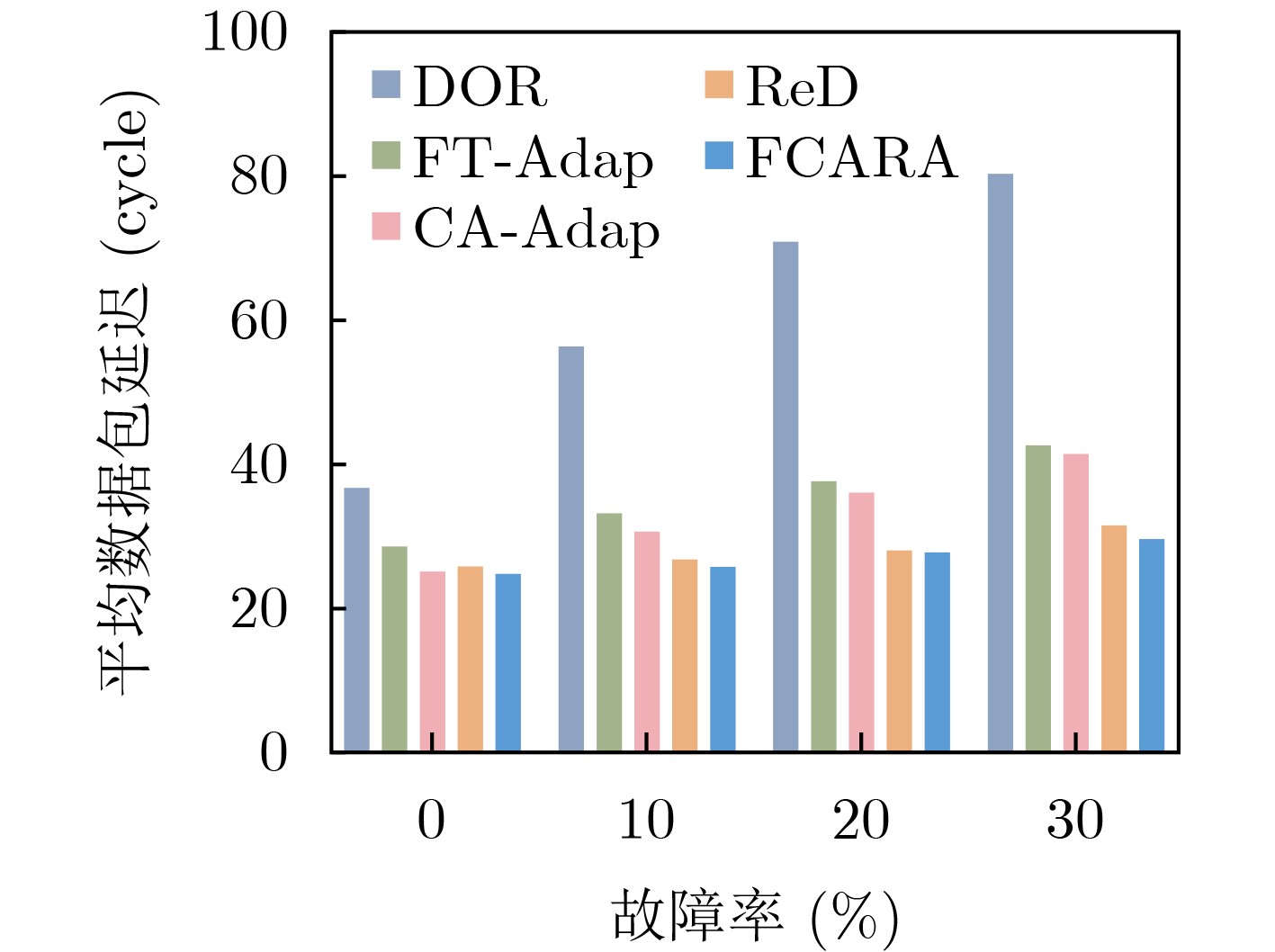
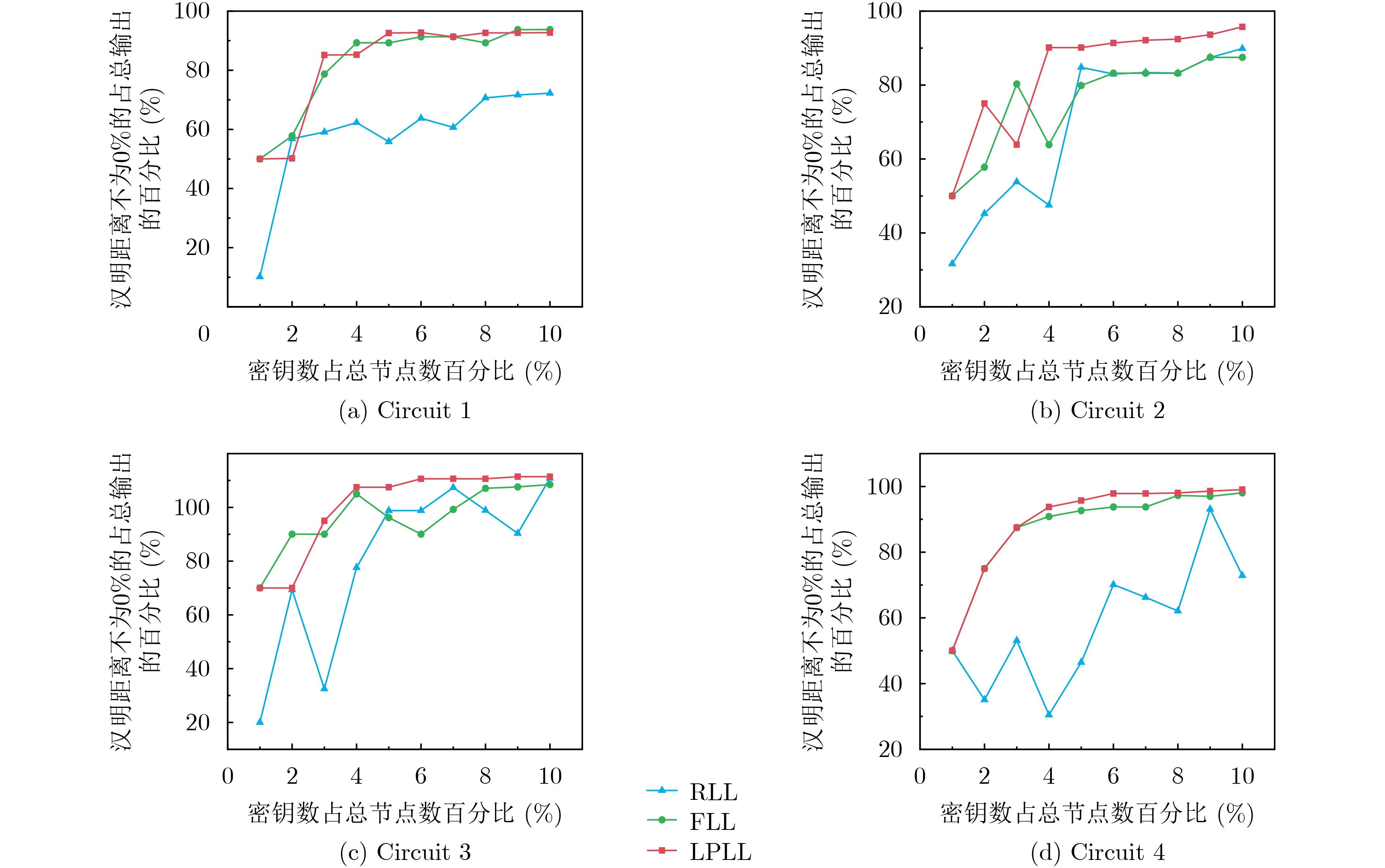
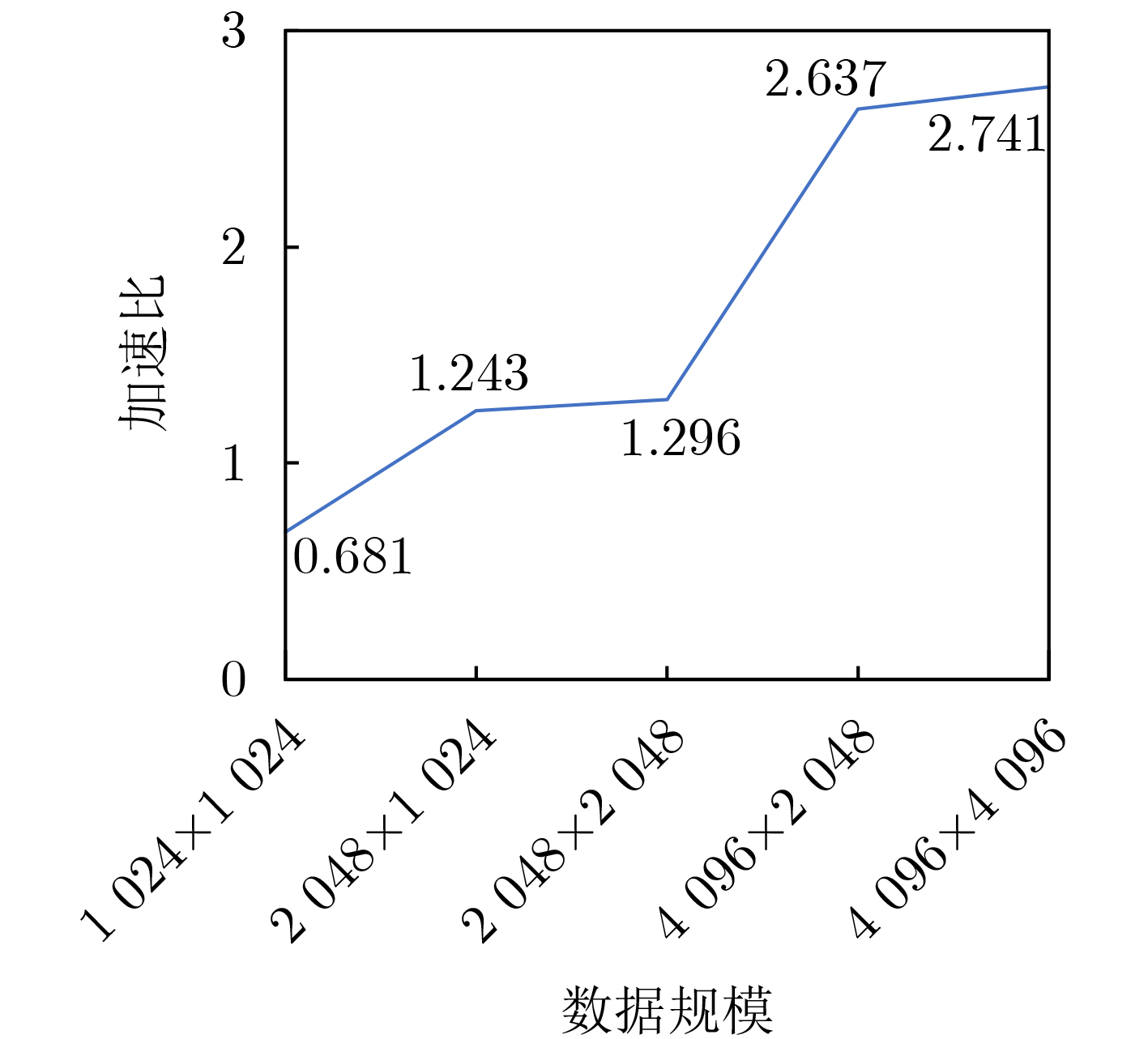
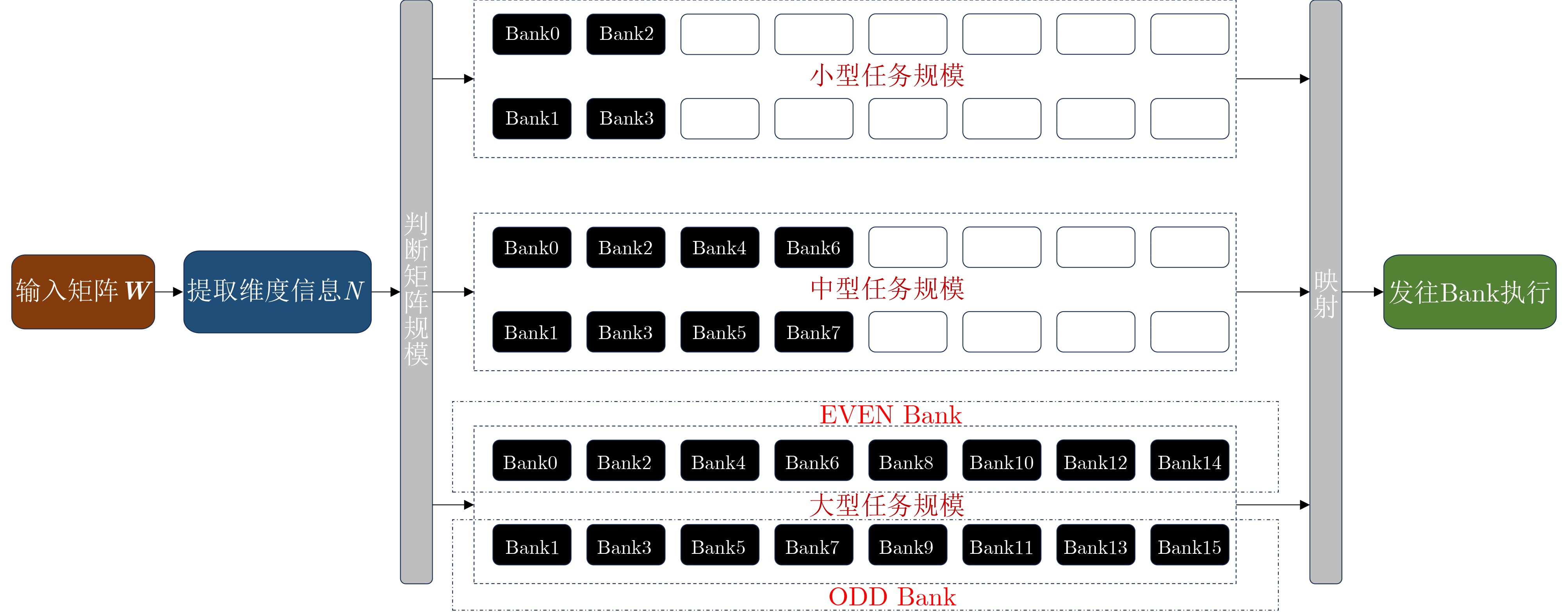
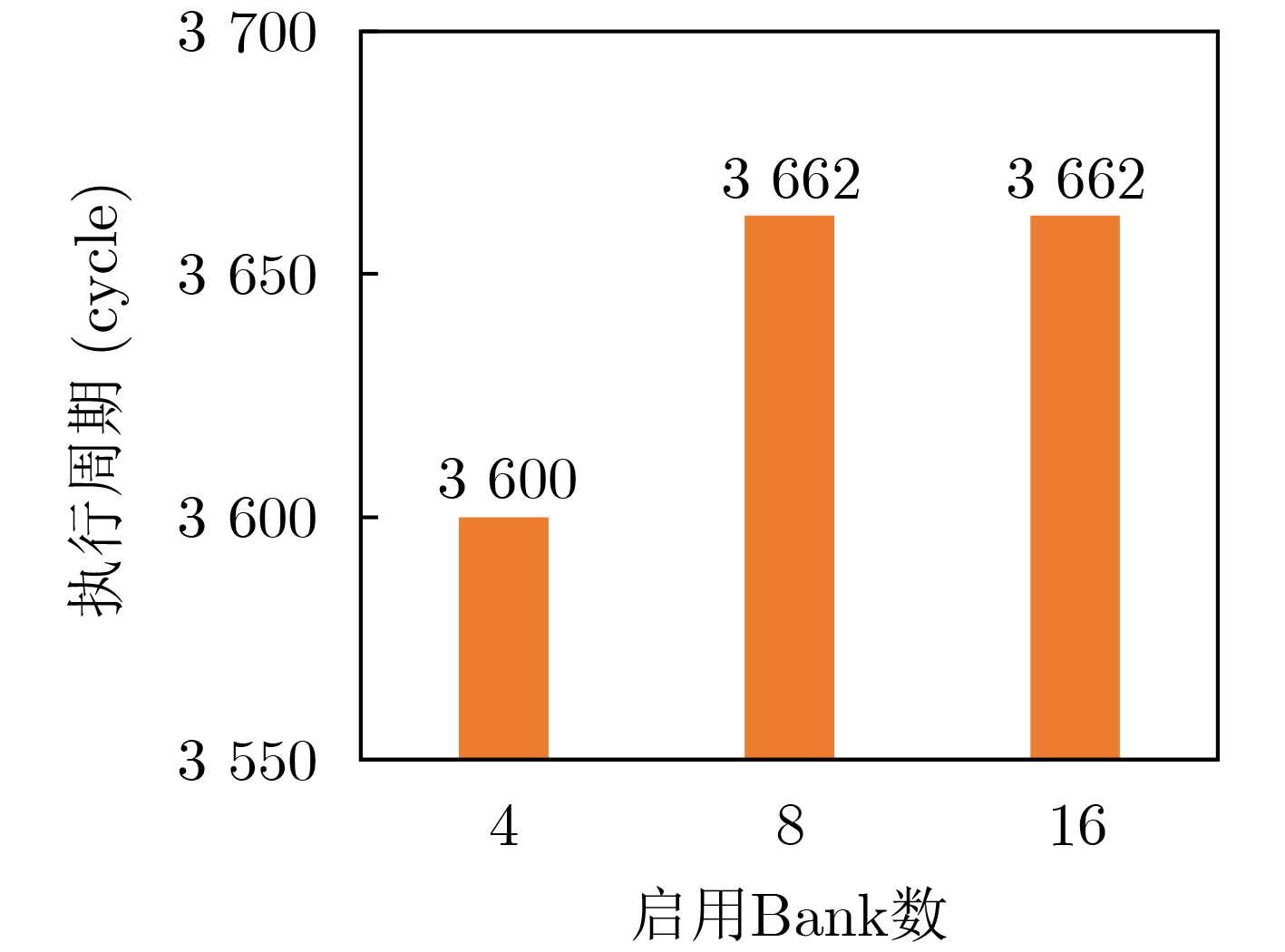
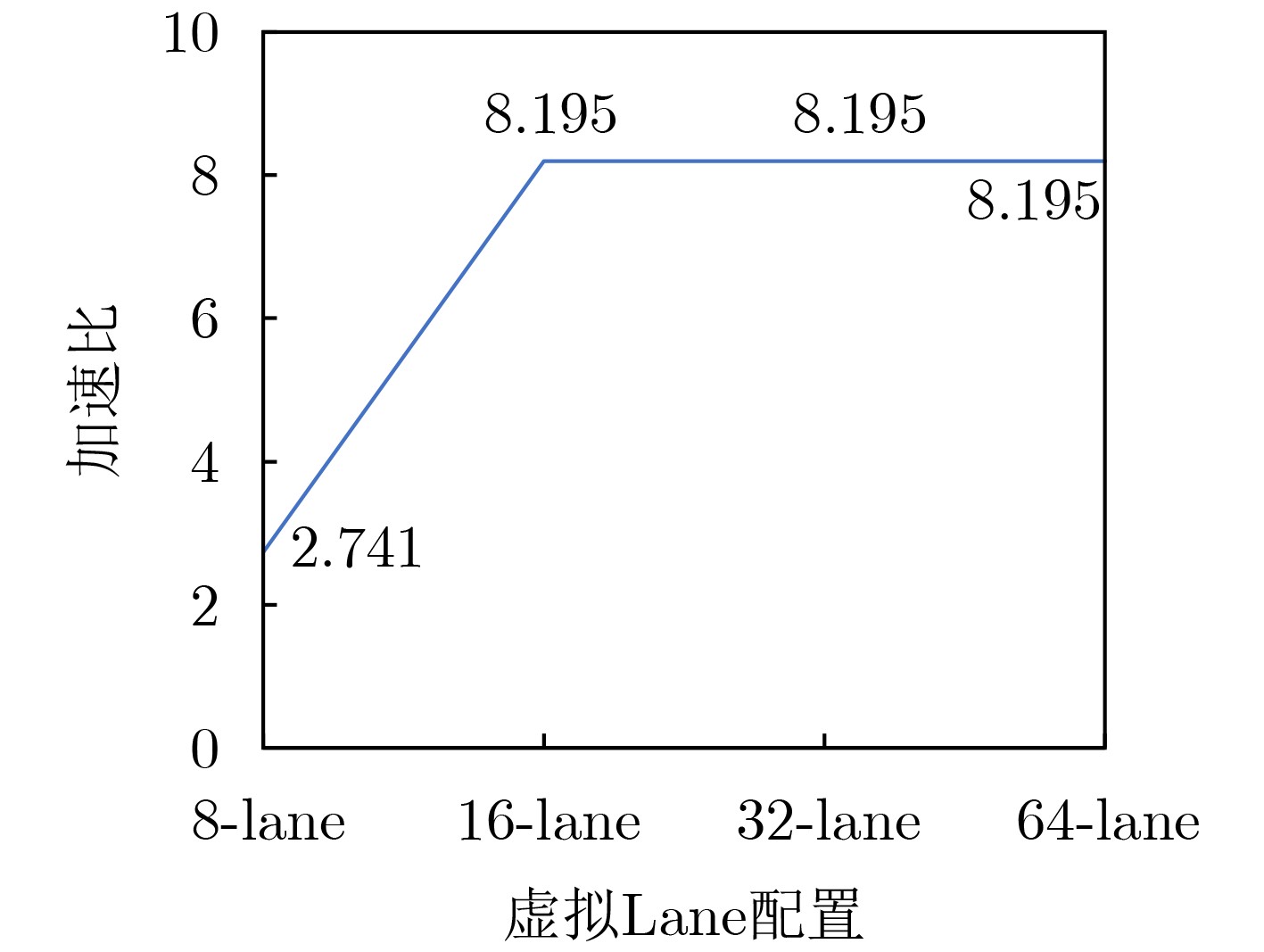
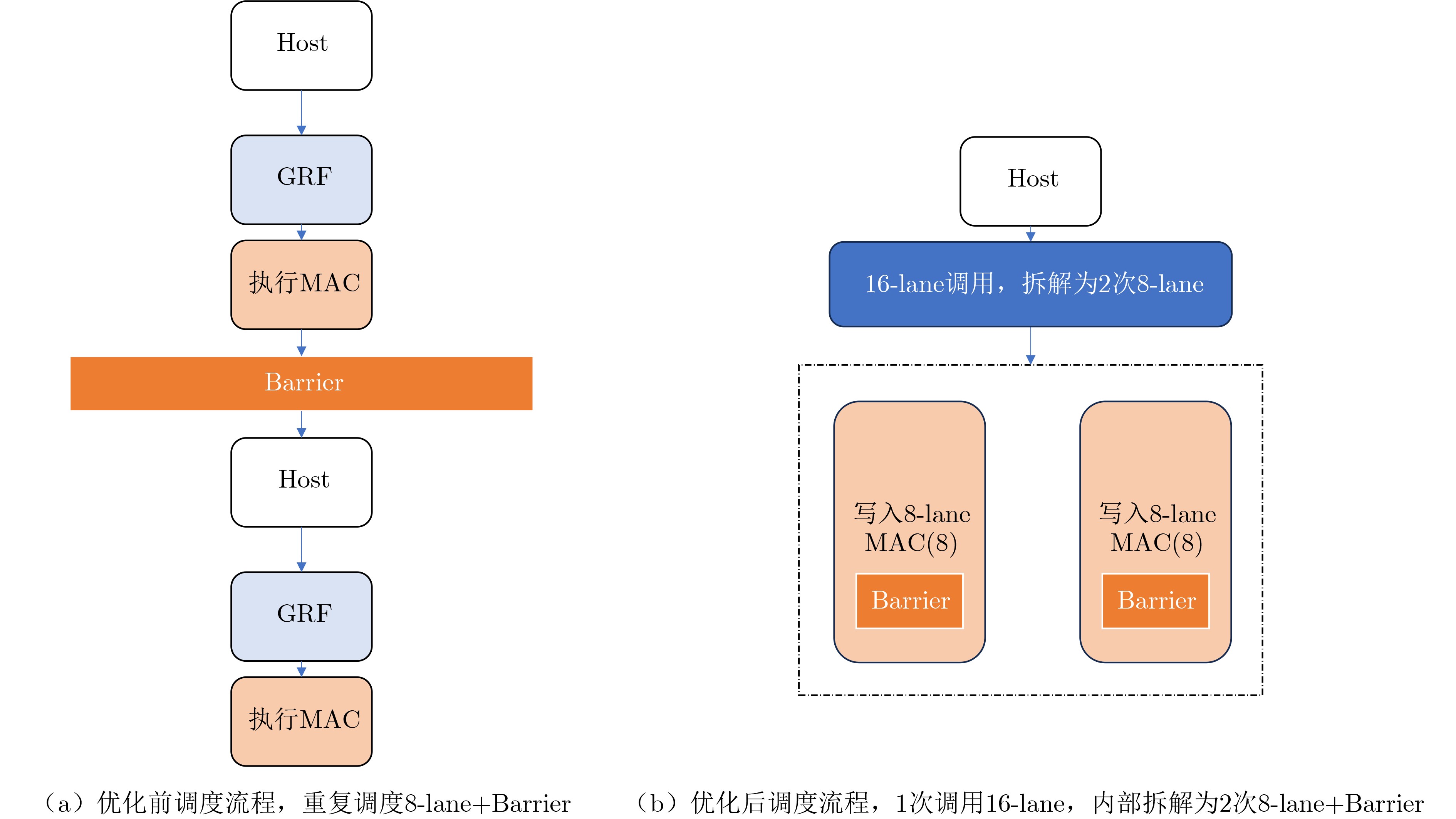
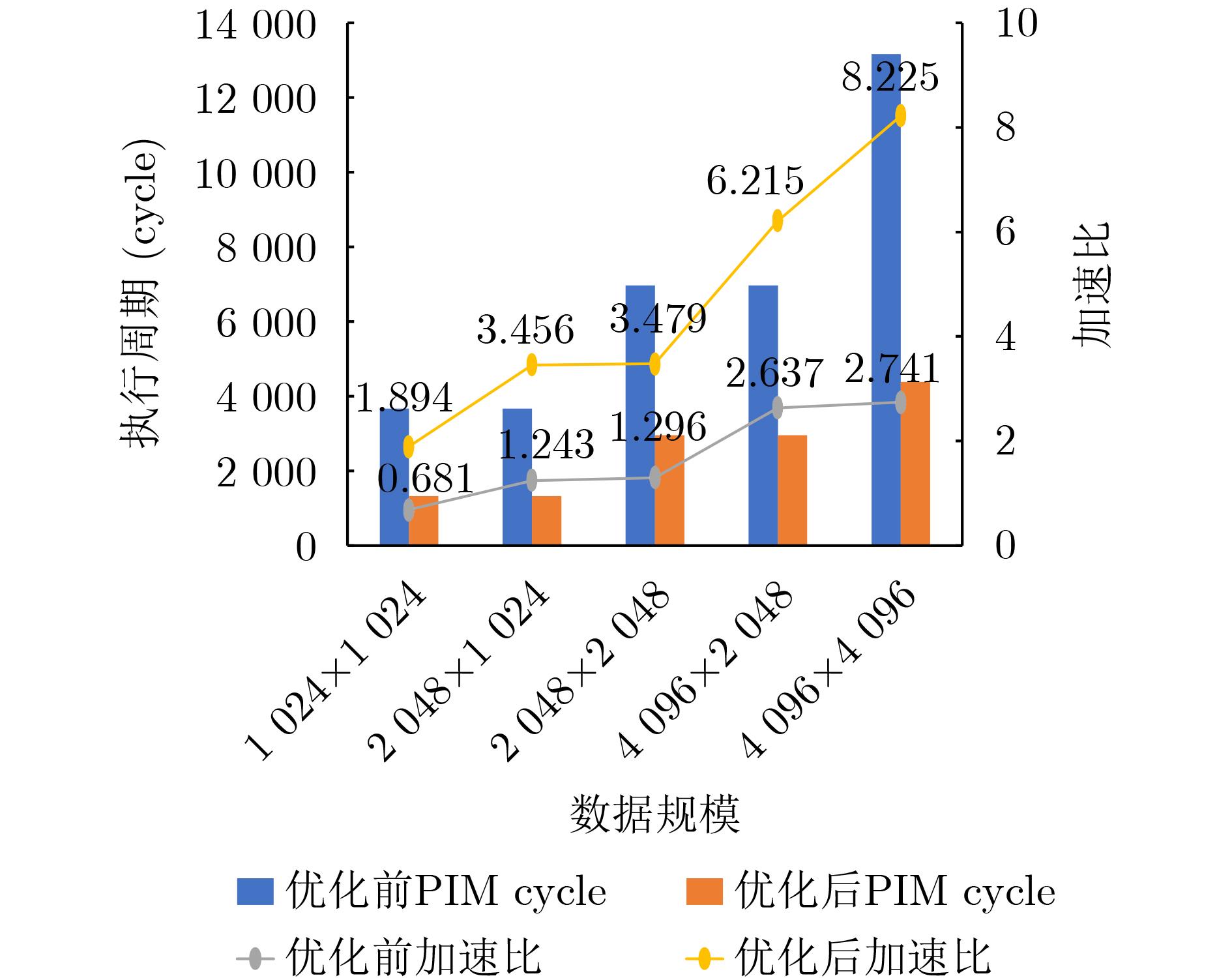
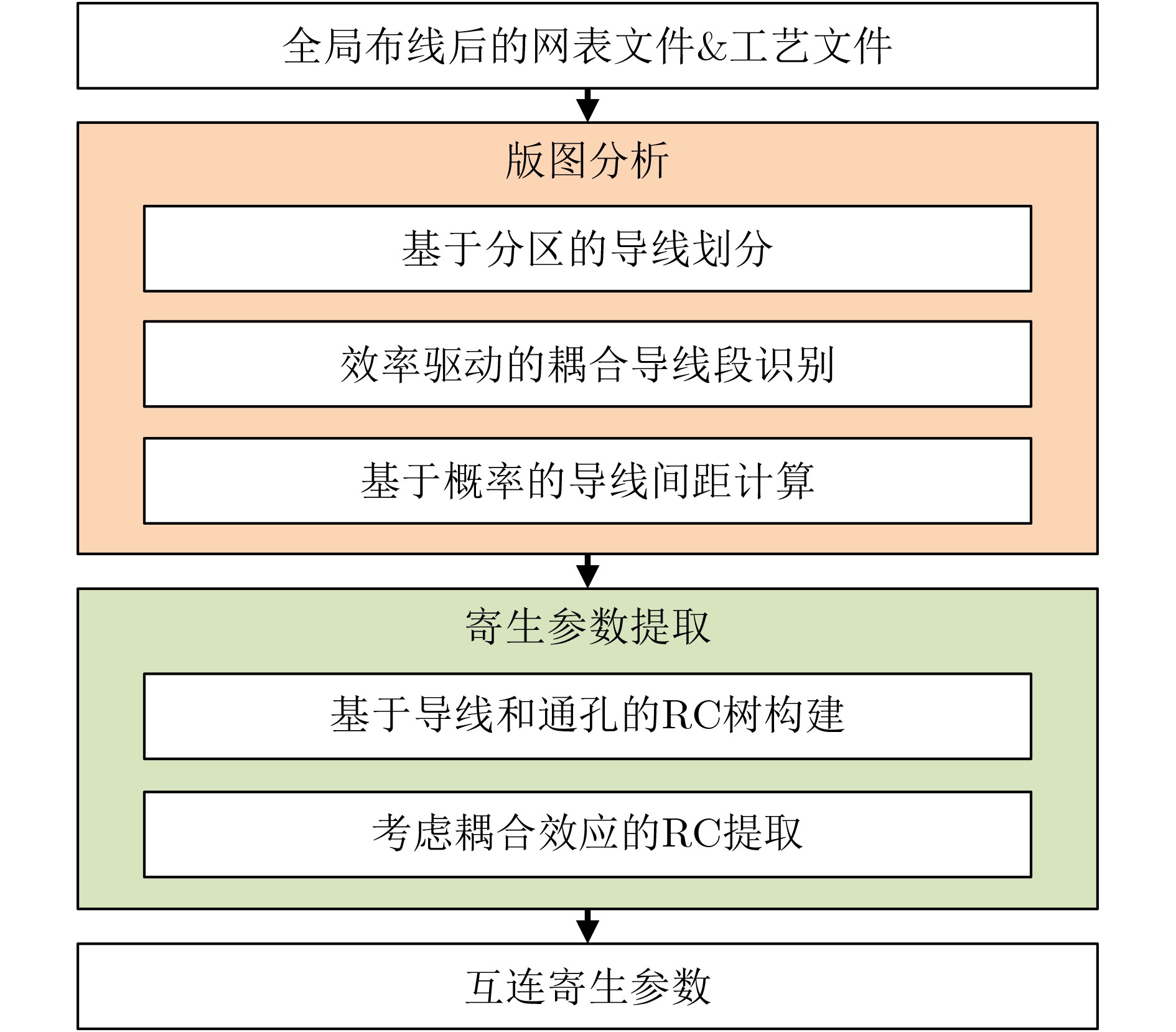
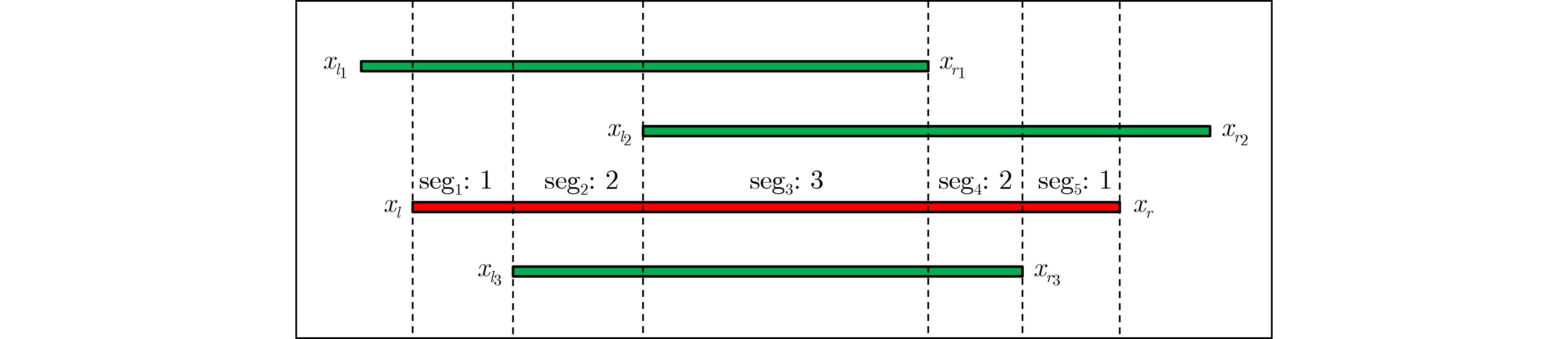
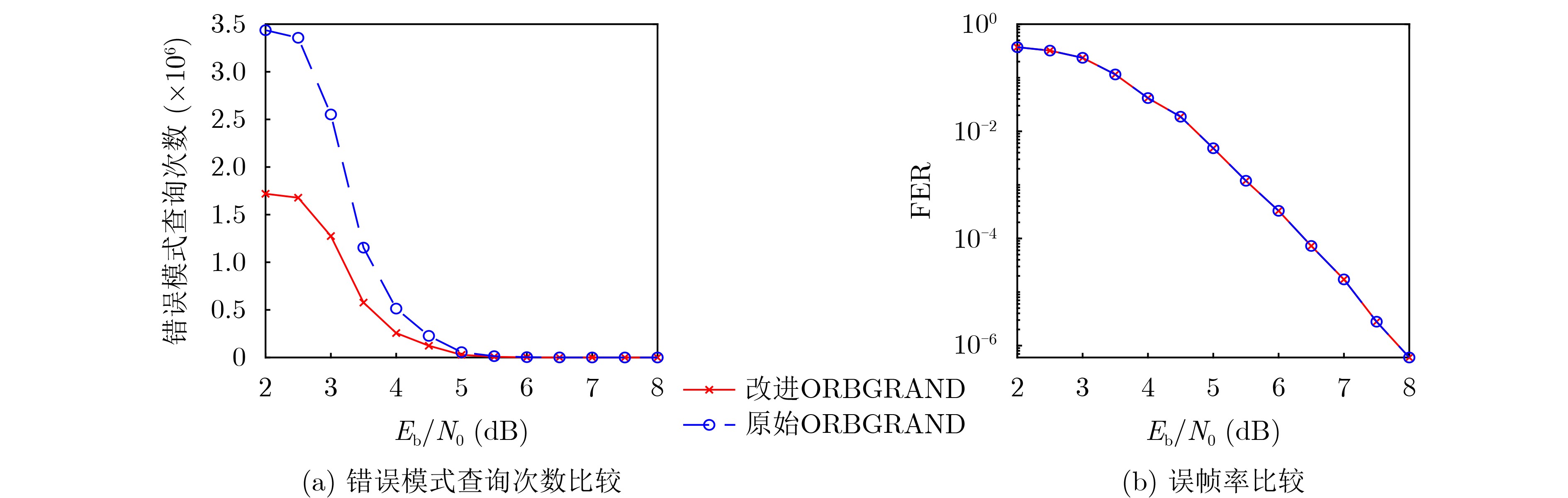
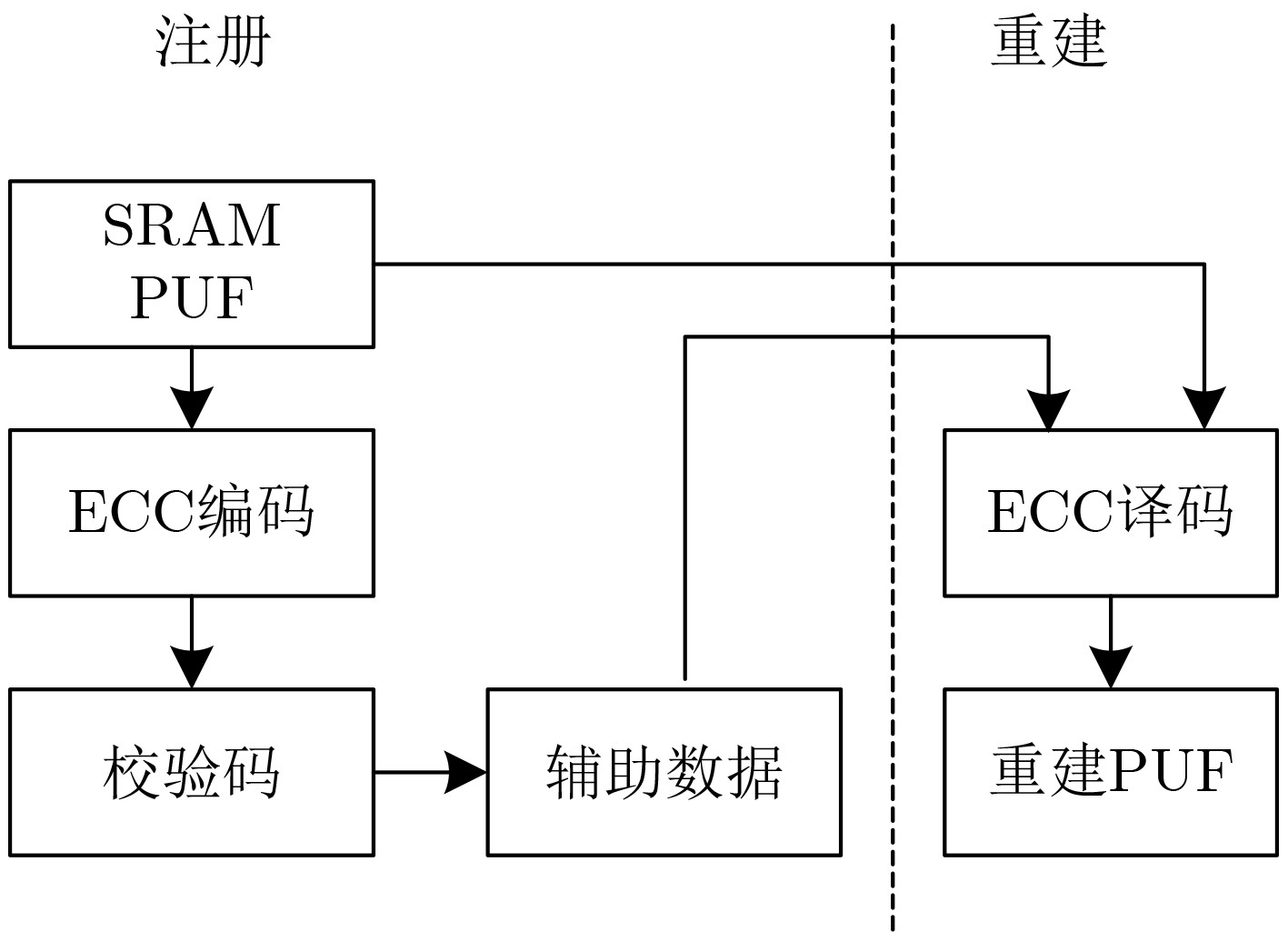
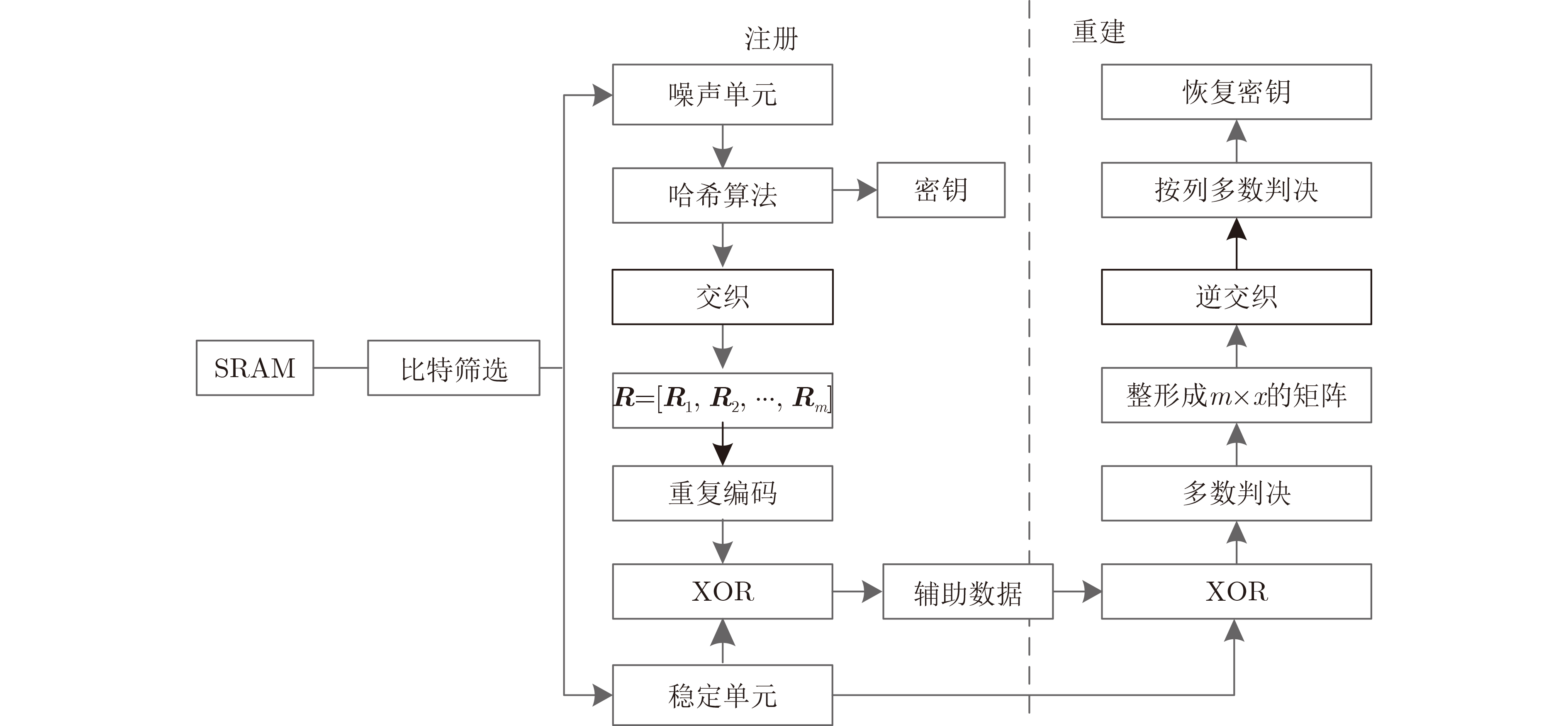
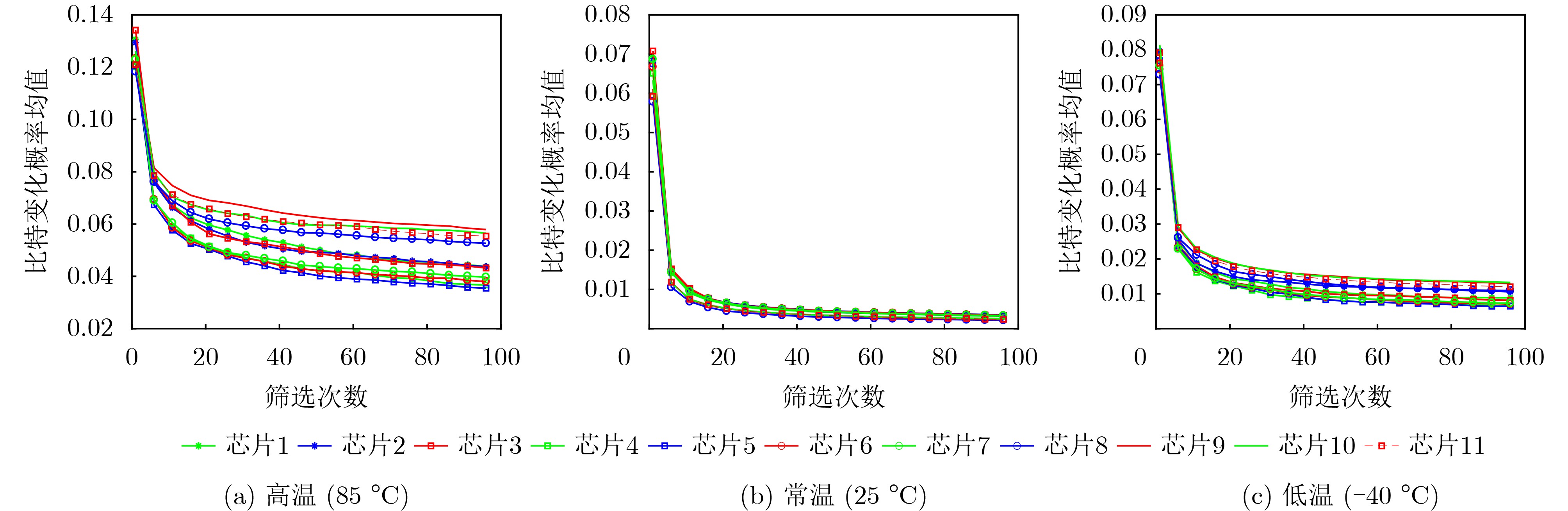
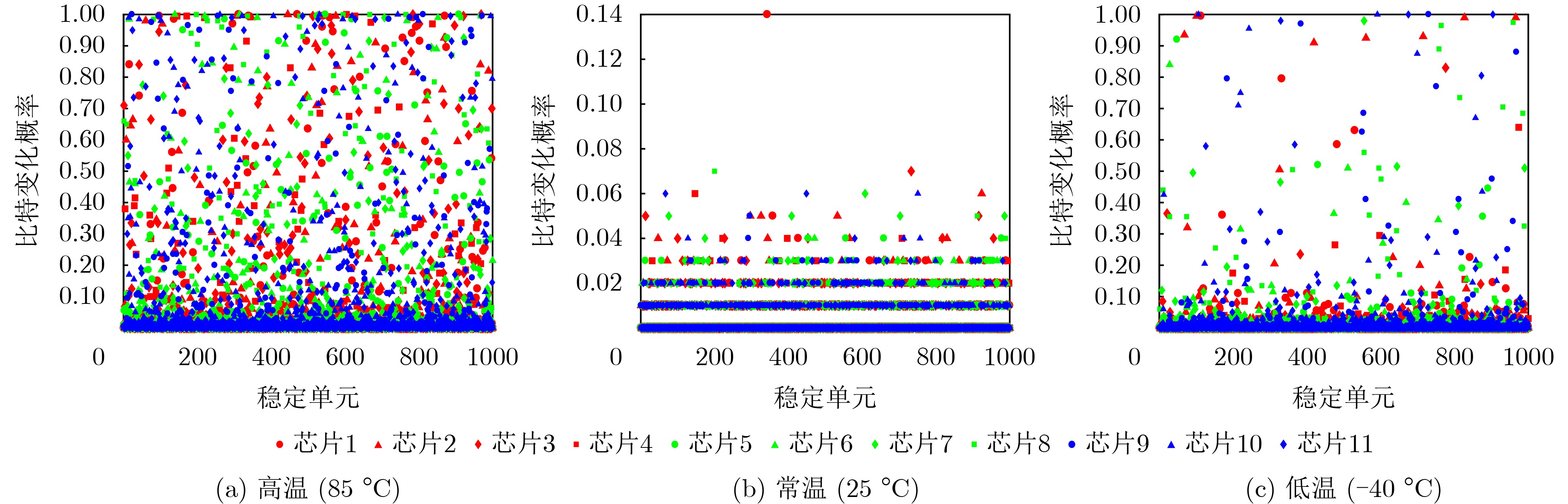
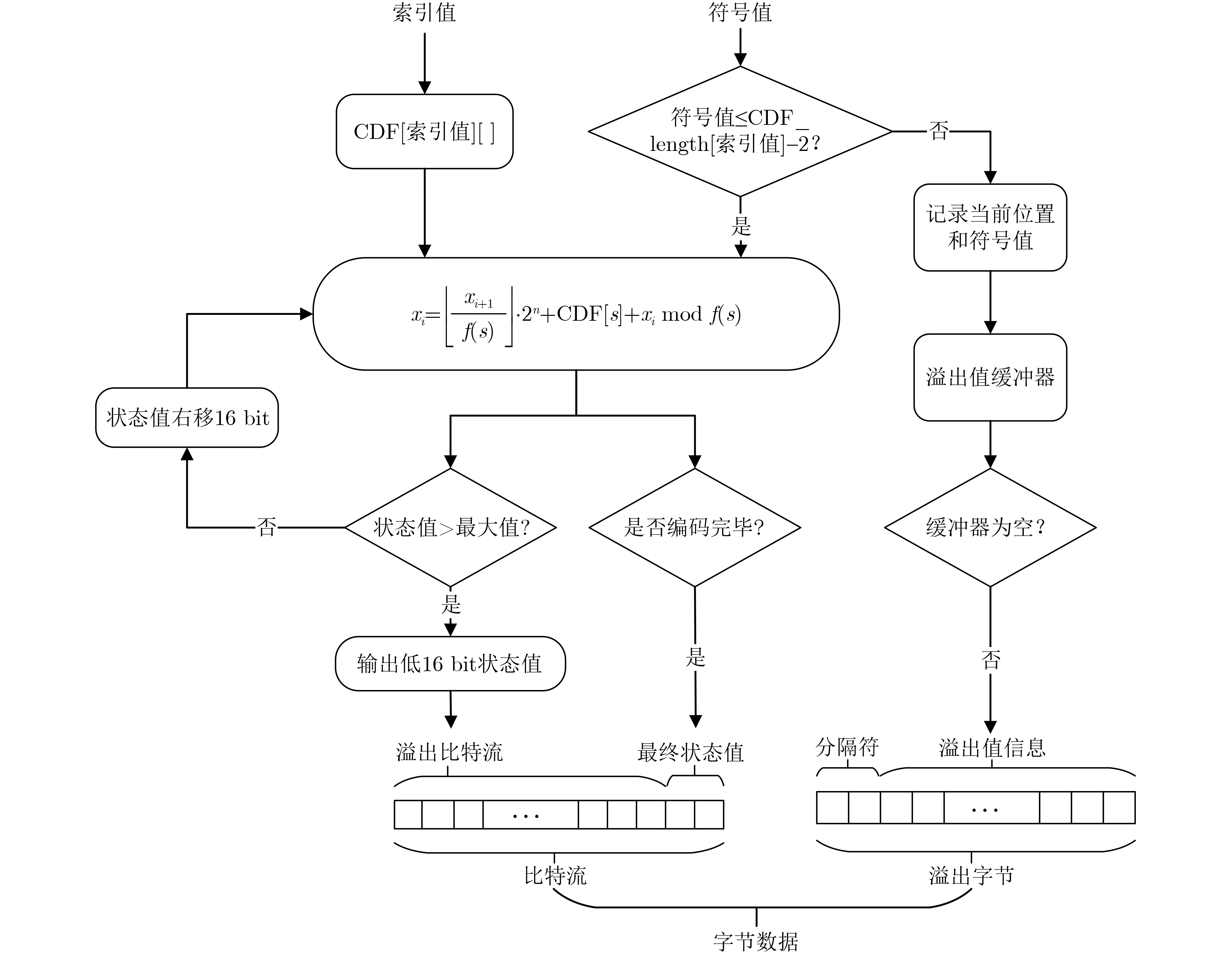
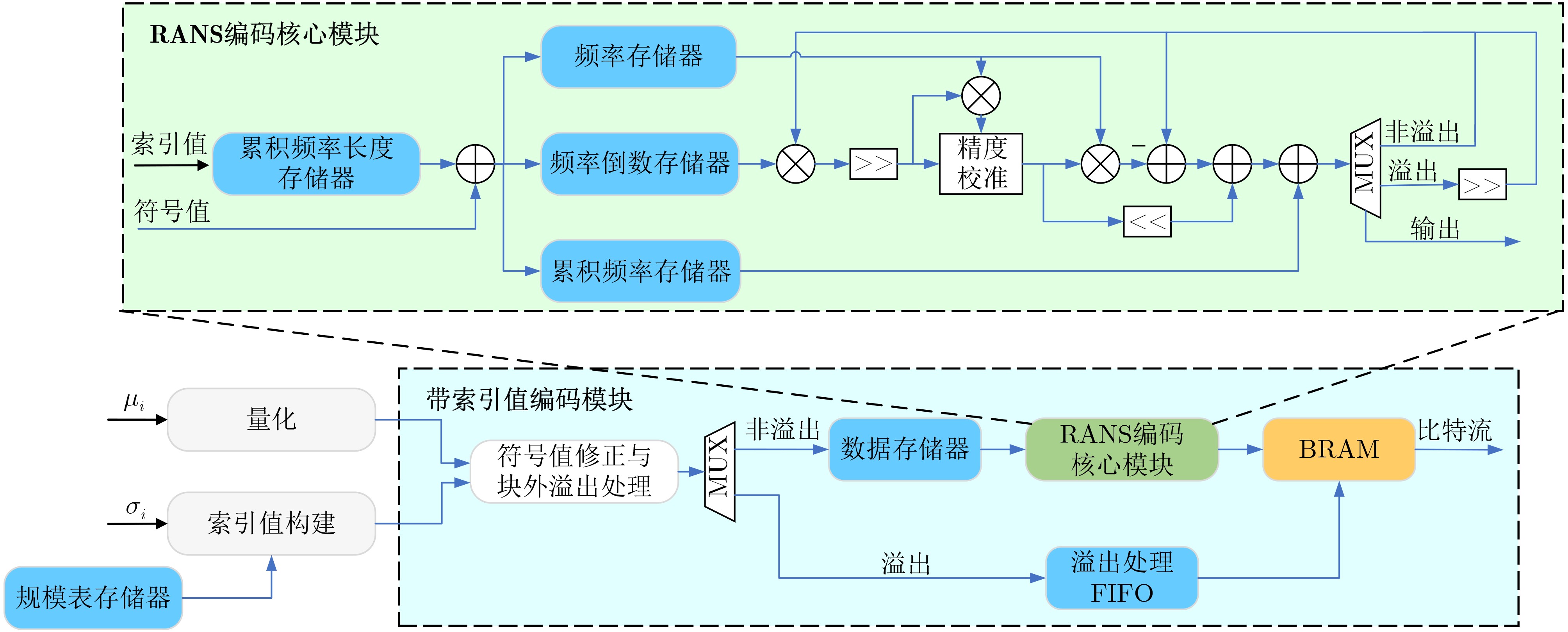
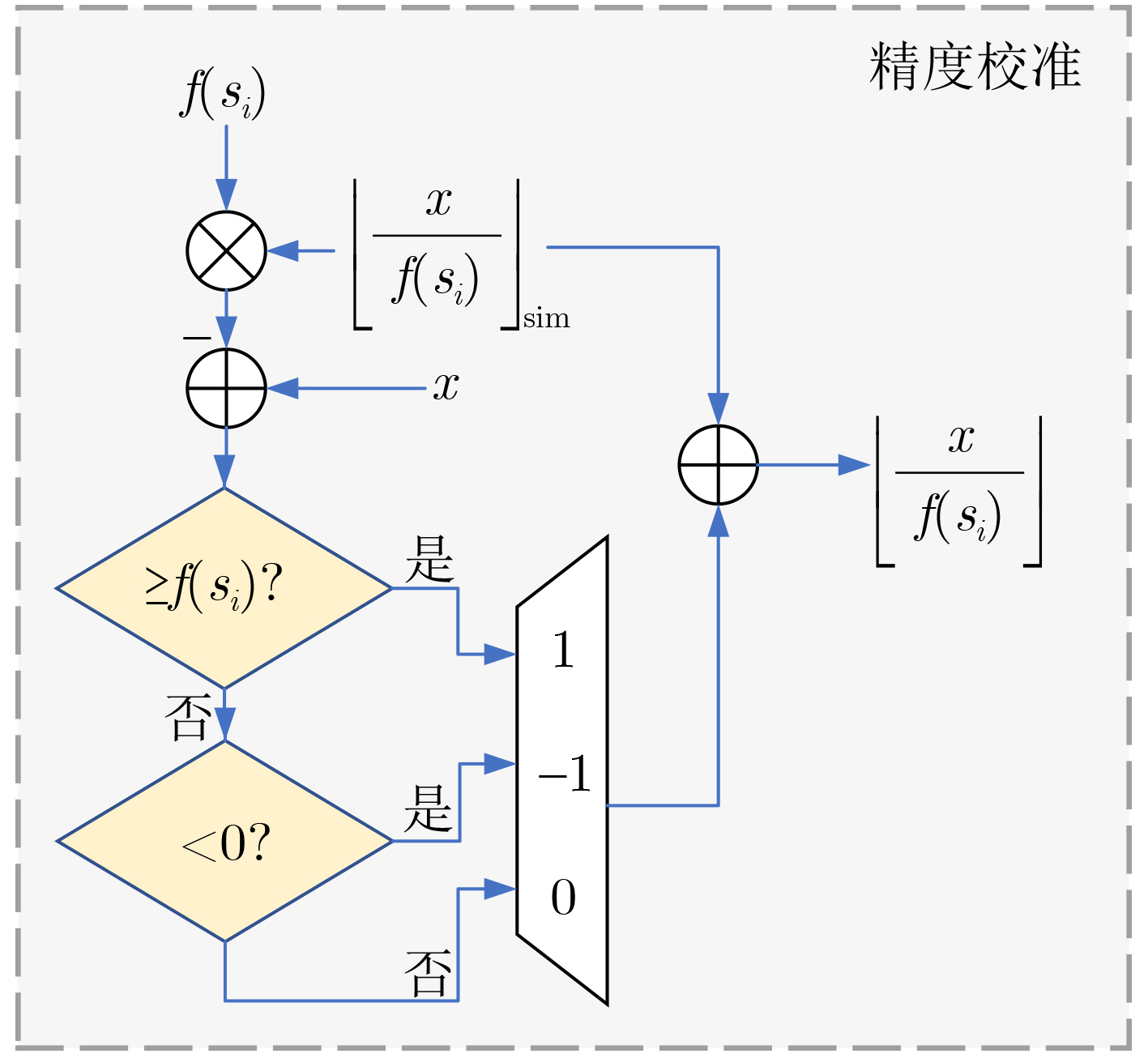
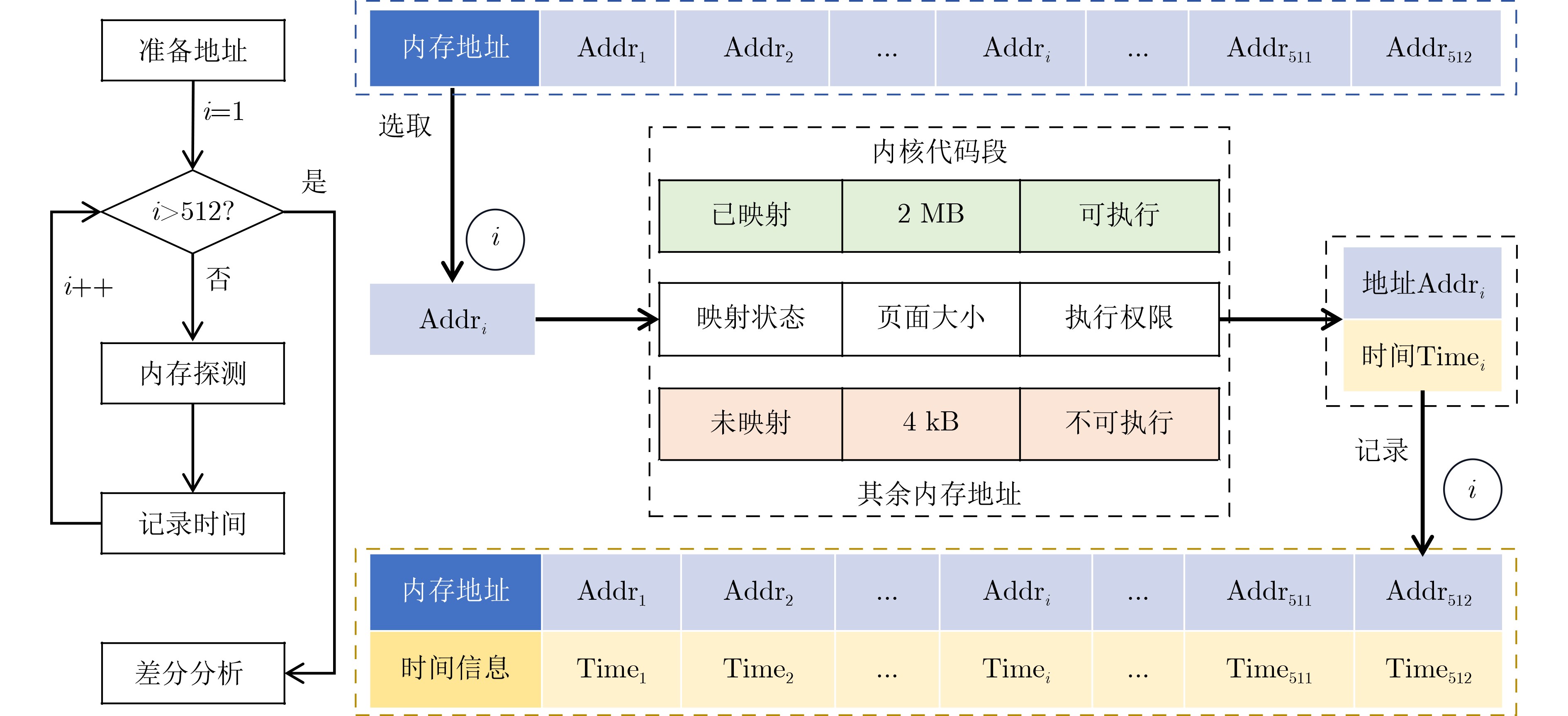
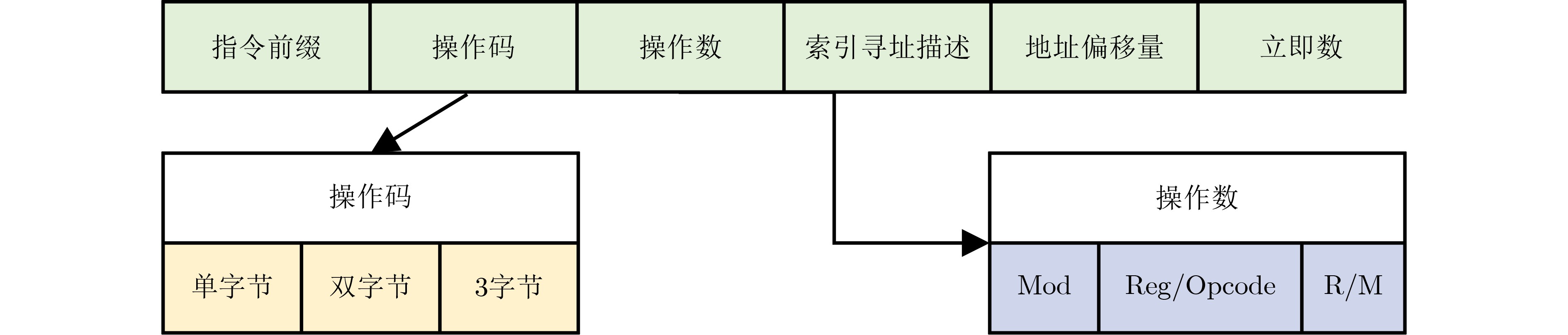
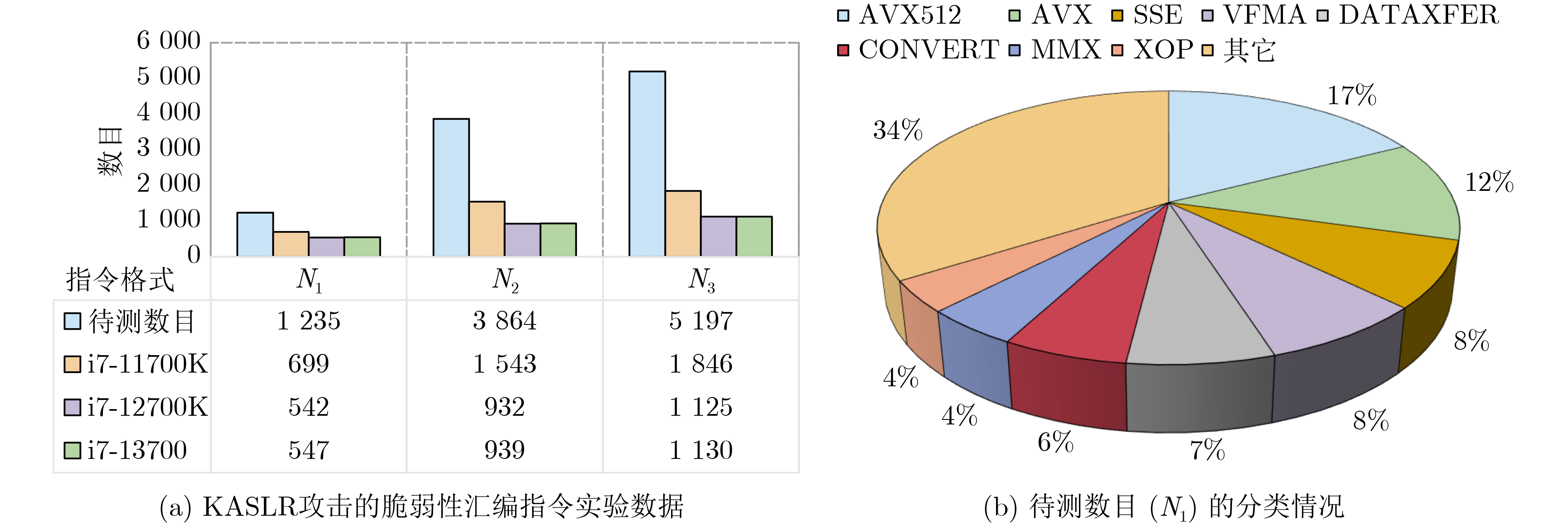
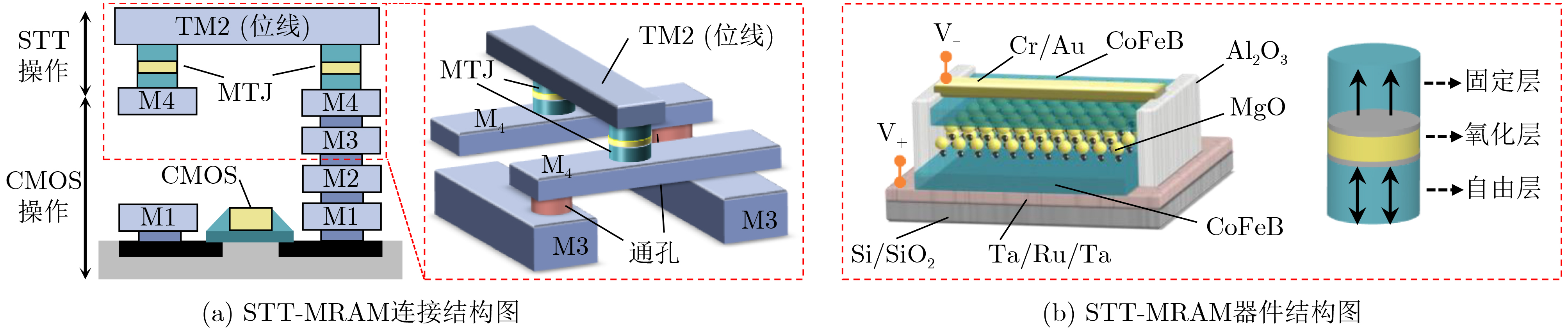
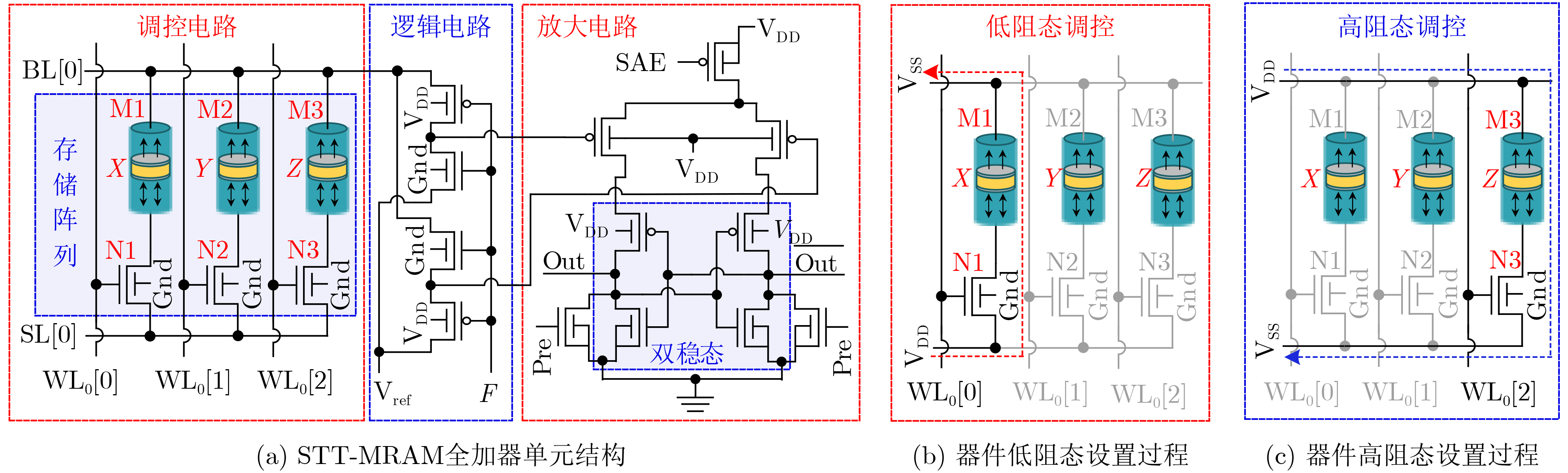
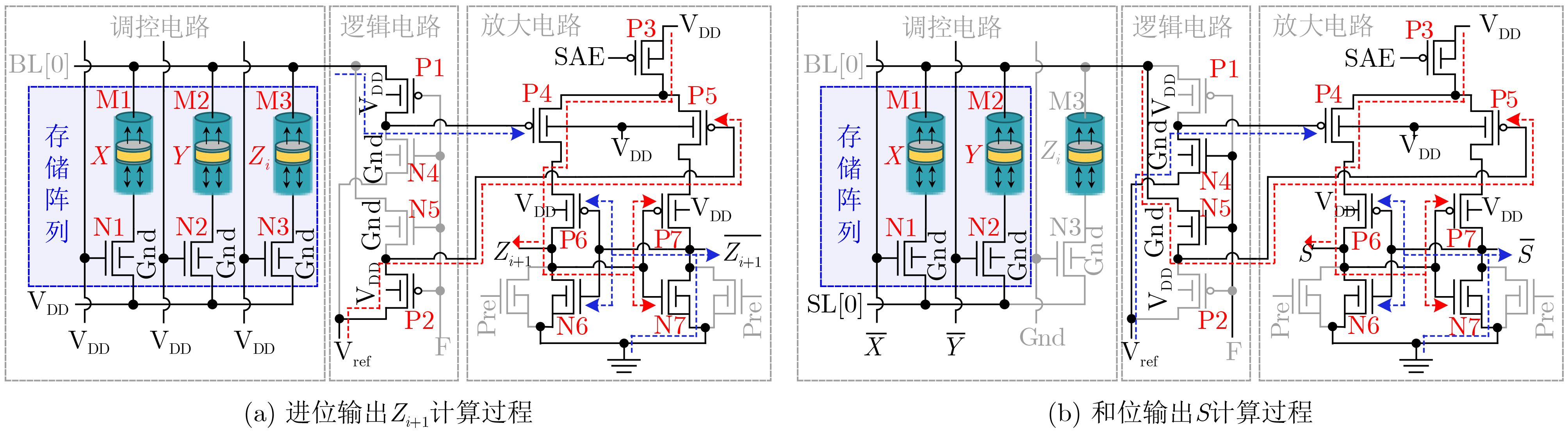
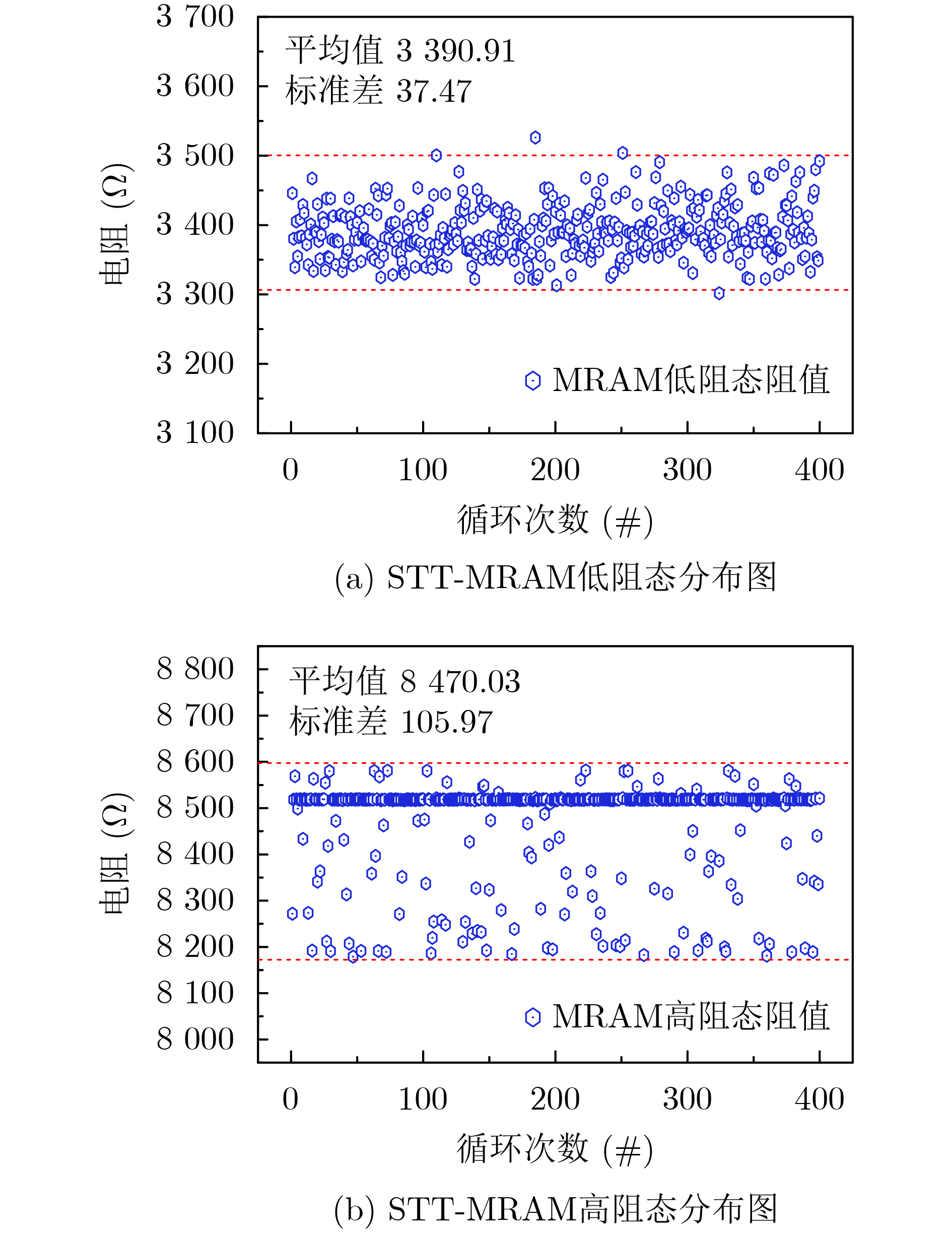
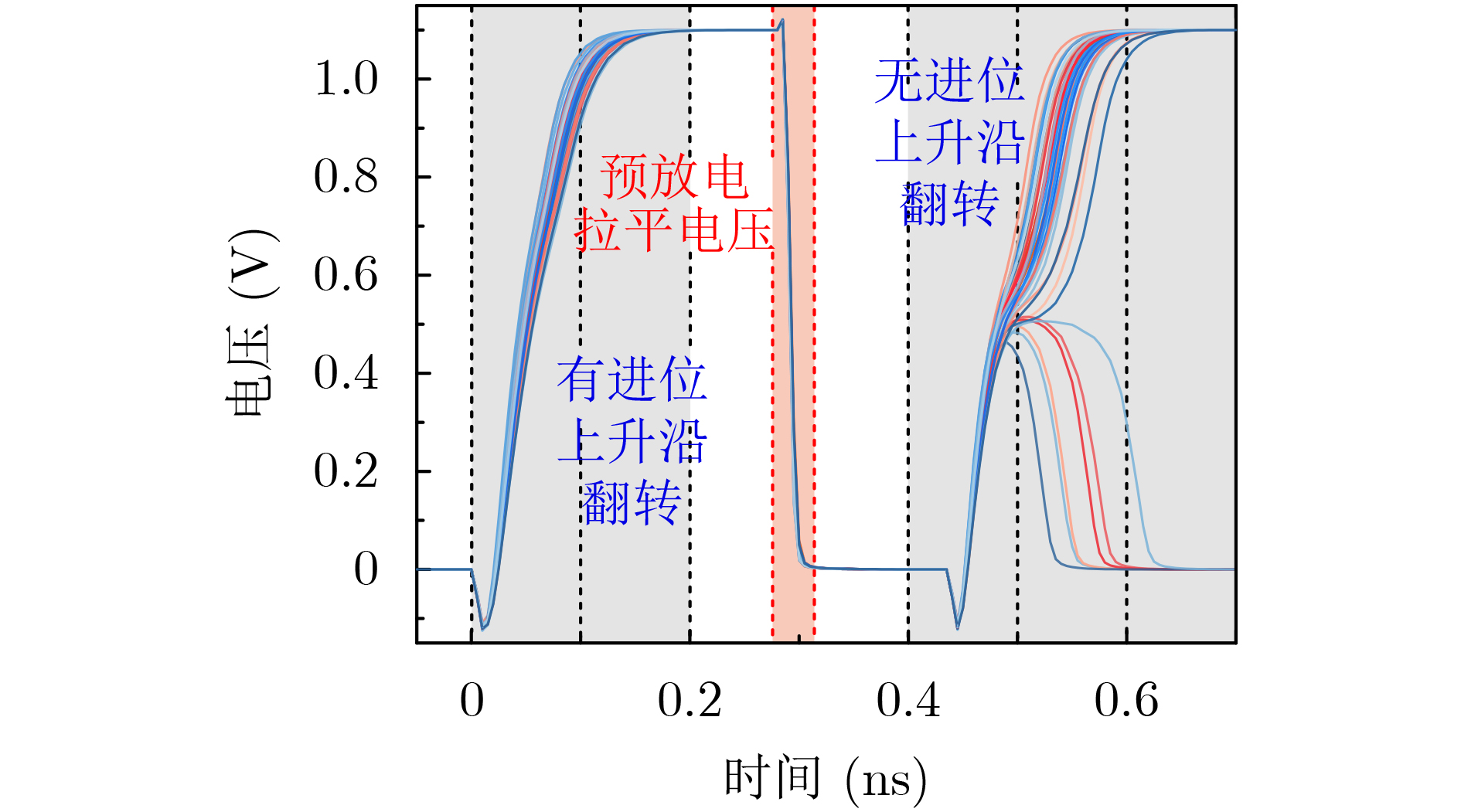
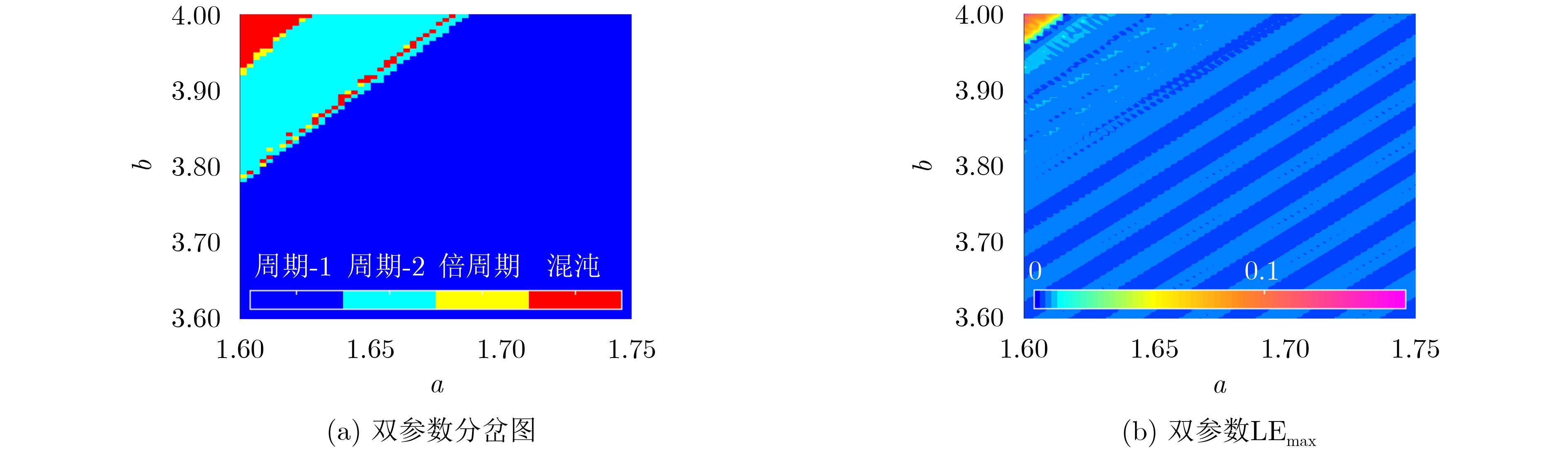
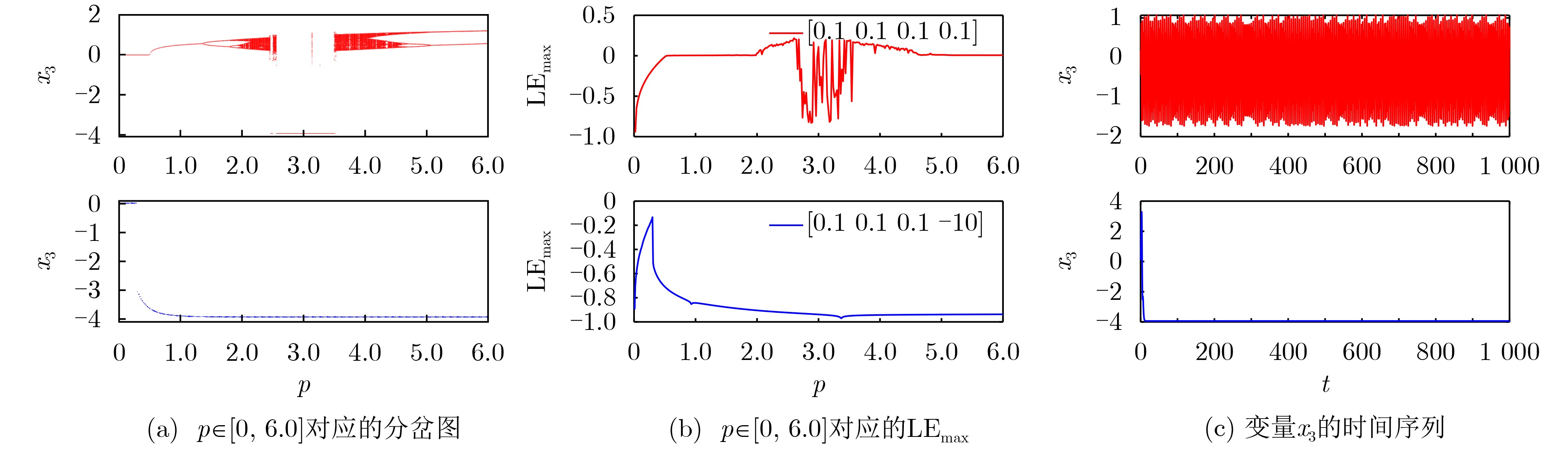
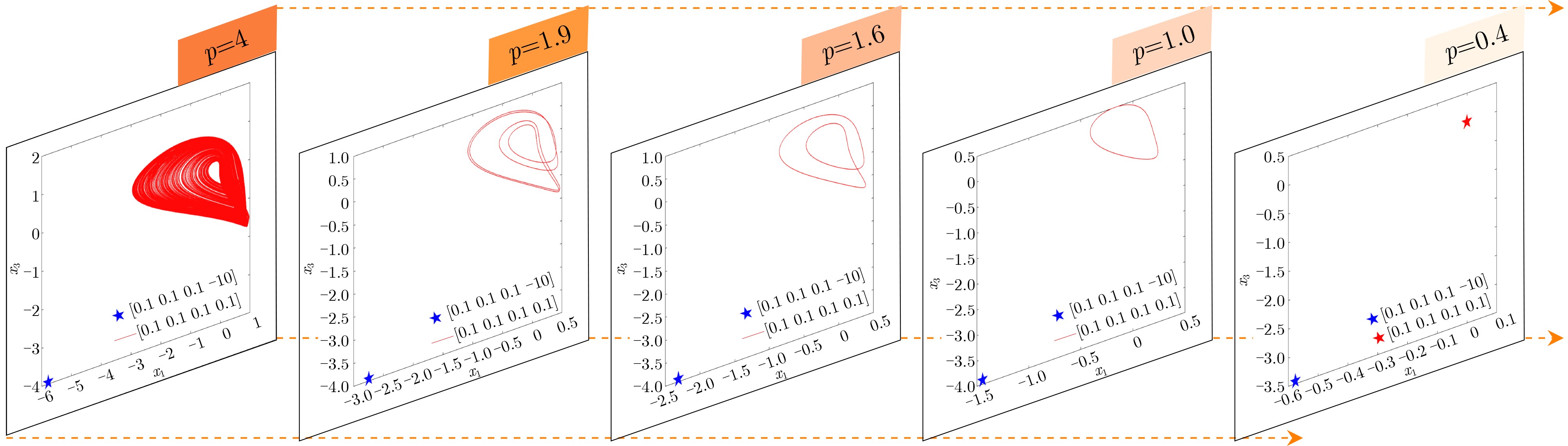
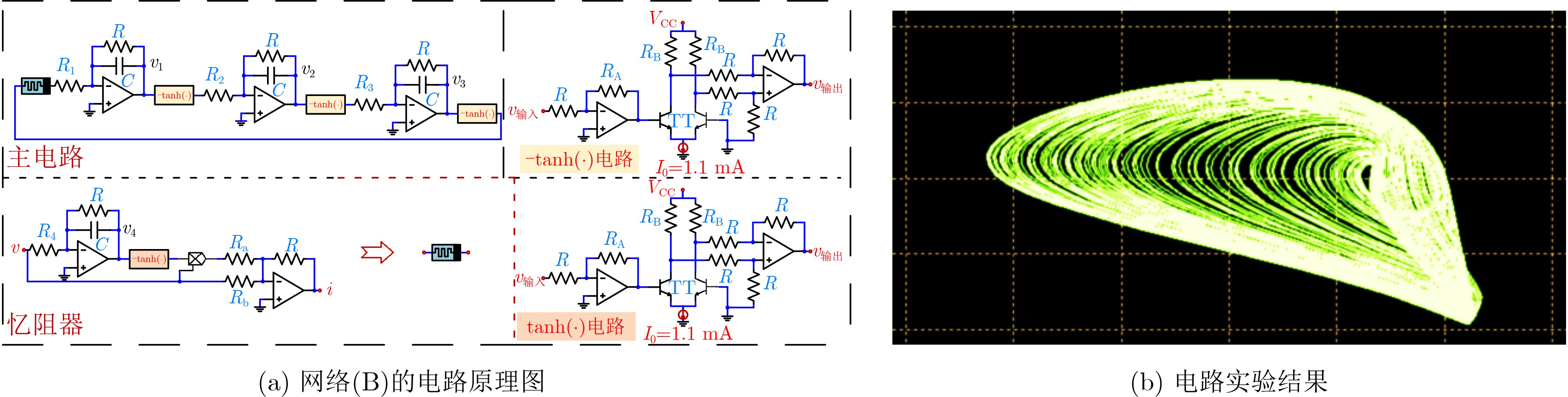
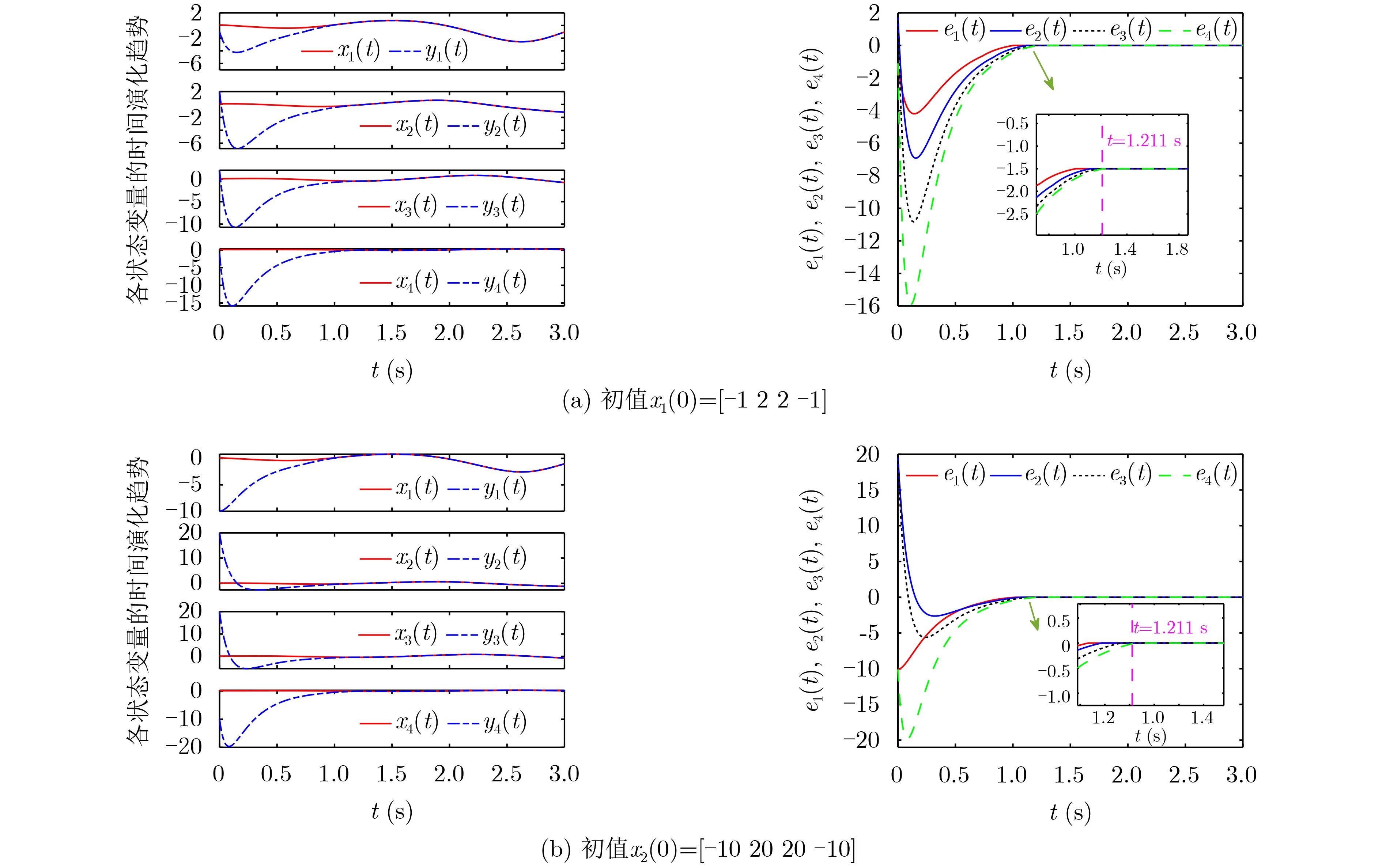
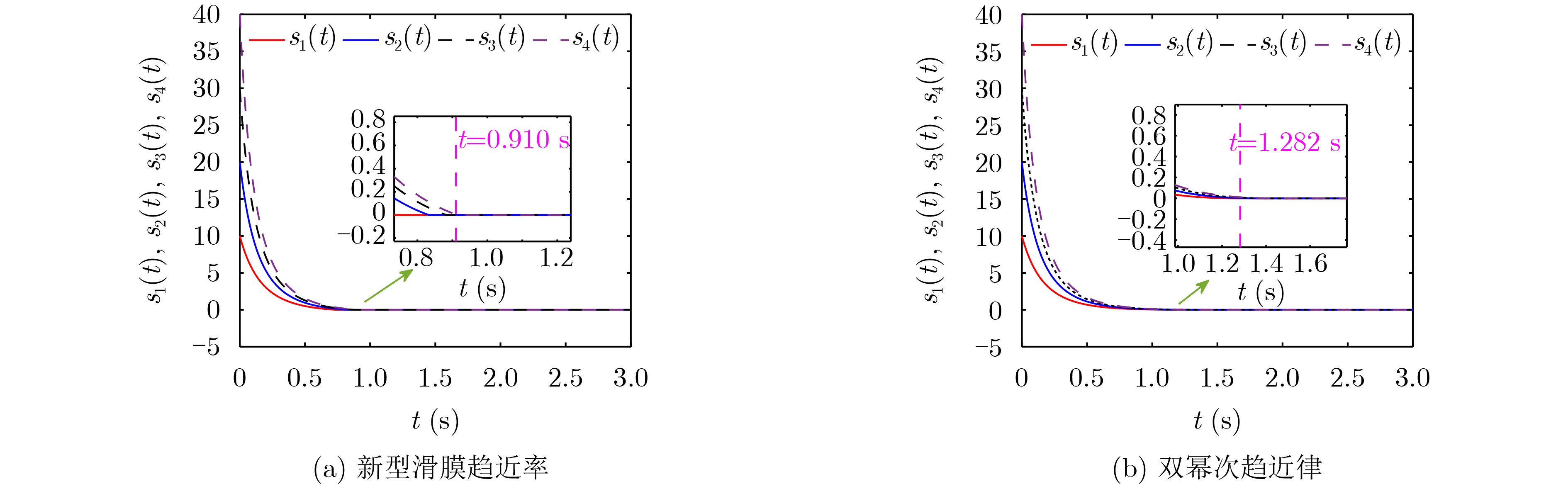
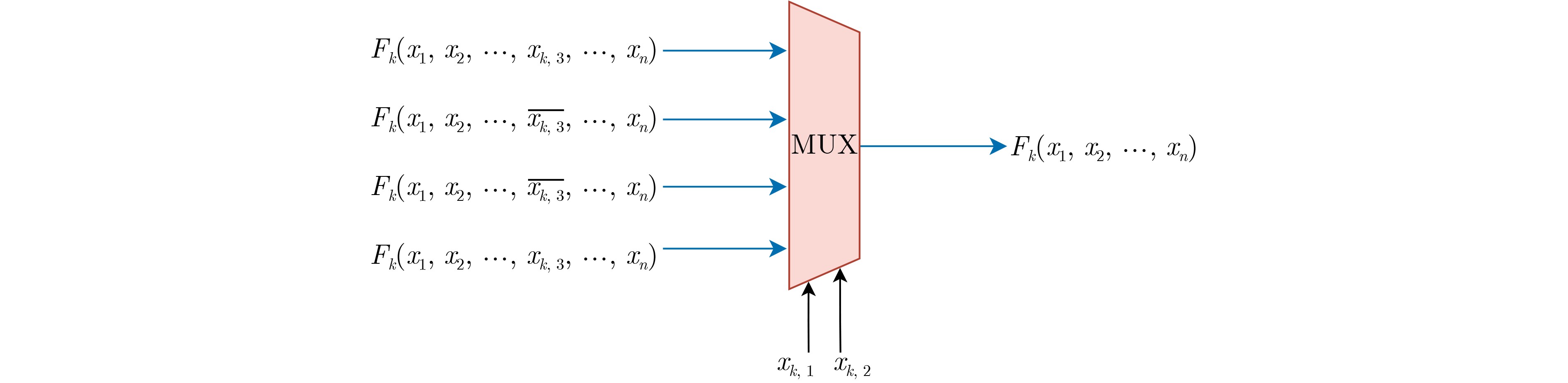
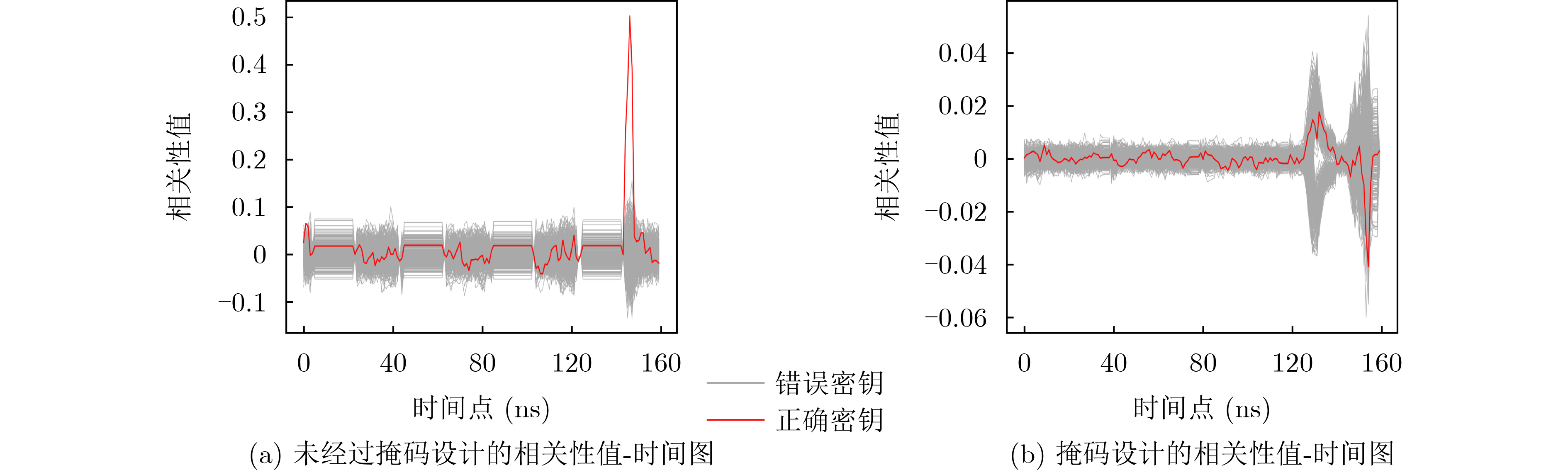
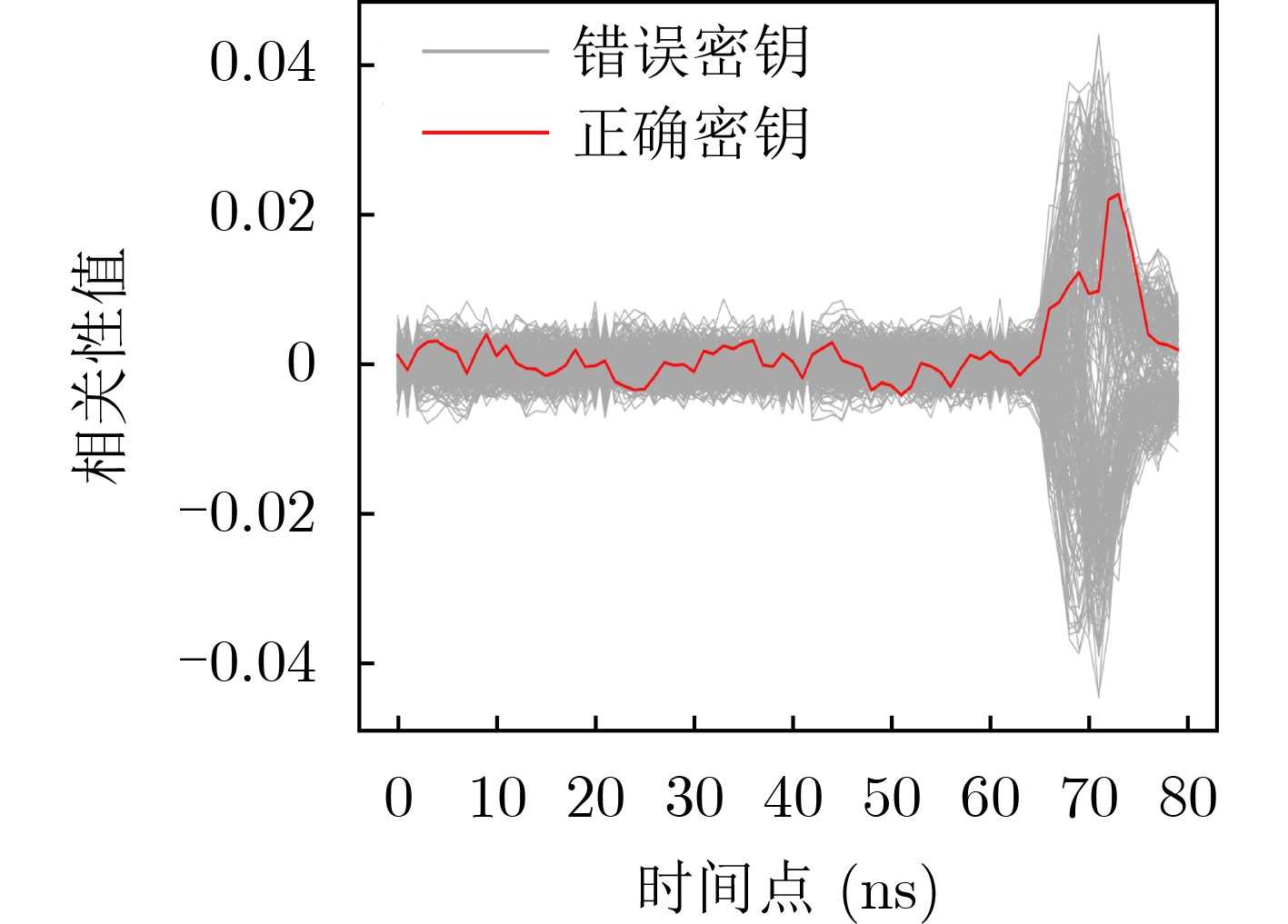
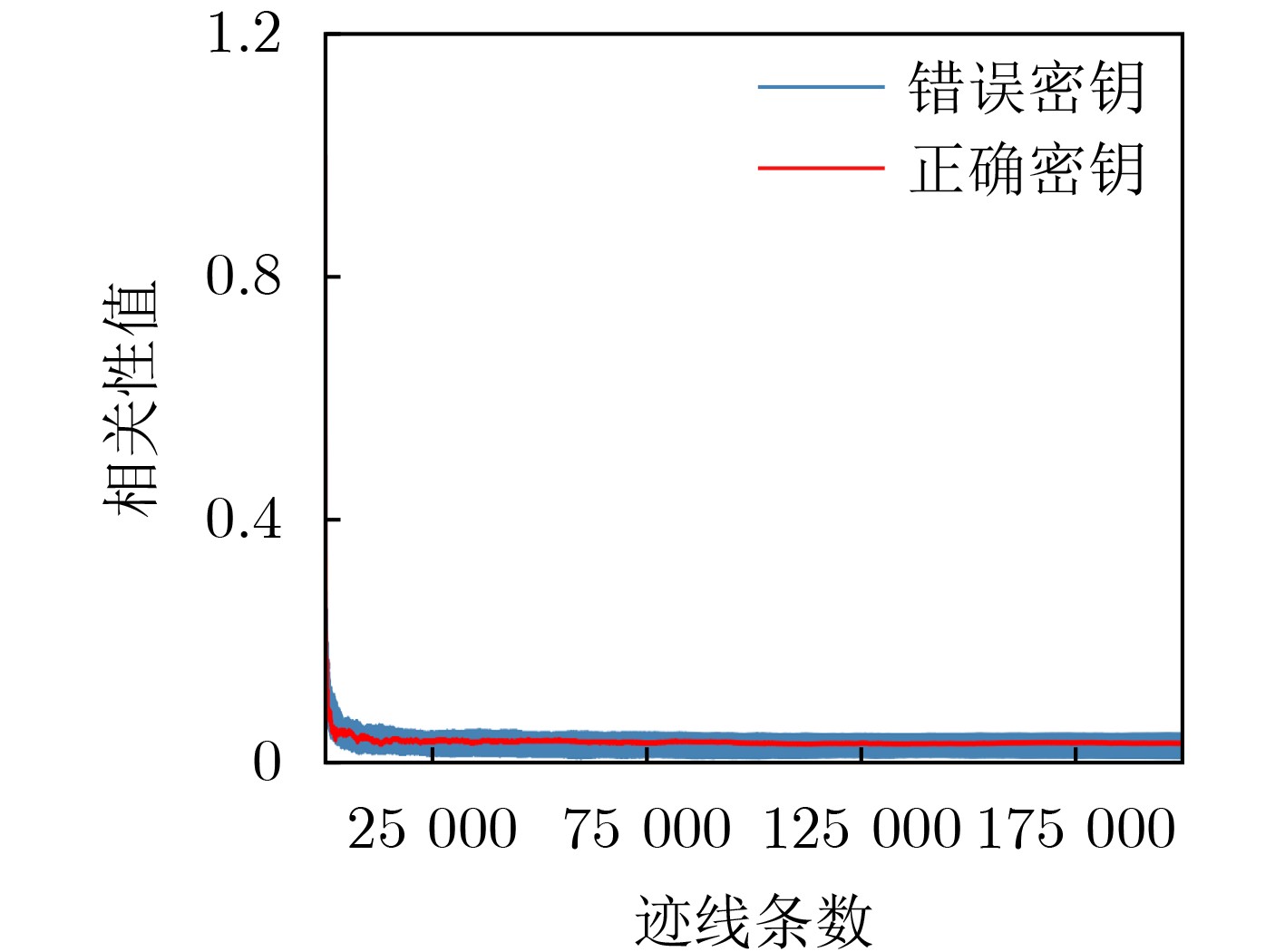
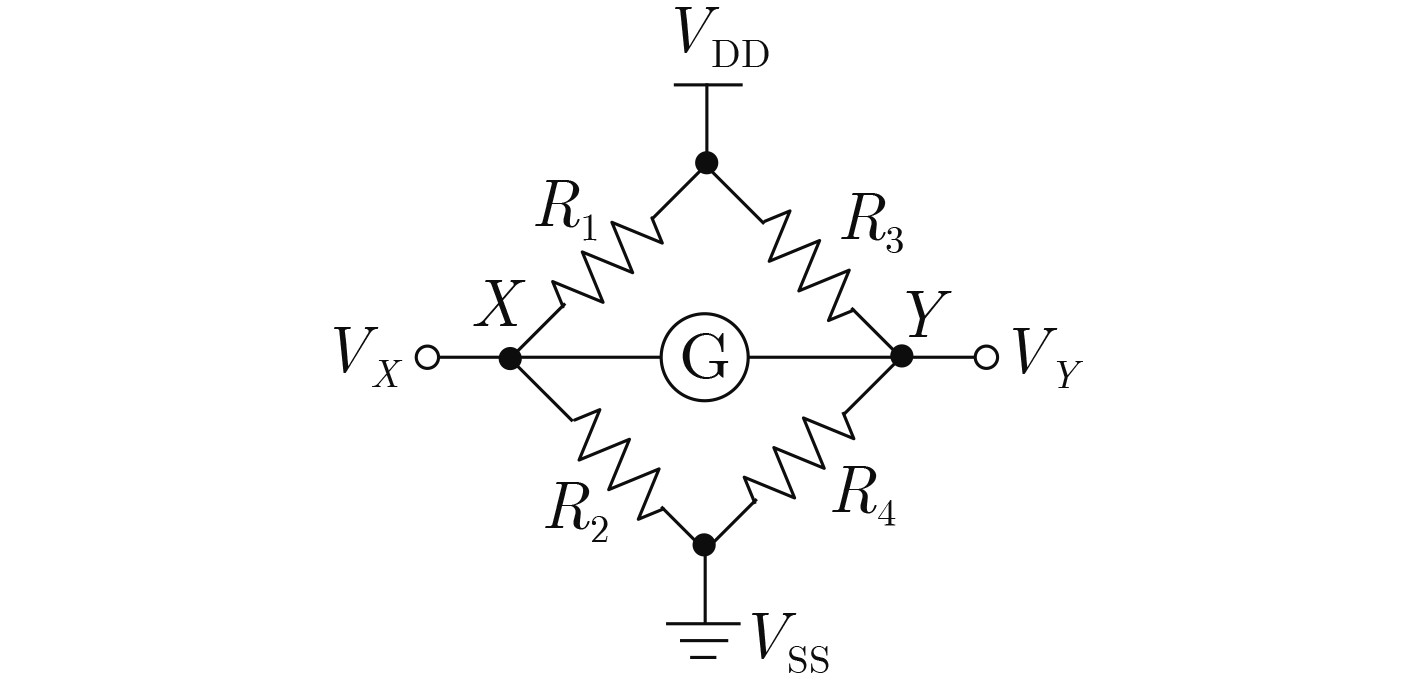
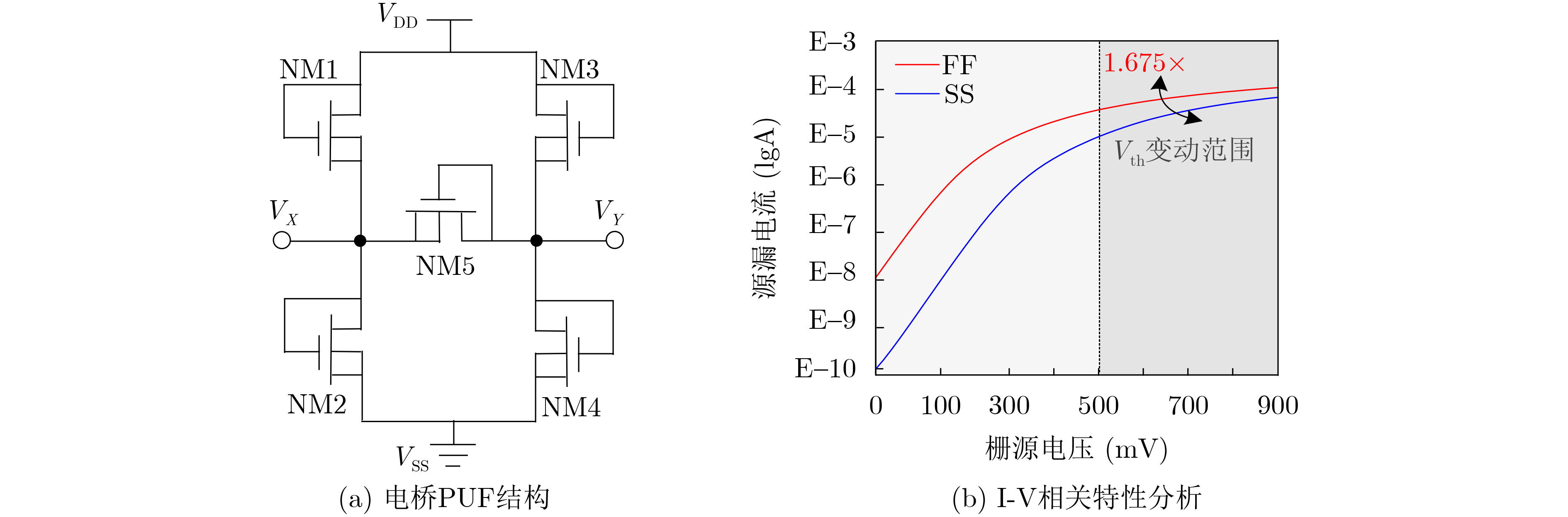
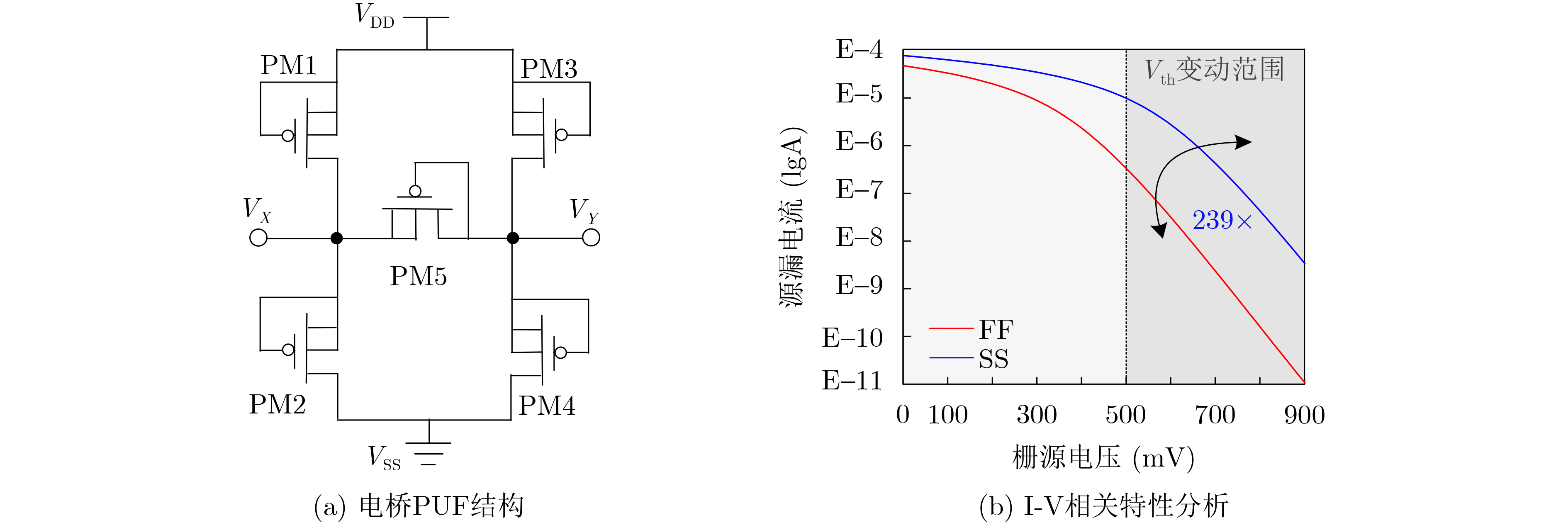
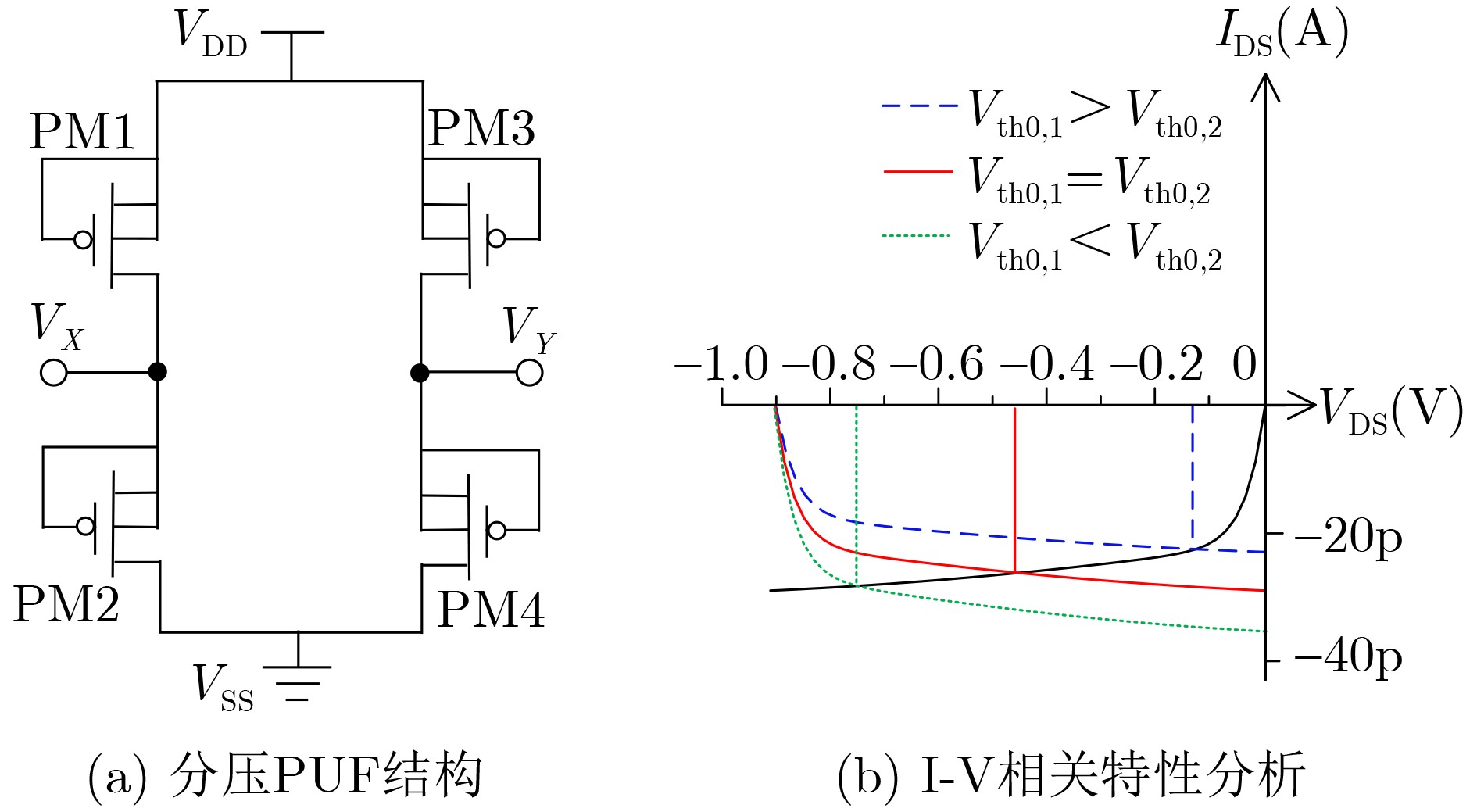
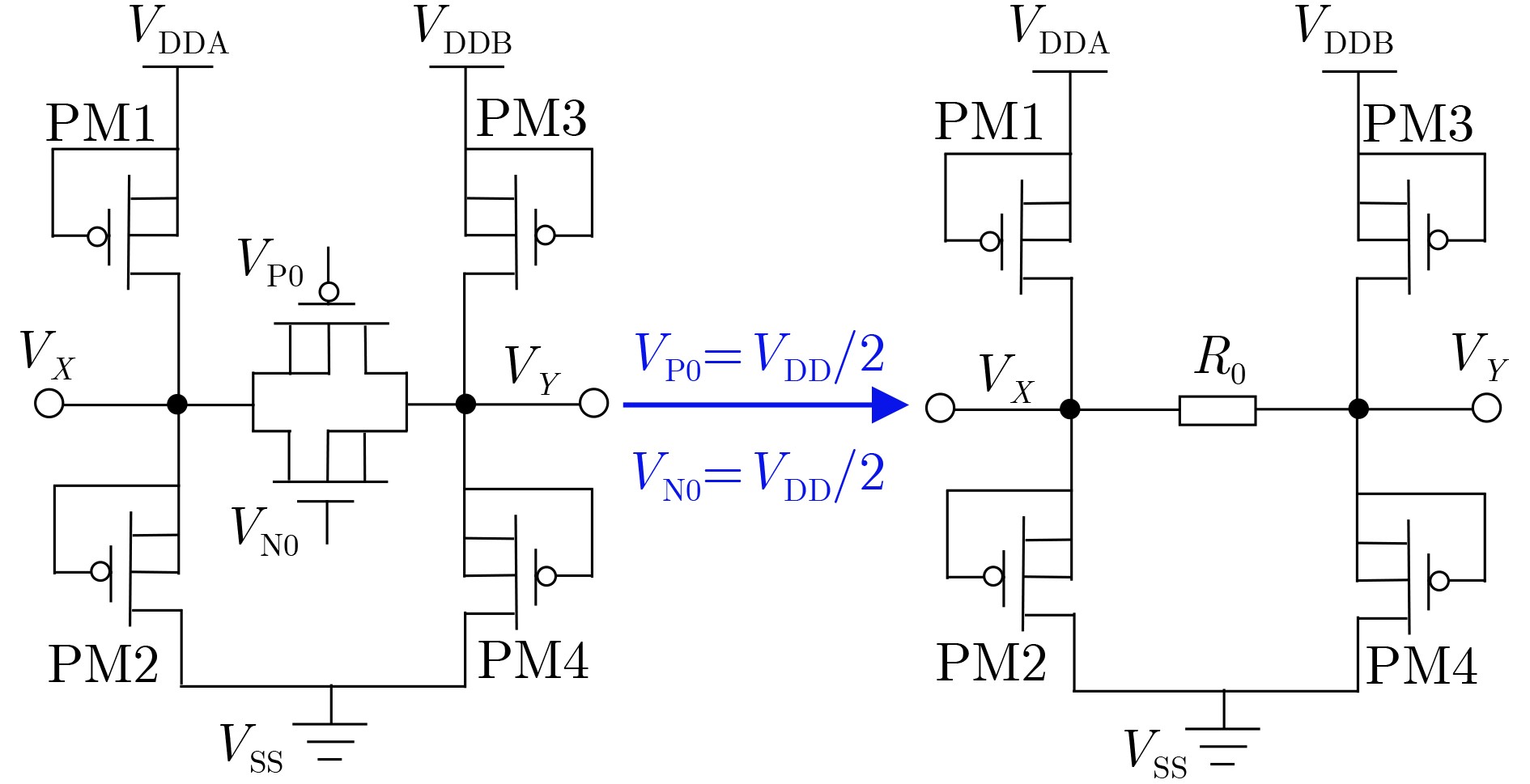
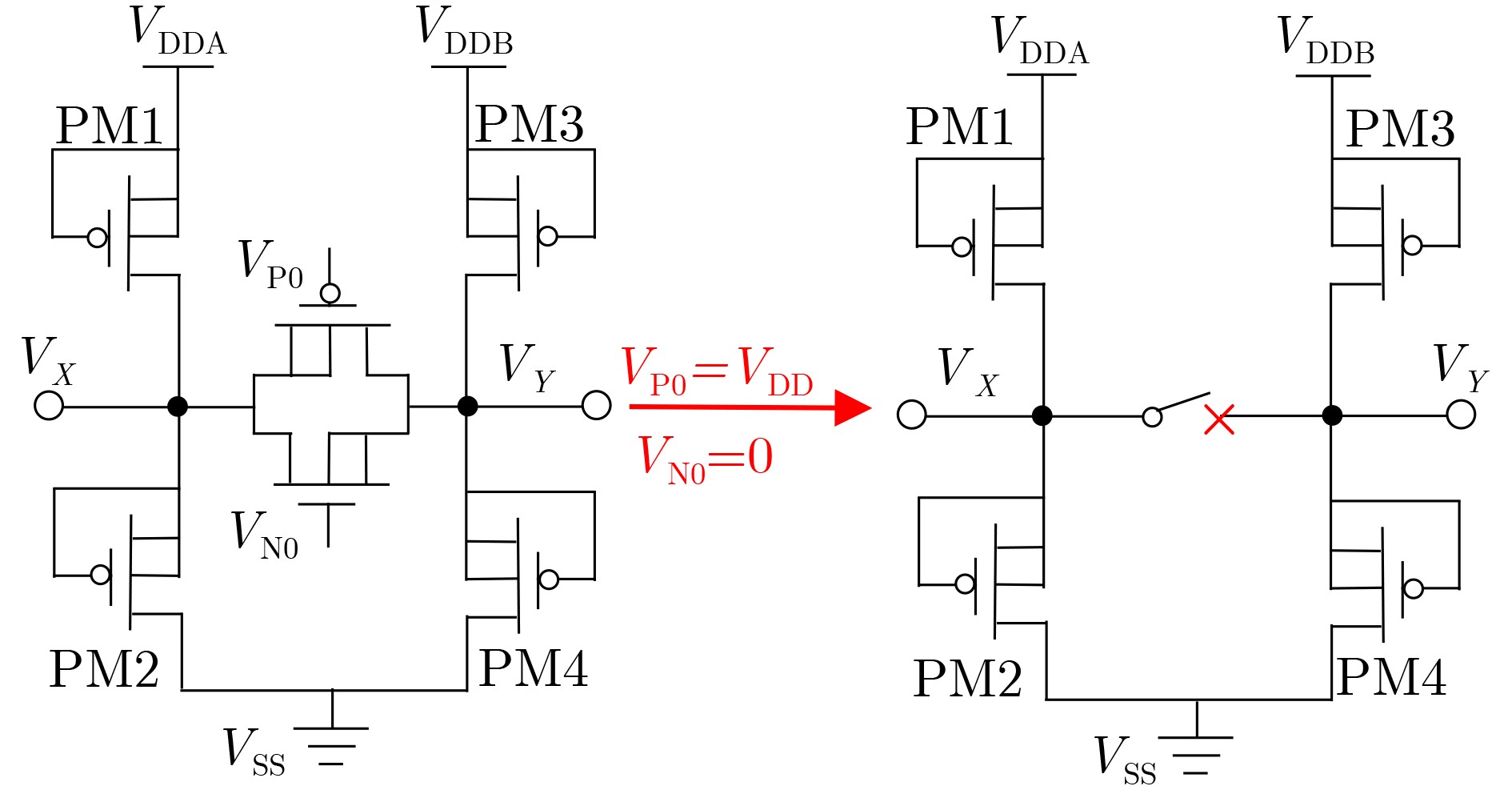
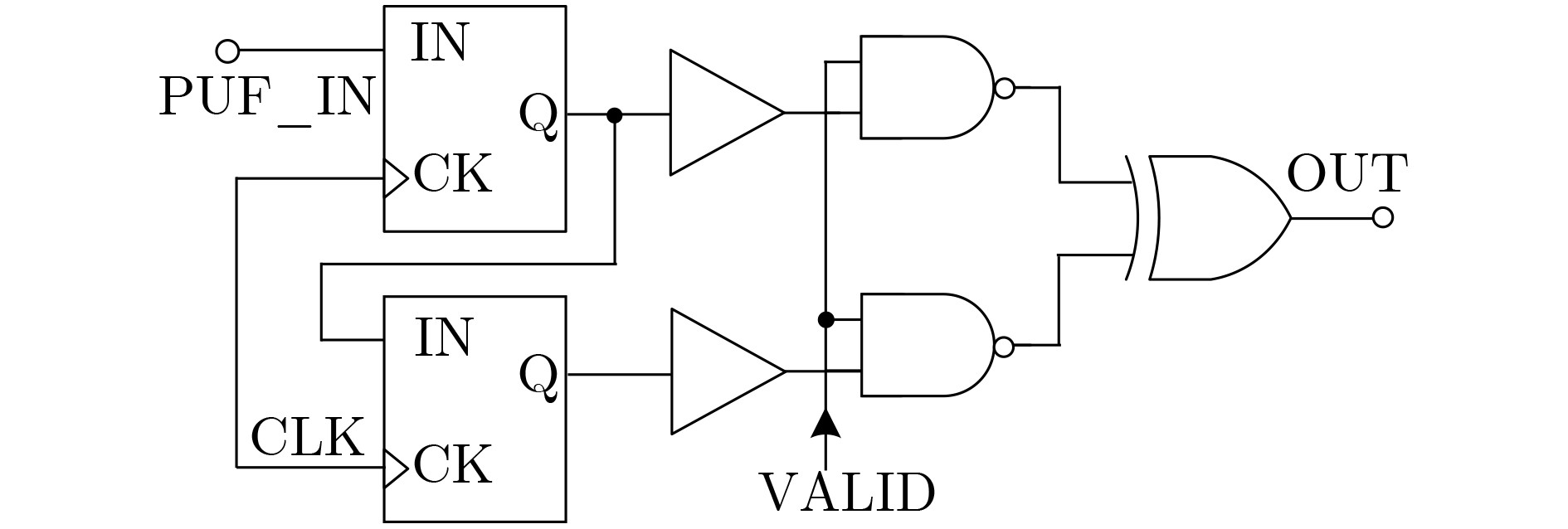
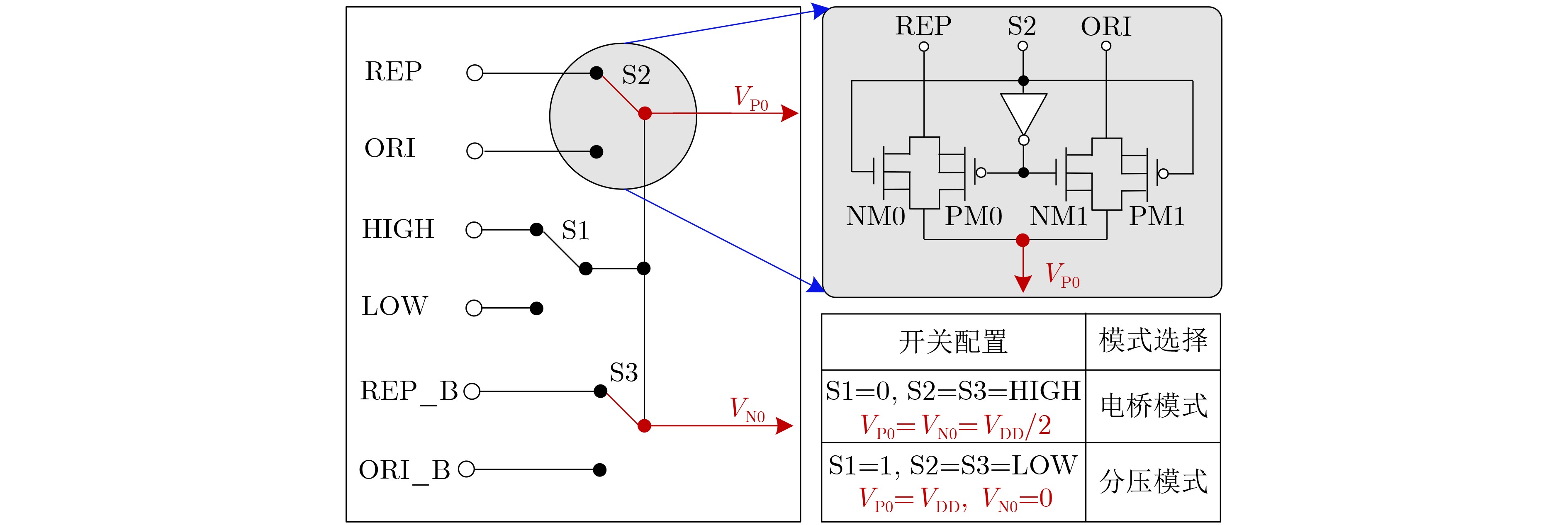
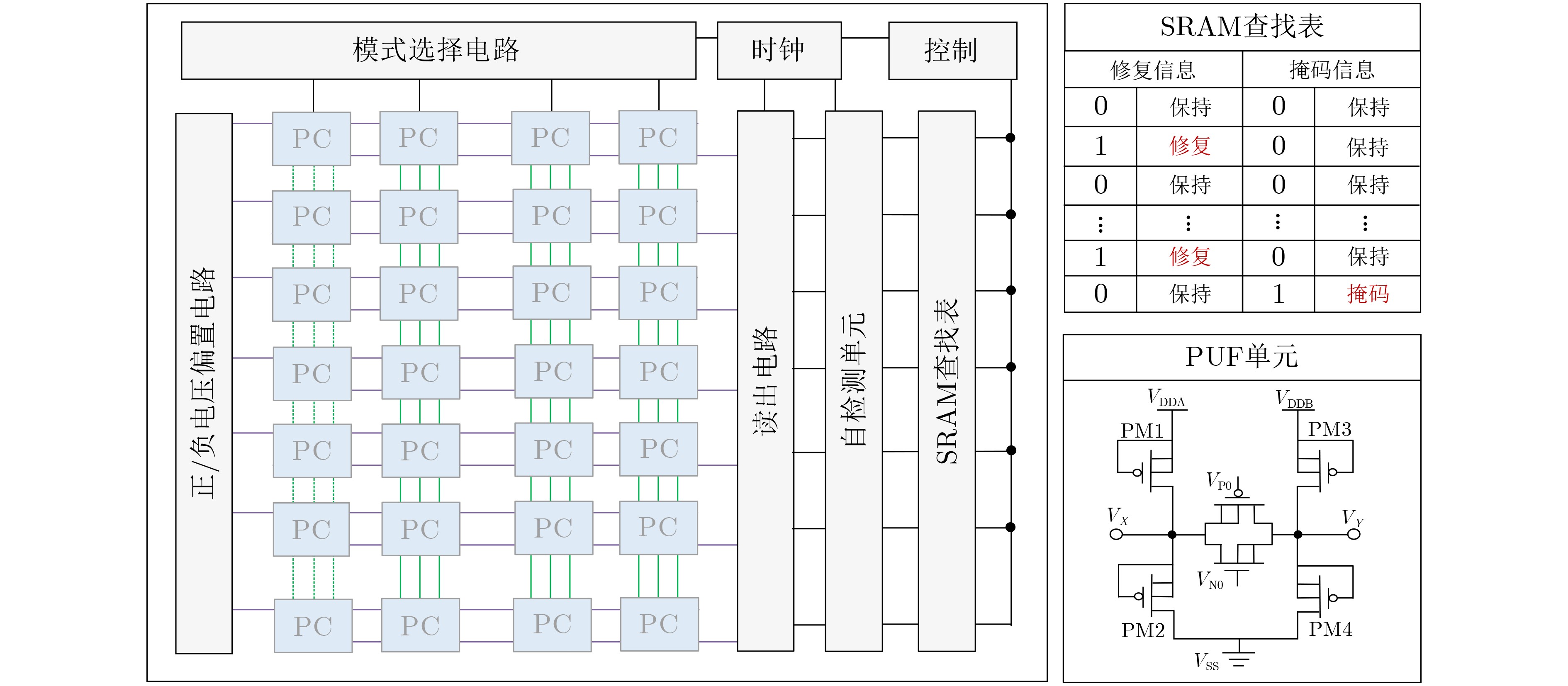
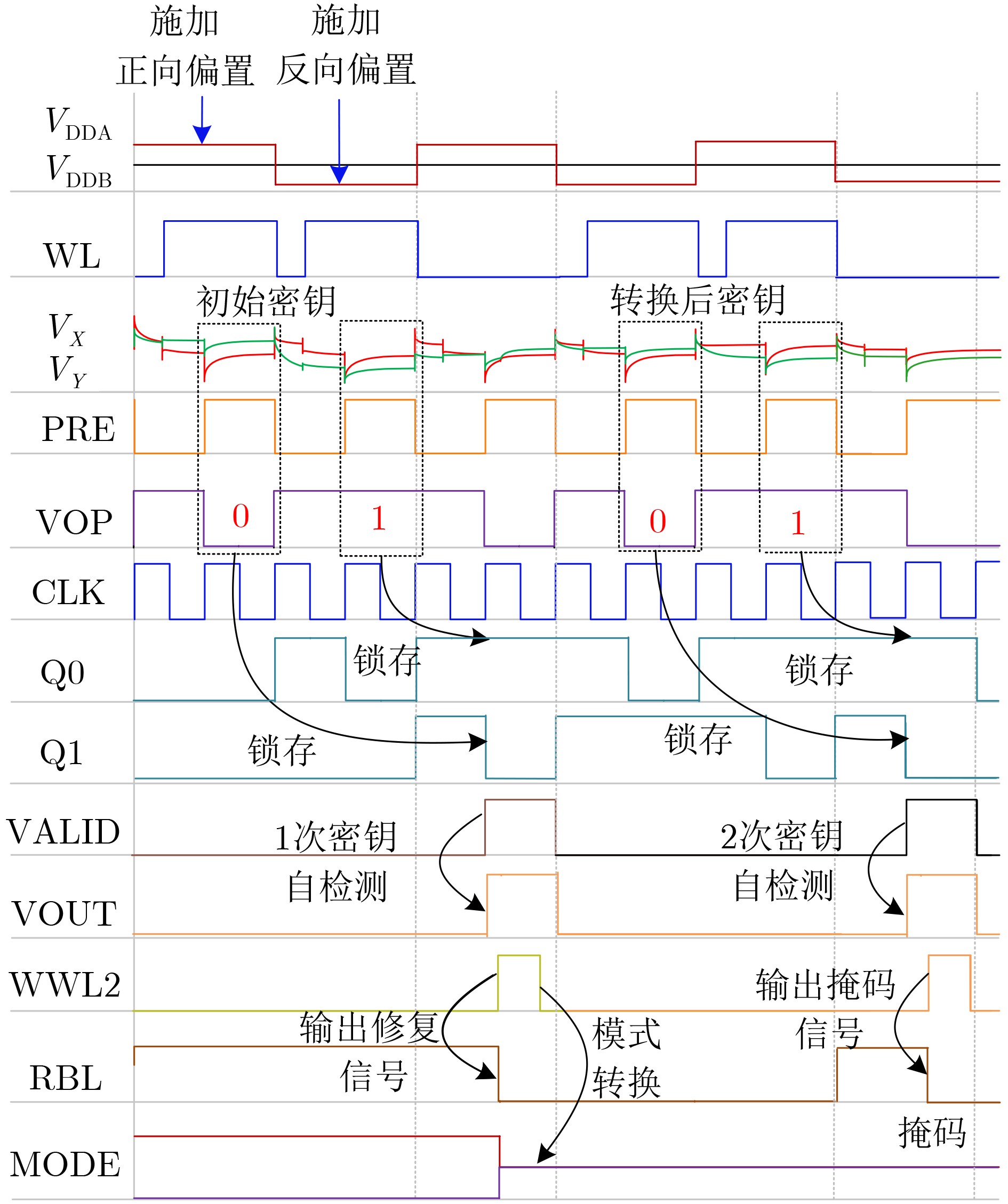
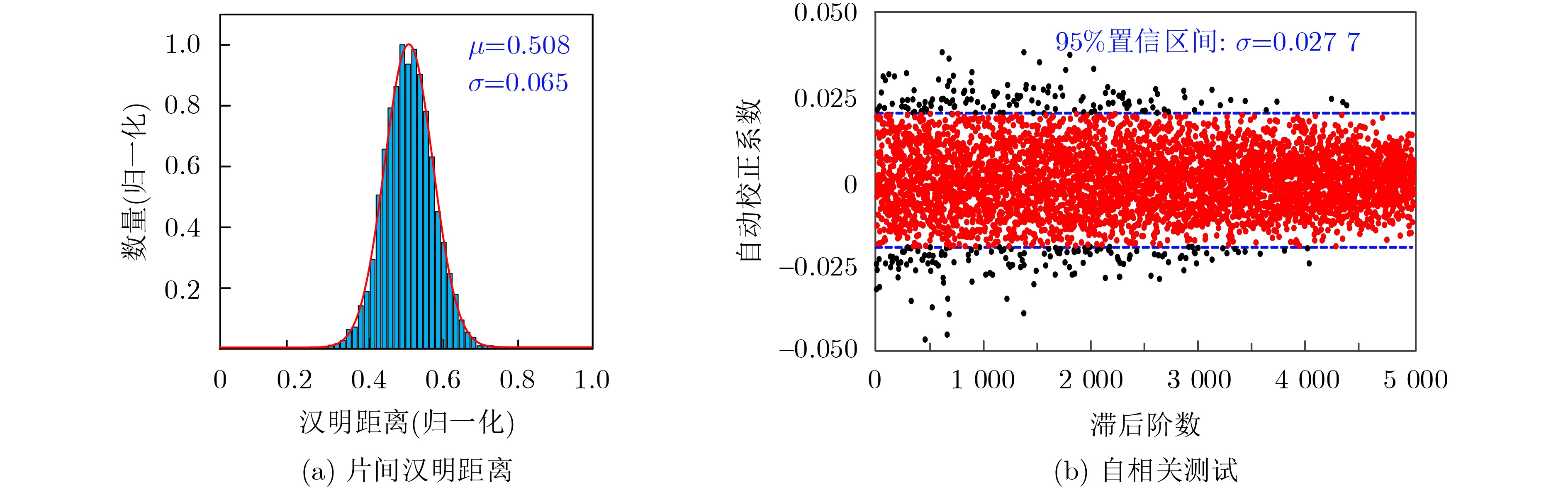
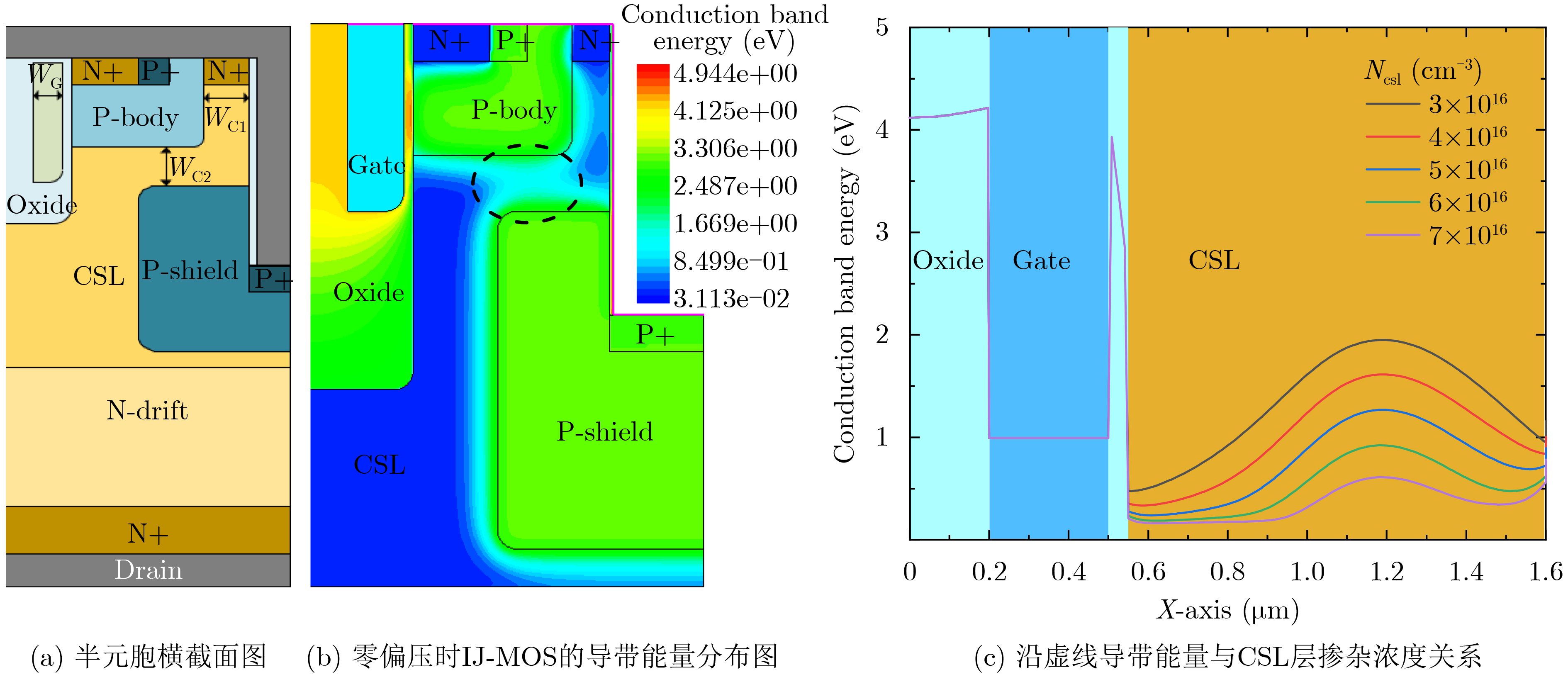
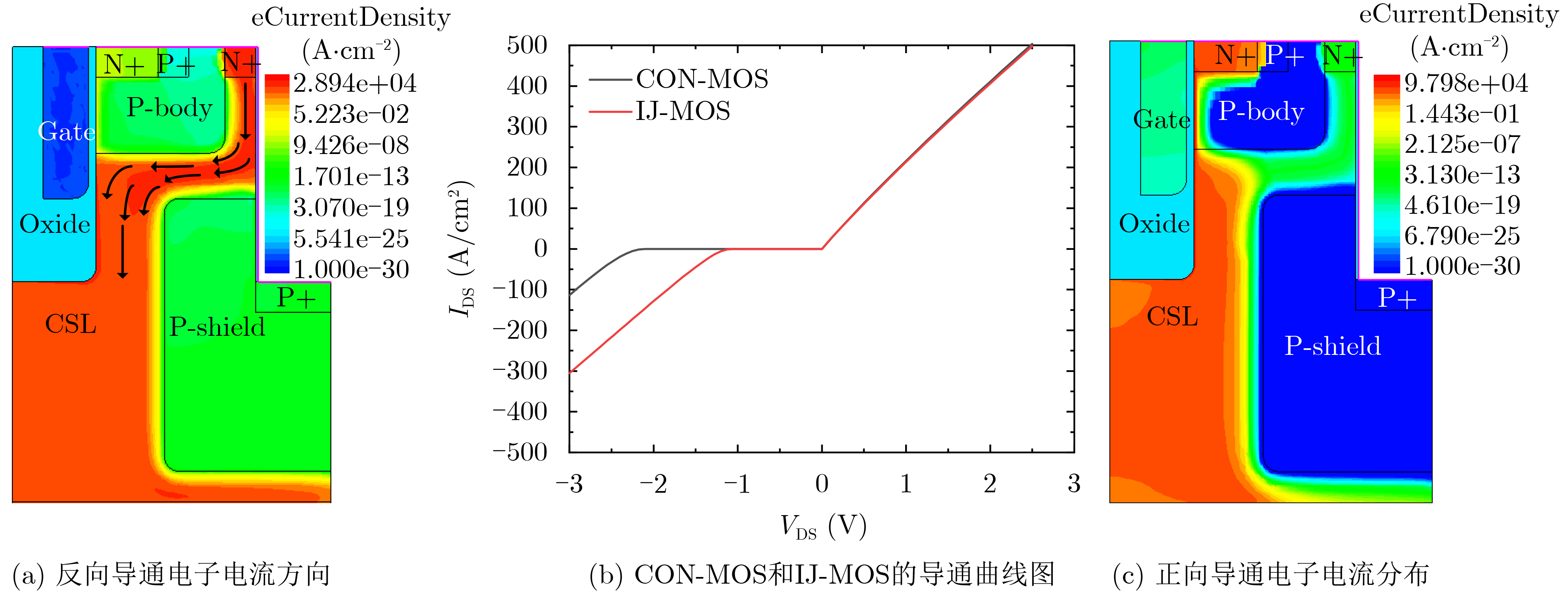
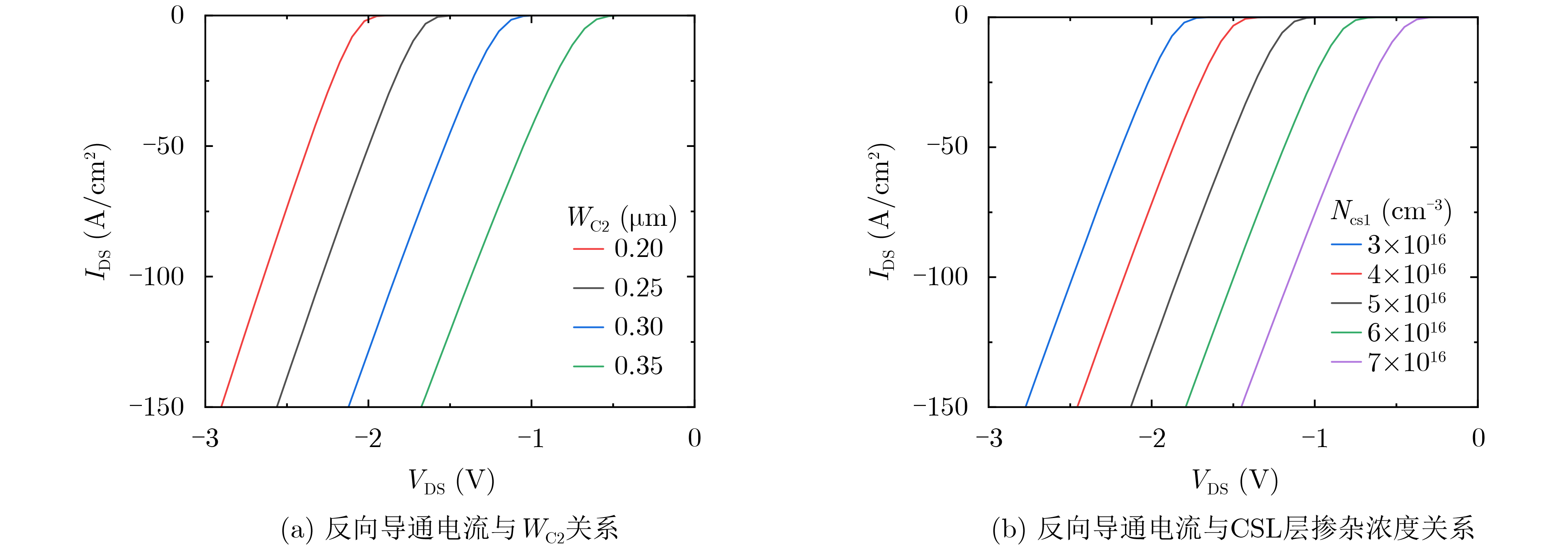
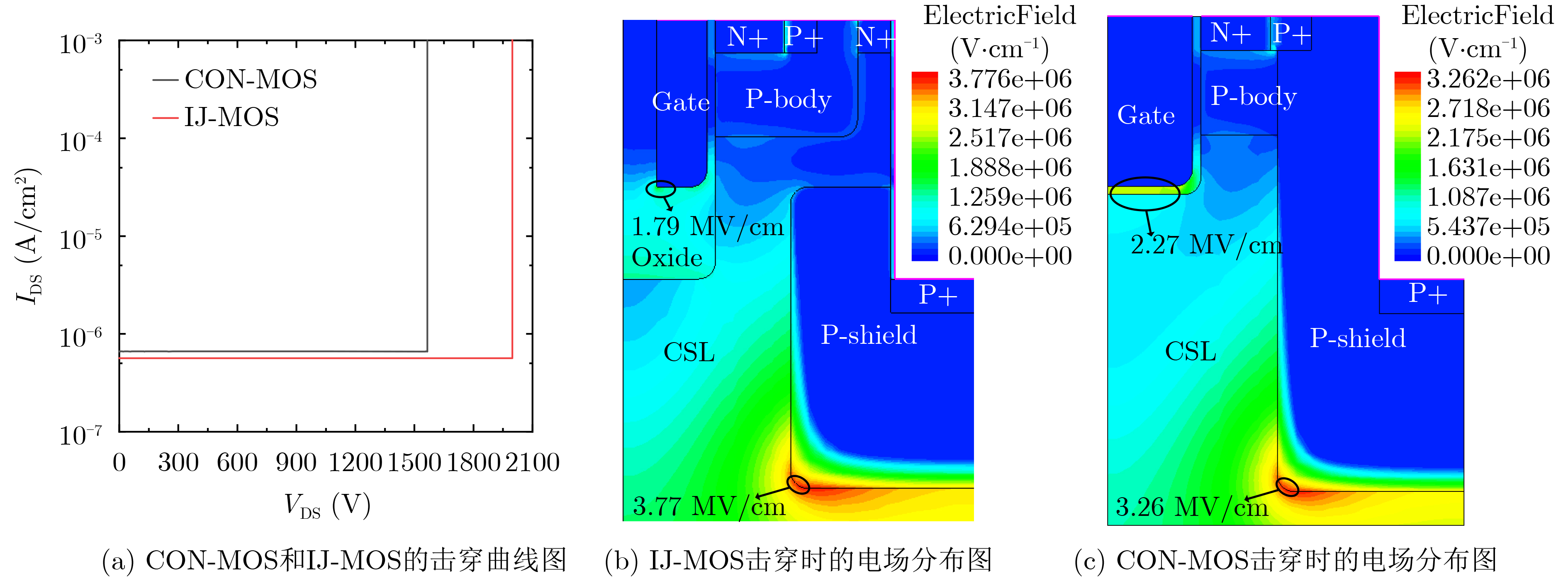
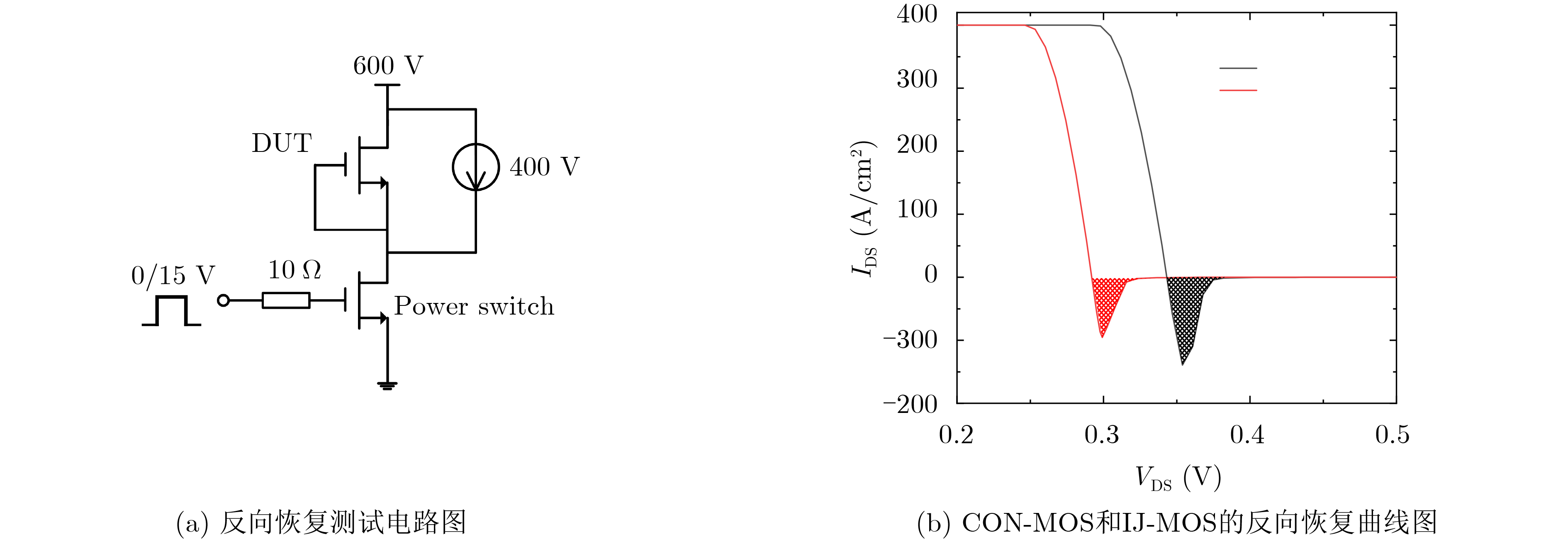
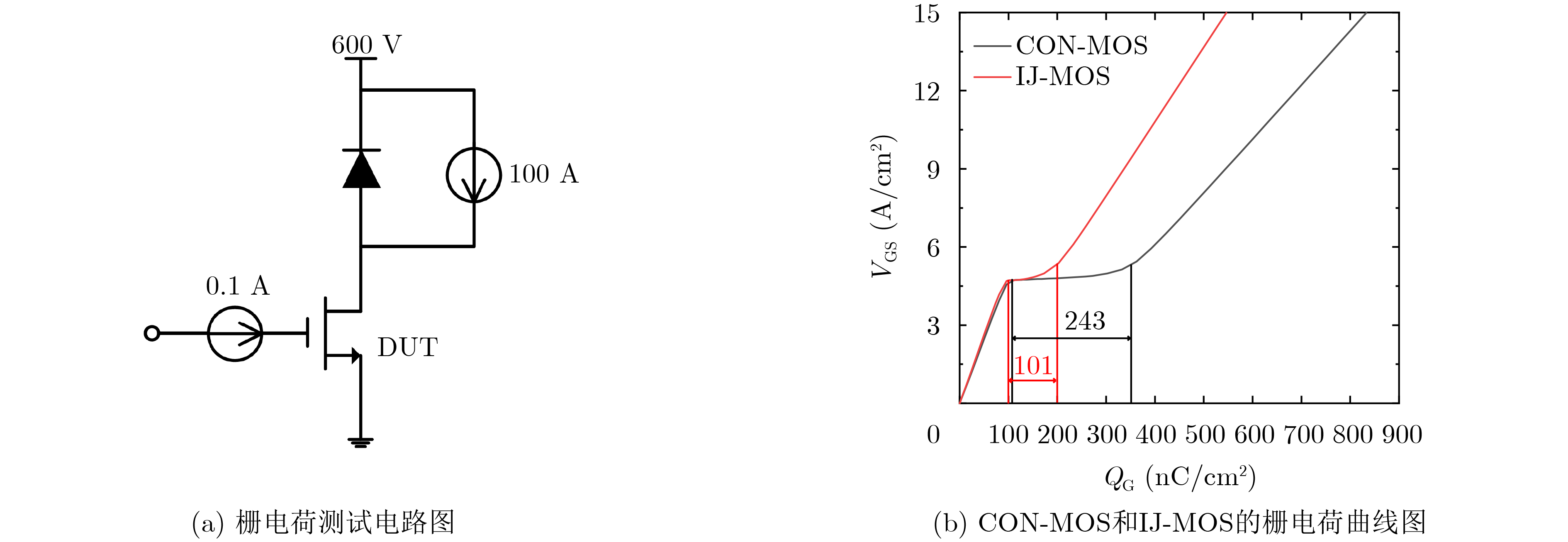
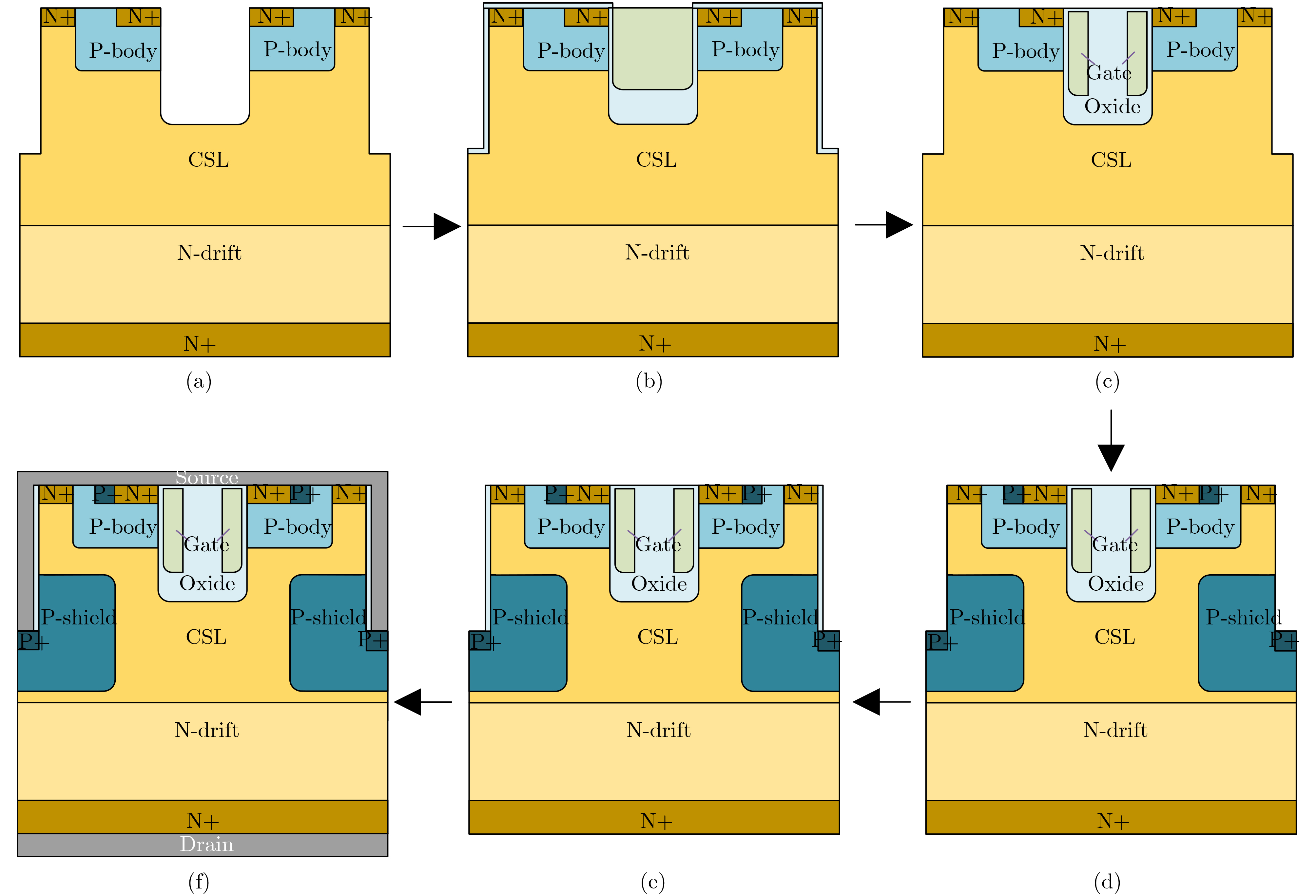
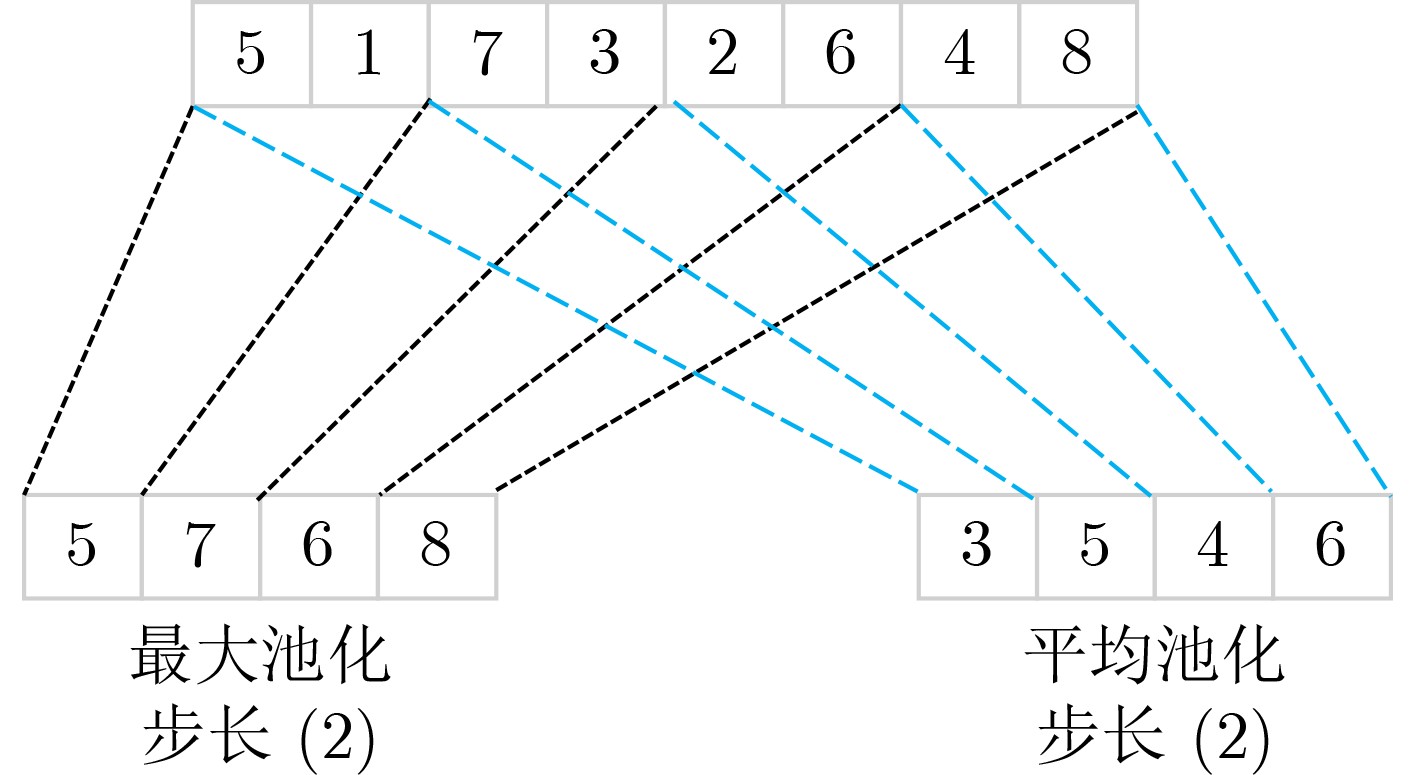
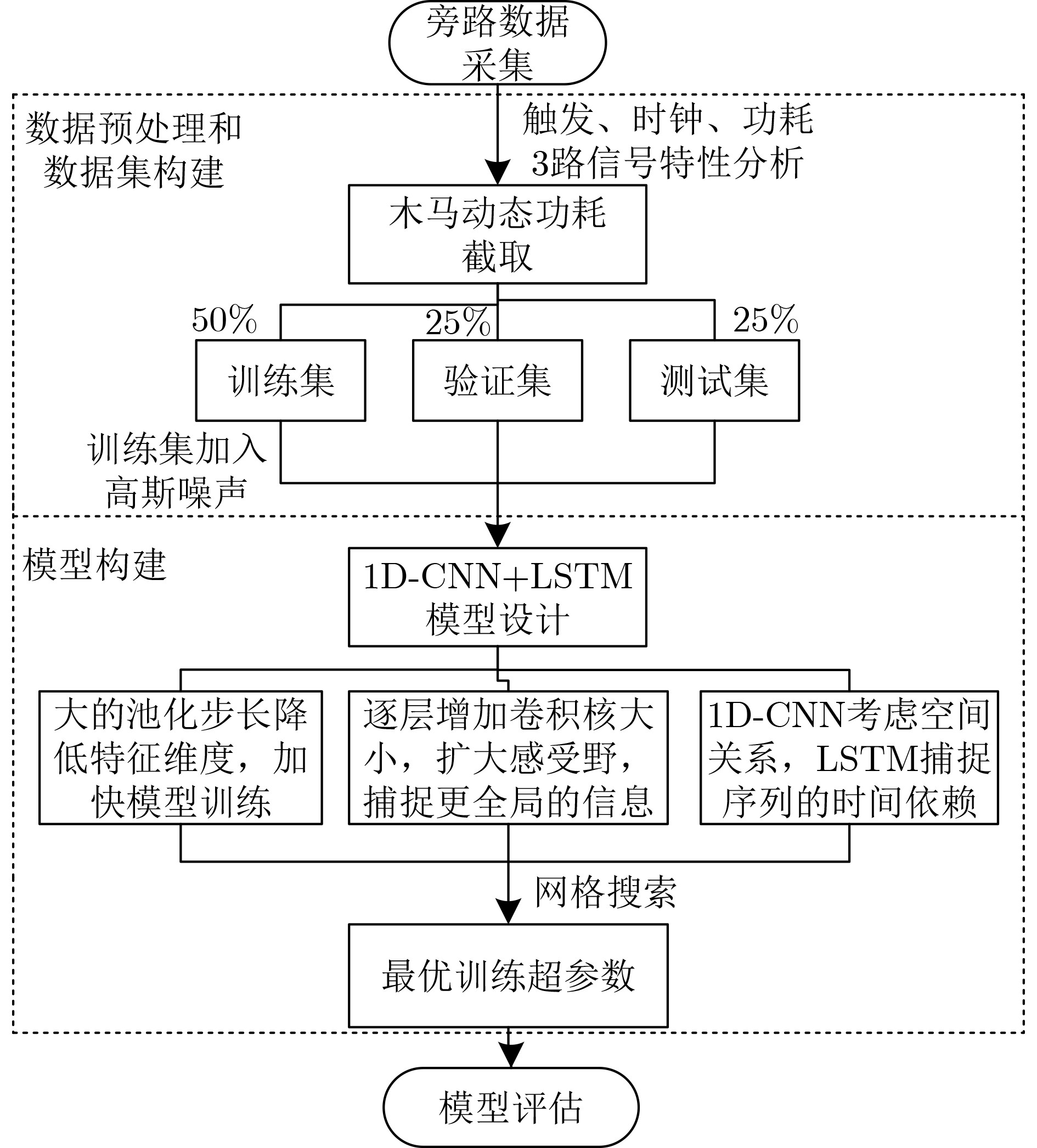
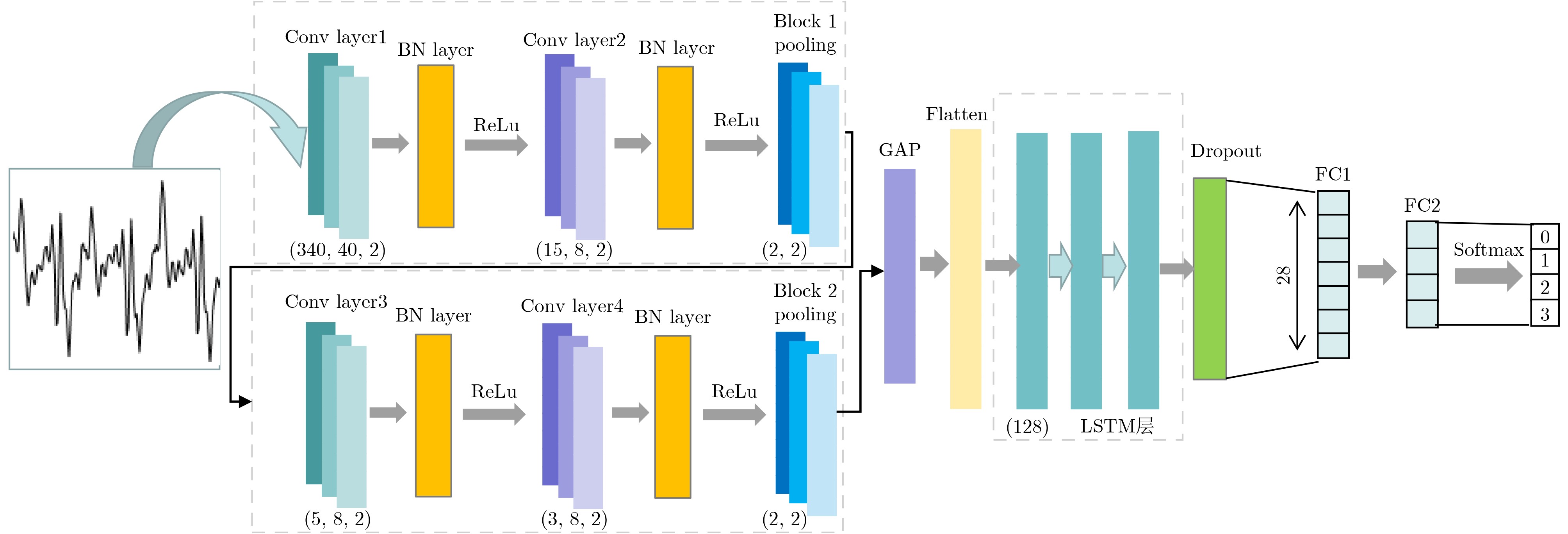
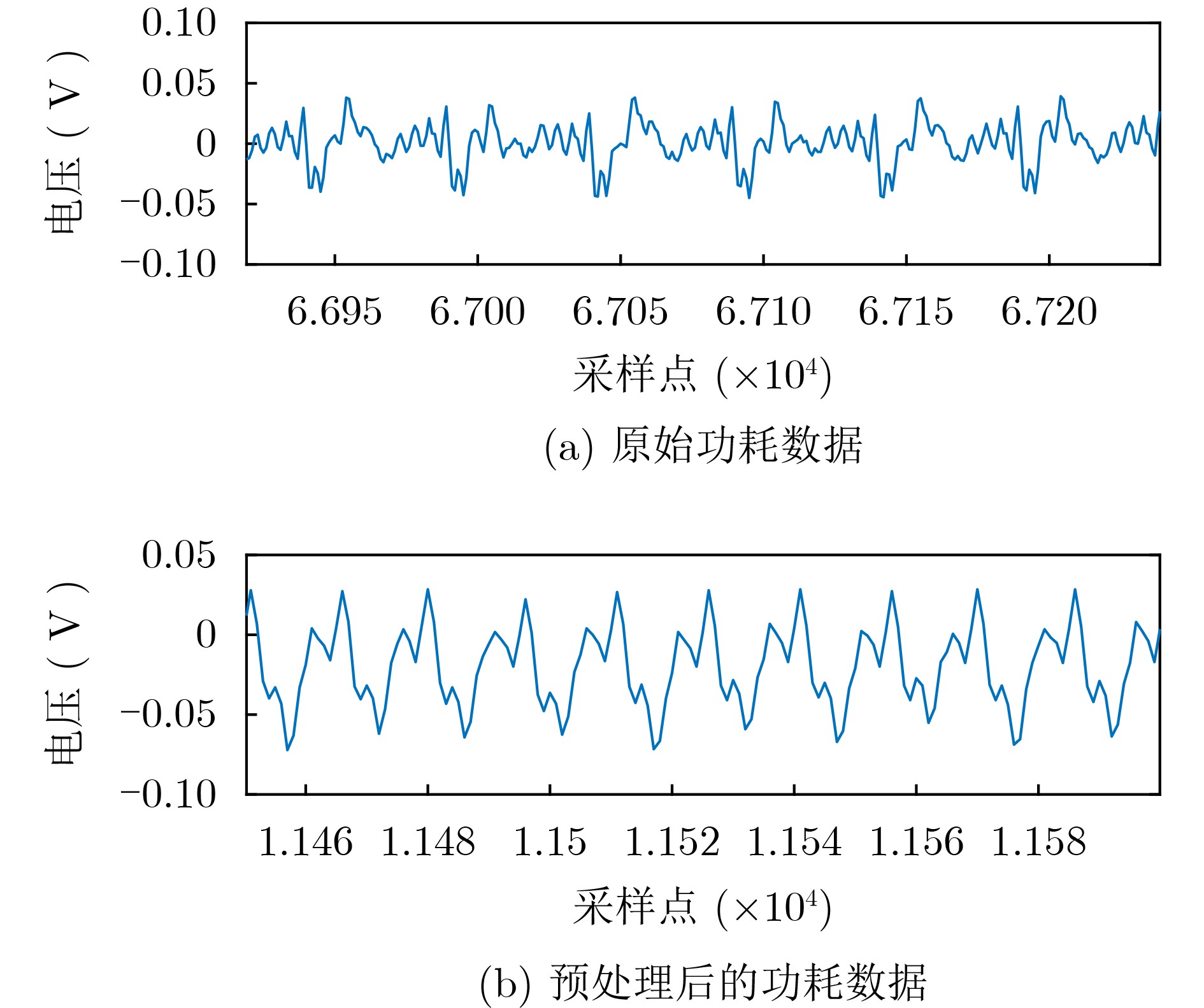
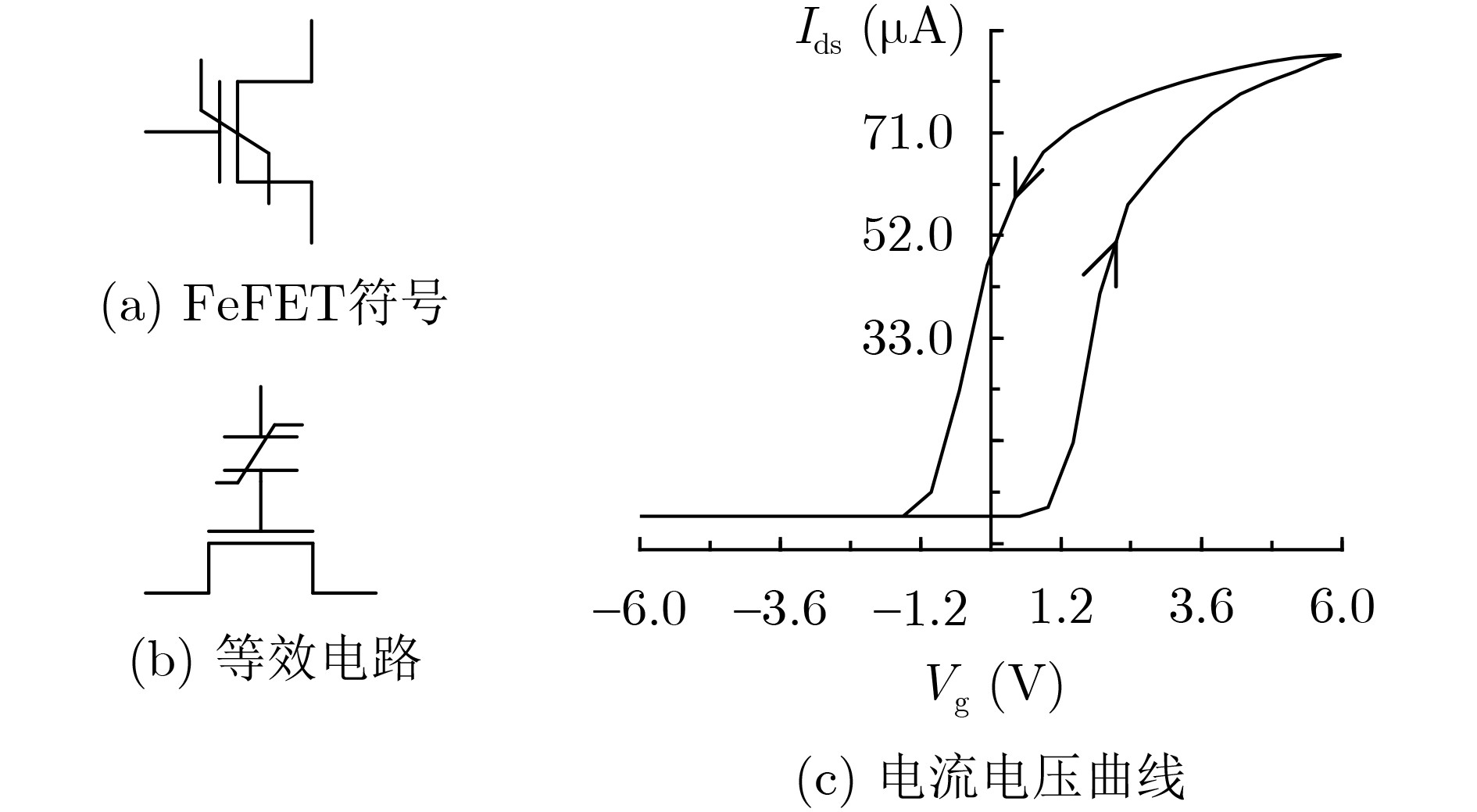
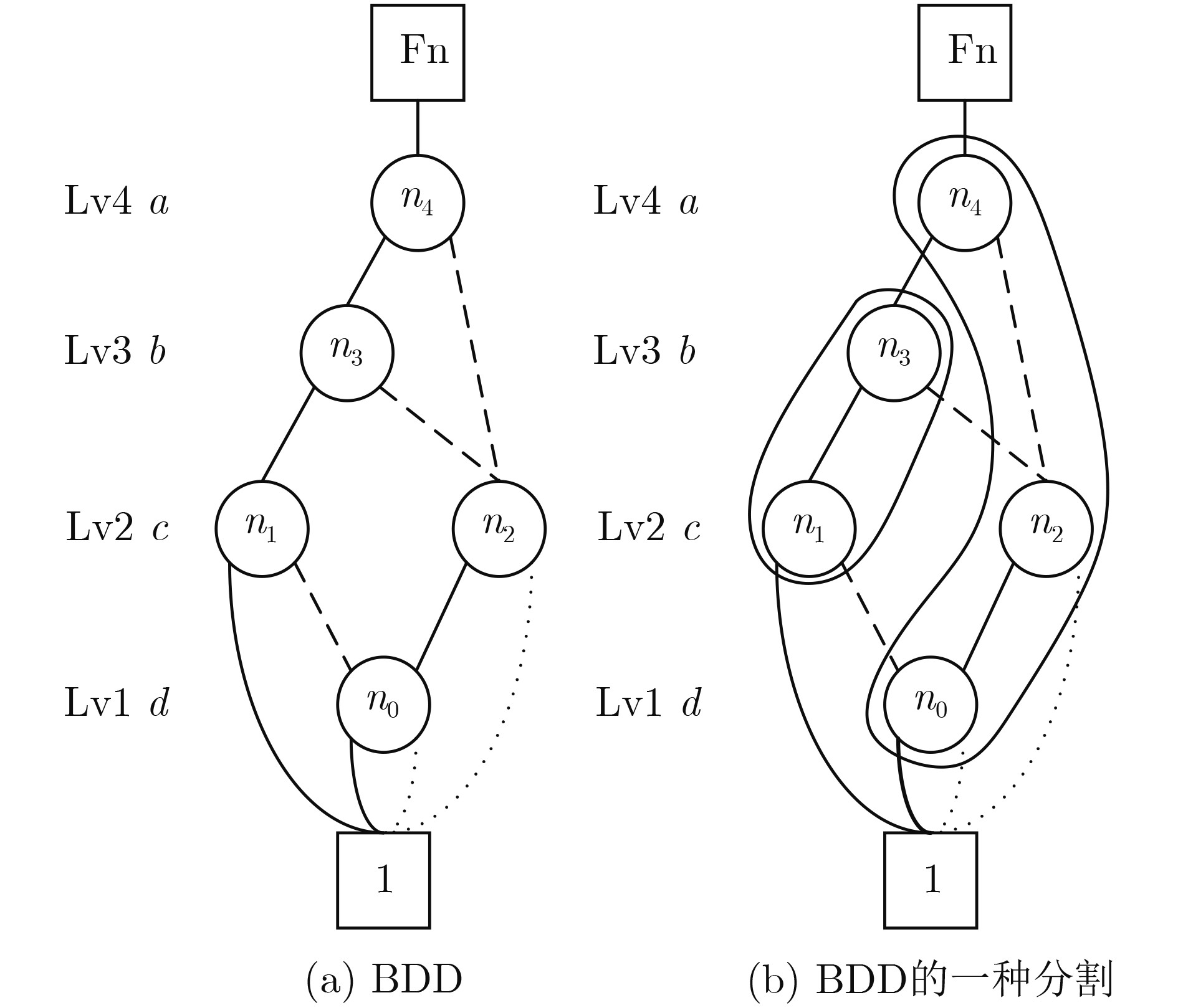
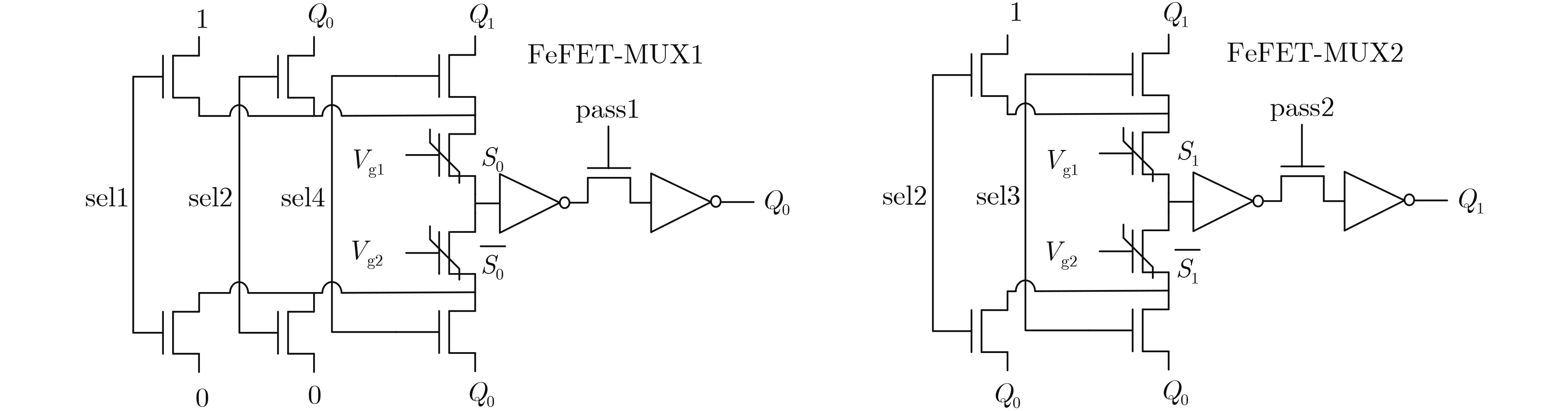
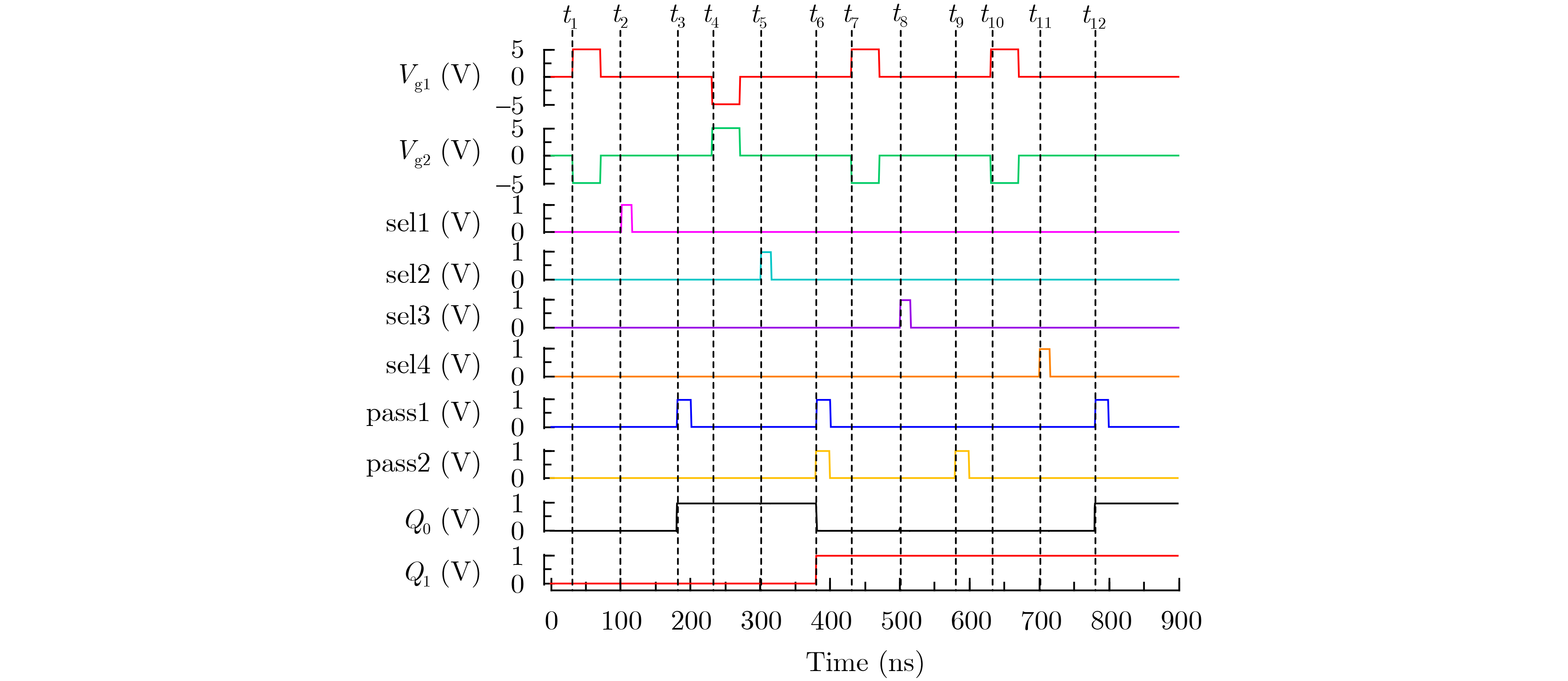
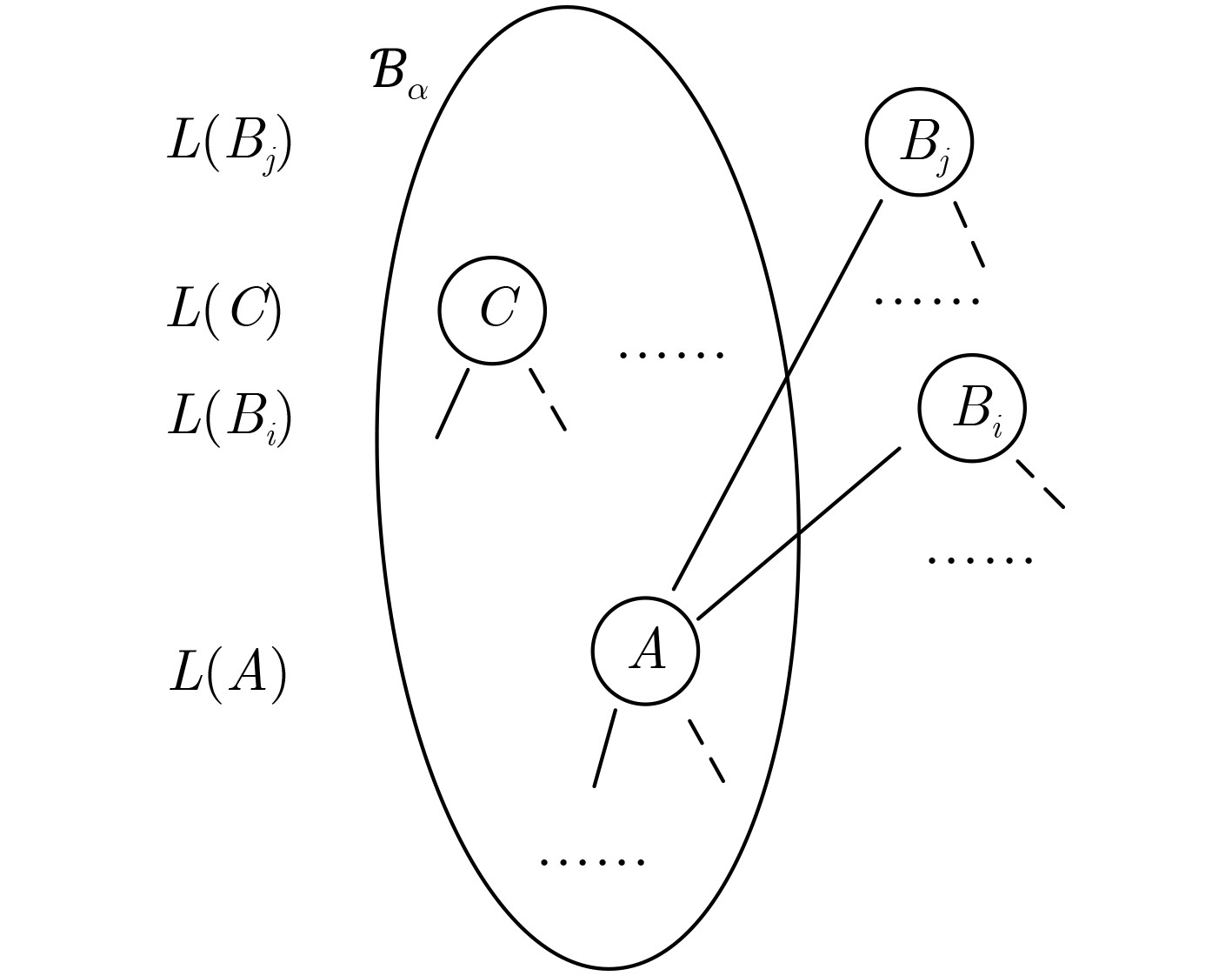
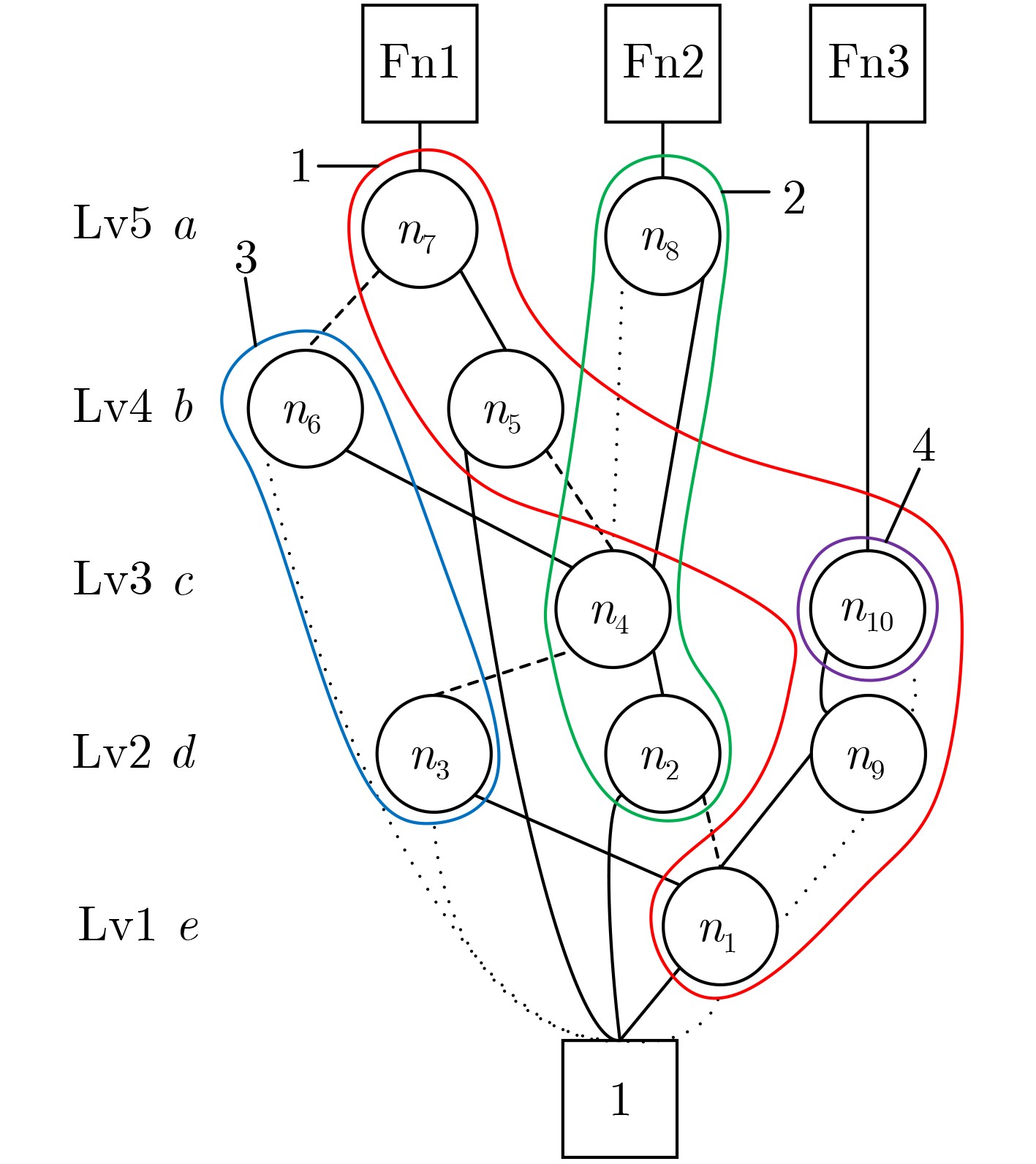
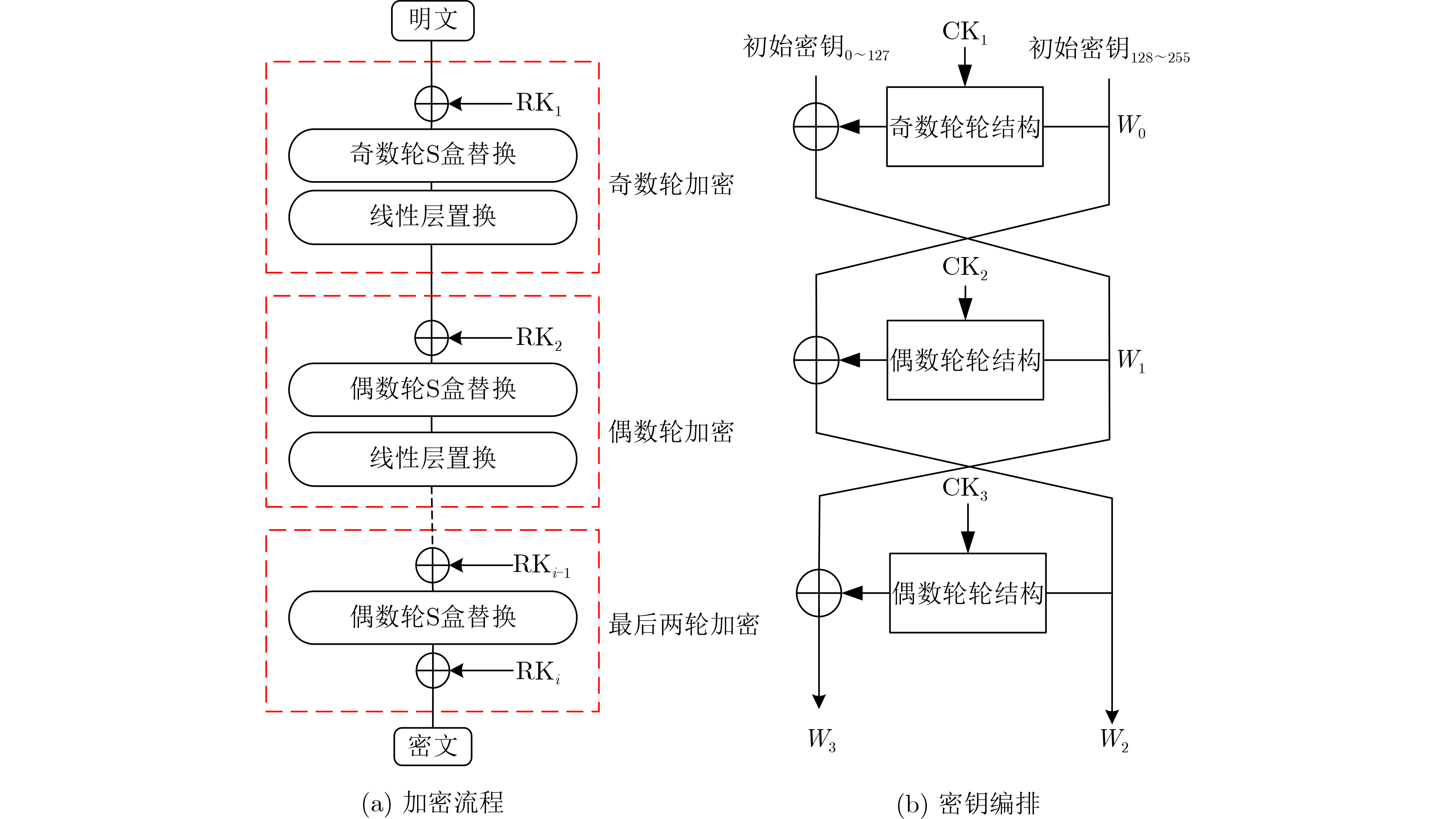
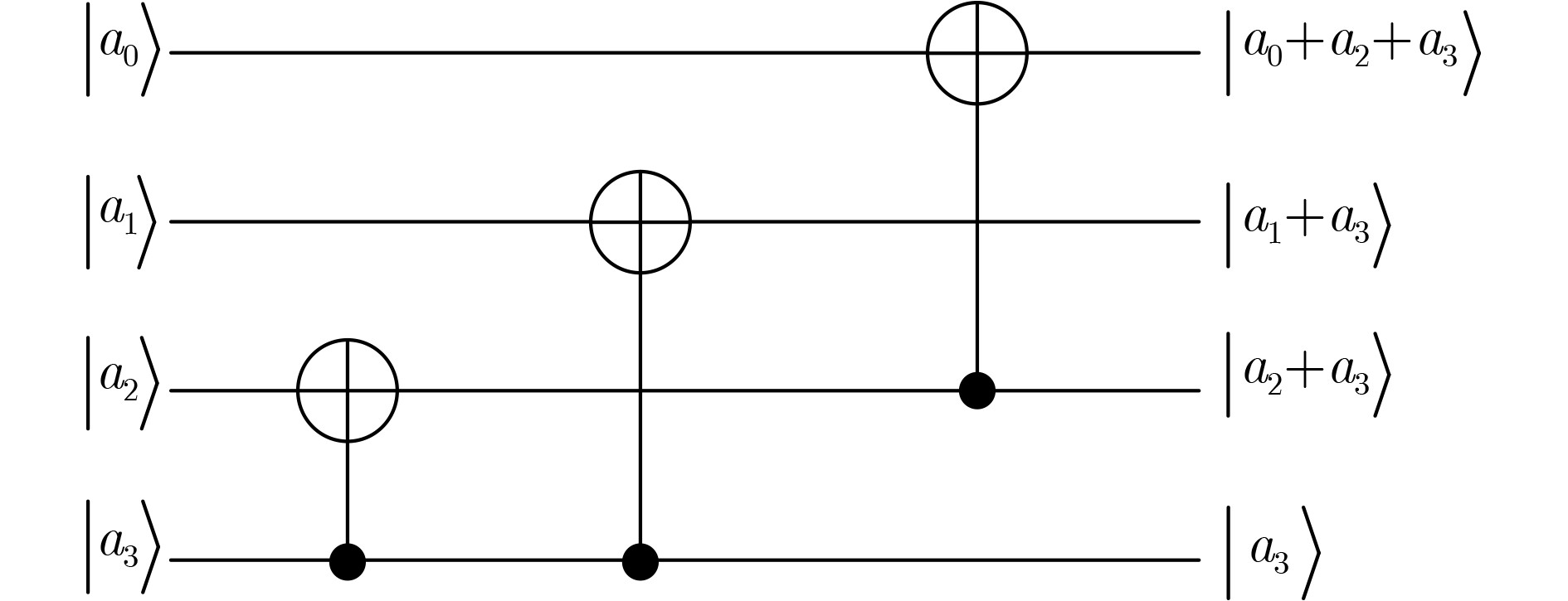
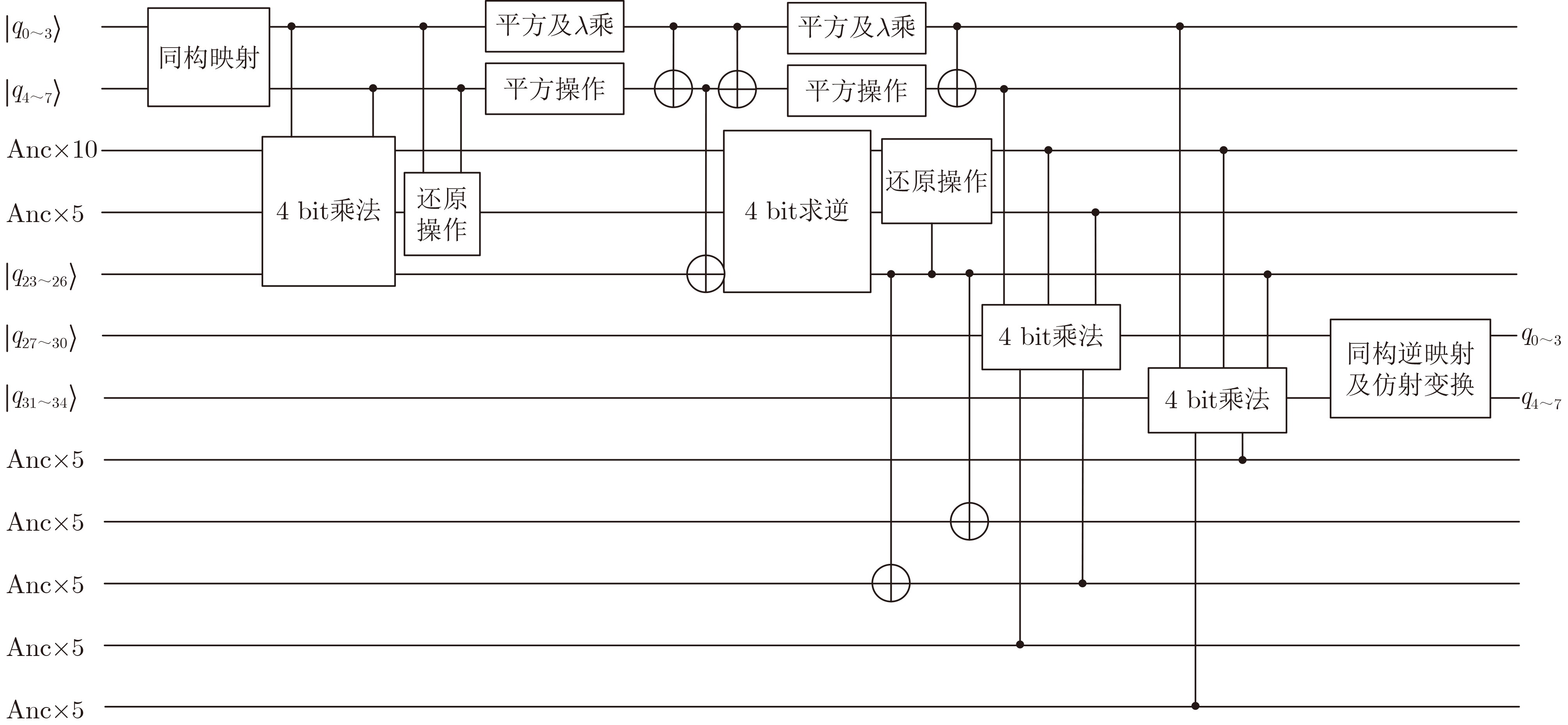
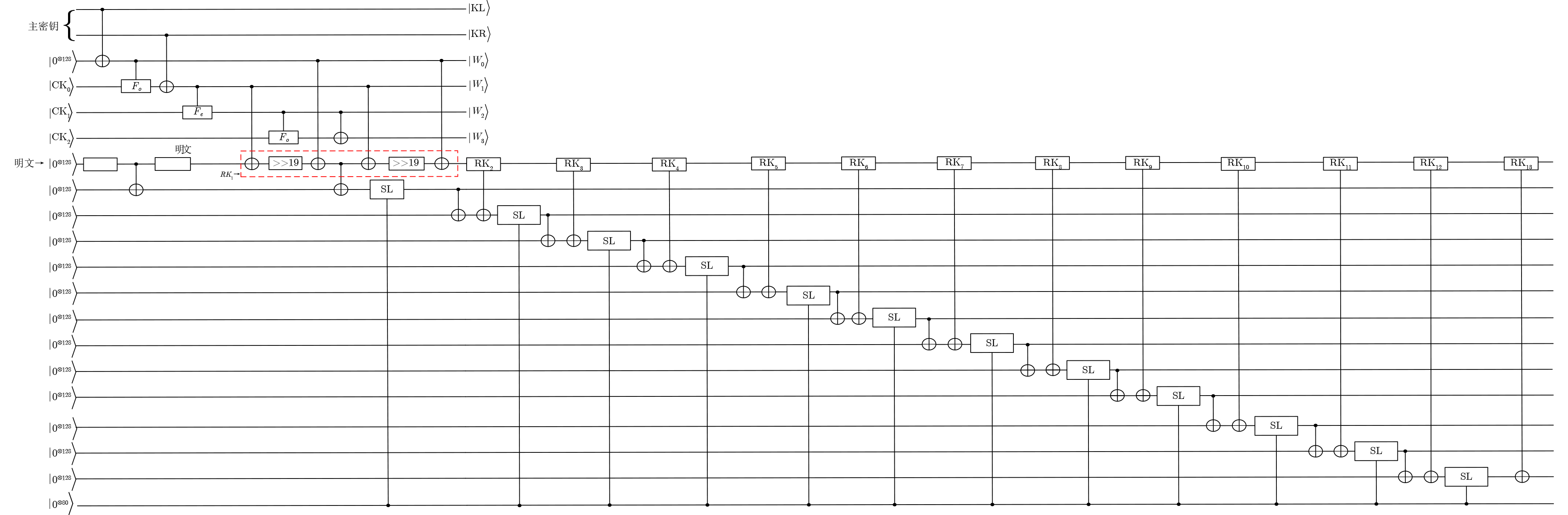
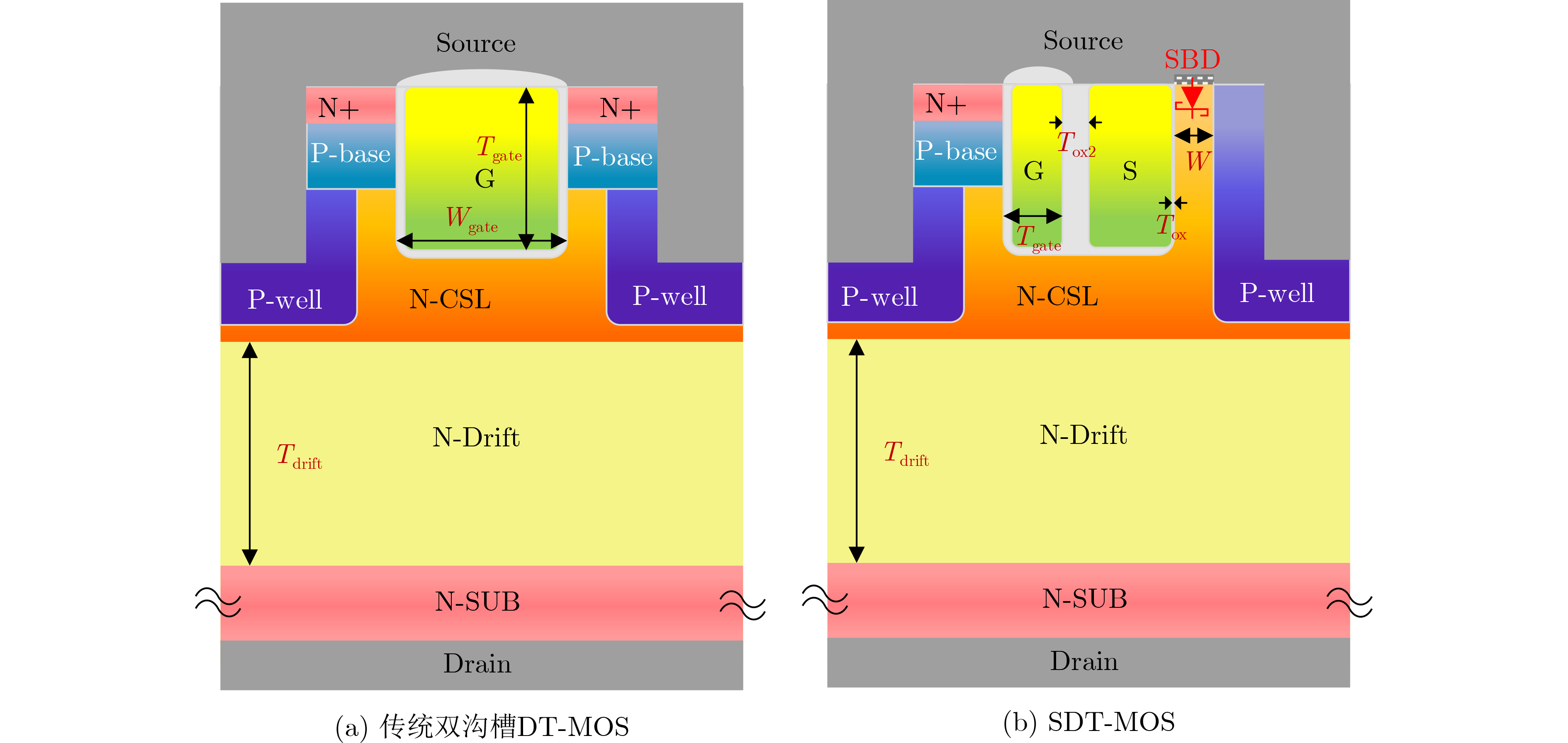
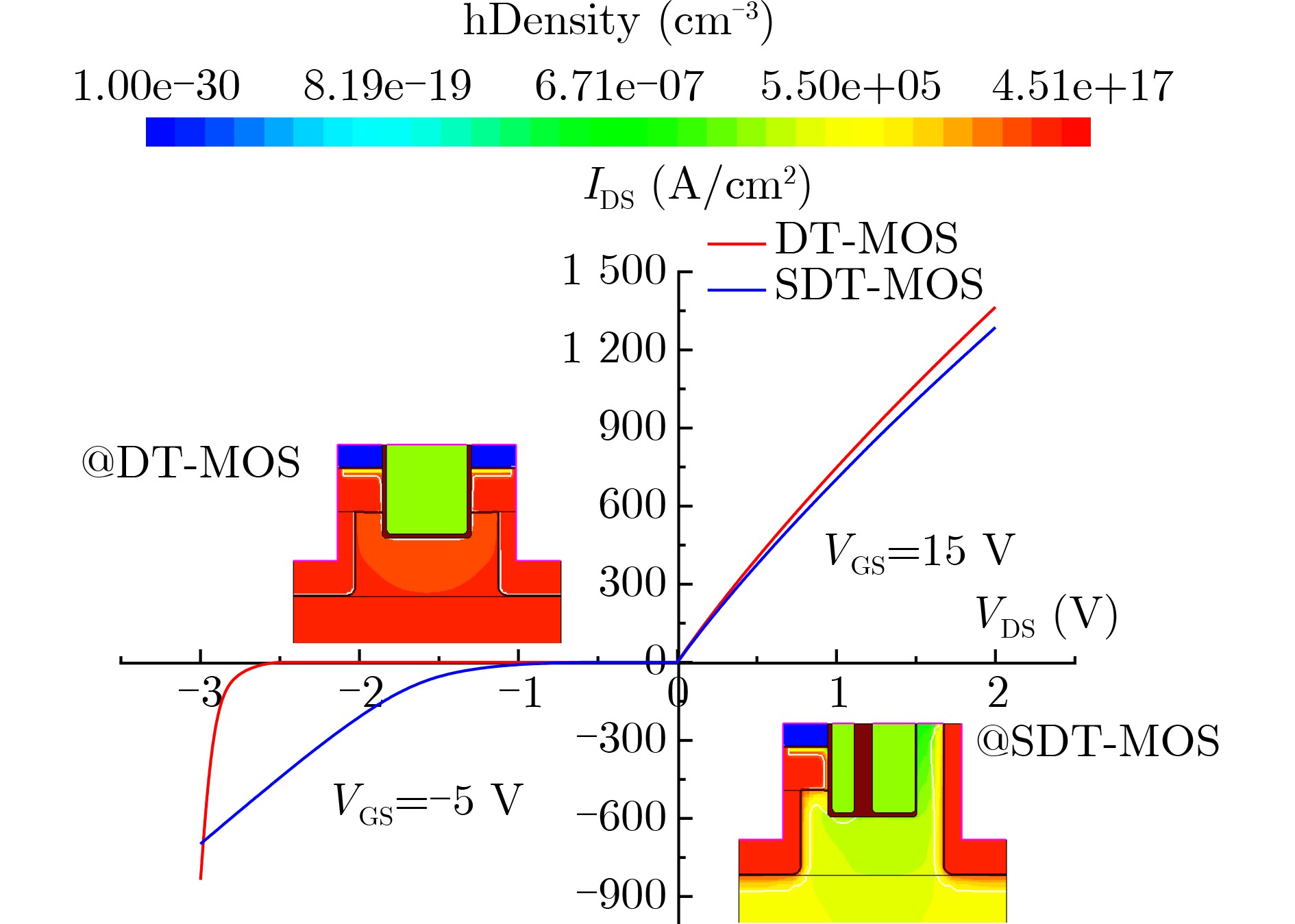
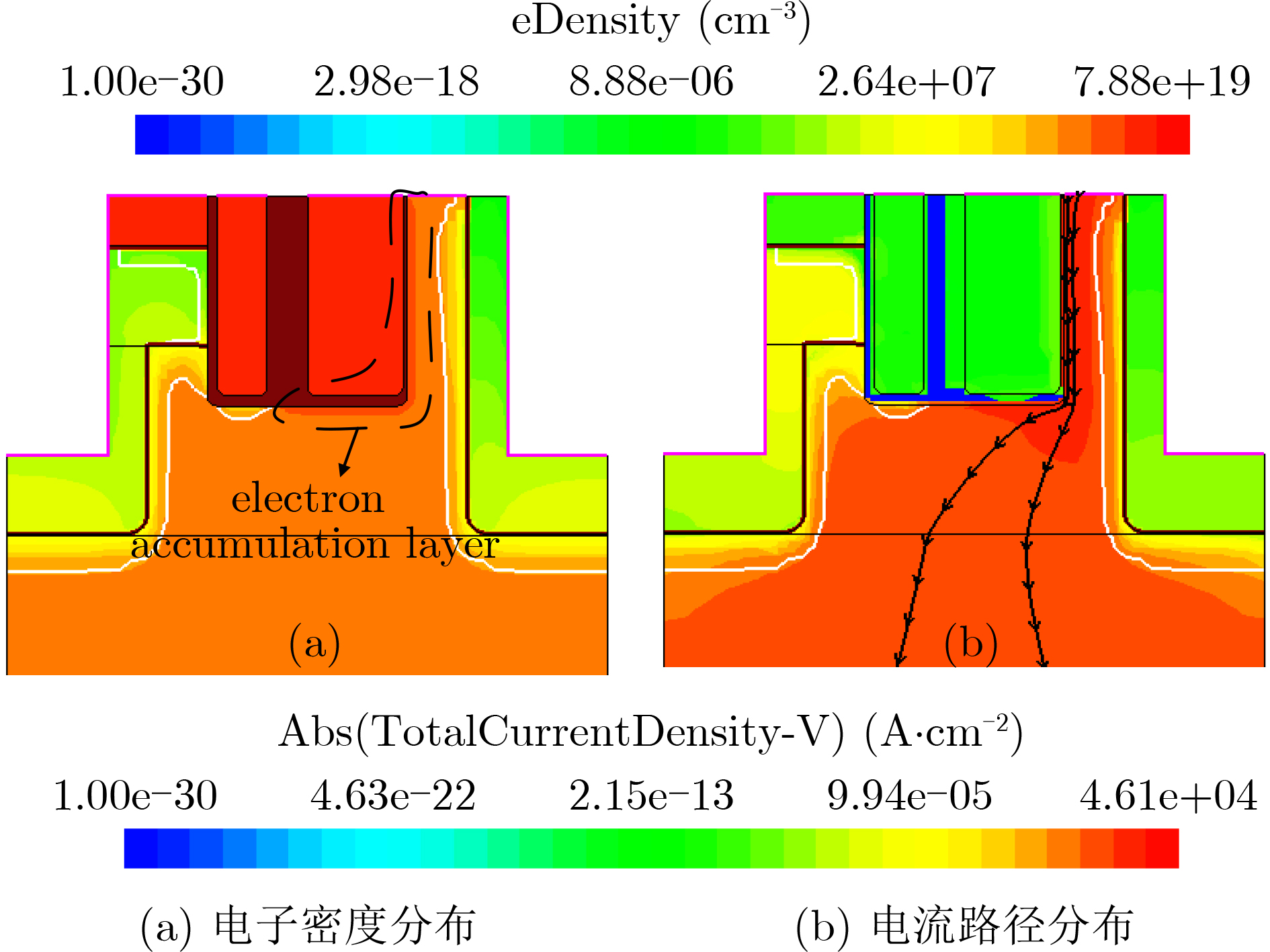
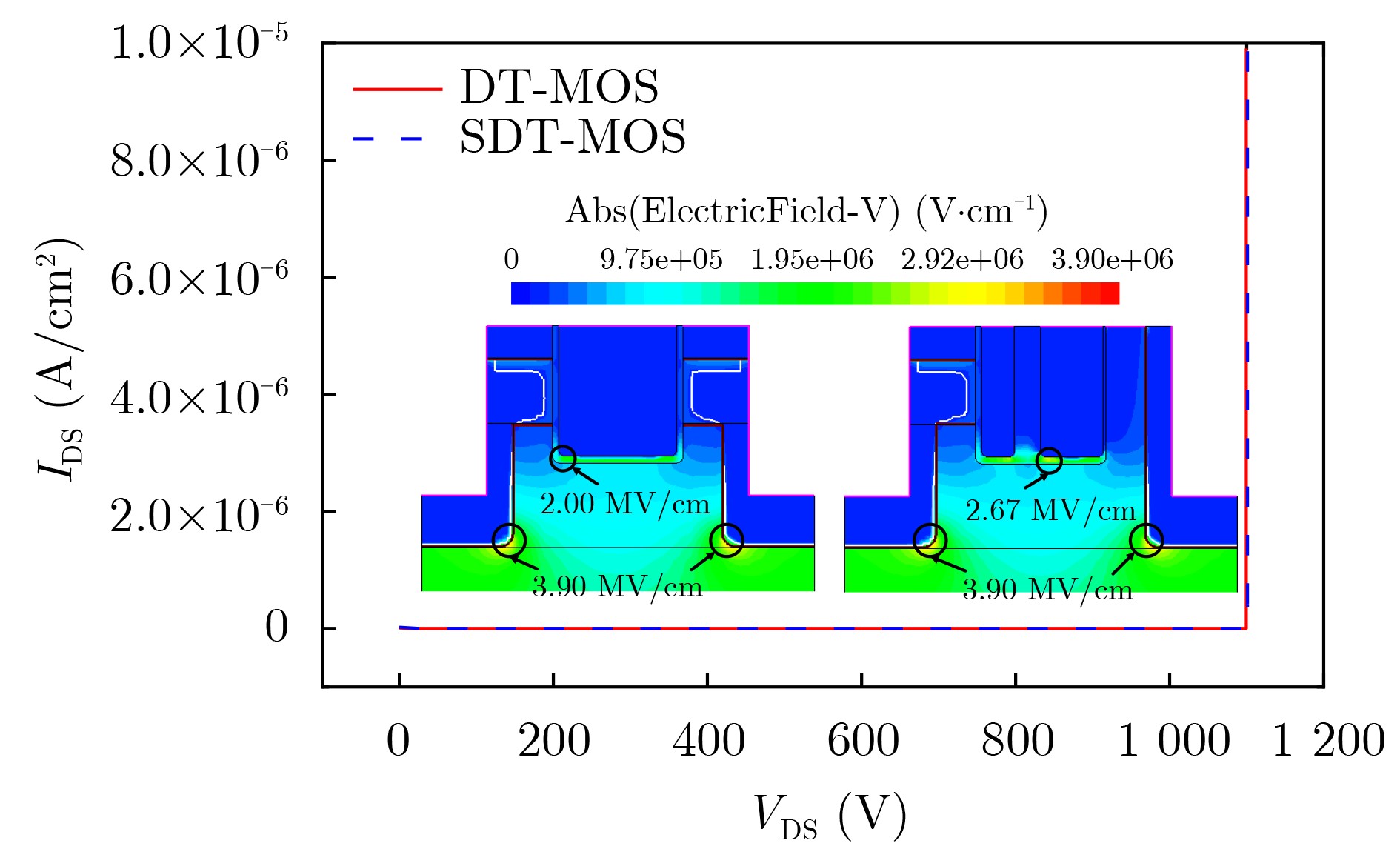
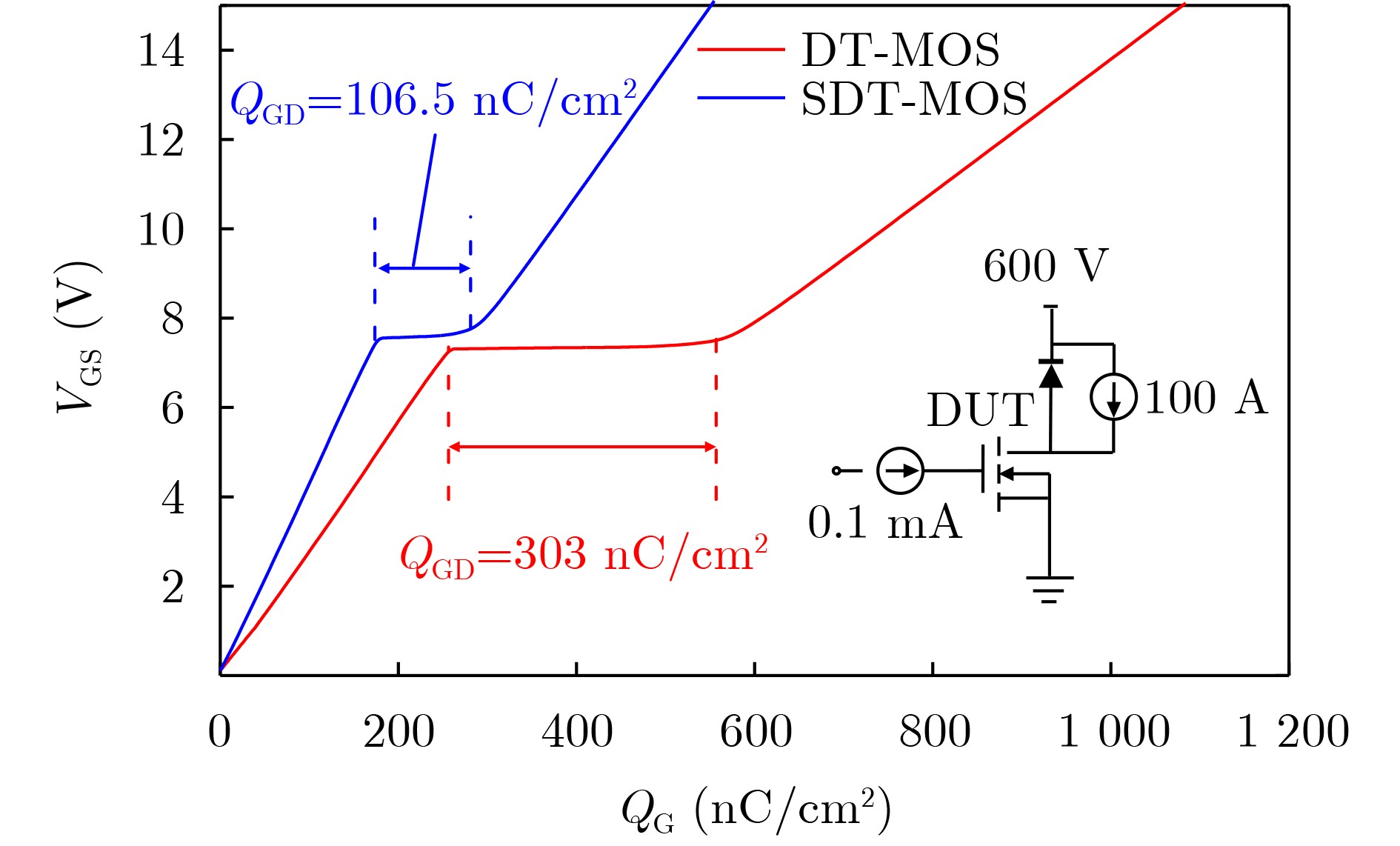
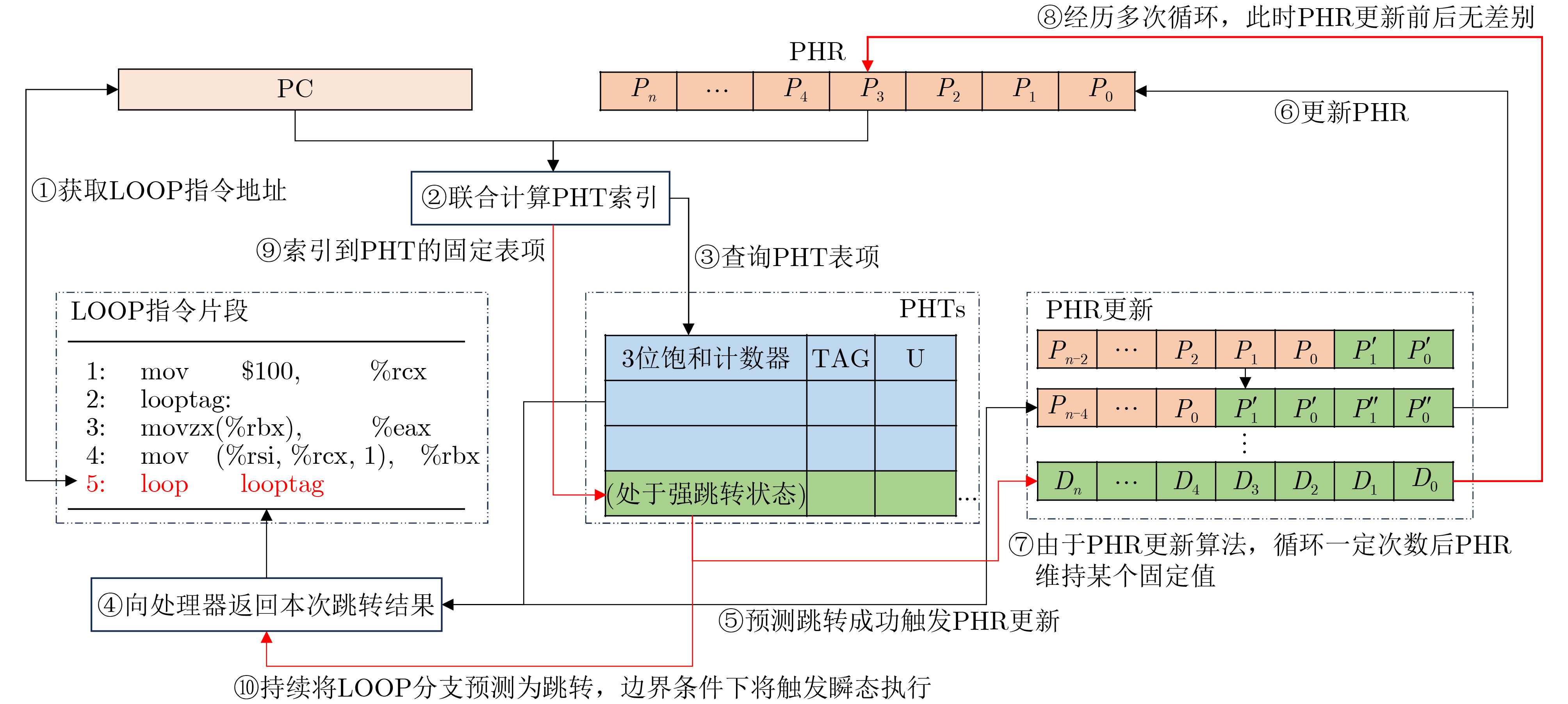
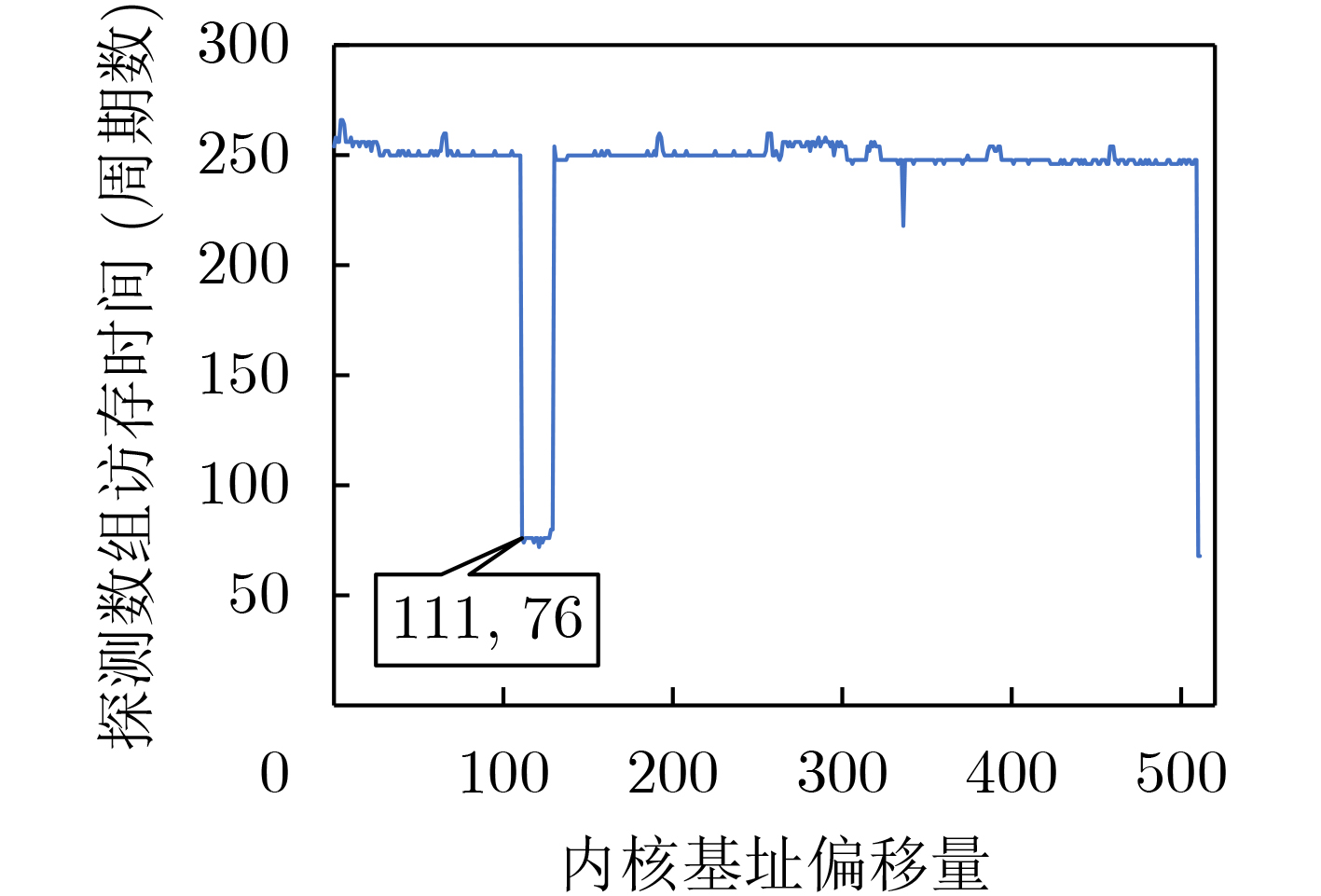
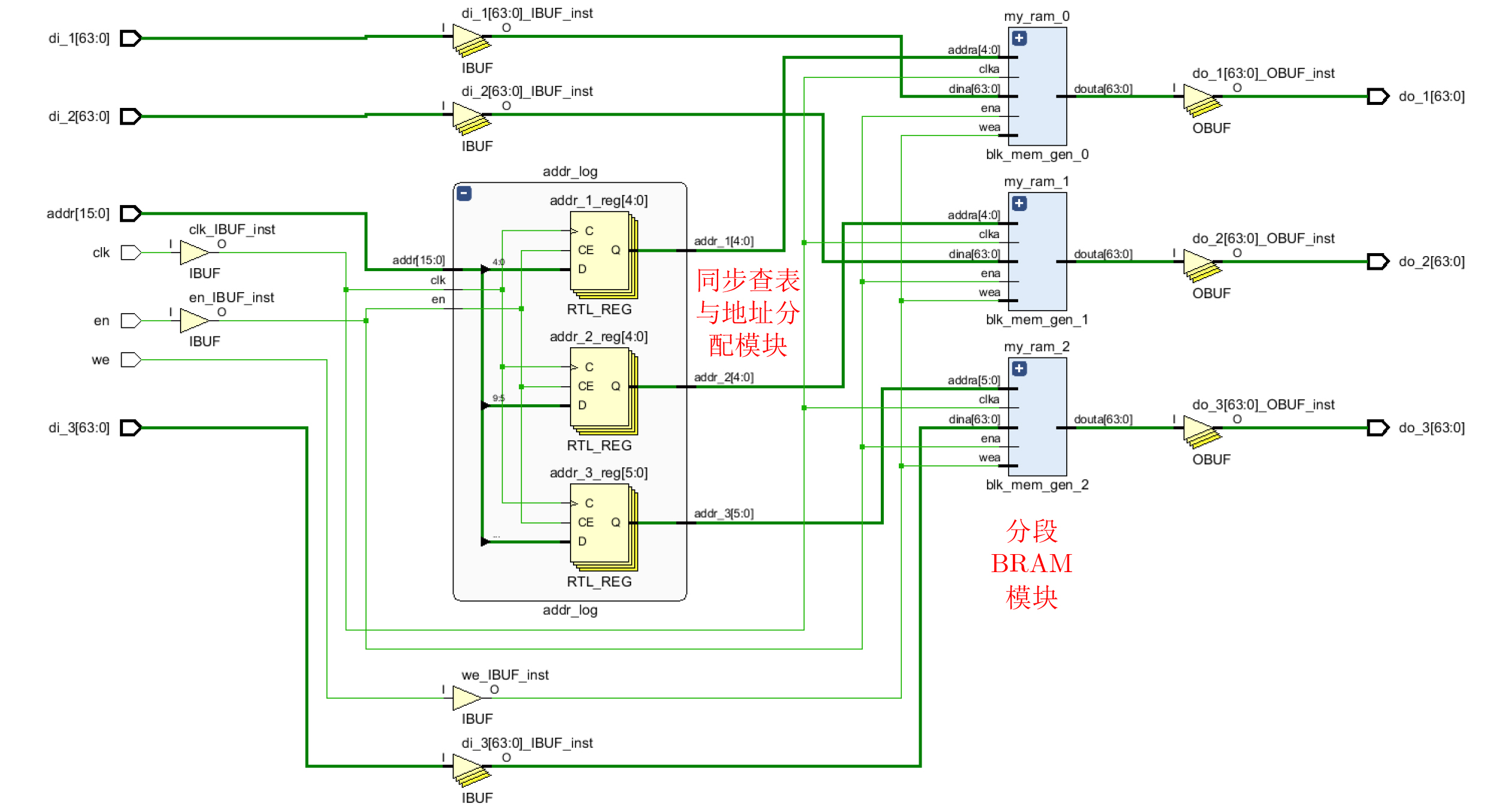
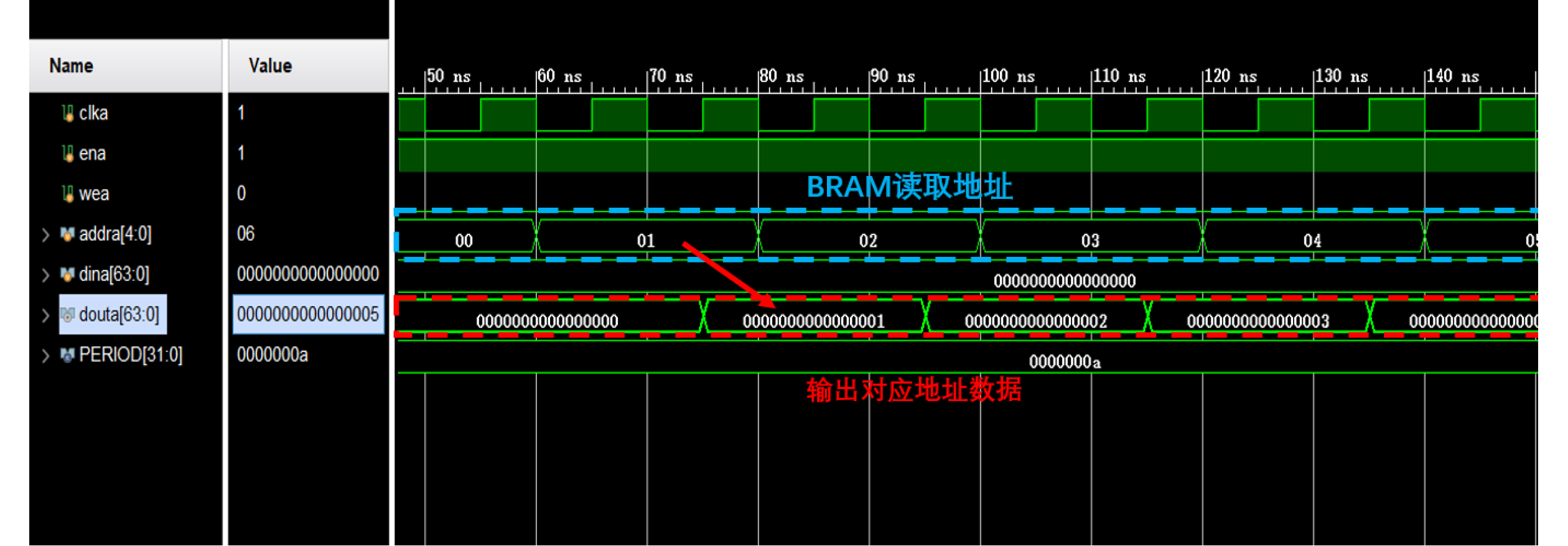
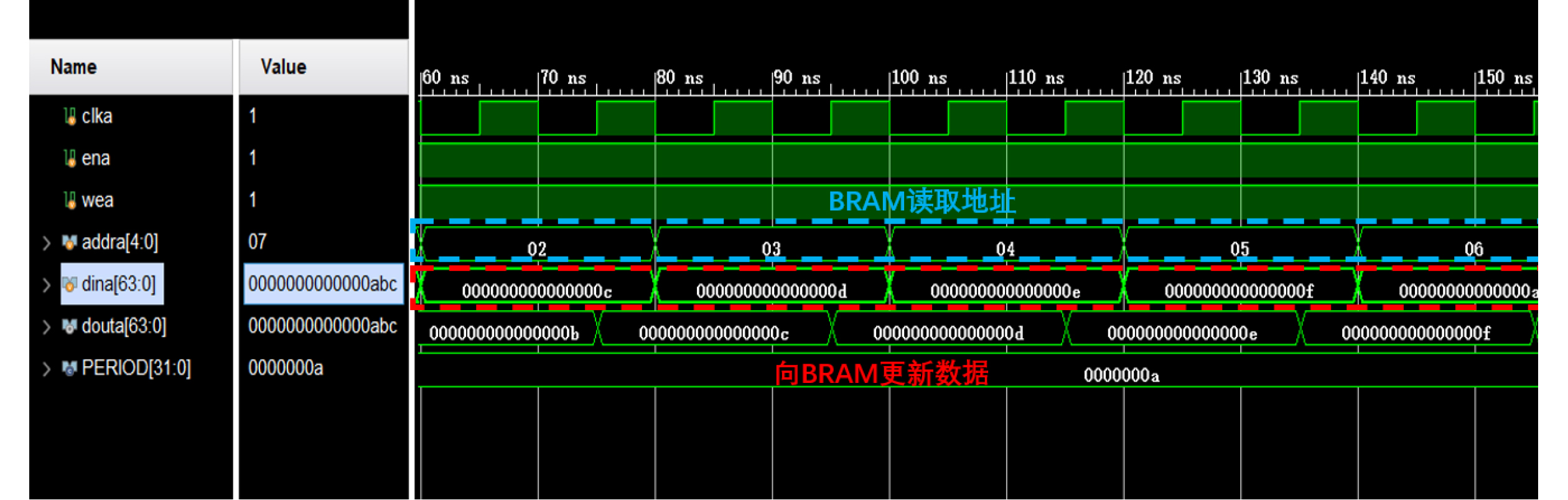
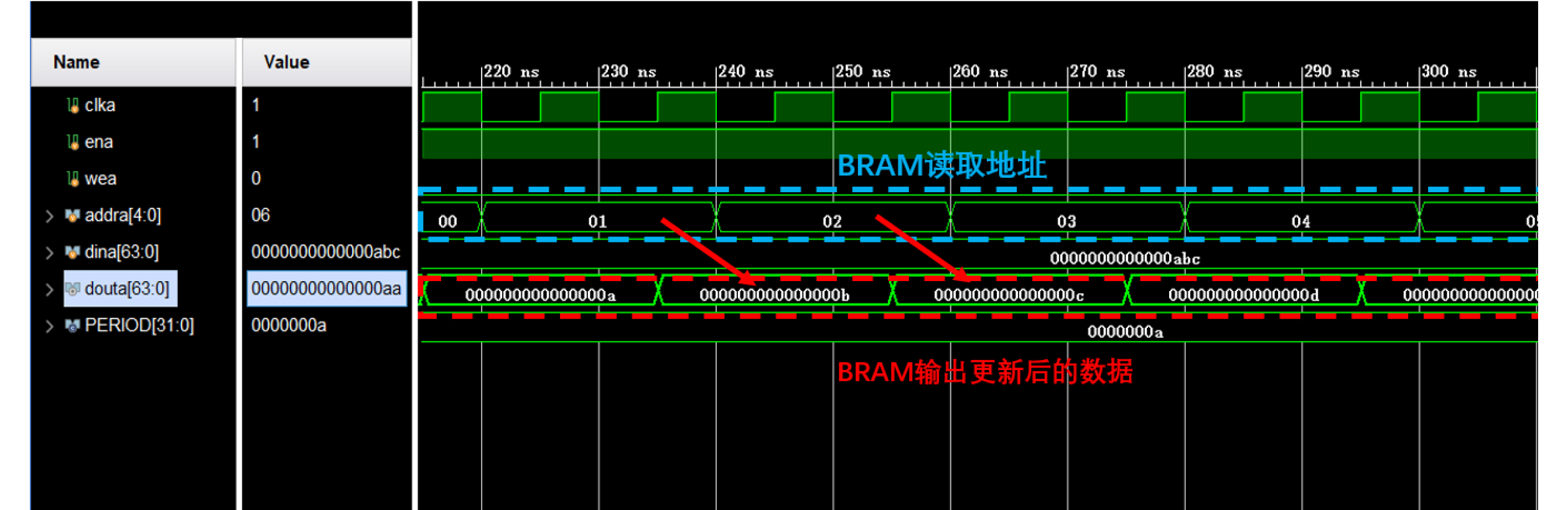
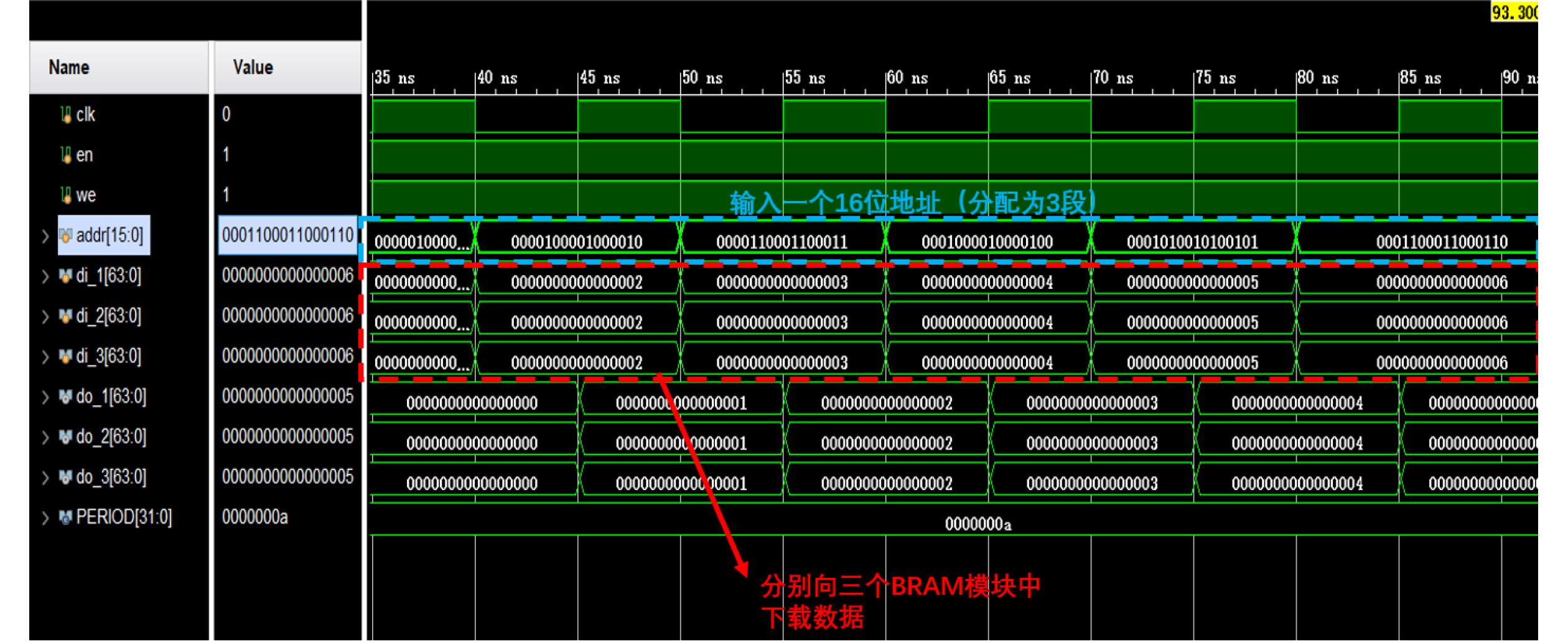
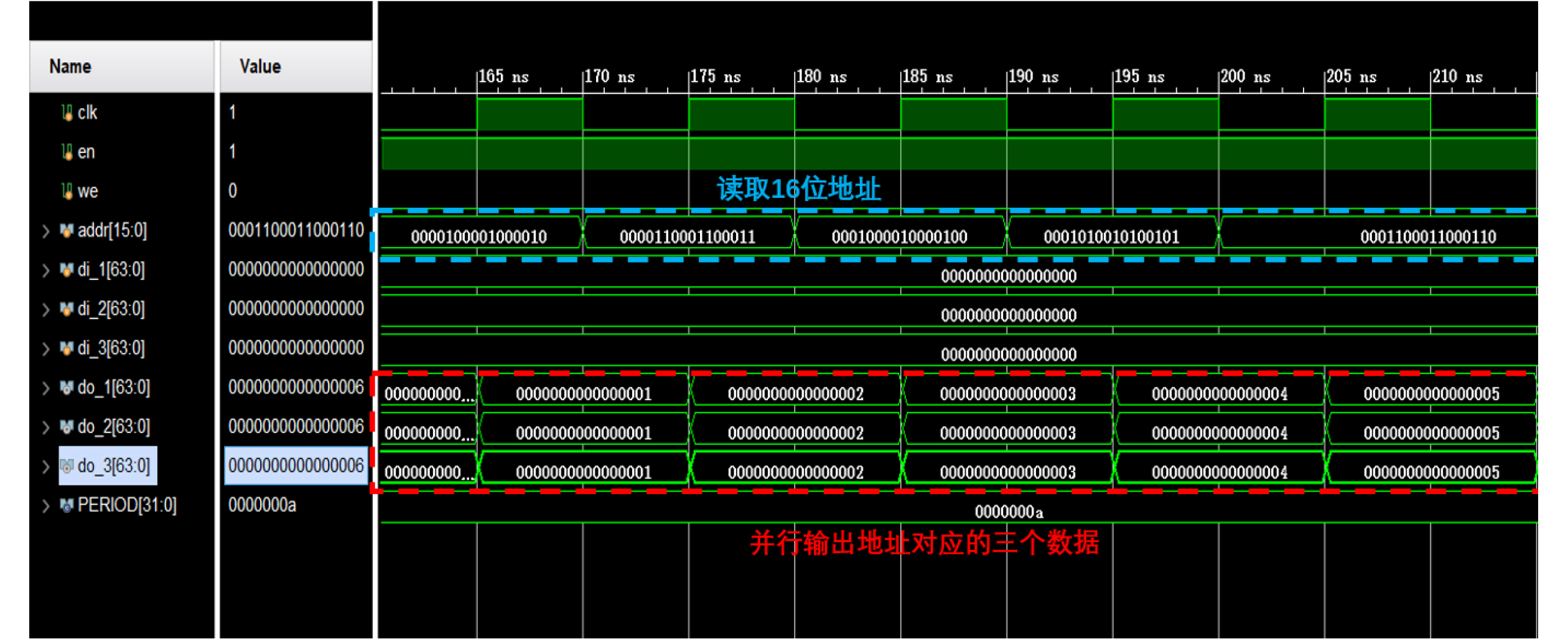
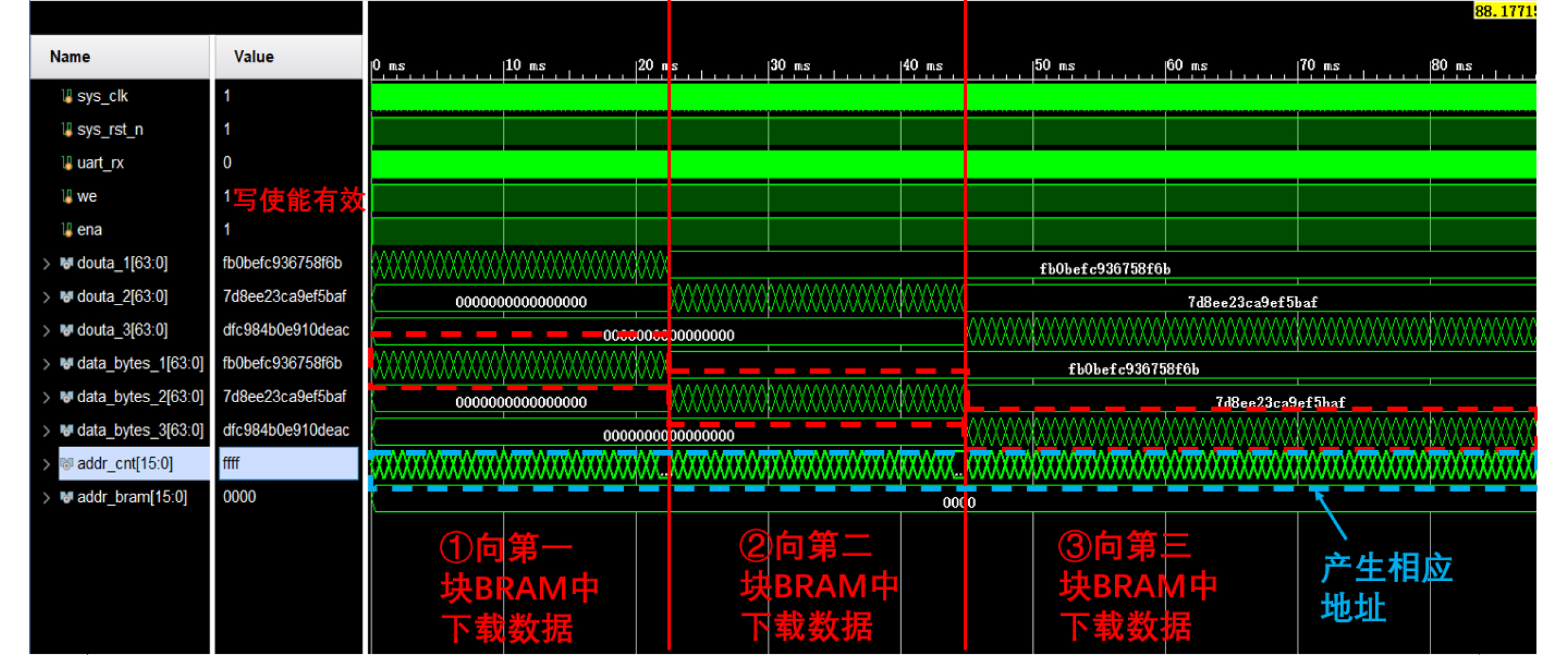
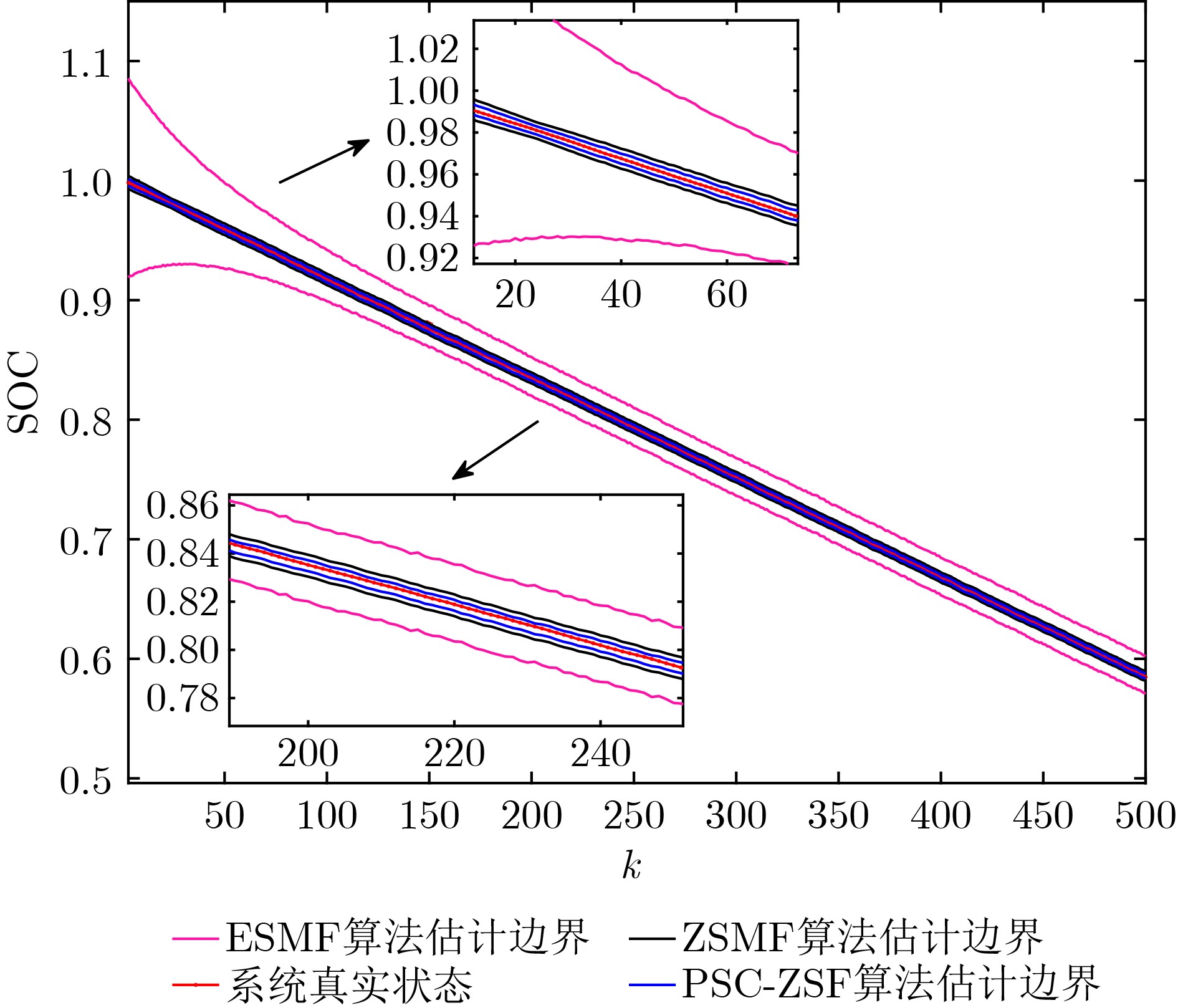
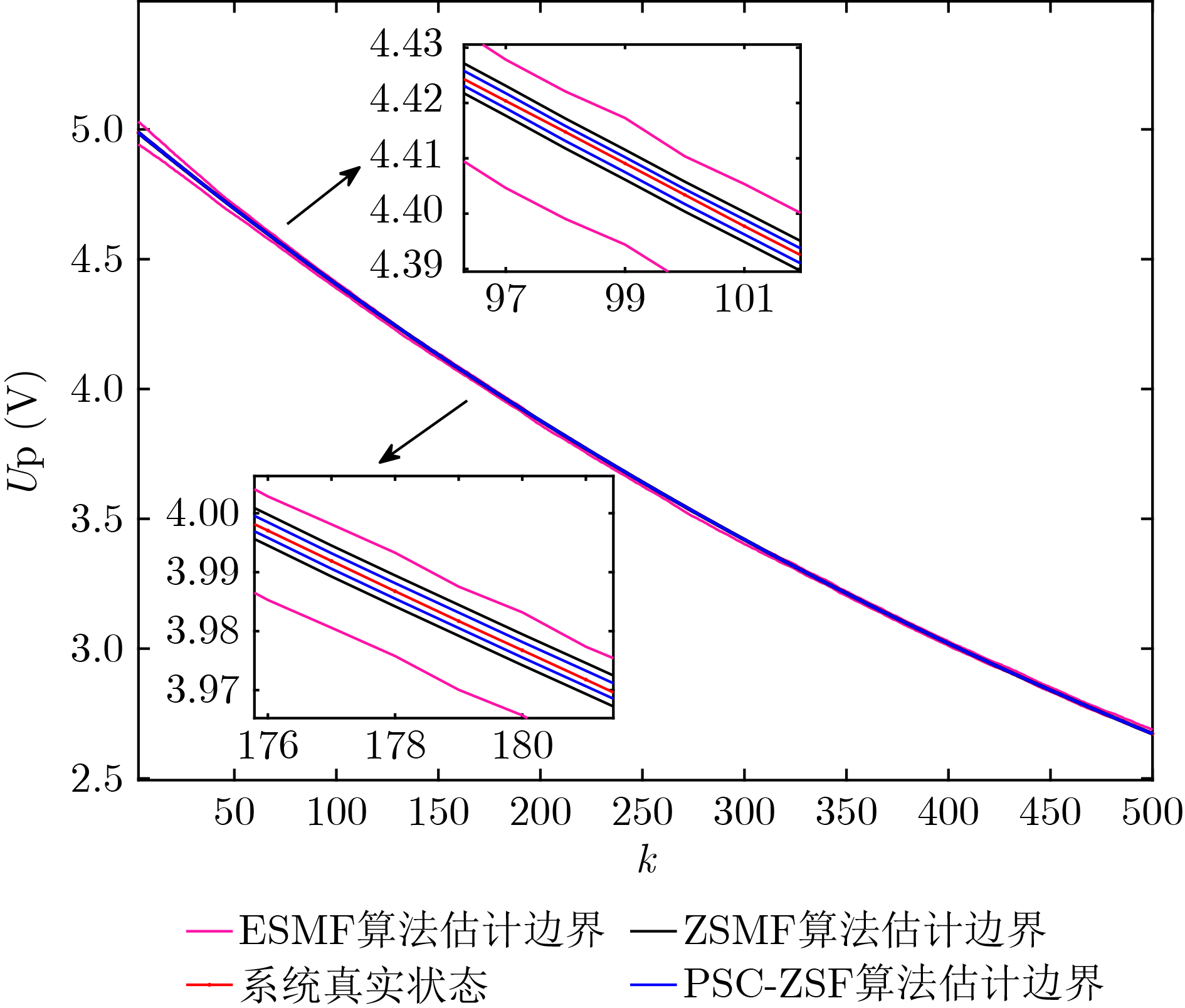
Significance Combinatorial Optimization Problems (COPs) are ubiquitous, profoundly impacting diverse fields from logistics and finance to advanced AI and drug discovery. At their core, these problems demand identifying the absolute best solution from an often unfathomably vast set of possibilities. The vast majority of COPs are classified as NP-hard problems, representing one of the most significant computational challenges in computer science. Traditional digital computers, operating on the von Neumann architecture, face immense difficulties in solving COPs; as problem scales expand, required computational resources, particularly latency, increase exponentially. Given these limitations, there’s an urgent need to explore novel architectures for efficiently solving COPs, a pursuit with both significant theoretical importance and profound practical implications for tackling complex, resource-intensive real-world problems. Addressing these challenges, researchers have actively explored various novel hardware-based combinatorial optimization solutions, often transforming COPs into Ising models or Quadratic Unconstrained Binary Optimization (QUBO) problems for hardware implementation. Broadly, existing approaches fall into two categories: digital Application-Specific Integrated Circuit (ASIC) annealers, which suffer from data movement bottlenecks, and dynamical system solvers, which leverage physical dynamics but often demand high device parameter precision, struggle with cross-chip scalability, and may find it difficult to integrate Ising model self-interaction terms. Beyond these, other non-traditional methods like quantum computing (e.g., D-Wave’s quantum annealers requiring cryogenic cooling and having limited connectivity) and certain optical computing approaches (e.g., relying on extremely long optical fibers) exist. While offering unique physical advantages, they generally face substantial challenges in integrating with mature silicon-based Very Large Scale Integration (VLSI) circuits. Consequently, despite a range of novel hardware solutions, their individual limitations highlight the critical need for new combinatorial optimization solvers that offer higher integration, better scalability, superior energy efficiency, and broader problem type support. Progress Ferroelectric Field-Effect Transistors (FeFETs), with their unique threshold voltage programmability and multi-port input structure, are opening exciting new avenues for efficiently solving combinatorial optimization problems (COPs). The FeFET-based compute-in-memory (CiM) architecture is particularly well-suited for these challenges, boasting high energy efficiency, low latency, and the inherent ability to accelerate complex operations like vector-matrix and vector-matrix-vector multiplications. Recent research has seen numerous works proposing FeFET-based CiM COP solvers to tackle a diverse range of problems, including those with equality constraints, inequality constraints, and Nash equilibrium scenarios. The overall solving process for these innovative FeFET-based CiM solutions generally involves four key steps: (1) Problem transformation, where the COP is converted into a hardware-friendly objective function, often by encoding equality constraints, introducing slack variables or penalty methods for inequality constraints, or formulating coupled optimization problems for Nash equilibrium scenarios; (2) Following transformation, the objective function undergoes a crucial compression process. This is specifically achieved by analyzing the simulated annealing algorithm itself, which allows for the partial activation of matrix columns, thus significantly reducing the typical computational complexity associated with fully active matrices. Furthermore, this step involves approximating and merging the exponential function components inherent in the algorithm directly into the matrix representation, thereby optimizing the function for efficient hardware implementation on the CiM array; (3) Leveraging the unique three-port and four-port structures of FeFETs, specialized CiM circuit designs are utilized to achieve high-speed acceleration of the compressed objective function. This allows for the efficient computation of a single iteration or a key part of the objective function often within a single clock cycle, significantly mitigating the von Neumann bottleneck; and (4) Finally, based on the optimized and simplified objective function, combinatorial optimization algorithms, such as simulated annealing, are simplified and applied over multiple cycles. This iterative process, efficiently accelerated by the underlying CiM hardware, aims to achieve high-quality and efficient solutions for the given problem. This structured approach highlights the adaptability and potential of FeFET-based CiM for a broad spectrum of challenging combinatorial optimization tasks. Conclusions This paper provides a comprehensive review of FeFET-based CiM solvers for solving COPs, which are prevalent across various domains and demand significant computational resources. It first outlines the device characteristics of FeFET and the fundamental process of solving COPs. The core of the paper focused on recent advancements in FeFET-based CiM solvers tailored for three specific scenarios: equality constraints, inequality constraints, and Nash equilibrium. The discussion highlighted how these architectures leverage the unique properties of FeFET to address the computational intensity of these problems. Prospects FeFET-based COP solvers show immense potential. By merging FeFET device strengths with CiM advantages, these solvers offer an efficient path to tackling highly complex optimization challenges, leading to substantial gains in speed and energy efficiency for real-world problems. However, significant challenges remain: (1) FeFET endurance is limited, restricting the number of processable problems. (2) Analog-to-digital converters (ADCs) in FeFET CiM arrays incur large area, power, and latency overheads. (3) Simulated annealing algorithms, when applied to large-scale problems, suffer from slow convergence due to increased iterations. Addressing these will be crucial for the widespread adoption and advancement of FeFET-based CiM solutions.