| Citation: | ZHOU Wu, NI Tianming, XU Dongyu, XU Sheng, LUO Le, CHEN Fulong. A Joint Fault and Congestion-Aware Adaptive Routing Algorithm for Chiplet Interconnect Networks[J]. Journal of Electronics & Information Technology, 2025, 47(9): 3155-3166. doi: 10.11999/JEIT250294

|

| [1] |
陈云霁, 蔡一茂, 汪玉, 等. 集成电路未来发展与关键问题——第347期“双清论坛(青年)”学术综述[J]. 中国科学: 信息科学, 2024, 54(1): 1–15. doi: 10.1360/SSI-2023-0356.
CHEN Yunji, CAI Yimao, WANG Yu, et al. Integrated circuit technology: Future development and key issues–review of the 347th “Shuangqing Forum(Youth)”[J]. Scientia Sinica Informationis, 2024, 54(1): 1–15. doi: 10.1360/SSI-2023-0356.
|
| [2] |
王梦迪, 王颖, 刘成, 等. Puzzle: 面向深度学习集成芯片的可扩展框架[J]. 计算机研究与发展, 2023, 60(6): 1216–1231. doi: 10.7544/issn1000-1239.202330059.
WANG Mengdi, WANG Ying, LIU Cheng, et al. Puzzle: A scalable framework for deep learning integrated chips[J]. Journal of Computer Research and Development, 2023, 60(6): 1216–1231. doi: 10.7544/issn1000-1239.202330059.
|
| [3] |
李韬, 杨惠, 厉俊男, 等. ChipletNP: 基于芯粒的敏捷可定制网络处理器架构[J]. 计算机研究与发展, 2024, 61(12): 2952–2968. doi: 10.7544/issn1000-1239.202220998.
LI Tao, YANG Hui, LI Junnan, et al. ChipletNP: Chiplet-based agile customizable network processor architecture[J]. Journal of Computer Research and Development, 2024, 61(12): 2952–2968. doi: 10.7544/issn1000-1239.202220998.
|
| [4] |
李雯, 王颖, 何银涛, 等. SMCA: 基于芯粒集成的存算一体加速器扩展框架[J]. 电子与信息学报, 2024, 46(11): 4081–4091. doi: 10.11999/JEIT240284.
LI Wen, WANG Ying, HE Yintao, et al. SMCA: A framework for scaling chiplet-based computing-in-memory accelerators[J]. Journal of Electronics & Information Technology, 2024, 46(11): 4081–4091. doi: 10.11999/JEIT240284.
|
| [5] |
陈桂林, 王观武, 胡健, 等. Chiplet封装结构与通信结构综述[J]. 计算机研究与发展, 2022, 59(1): 22–30. doi: 10.7544/issn1000-1239.20200314.
CHEN Guilin, WANG Guanwu, HU Jian, et al. Survey on chiplet packaging structure and communication structure[J]. Journal of Computer Research and Development, 2022, 59(1): 22–30. doi: 10.7544/issn1000-1239.20200314.
|
| [6] |
LAU J H. Chiplet Design and Heterogeneous Integration Packaging[M]. Singapore: Springer, 2023: 1–542. doi: 10.1007/978-981-19-9917-8.
|
| [7] |
FENG Yinxiao, XIANG Dong, and MA Kaisheng. A scalable methodology for designing efficient interconnection network of chiplets[C]. 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Montreal, Canada, 2023: 1059–1071. doi: 10.1109/HPCA56546.2023.10070981.
|
| [8] |
MA Xiaohan, WANG Ying, WANG Yujie, et al. Survey on chiplets: Interface, interconnect and integration methodology[J]. CCF Transactions on High Performance Computing, 2022, 4(1): 43–52. doi: 10.1007/s42514-022-00093-0.
|
| [9] |
WANG Tianqi, FENG Fan, XIANG Shaolin, et al. Application defined on-chip networks for heterogeneous chiplets: An implementation perspective[C]. 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Republic of Korea, 2022: 1198–1210. doi: 10.1109/HPCA53966.2022.00091.
|
| [10] |
LIU Yafei, LI Xiangyu, and YIN Shouyi. Review of chiplet-based design: System architecture and interconnection[J]. Science China Information Sciences, 2024, 67(10): 200401. doi: 10.1007/s11432-023-3926-8.
|
| [11] |
HAN Yinhe, XU Haobo, LU Meixuan, et al. The big chip: Challenge, model and architecture[J]. Fundamental Research, 2024, 4(6): 1431–1441. doi: 10.1016/j.fmre.2023.10.020.
|
| [12] |
NAFFZIGER S, BECK N, BURD T, et al. Pioneering chiplet technology and design for the AMD EPYCTM and RyzenTM processor families: Industrial product[C]. 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 2021: 57–70. doi: 10.1109/ISCA52012.2021.00014.
|
| [13] |
SINGH T, RANGARAJAN S, JOHN D, et al. 2.1 Zen 2: The AMD 7nm energy-efficient high-performance x86-64 microprocessor core[C]. 2020 IEEE International Solid-State Circuits Conference - (ISSCC), San Francisco, USA, 2020, 42–44. doi: 10.1109/ISSCC19947.2020.9063113.
|
| [14] |
NAFFZIGER S, LEPAK K, PARASCHOU M, et al. 2.2 AMD chiplet architecture for high-performance server and desktop products[C]. 2020 IEEE International Solid-State Circuits Conference - (ISSCC), San Francisco, USA, 2020: 44–45. doi: 10.1109/ISSCC19947.2020.9063103.
|
| [15] |
WANG Xiaohang, WANG Yifan, JIANG Yingtao, et al. On task mapping in multi-chiplet based many-core systems to optimize inter- and intra-chiplet communications[J]. IEEE Transactions on Computers, 2025, 74(2): 510–525. doi: 10.1109/TC.2024.3500354.
|
| [16] |
CHEN Chixiao, YIN Jieming, PENG Yarui, et al. Design challenges of intrachiplet and interchiplet interconnection[J]. IEEE Design & Test, 2022, 39(6): 99–109. doi: 10.1109/MDAT.2022.3203005.
|
| [17] |
ZHENG Hao, WANG Ke, and LOURI A. A versatile and flexible chiplet-based system design for heterogeneous manycore architectures[C]. 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, USA, 2020: 1–6. doi: 10.1109/DAC18072.2020.9218654.
|
| [18] |
HUANG Letian, ZHAO Tianjin, WANG Ziren, et al. Component dependencies based network-on-chip test[J]. IEEE Transactions on Computers, 2024, 73(12): 2805–2816. doi: 10.1109/TC.2024.3457732.
|
| [19] |
FENG Yinxiao and MA Kaisheng. Chiplet actuary: A quantitative cost model and multi-chiplet architecture exploration[C]. Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, USA, 2022: 121–126. doi: 10.1145/3489517.3530428.
|
| [20] |
DONG Xiao, SUN Songyu, JIANG Yangfan, et al. SPIRAL+: Efficient signal-power integrity co-analysis for inter-chiplet links validation[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025, 44(8): 3140–3153. doi: 10.1109/TCAD.2025.3532822.
|
| [21] |
EHRETT P, AUSTIN T, and BERTACCO V. SiPterposer: A fault-tolerant substrate for flexible system-in-package design[C]. 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 2019: 510–515. doi: 10.23919/DATE.2019.8714998.
|
| [22] |
TAHERI E, PASRICHA S, and NIKDAST M. DeFT: A deadlock-free and fault-tolerant routing algorithm for 2.5D chiplet networks[C]. 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 2022: 1047–1052. doi: 10.23919/DATE54114.2022.9774617.
|
| [23] |
XIONG Ruoting, REN Wei, ZHANG Chengzhuo, et al. A sampling-based acceleration method for heterogeneous chiplet noc simulations[J]. Future Generation Computer Systems, 2025, 166: 107643. doi: 10.1016/j.future.2024.107643.
|
| [24] |
FU Yuxiang, ZHANG Chuan, SONG Wenqing, et al. Optimizing vertical link placement and congestion aware dynamic elevator assignment for partially connected 3D-NoCs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2021, 40(10): 1957–1970. doi: 10.1109/TCAD.2020.3038338.
|
| [25] |
NEZARAT M and MOMENI M. TCAR: Thermal and congestion-aware routing algorithm in a partially connected 3D network on chip[C]. 2022 12th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 2022: 106–111. doi: 10.1109/ICCKE57176.2022.9960056.
|
| [26] |
TAHERI E, KIM R G, and NIKDAST M. AdEle+: An adaptive congestion-and-energy-aware elevator selection for partially connected 3D networks-on-chip[J]. IEEE Transactions on Computers, 2023, 72(8): 2278–2292. doi: 10.1109/TC.2023.3248260.
|
| [27] |
VIVET P, GUTHMULLER E, THONNART Y, et al. IntAct: A 96-core processor with six chiplets 3D-stacked on an active interposer with distributed interconnects and integrated power management[J]. IEEE Journal of Solid-State Circuits, 2021, 56(1): 79–97. doi: 10.1109/JSSC.2020.3036341.
|
| [28] |
ZHI Changle, DONG Gang, YANG Deguang, et al. Electrical and thermal characteristics optimization in interposer-based 2.5-D integrated circuits[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2025, 33(3): 627–637. doi: 10.1109/TVLSI.2024.3478846.
|
| [29] |
LIAO Chengyi, HE Huimin, LIU Fengman, et al. Enhanced fabrication and assembly of 3-D chiplets based on active interposer with frontside via-last TSVs[J]. IEEE Transactions on Components, Packaging and Manufacturing Technology, 2024, 14(9): 1692–1700. doi: 10.1109/TCPMT.2024.3443858.
|
| [30] |
FENG Yinxiao, XIANG Dong, and MA Kaisheng. Heterogeneous die-to-die interfaces: Enabling more flexible chiplet interconnection systems[C]. 2023 56th IEEE/ACM International Symposium on Microarchitecture (MICRO), Toronto, Canada, 2023: 930–943.
|
| [31] |
YIN Jieming, LIN Zhifeng, KAYIRAN O, et al. Modular routing design for chiplet-based systems[C]. 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, USA, 2018: 726–738. doi: 10.1109/ISCA.2018.00066.
|
| [32] |
TAHERI E, PASRICHA S, and NIKDAST M. ReD: A reliable and deadlock-free routing for 2.5-D chiplet-based interposer networks[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024, 43(12): 4599–4612. doi: 10.1109/TCAD.2024.3399660.
|
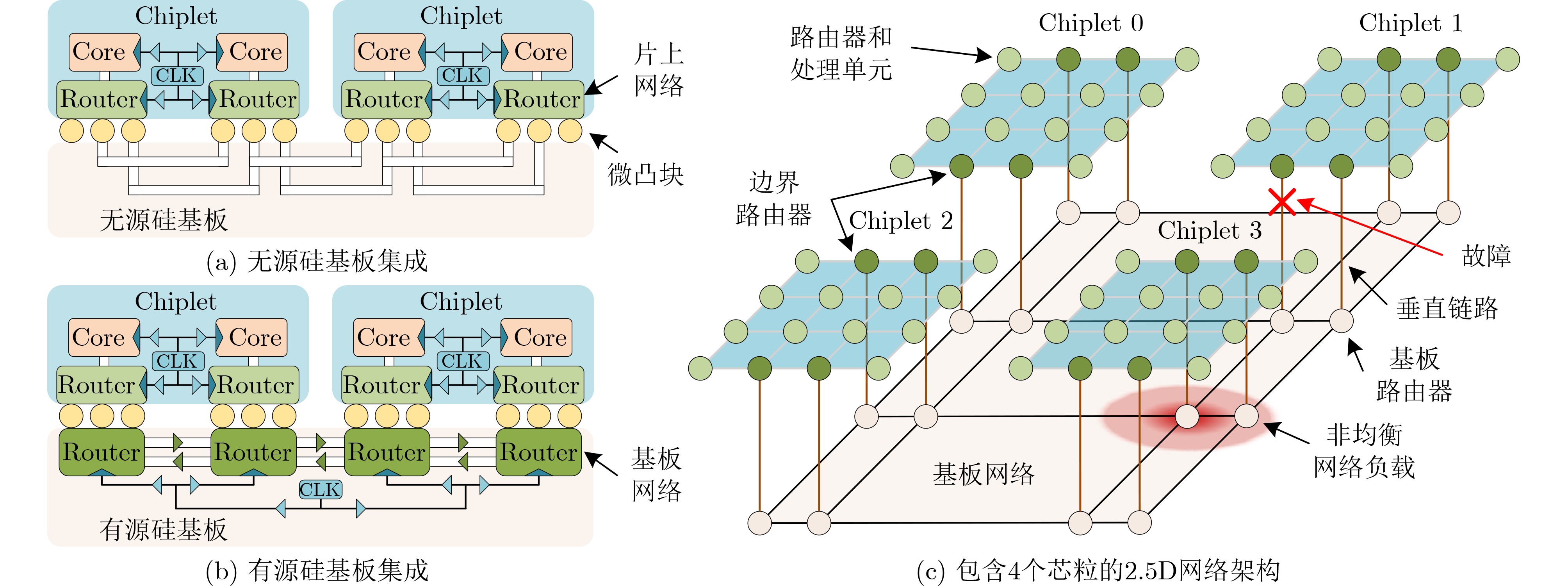
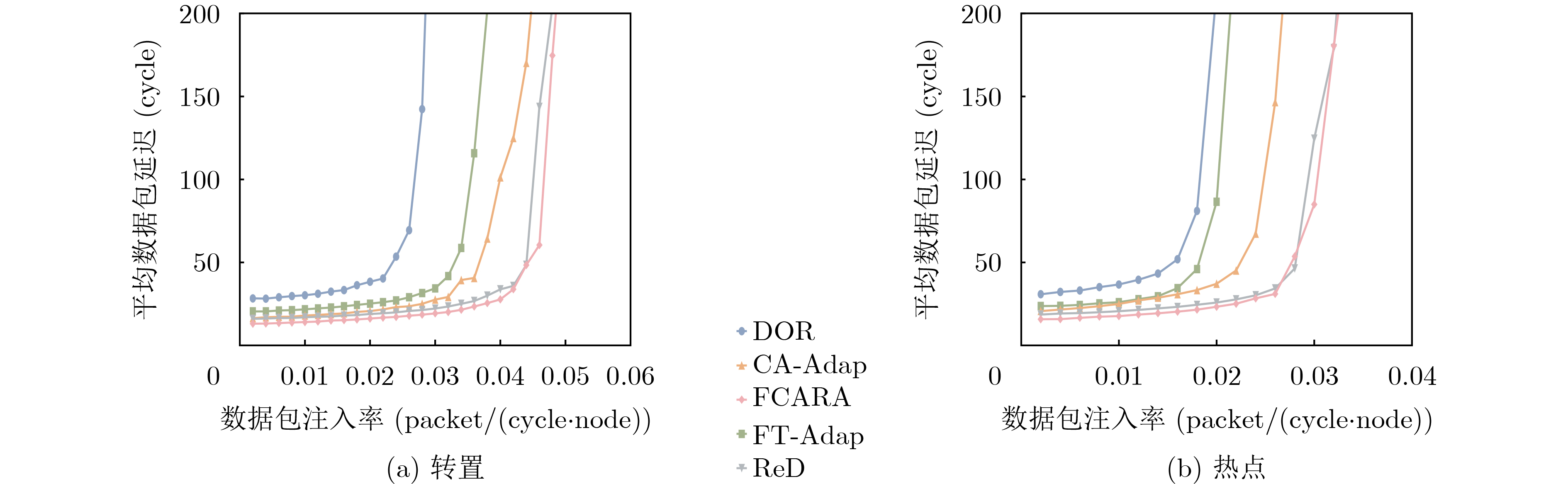
Figures(11) / Tables(4)


 DownLoad:
DownLoad: