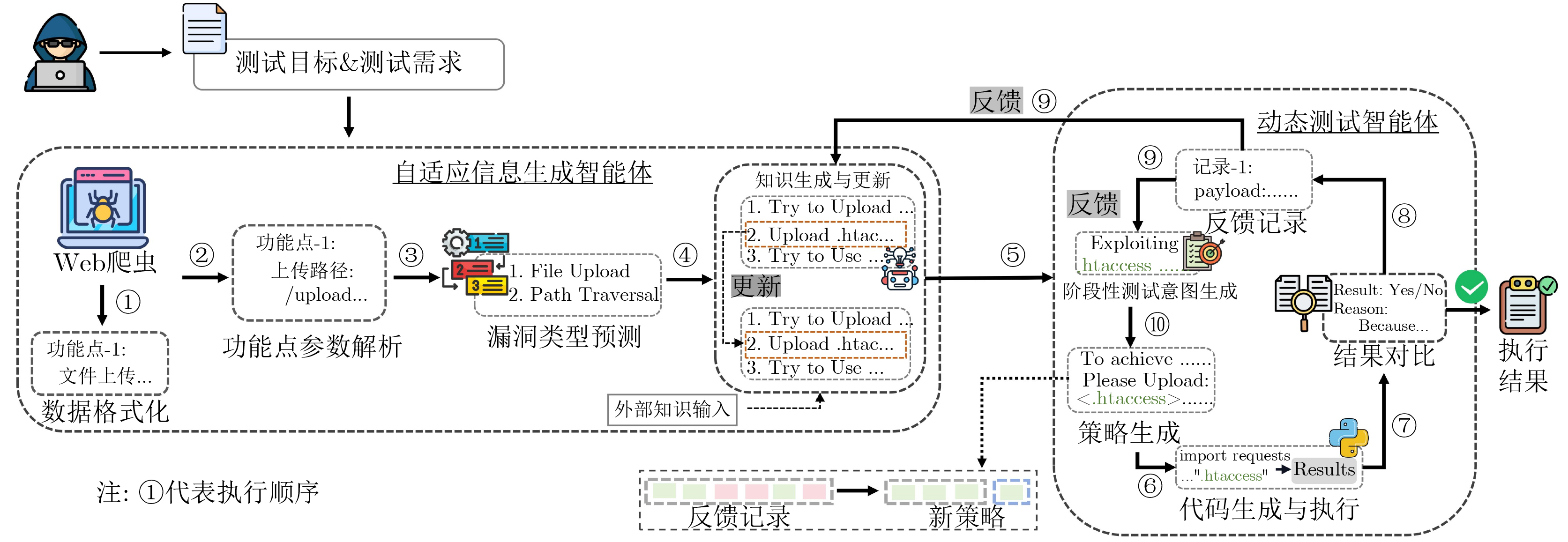
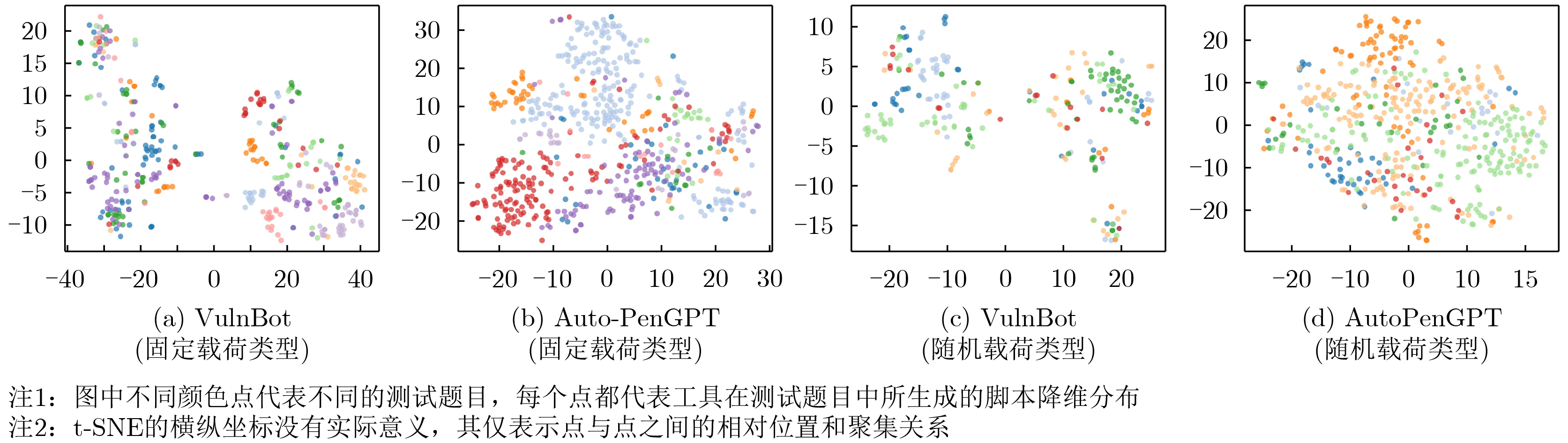
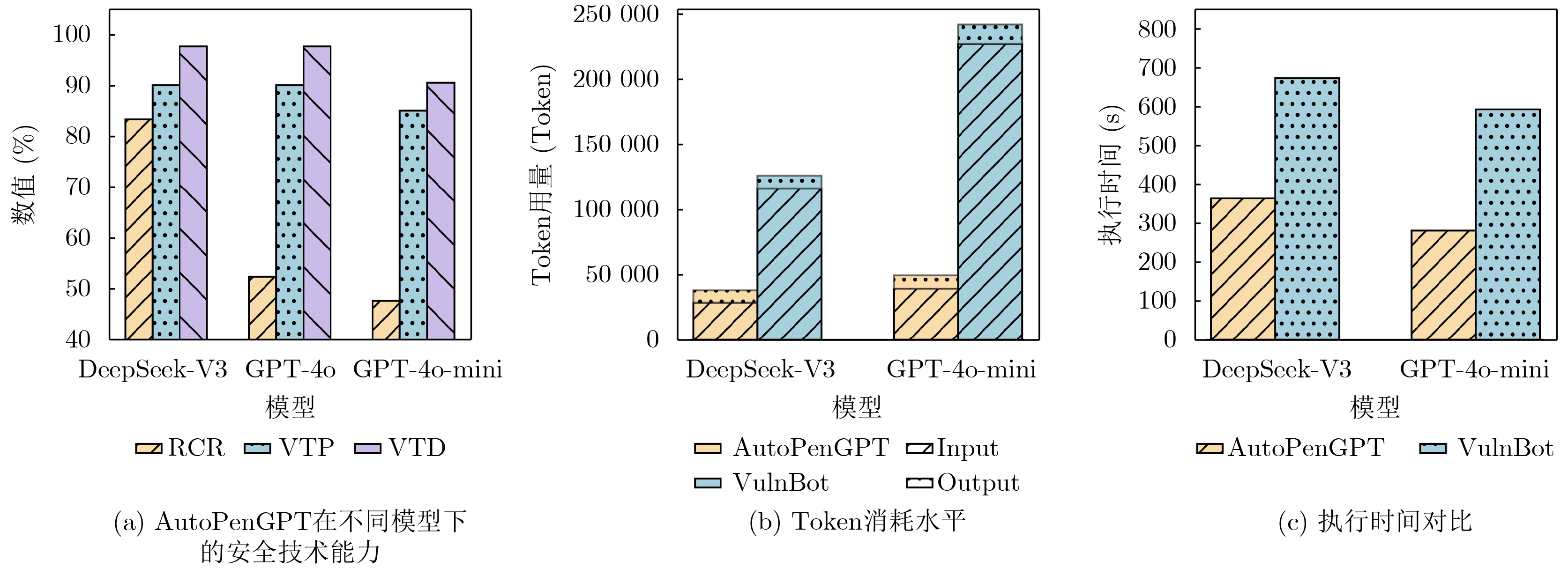
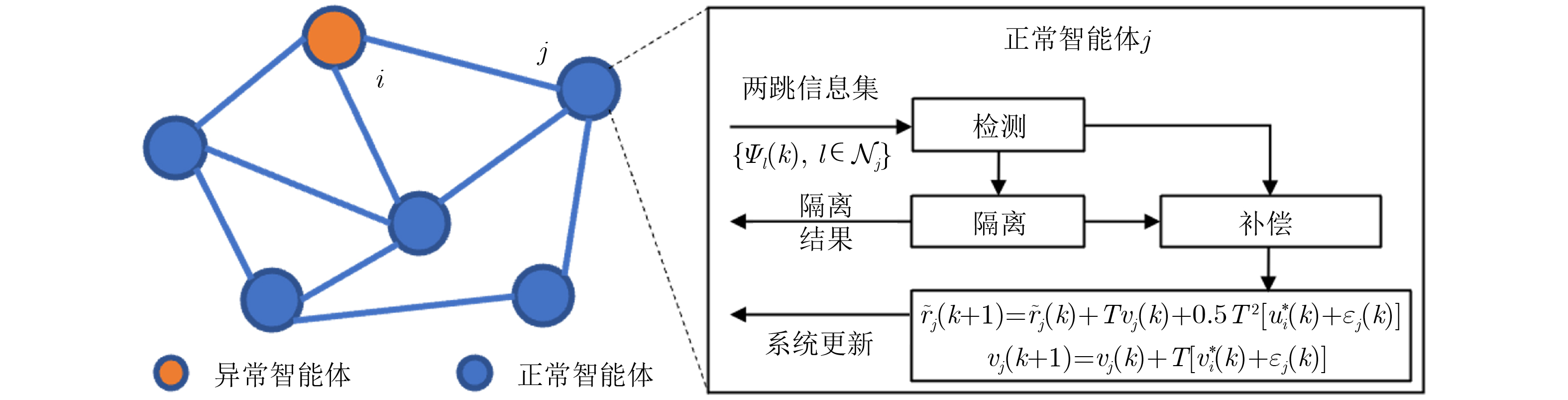
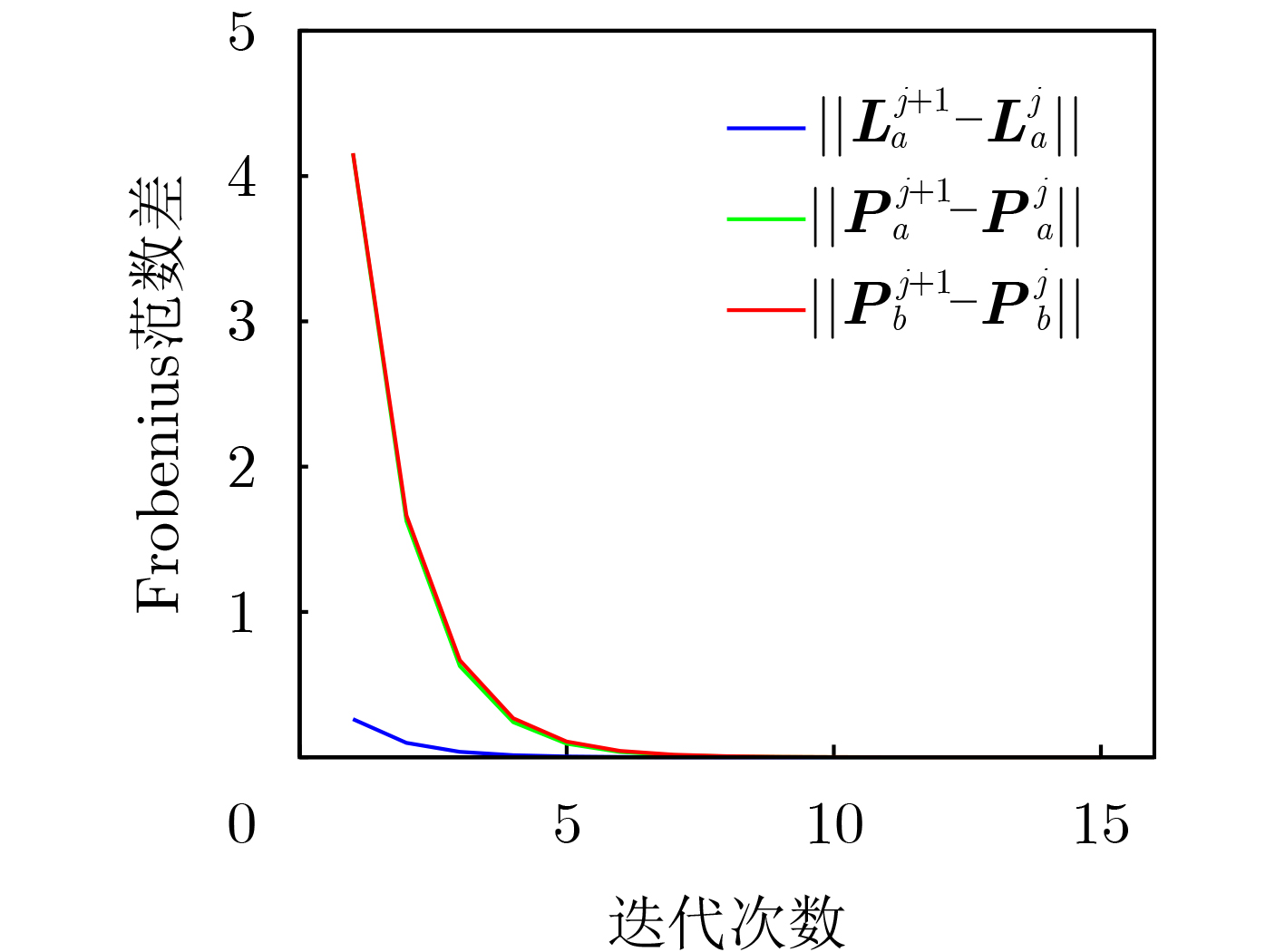
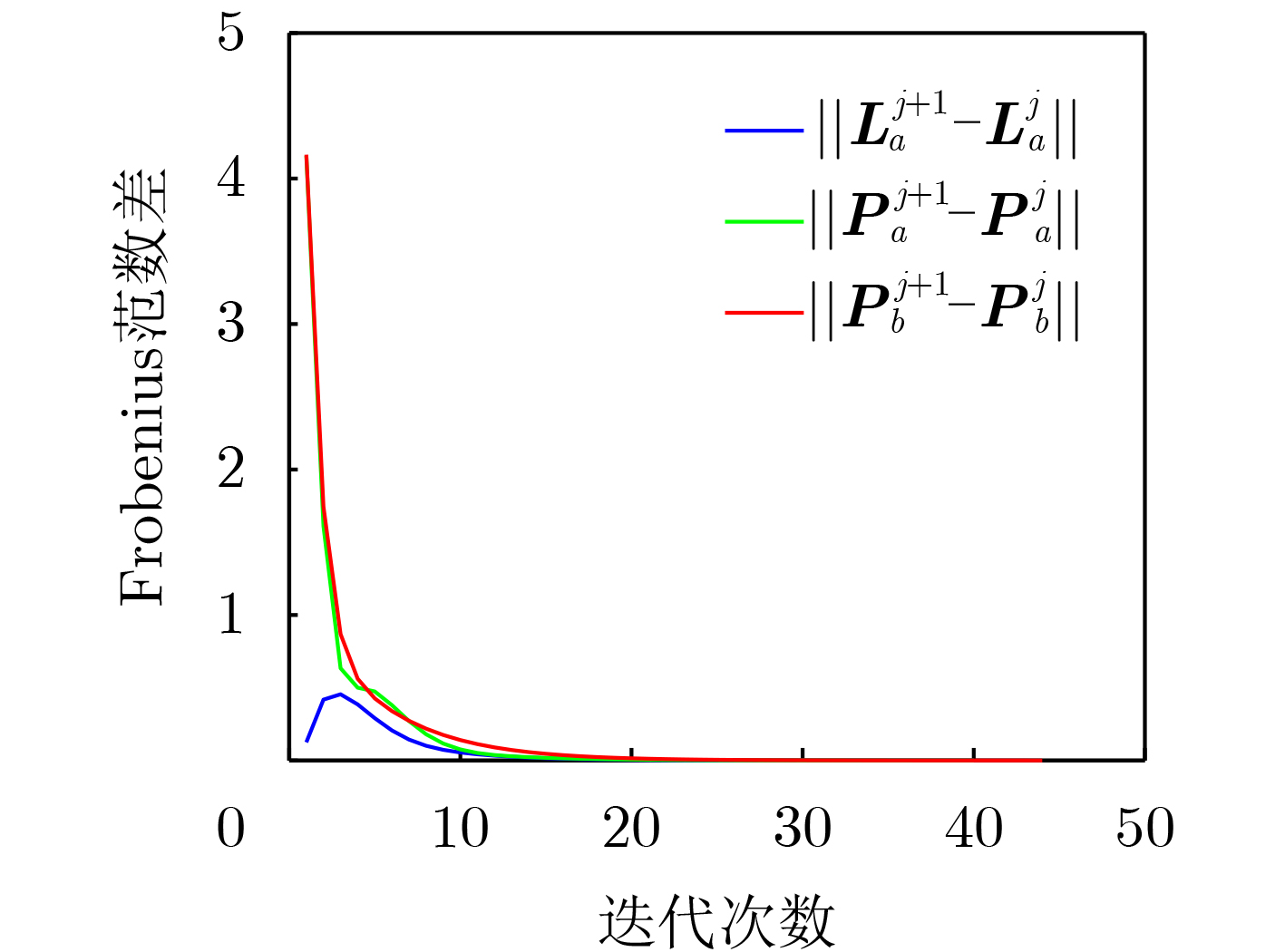
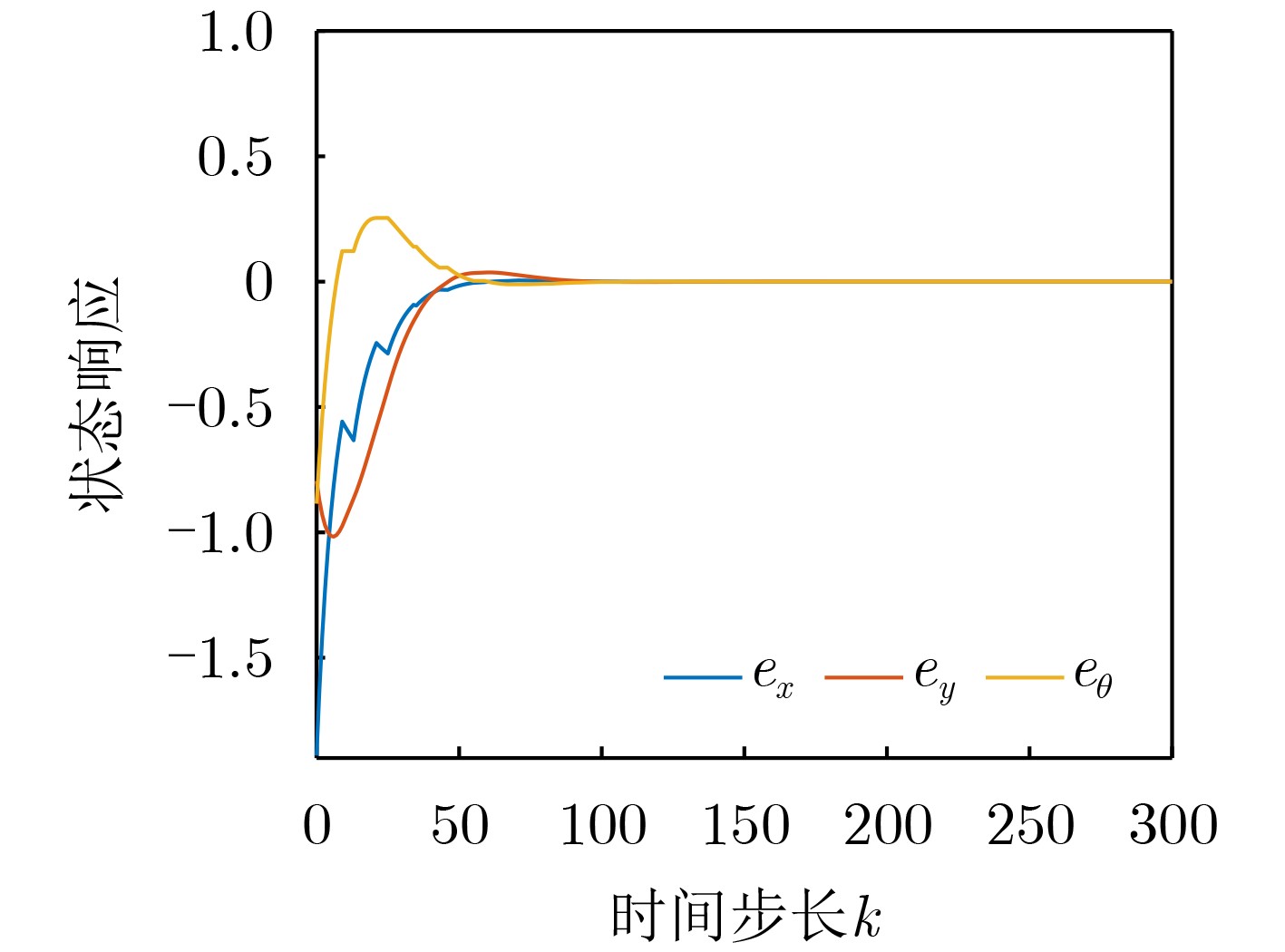
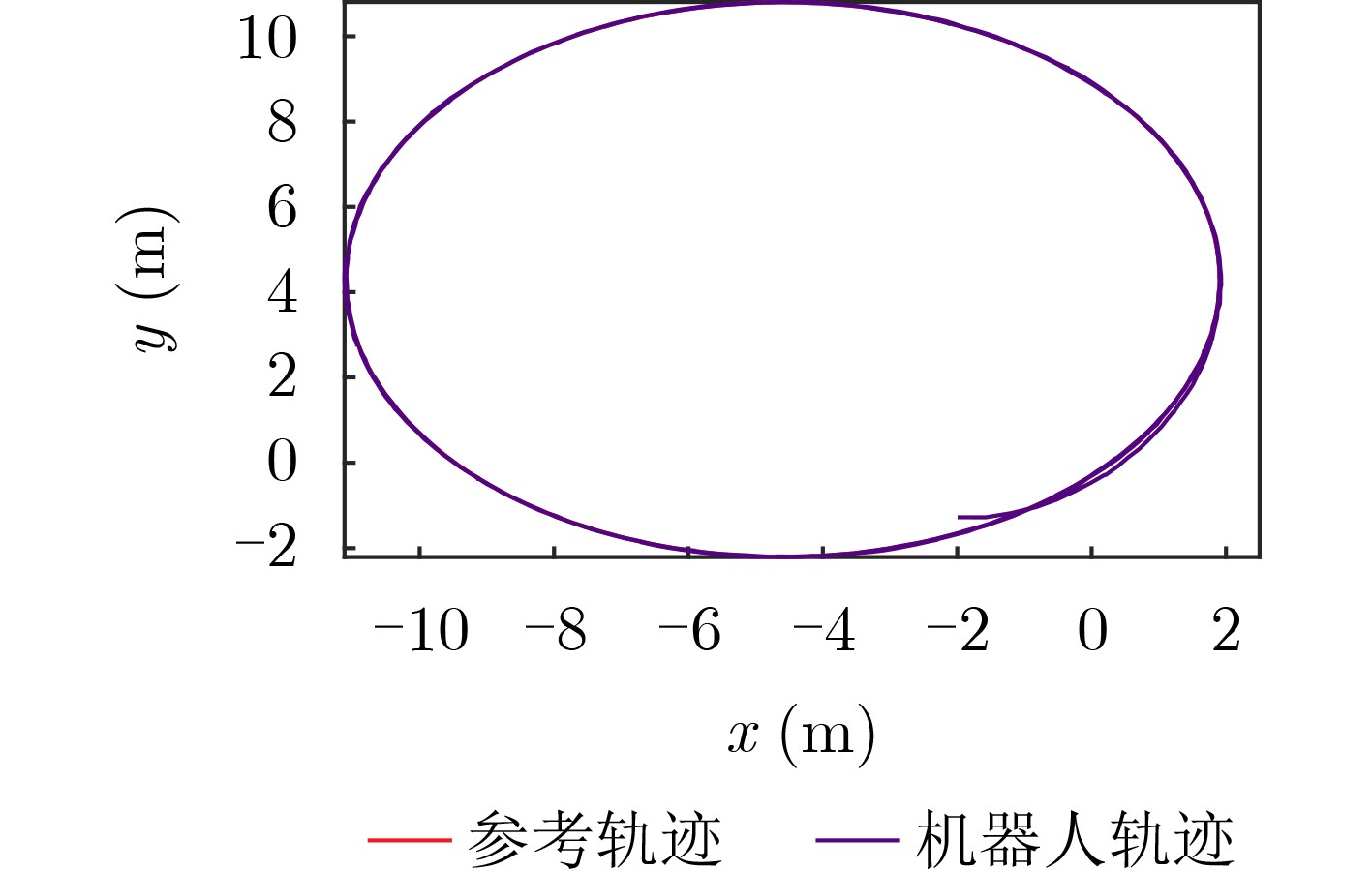
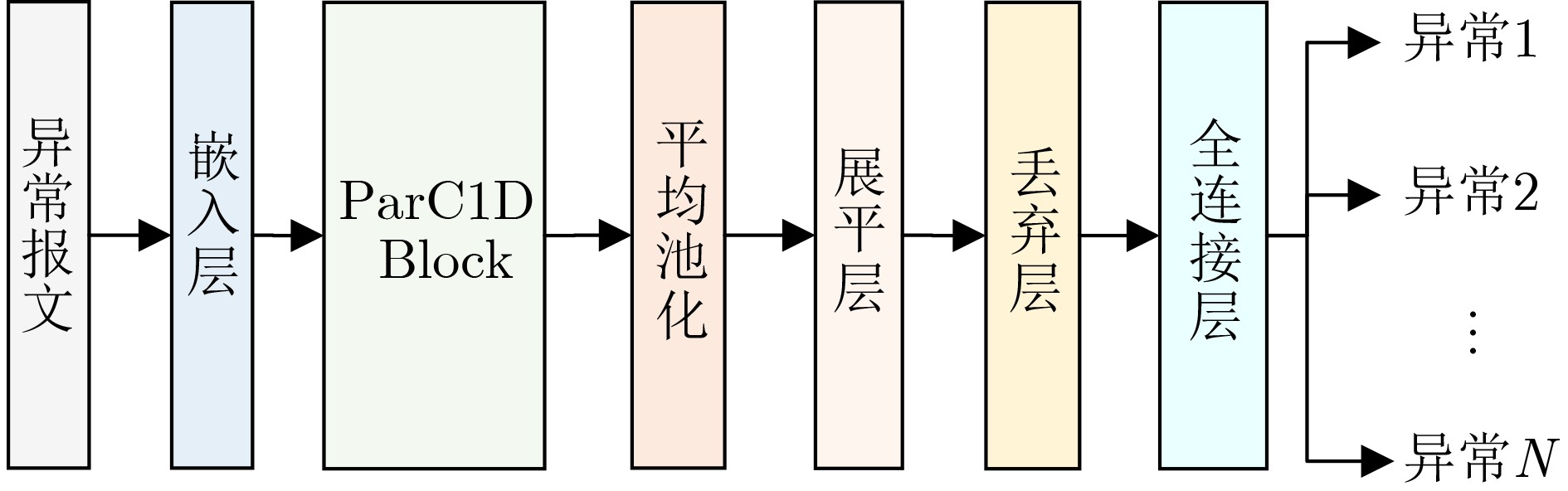
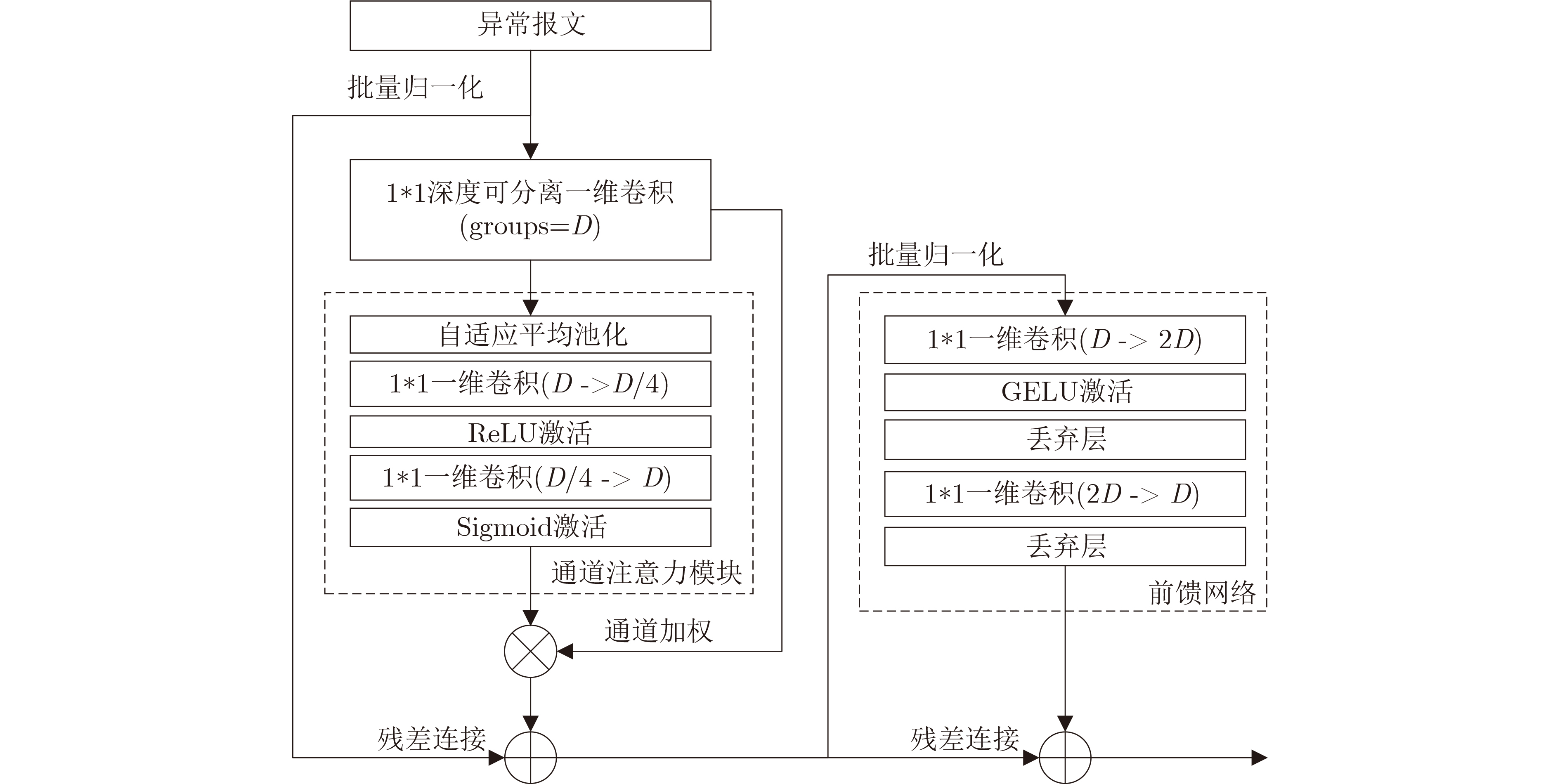
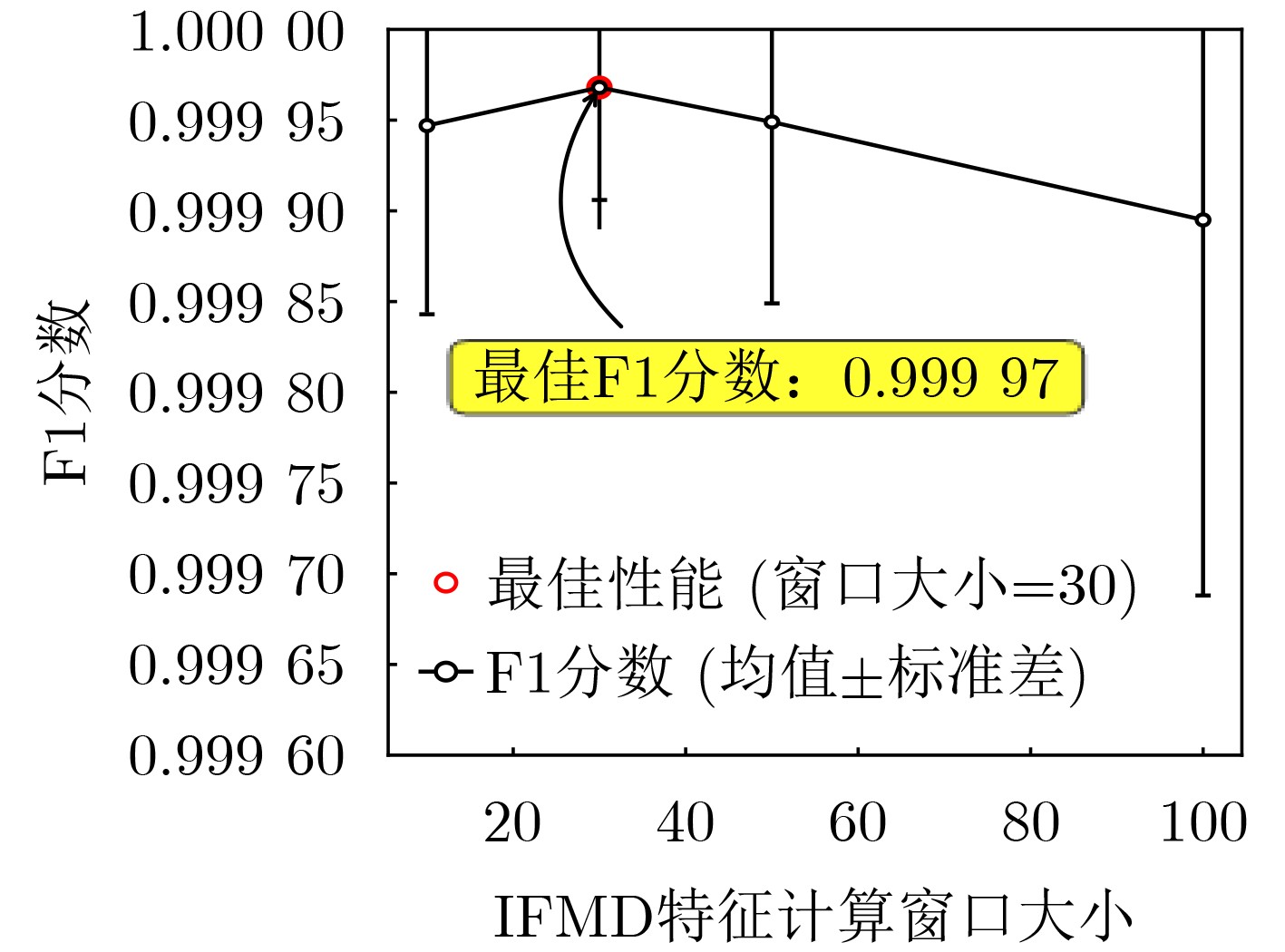
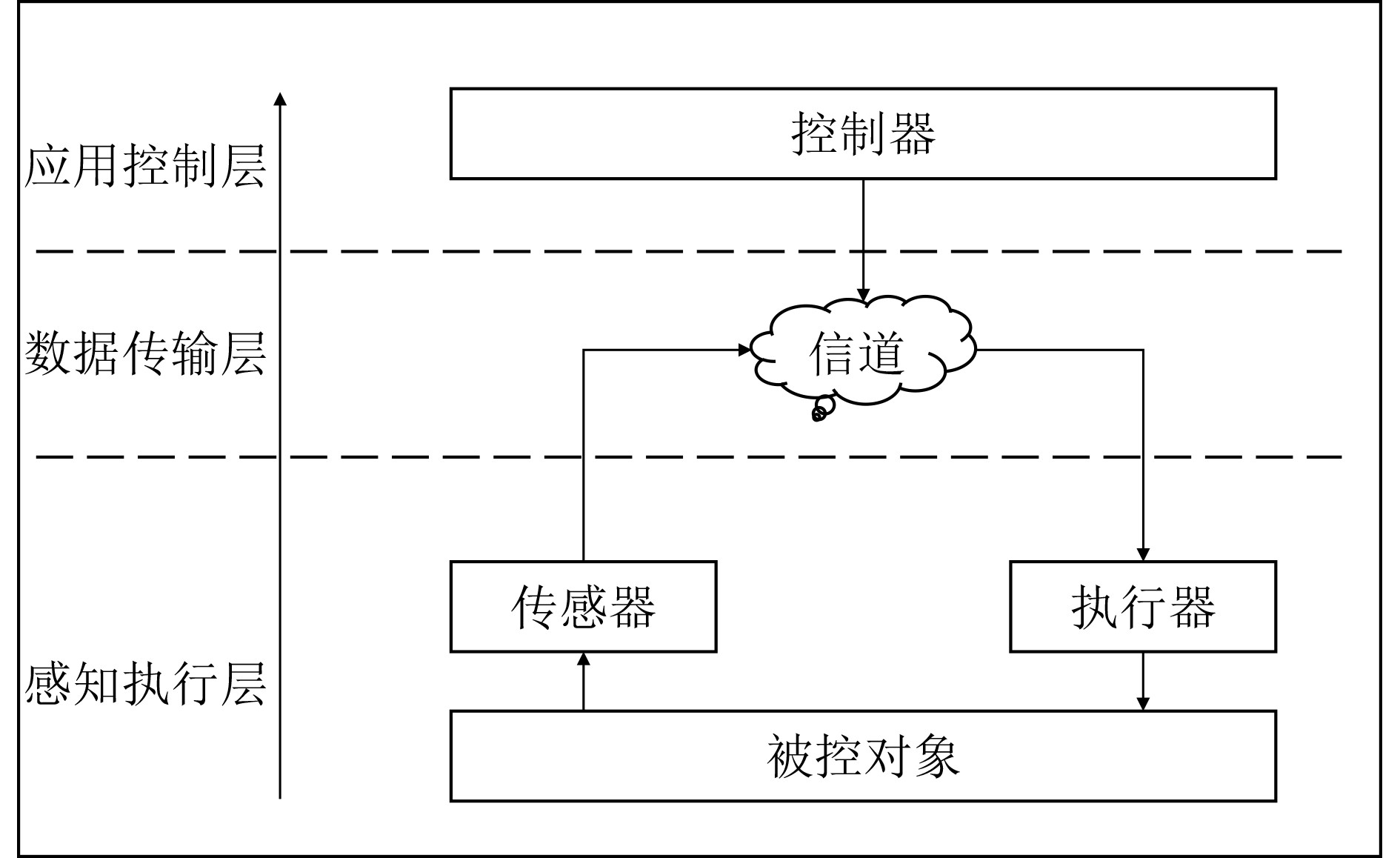
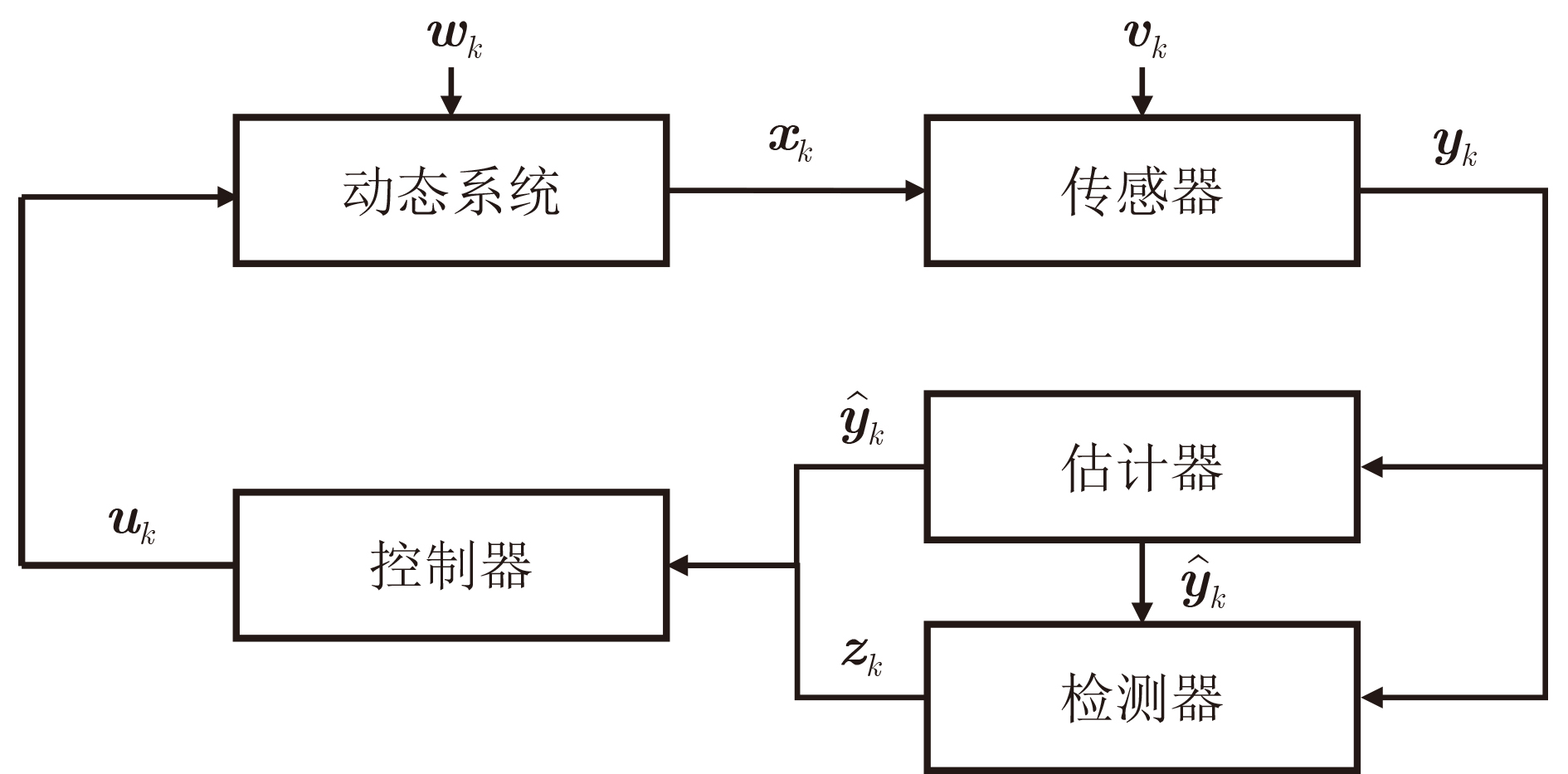
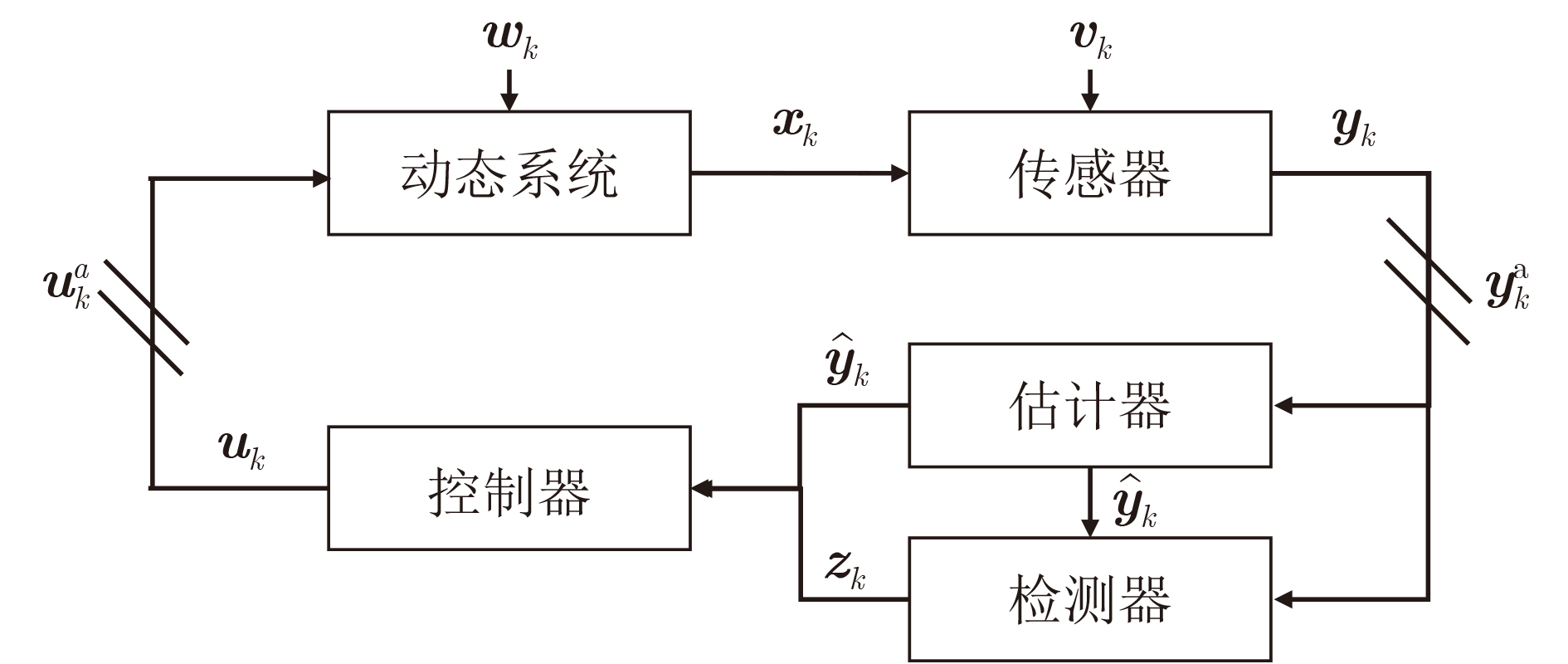
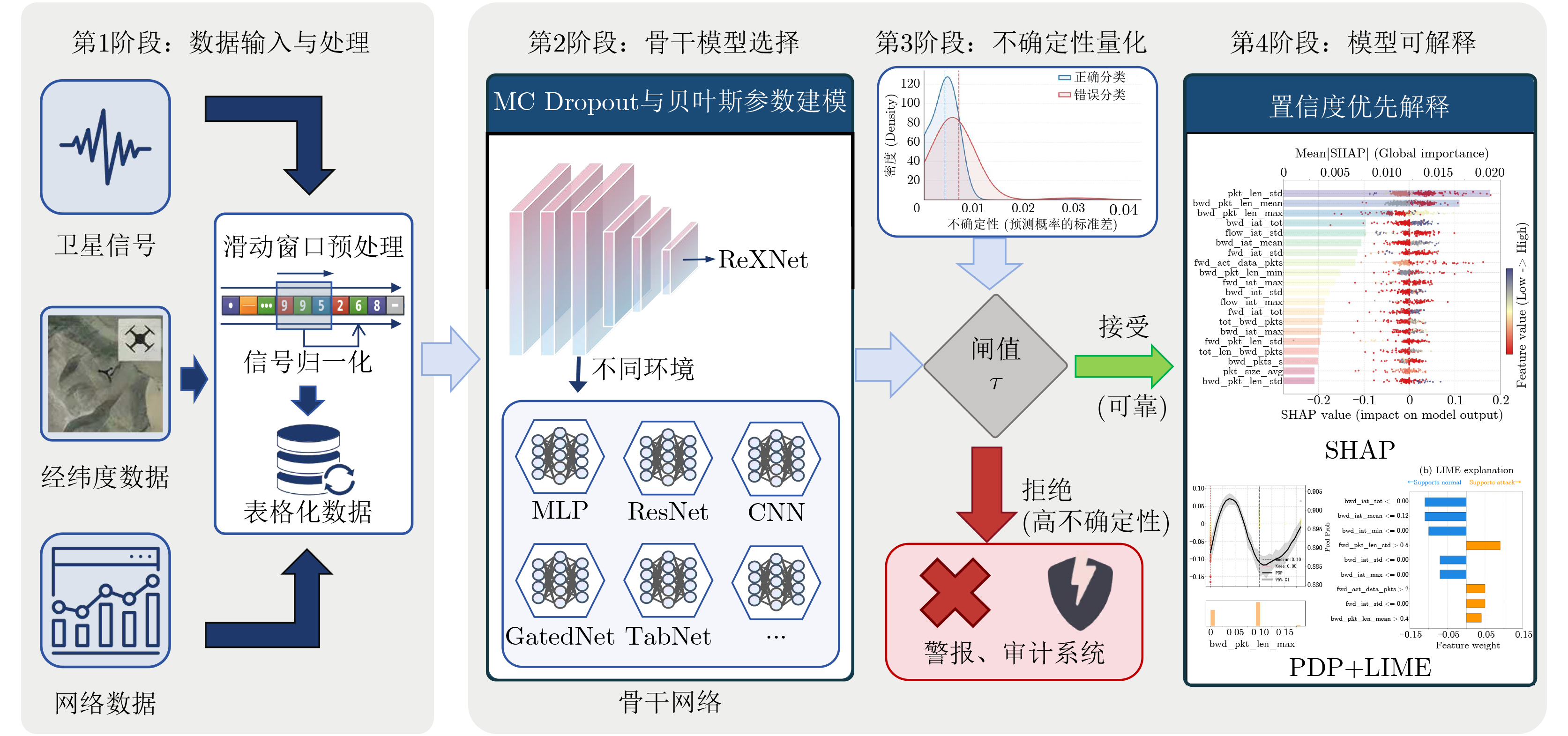
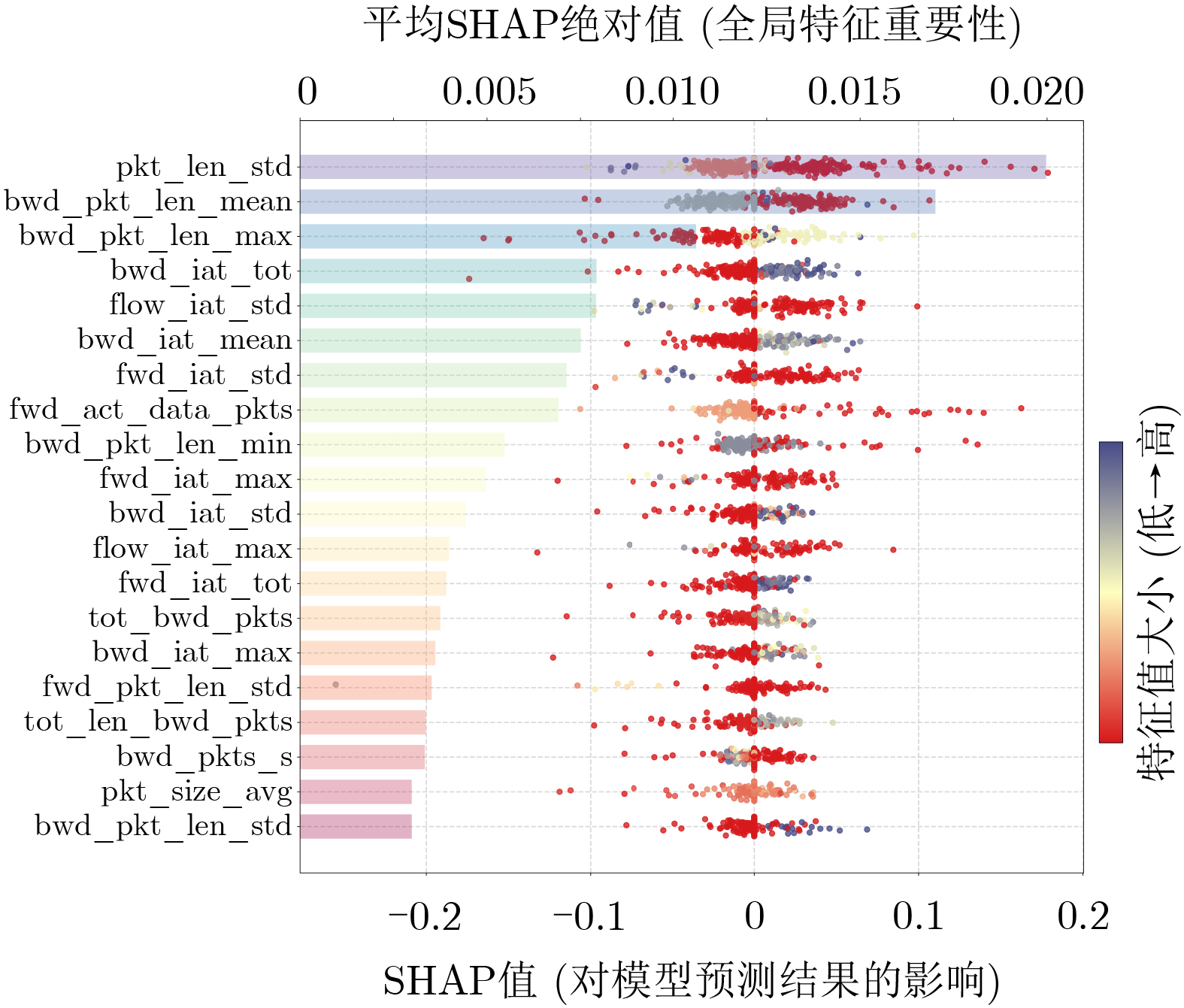
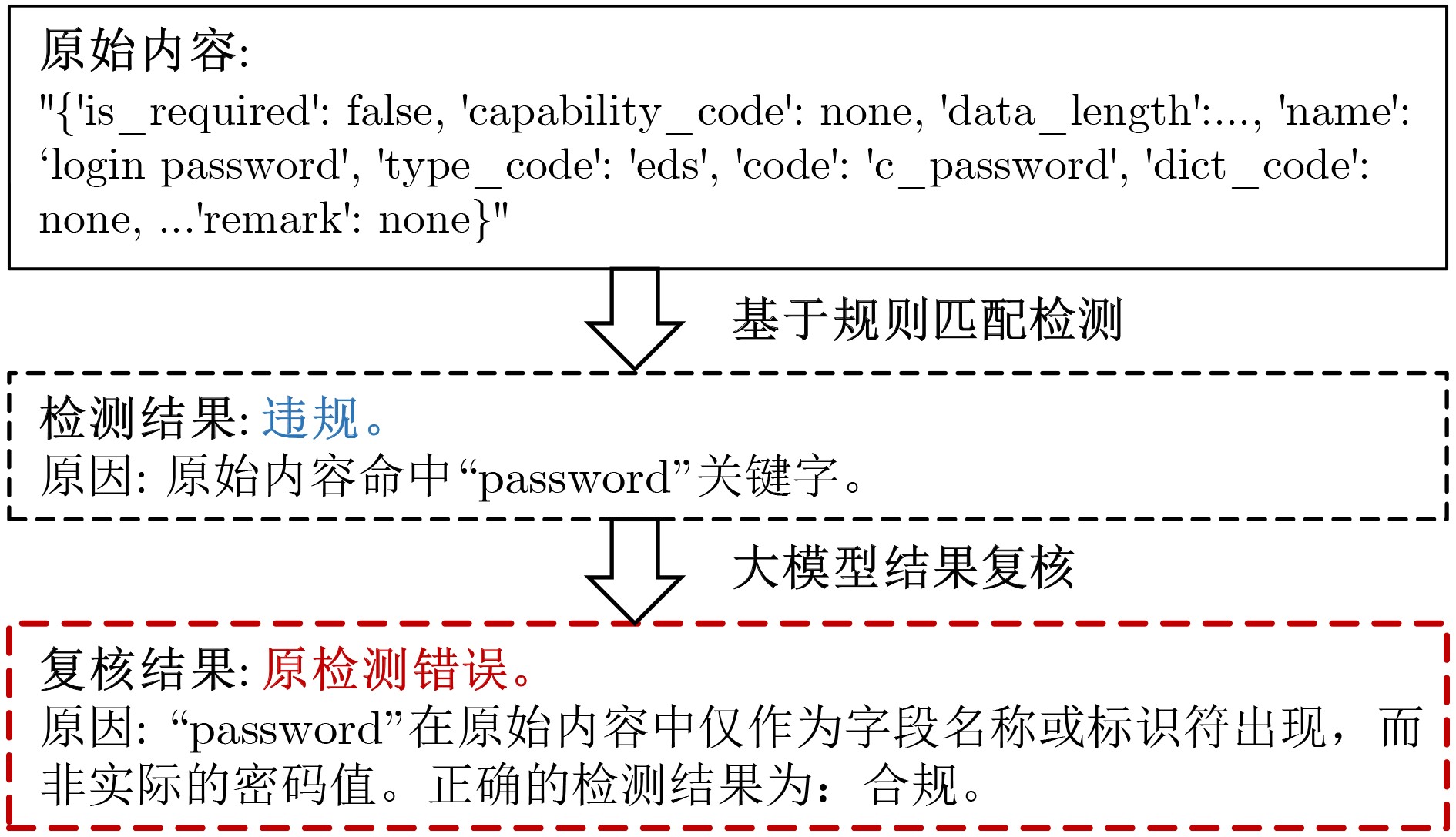
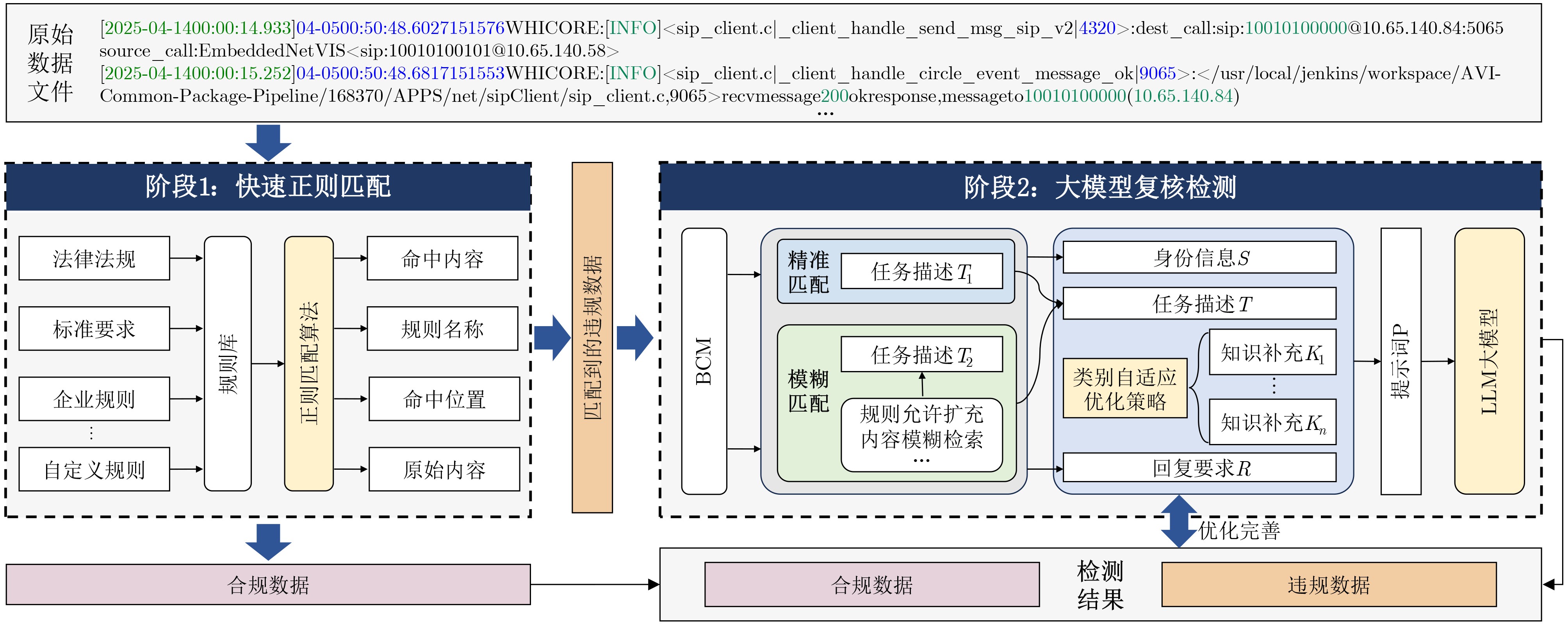
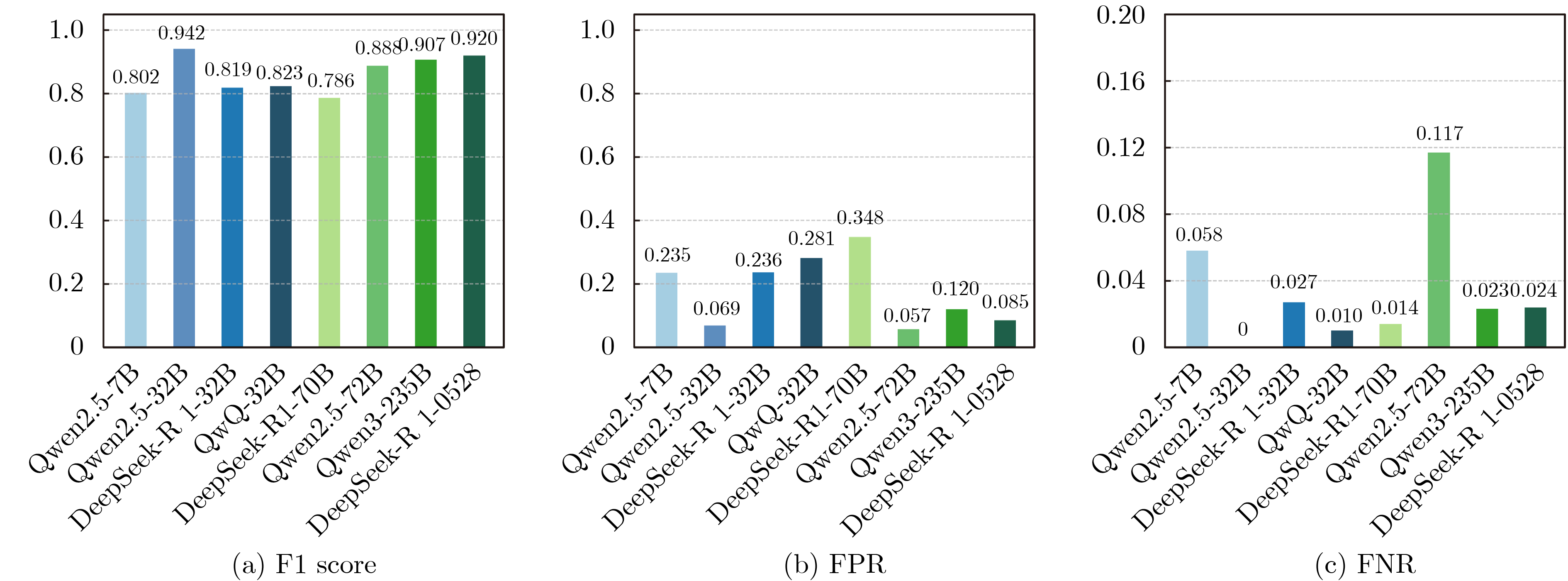
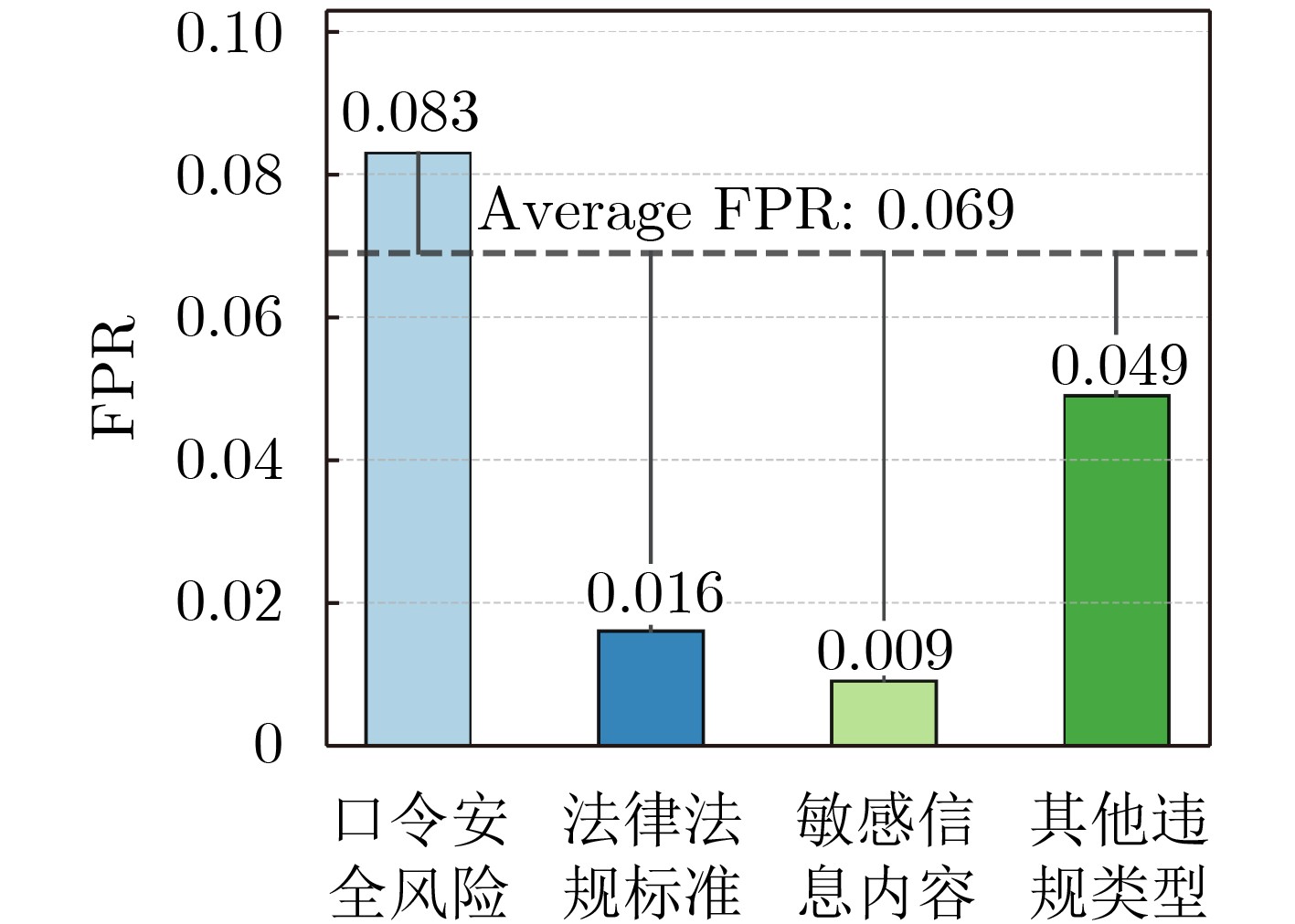
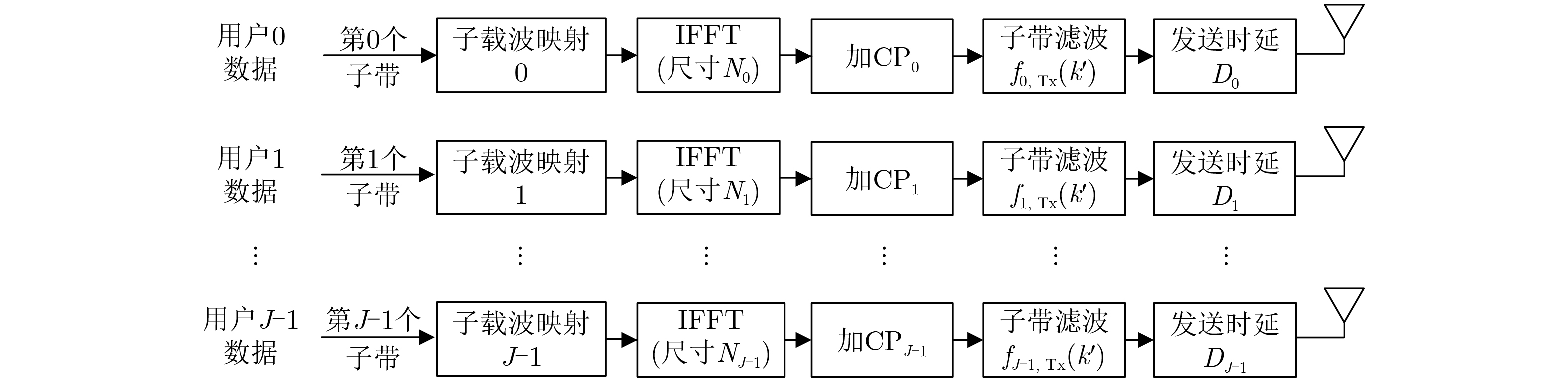
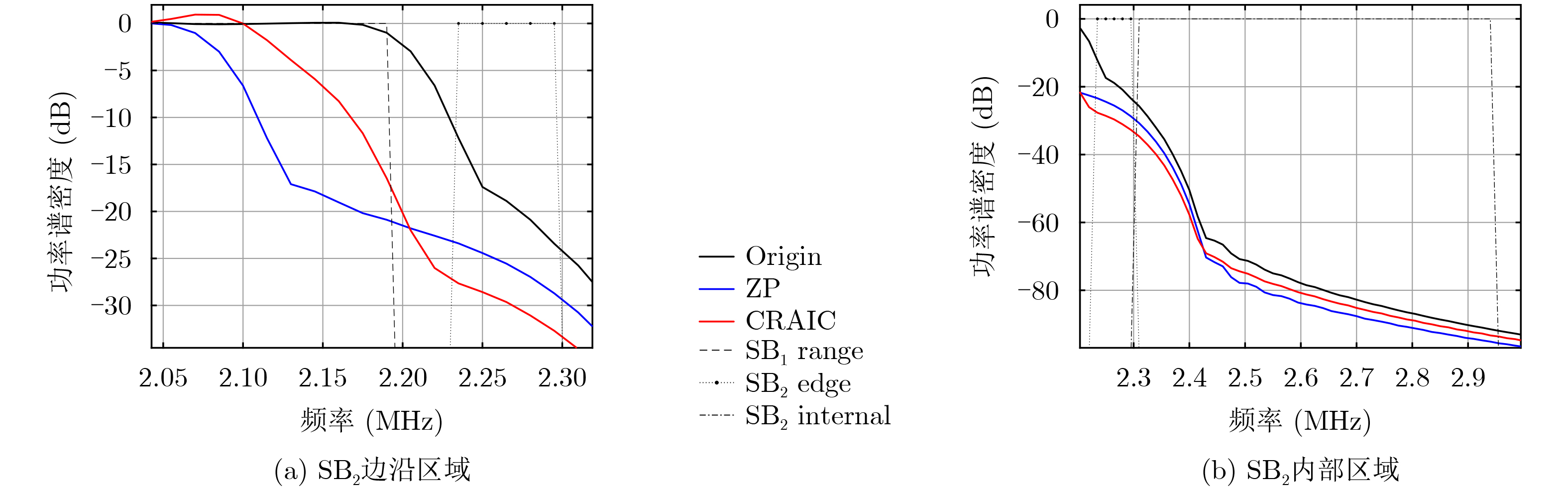
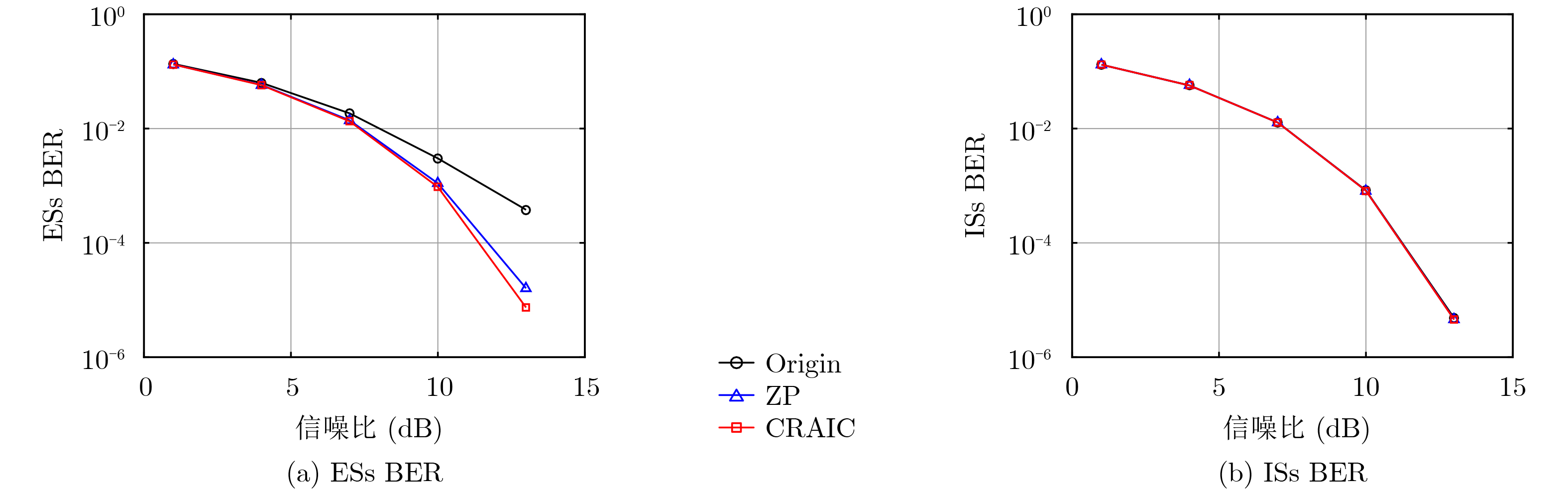
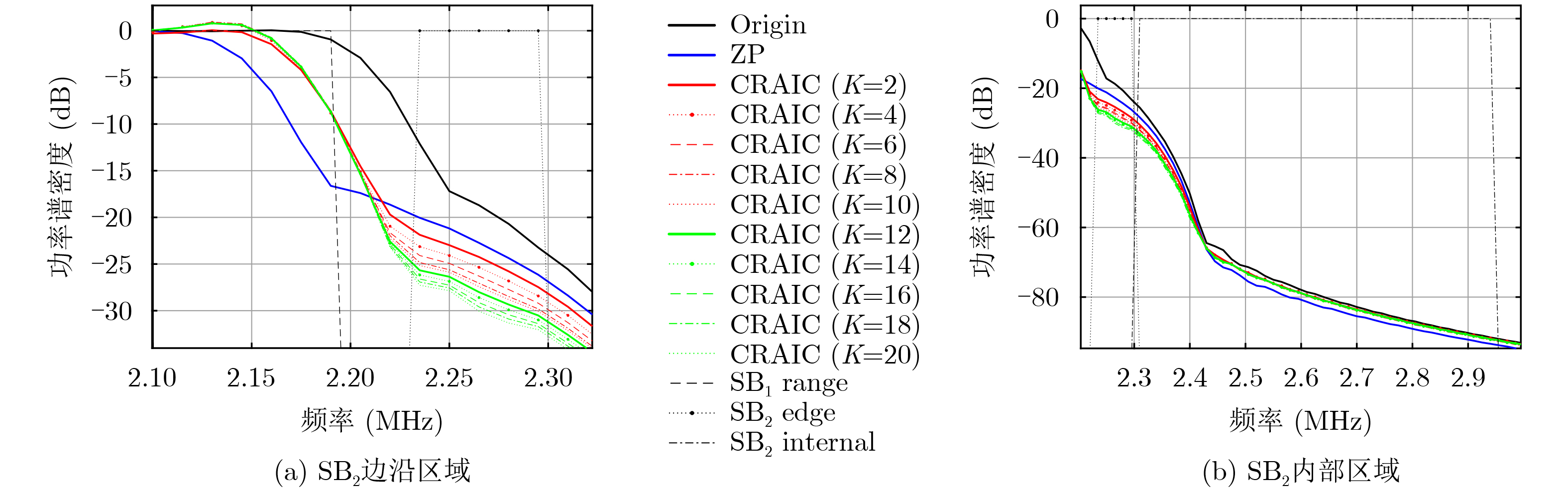
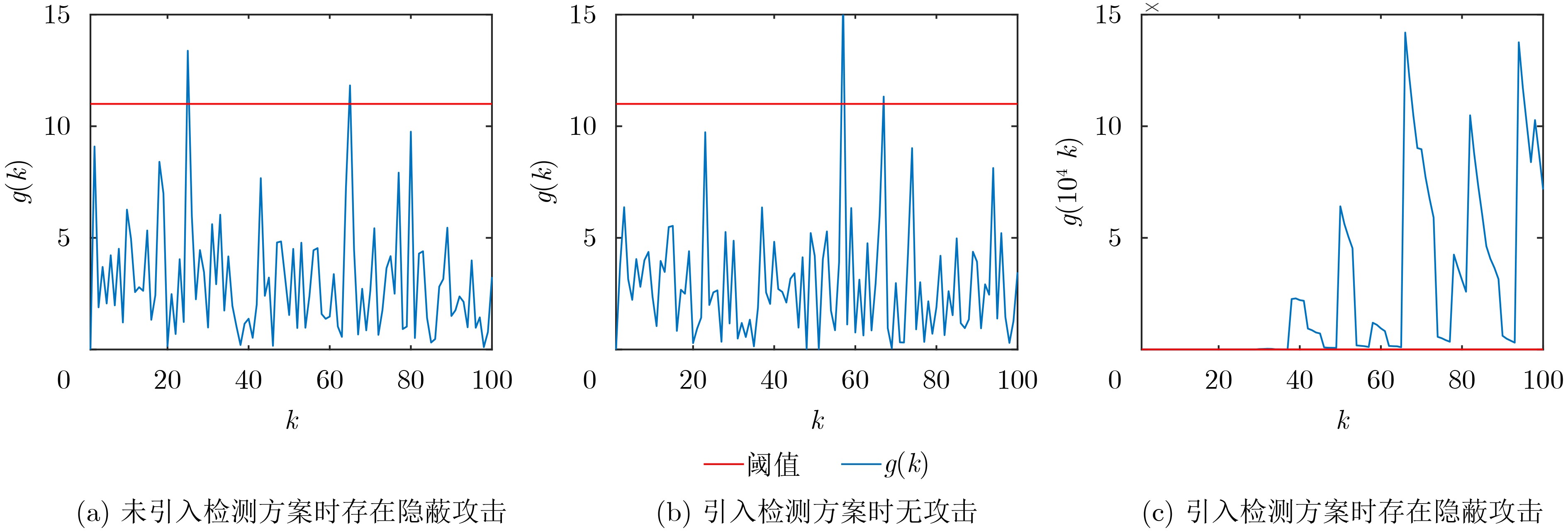
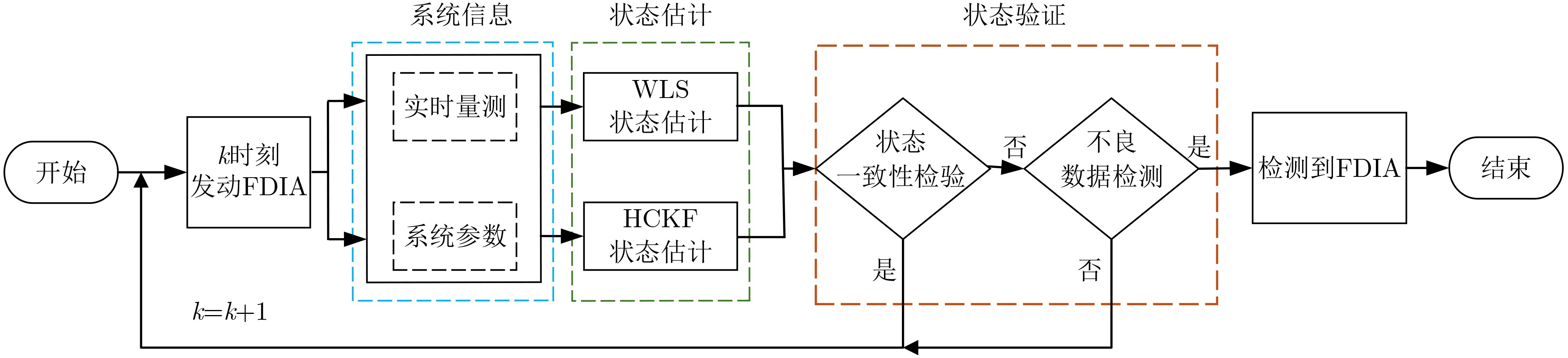
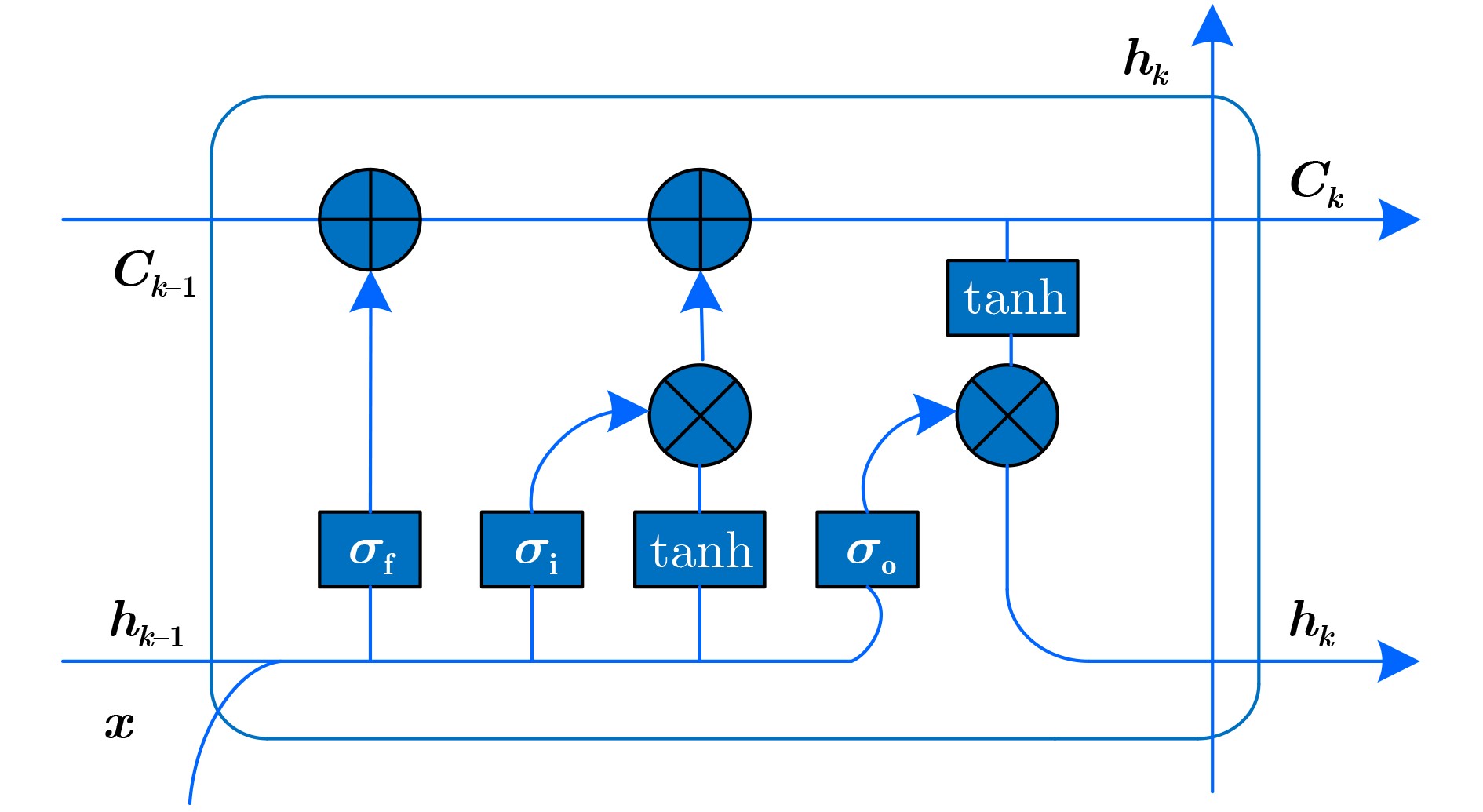
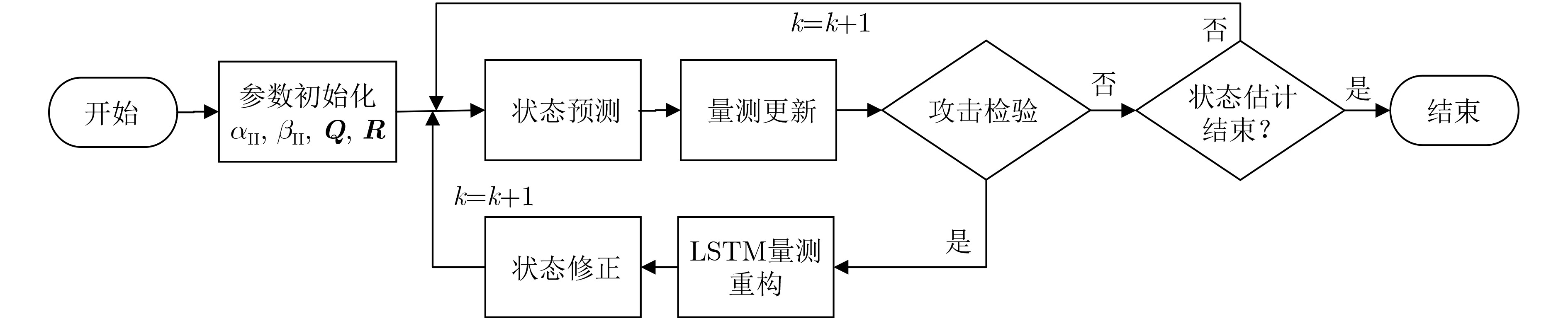
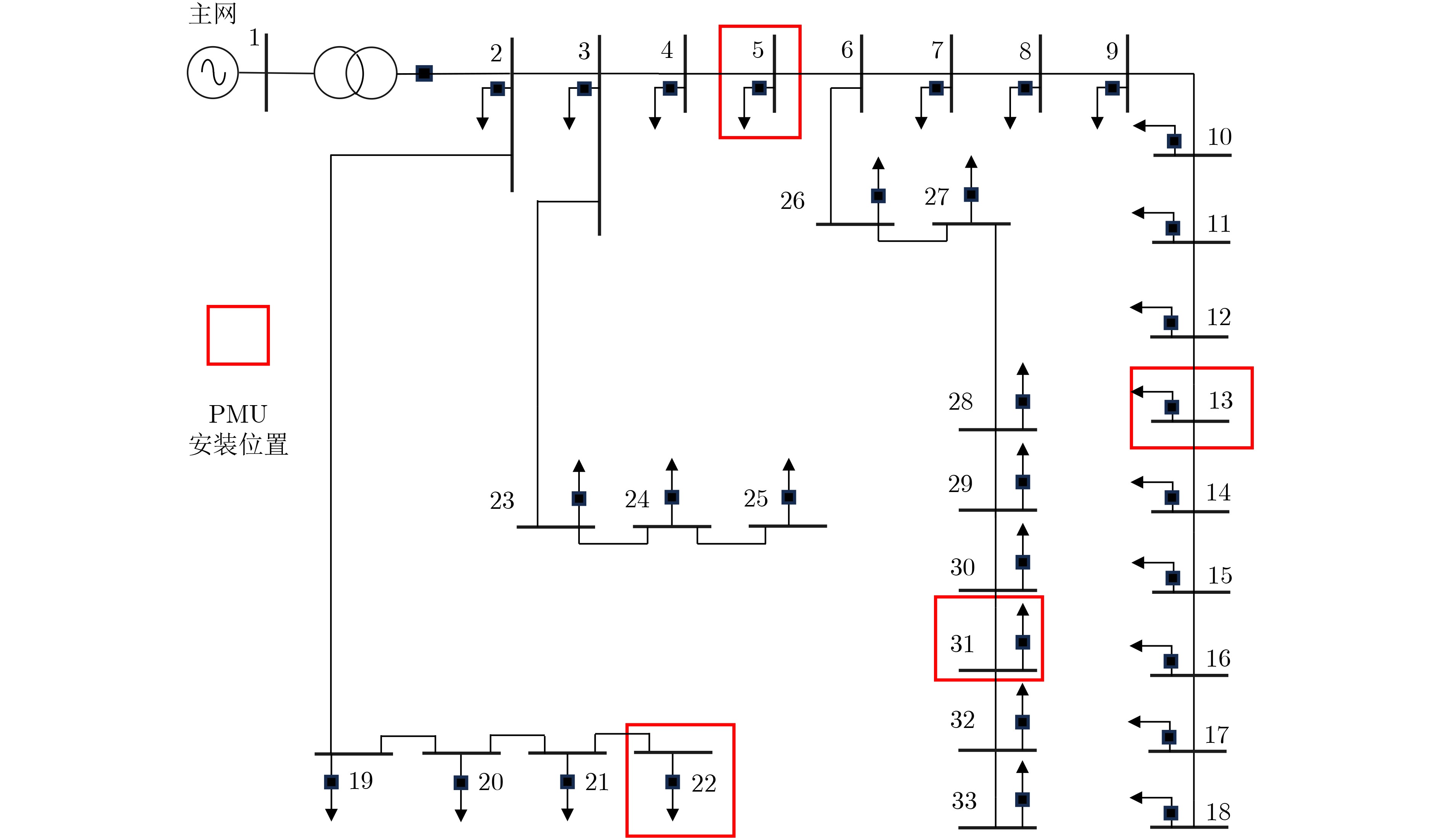
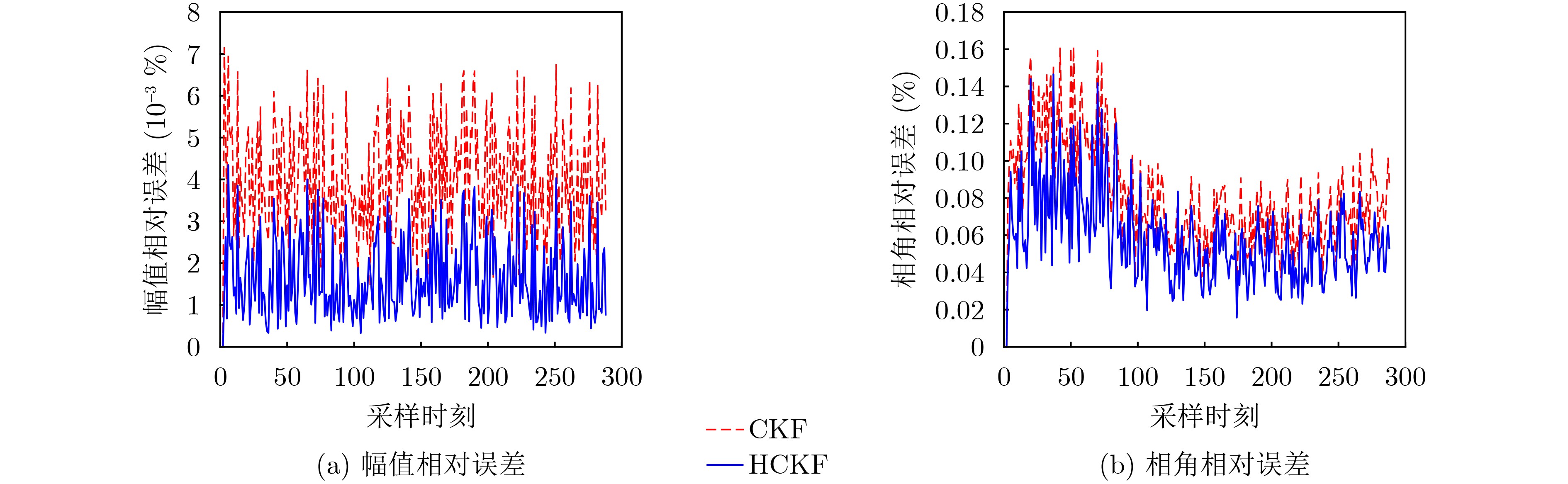
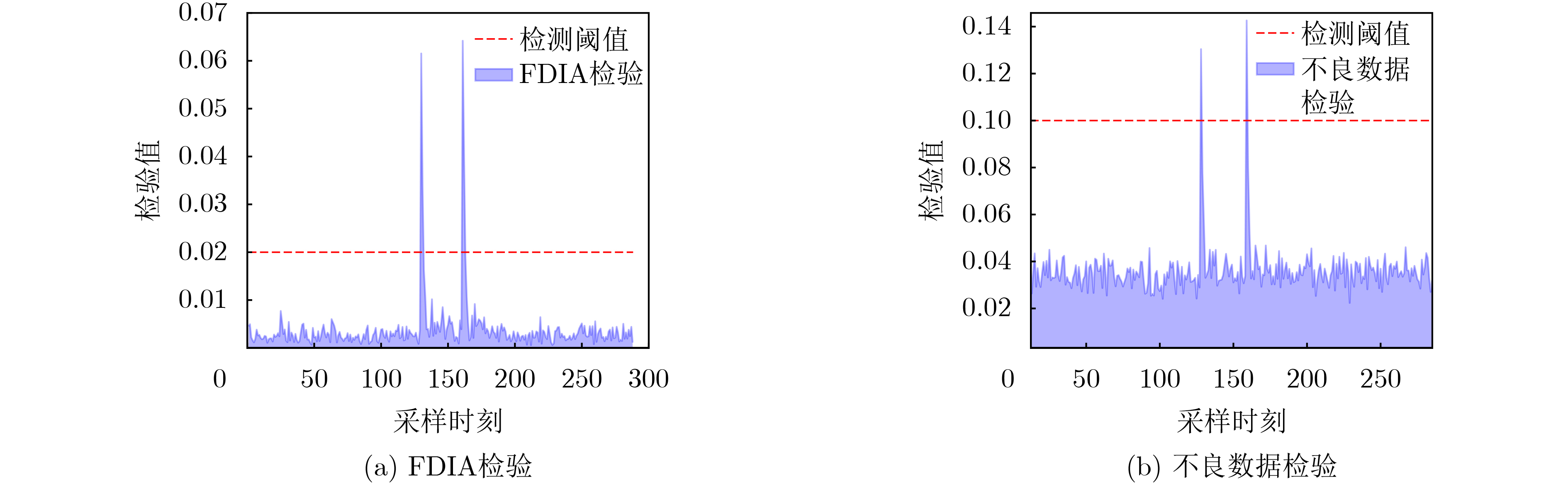
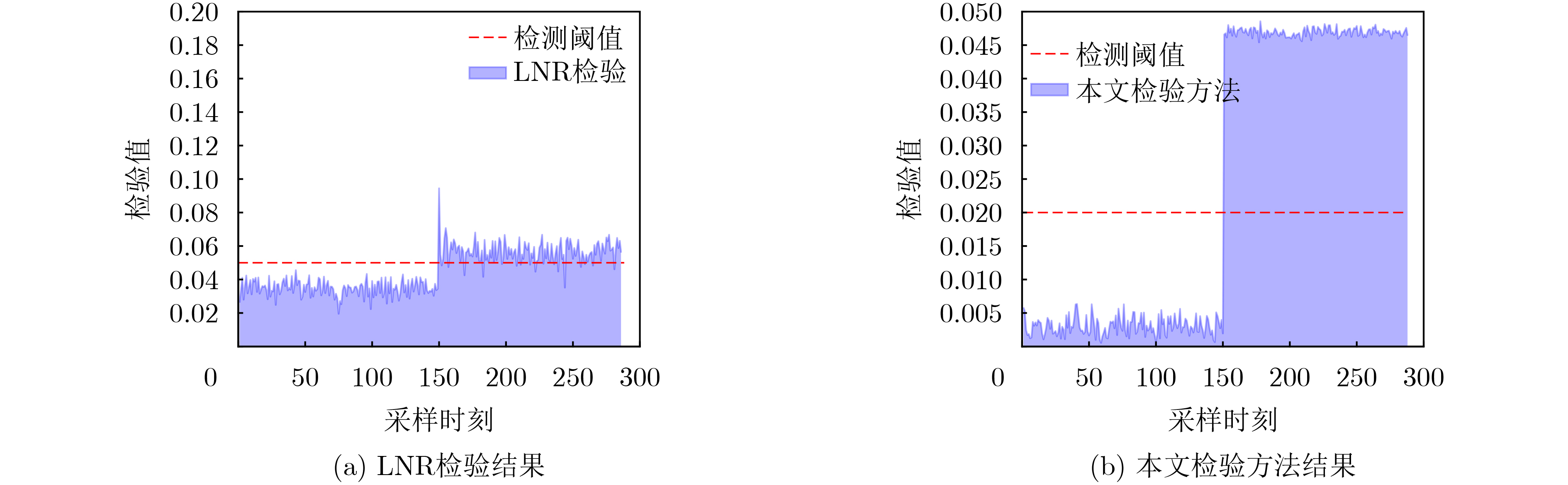
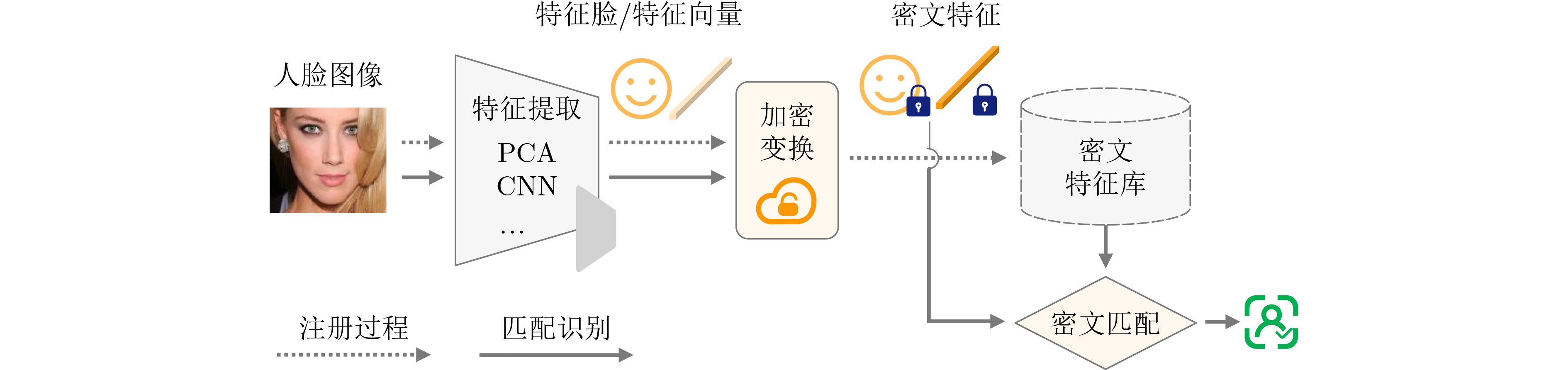
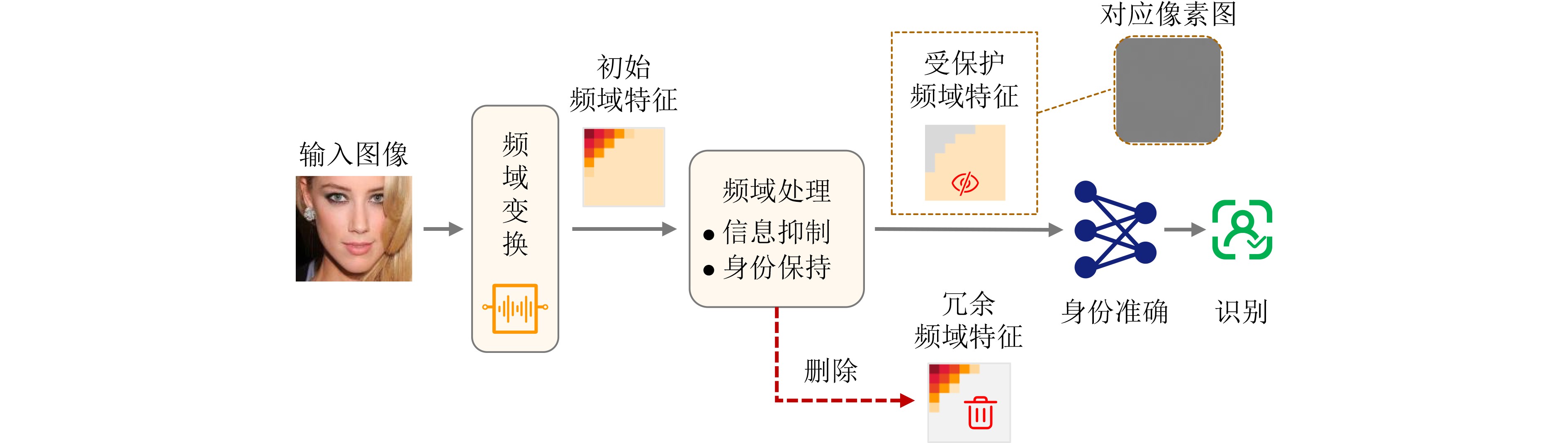
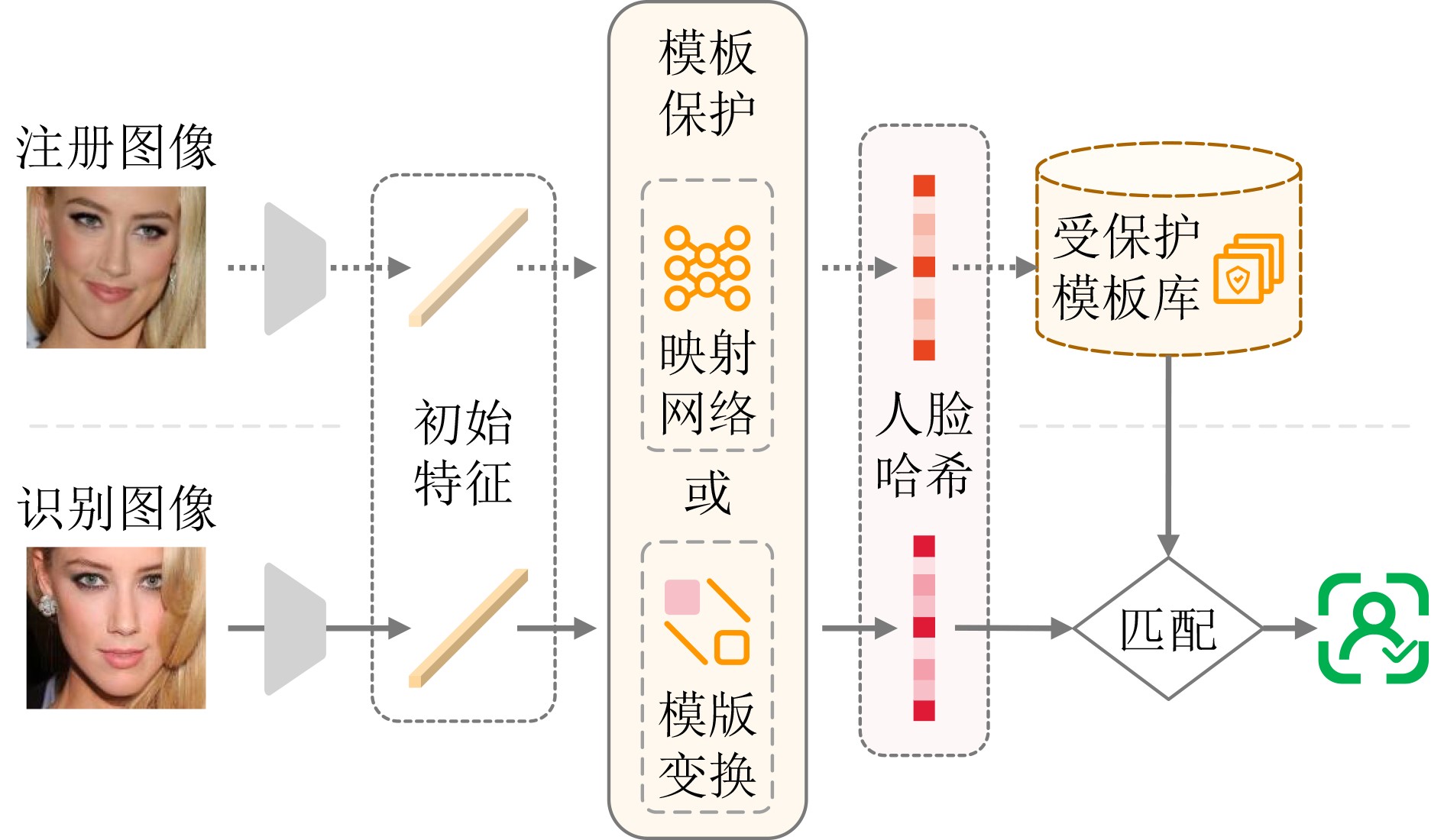
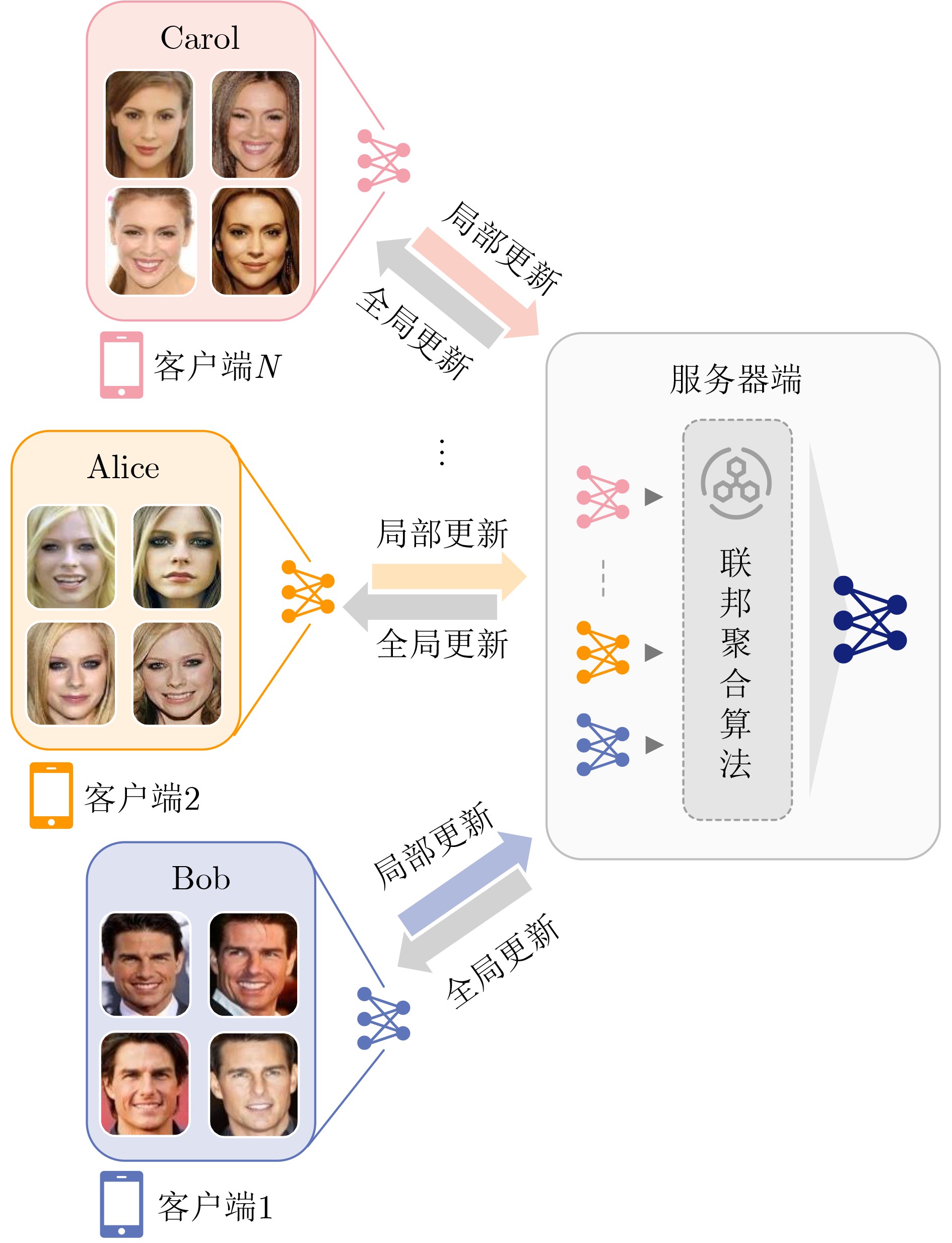
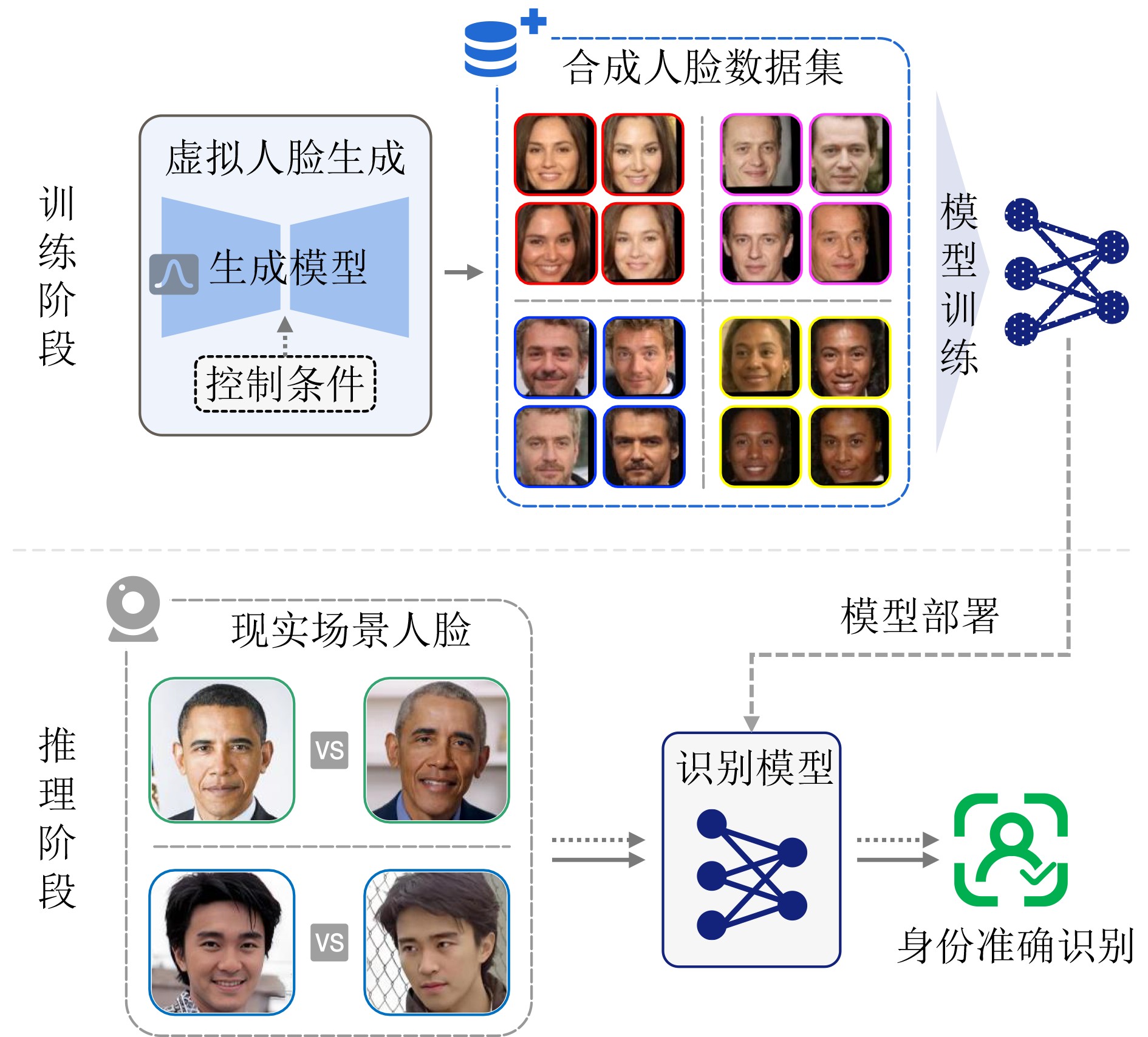
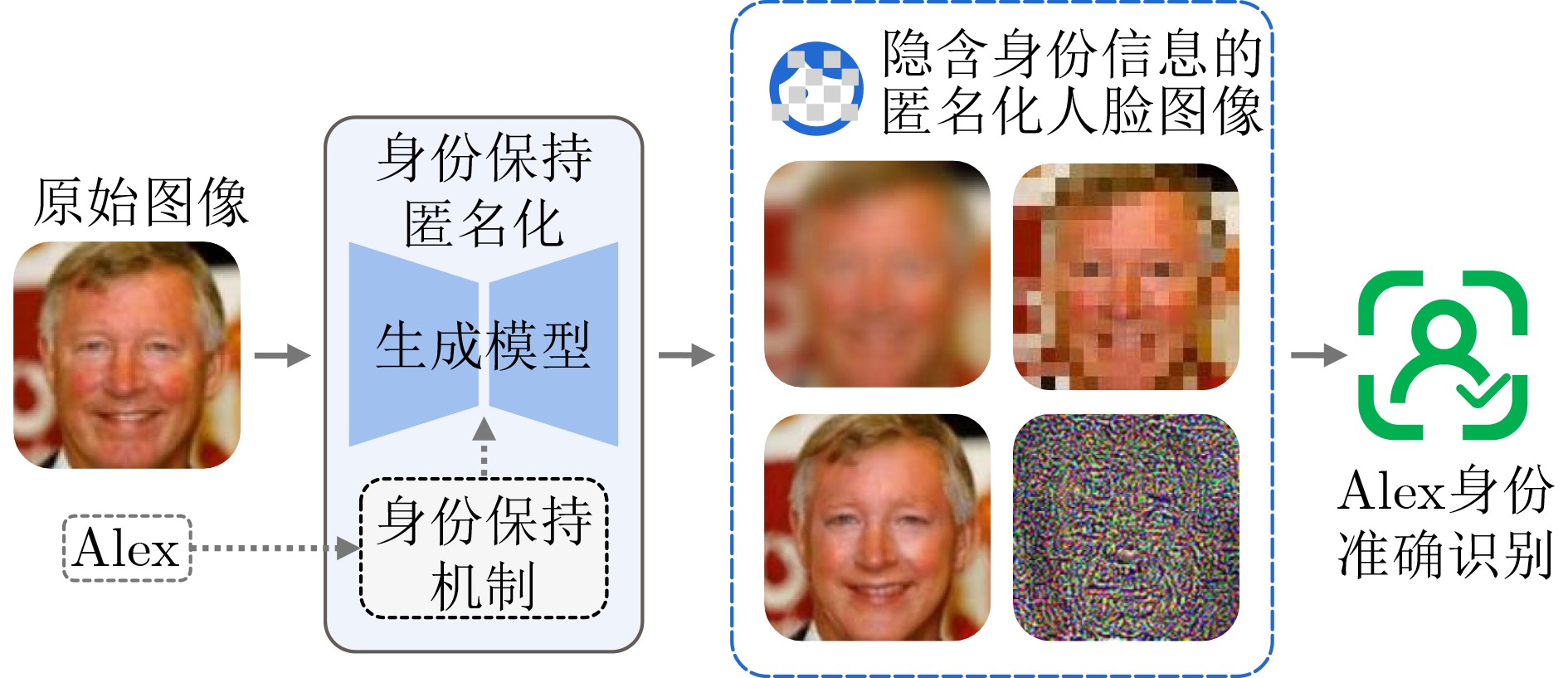
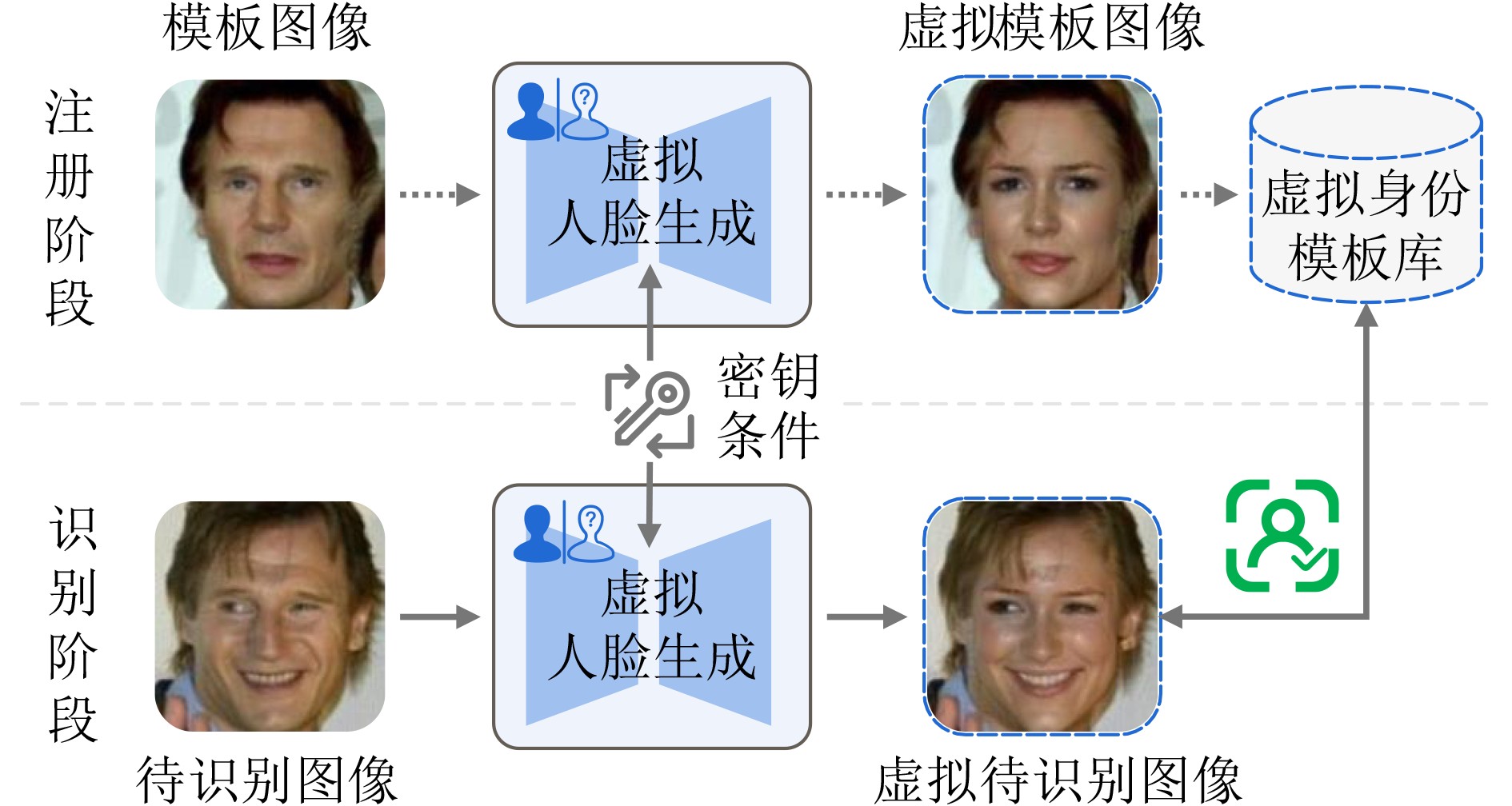
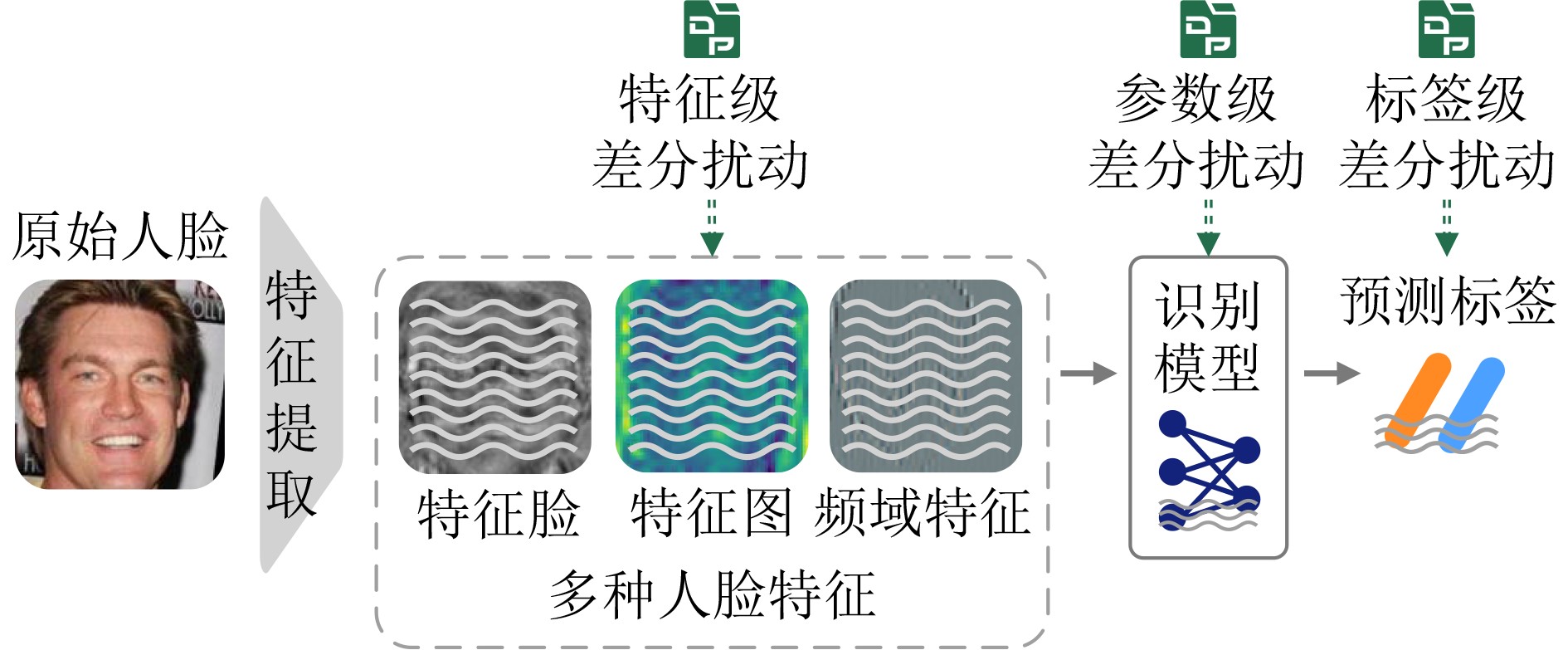
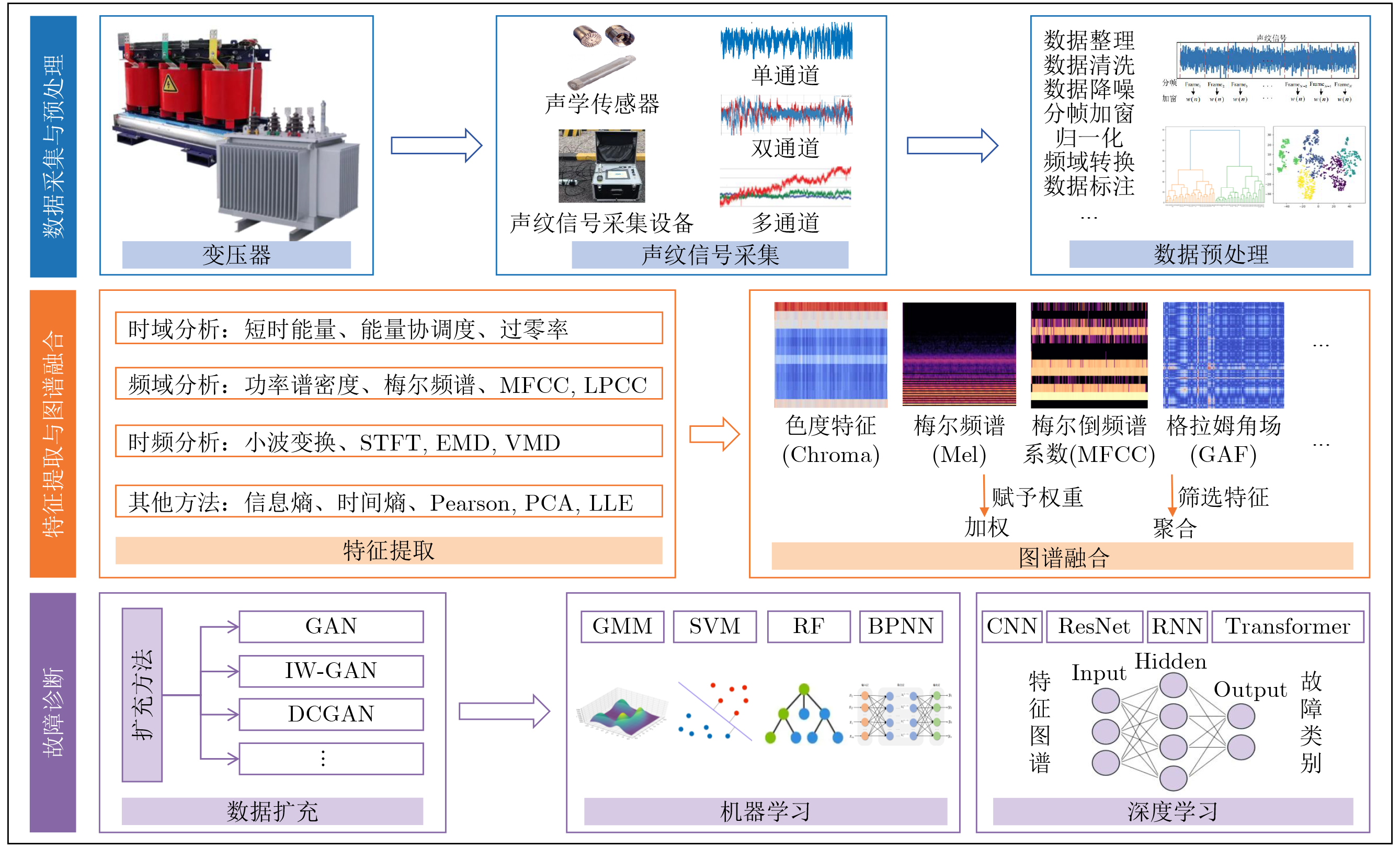
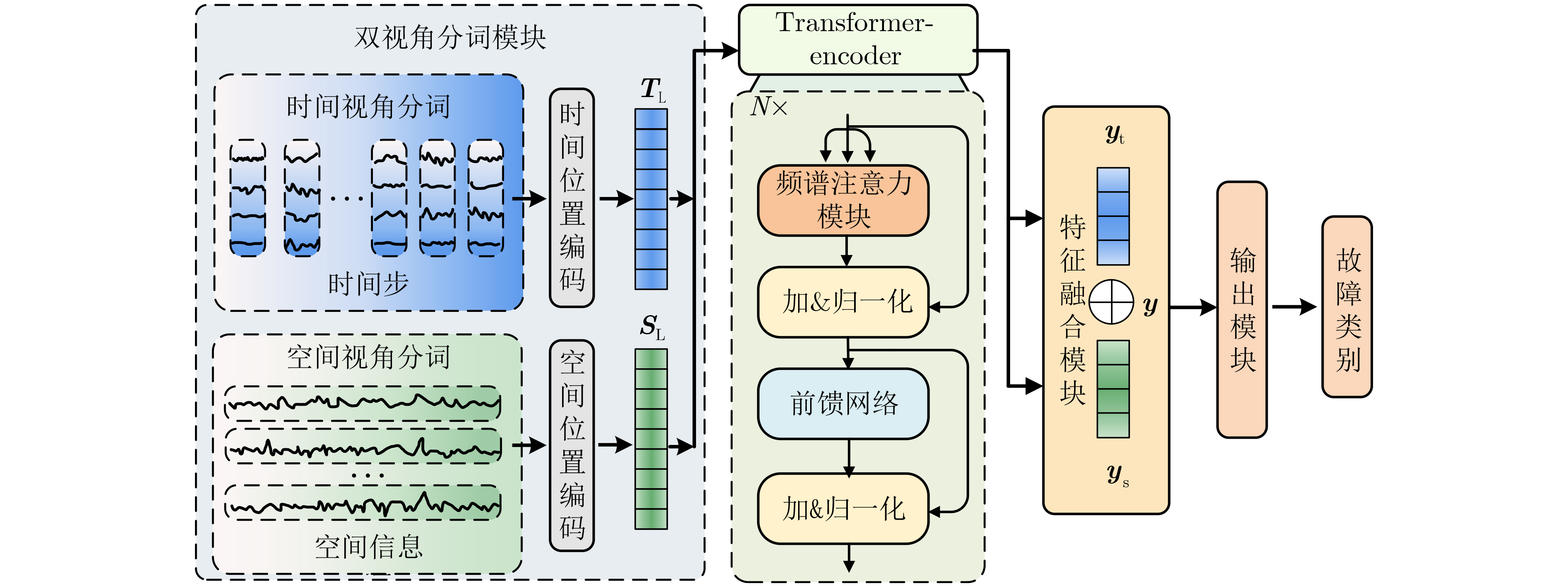
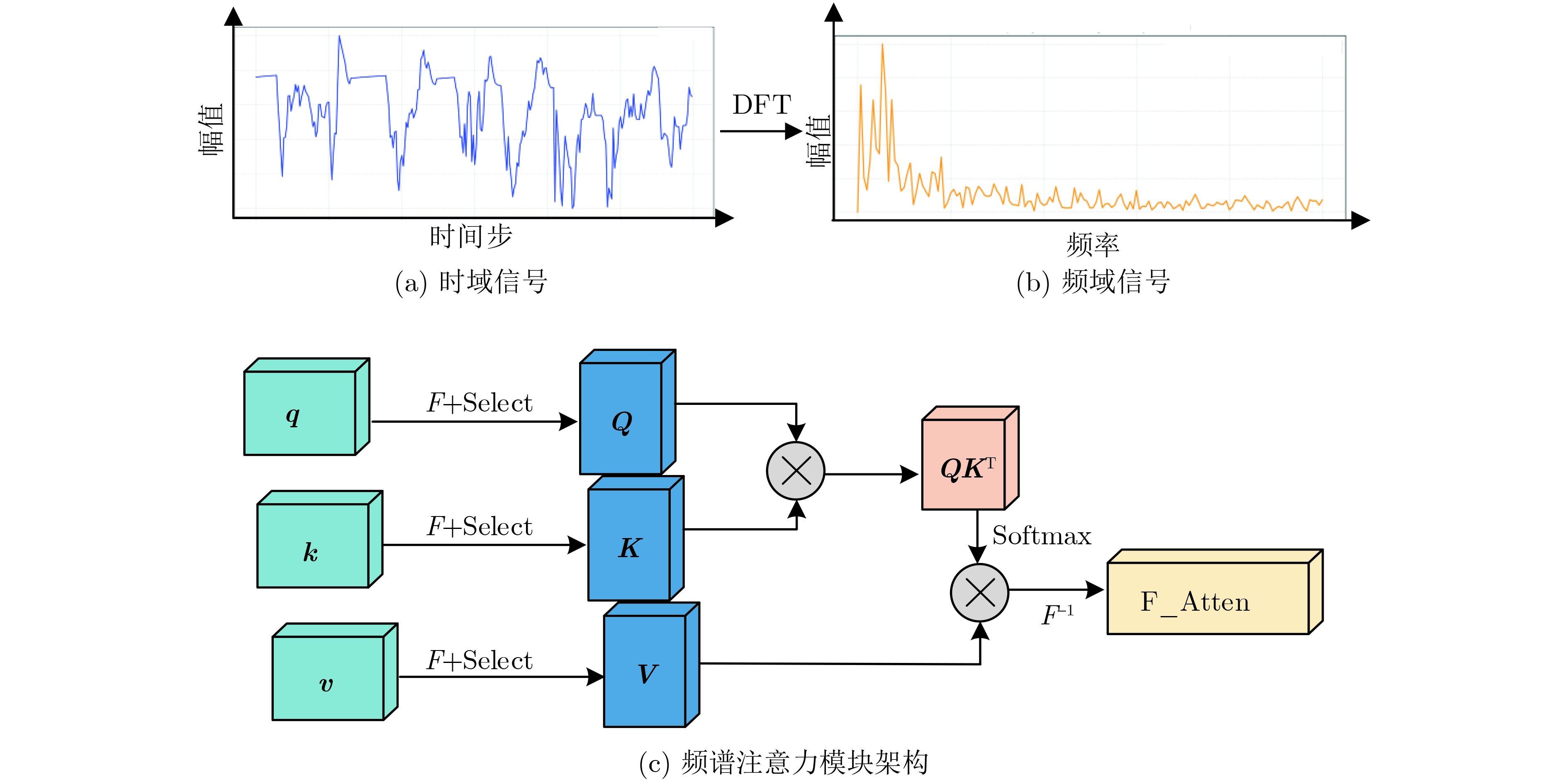
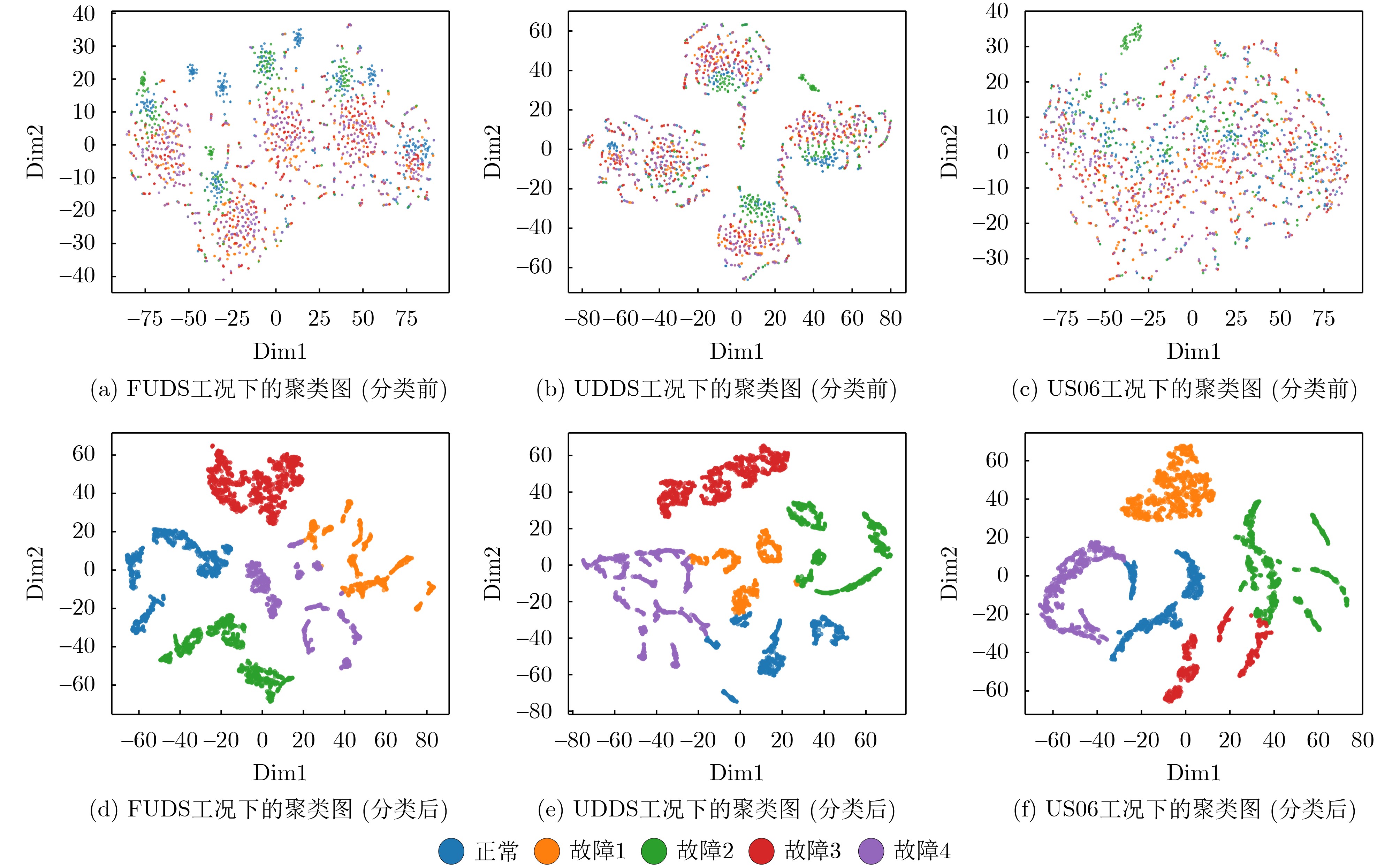
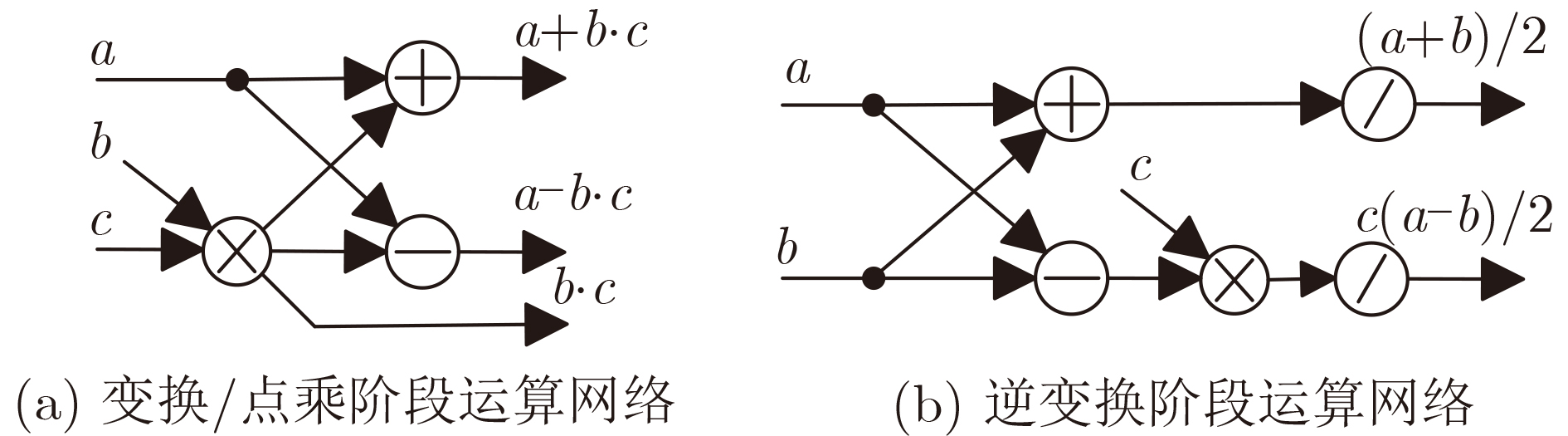
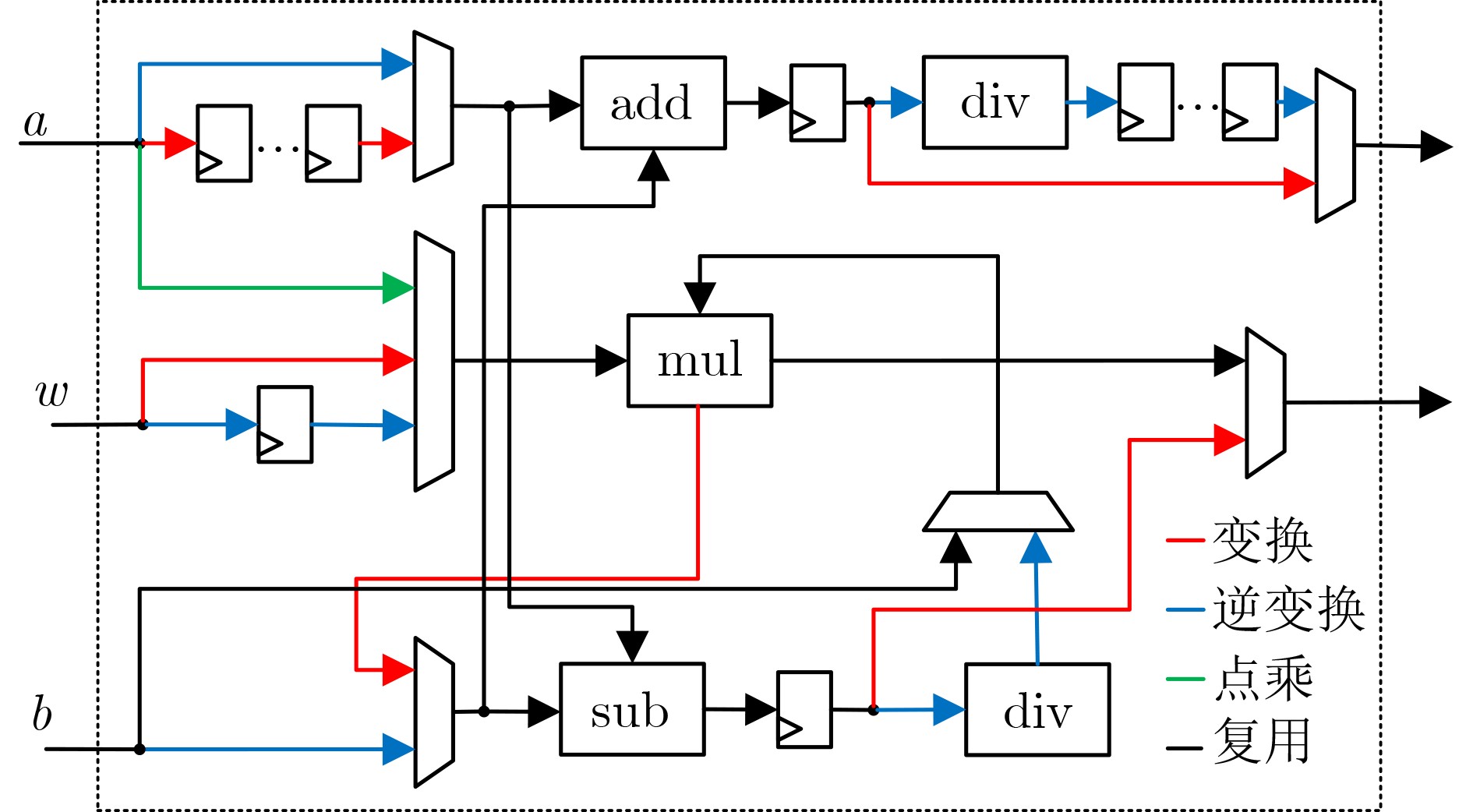
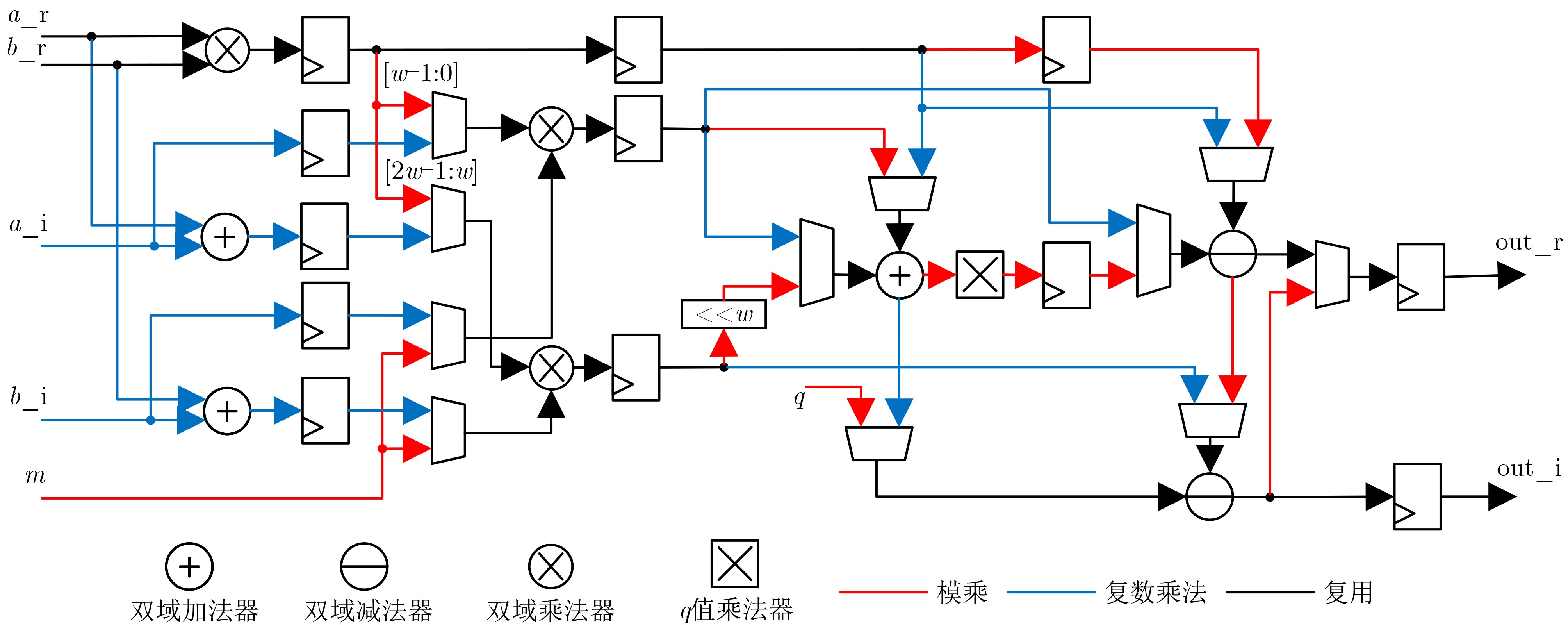
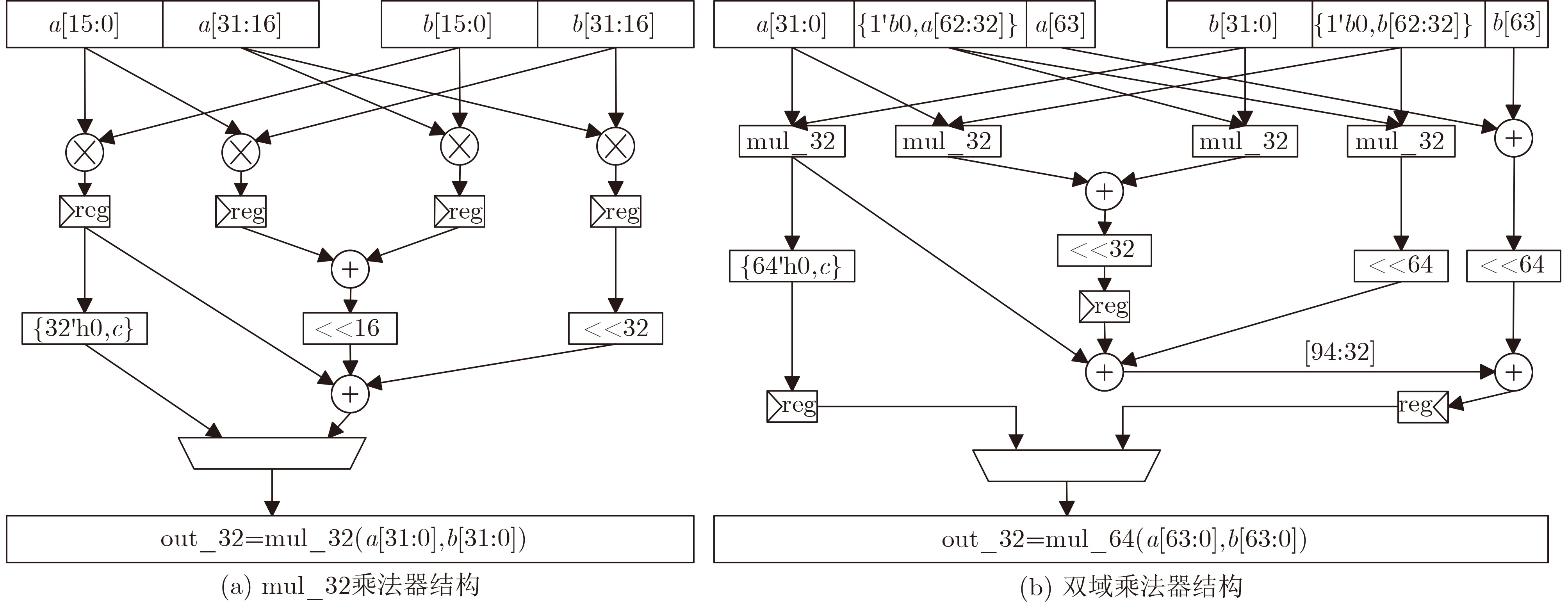
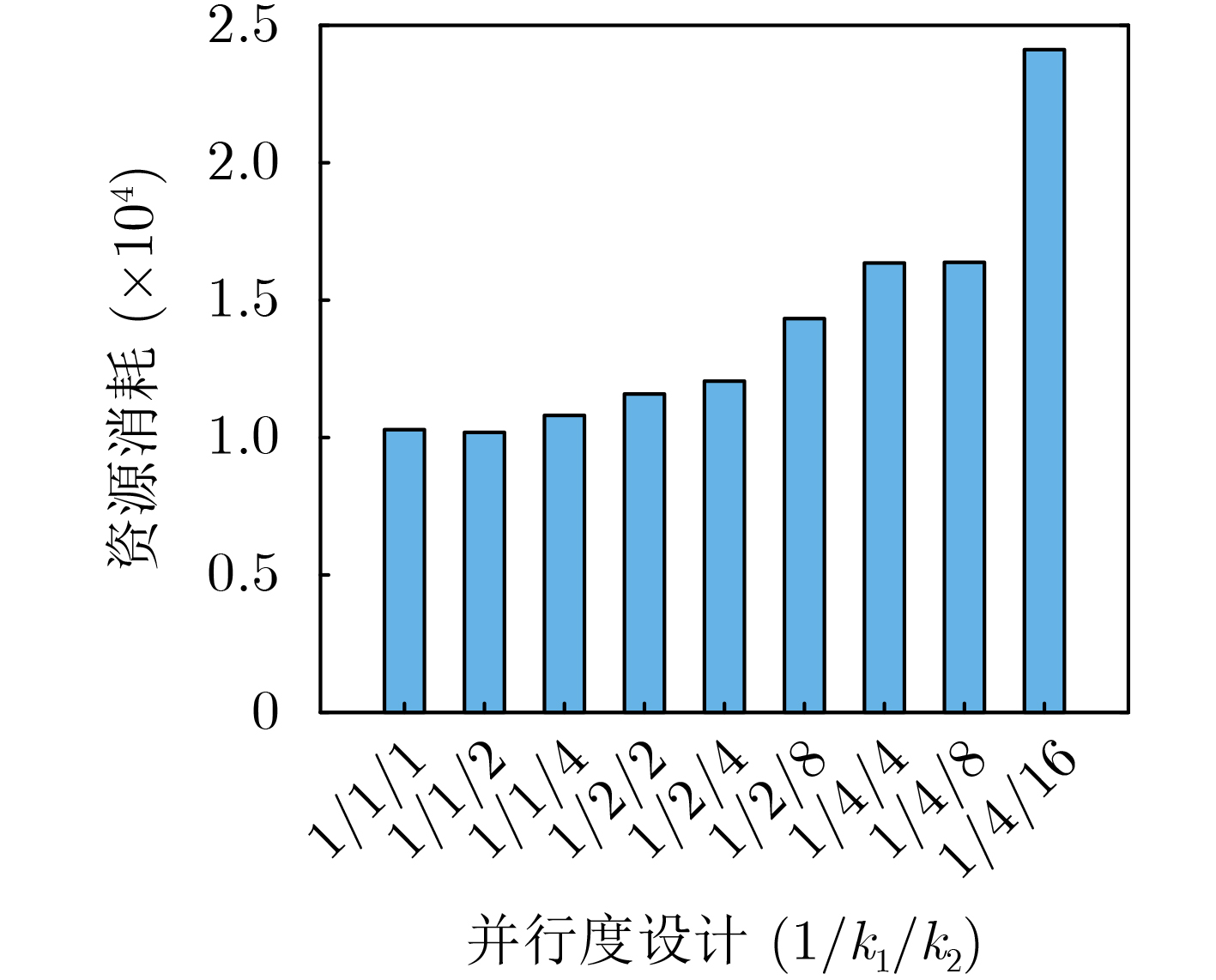
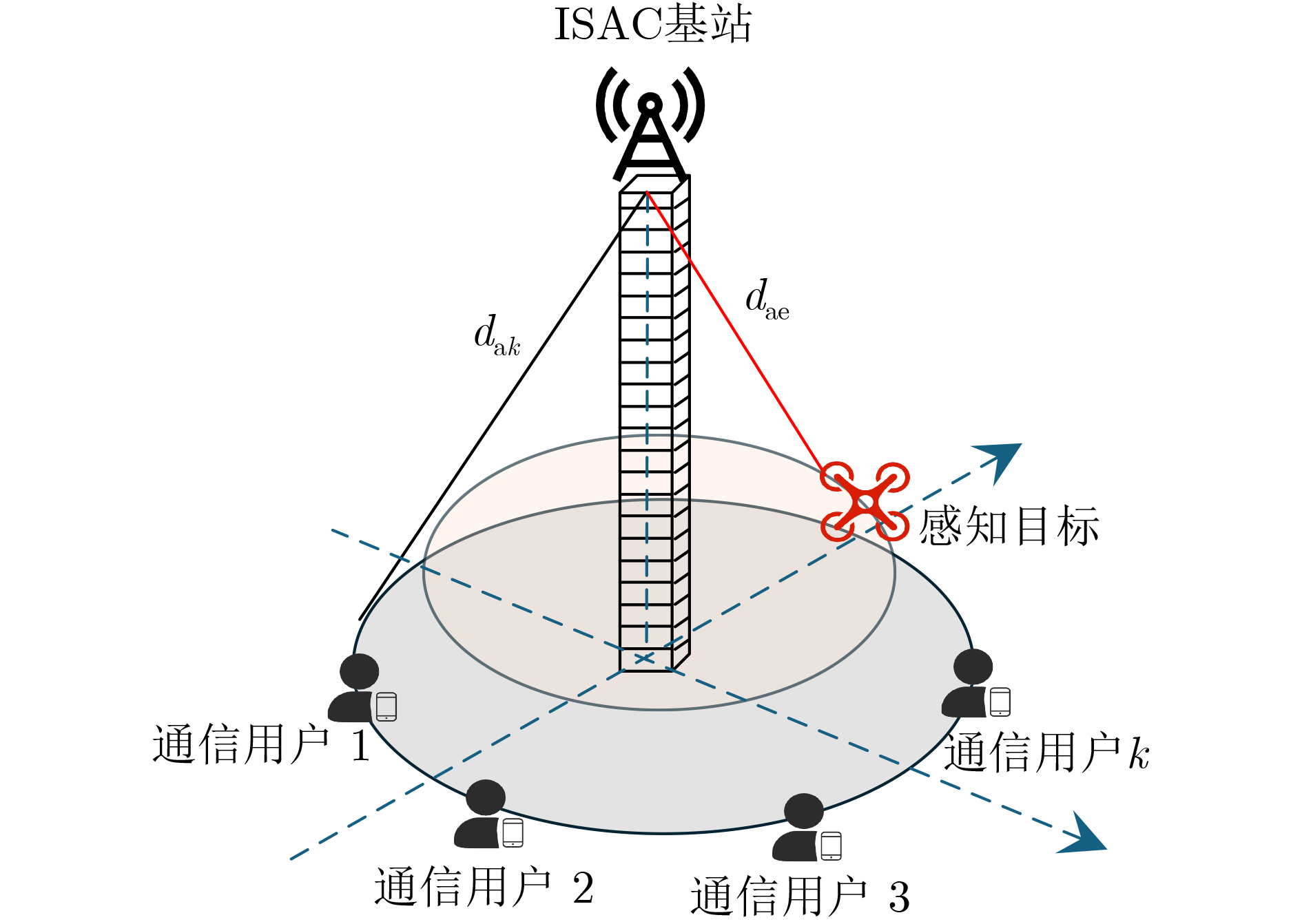
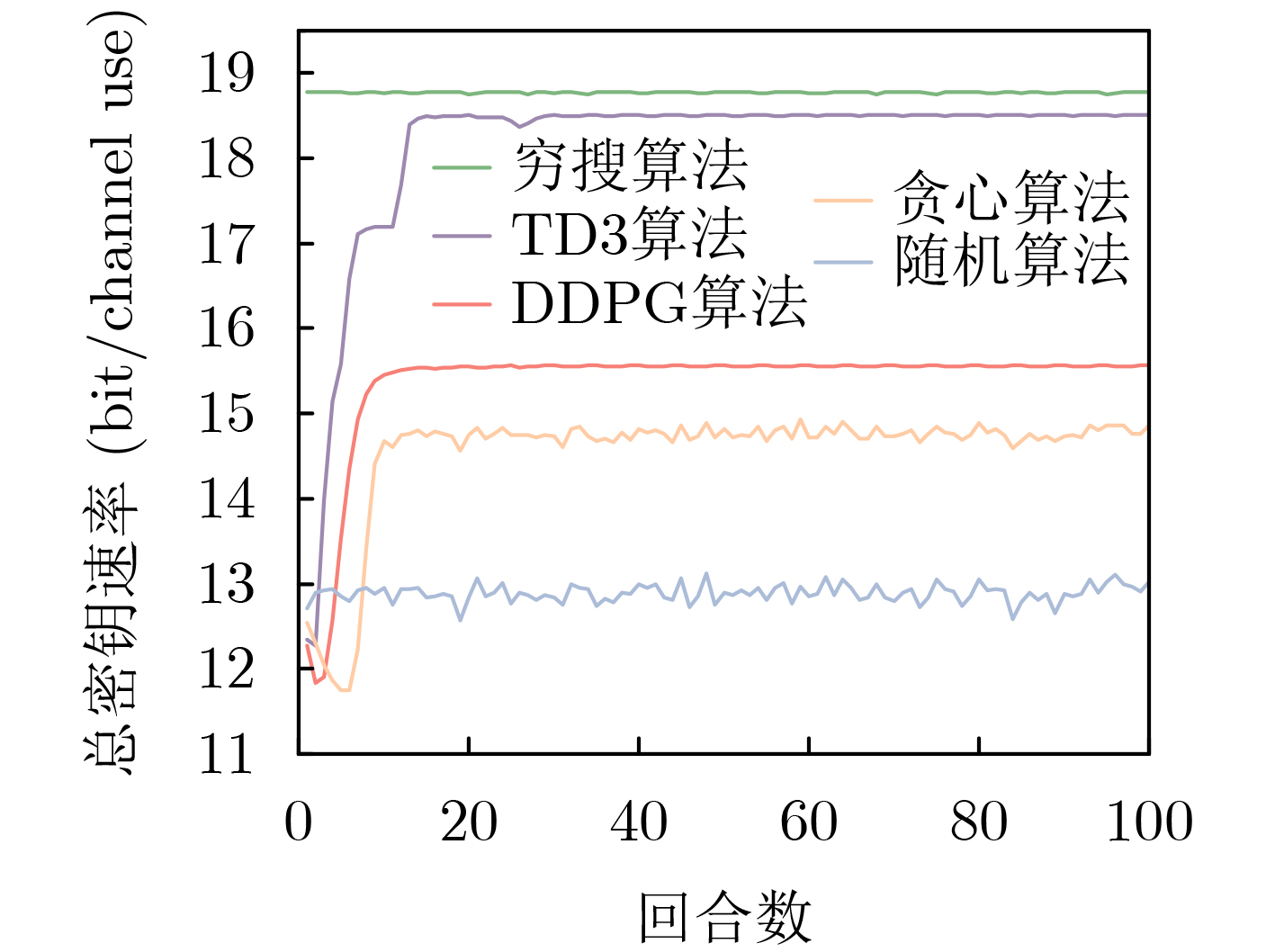
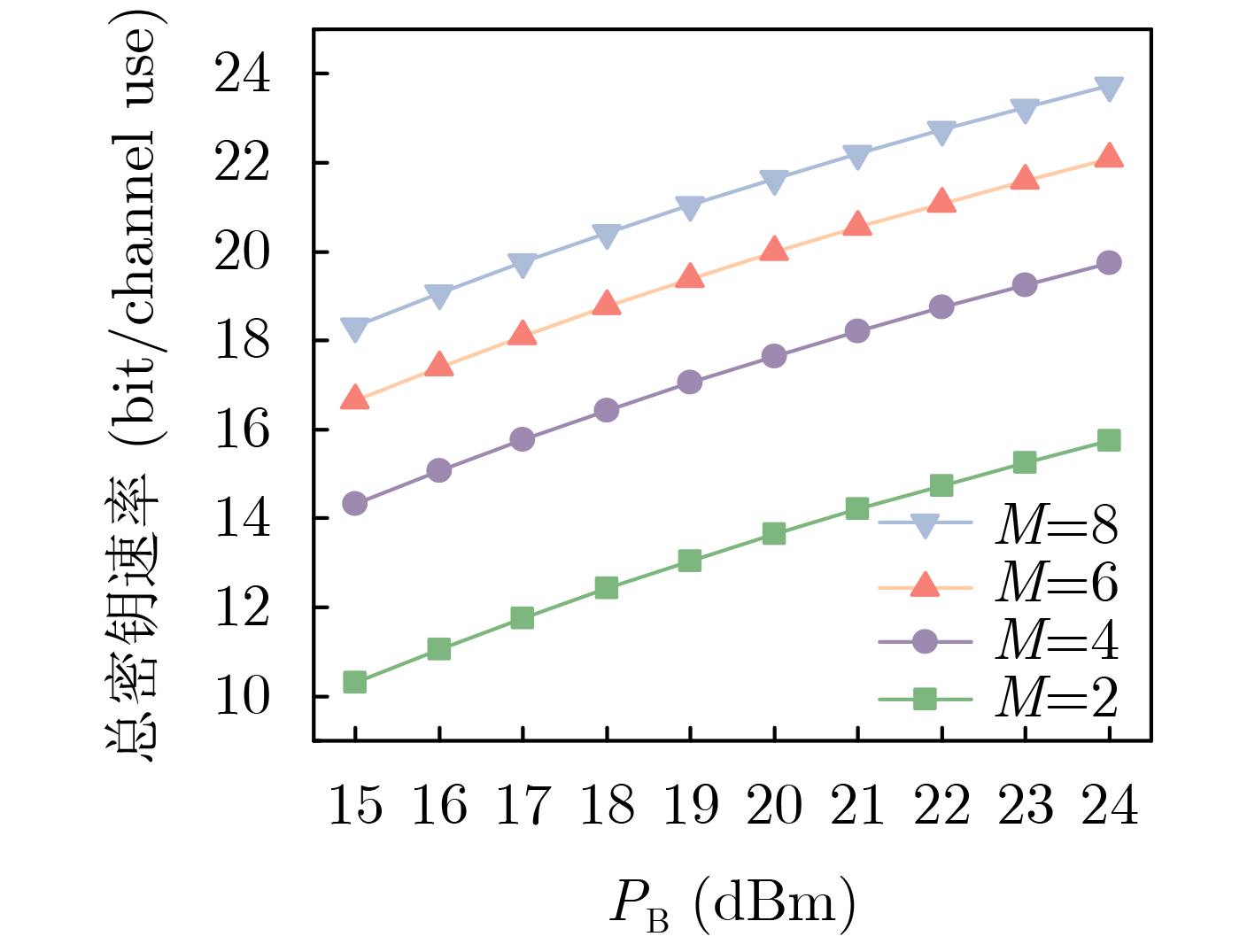
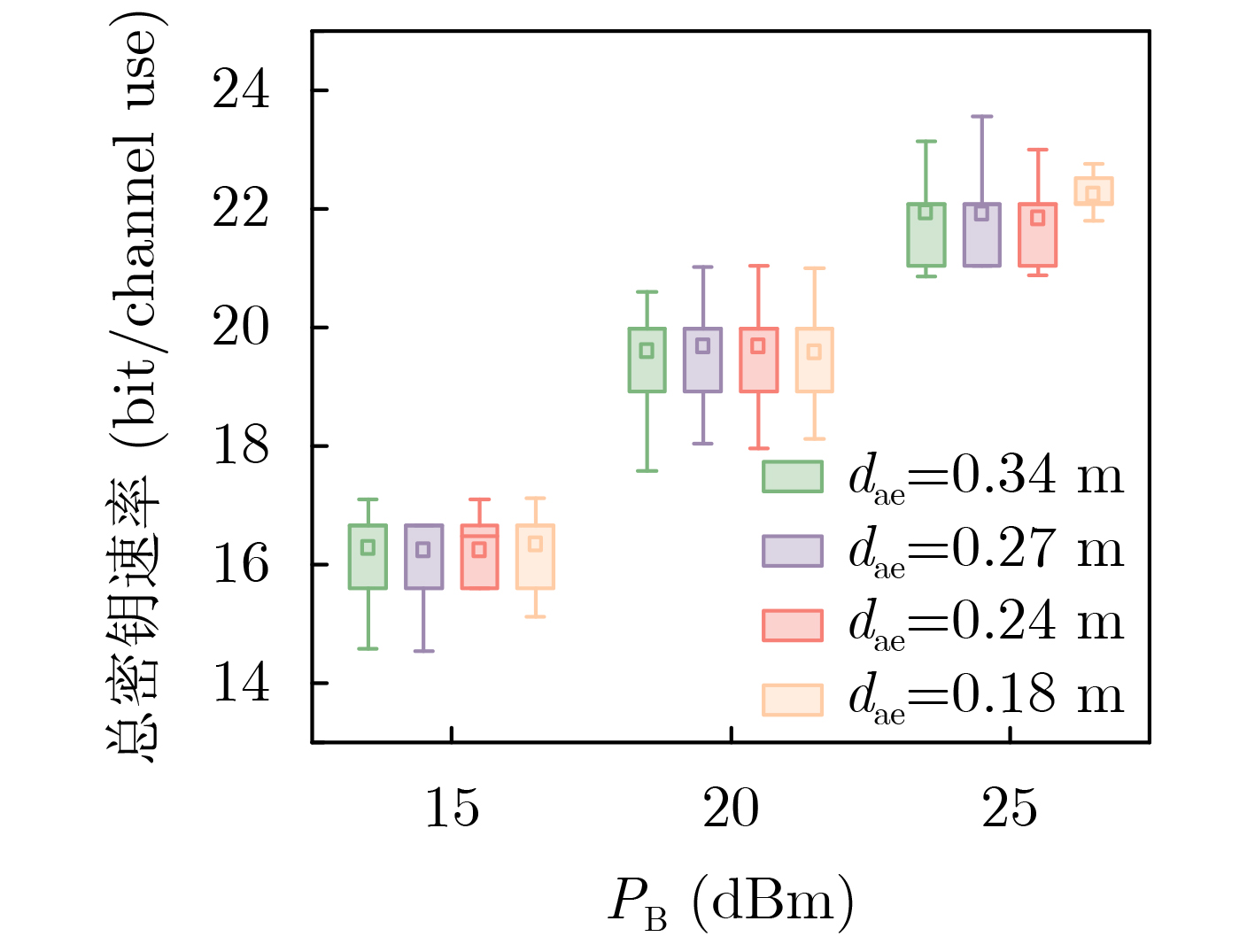
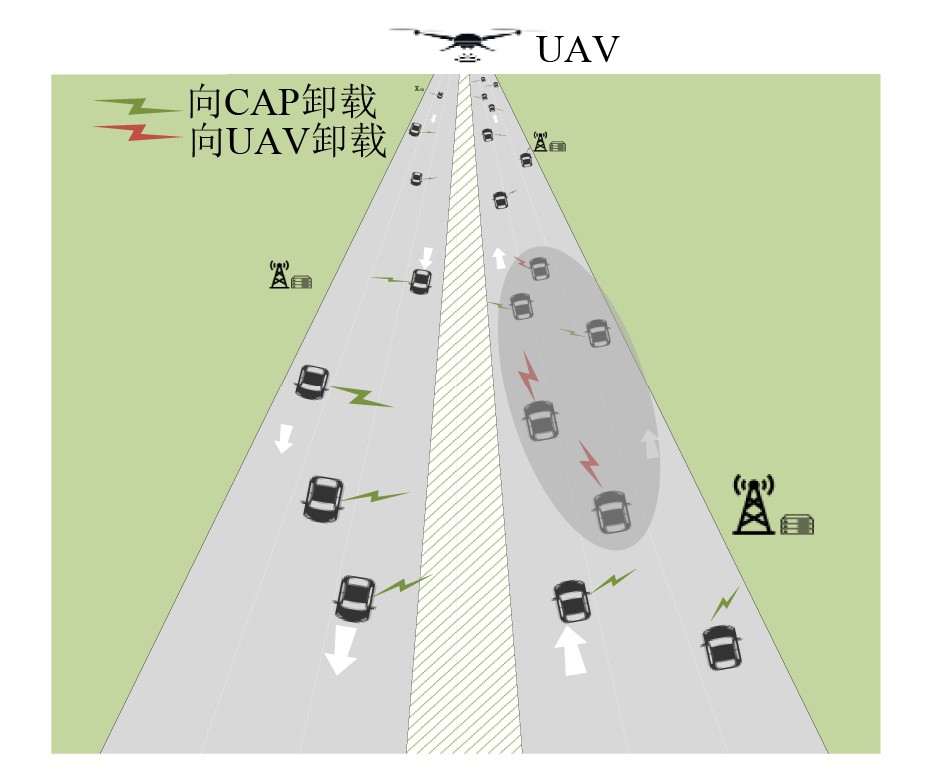
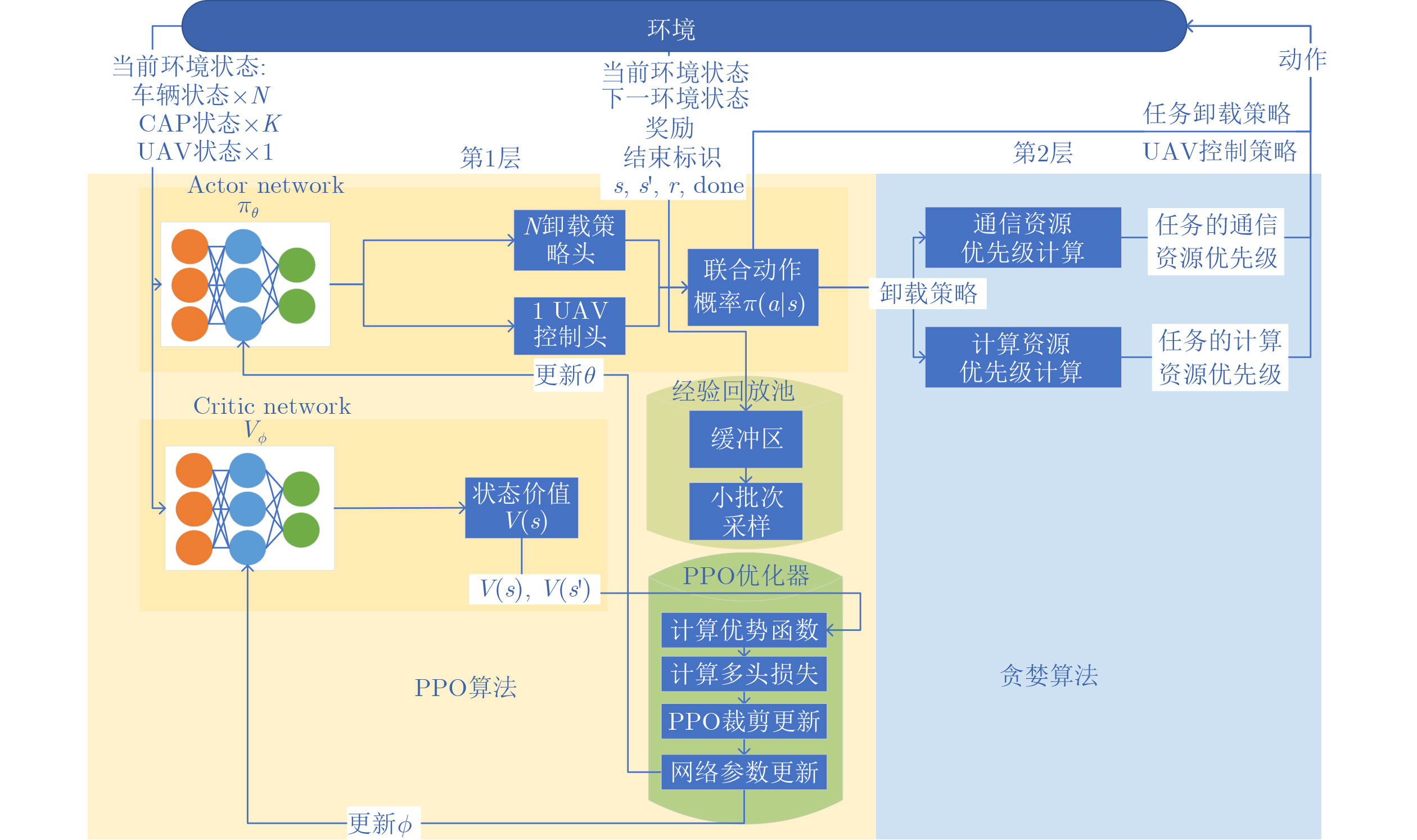
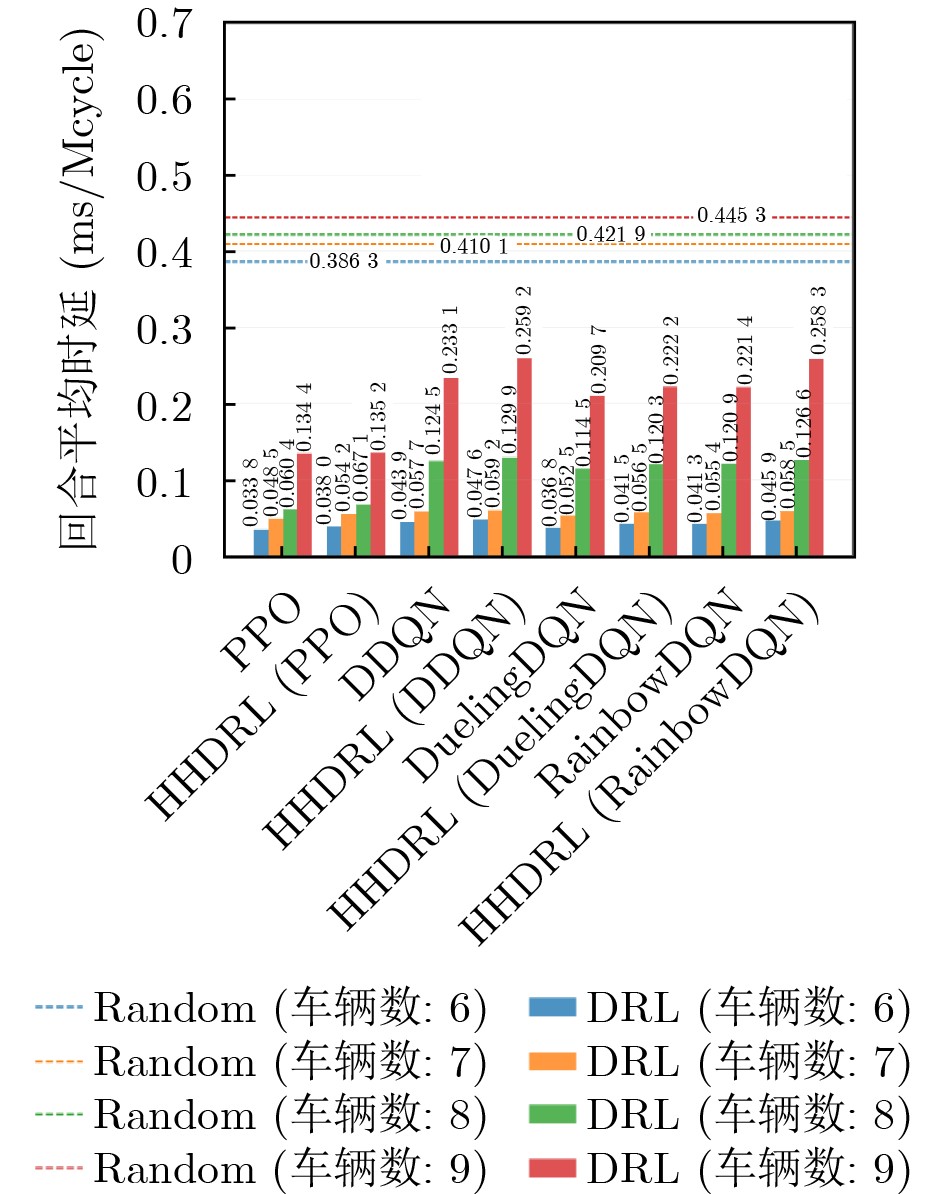
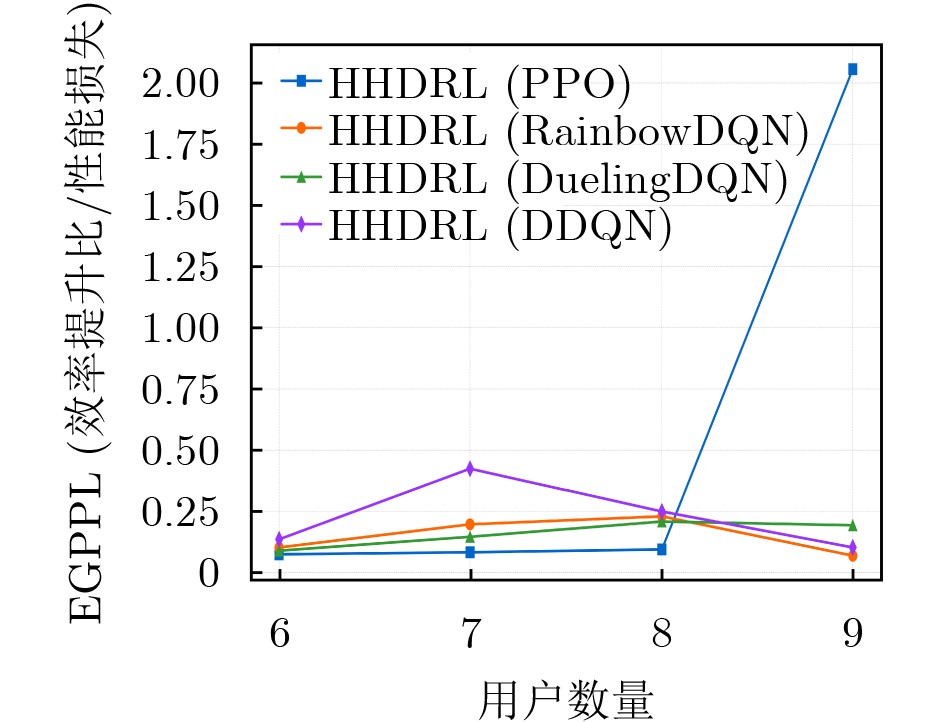
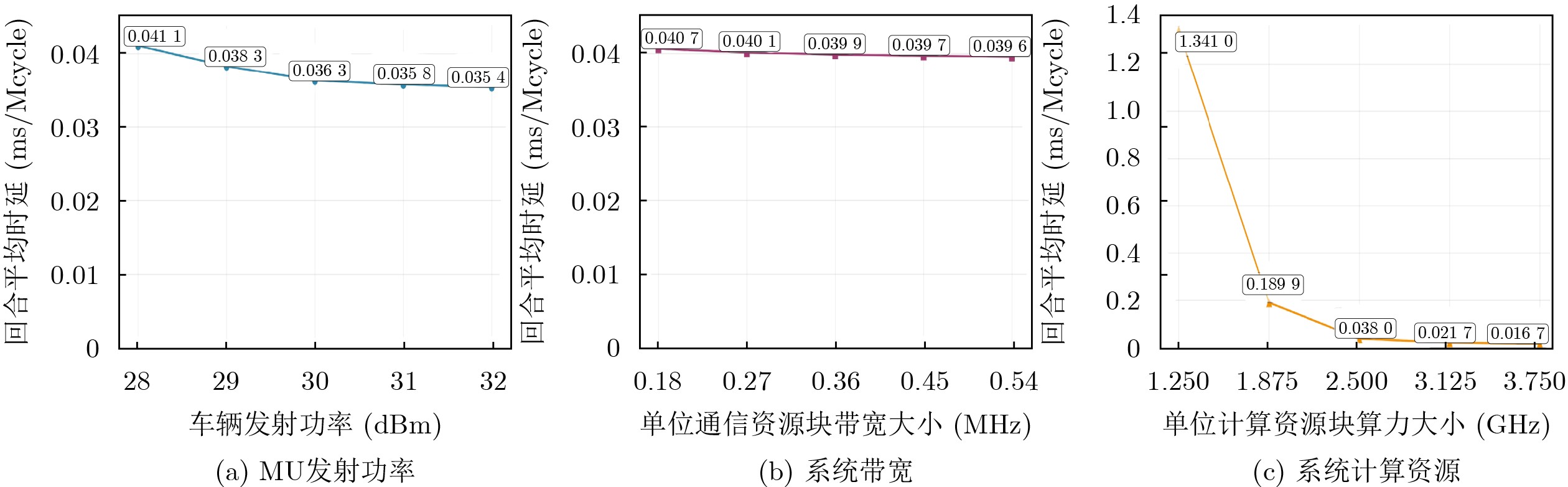
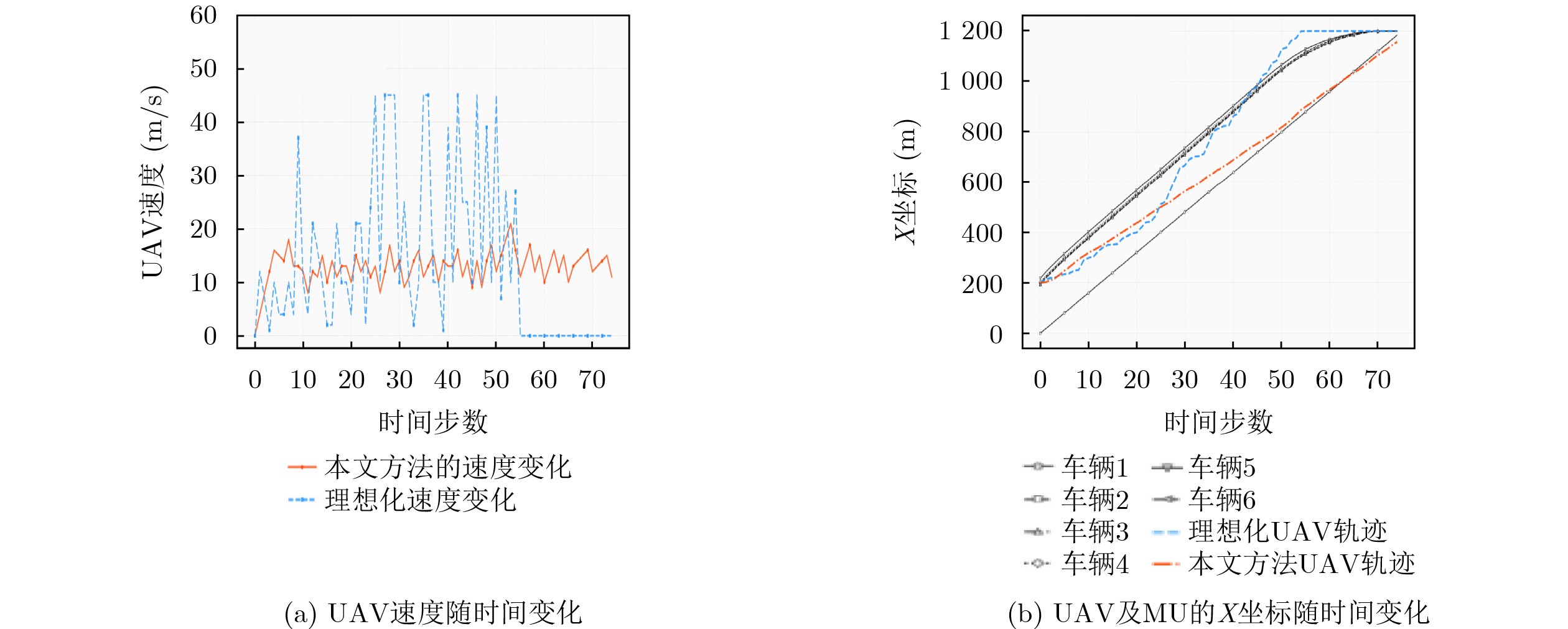
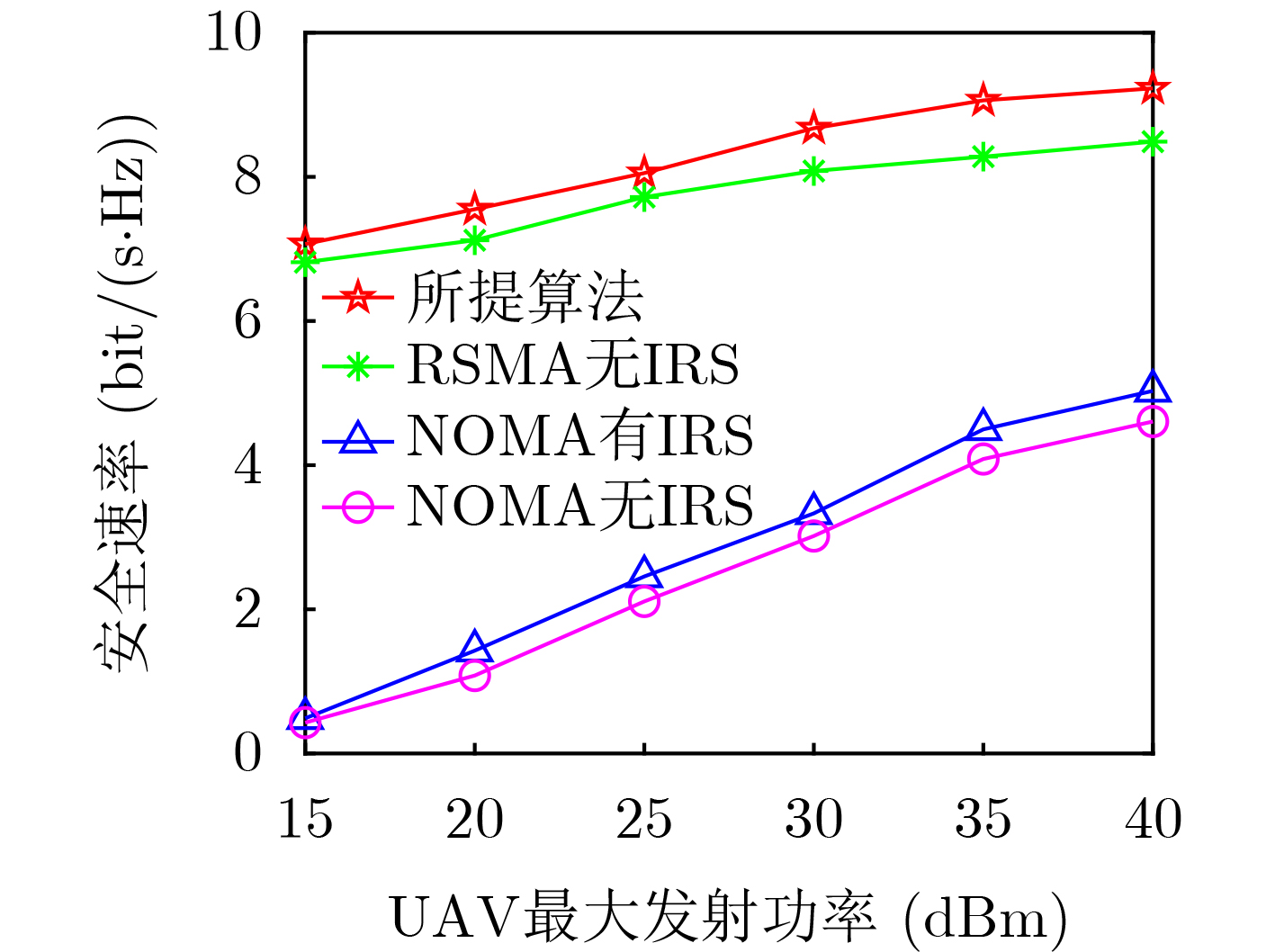
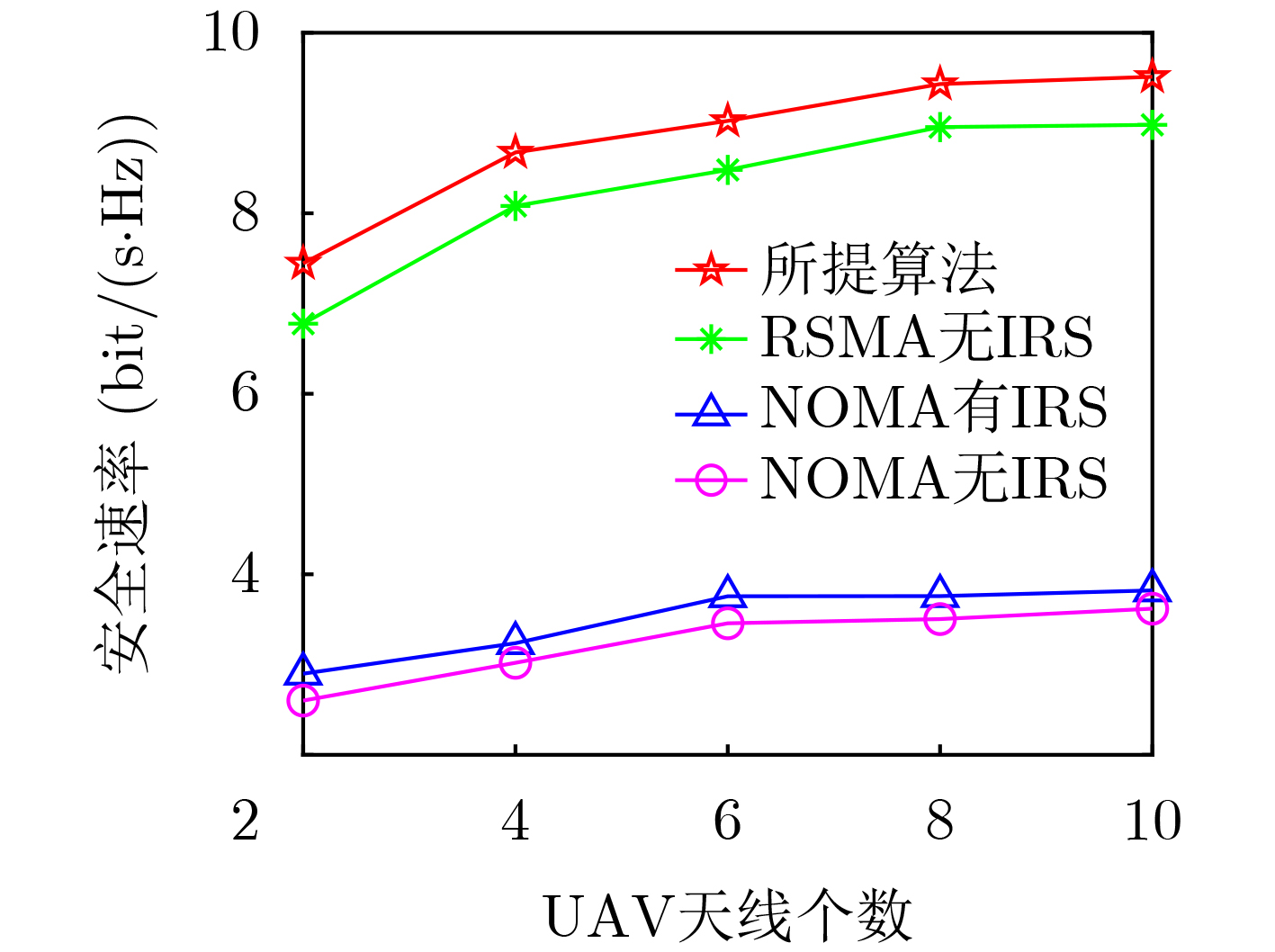
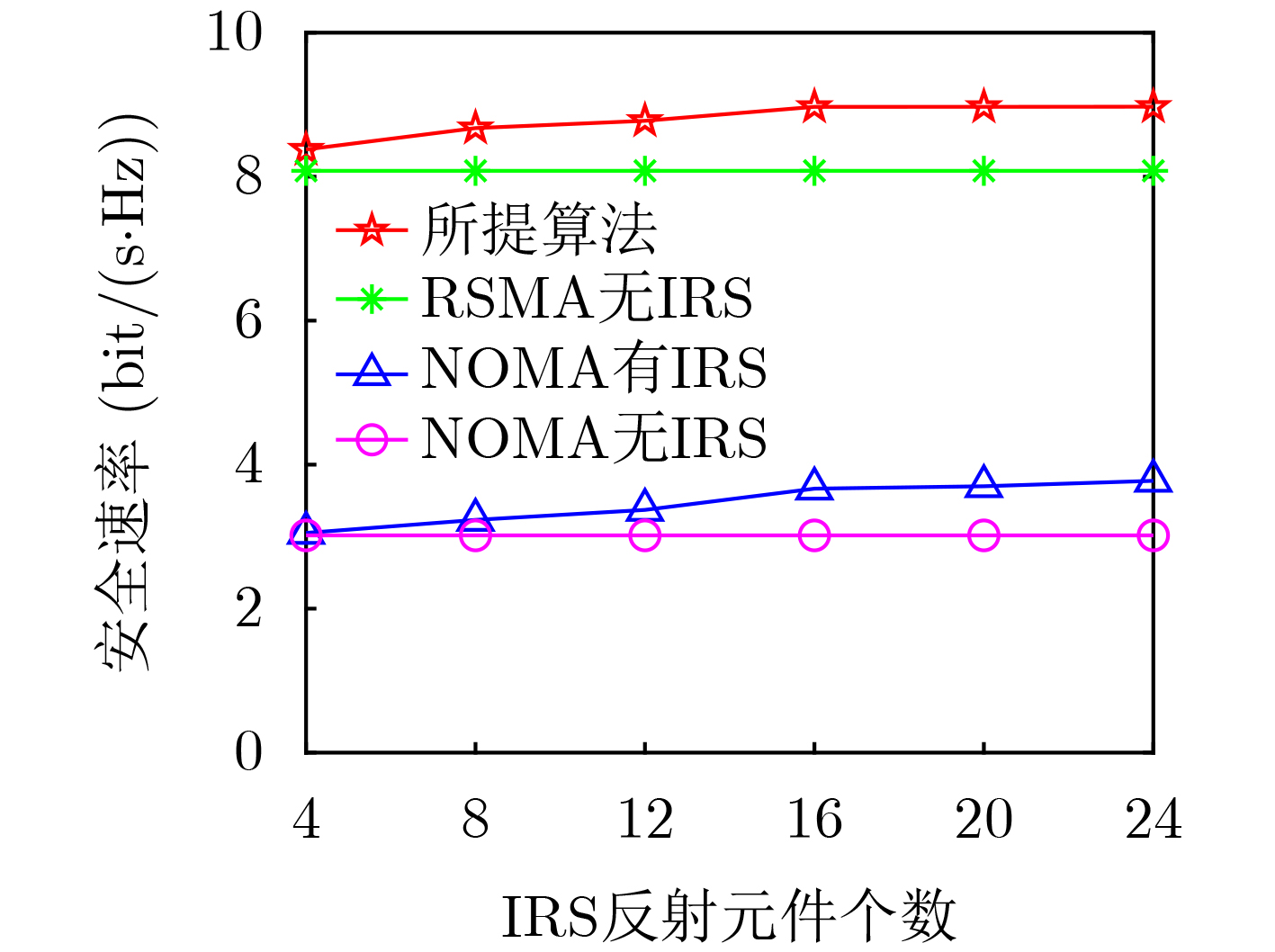
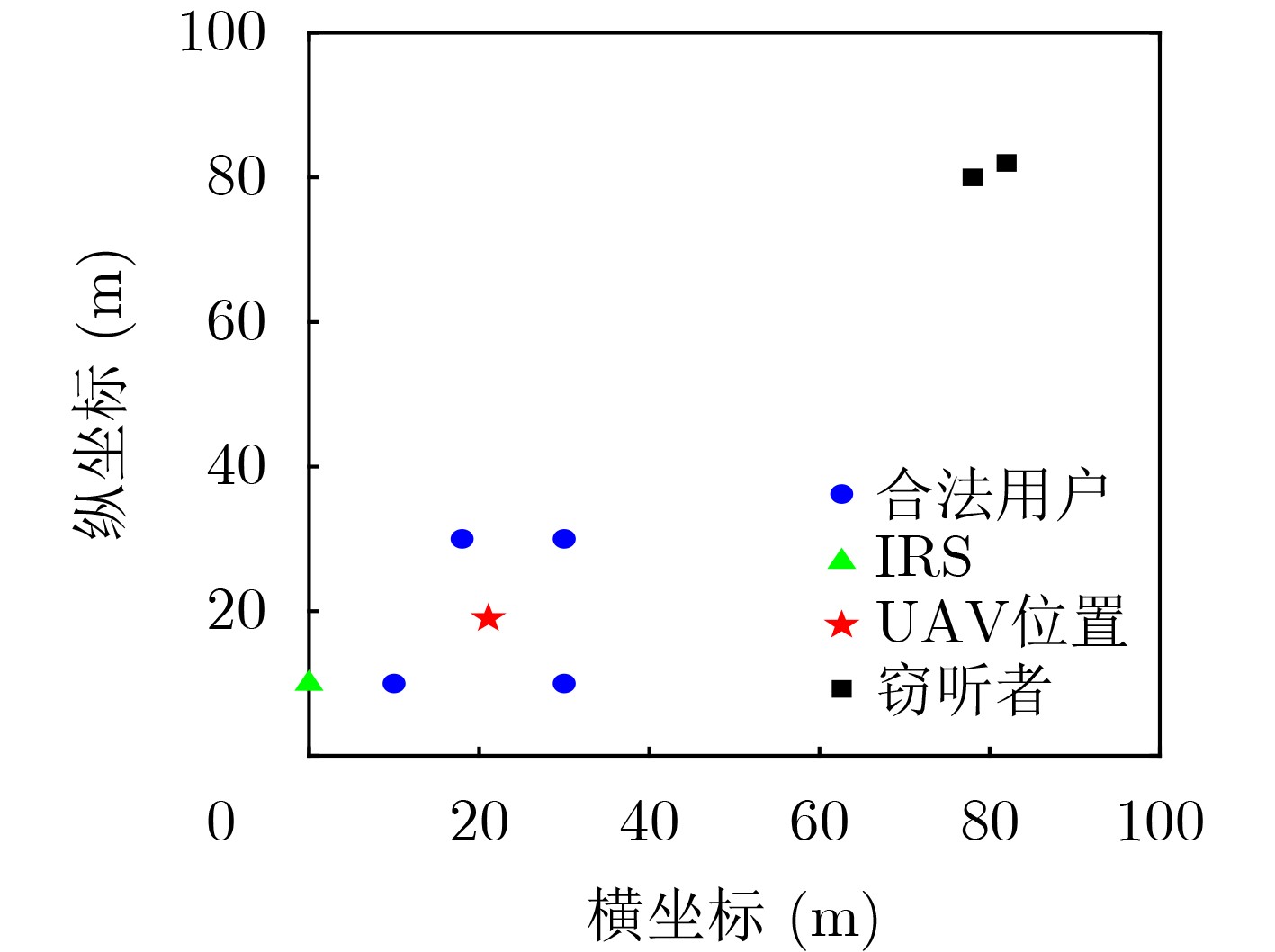
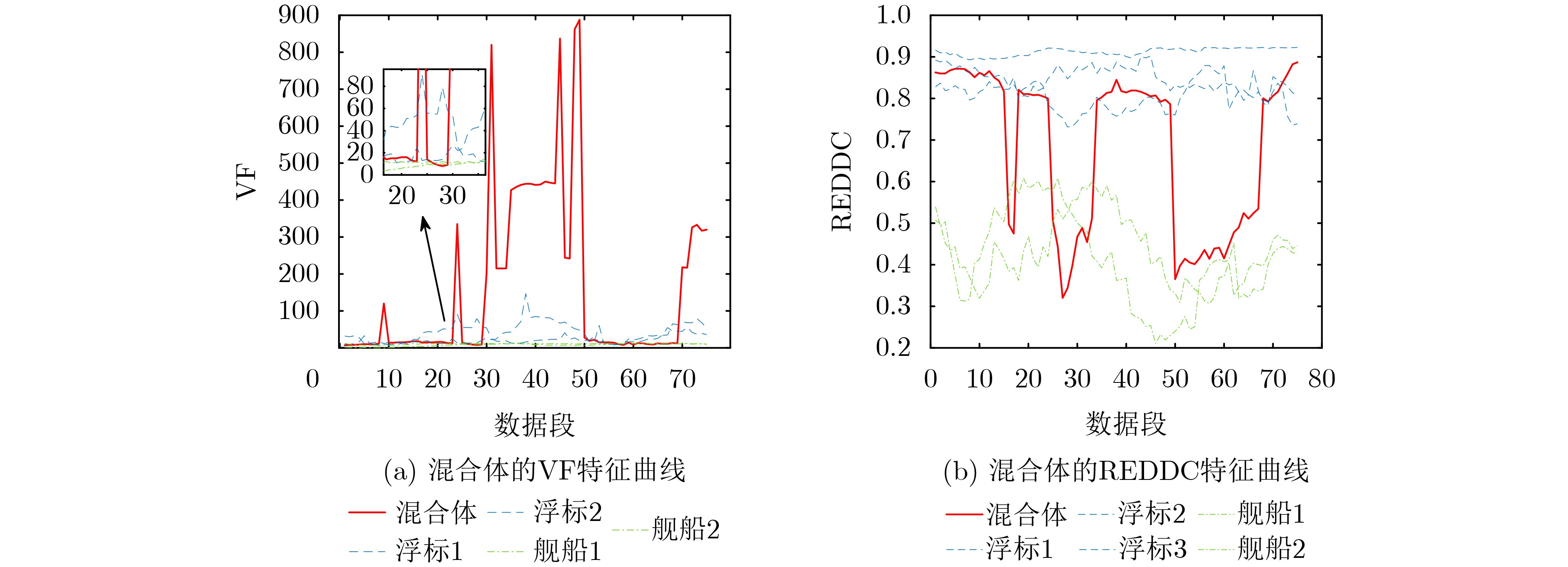
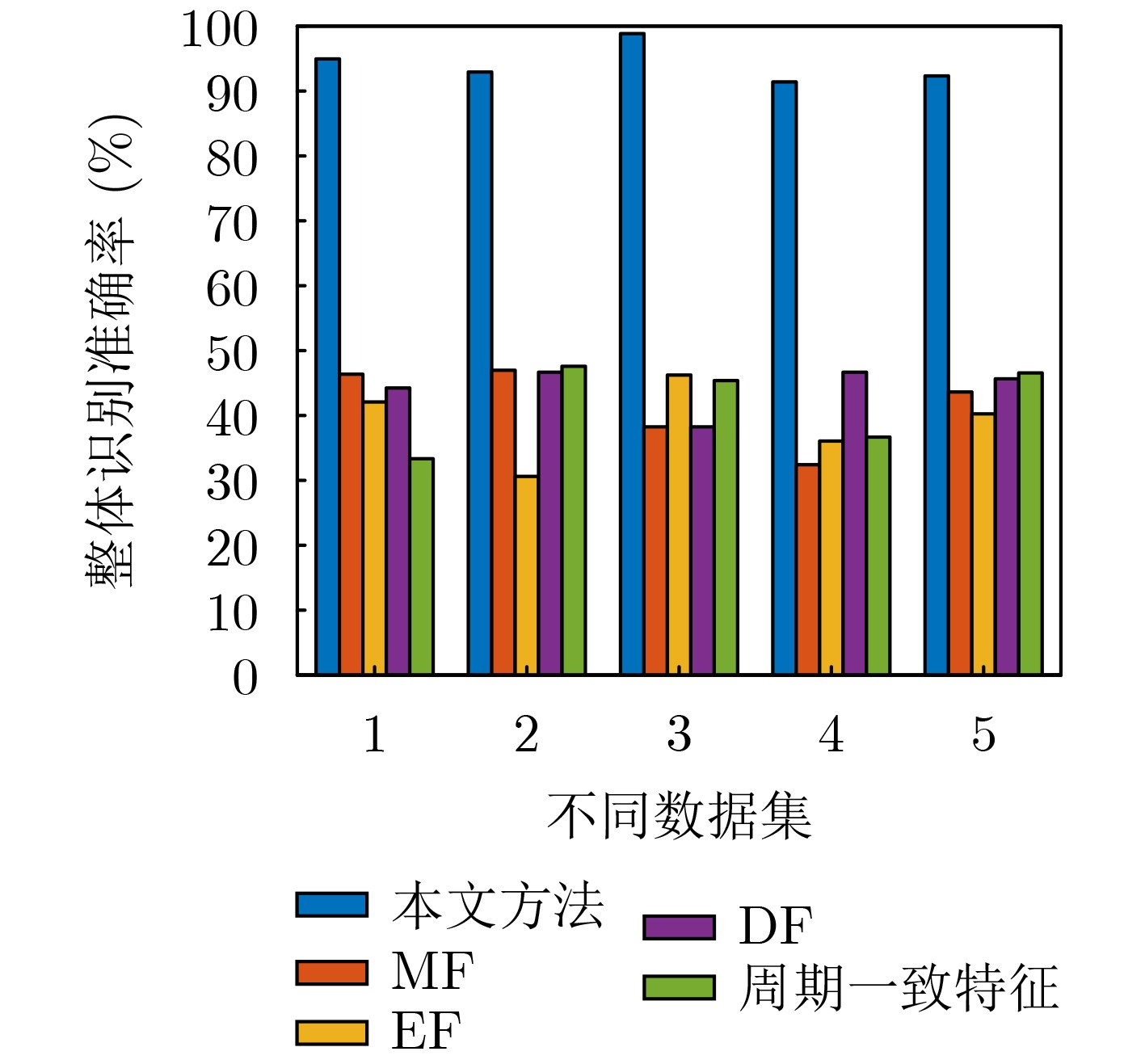
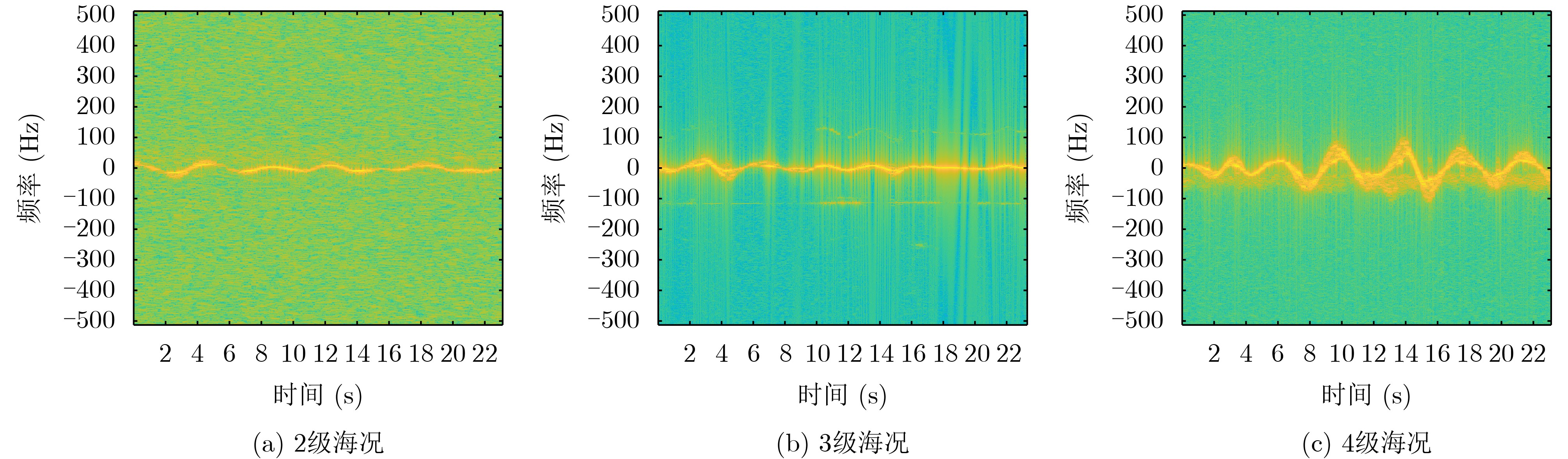
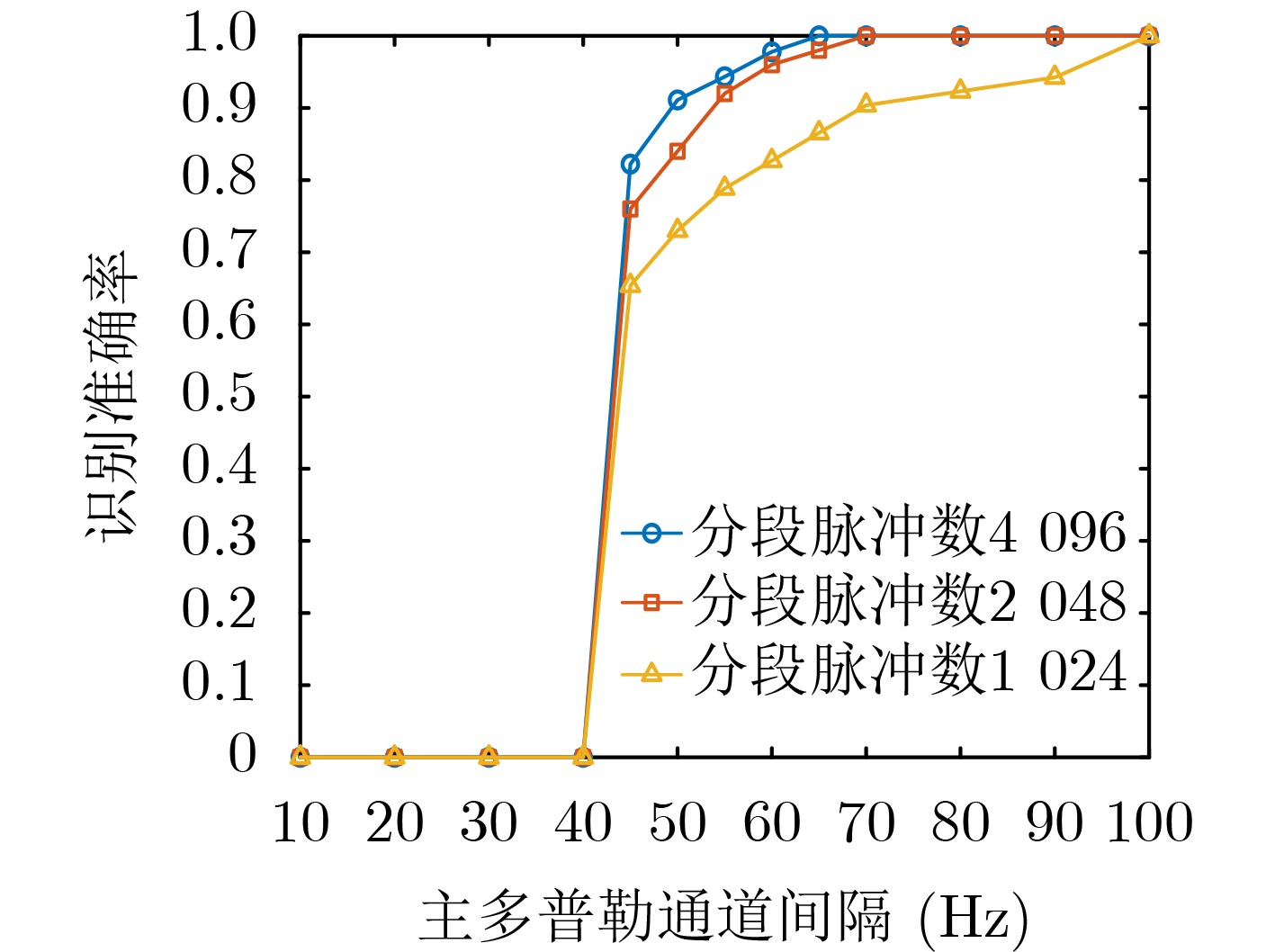
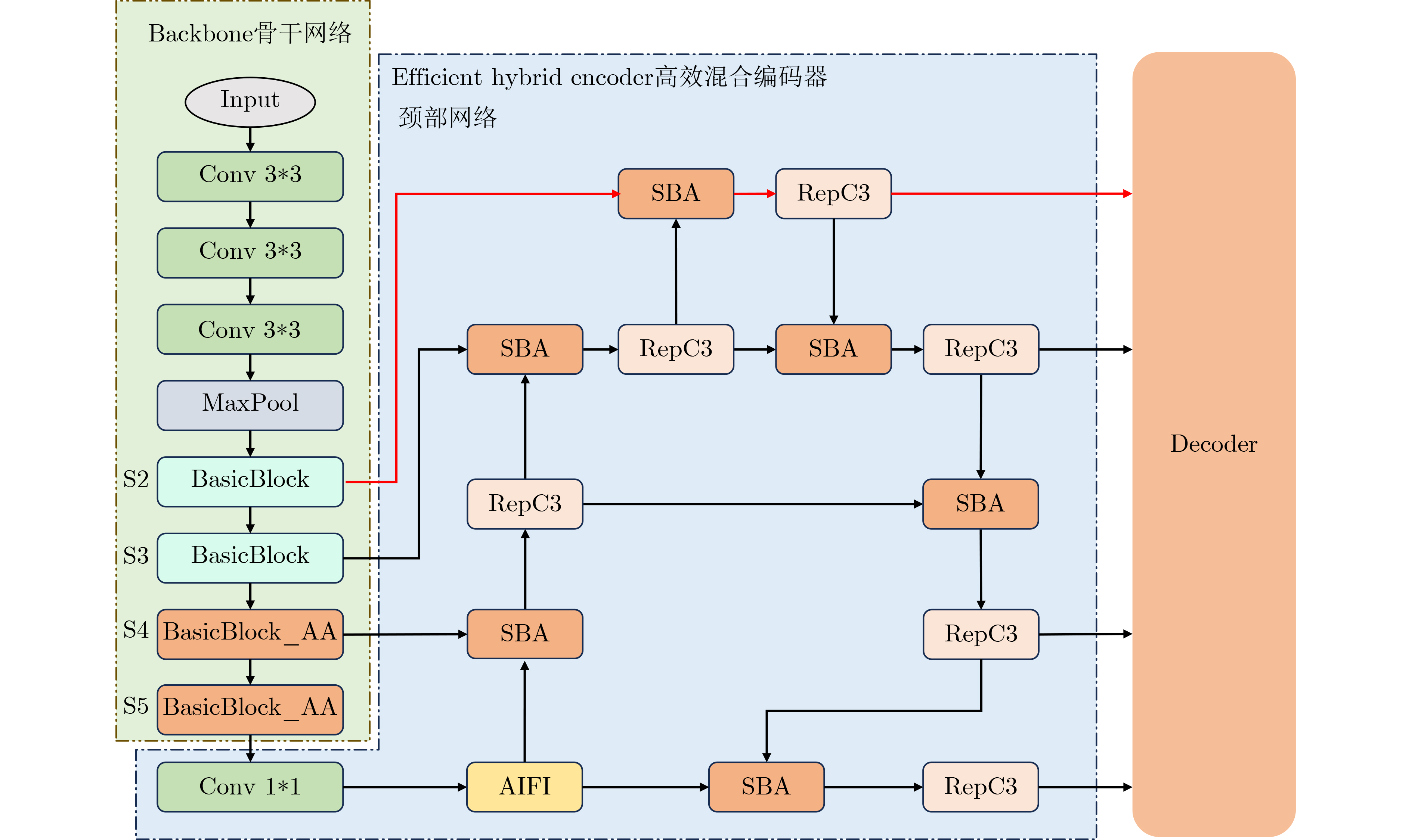
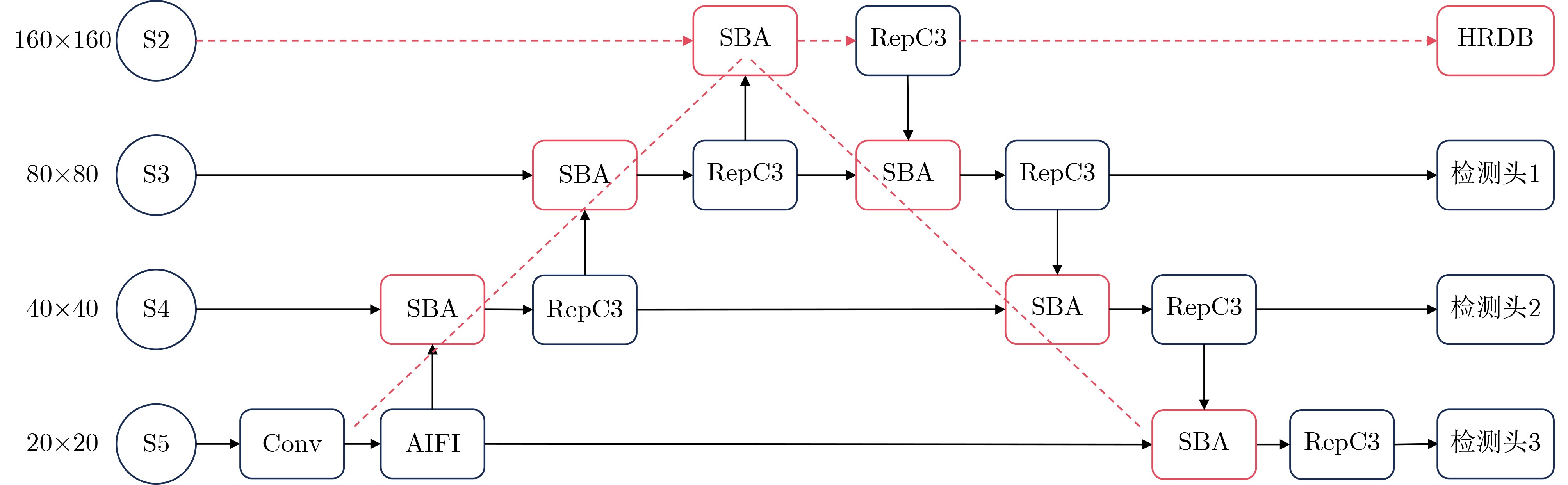
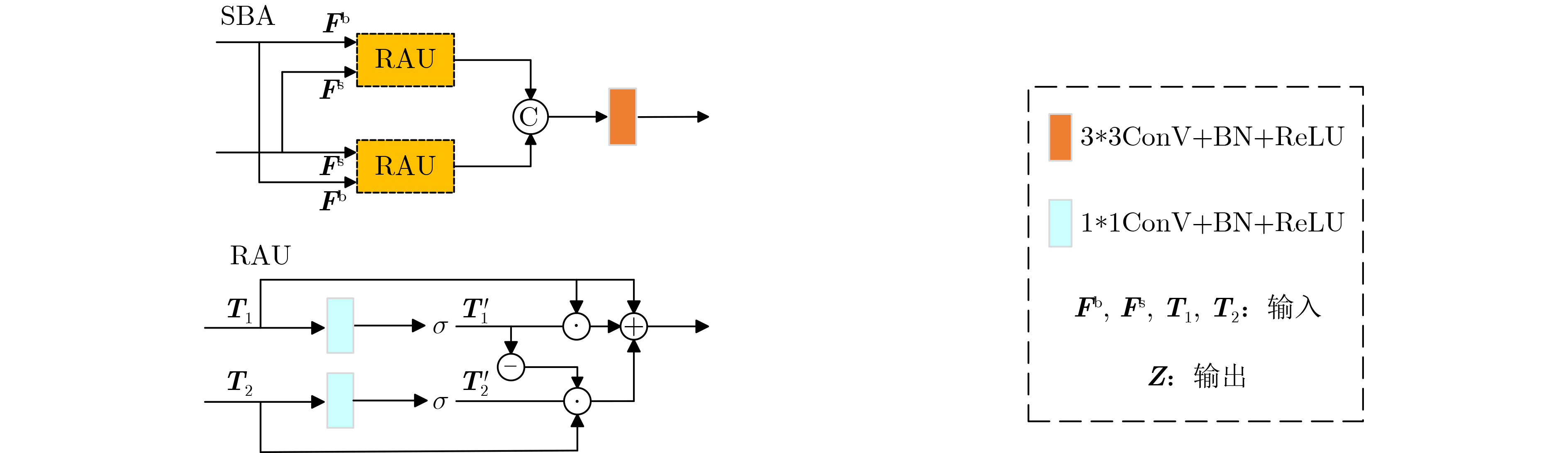
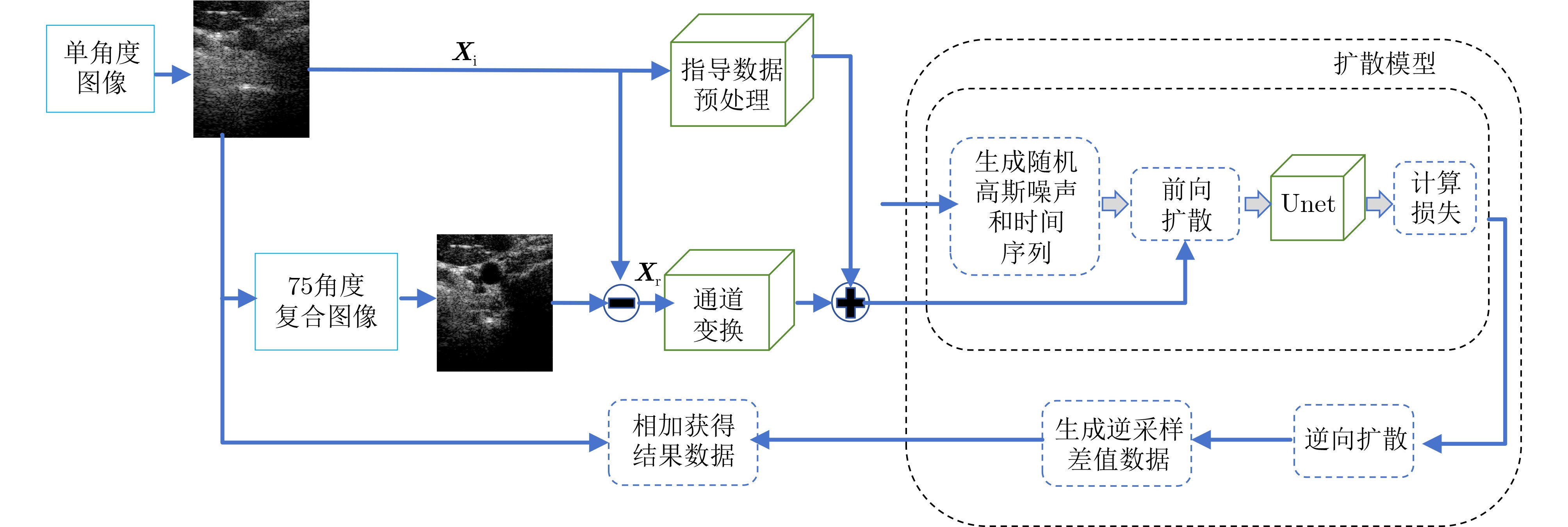
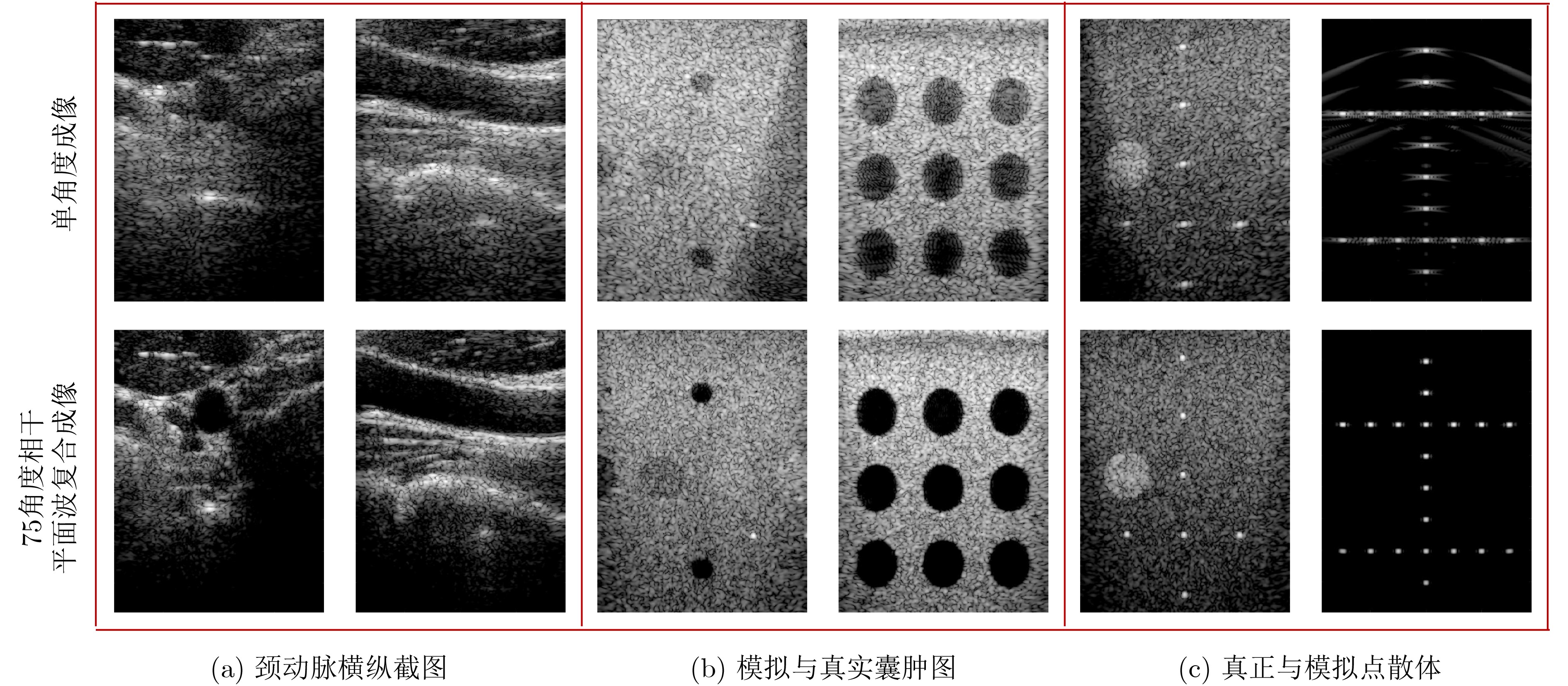
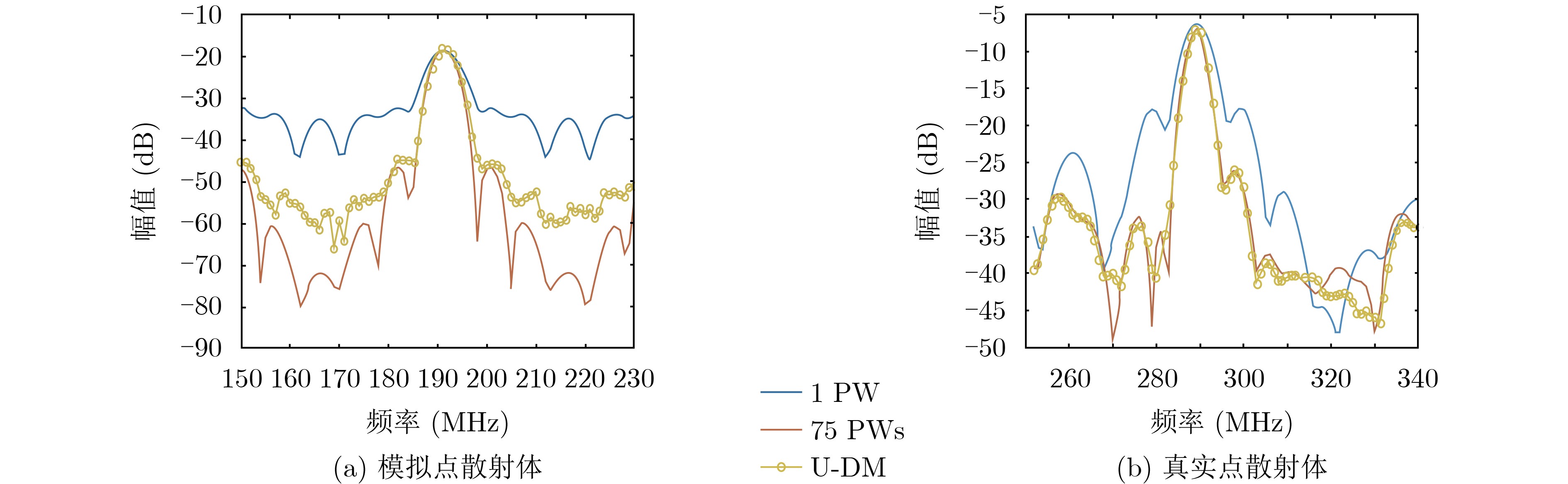
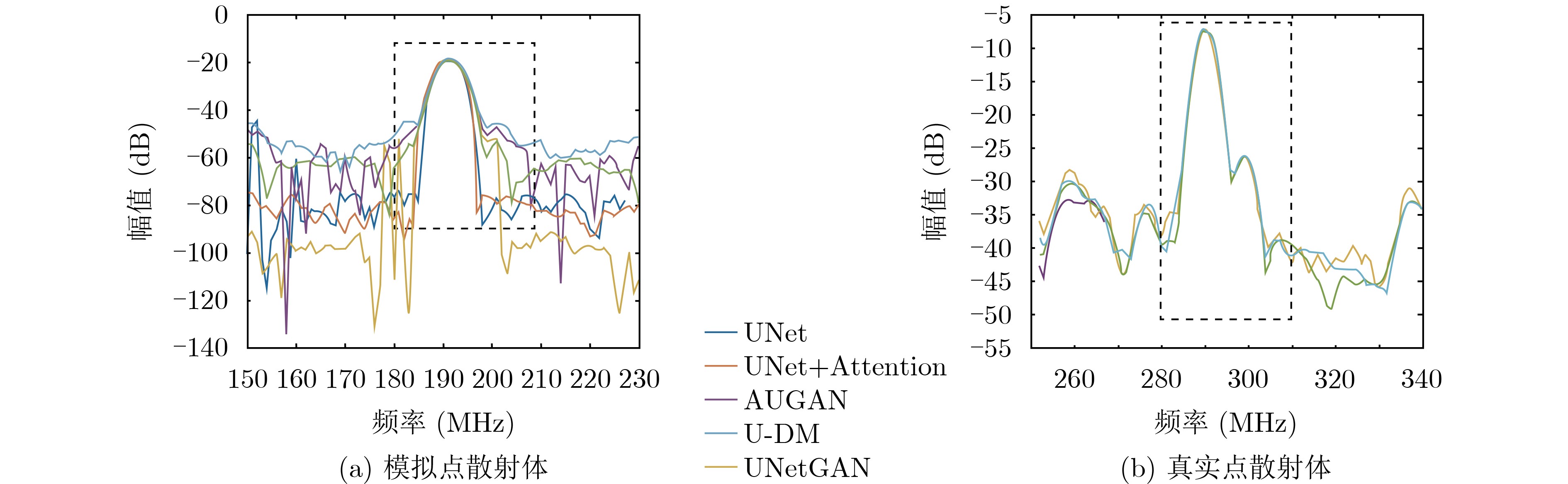
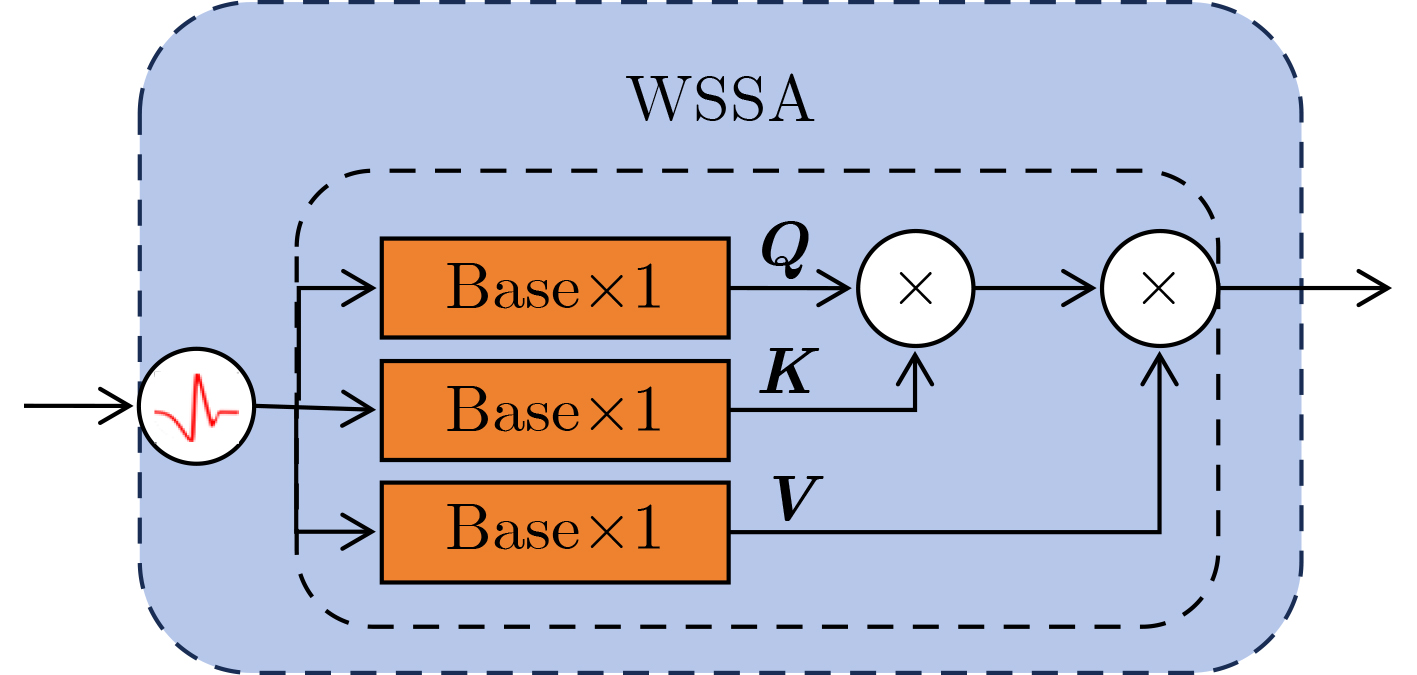
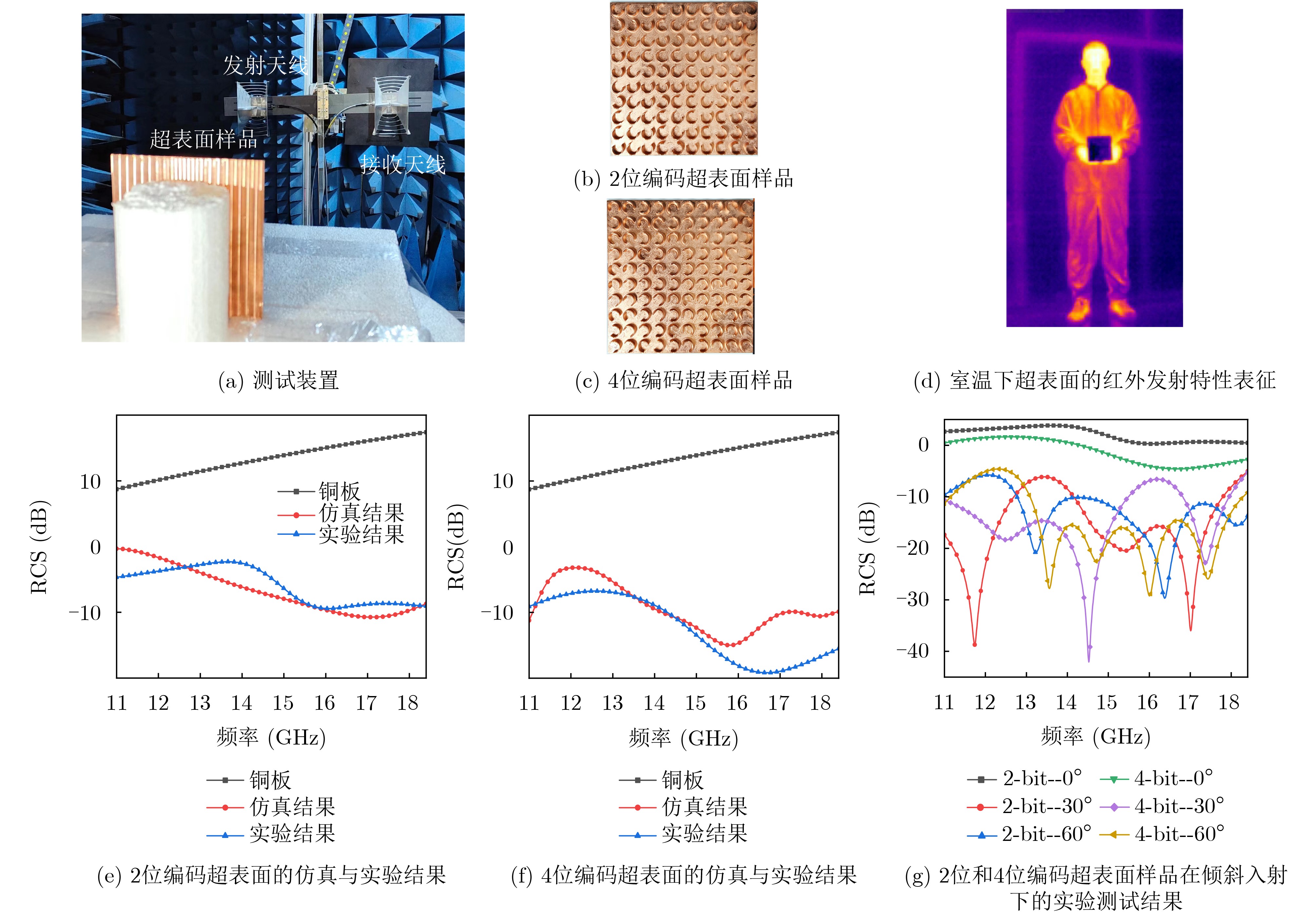
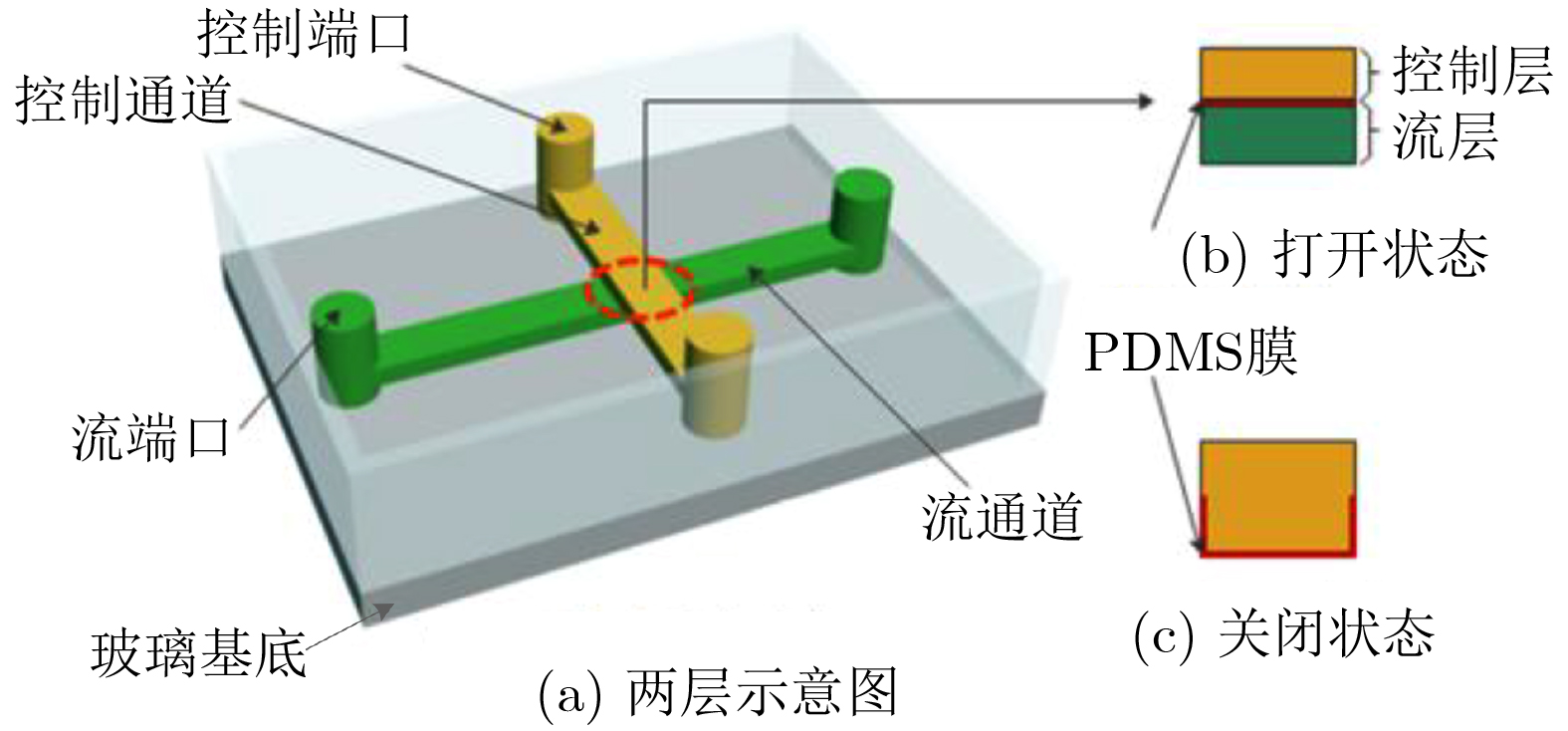
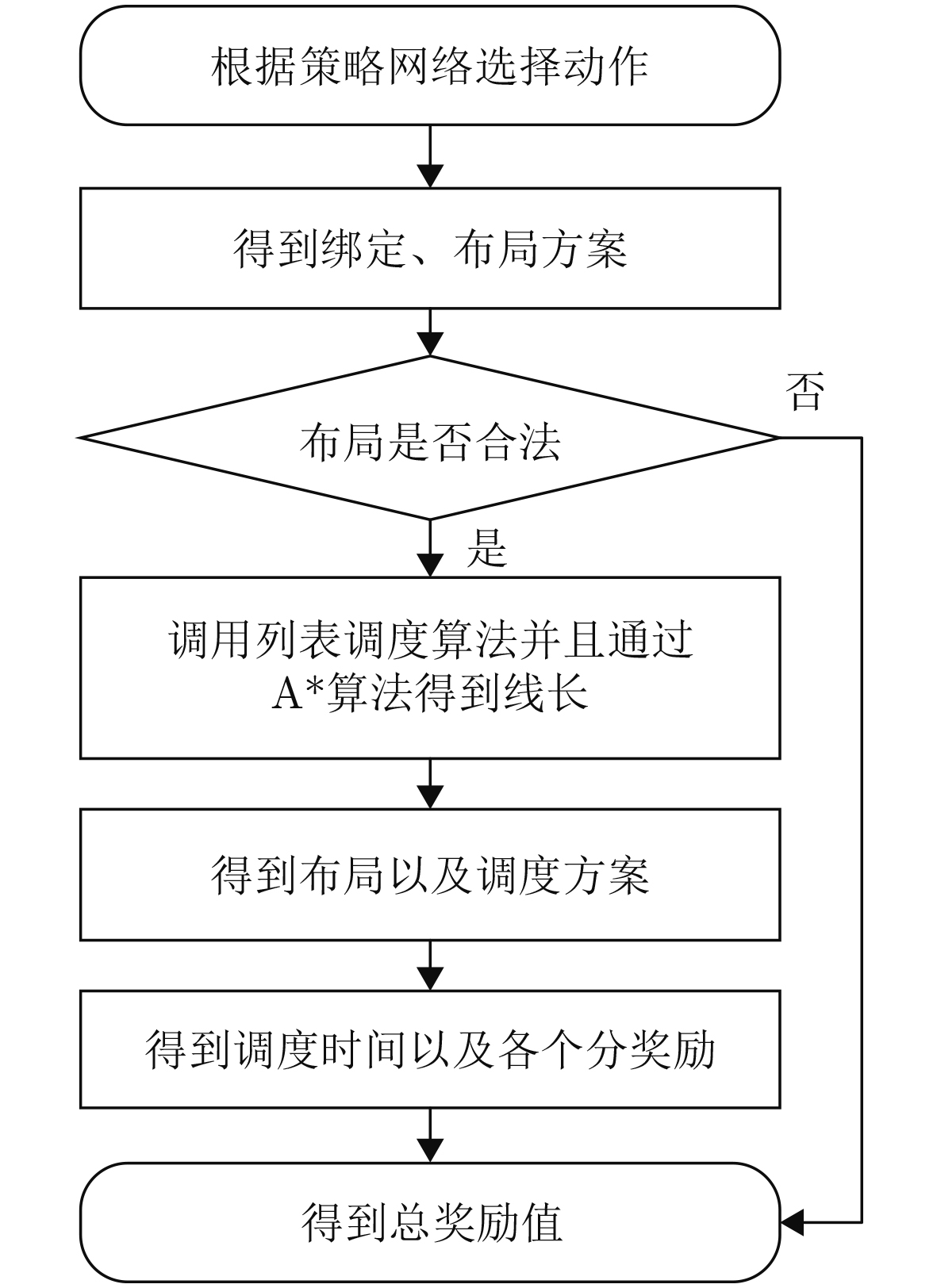
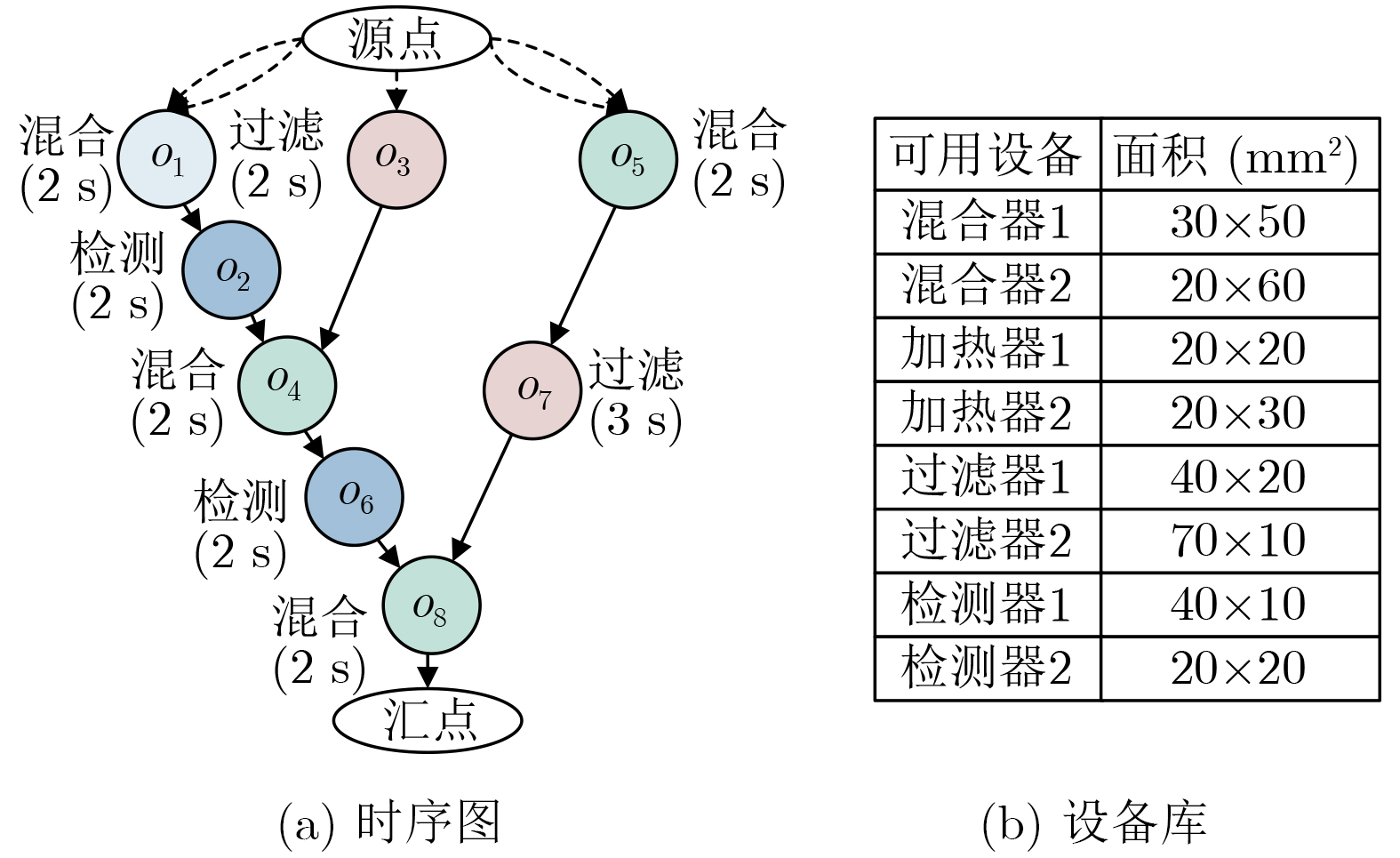
2026, 48(4): 1623-1632.
doi: 10.11999/JEIT250690
Abstract:
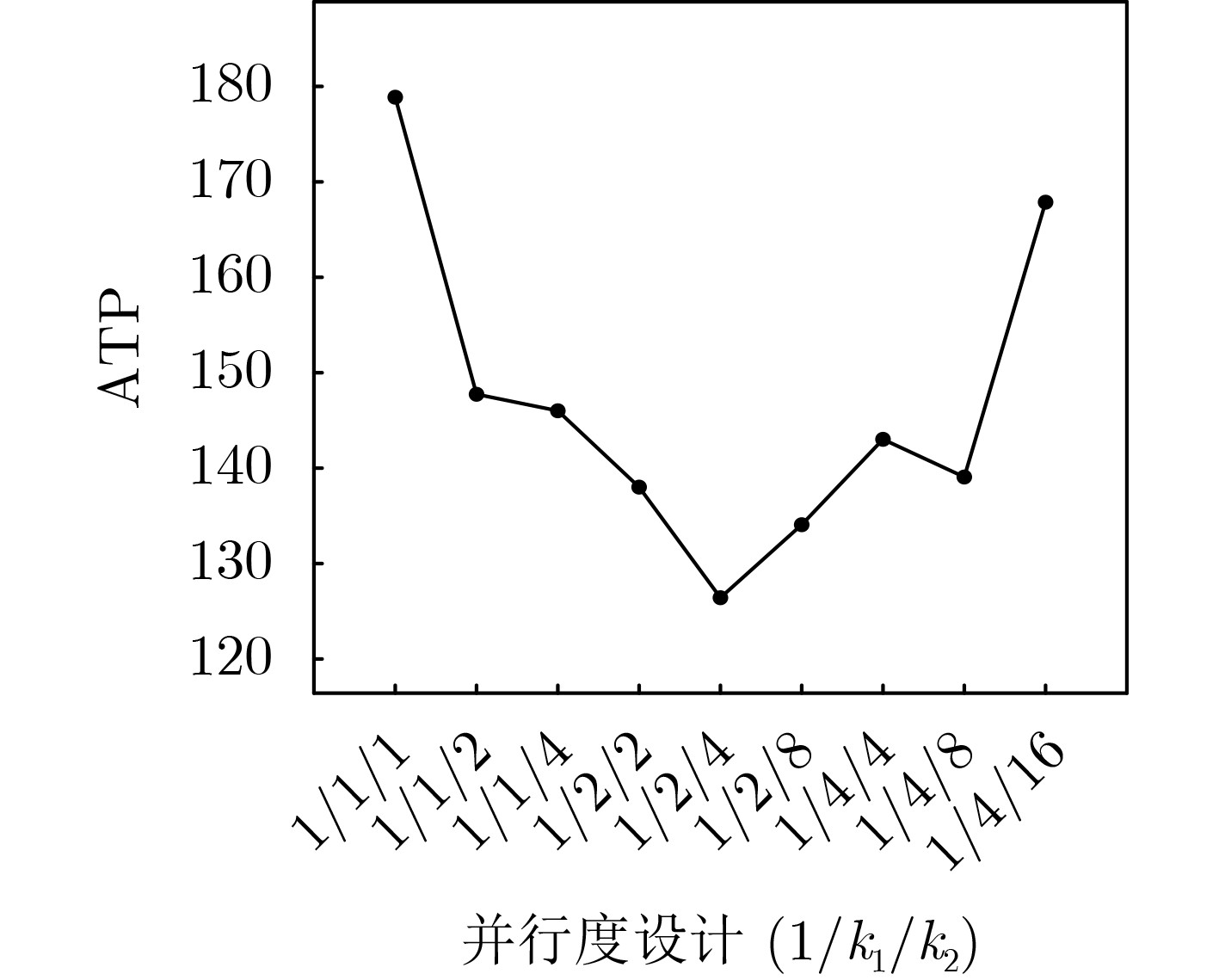
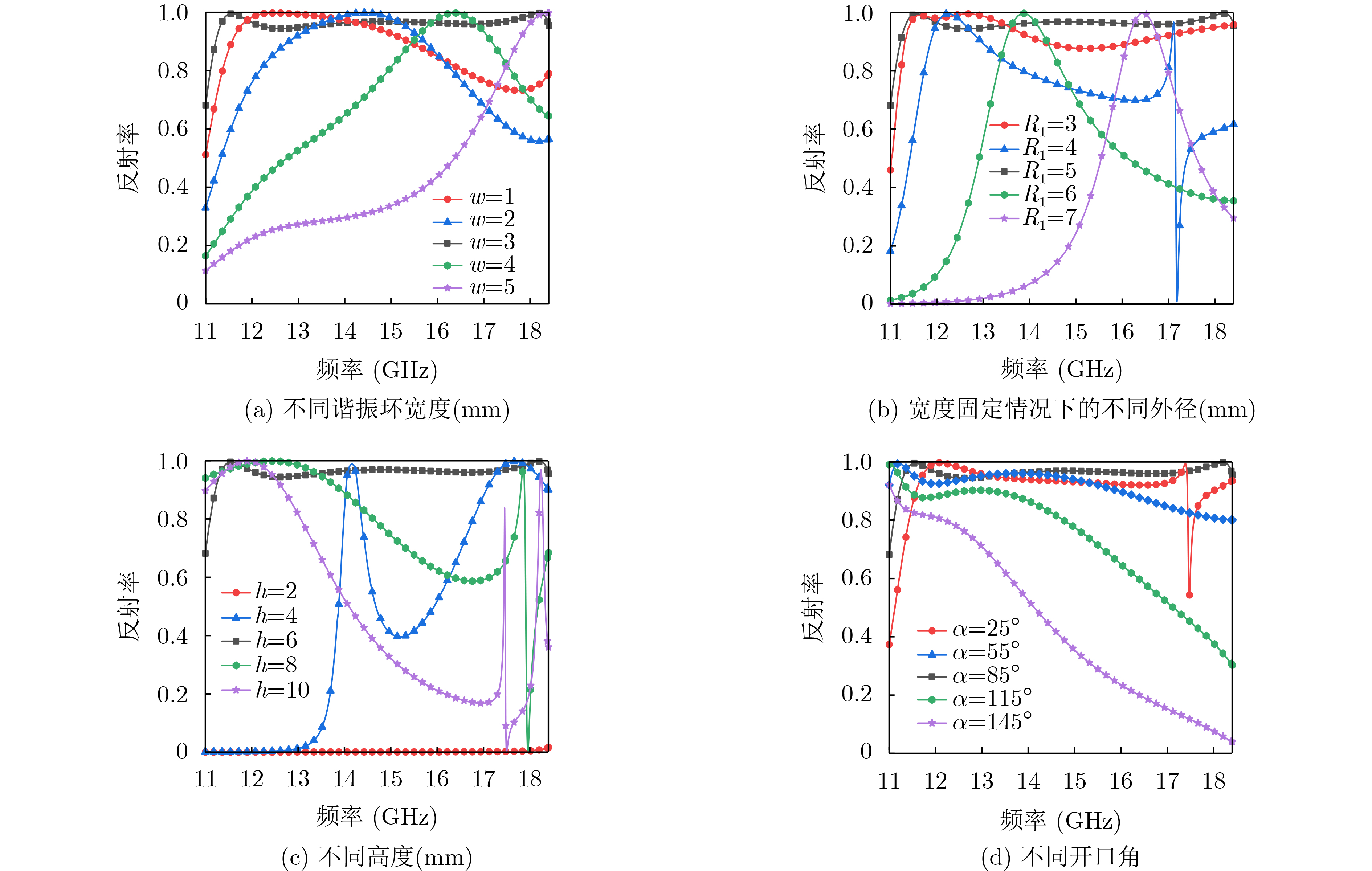
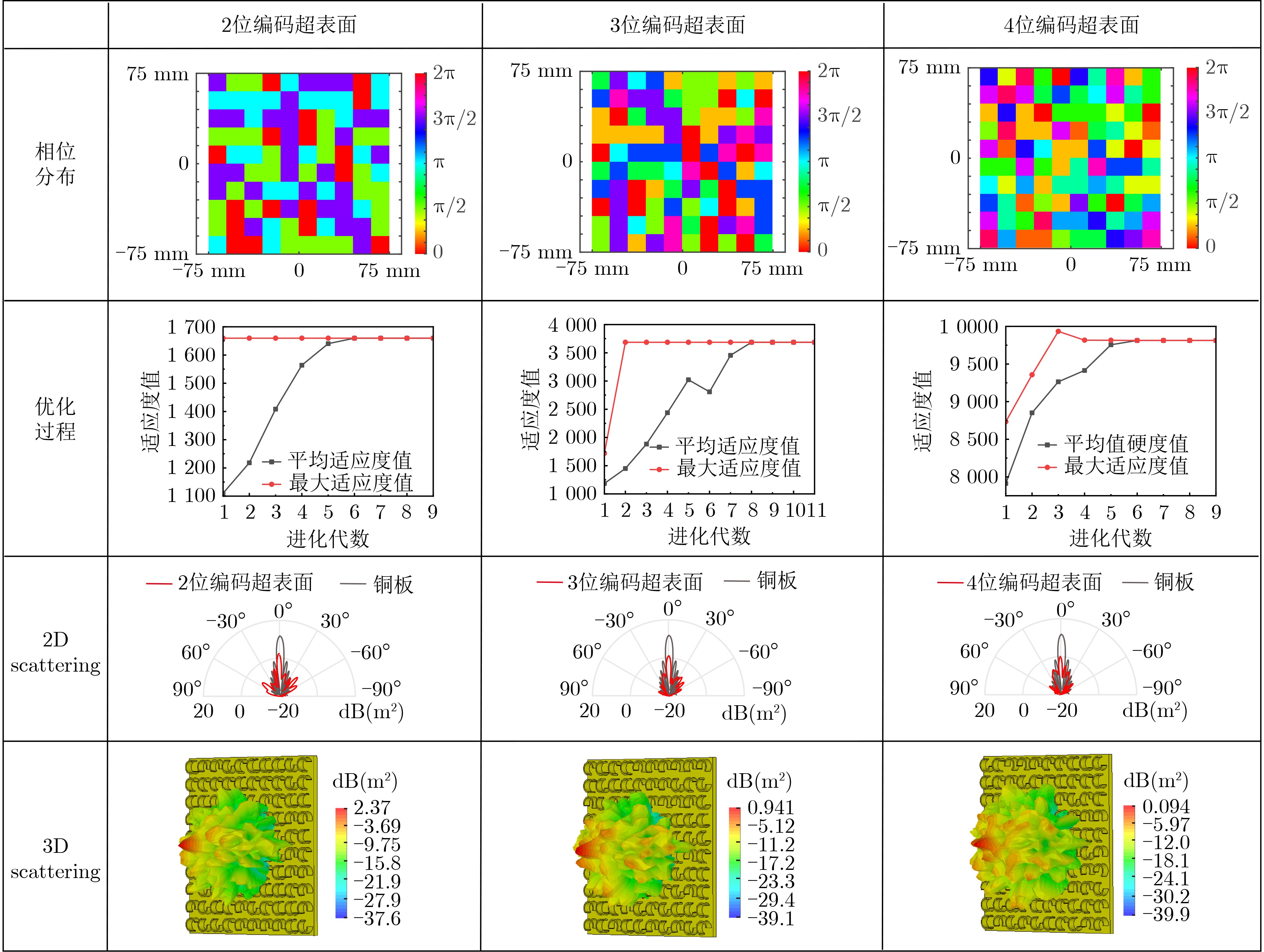
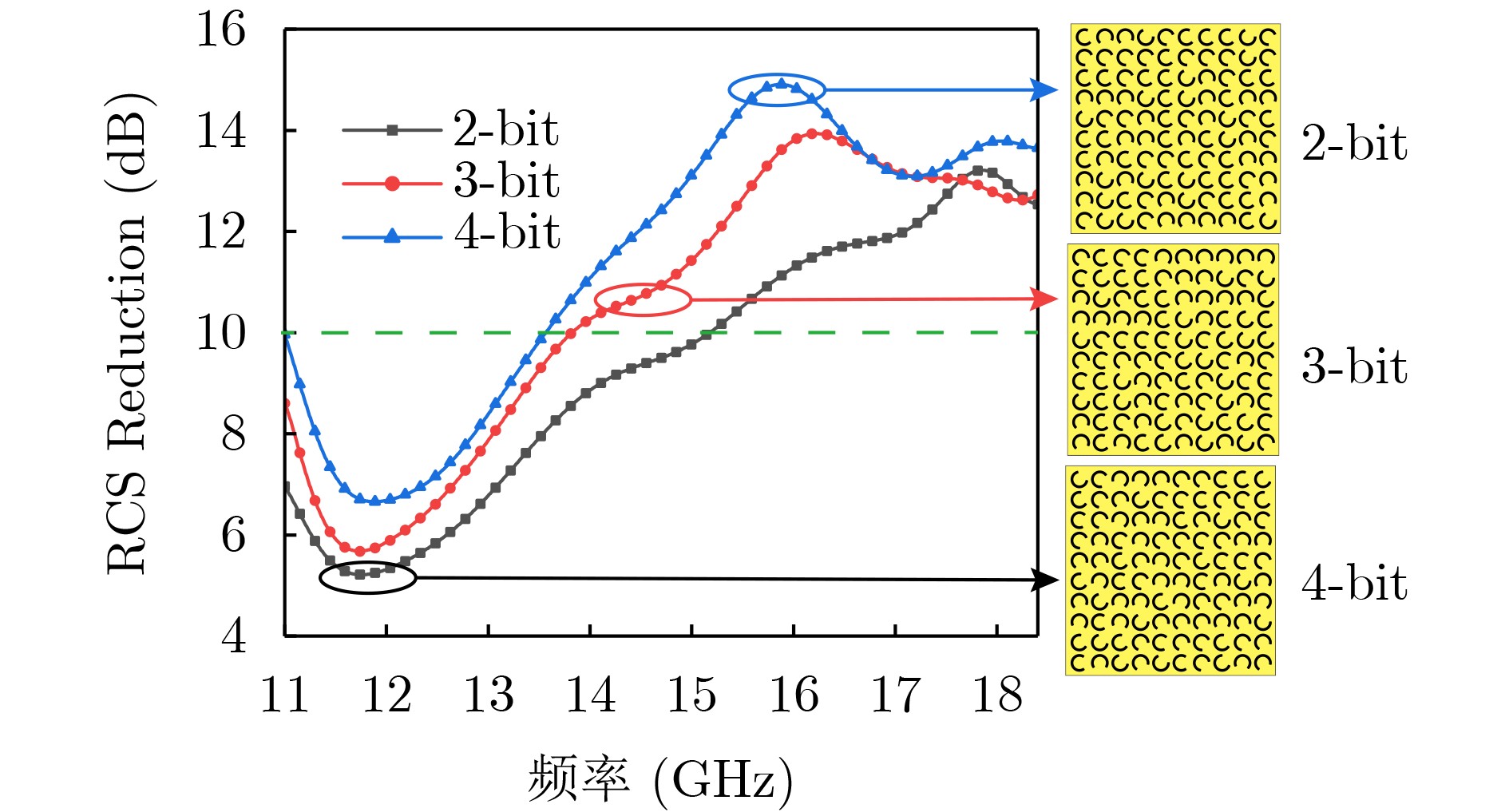
Objective With the rapid development and widespread deployment of the Internet of Things (IoT), embedded systems, and mobile computing devices, secure communication and data protection on resource-constrained platforms have become a central focus in information security. These devices are typically characterized by severe limitations in computational capability, storage capacity, and energy consumption. These limitations make traditional cryptographic algorithms inefficient or even infeasible in such environments. In response, lightweight cryptographic algorithms have been proposed as an effective class of solutions. Their primary objective is to achieve security levels comparable to those of traditional algorithms while significantly reducing hardware and computational overhead through algorithmic simplification and structural optimization. These algorithms are designed to operate efficiently under tight resource constraints and are particularly suitable for applications such as sensor networks, smart cards, RFID systems, and wearable devices. From the perspective of hardware implementation, the design of lightweight cryptographic algorithms must consider multiple performance metrics, including throughput, latency, power efficiency, chip area, and circuit depth. Among these metrics, chip area and circuit depth are particularly critical because they directly affect production cost and computational speed. The Substitution-box (S-Box), as the core nonlinear component that provides confusion in most symmetric encryption schemes, plays a decisive role in determining both the security and implementation efficiency of the entire cipher. Therefore, efficient methods for realizing low-area and low-depth S-Boxes are of fundamental importance for the design of secure and practical lightweight cryptographic systems. Methods In this work, a novel S-Box optimization algorithm based on Boolean satisfiability (SAT) solving is proposed to optimize two key hardware metrics simultaneously: logic area and circuit depth. A circuit model with depth k and width w is constructed for this purpose. Under a given area constraint, SAT-solving techniques are used to determine whether the circuit model can implement the target S-Box. By iteratively adjusting the circuit depth, width, and area parameters, an optimized S-Box implementation is obtained. The method is specifically developed for 4-bit S-Boxes, which are widely used in many lightweight block ciphers, and it provides implementations that are highly efficient in both structural compactness and computational depth. This dual optimization approach reduces hardware cost while maintaining low latency, making it particularly suitable for scenarios in which both performance and energy efficiency are critical. The proposed method begins by transforming the S-Box implementation problem into a formal SAT problem, which enables the use of powerful SAT solvers to exhaustively explore possible logic-level representations. In this transformation, a diverse set of logic gates, including 2-input, 3-input, and 4-input gates, is used to construct flexible logic networks. To enforce area and depth constraints, arithmetic operations such as binary addition and comparator logic are encoded into SAT-compatible Boolean constraints, which guide the solver toward low-area and low-depth solutions. To further accelerate the solving process and avoid redundant search paths, symmetry-breaking constraints are introduced. These constraints eliminate logically equivalent but structurally different representations, thereby significantly reducing the size of the solution space. The CaDiCaL SAT solver, known for its speed and efficiency in handling large-scale SAT problems, is used to compute optimized S-Box implementations that minimize both depth and area. The proposed approach not only generates efficient implementations but also provides a general modeling framework that can be extended to other logic-synthesis problems in cryptographic hardware design. Results and Discussions To validate the effectiveness of the proposed optimization method, a comprehensive set of experiments is conducted on 4-bit S-Boxes from several representative lightweight block ciphers, including Joltik, Piccolo, Rectangle, Skinny, Lblock, Lac, Midori, and Prøst. The results show that the method consistently produces high-quality implementations that are competitive with, or superior to, existing state-of-the-art results in both chip area and circuit depth. Specifically, for the S-Boxes of Joltik and Piccolo, as well as those used in Skinny and Rectangle, the generated implementations match the best known results in both metrics, indicating that the method can successfully reproduce optimal or near-optimal designs. In the cases of Lblock and Lac, although the logic area remains similar to previous results, the circuit depth is significantly reduced from 10 to 3, representing a substantial improvement in processing latency and suitability for real-time applications. For the inverse S-Box of the Rectangle cipher, the proposed implementation achieves the same circuit depth as previous designs but reduces the area from 24.33 Gate Equivalents (GE) to 17.66 GE, yielding a more compact and efficient realization. The optimization results for the Midori S-Box further confirm the effectiveness of the method: the depth is reduced from 4 to 3, and the area is reduced from 20.00 GE to 16.33 GE. For the Prøst cipher’s S-Box, two alternative implementations are presented to illustrate the trade-off between area and depth. The first achieves a depth of 4 with an area of 22.00 GE, matching the best known depth but at a higher area cost. The second increases the depth to 5 but reduces the area significantly to 13.00 GE. These results show that the method supports flexible optimization under different design constraints and also provides deeper insight into the complexity and trade-offs of S-Box implementation. Conclusions This paper presents a SAT-based method for jointly optimizing S-Box hardware implementations in terms of area and circuit depth. By modeling S-Box realization as a satisfiability problem and using advanced constraint encoding, multi-input logic gates, and symmetry-breaking techniques, the method effectively reduces hardware complexity while maintaining or improving depth performance. Extensive experiments on various 4-bit S-Boxes show that the proposed approach matches or outperforms existing results, particularly in reducing circuit depth and improving logic compactness. This makes it well suited to lightweight cryptographic systems operating under strict constraints on silicon area, speed, and energy consumption. Despite these advantages, the method still has limitations. Although it achieves optimal or near-optimal results for 4-bit S-Boxes, scalability to larger instances, such as 5-bit or 8-bit S-Boxes, remains challenging because of the exponential growth of the search space and solving time. As model complexity increases, solving becomes computationally expensive and may fail to converge in practice. Future work will focus on improving modeling efficiency and solver performance through refined constraint generation, stronger pruning strategies, and heuristic-guided search, with the goal of extending the method to more complex S-Boxes and other nonlinear components in lightweight and post-quantum cryptographic systems.