

Joint Optimization Method for Pairwise Constrained Projection Clustering Integrating Two-row Update Strategy
-
摘要: 现有的约束投影方法通常采用投影-聚类两步独立策略,导致投影误差直接传递至聚类过程;此外,成对约束仅局限于投影阶段,偏离由先验知识引导聚类的核心思想。为此,本文提出两行更新策略的成对约束投影-聚类联合优化方法。首先,将约束投影目标函数作为正则化项统一到聚类框架中,二者在交替优化的过程中共同逼近全局最优解;其次,为克服传统K-means易陷入局部次优解的缺陷,并旨在提升计算效率,采用了一种融合增量计算、提前存储、变量更新三步加速策略的改进坐标下降法求解指示矩阵;最后,将成对约束嵌入到聚类指示矩阵中,使有限的监督信息贯穿于整个学习流程,并设计了一种新颖的两行同时优化策略,在每次循环中精准且直接地分配勿连约束。仿真实验验证了本文所提方法的优越性。Abstract:
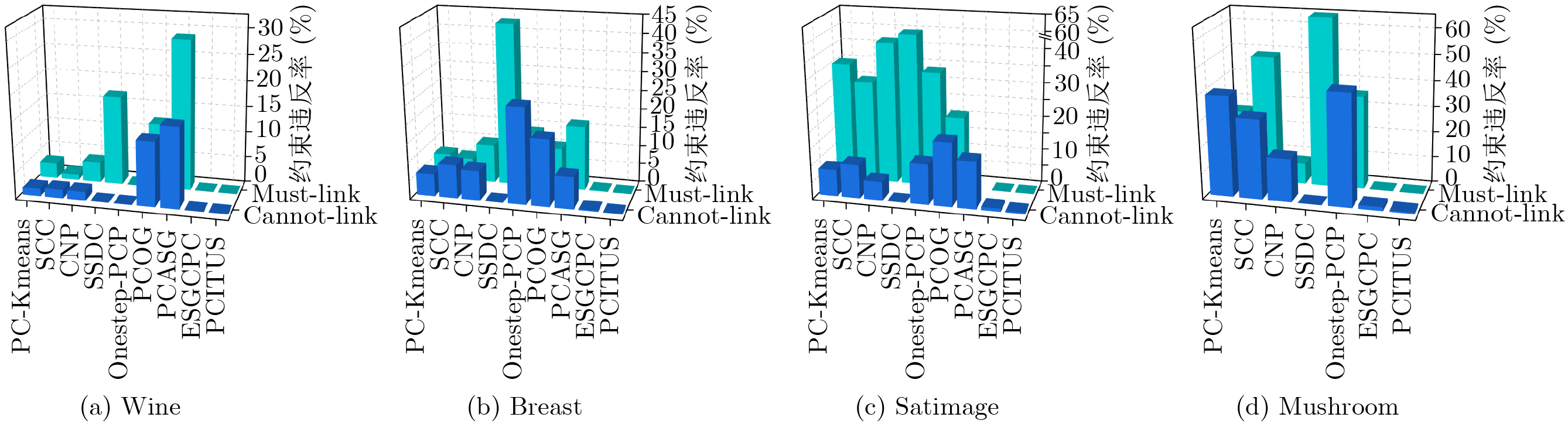
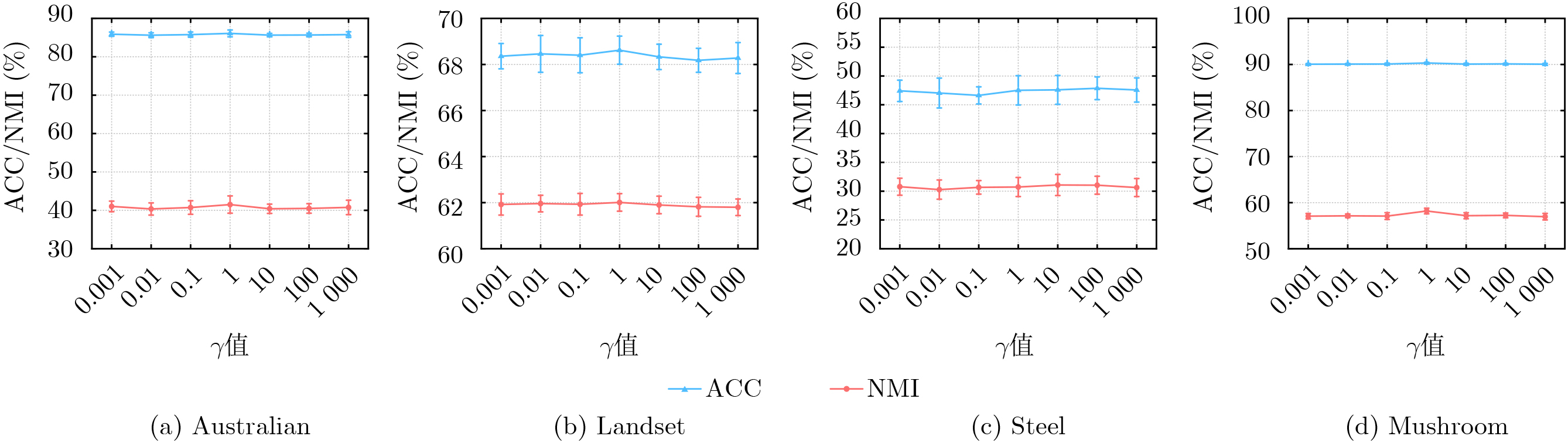
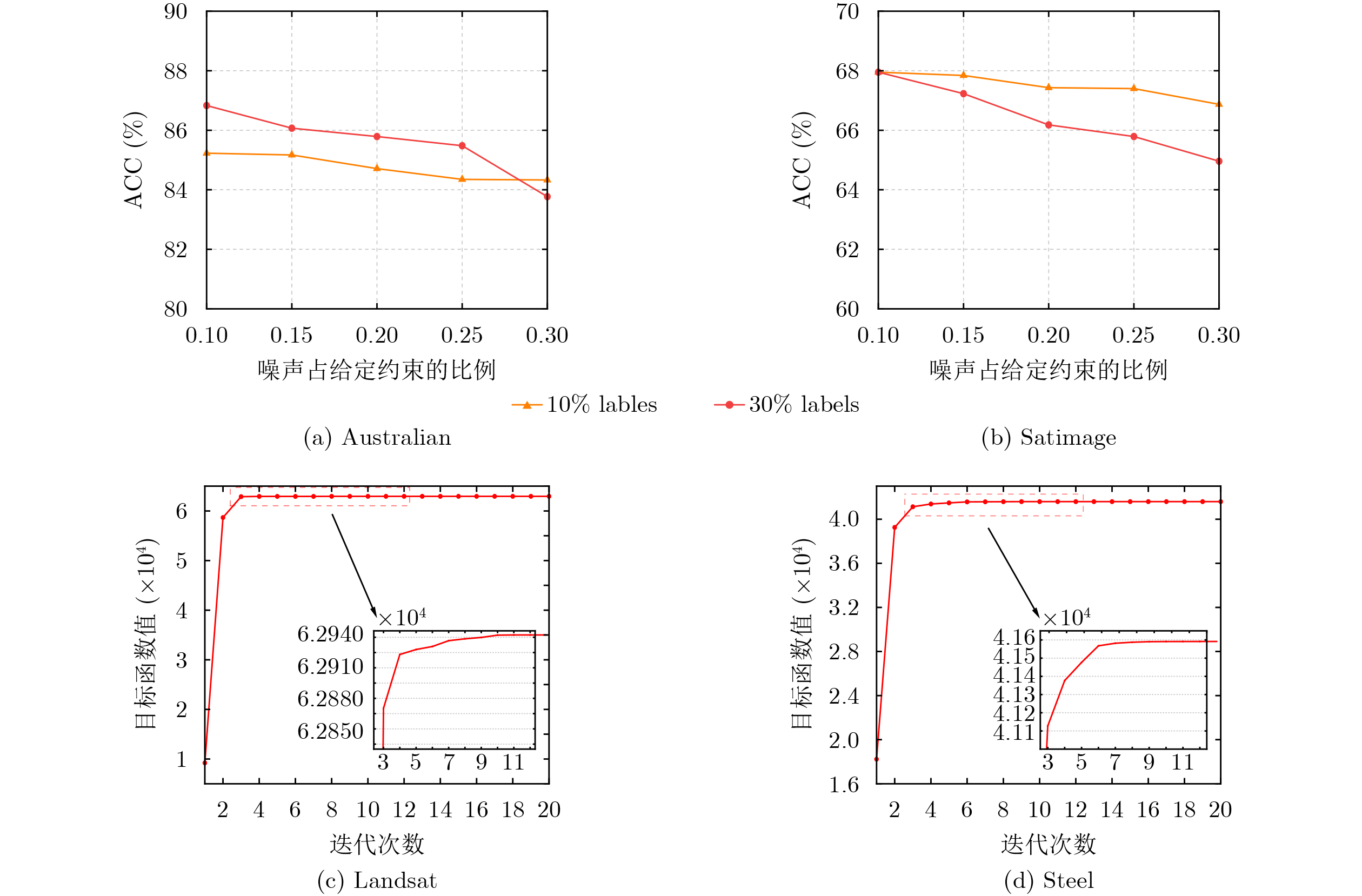
Objective As data structures grow increasingly complex, conventional unsupervised clustering techniques often fail to achieve satisfactory performance. Semi-supervised clustering, which leverages limited prior information, has thus become increasingly popular due to its ability to improve clustering quality. While existing methods have made progress, they suffer from two critical drawbacks. First, traditional constrained projection clustering algorithms typically adopt a two-step independent strategy: learning the projection matrix first and then performing kmeans clustering. This separation causes the projection deviation to propagate directly to the clustering process without correction, leading to the accumulation of learning errors. Moreover, applying pairwise constraints only at the projection stage deviates from the core principle of using prior information to guide the clustering process. Second, many current methods, such as those based on spectral clustering, handle pairwise constraints implicitly (e.g., through eigen-decomposition of a modified similarity matrix). This implicit handling often fails to strictly satisfy constraints, particularly Cannot-Link constraints which are non-transitive, resulting in high constraint violation rates. To this end, this paper proposes a Joint Optimization Method for Pairwise Constrained Projection Clustering Integrating Two-row Update Strategy (PCITUS). The primary objective is to unify dimensionality reduction and clustering into a single framework to avoid information loss and to design an explicit optimization strategy that minimizes constraint violations while enhancing computational efficiency. Methods The proposed PCITUS model integrates constraint projection and clustering into a unified objective function to achieve collaborative optimization, while directly optimizing pairwise constraints. First, the algorithm utilizes the transitive property of Must-Link (ML) constraints, where all samples belonging to the same ML connected component are merged into a single "hyper-point" in the feature space. This preprocessing step naturally ensures that all ML constraints are satisfied. Subsequently, a trade-off parameter is introduced to incorporate projection learning as a regularization term within the clustering framework, enabling the two components to be jointly optimized within a unified objective. Moreover, prior information is embedded into the clustering process by transforming pairwise constraints into row-wise constraints on the indicator matrix. Subsequently, this paper employs an improved coordinate descent method to solve the discrete indicator matrix directly, effectively enhances computational efficiency and find better results. Furthermore, a core innovation is the two-row simultaneous optimization strategy designed for handling Cannot-Link (CL) constraints. PCITUS explicitly checks for CL conflicts by simultaneously evaluating the objective function values for swapping conflicting rows to sub-optimal classes and selects the scenario yielding the higher value. Results and Discussions Extensive experiments were conducted on 8 benchmark datasets and compared against 9 state-of-the-art semi-supervised clustering algorithms. The quantitative results in terms of Accuracy (ACC) and Normalized Mutual Information (NMI) demonstrate the superiority of PCITUS ( Table 4 andTable 5 ). PCITUS achieves the highest performance on most datasets. Notably, on the Mushroom dataset, the NMI metric improved by 7.2% compared to the second-best algorithms. The comparison with CNP (a two-step projection method) confirms that the unified framework effectively mitigates error propagation and information loss, this also stems from the fact that a better projection space can lead to a clearer clustering structure, while a more reasonable clustering structure, in turn, guides the formation of a more discriminative projection space. The effectiveness of the explicit constraint handling is further illustrated (Fig. 1 ), PCITUS exhibits no ML constraint violations due to the hyper-point merging strategy. For CL constraints, because of the two-row simultaneous optimization strategy, PCITUS maintains an extremely low violation rate (e.g., 0.57% on Mushroom and 0.41% on Satimage), significantly outperforming methods that handle constraints implicitly. Additionally, parameter sensitivity analysis (Fig. 2 ) indicates that the performance of PCITUS is stable across a wide range of the trade-off parameter, and noise sensitivity experiments (Fig. 3a andFig. 3b ) highlights its robustness. The convergence curves (Fig. 3c andFig. 3d ) and runtime comparisons (Table 7 ) validate its computational efficiency, showing rapid convergence and typically reaching a stable objective function value within approximately 10 iterations.Conclusions To tackle the difficulties in optimizing cannot-link constraints, as well as the inherent limitations of traditional constraint projection clustering frameworks based on a two-step separation scheme, this paper presents PCITUS, a novel semi-supervised clustering framework that jointly optimizes pairwise constraint projection and clustering structures. By integrating the projection objective into the clustering framework as a regularizer, the proposed method ensures that the subspace learning and data partitioning processes mutually enhance each other, jointly approaching the global optimum. Furthermore, pairwise constraints are integrated throughout the entire learning process, ensuring that prior knowledge is fully utilized during optimization. The introduction of the coordinate descent method with a specific "two-row simultaneous update strategy" allows for the direct and precise allocation of Cannot-Link constraints, significantly reducing constraint violations. Experimental results validate that PCITUS not only outperforms existing algorithms in clustering performance but also exhibits strong robustness to parameter variations. -
表 1 本文主要符号说明
符号 描述 符号 描述 符号 描述 符号 描述 $ \boldsymbol{X}\in {\mathbb{R}}^{d\times n} $ 数据集矩阵 $ \tilde{\boldsymbol{Y}}\in {\mathbb{R}}^{\tilde{n}\times c} $ 合并后的指示矩阵 M(C) 必连(勿连)约束集合 d 样本原始特征维度 $ \boldsymbol{Y}\in {\mathbb{R}}^{n\times c} $ 指示矩阵 $ {\tilde{y}}_{i}\in {\mathbb{R}}^{\tilde{n}\times 1} $ $ \tilde{\boldsymbol{Y}} $的第i列 n 原始样本数 m 投影维度 $ \boldsymbol{W}\in {\mathbb{R}}^{d\times m} $ 投影矩阵 $ {\tilde{y}}^{i}\in {\mathbb{R}}^{1\times c} $ $ \tilde{\boldsymbol{Y}} $的第i行 $ \tilde{n} $ 合并后的样本数 c 类别数  下载: 导出CSV
下载: 导出CSV
1 式(6)下提出的PCITUS 算法
1:输入:数据$ \tilde{\boldsymbol{X}}\in {\mathbb{R}}^{d\times \tilde{n}} $,成对约束集合M和C, 类别数c,调
节参数$ \gamma $;2: 初始化: 通过式(5)利用必连传递闭包形成超链接点,得到合并
后的数据集$ \tilde{\boldsymbol{X}}\in {\mathbb{R}}^{d\times \tilde{n}} $,包含超链接点的CL约束集合$ \tilde{\boldsymbol{C}} $,随机
初始化指示矩阵$ \tilde{\boldsymbol{Y}}\in {\mathbb{R}}^{\tilde{n}\times c} $;3: repeat 4: 计算$ \boldsymbol{S}=\boldsymbol{P}+\gamma \boldsymbol{K} $; 5: 通过式 (7) 对S执行特征分解更新 W; 6: 通过算法2中坐标下降法更新 $ \tilde{\boldsymbol{Y}} $; 7: until convergence 8: 输出:总样本的预测标签Label.
下载: 导出CSV
2 坐标下降法求解问题(8)
1: 输入:合并后数据矩阵$ \tilde{\boldsymbol{X}}\in {\mathbb{R}}^{d\times \tilde{n}} $,投影矩阵$ \boldsymbol{W}\in {\mathbb{R}}^{d\times m} $,包含超链接点的CL约束集合$ \tilde{C} $; 2: 初始化:随机初始化指示矩阵$ \tilde{\boldsymbol{Y}}\in {\mathbb{R}}^{\tilde{n}\times c} $,计算$ \boldsymbol{A}={\tilde{\boldsymbol{X}}}^{\text{T}}\boldsymbol{W}{\boldsymbol{W}}^{\text{T}}\tilde{\boldsymbol{X}} $; 3: 计算并提前存储$ \boldsymbol{A}{\tilde{\boldsymbol{y}}}_{k} $,$ \tilde{\boldsymbol{y}}_{k}^{\mathrm{T}}\boldsymbol{A}{\tilde{\boldsymbol{y}}}_{k} $和$ \tilde{\boldsymbol{y}}_{k}^{\mathrm{T}}{\tilde{\boldsymbol{y}}}_{k}(k=1,2,\cdots ,c) $; 4: for i = 1 to$ \tilde{n} $$do 5: if $ {\tilde{\boldsymbol{x}}}_{i} $不包含在$ \tilde{C} $中 then 6: 通过式(14)计算$ \varphi (k)(k=1,2,\cdots c) $; 7: 通过式(15)更新$ \tilde{\boldsymbol{Y}} $的第i行$ {\tilde{\mathrm{h}}}^{\mathrm{i}} $$ {\tilde{\boldsymbol{y}}}^{i} $; 8: if $ q\neq p $ then 9: 通过式(16)更新$ \boldsymbol{A}{\tilde{\boldsymbol{y}}}_{k} $,$ \tilde{\boldsymbol{y}}_{k}^{\mathrm{T}}\boldsymbol{A}{\tilde{\boldsymbol{y}}}_{k} $和$ \tilde{\boldsymbol{y}}_{k}^{\mathrm{T}}{\tilde{\boldsymbol{y}}}_{k}(k=p,q) $; 10: end if 11: else if $ {\tilde{\boldsymbol{x}}}_{i} $和$ {\tilde{\boldsymbol{x}}}_{j} $包含在$ \tilde{C} $中then 12: 通过式(14)同时计算$ {\varphi }^{i}(k) $和$ {\varphi }^{j}(k) $; 13: 通过式(17)同时更新$ {\tilde{\boldsymbol{y}}}^{i} $$ {\tilde{\mathrm{h}}}^{\mathrm{i}} $和$ {\tilde{\boldsymbol{y}}}^{j} $;$ {\tilde{\mathrm{h}}}^{\mathrm{j}} $ 14: if $ q\neq p $ then 15: 通过式(16)分别更新$ {\tilde{\boldsymbol{y}}}^{i} $和$ {\tilde{\boldsymbol{y}}}^{j} $$ {\tilde{\mathrm{h}}}^{\mathrm{j}} $所对应的$ \boldsymbol{A}{\tilde{\boldsymbol{y}}}_{k} $,$ \tilde{\boldsymbol{y}}_{k}^{\mathrm{T}}\boldsymbol{A}{\tilde{\boldsymbol{y}}}_{k} $和$ \tilde{\boldsymbol{y}}_{k}^{\mathrm{T}}{\tilde{\boldsymbol{y}}}_{k}(k=p,q) $; 16: end if 17: end if 18: end for 19: 输出: 指示矩阵$ \tilde{\boldsymbol{Y}}\in {\mathbb{R}}^{\tilde{n}\times c} $.
下载: 导出CSV
表 2 数据集信息
数据集 样本数量 维度 类别 数据集 样本数量 维度 类别 Wine 178 13 3 Binalpha 1404 320 36 Breast 699 9 2 Steel 1941 27 7 Australian 690 14 2 Satimage 6435 36 6 Landset 2000 36 6 Mushroom 8124 112 2
下载: 导出CSV
表 3 不同算法参数设置
算法名称 参数描述 算法名称 参数描述 Cop-Kmeans 无参数调节 Onestep-PCP 权衡系数α=1 PC-Kmeans 权重系数ω=1 PCOG 正则化系数$y \in\left\{10^{-3}, 10^{-2}, 10^{-1}, 1,10,10^{-1}, 10^{-1}\right\} $ SCC 高斯核带宽$\sigma \in[0,2] $ PCASG 正则化系数$\lambda=1 ; \beta, \theta \in\left\{10^{-3}, 10^{-2}, 10^{-1}, 1,10,10^{2}, 10^{2}\right\} $ CNP $ \rho \in [0.1,0.2] $ ESGCPC 锚点个$m=\left\{2^{\prime}, 2^{\prime}, 2^{\prime}, 2^{\prime \prime}, 2^{n}\right\} $,近邻数$k=\{6,12,18,24\} $ SSDC 临时聚类数$ D=\sqrt{n} $ or $\sqrt{m} / 2 $ PCITUS 权衡系数$y \in\left\{10^{-3}, 10^{-2}, 10^{-1}, 1,10,10^{-1}, 10^{-1}\right\} $
下载: 导出CSV
表 5 不同方法在八个基准数据集上的NMI(%)比较(平均值±标准差)
Method Wine Breast Australian Landset Binalpha Steel Satimage Mushroom Cop-Kmeans 86.51±1.90 69.86±2.12 36.57±1.21 59.79±2.84 56.51±1.02 29.62±2.18 59.77±3.27 42.76±5.49 PC-Kmeans 87.10±1.86 70.52±1.15 37.85±0.98 58.83±2.39 57.83±1.01 30.58±2.03 58.13±4.73 40.39±4.36 SCC 87.28±1.39 72.68±2.80 35.79±1.63 51.41±2.81 61.89±0.49 31.41±2.36 60.89±0.15 50.90±2.25 CNP 82.75±4.51 70.42±1.28 38.81±2.02 57.53±4.31 58.53±1.13 30.44±1.95 60.95±0.21 45.84±3.77 SSDC 75.83±5.34 30.96±3.82 11.86±1.14 44.64±2.66 46.51±3.47 26.31±1.24 43.14±1.91 24.71±2.54 Onestep-PCP 84.44±0.00 37.12±0.00 8.71±0.00 62.52±0.00 61.33±0.37 26.92±1.66 61.65±0.02 13.61±0.00 PCOG 83.24±3.32 66.37±1.18 N/A 52.55±4.85 60.54±5.01 26.91±0.29 46.90±3.65 N/A PCASG 62.59±3.98 62.41±0.63 25.20±3.34 55.91±3.06 60.51±1.52 25.21±1.79 55.95±3.45 N/A ESGCPC 88.07±2.08 73.69±2.38 36.98±1.62 61.77±2.22 58.94±0.83 32.27±0.91 61.37±0.51 45.87±5.42 PCITUS 89.24±1.96 75.53±1.44 41.50±1.95 62.01±0.38 61.46±1.21 32.69±1.83 61.81±0.22 58.19±0.61
下载: 导出CSV
表 4 不同方法在八个基准数据集上的ACC(%)比较(平均值±标准差)
Method Wine Breast Australian Landset Binalpha Steel Satimage Mushroom Cop-Kmeans 96.15±0.88 95.09±0.46 84.03±0.51 67.32±1.86 40.25±1.78 44.75±2.77 67.31±2.58 81.52±5.76 PC-Kmeans 96.48±0.78 95.27±0.24 84.58±0.60 65.10±3.24 41.95±1.77 46.39±3.43 65.70±3.79 79.27±6.24 SCC 96.43±0.42 95.04±0.65 83.52±2.82 61.44±2.03 46.11±1.94 41.27±3.85 63.99±0.35 85.44±4.28 CNP 95.06±1.60 95.14±0.31 84.04±0.77 65.32±3.12 42.88±2.19 44.81±3.51 67.86±0.35 88.94±2.69 SSDC 90.34±4.18 66.82±4.61 31.48±3.59 52.95±4.61 29.20±2.18 32.65±3.32 53.27±3.64 49.48±6.15 Onestep-PCP 95.51±0.00 80.11±0.00 66.81±0.00 64.30±0.00 46.65±1.42 41.20±3.06 63.90±0.02 70.21±0.00 PCOG 94.94±2.28 94.07±0.42 N/A 61.75±5.35 42.53±2.66 42.28±1.49 61.49±4.24 N/A PCASG 82.70±2.88 93.62±0.14 78.84±4.21 67.97±1.58 44.07±2.79 41.04±0.83 54.80±5.16 N/A ESGCPC 96.91±0.69 95.91±0.48 84.19±0.65 69.28±2.79 44.04±2.07 46.29±2.60 68.39±0.30 86.19±4.07 PCITUS 97.11±0.56 96.28±0.29 86.07±0.76 68.62±0.61 46.89±2.08 47.59±2.51 70.91±1.11 90.13±0.15
下载: 导出CSV
表 6 不同约束比例对本文算法的性能(NMI)(%)影响(平均值±标准差)
Metrics Rate of pairwise links Wine Breast Australian Landset Binalpha Steel Satimage Mushroom NMI 0.1 89.24±1.96 75.53±1.44 41.50±1.95 62.01±0.38 61.20±1.21 31.07±1.83 61.81±0.22 58.19±0.61 0.2 89.91±2.81 78.51±2.75 45.72±2.84 62.89±0.61 63.04±0.99 31.97±1.36 62.63±0.23 61.47±0.88 0.3 91.29±3.17 81.88±2.22 50.13±2.59 63.72±0.51 64.83±1.08 33.27±1.39 63.40±0.38 65.48±1.08 0.4 91.81±2.55 84.42±1.94 54.29±3.41 64.70±0.63 66.55±1.30 34.35±2.01 64.13±0.44 69.67±1.10 0.5 92.75±2.41 87.05±2.32 56.95±2.72 65.59±0.87 68.38±1.25 35.34±1.53 64.38±2.15 72.99±1.07
下载: 导出CSV
表 7 不同方法在4个较大规模数据集上的运行时间对比(秒)
Method Cop-Kmeans PC-Kmeans SCC CNP SSDC Onestep-PCP ESGCPC PCITUS Landset 0.83 4.22 3.83 0.03 29.84 16.91 1.48 0.34 Steel 1.83 5.27 10.49 0.02 32.64 30.15 1.65 0.44 Satimage 5.64 82.35 514.76 0.53 415.92 669.77 5.11 4.82 Mushroom 2.68 8.62 320.49 1.56 723.55 1477.62 2.79 2.93
下载: 导出CSV
-
[1] 张朋飞, 程俊, 张治坤, 等. 满足本地差分隐私的混合噪音感知的模糊C均值聚类算法[J]. 电子与信息学报, 2025, 47(3): 739–757. doi: 10.11999/JEIT241067.ZHANG Pengfei, CHENG Jun, ZHANG Zhikun, et al. Fuzzy C-means clustering algorithm based on mixed noise-aware under local differential privacy[J]. Journal of Electronics & Information Technology, 2025, 47(3): 739–757. doi: 10.11999/JEIT241067. [2] 金极栋, 卢宛萱, 孙显, 等. 分布采样对齐的遥感半监督要素提取框架及轻量化方法[J]. 电子与信息学报, 2024, 46(5): 2187–2197. doi: 10.11999/JEIT240220.JIN Jidong, LU Wanxuan, SUN Xian, et al. Remote sensing semi-supervised feature extraction framework and lightweight method integrated with distribution-aligned sampling[J]. Journal of Electronics & Information Technology, 2024, 46(5): 2187–2197. doi: 10.11999/JEIT240220. [3] 霍纬纲, 朱旭, 张盼. 基于约束传递的深度主动时序聚类方法[J]. 电子与信息学报, 2025, 47(4): 1172–1181. doi: 10.11999/JEIT240855.HUO Weigang, ZHU Xu, and ZHANG Pan. Deep active time-series clustering based on constraint transitivity[J]. Journal of Electronics & Information Technology, 2025, 47(4): 1172–1181. doi: 10.11999/JEIT240855. [4] CHEN Jingwei, XIE Shiyu, YANG Hui, et al. Effective semi-supervised graph clustering with pairwise constraints[J]. Information Sciences, 2024, 681: 121249. doi: 10.1016/j.ins.2024.121249. [5] WAGSTAFF K, CARDIE C, ROGERS S, et al. Constrained K-means clustering with background knowledge[C]. The 18th International Conference on Machine Learning, San Francisco, USA, 2001: 577–584. [6] KAMVAR S D, KAMVAR D, and MANNING C DKAMVAR S D, KAMVAR D, and MANNING C DSpectral learning[C]. The 18th International Joint Conference on Artificial Intelligence, San Francisco, USA, 2003: 561–566. [7] JIA Yuheng, WU Wenhui, WANG Ran, et al. Joint optimization for pairwise constraint propagation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(7): 3168–3180. doi: 10.1109/TNNLS.2020.3009953. [8] NIE Feiping, ZHANG Han, WANG Rong, et al. Semi-supervised clustering via pairwise constrained optimal graph[C]. The 29th International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 2021: 3160–3166. doi: 10.24963/IJCAI.2020/437. [9] ZHANG Jing, FAN Ruidong, TAO Hong, et al. Constrained clustering with weak label prior[J]. Frontiers of Computer Science, 2024, 18(3): 183338. doi: 10.1007/s11704-023-3355-7. [10] ZHOU Jie, HUANG Chucheng, GAO Can, et al. Weighted subspace fuzzy clustering with adaptive projection[J]. International Journal of Intelligent Systems, 2024, 2024: 6696775. doi: 10.1155/2024/6696775. [11] TANG Wei, XIONG Hui, ZHONG Shi, et al. Enhancing semi-supervised clustering: A feature projection perspective[C]. The 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, USA, 2007: 707–716. doi: 10.1145/1281192.1281268. [12] WANG Hongjun, LI Tao, LI Tianrui, et al. Constraint neighborhood projections for semi-supervised clustering[J]. IEEE Transactions on Cybernetics, 2014, 44(5): 636–643. doi: 10.1109/TCYB.2013.2263383. [13] YU Zhiwen, LUO Peinan, LIU Jiming, et al. Semi-supervised ensemble clustering based on selected constraint projection[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(12): 2394–2407. doi: 10.1109/TKDE.2018.2818729. [14] NIE Feiping, XUE Jingjing, WU Danyang, et al. Coordinate descent method for k-means[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(5): 2371–2385. doi: 10.1109/TPAMI.2021.3085739. [15] ZHANG Chao, XU Deng, CHEN Chunlin, et al. Semi-supervised multi-view clustering with active constraints[C]. The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, Toronto, Canada, 2025: 1903–1912. doi: 10.1145/3690624.3709204. [16] BASU S, BANERJEE A, and MOONEY R J. Active semi-supervision for pairwise constrained clustering[C]. The 2004 SIAM International Conference on Data Mining, Lake Buena Vista, USA, 2004: 333–344. [17] REN Yazhou, HU Xiaohui, SHI Ke, et al. Semi-supervised DenPeak clustering with pairwise constraints[C]. The 15th Pacific RIM International Conference on Artificial Intelligence, Nanjing, China, 2018: 837–850. doi: 10.1007/978-3-319-97304-3_64. [18] CHEN Long and ZHONG Zhi. Adaptive and structured graph learning for semi-supervised clustering[J]. Information Processing & Management, 2022, 59(4): 102949. doi: 10.1016/j.ipm.2022.102949. -



图(3) / 表(9)
计量
- 文章访问数: 14
- HTML全文浏览量: 9
- PDF下载量: 0
- 被引次数: 0
 下载:
下载:
