

S4-UNET: A Long-Sequence Modeling Blind Source Separation Method for Single-Channel Co-Channel Overlapped Communication Signals
-
摘要: 针对单通道场景下通信信号盲源分离长序列建模能力不足,计算效率亟待提升;具有频偏的同频混叠通信信号分离有待进一步研究的问题,该文提出一种面向单通道同频混叠通信信号的盲源分离方法S4-UNET。该方法构建了融合U-NET与结构化状态空间序列模型(S4)的S4-UNET架构,以时序状态增强模块(TSEM)作为编码器和解码器的主干模块初步提取混合信号特征,并在编码器奇数阶段引入S4实现高效序列建模,达成长序列的近似线性复杂度处理。通过编码器-解码器结构结合跳跃连接进行特征融合,利用上采样恢复特征分辨率。在含微小频偏的同频混叠场景中,对相同调制方式、不同调制方式及不同带宽的信号混合情况实现了分离。在仿真与实测数据集上的实验表明,与深度学习模型(ConvTasNet, CTDCRN)和经典算法(TDE-ICA)相比,所提方法的分离准确率显著提升,不仅对长序列实现了高效建模,对短序列同样有效,且在不同数据域中展现出良好的适应能力与鲁棒性。Abstract:
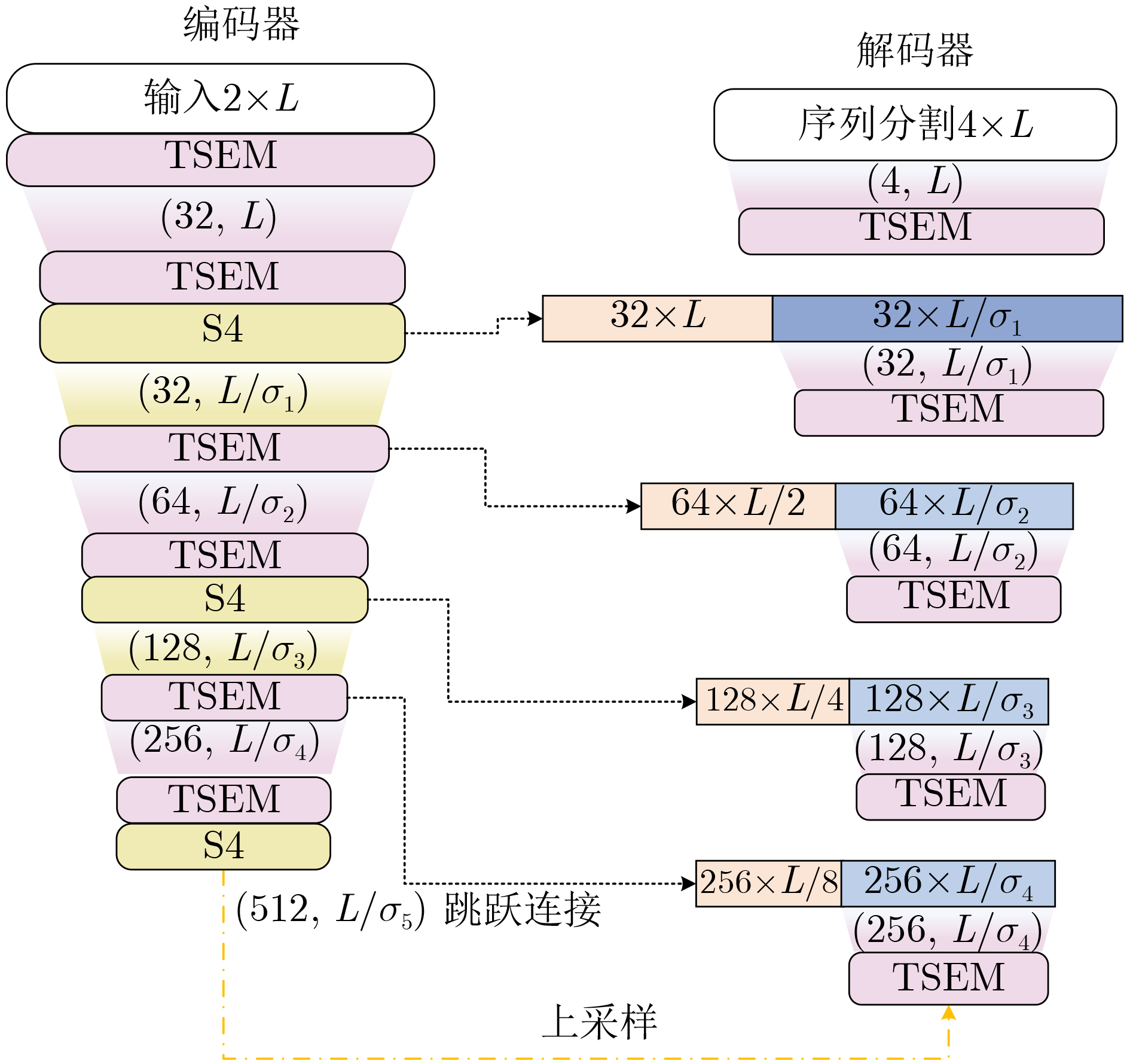
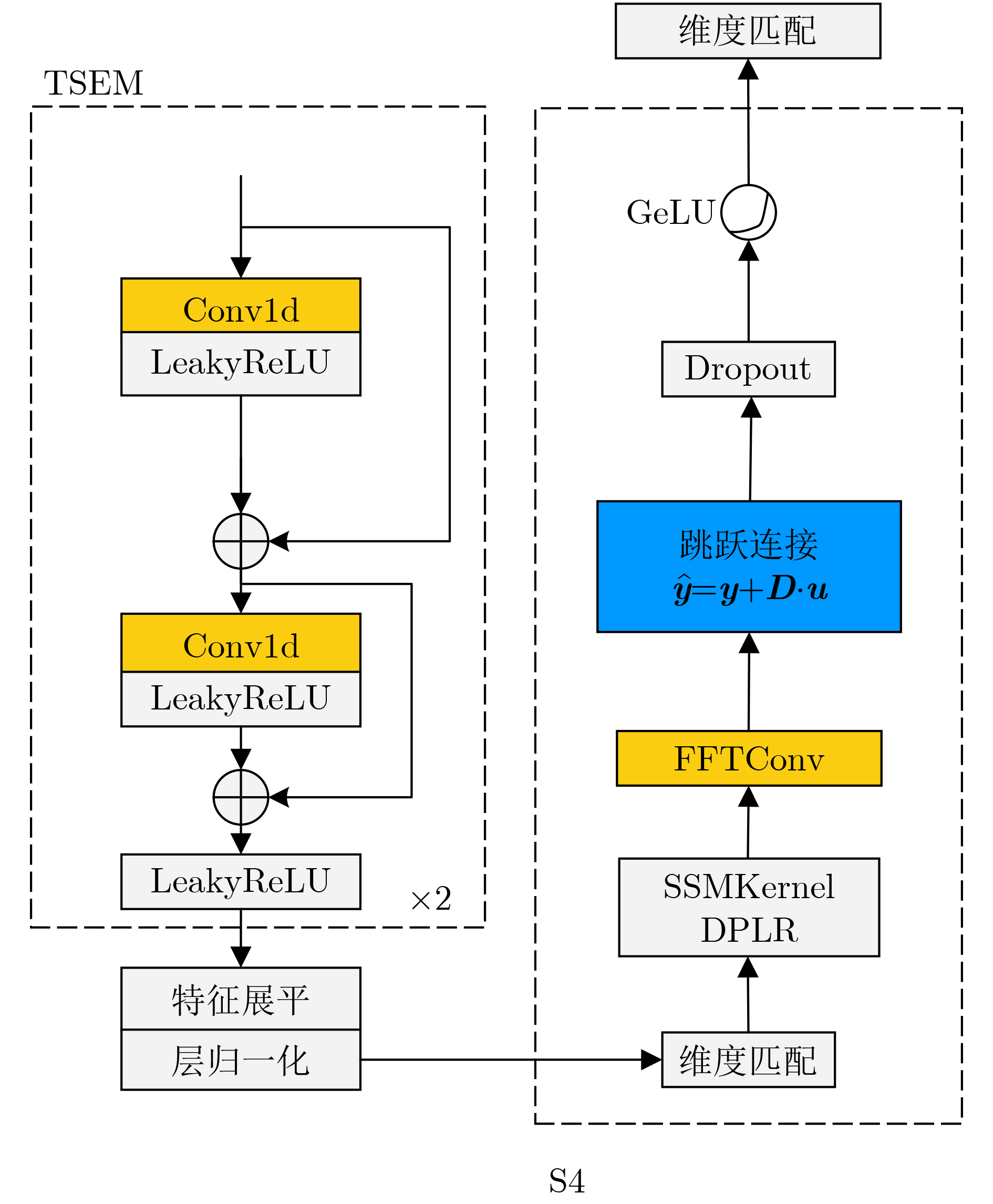
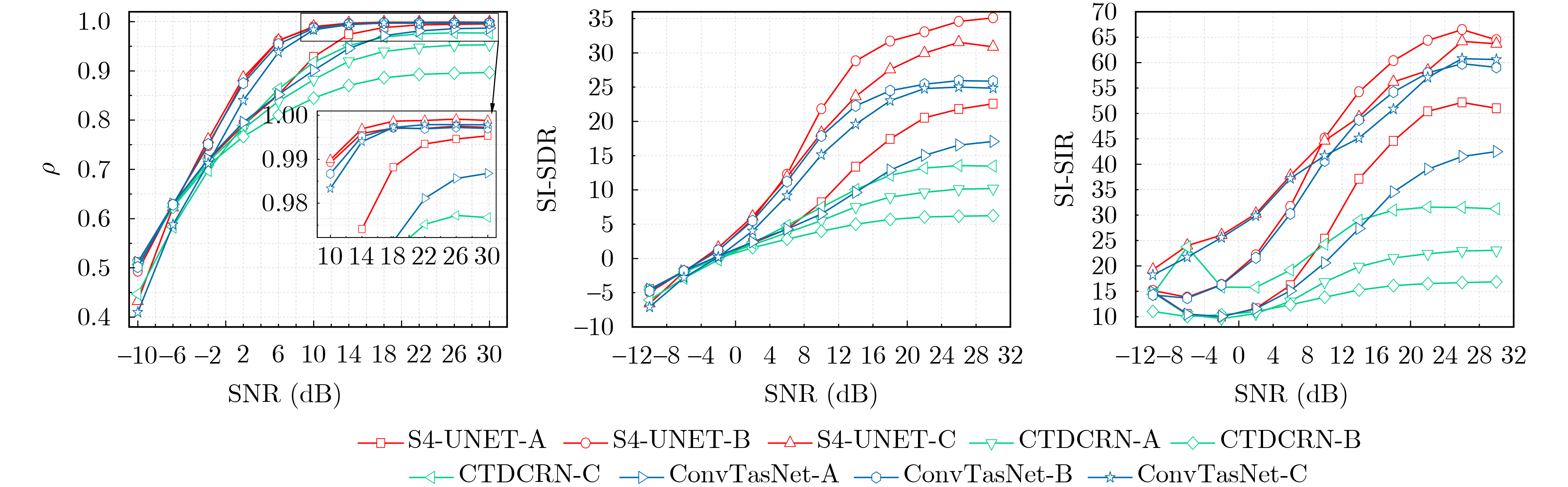
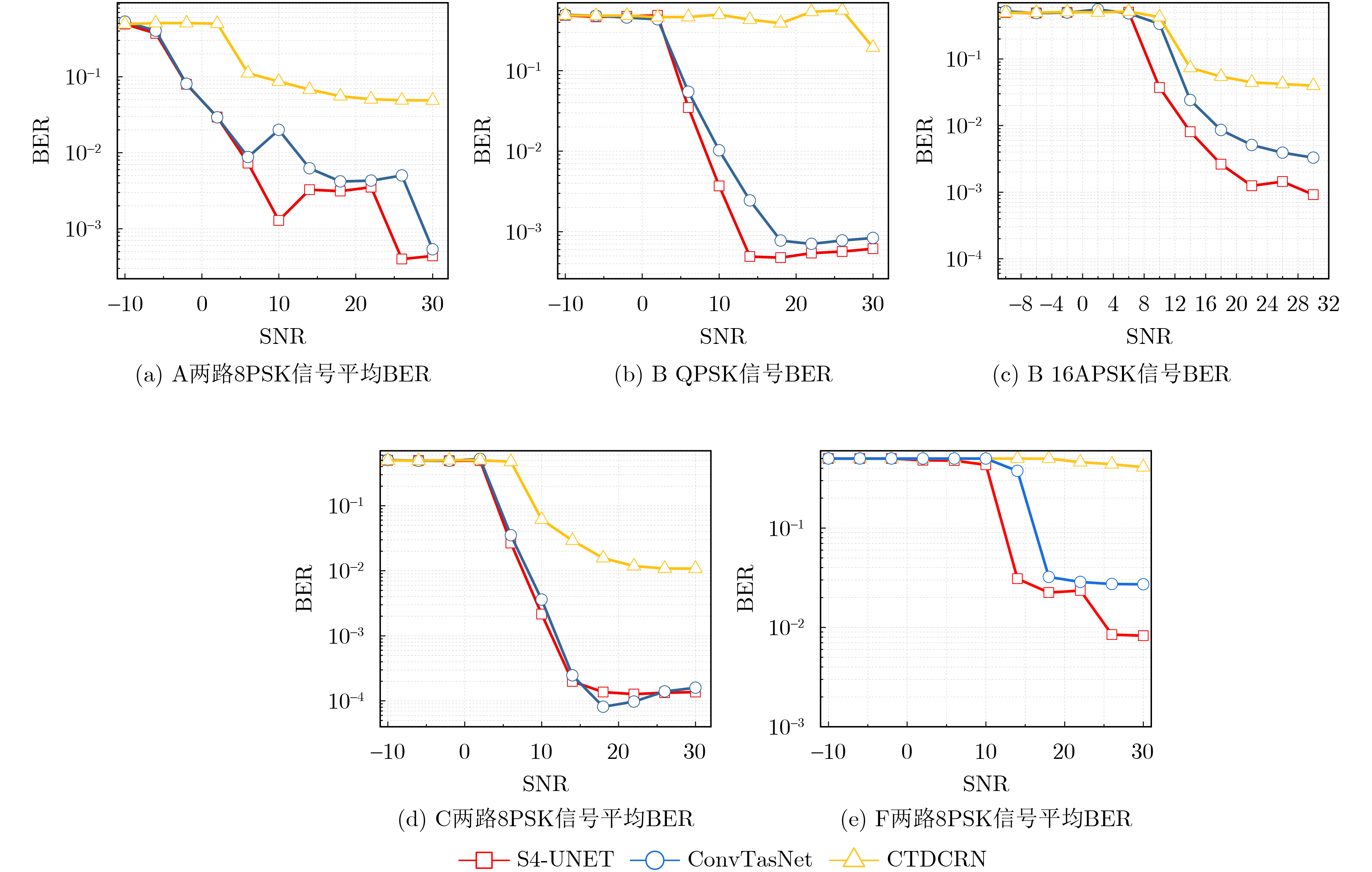
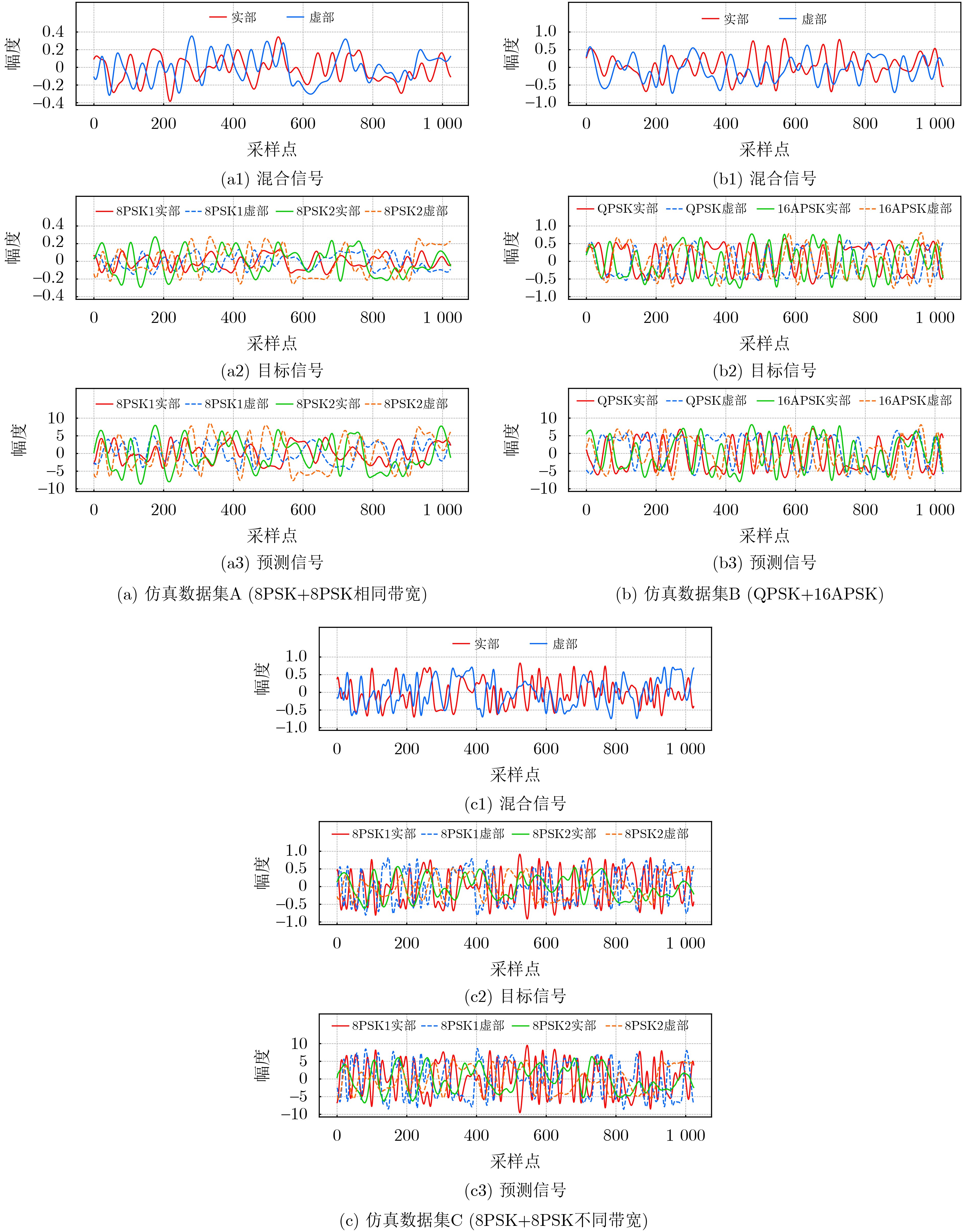
Objective Blind Source Separation (BSS) of single-channel co-channel overlapped communication signals remains challenging in non-cooperative reception. Conventional multi-channel methods are not applicable because of antenna limitations. Existing deep learning methods also show limited long-sequence modeling ability, high computational cost, and reduced performance for signals with small carrier frequency offsets. These limitations restrict the practical use of BSS techniques in dense electromagnetic environments. An efficient and robust framework is therefore needed to capture long-range temporal dependencies while maintaining computational feasibility. Methods S4-UNET integrates the U-NET encoder-decoder framework with the Structured State Space sequence model (S4). A Temporal State Enhancement Module (TSEM) is designed as the backbone block of both the encoder and decoder. It extracts local temporal features through residual learning. To model long-range dependencies, S4 is embedded in the odd-numbered stages of the encoder. This design captures global temporal correlations with near-linear computational complexity. S4 converts sequence modeling into a state-space evolution process and uses the Fast Fourier Transform (FFT) for efficient convolution. Skip connections and the Gated Linear Unit (GLU) are used to preserve fine-grained local details. Multi-scale feature fusion is achieved through skip connections between corresponding encoder and decoder stages. Signal resolution is then progressively restored by interpolation-based upsampling. The model also adaptively tokenizes feature maps in the temporal or channel dimension according to feature scale, which improves sequence representation. Results and Discussions Experiments are conducted on simulated datasets with small carrier frequency offsets, including same-modulation mixtures, mixed-modulation mixtures, and different-bandwidth mixtures. Public benchmark datasets and a measured dataset collected using hardware are also used. Quantitative results and visualizations ( Fig. 3 ,Fig. 5 ,Table 5 ) show that S4-UNET consistently outperforms representative deep learning baselines, including ConvTasNet and CTDCRN, and the classical Time-Delay Embedding Independent Component Analysis (TDE-ICA) algorithm across different signal lengths and modulation schemes. The model maintains robust separation fidelity under randomly distributed carrier frequency offsets and initial phase differences (Table 3 ), confirming its strong generalization ability. Ablation and sensitivity analyses (Table 6 ,Table 7 ,Table 8 ) show that placing S4 in the odd-numbered encoder stages, using suitable convolutional stride settings, and adopting GLU jointly support a favorable balance between separation accuracy and computational efficiency. The model also maintains competitive inference latency while processing both long and short sequences, indicating its practical value.Conclusions S4-UNET addresses the main challenges of single-channel co-channel BSS by combining multi-scale convolutional feature extraction with efficient state-space long-sequence modeling. It achieves superior separation performance, strong robustness to small carrier frequency offsets, and good generalization across different data domains. The present work focuses on dual-source mixtures. Its modular architecture provides a basis for future extensions to mixtures with an unknown number of sources by integrating source number estimation and iterative cancellation strategies. -
表 1 数据集参数
序号 调制方式 L f (MHz) $ \Delta f $(Hz) $ \Delta \tau $ $ \Delta \phi $ Rs (MBd) SNR (dB) A 8PSK+8PSK 4100 20 500 0.3T π/5 5 10:4:30 B QPSK+16APSK 4100 20 500 0.3T π/5 5 –10:4:30 C 8PSK+8PSK 4100 10 375 0.3T π/5 5,2.5 –10:4:30 D 8PSK+8PSK 4100 20 U(0,700) 0.3T U(0, π) 5 –10:4:30 E 8PSK+8PSK 8200 20 500 0.3T π/5 5 –10:4:30 F 8PSK+8PSK 4100 915 500 0.3T π/5 1 –10:4:30  下载: 导出CSV
下载: 导出CSV
表 2 模型超参数配置
阶段 特征
通道数TSEM卷积
核大小编码器TSEM
卷积块数量解码器TSEM
卷积块数量卷积步长(σi)
L=8200 卷积步长(σi)
L=4100 卷积步长(σi)
L=1024 卷积步长(σi)
L=1281 32 3 2 2 1 1 1 1 2 64 3 2 2 2 2 1 1 3 128 3 2 1 4 2 2 2 4 256 3 1 1 5 5 2 2 5 512 3 1 / 5 5 2 2
下载: 导出CSV
表 3 数据集A, D和F实验结果对比
模型-数据集 ρ SI-SDR(dB) SI-SIR(dB) S4-UNET A 0.852 9.49 29.46 ConvTasNet A 0.844 7.12 24.34 CTDCRN A 0.824 4.68 16.84 S4-UNET D 0.852 9.38 27.63 ConvTasNet D 0.845 7.23 24.66 CTDCRN D 0.834 5.71 19.09 S4-UNET F 0.879 8.01 31.54 ConvTasNet F 0.816 3.75 29.21 CTDCRN F 0.766 1.76 18.79
下载: 导出CSV
表 4 分离算法参数
ConvTasNet CTDCRN TDE-ICA 滤波器数量 64 CHE卷积核大小 3,1 时延嵌入维度 3 滤波器长度 32 CHE-1输出
通道数128 时延嵌入步数 1 瓶颈层通道数 128 CHE-2输出
通道数64 最大迭代次数 1000 TCN隐层通
道数256 CDCM模块
堆叠数量4 非线性函数 logcosh TCN卷积核大小 3 CDCM通道数 64 收敛容忍度 1e–6 每重复块卷积层 8 CDCM扩张
卷积核大小3 TCN重复次数 4 LSTM层数 1 输出源数量 2 LSTM隐层 64
下载: 导出CSV
表 5 序列建模能力对比
数据集 模型/算法 参数量 计算量(FLOPs) $ \rho $ 训练时间(Epoch/s) 推理时间(ms/sample) RML2016.10a
L=128ConvTasNet 2.21 M 1.53 G 0.765 16.4 0.294 CTDCRN 201.48 k 9.34 G 0.822 7.8 0.180 TDE-ICA 8 11.12 k 0.641 / 3.30 S4-UNET 3.55 M 21.71 G 0.828 8.9 0.321 RML2018.01a
L=1024 ConvTasNet 2.21 M 13.81 G 0.893 38.6 0.309 CTDCRN 201.48 k 74.71 G 0.888 28.2 0.217 TDE-ICA 8 161.97 k 0.621 / 3.10 S4-UNET 3.67 M 178.31 G 0.907 28.5 0.302 A
L=4100 ConvTasNet 2.21 M 55.88 G 0.844 50.6 0.288 CTDCRN 201.48 k 299.14 G 0.824 104.1 0.873 TDE-ICA 8 499.86 k 0.662 / 6.70 S4-UNET 3.61 M 240.85 G 0.852 40.4 0.402 E
L=8200 ConvTasNet 2.21 M 111.99 G 0.849 70.1 0.342 CTDCRN 201.48 k 598.28 G 0.806 216.7 1.971 TDE-ICA 8 852.93 k 0.672 / 4.33 S4-UNET 3.61 M 316.58 G 0.854 52.7 0.522
下载: 导出CSV
表 6 不同卷积步长实验结果
卷积步长 ρ SI-SDR(dB) 1, 2, 2, 2, 2 0.901 16.89 1, 1, 2, 2, 2 0.907 17.98 1, 1, 4, 2, 2 0.904 17.26 1, 1, 2, 4, 2 0.906 17.75
下载: 导出CSV
表 7 不同阶段数/卷积核大小实验结果
阶段数/
卷积核ρ SI-SDR(dB) 参数量 训练时间
(Epoch/s)推理时间
(ms/sample)3/3 0.903 15.59 423.05 k 18.5 0.162 4/3 0.904 17.33 1.6 M 24.8 0.215 5/3 0.907 17.98 3.67 M 28.5 0.302 6/3 0.902 16.20 13.91 M 40.2 0.518 5/5 0.906 18.73 5.65 M 28.9 0.347 5/7 0.905 18.39 7.64 M 30.1 0.387
下载: 导出CSV
表 8 S4与U-NET融合策略与激活函数消融实验结果
启用S4阶段 激活函数 ρ SI-SDR(dB) 参数量(M) 训练时间(Epoch/s) 推理时间(ms/sample) k mod 2 = 1 GLU 0.907 17.98 3.67 28.5 0.302 k mod 2 = 0 GLU 0.906 18.34 3.67 30.8 0.328 k GLU 0.904 17.26 3.89 37.7 0.364 None GLU 0.902 17.14 3.52 21.5 0.263 k mod 2 = 1 ReLU 0.909 19.22 3.63 26.3 0.347 k mod 2 = 1 None 0.908 17.39 3.63 26.6 0.319
下载: 导出CSV
-
[1] 侯进, 盛尧宝, 张波. 基于二阶统计特性的方向向量估计算法的DOA估计[J]. 电子与信息学报, 2024, 46(2): 697–704. doi: 10.11999/JEIT230172.HOU Jin, SHENG Yaobao, and ZHANG Bo. DOA estimation of direction vector estimation algorithm based on second-order statistical properties[J]. Journal of Electronics & Information Technology, 2024, 46(2): 697–704. doi: 10.11999/JEIT230172. [2] 刘强, 张敏, 郭福成, 等. 基于迭代二次优化算法的低截获波形序列设计[J]. 电子与信息学报, 2024, 46(5): 2048–2056. doi: 10.11999/JEIT231333.LIU Qiang, ZHANG Min, GUO Fucheng, et al. Low-intercept waveform sequence design based on iterative quadratic optimization algorithm[J]. Journal of Electronics & Information Technology, 2024, 46(5): 2048–2056. doi: 10.11999/JEIT231333. [3] 严丞, 李彤, 潘文生, 等. 无信道先验信息的双天线非合作干扰抑制技术研究[J]. 电子与信息学报, 2025, 47(12): 5061–5070. doi: 10.11999/JEIT250378.YAN Cheng, LI Tong, PAN Wensheng, et al. Research on non-cooperative interference suppression technology for dual antennas without channel prior information[J]. Journal of Electronics & Information Technology, 2025, 47(12): 5061–5070. doi: 10.11999/JEIT250378. [4] SCHWIEGELSHOHN F, OSSOVSKI E, and HÜBNER M. A resampling method for parallel particle filter architectures[J]. Microprocessors and Microsystems, 2016, 47: 314–320. doi: 10.1016/j.micpro.2016.07.017. [5] LIU Xiaobei and GUAN Yongliang. Single-channel blind separation of unsynchronized multiuser PSK signals with non-identical sampling frequency offsets[J]. IEEE Communications Letters, 2022, 26(11): 2774–2778. doi: 10.1109/LCOMM.2022.3202538. [6] LUO Yi and MESGARANI N. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256–1266. doi: 10.1109/TASLP.2019.2915167. [7] 兰朝凤, 杨国涛, 陈英淇, 等. 时频域多尺度信息交互策略的单声道语音分离方法研究[J]. 电子与信息学报, 2025, 预发表. doi: 10.11999/JEIT251340.LAN Chaofeng, YANG Guotao, CHEN Yingqi, et al. Research on monophonic speech separation method using time-frequency domain multi-scale information interaction strategy[J]. Journal of Electronics & Information Technology, 2025, in press. doi: 10.11999/JEIT251340. [8] HOU Xiaoqi and GAO Yong. Single-channel blind separation of co-frequency signals based on convolutional network[J]. Digital Signal Processing, 2022, 129: 103654. doi: 10.1016/j.dsp.2022.103654. [9] MA Hao, ZHENG Xiang, YU Lu, et al. A novel end‐to‐end deep separation network based on attention mechanism for single channel blind separation in wireless communication[J]. IET Signal Processing, 2023, 17(2): e12173. doi: 10.1049/sil2.12173. [10] YANG Boyi, CHEN Tao, and LEI Yu. Single-channel radar signal separation based on instance segmentation with mask optimization[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2024, 71(5): 2879–2883. doi: 10.1109/TCSII.2024.3350662. [11] GUO Pengcheng, YU Miao, SHEN Lei, et al. Single-channel blind source separation in wireless communications: A complex-domain deep learning approach[J]. IEEE Wireless Communications Letters, 2024, 13(6): 1645–1649. doi: 10.1109/LWC.2024.3384813. [12] DENG Wen, WANG Xiang, and HUANG Zhitao. Co-channel multiuser modulation classification using data-driven blind signal separation[J]. IEEE Internet of Things Journal, 2024, 11(8): 14829–14843. doi: 10.1109/JIOT.2023.3345023. [13] LUO Jian, QIU Zhaoyang, XIAO Jian, et al. Single-channel blind source separation of co-channel communication signals: A hybrid knowledge-data driven approach[J]. IEEE Transactions on Cognitive Communications and Networking, 2026, 12: 5704–5717. doi: 10.1109/TCCN.2026.3658769. [14] LU Weitsung, WANG Juchiang, KONG Qiuqiang, et al. Music source separation with band-split rope transformer[C]. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 2024: 481–485. doi: 10.1109/ICASSP48485.2024.10446843. [15] 付卫红, 张鑫钰, 刘乃安. 基于多尺度融合神经网络的同频同调制单通道盲源分离算法[J]. 系统工程与电子技术, 2025, 47(2): 641–649. doi: https://www.sys-ele.com/CN/10.12305/j.issn.1001-506X.2025.02.30.FU Weihong, ZHANG Xinyu, and LIU Naian. Single-channel blind source separation algorithm for co-frequency and co-modulation based on multi-scale fusion neural network[J]. Systems Engineering and Electronics, 2025, 47(2): 641–649. doi: https://www.sys-ele.com/CN/10.12305/j.issn.1001-506X.2025.02.30. [16] GU A, GOEL K, and RÉ C. Efficiently modeling long sequences with structured state spaces[C]. Proceedings of the 10th International Conference on Learning Representations (ICLR), 2022. [17] KALMAN R. On the general theory of control systems[J]. IRE Transactions on Automatic Control, 1959, 4(3): 110. doi: 10.1109/TAC.1959.1104873. [18] ROUX J L, WISDOM S, ERDOGAN H, et al. SDR – half-baked or well done?[C]. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 2019: 626–630. doi: 10.1109/ICASSP.2019.8683855. -

 下载:
下载:


图(5) / 表(8)
计量
- 文章访问数: 373
- HTML全文浏览量: 176
- PDF下载量: 49
- 被引次数: 0
