

PATC: Prototype Alignment and Topology-Consistent Pseudo-Supervision for Multimodal Semi-Supervised Semantic Segmentation of Remote Sensing Images
-
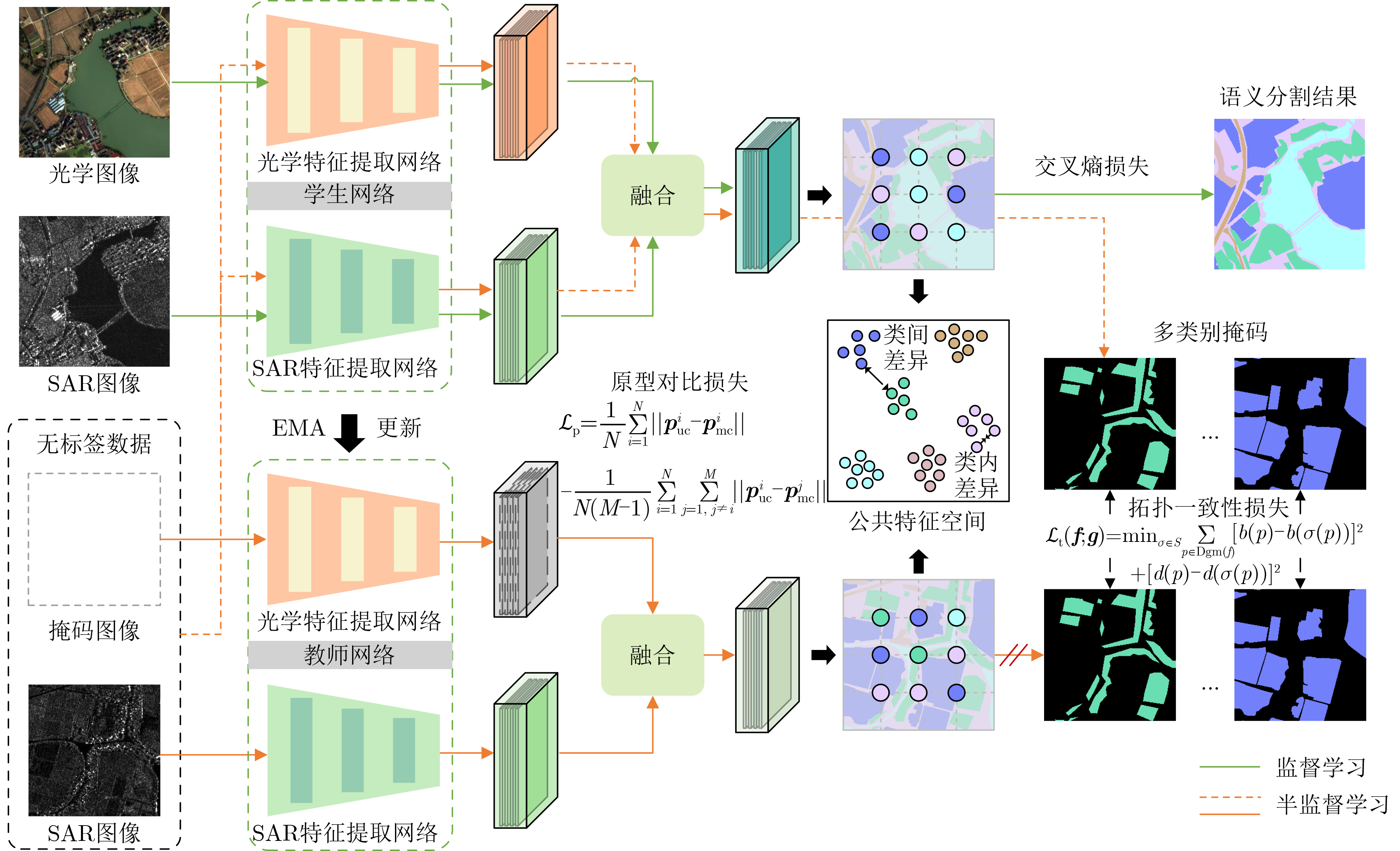
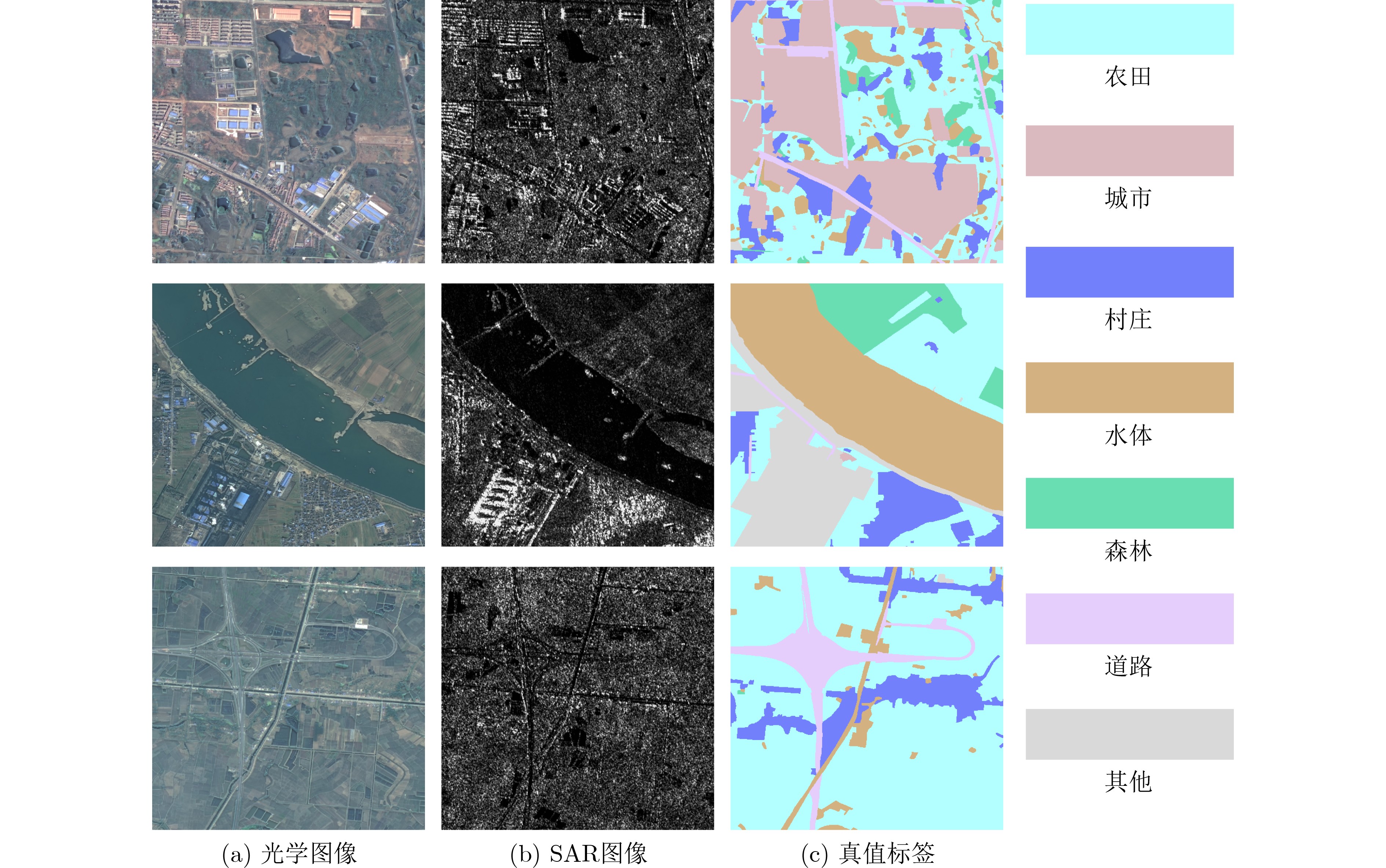
摘要: 在遥感图像语义分割任务中,模态异构性与标注成本高昂是制约模型性能提升的主要瓶颈。针对多模态遥感数据中标注样本有限的问题,该文提出一种原型对齐与拓扑一致性约束下的多模态半监督遥感图像语义分割方法。该方法以未标注的SAR图像为辅助信息,构建教师-学生框架,引入多模态类别原型对齐机制与拓扑一致性伪监督策略,以提升融合特征的判别性与结构稳定性。首先,构建光学与SAR模态的共享语义原型,并通过对比损失实现跨模态语义一致性学习;其次,设计基于持久同调理论的拓扑损失,从结构层面优化伪标签质量,有效缓解伪监督过程中的拓扑破坏问题。在公开数据集WHU-OPT-SAR数据集以及自建数据集Suzhou数据集两个多模态遥感数据集上的实验结果表明,该方法在标注不足条件下仍具备优异的分割性能与良好的泛化能力。Abstract:
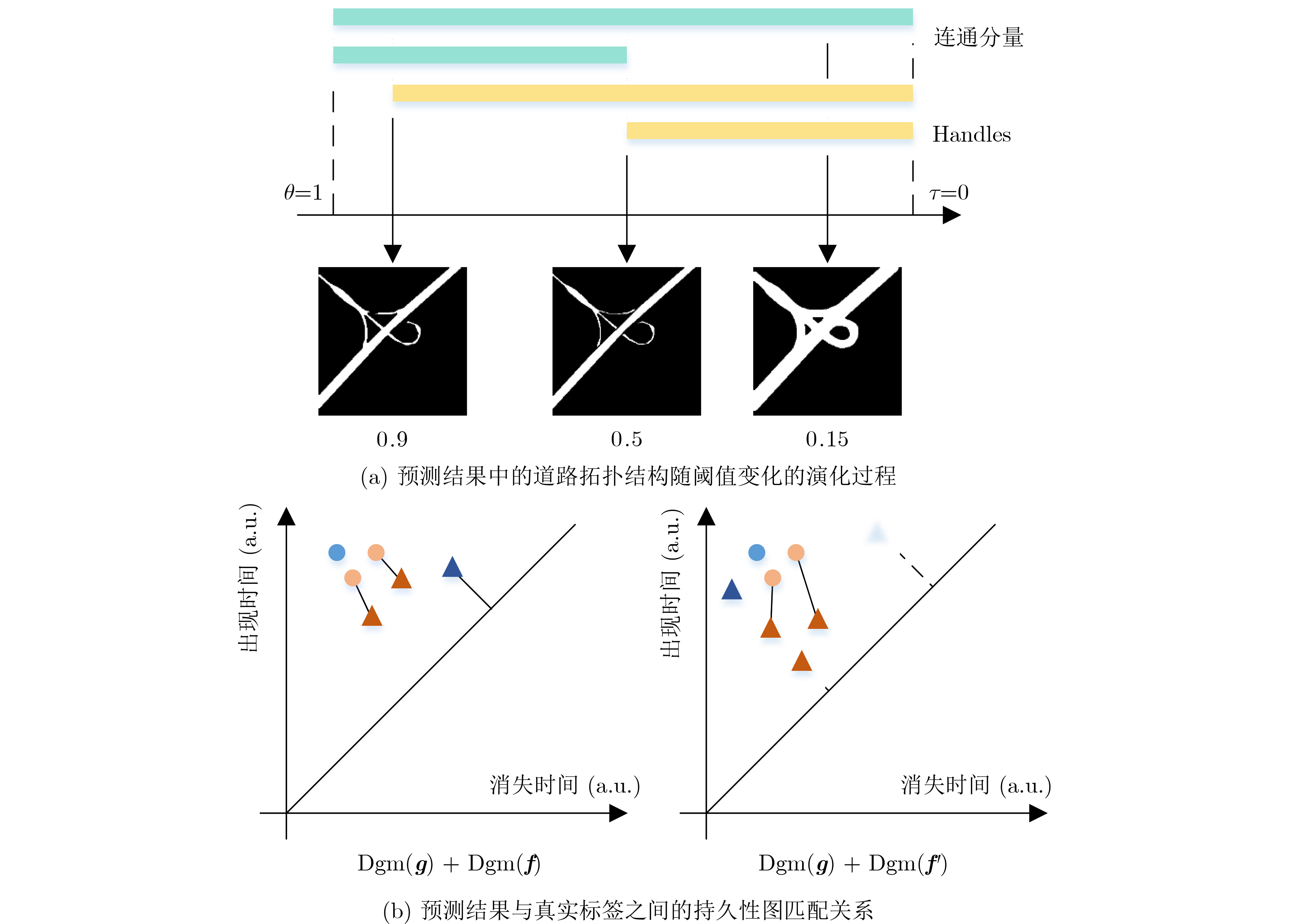
Objective The high annotation cost of remote sensing data and the heterogeneity between optical and SAR modalities limit the performance and scalability of semantic segmentation systems. This study examines a practical semi-supervised setting where only a small set of paired optical–SAR samples is labeled, whereas numerous single-modality SAR images remain unlabeled. The objective is to design a semi-supervised multimodal framework capable of learning discriminative and topology-consistent fused representations under sparse labels by aligning cross-modal semantics and preserving structural coherence through pseudo-supervision. The proposed Prototype Alignment and Topology Consistent (PATC) method aims to achieve robust land-cover segmentation on challenging multimodal datasets, improving region-level accuracy and connectivity-aware structure quality. Methods PATC adopts a teacher–student framework that exploits limited labeled optical–SAR pairs and abundant unlabeled SAR data. A shared semantic prototype space is first constructed to reduce modality gaps, where class prototypes are updated with a momentum mechanism for stability. A prototype-level contrastive alignment strategy enhances intra-class compactness and inter-class separability, guiding optical and SAR features of the same category to cluster around unified prototypes and improving cross-modal semantic consistency. To preserve structural integrity, a topology-consistent pseudo-supervision mechanism is incorporated. Inspired by persistent homology, a topology-aware loss constrains the teacher-generated pseudo-labels by penalizing errors such as incorrect formation or removal of connected components and holes. This structural constraint complements pixel-wise losses by maintaining boundary continuity and fine structures (e.g., roads and rivers), ensuring that pseudo-supervised learning remains geometrically and topologically coherent. Results and Discussions Experiments show that PATC reduces cross-modal semantic misalignment and topology degradation. By regularizing pseudo-labels with a topology-consistent loss derived from persistent homology, the method preserves connectivity and boundary integrity, especially for thin or fragmented structures. Evaluations on the WHU-OPT-SAR and Suzhou datasets demonstrate consistent improvements over state-of-the-art fully supervised and semi-supervised baselines under 1/16, 1/8, and 1/4 label regimes ( Fig. 4 ,Fig. 5 ,Fig. 6 ;Table 3 ,Table 4 ). Ablation studies confirm the complementary roles of prototype alignment and topology regularization (Table 5 ). The findings indicate that unlabeled SAR data provides structural priors that, when used through topology-aware consistency and prototype-level alignment, substantially enhance multimodal fusion under sparse annotation.Conclusions This study proposes PATC, a multimodal semi-supervised semantic segmentation method that addresses limited annotations, modality misalignment, and weak generalization. PATC constructs multimodal semantic prototypes in a shared feature subspace and applies prototype-level contrastive learning to improve cross-modal consistency and feature discriminability. A topology-consistent loss based on persistent homology further regularizes the student network, improving the connectivity and structural stability of segmentation results. By incorporating structural priors from unlabeled SAR data within a teacher-student framework with EMA updates, PATC achieves robust multimodal feature fusion and accurate segmentation under scarce labels. Future work will expand topology-based pseudo-supervision to broader multimodal configurations and integrate active learning to refine pseudo-label quality. -
表 1 WHU-OPT-SAR 数据集的训练集与测试集图像数量
标注
数据比例训练集 测试集 有标注 无标注 有标注 1/4 1408 4224 1408 1/8 704 4928 1408 1/16 352 5280 1408  下载: 导出CSV
下载: 导出CSV
表 2 Suzhou数据集的训练集与测试集图像数量
标注
数据比例训练集 测试集 有标注 无标注 有标注 1/4 124 372 125 1/8 62 434 125 1/16 31 465 125
下载: 导出CSV
表 3 不同方法在不同标注比例下在WHU-OPT-SAR 数据集上的性能对比(%)
方法 1/16 1/8 1/4 mIoU FWIoU OA mIoU FWIoU OA mIoU FWIoU OA MCANet 38.34 61.40 75.66 43.07 64.28 77.84 48.21 67.11 79.89 CMX 38.92 62.27 76.39 43.55 65.46 78.92 51.28 68.51 80.93 Dformer 35.72 60.78 75.29 40.20 62.42 76.5 44.99 65.74 78.93 Sigma 32.07 58.83 73.66 37.79 62.14 76.22 41.36 64.04 77.62 PATC(w/o SAR) 43.85 65.31 78.74 48.3 67.54 80.29 52.68 69.6 81.67 ST++ 46.74 66.71 79.72 52.28 69.39 81.54 55.64 71.21 82.88 MPRFN 46.76 66.47 79.45 48.70 67.96 80.59 54.29 70.28 82.13 PATC 53.08 69.68 81.87 54.99 70.77 82.55 56.46 72.00 83.44
下载: 导出CSV
表 4 不同方法在不同标注比例下在Suzhou 数据集上的性能对比(%)
方法 1/16 1/8 1/4 mIoU FWIoU OA mIoU FWIoU OA mIoU FWIoU OA MCANet 49.50 56.74 71.58 54.79 64.68 77.44 56.76 66.59 78.91 CMX 52.12 59.46 73.57 59.99 67.90 79.62 61.97 69.65 81.01 Dformer 43.74 51.82 67.75 51.12 58.55 72.97 56.86 63.74 76.83 Sigma 40.75 49.74 65.46 47.52 55.77 70.20 51.49 59.22 73.05 PATC(w/o SAR) 58.15 64.43 77.27 60.99 69.12 80.71 64.21 71.06 82.07 ST++ 56.76 66.59 78.91 63.81 70.74 81.83 65.25 71.58 82.48 MPRFN 58.90 64.98 77.70 63.47 70.85 81.82 64.58 71.35 82.21 PATC 60.37 68.69 80.39 64.60 71.26 82.22 67.68 73.54 83.82
下载: 导出CSV
表 5 各损失项与半监督策略对模型性能的影响分析(%)
半监督学习 $ \mathcal{L}\mathrm{_p} $ $ \mathcal{L}\mathrm{_t} $ 水体 林地 农田 道路 建筑物 未利用土地 mIoU FWIoU OA 89.56 29.12 83.34 38.09 74.49 51.35 60.99 69.12 80.71 √ √ 89.15 36.65 83.96 42.47 72.35 53.08 62.94 70.01 81.1 √ √ 89.03 38.17 84.24 41.36 73.71 52.45 63.16 70.24 81.5 √ √ √ 90.23 36.38 84.82 47.15 75.05 54.01 64.60 71.26 82.22
下载: 导出CSV
表 6 各模型复杂度与运算效率分析
方法 平均训练时间(s) 参数总量(M) 浮点运算次数(G) CMX 201.1 49.65 57.44 Sigma 205.8 60.60 71.71 MPRFN 322.5 88.11 101.07 本文方法 221.6 74.82 79.15
下载: 导出CSV
-
[1] 要旭东, 郭雅萍, 刘梦阳, 等. 遥感图像中不确定性驱动的像素级对抗噪声检测方法[J]. 电子与信息学报, 2025, 47(6): 1633–1644. doi: 10.11999/JEIT241157.YAO Xudong, GUO Yaping, LIU Mengyang, et al. An uncertainty-driven pixel-level adversarial noise detection method for remote sensing images[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1633–1644. doi: 10.11999/JEIT241157. [2] 尚可, 晏磊, 张飞舟, 等. 从BRDF到BPDF: 遥感反演基础模型的演进初探[J]. 中国科学: 信息科学, 2024, 54(8): 2001–2020. doi: 10.1360/SSI-2023-0193.SHANG Ke, YAN Lei, ZHANG Feizhou, et al. From BRDF to BPDF: A premilinary study on evolution of the basic remote sensing quantitative inversion model[J]. Scientia Sinica Informationis, 2024, 54(8): 2001–2020. doi: 10.1360/SSI-2023-0193. [3] 刁文辉, 龚铄, 辛林霖, 等. 针对多模态遥感数据的自监督策略模型预训练方法[J]. 电子与信息学报, 2025, 47(6): 1658–1668. doi: 10.11999/JEIT241016.DIAO Wenhui, GONG Shuo, XIN Linlin, et al. A model pre-training method with self-supervised strategies for multimodal remote sensing data[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1658–1668. doi: 10.11999/JEIT241016. [4] TIAN Jiaqi, ZHU Xiaolin, SHEN Miaogen, et al. Effectiveness of spatiotemporal data fusion in fine-scale land surface phenology monitoring: A simulation study[J]. Journal of Remote Sensing, 2024, 4: 0118. doi: 10.34133/remotesensing.0118. [5] LIU Shuaijun, LIU Jia, TAN Xiaoyue, et al. A hybrid spatiotemporal fusion method for high spatial resolution imagery: Fusion of Gaofen-1 and Sentinel-2 over agricultural landscapes[J]. Journal of Remote Sensing, 2024, 4: 0159. doi: 10.34133/remotesensing.0159. [6] SHI Qian, HE Da, LIU Zhengyu, et al. Globe230k: A benchmark dense-pixel annotation dataset for global land cover mapping[J]. Journal of Remote Sensing, 2023, 3: 0078. doi: 10.34133/remotesensing.0078. [7] LIN Junyan, CHEN Haoran, FAN Yue, et al. Multi-layer visual feature fusion in multimodal LLMs: Methods, analysis, and best practices[C]. The 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 4156–4166. doi: 10.1109/CVPR52734.2025.00393. [8] MAO Shasha, LU Shiming, DU Zhaolong, et al. Cross-rejective open-set SAR image registration[C]. The 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 23027–23036. doi: 10.1109/CVPR52734.2025.02144. [9] WANG Benquan, AN Ruyi, SO J K, et al. OpticalNet: An optical imaging dataset and benchmark beyond the diffraction limit[C]. The 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 10900–10912. doi: 10.1109/CVPR52734.2025.01018. [10] 高尚华, 周攀, 程明明, 等. 迈向可持续自监督学习: 基于目标增强的条件掩码重建自监督学习[J]. 中国科学: 信息科学, 2025, 55(2): 326–342. doi: 10.1360/SSI-2024-0176.GAO Shanghua, ZHOU Pan, CHENG Mingming, et al. Towards sustainable self-supervised learning: Target-enhanced conditional mask-reconstruction for self-supervised learning[J]. Scientia Sinica Informationis, 2025, 55(2): 326–342. doi: 10.1360/SSI-2024-0176. [11] 毕秀丽, 徐培君, 范骏超, 等. 基于亲和向量一致性的弱监督语义分割[J]. 中国科学: 信息科学, 2025, 55(5): 1088–1107. doi: 10.1360/SSI-2024-0222.BI Xiuli, XU Peijun, FAN Junchao, et al. Weakly supervised semantic segmentation based on affinity vector consistency[J]. Scientia Sinica Informationis, 2025, 55(5): 1088–1107. doi: 10.1360/SSI-2024-0222. [12] HU Jie, CHEN Chen, CAO Liujuan, et al. Pseudo-label alignment for semi-supervised instance segmentation[C]. The 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 16291–16301. doi: 10.1109/ICCV51070.2023.01497. [13] CHENG Bowen, MISRA I, SCHWING A G, et al. Masked-attention mask transformer for universal image segmentation[C]. The 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 1280–1289. doi: 10.1109/CVPR52688.2022.00135. [14] MEI Shaohui, LIAN Jiawei, WANG Xiaofei, et al. A comprehensive study on the robustness of deep learning-based image classification and object detection in remote sensing: Surveying and benchmarking[J]. Journal of Remote Sensing, 2024, 4: 0219. doi: 10.34133/remotesensing.0219. [15] WANG Haoyu and LI Xiaofeng. Expanding horizons: U-Net enhancements for semantic segmentation, forecasting, and super-resolution in ocean remote sensing[J]. Journal of Remote Sensing, 2024, 4: 0196. doi: 10.34133/remotesensing.0196. [16] XU Zhiyong, ZHANG Weicun, ZHANG Tianxiang, et al. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images[J]. Remote Sensing, 2021, 13(1): 71. doi: 10.3390/rs13010071. [17] LI Rui, ZHENG Shunyi, ZHANG Ce, et al. Multiattention network for semantic segmentation of fine-resolution remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5607713. doi: 10.1109/TGRS.2021.3093977. [18] XIE Enze, WANG Wenhai, YU Zhiding, et al. SegFormer: Simple and efficient design for semantic segmentation with transformers[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 924. doi: 10.5555/3540261.3541185. [19] GAO Feng, JIN Xuepeng, ZHOU Xiaowei, et al. MSFMamba: Multiscale feature fusion state space model for multisource remote sensing image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5504116. doi: 10.1109/TGRS.2025.3535622. [20] XU Xiaodong, LI Wei, RAN Qiong, et al. Multisource remote sensing data classification based on convolutional neural network[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(2): 937–949. doi: 10.1109/TGRS.2017.2756851. [21] LI Xue, ZHANG Guo, CUI Hao, et al. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 106: 102638. doi: 10.1016/j.jag.2021.102638. [22] ZHANG Jiaming, LIU Huayao, YANG Kailun, et al. CMX: Cross-modal fusion for RGB-X semantic segmentation with transformers[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(12): 14679–14694. doi: 10.1109/TITS.2023.3300537. [23] OUALI Y, HUDELOT C, and TAMI M. Semi-supervised semantic segmentation with cross-consistency training[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 12671–12681. doi: 10.1109/CVPR42600.2020.01269. [24] LAI Xin, TIAN Zhuotao, JIANG Li, et al. Semi-supervised semantic segmentation with directional context-aware consistency[C]. The 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 1205–1214. doi: 10.1109/CVPR46437.2021.00126. [25] HAN Wenqi, GENG Jie, DENG Xinyang, et al. Enhancing multimodal fusion with only unimodal data[C]. IGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 2024: 2962–2965. doi: 10.1109/IGARSS53475.2024.10641451. [26] JIANG Pengtao, ZHANG Changbin, HOU Qibin, et al. LayerCAM: Exploring hierarchical class activation maps for localization[J]. IEEE Transactions on Image Processing, 2021, 30: 5875–5888. doi: 10.1109/TIP.2021.3089943. [27] ZOU Yuliang, ZHANG Zizhao, ZHANG Han, et al. PseudoSeg: Designing pseudo labels for semantic segmentation[C]. 9th International Conference on Learning Representations, 2021. [28] YANG Lihe, ZHUO Wei, QI Lei, et al. ST++: Make self-trainingWork better for semi-supervised semantic segmentation[C]. The 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 4258–4267. doi: 10.1109/CVPR52688.2022.00423. [29] ZOMORODIAN A and CARLSSON G. Computing persistent homology[C]. The 20th Annual Symposium on Computational Geometry, Brooklyn, USA, 2004: 347–356. doi: 10.1145/997817.997870. [30] HU Xiaoling, LI Fuxin, SAMARAS D, et al. Topology-preserving deep image segmentation[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 508. doi: 10.5555/3454287.3454795. [31] KLINKER F. Exponential moving average versus moving exponential average[J]. Mathematische Semesterberichte, 2011, 58(1): 97–107. doi: 10.1007/s00591-010-0080-8. [32] KINGMA D P and BA J. Adam: A method for stochastic optimization[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015. [33] YIN Bowen, ZHANG Xuying, LI Zhongyu, et al. DFormer: Rethinking RGBD representation learning for semantic segmentation[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024. [34] WAN Zifu, ZHANG Pingping, WANG Yuhao, et al. Sigma: Siamese mamba network for multi-modal semantic segmentation[C]. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, USA, 2025: 1734–1744. doi: 10.1109/WACV61041.2025.00176. -






图(6) / 表(6)
计量
- 文章访问数: 478
- HTML全文浏览量: 290
- PDF下载量: 32
- 被引次数: 0
 下载:
下载:
