

Multi-dimensional Spatio-temporal Feature Enhancement for Lip Reading
-
摘要: 唇部运动的微小变化和相似音素的视觉歧义导致唇语识别模型的时空特征提取能力不足。为此,该文提出多维时空特征增强的唇语识别方法。首先设计自调节时空注意力(SaSTA),关注全局时空关键特征;其次提出三维增强残差块(TE-ResBlock),通过时序位移、多尺度卷积与通道混洗增强时空特征提取能力;然后设计多维时空增强网络(MSTEN),逐层提取时空特征并深度融合时间、空间和通道特征;最后基于MSTEN和DC-TCN构建唇语识别模型,并在LRW数据集和GRID数据集上验证模型性能。实验结果表明,所提方法在LRW和GRID上的准确率分别达到91.18%和97.82%,优于所有对比方法。Abstract:
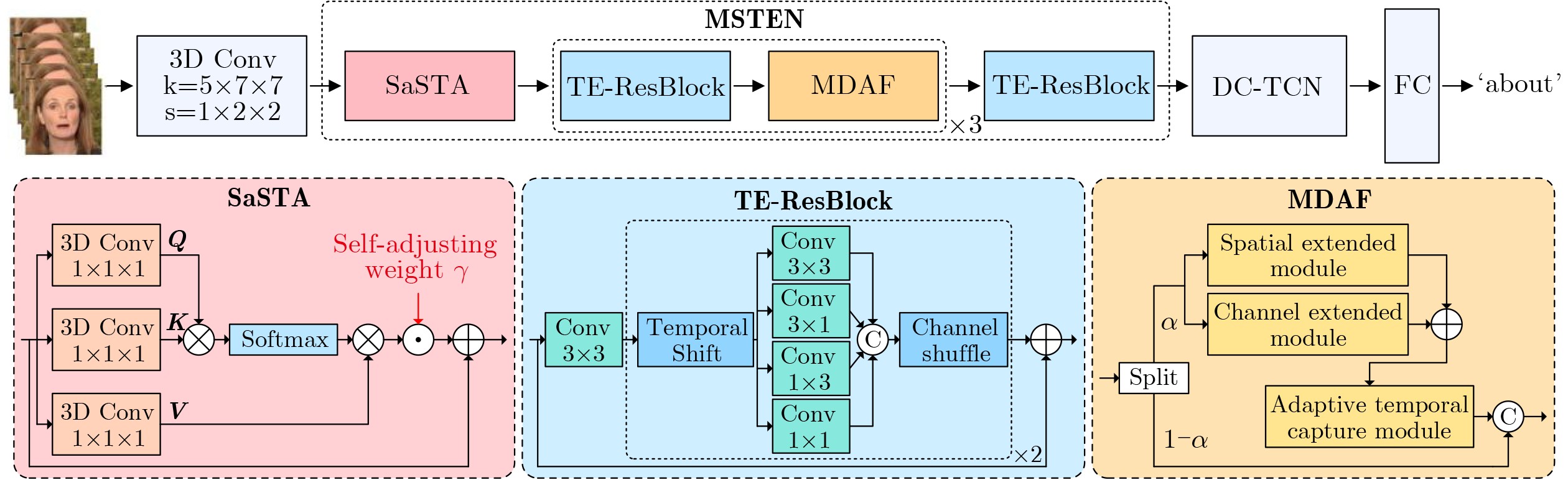
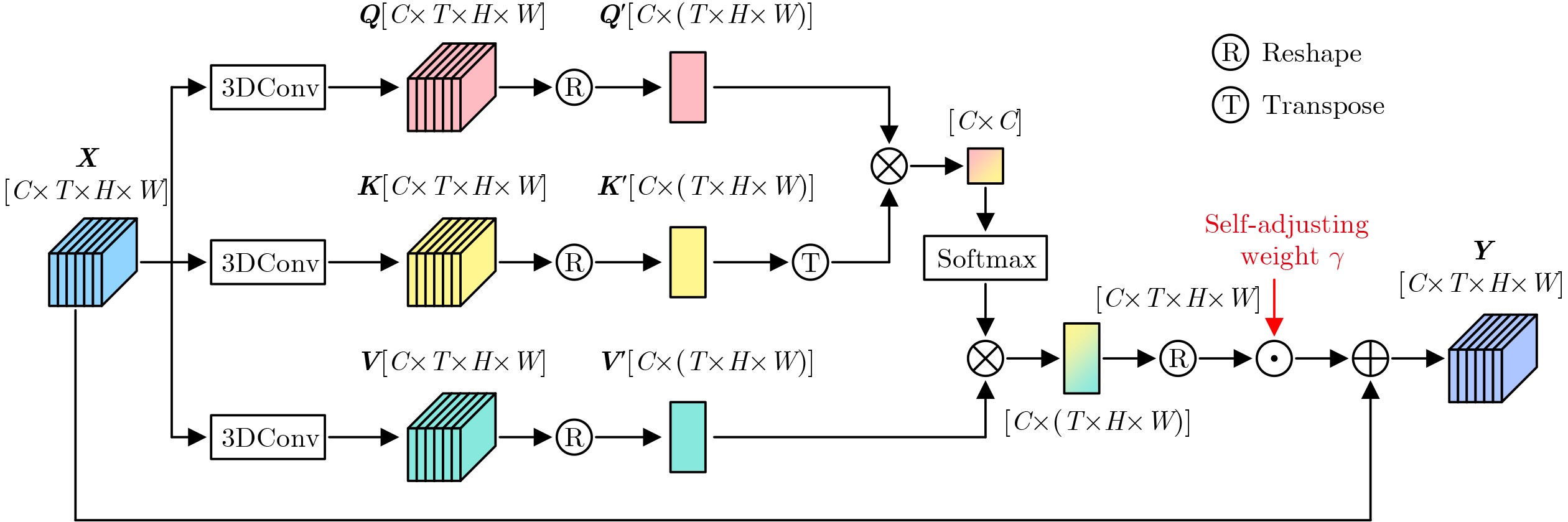
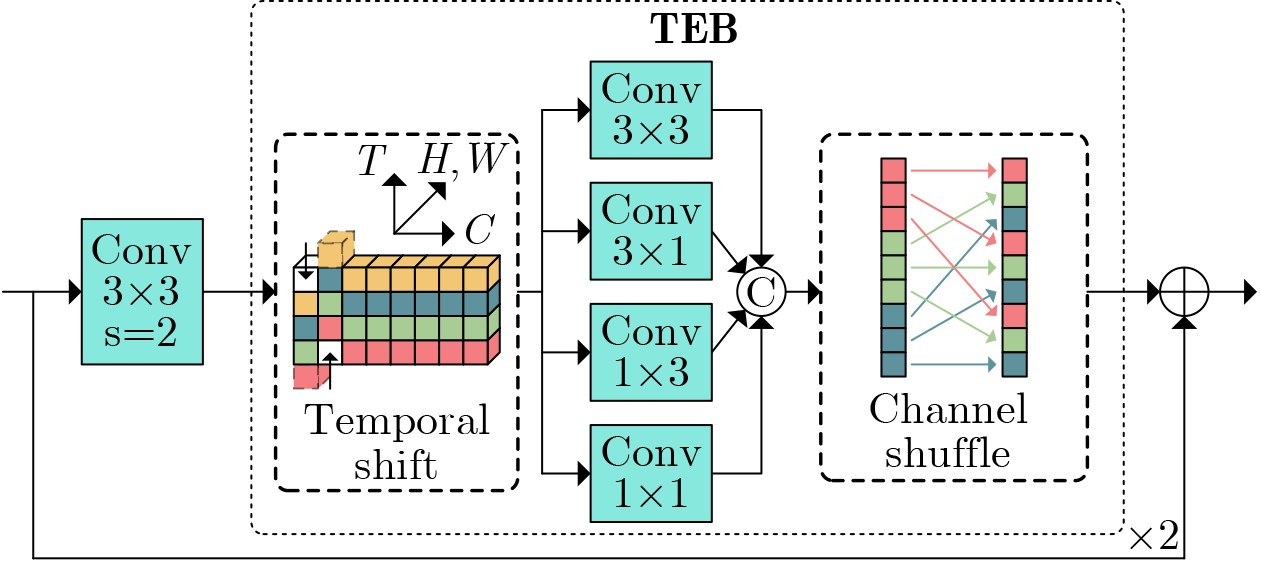
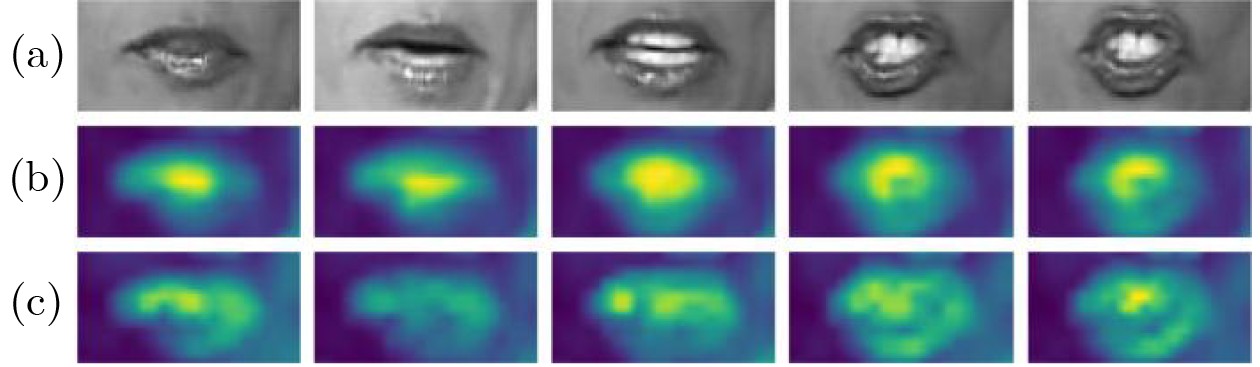
Objective Lip reading is a challenging yet important task in computer vision that aims to decode spoken language solely from visual lip movements. The task is difficult mainly because of inherent ambiguity in visual speech signals. On one hand, articulatory movements for different visemes can be highly subtle. For instance, lip displacement differences for confusable pairs such as /p/–/b/ and /m/–/n/ may be as small as 0.3~0.7 mm. These fine-grained spatial variations often fall below the effective resolution limits of conventional 3D convolutional neural networks. On the other hand, natural coarticulation in speech introduces temporal ambiguity, as mouth shapes may transiently blend multiple phonemes and make distinct visual units difficult to separate. These challenges are further aggravated by real-world factors such as uneven lighting and substantial inter-speaker differences in articulation. Current lip-reading models therefore often show limited ability to capture discriminative spatiotemporal features, which leads to suboptimal performance, particularly for phonemes with minimal visual differences. To address these issues, a robust lip-reading framework is developed to capture and exploit fine-grained spatiotemporal dependencies and improve recognition accuracy under diverse and realistic conditions. Methods To address the above limitations, a novel lip-reading framework, termed the Multi-dimensional Spatio-Temporal Enhancement Network (MSTEN), is proposed. The framework is designed to strengthen spatial and temporal representations through integrated attention mechanisms and advanced residual learning. It contains three core components that collaboratively model dependencies between spatial and temporal features, which are often insufficiently used in conventional architectures. The first component, the Self-adjusting Spatio-temporal Attention (SaSTA) module, adopts a self-adjusting mechanism that operates simultaneously across the height, width, and temporal dimensions. Query, key, and value tensors are generated through 1×1×1 3D convolutions, flattened across spatial and temporal dimensions, and used to compute attention weights by multiplying the query tensor with the transposed key tensor, followed by softmax normalization. The resulting attention map is multiplied by the value tensor and then combined with the original input through learnable parameters and a residual connection, thereby preserving contextual information and producing globally enhanced features. The second component, the Three-dimensional Enhanced Residual Block (TE-ResBlock), improves spatiotemporal feature extraction through temporal shift, multi-scale convolution, and channel shuffle. The temporal shift operation moves one quarter of the feature channels along the time axis to fuse information from adjacent frames without adding parameters. Multi-scale convolution adopts parallel branches with kernel sizes of 3×3, 3×1, 1×3, and 1×1 to capture features at different receptive fields. The outputs are concatenated and processed by channel shuffle to improve information exchange across groups, and four TE-ResBlocks are stacked to achieve progressive feature refinement. The third component, the Multi-dimensional Adaptive Fusion (MDAF) module, integrates spatial, temporal, and channel information through three submodules. These are a Channel Enhancement Module (CEM), which recalibrates features through max pooling, temporal convolution, and sigmoid activation, a Spatial Enhancement Module (SEM), which expands the receptive field through identity mapping and both standard and dilated convolution, and an Adaptive Temporal Capture Module (ATCM), which emphasizes dynamic movements through frame-difference features and temporal weight maps. The MDAF modules are inserted between TE-ResBlock stacks for iterative refinement. Finally, features extracted by the MSTEN front end are fed into a Densely Connected Temporal Convolutional Network (DC-TCN) back end, which consists of four blocks, each containing three temporal convolutional layers with dense connections, to model long-range phonological dependencies effectively. Results and Discussions The proposed framework is evaluated comprehensively on the widely used LRW and GRID datasets. The LRW dataset contains more than 500,000 video clips from over 1,000 speakers. The GRID dataset contains video clips from 34 speakers, each providing 1,000 utterances, with a total duration of 28 h. The proposed model achieves an accuracy of 91.18%, which is an absolute improvement of 2.82 percentage points over a strong ResNet18 baseline, demonstrating its substantial effectiveness. Ablation studies are further conducted to analyze the contribution of each key component. The results show clearly that each proposed module yields a meaningful performance gain. Specifically, the SaSTA module alone improves accuracy by 2.09%, which confirms the key role of global spatiotemporal attention. The TE-ResBlock increases accuracy by 1.73%, which verifies its effectiveness in multi-scale local feature extraction and inter-frame information fusion. The MDAF module provides a further 1.74% improvement, which highlights the benefit of adaptive multi-dimensional feature fusion, as shown in Table 2 .Conclusions This study advances lip reading through the proposed MSTEN front-end network. The framework is built on three main contributions. First, the SaSTA module proposes an effective mechanism for global context aggregation and performs multi-dimensional feature weighting across height, width, and temporal sequences. Second, the TE-ResBlock addresses central challenges in spatiotemporal modeling through the combined use of temporal displacement, multi-scale convolution, and enhanced channel interaction. Third, the MDAF module enables deep and coordinated integration of spatial, temporal, and channel information. Together, these components improve model performance substantially and achieve accuracies of 91.18% on the challenging LRW dataset and 97.82% on the GRID dataset. Ablation studies further confirm the individual and combined effectiveness of the proposed components. Future work will examine the extension of this framework to audio-visual speech recognition under noisy conditions and the development of domain adaptation strategies to improve robustness in low-resolution or resource-constrained scenarios. -
Key words:
- Lip reading /
- Attention mechanism /
- Spatiotemporal enhancement /
- Multi-scale convolution
-
表 1 模块消融实验结果
SaSTA TE−ResBlock MDAF 准确率(%) 参数量(M) 计算复杂度(GFLOPs) 推理速度(FPS) 88.36 52.54 342.04 210.64 √ 90.45 52.56 347.56 202.53 √ 90.09 51.85 326.39 173.09 √ 90.10 52.65 345.20 195.43 √ √ 90.76 51.86 331.91 167.82 √ √ 90.58 52.66 350.72 188.48 √ √ 90.54 51.96 329.53 162.16 √ √ √ 91.18 51.97 335.05 157.85 注:加粗数值表示最优值。  下载: 导出CSV
下载: 导出CSV
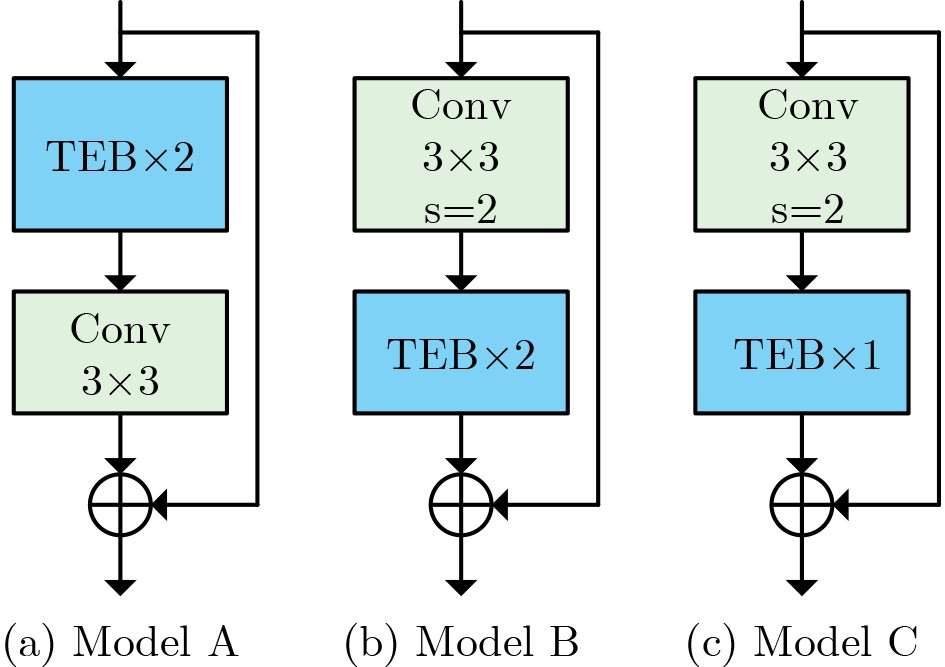
表 3 TEB的位置和堆叠数量实验结果
Model 准确率(%) 参数量(M) Model A 91.12 52.83 Model B 91.18 51.97 Model C 90.88 49.18 注:加粗数值表示最优值。
下载: 导出CSV
表 4 MDAF比例因子实验结果
比例因子取值 准确率(%) 参数量(M) 0.25 90.82 51.89 0.50 91.18 51.97 0.75 91.07 52.11 1 90.95 52.30 注:加粗数值表示最优值。
下载: 导出CSV
表 5 在LRW数据集上的对比实验结果
时空特征增强方法 唇语识别方法 前端网络 后端网络 年份 准确率(%) 混合3D/2D架构 方法[6] 3DConv+ResNet18 MS−TCN 2020 85.30 方法[8] 3DConv+ResNet18 DC−TCN 2021 88.36 方法[19] 3DConv+ResNet18 MVM+MS−TCN 2022 88.50 方法[20] 3DConv+ResNet18+ResFormer Transformer 2023 85.25 动态轻量化网络 方法[21] 3DConv+iGhostBottleneck BiGRU 2022 87.30 方法[22] GhostNet+TSM+解耦同类自知识蒸馏 2023 85.20 方法[12] 3Dconv+DSTE+GhostNet+ME Transformer+MS−TCN 2024 89.21 跨模态自监督 方法[23] ADC-SSL结合对比学习和对抗训练 2021 84.00 方法[24] 音频自监督学习视觉语音表示 2021 88.10 方法[25] 单模态自监督预训练提升多模态AVSR 2022 85.00 结构化增强的ResNet 方法[26] ResGNet C−TCN 2024 89.10 方法[27] HP−ResNet18−TSM DC−TCN 2024 90.75 方法[28] 3DConv+STABNet MS−TCN 2025 89.45 本文方法 MSTEN DC−TCN 91.18 注:加粗数值表示最优值。
下载: 导出CSV
表 6 在GRID数据集上的对比实验结果
改进方向 唇语识别方法 前端网络 后端网络 年份 准确率(%) 说话人依赖填充 方法[29] 3DConv+ResNet18 MS−TCN 2022 92.80 非自回归+对应关系建模 方法[30] STCNN Transformer 2020 95.50 时空特征增强+级联注意力CTC 方法[31] 3DConv+HighwayNetworks BiGRU 2018 97.10 方法[32] STCNN+ResNet50 BiGRU 2019 97.30 方法[33] 3DConv+EfficientNet BiLSTM 2024 96.70 时空特征增强 方法[28] 3DConv+STABNet MS−TCN 2025 97.45 本文方法 MSTEN DC−TCN 97.82 注:加粗数值表示最优值。
下载: 导出CSV
-
[1] NODA K, YAMAGUCHI Y, NAKADAI K, et al. Lipreading using convolutional neural network[C]. 15th Annual Conference of the International Speech Communication Association, Singapore, Singapore, 2014: 1149–1153. doi: 10.21437/Interspeech.2014-293. [2] ASSAEL Y M, SHILLINGFORD B, WHITESON S, et al. LipNet: End-to-end sentence-level lipreading[EB/OL]. https://arxiv.org/abs/1611.01599, 2016. [3] JEON S, ELSHARKAWY A, and KIM M S. Lipreading architecture based on multiple convolutional neural networks for sentence-level visual speech recognition[J]. Sensors, 2021, 22(1): 72. doi: 10.3390/s22010072. [4] 韩宗旺, 杨涵, 吴世青, 等. 时空自适应图卷积与Transformer结合的动作识别网络[J]. 电子与信息学报, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551.HAN Zongwang, YANG Han, WU Shiqing, et al. Action recognition network combining spatio-temporal adaptive graph convolution and Transformer[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551. [5] STAFYLAKIS T and TZIMIROPOULOS G. Combining residual networks with LSTMs for lipreading[C]. 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 2017: 3652–3656. doi: 10.21437/Interspeech.2017-85. [6] MARTINEZ B, MA Pingchuan, PETRIDIS S, et al. Lipreading using temporal convolutional networks[C]. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 6319–6323. doi: 10.1109/ICASSP40776.2020.9053841. [7] CHUNG J S and ZISSERMAN A. Lip reading in the wild[C]. 13th Asian Conference on Computer Vision on Computer Vision – ACCV 2016, Taipei, China, 2017: 87–103. doi: 10.1007/978-3-319-54184-6_6. [8] MA Pingchuan, WANG Yujiang, SHEN Jie, et al. Lip-reading with densely connected temporal convolutional networks[C]. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2021: 2856–2865. doi: 10.1109/WACV48630.2021.00290. [9] XU Bo, LU Cheng, GUO Yandong, et al. Discriminative multi-modality speech recognition[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 14421–14430. doi: 10.1109/CVPR42600.2020.01444. [10] 王春丽, 李金絮, 高玉鑫, 等. 一种基于时空频多维特征的短时窗口脑电听觉注意解码网络[J]. 电子与信息学报, 2025, 47(3): 814–824. doi: 10.11999/JEIT240867.WANG Chunli, LI Jinxu, GAO Yuxin, et al. A short-time window electroencephalogram auditory attention decoding network based on multi-dimensional characteristics of temporal-spatial-frequency[J]. Journal of Electronics & Information Technology, 2025, 47(3): 814–824. doi: 10.11999/JEIT240867. [11] 孙强, 陈远. 多层次时空特征自适应集成与特有-共享特征融合的双模态情感识别[J]. 电子与信息学报, 2024, 46(2): 574–587. doi: 10.11999/JEIT231110.SUN Qiang and CHEN Yuan. Bimodal emotion recognition with adaptive integration of multi-level spatial-temporal features and specific-shared feature fusion[J]. Journal of Electronics & Information Technology, 2024, 46(2): 574–587. doi: 10.11999/JEIT231110. [12] 马金林, 吕鑫, 马自萍, 等. 微运动激励与时间感知的唇语识别方法[J]. 电子学报, 2024, 52(11): 3657–3668. doi: 10.12263/DZXB.20230888.MA Jinlin, LYU Xin, MA Ziping, et al. Micro-motion excitation and time perception for lip reading[J]. Acta Electronica Sinica, 2024, 52(11): 3657–3668. doi: 10.12263/DZXB.20230888. [13] 丁建睿, 张听, 刘家栋, 等. 融合邻域注意力和状态空间模型的医学视频分割算法[J]. 电子与信息学报, 2025, 47(5): 1582–1595. doi: 10.11999/JEIT240755.DING Jianrui, ZHANG Ting, LIU Jiadong, et al. A medical video segmentation algorithm integrating neighborhood attention and state space model[J]. Journal of Electronics & Information Technology, 2025, 47(5): 1582–1595. doi: 10.11999/JEIT240755. [14] WEI Dafeng, TIAN Ye, WEI Liqing, et al. Efficient dual attention slowfast networks for video action recognition[J]. Computer Vision and Image Understanding, 2022, 222: 103484. doi: 10.1016/j.cviu.2022.103484. [15] LIN Ji, GAN Chuang, and HAN Song. TSM: Temporal shift module for efficient video understanding[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019: 7082–7092. doi: 10.1109/ICCV.2019.00718. [16] ZHANG Xiangyu, ZHOU Xinyu, LIN Mengxiao, et al. ShuffleNet: An extremely efficient convolutional neural network for mobile devices[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6848–6856. doi: 10.1109/CVPR.2018.00716. [17] WANG Bin, CHANG Faliang, LIU Chunsheng, et al. An efficient motion visual learning method for video action recognition[J]. Expert Systems with Applications, 2024, 255: 124596. doi: 10.1016/j.eswa.2024.124596. [18] COOKE M, BARKER J, CUNNINGHAM S, et al. An audio-visual corpus for speech perception and automatic speech recognition[J]. The Journal of the Acoustical Society of America, 2006, 120(5): 2421–2424. doi: 10.1121/1.2229005. [19] KIM M, YEO J H, and RO Y M. Distinguishing homophenes using multi-head visual-audio memory for lip reading[C]. The 36th AAAI Conference on Artificial Intelligence, 2022: 1174–1182. doi: 10.1609/aaai.v36i1.20003. [20] XUE Junxiao, HUANG Shibo, SONG Huawei, et al. Fine-grained sequence-to-sequence lip reading based on self-attention and self-distillation[J]. Frontiers of Computer Science, 2023, 17(6): 176344. doi: 10.1007/s11704-023-2230-x. [21] 马金林, 刘宇灏, 马自萍, 等. HSKDLR: 同类自知识蒸馏的轻量化唇语识别方法[J]. 计算机科学与探索, 2023, 17(11): 2689–2702. doi: 10.3778/j.issn.1673-9418.2208032.MA Jinlin, LIU Yuhao, MA Ziping, et al. HSKDLR: Lightweight lip reading method based on homogeneous self-knowledge distillation[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(11): 2689–2702. doi: 10.3778/j.issn.1673-9418.2208032. [22] 马金林, 刘宇灏, 马自萍, 等. 解耦同类自知识蒸馏的轻量化唇语识别方法[J]. 北京航空航天大学学报, 2024, 50(12): 3709–3719. doi: 10.13700/j.bh.1001-5965.2022.0931.MA Jinlin, LIU Yuhao, MA Ziping, et al. Lightweight lip reading method based on decoupling homogeneous self-knowledge distillation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(12): 3709–3719. doi: 10.13700/j.bh.1001-5965.2022.0931. [23] SHENG Changchong, PIETIKÄINEN M, TIAN Qi, et al. Cross-modal self-supervised learning for lip reading: When contrastive learning meets adversarial training[C]. The 29th ACM International Conference on Multimedia, 2021: 2456–2464. doi: 10.1145/3474085.3475415. [24] MA Pingchuan, MIRA R, PETRIDIS S, et al. LiRA: Learning visual speech representations from audio through self-supervision[C]. 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 2021: 3011–3015. doi: 10.21437/Interspeech.2021-1360. [25] PAN Xichen, CHEN Peiyu, GONG Yichen, et al. Leveraging unimodal self-supervised learning for multimodal audio-visual speech recognition[EB/OL]. https://arxiv.org/abs/2203.07996, 2022. [26] JIANG Junxia, ZHAO Zhongqiu, YANG Yi, et al. GSLip: A global lip-reading framework with solid dilated convolutions[C]. 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 2024: 1–8. doi: 10.1109/IJCNN60899.2024.10651423. [27] CHEN Hang, WANG Qing, DU Jun, et al. Collaborative viseme subword and end-to-end modeling for word-level lip reading[J]. IEEE Transactions on Multimedia, 2024, 26: 9358–9371. doi: 10.1109/TMM.2024.3390148. [28] 马金林, 郭兆伟, 马自萍, 等. 多尺度门控时空增强的唇语识别方法[J]. 计算机辅助设计与图形学学报, 2025, 37(7): 1228–1238. doi: 10.3724/SP.J.1089.2023-00478.MA Jinlin, GUO Zhaowei, MA Ziping, et al. Multi-scale gated spatio-temporal enhancement for lip recognition[J]. Journal of Computer-Aided Design & Computer Graphics, 2025, 37(7): 1228–1238. doi: 10.3724/SP.J.1089.2023-00478. [29] KIM M, KIM H, and RO Y M. Speaker-adaptive lip reading with user-dependent padding[C]. 17th European Conference on Computer Vision – ECCV 2022, Tel Aviv, Israel, 2022: 576–593. doi: 10.1007/978-3-031-20059-5_33. [30] LIU Jinglin, REN Yi, ZHAO Zhou, et al. FastLR: Non-autoregressive lipreading model with integrate-and-fire[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 4328–4336. doi: 10.1145/3394171.3413740. [31] XU Kai, LI Dawei, CASSIMATIS N, et al. LCANet: End-to-end lipreading with cascaded attention-CTC[C]. 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 2018: 548–555. doi: 10.1109/FG.2018.00088. [32] RASTOGI A, AGARWAL R, GUPTA V, et al. LRNeuNet: An attention based deep architecture for lipreading from multitudinous sized videos[C]. 2019 International Conference on Computing, Power and Communication Technologies (GUCON), New Delhi, India, 2019: 1001–1007. [33] JEEVAKUMARI S A A and DEY K. LipSyncNet: A novel deep learning approach for visual speech recognition in audio-challenged situations[J]. IEEE Access, 2024, 12: 110891–110904. doi: 10.1109/ACCESS.2024.3436931. -

 下载:
下载:




图(8) / 表(6)
计量
- 文章访问数: 374
- HTML全文浏览量: 204
- PDF下载量: 38
- 被引次数: 0
