

Facial Expression Recognition Model Based on an Improved YOLO12n
-
摘要: 针对低分辨率、光照复杂、部分遮挡等场景下人脸表情识别精度下降的问题,该文提出一种基于YOLO12n改进的人脸表情识别模型(YOLO-FER)。该模型通过设计NewStarBlock模块优化原有C3k2瓶颈结构以缓解高维特征缺失,并引入多维协作注意力(MCA)模块,在通道、高度和宽度3个维度协同建模以增强细粒度特征提取能力,同时增加低分辨率特征增强模块(LRFE)提升弱光及模糊场景下的鲁棒性,并采用自适应阈值焦点损失函数(ATFL)动态调整难易样本权重以缓解类别不平衡问题。在RAF-DB和Low Light Dataset数据集上实验表明,YOLO-FER在mAP@0.5指标上较基线YOLO12n分别提升了3.8%和5.0%,在保持实时检测速度的同时提升了模型的泛化能力与鲁棒性,能够更准确地捕捉表情关键区域,适用于表情识别实际场景。Abstract:
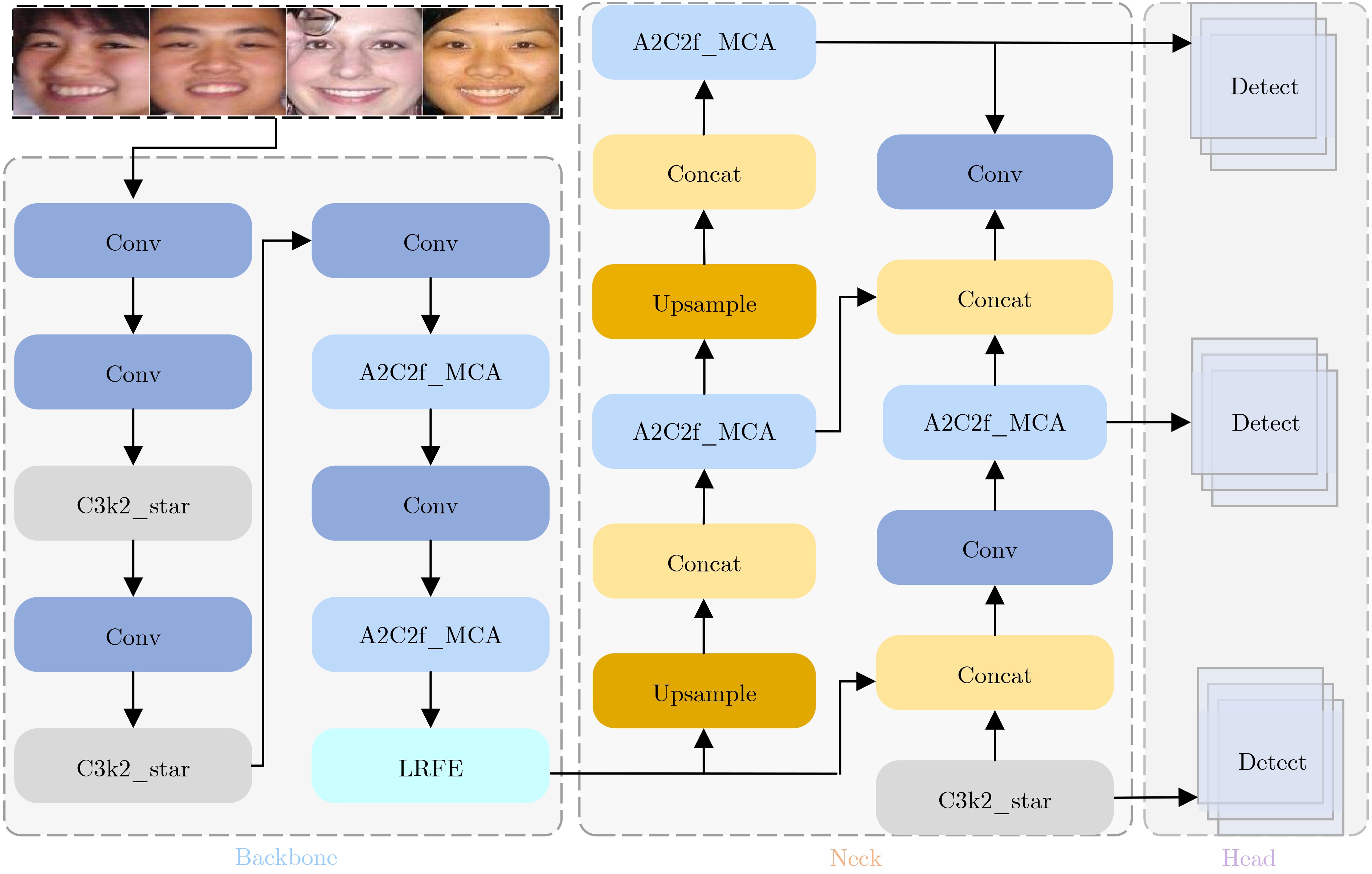
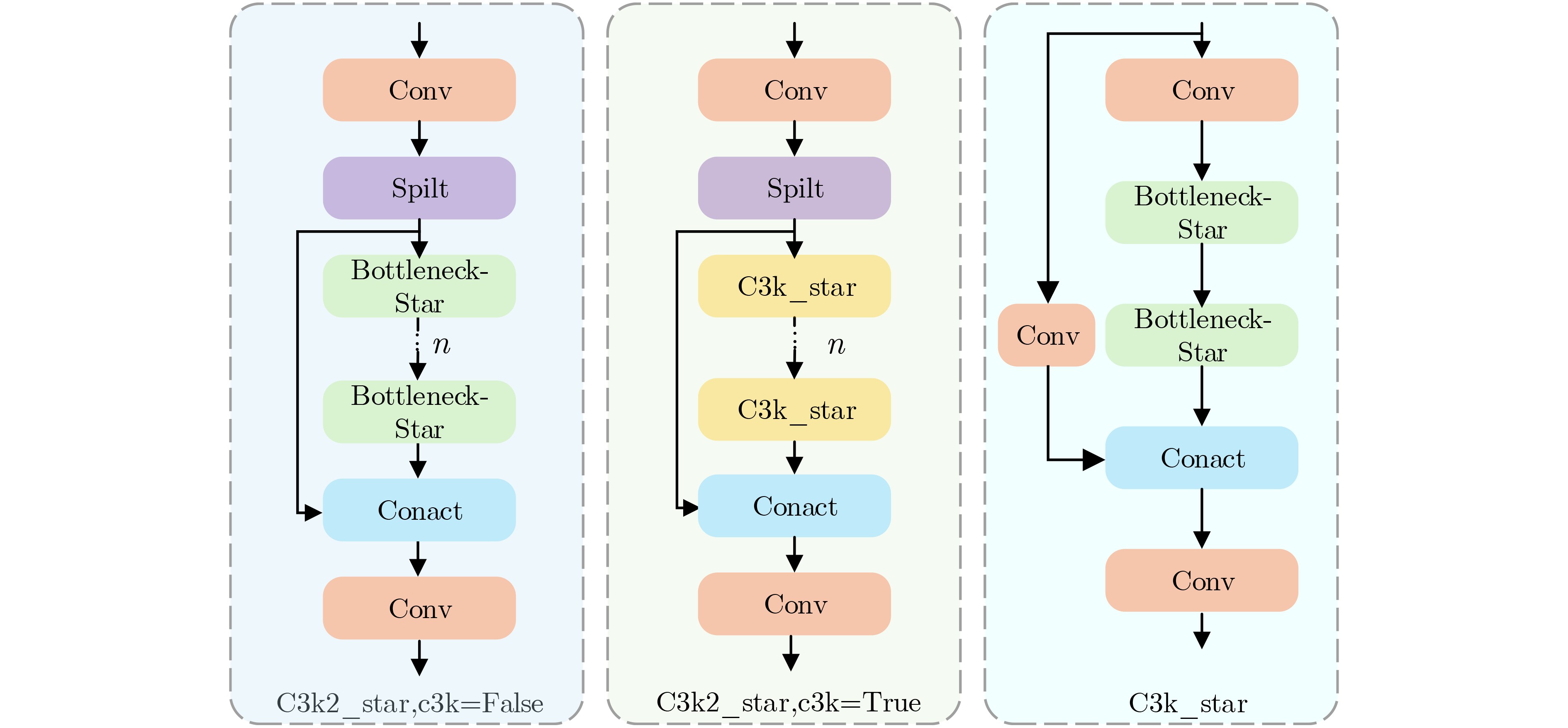
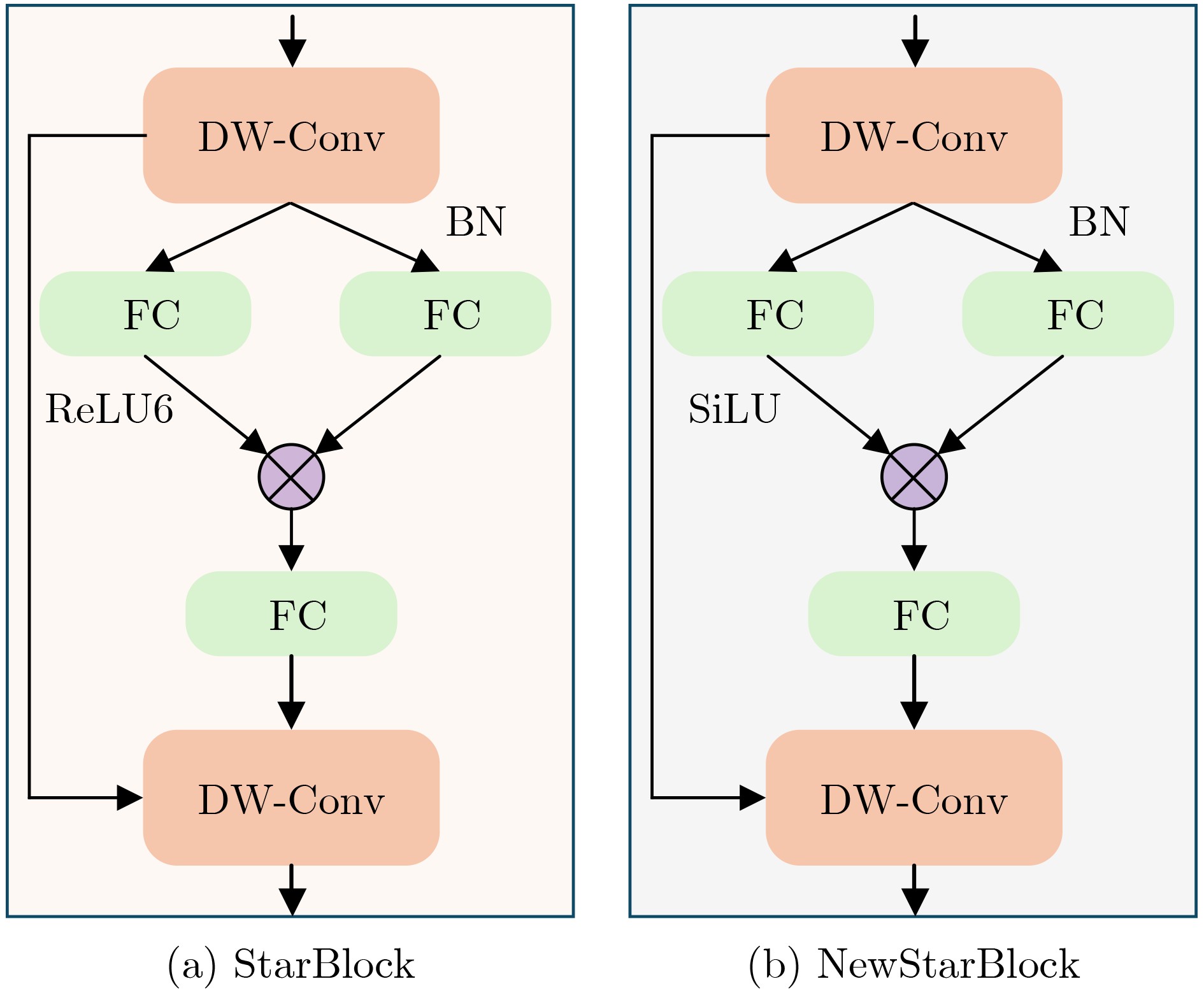
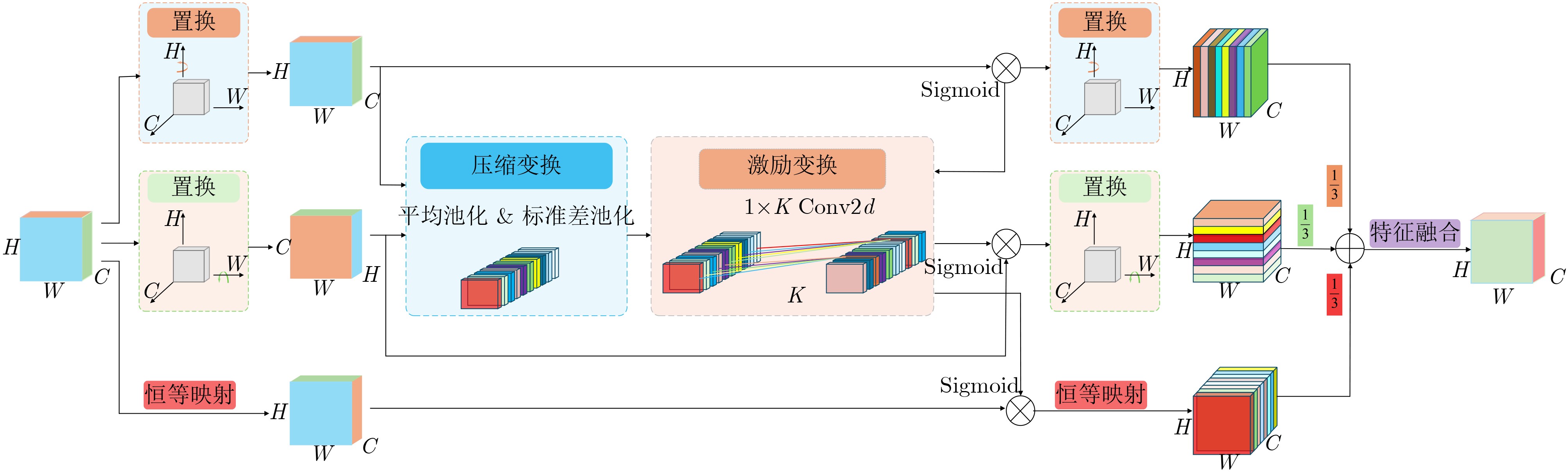
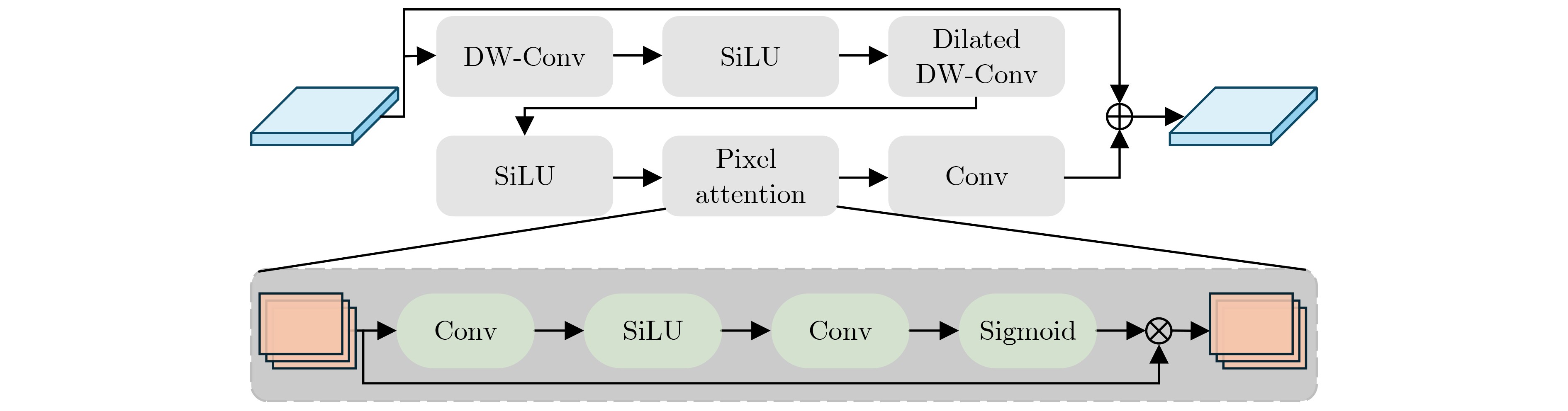
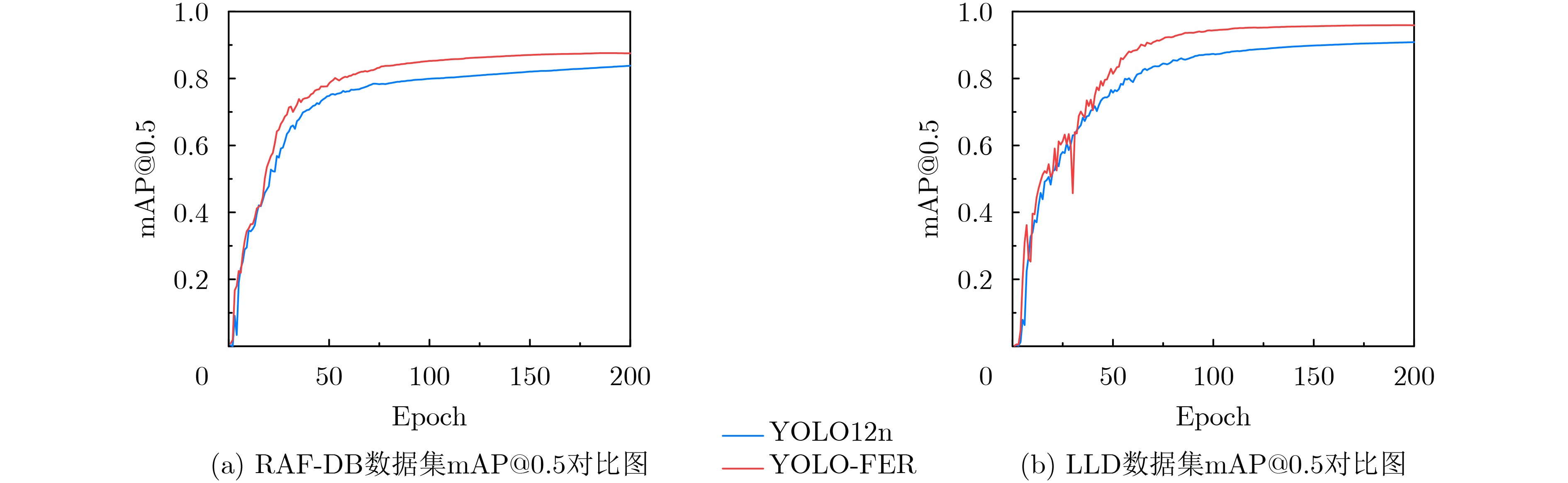
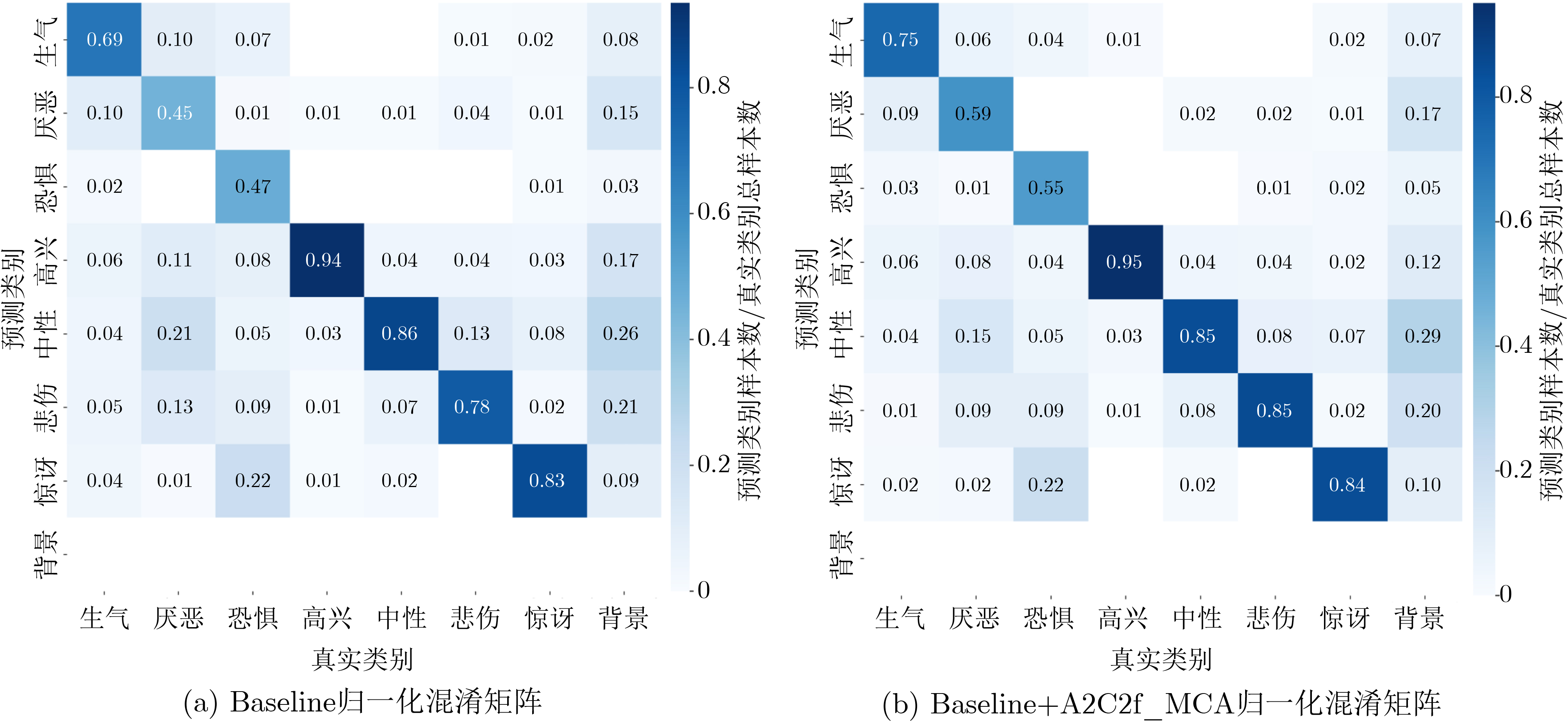
Objective Facial Expression Recognition (FER) is a key technology in affective computing and intelligent human-computer interaction. In practical scenarios, recognition performance is often degraded by low resolution, complex illumination, partial occlusion, and class imbalance. Although deep learning-based methods have made substantial progress, lightweight models such as You Only Look Once version 12 nano (YOLO12n) still have limited feature extraction ability and reduced robustness under degraded imaging conditions. To address these limitations, this paper proposes an improved FER model, termed YOLO-FER. The model is designed to enhance feature representation, improve the discrimination of similar expressions, and maintain real-time detection performance in low-quality environments. Methods Based on the YOLO12n model, YOLO-FER introduces several targeted improvements. First, a C3k2_star module is constructed by embedding NewStarBlock into the original bottleneck structure. This design enhances high-dimensional nonlinear feature representation and alleviates feature loss during fusion, as shown in Fig. 2 andFig. 3 . Second, Multidimensional Collaborative Attention (MCA) is integrated with the A2C2f module to form A2C2f_MCA. This module performs joint modeling across the channel, height, and width dimensions to capture fine-grained facial features (Fig. 4 ). Third, a Low Resolution Feature Extractor (LRFE) module is placed at the end of the backbone. It enhances pixel-level feature representation under low-resolution and low-light conditions through dilated convolution and pixel attention (Fig. 5 ). Finally, Adaptive Threshold Focal Loss (ATFL) is used to dynamically adjust the contributions of easy and hard samples. This function mitigates class imbalance and improves the discrimination of similar expressions. The overall model structure is shown in Fig. 1. Experiments are conducted on the RAF-DB and Low Light Dataset (LLD) datasets. Precision (P), recall (R), F1 score, and mAP@0.5 are used as evaluation metrics.Results and Discussions Extensive experiments show that YOLO-FER outperforms the baseline YOLO12n and other YOLO-series models. As shown in Table 2 , on the RAF-DB dataset, YOLO-FER achieves P=81.8%, R=81.9%, and mAP@0.5=87.6%, with a 3.8% improvement in mAP@0.5 over the baseline. On the LLD dataset (Table 3 ), YOLO-FER achieves an mAP@0.5 of 95.9%, representing a 5.0% improvement. These results indicate strong robustness under low-light conditions. The ablation studies in Table 2 and Table 3 confirm that each proposed module contributes to performance improvement. C3k2_star, A2C2f_MCA, LRFE, and ATFL all lead to consistent gains in detection accuracy. Their combination achieves the best performance with only a slight increase in parameters. The comparison with other YOLO variants in Table 5 further shows that YOLO-FER achieves a favorable balance between accuracy and model complexity. The mAP@0.5 curves inFig. 8 show that the proposed model maintains consistent performance gains during training. The confusion matrix analysis inFig. 9 andTable 4 demonstrates that the MCA module improves the discrimination of similar expressions, such as Angry and Disgust, and reduces misclassification. Grad-CAM visualization results (Fig. 13 ) indicate that YOLO-FER focuses more accurately on key facial regions, including the eyes, eyebrows, and mouth, than the baseline model. Experiments under degraded conditions (Fig. 14 andTable 13 ) further show that YOLO-FER maintains higher detection performance than YOLO12n and has a smaller overall performance drop. These findings confirm its robustness in low-quality scenarios. Although the number of parameters increases slightly from 2.5 M to 3.0 M, the inference speed remains competitive (Table 7 ), indicating that the proposed method retains real-time capability.Conclusions This paper proposes YOLO-FER, an improved FER model based on YOLO12n. The model improves feature extraction and robustness in low-quality image scenarios. By integrating C3k2_star, MCA, LRFE, and ATFL, YOLO-FER improves recognition performance and generalization ability. Experimental results on the RAF-DB and LLD datasets confirm that the model achieves high detection performance while maintaining efficient inference speed. The proposed method provides a practical solution for real-time FER applications in complex environments. Future work will focus on improving performance under extremely low-resolution conditions and exploring cross-domain generalization and micro-expression recognition. -
表 1 RAF-DB与LLD数据集表情类别分布
类别(英文) 类别(中文) RAF-DB样本数 LLD样本数 Angry 生气 867 1156 Disgust 厌恶 877 1726 Fear 恐惧 355 - Happy 高兴 5957 2064 Neutral 中性 3204 1748 Sad 悲伤 2460 1 896 Surprise 惊讶 1619 2158  下载: 导出CSV
下载: 导出CSV
表 2 基于RAF-DB数据集消融实验
Baseline C3k2_star A2C2f_MCA LRFE ATFL P(%) R(%) F1 mAP@0.5(%) Params(M) √ 78.4 78.6 0.78 83.8 2.5 √ √ 78.8 80.7 0.79 85.9 2.5 √ √ 78.6 82.7 0.81 86.9 2.5 √ √ 81.2 80.8 0.81 86.8 2.8 √ √ 78.7 81.3 0.80 86.7 2.5 √ √ √ 80.1 81.5 0.81 87.0 2.8 √ √ √ √ 80.6 81,7 0.81 87.3 3.0 √ √ √ √ √ 81.8 81.9 0.82 87.6 3.0
下载: 导出CSV
表 3 基于LLD数据集消融实验
Baseline C3k2_star A2C2f_MCA LRFE ATFL P(%) R(%) F1 mAP@0.5(%) Params(M) √ 87.3 82.8 0.85 90.9 2.5 √ √ 91.0 87.5 0.89 94.0 2.5 √ √ 89.6 87.3 0.88 93.2 2.5 √ √ 92.4 87.4 0.90 94.4 2.8 √ √ 90.1 87.9 0.89 93.8 2.5 √ √ √ 89.2 89.6 0.90 94.2 2.8 √ √ √ √ 92.3 89.4 0.91 95.0 3.0 √ √ √ √ √ 91.9 91.2 0.92 95.9 3.0
下载: 导出CSV
表 4 相似表情(生气-厌恶)区分能力对比
模型 R(生气) R(厌恶) 混淆(生气→厌恶) 混淆(厌恶→生气) YOLO12n 0.69 0.45 0.10 0.10 YOLO12n+A2C2f_MCA 0.75 0.59 0.09 0.06 Δ +0.06 +0.14 –0.01 –0.04
下载: 导出CSV
表 5 YOLO系列模型对比实验
模型 P(%) R(%) F1 mAP@0.5(%) mAP@0.5标准差 Params(M) YOLOv8n 81.4 77.9 0.79 84.1 0.0035 3.0 YOLOV10n 71.3 77.8 0.74 81.6 0.0062 2.7 YOLO11n 81.5 79.4 0.80 85.9 0.0052 2.6 YOLO12n 78.4 78.6 0.78 83.8 0.0041 2.5 YOLO-FER 81.8 81.9 0.82 87.6 0.0029 3.0
下载: 导出CSV
表 7 不同模型在RTX4090上的计算复杂度与推理速度对比
模型 输入分辨率 GFLOPs fps Params(M) YOLOv8n 640×640 8.2 603.86 3.0 YOLOV10n 640×640 8.4 781.71 2.7 YOLO11n 640×640 6.4 677.36 2.6 YOLO12n 640×640 5.8 619.49 2.5 YOLO-FER 640×640 7.7 503.53 3.0
下载: 导出CSV
表 8 YOLO-FER在不同输入分辨率下的计算复杂度与推理速度
输入分辨率 GFLOPs fps 320×320 7.7 1291.76 480×480 7.7 803.41 640×640 7.7 503.53
下载: 导出CSV
表 9 超参数取值范围
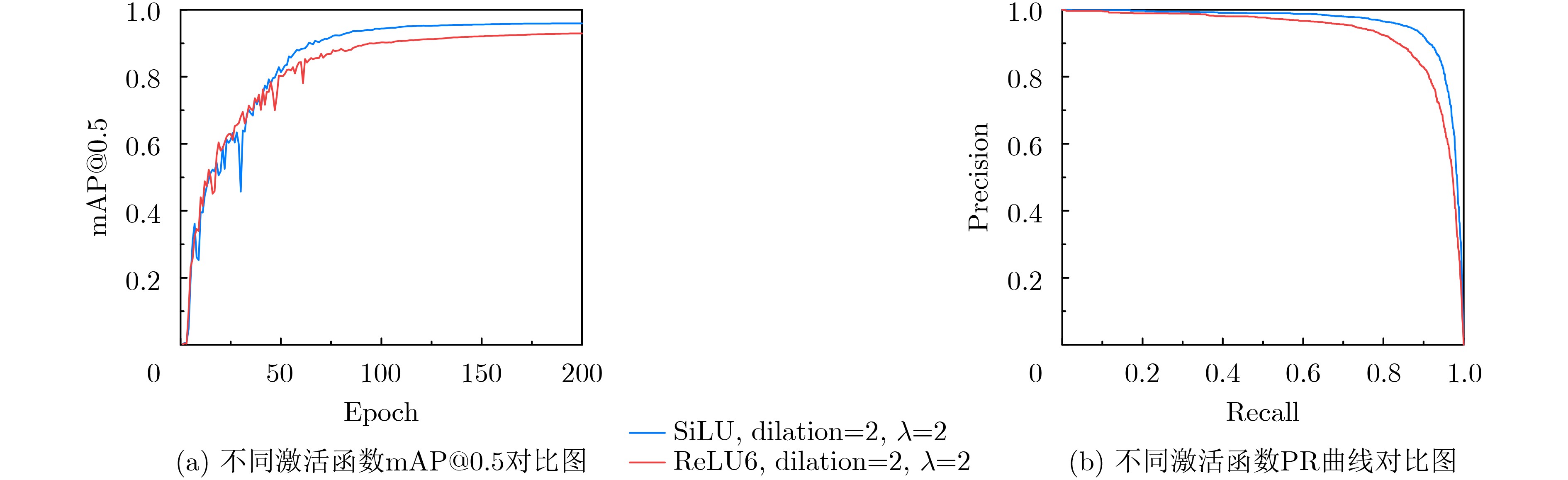
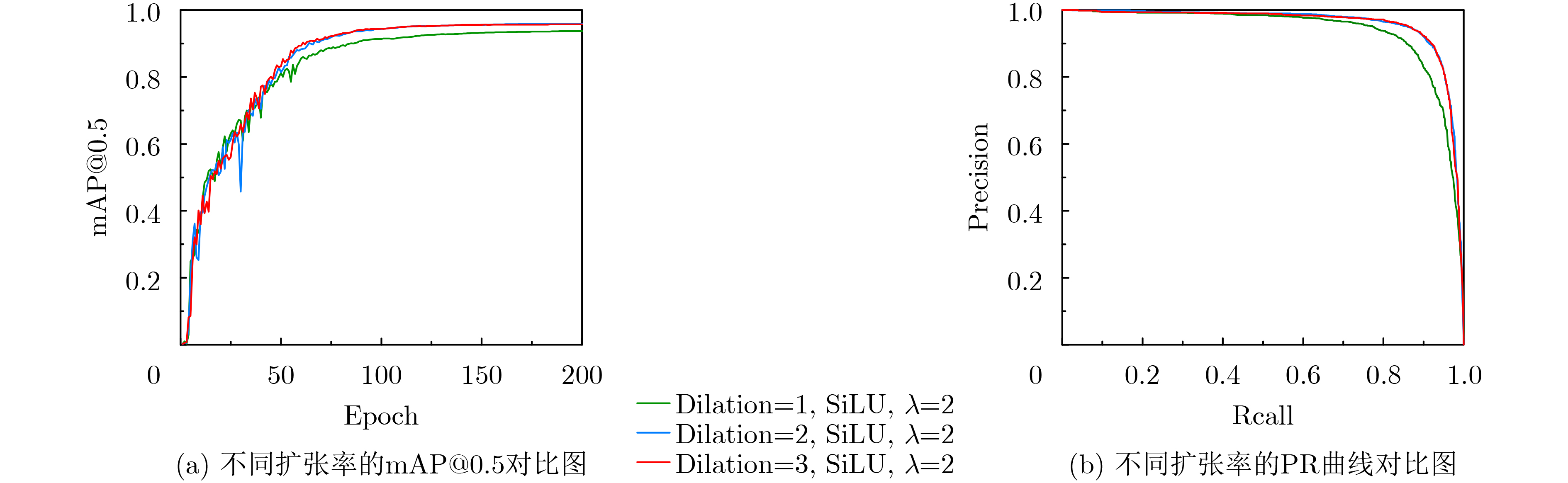
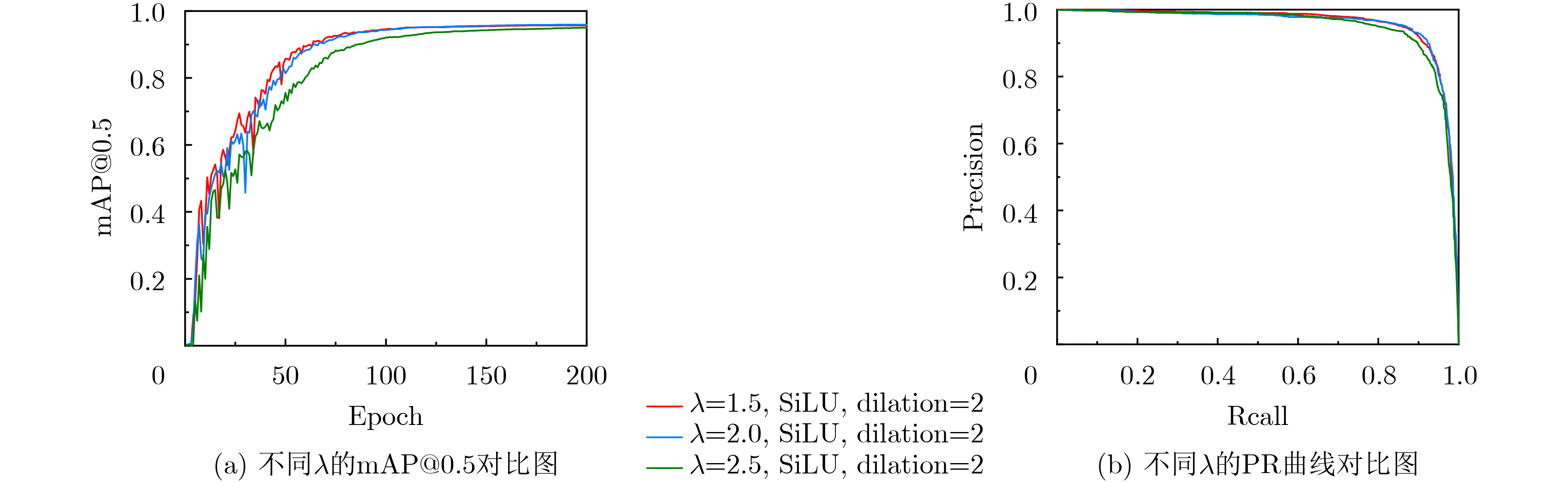
模块 超参数 取值范围 基准值 NewStarBlock 激活函数 ReLU6, SiLU SiLU LRFE dilation(扩张率) 1, 2, 3 2 ATFL λ(损失调制系数) 1.5, 2.0, 2.5 2.0
下载: 导出CSV
表 10 激活函数敏感性分析实验结果
激活函数 P (%) R (%) F1 mAP@0.5 (%) ReLU6 88.5 86.3 0.87 93 SiLU 91.9 91.2 0.92 95.9
下载: 导出CSV
表 11 扩张率敏感性分析实验结果
扩张率dilation P (%) R (%) F1 mAP@0.5 (%) 1 88.9 87.8 0.88 93.7 2 91.9 91.2 0.92 95.9 3 91.8 91.1 0.91 95.7
下载: 导出CSV
表 12 λ敏感性分析实验结果
λ P (%) R (%) F1 mAP@0.5 (%) 1.5 91.9 91.1 0.91 95.7 2 91.9 91.2 0.92 95.9 2.5 89.8 90.0 0.90 95.0
下载: 导出CSV
表 13 原始测试集与随机退化测试集上的性能对比(YOLO-FER/YOLO12n)
表情类别 生气 厌恶 恐惧 高兴 中性 悲伤 惊讶 平均 原图 91.1/85.7 67.1/59.2 75.4/66.3 98.6/98.2 92.7/90.8 93.6/92.9 94.6/93.5 87.6/83.8 退化后 85.6/80.9 66.4/54.2 70.4/58.8 98.1/97.9 88.7/88.2 91.6/90.2 92.5/90.2 84.8/80.1 Δ –5.5/–4.8 –0.7/–5.0 –5.0/–7.5 –0.5/–0.5 –4.0/–2.6 –2.0/–2.7 –2.1/–3.3 –2.8/–3.7
下载: 导出CSV
-
[1] ADYAPADY R R and ANNAPPA B. A comprehensive review of facial expression recognition techniques[J]. Multimedia Systems, 2023, 29(1): 73–103. doi: 10.1007/S00530-022-00984-w. [2] LI Shan and DENG Weihong. Deep facial expression recognition: A survey[J]. IEEE Transactions on Affective Computing, 2022, 13(3): 1195–1215. doi: 10.1109/taffc.2020.2981446. [3] 张国祥, 孙运卓. 复杂光线环境下局部二值模式的CNN人脸识别方法[J]. 湖北师范大学学报: 自然科学版, 2023, 43(4): 49–55. doi: 10.3969/j.issn.2096-3149.2023.04.007.ZHANG Guoxiang and SUN Yunzhuo. CNN facialrecognition method based on local binary pattern in complex light environment[J]. Journal of Hubei Normal University: Natural Science, 2023, 43(4): 49–55. doi: 10.3969/j.issn.2096-3149.2023.04.007. [4] 李蕊, 刘鹏宇, 贾克斌. 局部遮挡条件下的人脸表情识别[J]. 计算机应用与软件, 2016, 33(9): 147–150,175. doi: 10.3969/j.issn.1000-386x.2016.09.035.LI Rui, LIU Pengyu, and JIA Kebin. Facial expression recognition under partial occlusion[J]. Computer Applications and Software, 2016, 33(9): 147–150,175. doi: 10.3969/j.issn.1000-386x.2016.09.035. [5] 李珊, 邓伟洪. 深度人脸表情识别研究进展[J]. 中国图象图形学报, 2020, 25(11): 2306–2320. doi: 10.11834/jig.200233.LI Shan and DENG Weihong. Deep facial expression recognition: A survey[J]. Journal of Image and Graphics, 2020, 25(11): 2306–2320. doi: 10.11834/jig.200233. [6] WANG Kai, PENG Xiaojiang, YANG Jianfei, et al. Region attention networks for pose and occlusion robust facial expression recognition[J]. IEEE Transactions on Image Processing, 2020, 29: 4057–4069. doi: 10.1109/TIP.2019.2956143. [7] MAO Jiawei, XU Rui, YIN Xuesong, et al. POSTER++: A simpler and stronger facial expression recognition network[J]. Pattern Recognition, 2025, 157: 110951. doi: 10.1016/J.PATCOG.2024.110951. [8] 赵明华, 董爽爽, 胡静, 等. 注意力引导的三流卷积神经网络用于微表情识别[J]. 中国图象图形学报, 2024, 29(1): 111–122. doi: 10.11834/jig.230053.ZHAO Minghua, DONG Shuangshuang, HU Jing, et al. Attention-guided three-stream convolutional neural network for microexpression recognition[J]. Journal of Image and Graphics, 2024, 29(1): 111–122. doi: 10.11834/jig.230053. [9] YANG Qiaohe, HE Yueshun, CHEN Hongmao, et al. A novel lightweight facial expression recognition network based on deep shallow network fusion and attention mechanism[J]. Algorithms, 2025, 18(8): 473. doi: 10.3390/A18080473. [10] WEN Zhengyao, LIN Wenzhong, WANG Tao, et al. Distract your attention: Multi-head cross attention network for facial expression recognition[J]. Biomimetics, 2023, 8(2): 199. doi: 10.3390/BIOMIMETICS8020199. [11] LAI Zhenyi, CHEN Renhe, JIA Jinlu, et al. Real-time micro-expression recognition based on ResNet and atrous convolutions[J]. Journal of Ambient Intelligence and Humanized Computing, 2023, 14(11): 15215–15226. doi: 10.1007/s12652-020-01779-5. [12] 薛珮芸, 戴书涛, 白静, 等. 借助语音和面部图像的双模态情感识别[J]. 电子与信息学报, 2024, 46(12): 4542–4552. doi: 10.11999/JEIT240087.XUE Peiyun, DAI Shutao, BAI Jing, et al. Emotion recognition with speech and facial images[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4542–4552. doi: 10.11999/JEIT240087. [13] 张嘉淏, 刘峰, 齐佳音. 一种基于Bottleneck Transformer的轻量级微表情识别架构[J]. 计算机科学, 2022, 49(6A): 370–377. doi: 10.11896/jsjkx.210500023.ZHANG Jiahao, LIU Feng, and QI Jiayin. Lightweight micro-expression recognition architecture based on Bottleneck Transformer[J]. Computer Science, 2022, 49(6A): 370–377. doi: 10.11896/jsjkx.210500023. [14] 张鹏, 孔韦韦, 滕金保. 基于多尺度特征注意力机制的人脸表情识别[J]. 计算机工程与应用, 2022, 58(1): 182–189. doi: 10.3778/j.issn.1002-8331.2106-0174.ZHANG Peng, KONG Weiwei, and TENG Jinbao. Facial expression recognition based on multi-scale feature attention mechanism[J]. Computer Engineering and Applications, 2022, 58(1): 182–189. doi: 10.3778/j.issn.1002-8331.2106-0174. [15] 邵延华, 张铎, 楚红雨, 等. 基于深度学习的YOLO目标检测综述[J]. 电子与信息学报, 2022, 44(10): 3697–3708. doi: 10.11999/JEIT210790.SHAO Yanhua, ZHANG Duo, CHU Hongyu, et al. A review of YOLO object detection based on deep learning[J]. Journal of Electronics & Information Technology, 2022, 44(10): 3697–3708. doi: 10.11999/JEIT210790. [16] MA Xu, DAI Xiyang, BAI Yue, et al. Rewrite the stars[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 5694–5703. doi: 10.1109/CVPR52733.2024.00544. [17] YU Yang, ZHANG Yi, CHENG Zeyu, et al. MCA: Multidimensional collaborative attention in deep convolutional neural networks for image recognition[J]. Engineering Applications of Artificial Intelligence, 2023, 126: 107079. doi: 10.1016/j.engappai.2023.107079. [18] YANG Bo, ZHANG Xinyu, ZHANG Jian, et al. EFLNet: Enhancing feature learning network for infrared small target detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5906511. doi: 10.1109/TGRS.2024.3365677. [19] LI Shan and DENG Weihong. Reliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognition[J]. IEEE Transactions on Image Processing, 2019, 28(1): 356–370. doi: 10.1109/TIP.2018.2868382. [20] Emotiscore. Low light dataset computer vision model[EB/OL]. https://universe.roboflow.com/emotiscore/low-light-dataset, 2024. -

 下载:
下载:






计量
- 文章访问数: 827
- HTML全文浏览量: 285
- PDF下载量: 101
- 被引次数: 0
