

Research on Proximal Policy Optimization for Autonomous Long-Distance Rapid Rendezvous of Spacecraft
-
摘要: 在考虑地球扁率J2摄动的影响下,该文针对限定携带燃料和限定转移时间下的异面轨道航天器远距离快速转移的最省燃料轨迹优化问题,基于近端策略优化(PPO)设计脉冲机动的时长与脉冲增量大小,实现最省燃料消耗的转移轨迹设计。首先构筑J2摄动下航天器转移变轨的动力学模型,并进行航天器在轨运行中的不确定性分析,其次,将问题转化为最优控制问题,并建立强化学习训练框架;此后,设计基于过程约束和终端约束的合适的奖励函数,提高算法的探索能力和训练过程的稳定性;最后,在该强化学习框架下进行训练得到模型,生成变轨机动策略,通过仿真并进行对比实验验证算法性能。相较已有深度强化学习(DRL)方法,该文设计的改进型密集奖励函数结合位置势函数与速度引导机制,显著提升了算法的收敛速度、鲁棒性与燃料优化性能,仿真结果表明,该方法能够很好地生成策略并达到预期抵近要求。Abstract:
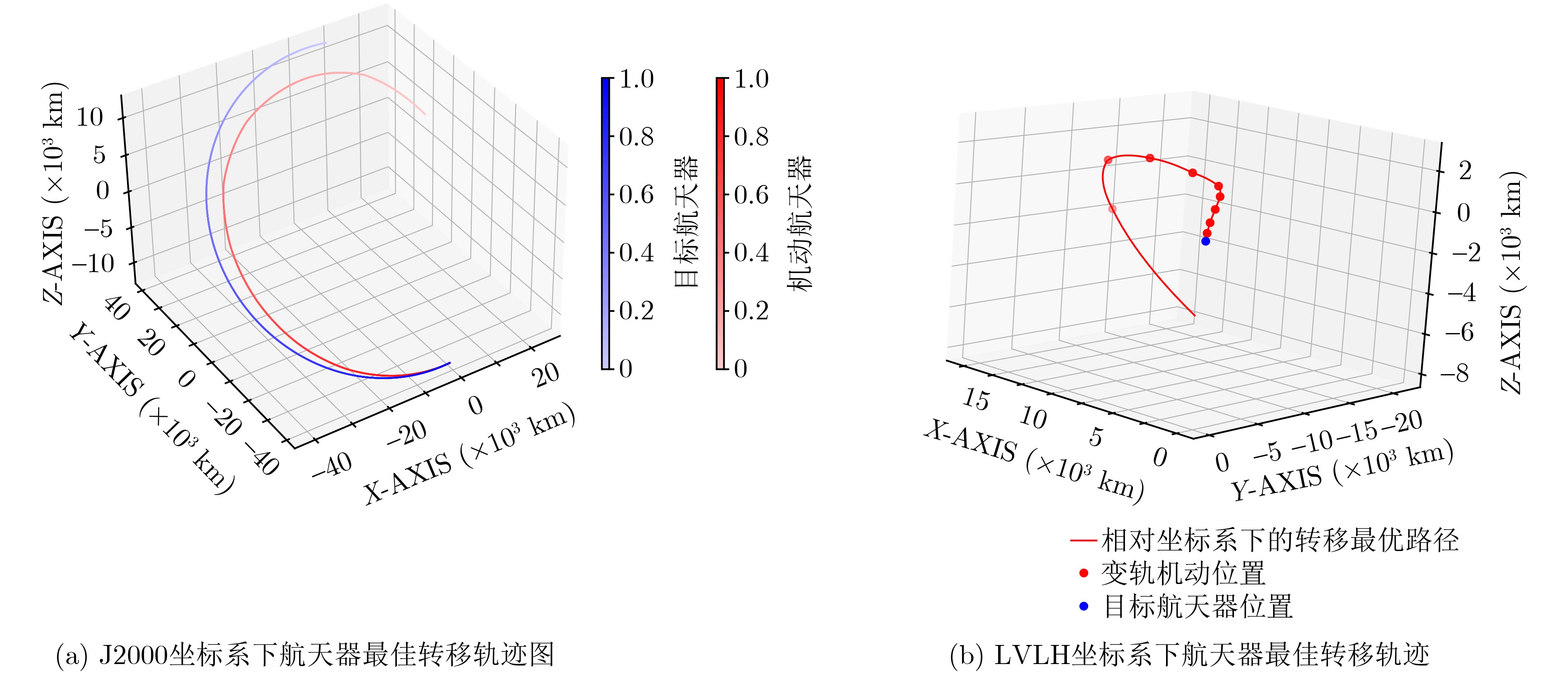
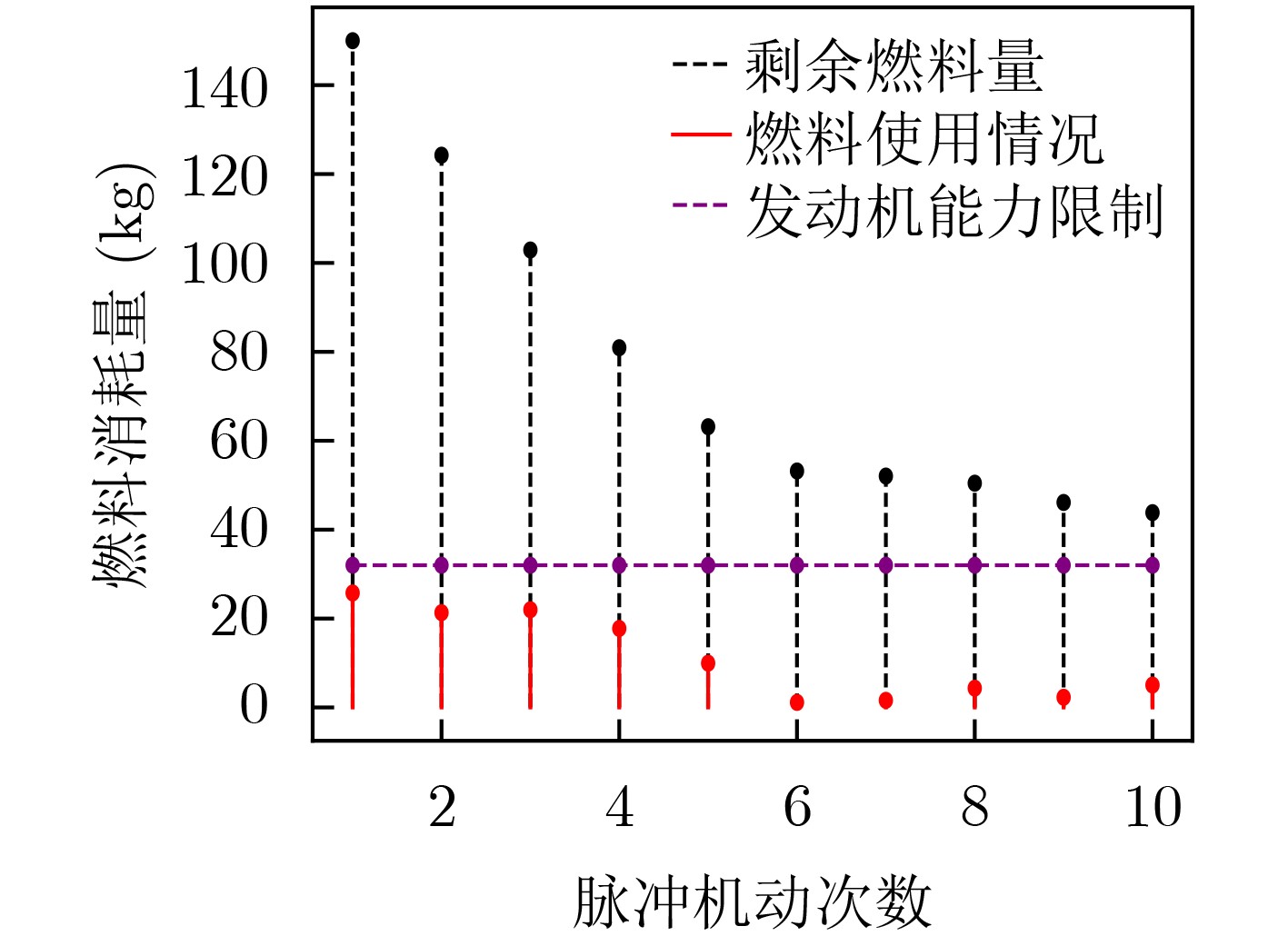
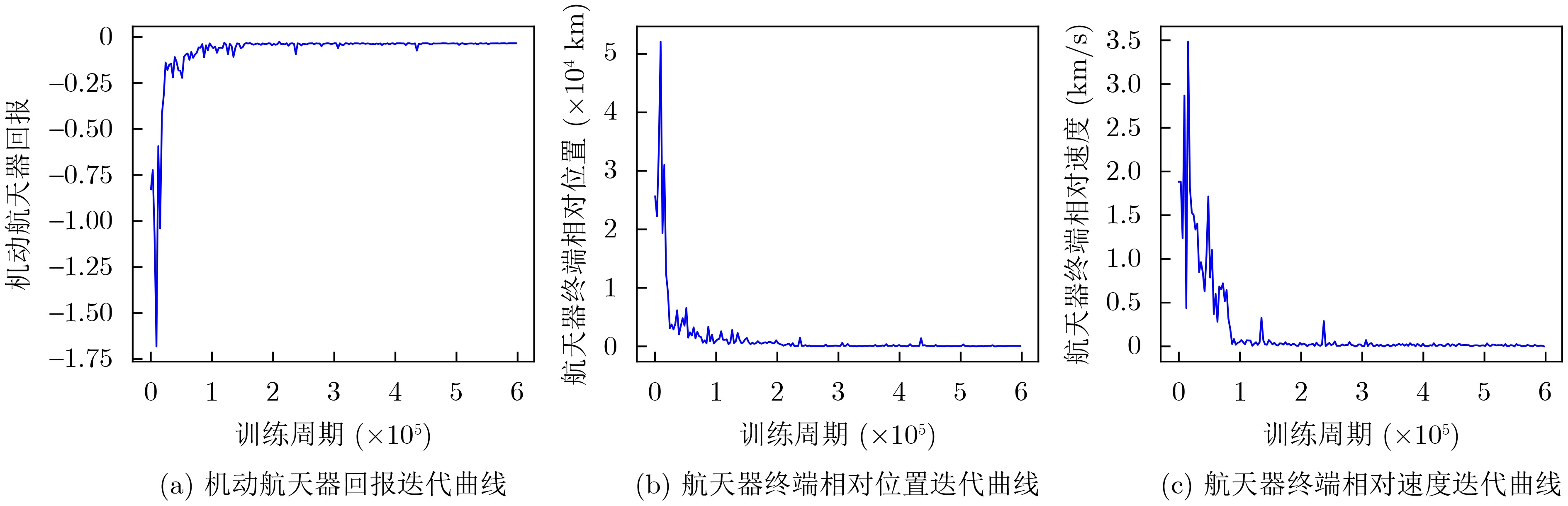
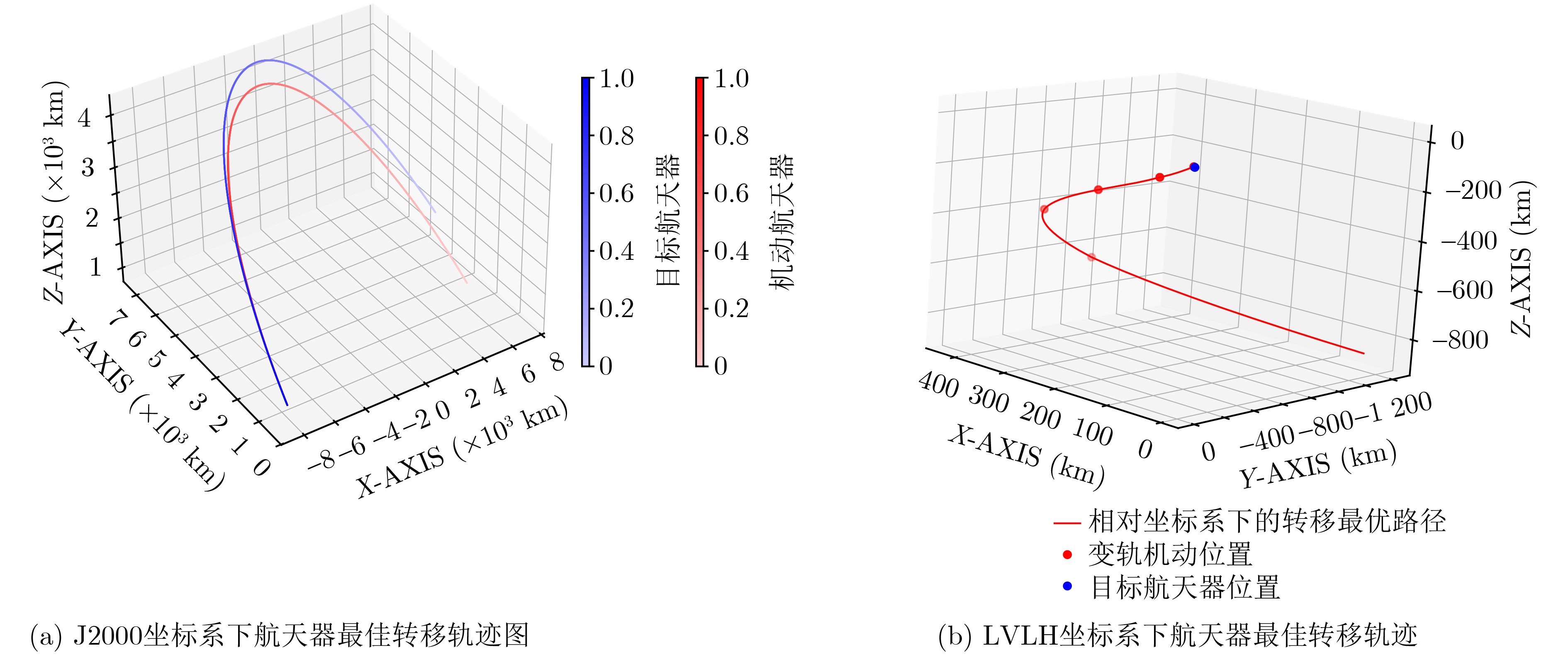
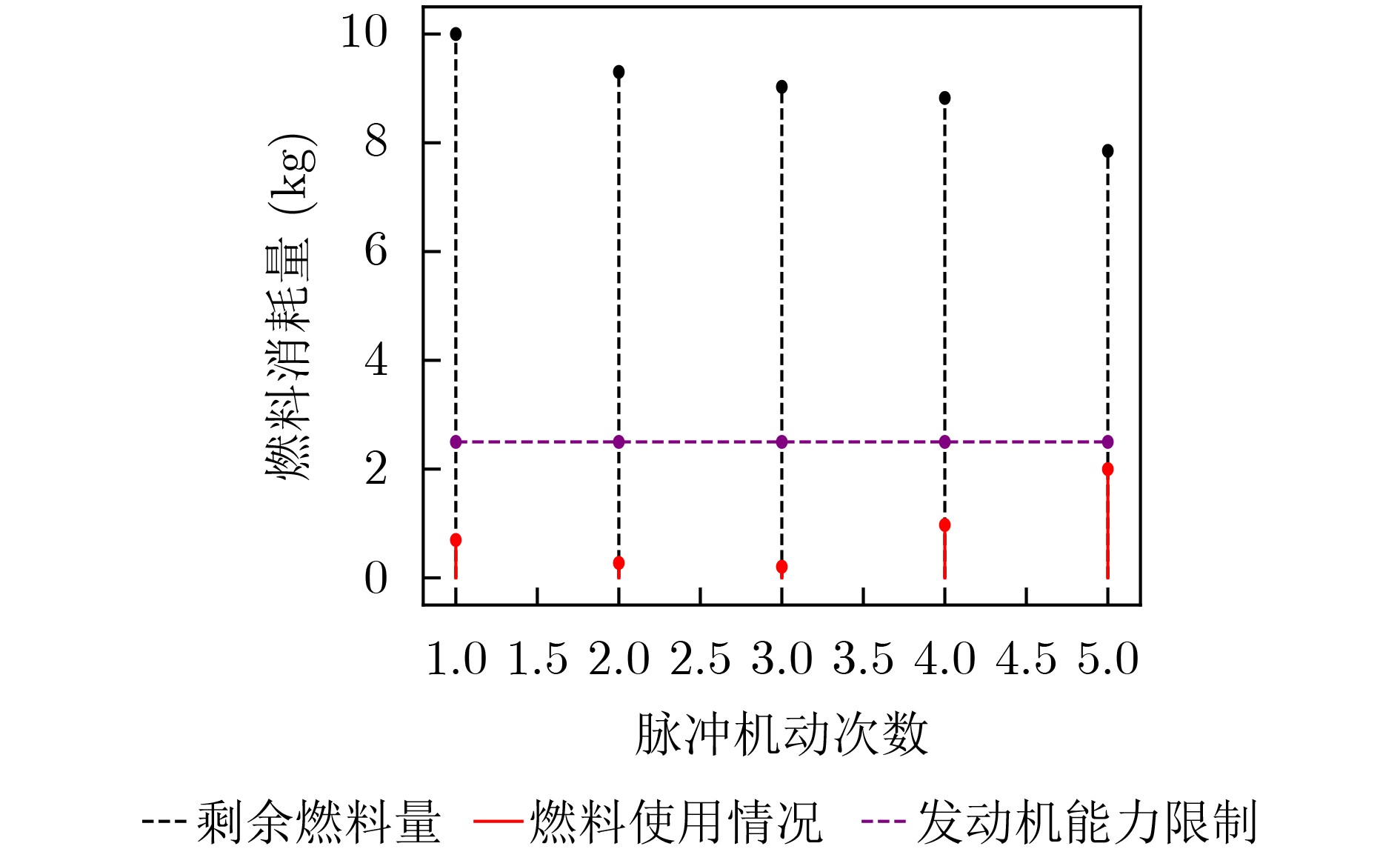
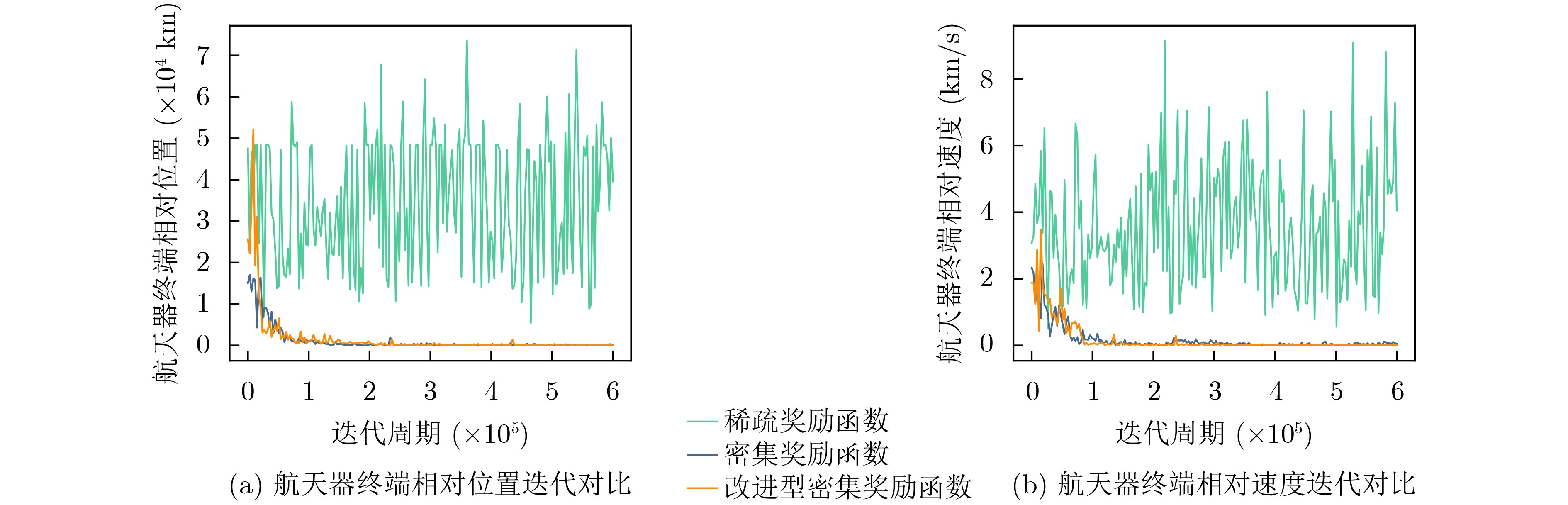
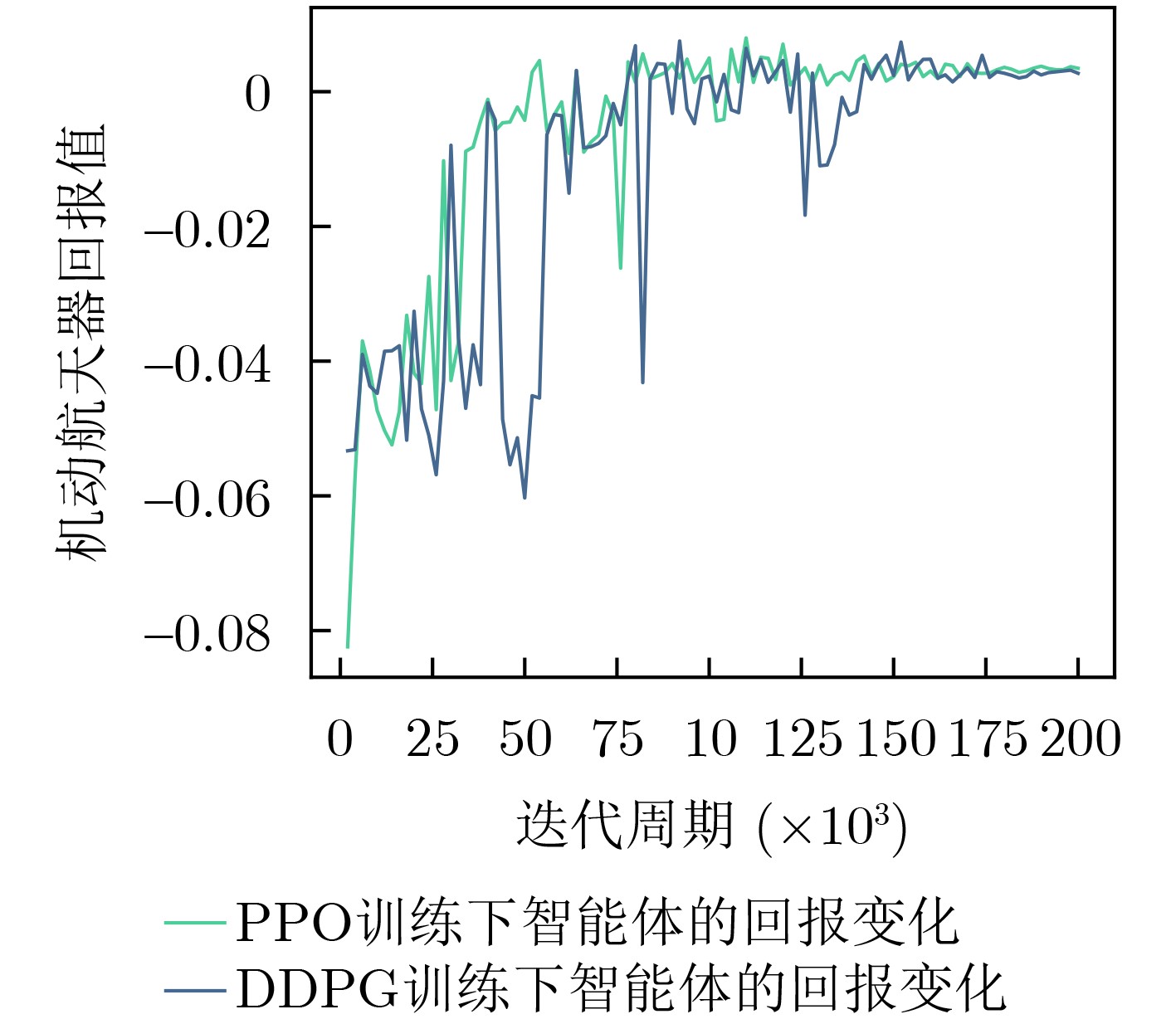
Objective With increasing demands from deep-space exploration, on-orbit servicing, and space debris removal missions, autonomous long-distance rapid rendezvous capabilities are required for future space operations. Traditional trajectory planning approaches based on analytical methods or heuristic optimization show limitations when complex dynamics, strong disturbances, and uncertainties are present, which makes it difficult to balance efficiency and robustness. Deep Reinforcement Learning (DRL) combines the approximation capability of deep neural networks with reinforcement learning-based decision-making, which supports adaptive learning and real-time decisions in high-dimensional continuous state and action spaces. In particular, Proximal Policy Optimization (PPO) is a representative policy gradient method because of its training stability, sample efficiency, and ease of implementation. Integration of DRL with PPO for spacecraft long-distance rapid rendezvous is therefore expected to overcome the limits of conventional methods and provide an intelligent, efficient, and robust solution for autonomous guidance in complex orbital environments. Methods A spacecraft orbital dynamics model is established by incorporating J2 perturbation, together with uncertainties arising from position and velocity measurement errors and actuator deviations during on-orbit operations. The long-distance rapid rendezvous problem is formulated as a Markov Decision Process, in which the state space includes position, velocity, and relative distance, and the action space is defined by impulse duration and direction. Fuel consumption and terminal position and velocity constraints are integrated into the model. On this basis, a DRL framework based on PPO is constructed. The policy network outputs maneuver command distributions, whereas the value network estimates state values to improve training stability. To address convergence difficulties caused by sparse rewards, an enhanced dense reward function is designed by combining a position potential function with a velocity guidance function. This design guides the agent toward the target while enabling gradual deceleration and improved fuel efficiency. The optimal maneuver strategy is obtained through simulation-based training, and robustness is evaluated under different uncertainty conditions. Results and Discussions Based on the proposed DRL framework, comprehensive simulations are conducted to assess effectiveness and robustness. In Case 1, three reward structures are examined: sparse reward, traditional dense reward, and an improved dense reward that integrates a relative position potential function with a velocity guidance term. The results show that reward design strongly affects convergence behavior and policy stability. Under sparse rewards, insufficient process feedback limits exploration of feasible actions. Traditional dense rewards provide continuous feedback and enable gradual convergence, but terminal velocity deviations are not fully corrected at later stages, which leads to suboptimal convergence and incomplete satisfaction of terminal constraints. In contrast, the improved dense reward guides the agent toward favorable behaviors from early training stages while penalizing undesirable actions at each step, which accelerates convergence and improves robustness. The velocity guidance term allows anticipatory adjustments during mid-to-late approach phases rather than delaying corrections to the terminal stage, resulting in improved fuel efficiency.Simulation results show that the maneuvering spacecraft performs 10 impulsive maneuvers, achieving a terminal relative distance of 21.326 km, a relative velocity of 0.005 0 km/s, and a total fuel consumption of 111.212 3 kg. To evaluate robustness under realistic uncertainties, 1 000 Monte Carlo simulations are performed. As summarized in Table 6 , the mission success rate reaches 63.40%, and fuel consumption in all trials remains within acceptable bounds. In Case 2, PPO performance is compared with that of Deep Deterministic Policy Gradient (DDPG) for a multi-impulse fast-approach rendezvous mission. PPO results show five impulsive maneuvers, a terminal separation of 2.281 8 km, a relative velocity of 0.003 8 km/s, and a total fuel consumption of 4.148 6 kg. DDPG results show a fuel consumption of 4.322 5 kg, a final separation of 4.273 1 km, and a relative velocity of 0.002 0 km/s. Both methods satisfy mission requirements with comparable fuel use. However, DDPG requires a training time of 9 h 23 min, whereas PPO converges within 6 h 4 min, indicating lower computational cost. Overall, the improved PPO framework provides better learning efficiency, policy stability, and robustness.Conclusions The problem of autonomous long-distance rapid rendezvous under J2 perturbation and uncertainties is investigated, and a PPO-based trajectory optimization method is proposed. The results demonstrate that feasible maneuver trajectories satisfying terminal constraints can be generated under limited fuel and transfer time, with improved convergence speed, fuel efficiency, and robustness. The main contributions include: (1) development of an orbital dynamics framework that incorporates J2 perturbation and uncertainty modeling, with formulation of the rendezvous problem as a Markov Decision Process; (2) design of an enhanced dense reward function that combines position potential and velocity guidance, which improves training stability and convergence efficiency; and (3) simulation-based validation of PPO robustness in complex orbital environments. Future work will address sensor noise, environmental disturbances, and multi-spacecraft cooperative rendezvous in more complex mission scenarios to further improve practical applicability and generalization. -
表 1 各摄动相对量级(面质比$ 0.01\;\mathrm{m}^2/\text{kg} $)
各摄动相对量级 低轨 中轨 高轨 非球形引力J2项 10–3 10–4 10–4 非球形引力其他项 10–7 10–7 10–7 太阳引力 10–8 10–6 10–6 月球引力 10–7 10–6 10–5 大气阻力 10–6~10–10 <10–10 <10–10 太阳光压 10–8 10–7 10–7 潮汐 10–8 10–9 10–10  下载: 导出CSV
下载: 导出CSV
表 2 机动航天器性能参数
性能参数 性能指标 算例1 算例2 $ {{{m}_{\mathcal{F}}}}_{0} $(kg)
$ {m}_{0} $(kg)
$ \dot{m} $(kg/s)
$ {{I}}_{\text{sp}} $(s)
$ \Delta {{{t}_{\mathcal{F}}}}_{\max } $(s)150
250
1.6
400
2010
20
0.5
400
5
下载: 导出CSV
表 3 航天器初始轨道参数
轨道参数 算例1 算例2 机动航天器 目标航天器 机动航天器 目标航天器 半长轴(km) 30 378.136 3 40 378.136 3 7 978.136 3 8 378.136 3 偏心率 0.05 0.01 0.05 0.01 轨道倾角(°) 25.5 18 30 31 升交点赤经(°) 14.4 352.8 0 5 近地点幅角 (°) 14.4 14.4 10 10 真近点角(°) 7.2 72 12 18
下载: 导出CSV
表 4 算法超参数设计
超参数 算例1参数值 算例2参数值 $ {L}_{\text{ub}} $/$ {L}_{\text{lb}} $ [km] 10000 /45000 300/ 4000 $ {\rho }_{1} $/$ {\rho }_{2} $ 3e–2/3e–2 3e–2/3e–2 $ \tau $ [km] 1e–4 1e–4 $ {d}_{\mathrm{c}} $ [km] 500 100 $ {N}_{\mathrm{g}} $ 2 2 $ {c}_{1} $/$ {c}_{2} $/$ {c}_{3} $/$ {c}_{4} $/$ {c}_{5} $/$ {c}_{\text{PBRS}} $/$ {c}_{\parallel } $/$ {c}_{\bot } $ 0.14/0.4/0.4/0.2/0.2/1e–3/0.18/0.18 0.14/0.4/0.4/2/2/1e–3/0.18/0.18 $ \gamma $ 0.99 0.9 学习率 1e–5 1e–5 迭代周期数 6e5 2e5
下载: 导出CSV
表 5 轨道不确定性高斯拟合噪声设计
不确定性项 均值 标准差 $ \delta {\boldsymbol{r}}_{{\rm s},i} $ 0 km 1 km $ \delta {\boldsymbol{v}}_{{\rm s},i} $ 0 km/s 0.02 km/s $ \delta {\boldsymbol{r}}_{{\rm m},i} $ 0 km 1 km $ \delta {\boldsymbol{v}}_{{\rm m},i} $ 0 km/s 0.02 km/s $ \delta v_{\mathrm{\mathit{x}_{\mathit{\mathrm{v},i}}}} $/$ \delta v_{\mathrm{\mathit{y}_{\mathit{\mathrm{v},i}}}} $/$ \delta v_{\mathrm{\mathit{z}}_{\mathrm{v},i}} $ 0 0.006
下载: 导出CSV
表 6 鲁棒性测试结果
测试指标 成功率(%) 燃料消耗(kg) 平均值 标准差 $ \mathcal{N}_{\mathrm{s},i} $ 89.30 111.7205 0.6441 $ \mathcal{N}_{\mathrm{m},i} $ 87.30 111.5226 0.5008 $ \mathcal{N}_{\mathrm{v},i} $ 71.90 110.9310 0.0782 $ \mathcal{N}_{\mathrm{s},i}+\mathcal{N}_{\mathrm{m},i}+\mathcal{N}_{\mathrm{v},i} $ 63.40 111.9222 0.8903
下载: 导出CSV
-
[1] LI Weijie, CHENG Dayi, LIU Xigang, et al. On-Orbit Service (OOS) of spacecraft: A review of engineering developments[J]. Progress in Aerospace Sciences, 2019, 108: 32–120. doi: 10.1016/j.paerosci.2019.01.004. [2] NALLAPU R T and THANGAVELAUTHAM J. Design and sensitivity analysis of spacecraft swarms for planetary moon reconnaissance through co-orbits[J]. Acta Astronautica, 2021, 178: 854–896. doi: 10.1016/j.actaastro.2020.10.008. [3] NIU Shangwei, LI Dongxu, and JI Haoran. Research on mission time planning and autonomous interception guidance method for low-thrust spacecraft in long-distance interception[C]. 2020 5th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 2020: 117–123. doi: 10.1109/CACRE50138.2020.9230051. [4] LEDKOV A and ASLANOV V. Review of contact and contactless active space debris removal approaches[J]. Progress in Aerospace Sciences, 2022, 134: 100858. doi: 10.1016/j.paerosci.2022.100858. [5] 陈宏宇, 吴会英, 周美江, 等. 微小卫星轨道工程应用与STK仿真[M]. 北京: 科学出版社, 2016. CHEN Hongyu, WU Huiying, ZHOU Meijiang, et al. Orbit Engineering Application and STK Simulation for Microsatellite[M]. Beijing: Science Press, 2016. [6] ABDELKHALIK O and MORTARI D. N-impulse orbit transfer using genetic algorithms[J]. Journal of Spacecraft and Rockets, 2007, 44(2): 456–460. doi: 10.2514/1.24701. [7] PONTANI M, GHOSH P, and CONWAY B A. Particle swarm optimization of multiple-burn rendezvous trajectories[J]. Journal of Guidance, Control, and Dynamics, 2012, 35(4): 1192–1207. doi: 10.2514/1.55592. [8] YU Jing, CHEN Xiaoqian, CHEN Lihu, et al. Optimal scheduling of GEO debris removing based on hybrid optimal control theory[J]. Acta Astronautica, 2014, 93: 400–409. doi: 10.1016/j.actaastro.2013.07.015. [9] MNIH V, KAVUKKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. https://arxiv.org/abs/1312.5602, 2013. [10] DONG Zhicai, ZHU Yiman, WANG Lu, et al. Motion planning of free-floating space robots for tracking tumbling targets by two-axis matching via reinforcement learning[J]. Aerospace Science and Technology, 2024, 155: 109540. doi: 10.1016/j.ast.2024.109540. [11] TIWARI M, PRAZENICA R, and HENDERSON T. Direct adaptive control of spacecraft near asteroids[J]. Acta Astronautica, 2023, 202: 197–213. doi: 10.1016/j.actaastro.2022.10.014. [12] SCORSOGLIO A, FURFARO R, LINARES R, et al. Relative motion guidance for near-rectilinear lunar orbits with path constraints via actor-critic reinforcement learning[J]. Advances in Space Research, 2023, 71(1): 316–335. doi: 10.1016/j.asr.2022.08.002. [13] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. https://arxiv.org/abs/1707.06347, 2017. [14] 王禄丰, 李爽. J2摄动下非线性轨道不确定性传播方法[C]. 2024年中国航天大会论文集, 武汉, 2024: 59–64. doi: 10.26914/c.cnkihy.2024.081107.WANG Lufeng and LI Shuang. Nonlinear orbit uncertainty propagation method under J2 perturbation[C]. 2024 China Aerospace Congress, Wuhan, 2024: 59–64. doi: 10.26914/c.cnkihy.2024.081107. [15] 孙盼, 李爽. 连续方程与高斯和框架下轨道不确定性传播方法综述[J]. 中国科学: 物理学 力学 天文学, 2025, 55(9): 294501. doi: 10.1360/SSPMA-2024-0300.SUN Pan and LI Shuang. A review of uncertainty propagation methods within continuity equation and Gaussian mixture model frameworks[J]. SCIENTIA SINICA Physica, Mechanica & Astronomica, 2025, 55(9): 294501. doi: 10.1360/SSPMA-2024-0300. [16] BAILLIEUL J and SAMAD T. Encyclopedia of Systems and Control[M]. 2nd ed. Cham: Springer, 2021. doi: 10.1007/978-3-030-44184-5. [17] LANDERS M and DORYAB A. Deep reinforcement learning verification: A survey[J]. ACM Computing Surveys, 2023, 55(14s): 1–31. doi: 10.1145/3596444. [18] XU Haotian, XUAN Junyu, ZHANG Guangquan, et al. Trust region policy optimization via entropy regularization for Kullback-Leibler divergence constraint[J]. Neurocomputing, 2024, 589: 127716. doi: 10.1016/j.neucom.2024.127716. [19] IBRAHIM S, MOSTAFA M, JNADI A, et al. Comprehensive overview of reward engineering and shaping in advancing reinforcement learning applications[J]. IEEE Access, 2024, 12: 175473–175500. doi: 10.1109/access.2024.3504735. [20] PAOLO G, CONINX M, LAFLAQUIÈRE A, et al. Discovering and exploiting sparse rewards in a learned behavior space[J]. Evolutionary Computation, 2024, 32(3): 275–305. doi: 10.1162/evco_a_00343. [21] NG A Y, HARADA D, and RUSSELL S. Policy invariance under reward transformations: Theory and application to reward shaping[R]. 2016. [22] MONTENBRUCK O and GILL E. Satellite Orbits: Models, Methods and Applications[M]. Berlin: Springer, 2000. doi: 10.1007/978-3-642-58351-3. [23] ZAVOLI A and FEDERICI L. Reinforcement learning for robust trajectory design of interplanetary missions[J]. Journal of Guidance, Control, and Dynamics, 2021, 44(8): 1440–1453. doi: 10.2514/1.G005794. -

 下载:
下载:


图(10) / 表(6)
计量
- 文章访问数: 681
- HTML全文浏览量: 479
- PDF下载量: 79
- 被引次数: 0
