

Swin Transformer-based Wideband Wireless Image Transmission Semantic Joint Encoding and Decoding Method
-
摘要: 现有的图像语义通信研究大多集中在高斯信道和瑞利衰落信道等理想化场景中。在实际的无线通信环境中,信道特性往往表现为复杂的多径衰落效应,需要复杂的收发端链路信号处理机制。针对这一现状,该文结合正交频分复用(OFDM)技术,提出一种基于Swin Transformer的宽带无线图像传输语义通信(WWIT-SC)系统,旨在解决多径衰落信道下的图像传输问题。WWIT-SC采用Swin Transformer作为语义编解码器的骨干网络,通过在语义编解码器处引入基于信道状态信息(CSI)和坐标注意力(CA)机制,使模型能够将关键的语义特征精确地映射到子载波上,并可以适应时变的信道条件。此外,在接收端设计了信道估计子网(CES)以补偿信道估计误差,从而提升CSI的精确度。实验结果表明,相较于现有最优的基于注意力机制的联合信源信道语义编码方法, WWIT-SC取得了最高9.8%的PSNR增益。
-
关键词:
- 语义通信 /
- Swin Transformer /
- 正交频分复用 /
- 图像传输
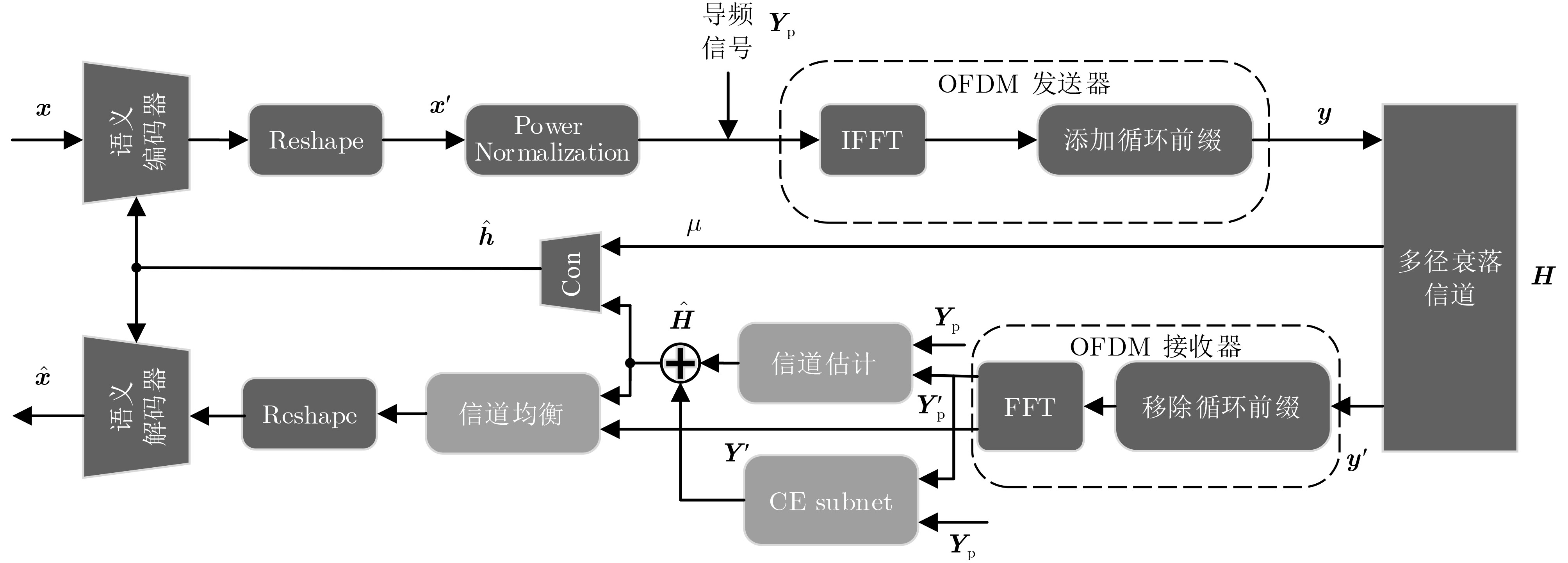
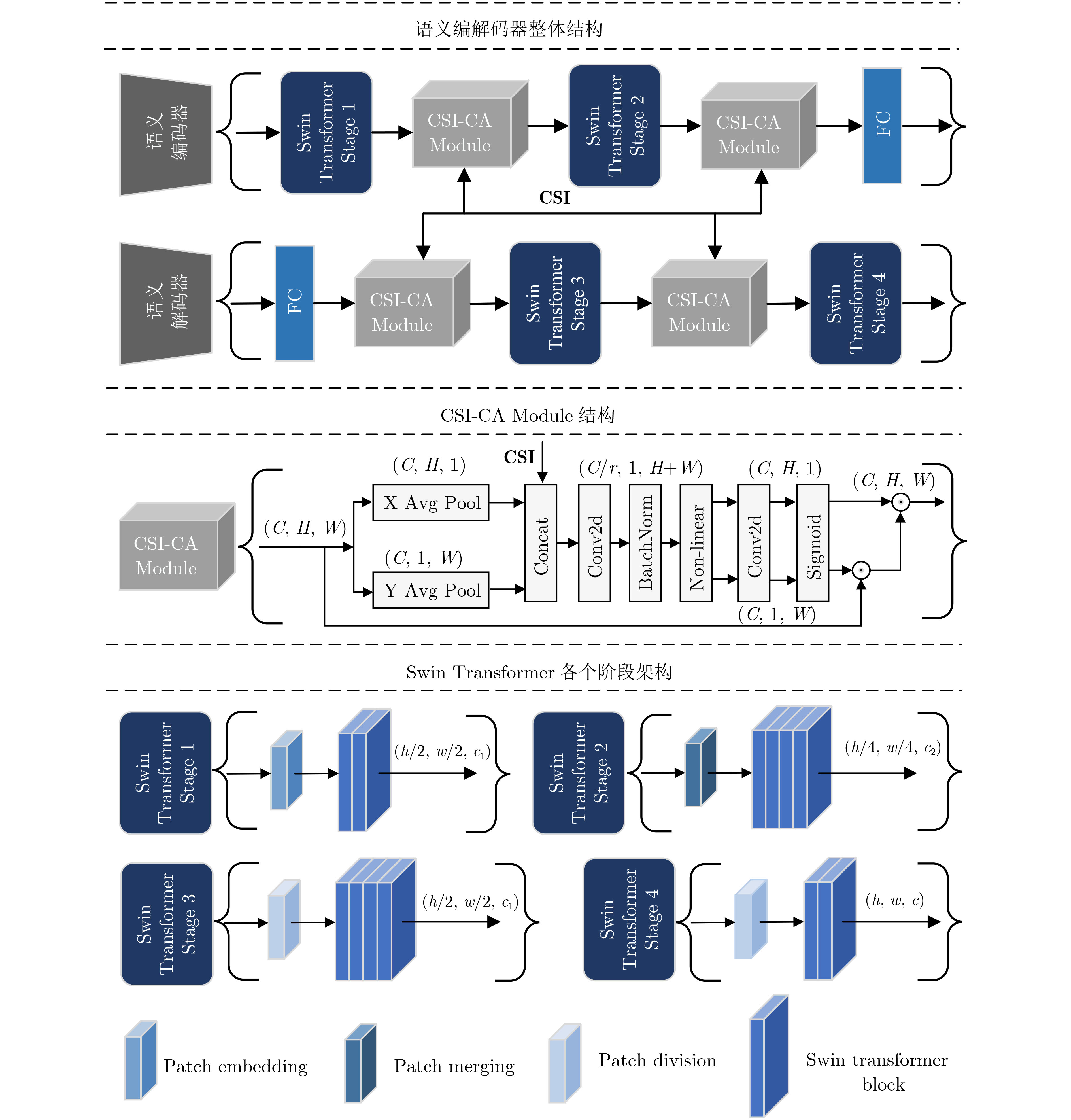
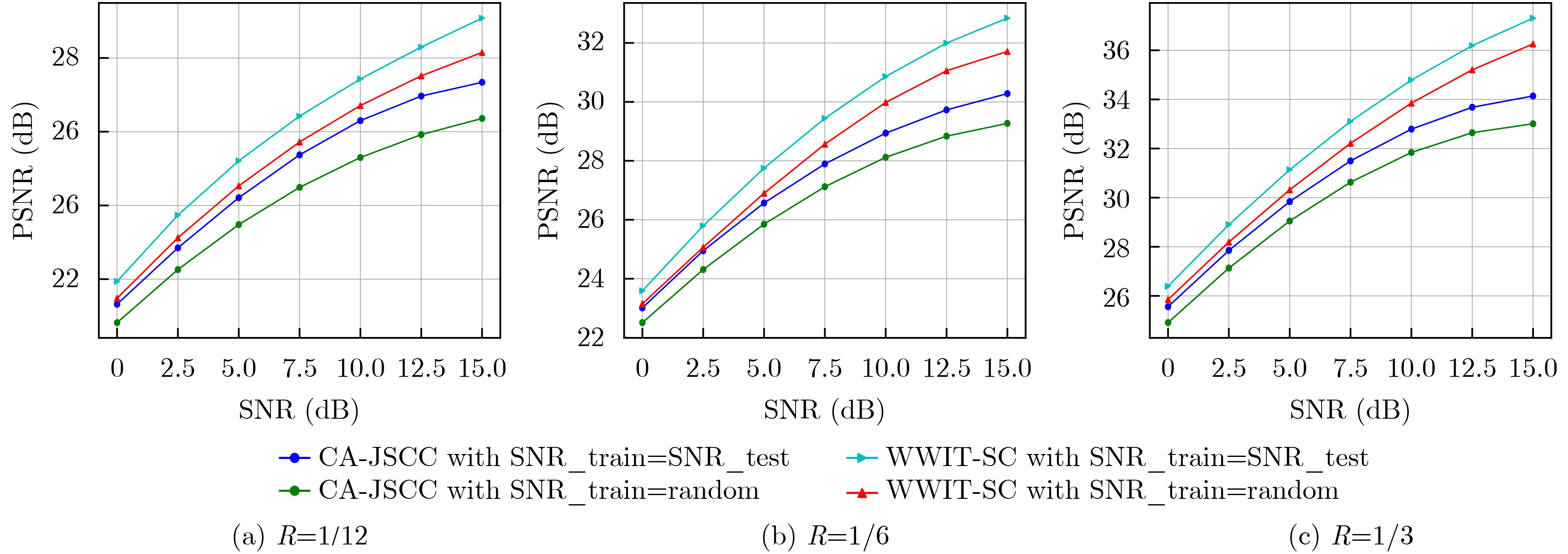
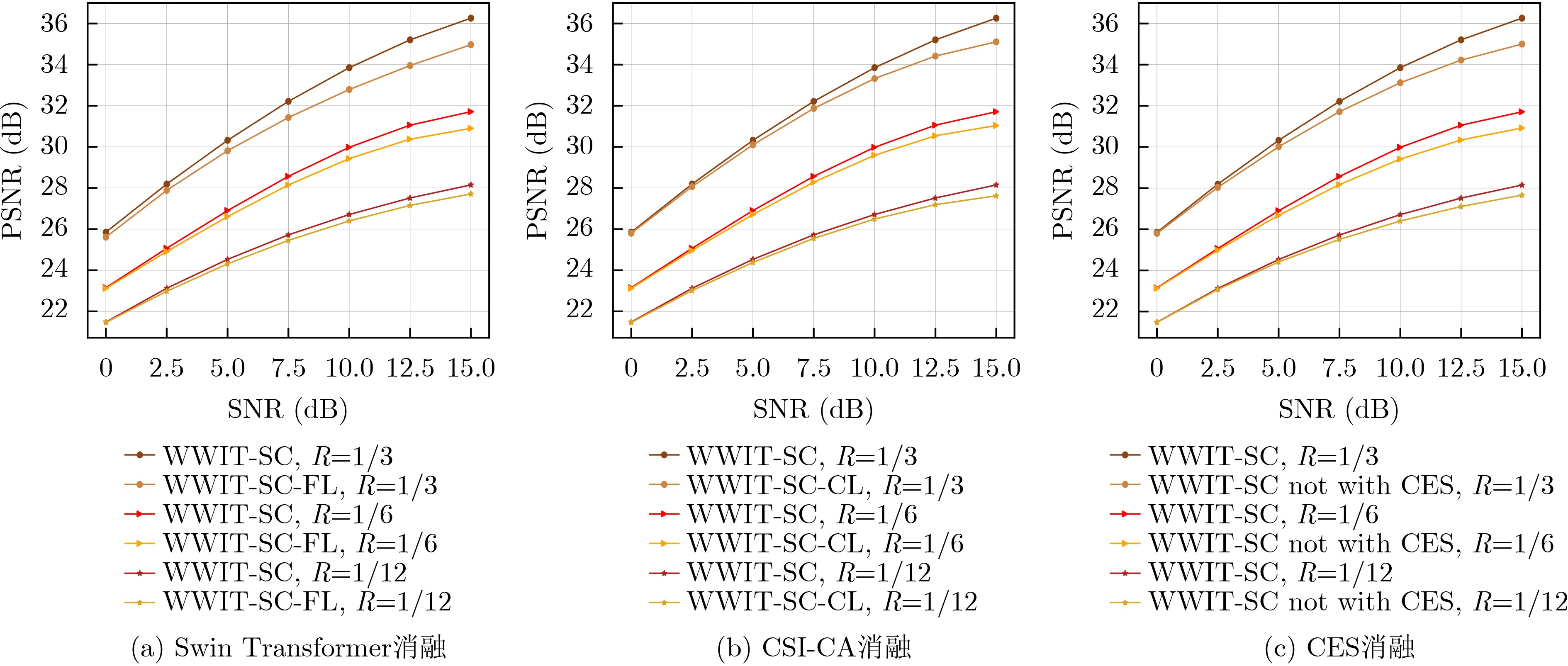
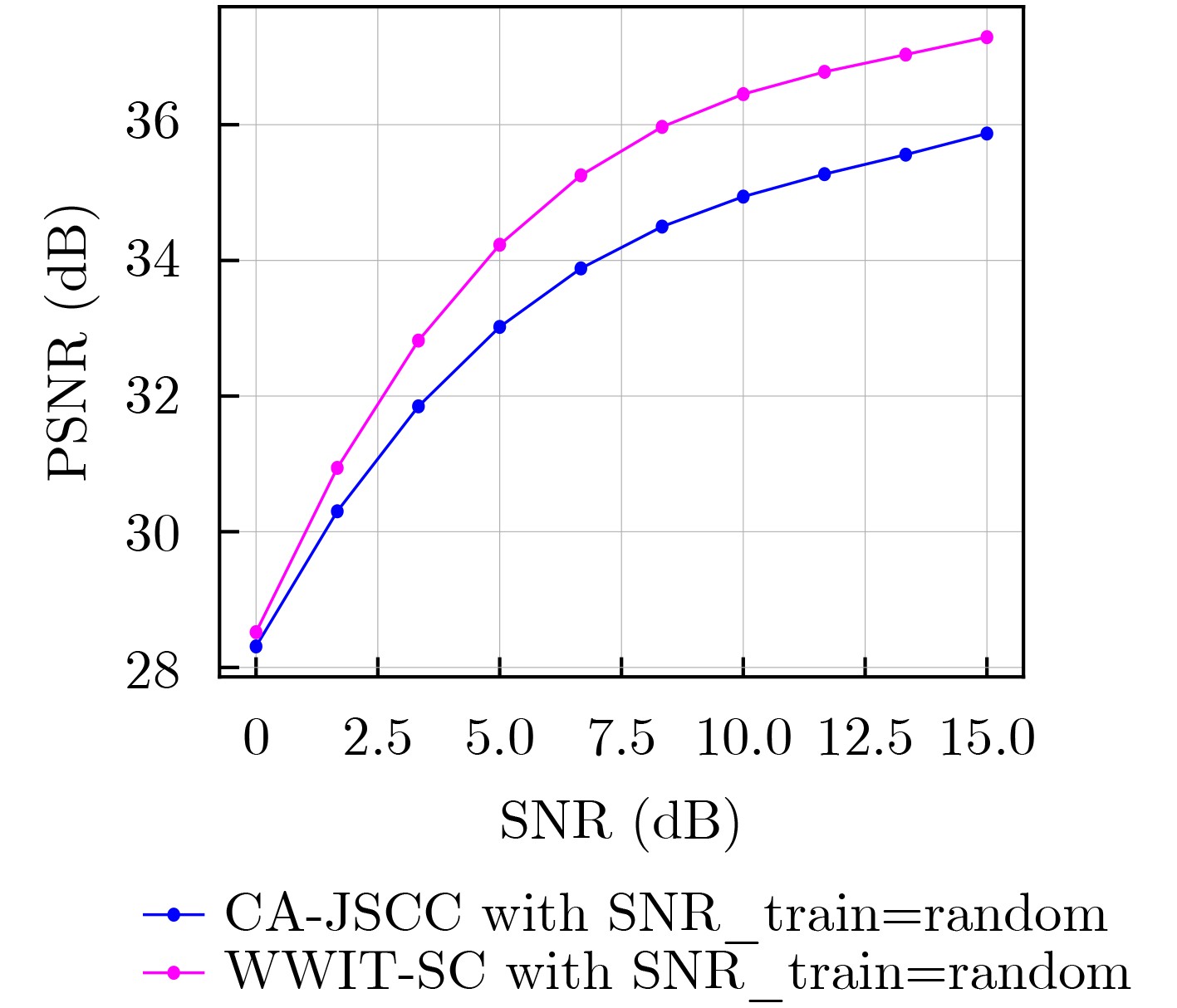
Abstract:Objective Conventional studies on image semantic communication primarily address simplified channel models, such as Gaussian and Rayleigh fading channels. However, real-world wireless communication environments are characterized by complex multipath fading, which necessitates advanced signal processing at both the transmitter and receiver. To address this challenge, this paper proposes a Wideband Wireless Image Transmission Semantic Communication (WWIT-SC) system based on the Swin Transformer. The proposed method enhances image transmission performance in multipath fading channels through end-to-end semantic joint encoding and decoding. Methods The WWIT-SC system adopts the Swin Transformer as the core architecture for semantic encoding and decoding. This network not only processes semantic image representations but also improves adaptability to complex channel conditions through a joint mechanism based on Channel State Information (CSI) and Coordinate Attention (CA). CSI, a key signal in wireless systems, enables accurate estimation of channel conditions. However, due to temporal variations in wireless channels, CSI is often subject to attenuation and distortion, reducing its effectiveness when used in isolation. To address this limitation, the system incorporates a CSI-guided CA mechanism that enables fine-grained mapping and adjustment of semantic features across subcarriers. This mechanism integrates spatial and channel-domain features to localize critical information adaptively, thereby accommodating the channel’s time-varying behavior. A Channel Estimation Subnetwork (CES) is further implemented at the receiver to correct CSI estimation errors introduced by noise and dynamic channel variations. The CES enhances CSI accuracy during decoding, resulting in improved semantic image reconstruction quality. Results and Discussions The WWIT-SC and CA-JSCC models are trained under fixed Signal-to-Noise Ratio (SNR) conditions and evaluated at the same SNR values. Across all SNR levels, the WWIT-SC model consistently outperforms CA-JSCC. Specifically, Peak Signal-to-Noise Ratio (PSNR) improves by 6.4%, 8.5%, and 9.3% at different bandwidth ratios (R=1/12, 1/6, 1/3)( Fig.4 ). Both models are also trained using SNR values randomly selected from the range [0, 15] dB and tested at various SNR levels. Although random SNR training leads to reduced overall performance compared to fixed SNR training, WWIT-SC maintains superior performance over CA-JSCC across all conditions. Under these settings, PSNR gains of up to 6.8%, 8.3%, and 9.8% are achieved at different bandwidth ratios (R=1/12, 1/6, 1/3)(Fig. 4 ). Further evaluation is conducted by training both models on randomly cropped ImageNet images and testing them on the Kodak dataset. The WWIT-SC model trained on the larger dataset achieves up to a 4% PSNR improvement over CA-JSCC on Kodak (Fig. 6 ). A series of ablation experiments are conducted to assess the contributions of each module in WWIT-SC. First, the Swin Transformer is replaced with the Feature Learning (FL) module from CA-JSCC. Across all three bandwidth ratios, PSNR values for WWIT-SC exceed those of the modified WWIT-SC-FL variant at all SNR levels (Fig. 5(a) ), confirming the importance of multi-scale feature extraction. Next, the CSI-CA module is replaced with the Channel Learning (CL) module from CA-JSCC. Again, WWIT-SC outperforms the modified WWIT-SC-CL model across all bandwidth ratios and SNR values (Fig. 5(b) ), highlighting the role of the long-range dependency mechanism in enhancing feature localization and adaptation. Finally, the CES is removed to assess its contribution. The original WWIT-SC model consistently achieves higher PSNR values than the variant without CES at all bandwidth ratios and SNR levels (Fig. 5(c) ), demonstrating that the inclusion of CES substantially improves channel decoding accuracy.Conclusions This paper proposes a Swin Transformer-based WWIT-SC system, integrating Orthogonal Frequency Division Multiplexing (OFDM) technology to enhance semantic image transmission under multipath fading channels. The scheme employs the Swin Transformer as the backbone for the semantic encoder-decoder and incorporates a CSI-assisted CA mechanism to accurately map critical semantic features to subcarriers, adapting to time-varying channel conditions. In addition, a CES at the receiver compensates for channel estimation errors, improving CSI accuracy. Experimental results show that, compared to CA-JSCC, the WWIT-SC system achieves up to a 9.8% PSNR improvement. This work presents a novel solution for semantic image transmission in complex broadband wireless communication environments. -
1 CSI辅助的CA机制
输入:多尺度语义特征${\boldsymbol{x}}_{\mathrm{ms}} $,CSI向量$\hat {\boldsymbol{h}} $ 输出:增强多尺度语义特征$\hat {\boldsymbol{x}}_{\mathrm{ms}} $ (1) for k=0:1:C do (2) for l=0:1:H do (3) ${\boldsymbol{x}}_{\mathrm{ms}}^k(l)={{\textit{0}}} $ (4) for i=0:1:W (5) ${\boldsymbol{x}}_{\mathrm{ms}}^k(l)+={\boldsymbol{x}}_{\mathrm{ms}}^k(l,i) $ (6) ${\boldsymbol{z}}_k^l(l)=\dfrac{1}{W}{\boldsymbol{x}}_{\mathrm{ms}}^k(l) $ (7) end for (8) end for (9) for b=0:1:W do (10) ${\boldsymbol{x}}_{\mathrm{ms}}^k (b)={{\textit{0}}}$ (11) for j=0:1:H do (12) ${\boldsymbol{x}}_{\mathrm{ms}}^k(b)+={\boldsymbol{x}}_{\mathrm{ms}}^k(b,j) $ (13) end for (14) ${\boldsymbol{z}}_k^b(b)=\dfrac{1}{H} {\boldsymbol{x}}_{\mathrm{ms}}^k(b)$ (15) end for (16) end for (17) ${\boldsymbol{f}}= \delta(F_1([{\boldsymbol{z}}^l,{\boldsymbol{z}}^b,\hat {\boldsymbol{h}}]))$ (18) for $l= $0:1:H do (19) ${\boldsymbol{g}}^l= \sigma(F_l({\boldsymbol{f}}^l))$ (20) end for (21) for $b= $0:1:W do (22) ${\boldsymbol{g}}^b=\sigma(F_b({\boldsymbol{f}}^l)) $ (23) end for (24) for k=0:1:C do (25) for i=0:1:W do (26) for j=0:1:H do (27) ${\boldsymbol{x}}_{\mathrm{ms}}^k={\boldsymbol{x}}_{\mathrm{ms}}^k(i,j)\times {\boldsymbol{g}}_k^l(i)\times {\boldsymbol{g}}_k^b(j) $ (28) end for (29) end for (30) end for  下载: 导出CSV
下载: 导出CSV
表 1 参数信息
参数 数值 H, W, C 8, 8, 256 h, w, c 3,32,32 Ns, Lf 8,64 Np, Lcp 2, 16 r, c1, c2 32, 128, 256 $\mu $ [0, 15]
下载: 导出CSV
-
[1] SAAD W, BENNIS M, and CHEN Mingzhe. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems[J]. IEEE Network, 2020, 34(3): 134–142. doi: 10.1109/MNET.001.1900287. [2] XIE Huiqiang, QIN Zhijin, LI G Y, et al. Deep learning enabled semantic communication systems[J]. IEEE Transactions on Signal Processing, 2021, 69: 2663–2675. doi: 10.1109/TSP.2021.3071210. [3] SHANNON C E. A mathematical theory of communication[J]. ACM SIGMOBILE Mobile Computing and Communications Review, 2001, 5(1): 3–55. doi: 10.1145/584091.584093. [4] ZHANG Zhenguo, YANG Qianqian, HE Shibo, et al. Wireless transmission of images with the assistance of multi-level semantic information[C]. International Symposium on Wireless Communication Systems (ISWCS), Hangzhou, China, 2022: 1–6. doi: 10.1109/ISWCS56560.2022.9940401. [5] SHAO Yulin and GUNDUZ D. Semantic communications with discrete-time analog transmission: A PAPR perspective[J]. IEEE Wireless Communications Letters, 2023, 12(3): 510–514. doi: 10.1109/LWC.2022.3232946. [6] JANKOWSKI M, GÜNDÜZ D, and MIKOLAJCZYK K. Deep joint source-channel coding for wireless image retrieval[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020: 5070–5074. doi: 10.1109/ICASSP40776.2020.9054078. [7] 江沸菠, 彭于波, 董莉. 面向6G的深度图像语义通信模型[J]. 通信学报, 2023, 44(3): 198–208. doi: 10.11959/j.issn.1000-436x.2023050.JIANG Feibo, PENG Yubo, and DONG Li. Deep image semantic communication model for 6G[J]. Journal on Communications, 2023, 44(3): 198–208. doi: 10.11959/j.issn.1000-436x.2023050. [8] DENG Zhaokai, LI Shufeng, CAI Yujun, et al. Federated learning for image semantic communication system based on CNN and Transformer[C]. International Conference on Ubiquitous Communication (UCOM), Xi’an, China, 2023: 408–414. doi: 10.1109/Ucom59132.2023.10257622. [9] YANG Ke, WANG Sixian, DAI Jincheng, et al. WITT: A wireless image transmission Transformer for semantic communications[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10094735. [10] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 9992–10002. doi: 10.1109/ICCV48922.2021.00986. [11] YANG Mingyu and KIM H S. Deep joint source-channel coding for wireless image transmission with adaptive rate control[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, Singapore, 2022: 5193–5197. doi: 10.1109/ICASSP43922.2022.9746335. [12] DING Mingze, LI Jiahui, MA Mengyao, et al. SNR-adaptive deep joint source-channel coding for wireless image transmission[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, Canada, 2021: 1555–1559. doi: 10.1109/ICASSP39728.2021.9414037. [13] CHEN Weixuan, CHEN Yuhao, YANG Qianqian, et al. Deep joint source-channel coding for wireless image transmission with entropy-aware adaptive rate control[C]. IEEE Global Communications Conference, Kuala Lumpur, Malaysia, 2023: 2239–2244. doi: 10.1109/GLOBECOM54140.2023.10437482. [14] XU Jialong, AI Bo, CHEN Wei, et al. Wireless image transmission using deep source channel coding with attention modules[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(4): 2315–2328. doi: 10.1109/TCSVT.2021.3082521. [15] YANG Mingyu, BIAN Chenghong, and KIM H S. OFDM-guided deep joint source channel coding for wireless multipath fading channels[J]. IEEE Transactions on Cognitive Communications and Networking, 2022, 8(2): 584–599. doi: 10.1109/TCCN.2022.3151935. [16] WU Haotian, SHAO Yulin, MIKOLAJCZYK K, et al. Channel-adaptive wireless image transmission with OFDM[J]. IEEE Wireless Communications Letters, 2022, 11(11): 2400–2404. doi: 10.1109/LWC.2022.3204837. [17] HOU Qibin, ZHOU Daquan, and FENG Jiashi. Coordinate attention for efficient mobile network design[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 13708–13717. doi: 10.1109/CVPR46437.2021.01350. [18] PASZKE A, GROSS S, MASSA F, et al. PyTorch: An imperative style, high-performance deep learning library[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 721. [19] KINGMA D P and BA J. Adam: A method for stochastic optimization[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015. -




图(6) / 表(2)
计量
- 文章访问数: 973
- HTML全文浏览量: 510
- PDF下载量: 99
- 被引次数: 0
 下载:
下载:
