

Double Deep Q Network Algorithm-based Unmanned Aerial Vehicle-assisted Dense Network Resource Optimization Strategy
-
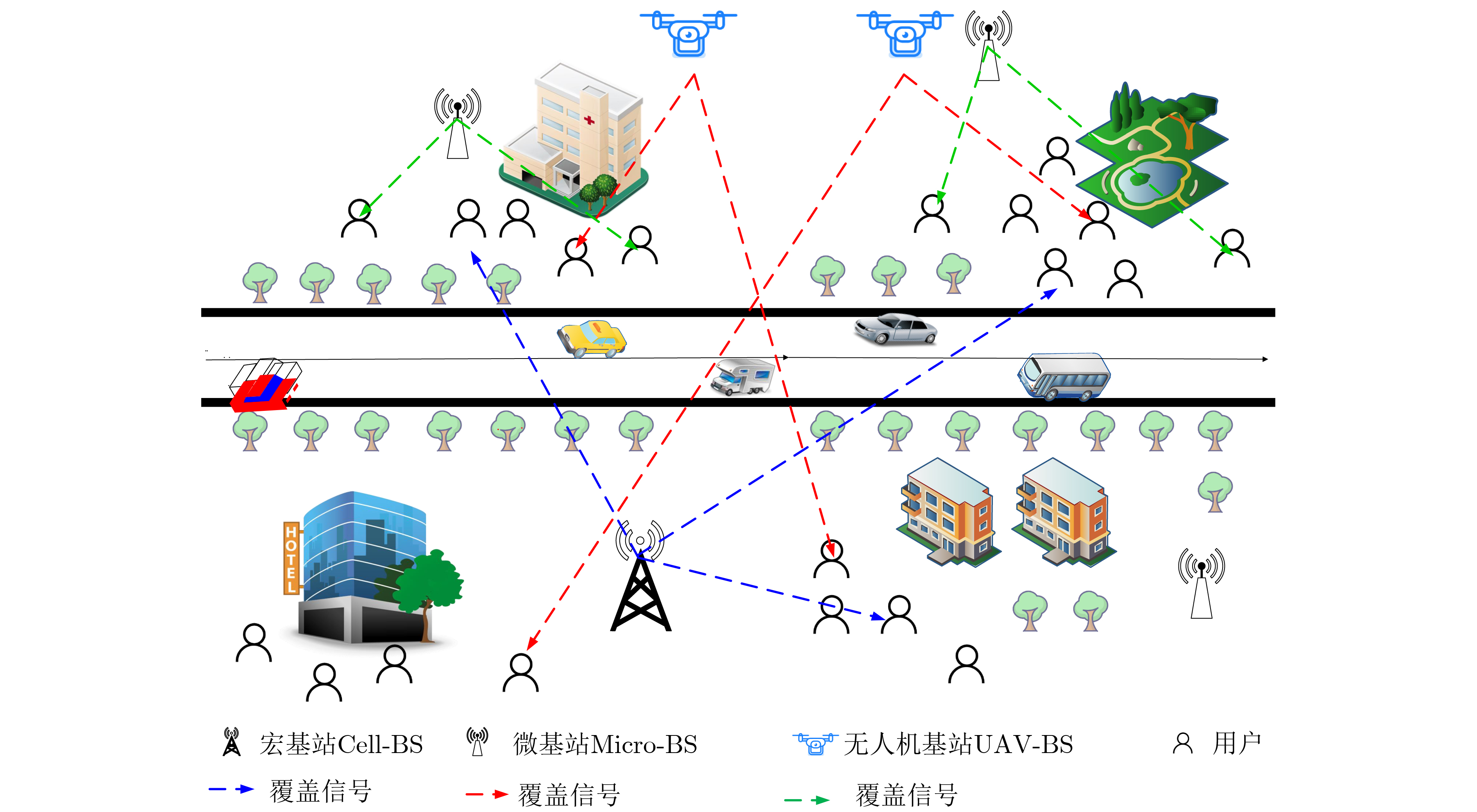
摘要: 为顺应未来网络向密集化与空间化方向的发展趋势,该文提出构建一种多基站共存的空地结合超密集复杂网络,并开发半分布式方案以优化网络资源。首先,建立包括宏基站、微基站和无人机(UAV)空中基站在内的多种基站共存的超密集复杂网络构架。在此基础上,针对传统完全集中式方案存在的计算负担重、响应速度慢以及分布式方案缺乏全局优化视角等问题,提出一种半分布式的双深度Q网络(DDQN)功率控制方案。该方案旨在优化网络能效,通过分布式决策与集中训练相结合的方式,有效平衡了计算复杂度和性能优化。具体而言,半分布式方案利用DDQN算法在基站侧进行分布式决策,同时引入集中式网络训练器以确保整体网络的能效最优。仿真结果表明,所提出的半分布式DDQN方案能够很好地适应密集复杂网络结构,与传统深度Q网络(DQN)相比,在能效和总吞吐量方面均取得了显著提升。Abstract:
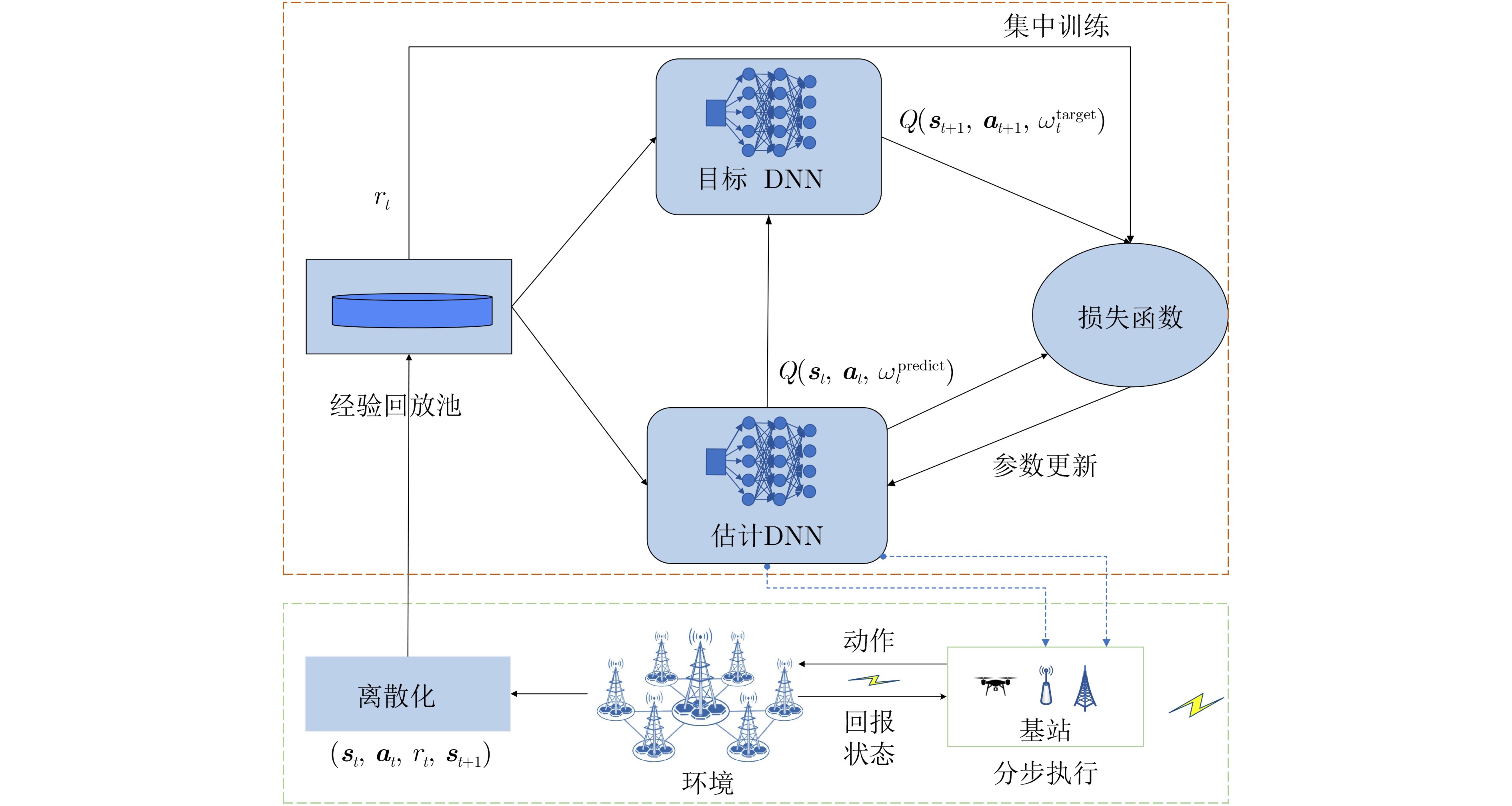
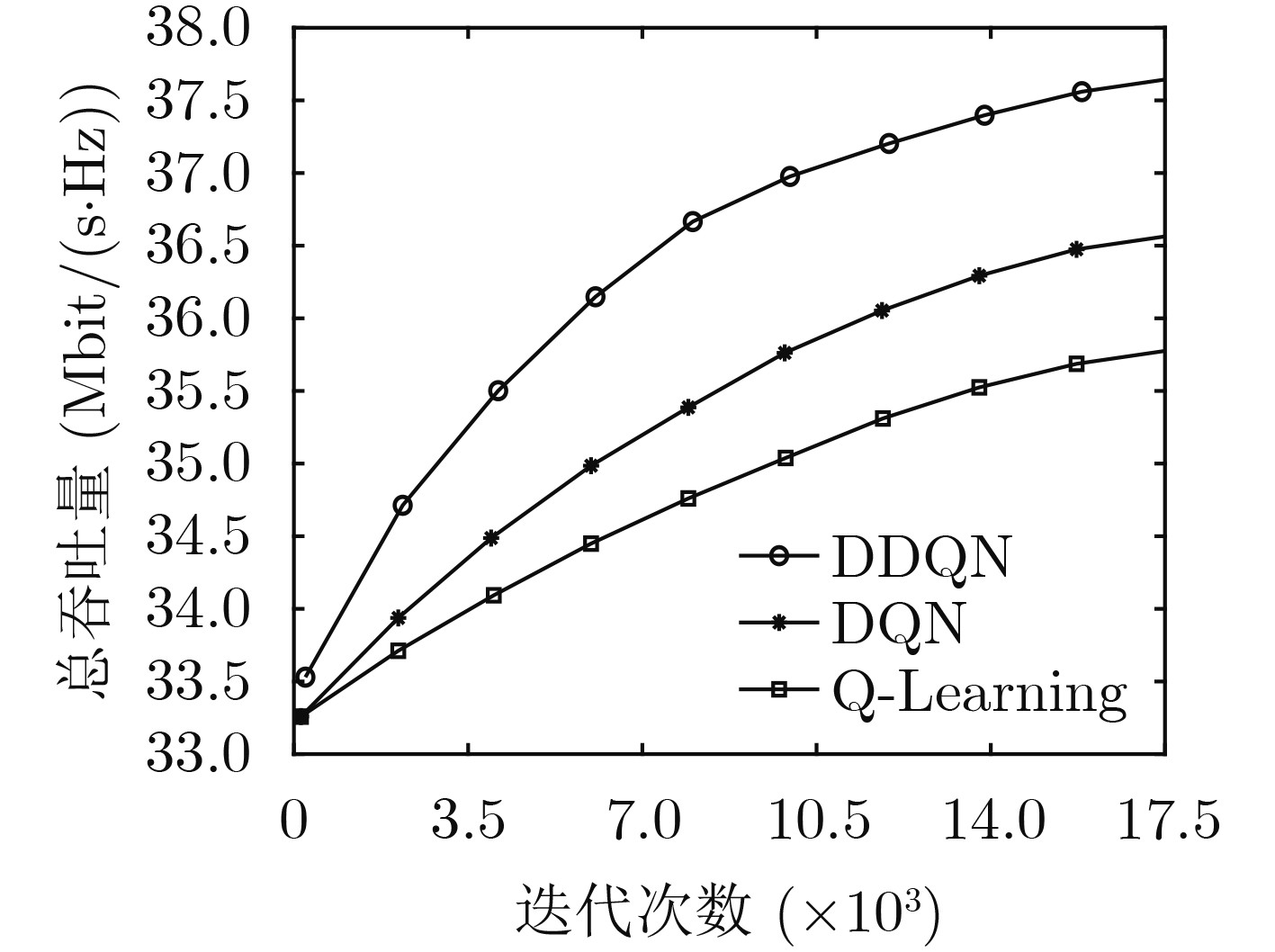
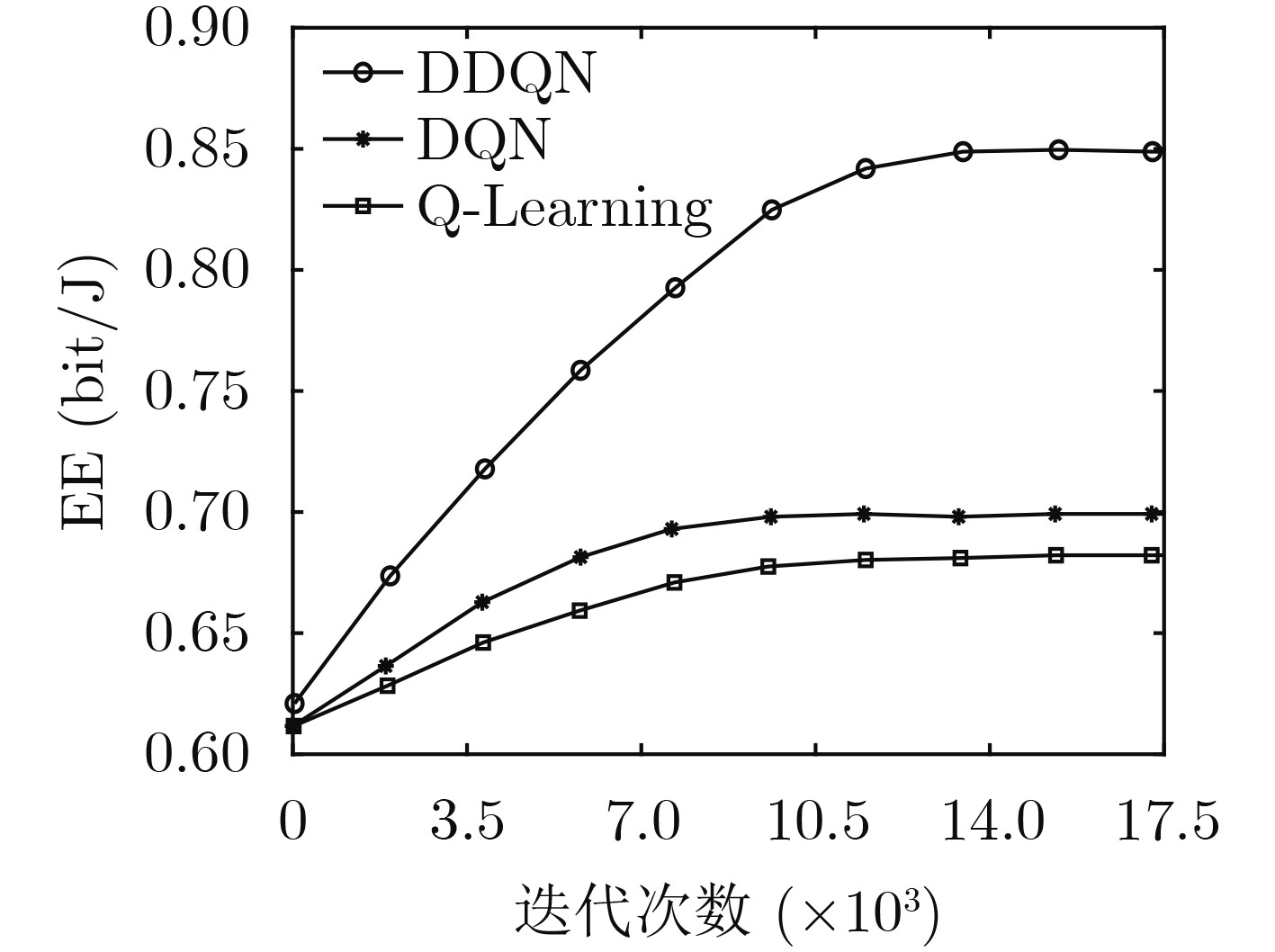
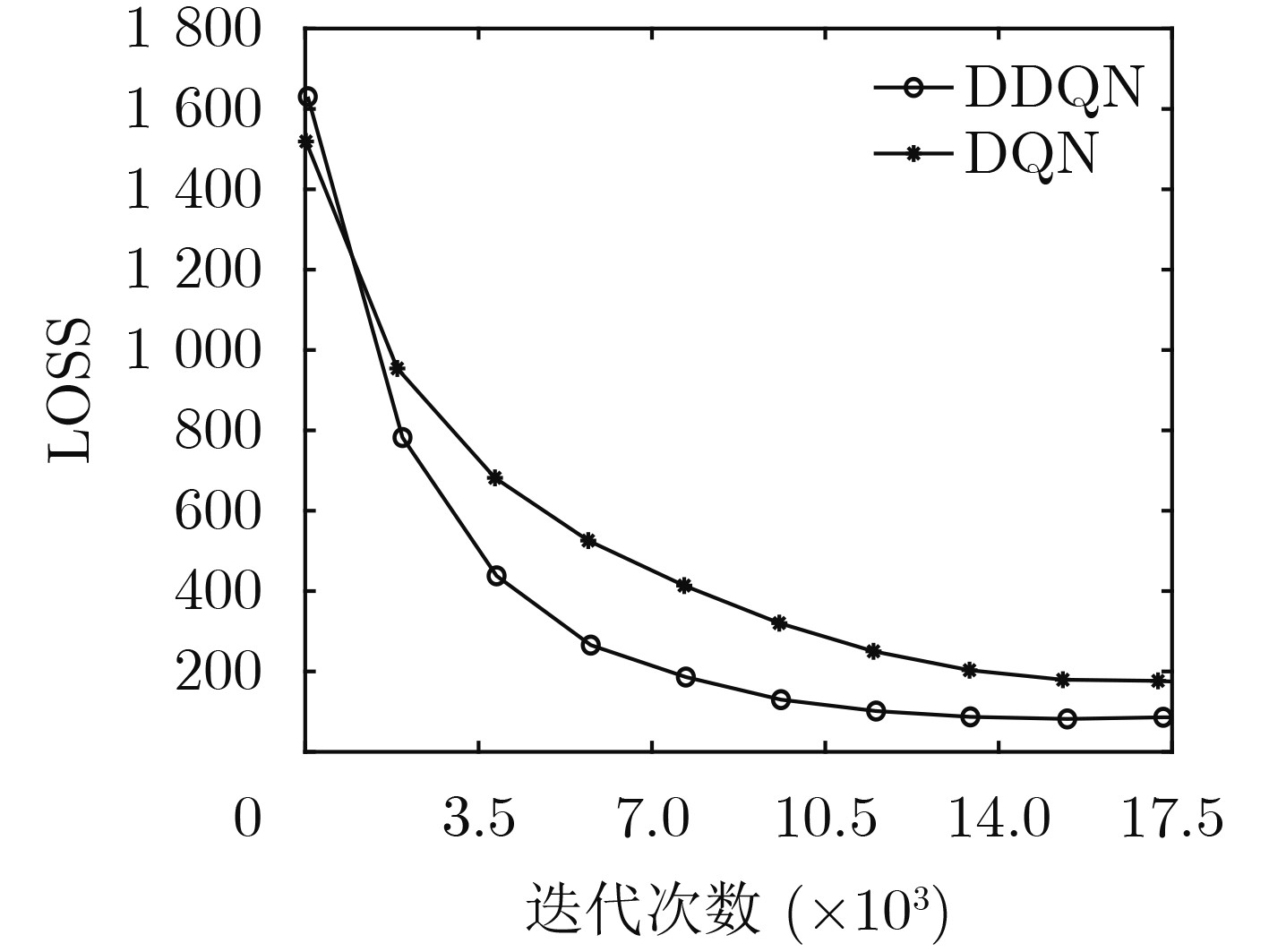
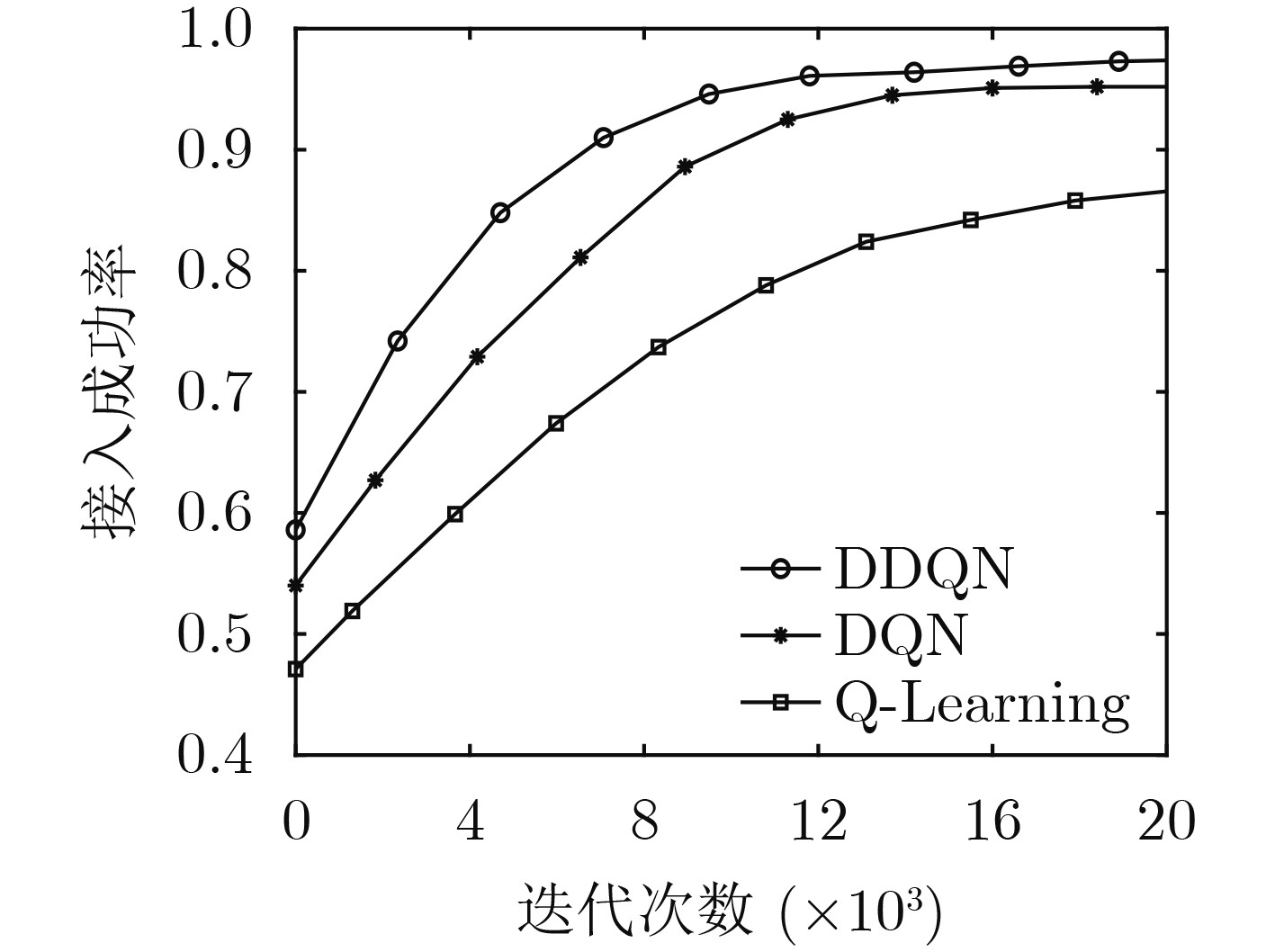
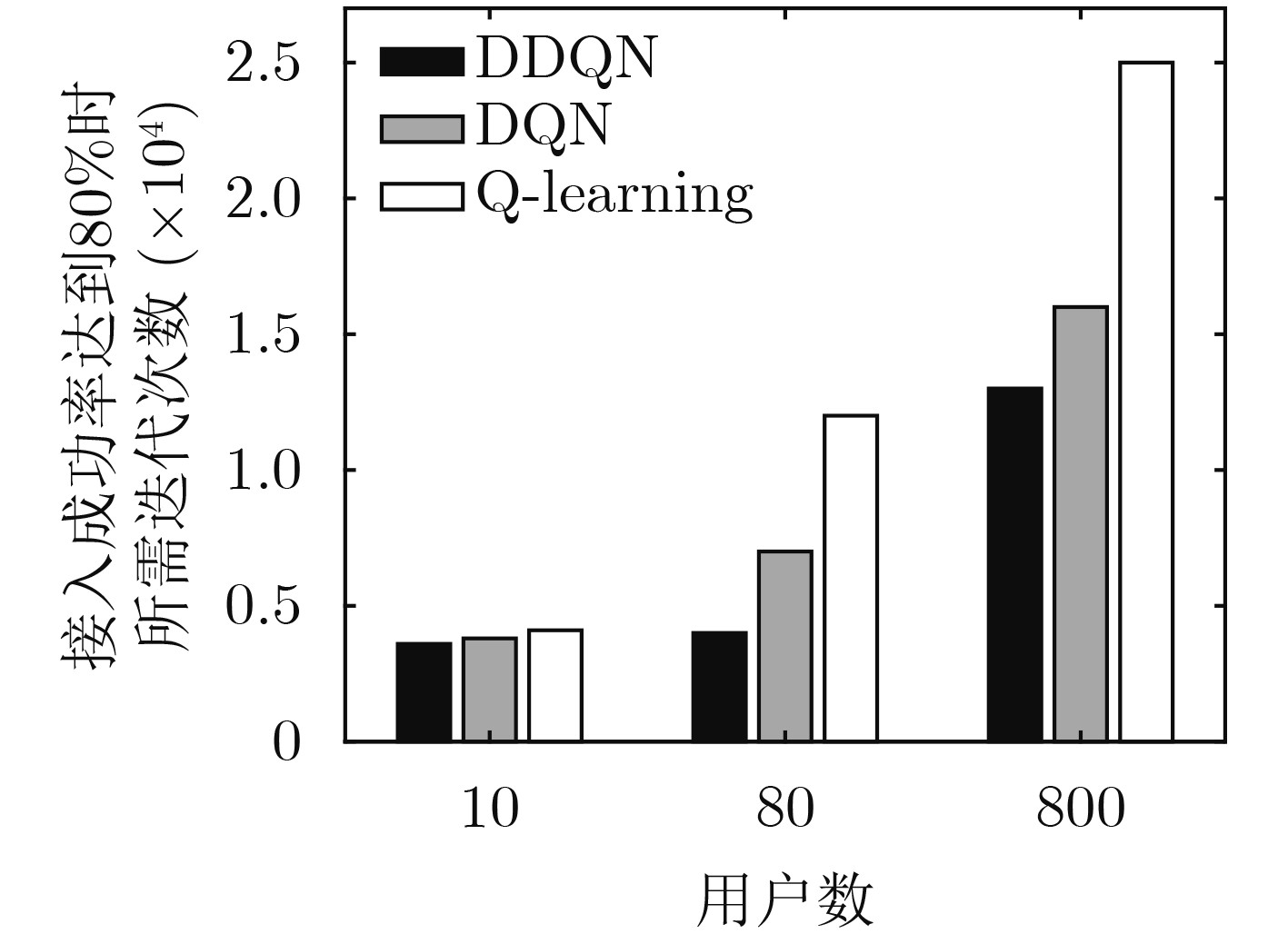
Objective To address the future trend of network densification and spatial distribution, this study proposes a multi-base station air–ground integrated ultra-dense network architecture and develops a semi-distributed scheme for resource optimization. The network comprises coexisting macro, micro, and Unmanned Aerial Vehicle (UAV) base stations. A semi-distributed Double Deep Q Network (DDQN)-based power control scheme is designed to reduce computational burden, improve response speed, and overcome the lack of global optimization in conventional fully centralized approaches. The proposed scheme enhances energy efficiency by combining distributed decision-making at the base station level with centralized training via a network trainer, enabling a balance between computational complexity and performance. The DDQN algorithm facilitates local decision-making while centralized coordination ensures overall network optimization. Methods This study establishes a complex dense network model for air–ground integration with coexisting macro, micro, and UAV base stations, and proposes a semi-distributed DDQN scheme to improve network energy efficiency. The methods are as follows: (1) Construct an integrated air–ground dense network model in which macro, micro, and UAV base stations share the spectrum through a cooperative mechanism, thereby overcoming the performance bottlenecks of conventional heterogeneous networks. (2) Develop an improved semi-distributed DDQN algorithm that enhances Q-value estimation accuracy, addressing the limitations of traditional centralized and distributed control modes and mitigating Q-value overestimation observed in conventional Deep Q Network (DQN) approaches. (3) Introduce a disturbance factor to increase the probability of exploring random actions, strengthen the algorithm’s ability to escape local optima, and improve estimation accuracy. Results and Discussions Simulation results demonstrate that the proposed semi-distributed DDQN scheme effectively adapts to dense and complex network topologies, yielding marked improvements in both energy efficiency and total throughput relative to traditional DQN and Q-learning algorithms. Key results include the following: The total throughput achieved by DDQN exceeds that of the baseline DQN and Q-learning algorithms ( Fig. 3 ). In terms of energy efficiency, DDQN exhibits a clear advantage, converging to 84.60%, which is 15.18% higher than DQN (69.42%) and 17.1% higher than Q-learning (67.50%) (Fig. 4 ). The loss value of DDQN also decreases more rapidly and stabilizes at a lower level. With increasing iterations, the loss curve becomes smoother and ultimately converges to 100, which is 100 lower than that of DQN (Fig. 5 ). Moreover, DDQN achieves the highest user access success rate compared with DQN and Q-learning (Fig. 6 ). When the access success rate reaches 80%, DDQN requires significantly fewer iterations than the other two algorithms. This advantage becomes more pronounced under high user density. For example, when the number of users reaches 800, DDQN requires fewer iterations than both DQN and Q-learning to achieve comparable performance (Fig. 7 ).Conclusions This study proposes a semi-distributed DDQN strategy for intelligent control of base station transmission power in ultra-dense air–ground networks. Unlike traditional methods that target energy efficiency at the individual base station level, the proposed strategy focuses on optimizing the overall energy efficiency of the network system. By dynamically adjusting the transmission power of macro, micro, and airborne base stations through intelligent learning, the scheme achieves system-level coordination and adaptation. Simulation results confirm the superior adaptability and performance of the proposed DDQN scheme under complex and dynamic network conditions. Compared with conventional DQN and Q-learning approaches, DDQN exhibits greater flexibility and effectiveness in resource control, achieving higher energy efficiency and sustained improvements in total throughput. These findings offer a new approach for the design and management of integrated air–ground networks and provide a technical basis for the development of future large-scale dense network architectures. -
1 DDQN功率分配算法
(1)输入:动作值函数$ Q{\text{(}}{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{a}}_t}{\text{,}}{\omega ^{{\mathrm{predict}}}}{\text{)}} $的初始值,状态与动作的
初始值为随机值$ {{\boldsymbol{s}}_t} = {{\boldsymbol{s}}_0} $, $ {{\boldsymbol{a}}_t} = {{\boldsymbol{a}}_0} $,初始权重为随机值
$ {\omega ^{{\mathrm{predict}}}} = \omega _0^{{\mathrm{predict}}} $(2)输出:功率控制策略$ {P_n} $ (3)初始化容量为$ D $的经验回放池缓冲区 (4)初始化目标DNN权重,该权重与估计DNN权重相等 (5)对于$ k $=1,$ K $ (6) 0~1选择随机值作为$ \varepsilon $ (7) 以概率$ \varepsilon $选择一个随机动作$ {{\boldsymbol{a}}_t} $ (8) 以概率$ 1 - \varepsilon $选择$ {{\boldsymbol{a}}_{t + 1}} = \max Q{\text{(}}{{\boldsymbol{s}}_t},{{\boldsymbol{a}}_t},{\omega ^{{\mathrm{target}}}}{\text{)}} $ (9) 根据式(22)减小$ \varepsilon $的值 (10) 获得下一状态$ {\boldsymbol{{s}}_{t + 1}} $和奖励$ {r_t} $ (11) 在经验回放池缓冲区中存储$ \left\langle {{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{a}}_t}{\text{,}}{r_t}{\text{,}}{{\boldsymbol{s}}_{t + 1}}} \right\rangle $ (12) 如果$ k {\text{ \gt }}D $,则 (13) 选择从经验回放池缓冲区选择$ J $组$ \left\langle {{{\boldsymbol{s}}_t}{\text{,}}{{\boldsymbol{a}}_t}{\text{,}}{r_t}{\text{,}}{{\boldsymbol{s}}_{t + 1}}} \right\rangle $ (14) 根据式(21)通过最小化损失函数更新$ {\omega ^{{\mathrm{predict}}}} $ (15) 如果$ k = g $,则 (16) 将估计DNN的参数复制到目标DNN中 (17) 结束 (18) 结束 (19)结束  下载: 导出CSV
下载: 导出CSV
-
[1] ZHANG Jifa, LU Weidang, XING Chengwei, et al. Intelligent integrated sensing and communication: A survey[J]. Science China Information Sciences, 2025, 68(3): 131301. doi: 10.1007/s11432-024-4205-8. [2] 林永昌. 海上应急关键信息数据收集与传输技术研究[J]. 数字通信世界, 2024(6): 69–71. doi: 10.3969/J.ISSN.1672-7274.2024.06.021.LIN Yongchang. Research on data collection and transmission technology for key emergency information at sea[J]. Digital Communication World, 2024(6): 69–71. doi: 10.3969/J.ISSN.1672-7274.2024.06.021. [3] 付振江, 罗俊松, 宁进, 等. 无人机集群通信的应用现状及展望[J]. 无线电工程, 2023, 53(1): 3–10. doi: 10.3969/j.issn.1003-3106.2023.01.001.FU Zhenjiang, LUO Junsong, NING Jin, et al. Application status and prospect of UAV swarm communications[J]. Radio Engineering, 2023, 53(1): 3–10. doi: 10.3969/j.issn.1003-3106.2023.01.001. [4] CHENG Longbo, XU Zixuan, ZHOU Jianshan, et al. Adaptive spectrum anti-jamming in UAV-enabled air-to-ground networks: A bimatrix stackelberg game approach[J]. Electronics, 2023, 12(20): 4344. doi: 10.3390/ELECTRONICS12204344. [5] LI Yifan, SHU Feng, SHI Baihua, et al. Enhanced RSS-based UAV localization via trajectory and multi-base stations[J]. IEEE Communications Letters, 2021, 25(6): 1881–1885. doi: 10.1109/LCOMM.2021.3061104. [6] YANG Siming, SHAN Zheng, CAO Jiang, et al. Path planning of UAV base station based on deep reinforcement learning[J]. Procedia Computer Science, 2022, 202: 89–104. doi: 10.1016/J.PROCS.2022.04.013. [7] 熊婉寅, 毛剑, 刘子雯, 等. 软件定义网络中流规则安全性研究进展[J]. 西安电子科技大学学报, 2023, 50(6): 172–194. doi: 10.19665/j.issn1001-2400.20230904.XIONG Wanyin, MAO Jian, LIU Ziwen, et al. Advances in security analysis of software-defined networking flow rules[J]. Journal of Xidian University, 2023, 50(6): 172–194. doi: 10.19665/j.issn1001-2400.20230904. [8] XIA Jingming, LIU Yufeng, and TAN Ling. Joint optimization of trajectory and task offloading for cellular-connected multi-UAV mobile edge computing[J]. Chinese Journal of Electronics, 2024, 33(3): 823–832. doi: 10.23919/cje.2022.00.159. [9] CONG Jiayi, LI Bin, GUO Xianzhen, et al. Energy management strategy based on deep Q-network in the solar-powered UAV communications system[C]. IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, Canada, 2021: 1–6. doi: 10.1109/ICCWorkshops50388.2021.9473509. [10] DAI Zhaojun, ZHANG Yan, ZHANG Wancheng, et al. A multi-agent collaborative environment learning method for UAV deployment and resource allocation[J]. IEEE Transactions on Signal and Information Processing over Networks, 2022, 8: 120–130. doi: 10.1109/tsipn.2022.3150911. [11] FU Shu, FENG Xue, SULTANA A, et al. Joint power allocation and 3D deployment for UAV-BSs: A game theory based deep reinforcement learning approach[J]. IEEE Transactions on Wireless Communications, 2024, 23(1): 736–748. doi: 10.1109/TWC.2023.3281812. [12] SILVA F A, FE I, BRITO C, et al. Aerial computing: Enhancing mobile cloud computing with unmanned aerial vehicles as data bridges—A Markov chain based dependability quantification[J]. ICT Express, 2024, 10(2): 406–411. doi: 10.1016/J.ICTE.2023.10.002. [13] CHEN Lin, WANG Jianxiao, WU Zhanyuan, et al. 5G and energy internet planning for power and communication network expansion[J]. iScience, 2024, 27(3): 109290. doi: 10.1016/J.ISCI.2024.109290. [14] Propagation data and prediction methods for the design of terrestrial broadband millimetric radio access systems[R]. Geneva, Switzerland, Rec. P. 1410–2, P Series, Radiowave Propagation, 2003. [15] MIAO Wang, LUO Chunbo, MIN Geyong, et al. Lightweight 3-D beamforming design in 5G UAV broadcasting communications[J]. IEEE Transactions on Broadcasting, 2020, 66(2): 515–524. doi: 10.1109/TBC.2020.2990564. -



图(7) / 表(1)
计量
- 文章访问数: 750
- HTML全文浏览量: 439
- PDF下载量: 80
- 被引次数: 0
 下载:
下载:
