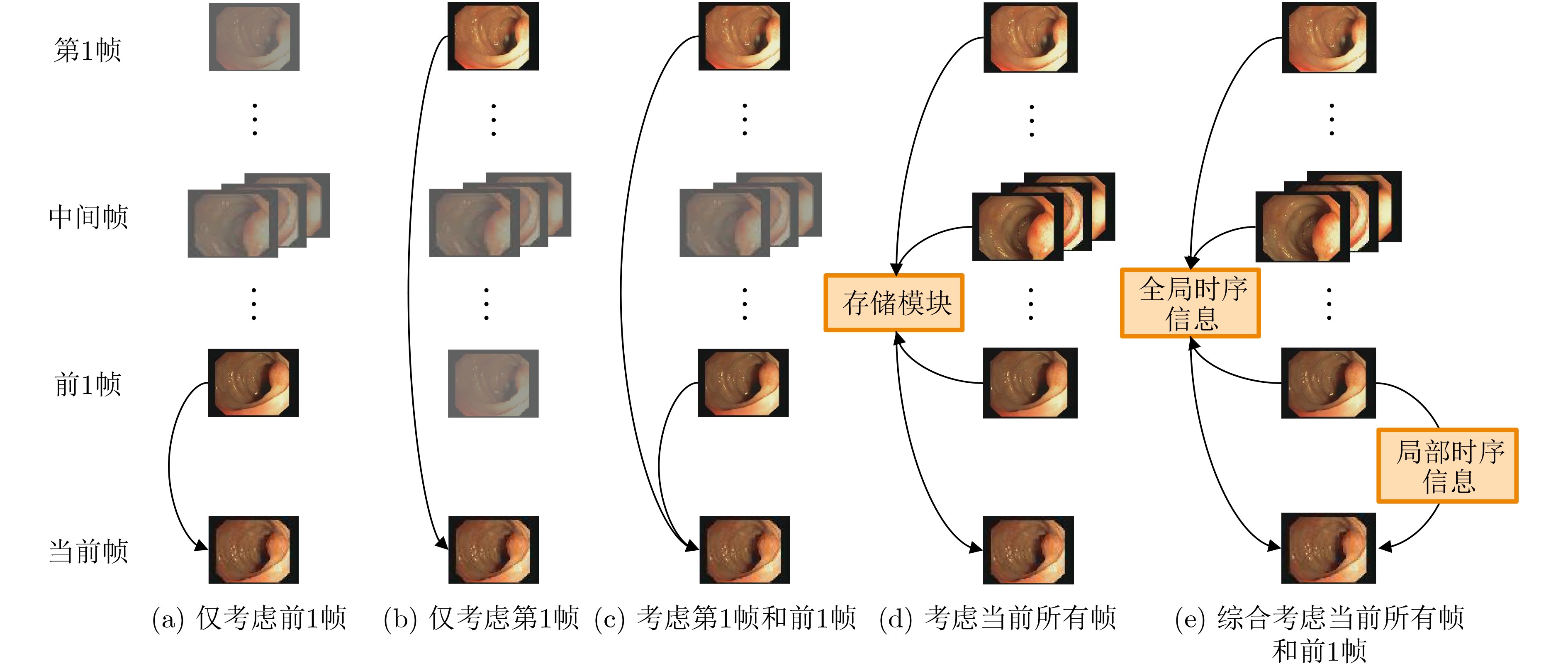
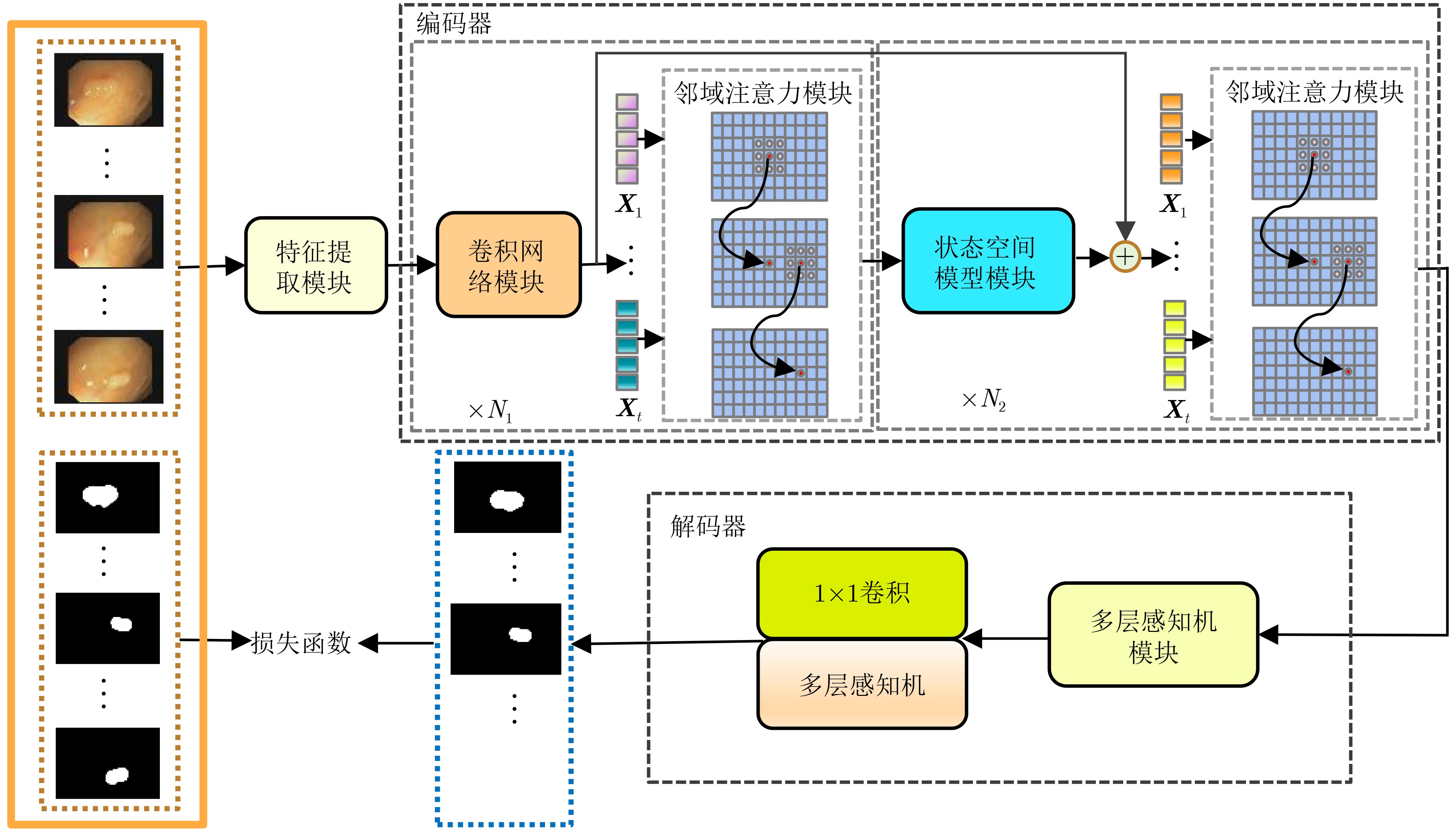
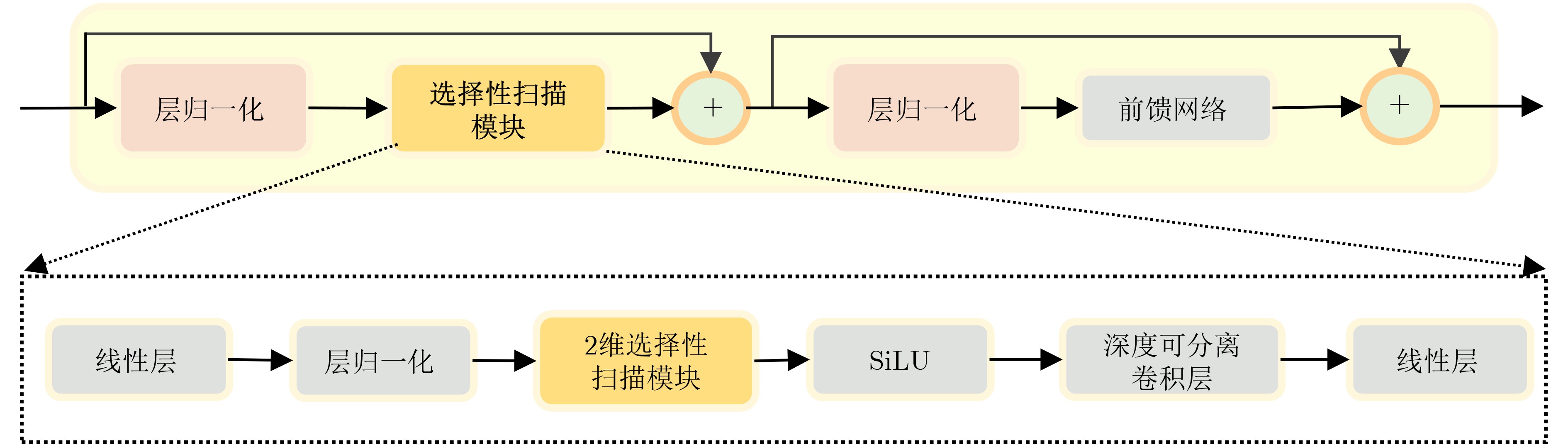
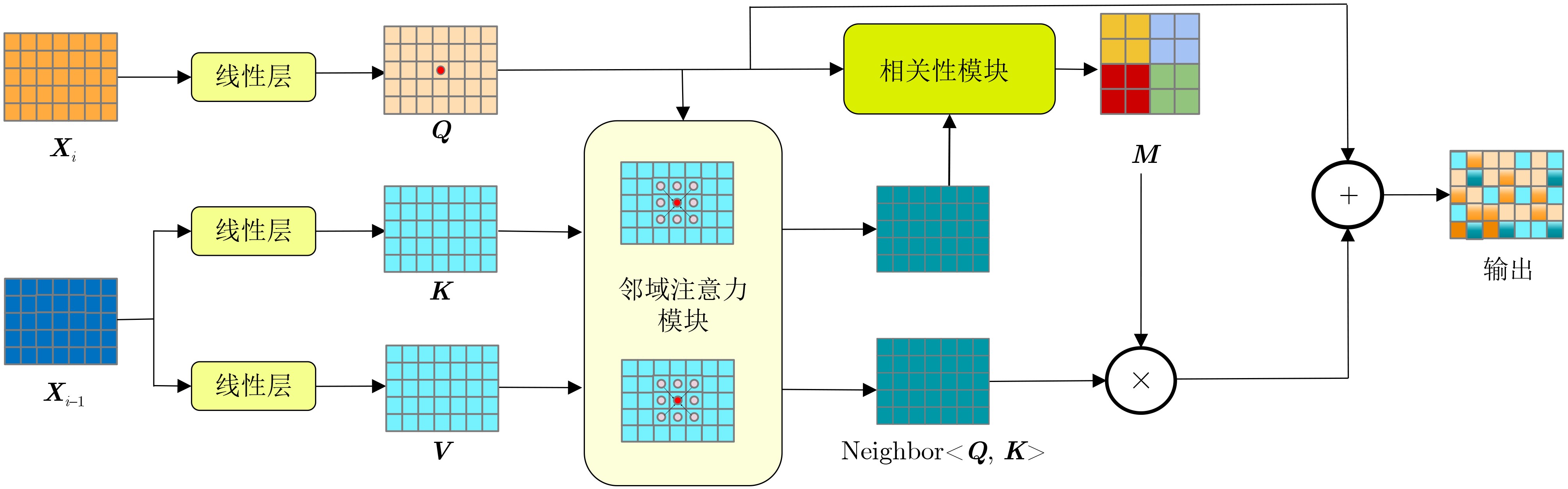
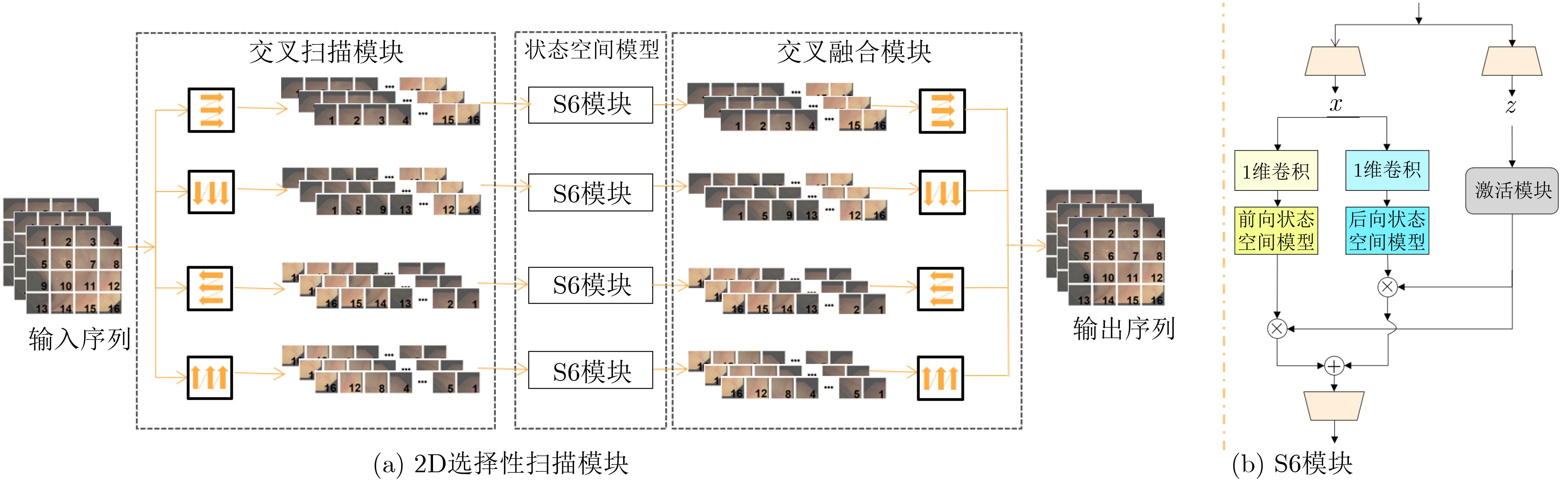
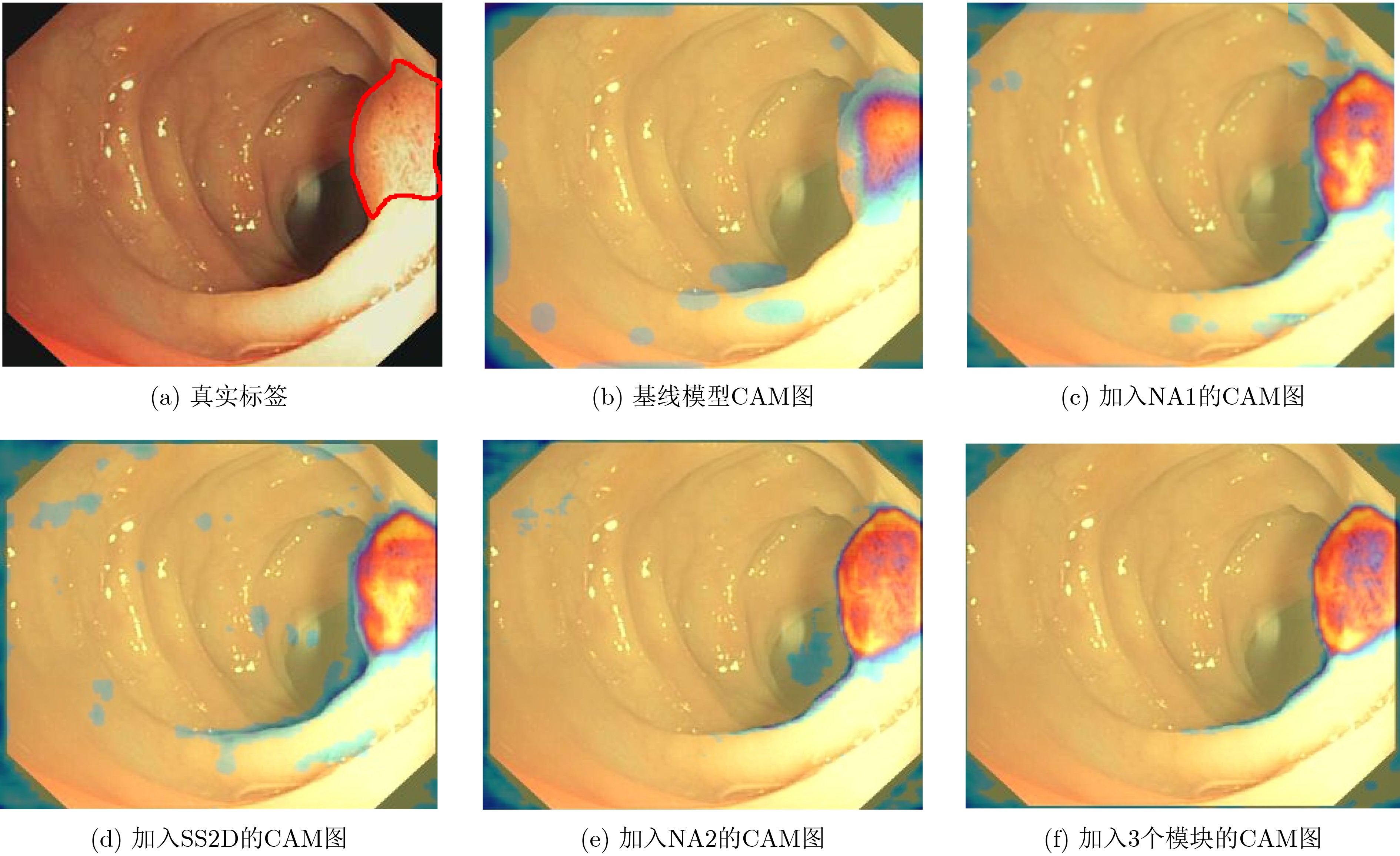
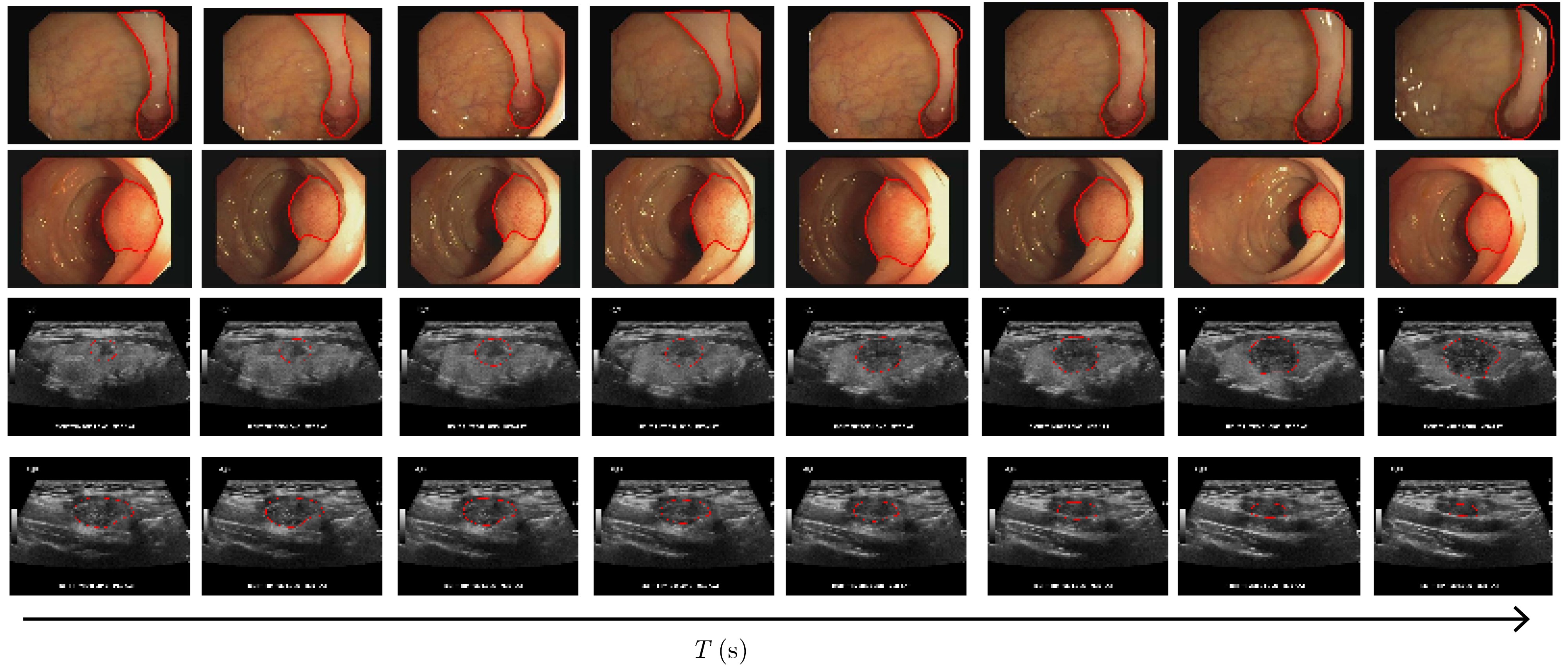
| Citation: | DING Jianrui, ZHANG Ting, LIU Jiadong, NING Chunping. A Medical Video Segmentation Algorithm Integrating Neighborhood Attention and State Space Model[J]. Journal of Electronics & Information Technology, 2025, 47(5): 1582-1595. doi: 10.11999/JEIT240755

|

| [1] |
MINAEE S, BOYKOV Y, PORIKLI F, et al. Image segmentation using deep learning: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3523–3542. doi: 10.1109/TPAMI.2021.3059968.
|
| [2] |
GHOSH S, DAS N, DAS I, et al. Understanding deep learning techniques for image segmentation[J]. ACM Computing Surveys, 2020, 52(4): 73. doi: 10.1145/3329784.
|
| [3] |
MA Jun, HE Yuting, LI Feifei, et al. Segment anything in medical images[J]. Nature Communications, 2024, 15(1): 654. doi: 10.1038/s41467-024-44824-z.
|
| [4] |
PATIL D D and DEORE S G. Medical image segmentation: A review[J]. International Journal of Computer Science and Mobile Computing, 2013, 2(1): 22–27.
|
| [5] |
RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. 18th International Conference on Medical Image Computing and Computer Assisted Intervention, Munich, Germany, 2015: 234–241. doi: 10.1007/978-3-319-24574-4_28.
|
| [6] |
VALANARASU J M J and PATEL V M. UNeXt: MLP-based rapid medical image segmentation network[C]. 25th International Conference on Medical Image Computing and Computer Assisted Intervention, Singapore, 2022: 23–33. doi: 10.1007/978-3-031-16443-9_3.
|
| [7] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–601.
|
| [8] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. 9th International Conference on Learning Representations, Austria, 2021.
|
| [9] |
CHEN Jieneng, LU Yongyi, YU Qihang, et al. TransUNet: Transformers make strong encoders for medical image segmentation[Z]. arXiv: 2102.04306, 2021. doi: 10.48550/arXiv.2102.04306.
|
| [10] |
CHOROMANSKI K M, LIKHOSHERSTOV V, DOHAN D, et al. Rethinking attention with performers[C]. 9th International Conference on Learning Representations, Austria, 2021.
|
| [11] |
KITAEV N, KAISER Ł, and LEVSKAYA A. Reformer: The efficient transformer[C]. 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 2020.
|
| [12] |
QIN Zhen, YANG Songlin, and ZHONG Yiran. Hierarchically gated recurrent neural network for sequence modeling[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1442.
|
| [13] |
BASAR T. A new approach to linear filtering and prediction problems[M]. BASAR T. Control Theory: Twenty-Five Seminal Papers (1932–1981). Wiley-IEEE Press, 2001: 167–179. doi: 10.1109/9780470544334.ch9.
|
| [14] |
GU A and DAO T. Mamba: Linear-time sequence modeling with selective state spaces[Z]. arXiv: 2312.00752, 2023. doi: 10.48550/arXiv.2312.00752.
|
| [15] |
GU A, GOEL K, and RÉ C. Efficiently modeling long sequences with structured state spaces[C]. 10th International Conference on Learning Representations, 2022.
|
| [16] |
GU A, JOHNSON I, GOEL K, et al. Combining recurrent, convolutional, and continuous-time models with linear state-space layers[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 44.
|
| [17] |
ZHU Lianghui, LIAO Bencheng, ZHANG Qian, et al. Vision mamba: Efficient visual representation learning with bidirectional state space model[C]. The Forty-first International Conference on Machine Learning, Vienna, Austria, 2024.
|
| [18] |
NGUYEN E, GOEL K, GU A, et al. S4ND: Modeling images and videos as multidimensional signals using state spaces[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 206.
|
| [19] |
LIU Yue, TIAN Yunjie, ZHAO Yuzhong, et al. VMamba: Visual state space model[C]. The 38th Conference on Neural Information Processing Systems, Vancouver, Canada, 2024.
|
| [20] |
MA Jun, LI Feifei, and WANG Bo. U-Mamba: Enhancing long-range dependency for biomedical image segmentation[Z]. arXiv: 2401.04722, 2024. doi: 10.48550/arXiv.2401.04722.
|
| [21] |
XING Zhaohu, YE Tian, YANG Yijun, et al. SegMamba: Long-range sequential modeling mamba for 3D medical image segmentation[C]. 27th International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco, 2024: 578–588. doi: 10.1007/978-3-031-72111-3_54.
|
| [22] |
WANG Jinhong, CHEN Jintai, CHEN D, et al. LKM-UNet: Large kernel vision mamba UNet for medical image segmentation[C]. 27th International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco, 2024: 360–370. doi: 10.1007/978-3-031-72111-3_34.
|
| [23] |
XU Zhongxing, TANG Feilong, CHEN Zhe, et al. Polyp-Mamba: Polyp segmentation with visual mamba[C]. 27th International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco, 2024: 510–521. doi: 10.1007/978-3-031-72111-3_48.
|
| [24] |
ARNAB A, DEHGHANI M, HEIGOLD G, et al. ViViT: A video vision transformer[C]. The IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 6816–6826. doi: 10.1109/ICCV48922.2021.00676.
|
| [25] |
ZHANG Miao, LIU Jie, WANG Yifei, et al. Dynamic context-sensitive filtering network for video salient object detection[C]. The IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 1533–1543. doi: 10.1109/ICCV48922.2021.00158.
|
| [26] |
LI Jialu, ZHENG Qingqing, LI Mingshuang, et al. Rethinking breast lesion segmentation in ultrasound: A new video dataset and a baseline network[C]. 25th International Conference on Medical Image Computing and Computer Assisted Intervention, Singapore, Singapore, 2022: 391–400. doi: 10.1007/978-3-031-16440-8_38.
|
| [27] |
LIN Junhao, DAI Qian, ZHU Lei, et al. Shifting more attention to breast lesion segmentation in ultrasound videos[C]. 26th International Conference on Medical Image Computing and Computer Assisted Intervention, Vancouver, Canada, 2023: 497–507. doi: 10.1007/978-3-031-43898-1_48.
|
| [28] |
HU Xifeng, CAO Yankun, HU Weifeng, et al. Refined feature-based Multi-frame and Multi-scale Fusing Gate network for accurate segmentation of plaques in ultrasound videos[J]. Computers in Biology and Medicine, 2023, 163: 107091. doi: 10.1016/j.compbiomed.2023.107091.
|
| [29] |
SONG Qi, LI Jie, LI Chenghong, et al. Fully attentional network for semantic segmentation[C]. The 36th AAAI Conference on Artificial Intelligence, Washington, USA, 2022: 2280–2288. doi: 10.1609/aaai.v36i2.20126.
|
| [30] |
DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: Learning optical flow with convolutional networks[C]. The IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 2758–2766. doi: 10.1109/ICCV.2015.316.
|
| [31] |
JI Gepeng, CHOU Yucheng, FAN Dengping, et al. Progressively normalized self-attention network for video polyp segmentation[C]. 24th International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 2021: 142–152. doi: 10.1007/978-3-030-87193-2_14.
|
| [32] |
HU Qiang, YI Zhenyu, ZHOU Ying, et al. SALI: Short-term alignment and long-term interaction network for colonoscopy video polyp segmentation[C]. 27th International Conference on Medical Image Computing and Computer Assisted Intervention, Marrakesh, Morocco, 2024: 531–541. doi: 10.1007/978-3-031-72089-5_50.
|
| [33] |
HU Yuanting, HUANG Jiabin, and SCHWING A G. MaskRNN: Instance level video object segmentation[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 324–333.
|
| [34] |
HU Yuanting, HUANG Jiabin, and SCHWING A G. VideoMatch: Matching based video object segmentation[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 56–73. doi: 10.1007/978-3-030-01237-3_4.
|
| [35] |
Seoung W O, LEE J Y, SUNKAVALLI K, et al. Fast video object segmentation by reference-guided mask propagation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7376–7385. doi: 10.1109/CVPR.2018.00770.
|
| [36] |
Seoung W O, LEE J Y, XU Ning, et al. Video object segmentation using space-time memory networks[C]. Tthe IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 9225–9234. doi: 10.1109/ICCV.2019.00932.
|
| [37] |
YANG Yijun, XING Zhaohu, and ZHU Lei. Vivim: A video vision mamba for medical video object segmentation[Z]. arXiv: 2401.14168, 2024. doi: 10.48550/arXiv.2401.14168.
|
| [38] |
HASSANI A, WALTON S, LI Jiachen, et al. Neighborhood attention transformer[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 6185–6194. doi: 10.1109/CVPR52729.2023.00599.
|
| [39] |
WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803. doi: 10.1109/CVPR.2018.00813.
|
| [40] |
PENG Chao, ZHANG Xiangyu, YU Gang, et al. Large kernel matters — Improve semantic segmentation by global convolutional network[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1743–1751. doi: 10.1109/CVPR.2017.189.
|
| [41] |
BERNAL J, SÁNCHEZ F J, FERNÁNDEZ-ESPARRACH G, et al. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. Saliency maps from physicians[J]. Computerized Medical Imaging and Graphics, 2015, 43: 99–111. doi: 10.1016/j.compmedimag.2015.02.007.
|
| [42] |
BERNAL J, SÁNCHEZ J, and VILARIÑO F. Towards automatic polyp detection with a polyp appearance model[J]. Pattern Recognition, 2012, 45(9): 3166–3182. doi: 10.1016/j.patcog.2012.03.002.
|
| [43] |
Stanford AIMI. AIMI dataset[EB/OL]. https://stanfordaimi.azurewebsites.net/datasets/a72f2b02–7b53–4c5d-963c-d7253220bfd5, 2021.
|
| [44] |
WANG Yi, DENG Zijun, HU Xiaowei, et al. Deep attentional features for prostate segmentation in ultrasound[C]. 21st International Conference on Medical Image Computing and Computer Assisted Intervention, Granada, Spain, 2018: 523–530. doi: 10.1007/978-3-030-00937-3_60.
|
| [45] |
FAN Dengping, JI Gepeng, ZHOU Tao, et al. PraNet: Parallel reverse attention network for polyp segmentation[C]. 23rd International Conference on Medical Image Computing and Computer Assisted Intervention, Lima, Peru, 2020: 263–273. doi: 10.1007/978-3-030-59725-2_26.
|
| [46] |
MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. ShuffleNet V2: Practical guidelines for efficient CNN architecture design[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 122–138. doi: 10.1007/978-3-030-01264-9_8.
|
| [47] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]. IEEE International Conference on Computer Vision, Venice, Italy, 2017: 618–626. doi: 10.1109/ICCV.2017.74.
|
Figures(10) / Tables(3)



 DownLoad:
DownLoad: