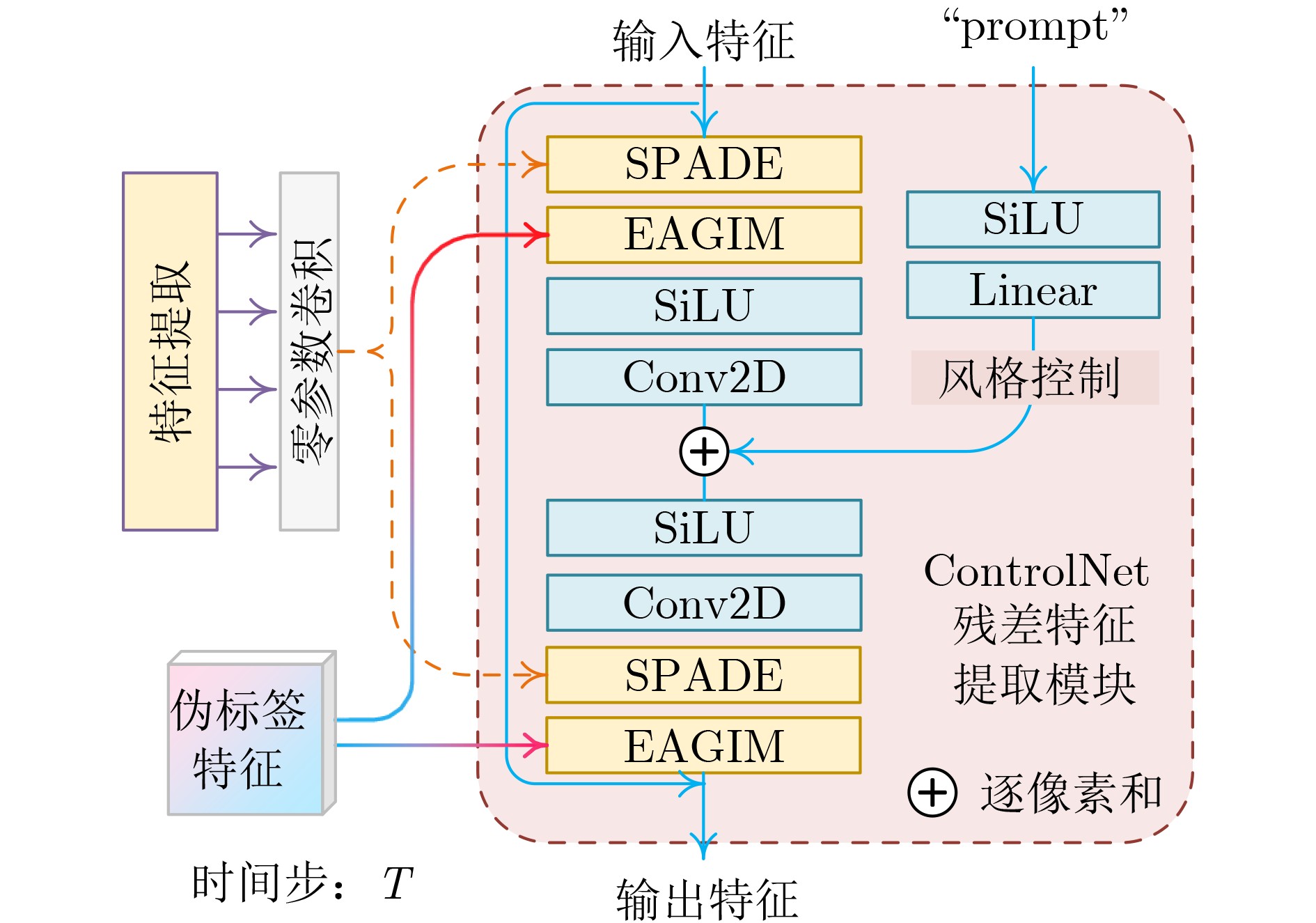
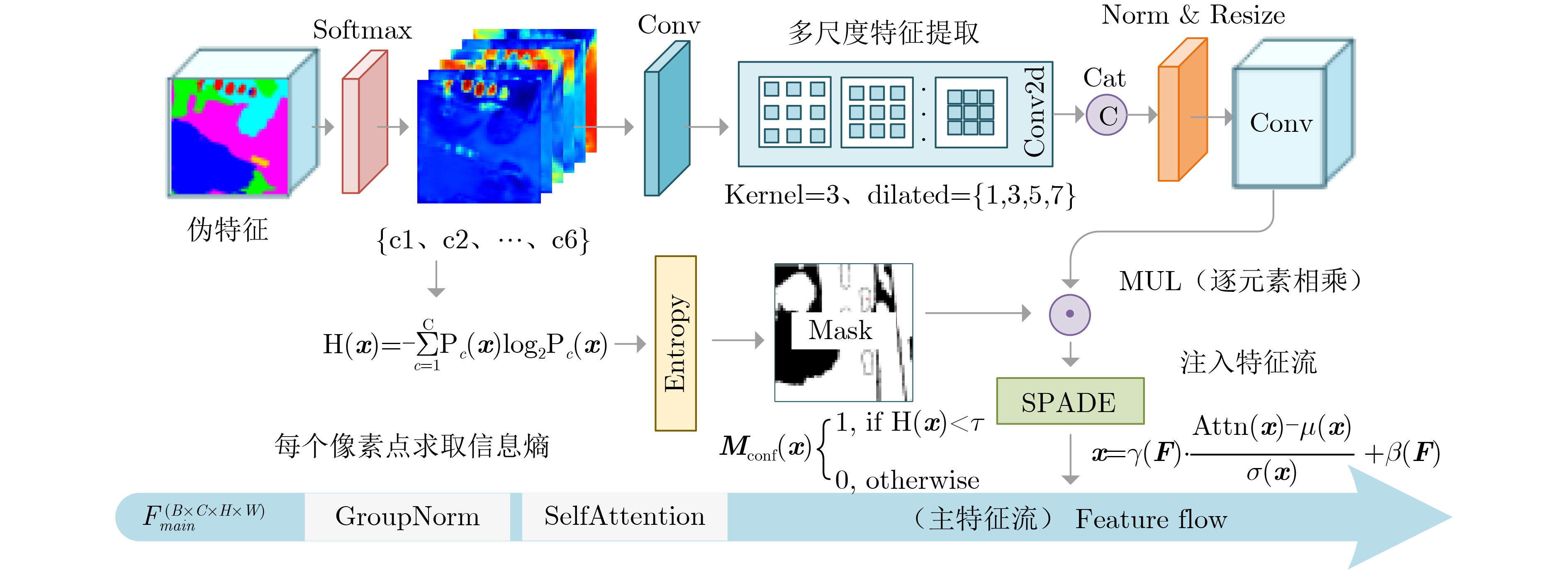
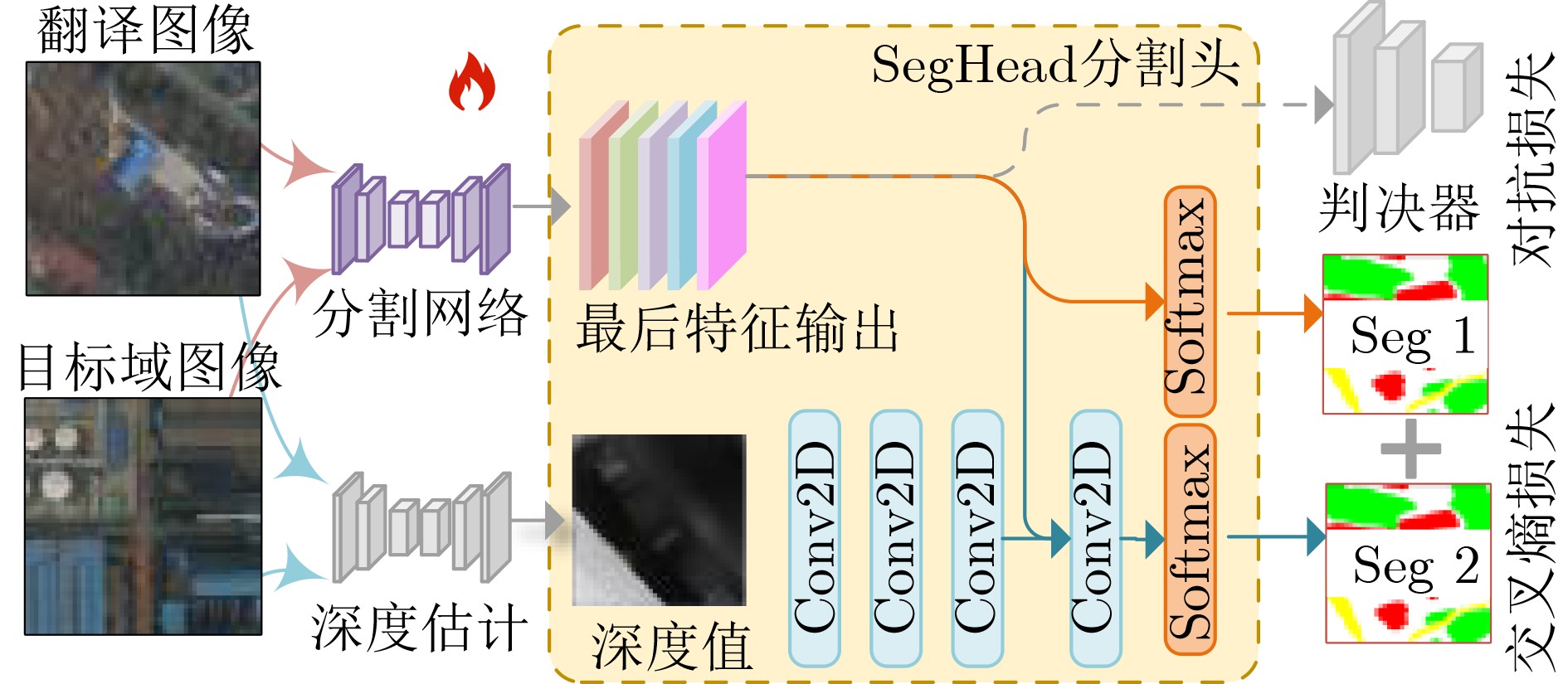
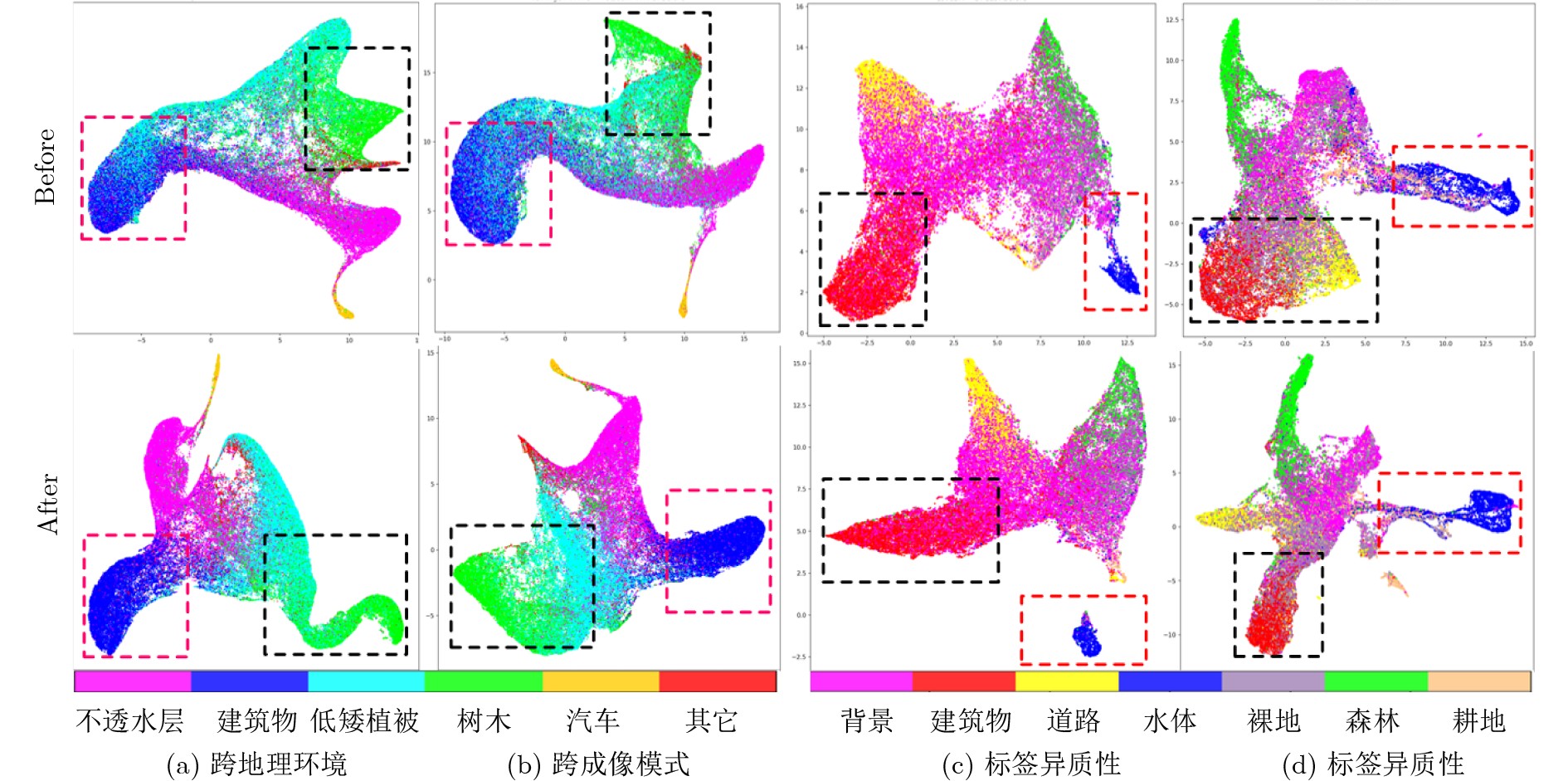
| Citation: | LIANG Yan, LI Jun-Fan, SHAO Kai, HU Lin. Spatial Information-guided Diffusion for Domain Adaptation Semantic Segmentation of Remote Sensing Images[J]. Journal of Electronics & Information Technology. doi: 10.11999/JEIT260031

|

| [1] |
宋淼, 陈志强, 王培松, 等. DetDiffRS: 面向细节优化的遥感图像超分辨率扩散模型[J]. 电子与信息学报, 2025, 47(12): 4763–4778. doi: 10.11999/JEIT250995.
SONG Miao, CHEN Zhiqiang, WANG Peisong, et al. DetDiffRS: A detail-enhanced diffusion model for remote sensing image super-resolution[J]. Journal of Electronics & Information Technology, 2025, 47(12): 4763–4778. doi: 10.11999/JEIT250995.
|
| [2] |
刁文辉, 龚铄, 辛林霖, 等. 针对多模态遥感数据的自监督策略模型预训练方法[J]. 电子与信息学报, 2025, 47(6): 1658–1668. doi: 10.11999/JEIT241016.
DIAO Wenhui, GONG Shuo, XIN Linlin, et al. A model pre-training method with self-supervised strategies for multimodal remote sensing data[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1658–1668. doi: 10.11999/JEIT241016.
|
| [3] |
余翔, 庞志濠. 融合FEB的YOLOX遥感图像目标检测算法[J]. 重庆邮电大学学报: 自然科学版, 2024, 36(2): 319–327. doi: 10.3979/j.issn.1673-825X.202302120032.
YU Xiang and PANG Zhihao. YOLOX remote sensing image object detection algorithm based on FEB[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition, 2024, 36(2): 319–327. doi: 10.3979/j.issn.1673-825X.202302120032.
|
| [4] |
厉行, 樊养余, 郭哲, 等. 基于边缘领域自适应的立体匹配算法[J]. 电子与信息学报, 2024, 46(7): 2970–2980. doi: 10.11999/JEIT231113.
LI Xing, FAN Yangyu, GUO Zhe, et al. Edge domain adaptation for stereo matching[J]. Journal of Electronics & Information Technology, 2024, 46(7): 2970–2980. doi: 10.11999/JEIT231113.
|
| [5] |
TEE Y Y, HONG Xuenong, CHENG Deruo, et al. Unsupervised domain adaptation with pseudo shape supervision for IC image segmentation[C]. 2024 IEEE International Symposium on the Physical and Failure Analysis of Integrated Circuits (IPFA), Singapore, Singapore, 2024: 1–6. doi: 10.1109/IPFA61654.2024.10690992.
|
| [6] |
HOFFMAN J, WANG Dequan, YU F, et al. FCNs in the wild: Pixel-level adversarial and constraint-based adaptation[EB/OL]. https://arxiv.org/abs/1612.02649, 2016.
|
| [7] |
VU T H, JAIN H, BUCHER M, et al. ADVENT: Adversarial entropy minimization for domain adaptation in semantic segmentation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 2512–2521. doi: 10.1109/CVPR.2019.00262.
|
| [8] |
ZOU Yang, YU Zhiding, VIJAYA KUMAR B V K, et al. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 297–313. doi: 10.1007/978-3-030-01219-9_18.
|
| [9] |
VU T H, JAIN H, BUCHER M, et al. DADA: Depth-aware domain adaptation in semantic segmentation[C]. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 2019: 7363–7372. doi: 10.1109/ICCV.2019.00746.
|
| [10] |
WANG Qin, DAI Dengxin, HOYER L, et al. Domain adaptive semantic segmentation with self-supervised depth estimation[C]. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 8495–8505. doi: 10.1109/ICCV48922.2021.00840.
|
| [11] |
ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2017: 2242–2251. doi: 10.1109/ICCV.2017.244.
|
| [12] |
HOFFMAN J, TZENG E, PARK T, et al. CyCADA: Cycle-consistent adversarial domain adaptation[C]. 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 1989–1998.
|
| [13] |
ZHANG Lvmin, RAO Anyi, and AGRAWALA M. Adding conditional control to text-to-image diffusion models[C]. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 3813–3824. doi: 10.1109/ICCV51070.2023.00355.
|
| [14] |
DONG Xiao, HUANG Runhui, WEI Xiaoyong, et al. UniDiff: Advancing vision-language models with generative and discriminative learning[EB/OL]. https://arxiv.org/abs/2306.00813, 2023.
|
| [15] |
TANG Datao, CAO Xiangyong, HOU Xingsong, et al. CRS-Diff: Controllable remote sensing image generation with diffusion model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5638714. doi: 10.1109/TGRS.2024.3453414.
|
| [16] |
KINGMA D P and WELLING M. Auto-encoding variational Bayes[EB/OL]. https://arxiv.org/abs/1312.6114v11, 2022.
|
| [17] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. 38th International Conference on Machine Learning, 2021: 8748–8763.
|
| [18] |
PARK T, LIU Mingyu, WANG Tingchun, et al. Semantic image synthesis with spatially-adaptive normalization[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 2332–2341. doi: 10.1109/CVPR.2019.00244.
|
| [19] |
梁燕, 易春霞, 王光宇, 等. 基于多尺度语义编解码网络的遥感图像语义分割[J]. 电子学报, 2023, 51(11): 3199–3214. doi: 10.12263/DZXB.20220503.
LIANG Yan, YI Chunxia, WANG Guangyu, et al. Semantic segmentation of remote sensing image based on multi-scale semantic encoder-decoder network[J]. Acta Electronica Sinica, 2023, 51(11): 3199–3214. doi: 10.12263/DZXB.20220503.
|
| [20] |
ZHANG Xiaoke, HU Zongsheng, ZHANG Guoliang, et al. Dose calculation in proton therapy using a discovery cross-domain generative adversarial network (DiscoGAN)[J]. Medical Physics, 2021, 48(5): 2646–2660. doi: 10.1002/mp.14781.
|
| [21] |
LUO Yawei, ZHENG Liang, GUAN Tao, et al. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2019: 2502–2511. doi: 10.1109/CVPR.2019.00261.
|
| [22] |
XU Tao, SUN Xian, DIAO Wenhui, et al. FADA: Feature aligned domain adaptive object detection in remote sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5617916. doi: 10.1109/TGRS.2022.3147224.
|
| [23] |
TSAI Y H, HUNG W C, SCHULTER S, et al. Learning to adapt structured output space for semantic segmentation[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7472–7481. doi: 10.1109/CVPR.2018.00780.
|
| [24] |
HOYER L, DAI Dengxin, and VAN GOOL L. DAFormer: Improving network architectures and training strategies for domain-adaptive semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 9914–9925. doi: 10.1109/CVPR52688.2022.00969.
|
| [25] |
JI Yuxiang, HE Boyong, QU Chenyuan, et al. Diffusion features to bridge domain gap for semantic segmentation[C]. 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 2025: 1–5. doi: 10.1109/ICASSP49660.2025.10888537.
|
| [26] |
WANG Libo, LI Rui, ZHANG Ce, et al. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 190: 196–214. doi: 10.1016/j.isprsjprs.2022.06.008.
|
| [27] |
梁燕, 杨会林, 邵凯. 自适应特征选择的车路协同3D目标检测方案[J]. 电子与信息学报, 2025, 47(12): 5214–5225. doi: 10.11999/JEIT250601.
LIANG Yan, YANG Huilin, and SHAO Kai. A vehicle-infrastructure cooperative 3D object detection scheme based on adaptive feature selection[J]. Journal of Electronics & Information Technology, 2025, 47(12): 5214–5225. doi: 10.11999/JEIT250601.
|
Figures(9) / Tables(7)


 DownLoad:
DownLoad: