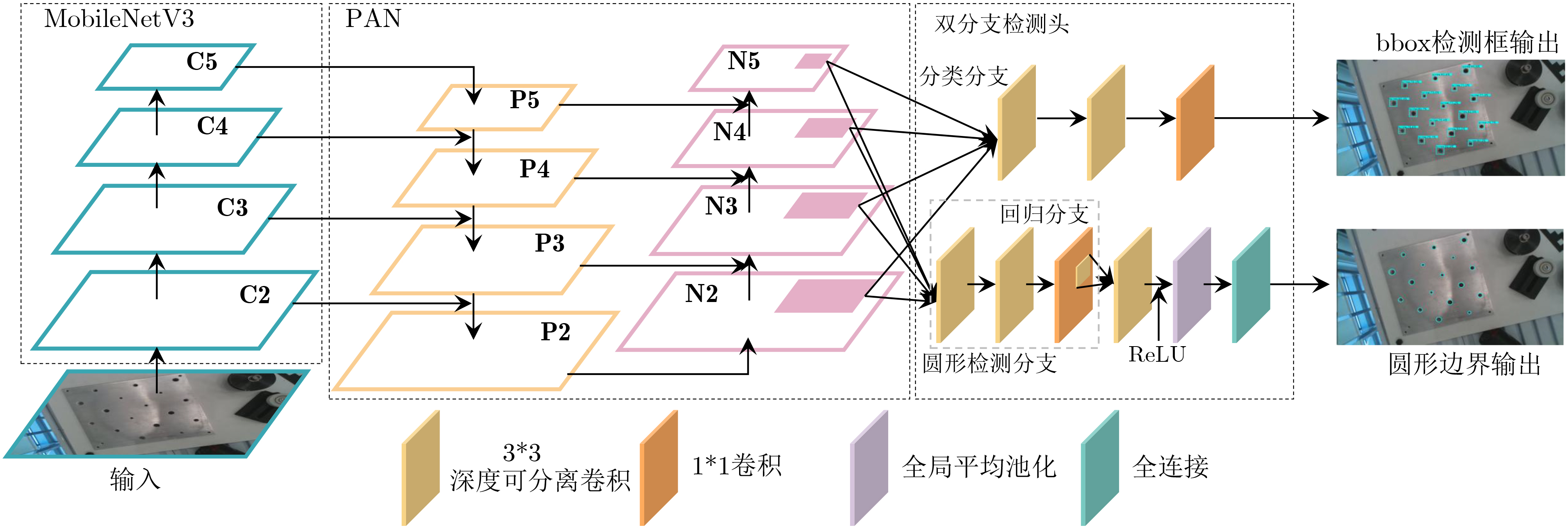
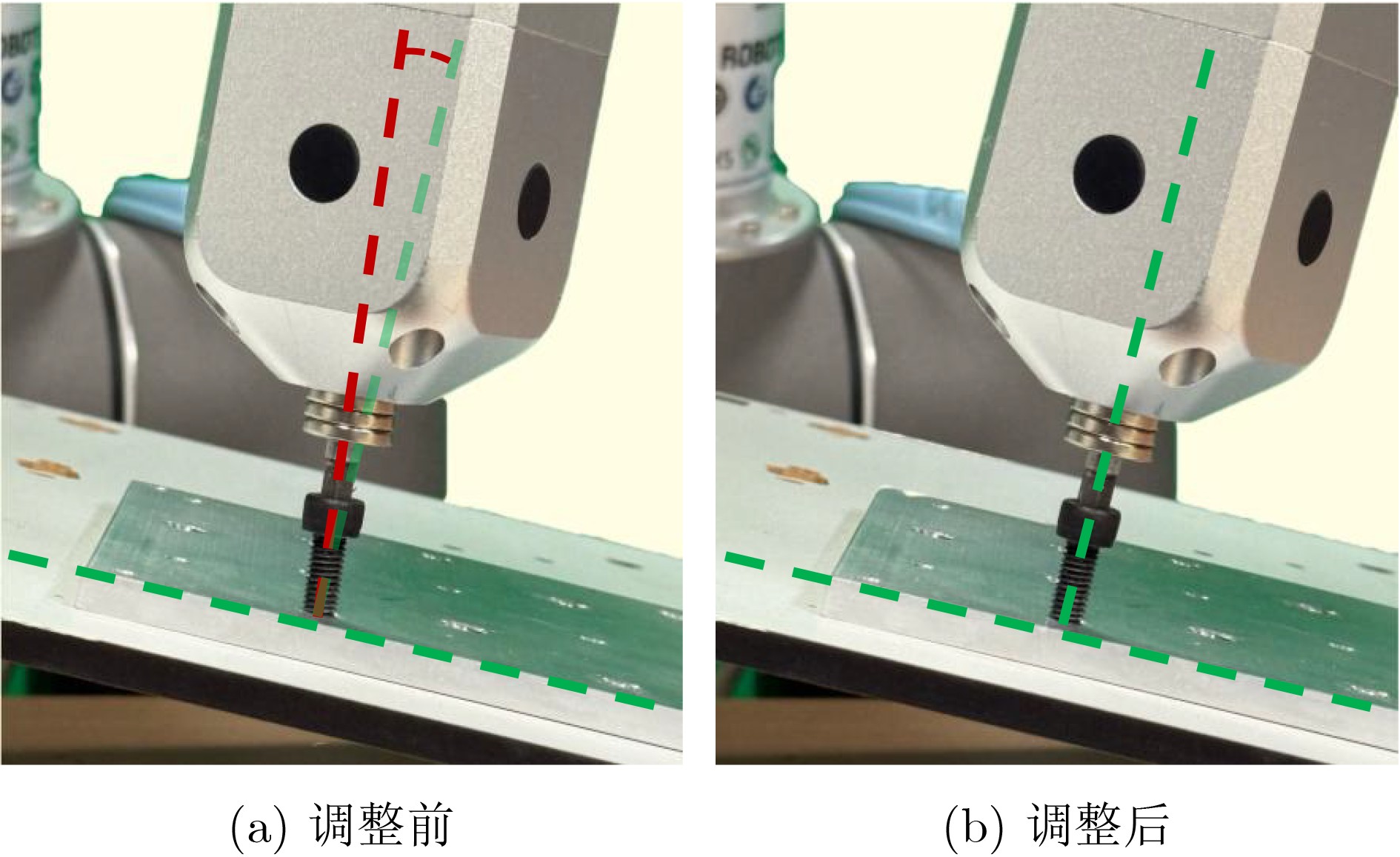
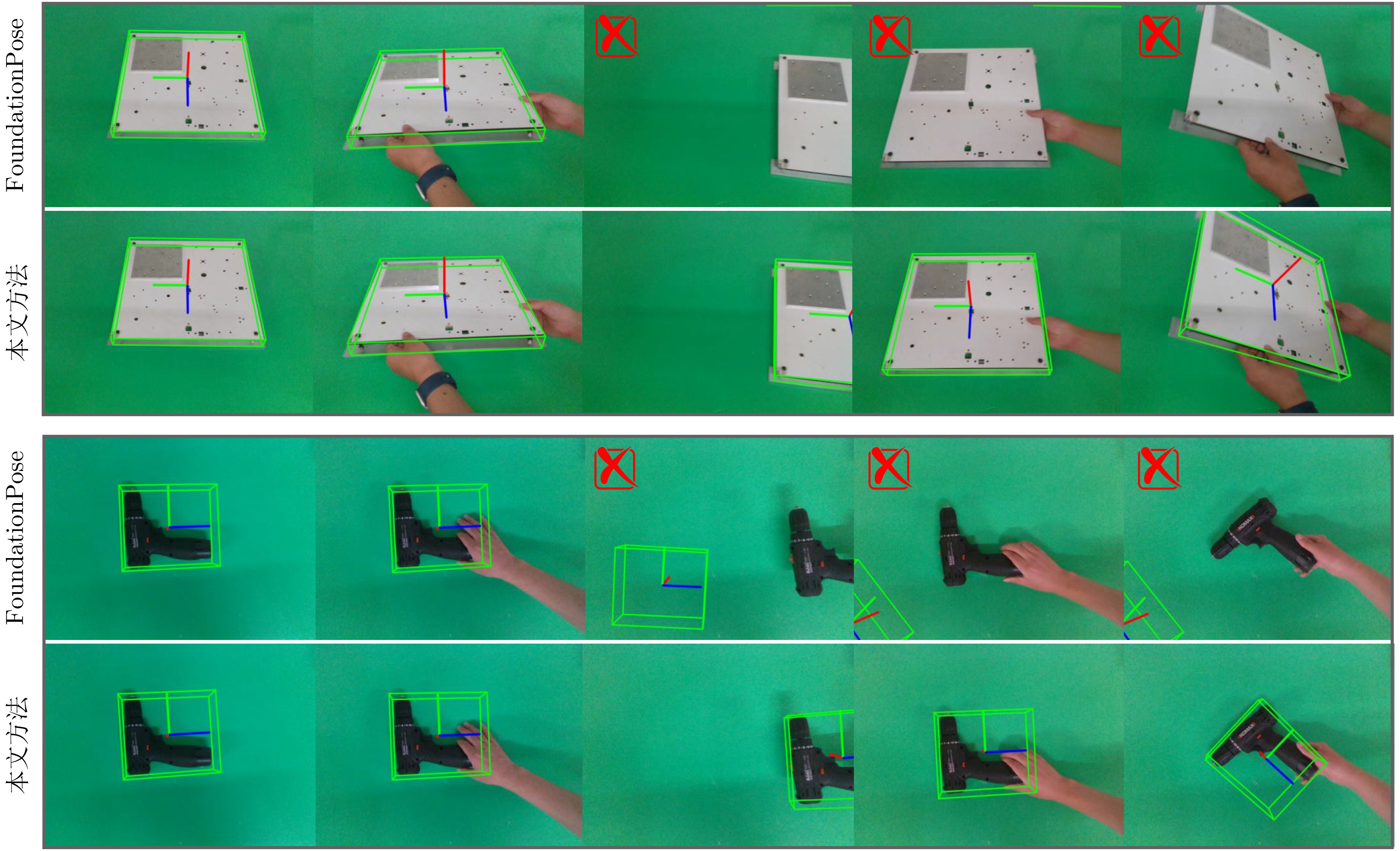
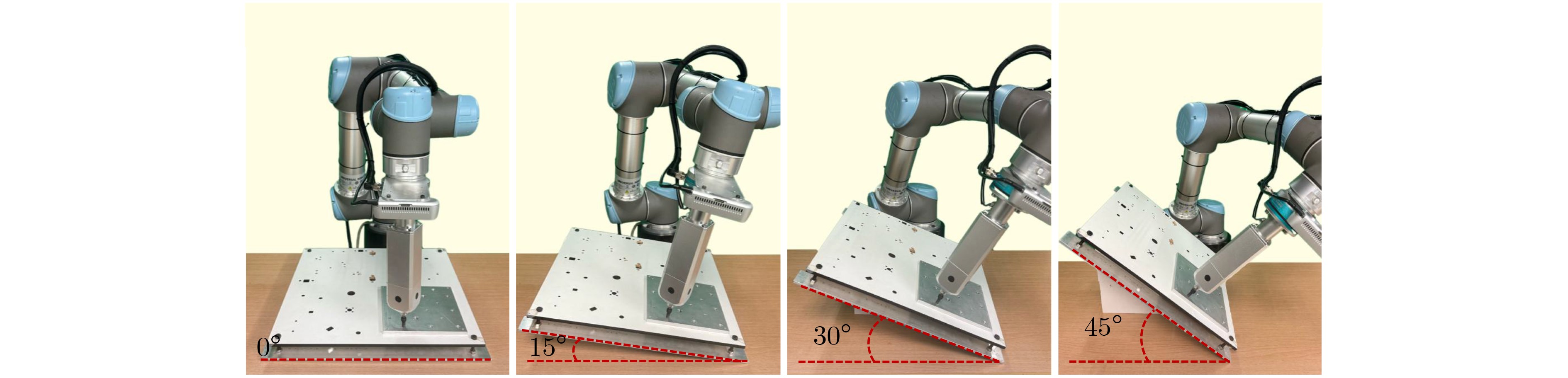
| Citation: | ZHANG Chunyun, MENG Xintong, TAO Tao, ZHOU Huaidong. Vision-Guided and Force-Controlled Method for Robotic Screw Assembly[J]. Journal of Electronics & Information Technology, 2026, 48(5): 2053-2065. doi: 10.11999/JEIT251193

|

| [1] |
王耀南, 江一鸣, 姜娇, 等. 机器人感知与控制关键技术及其智能制造应用[J]. 自动化学报, 2023, 49(3): 494–513. doi: 10.16383/j.aas.c220995.
WANG Yaonan, JIANG Yiming, JIANG Jiao, et al. Key technologies of robot perception and control and its intelligent manufacturing applications[J]. Acta Automatica Sinica, 2023, 49(3): 494–513. doi: 10.16383/j.aas.c220995.
|
| [2] |
SUN Fuchun, MIAO Shengyi, ZHONG Daming, et al. Manipulation skill representation and knowledge reasoning for 3C assembly[J]. IEEE/ASME Transactions on Mechatronics, 2025, 30(6): 5387–5397. doi: 10.1109/TMECH.2025.3543739.
|
| [3] |
LIU Yang, CHEN Weixing, BAI Yongjie, et al. Aligning cyber space with physical world: A comprehensive survey on embodied AI[J]. IEEE/ASME Transactions on Mechatronics, 2025, 30(6): 7253–7274. doi: 10.1109/TMECH.2025.3574943.
|
| [4] |
WEN Bowen, YANG Wei, KAUTZ J, et al. FoundationPose: Unified 6D pose estimation and tracking of novel objects[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 17868–17879. doi: 10.1109/CVPR52733.2024.01692.
|
| [5] |
ZHOU Chuangchuang, WU Yifan, STERKENS W, et al. Towards robotic disassembly: A comparison of coarse-to-fine and multimodal fusion screw detection methods[J]. Journal of Manufacturing Systems, 2024, 74: 633–646. doi: 10.1016/j.jmsy.2024.04.024.
|
| [6] |
HE Yisheng, SUN Wei, HUANG Haibin, et al. PVN3D: A deep point-wise 3D keypoints voting network for 6DoF pose estimation[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11629–11638. doi: 10.1109/CVPR42600.2020.01165.
|
| [7] |
HE Yisheng, HUANG Haibin, FAN Haoqiang, et al. FFB6D: A full flow bidirectional fusion network for 6D pose estimation[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 3002–3012. doi: 10.1109/CVPR46437.2021.00302.
|
| [8] |
LEE T, TREMBLAY J, BLUKIS V, et al. TTA-COPE: Test-time adaptation for category-level object pose estimation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 21285–21295. doi: 10.1109/CVPR52729.2023.02039.
|
| [9] |
ZHANG Ruida, DI Yan, MANHARDT F, et al. SSP-pose: Symmetry-aware shape prior deformation for direct category-level object pose estimation[C]. 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 2022: 7452–7459. doi: 10.1109/IROS47612.2022.9981506.
|
| [10] |
LABBÉ Y, MANUELLI L, MOUSAVIAN A, et al. MegaPose: 6D pose estimation of novel objects via render & compare[C]. The 6th Conference on Robot Learning, Auckland, New Zealand, 2023: 715–725.
|
| [11] |
LI Fu, VUTUKUR S R, YU Hao, et al. NeRF-pose: A first-reconstruct-then-regress approach for weakly-supervised 6D object pose estimation[C]. 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Paris, France, 2023: 2115–2125. doi: 10.1109/ICCVW60793.2023.00226.
|
| [12] |
SUN Jiaming, WANG Zihao, ZHANG Siyu, et al. OnePose: One-shot object pose estimation without CAD models[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 6815–6824. doi: 10.1109/CVPR52688.2022.00670.
|
| [13] |
HE Xingyi, SUN Jiaming, WANG Yuang, et al. OnePose++: Keypoint-free one-shot object pose estimation without CAD models[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 2544. doi: 10.5555/3600270.3602814.
|
| [14] |
KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[C]. The 26th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2012: 1097–1105. doi: 10.5555/2999134.2999257.
|
| [15] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. doi: 10.1109/TPAMI.2015.2389824.
|
| [16] |
REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031.
|
| [17] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 779–788. doi: 10.1109/CVPR.2016.91.
|
| [18] |
JOCHER G. Ultralytics YOLOv5[EB/OL]. https://github.com/ultralytics/yolov5, 2022.
|
| [19] |
JOCHER G, CHAURASIA A, and QIU J. Ultralytics YOLOv8[EB/OL]. https://github.com/ultralytics/ultralytics, 2023.
|
| [20] |
JOCHER G and QIU J. Ultralytics YOLO11[EB/OL]. https://github.com/ultralytics/ultralytics, 2024.
|
| [21] |
JHA D K, ROMERES D, JAIN S, et al. Design of adaptive compliance controllers for safe robotic assembly[C]. 2023 European Control Conference (ECC), Bucharest, Romania, 2023: 1–8. doi: 10.23919/ECC57647.2023.10178229.
|
| [22] |
SPECTOR O, TCHUIEV V, and DI CASTRO D. InsertionNet 2.0: Minimal contact multi-step insertion using multimodal multiview sensory input[C]. 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, USA, 2022: 6330–6336. doi: 10.1109/ICRA46639.2022.9811798.
|
| [23] |
LEE G, LEE J, NOH S, et al. PolyFit: A peg-in-hole assembly framework for unseen polygon shapes via sim-to-real adaptation[C]. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 2024: 533–540. doi: 10.1109/IROS58592.2024.10802554.
|
| [24] |
OTA K, JHA D K, JAIN S, et al. Autonomous robotic assembly: From part singulation to precise assembly[C]. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 2024: 13525–13532. doi: 10.1109/IROS58592.2024.10802423.
|
| [25] |
LIU Shilong, ZENG Zhaoyang, REN Tianhe, et al. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2025: 38–55. doi: 10.1007/978-3-031-72970-6_3.
|
| [26] |
RAVI N, GABEUR V, HU Yuanting, et al. SAM 2: Segment anything in images and videos[J]. arXiv preprint arXiv: 2408.00714, 2024. doi: 10.48550/arXiv.2408.00714.
|
| [27] |
RANGILYU. NanoDet-plus: Super fast and high accuracy lightweight anchor-free object detection model[EB/OL]. https://github.com/RangiLyu/nanodet, 2021.
|
| [28] |
HOWARD A, SANDLER M, CHEN Bo, et al. Searching for MobileNetV3[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 1314–1324. doi: 10.1109/ICCV.2019.00140.
|
| [29] |
张立建, 胡瑞钦, 易旺民. 基于六维力传感器的工业机器人末端负载受力感知研究[J]. 自动化学报, 2017, 43(3): 439–447. doi: 10.16383/j.aas.2017.c150753.
ZHANG Lijian, HU Ruiqin, and YI Wangmin. Research on force sensing for the end-load of industrial robot based on a 6-axis force/torque sensor[J]. Acta Automatica Sinica, 2017, 43(3): 439–447. doi: 10.16383/j.aas.2017.c150753.
|

Figures(13) / Tables(8)



 DownLoad:
DownLoad: