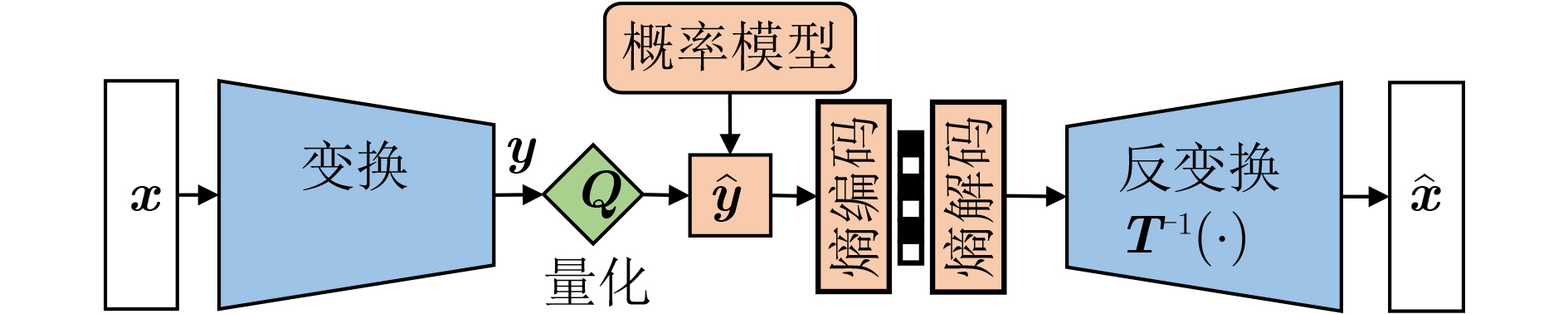
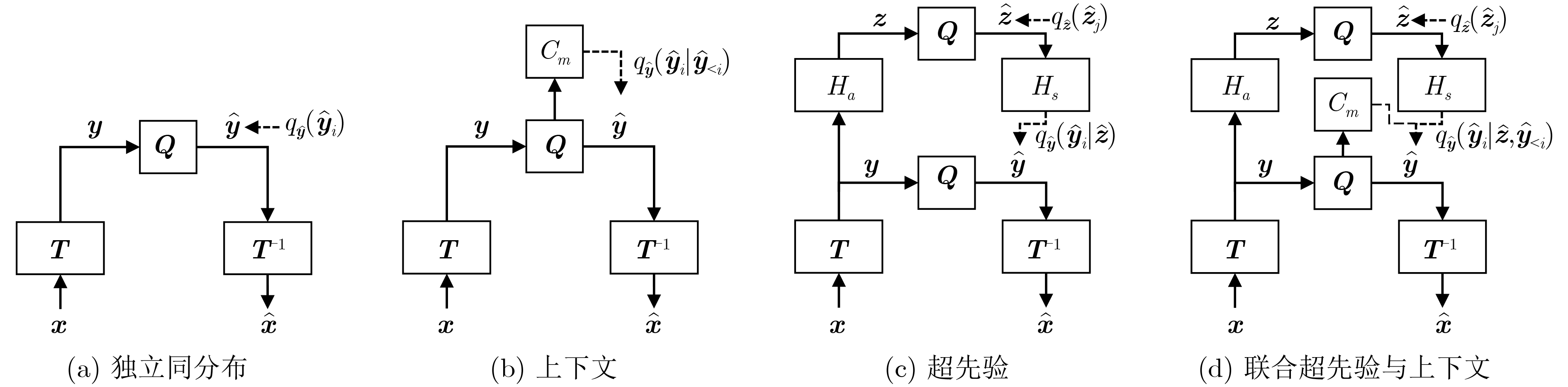
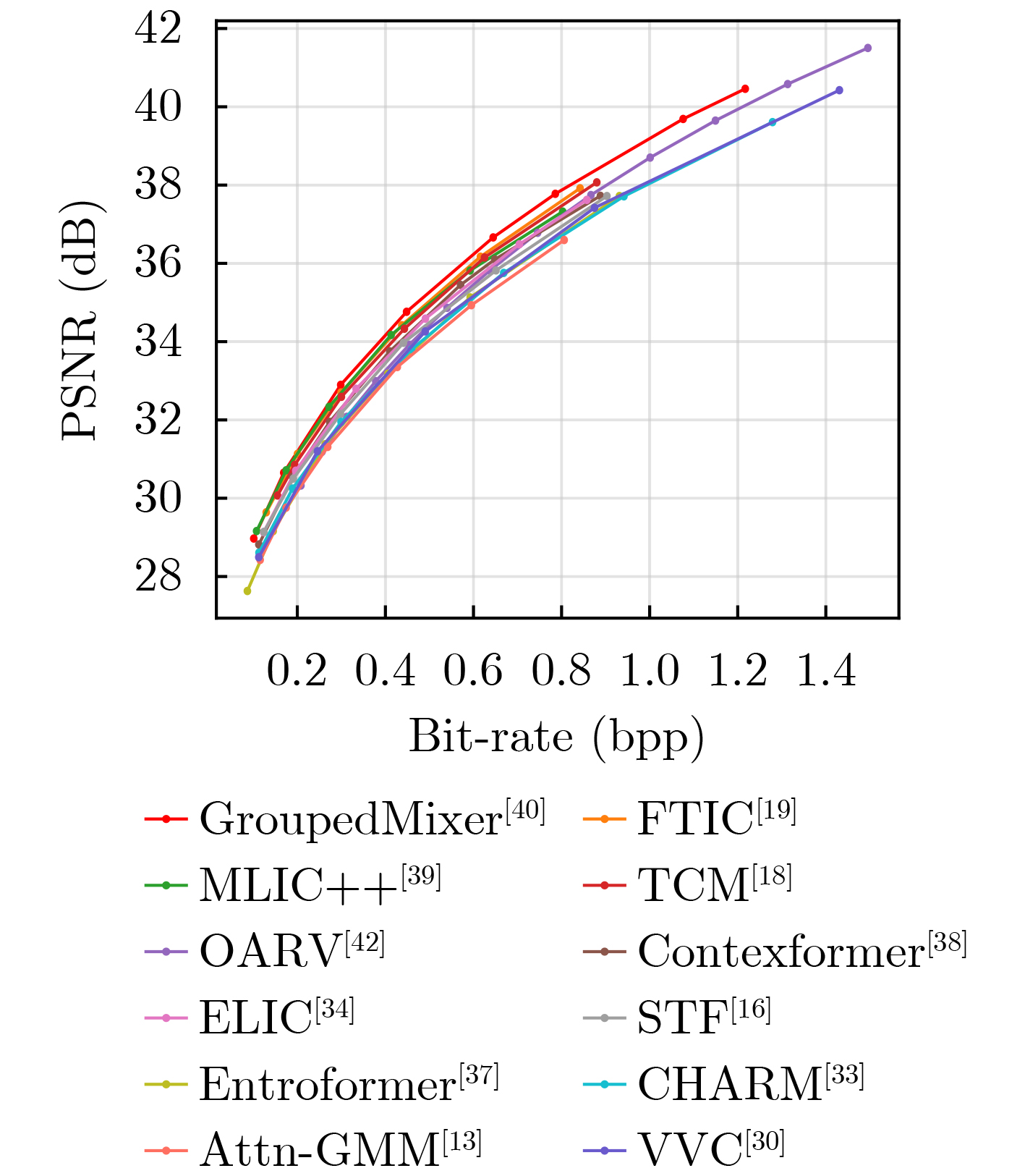
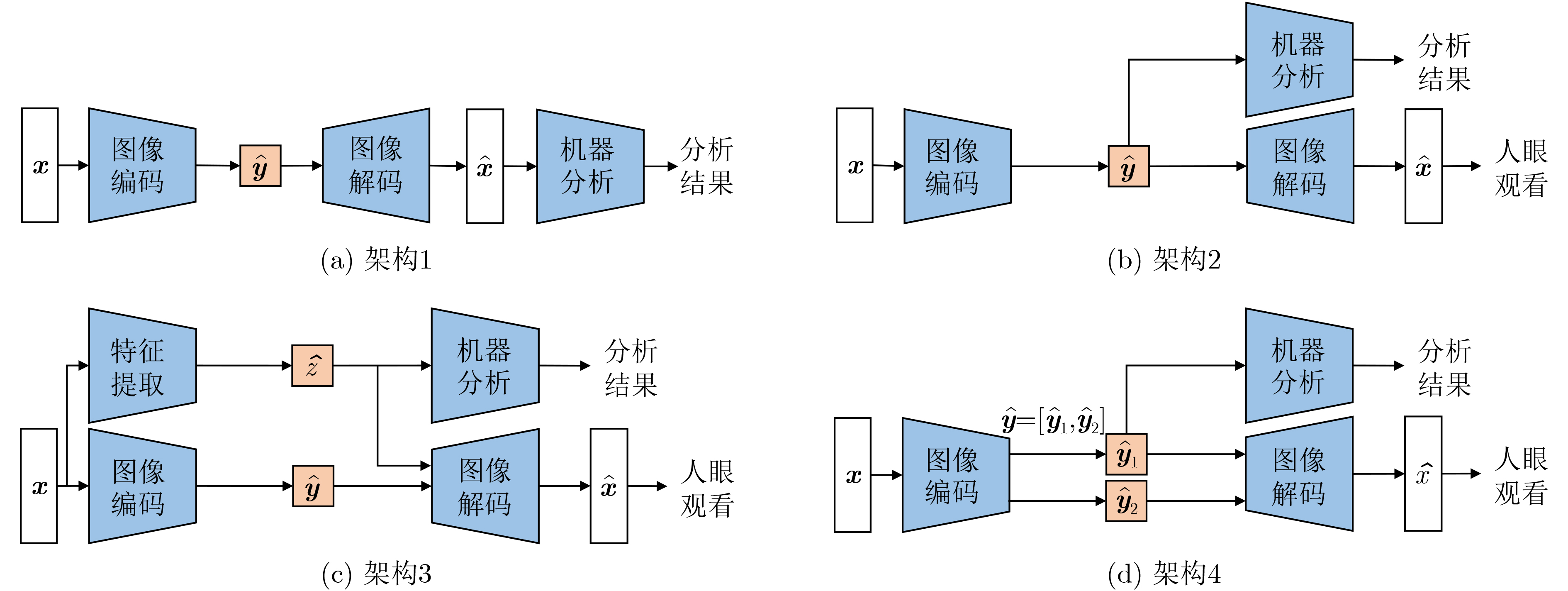
| Citation: | BAI Yuanchao, LIU Wenchang, JIANG Junjun, LIU Xianming. Advances in Deep Neural Network Based Image Compression: A Survey[J]. Journal of Electronics & Information Technology, 2025, 47(11): 4112-4128. doi: 10.11999/JEIT250567

|

| [1] |
BLAU Y and MICHAELI T. The perception-distortion tradeoff[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6228–6237. doi: 10.1109/CVPR.2018.00652.
|
| [2] |
BLAU Y and MICHAELI T. Rethinking lossy compression: The rate-distortion-perception tradeoff[C]. The 36th International Conference on Machine Learning, Long Beach, USA, 2019: 675–685.
|
| [3] |
YANG Wenhan, HUANG Haofeng, HU Yueyu, et al. Video coding for machines: Compact visual representation compression for intelligent collaborative analytics[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(7): 5174–5191. doi: 10.1109/TPAMI.2024.3367293.
|
| [4] |
高文, 田永鸿, 王坚. 数字视网膜: 智慧城市系统演进的关键环节[J]. 中国科学: 信息科学, 2018, 48(8): 1076–1082. doi: 10.1360/N112018-00025.
GAO Wen, TIAN Yonghong, and WANG Jian. Digital retina: Revolutionizing camera systems for the smart city[J]. SCIENTIA SINICA Informationis, 2018, 48(8): 1076–1082. doi: 10.1360/N112018-00025.
|
| [5] |
GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. The 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680.
|
| [6] |
HO J, JAIN A, and ABBEEL P. Denoising diffusion probabilistic models[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 574.
|
| [7] |
BALLÉ J, LAPARRA V, and SIMONCELLI E P. End-to-end optimized image compression[C]. The 5th International Conference on Learning Representations, Toulon, France, 2017.
|
| [8] |
THEIS L, SHI Wenzhe, CUNNINGHAM A, et al. Lossy image compression with compressive autoencoders[C]. The 5th International Conference on Learning Representations, Toulon, France, 2017.
|
| [9] |
WITTEN I H, NEAL R M, and CLEARY J G. Arithmetic coding for data compression[J]. Communications of the ACM, 1987, 30(6): 520–540. doi: 10.1145/214762.214771.
|
| [10] |
DUDA J. Asymmetric numeral systems[J]. arXiv: 0902.0271, 2009. doi: 10.48550/arXiv.0902.0271.
|
| [11] |
SHANNON C E. A mathematical theory of communication[J]. Bell System Technical Journal, 1948, 27(3): 379–423. doi: 10.1002/j.1538-7305.1948.tb01338.x.
|
| [12] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90.
|
| [13] |
CHENG Zhengxue, SUN Heming, TAKEUCHI M, et al. Learned image compression with discretized gaussian mixture likelihoods and attention modules[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7936–7945. doi: 10.1109/CVPR42600.2020.00796.
|
| [14] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021.
|
| [15] |
ZHU Yinhao, YANG Yang, and COHEN T. Transformer-based transform coding[C/OL]. The 10th International Conference on Learning Representations, 2022.
|
| [16] |
ZOU Renjie, SONG Chunfeng, and ZHANG Zhaoxiang. The devil is in the details: Window-based attention for image compression[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 17471–17480. doi: 10.1109/CVPR52688.2022.01697.
|
| [17] |
LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 9992–10002. doi: 10.1109/ICCV48922.2021.00986.
|
| [18] |
LIU Jinming, SUN Heming, and KATTO J. Learned image compression with mixed transformer-CNN architectures[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 14388–14397. doi: 10.1109/CVPR52729.2023.01383.
|
| [19] |
LI Han, LI Shaohui, DAI Wenrui, et al. Frequency-aware transformer for learned image compression[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024.
|
| [20] |
ZENG Fanhu, TANG Hao, SHAO Yihua, et al. MambaIC: State space models for high-performance learned image compression[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 18041–18050. doi: 10.1109/CVPR52734.2025.01681.
|
| [21] |
LI Mu, ZUO Wangmeng, GU Shuhang, et al. Learning content-weighted deep image compression[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3446–3461. doi: 10.1109/TPAMI.2020.2983926.
|
| [22] |
CUI Ze, WANG Jing, GAO Shangyin, et al. Asymmetric gained deep image compression with continuous rate adaptation[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 10527–10536. doi: 10.1109/CVPR46437.2021.01039.
|
| [23] |
GE Ziqing, MA Siwei, GAO Wen, et al. NLIC: Non-uniform quantization-based learned image compression[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(10): 9647–9663. doi: 10.1109/TCSVT.2024.3401872.
|
| [24] |
AGUSTSSON E and THEIS L. Universally quantized neural compression[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1037.
|
| [25] |
GUO Zongyu, ZHANG Zhizheng, FENG Runsen, et al. Soft then hard: Rethinking the quantization in neural image compression[C/OL]. The 38th International Conference on Machine Learning, 2021: 3920–3929.
|
| [26] |
YANG Yibo, BAMLER R, and MANDT S. Improving inference for neural image compression[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 49.
|
| [27] |
MENTZER F, AGUSTSSON E, TSCHANNEN M, et al. Conditional probability models for deep image compression[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 4394–4402. doi: 10.1109/CVPR.2018.00462.
|
| [28] |
BALLÉ J, MINNEN D, SINGH S, et al. Variational image compression with a scale hyperprior[C]. The 6th International Conference on Learning Representations, Vancouver, Canada, 2018.
|
| [29] |
MINNEN D, BALLÉ J, and TODERICI G D. Joint Autoregressive and hierarchical priors for learned image compression[C]. The 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 10794–10803.
|
| [30] |
BROSS B, WANG Yekui, YE Yan, et al. Overview of the Versatile Video Coding (VVC) standard and its applications[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(10): 3736–3764. doi: 10.1109/TCSVT.2021.3101953.
|
| [31] |
SALIMANS T, KARPATHY A, CHEN Xi, et al. PixelCNN++: Improving the PixelCNN with discretized logistic mixture likelihood and other modifications[C]. The 5th International Conference on Learning Representations, Toulon, France, 2017.
|
| [32] |
HE Dailan, ZHENG Yaoyan, SUN Baocheng, et al. Checkerboard context model for efficient learned image compression[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 14766–14775. doi: 10.1109/CVPR46437.2021.01453.
|
| [33] |
MINNEN D and SINGH S. Channel-wise autoregressive entropy models for learned image compression[C]. IEEE International Conference on Image Processing, Abu Dhabi, United Arab Emirates, 2020: 3339–3343. doi: 10.1109/ICIP40778.2020.9190935.
|
| [34] |
HE Dailan, YANG Ziming, PENG Weikun, et al. ELIC: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5708–5717. doi: 10.1109/CVPR52688.2022.00563.
|
| [35] |
MENTZER F, AGUSTSON E, and TSCHANNEN M. M2T: Masking transformers twice for faster decoding[C]. IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 5317–5326. doi: 10.1109/ICCV51070.2023.00492.
|
| [36] |
CHANG Huiwen, ZHANG Han, JIANG Lu, et al. MaskGIT: Masked generative image transformer[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11305–11315. doi: 10.1109/CVPR52688.2022.01103.
|
| [37] |
QIAN Yichen, SUN Xiuyu, LIN Ming, et al. Entroformer: A transformer-based entropy model for learned image compression[C/OL]. The 10th International Conference on Learning Representations, 2022.
|
| [38] |
KOYUNCU A B, GAO Han, BOEV A, et al. Contextformer: A transformer with spatio-channel attention for context modeling in learned image compression[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 447–463. doi: 10.1007/978-3-031-19800-7_26.
|
| [39] |
JIANG Wei, YANG Jiayu, ZHAI Yongqi, et al. MLIC++: Linear complexity multi-reference entropy modeling for learned image compression[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, 2025, 21(5): 142. doi: 10.1145/3719011.
|
| [40] |
LI Daxin, BAI Yuanchao, WANG Kai, et al. GroupedMixer: An entropy model with group-wise token-mixers for learned image compression[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(10): 9606–9619. doi: 10.1109/TCSVT.2024.3395481.
|
| [41] |
HU Yueyu, YANG Wenhan, MA Zhan, et al. Learning end-to-end lossy image compression: A benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(8): 4194–4211. doi: 10.1109/TPAMI.2021.3065339.
|
| [42] |
DUAN Zhihao, LU Ming, MA J, et al. QARV: Quantization-aware ResNet VAE for lossy image compression[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(1): 436–450. doi: 10.1109/TPAMI.2023.3322904.
|
| [43] |
LU Jingbo, ZHANG Leheng, ZHOU Xingyu, et al. Learned image compression with dictionary-based entropy model[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 12850–12859. doi: 10.1109/CVPR52734.2025.01199.
|
| [44] |
CHOI Y, EL-KHAMY M, and LEE J. Variable rate deep image compression with a conditional autoencoder[C]. IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 3146–3154. doi: 10.1109/ICCV.2019.00324.
|
| [45] |
YANG Fei, HERRANZ L, CHENG Yongmei, et al. Slimmable compressive autoencoders for practical neural image compression[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 4996–5005. doi: 10.1109/CVPR46437.2021.00496.
|
| [46] |
SONG M, CHOI J, and HAN B. Variable-rate deep image compression through spatially-adaptive feature transform[C]. IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 2360–2369. doi: 10.1109/ICCV48922.2021.00238.
|
| [47] |
GAO Chenjian, XU Tongda, HE Dailan, et al. Flexible neural image compression via code editing[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 885.
|
| [48] |
DIAZ Y P, GANSEKOELE A, and BHULAI S. Robustly overfitting latents for flexible neural image compression[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 3388.
|
| [49] |
IEEE. IEEE 1857.11-2024 IEEE standard for neural network-based image coding[S]. IEEE, 2024. doi: 10.1109/IEEESTD.2024.10810316.
|
| [50] |
ALSHINA E, ASCENSO J, and EBRAHIMI T. JPEG AI: The first international standard for image coding based on an end-to-end learning-based approach[J]. IEEE MultiMedia, 2024, 31(4): 60–69. doi: 10.1109/MMUL.2024.3485255.
|
| [51] |
JIA Chuanmin, HANG Xinyu, WANG Shanshe, et al. FPX-NIC: An FPGA-accelerated 4K ultra-high-definition neural video coding system[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(9): 6385–6399. doi: 10.1109/TCSVT.2022.3164059.
|
| [52] |
SUN Heming, YI Qingyang, and FUJITA M. FPGA codec system of learned image compression with algorithm-architecture co-optimization[J]. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2024, 14(2): 334–347. doi: 10.1109/JETCAS.2024.3386328.
|
| [53] |
AGUSTSSON E, TSCHANNEN M, MENTZER F, et al. Generative adversarial networks for extreme learned image compression[C]. IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 221–231. doi: 10.1109/ICCV.2019.00031.
|
| [54] |
MENTZER F, TODERICI G, TSCHANNEN M, et al. High-fidelity generative image compression[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 999.
|
| [55] |
MUCKLEY M, EL-NOUBY A, ULLRICH K, et al. Improving statistical fidelity for neural image compression with implicit local likelihood models[C]. The 40th International Conference on Machine Learning, Honolulu, USA, 2023: 25426–25443.
|
| [56] |
KÖRBER N, KROMER E, SIEBERT A, et al. EGIC: Enhanced low-bit-rate generative image compression guided by semantic segmentation[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 202–220. doi: 10.1007/978-3-031-72761-0_12.
|
| [57] |
ZHANG G, QIAN Jingjing, CHEN Jun, et al. Universal rate-distortion-perception representations for lossy compression[C/OL]. The 35th International Conference on Neural Information Processing Systems, 2021: 880.
|
| [58] |
YAN Zeyu, WEN Fei, and LIU Peilin. Optimally controllable perceptual lossy compression[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 24911–24928.
|
| [59] |
AGUSTSSON E, MINNEN D, TODERICI G, et al. Multi-realism image compression with a conditional generator[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 22324–22333. doi: 10.1109/CVPR52729.2023.02138.
|
| [60] |
HOOGEBOOM E, AGUSTSSON E, MENTZER F, et al. High-fidelity image compression with score-based generative models[J]. arXiv: 2305.18231, 2024. doi: 10.48550/arXiv.2305.18231.
|
| [61] |
GHOUSE N F, PETERSEN J, WIGGERS A, et al. A residual diffusion model for high perceptual quality codec augmentation[J]. arXiv: 2301.05489, 2023. doi: 10.48550/arXiv.2301.05489.
|
| [62] |
YANG Ruihan and MANDT S. Lossy image compression with conditional diffusion models[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 2835.
|
| [63] |
KHOSHKHAHTINAT A, ZAFARI A, MEHTA P M, et al. Laplacian-guided entropy model in neural codec with blur-dissipated synthesis[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 3045–3054. doi: 10.1109/CVPR52733.2024.00294.
|
| [64] |
HOOGEBOOM E and SALIMANS T. Blurring diffusion models[C]. The 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.
|
| [65] |
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10674–10685. doi: 10.1109/CVPR52688.2022.01042.
|
| [66] |
RELIC L, AZEVEDO R, GROSS M, et al. Lossy image compression with foundation diffusion models[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 303–319. doi: 10.1007/978-3-031-73030-6_17.
|
| [67] |
CAREIL M, MUCKLEY M J, VERBEEK J, et al. Towards image compression with perfect realism at ultra-low bitrates[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024.
|
| [68] |
LI Zhiyuan, ZHOU Yanhui, WEI Hao, et al. Toward extreme image compression with latent feature guidance and diffusion prior[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(1): 888–899. doi: 10.1109/TCSVT.2024.3455576.
|
| [69] |
SHI Guangming, XIAO Yong, LI Yingyu, et al. From semantic communication to semantic-aware networking: Model, architecture, and open problems[J]. IEEE Communications Magazine, 2021, 59(8): 44–50. doi: 10.1109/MCOM.001.2001239.
|
| [70] |
牛凯, 张平. 语义通信的数学理论[J]. 通信学报, 2024, 45(6): 7–59. doi: 10.11959/j.issn.1000-436x.2024111.
NIU Kai and ZHANG Ping. A mathematical theory of semantic communication[J]. Journal of Communications, 2024, 45(6): 7–59. doi: 10.11959/j.issn.1000-436x.2024111.
|
| [71] |
VAN DEN OORD A, LI Yazhe, and VINYALS O. Representation learning with contrastive predictive coding[J]. arXiv: 1807.03748, 2018. doi: 10.48550/arXiv.1807.03748.
|
| [72] |
HE Kaiming, FAN Haoqi, WU Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 9726–9735. doi: 10.1109/CVPR42600.2020.00975.
|
| [73] |
HE Kaiming, CHEN Xinlei, XIE Saining, et al. Masked autoencoders are scalable vision learners[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 15979–15988. doi: 10.1109/CVPR52688.2022.01553.
|
| [74] |
WANG Shurun, WANG Zhao, WANG Shiqi, et al. Deep image compression toward machine vision: A unified optimization framework[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(6): 2979–2989. doi: 10.1109/TCSVT.2022.3230843.
|
| [75] |
CHEN Y, WENG Y, KAO C, et al. TransTIC: Transferring transformer-based image compression from human perception to machine perception[C]. IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 23240–23250. doi: 10.1109/ICCV51070.2023.02129.
|
| [76] |
JIA Menglin, TANG Luming, CHEN B, et al. Visual prompt tuning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 709–727. doi: 10.1007/978-3-031-19827-4_41.
|
| [77] |
LI Han, LI Shaohui, DING Shuangrui, et al. Image compression for machine and human vision with spatial-frequency adaptation[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 382–399. doi: 10.1007/978-3-031-72983-6_22.
|
| [78] |
YANG Zhaohui, WANG Yunhe, XU Chang, et al. Discernible image compression[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 1561–1569. doi: 10.1145/3394171.3413968.
|
| [79] |
ZHANG Qi, WANG Shanshe, ZHANG Xinfeng, et al. Just recognizable distortion for machine vision oriented image and video coding[J]. International Journal of Computer Vision, 2021, 129(10): 2889–2906. doi: 10.1007/s11263-021-01505-4.
|
| [80] |
ZHANG Qi, WANG Shanshe, ZHANG Xinfeng, et al. Perceptual video coding for machines via satisfied machine ratio modeling[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 7651–7668. doi: 10.1109/TPAMI.2024.3393633.
|
| [81] |
DUBOIS Y, BLOEM-REDDY B, ULLRICH K, et al. Lossy compression for lossless prediction[C/OL]. The 35th International Conference on Neural Information Processing Systems, 2021: 1074.
|
| [82] |
FENG Ruoyu, JIN Xin, GUO Zongyu, et al. Image coding for machines with omnipotent feature learning[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 510–528. doi: 10.1007/978-3-031-19836-6_29.
|
| [83] |
TIAN Yuan, LU Guo, ZHAI Guangtao, et al. Non-semantics suppressed mask learning for unsupervised video semantic compression[C]. IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 13564–13576. doi: 10.1109/ICCV51070.2023.01252.
|
| [84] |
TIAN Yuan, LU Guo, and ZHAI Guangtao. Free-VSC: Free semantics from visual foundation models for unsupervised video semantic compression[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 163–183. doi: 10.1007/978-3-031-72967-6_10.
|
| [85] |
BAI Yuanchao, YANG Xu, LIU Xianming, et al. Towards end-to-end image compression and analysis with transformers[C]. The 36th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2022: 104–112. doi: 10.1609/aaai.v36i1.19884
|
| [86] |
WANG Shurun, WANG Shiqi, YANG Wenhan, et al. Towards analysis-friendly face representation with scalable feature and texture compression[J]. IEEE Transactions on Multimedia, 2022, 24: 3169–3181. doi: 10.1109/TMM.2021.3094300.
|
| [87] |
LIU Jinming, FENG Ruoyu, QI Yunpeng, et al. Rate-distortion-cognition controllable versatile neural image compression[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 329–348. doi: 10.1007/978-3-031-72992-8_19.
|
| [88] |
CHOI H and BAJIĆ I V. Scalable image coding for humans and machines[J]. IEEE Transactions on Image Processing, 2022, 31: 2739–2754. doi: 10.1109/TIP.2022.3160602.
|
| [89] |
LIU Lei, HU Zhihao, CHEN Zhenghao, et al. ICMH-Net: Neural image compression towards both machine vision and human vision[C]. The 31st ACM International Conference on Multimedia, Ottawa, Canada, 2023: 8047–8056. doi: 10.1145/3581783.3612041.
|
| [90] |
YU Yi, WANG Yufei, YANG Wenhan, et al. Backdoor attacks against deep image compression via adaptive frequency trigger[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 12250–12259. doi: 10.1109/CVPR52729.2023.01179.
|
| [91] |
CHEN Tong and MA Zhan. Toward robust neural image compression: Adversarial attack and model finetuning[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(12): 7842–7856. doi: 10.1109/TCSVT.2023.3276442.
|
| [92] |
DUAN Zhihao, LU Ming, YANG J, et al. Towards backward-compatible continual learning of image compression[C]. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 25564–25573. doi: 10.1109/CVPR52733.2024.02415.
|

Figures(8) / Tables(2)



 DownLoad:
DownLoad: