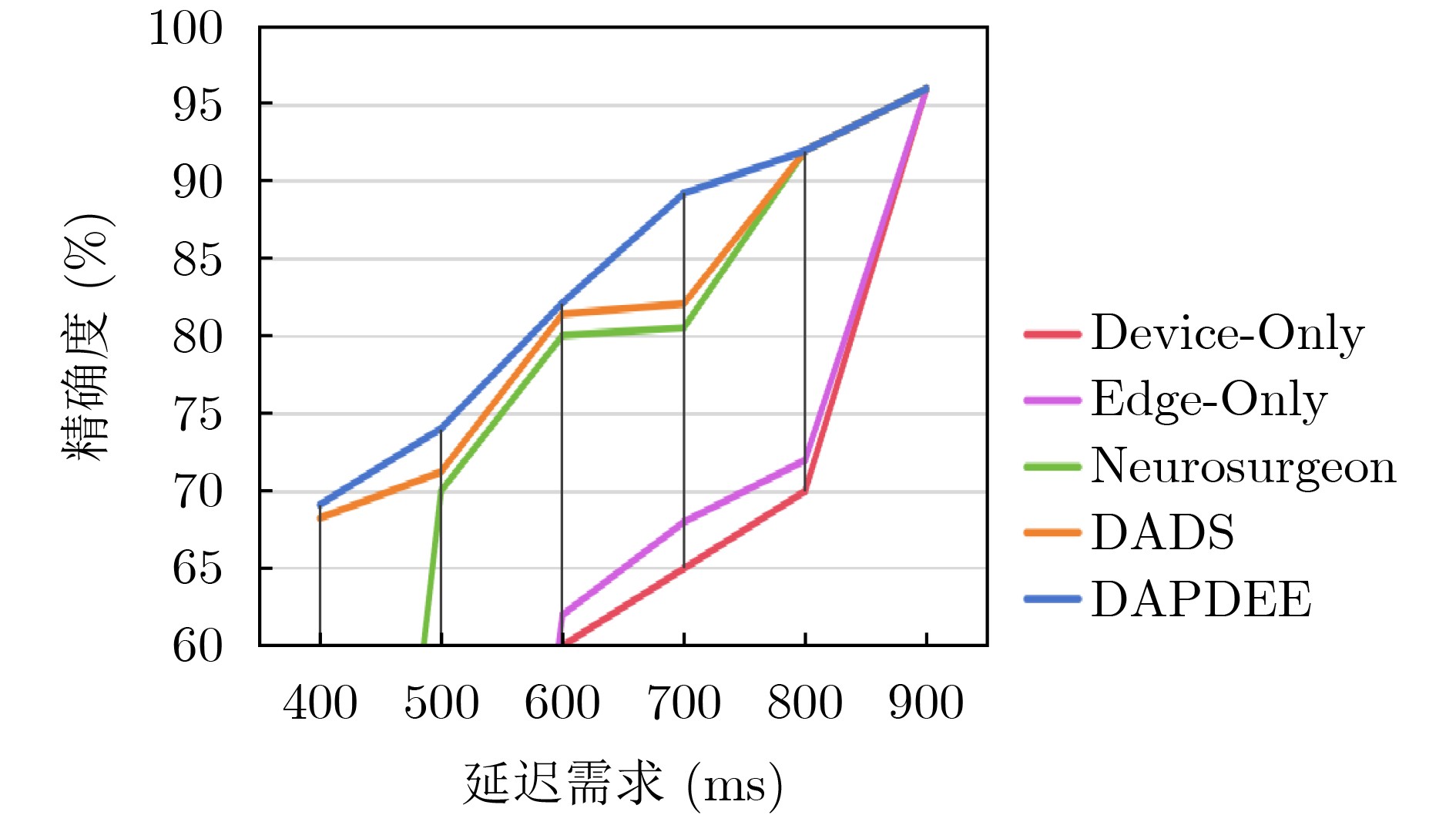
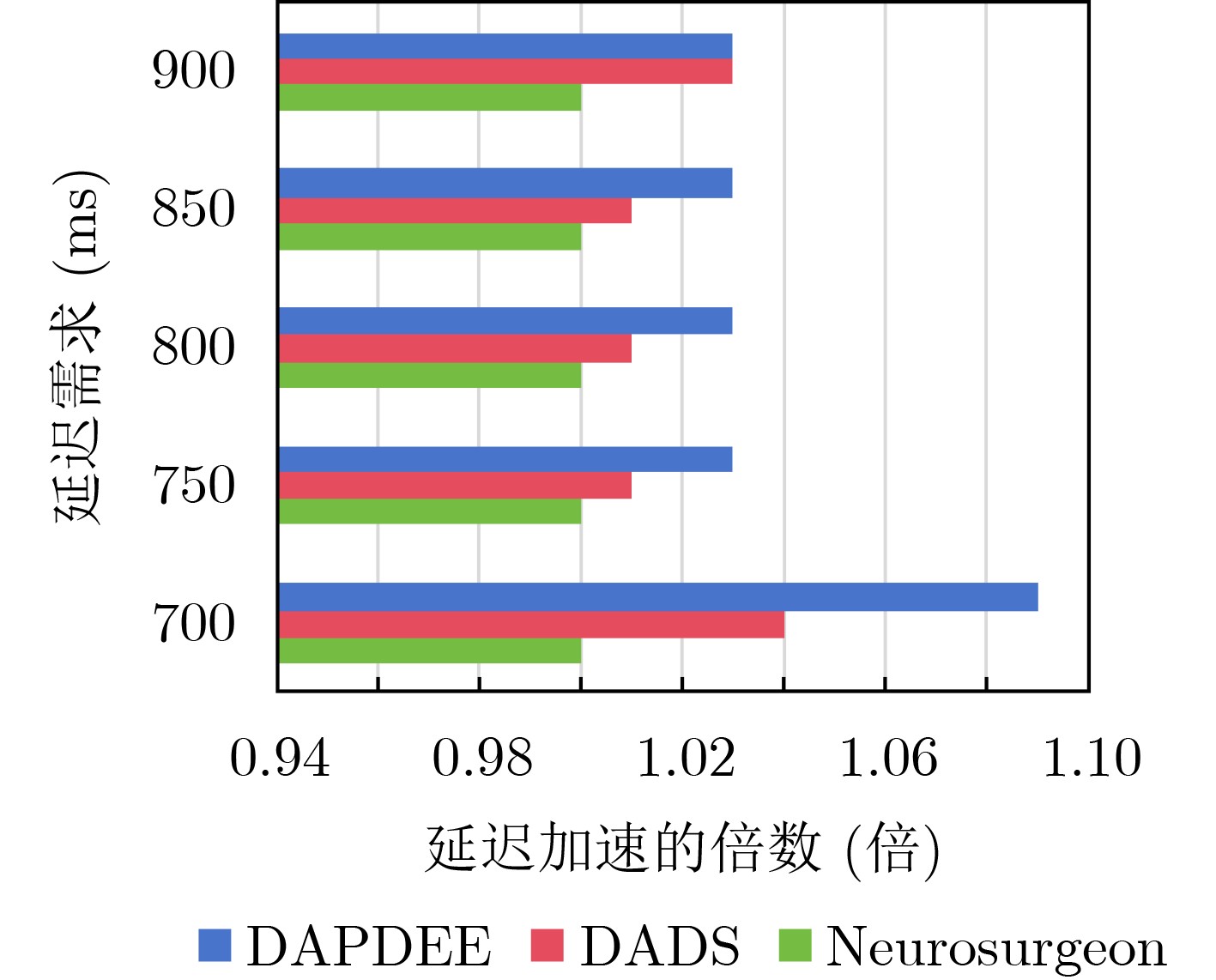
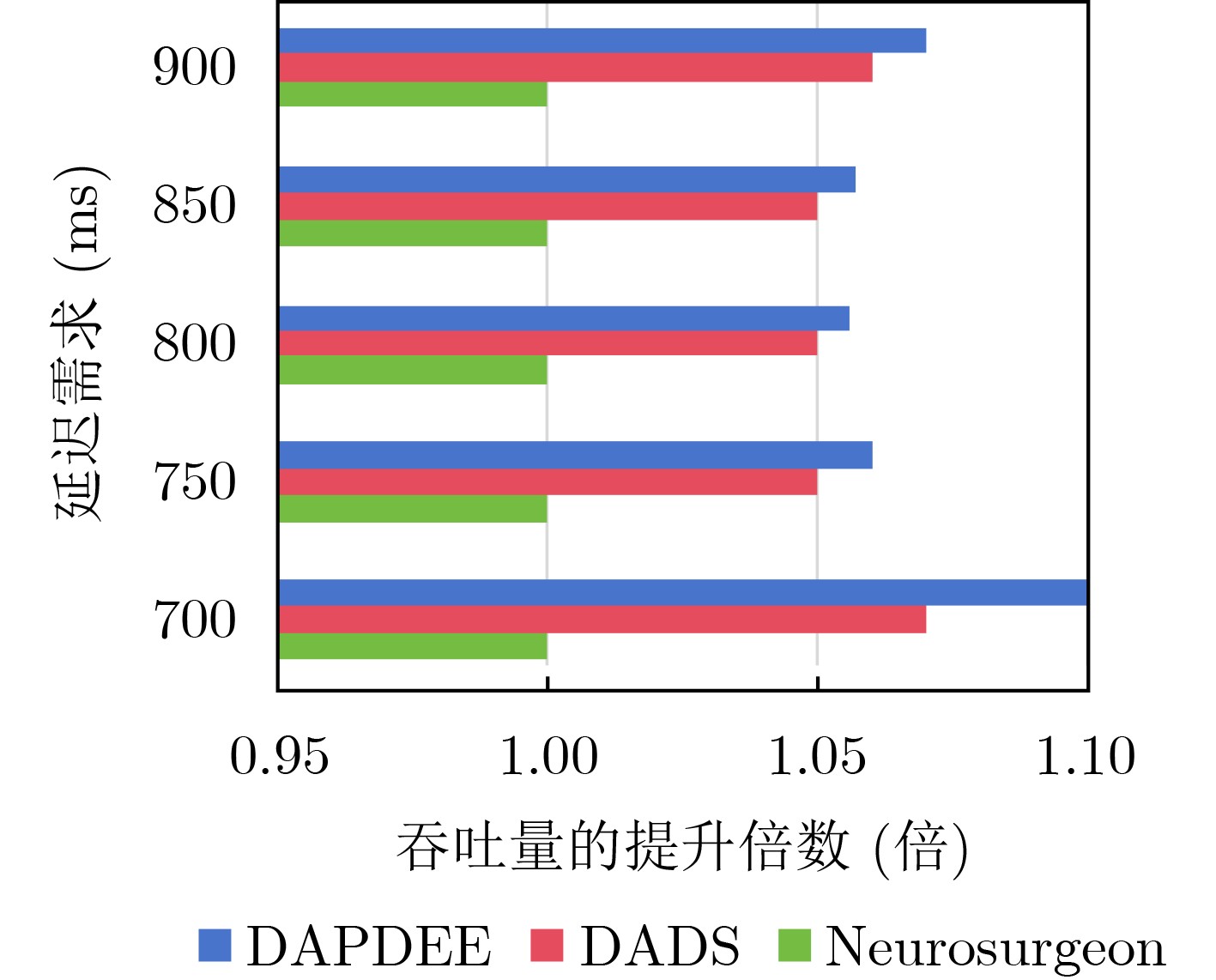
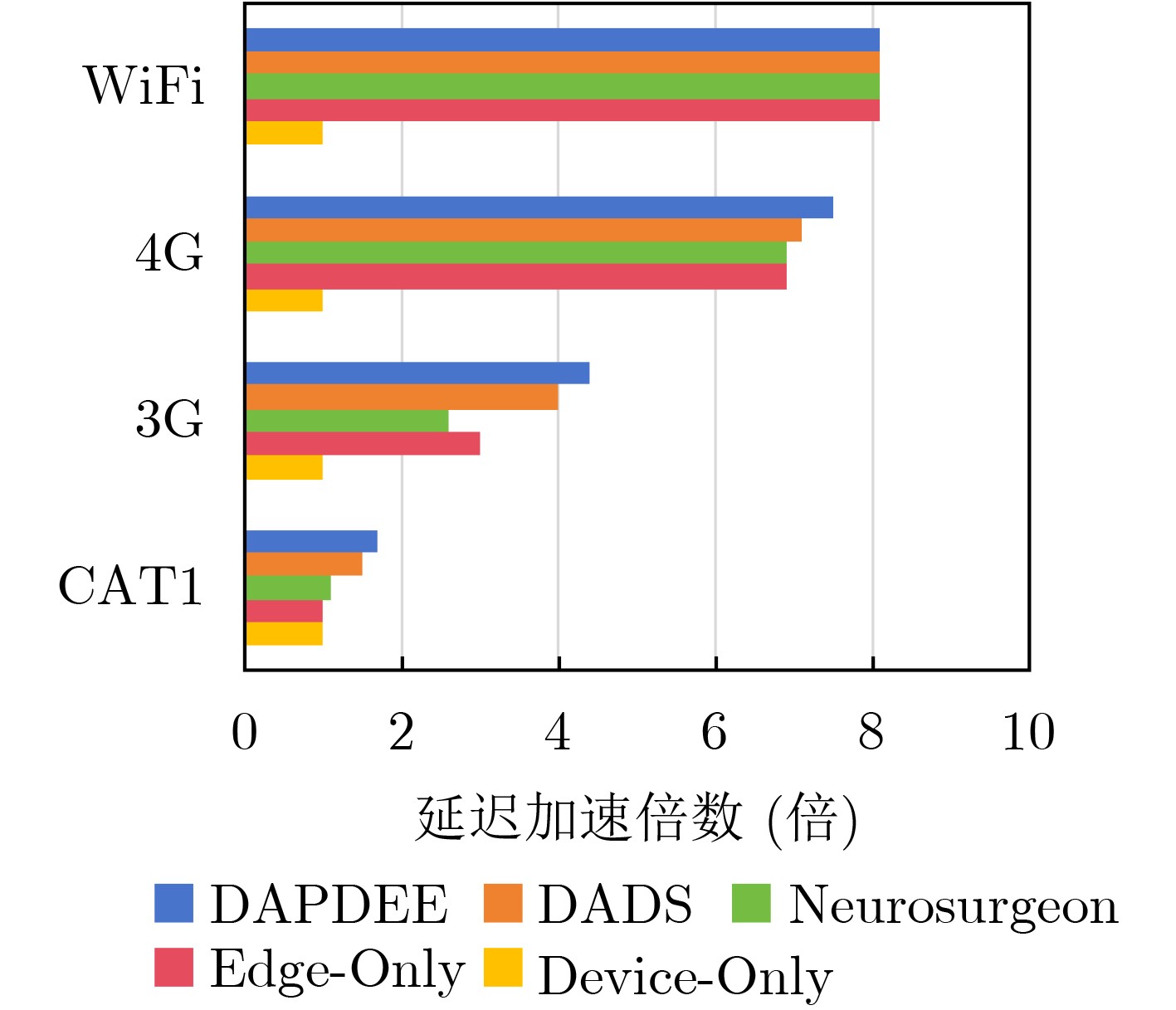
| Citation: | DING Nan, WANG Jiajia, JI Chenghui, HU Chuangye, XU Li. Dynamic Adaptive Partitioning of Deep Neural Networks Based on Early Exit Mechanism under Edge-End Collaboration[J]. Journal of Electronics & Information Technology, 2025, 47(10): 4005-4017. doi: 10.11999/JEIT250291

|

| [1] |
BASHA S H S, FARAZUDDIN M, PULABAIGARI V, et al. Deep model compression based on the training history[J]. Neurocomputing, 2024, 573: 127257. doi: 10.1016/j.neucom.2024.127257.
|
| [2] |
CHENG Hongrong, ZHANG Miao, and SHI J Q. A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 10558–10578. doi: 10.1109/TPAMI.2024.3447085.
|
| [3] |
HUANG Mingzhong, LIU Yan, ZHAO Lijie, et al. A lightweight deep neural network model and its applications based on channel pruning and group vector quantization[J]. Neural Computing and Applications, 2024, 36(10): 5333–5346. doi: 10.1007/s00521-023-09332-z.
|
| [4] |
SAPKAL A, HEISNAM L, and KUSI S S. Evolution of cloud computing: Milestones, innovations, and adoption trends[J]. International Research Journal of Engineering and Technology (IRJET), 2024, 11(3): 548–563.
|
| [5] |
FU Ziyan, ZHOU Yuezhi, WU Chao, et al. Joint optimization of data transfer and co-execution for DNN in edge computing[C]. ICC 2021-IEEE International Conference on Communications, Montreal, Canada, 2021: 1–6. doi: 10.1109/ICC42927.2021.9500513.
|
| [6] |
曹绍华, 陈辉, 陈舒, 等. AccFed: 物联网中基于模型分割的联邦学习加速[J]. 电子与信息学报, 2023, 45(5): 1678–1687. doi: 10.11999/JEIT220240.
CAO Shaohua, CHEN Hui, CHEN Shu, et al. AccFed: Federated learning acceleration based on model partitioning in internet of things[J]. Journal of Electronics & Information Technology, 2023, 45(5): 1678–1687. doi: 10.11999/JEIT220240.
|
| [7] |
WANG Yingchao, YANG Chen, LAN Shulin, et al. End-edge-cloud collaborative computing for deep learning: A comprehensive survey[J]. IEEE Communications Surveys & Tutorials, 2024, 26(4): 2647–2683. doi: 10.1109/COMST.2024.3393230.
|
| [8] |
LIANG Huanghuang, SANG Qianlong, HU Chuang, et al. DNN surgery: Accelerating DNN inference on the edge through layer partitioning[J]. IEEE Transactions on Cloud Computing, 2023, 11(3): 3111–3125. doi: 10.1109/TCC.2023.3258982.
|
| [9] |
李峰, 毕冉, 马野, 等. 带优先级DAG实时任务图模型的响应时间分析[J]. 计算机学报, 2024, 47(12): 2909–2924. doi: 10.11897/SP.J.1016.2024.02909.
LI Feng, BI Ran, MA Ye, et al. Response time analysis for prioritized DAG task[J]. Chinese Journal of Computers, 2024, 47(12): 2909–2924. doi: 10.11897/SP.J.1016.2024.02909.
|
| [10] |
RAHMATH P H, SRIVASTAVA V, CHAURASIA K, et al. Early-exit deep neural network - A comprehensive survey[J]. ACM Computing Surveys, 2024, 57(3): 75. doi: 10.1145/3698767.
|
| [11] |
KANG, Yiping, HAUSWALD J, GAO Cao, et al. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge[C]. The Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, Xi’an, China, 2017: 615–629. doi: 10.1145/3037697.3037698.
|
| [12] |
HU Chuang, BAO Wei, WANG Dan, et al. Dynamic adaptive DNN surgery for inference acceleration on the edge[C]. IEEE INFOCOM 2019 - IEEE Conference on Computer Communications, Paris, France, 2019: 1423–1431. doi: 10.1109/INFOCOM.2019.8737614.
|
| [13] |
WANG Huitian, CAI Guangxing, HUANG Zhaowu, et al. ADDA: Adaptive distributed DNN inference acceleration in edge computing environment[C]. 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 2019: 438–445. doi: 10.1109/ICPADS47876.2019.00069.
|
| [14] |
施建锋, 陈忻阳, 李宝龙. 面向物联网的云边端协同计算中任务卸载与资源分配算法研究[J]. 电子与信息学报, 2025, 47(2): 458–469. doi: 10.11999/JEIT240659.
SHI Jianfeng, CHEN Xinyang, and LI Baolong. Research on task offloading and resource allocation algorithms in cloud-edge-end collaborative computing for the internet of things[J]. Journal of Electronics & Information Technology, 2025, 47(2): 458–469. doi: 10.11999/JEIT240659.
|
| [15] |
TEERAPITTAYANON S, MCDANEL B, and KUNG H T. BranchyNet: Fast inference via early exiting from deep neural networks[C]. 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 2016: 2464–2469. doi: 10.1109/ICPR.2016.7900006.
|
| [16] |
TEERAPITTAYANON S, MCDANEL B, and KUNG H T. Distributed deep neural networks over the cloud, the edge and end devices[C]. 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, USA, 2017: 328–339. doi: 10.1109/ICDCS.2017.226.
|
| [17] |
LANE N, BHATTACHARYA S, MATHUR A, et al. DXTK: Enabling resource-efficient deep learning on mobile and embedded devices with the DeepX toolkit[C]. The 8th EAI International Conference on Mobile Computing, Applications and Services, Cambridge, UK, 2016: 98–107. doi: 10.4108/eai.30-11-2016.2267463.
|
Figures(17) / Tables(4)



 DownLoad:
DownLoad: