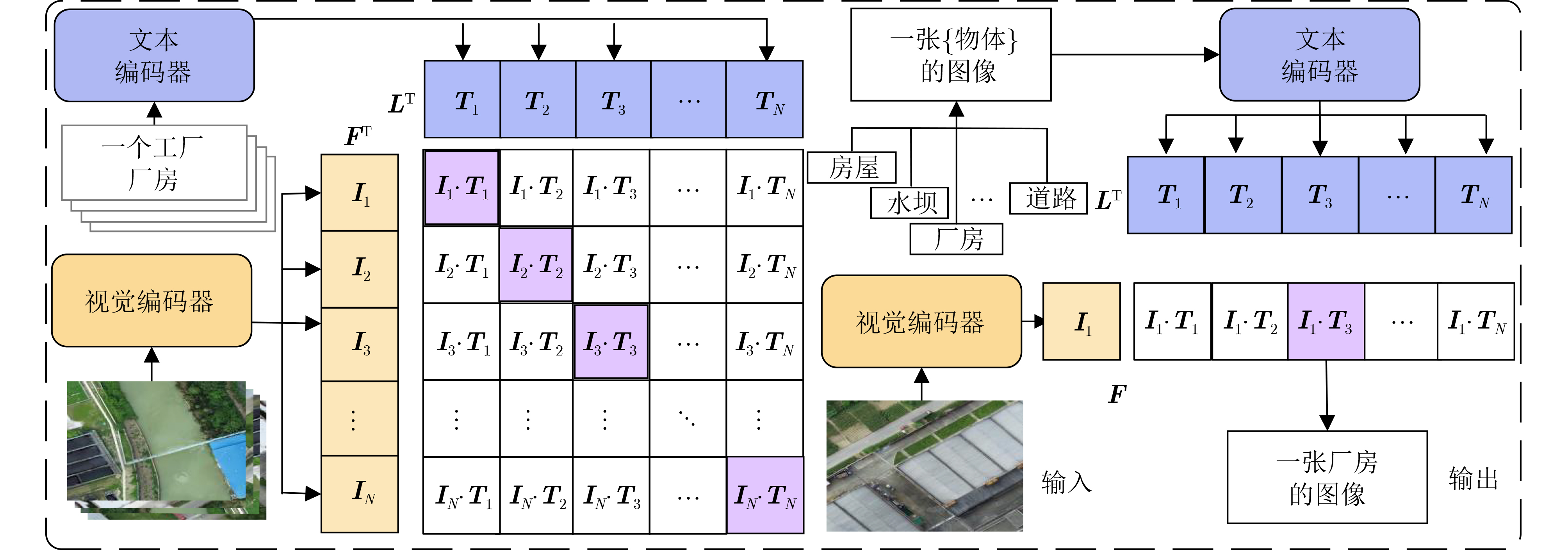
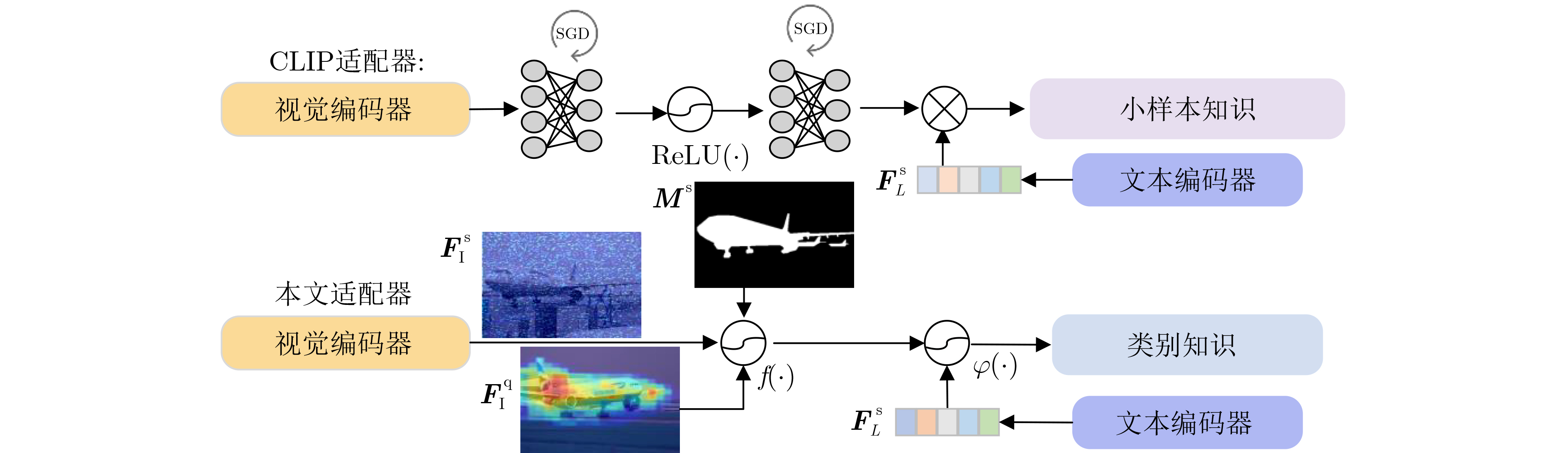
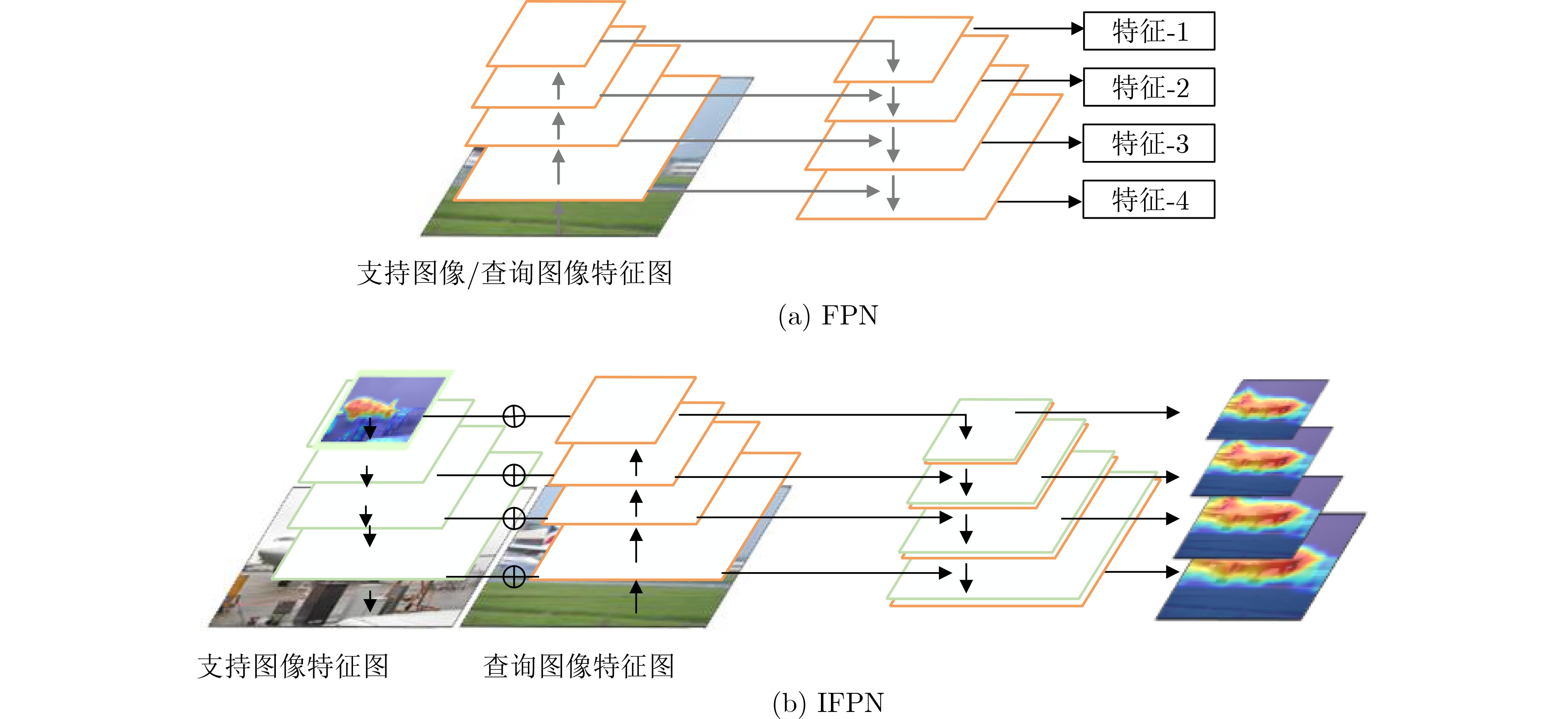
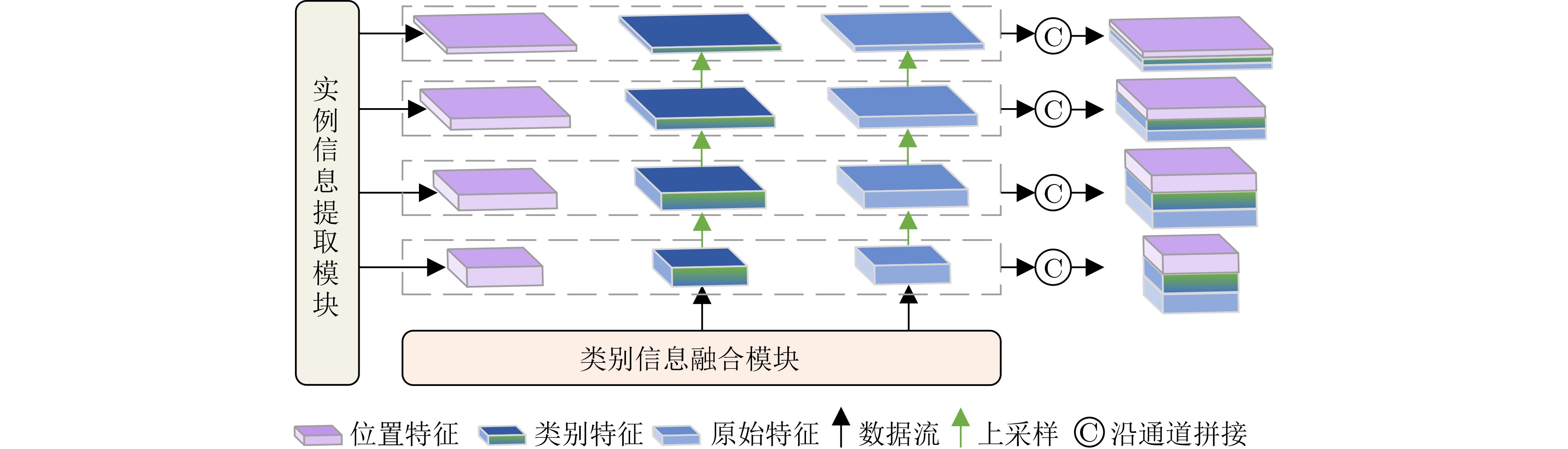
| Citation: | ZHOU Wei, WEI Mingan, XU Haixia, WU Zhiming. A Few-Shot Land Cover Classification Model for Remote Sensing Images Based on Multimodality[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1747-1761. doi: 10.11999/JEIT241057

|

| [1] |
谢雯, 王若男, 羊鑫, 等. 融合深度可分离卷积的多尺度残差UNet在PolSAR地物分类中的研究[J]. 电子与信息学报, 2023, 45(8): 2975–2985. doi: 10.11999/JEIT220867.
XIE Wen, WANG Ruonan, YANG Xin, et al. Research on multi-scale residual UNet fused with depthwise separable convolution in PolSAR terrain classification[J]. Journal of Electronics & Information Technology, 2023, 45(8): 2975–2985. doi: 10.11999/JEIT220867.
|
| [2] |
LONG J, SHELHAMER E, and DARRELL T. Fully convolutional networks for semantic segmentation[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015. doi: 10.1109/CVPR.2015.7298965.
|
| [3] |
ZHOU Zongwei, RAHMAN SIDDIQUEE M, TAJBAKHSH N, et al. UNet++: A nested U-Net architecture for medical image segmentation[C]. The 4th International Workshop Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 2018. doi: 10.1007/978-3-030-00889-5_1.
|
| [4] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. doi: 10.1109/TPAMI.2017.2699184.
|
| [5] |
SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. The 3rd International Conference on Learning Representations, San Diego, USA, 2015.
|
| [6] |
HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016. doi: 10.1109/CVPR.2016.90.
|
| [7] |
XU Zhiyong, ZHANG Weicun, ZHANG Tianxiang, et al. Efficient transformer for remote sensing image segmentation[J]. Remote Sensing, 2021, 13(18): 3585. doi: 10.3390/rs13183585.
|
| [8] |
MA Xianping, ZHANG Xiaokang, PUN M O, et al. A multilevel multimodal fusion transformer for remote sensing semantic segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5403215. doi: 10.1109/TGRS.2024.3373033.
|
| [9] |
CRESWELL A, WHITE T, DUMOULIN V, et al. Generative adversarial networks: An overview[J]. IEEE Signal Processing Magazine, 2018, 35(1): 53–65. doi: 10.1109/MSP.2017.2765202.
|
| [10] |
PAN S J and YANG Qiang. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345–1359. doi: 10.1109/TKDE.2009.191.
|
| [11] |
陈龙, 张建林, 彭昊, 等. 多尺度注意力与领域自适应的小样本图像识别[J]. 光电工程, 2023, 50(4): 220232. doi: 10.12086/oee.2023.220232.
CHEN Long, ZHANG Jianlin, PENG Hao, et al. Few-shot image classification via multi-scale attention and domain adaptation[J]. Opto-Electronic Engineering, 2023, 50(4): 220232. doi: 10.12086/oee.2023.220232.
|
| [12] |
RAKELLY K, SHELHAMER E, DARRELL T, et al. Few-shot segmentation propagation with guided networks[J]. arXiv preprint arXiv: 1806.07373, 2018.
|
| [13] |
ZHANG Chi, LIN Guosheng, LIU Fayao, et al. CANet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019. doi: 10.1109/CVPR.2019.00536.
|
| [14] |
刘晓敏, 余梦君, 乔振壮, 等. 面向多源遥感数据分类的尺度自适应融合网络[J]. 电子与信息学报, 2024, 46(9): 3693–3702. doi: 10.11999/JEIT240178.
LIU Xiaomin, YU Mengjun, QIAO Zhenzhuang, et al. Scale adaptive fusion network for multimodal remote sensing data classification[J]. Journal of Electronics & Information Technology, 2024, 46(9): 3693–3702. doi: 10.11999/JEIT240178.
|
| [15] |
LI Boyi, WEINBERGER K Q, BELONGIE S J, et al. Language-driven semantic segmentation[C]. The 10th International Conference on Learning Representations, 2022.
|
| [16] |
XU Mengde, ZHANG Zheng, WEI Fangyun, et al. A simple baseline for open-vocabulary semantic segmentation with pre-trained vision-language model[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022. doi: 10.1007/978-3-031-19818-2_42.
|
| [17] |
YANG Yong, CHEN Qiong, FENG Yuan, et al. MIANet: Aggregating unbiased instance and general information for few-shot semantic segmentation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023. doi: 10.1109/CVPR52729.2023.00689.
|
| [18] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, 2021.
|
| [19] |
LIN Bingqian, ZHU Yi, CHEN Zicong, et al. ADAPT: Vision-language navigation with modality-aligned action prompts[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.01496.
|
| [20] |
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017. doi: 10.1109/CVPR.2017.106.
|
| [21] |
EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The PASCAL visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. doi: 10.1007/s11263-009-0275-4.
|
| [22] |
WANG Junjue, ZHENG Zhuo, MA Ailong, et al. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation[C]. The 1st Neural Information Processing Systems Track on Datasets and Benchmarks, 2021.
|
| [23] |
KRIZHEVSKY A. Convolutional deep belief networks on cifar-10[J]. Unpublished Manuscript, 2010, 40(7): 1–9.
|
| [24] |
HENDRYCKS D and DIETTERICH T G. Benchmarking neural network robustness to common corruptions and perturbations[C]. The 7th International Conference on Learning Representations, New Orleans, USA, 2019.
|
| [25] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, 2021.
|
| [26] |
OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: Learning robust visual features without supervision[J]. Transactions on Machine Learning Research Journal, 2024.
|
| [27] |
GESMUNDO A and DEAN J. An evolutionary approach to dynamic introduction of tasks in large-scale multitask learning systems[J]. arXiv preprint arXiv: 2205.12755, 2022.
|
| [28] |
YUAN Kun, GUO Shaopeng, LIU Ziwei, et al. Incorporating convolution designs into visual transformers[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021. doi: 10.1109/ICCV48922.2021.00062.
|
| [29] |
DAGLI R. Astroformer: More Data Might not be all you need for Classification[J]. arXiv preprint arXiv: 2304.05350, 2023.
|
| [30] |
LEE M, KIM D, and SHIM H. Threshold matters in WSSS: Manipulating the activation for the robust and accurate segmentation model against thresholds[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.00429.
|
| [31] |
RONG Shenghai, TU Bohai, WANG Zilei, et al. Boundary-enhanced Co-training for weakly supervised semantic segmentation[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023. doi: 10.1109/CVPR52729.2023.01875.
|
| [32] |
CHEN Zhaozheng and SUN Qianru. Extracting class activation maps from non-discriminative features as well[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023. doi: 10.1109/CVPR52729.2023.00306.
|
| [33] |
HAN W, KANG S, CHOO K, et al. CoBra: Complementary branch fusing class and semantic knowledge for robust weakly supervised semantic segmentation[J]. arXiv preprint arXiv: 2403.08801, 2024.
|
| [34] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017. doi: 10.1109/ICCV.2017.74.
|
| [35] |
CHEN L C, ZHU Yukun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018. doi: 10.1007/978-3-030-01234-2_49.
|
| [36] |
LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021. doi: 10.1109/ICCV48922.2021.00986.
|
| [37] |
WANG Libo, LI Rui, DUAN Chenxi, et al. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 6506105. doi: 10.1109/LGRS.2022.3143368.
|
| [38] |
WANG Libo, LI Rui, ZHANG Ce, et al. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 190: 196–214. doi: 10.1016/j.isprsjprs.2022.06.008.
|
| [39] |
CHEN Yuxia, FANG Pengcheng, YU Jianhui, et al. Hi-ResNet: Edge detail enhancement for high-resolution remote sensing segmentation[J]. arXiv preprint arXiv: 2305.12691, 2023.
|
| [40] |
TIAN Zhuotao, ZHAO Hengshuang, SHU M, et al. Prior guided feature enrichment network for few-shot segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(2): 1050–1065. doi: 10.1109/TPAMI.2020.3013717.
|
| [41] |
WANG Haohan, LIU Liang, ZHANG Wuhao, et al. Iterative few-shot semantic segmentation from image label text[C]. The 31st International Joint Conference on Artificial Intelligence, Vienna, Austria, 2022. doi: 10.24963/ijcai.2022/193.
|
| [42] |
LIU Jie, BAO Yanqi, XIE Guosen, et al. Dynamic prototype convolution network for few-shot semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.01126.
|
| [43] |
LANG Chunbo, CHENG Gong, TU Binfei, et al. Learning what not to segment: A new perspective on few-shot segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.00789.
|
| [44] |
LIU Yuanwei, LIU Nian, CAO Qinglong, et al. Learning non-target knowledge for few-shot semantic segmentation[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022. doi: 10.1109/CVPR52688.2022.01128.
|
| [45] |
CHEN Hao, DONG Yonghan, LU Zheming, et al. Pixel matching network for cross-domain few-shot segmentation[C]. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2024. doi: 10.1109/WACV57701.2024.00102.
|
| [46] |
ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M and GeoRSCLIP: A large-scale vision- language dataset and a large vision-language model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5642123. doi: 10.1109/TGRS.2024.3449154.
|
| [47] |
LI Kaiyu, LIU Ruixun, CAO Xiangyong, et al. SegEarth-OV: Towards training-free open-vocabulary segmentation for remote sensing images[J]. arXiv preprint arXiv: 2410.01768, 2024.
|
| [48] |
方秀秀, 黄旻, 王德志, 等. 基于高程和地物光谱约束的多光谱图像预处理算法[J]. 半导体光电, 2020, 41(2): 264–267, 272. doi: 10.16818/j.issn1001-5868.2020.02.023.
FANG Xiuxiu, HUANG Min, WANG Dezhi, et al. Multispectral image preprocessing based on elevation and surface feature spectrum constraints[J]. Semiconductor Optoelectronics, 2020, 41(2): 264–267, 272. doi: 10.16818/j.issn1001-5868.2020.02.023.
|
| [49] |
WANG Jingdong, SUN Ke, CHENG Tianheng, et al. Deep high-resolution representation learning for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(10): 3349–3364. doi: 10.1109/TPAMI.2020.2983686.
|
Figures(14) / Tables(10)



 DownLoad:
DownLoad: