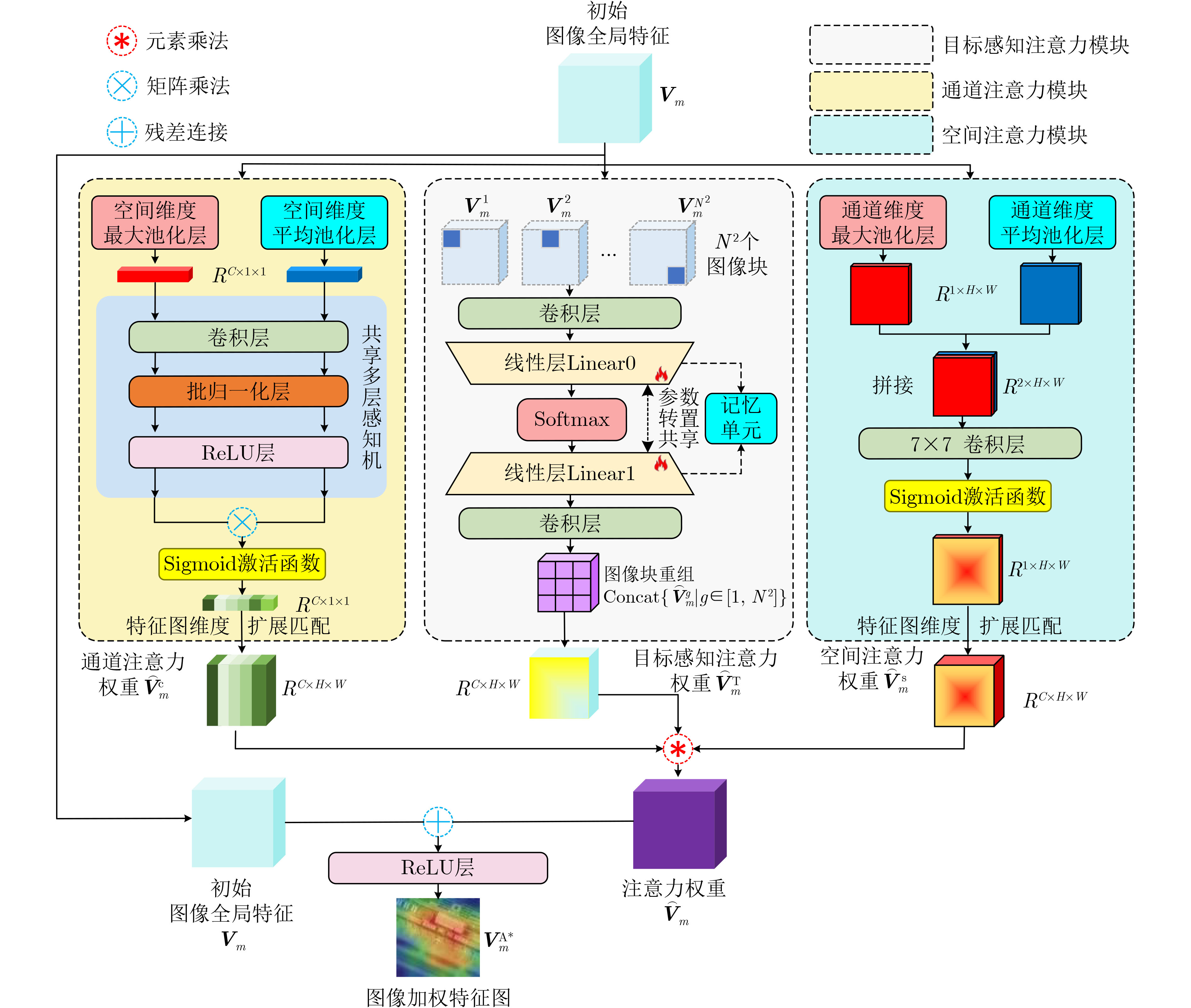
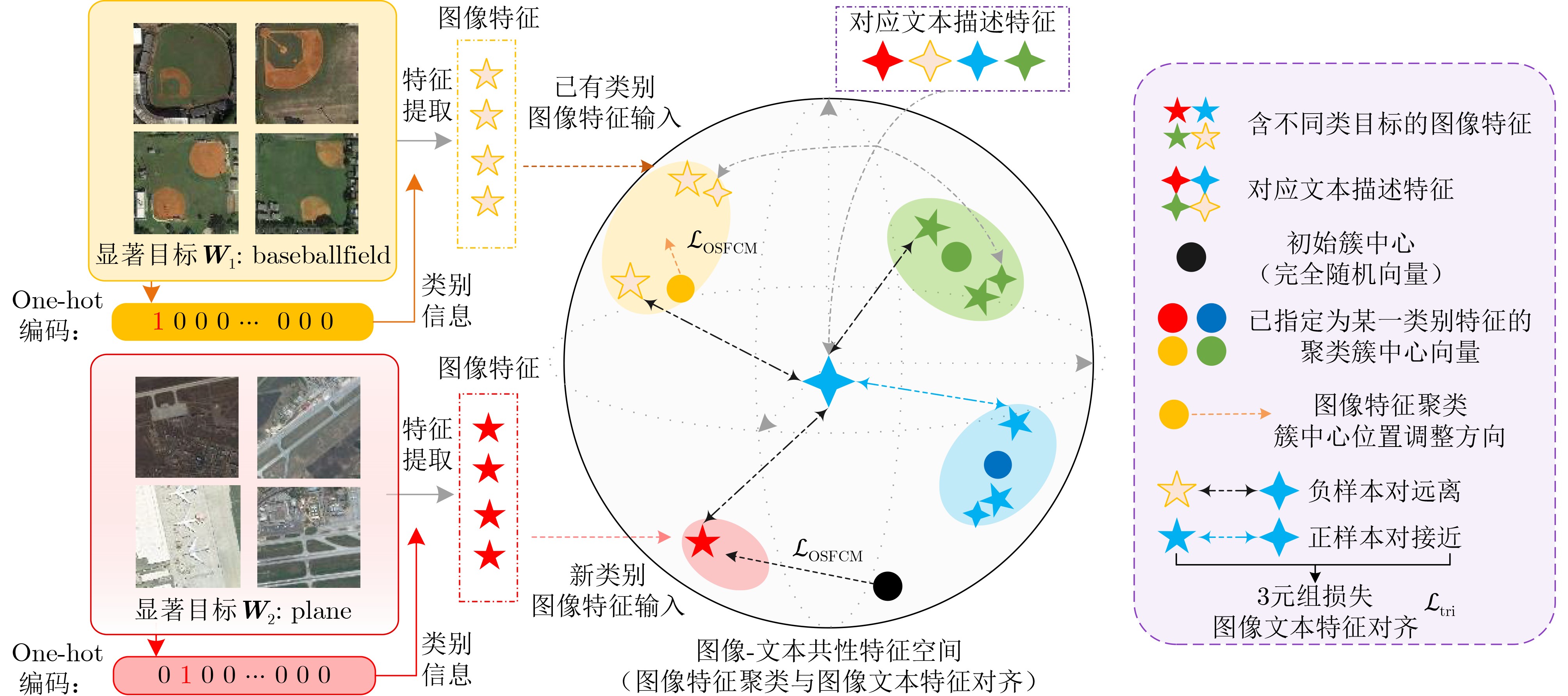
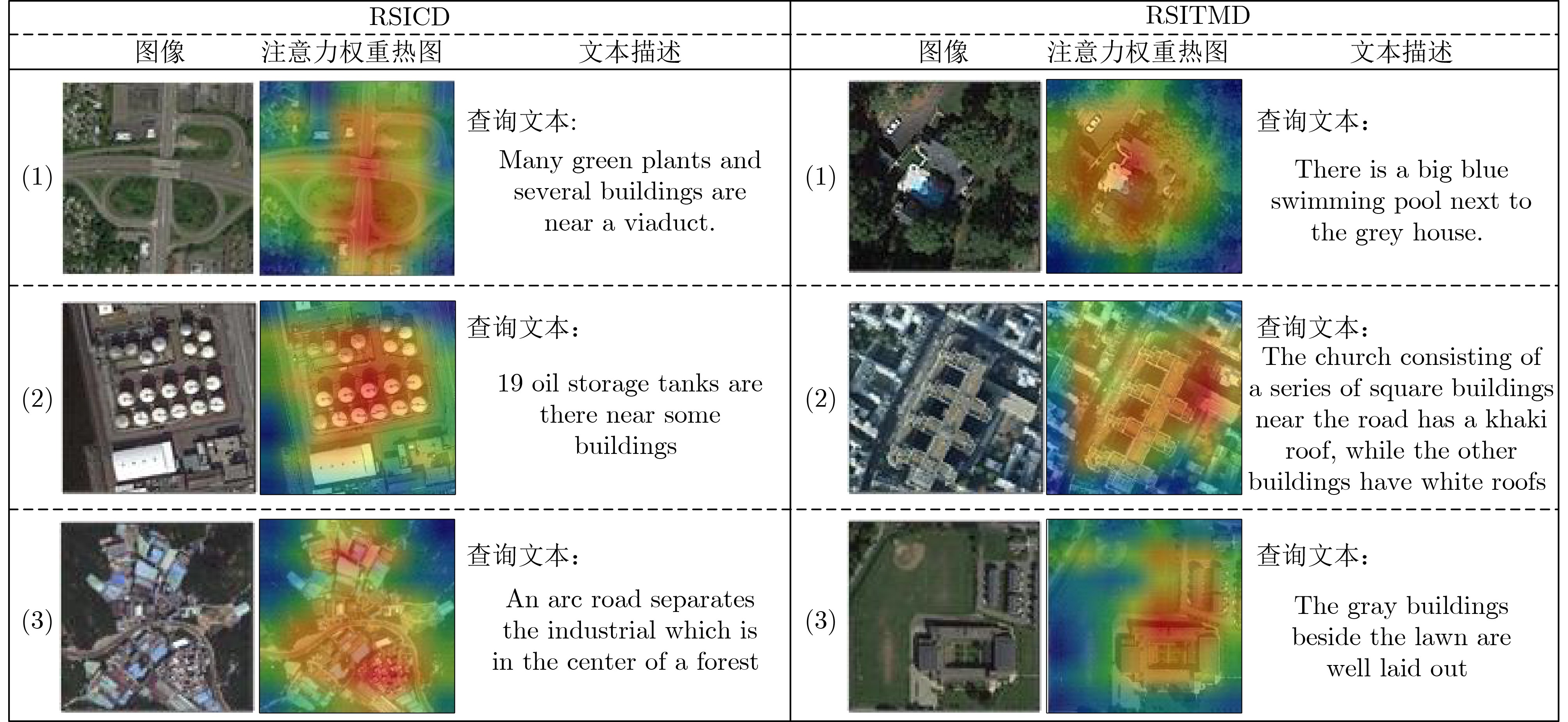
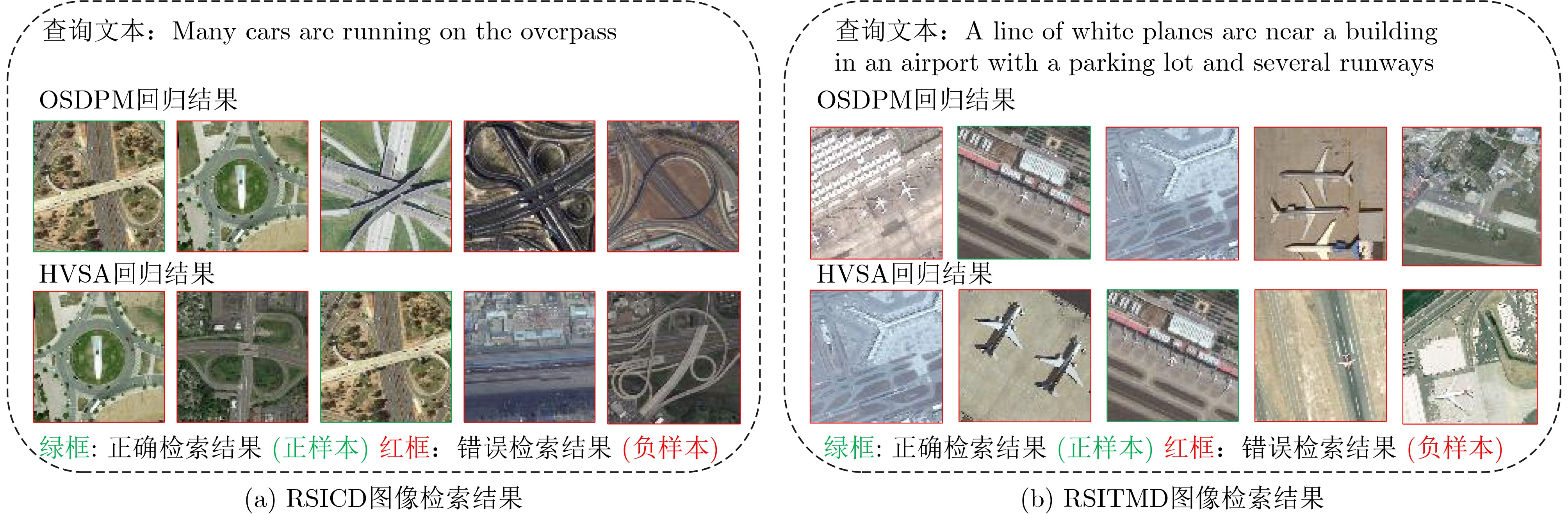
| Citation: | TIAN Shu, ZHANG Bingxi, CAO Lin, XING Xiangwei, TIAN Jing, SHEN Bo, DU Kangning, ZHANG Ye. Remote Sensing Image Text Retrieval Method Based on Object Semantic Prompt and Dual-Attention Perception[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1734-1746. doi: 10.11999/JEIT240946

|

| [1] |
SUDMANNS M, TIEDE D, LANG S, et al. Big earth data: Disruptive changes in Earth observation data management and analysis?[J]. International Journal of Digital Earth, 2020, 13(7): 832–850. doi: 10.1080/17538947.2019.1585976.
|
| [2] |
ZHOU Weixun, NEWSAM S, LI Congmin, et al. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 145: 197–209. doi: 10.1016/j.isprsjprs.2018.01.004.
|
| [3] |
翁星星, 庞超, 许博文, 等. 面向遥感图像解译的增量深度学习[J]. 电子与信息学报, 2024, 46(10): 3979–4001. doi: 10.11999/JEIT240172.
WENG Xingxing, PANG Chao, XU Bowen, et al. Incremental deep learning for remote sensing image interpretation[J]. Journal of Electronics & Information Technology, 2024, 46(10): 3979–4001. doi: 10.11999/JEIT240172.
|
| [4] |
HUANG Jiaxiang, FENG Yong, ZHOU Mingliang, et al. Deep multiscale fine-grained hashing for remote sensing cross-modal retrieval[J]. IEEE Geoscience and Remote Sensing Letters, 2024, 21: 6002205. doi: 10.1109/LGRS.2024.3351368.
|
| [5] |
金澄, 弋步荣, 曾志昊, 等. 一种顾及空间语义的跨模态遥感影像检索技术[J]. 中国电子科学研究院学报, 2023, 18(4): 328–335,385. doi: 10.3969/j.issn.1673-5692.2023.04.005.
JIN Cheng, YI Burong, ZENG Zhihao, et al. A cross-modal remote sensing image retrieval technique considering spatial semantics[J]. Journal of China Academy of Electronics and Information Technology, 2023, 18(4): 328–335,385. doi: 10.3969/j.issn.1673-5692.2023.04.005.
|
| [6] |
冯孝鑫, 王子健, 吴奇. 基于三元采样图卷积网络的半监督遥感图像检索[J]. 电子与信息学报, 2023, 45(2): 644–653. doi: 10.11999/JEIT211478.
FENG Xiaoxin, WANG Zijian, and WU Qi. Semi-supervised learning remote sensing image retrieval method based on triplet sampling graph convolutional network[J]. Journal of Electronics & Information Technology, 2023, 45(2): 644–653. doi: 10.11999/JEIT211478.
|
| [7] |
ZHAO Zuopeng, MIAO Xiaoran, HE Chen, et al. Masking-based cross-modal remote sensing image–text retrieval via dynamic contrastive learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5626215. doi: 10.1109/TGRS.2024.3406897.
|
| [8] |
WANG Fei, ZHU Xianzhang, LIU Xiaojian, et al. Scene graph-aware hierarchical fusion network for remote sensing image retrieval with text feedback[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4705116. doi: 10.1109/TGRS.2024.3404605.
|
| [9] |
张若愚, 聂婕, 宋宁, 等. 基于布局化-语义联合表征遥感图文检索方法[J]. 北京航空航天大学学报, 2024, 50(2): 671–683. doi: 10.13700/j.bh.1001-5965.2022.0527.
ZHANG Ruoyu, NIE Jie, SONG Ning, et al. Remote sensing image-text retrieval based on layout semantic joint representation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(2): 671–683. doi: 10.13700/j.bh.1001-5965.2022.0527.
|
| [10] |
CHEN Yaxiong, HUANG Jinghao, LI Xiaoyu, et al. Multiscale salient alignment learning for remote-sensing image-text retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4700413. doi: 10.1109/TGRS.2023.3340870.
|
| [11] |
YANG Rui, WANG Shuang, HAN Yingping, et al. Transcending fusion: A multiscale alignment method for remote sensing image-text retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4709217 . doi: 10.1109/TGRS.2024.3496898.
|
| [12] |
XU Yahui, BIN Yi, WEI Jiwei, et al. Align and retrieve: Composition and decomposition learning in image retrieval with text feedback[J]. IEEE Transactions on Multimedia, 2024, 26: 9936–9948. doi: 10.1109/TMM.2024.3417694.
|
| [13] |
MA Qing, PAN Jiancheng, and BAI Cong. Direction-oriented visual-semantic embedding model for remote sensing image-text retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4704014. doi: 10.1109/TGRS.2024.3392779.
|
| [14] |
钟金彦, 陈俊, 李宇, 等. 基于MFF-SFE的遥感图文跨模态检索方法[J]. 中国科学院大学学报(中英文), 2025, 42(2): 236–247. doi: 10.7523/j.ucas.2024.025.
ZHONG Jinyan, CHEN Jun, LI Yu, et al. Cross-modal retrieval method based on MFF-SFE for remote sensing image-text[J]. Journal of University of Chinese Academy of Sciences, 2025, 42(2): 236–247. doi: 10.7523/j.ucas.2024.025.
|
| [15] |
SUN Yuli, LEI Lin, LI Xiao, et al. Nonlocal patch similarity based heterogeneous remote sensing change detection[J]. Pattern Recognition, 2021, 109: 107598. doi: 10.1016/j.patcog.2020.107598.
|
| [16] |
ZHANG Shun, LI Yupeng, and MEI Shaohui. Exploring uni-modal feature learning on entities and relations for remote sensing cross-modal text-image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5626317. doi: 10.1109/TGRS.2023.3333375.
|
| [17] |
ZHU Jingru, GUO Ya, SUN Geng, et al. Unsupervised domain adaptation semantic segmentation of high-resolution remote sensing imagery with invariant domain-level prototype memory[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5603518. doi: 10.1109/TGRS.2023.3243042.
|
| [18] |
LIU Zejun, CHEN Fanglin, XU Jun, et al. Image-text retrieval with cross-modal semantic importance consistency[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(5): 2465–2476. doi: 10.1109/TCSVT.2022.3220297.
|
| [19] |
ZHUANG Jiamin, YU Jing, DING Yang, et al. Towards fast and accurate image-text retrieval with self-supervised fine-grained alignment[J]. IEEE Transactions on Multimedia, 2024, 26: 1361–1372. doi: 10.1109/TMM.2023.3280734.
|
| [20] |
YU Hongfeng, YAO Fanglong, LU Wanxuan, et al. Text-image matching for cross-modal remote sensing image retrieval via graph neural network[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023, 16: 812–824. doi: 10.1109/JSTARS.2022.3231851.
|
| [21] |
ABDULLAH T, BAZI Y, AL RAHHAL M M, et al. TextRS: Deep bidirectional triplet network for matching text to remote sensing images[J]. Remote Sensing, 2020, 12(3): 405. doi: 10.3390/rs12030405.
|
| [22] |
TANG Xu, HUANG Dabiao, MA Jingjing, et al. Prior-experience-based vision-language model for remote sensing image-text retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5641913. doi: 10.1109/TGRS.2024.3464468.
|
| [23] |
YUAN Zhiqiang, ZHANG Wenkai, TIAN Changyuan, et al. Remote sensing cross-modal text-image retrieval based on global and local information[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5620616. doi: 10.1109/TGRS.2022.3163706.
|
| [24] |
YUAN Zhiqiang, ZHANG Wenkai, FU Kun, et al. Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 4404119. doi: 10.1109/TGRS.2021.3078451.
|
| [25] |
MI Li, DAI Xianjie, CASTILLO-NAVARRO J, et al. Knowledge-aware text-image retrieval for remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5646813. doi: 10.1109/TGRS.2024.3486977.
|
| [26] |
LU Xiaoqiang, WANG Binqiang, ZHENG Xiangtao, et al. Exploring models and data for remote sensing image caption generation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2183–2195. doi: 10.1109/TGRS.2017.2776321.
|
| [27] |
ZHANG Weihang, LI Jihao, LI Shuoke, et al. Hypersphere-based remote sensing cross-modal text–image retrieval via curriculum learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5621815. doi: 10.1109/TGRS.2023.3318227.
|
| [28] |
XU Xing, WANG Tan, YANG Yang, et al. Cross-modal attention with semantic consistence for image–text matching[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(12): 5412–5425. doi: 10.1109/TNNLS.2020.2967597.
|
Figures(8) / Tables(3)



 DownLoad:
DownLoad: