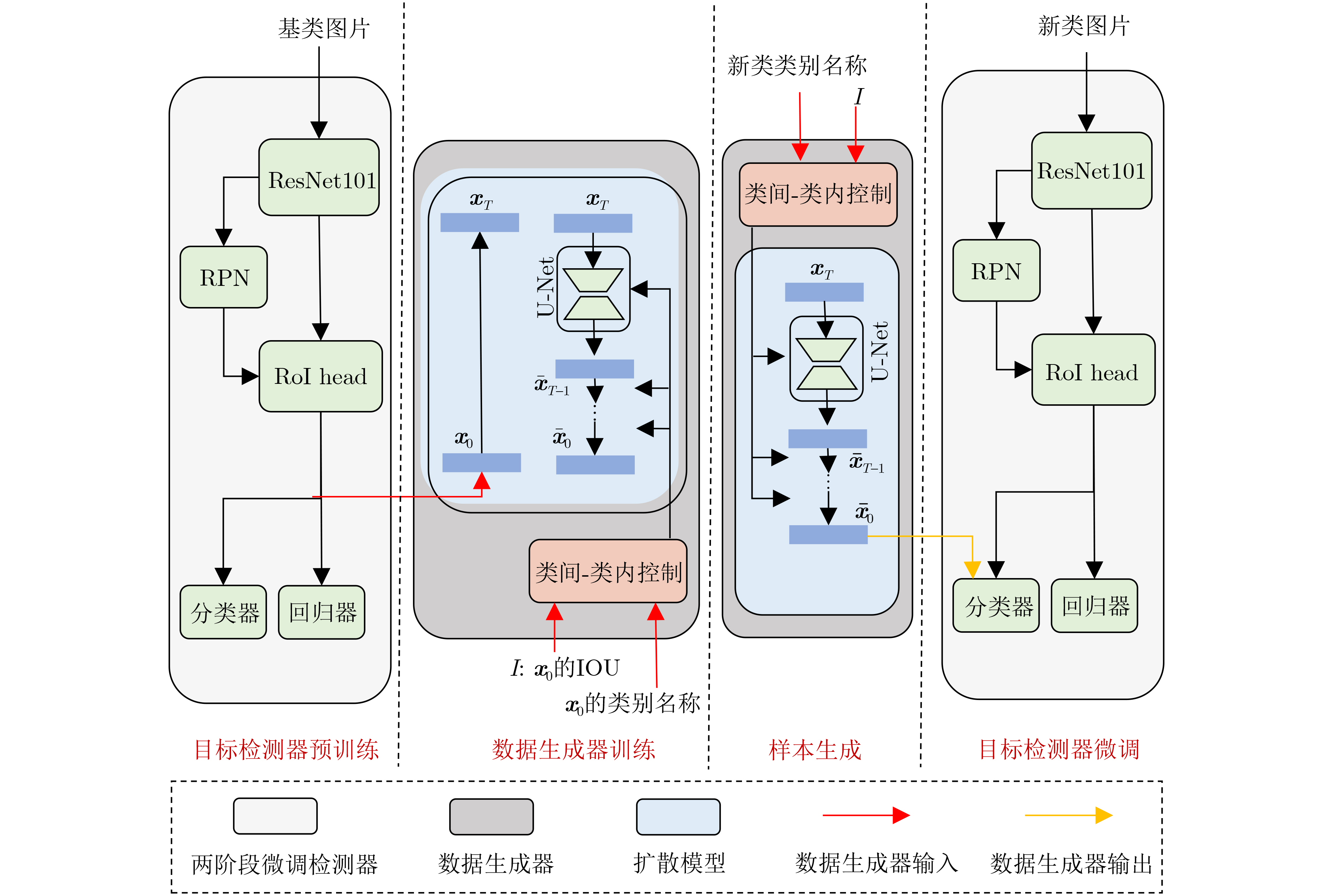
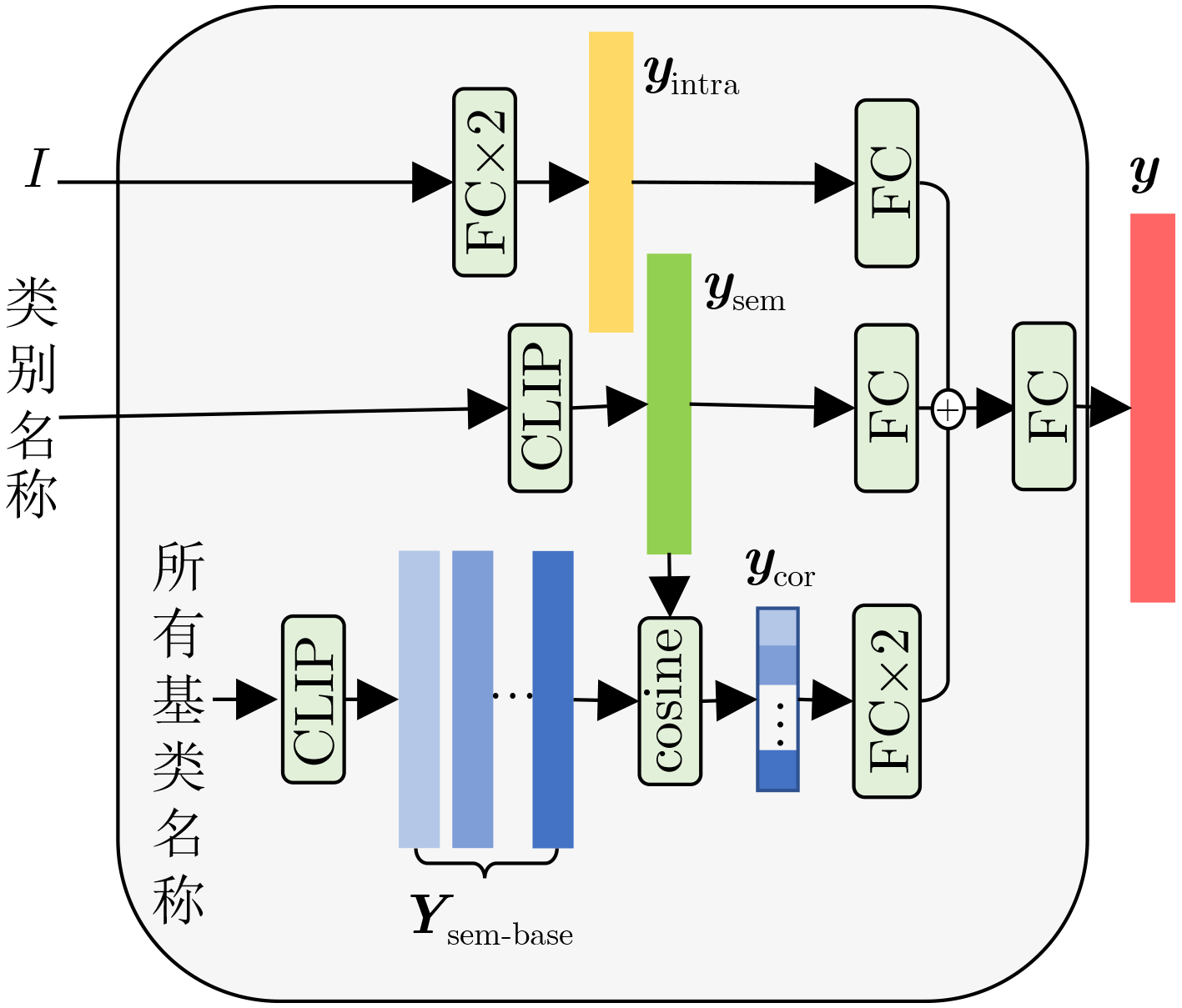
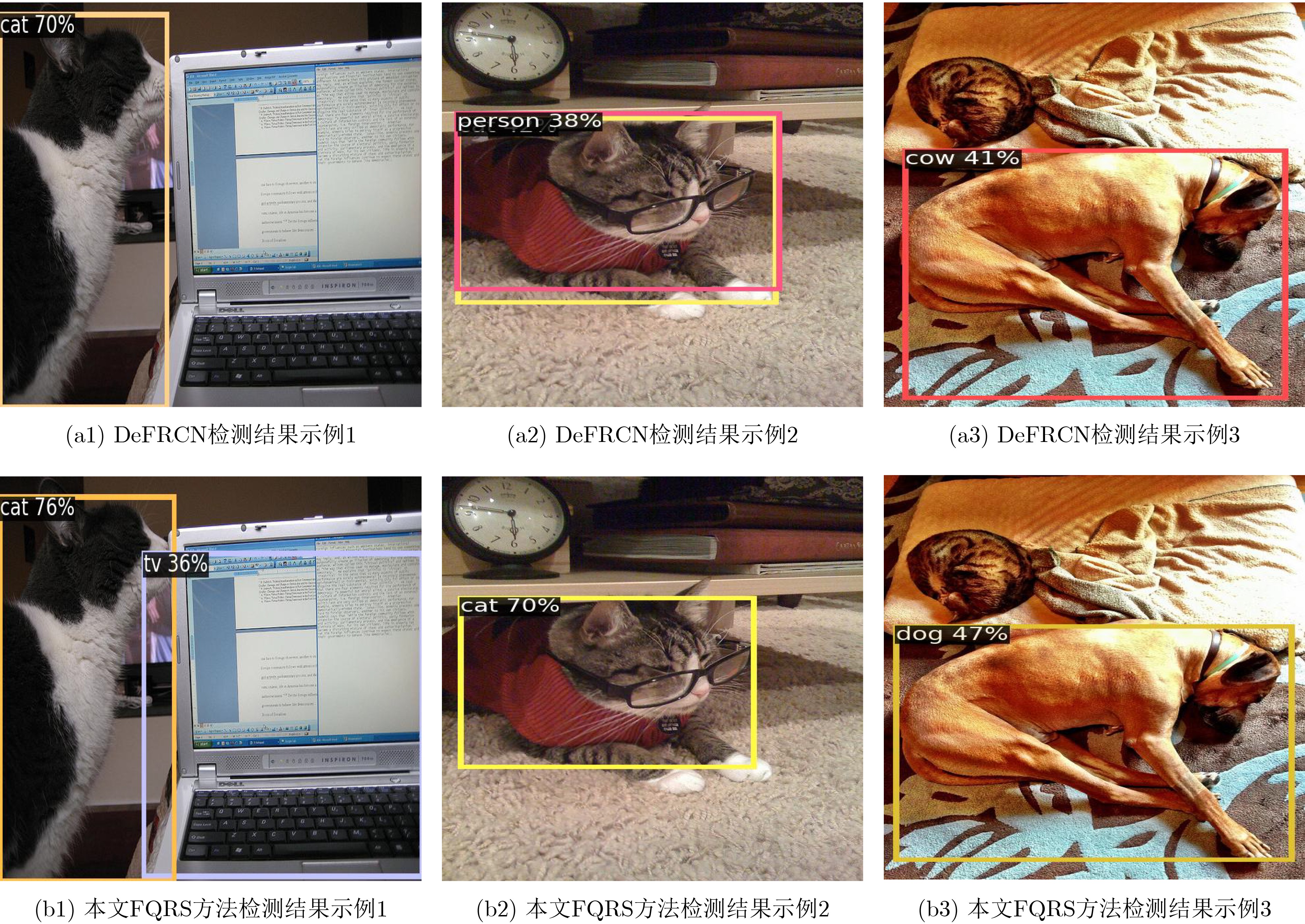
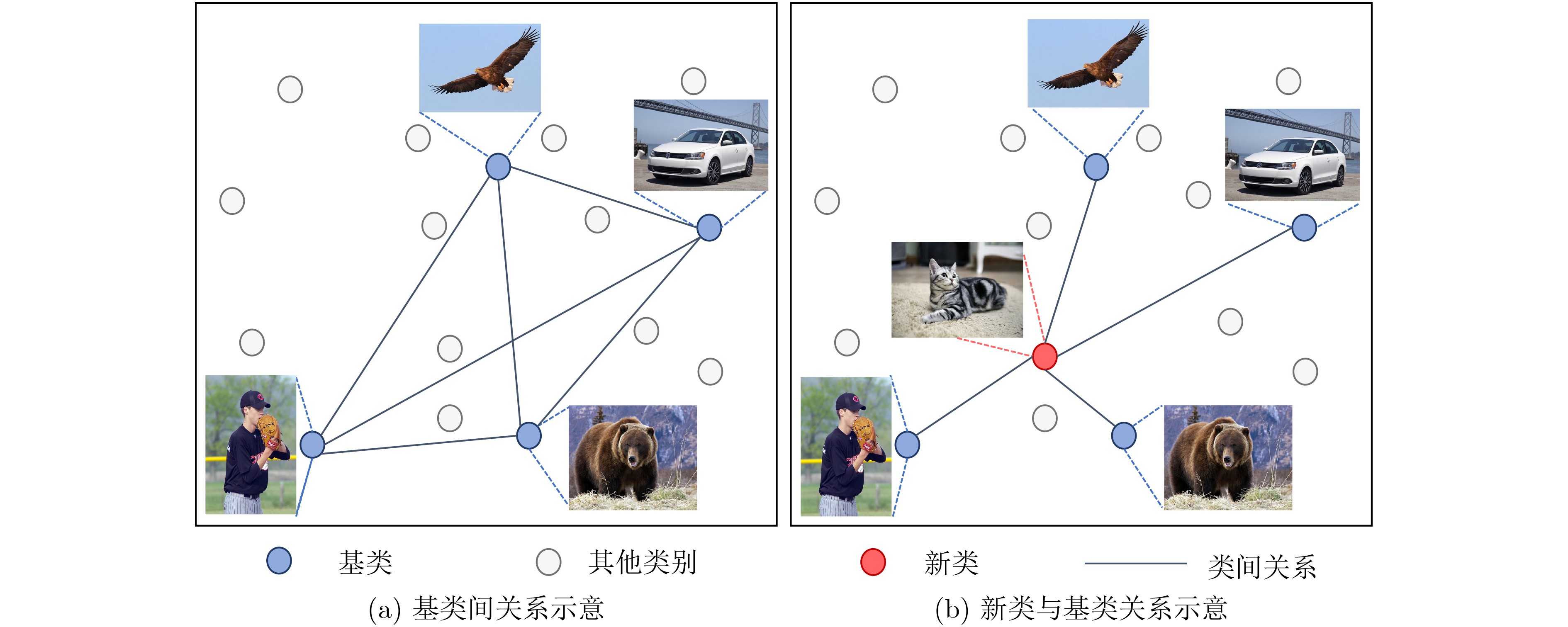
| Citation: | MEI Tiancan, WANG Yaru, CHEN Yuanhao. Sample Generation Based on Conditional Diffusion Model for Few-Shot Object Detection[J]. Journal of Electronics & Information Technology, 2025, 47(4): 1182-1191. doi: 10.11999/JEIT240841

|

| [1] |
LIU Qiankun, LIU Rui, ZHENG Bolun, et al. Infrared small target detection with scale and location sensitivity[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 17490–17499. doi: 10.1109/CVPR52733.2024.01656.
|
| [2] |
ZHANG Gang, CHEN Junnan, GAO Guohuan, et al. SAFDNet: A simple and effective network for fully sparse 3D object detection[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 14477–14486. doi: 10.1109/CVPR52733.2024.01372.
|
| [3] |
YE Mingqiao, KE Lei, LI Siyuan, et al. Cascade-DETR: Delving into high-quality universal object detection[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 6704–6714. doi: 10.1109/ICCV51070.2023.00617.
|
| [4] |
WANG C Y, BOCHKOVSKIY A, and LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 7464–7475. doi: 10.1109/CVPR52729.2023.00721.
|
| [5] |
WANG Yuxiong, RAMANAN D, and HEBERT M. Meta-learning to detect rare objects[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 9925–9934. doi: 10.1109/ICCV.2019.01002.
|
| [6] |
WANG Xin, HUANG T E, DARRELL T, et al. Frustratingly simple few-shot object detection[C]. The 37th International Conference on Machine Learning, 2020: 920.
|
| [7] |
SUN Bo, LI Banghuai, CAI Shengcai, et al. FSCE: Few-shot object detection via contrastive proposal encoding[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 7352–7362. doi: 10.1109/CVPR46437.2021.00727.
|
| [8] |
YAN Xiaopeng, CHEN Ziliang, XU Anni, et al. Meta R-CNN: Towards general solver for instance-level low-shot learning[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 9577–9586. doi: 10.1109/ICCV.2019.00967.
|
| [9] |
QIAO Limeng, ZHAO Yuxuan, LI Zhiyuan, et al. DeFRCN: Decoupled faster R-CNN for few-shot object detection[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 8681–8690. doi: 10.1109/ICCV48922.2021.00856.
|
| [10] |
ZHU Chenchen, CHEN Fangyi, AHMED U, et al. Semantic relation reasoning for shot-stable few-shot object detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 8782–8791. doi: 10.1109/CVPR46437.2021.00867.
|
| [11] |
REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031.
|
| [12] |
ZHANG Weilin and WANG Yuxiong. Hallucination improves few-shot object detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13008–13017. doi: 10.1109/CVPR46437.2021.01281.
|
| [13] |
ZHU Pengkai, WANG Hanxiao, and SALIGRAMA V. Don’t even look once: Synthesizing features for zero-shot detection[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 11693–11702. doi: 10.1109/CVPR42600.2020.01171.
|
| [14] |
XU Jingyi, LE H, and SAMARAS D. Generating features with increased crop-related diversity for few-shot object detection[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 19713–19722. doi: 10.1109/CVPR52729.2023.01888.
|
| [15] |
HO J, JAIN A, and ABBEEL P. Denoising diffusion probabilistic models[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 574.
|
| [16] |
HO J and SALIMANS T. Classifier-free diffusion guidance[EB/OL]. https://arxiv.org/abs/2207.12598, 2022.
|
| [17] |
QI Tianhao, FANG Shancheng, WU Yanze, et al. DEADiff: An efficient stylization diffusion model with disentangled representations[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 8693–8702. doi: 10.1109/CVPR52733.2024.00830.
|
| [18] |
GARBER T and TIRER T. Image restoration by denoising diffusion models with iteratively preconditioned guidance[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 25245–25254. doi: 10.1109/CVPR52733.2024.02385.
|
| [19] |
LI Muyang, CAI Tianle, CAO Jiaxin, et al. DistriFusion: Distributed parallel inference for high-resolution diffusion models[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 7183–7193. doi: 10.1109/CVPR52733.2024.00686.
|
| [20] |
HUANG Ziqi, CHAN K C K, JIANG Yuming, et al. Collaborative diffusion for multi-modal face generation and editing[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 6080–6090. doi: 10.1109/CVPR52729.2023.00589.
|
| [21] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, 2021: 8748–8763.
|
| [22] |
RONNEBERGER O, FISCHER P, and BROX T. U-net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 2015: 234–241. doi: 10.1007/978-3-319-24574-4_28.
|
| [23] |
WU Jiaxi, LIU Songtao, HUANG Di, et al. Multi-scale positive sample refinement for few-shot object detection[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 456–472. doi: 10.1007/978-3-030-58517-4_27.
|
| [24] |
LI Aoxue and LI Zhenguo. Transformation invariant few-shot object detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 3094–3102. doi: 10.1109/CVPR46437.2021.00311.
|
| [25] |
HU Hanzhe, BAI Shuai, LI Aoxue, et al. Dense relation distillation with context-aware aggregation for few-shot object detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 10185–10194. doi: 10.1109/CVPR46437.2021.01005.
|
| [26] |
LI Bohao, YANG Boyu, LIU Chang, et al. Beyond max-margin: Class margin equilibrium for few-shot object detection[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 7363–7372. doi: 10.1109/CVPR46437.2021.00728.
|
| [27] |
CAO Yuhang, WANG Jiaqi, JIN Ying, et al. Few-shot object detection via association and discrimination[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 1267.
|
| [28] |
HAN Guangxing, MA Jiawei, HUANG Shiyuan, et al. Few-shot object detection with fully cross-transformer[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5321–5330. doi: 10.1109/CVPR52688.2022.00525.
|
| [29] |
ZHANG Gongjie, LUO Zhipeng, CUI Kaiwen, et al. Meta-DETR: Image-level few-shot detection with inter-class correlation exploitation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 12832–12843. doi: 10.1109/TPAMI.2022.3195735.
|
| [30] |
XIAO Yang, LEPETIT V, and MARLET R. Few-shot object detection and viewpoint estimation for objects in the wild[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3090–3106. doi: 10.1109/TPAMI.2022.3174072.
|
Figures(6) / Tables(7)



 DownLoad:
DownLoad: