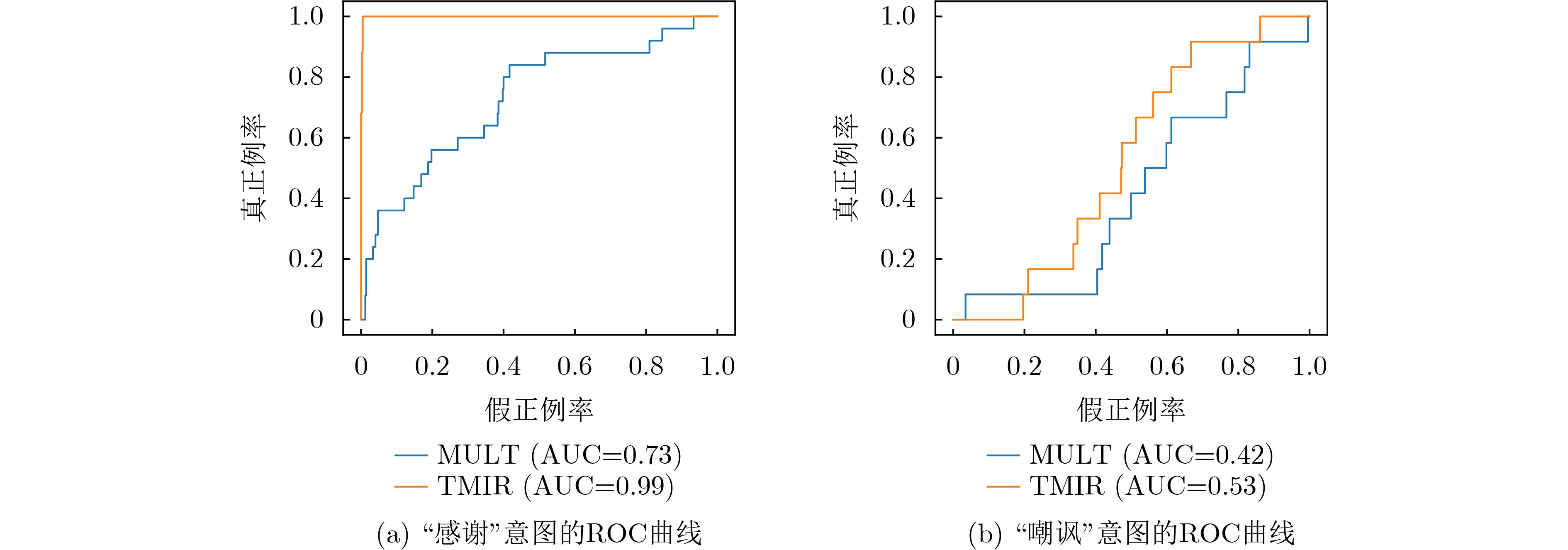
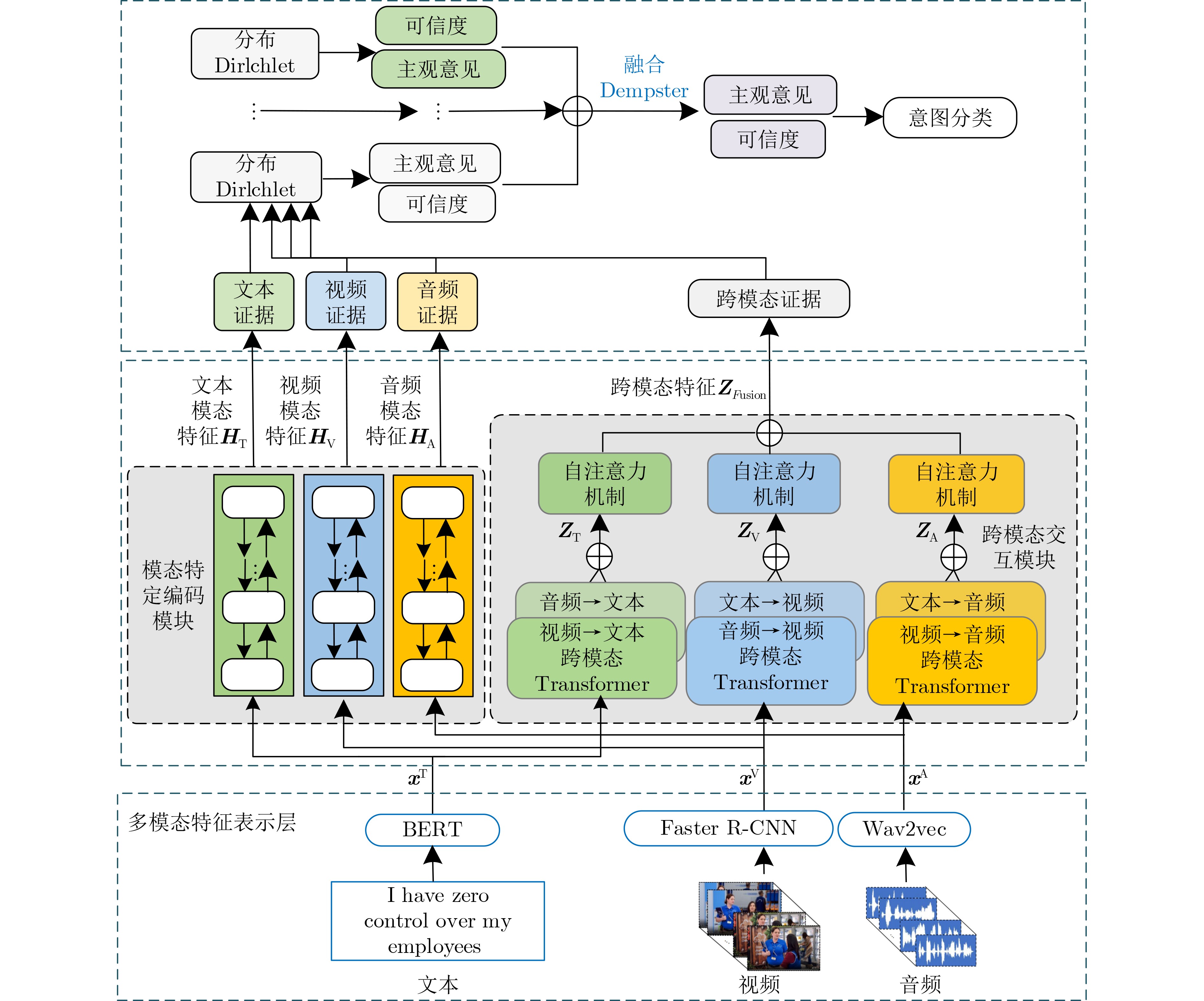
| Citation: | YANG Ying, YANG Yanqiu, YU Bengong. Multimodal Intent Recognition Method with View Reliability[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1966-1975. doi: 10.11999/JEIT240778

|

| [1] |
ZHANG Hanlei, XU Hua, WANG Xin, et al. MIntRec: A new dataset for multimodal intent recognition[C]. The 30th ACM International Conference on Multimedia, Lisboa, Portugal, 2022: 1688–1697. doi: 10.1145/3503161.3547906.
|
| [2] |
SINGH U, ABHISHEK K, and AZAD H K. A survey of cutting-edge multimodal sentiment analysis[J]. ACM Computing Surveys, 2024, 56(9): 227. doi: 10.1145/3652149.
|
| [3] |
HAO Jiaqi, ZHAO Junfeng, and WANG Zhigang. Multi-modal sarcasm detection via graph convolutional network and dynamic network[C]. The 33rd ACM International Conference on Information and Knowledge Management, Boise, USA, 2024: 789–798. doi: 10.1145/3627673.3679703.
|
| [4] |
KRUK J, LUBIN J, SIKKA K, et al. Integrating text and image: Determining multimodal document intent in Instagram posts[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 2019: 4622–4632. doi: 10.18653/v1/D19-1469.
|
| [5] |
ZHANG Lu, SHEN Jialie, ZHANG Jian, et al. Multimodal marketing intent analysis for effective targeted advertising[J]. IEEE Transactions on Multimedia, 2022, 24: 1830–1843. doi: 10.1109/TMM.2021.3073267.
|
| [6] |
MAHARANA A, TRAN Q, DERNONCOURT F, et al. Multimodal intent discovery from livestream videos[C]. Findings of the Association for Computational Linguistics: NAACL, Seattle, USA, 2022: 476–489. doi: 10.18653/v1/2022.findings-naacl.36.
|
| [7] |
SINGH G V, FIRDAUS M, EKBAL A, et al. EmoInt-trans: A multimodal transformer for identifying emotions and intents in social conversations[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 290–300. doi: 10.1109/TASLP.2022.3224287.
|
| [8] |
钱岳, 丁效, 刘挺, 等. 聊天机器人中用户出行消费意图识别方法[J]. 中国科学: 信息科学, 2017, 47(8): 997–1007. doi: 10.1360/N112016-00306.
QIAN Yue, DING Xiao, LIU Ting, et al. Identification method of user's travel consumption intention in chatting robot[J]. Scientia Sinica Informationis, 2017, 47(8): 997–1007. doi: 10.1360/N112016-00306.
|
| [9] |
TSAI Y H H, BAI Shaojie, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]. The 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019: 6558–6569. doi: 10.18653/v1/P19-1656.
|
| [10] |
HAZARIKA D, ZIMMERMANN R, and PORIA S. MISA: Modality-invariant and -specific representations for multimodal sentiment analysis[C]. The 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 1122–1131. doi: 10.1145/3394171.3413678.
|
| [11] |
HUANG Xuejian, MA Tinghuai, JIA Li, et al. An effective multimodal representation and fusion method for multimodal intent recognition[J]. Neurocomputing, 2023, 548: 126373. doi: 10.1016/j.neucom.2023.126373.
|
| [12] |
HAN Zongbo, ZHANG Changqing, FU Huazhu, et al. Trusted multi-view classification with dynamic evidential fusion[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2551–2566. doi: 10.1109/TPAMI.2022.3171983.
|
| [13] |
BAEVSKI A, ZHOU H, MOHAMED A, et al. Wav2vec 2.0: A framework for self-supervised learning of speech representations[C]. Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1044. doi: 10.5555/3495724.3496768.
|
| [14] |
LIU Wei, YUE Xiaodong, CHEN Yufei, et al. Trusted multi-view deep learning with opinion aggregation[C]. The Thirty-Sixth AAAI Conference on Artificial Intelligence, 2022: 7585–7593. doi: 10.1609/aaai.v36i7.20724.
|
| [15] |
ZHANG Zhu, WEI Xuan, ZHENG Xiaolong, et al. Detecting product adoption intentions via multiview deep learning[J]. INFORMS Journal on Computing, 2022, 34(1): 541–556. doi: 10.1287/ijoc.2021.1083.
|
| [16] |
RAHMAN W, HASAN M K, LEE S, et al. Integrating multimodal information in large pretrained transformers[C]. The 58th Annual Meeting of the Association for Computational Linguistics, 2020: 2359–2369. doi: 10.18653/v1/2020.acl-main.214.
|
| [17] |
ZHOU Qianrui, XU Hua, LI Hao, et al. Token-level contrastive learning with modality-aware prompting for multimodal intent recognition[C]. The Thirty-Eighth AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 17114–17122. doi: 10.1609/aaai.v38i15.29656.
|
Figures(2) / Tables(4)



 DownLoad:
DownLoad: