| Citation: | GAO Xueyao, ZHANG Yunkai, ZHANG Chunxiang. 3D Model Classification Based on Central Anchor Hard Triplet Loss and Multi-view Feature Fusion[J]. Journal of Electronics & Information Technology, 2025, 47(6): 1937-1949. doi: 10.11999/JEIT240633

|

| [1] |
周燕, 李文俊, 党兆龙, 等. 深度学习的三维模型识别研究综述[J]. 计算机科学与探索, 2024, 18(4): 916–929. doi: 10.3778/j.issn.1673-9418.2309010.
ZHOU Yan, LI Wenjun, DANG Zhaolong, et al. Survey of 3D model recognition based on deep learning[J]. Journal of Frontiers of Computer Science & Technology, 2024, 18(4): 916–929. doi: 10.3778/j.issn.1673-9418.2309010.
|
| [2] |
QI C R, SU Hao, MO Kaichun, et al. PointNet: Deep learning on point sets for 3D classification and segmentation[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 77–85. doi: 10.1109/CVPR.2017.16.
|
| [3] |
QI C R, YI Li, SU Hao, et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5105–5114.
|
| [4] |
YAN Xu, ZHENG Chaoda, LI Zhen, et al. PointASNL: Robust point clouds processing using nonlocal neural networks with adaptive sampling[C]. The 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 5588–5597. doi: 10.1109/CVPR42600.2020.00563.
|
| [5] |
YU Ying and ZHANG Jun. Classification model of 3D point cloud based on linked adaptive graph convolution[J]. Journal of Physics: Conference Series, 2022, 2303(1): 012003. doi: 10.1088/1742-6596/2303/1/012003.
|
| [6] |
HUANG Changqin, JIANG Fan, HUANG Qionghao, et al. Dual-graph attention convolution network for 3-D point cloud classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 4813–4825. doi: 10.1109/TNNLS.2022.3162301.
|
| [7] |
XUE Jiaming, MEN Chaoguang, LIU Yongmei, et al. Adaptive neighbourhood recovery method for machine learning based 3D point cloud classification[J]. International Journal of Remote Sensing, 2023, 44(1): 311–340. doi: 10.1080/01431161.2022.2162354.
|
| [8] |
HASSAN R, FRAZ M M, RAJPUT A, et al. Residual learning with annularly convolutional neural networks for classification and segmentation of 3D point clouds[J]. Neurocomputing, 2023, 526: 96–108. doi: 10.1016/j.neucom.2023.01.026.
|
| [9] |
MATURANA D and SCHERER S. VoxNet: A 3D convolutional neural network for real-time object recognition[C]. 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 2015: 922–928. doi: 10.1109/IROS.2015.7353481.
|
| [10] |
WU Zhirong, SONG Shuran, KHOSLA A, et al. 3D ShapeNets: A deep representation for volumetric shapes[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 1912–1920. doi: 10.1109/CVPR.2015.7298801.
|
| [11] |
WANG Cheng, CHENG Ming, SOHEL F, et al. NormalNet: A voxel-based CNN for 3D object classification and retrieval[J]. Neurocomputing, 2019, 323: 139–147. doi: 10.1016/j.neucom.2018.09.075.
|
| [12] |
HE Yunqian, XIA Guihua, LUO Yongkang, et al. DVFENet: Dual-branch voxel feature extraction network for 3D object detection[J]. Neurocomputing, 2021, 459: 201–211. doi: 10.1016/j.neucom.2021.06.046.
|
| [13] |
CAI Weiwei, LIU Dong, NING Xin, et al. Voxel-based three-view hybrid parallel network for 3D object classification[J]. Displays, 2021, 69: 102076. doi: 10.1016/j.displa.2021.102076.
|
| [14] |
WANG Bingxu, LAN Jinhui, and LI Feifan. MSG-voxel-GAN: Multi-scale gradient voxel GAN for 3D object generation[J]. Multimedia Tools and Applications, 2023, 83(10): 88505–88522. doi: 10.1007/s11042-023-17116-9.
|
| [15] |
LIU Daikun, WANG Teng, and SUN Changyin. Voxel-based multi-scale transformer network for event stream processing[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(4): 2112–2124. doi: 10.1109/TCSVT.2023.3301176.
|
| [16] |
MA Ziping, ZHOU Jie, MA Jinlin, et al. A novel 3D shape recognition method based on double-channel attention residual network[J]. Multimedia Tools and Applications, 2022, 81(22): 32519–32548. doi: 10.1007/s11042-022-12041-9.
|
| [17] |
SHI Baoguang, BAI Song, ZHOU Zhichao, et al. DeepPano: Deep panoramic representation for 3-D shape recognition[J]. IEEE Signal Processing Letters, 2015, 22(12): 2339–2343. doi: 10.1109/LSP.2015.2480802.
|
| [18] |
GAO Xueyao, YANG Boyu, and ZHANG Chunxiang. Combine EfficientNet and CNN for 3D model classification[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 9062–9079. doi: 10.3934/mbe.2023398.
|
| [19] |
王鹏宇, 水盼盼, 余锋根, 等. 基于多视角卷积神经网络的三维模型分类方法[J]. 中国科学: 信息科学, 2019, 49(4): 436–449. doi: 10.1360/N112018-00254.
WANG Pengyu, SHUI Panpan, YU Fenggen, et al. 3D shape classification based on convolutional neural networks fusing multi-view information[J]. Scientia Sinica Informationis, 2019, 49(4): 436–449. doi: 10.1360/N112018-00254.
|
| [20] |
SU Hang, MAJI S, KALOGERAKIS E, et al. Multi-view convolutional neural networks for 3D shape recognition[C]. 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 945–953. doi: 10.1109/ICCV.2015.114.
|
| [21] |
白静, 姬卉, 邵会会, 等. 基于深度集成及细节感知的细粒度三维模型分类[J]. 计算机辅助设计与图形学学报, 2022, 34(10): 1580–1589. doi: 10.3724/SP.J.1089.2022.19180.
BAI Jing, JI Hui, SHAO Huihui, et al. Fine-grained 3D model classification based on deep ensemble and detail awareness[J]. Journal of Computer-Aided Design & Computer Graphics, 2022, 34(10): 1580–1589. doi: 10.3724/SP.J.1089.2022.19180.
|
| [22] |
LIU Anan, GUO Fubin, ZHOU Heyu, et al. Semantic and context information fusion network for view-based 3D model classification and retrieval[J]. IEEE Access, 2020, 8: 155939–155950. doi: 10.1109/ACCESS.2020.3018875.
|
| [23] |
LIANG Qi, WANG Yixin, NIE Weizhi, et al. MVCLN: Multi-view convolutional LSTM network for cross-media 3D shape recognition[J]. IEEE Access, 2020, 8: 139792–139802. doi: 10.1109/ACCESS.2020.3012692.
|
| [24] |
白静, 司庆龙, 秦飞巍. 基于卷积神经网络和投票机制的三维模型分类与检索[J]. 计算机辅助设计与图形学学报, 2019, 31(2): 303–314. doi: 10.3724/SP.J.1089.2019.17160.
BAI Jing, SI Qinglong, and QIN Feiwei. 3D model classification and retrieval based on CNN and voting scheme[J]. Journal of Computer-Aided Design & Computer Graphics, 2019, 31(2): 303–314. doi: 10.3724/SP.J.1089.2019.17160.
|
| [25] |
LIU Anan, ZHOU Heyu, LI Mengjie, et al. 3D model retrieval based on multi-view attentional convolutional neural network[J]. Multimedia Tools and Applications, 2020, 79(7): 4699–4711. doi: 10.1007/s11042-019-7521-8.
|
| [26] |
WEI Xin, YU Ruixuan, and SUN Jian. View-GCN: View-based graph convolutional network for 3D shape analysis[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1847–1856. doi: 10.1109/CVPR42600.2020.00192.
|
| [27] |
WEI Xin, YU Ruixuan, and SUN Jian. Learning view-based graph convolutional network for multi-view 3D shape analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 7525–7541. doi: 10.1109/TPAMI.2022.3221785.
|
| [28] |
SHI Shaojun, NIE Feiping, WANG Rong, et al. When multi-view classification meets ensemble learning[J]. Neurocomputing, 2022, 490: 17–29. doi: 10.1016/j.neucom.2022.02.052.
|
| [29] |
HAN Zongbo, ZHANG Changqing, FU Huazhu, et al. Trusted multi-view classification with dynamic evidential fusion[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2551–2566. doi: 10.1109/TPAMI.2022.3171983.
|
| [30] |
SCHROFF F, KALENICHENKO D, and PHILBIN J. FaceNet: A unified embedding for face recognition and clustering[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 815–823. doi: 10.1109/CVPR.2015.7298682.
|
| [31] |
WANG Jian, ZHOU Feng, WEN Shilei, et al. Deep metric learning with angular loss[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2612–2620. doi: 10.1109/ICCV.2017.283.
|
| [32] |
HERMANS A, BEYER L, and LEIBE B. In defense of the triplet loss for person re-identification[EB/OL]. https://arxiv.org/abs/1703.07737, 2017.
|
| [33] |
WEN Yandong, ZHANG Kaipeng, LI Zhifeng, et al. A discriminative feature learning approach for deep face recognition[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 499–515. doi: 10.1007/978-3-319-46478-7_31.
|
| [34] |
QIU Yuan, LIU Hongli, LIU Jianwei, et al. Center-triplet loss for railway defective fastener detection[J]. IEEE Sensors Journal, 2024, 24(3): 3180–3190. doi: 10.1109/JSEN.2023.3339883.
|
| [35] |
FARZANEH A H and QI Xiaojun. Facial expression recognition in the wild via deep attentive center loss[C]. The 2021 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2021: 2401–2410. doi: 10.1109/WACV48630.2021.00245.
|
| [36] |
JIAO Jinyue, GONG Zhiqiang, and ZHONG Ping. Triplet spectralwise transformer network for hyperspectral target detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5519817. doi: 10.1109/TGRS.2023.3306084.
|
| [37] |
CHEN Kanghao, LEI Weixian, ZHAO Shen, et al. PCCT: Progressive class-center triplet loss for imbalanced medical image classification[J]. IEEE Journal of Biomedical and Health Informatics, 2023, 27(4): 2026–2036. doi: 10.1109/JBHI.2023.3240136.
|
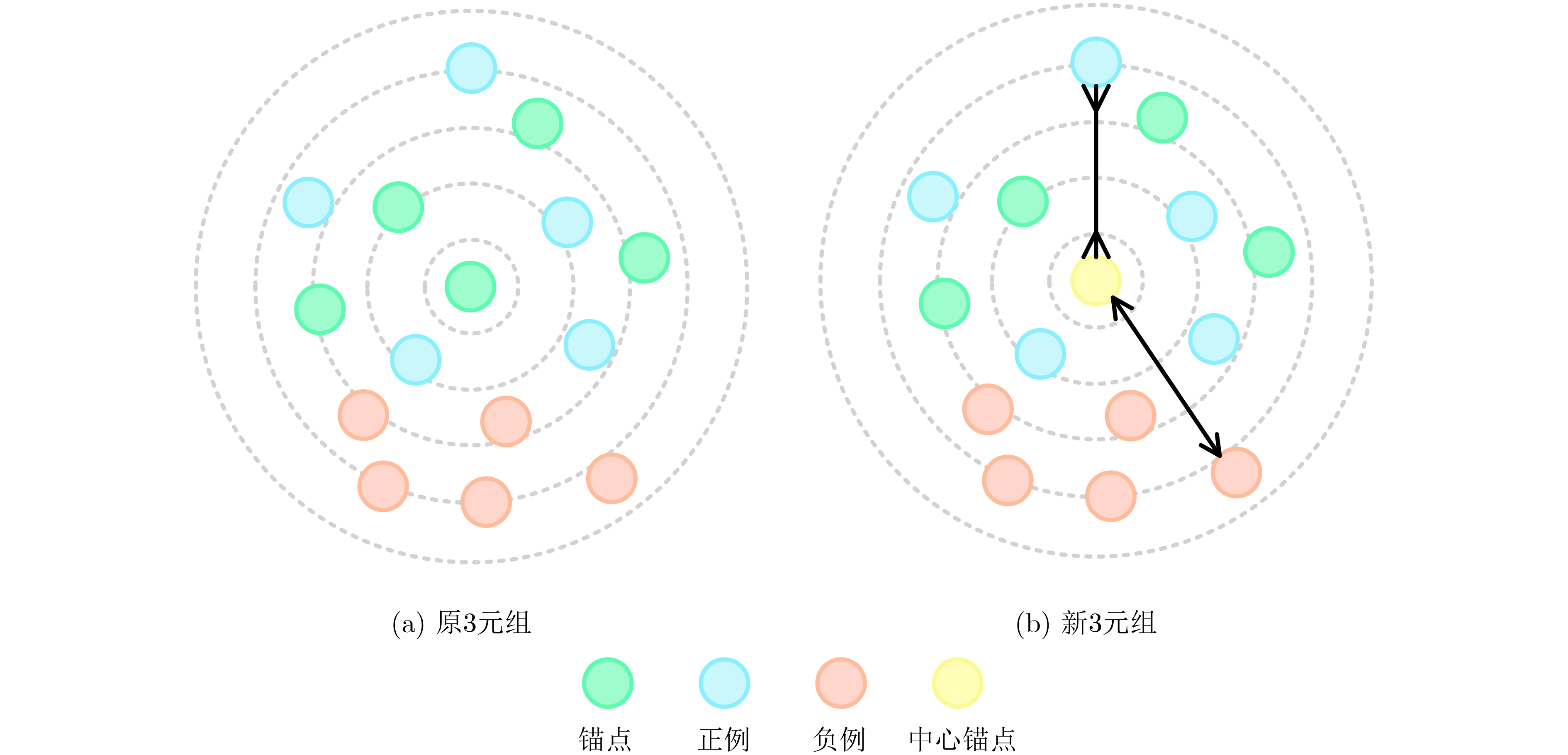
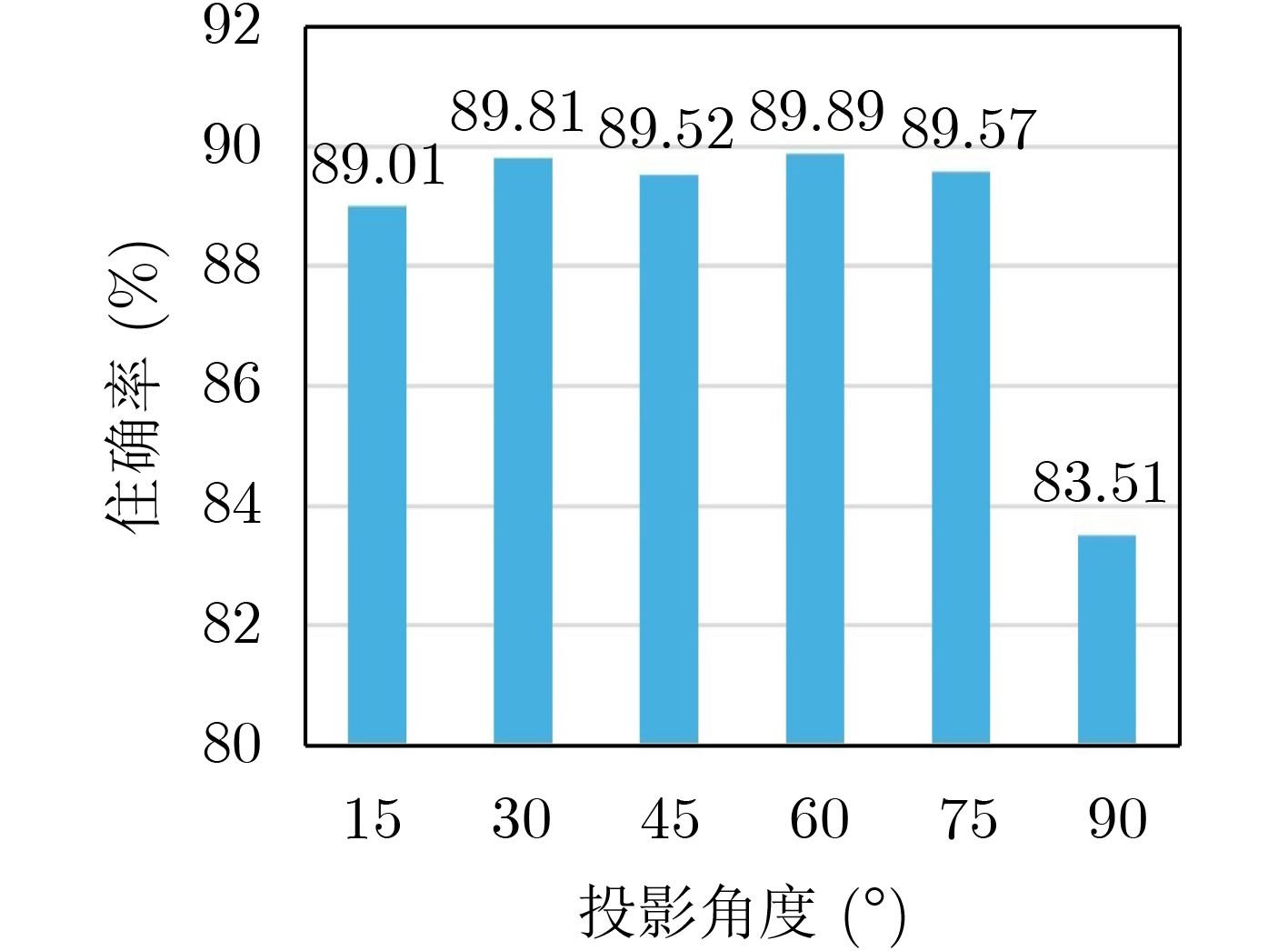
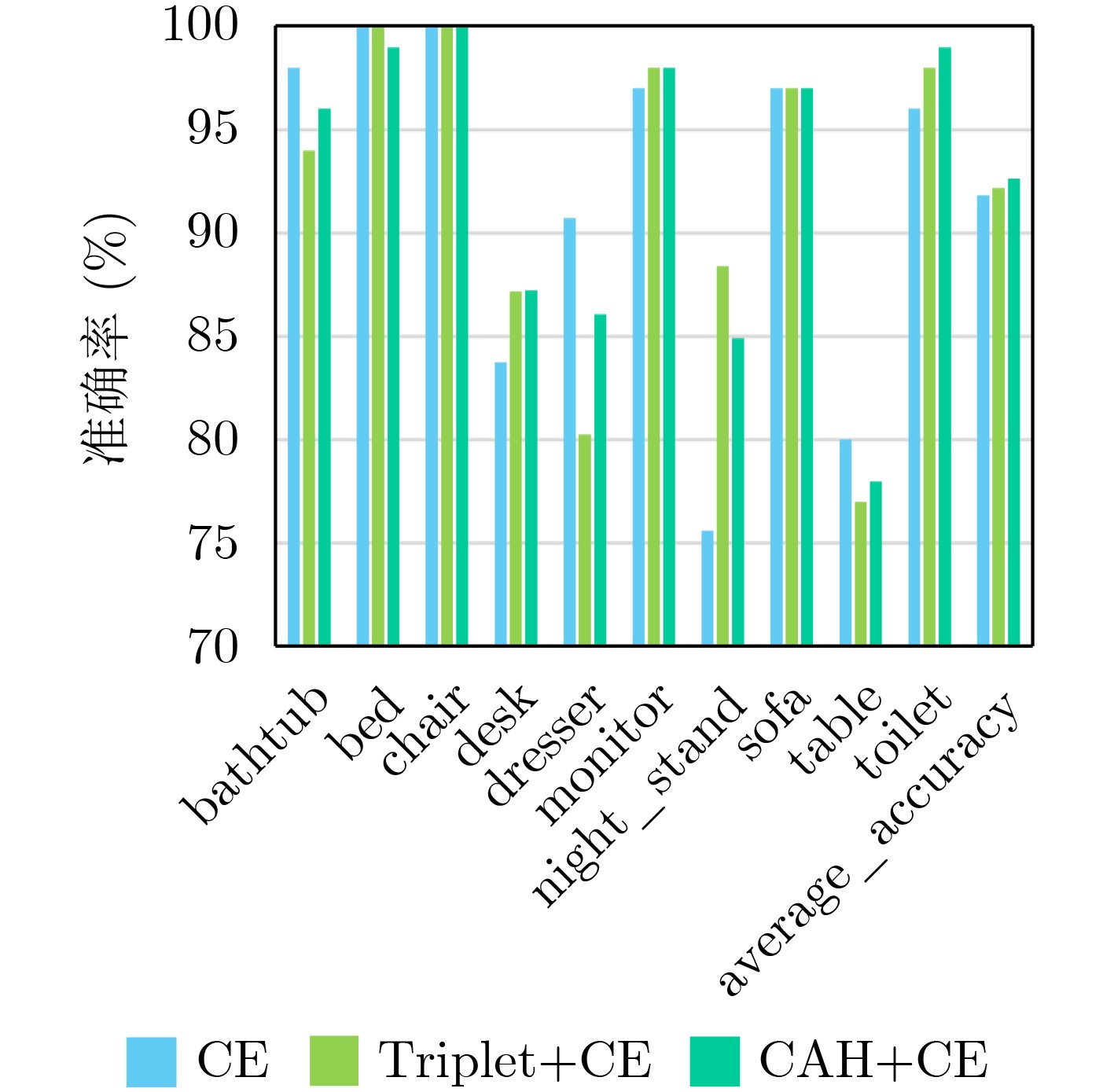
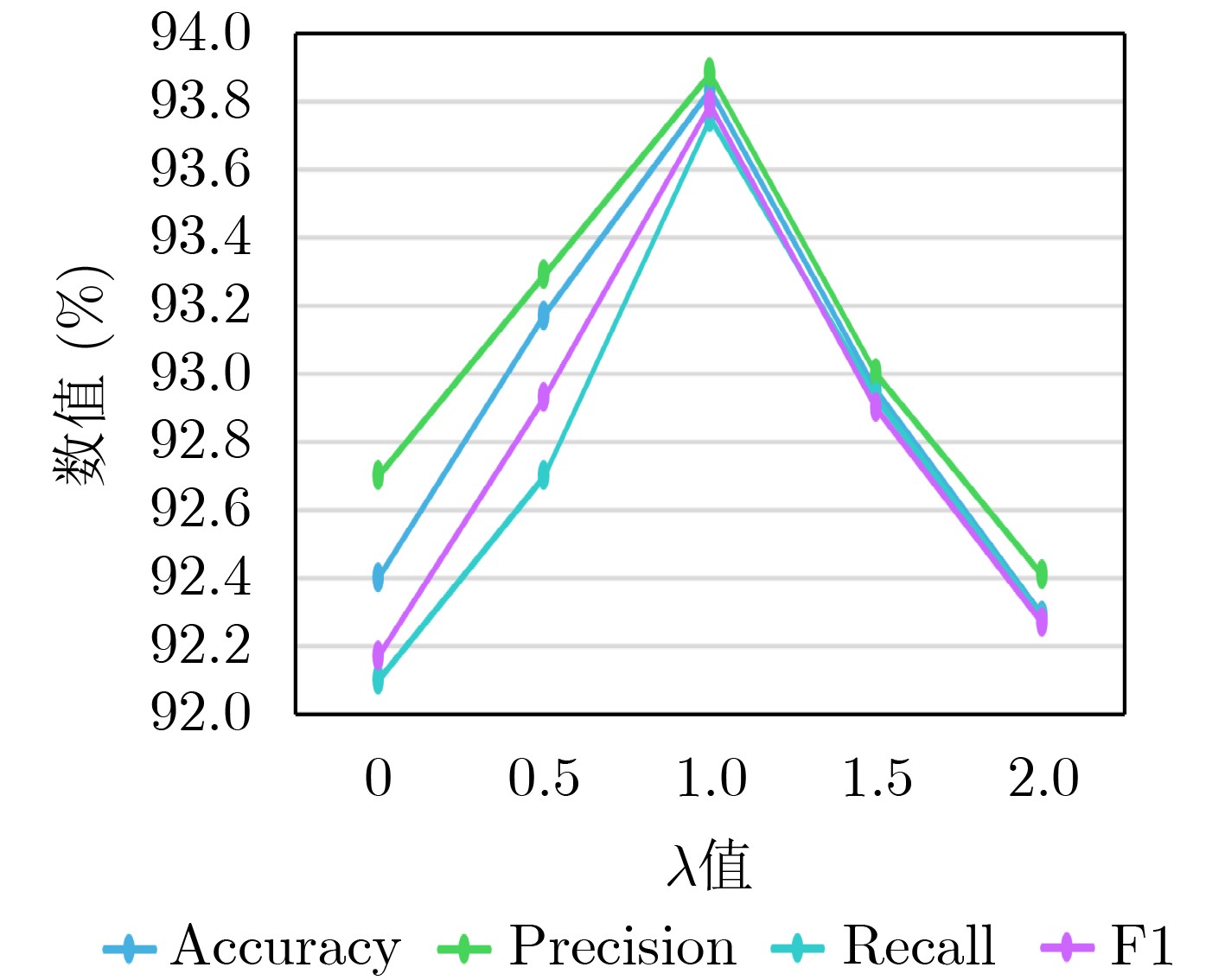
Figures(7) / Tables(6)



 DownLoad:
DownLoad: